
Contrastive Learning-Based Hyperspectral Image Target Detection Using a Gated Dual-Path Network



Abstract
1. Introduction
- (1)
- A new contrastive learning framework is investigated in this paper, aiming at enabling the model to learn the ability to distinguish spectral similarities and dissimilarities in an unsupervised manner. Specifically, the Gated Dual-Path Network reuses and explores features of the spectrum, allowing the model to capture the subtle and crucial differences between target and background, while the Weighted Information Noise Contrastive Estimation (WIN) loss simultaneously enhances the similarity of positive samples and increases the separation from negative samples.
- (2)
- We propose a physically interpretable spectral-level data augmentation based on pixel mixing. Unlike existing methods, it constructs positive and negative samples for each pixel, significantly reducing false negatives in contrastive learning. Refining sample pair selection minimizes the risk of mistakenly treating semantically related samples as negatives, thereby improving representation quality and enhancing the model’s ability to distinguish targets from backgrounds in high-dimensional spectral data. The code for this work will be made publicly available at https://github.com/liurongwhm (accessed on 28 June 2025) upon publication.
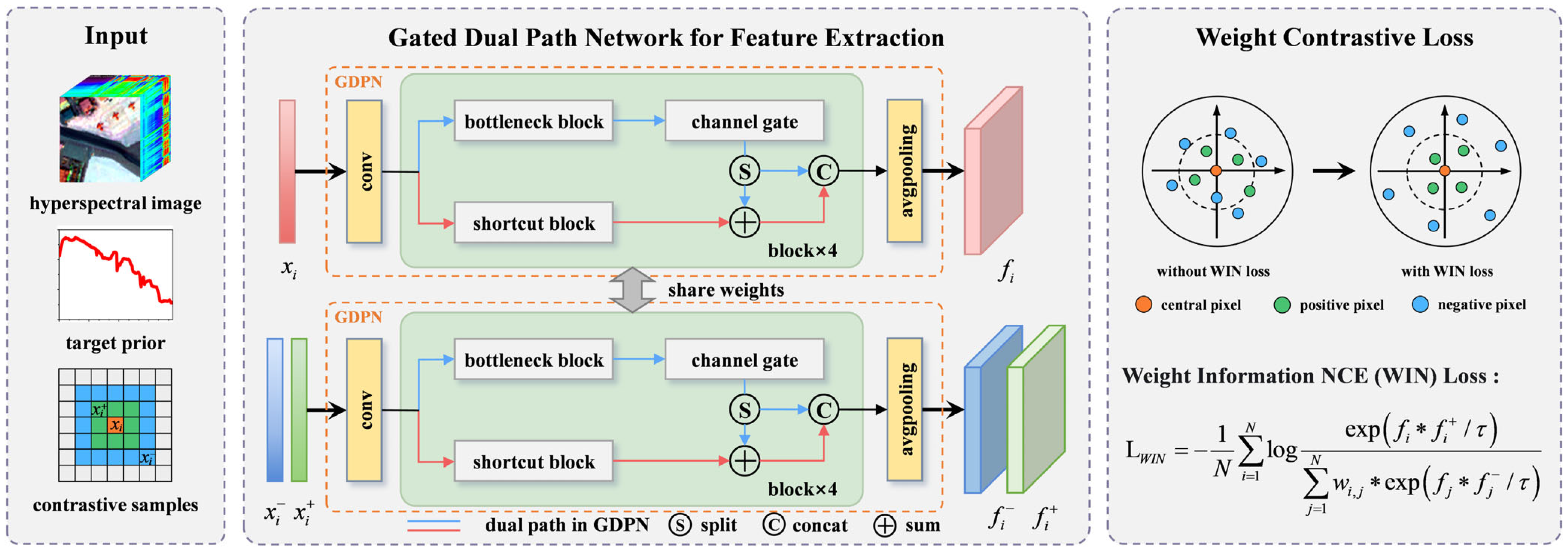
2. The Proposed Method
- (1)
- Data Augmentation Module: This module employs spectral data augmentation to generate sample pairs for contrastive learning. By augmenting the spectral data, the model is provided with a diverse set of samples, enhancing the learning process and improving its robustness.
- (2)
- Network Module: This module is built upon the Gated Dual-Path Network (GDPN), which facilitates contrastive learning by extracting spectral features. It incorporates a weighted contrastive loss framework to promote similarity learning, and the GDPN efficiently captures the spectral characteristics, enabling the differentiation of negative samples under the constraint of the WIN loss, thereby optimizing the overall learning performance.
2.1. Spectral Data Augmentation
- (1)
- Synthesizing the embedded signal: using ( ) pixels from the inner window, the embedded signal is synthesized as follows:
- (2)
- Constructing positive samples: After synthesizing the embedded signal from the inner window, the positive sample is constructed by incorporating a certain proportion of the signal into the central pixel:
- (3)
- Selecting negative samples from the outer window: For each pixel in the outer window, its Euclidean distance to the central pixel is calculated. The pixel with the maximum distance is chosen as the negative sample:
2.2. Gated Dual-Path Network
- (1)
- Residual-like path: The residual path ensures that important spectral features are preserved as the network deepens. This is achieved by reusing previously extracted information, a strategy that enhances the ability of the network to extract features from the input data. For the m-th block in the GDPN encoder, the output from the residual-like path is given using the following:
- (2)
- Dense-like path and channel gate: The dense path focuses on exploring new features by capturing local discriminative spectral information, helping the network identify subtle spectral differences between targets and backgrounds. However, the dense-like path may introduce irrelevant features, potentially accumulating bias during the learning process. To address this, we propose assigning weights to the features derived from the dense path through the learnable channel gate . The gate automatically learns channel-wise weights using a fully-connected layer, based on the current features, suppressing less relevant channels before the next DPN block. This ensures that only the most informative features for representation learning contribute significantly.
2.3. Loss Function
2.4. Pixel Detection
| Algorithm 1. GDPNCL for Hyperspectral Target Detection |
| Input: hyperspectral data , target samples , parameters , , and . |
| Output: Two-dimensional plot of detection results. |
| Spectral Data Augmentation: |
| For each x in image , (1) construct positive sample of pixel via Equations (1)–(4) (2) select negative sample of pixel via Equation (5) End for |
| Contrastive learning: |
| Training the GDPN network using contrastive samples and generated from data augmentation with WIN loss in Equations (14) and (15) |
| Target Detection for HSI: Calculate the target feature via GDPN network . |
| For each x in image , |
| (1) calculate the pixel feature via GDPN network . |
| (2) obtain detection statistics via Equation (16). |
| End for |
3. Experiments and Analysis
3.1. Data Description
3.2. Experimental Settings
3.2.1. Performance Metrics
3.2.2. Comparison Detectors and Parameter Settings
3.3. Detection Performance
3.4. Analysis of Parameters
3.4.1. Analysis of Window Size
3.4.2. Analysis of the Proportion of Implantation
3.5. Analysis of the Model and WIN Loss
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Manolakis, D.; Shaw, G. Detection algorithms for hyperspectral imaging applications. IEEE Signal Process. Mag. 2002, 19, 29–43. [Google Scholar] [CrossRef]
- Landgrebe, D. Hyperspectral image data analysis. IEEE Signal Process. Mag. 2002, 19, 17–28. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Liu, J.; Hou, Z.; Li, W.; Tao, R.; Orlando, D.; Li, H. Multipixel Anomaly Detection with Unknown Patterns for Hyperspectral Imagery. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 5557–5567. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Ou, J.; Zhou, M.; Hu, M.; Sun, L.; Qiu, S.; Li, Q.; Chu, J. Spatial-spectral identification of abnormal leukocytes based on microscopic hyperspectral imaging technology. J. Innov. Opt. Health Sci. 2020, 13, 2050005. [Google Scholar] [CrossRef]
- Sneha; Kaul, A. Hyperspectral imaging and target detection algorithms: A review. Multimed. Tools Appl. 2022, 81, 44141–44206. [Google Scholar] [CrossRef]
- Manolakis, D.; Marden, D.; Shaw, G.A. Hyperspectral image processing for automatic target detection applications. Linc. Lab. J. 2003, 14, 79–116. [Google Scholar]
- Kraut, S.; Scharf, L.L.; Butler, R.W. The adaptive coherence estimator: A uniformly most-powerful-invariant adaptive detection statistic. IEEE Trans. Signal Process. 2005, 53, 427–438. [Google Scholar] [CrossRef]
- Manolakis, D.; Lockwood, R.; Cooley, T.; Jacobson, J. Is there a best hyperspectral detection algorithm? In Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XV; SPIE: Orlando, FL, USA, 2009; Volume 7334, pp. 13–28. [Google Scholar]
- Farrand, W.H.; Harsanyi, J.C. Mapping the distribution of mine tailings in the Coeur d’Alene River Valley, Idaho, through the use of a constrained energy minimization technique. Remote Sens. Environ. 1997, 59, 64–76. [Google Scholar] [CrossRef]
- Chang, C.I. Orthogonal subspace projection (OSP) revisited: A comprehensive study and analysis. IEEE Trans. Geosci. Remote Sens. 2005, 43, 502–518. [Google Scholar] [CrossRef]
- Jiao, X.; Chang, C.I. Kernel-based constrained energy minimization (K-CEM). In Proceedings of the Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XIV; SPIE: Bellingham, WA, USA, 2008; Volume 6966, pp. 523–533. [Google Scholar]
- Kwon, H.; Nasrabadi, N.M. Kernel spectral matched filter for hyperspectral imagery. Int. J. Comput. Vis. 2007, 71, 127–141. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Sparse representation for target detection in hyperspectral imagery. IEEE J. Sel. Top. Signal Process. 2011, 5, 629–640. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, L. A sparse representation-based binary hypothesis model for target detection in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1346–1354. [Google Scholar] [CrossRef]
- Liu, R.; Wu, J.; Zhu, D.; Du, B. Weighted Discriminative Collaborative Competitive Representation with Global Dictionary for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 63, 1–13. [Google Scholar] [CrossRef]
- Zhao, X.; Li, W.; Zhao, C.; Tao, R. Hyperspectral Target Detection Based on Weighted Cauchy Distance Graph and Local Adaptive Collaborative Representation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Hu, M.; Dong, Y.; Zhang, L. Collaborative-guided spectral abundance learning with bilinear mixing model for hyperspectral subpixel target detection. Neural Netw. 2023, 163, 205–218. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, K.; Gao, K.; Li, W. Hyperspectral time-series target detection based on spectral perception and spatial-temporal tensor decomposition. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5520812. [Google Scholar] [CrossRef]
- Jiao, C.; Yang, B.; Wang, Q.; Wang, G.; Wu, J. Discriminative Multiple-Instance Hyperspectral Subpixel Target Characterization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5521420. [Google Scholar] [CrossRef]
- Du, J.; Li, Z. A hyperspectral target detection framework with subtraction pixel pair features. IEEE Access 2018, 6, 45562–45577. [Google Scholar] [CrossRef]
- Gao, H.; Zhang, Y.; Chen, Z.; Xu, F.; Hong, D.; Zhang, B. Hyperspectral Target Detection via Spectral Aggregation and Separation Network With Target Band Random Mask. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5515516. [Google Scholar] [CrossRef]
- Qin, H.; Xie, W.; Li, Y.; Du, Q. HTD-VIT: Spectral-Spatial Joint Hyperspectral Target Detection with Vision Transformer. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1967–1970. [Google Scholar]
- Zhang, G.; Zhao, S.; Li, W.; Du, Q.; Ran, Q.; Tao, R. HTD-net: A deep convolutional neural network for target detection in hyperspectral imagery. Remote Sens. 2020, 12, 1489. [Google Scholar] [CrossRef]
- Shen, D.; Ma, X.; Kong, W.; Liu, J.; Wang, J.; Wang, H. Hyperspectral Target Detection Based on Interpretable Representation Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Dong, W.; Wu, X.; Qu, J.; Gamba, P.; Xiao, S.; Vizziello, A.; Li, Y. Deep spatial–spectral joint-sparse prior encoding network for hyperspectral target detection. IEEE Trans. Cybern. 2024, 54, 7780–7792. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Geng, S.; Xu, P.; Chen, Z.; Gao, H. Cognitive fusion of graph neural network and convolutional neural network for enhanced hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Li, Y.; Shi, Y.; Wang, K.; Xi, B.; Li, J.; Gamba, P. Target detection with unconstrained linear mixture model and hierarchical denoising autoencoder in hyperspectral imagery. IEEE Trans. Image Process. 2022, 31, 1418–1432. [Google Scholar] [CrossRef]
- Xie, W.; Lei, J.; Yang, J.; Li, Y.; Du, Q.; Li, Z. Deep latent spectral representation learning-based hyperspectral band selection for target detection. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2015–2026. [Google Scholar] [CrossRef]
- Li, Y.; Qin, H.; Xie, W. HTDFormer: Hyperspectral Target Detection Based on Transformer With Distributed Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Yang, Q.; Wang, X.; Chen, L.; Zhou, Y.; Qiao, S. CS-TTD: Triplet Transformer for Compressive Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5533115. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Zhang, L. Two-stream convolutional networks for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6907–6921. [Google Scholar] [CrossRef]
- Gao, Y.; Feng, Y.; Yu, X. Hyperspectral Target Detection with an Auxiliary Generative Adversarial Network. Remote Sens. 2021, 13, 4454. [Google Scholar] [CrossRef]
- Jiao, J.; Gong, Z.; Zhong, P. Triplet spectralwise transformer network for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Tian, Q.; He, C.; Xu, Y.; Wu, Z.; Wei, Z. Hyperspectral Target Detection: Learning Faithful Background Representations via Orthogonal Subspace-Guided Variational Autoencoder. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5516714. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; Wang, F.; Song, M.; Yu, C. Meta-Learning based Hyperspectral Target Detection using Siamese Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5527913. [Google Scholar] [CrossRef]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Misra, I.; van der Maaten, L. Self-Supervised Learning of Pretext-Invariant Representations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6706–6716. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chung, Y.A.; Zhang, Y.; Han, W.; Chiu, C.C.; Qin, J.; Pang, R.; Wu, Y. w2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 244–250. [Google Scholar]
- Wang, Y.; Chen, X.; Zhao, E.; Song, M. Self-supervised Spectral-level Contrastive Learning for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5510515. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; Zhao, E.; Zhao, C.; Song, M.; Yu, C. An Unsupervised Momentum Contrastive Learning Based Transformer Network for Hyperspectral Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 9053–9068. [Google Scholar] [CrossRef]
- Hu, Q.; Wang, X.; Hu, W.; Qi, G.-J. Adco: Adversarial contrast for efficient learning of unsupervised representations from self-trained negative adversaries. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1074–61083. [Google Scholar]
- Tian, Y.; Sun, C.; Poole, B.; Krishnan, D.; Schmid, C.; Isola, P. What makes for good views for contrastive learning? In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; pp. 6827–6839. [Google Scholar]
- Wang, X.; Qi, G.J. Contrastive Learning With Stronger Augmentations. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5549–5560. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 9726–9735. [Google Scholar]
- Chen, X.; Zhang, Y.; Dong, Y.; Du, B. Spatial-Spectral Contrastive Self-Supervised Learning With Dual Path Networks for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Jing, T.; Wei-Yu, Y.; Sheng-Li, X. On the kernel function selection of nonlocal filtering for image denoising. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 2964–2969. [Google Scholar]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Kerekes, J. Receiver operating characteristic curve confidence intervals and regions. IEEE Geosci. Remote Sens. Lett. 2008, 5, 251–255. [Google Scholar] [CrossRef]
- Khazai, S.; Homayouni, S.; Safari, A.; Mojaradi, B. Anomaly detection in hyperspectral images based on an adaptive support vector method. IEEE Geosci. Remote Sens. Lett. 2011, 8, 646–650. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Li, L.; Tao, R.; Du, Q. Hyperspectral change detection based on multiple morphological profiles. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5507312. [Google Scholar] [CrossRef]
- Zhu, D.; Du, B.; Dong, Y.; Zhang, L. Target Detection with Spatial-Spectral Adaptive Sample Generation and Deep Metric Learning for Hyperspectral Imagery. IEEE Trans. Multimed. 2022, 25, 6538–6550. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, B.; Zhang, Y.; Zhang, L. Spatially adaptive sparse representation for target detection in hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1923–1927. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Bands | Sensor | Image Size | Spatial Resolution | Target | Target Proportion |
|---|---|---|---|---|---|---|
| Urban-1 | 204 | AVIRIS | 100 × 100 | 17.2 m/pixel | / | 0.17% |
| Urban-2 | 191 | AVIRIS | 100 × 100 | 3.5 m/pixel | boat | 0.13% |
| AVIRIS | 189 | AVIRIS | 100 × 100 | 3.5 m/pixel | plane | 0.15% |
| RIT Campus | 360 | ProSpecTIR | 200 × 200 | 1 m/pixel | red panel | 0.20% |
| Dataset | Urban-1 | Urban-2 | AVIRIS | RIT Campus |
|---|---|---|---|---|
| CEM | 0.6775 | 0.9836 | 0.9849 | 0.9972 |
| SRBBH | 0.8684 | 0.7792 | 0.7800 | 0.7465 |
| SASTD | 0.8585 | 0.9404 | 0.9535 | 0.8253 |
| CSTTD | 0.9946 | 0.9932 | 0.9992 | 0.7788 |
| MCLT | 0.6613 | 0.9939 | 0.9867 | 0.7101 |
| TSTTD | 0.9900 | 0.9880 | 0.9953 | 0.9821 |
| MLSN | 0.9767 | 0.9291 | 0.9918 | 0.9888 |
| Proposed | 0.9957 | 0.9956 | 0.9974 | 0.9983 |
| CSTTD | MCLT | TSTTD | MLSN | GDPNCL | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| Urban-1 | 593.04 | 0.27 | 65.57 | 0.72 | 350.02 | 1.10 | 637.37 | 13.08 | 46.61 | 0.43 |
| Urban-2 | 677.85 | 0.28 | 59.98 | 0.69 | 349.51 | 1.10 | 667.76 | 12.80 | 52.56 | 0.11 |
| AVIRIS | 419.35 | 0.26 | 59.73 | 0.66 | 348.89 | 1.13 | 662.36 | 12.24 | 44.47 | 0.39 |
| RIT Campus | 842.98 | 0.42 | 582.23 | 6.82 | 603.74 | 3.45 | 1126.45 | 72.84 | 222.77 | 15.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Liu, R.; Wang, N. Contrastive Learning-Based Hyperspectral Image Target Detection Using a Gated Dual-Path Network. Remote Sens. 2025, 17, 2345. https://doi.org/10.3390/rs17142345
Wu J, Liu R, Wang N. Contrastive Learning-Based Hyperspectral Image Target Detection Using a Gated Dual-Path Network. Remote Sensing. 2025; 17(14):2345. https://doi.org/10.3390/rs17142345
Chicago/Turabian StyleWu, Jiake, Rong Liu, and Nan Wang. 2025. "Contrastive Learning-Based Hyperspectral Image Target Detection Using a Gated Dual-Path Network" Remote Sensing 17, no. 14: 2345. https://doi.org/10.3390/rs17142345
APA StyleWu, J., Liu, R., & Wang, N. (2025). Contrastive Learning-Based Hyperspectral Image Target Detection Using a Gated Dual-Path Network. Remote Sensing, 17(14), 2345. https://doi.org/10.3390/rs17142345