


CropSTS: A Remote Sensing Foundation Model for Cropland Classification with Decoupled Spatiotemporal Attention

Abstract
1. Introduction
- We introduce CropSTS, the first compute-efficient GFM designed with a temporally decoupled attention structure for remote sensing cropland classification.
- We develop a hybrid training strategy combining joint-embedding predictive architecture and knowledge distillation, enabling efficient model transfer from vision-scale pre-trained backbones to agricultural domains, as well as the enhancement of cropland boundary delineation.
- We empirically validate the effectiveness of our approach on the PASTIS-R benchmark, achieving strong performance under limited training and data settings.
2. Related Work
2.1. Vision Transformers in Remote Sensing
2.2. Geospatial Foundation Models
2.3. Self-Supervised Learning
2.4. Knowledge Distillation in Earth Observation
2.5. Current Limitations
3. Method
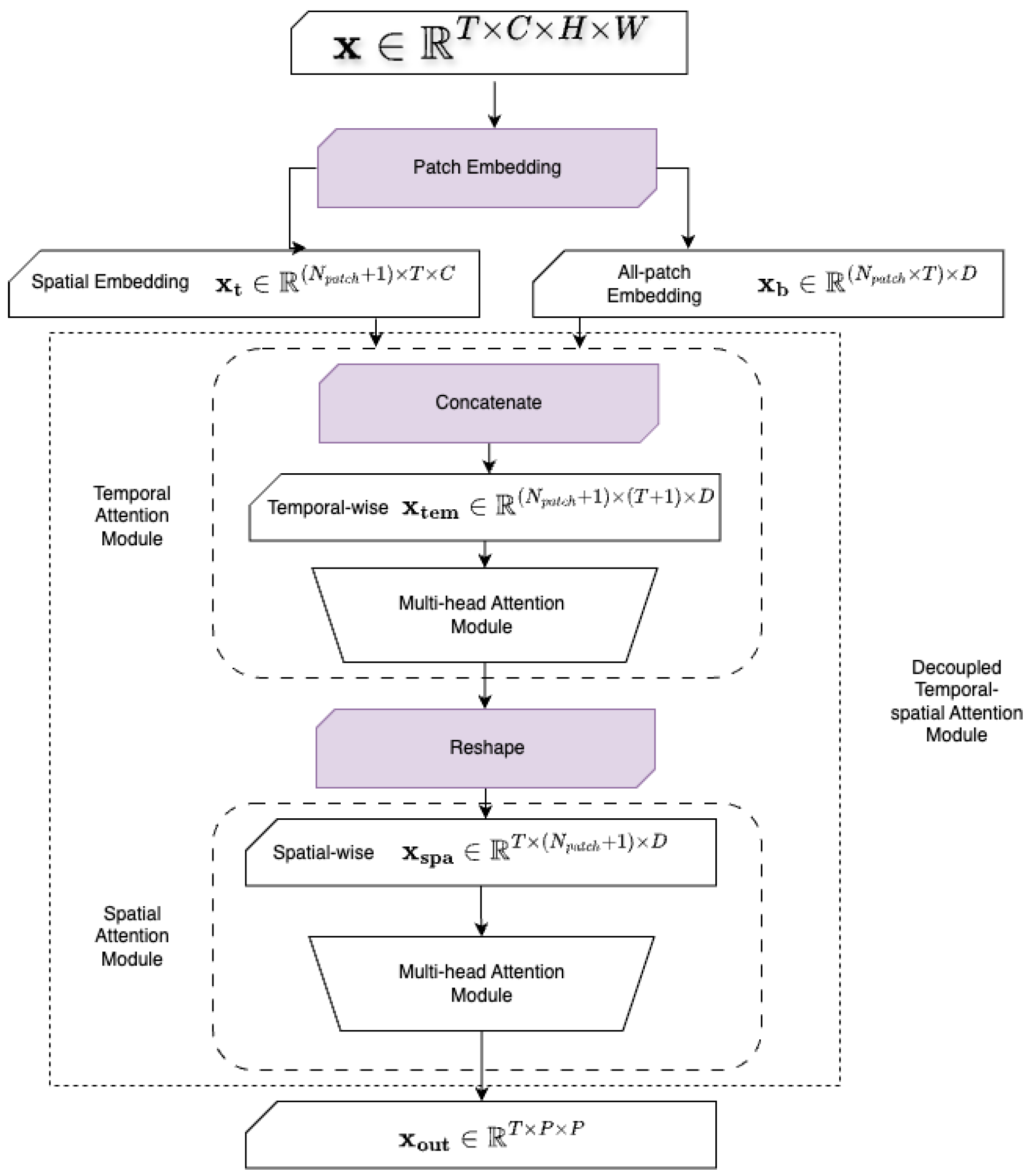
3.1. Model Architecture
3.1.1. Decoupled Temporal–Spatial Attention Mechanism
| Algorithm 1 Spatial–temporal alternating processing. |
Require: Input sequence
|
3.1.2. Complexity Analysis
3.2. Self-Supervised Learning
- -
- The student network receives partially masked inputs, where cropland regions are selectively occluded using plot-wise masks.
- -
- The teacher network receives the full, unmasked input.
3.3. Knowledge Distillation
4. Results and Discussion
4.1. Experimental Setup
4.2. Feature Representation Evaluation
4.3. Fine-Tuning Results on Cropland Classification
4.4. Per-Class IoU Analysis
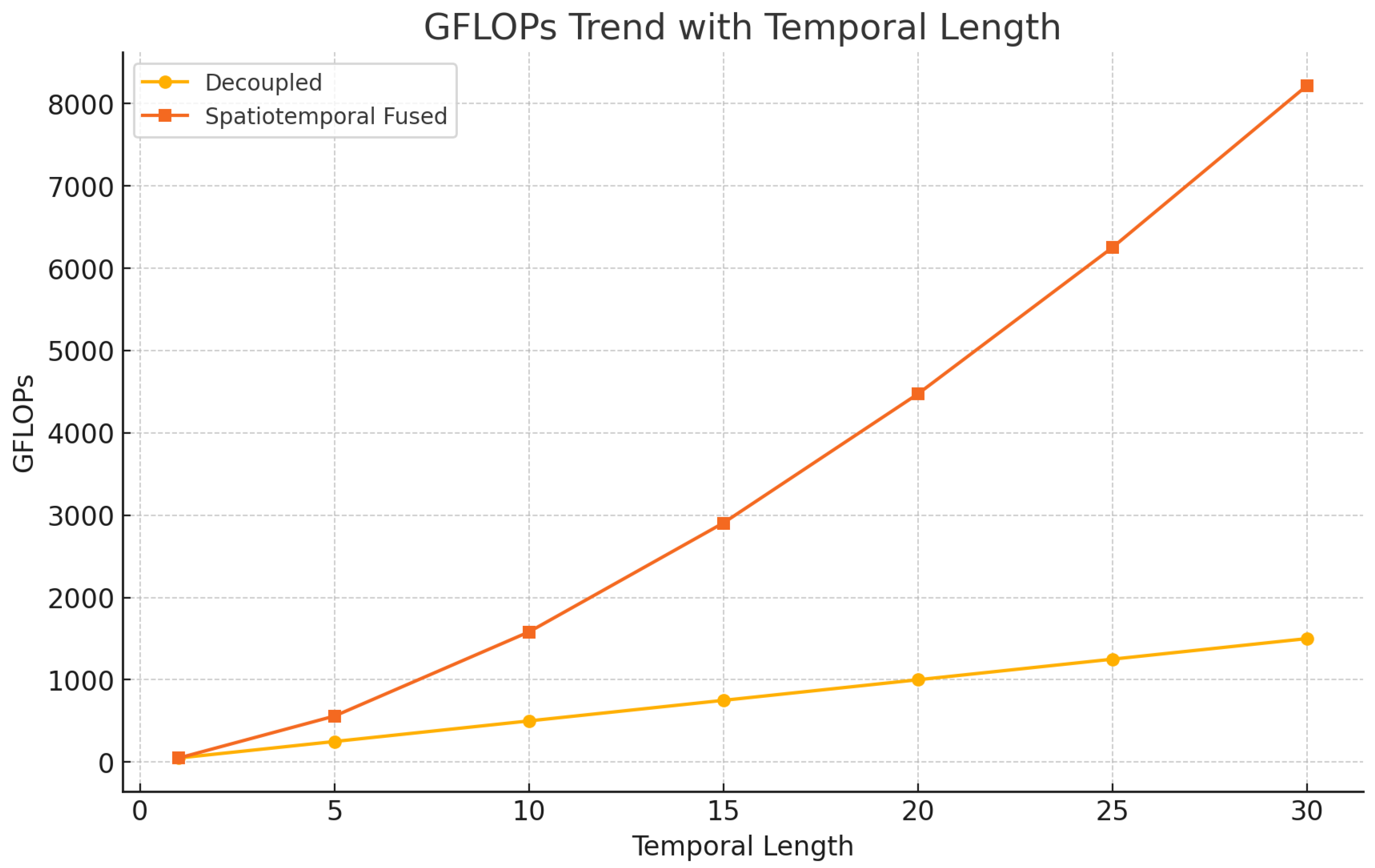
4.5. Efficiency vs. Temporal Sequence Length
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250m vegetation index data for crop classification in the U.S. Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef]
- Wang, Y.; Braham, N.; Xiong, Z.; Liu, C.; Albrecht, C.; Zhu, X. SSL4EO-S12: A Large-Scale Multimodal, Multitemporal Dataset for Self-Supervised Learning in Earth Observation. IEEE Geosci. Remote. Sens. Mag. 2023, 11, 98–106. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, C.; Li, J.; Chen, X. Crop type mapping based on remote sensing foundation models: A self-supervised paradigm for few-label settings. Remote Sens. 2023, 15, 578. [Google Scholar] [CrossRef]
- Tian, X.; Ran, H.; Wang, Y.; Zhao, H. GeoMAE: Masked Geometric Target Prediction for Self-supervised Point Cloud Pre-Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13037–13046. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Rong, X.; Yang, Z.; Chang, H.; et al. RingMo: A Remote Sensing Foundation Model with Masked Image Modeling. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5612822. [Google Scholar] [CrossRef]
- Marsocci, V.; Jia, Y.; Bellier, G.L.; Kerekes, D.; Zeng, L.; Hafner, S.; Gerard, S.; Brune, E.; Yadav, R.; Shibli, A.; et al. PANGAEA: A Global and Inclusive Benchmark for Geospatial Foundation Models. arXiv 2024, arXiv:2412.04204. [Google Scholar]
- Rußwurm, M.; Körner, M. Temporal vegetation modelling using long short-term memory networks for crop identification from medium-resolution multi-spectral satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–8. [Google Scholar]
- Bannur, S.; Hyland, S.; Liu, Q.; Pérez-García, F.; Ilse, M.; Castro, D.C.; Boecking, B.; Sharma, H.; Bouzid, K.; Thieme, A.; et al. Learning to exploit temporal structure for biomedical vision-language processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15016–15027. [Google Scholar]
- Liu, F.; Chen, D.; Guan, Z.; Zhou, X.; Zhu, J.; Ye, Q.; Fu, L.; Zhou, J. RemoteCLIP: A Vision Language Foundation Model for Remote Sensing. arXiv 2023, arXiv:2306.11029. [Google Scholar] [CrossRef]
- Xiong, Z.; Wang, Y.; Zhang, F.; Stewart, A.J.; Dujardin, J.; Borth, D.; Zhu, X.X. Neural Plasticity-Inspired Foundation Model for Observing the Earth Crossing Modalities. arXiv 2024, arXiv:2403.15356. [Google Scholar]
- Gao, H.; Jiang, R.; Dong, Z.; Deng, J.; Ma, Y.; Song, X. Spatial-temporal-decoupled masked pre-training for spatiotemporal forecasting. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, Jeju, Republic of Korea, 3–9 August 2024; pp. 3998–4006. [Google Scholar]
- Wang, Y.; Albrecht, C.; Braham, N.; Mou, L.; Zhu, X. Self-supervised Learning in Remote Sensing: A Review. IEEE Geosci. Remote. Sens. Mag. 2022, 10, 213–247. [Google Scholar] [CrossRef]
- Schultz, M.; Kruspe, A.; Bethge, M.; Zhu, X.X. OpenStreetMap: Challenges and opportunities in machine learning and remote sensing. IEEE Geosci. Remote Sens. Mag. 2021, 9, 184–207. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bastani, F.; Wolters, P.; Gupta, R.; Ferdinando, J.; Kembhavi, A. Satlas: A Large-Scale, Multi-Task Dataset for Remote Sensing Image Understanding. arXiv 2022, arXiv:2211.15660. [Google Scholar]
- Toker, A.; Kondmann, L.; Weber, M.; Eisenberger, M.; Camero, A.; Hu, J.; Hoderlein, A.P.; Senaras, C.; Davis, T.; Cremers, D.; et al. DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21158–21167. [Google Scholar]
- Jakubik, J.; Roy, S.; Phillips, C.E.; Fraccaro, P.; Godwin, D.; Zadorzny, B.; Szwarcman, D.; Gomes, C.; Nyirjesy, G.; Edwards, B.; et al. Foundation Models for Generalist Geospatial Artificial Intelligence. arXiv 2023, arXiv:2301.12345. [Google Scholar]
- Rustowicz, R.; Cheong, R.; Wang, L.; Ermon, S.; Burke, M.; Lobell, D. Semantic Segmentation of Crop Type in Africa: A Novel Dataset and Analysis of Deep Learning Methods. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 75–82. [Google Scholar]
- Garnot, V.S.F.; Landrieu, L.; Chehata, N. Multi-Modal Temporal Attention Models for Crop Mapping from Satellite Time Series. ISPRS J. Photogramm. Remote Sens. 2022, 187, 294–305. [Google Scholar] [CrossRef]
- Mendieta, M.; Han, B.; Shi, X.; Zhu, Y.; Chen, C. GFM: Building Geospatial Foundation Models via Continual Pretraining. arXiv 2023, arXiv:2302.04476. [Google Scholar]
- Fuller, A.; Millard, K.; Green, J.R. SatViT: Pretraining Transformers for Earth Observation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3513205. [Google Scholar] [CrossRef]
- Manas, O.; Lacoste, A.; Gidel, G.; Le Jeune, G.; Alahi, A.; Rusu, A. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9414–9423. [Google Scholar]
- Wang, G.; Chen, H.; Chen, L.; Zhuang, Y.; Zhang, S.; Zhang, T.; Dong, H.; Gao, P. P2FEViT: Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer for Remote Sensing Image Classification. Remote Sens. 2023, 15, 1773. [Google Scholar] [CrossRef]
- Guo, X.; Feng, Q.; Guo, F. CMTNet: A Hybrid CNN-Transformer Network for UAV-Based Hyperspectral Crop Classification in Precision Agriculture. Sci. Rep. 2025, 15, 12383. [Google Scholar] [CrossRef]
- Garnot, V.S.F.; Chehata, N.; Landrieu, L.; Boulch, A. Few-Shot Learning for Crop Mapping from Satellite Image Time Series. Remote Sens. 2024, 16, 1026. [Google Scholar] [CrossRef]
- Keraani, M.K.; Mansour, K.; Khlaifia, B.; Chehata, N. Few-Shot Crop Mapping Using Transformers and Transfer Learning with Sentinel-2 Time Series: Case of Kairouan, Tunisia. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2022, XLIII-B3-2022, 899–906. [Google Scholar] [CrossRef]
- Luo, Y.; Yao, T. Remote-Sensing Foundation Model for Agriculture: A Survey. In Proceedings of the ACM Multimedia Asia Workshops (MMAsia ’24), Auckland, New Zealand, 3–6 December 2024; ACM: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; Volume 33, pp. 21271–21284. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 16000–16009. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. BEiT: BERT Pre-Training of Image Transformers. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Bao, J.; Yao, Z.; Dai, Z.; Lin, Q.; Hu, H. SimMIM: A Simple Framework for Masked Image Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014; Volume 27, pp. 2672–2680. [Google Scholar]
- Bardes, A.; Ponce, J.; LeCun, Y. VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 25–29 April 2022. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9630–9640. [Google Scholar]
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, B.; Burke, M.; Lobell, D.; Ermon, S. Geography-aware self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10257–10266. [Google Scholar]
- Fang, H.; Yu, K.; Wu, S.; Tang, Y.; Misra, I.; Belongie, S. Scaling Language-Free Visual Representation Learning. arXiv 2024, arXiv:2504.01017. [Google Scholar]
- Wagner, S.S.; Harmeling, S. Object-Aware DINO (Oh-A-DINO): Enhancing Self-Supervised Representations for Multi-Object Instance Retrieval. arXiv 2025, arXiv:2503.09867. [Google Scholar]
- Locatello, F.; Weissenborn, D.; Unterthiner, T.; Mahendran, A.; Heigold, G.; Uszkoreit, J.; Dosovitskiy, A.; Kipf, T. Object-Centric Learning with Slot Attention. arXiv 2020, arXiv:2006.15055. [Google Scholar]
- Wu, Z.; Hu, J.; Lu, W.; Gilitschenski, I.; Garg, A. SlotDiffusion: Object-Centric Generative Modeling with Diffusion Models. arXiv 2023, arXiv:2305.11281. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Himeur, Y.; Aburaed, N.; Elharrouss, O.; Varlamis, I.; Atalla, S.; Mansoor, W.; Al Ahmad, H. Applications of Knowledge Distillation in Remote Sensing: A Survey. arXiv 2024, arXiv:2409.12111. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Type | Principle | Representative Methods |
|---|---|---|
| Contrastive Learning | Learning from positive and negative sample pairs | SimCLR [30], MoCo [31], BYOL [32] |
| Masked Image Modeling | Reconstructing masked information | MAE [33], BEiT [34], SimMIM [35] |
| Generative Self-Supervised Learning | Autoencoder architecture | Autoencoder [36], VAE [37], GAN [38] |
| Non-Contrastive Learning | Constructing guiding models | VICReg [39], DINO [40] |
| Model | Structure | Network | Training Param. | Overall Param. | Pre-training Data | Data Source |
|---|---|---|---|---|---|---|
| CROMA | CL | ViT-B | 47 M | 350 M | 3 M | Sentinel |
| DOFA | CL | ViT-B | 39.4 M | 151 M | 8.08 M | Sentinel |
| RemoteCLIP | CL | ViT-L | 39.4 M | 168 M | 1 TB | SEG-4, etc. |
| scaleMAE | MAE | ViT-L | 47 M | 350 M | 363.6 K | FMoW |
| spectralGPT | SR | SpectralGPT | 164 M | 250 M | 1.47 M | FMoW, etc. |
| SSL4EO_Data2Vec | RL | ViT-S/16 | 31 M | 53.5 M | 3 M | Sentinel |
| SSL4EO_MAE | MAE | ViT-S/16 | 47 M | 350 M | 4 M | Sentinel |
| SSL4EO_DINO | TS | ViT-S/16 | 31 M | 53.5 M | 5 M | Sentinel |
| SSL4EO_MoCo | MCL | ViT-S/16 | 31 M | 53.5 M | 6 M | Sentinel |
| CropSTS | TS + KD | ViT-S | 22.42 M | 22.42 M | 3300 | Sentinel |
| ViT | TS | ViT-S | 85.5 M | 85.5 M | - | - |
| Model | KNN | Linear Probe | ||
|---|---|---|---|---|
| mIoU (%) | Acc. (%) | mIoU (%) | Acc. (%) | |
| CROMA | 6.00 | 29.43 | 8.56 | 45.63 |
| DOFA | 4.46 | 21.70 | 5.01 | 28.49 |
| RemoteCLIP | 4.40 | 23.15 | 5.27 | 31.91 |
| scaleMAE | 3.73 | 19.04 | 4.05 | 24.83 |
| SpectralGPT | 3.87 | 19.97 | 4.93 | 28.72 |
| SSL4EO_Data2Vec | 4.16 | 22.51 | 6.35 | 39.31 |
| SSL4EO_MAE | 4.74 | 22.88 | 7.27 | 39.79 |
| SSL4EO_DINO | 5.40 | 24.88 | 7.23 | 36.79 |
| SSL4EO_MoCo | 4.70 | 22.77 | 6.80 | 39.56 |
| CropSTS | 9.73 | 37.19 | 12.71 | 51.85 |
| ViT | 4.16 | 21.88 | 3.91 | 28.74 |
| Model | mIoU (%) | F1 Score (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|
| CROMA_Optical | 37.123 | 50.711 | 47.687 | 59.469 |
| DOFA | 28.108 | 39.914 | 37.094 | 48.212 |
| RemoteCLIP | 16.781 | 25.499 | 24.330 | 30.429 |
| scaleMAE | 23.943 | 34.422 | 31.601 | 43.189 |
| SpectralGPT | 33.872 | 47.035 | 44.173 | 54.271 |
| SSL4EO_Data2Vec | 33.172 | 46.101 | 43.124 | 55.112 |
| SSL4EO_MAE_Optical | 31.818 | 43.779 | 40.455 | 53.247 |
| SSL4EO_DINO | 33.924 | 46.865 | 43.790 | 55.382 |
| SSL4EO_MoCo | 32.840 | 46.96 | 42.788 | 55.657 |
| CropSTS | 39.093 | 52.769 | 49.620 | 60.093 |
| ViT | 12.148 | 19.276 | 18.752 | 24.854 |
| Model | Meadow | Soft Wheat | Corn | WB | WR | SB | Grapevine | Beet | WT | WDW | FVF | Potatoes | LF | Soybeans | Orchard | MC | Sorghum | Void | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CROMA | 54.821 | 66.066 | 59.890 | 48.878 | 70.320 | 25.955 | 33.986 | 42.040 | 58.185 | 17.223 | 43.408 | 20.196 | 27.434 | 21.910 | 34.385 | 30.318 | 6.936 | 0 | 37.123 |
| DOFA | 54.535 | 56.162 | 57.101 | 33.483 | 62.555 | 7.825 | 20.806 | 24.005 | 52.561 | 9.705 | 31.052 | 14.381 | 15.840 | 13.383 | 28.466 | 16.053 | 3.488 | 0 | 28.108 |
| RemoteCLIP | 43.483 | 37.420 | 34.011 | 11.693 | 20.042 | 1.926 | 13.121 | 33.229 | 20.142 | 2.865 | 18.522 | 4.244 | 0.260 | 5.445 | 10.074 | 12.836 | 0.262 | 0 | 16.781 |
| scaleMAE | 51.263 | 51.242 | 50.690 | 26.538 | 46.872 | 8.761 | 12.580 | 31.940 | 42.811 | 10.056 | 30.231 | 14.465 | 2.636 | 6.869 | 9.193 | 13.712 | 0.751 | 0 | 23.943 |
| SpectralGPT | 52.595 | 61.687 | 53.955 | 43.429 | 65.609 | 26.232 | 31.085 | 41.474 | 51.065 | 13.988 | 43.025 | 16.948 | 19.496 | 16.338 | 26.955 | 28.690 | 10.187 | 0 | 33.872 |
| SSL4EO_Data2Vec | 53.580 | 61.227 | 55.130 | 43.432 | 68.222 | 22.592 | 29.860 | 39.561 | 51.681 | 8.870 | 38.120 | 14.764 | 23.371 | 17.808 | 30.384 | 27.396 | 7.615 | 0 | 33.172 |
| SSL4EO_MAE | 51.904 | 57.415 | 51.351 | 37.192 | 59.438 | 20.166 | 33.333 | 33.712 | 48.151 | 11.623 | 36.267 | 18.460 | 23.962 | 10.564 | 24.111 | 22.685 | 6.462 | 0 | 31.818 |
| SSL4EO_DINO | 52.446 | 63.264 | 57.044 | 48.069 | 66.237 | 23.774 | 34.525 | 38.226 | 53.691 | 11.660 | 43.386 | 13.425 | 23.300 | 19.727 | 32.228 | 20.962 | 2.413 | 0 | 33.924 |
| SSL4EO_MoCo | 54.938 | 58.542 | 60.205 | 42.965 | 61.513 | 19.013 | 30.001 | 37.584 | 54.516 | 19.666 | 41.365 | 18.450 | 10.545 | 20.263 | 29.674 | 20.018 | 7.534 | 0 | 32.840 |
| CropSTS | 57.477 | 65.854 | 67.456 | 51.789 | 70.517 | 28.944 | 44.963 | 39.020 | 67.445 | 25.534 | 43.457 | 25.841 | 25.171 | 28.721 | 36.519 | 27.386 | 6.369 | 0 | 39.093 |
| ViT_MI | 30.957 | 20.574 | 30.831 | 3.031 | 9.775 | 9.910 | 7.343 | 25.160 | 2.172 | 3.532 | 14.228 | 2.618 | 0.000 | 0.140 | 13.922 | 12.639 | 0.000 | 0 | 12.148 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Gu, X.; Chen, Y. CropSTS: A Remote Sensing Foundation Model for Cropland Classification with Decoupled Spatiotemporal Attention. Remote Sens. 2025, 17, 2481. https://doi.org/10.3390/rs17142481
Yan J, Gu X, Chen Y. CropSTS: A Remote Sensing Foundation Model for Cropland Classification with Decoupled Spatiotemporal Attention. Remote Sensing. 2025; 17(14):2481. https://doi.org/10.3390/rs17142481
Chicago/Turabian StyleYan, Jian, Xingfa Gu, and Yuxing Chen. 2025. "CropSTS: A Remote Sensing Foundation Model for Cropland Classification with Decoupled Spatiotemporal Attention" Remote Sensing 17, no. 14: 2481. https://doi.org/10.3390/rs17142481
APA StyleYan, J., Gu, X., & Chen, Y. (2025). CropSTS: A Remote Sensing Foundation Model for Cropland Classification with Decoupled Spatiotemporal Attention. Remote Sensing, 17(14), 2481. https://doi.org/10.3390/rs17142481