


Improved Real-Time SPGA Algorithm and Hardware Processing Architecture for Small UAVs

 ,
, 
Abstract
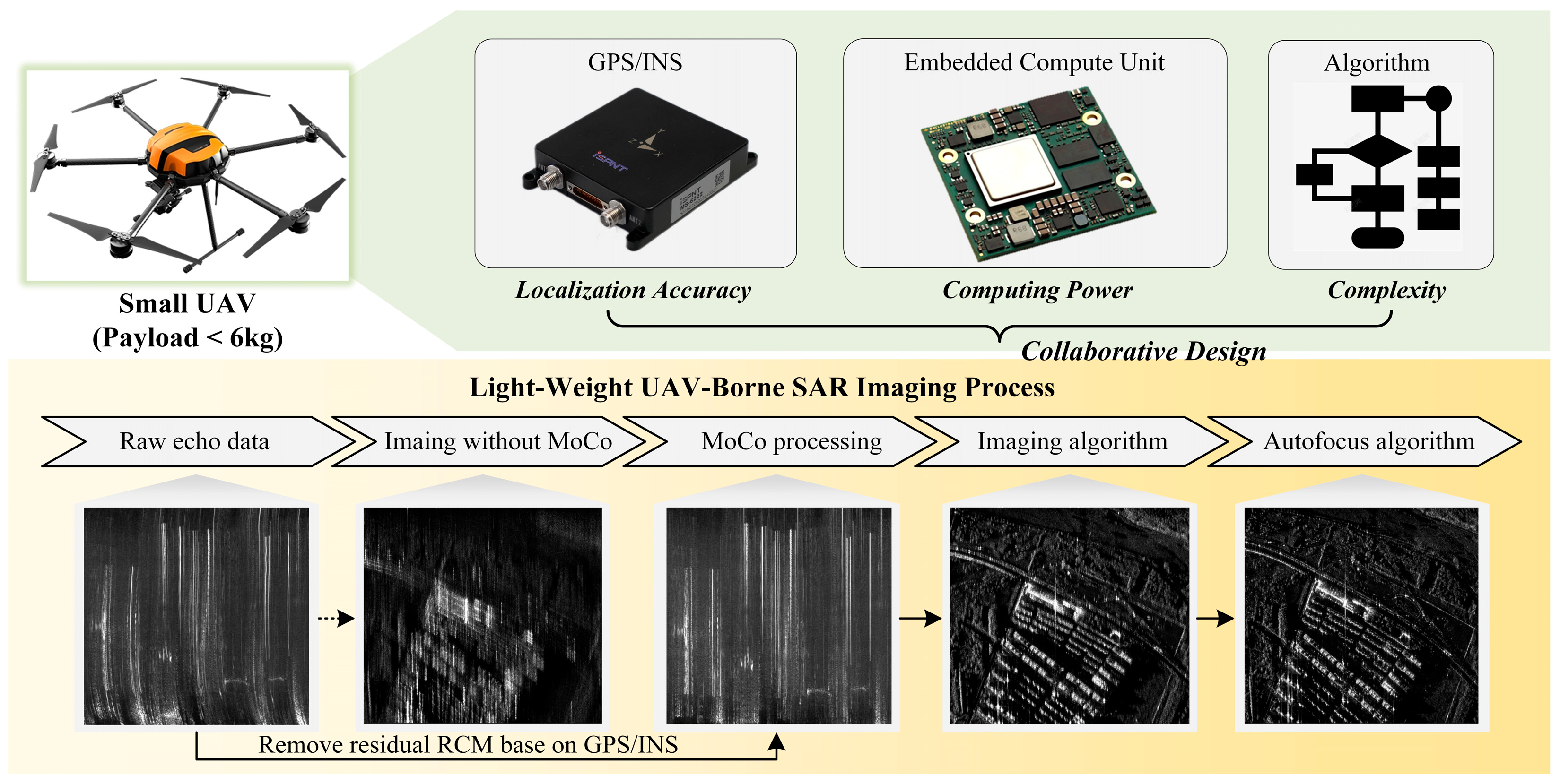
1. Introduction
2. Theory and Problem Analysis
2.1. Residual Motion Error Model for SAR
2.2. Real-Time Autofocus for UAV SAR Problem Analysis
3. Lightweight Autofocusing Algorithm Design
3.1. Selection of High-Quality Scattering Points
3.2. Feature Sub-Image Construction
3.3. Phase Error Estimation
4. Architecture Design and Implementation
4.1. System Hardware Architecture
4.2. Algorithm Decomposition and Operator Mapping
4.3. Hardware Computing Unit Design Based on FPGA
4.3.1. FPGA Hardware Accelerator Model
4.3.2. D-CFAR Hardware Accelerator
4.3.3. Reconfigurable Matched Filtering (RMF) Hardware Accelerator
5. Experiments and Results
5.1. SAR System
5.2. Comparison of Algorithm Accuracy
5.3. Algorithm Robustness Verification
5.4. FPGA Hardware Accelerator Verification Experiments
6. Discussion
6.1. Analysis of Algorithm Computational Complexity and Limitations
6.2. Analysis of Computational Performance on Hardware Architectures
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Trinder, J.C. Editorial for Special Issue “Applications of Synthetic Aperture Radar (SAR) for Land Cover Analysis”. Remote Sens. 2020, 12, 2428. [Google Scholar] [CrossRef]
- Agarwal, R. Recent Advances in Aircraft Technology; InTech: Rijeka, Croatia, 2012. [Google Scholar]
- Lort, M.; Aguasca, A.; López-Martínez, C.; Marín, T.M. Initial evaluation of SAR capabilities in UAV multicopter platforms. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 127–140. [Google Scholar] [CrossRef]
- Fornado, G. Trajectory deviations in airborne SAR: Analysis and compensation. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 997–1009. [Google Scholar] [CrossRef]
- Fornaro, G.; Franceschetti, G.; Perna, S. Motion compensation errors: Effects on the accuracy of airborne SAR images. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 1338–1352. [Google Scholar] [CrossRef]
- Moreira, A.; Huang, Y. Airborne SAR processing of highly squinted data using a chirp scaling approach with integrated motion compensation. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1029–1040. [Google Scholar] [CrossRef]
- Wang, R.; Loffeld, O.; Nies, H.; Knedlik, S.; Ender, J.H. Chirp-scaling algorithm for bistatic SAR data in the constant-offset configuration. IEEE Trans. Geosci. Remote Sens. 2009, 47, 952–964. [Google Scholar] [CrossRef]
- Chen, J.; Xing, M.; Yu, H.; Liang, B.; Peng, J.; Sun, G.-C. Motion compensation/autofocus in airborne synthetic aperture radar: A review. IEEE Geosci. Remote Sens. 2022, 10, 185–206. [Google Scholar] [CrossRef]
- Gryte, K.; Bryne, T.H.; Albrektsen, S.M.; Johansen, T.A. Field test results of GNSS-denied inertial navigation aided by phased-array radio systems for UAVs. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019; pp. 1398–1406. [Google Scholar]
- Zhang, J.; Fu, Y.; Zhang, W.; Yang, W. Signal characteristics analysis and intra-pulse motion compensation for FMCW CSAR. IEEE Sens. 2019, 19, 10461–10476. [Google Scholar] [CrossRef]
- Henke, D. Miranda35 experiments in preparation for small UAV-based SAR. In Proceedings of the GARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar]
- Xing, M.; Jiang, X.; Wu, R.; Zhou, F.; Bao, Z. Motion compensation for UAV SAR based on raw radar data. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2870–2883. [Google Scholar] [CrossRef]
- Xu, G.; Xing, M.; Zhang, L.; Bao, Z. Robust autofocusing approach for highly squinted SAR imagery using the extended wavenumber algorithm. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5031–5046. [Google Scholar] [CrossRef]
- Bezvesilniy, O.O.; Gorovyi, I.M.; Vavriv, D.M. Estimation of phase errors in SAR data by local-quadratic map-drift autofocus. In Proceedings of the 2012 13th International Radar Symposium, Warsaw, Poland, 23–25 May 2012. [Google Scholar]
- Calloway, T.M.; Donohoe, G.W. Subaperture autofocus for synthetic aperture radar. IEEE Trans. Aerosp. Electron. Syst. 1994, 30, 617–621. [Google Scholar] [CrossRef]
- Samczynski, P.; Kulpa, K.S. Coherent mapdrift technique. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2010. [Google Scholar] [CrossRef]
- Wang, J.; Liu, X. SAR minimum-entropy autofocus using an adaptive-order polynomial model. IEEE Geosci. Remote Sens. Lett. 2006, 3, 512–516. [Google Scholar] [CrossRef]
- Xiong, T.; Xing, M.; Wang, Y.; Wang, S.; Sheng, J.; Guo, L. Minimum-entropy-based autofocus algorithm for SAR data using Chebyshev approximation and method of series reversion, and its implementation in a data processor. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1719–1728. [Google Scholar] [CrossRef]
- Cacciamano, A.; Giusti, E.; Capria, A.; Martorella, M.; Berizzi, F. Contrast-optimization-based range-profile autofocus for polarimetric stepped-frequency radar. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2049–2056. [Google Scholar] [CrossRef]
- Wahl, D.E.; Eichel, P.; Ghiglia, D.C.; Jakowatz, C.V., Jr. Phase gradient autofocus—A robust tool for high resolution SAR phase correction. IEEE Trans. Aerosp. Electron. Syst. 1994, 30, 827–835. [Google Scholar] [CrossRef]
- Chan, H.L.; Yeo, T.S. Noniterative quality phase-gradient autofocus (QPGA) algorithm for spotlight SAR imagery. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1531–1539. [Google Scholar] [CrossRef]
- Ye, W.; Yeo, T.S.; Bao, Z. Weighted least-squares estimation of phase errors for SAR/ISAR autofocus. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2487–2494. [Google Scholar] [CrossRef]
- Wahl, D.E.; Jakowatz, C.V.; Thompson, P.A.; Ghiglia, D.C. New approach to strip-map SAR autofocus. In Proceedings of the IEEE 6th Digital Signal Processing Workshop, Yosemite National Park, CA, USA, 2–5 October 1994. [Google Scholar]
- Thompson, D.G.; Bates, J.S.; Arnold, D.V.; Long, D.G. Extending the phase gradient autofocus algorithm for low-altitude stripmap mode SAR. In Proceedings of the 1999 IEEE Radar Conference. Radar into the Next Millennium (Cat. No.99CH36249), Waltham, MA, USA, 22 April 1999. [Google Scholar]
- Callow, H.J. Signal Processing for Synthetic Aperture Sonar Image Enhancement. Ph.D. Thesis, Department of Electrical and Electronic Engineering University Canterbury, Christchurch, New Zealand, 2003. [Google Scholar]
- Li, N. Extension and evaluation of PGA in ScanSAR mode using full-aperture approach. IEEE Geosci. Remote Sens. Lett. 2015, 12, 870–874. [Google Scholar]
- Li, Y.; O’Young, S. Kalman Filter Disciplined Phase Gradient Autofocus for Stripmap SAR. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6298–6308. [Google Scholar] [CrossRef]
- Evers, A.; Jackson, J.A. A generalized phase gradient autofocus algorithm. IEEE Trans. Comput. Imag. 2019, 5, 606–619. [Google Scholar] [CrossRef]
- Jin, Y. Ultrahigh-Resolution Autofocusing for Squint Airborne SAR Based on Cascaded MD-PGA. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4017305. [Google Scholar] [CrossRef]
- Deng, Y. A High-Resolution Airborne SAR Autofocusing Approach Based on SR-PGA and Subimage Resampling with Precise Hyperbolic Model. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 2327–2338. [Google Scholar] [CrossRef]
- Xie, Y.; Luan, Y.; Chen, L.; Zhang, X. A Modified Iteration-Free SPGA Based on Removing the Linear Phase. Remote Sens. 2023, 15, 5535. [Google Scholar] [CrossRef]
- Wang, D.; Ali, M.; Blinka, E. Synthetic Aperture Radar (SAR) Implementation on a TMS320C6678 Multicore DSP. Texas Instruments 2015. Available online: https://www.ti.com.cn/cn/lit/wp/spry276/spry276.pdf (accessed on 1 January 2025).
- Wang, Y.; Li, W.; Liu, T.; Zhou, L.; Wang, B.; Fan, Z.; Ye, X.; Fan, D.; Ding, C. Characterization and Implementation of Radar System Applications on a Reconfigurable Dataflow Architecture. IEEE Comput. Archit. Lett. 2022, 21, 121–124. [Google Scholar] [CrossRef]
- Wielage, M.; Cholewa, F.; Fahnemann, C.; Pirsch, P.; Blume, H. High Performance and Low Power Architectures: GPU vs. FPGA for Fast Factorized Backprojection. In Proceedings of the 2017 Fifth International Symposium on Computing and Networking (CANDAR), Aomori, Japan, 19–22 November 2017. [Google Scholar]
- Mota, D.; Cruz, H.; Miranda, P.R.; Duarte, R.P.; de Sousa, J.T.; Neto, H.C.; Véstias, M.P. Onboard Processing of Synthetic Aperture Radar Backprojection Algorithm in FPGA. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 15, 3600–3611. [Google Scholar] [CrossRef]
- Li, N.; Wang, R.; Deng, Y.; Yu, W.; Zhang, Z.; Liu, Y. Autofocus Correction of Residual RCM for VHR SAR Sensors With Light-Small Aircraft. IEEE Trans. Geosci. Remote Sens. 2017, 55, 441–452. [Google Scholar] [CrossRef]
- Zeng, H.; Yang, W.; Wang, P.; Chen, J. A Modified PGA for Spaceborne SAR Scintillation Compensation Based on the Weighted Maximum Likelihood Estimator and Data Division. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 3938–3947. [Google Scholar] [CrossRef]
- Cruz, H.; Véstias, M.; Monteiro, J.; Neto, H.; Duarte, R.P. A Review of Synthetic-Aperture Radar Image Formation Algorithms and Implementations. Remote Sens. 2022, 14, 1258. [Google Scholar] [CrossRef]
- RCbenchmark. Drone Building and Optimization: How to Increase Your Flight Time, Payload and Overall Efficiency. RCbenchmark. 2021. Available online: https://cdn.rcbenchmark.com/landing_pages/eBook/eBook_%20Drone%20Building%20and%20Optimization%20Chapters%201%20-%203.pdf (accessed on 14 January 2025).
- Diao, P.S.; Alves, T.; Poussot, B.; Azarian, S. A Review of Radar Detection Fundamentals. IEEE Trans. Aerosp. Electron. Syst. 2024, 39, 4–24. [Google Scholar] [CrossRef]
- Cumming, I.G.; Wong, F.H.-C. Digital Processing of Synthetic Aperture Radar Data: Algorithms and Implementation; Artech House: Boston, MA, USA, 2005. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Parameters | Values (Units) |
|---|---|---|
| Imaging Mode | Stripmap | |
| Waveform | Chirp pulses | |
| Band | Ku | |
| Frequency Bandwidth | 480 MHz | |
| Azimuth Beam Width | 6° | |
| Incident Angle | 82° | |
| Sampling Rate | 480 MHz | |
| Flying Height | 500 m | |
| Platform Velocity | 12 m/s |
| Autofocus Algorithm | Strong Scatterer | Azimuth PSF | Full Image | ||||
|---|---|---|---|---|---|---|---|
| Res. (m) | PSLR (dB) | ISLR (dB) | Entropy | Contrast | Runtime (s) | ||
| Initial MoCo | P1 | 0.33 | −1.00 | 6.26 | 5.48 | 4.33 | 6.21 |
| P2 | 1.23 | −4.21 | −2.66 | ||||
| P3 | 0.40 | −1.68 | 4.93 | ||||
| P4 | 0.95 | −6.00 | −1.08 | ||||
| SPGA (8 iterations) | P1 | 0.46 | −4.42 | −1.03 | 5.13 | 6.25 | 95.6 |
| P2 | 0.38 | −9.74 | −5.94 | ||||
| P3 | 0.44 | −7.88 | −7.18 | ||||
| P4 | 0.36 | −13.80 | −11.21 | ||||
| QW-SPGA (8 iterations) | P1 | 0.28 | −12.44 | −10.38 | 4.91 | 7.19 | 83.4 |
| P2 | 0.28 | −17.48 | −9.20 | ||||
| P3 | 0.31 | −10.91 | −9.10 | ||||
| P4 | 0.28 | −16.91 | −11.41 | ||||
| FSI-SPGA (1 iteration) | P1 | 0.30 | −10.82 | −7.82 | 4.98 | 7.16 | 6.12 |
| P2 | 0.29 | −13.18 | −8.47 | ||||
| P3 | 0.29 | −17.51 | −10.68 | ||||
| P4 | 0.28 | −14.21 | −11.61 | ||||
| Autofocus Algorithm | SAR Image | Entropy | Contrast | Runtime (s) |
|---|---|---|---|---|
| Initial MoCo | D1 | 6.84 | 10.71 | 3.1 |
| D2 | 5.46 | 27.59 | 3.2 | |
| D3 | 6.22 | 21.03 | 3.3 | |
| D4 | 6.10 | 11.44 | 3.2 | |
| QW-SPGA (8 iterations) | D1 | 6.62 | 35.15 | 14.5 |
| D2 | 5.07 | 61.12 | 14.2 | |
| D3 | 6.10 | 29.01 | 15.1 | |
| D4 | 6.06 | 13.59 | 13.9 | |
| FSI-SPGA (1 iteration) | D1 | 6.62 | 33.99 | 3.3 |
| D2 | 5.10 | 54.93 | 3.4 | |
| D3 | 6.10 | 27.70 | 3.6 | |
| D4 | 6.05 | 17.61 | 3.1 |
| Area | Accel | Clock | LUT | FF | BRAM | DSPs |
|---|---|---|---|---|---|---|
| Static Region | / | 300 MHz | 2591 | 6109 | 64 | 26 |
| Dynamic Region | 2D-CFAR | 18,233 | 26,286 | 128.5 | 14 | |
| RMF | 82,982 | 129,400 | 472.5 | 379 |
| Platform | Processor Model | Algorithm | Image Size (pixel × pixel) | Runtime (s) | Power (W) | PPR (pixels/J) |
|---|---|---|---|---|---|---|
| ARM | AMD ZU9EG (16 nm) | QW-SPGA | 4 K × 12 K | 566.4 | 2.5 | 37,026 |
| 8 K × 12 K | 1305.2 | 32,135 | ||||
| FSI-SPGA | 4 K × 12 K | 83.4 | 317,630 | |||
| 8 K × 12 K | 162.9 | 325,230 | ||||
| CPU | AMD 5800 H (7 nm) | QW-SPGA | 4 K × 12 K | 56.5 | 30 | 29,694 |
| 8 K × 12 K | 130.3 | 25,751 | ||||
| FSI-SPGA | 4 K × 12 K | 7.3 | 229,824 | |||
| 8 K × 12 K | 16.8 | 199,728 | ||||
| MPSoC (ARM + FPGA) | AMD ZU9EG (16 nm) | FSI-SPGA | 4 K × 12 K | 6.12 | 6.9 | 1,191,902 |
| 8 K × 12 K | 6.36 | 2,293,849 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Liu, Y.; Li, Y.; Li, H.; Ge, X.; Xin, J.; Liang, X. Improved Real-Time SPGA Algorithm and Hardware Processing Architecture for Small UAVs. Remote Sens. 2025, 17, 2232. https://doi.org/10.3390/rs17132232
Wang H, Liu Y, Li Y, Li H, Ge X, Xin J, Liang X. Improved Real-Time SPGA Algorithm and Hardware Processing Architecture for Small UAVs. Remote Sensing. 2025; 17(13):2232. https://doi.org/10.3390/rs17132232
Chicago/Turabian StyleWang, Huan, Yunlong Liu, Yanlei Li, Hang Li, Xuyang Ge, Jihao Xin, and Xingdong Liang. 2025. "Improved Real-Time SPGA Algorithm and Hardware Processing Architecture for Small UAVs" Remote Sensing 17, no. 13: 2232. https://doi.org/10.3390/rs17132232
APA StyleWang, H., Liu, Y., Li, Y., Li, H., Ge, X., Xin, J., & Liang, X. (2025). Improved Real-Time SPGA Algorithm and Hardware Processing Architecture for Small UAVs. Remote Sensing, 17(13), 2232. https://doi.org/10.3390/rs17132232