3.1. Framework of MHGAN
The primary objective of heterogeneous remote sensing image change detection is to quantitatively analyze and identify substantial changes on the Earth’s surface by comparing images data acquired at different times and from various sensors while filtering out minor or low-confidence changes. A key challenge in this process is addressing “false changes”, which arise from factors such as noise, radiometric discrepancies, lighting variations, and adverse weather conditions. Drawing inspiration from the concept of image-to-image (I2I) translation [
37,
38], which aims to transform images with differing styles into a shared domain with uniform feature representations, heterogeneous remote sensing images can similarly be translated into a common domain. By doing so, data from different temporal and modal sources become directly comparable. In this context, heterogeneous remote sensing images from dual temporal instances are treated as stylistically distinct representations of the same geographic region.
Thus, the core task in heterogeneous remote sensing image change detection is to develop a robust one-to-one mapping mechanism for heterogeneous data. This approach should effectively establish relationships between images with different visual and spectral characteristics while preserving essential semantic and structural information. Moreover, the mapping process must minimize the impact of “false changes” to enhance the reliability and precision of CD outcomes. To address this, a new bidirectional adversarial autoencoder network model (MHGAN) based on images style transfer is proposed for data transformation of heterogeneous remote sensing images, enabling precise detection of change areas. Specifically, let
and
represent a pair of input dual-temporal remote sensing images. The goal is to achieve two transformations:
and
, where
:
→
and
:
→
, thus enabling data mapping between the image domains. Through this approach, input image
(or
) can be mapped to the opposite domain
(or
), allowing for CD by computing the difference image
as a weighted average:
where
represents a pixel-level distance metric, where Euclidean distance is used due to the computational cost of large-scale data.
represents the number of channels in image
, and
represents the number of channels in image
.
To implement and , a framework composed of two autoencoders is used, with each autoencoder associated with one of the image domains, and . The bidirectional autoencoder network model consists of two sets of encoder–decoder sub-networks:
The encoder and its corresponding decoder , denoted as ;
The encoder and its corresponding decoder , denoted as .
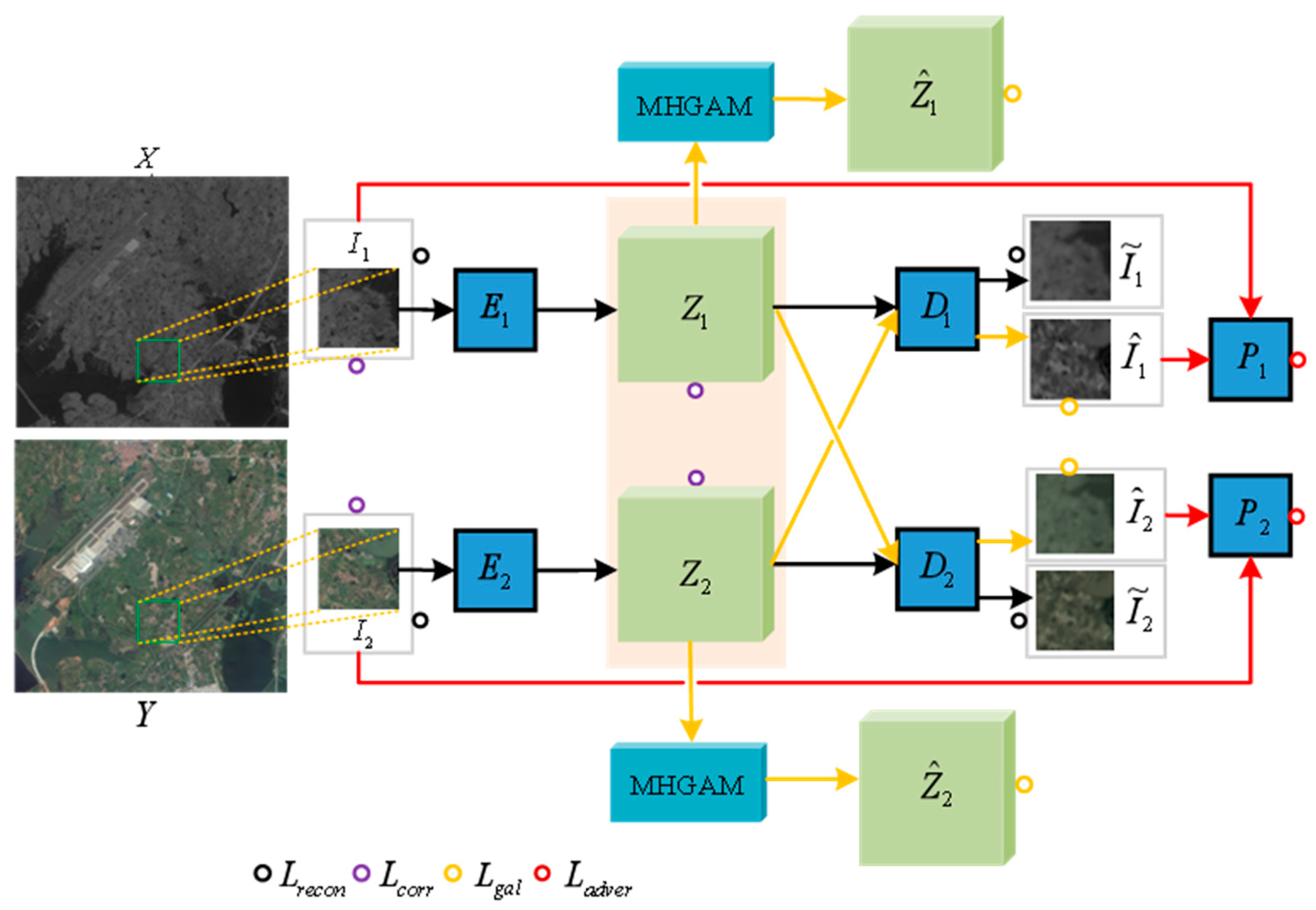
The overall architecture is shown in
Figure 1, which realizes domain transformation and feature alignment of heterogeneous images through bidirectional mapping of encoder-decoder. The two encoder–decoder pairs are constructed using deep fully convolutional networks, where
and
represent the encoding layers or latent spaces of encoders
and
respectively.
denotes the encoding layer representation of the tensors in
and
With appropriate regularization, the bidirectional autoencoders can be jointly trained to learn the mapping of their inputs to the latent space domain. The latent features are then projected back into their original domains through the cascading of the encoder and corresponding decoder, producing high-fidelity reconstructions. Additionally, the data are mapped through the opposite decoder, which leads to the desired style transformation, as illustrated in
Figure 2.
However, without any external guidance, the feature representations of and , and are typically not aligned, making it impossible to directly use them for generating difference maps. To address this, we introduce a loss term to enhance their transformation alignment. If the features of and , and are successfully aligned, changes can be detected more accurately.
Specifically, the proposed MHGAN for heterogeneous remote sensing image change detection is based on two sets of autoencoder networks that fit the functions and , respectively, to achieve domain transformation for dual-temporal remote sensing images. The training of the bidirectional autoencoders is carried out by minimizing a loss function with respect to the parameter of the constructed network. The loss function consists of four components: reconstruction loss, code correlation loss, graph attention loss, and adversarial loss.
3.3. Code Correlation Loss
To align the feature representations of the encoding layer, a specific loss term known as the code correlation loss [
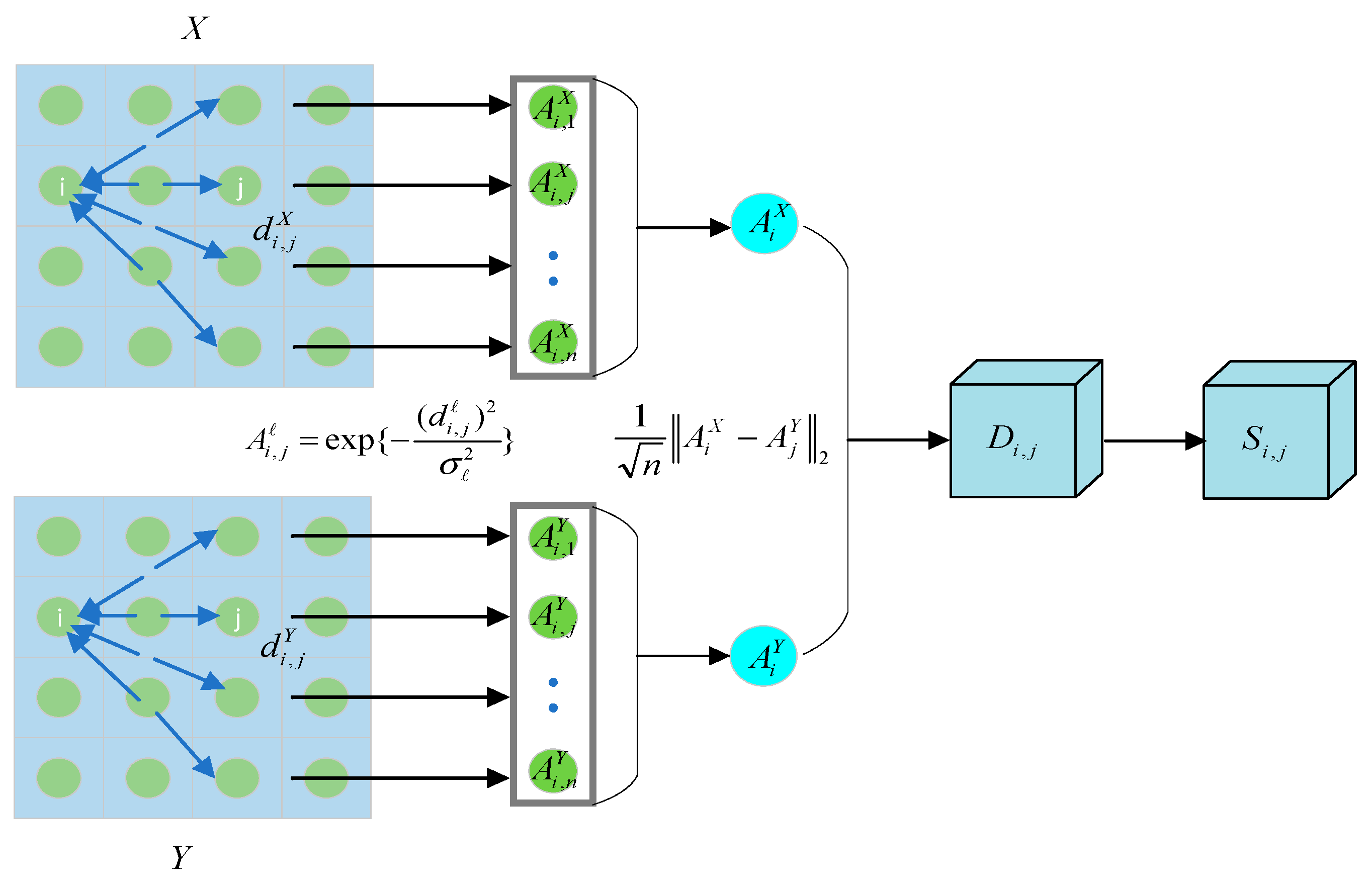
2] has been introduced, as depicted in
Figure 3. The objective is to synchronize the code layers of two autoencoders, treating them as a shared latent space. This allows the output of one encoder to serve as the input for both decoders, enabling the reconstruction of data within its native domain as well as its transformation into another domain. When pixel pairs
are similar in the input space, their distances in the code space should also be close. Conversely, when pixel pairs
are dissimilar in the input space, their distances in the code space should be more distant.
For any modality
or
, the feature distance for all pixel pairs
within the same training patch is defined as
where
and
are the feature vectors of the
-th and
-th pixels in patch
, respectively;
and
are the feature vectors of the
-th and
-th pixels in patch
, respectively.
and
are specific distance metrics, with Euclidean distance being the choice for this paper, formulated as
Based on the aforementioned distance, the affinity matrix for local pixel pairs is calculated as follows:
where
represent the similarity between pixel pairs (with values closer to 1 indicating higher similarity). The Gaussian kernel function smoothly maps distances in the feature space to similarity scores, enhancing robustness against noise.
is the kernel width, and in CAA,
is set as a fixed value, typically the mean distance of the
-nearest neighbors. However, determining kernel width in this manner depends on the ranked distances of neighboring points (e.g., the closest 25% of data points) and does not explicitly account for the density distribution of the entire image. Since data often exhibit varying densities across different regions, using a fixed kernel width may lead to the following issues:
High-density regions: If the kernel width is too large, local structural information may become blurred, making it difficult to capture fine details.
Low-density regions: If the kernel width is too small, the kernel function may fail to adequately cover the data, resulting in insufficient information.
To address this issue, this study adopts a density estimation-based approach, where a dynamic kernel width is assigned to each pixel based on its local density. High-density regions are assigned smaller kernel widths, while low-density regions are assigned larger kernel widths, thereby better accommodating the non-uniform distribution of the data The local density
of each pixel
is first calculated through kernel density estimation based on the surrounding pixels:
where
represents the total number of surrounding pixels, and
denotes the Euclidean distance between pixel
and pixel
The kernel width
is then calculated as the inverse of the local density:
where
is a tuning parameter determined via cross-validation on the training subsets of all four datasets. It controls the sensitivity of kernel width to local density: smaller values of
(e.g., 0.1) make kernel width more responsive to density variations, while larger values (e.g., 0.5) produce a smoother effect. Based on validation results, the selected value of
achieves a balance between capturing fine local details in high-density regions and ensuring robustness to noise in low-density areas.
The affinity calculation used in this study is better adapted to the local characteristics of the data distribution. High-density regions capture finer local differences, while low-density regions mitigate the effects of excessive noise amplification. Compared to fixed kernel widths, dynamic kernel widths can more effectively reflect both local and global variations within the image. This method is particularly suitable for scenarios where significant distribution differences exist between modalities, such as SAR and optical imagery, infrared and multispectral imagery, etc.
Each row of the affinity matrix is considered as the feature representation of a pixel:
where
is a vector that encompasses the similarity values of pixel
with all other pixels in modality
. Similarly,
contains the similarity values of pixel
with all other pixels in modality
. By calculating the cross-modal distance, the following distance in the cross-modal space is obtained:
where
, representing the normalized distance that indicates the degree of similarity between pixels across modalities. The essence of this formula is that if two pixels exhibit similar patterns of similarity with other pixels in different modalities (i.e., their similarity vectors are alike), then the cross-modal distance between these two pixels should be small. Conversely, if there is a significant difference in the similarity vectors, the cross-modal distance will be larger. By representing each pixel with its affinity vector relative to other pixels, a relational feature is formed for each pixel. These relational features reflect the distribution characteristics of pixels within the local context. The features of a single pixel may not be sufficient to capture global or local changes, but by considering its relationships (affinity) with other pixels, a more comprehensive description of the structural information between pixels can be provided. These relational features are well suited for transfer to cross-modal alignment tasks.
To ensure that the similarity in the input space is maintained in the encoding layer, a similarity matrix
is defined as follows:
As
Figure 3 illustrated,
. The encodings in the encoding layer are denoted as
and
, corresponding to the encodings of pixel
in modality
and pixel
in modality
, respectively. By optimizing the encoding alignment loss, the similarity between
and
is constrained to be consistent with
where
representing the cosine similarity between the encodings, with the goal of making
. The cosine similarity
between pixel pairs in the encoding space serves as a representation of similarity at the encoding layer.
Ultimately, the similarity
between pixel pairs in the encoding space is enforced to be consistent with the similarity
in the input space. The code correlation loss
is defined as
where
represents the similarity matrix of all pixel pairs in the encoding layer.
denotes the similarity matrix of pixel pairs between the input images
and
. This loss function
is the expected value of the squared Frobenius norm of the difference between the similarity matrices
and
, which encourages the encodings to preserve the input space similarities.
3.4. Graph Attention Loss
As illustrated in
Figure 2, the methodology for data transformation employing a unidirectional convolutional autoencoder is outlined. For image
, a random image patch
is selected and encoded into the latent space using encoder
. Subsequently, the decoder
, associated with image
, is utilized to decode the features from the latent space, resulting in an image patch
that mirrors the style of image
. This transformation is mathematically expressed as
. Analogously, for image
, an image patch
is randomly extracted and encoded using encoder
. Then, the decoder
, corresponding to image
, decodes the features to generate an image patch
that aligns with the style of image
. This process is represented as
. To synchronize the image representations of
with
and
with
, a novel structure based on the MHGAM is introduced, as shown in
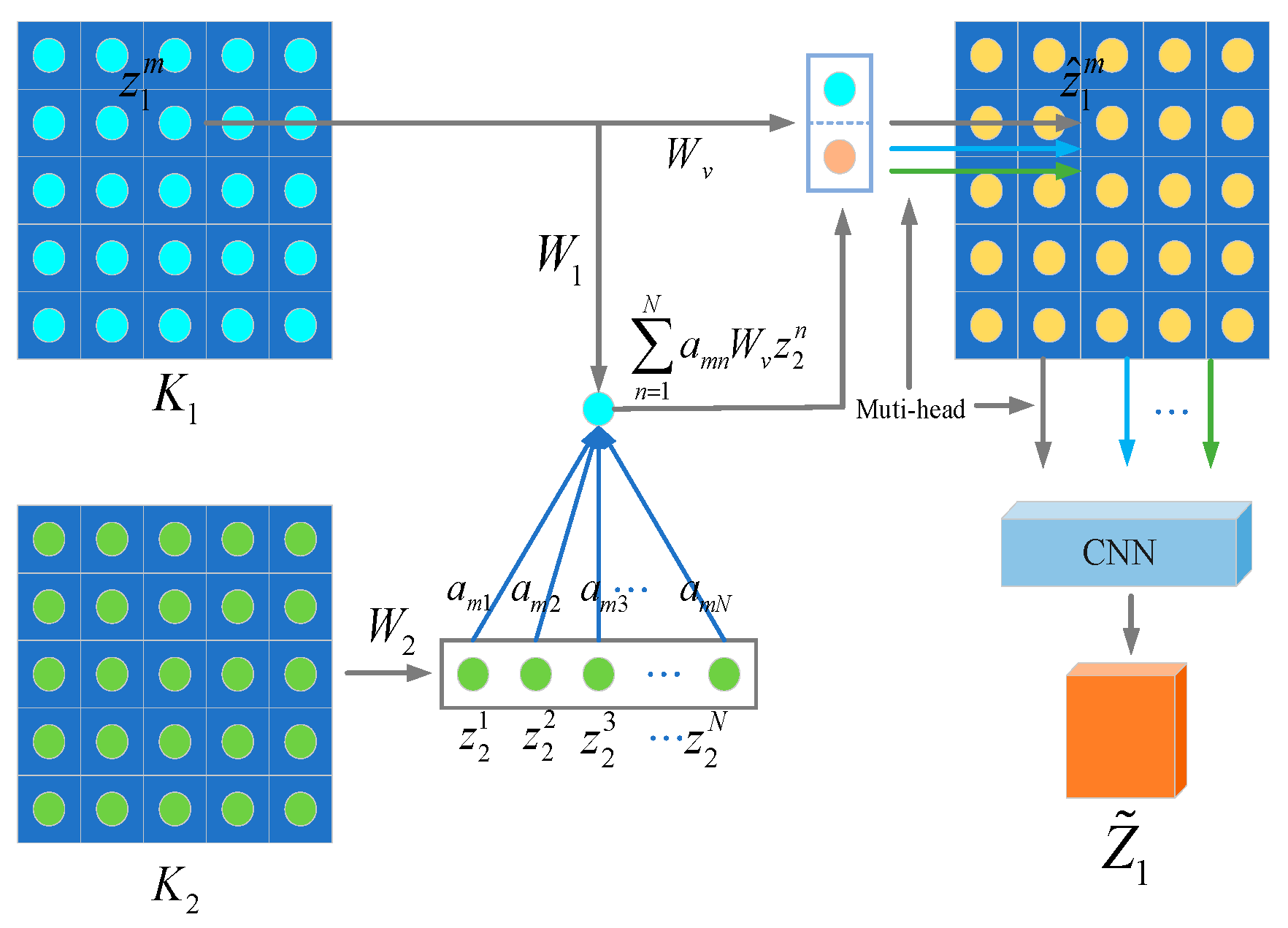
Figure 4.
This approach leverages the MHGAM to uncover latent spatial feature relationships within the spatial domain. It is independent of manual labeling and does not require specific prior knowledge. The assumption is that regions that remain unchanged can capture a greater degree of spatial correlation, thereby enhancing the effectiveness of feature representation.
Giving encoders
and
to obtain feature maps
and
, respectively, these feature maps are then subjected to a linear transformation using a
convolutional kernel to derive node representations. This transformation results in the creation of a graph that represents the relationships between each node, where
denotes the number of the feature channels. Let
represent the set of all nodes contained within
and
represent the set of all nodes contained within
. A bipartite graph is constructed to model the images’ before and after change for each pair
, where
and
, and the coefficient
signifies the correlation between nodes
and
. The feature vectors
and
represent the nodes
and
in the latent space. The greater the similarity between the features of the images before and after change, the higher the likelihood that the region remains unchanged. Consequently, more spatial correction information should be conveyed to such regions. The correlation
is thus defined to be directly proportional to the similarity of the feature vectors of nodes
and
. The inner product of the feature vectors is used to calculate this similarity:
where
and
are linear transformations applied to each node in
and
, respectively. They can also be interpreted as two weight matrices. This formula quantifies the correlation between nodes
and
using the inner product of linearly transformed feature vectors. From a technical mechanism perspective, the linear transformation (via weight matrices
,
) projects features into a shared subspace, enabling cross-domain comparison. The inner product then measures the similarity of these projected features, reflecting the spatial coupling strength between bitemporal features. A higher value indicates stronger similarity in structural characteristics (e.g., unchanged regions like stable terrain) as the mechanism effectively captures consistent spatial patterns across domains.
Based on the correlation coefficient
, a self-attention mechanism is applied to the nodes. The influence of node
on node
is represented by
, which is obtained by normalizing the correlation coefficient
using the SoftMax function:
where the SoftMax normalization ensures that attention weights
sum to 1, quantifying the proportion of information from node n, which propagates to node m. Technically, SoftMax operates by exponentiating and normalizing the similarity scores from Formula (15), which inherently prioritizes nodes with larger raw similarity values. This mechanism leverages the structural consistency encoded in the graph-nodes with stronger spatial correlations (e.g., adjacent pixels in unchanged urban areas) receiving higher weights, while noise-induced false correlations (from speckle or sensor artifacts) are suppressed due to their lower relative similarity.
The coefficient
determines the extent to which information from all nodes in
is propagated to the
-th node in
. A linear transformation matrix
is applied to the features of
, resulting in the aggregation of information for node
as follows:
By integrating the aggregated representation
with the node feature
, a more robust feature representation
is obtained:
where
denotes the vector concatenation operator. This attention mechanism functions as a unidirectional feed forward neural layer. The process is parallelized for all
, where
, resulting in a new feature map
. Similarly, a new feature map
can be computed for image
using the same method. These formulas aggregate context-aware information from cross-domain nodes and fuse it with the original features. From a technical standpoint, the aggregation leverages the attention weights to selectively combine relevant cross-domain features. The fusion with original features balances new context acquisition and preservation of raw input information. This enhances the representation of consistent regions by reinforcing shared structural patterns while preserving discriminative features of changed regions (e.g., newly built roads) through retention of unique local characteristics, ultimately balancing stability and sensitivity to changes.
After this step, the feature maps and have been updated once. However, in the context of CD in heterogeneous remote sensing images, the features of the images before and after change may differ significantly. A single update of the feature maps could potentially overlook important feature information. To address this, the MHGAM is designed to include additional attention heads. By repeating the process for each attention head , and then concatenating the feature maps obtained from each attention head, the final output of the MHGAM is produced:
The aggregated feature representation
is calculated by summing the feature maps from each attention head and then taking their average:
where
is a pixel-level distance metric function. The number of attention heads
was determined experimentally. We tested
= 2, 4, and 8 and found that
= 4 provides the optimal balance. Fewer heads (e.g., 2) fail to capture diverse feature relationships (e.g., both spectral and spatial correlations), while a larger number of heads (e.g., 8) increases computational cost without yielding significant performance improvements. In Equation (19), features from the
heads are aggregated by averaging, effectively fusing complementary information from different subspaces (each head learns distinct spatial correlation patterns). This strategy avoids over-reliance on a single attention head and enhances the robustness of the feature representation. To meet computational cost constraints, the Euclidean distance is preferred.
where
is a pixel-level distance metric function. To meet computational cost constraints, the Euclidean distance is preferred.
By utilizing the graph attention loss, a node matching relationship between feature images is established, which helps to reduce the impact of spectral feature differences between image pairs on the analysis of the target area. The MHGAM allows the model to learn features in different spaces. It processes input features in parallel using multiple independent attention heads, with each head capable of learning different feature representations and relationships, thereby enhancing the model’s expressive power. The MHGAM maps spatial information from one feature domain to another, resulting in more effective image embedding representations. This approach better handles the heterogeneity between cross-domain image pairs.









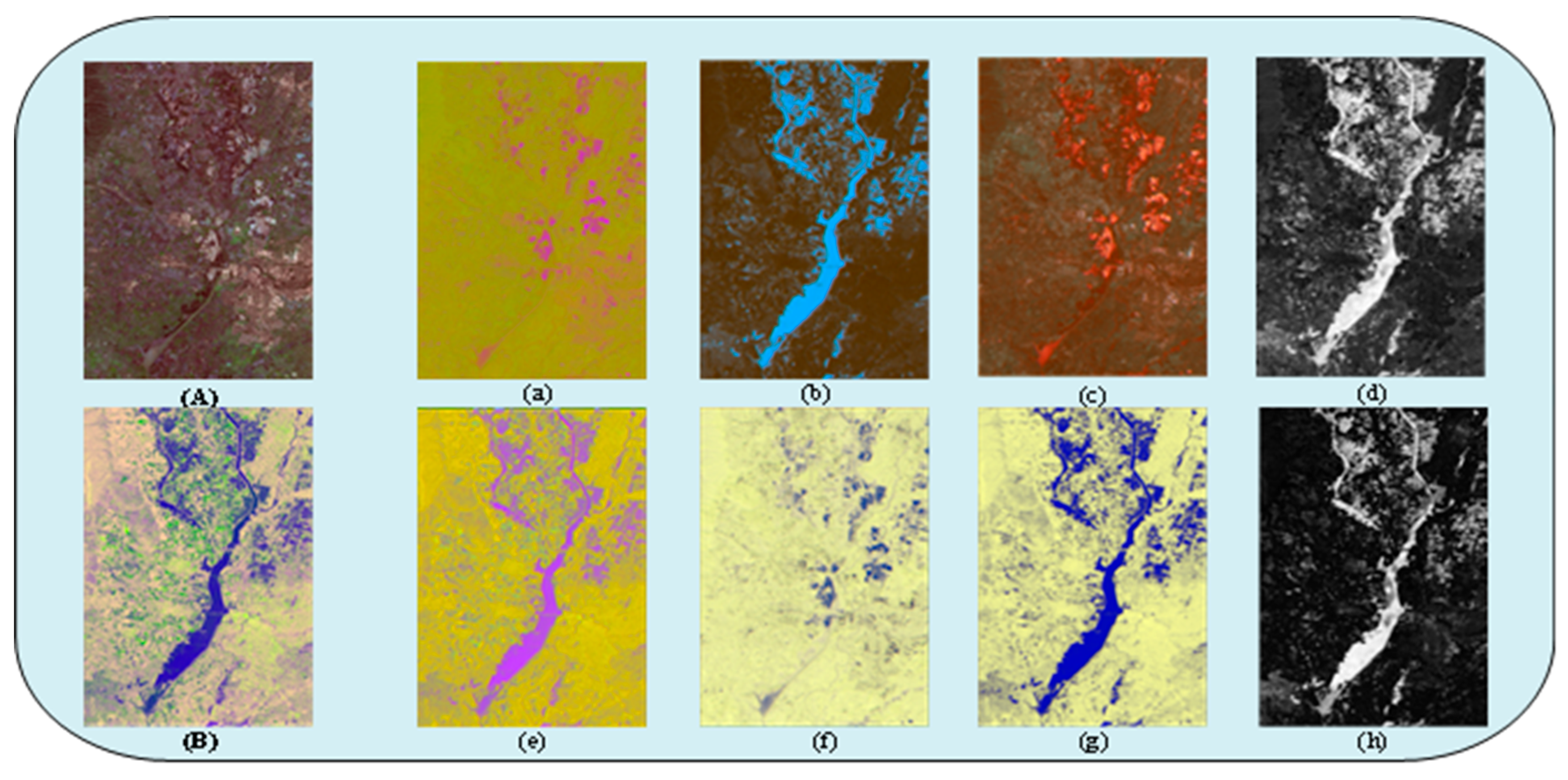
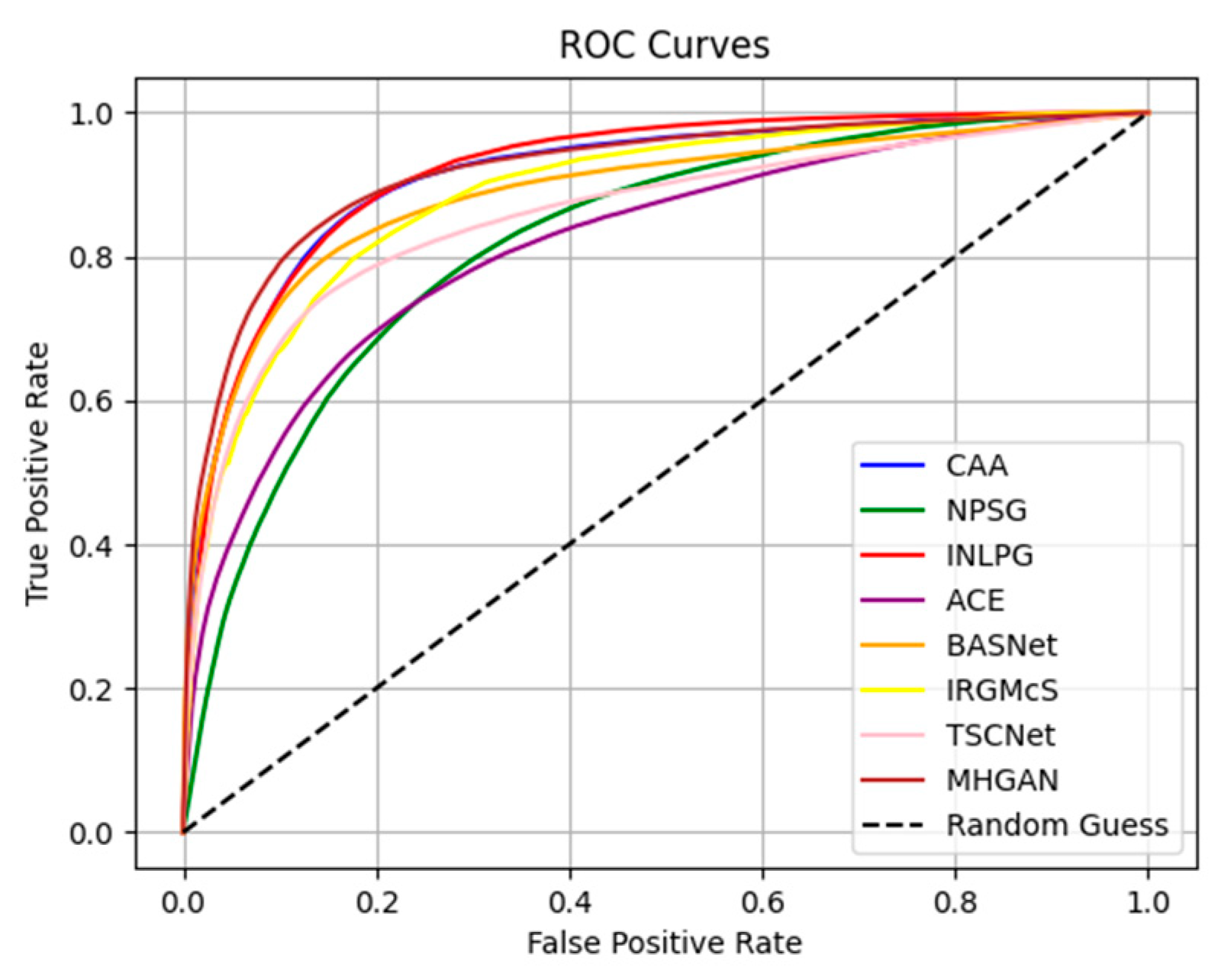
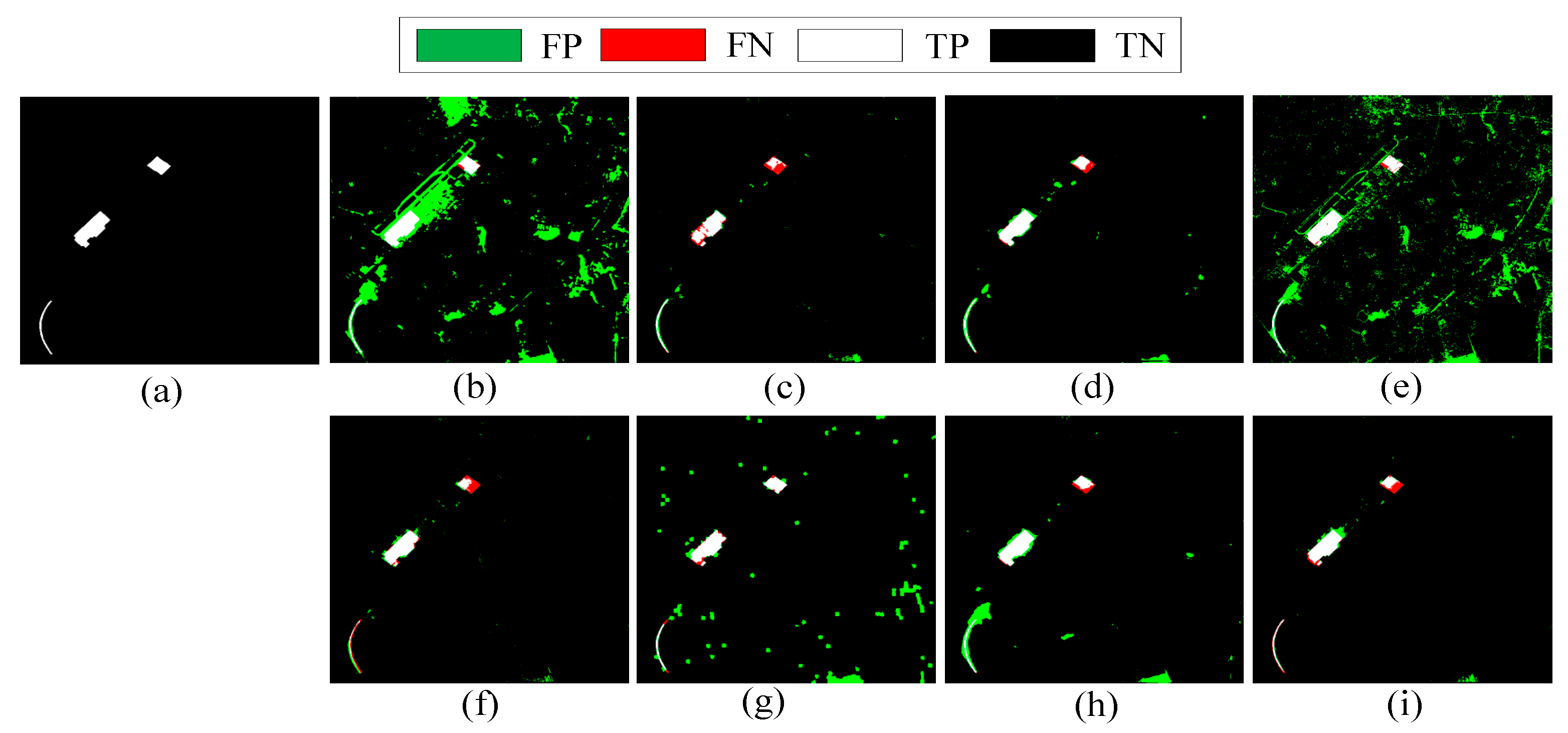




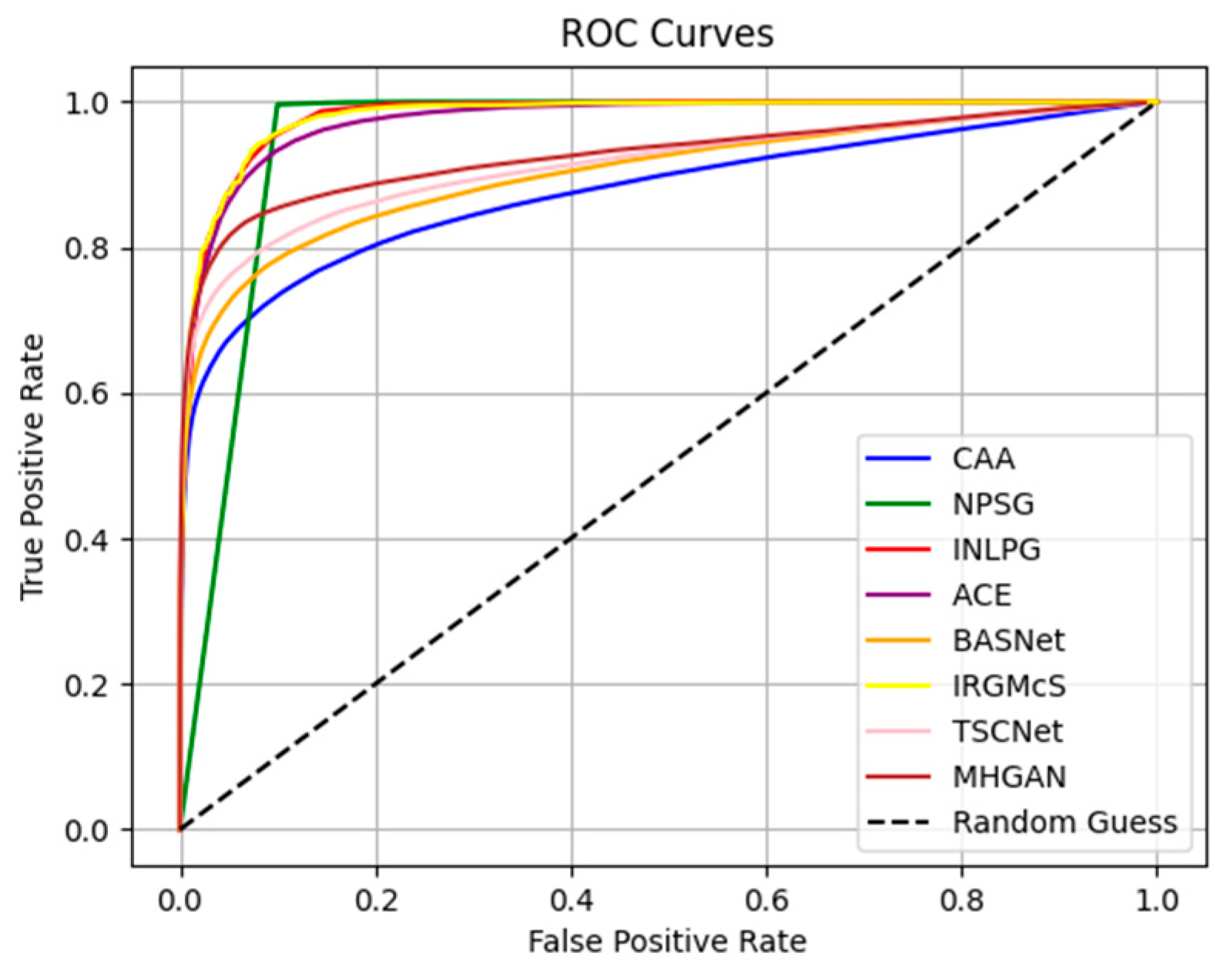

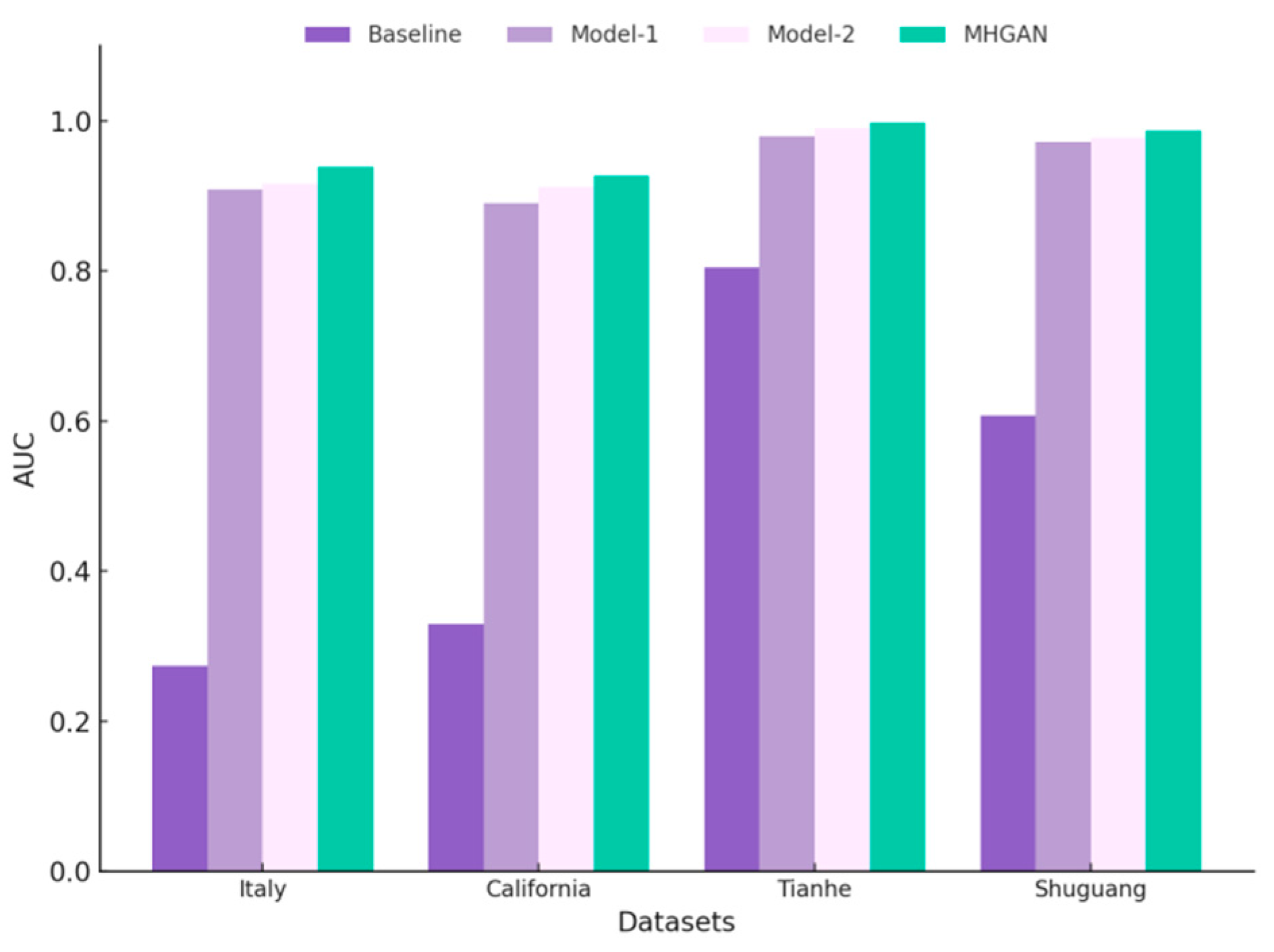

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}