1. Introduction
Drought has been one of the most negatively impactful natural disasters in the past few decades, often triggering food crises and irreversible damage to ecosystems and causing huge socio-economic losses [
1]. Against the backdrop of global warming, extreme climate phenomena have intensified, further exacerbating these negative impacts, and the defense against drought has received widespread attention. Soil moisture (SM) is an important component of the global water cycle system [
2] and is widely used in drought assessment, playing a key role in it [
3]. Large-scale, long-term series and high-precision SM prediction has significant scientific value and strategic significance for regional and even global climate change research, water cycle analysis, vegetation status monitoring, and drought and flood early warning [
4,
5]. Accurate SM prediction has played a significant role in formulating irrigation systems and drought prevention and resistance measures [
6]. In soil and environmental management applications, it is usually necessary to conduct SM prediction one month in advance. SM is affected by various factors such as precipitation, soil properties and topography [
7,
8], making SM prediction both deterministic and obviously nonlinear, and making accurate prediction complex. The commonly used SM simulation methods mainly include remote sensing technology, mechanism model simulation, and machine learning (ML) models.
Remote sensing technology makes up for shortcomings in the spatial coverage of site monitoring, can provide a wide range of SM results, and has a high temporal and spatial resolution. In recent years, multiple SM observation satellites have been launched successively, for example the Advanced Microwave Scanning Radiometer for Earth Observing System (AMSR-E), Soil Moisture Ocean Salinity (SMOS), and Soil Moisture Active and Passive (SMAP). These satellites provide long-term and global SM, offering significant support for global agricultural drought prediction [
9,
10]. Among these data, the SMAP SM product has excellent performance and a high temporal resolution, providing reliable SM information worldwide [
11]. Its superiority has been widely validated [
10,
12]. In real-world application, the overall accuracy of SMAP products is superior to that of AMSR2 products. The SM state is jointly affected by dynamic surface parameters and static underlying surfaces. However, remote sensing technology is still limited to surface measurement (<5 cm), is hindered by vegetation interference, and is mainly focused on monitoring.
The mechanism model is a method used to predict the changes in SM. Over the past few decades, many scholars have attempted to predict SM using control equations based on complex hydrological processes [
13,
14]. With the development of technology, the use of hydrological models has become widespread, and the reliability of these models has been confirmed [
15]. The VIC model can take into account factors such as soil texture, vegetation coverage and climatic conditions, and can obtain continuous spatiotemporal sequences of SM. It is widely used in SM simulation [
16,
17]. Other models used to simulate SM also include SWAP, SWAT, and HYDRUS. The selection of a model depends on the simulation’s purpose, spatial resolution, model complexity and available parameter information [
18]. However, due to the unclear mechanisms of each link from rainfall to SM transport, a large number of parameters of the model need to be generalized, reducing the accuracy of simulation [
19,
20].
In recent years, ML has developed rapidly. Some studies have evaluated the performance and limitations of physical models and explored ML models as alternatives [
21,
22]. Research shows that models based on artificial intelligence can outperform those based on physics, demonstrating significant value [
23,
24]. ML methods are widely used to estimate SM [
25,
26]. Traditional ML methods, such as random forest (RF), multiple linear regression (MLR), support vector machine (SVM), and gradient boosting regression tree (GBRT), provide effective approaches for SM prediction, fully demonstrating the application potential of ML in this field [
27,
28]. The hourly SM in Taichung area, Taiwan, was predicted using the RF by Chen et al. [
29]. Li et al., in 2024 [
30], improved global SM prediction based on the meta-learning model using the Koppen–Geigel climate classification. This rapidly developing deep learning (DL) technology also provides an effective approach for understanding data-driven Earth system science [
31] and establishing nonlinear relationships between model inputs and outputs. A large number of studies have shown that the correlation between the predictions and measured values of artificial neural network (ANN) models is good [
32]. The DL models can take dynamic climate variables and surface features as inputs to predict SM [
33]. DL models commonly used for predicting SM include ANNs, deep neural networks (DNNs), recurrent neural networks (RNNs), and long short-term memory (LSTM) [
34]. ANNs provide new opportunities to estimate global SM through learning a generative model from a series of available SM products. In recent years, the classic shallow ANN has been successfully applied for SMOS and SMAP SM retrievals. Gao et al., in 2022 [
33], presented a DNN that combines the advantages of a suite of existing satellite and reanalysis products to produce a new SM product with minimum (maximum) bias (correlation), using NASA’s SMAP data and ERA5 reanalysis. In 2024, Zhao et al. [
35] compared the performance of an RNN and a CNN in hydrological prediction. Transformer-based models have shown remarkable capabilities in improving the accuracy of SM prediction [
36]. Furthermore, studies have shown that LSTM demonstrates superior performance [
37]. LSTM is a type of time-recurrent neural network specifically designed to address the long-term dependency issue that exists in general RNNs. All RNNs have a chain-like form of repetitive neural network modules. The improved and derived methods based on LSTM have effectively enhanced the accuracy in SM simulation and prediction [
38]. They can predict the SM changes in the next month and perform well in predicting meteorological droughts in the next three months; they are also capable of issuing drought warnings 5 to 7 days in advance.
The memory characteristics of SM at different time scales have different influences on long-term SM prediction in data-driven models [
39]. Although LSTM excels in capturing long-term correlations [
21], its original design is mainly based on historical information rather than the overall time series when predicting individual future time points, which may make it difficult for the model to fully mine or appropriately allocate key information in long-term data analysis. Encoder–decoder architecture and location coding can effectively handle complex patterns in meteorological data, thereby improving the accuracy of deterministic prediction and extreme weather prediction. The encoder–decoder model shows significant potential in predicting Earth system processes such as SM time series and agricultural drought. Li et al. [
40] proposed a multi-step SM prediction model based on spatio-temporal deep encoder–decoder networks, demonstrating its adaptability to different climate regions. Li et al. [
41] proposed a novel SM prediction model, REDF-LSTM, and enhanced the model’s ability to capture complex nonlinear relationships.
SM is influenced by multiple factors such as precipitation, radiation, temperature, humidity, wind speed, land cover, and soil properties, and has memory for historical data. These relationships are usually nonlinear, so predicting SM is particularly challenging. The selection of both models and data is very important. Some achievements have been made in this area of research. The research suggests that meteorological factors have the greatest impact on SM prediction [
42], and that previous and current SM has an influence on estimating future SM [
43]. Yu et al. [
44] established the ResBiLSTM SM prediction model using grid meteorological data and SM. Multiple variables, including soil temperature, relative humidity, temperature, total radiation and evapotranspiration, were used as ML inputs to improve the accuracy of SM prediction at different depths. Considering historical and meteorological data for SM prediction in the ML model can better improve the accuracy of SM prediction. Fedasyuk and Kostiuk [
45] used historical data and weather forecast data to develop ML models for SM prediction. This coupled modeling method combines process-based models with AI-based ML techniques, providing enhanced predictive performance [
46]. Coupling mechanism models with ML has become a research hotspot. A large number of studies have shown that the coupling of mechanism models with ML has significant advantages for mining and capturing complex meteorological, hydrological and underlying surface features to improve the prediction ability of SM, providing a new technical path for hydrological simulation. Zhao et al. [
47] significantly improved the accuracy of SM simulation by enhancing the parameterization scheme of the land surface process model (LSM) and combining it with ML techniques.
Remote sensing, mechanism models and ML each have their advantages in SM monitoring and prediction, but they also have limitations. At present, there are relatively few studies on SM prediction models that combine these three methods. Commonly used DL models (such as LSTM) and ML models require regular matrix input and are often constructed by data dimensionality reduction or feature information reduction. There are relatively few studies on multi-step prediction models of daily-scale SM with time dependence, different feature lengths and different quantities. In this study, a VIC-LSTMseq2seq model was constructed. The input included the meteorological and SM from the past N days, as well as the meteorological data and VIC model simulation results for the next M days. The SM on the M day in the future was predicted, and it was compared with that of classical ML models, classic DL models such as the LSTM model, and the advanced transformer model. The key points of innovation in this research include the following: (1) we integrated physical mechanisms and DL, comprehensively considering the characteristics of the past and the future; (2) the model we constructed can handle feature inputs of different lengths and quantities, taking into account the SM memory; (3) this research explains the model’s behavior through feature importance analysis and identifies the main influencing factors. This research is innovative in its design of the coupled model and performance validation, and contributes to improving prediction accuracy.
3. Results
3.1. Construction of the Hybrid Data-Driven Model
We developed a hybrid data-driven model based on the VIC-LSTMseq2seq architecture, incorporating both past and future simulated features. The past observational data included meteorological and SM, while the future simulated data were based on potential future meteorological conditions, using the VIC model to simulate future hydrological states. SMAP SM served as the target variable. To evaluate the model’s performance in simulating SM, the meteorological driving data required by the VIC model during training were sourced from actual future meteorological data to minimize model error uncertainty arising from meteorological forecast inaccuracies.
The model integrates multiple meteorological elements and antecedent SM over a past time period, rather than relying solely on current meteorological and hydrological conditions. This approach considers the collective influence of meteorological elements over a given time span on SM. The meteorological elements primarily included precipitation, air temperature, wind speed, and relative humidity. Precipitation, being the primary source of SM, directly affects its increase, with the amount and frequency of precipitation playing a crucial role in SM dynamics. Higher temperatures accelerate evaporation, thereby reducing SM. Average temperatures reflect diurnal and nocturnal temperature variations, significantly influencing SM evaporation and plant transpiration. Maximum temperatures affect the evaporation rate from the soil surface and plant transpiration. Wind speed influences the evaporation rate from the soil surface, with higher wind speeds accelerating SM evaporation and reducing SM. Relative humidity, indicating the moisture content in the atmosphere, affects the evaporation rate from the soil surface, with higher relative humidity reducing evaporation and helping to maintain SM. Current SM, as a direct measurement, reflects changes in SM and serves as a crucial benchmark for predicting future SM levels. Each past feature was structured as (T_hist, S_hist), where T_hist represents the number of past days and S_hist denotes the number of features.
Outputs from the VIC model, including future evaporation, surface runoff, baseflow, canopy interception, the SM of the first layer (FLSWC), and the SM of the second layer (SLSWC), were used as input variables for the VIC-LSTMseq2seq model. FLSWC reflects the moisture conditions in the soil surface layer, a key indicator of SM that directly affects plant growth and soil evaporation rates. SLSWC reflects SM conditions at greater depths, significantly influencing long-term SM changes, groundwater recharge, and SM retention capacity. In this study, the FLSWC and the SLSWC were not directly utilized. Instead, the absolute values of the model simulations for the current day and the previous day were considered. This approach was adopted to better capture the dynamic changes in SM, reduce redundant information, enhance prediction capabilities, and minimize the impact of absolute value errors in the VIC model simulation. Simulated features were also organized into “feature blocks,” with each feature shaped as (T_forcast, S_forcast), where T_forcast represents the number of future days and S_forcast denotes the number of features. We used eight types of features (precipitation, maximum temperature, minimum temperature, average temperature, wind speed, relative humidity, difference in FLSWC, difference in SLSWC) over the next 7 days, with S_forcast = 8 and T_forcast = 7.
The combination of past observational features and simulated future hydrological features provides comprehensive input information for SM prediction. The selection of these features was based on their direct correlation with SM and their significance in climatology and soil science. For the target variable, we utilized the SMAP L4 SM observational dataset as the primary data source, reflecting SM at a depth of 0–10 cm. This daily dataset has a high temporal resolution, with an acquisition delay of approximately 2–3 days.
Data from 1 January 2016 to 31 December 2022 were selected. To prevent data leakage, the first 60% is used for model training, followed by 20% for validation, and the remaining 20% for testing. That is, the data from 2016 to March 2020, approximately, were used for training, the data from March 2020 to August 2021 were used for validation, and the data from August 2021 to December 2022 were not used for training but used to test the performance of the model. The time range of the SMAP also spanned 2016–2022. We preprocessed the collected datasets to ensure data quality, removing missing and outlier values. The target variable retained its original units, and the SMAP data were resampled to match the 0.0625 resolution of the VIC model output. The validation set was used to tune the model’s hyperparameters. Given the temporal nature of the data, the dataset was split chronologically to prevent data leakage, ensuring that the training set always preceded the validation set. The testing set was employed to assess the model’s performance on unseen data. This structure ensured the model’s robustness and generalizability, enabling it to effectively handle real-world scenarios. The model framework is illustrated in
Figure 3.
3.2. Ablation Experiment
The performance of the LSTMseq2seq model is significantly influenced by the setting of hyperparameters. By adjusting the learning rate, the size of the hidden layer, the batch size, and the number of training iterations, the accuracy and generalization ability of the model can be optimized. Through the analysis of the optimal parameters, it was determined that when the learning rate is 0.0001, the hidden layer size is 32, the batch size is 8, and the Epoch is 500, the R2 is the highest; these factors are used as the hyperparameters of the model in this paper. The experiment was executed on a computer with an Intel(R) Core(TM) i5-9400F CPU @ 2.90GHz, and the operating system used was Windows. The DL framework selected was PyTorch 1.13.0, which utilizes NVIDIA’s CUDA backend to enhance computational efficiency and performance. To reduce the random fluctuations in the experimental results, the experiment was repeated 5 times and the average value was taken to ensure the stability and reliability of the results. Additionally, all comparative experiments adopted the same random seed value to ensure the consistency of the experimental conditions. Through the design of the experimental process and strict condition control, the scientific nature of the experimental results and the credibility of the model’s predictive ability were ensured.
To compare the effect of incorporating the VIC model and using the seq2seq framework, this study conducted ablation experiments. The LSTMseq2seq model with the difference in FLSWC and the difference in SLSWC from the VIC output was set as the baseline. Data feature ablation experiments and model structure ablation experiments were carried out to compare and analyze the impact of VIC output data parameters and the removal of VIC output data on SM prediction, respectively, as well as to compare and analyze the effects of removing the LSTM encoder and the LSTM decoder. Taking the predictions for the next 90 days as an example, the results are shown in
Table 1. Overall, the accuracy of the baseline model is higher, and the accuracy of removing the decoder is the lowest.
3.3. Comparison of Prediction Accuracy for Soil Moisture Across Multiple Time Steps Using Different Models
To systematically assess the impact mechanism of simulation step length on SM prediction accuracy, this study designed comparative experiments across multiple time scales. Using 30 days of historical meteorological data and SMAP SM, as well as future hydrological states simulated by the VIC model, we selected five typical step lengths—3 days, 7 days, 30 days, 60 days, and 90 days—as the subjects of our study. The experimental data presented in
Table 2 reveal a clear pattern: model accuracy decreases nonlinearly with increasing step length. Specifically, under the optimal 3-day step length condition, the model demonstrated exceptional predictive capability (R
2 = 0.9490, MSE = 0.0003). When the step length was extended to 30 days, although the R remained at a high level of 0.9414, the metrics showed significant degradation. By the 90-day step length, R
2 plummeted to 0.7451, and the MSE surged to 0.0014. By establishing the step size–accuracy response curve, it was found that the accuracy was better when the step size changed within 7 days, but it decreased rapidly when the step size changed after 30 days. This research result not only verified the basic rule of “short step size for high accuracy”, but also precisely quantified the accuracy loss characteristics at different time scales. For scenarios such as drought warning, it is recommended to use a step size of ≤7 days. For medium- and long-term water resource planning, a step size of ≤30 days can be selected. For predictions longer than 60 days, it is recommended to combine the model with other auxiliary methods to improve reliability.
To compare the superiority of the model, the hybrid data-driven LSTMseq2seq model was compared with classical ML models such as the support vector machine (SVM), the 1D convolutional neural network (1D-CNN), random forest (RF), as well as the classic DL model, LSTM, and the advanced transformer model. Among these methods, the meteorological elements from the past N days were used as feature blocks and applied to the future SM simulation results, rather than just using the current
t0 moment’s meteorological data. In the LSTMseq2seq model, the simulation features for the future M days were also used as feature blocks, jointly simulating the SM on the M day in the future with the past observed data. The
Figure 4 shows the scatter plots and step length–accuracy response curves for SM predictions.The accuracy comparison is shown in
Table 2. The results indicate that the R
2 (0.9490) of the LSTMseq2seq model is significantly higher than that of the traditional ML models, the classic DL model (LSTM), and the advanced transformer model. This fully proves that the LSTMseq2seq model, by integrating physical mechanisms with DL methods, has significant advantages in terms of the accuracy (MSE significantly reduced), stability (MAE improved), and interpretability (R
2 improvement) of SM simulation. When compared with other models, it can be seen that in terms of soil prediction ability, for prediction steps shorter than 30 days (<30 days), the performance ranking is LSTMseq2seq > LSTM > SVM > transformer > RF > 1D-CNN. For prediction steps longer than 60 days (>60 days), the performance ranking is LSTMseq2seq > LSTM > RF > SVM > transformer > 1D-CNN. This provides a new technical approach for developing SM prediction models that integrate physical mechanisms and data-driven methods.
3.4. Feature Importance Evaluation
The input variable system selected in this study comprehensively considers the synergistic mechanisms of meteorological forcing factors and hydrological process variables. Taking the simulation of SM on the 7 future day as an example, 30 days of historical meteorological observations, SMAP SM, future meteorological data, and differences in FLSWC and SLSWC output by the VIC model were selected. The selected variables cover two major dimensions: (1) the historical 30-day dynamic feature group, with the following parameters: precipitation (direct water input source, with significant cumulative daily effects), wind speed (which regulates surface evaporation through turbulent exchange, with evaporation losses exacerbated at critical wind speeds ≥ 3 m/s), maximum/minimum/average air temperature (which jointly constrain surface energy balance), relative humidity (which regulates soil–atmosphere vapor exchange through vapor pressure deficit), and SMAP SM (which provides initial moisture field observational constraints); (2) the future meteorology and VIC model output group, with the following parameters: precipitation, wind speed, maximum/minimum/average air temperature, and the difference in FLSWC (0–30 cm) and SLSWC (30–100 cm) (characterizing the vertical movement of water).
To systematically evaluate the relative importance of different time scales and feature types in the SM prediction model, this study employed the SHAP feature importance analysis method. We quantitatively analyzed the impacts of 30-day historical meteorological factors and SM (from t0 − 29 to t0), as well as future meteorological data and VIC-simulated differences in SM between the FLSWC and SLSWC for the subsequent 7 days (from t0 + 1 to t0 + 7), on the model’s prediction accuracy. The results are presented in
Figure 5. The findings reveal a significant “recency effect” across the entire time dimension in the time sensitivity analysis. Specifically, precipitation on day 7 (precipitation_t0 + 7, accounting for 5.66%) and the minimum air temperature on day 7 (min_temp_t0 + 7, accounting for 4.34%) exhibit the most prominent contributions to the model. Meanwhile, the importance of historical features decreases with time, while the observed historical SM status demonstrates considerable predictive value. The contribution of same-day precipitation (5.66%) to SM likely reflects its direct driving effect on abrupt changes in SM. As the primary input source of SM, precipitation particularly influences surface soil, with its impact typically manifesting on hourly to daily scales. The same-day minimum air temperature may indirectly regulate SM by affecting evapotranspiration or vegetation water use efficiency—for instance, low temperatures suppress evaporation, prolonging SM retention time.
In the feature contribution analysis without considering temporal factors (
Figure 6a), historical SM features dominated (SMAP hist, accounting for 28.4%), followed by meteorological factors such as average air temperature (avg temp, 19.28%), observed minimum temperature (min temp, 15.5%), and precipitation (precipitation, 13.39%). The importance of past SM features (28.4%) far exceeds that of meteorological factors (e.g., air temperature, precipitation), possibly due to the following: (1) the memory effect of SM, where changes exhibit hysteresis and the current state is the result of cumulative past meteorological conditions; (2) nonlinear hydrological responses, where SM changes are influenced by the complex interactions of the soil–vegetation–atmosphere continuum; (3) the impact of vertical heterogeneity, where SM at great depths changes slowly but affects surface moisture through upward replenishment.
In the time sensitivity analysis, as shown in
Figure 6b, the importance of the prediction day typically exceeds that of historical features. The closer the feature is to the prediction date, the greater its contribution, and the cumulative contribution of historical features in the most recent three days is particularly prominent, exhibiting a “recency effect”: (1) features closer to the prediction date contribute more, consistent with the “Markov property” of SM changes; (2) the significant cumulative contribution of historical features in the most recent three days reflects the time scale of SM redistribution.
The SHAP importance analysis revealed results that are highly consistent with classic theories in hydrometeorology, supporting the following optimization recommendations for SM prediction models: (1) retain 30-day historical SM data, consistent with the memory time scale of SM; (2) simplify meteorological inputs and focus on key periods (e.g., the 7 days before prediction) because the contribution of meteorological factors decays with time. Based on the above findings, this study draws the following conclusions: (1) the dynamic changes in SM exhibit a significant temporal memory effect, and a 30-day time window can effectively support predictions; (2) the predictive value of vertical heterogeneity information on SM exceeds that of meteorological driving data; (3) model optimization should prioritize retaining 30-day historical SM observation data while appropriately simplifying meteorological inputs to improve computational efficiency.
Through SHAP analysis, we further validated the importance of these input variables for the SM. The selection of these features was not only based on their physical signifi-cance but also validated through data analysis, ensuring the accuracy and reliability of the model.
3.5. Uncertainty Analysis
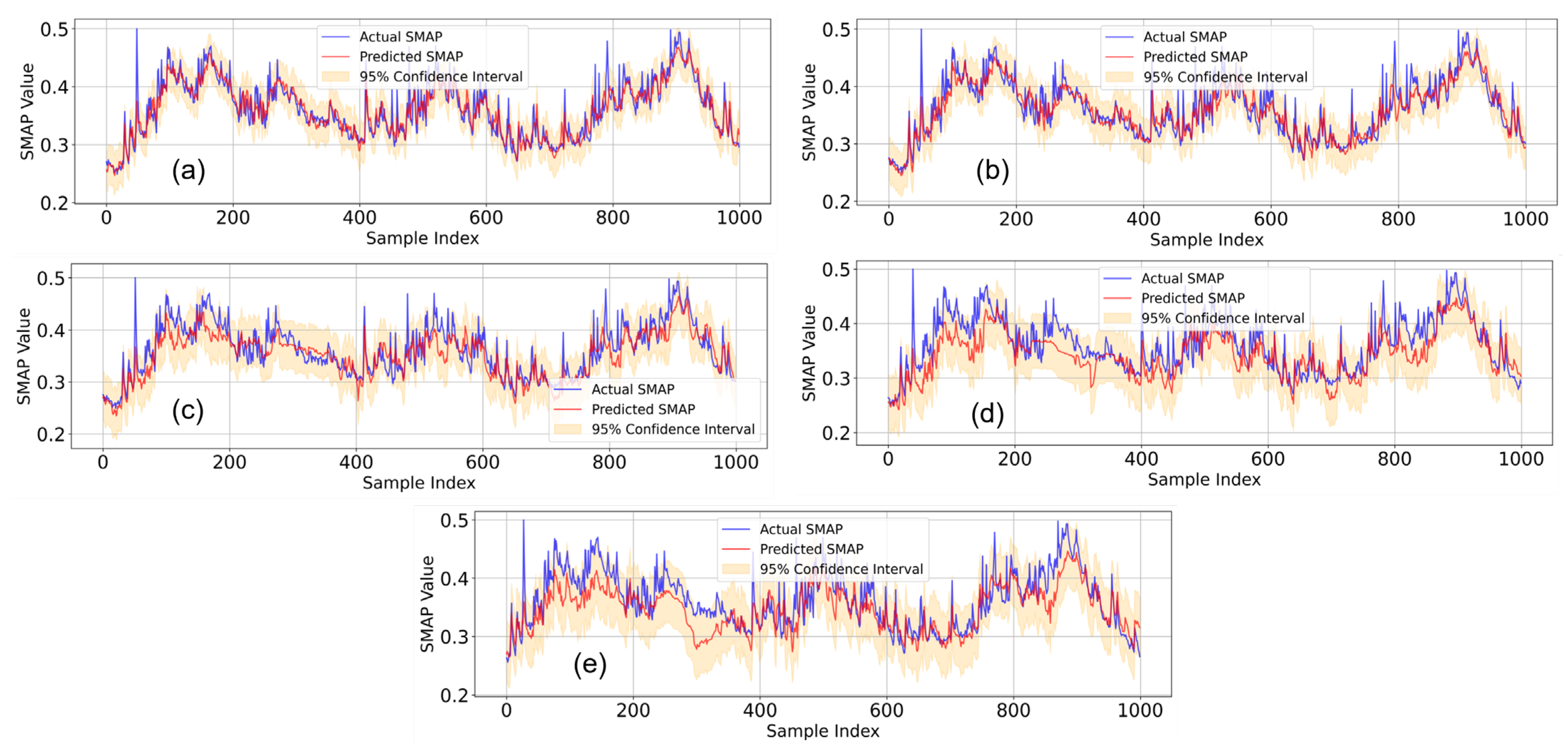
To analyze the uncertainty of the model, we utilized the VIC-LSTMseq2seq model to conduct confidence interval and probability distribution analyses for SM predictions over future 3-, 7-, 30-, 60-, and 90-day time steps, based on 30 days of historical meteorological data and future hydrological states simulated by the VIC model. The results are presented in
Table 3,
Figure 7 and
Figure 8.
The standard deviation of residuals is an indicator of the dispersion of model prediction errors, reflecting the magnitude of fluctuations in the differences between actual and predicted values. As shown in
Table 3, the residual standard deviation of our model ranges from 0.0169 to 0.0371, indicating relatively small and stable prediction errors. The 95% confidence interval of the model generally spans from 0.0332 to 0.0727, with a slight increase as the prediction step length increases. This implies that for any given prediction, we are 95% confident that the actual value will fall within the range defined by the confidence interval around the predicted value. The prediction range, calculated based on the standard deviation of residuals, provides the possible minimum and maximum values of the predictions. This range helps us understand the overall distribution of model predictions and identify any extreme or outlier values. The coverage probability (95% CI) indicates that the actual proportion of true values falling within the 95% confidence interval is greater than 94%, approaching or exceeding 95%. A high coverage probability suggests that the model’s uncertainty estimates are relatively accurate, meaning that the model can effectively capture the variations in actual values in most cases. Overall, the small residual standard deviation and narrow width of the 95% confidence interval indicate that the model has small and stable prediction errors, suggesting a good fit to the data and that high reliability of the prediction results. The prediction range (0.09–0.48) is consistent with the data range in practical applications, indicating that the model’s prediction range is reasonable.
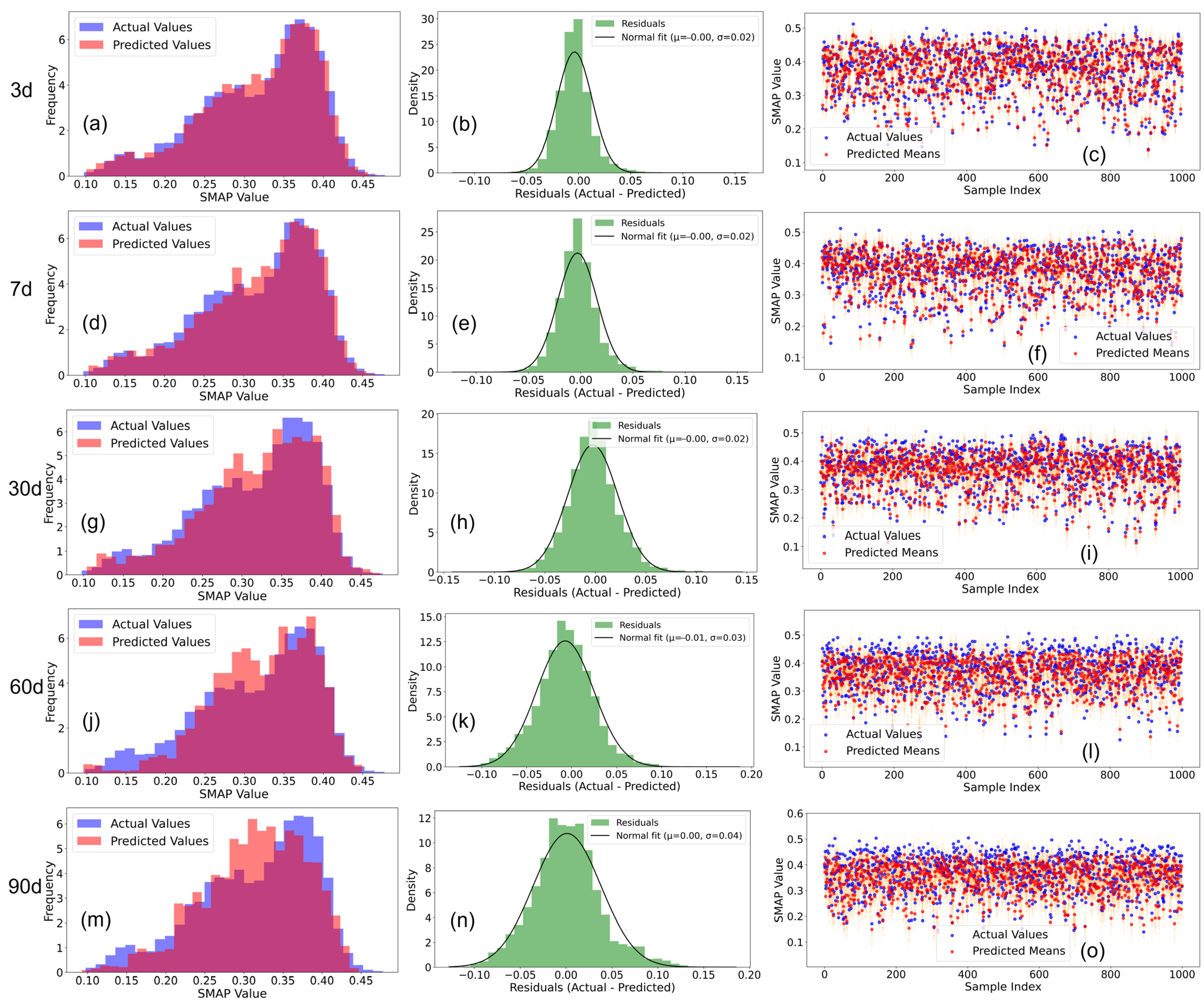
Figure 7 presents a comparison between the actual SM values and the predicted values for the first 1000 validation samples, along with the uncertainty range of the 95% confidence interval predictions. The majority of the data points fall within the 95% confidence interval, indicating that the model’s predictions are well calibrated and reliable.
Figure 8 displays the distribution of predicted and actual SM using SMAP across different prediction steps. The overlap between the frequency distributions of predicted values and actual values is substantial, suggesting high prediction accuracy and minimal differences between predicted and actual values. The similarity in the tails of the distributions indicates that the model performs well in predicting extreme values. The ability of the predicted distribution to cover most of the actual distribution demonstrates that the model effectively captures the uncertainty in the data, with reasonable prediction intervals. The high coverage probability and narrow confidence intervals of the model indicate superior predictive performance and low uncertainty.
Residuals are listed in
Table 2 for various prediction steps (3, 7, 30, 60, and 90 days). The distribution centers of the residuals range from 0.0169 to 0.0371, close to zero, indicating minimal deviation between predicted and actual values. The second column in
Figure 8, showing the residual deviations, reveals that the residuals are approximately normally distributed, suggesting that the prediction errors are random and lack systematic bias. Although the standard deviation of the residuals increases slightly with longer prediction steps, the overall variability remains low, indicating stable model predictions. The bell-shaped distribution of residuals, close to a normal distribution, further confirms the random nature of prediction errors and the absence of systematic bias. The symmetry of the residual distribution indicates balanced prediction capabilities for positive and negative errors, while the short tails suggest few extreme errors, enhancing the reliability of the model’s predictions.
The third column in
Figure 8 shows that the actual values and predicted values are closely aligned, indicating high prediction accuracy and minimal differences between predicted and actual values. The concentration of predicted values suggests stable model predictions with low variability. The model’s ability to predict extreme values, particularly within 30 days, demonstrates its robustness in handling anomalies.
3.6. Soil Moisture Simulation Distribution Maps
We conducted simulation predictions for SM on the 7, 30, 60, and 90 future days and compared the spatiotemporal distribution of SM predicted by the VIC-LSTMseq2seq model with the observations from the SMAP. As shown in
Figure 9, the temporal and spatial variations in the observed values from SMAP and the simulation results for the 7, 30, 60, and 90 days are highly consistent. The predicted results closely match the observed results from SMAP in terms of both temporal trends and spatial patterns. In terms of temporal trends, the variations in SM across different prediction steps align well with the observed changes in 2022. In early August 2022, some regions experienced mild SM deficits, while other areas faced moderate deficits. As time progressed, the drought conditions continued to intensify, reaching their peak in October and November, when severe drought conditions were observed across almost the entire province. In mid-to-late November, rainfall alleviated the drought conditions, and the SM status improved significantly by December. Spatially, the distribution of mild, moderate, and severe SM deficits predicted by the model closely matches the observed patterns. These results that confirm the VIC-LSTMseq2seq model demonstrates strong simulation and predictive capabilities for SM on days 3, 7, 30, and 60 into the future, highlighting its exceptional forecasting performance.
4. Discussion
4.1. Soil Moisture Autocorrelation Analysis
To investigate the improvement effects of DL in SM simulation and prediction, we used the SMAP SM as the true value and conducted an analysis of the temporal autocorrelation characteristics of SM. In this study, we calculated the autocorrelation coefficients for individual sites and the entire dataset at different lag days (0–1000 days) to analyze the temporal memory effect of SM, as shown in
Figure 10. The experimental results indicate that the data exhibit similar autocorrelation characteristics. Specifically, the most significant changes in the autocorrelation coefficients occur at lags below 10 days. At a lag of 2 days, the
R is within 0.9, indicating extremely strong short-term correlation. Within 6 days, the
R remains above 0.8, and it decreases as the lag time increases. Around a lag of 40 days, the autocorrelation of the sequence data drop to the level of 0.5, further reflecting the strong correlation between current drought conditions and previous droughts. Data from the past 40 days still have a certain predictive effect on current SM. Around a lag of 100 days, the autocorrelation of the sequence data drop to the level of 0–0.1. After a lag of 180 days, the data show fluctuating changes, which have distinct interannual variation characteristics. For short-term predictions (<10 days), relying solely on the autocorrelation of historical data can still yield relatively good simulation and prediction results. For medium-term predictions (10–40 days), the use of historical data still has some effect. However, for long-term predictions (>100 days), the effectiveness is less suitable. These findings provide a theoretical basis for the time-specific design of SM prediction models, confirming the important guiding role of temporal-scale characteristics in model architecture selection and feature engineering.
4.2. Comparison of Prediction Performance
By comparing the LSTM Seq2Seq model with traditional ML models such as the CNN and SVM, as well as with the LSTM model and advanced transformer model, it was found that the LSTM model outperformed other models in terms of prediction accuracy among the traditional models. In the field of SM prediction, although the LSTM model based on historical statistical methods can capture the autocorrelation characteristics of time series, its prediction accuracy decreases rapidly with the increase in the prediction step size. This is mainly because the LSTM model does not consider the “future” element and lacks constraints on future and physical processes, resulting in its prediction ability being limited by tis correlation with historical data and making it difficult to accurately represent the evolution characteristics of SM. For instance, Kratzert et al. [
48] pointed out that the LSTM model performs well when dealing with nonlinear dynamic systems, but its performance is significantly limited when facing the prediction of long time series. To overcome this limitation, the coupled modeling method has gradually drawn attention. Some studies have combined the physical model with the LSTM model to construct a physical-guided ML model which performs better than the traditional historical data-driven LSTM model in hydrological simulation. Similarly, another study combined the meteorological forecast data from the European Centre for Medium-Range Weather Forecasts (ECMWFs) with the LSTM model to create a hybrid dynamic LSTM model, effectively predicting drought. This physical constraint mechanism enables the model to have a stronger error correction ability, thereby improving the stability of the prediction. Providing regularization constraints for the LSTM network using physical prior knowledge can significantly improve the error control ability of the model. Furthermore, through integrating physical laws and the advantages of ML, progress can be made in this field of research.
The LSTM Seq2Seq method is a novel method for SM prediction. Through the encoder–decoder architecture, it solves the problems of gradient disappearance and insufficient feature capture in traditional hybrid models when modeling long sequences. Compared with traditional LSTM or SVM and other classic ML models, Seq2Seq can better capture long-term dependencies, support multi-step predictions, and effectively integrate temporal and spatial features. This makes it perform better in SM prediction and means that it can more accurately reflect the trend of SM changes. The VIC-LSTMseq2seq model combines the physical mechanism with data learning by introducing the hydrological state simulation data generated by the VIC model, allowing for the ability to predict future scenarios. This coupling method not only retains the autocorrelation characteristics of the time series, but also introduces the predictive ability of the physical model for future scenarios. Models that introduce physical mechanisms can still maintain high simulation and prediction accuracy within a relatively long prediction step size. The innovation of the VIC-LSTMseq2seq model in this paper lies in its integration of the hydrological state simulation data generated by the VIC physical model, achieving a dual coupling of the physical mechanism and data learning. Meanwhile, this model takes into account the overall dependence of SM on historical meteorological and hydrological conditions. The features input into the model include historical features and simulated “future” hydrological state features. Moreover, the lengths and quantities of these features in the time series are different, facilitating efforts to solve the problem associated with the overall input of features of different lengths and allowing for the screening and selection of feature information related to soil to be avoided. The VIC-LSTMseq2seq model has achieved significant improvements in both prediction accuracy and physical rationality.
The coupled modeling method, combining physical models and DL techniques, can effectively improve the accuracy and stability of SM prediction. Future research can further explore how to optimize the interaction mechanism between physical models and DL models to achieve more efficient prediction performance.
4.3. Model Efficiency and Transferability
The LSTM Seq2Seq model structure in this study is relatively complex, and it requires a long training time due to its level of computational efficiency, requiring high-performance hardware support such as GPU acceleration. This experiment was executed on a computer with an Intel(R) Core(TM) i5-9400F CPU @ 2.90 GHz. One training process lasted for over half an hour. The model training costs were relatively high. However, by optimizing the architecture and parameters, the computational burden could be reduced to a certain extent. At the same time, this experiment included the features output by the VIC model, which also increased the complexity of the model. Due to the increase in running time and training costs, higher requirements were also imposed on the used hardware. Future research can further explore the adaptability of the model in different environments and optimize the computational efficiency.
The transferability of this research method is also worth discussing. Under different hydrological or climatic conditions, such as in arid or snow-covered areas, the differences in SM dynamics and processes such as precipitation and evaporation may affect model performance. For example, SM in arid areas is more sensitive to precipitation, while in snow-covered areas, the melting of snow needs to be considered with regards to the replenishment of moisture. In addition, the availability of the VIC model and SMAP data is limited, posing certain limitations to this research, and missing data or insufficient accuracy of the model may affect the model’s training and prediction results.
4.4. Impact of the Datasets Used
To analyze the effectiveness of the proposed model in simulating daily-scale SM and to construct a SM prediction model with high accuracy and applicability for daily operational use, this study utilized the SMAP L4 SM. Although SMAP L4 data have an acquisition delay of 2–3 days, the correlation coefficient for simulating and predicting SM up to 7 days in the future still exceeds 0.96. Therefore, it can be considered the primary data source for SM simulation, offering high spatiotemporal continuity and accuracy. Despite the advantages of its temporal resolution its complete spatial coverage of SMAP data, the process of downscaling it to a 0.0625° resolution may have introduced scale errors. To improve data quality, future work could involve integrating multi-source satellite data (e.g., Sentinel-1) for joint calibration and for developing dynamic bias correction algorithms that account for soil texture and vegetation cover. Additionally, optimizing the layout of ground-based observation stations can enhance the spatial representativeness and temporal continuity of in situ data. In terms of feature engineering, this study innovatively combined 30 days of historical meteorological observations (seven features, including precipitation, wind speed, and temperature) with hydrological elements simulated by the VIC model for the next M days (six features, including evaporation and runoff). Although this combination of features at different temporal scales can characterize SM dynamics, errors in meteorological observations and uncertainties in VIC model parameterization may propagate through the features and affect prediction results. Future work could introduce data assimilation techniques to reduce initial condition errors and employ ensemble forecasting methods to quantify model uncertainty, thereby further enhancing the robustness of the prediction system.
4.5. Future Directions for Improving Explainability of Deep Learning Models
This study innovatively constructed a DL model based on a fusion of multi-source data, proposing a multimodal fusion architecture that integrates past meteorological observations with future hydrological simulations. It effectively addressed the issue of insufficient feature utilization in traditional methods, developed a heterogeneous feature encoding mechanism for SM prediction, and established a joint calibration framework between SMAP satellite data and ground observations. These advancements significantly improved the quality and reliability of the input data, enabling the high-precision temporal prediction of SM. This not only provides a new technical means for regional SM monitoring but also offers a paradigm for multi-source data fusion modeling in the field of hydro-meteorology.
In terms of model explainability, future research will focus on three important trends: first, the development of physics-informed explainable AI (XAI) techniques, which embed hydrological process equations as differential constraints within neural networks to achieve bidirectional validation between prediction results and physical mechanisms; second, the innovation value of dynamic explainability methods, which develop time-aware feature importance analysis tools to reveal the temporal variations in SM memory effects; third, the refinement of multimodal explanation frameworks, which establish a unified evaluation system capable of parsing the contributions of multi-source data, including remote sensing observations, ground monitoring data, and model simulations. Developing this field on research in these directions will further enhance the credibility and application value of DL models in the field of hydrology, providing more reliable decision support for smart agriculture and water resource management.
5. Conclusions
This study introduced an SM simulation model, VIC-LSTMseq2seq, which couples the VIC land surface hydrological model with DL. The model considers both past SM states and historical time series dependencies, as well as future states simulated by the VIC model. By integrating an encoder–decoder architecture with feature attention mechanisms (AMs) and LSTM networks, the model can handle inputs with varying temporal steps and feature counts. Comprehensive evaluations demonstrate that the VIC-LSTMseq2seq model outperforms traditional statistical LSTM models in SM simulation and prediction tasks, particularly in terms of accuracy and reliability. It shows great potential for drought simulation and prediction.
It should be noted that although the VIC-LSTMseq2seq model achieved satisfactory prediction results in this study, its performance may be influenced by regional geographical characteristics, soil type differences, and climate change factors. The model’s generalizability across different regions needs to be validated through the use of a broader range of geographical samples. Additionally, the current study mainly focused on improving prediction performance, with relatively limited research on the explainability of the model’s internal mechanisms being conducted.
Future research can follow the following three recommendations in depth. Firstly, researchers should conduct multi-scale validation experiments to systematically assess this model’s applicability in different climatic zones and soil types. Secondly, they should develop hybrid modeling methods that incorporate physical mechanisms by embedding hydrological process equations as constraints within neural networks to enhance the model’s physical explainability. Finally, they should explore strategies for implementing the model in practical applications such as smart agriculture and water resource management, particularly focusing on how to effectively integrate model predictions into existing decision support systems. These studies will not only help further refine the VIC-LSTMseq2seq model but also provide new ideas for the development of intelligent prediction methods in the field of hydro-meteorology.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}