1. Introduction
Cloud contamination represents one of the most significant challenges in optical remote sensing, with studies indicating that up to 66% of satellite images may be partially or completely affected by cloud cover [
1,
2]. This widespread occlusion severely limits the effective utilization of Earth observation data by masking critical land surface features and introducing radiometric uncertainties that compromise downstream analysis. Consequently, accurate and efficient cloud detection has become an indispensable preprocessing step for numerous remote sensing applications, including land cover classification, environmental monitoring, and change detection [
3,
4].
The complexity of cloud detection stems from the highly variable nature of cloud formations—ranging from thin, semi-transparent cirrus to thick stratocumulus—which often exhibit spectral signatures similar to other bright surface features such as snow and ice [
5,
6]. Additionally, cloud boundaries are frequently irregular and diffuse [
7], while cloud shadows introduce further complexity, as they often share low reflectance characteristics with other dark surfaces [
8] such as water bodies and terrain shadows. These spectral ambiguities increase the risk of misclassification, rendering robust pixel-wise discrimination particularly challenging [
2].
Early cloud detection methods primarily relied on rule-based algorithms and spectral thresholding techniques such as FMask [
9]. While computationally efficient, these methods exhibit limited generalization capability across diverse atmospheric conditions and sensor characteristics. The advent of deep learning revolutionized cloud detection methodologies, with CNNs emerging as the dominant paradigm. Representative models like CDNet [
10], LPMSNet [
11], and CRSNet [
12] employ encoder–decoder architectures enhanced with attention mechanisms and multi-scale feature fusion. However, CNNs face inherent limitations in capturing long-range spatial dependencies due to their localized receptive fields [
13,
14]. This makes it difficult to exploit the contextual relationship between spatially disconnected but semantically related regions, such as clouds and their corresponding shadows [
15], especially in large-scale scenes.
To address these limitations, Vision Transformers have been increasingly adopted in remote sensing applications [
16,
17], leveraging self-attention mechanisms to capture global dependencies. Many hybrid approaches [
18,
19,
20,
21] combine Transformers with CNNs, seeking to balance global semantic understanding with fine-grained spatial detail preservation. Despite their effectiveness, Transformer-based architectures introduce significant computational overhead due to quadratic attention complexity, limiting their scalability for high-resolution imagery and real-time applications [
22]. Recently, State Space Models (SSMs) have emerged as a compelling alternative. The Mamba architecture [
23] introduces selective state space modeling with linear time complexity, while VMamba [
24] adapts this to 2D spatial modeling. Remote sensing applications including ChangeMamba [
25], RSCaMa [
26], and LCCDMamba [
27] have demonstrated Mamba’s effectiveness for scalable representation learning.
While Mamba-based architectures show promise for efficient global modeling, they do not fully address specific structural challenges in encoder–decoder segmentation networks. Two critical limitations persist: first, conventional skip connections often introduce semantic misalignment between spatially detailed shallow features and semantically rich deep features, particularly problematic for thin cloud boundaries; second, standard decoders lack explicit multi-scale context integration, reducing their ability to distinguish between small fragmented clouds and large homogeneous formations. To address these challenges, we propose FEMNet, a dual-stream architecture combining Mamba-based long-range modeling with lightweight CNN-based spatial encoding. Our approach incorporates two specialized modules as follows: the cross-stage semantic enhancement (CSSE) module addresses semantic misalignment through adaptive gating, while the multi-scale context aggregation (MSCA) module enriches multi-scale understanding through resolution-aware pooling and fusion.
We evaluate FEMNet on five public datasets covering both binary and multi-class cloud segmentation scenarios. Our results demonstrate consistent improvements over state-of-the-art methods, including SCTNet and HRCloudNet, while maintaining computational efficiency. Notably, FEMNet achieves a 3.67% improvement in mIoU on the L8 Biome dataset with only 4.4 million parameters and 1.3G MACs, confirming its practical value for operational deployment.
Our main contributions are as follows:
We propose FEMNet, a novel dual-stream architecture that effectively combines Mamba-based global modeling with CNN-based spatial detail encoding for efficient and accurate cloud segmentation.
We design the cross-stage semantic enhancement (CSSE) module to resolve semantic misalignment between encoder and decoder features through adaptive gating guided by high-level contextual information.
We introduce the multi-scale context aggregation (MSCA) module to enhance decoder-scale awareness through lightweight multi-resolution pooling and fusion strategies.
We demonstrate superior segmentation accuracy and computational efficiency across five diverse datasets, validating FEMNet’s effectiveness.
3. Methodology
FEMNet is a lightweight yet effective semantic segmentation framework, developed for multi-class cloud detection in remote sensing imagery. It is specifically designed to tackle the challenges posed by spectral ambiguity—such as the confusion between clouds, snow, and bright land surfaces—and the need for fine-grained structural delineation across diverse terrestrial backgrounds. The architecture simultaneously captures high-resolution spatial textures and long-range semantic dependencies, while maintaining computational efficiency suitable for large-scale satellite data processing.
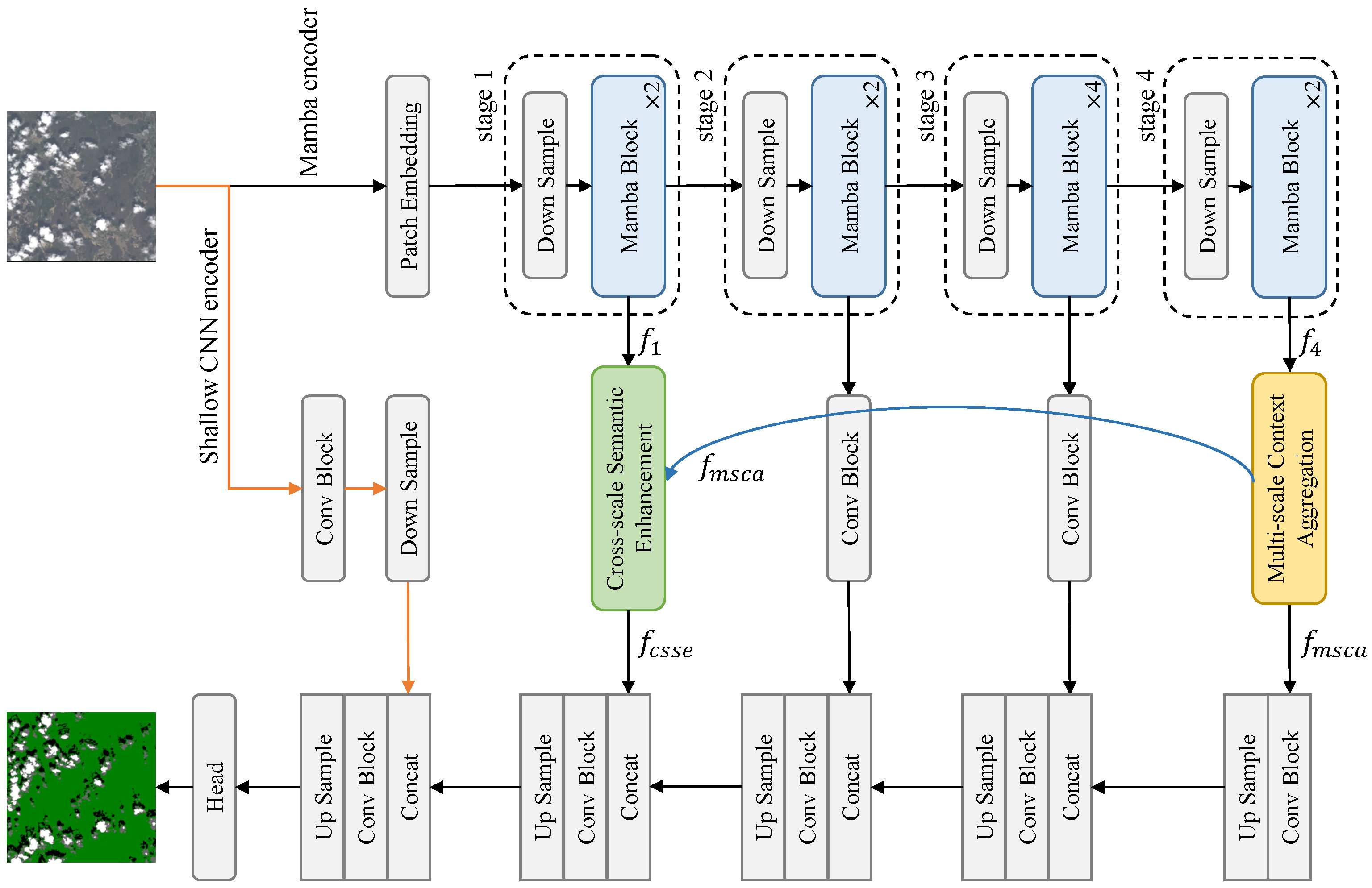
As shown in
Figure 1, FEMNet comprises the following four main components: a dual-branch encoder, a multi-scale context aggregator (MSCA), a cross-scale semantic enhancement (CSSE) module, and a lightweight decoder. The encoder integrates convolutional blocks for spatial detail extraction with a Mamba-based sequence encoder for capturing semantic context. The MSCA module refines deep features by integrating contextual cues across scales. In parallel, the CSSE module modulates early-stage features using semantic information from deeper layers, promoting alignment between low- and high-level representations. The decoder then progressively fuses features from multiple levels to produce the final segmentation map.
3.1. Network Architecture Overview
FEMNet processes the input image using two parallel encoding branches. The first pathway is a shallow convolutional encoder that extracts high-resolution spatial details, which are essential for recovering thin cloud edges and subtle shadow boundaries. In parallel, the second pathway utilizes a Mamba-based SegMAN encoder that operates hierarchically to extract multi-level semantic representations. This dual-stream design ensures that both local textures and global context are preserved throughout the network.
Formally, given an input image , the CNN branch generates a low-level feature map through a sequence of convolutional and downsampling blocks. Simultaneously, the SegMAN encoder produces a set of hierarchical semantic features with progressively decreasing spatial resolutions and increasing channel dimensions. Specifically, , , , and , capturing increasingly abstract semantic representations.
The deepest feature is refined by the MSCA module, while the lowest-level feature is modulated by the CSSE block using high-level priors from . The decoder integrates these representations through progressive upsampling and convolution, with skip connections enabling multi-scale fusion. At the final stage, the decoder output is concatenated with the shallow CNN feature (projected to a compatible dimension), and it is fused through a convolutional block. This design ensures both semantic completeness and spatial precision in the final prediction.
To qualitatively assess the contributions of the dual-stream encoder design, we visualize the intermediate feature maps from the CNN and Mamba branches, along with the fused representation. As shown in
Figure 2, the CNN branch captures fine-grained texture details such as thin clouds and sharp edges, but it tends to produce noisy or fragmented responses. In contrast, the Mamba encoder focuses on global semantic consistency, leading to smoother but spatially coarser activation maps. The fused features successfully combine the strengths of both branches, which aligns well with our design motivation for combining local and global representations in FEMNet.
3.2. Mamba-Based Multi-Scale Encoder
Traditional convolutional encoders, while efficient for local feature extraction, struggle to model long-range dependencies, which are critical for capturing large-scale and spatially disconnected cloud patterns. Transformer-based models address this limitation through global self-attention but suffer from quadratic computational cost, which hinders their scalability for high-resolution remote sensing imagery. To balance efficiency and modeling capacity, we adopt Mamba—a state space model (SSM) that offers linear-time sequence modeling with dynamic parameterization.
Mamba formulates sequence modeling as a continuous-time dynamical system as follows:
where
is the latent state vector and
are learnable matrices. Discretization via zero-order hold yields the following:
To enable adaptive modeling, Mamba [
23,
24] makes the parameters
and step size
input-dependent. As illustrated in
Figure 3, each SS2D block consists of the following three key components: cross-scan, selective scanning with S6 blocks, and cross-merge. Cross-scan unfolds the 2D feature map into four sequences along different spatial traversal directions (e.g., left-to-right, top-to-bottom, and their reverses), enabling each pixel to participate in multiple directional contexts. Selective scanning applies a dedicated S6 block to each directional sequence independently, allowing efficient 1D modeling with selective information flow. Finally, cross-merge reshapes and aggregates the four directional outputs to reconstruct the 2D feature map, typically by summing corresponding pixel responses across directions.
This SS2D design empowers each pixel to aggregate contextual information from multiple orientations, thereby constructing a global receptive field in a computation-friendly manner. Compared to traditional 2D convolutions or attention, SS2D maintains linear complexity while enhancing spatial awareness. Integrated into a four-stage encoder with neighborhood attention and residual connections, this module enables FEMNet to capture both local detail and long-range semantic structure in complex cloud scenes.
3.3. Multi-Scale Context Aggregation
Contextual modeling plays a crucial role in cloud detection, particularly when segmenting large or diffuse cloud regions where local features alone may be insufficient. However, deep layers in encoder–decoder networks typically suffer from a loss of spatial resolution, which limits their ability to retain multi-scale semantic cues. To address this limitation, we propose the Multi-Scale Context Aggregation (MSCA) module to enhance the semantic depth of high-level features while recovering spatial context.
As illustrated in
Figure 4a, the Multi-Scale Context Aggregation (MSCA) module enhances the deepest semantic feature
by aggregating contextual cues from multiple spatial scales.
Specifically, two parallel branches apply average pooling with kernel sizes of 2 and 4, respectively, followed by bilinear upsampling to restore the original resolution. The resulting pooled features are concatenated with the original
, yielding an aggregated tensor of size
:
The fused representation
is then passed through a convolutional layer and a ReLU activation to produce the output feature
:
This design enables FEMNet to capture richer contextual information across multiple receptive fields without significantly increasing model complexity. As illustrated in
Figure 5, the MSCA module transforms fragmented semantic features into more regionally coherent activations, reinforcing large-area consistency and improving the network’s ability to delineate spatially extensive or spectrally ambiguous cloud structures.
3.4. Cross-Stage Semantic Enhancement
Encoder–decoder architectures often suffer from semantic inconsistencies when merging low-level features (rich in spatial detail) with high-level features (rich in semantics). This is especially detrimental in cloud segmentation, where boundary precision and semantic coherence are critical. To alleviate this, we propose the Cross-Stage Semantic Enhancement (CSSE) module.
As illustrated in
Figure 4b, the CSSE module takes a low-level spatial feature
and a high-level semantic feature
as inputs.
First,
is projected using a
convolution and activated by a sigmoid function to generate a spatial attention map
M, which is then upsampled to match the resolution of
:
where
denotes the sigmoid activation.
Meanwhile,
is refined through two convolutional layers with interleaved ReLU and batch normalization as follows:
Then, the attention map
M is applied to the refined feature
via element-wise multiplication, and the result is concatenated with the original
as follows:
where ⊙ denotes element-wise multiplication.
Finally, the concatenated feature is passed through another convolution–BN–ReLU sequence to produce the output feature
as follows:
As shown in
Figure 6, the CSSE module suppresses redundant textures in shallow features and emphasizes cloud boundaries, promoting more semantically consistent decoding. By selectively preserving spatially relevant information, it improves the network’s ability to recover fine cloud structures and mitigate false positives in complex backgrounds.
3.5. Loss Function and Evaluation Metrics
To supervise the multi-class cloud segmentation task, we adopt the standard pixel-wise cross-entropy loss, formulated as follows:
where
N denotes the number of training pixels (or samples),
K is the number of cloud categories (e.g., clear sky, cloud shadow, thin cloud, and thick cloud),
is the ground truth label for the
k-th class of the
n-th sample, and
is the predicted probability for that class. This formulation penalizes class-wise divergence between predictions and ground truth distributions.
To evaluate segmentation performance, we adopt four commonly used metrics computed at the pixel level: overall accuracy (aAcc), mean accuracy (mAcc), mean Intersection over Union (mIoU), and mean Dice coefficient (mDice). These metrics are defined as follows:
Overall Accuracy (aAcc) measures the proportion of correctly classified pixels over the entire dataset as follows:
where
,
,
, and
denote the total number of true positives, true negatives, false positives, and false negatives across all classes.
Mean Accuracy (mAcc) computes the average per-class accuracy, helping mitigate class imbalance as follows:
where
and
refer to the number of true positives and false negatives for class
i, respectively.
Mean Intersection over Union (mIoU) evaluates the average region overlap between prediction and ground truth for each class as follows:
Mean Dice Coefficient (mDice) provides a harmonic measure of precision and recall, particularly sensitive to boundary and small-object segmentation as follows:
These metrics jointly reflect the model’s performance in both region-level accuracy and class-specific consistency, providing a comprehensive evaluation for multi-class cloud segmentation tasks.
5. Discussion
5.1. Ablation Study
To assess the contribution of each proposed component, we conducted an ablation study on the L8 Biome dataset, as shown in
Table 7. The baseline model comprises a Mamba-based encoder and a UNet-style decoder.
Among the variants, removing the Dual-Stream Encoder (DSE) causes the most notable performance degradation, with mIoU dropping from 69.70% to 66.67% and mDice from 80.49% to 78.00%. This emphasizes the essential role of combining convolutional and Mamba-based features for effective semantic segmentation. Similarly, excluding the CSSE module results in a substantial performance drop, particularly in mIoU (69.01%) and mDice (79.79%), underlining its efficacy in modeling long-range contextual dependencies. Interestingly, removing the MSCA module yields the highest aAcc (90.19%), yet it significantly lowers mAcc (76.33%), suggesting that although overall pixel-level accuracy improves, class-wise balance deteriorates. Collectively, these results confirm that the integration of DSE, CSSE, and MSCA contributes complementary strengths, leading to optimal overall performance.
5.2. Model Efficiency
We evaluate FEMNet’s efficiency in terms of parameter count, computation, inference speed, model size, and memory usage. As shown in
Table 8, FEMNet contains only 4.4 million parameters and 1.3 billion MACs, which is substantially lower than heavy models like DBNet and KappaMask. While SCTNet is even smaller (0.7M parameters), FEMNet achieves better segmentation performance with only a slight increase in computation.
On an NVIDIA RTX 2080Ti (batch size 64), FEMNet processes 331 images per second, offering a good trade-off between speed and accuracy. Although SCTNet reaches a higher throughput (1047 img/s), its segmentation quality is notably lower.
FEMNet also demonstrates compactness in storage and memory usage. The model file is only 17.9 MB, and inference with 256 × 256 inputs (batch size 1) requires 548 MB of GPU memory as measured by gpustat. This enables efficient deployment on memory-limited platforms such as edge devices and satellite systems.
6. Conclusions
This paper presents FEMNet, a lightweight and feature-enriched architecture for cloud detection in optical remote sensing imagery. By combining a Mamba-based state space encoder with a parallel CNN stream, FEMNet effectively captures both long-range semantic dependencies and fine-grained spatial details. To mitigate semantic inconsistency and enhance contextual awareness, which are two key limitations in conventional encoder–decoder frameworks, we introduce the following two targeted modules: the cross-stage semantic enhancement block for semantic alignment across feature hierarchies, and the multi-scale context aggregation module for efficient context fusion across spatial resolutions. Extensive experiments across five benchmark datasets validate FEMNet’s superior performance over existing CNN-, Transformer-, and hybrid-based methods in both binary and multi-class segmentation scenarios. In future work, we aim to extend FEMNet with domain-adaptive training strategies to improve its generalization across varying seasonal patterns, geographic regions, and sensor modalities.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}