
Analyzing the Adversarial Robustness and Interpretability of Deep SAR Classification Models: A Comprehensive Examination of Their Reliability




Abstract
1. Introduction
- Through extensive experiments based on the MSTAR and OpenSARShip datasets, we conducted a comparative analysis of standard and robust models, revealing the factors that may influence the adversarial robustness of SAR image classification.
- We applied Layer-wise Relevance Propagation (LRP) to analyze the behavior of standard/robust models and the impact of AEs. The experimental results show that XAI methods provide new tools for understanding adversarial robustness, with significant potential in enhancing and evaluating robustness.
- We offered suggestions to improve the adversarial robustness of SAR classification models based on the experimental findings. We also highlighted the potential of XAI methods for thoroughly examining the model and discussed the rationale for expanding the experimental setting from single-target to complex scene SAR images.
2. Materials and Methods
2.1. Deep Models for SAR Classification

| Network Family | Tested Variant | Architectural Features | Params (M) (MSTAR/OpenSARShip) | Adaptations |
|---|---|---|---|---|
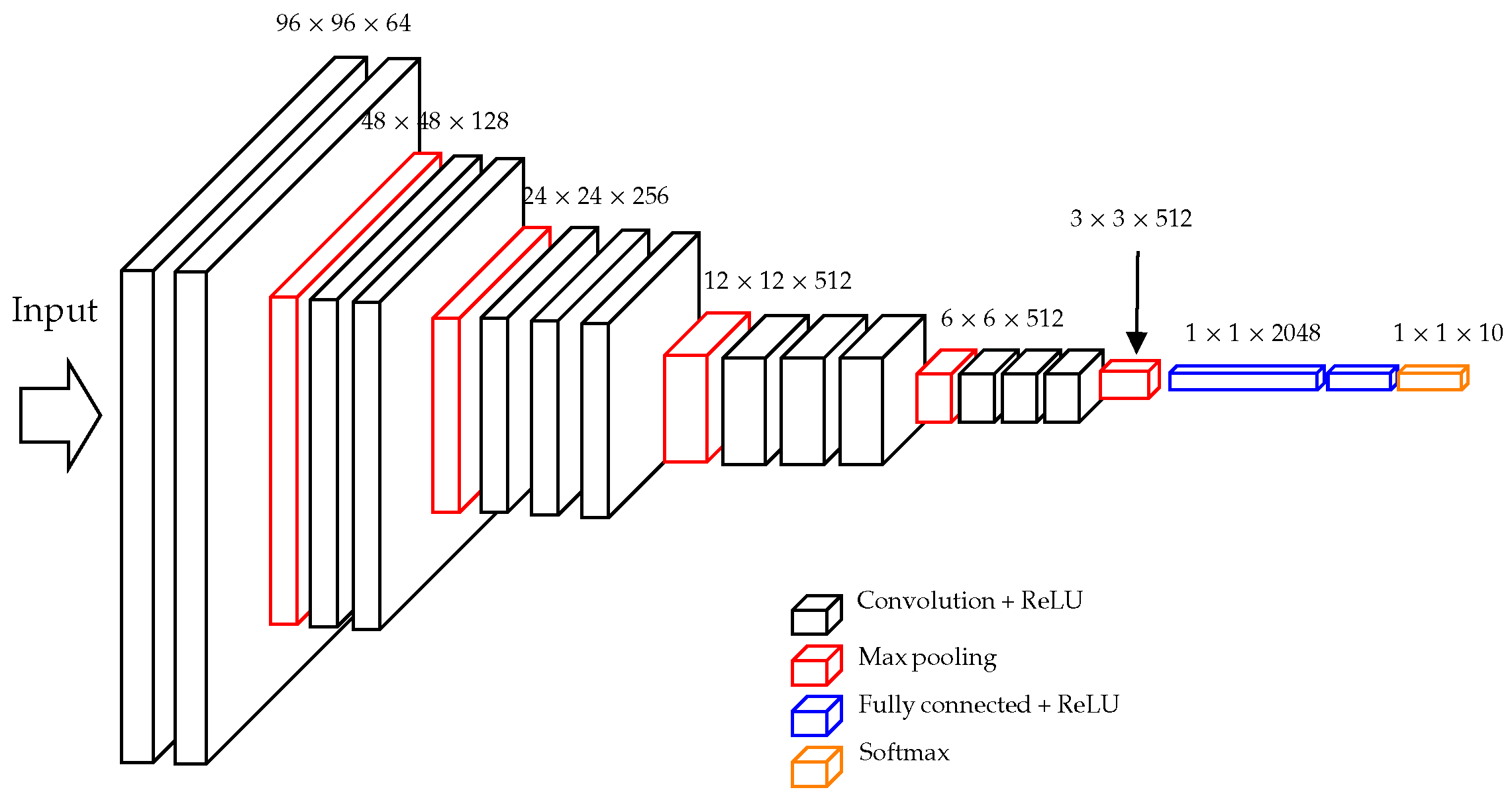
| VGGNet [36] | VGG11 VGG16 |
| VGG11: 18.68/26.0 VGG16: 24.17/31.49 | As shown in Figure 5, only two FC layers retained. |
| ResNet [37] | ResNet18 ResNet101 |
| ResNet18: 11.17/11.17 ResNet101: 42.5/42.5 | None |
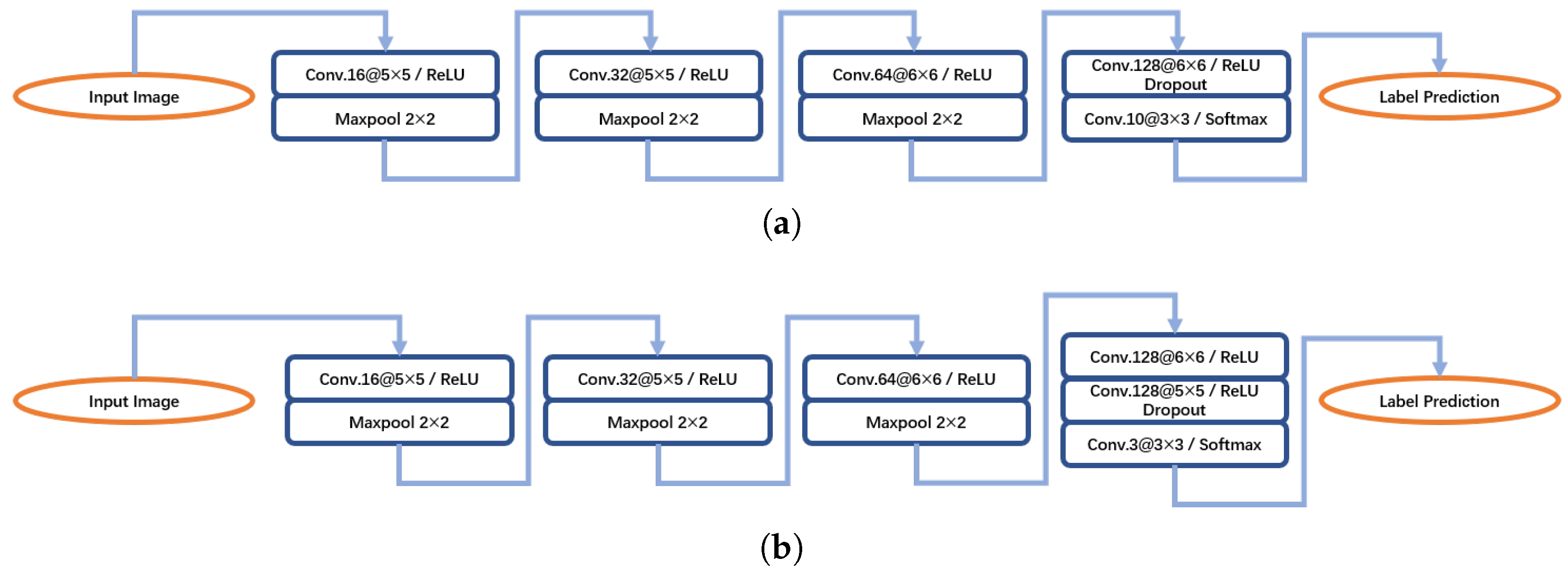
| AConvNet [10] | AConvNet |
| 0.39/0.79 | As shown in Figure 6. |
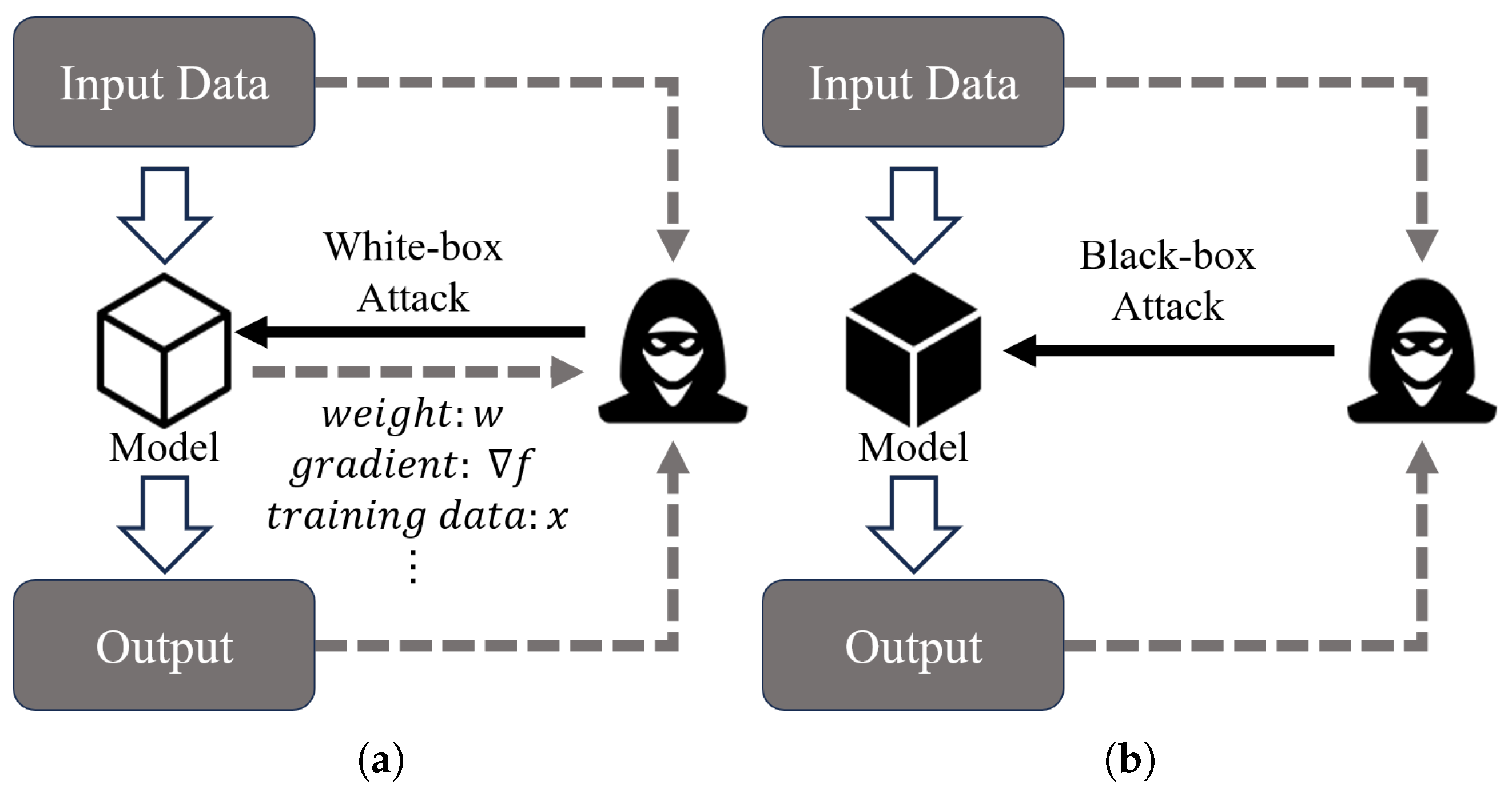
2.2. Adversarial Attack Algorithms
2.2.1. Fast Gradient Sign Attack (FGSM)
2.2.2. Basic Iterative Method (BIM)
2.2.3. Project Gradient Descent (PGD)
2.2.4. Carlini & Wagner (C&W)
2.2.5. Fast Minimum-Norm Attack (FMN)
2.2.6. DeepFool
3. Experiments and Results
3.1. Experimental Setup
3.1.1. Dataset
3.1.2. Implementation Details
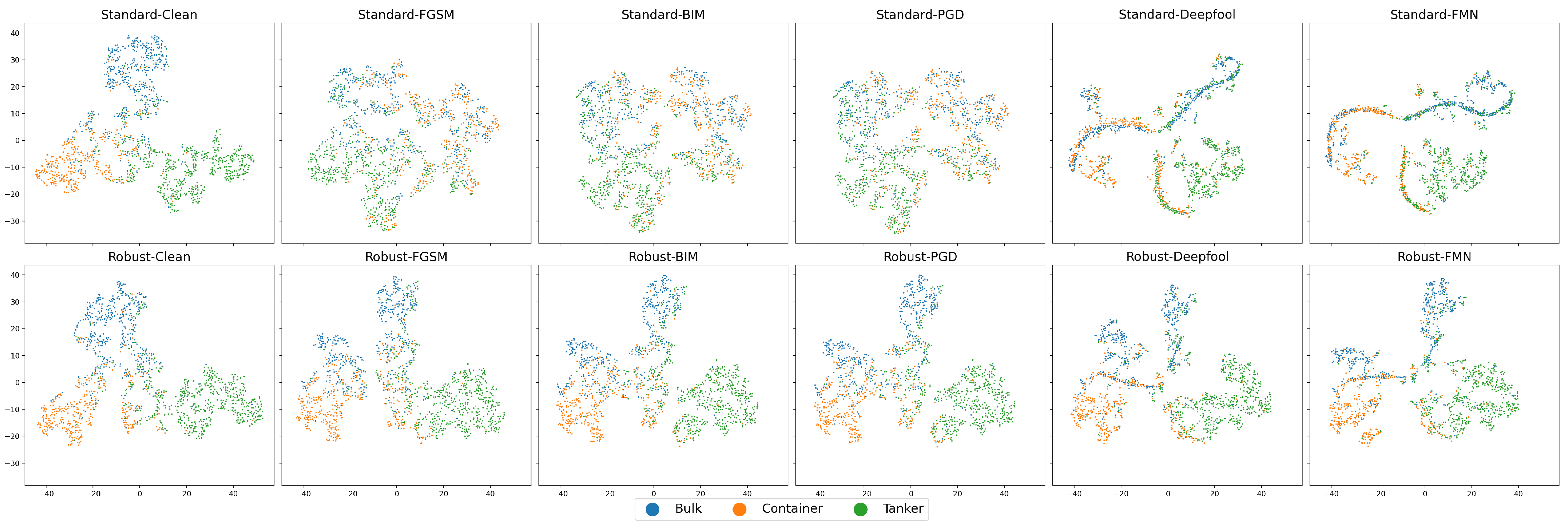
3.2. Results and Discussion
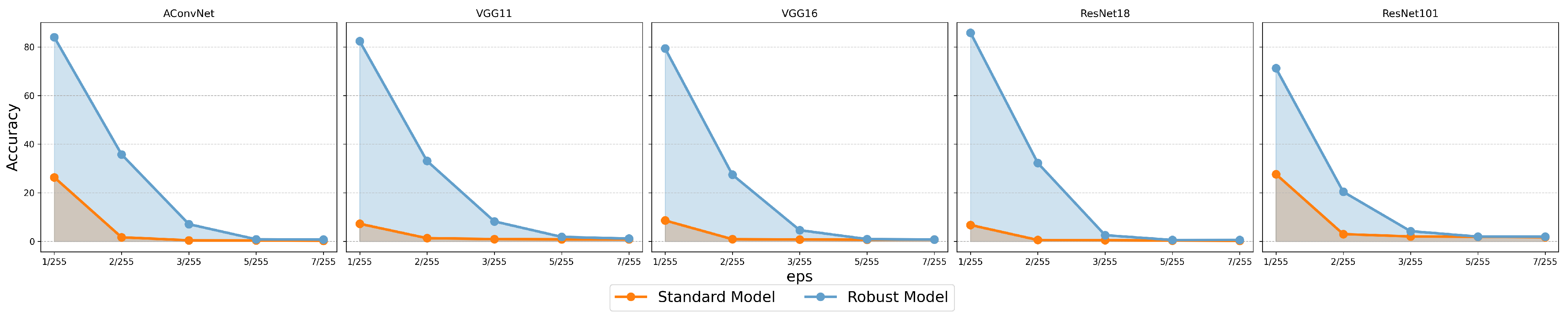
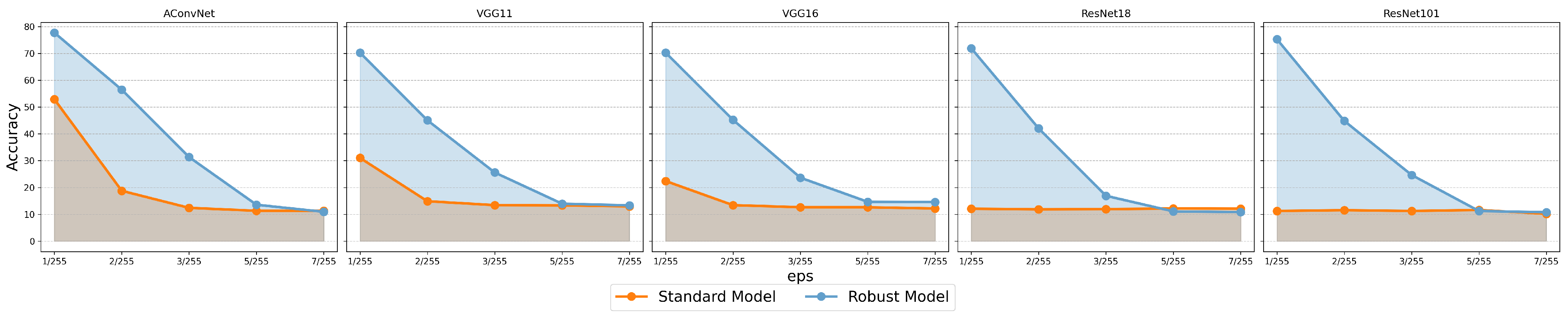
3.2.1. Experiments on the MSTAR Dataset
3.2.2. Experiments on the OpenSARShip Dataset
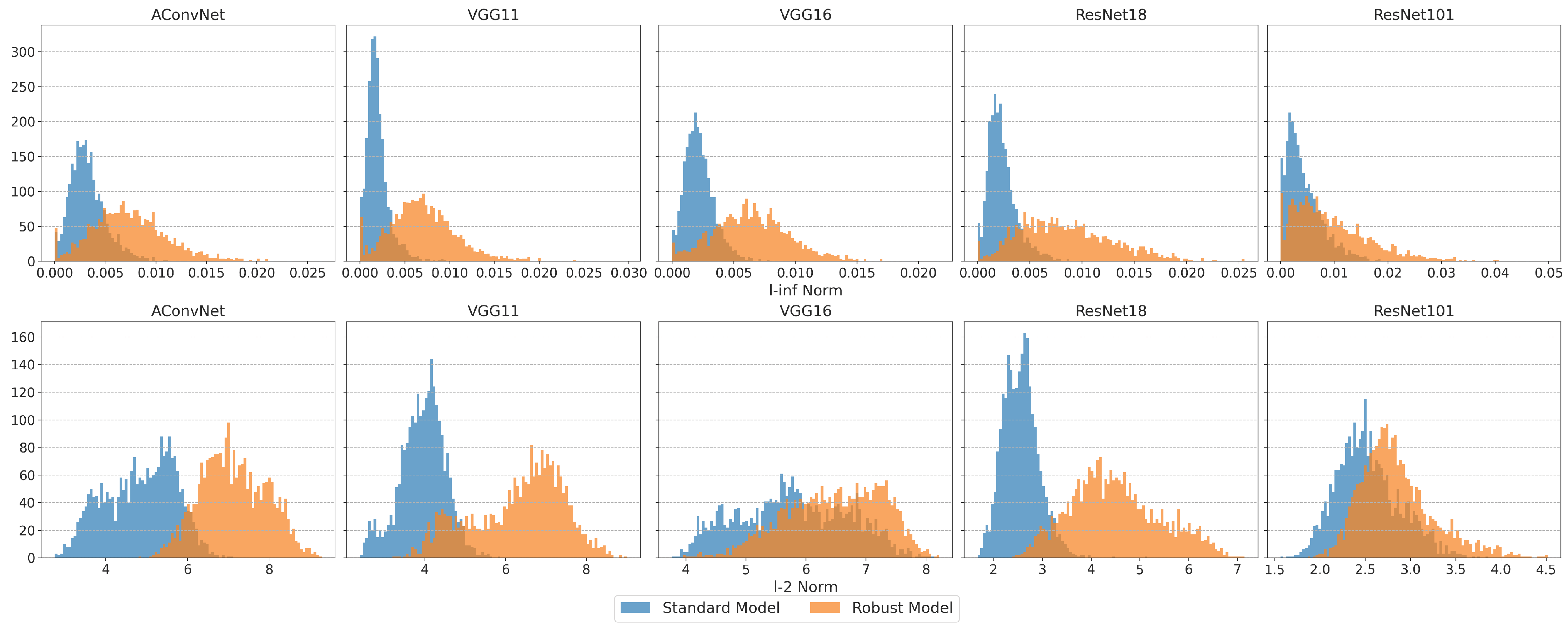
- Model-Specific Perturbation Norms: Adversarial perturbation magnitudes vary by architecture and are incomparable across models.
- Complex Decision Boundary: FMN’s -ball projection enables successful large-norm attacks, revealing mismatches between perturbation magnitude and robustness.
- Unstable Defense Gains: PGD adversarial training inconsistently increases perturbation norms across models and images, limiting reliability.
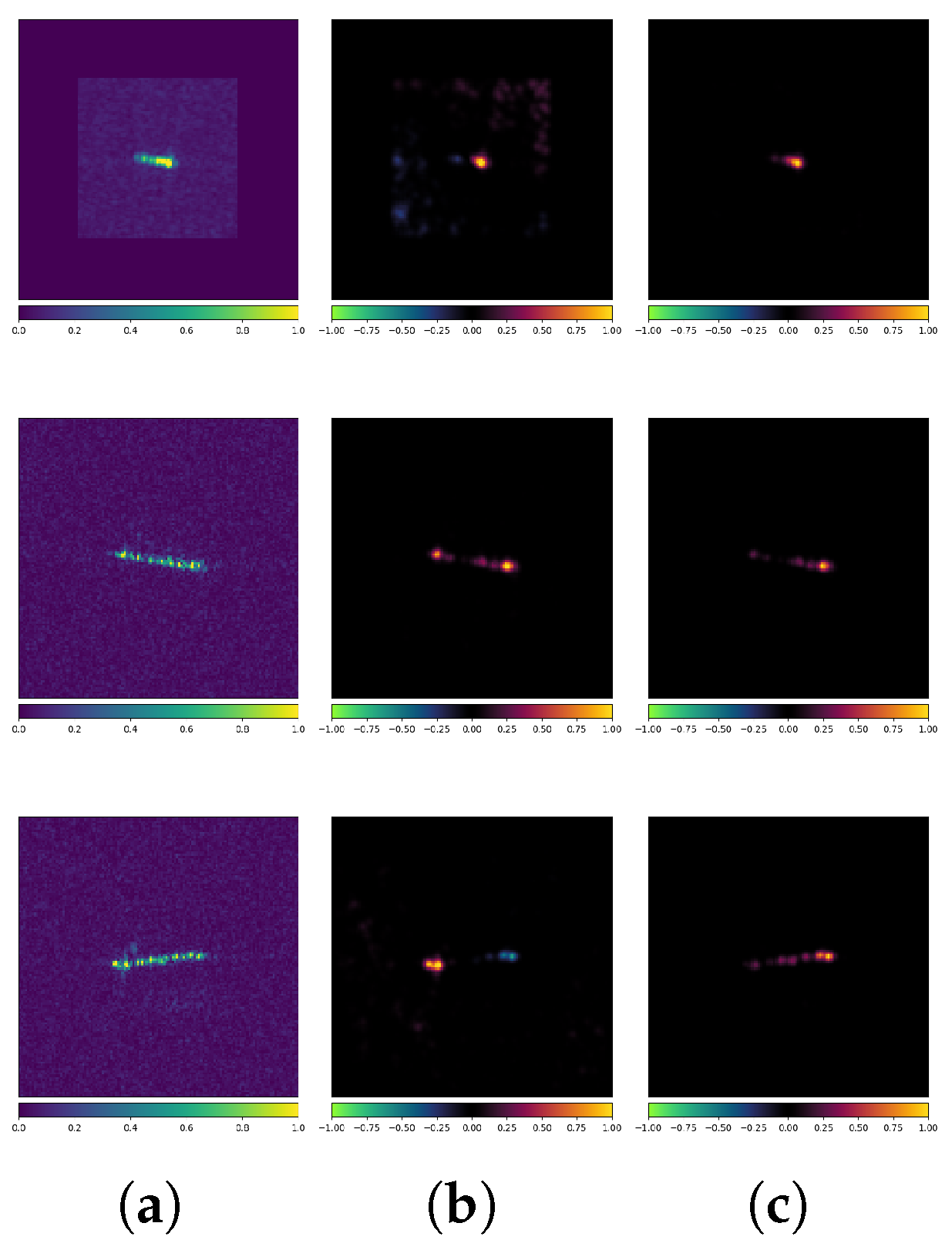
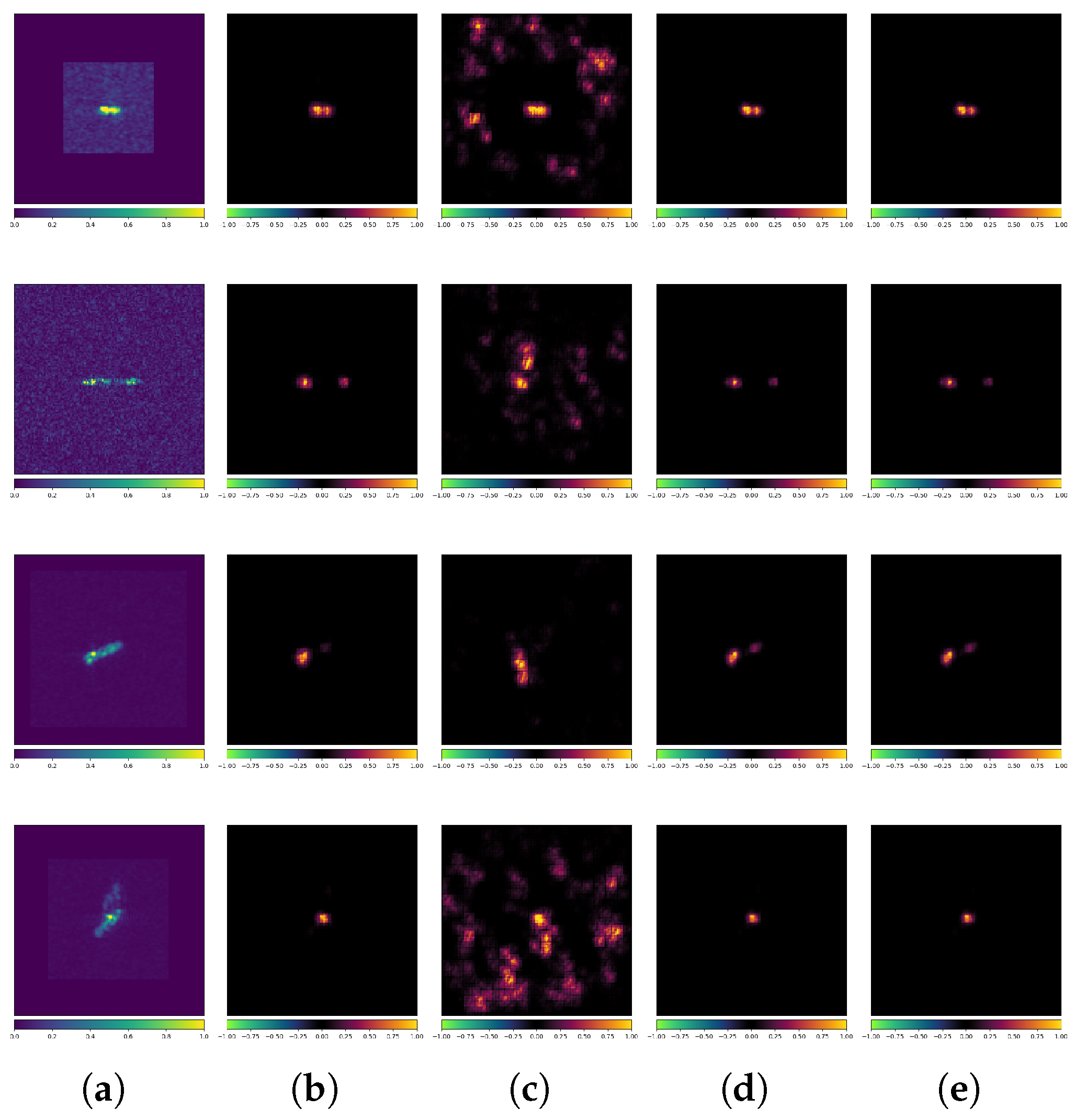
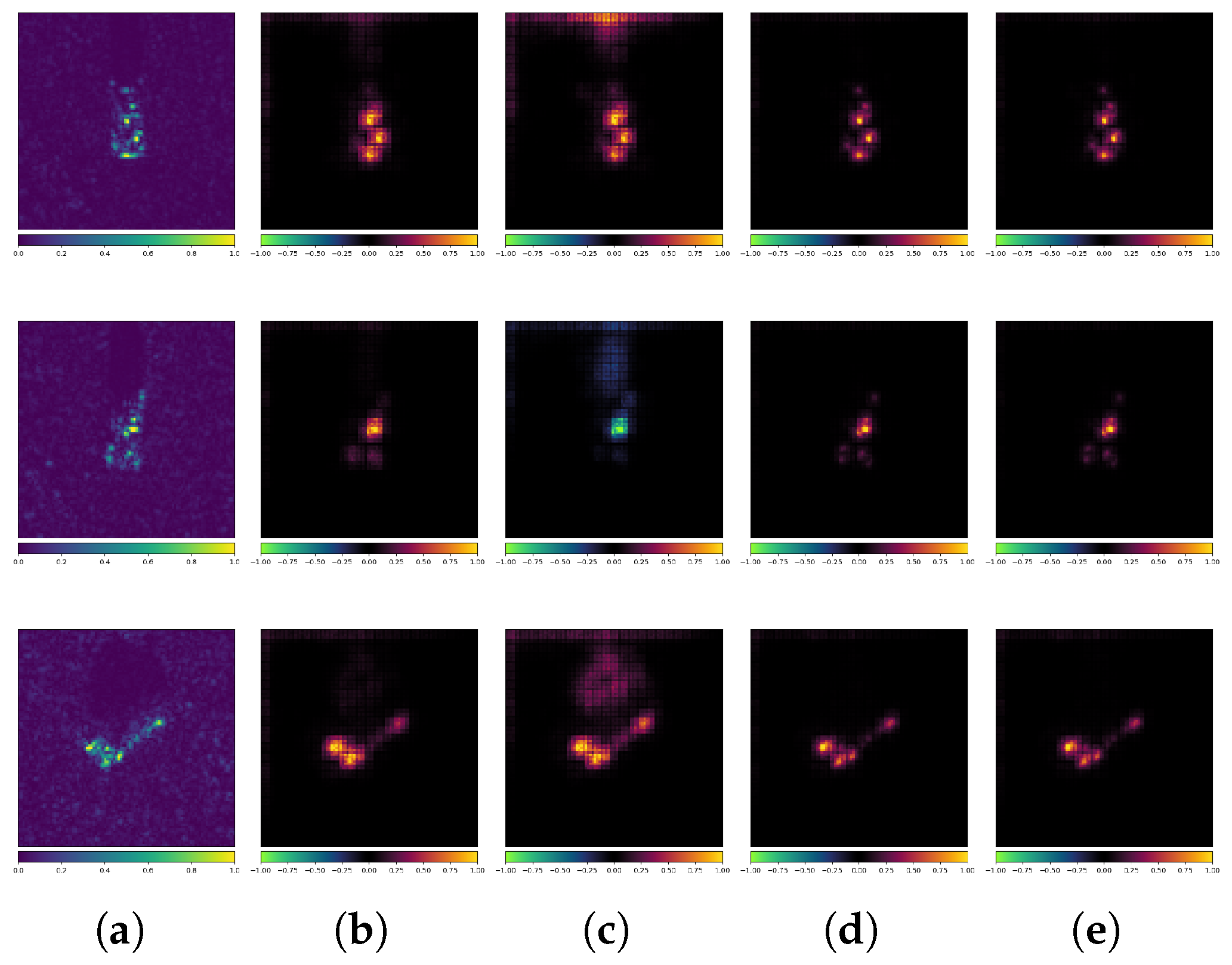
3.3. Interpretability Analysis
- Grad-CAM: High computational efficiency but low resolution, making it challenging to capture detailed structures in SAR images.
- LIME: Not limited by model structure, but results are influenced by perturbations, leading to instability.
- SHAP: High computational complexity, making it unsuitable for large datasets with high resolution.
- LRP: High-precision attribution, moderate computational complexity, closely related to the network architecture.
- Enhanced Learning of Strong Scattering Characteristics: In SAR image classification, PGD adversarial training helps the model to better learn the strong scattering characteristics within SAR images.
- Mitigation of Overfitting: PGD adversarial training helps mitigate overfitting, enabling the model to learn real features rather than spurious ones.
- Anomalies in Misclassified AEs: When misclassification occurs, the attribution maps for AEs often show significant anomalies, which may be related to the model’s adversarial vulnerability.
- Selective Scattering Attention in Attribution Maps: SAR image classification models exhibit selective focus on scattering characteristics. This explainability gap suggests adversarial robustness mechanisms may diverge from human-physics expectations.
4. Discussion and Prospects for Intricate Urban Classification Datasets
4.1. Discussions
- Large networks are not as robust as expected in SAR image classification. Pre-trained models or more effective data augmentation methods are necessary.Due to the generally small size of SAR image datasets, the training strategy has a significant impact on model performance and robustness. Larger networks within the same family, such as VGGNet and ResNet, often perform worse than smaller ones. At the same time, large networks, such as VGG16 and ResNet101, often perform worse than smaller networks like AConvNet. AEs, an effective data augmentation technique, help mitigate overfitting and enhance the robustness of larger models, warranting further study and application in SAR image classification.
- Low-intensity adversarial training achieves contextual robustness for SAR image classification but has intrinsic limitations.Our controlled experiments identify that low-intensity PGD adversarial training (eps = 1/255) enhance model robustness with minimal accuracy loss (<1% on both datasets). This aligns with adversarial training’s dual role as regularizer and implicit data augmenter [27]. However, three fundamental limitations persist:
- Attack-type overfitting: Defense efficacy collapses under unseen threat models.
- Intensity brittleness: Robustness plummets beyond trained eps thresholds.
- Semantic blindness: Digital adversarial perturbations lack semantic and physical information.
We thus advocate a multi-layered defense strategy combining adversarial detection (artifact screening) and feature disentanglement (scattering physics preservation) for operational SAR image classification systems. - DNN architecture determines the adversarial robustness of the SAR image classification model.While clean-data accuracy was comparable across networks, robustness varied substantially: Linear layers (e.g., in VGGNet) increased overfitting without improving robustness. Residual connections (e.g., in ResNet) enhanced adversarial trainability despite initial BIM/PGD vulnerability. Large convolutional kernels (e.g., in ACN) optimally captured scattering features with inherent robustness.The recommended design principles are abort linear layers and apply large convolutional kernels and adversarial-trained residual blocks for SAR image classifiers.
- XAI reveals the underlying mechanisms of adversarial robustness in SAR through saliency physics.Beyond conventional metrics, attribution maps generated by LRP expose sample-specific decision logic:
- Adversarial training induces saliency shift from background artifacts to target scattering signatures.
- Robust models develop scattering-point coherence—preserving key bright spots under perturbation.
This human-aligned interpretability bridges geometric scattering principles with DNN’s hierarchical feature learning, enabling causal analysis of adversarial vulnerabilities.
4.2. Prospects for LULC
- Hierarchical attention mechanisms bridging atomic (single-target) and molecular (scene-level) scattering patterns.
- Invariant feature learning capturing scale-independent scattering topologies through equivariant networks.
- Curriculum Adversarial Training (CAT) [58] progressively increasing scene complexity from isolated targets to cluttered urban mosaics.
- The DNN structure should be adapted to the characteristics of the dataset. Larger models do not necessarily have better performance or adversarial robustness.
- Reduce unnecessary weight parameters in DNNs. Using adaptive pooling or convolutional layer instead of fully connected layers may result in better adversarial robustness.
- In SAR image classification, AEs should be used as an effective means of regularization and overfitting mitigation, which may potentially improve model performance in certain cases.
- Adversarial training using pre-trained models can accelerate convergence, making the model’s accuracy more controllable.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, W.; Zhang, Z.; Yu, W.; Sun, X. Perspective on explainable SAR target recognition. J. Radars 2020, 9, 462–476. [Google Scholar] [CrossRef]
- Huang, Z.; Yao, X.; Liu, Y.; Dumitru, C.O.; Datcu, M.; Han, J. Physically explainable CNN for SAR image classification. ISPRS J. Photogramm. Remote Sens. 2022, 190, 25–37. [Google Scholar] [CrossRef]
- Huang, Z.; Wu, C.; Yao, X.; Zhao, Z.; Huang, X.; Han, J. Physics inspired hybrid attention for SAR target recognition. ISPRS J. Photogramm. Remote Sens. 2024, 207, 164–174. [Google Scholar] [CrossRef]
- Huang, Z.; Datcu, M.; Pan, Z.; Lei, B. Deep SAR-Net: Learning objects from signals. ISPRS J. Photogramm. Remote Sens. 2020, 161, 179–193. [Google Scholar] [CrossRef]
- Zhu, Y.; Ai, J.; Wu, L.; Guo, D.; Jia, W.; Hong, R. An Active Multi-Target Domain Adaptation Strategy: Progressive Class Prototype Rectification. IEEE Trans. Multimed. 2025, 27, 1874–1886. [Google Scholar] [CrossRef]
- Tian, Z.; Wang, W.; Zhou, K.; Song, X.; Shen, Y.; Liu, S. Weighted Pseudo-Labels and Bounding Boxes for Semisupervised SAR Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 5193–5203. [Google Scholar] [CrossRef]
- Deng, J.; Wang, W.; Zhang, H.; Zhang, T.; Zhang, J. PolSAR Ship Detection Based on Superpixel-Level Contrast Enhancement. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H. SAR target recognition based on deep learning. In Proceedings of the 2014 International Conference on Data Science and Advanced Analytics (DSAA), Shanghai, China, 30 October–1 November 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 541–547. [Google Scholar]
- Morgan, D.A.E. Deep convolutional neural networks for ATR from SAR imagery. In Algorithms for Synthetic Aperture Radar Imagery XXII; Zelnio, E., Garber, F.D., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2015; Volume 9475, p. 94750F. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.Q. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Kang, M.; Leng, X.; Zou, H. Deep Convolutional Highway Unit Network for SAR Target Classification With Limited Labeled Training Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1091–1095. [Google Scholar] [CrossRef]
- Zhao, P.; Liu, K.; Zou, H.; Zhen, X. Multi-stream convolutional neural network for SAR automatic target recognition. Remote Sens. 2018, 10, 1473. [Google Scholar] [CrossRef]
- Huang, G.; Liu, X.; Hui, J.; Wang, Z.; Zhang, Z. A novel group squeeze excitation sparsely connected convolutional networks for SAR target classification. Int. J. Remote Sens. 2019, 40, 4346–4360. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, C.; Tian, J.; Ou, J.; Li, J. A SAR Image Target Recognition Approach via Novel SSF-Net Models. Comput. Intell. Neurosci. 2020, 2020, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Jiang, Q.; Song, D.; Zhang, Q.; Sun, M.; Fu, X.; Wang, J. SAR vehicle recognition via scale-coupled Incep_Dense Network (IDNet). Int. J. Remote Sens. 2021, 42, 9109–9134. [Google Scholar] [CrossRef]
- Feng, S.; Ji, K.; Wang, F.; Zhang, L.; Ma, X.; Kuang, G. PAN: Part Attention Network Integrating Electromagnetic Characteristics for Interpretable SAR Vehicle Target Recognition. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Xu, F.; Jin, Y.Q. Polarimetric SAR Image Classification Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1935–1939. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.Q. Complex-Valued Convolutional Neural Network and Its Application in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Chen, S.W.; Tao, C.S. PolSAR image classification using polarimetric-feature-driven deep convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 627–631. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, L.; Tang, X.; Sun, Q.; Zhang, D. Polarimetric Convolutional Network for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3040–3054. [Google Scholar] [CrossRef]
- Dong, H.; Zou, B.; Zhang, L.; Zhang, S. Automatic Design of CNNs via Differentiable Neural Architecture Search for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6362–6375. [Google Scholar] [CrossRef]
- Cao, Y.; Wu, Y.; Li, M.; Liang, W.; Hu, X. DFAF-Net: A Dual-Frequency PolSAR Image Classification Network Based on Frequency-Aware Attention and Adaptive Feature Fusion. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Zhang, Q.; He, C.; He, B.; Tong, M. Learning Scattering Similarity and Texture-Based Attention With Convolutional Neural Networks for PolSAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–19. [Google Scholar] [CrossRef]
- Ibrahim, M.; Louie, M.; Modarres, C.; Paisley, J. Global Explanations of Neural Networks: Mapping the Landscape of Predictions. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 279–287. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Datcu, M.; Huang, Z.; Anghel, A.; Zhao, J.; Cacoveanu, R. Explainable, Physics-Aware, Trustworthy Artificial Intelligence: A paradigm shift for synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2023, 11, 8–25. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–23. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Rony, J.; Hafemann, L.G.; Oliveira, L.S.; Ben Ayed, I.; Sabourin, R.; Granger, E. Decoupling Direction and Norm for Efficient Gradient-Based L2 Adversarial Attacks and Defenses. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4317–4325. [Google Scholar] [CrossRef]
- Pintor, M.; Roli, F.; Brendel, W.; Biggio, B. Fast Minimum-norm Adversarial Attacks through Adaptive Norm Constraints. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Online, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 20052–20062. [Google Scholar]
- Wang, J.; Quan, S.; Xing, S.; Li, Y.; Wu, H.; Meng, W. PSO-based fine polarimetric decomposition for ship scattering characterization. ISPRS J. Photogramm. Remote Sens. 2025, 220, 18–31. [Google Scholar] [CrossRef]
- Huang, B.; Zhang, T.; Quan, S.; Wang, W.; Guo, W.; Zhang, Z. Scattering Enhancement and Feature Fusion Network for Aircraft Detection in SAR Images. IEEE Trans. Circuits Syst. Video Technol. 2025, 35, 1936–1950. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 4700–4708. [Google Scholar]
- Gu, Y.; Tao, J.; Feng, L.; Wang, H. Using VGG16 to Military Target Classification on MSTAR Dataset. In Proceedings of the 2nd China International SAR Symposium (CISS), Shanghai, China, 3–5 November 2021; pp. 1–3. [Google Scholar] [CrossRef]
- Arnab, A.; Miksik, O.; Torr, P.H. On the Robustness of Semantic Segmentation Models to Adversarial Attacks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tu, J.; Ren, M.; Manivasagam, S.; Liang, M.; Yang, B.; Du, R.; Cheng, F.; Urtasun, R. Physically Realizable Adversarial Examples for LiDAR Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wu, W.; Su, Y.; Chen, X.; Zhao, S.; King, I.; Lyu, M.R.; Tai, Y.W. Boosting the Transferability of Adversarial Samples via Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. HopSkipJumpAttack: A Query-Efficient Decision-Based Attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1277–1294. [Google Scholar] [CrossRef]
- Uesato, J.; O’Donoghue, B.; Kohli, P.; van den Oord, A. Adversarial Risk and the Dangers of Evaluating Against Weak Attacks. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5025–5034. [Google Scholar]
- Huang, L.; Liu, B.; Li, B.; Guo, W.; Yu, W.; Zhang, Z.; Yu, W. OpenSARShip: A Dataset Dedicated to Sentinel-1 Ship Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 195–208. [Google Scholar] [CrossRef]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A.; et al. Technical Report on the CleverHans v2.1.0 Adversarial Examples Library. arXiv 2018, arXiv:1610.00768. [Google Scholar]
- Rauber, J.; Zimmermann, R.; Bethge, M.; Brendel, W. Foolbox native: Fast adversarial attacks to benchmark the robustness of machine learning models in pytorch, tensorflow, and jax. J. Open Source Softw. 2020, 5, 2607. [Google Scholar] [CrossRef]
- Rauber, J.; Brendel, W.; Bethge, M. Foolbox: A python toolbox to benchmark the robustness of machine learning models. arXiv 2017, arXiv:1707.04131. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Lapuschkin, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Zhang, Y.; Hu, S.; Zhang, L.Y.; Shi, J.; Li, M.; Liu, X.; Wan, W.; Jin, H. Why Does Little Robustness Help? A Further Step Towards Understanding Adversarial Transferability. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2024; pp. 3365–3384. [Google Scholar] [CrossRef]
- Bai, S.; Li, Y.; Zhou, Y.; Li, Q.; Torr, P.H. Adversarial Metric Attack and Defense for Person Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2119–2126. [Google Scholar] [CrossRef] [PubMed]
- Peng, B.; Peng, B.; Xia, J.; Liu, T.; Liu, Y.; Liu, L. Towards assessing the synthetic-to-measured adversarial vulnerability of SAR ATR. ISPRS J. Photogramm. Remote Sens. 2024, 214, 119–134. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Z.; Yao, W.; Datcu, M.; Xiong, H.; Yu, W. OpenSARUrban: A Sentinel-1 SAR Image Dataset for Urban Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 187–203. [Google Scholar] [CrossRef]
- Mohammadi Asiyabi, R.; Datcu, M.; Anghel, A.; Nies, H. Complex-Valued End-to-End Deep Network With Coherency Preservation for Complex-Valued SAR Data Reconstruction and Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Cai, Q.Z.; Liu, C.; Song, D. Curriculum Adversarial Training. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3740–3747. [Google Scholar]
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting adversarial samples from artifacts. arXiv 2017, arXiv:1703.00410. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 23–25 May 2016; pp. 582–597. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




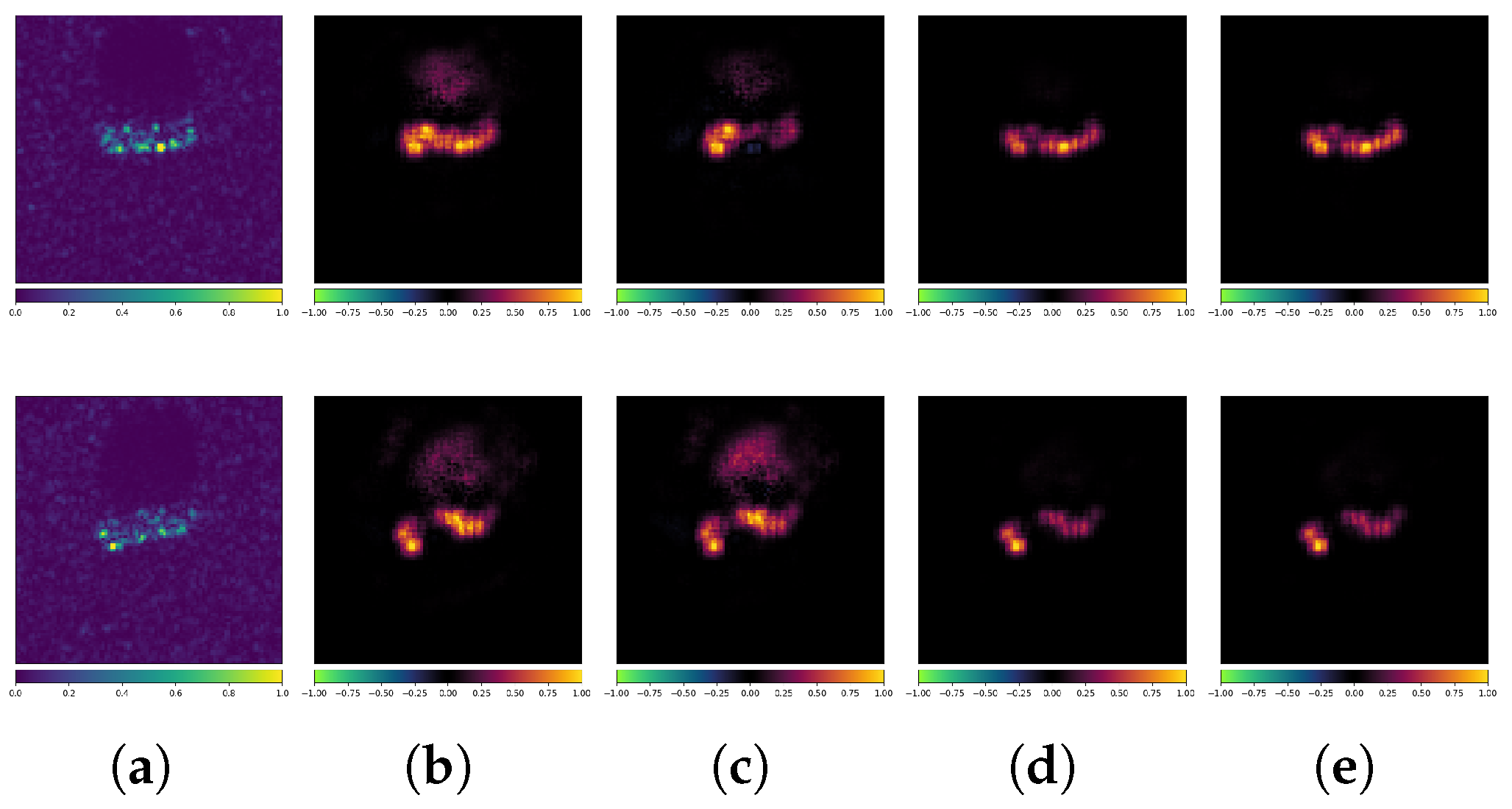
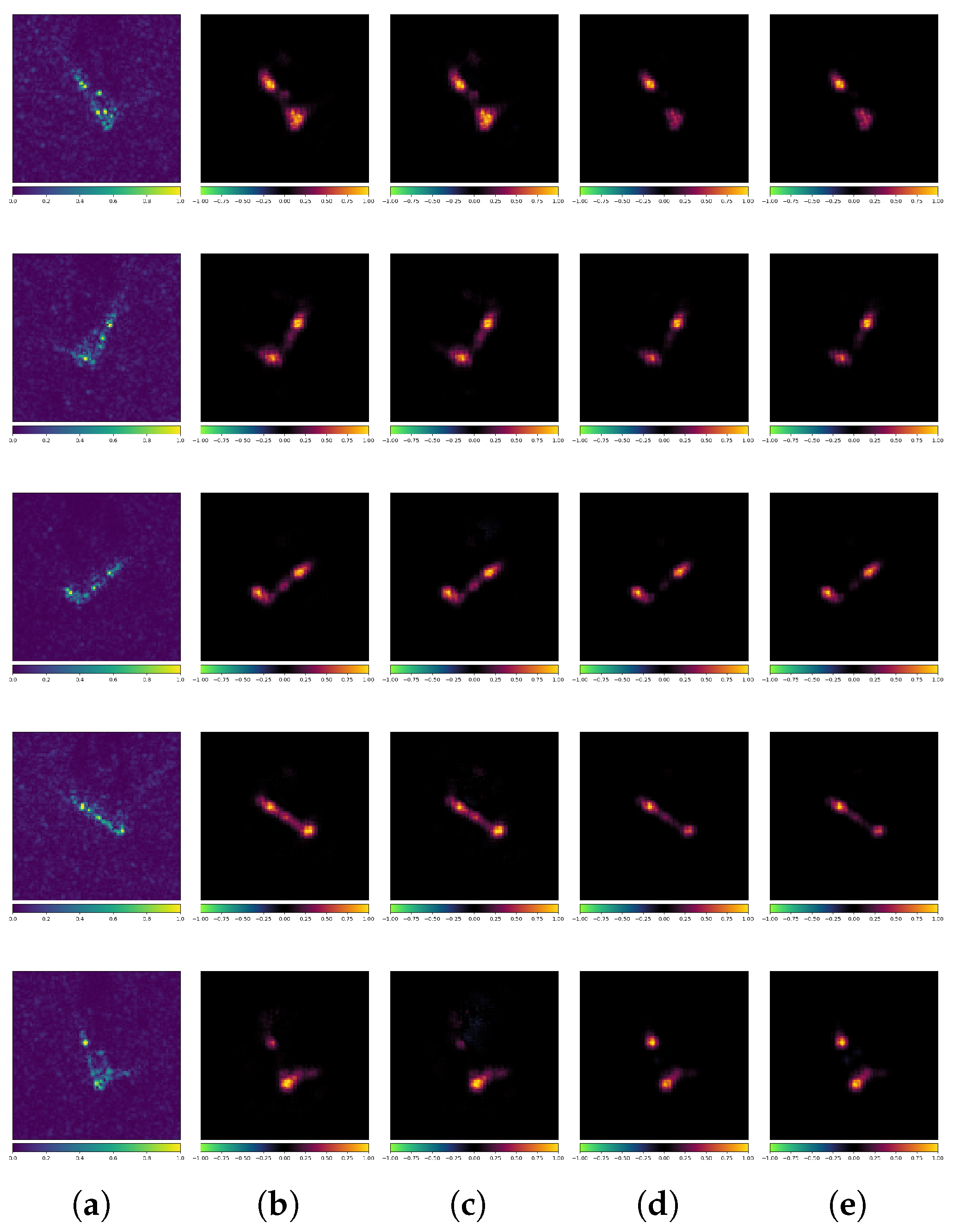
| Class | Train Set | Test Set | ||
|---|---|---|---|---|
| Depression | Number | Depression | Number | |
| 2S1 | 17° | 299 | 15° | 274 |
| BMP2 | 17° | 233 | 15° | 195 |
| BRDM2 | 17° | 298 | 15° | 274 |
| BTR60 | 17° | 256 | 15° | 195 |
| BTR70 | 17° | 233 | 15° | 196 |
| D7 | 17° | 299 | 15° | 274 |
| T62 | 17° | 299 | 15° | 273 |
| T72 | 17° | 232 | 15° | 196 |
| ZIL131 | 17° | 299 | 15° | 274 |
| ZSU23/4 | 17° | 299 | 15° | 274 |
| Class | Train Set Number | Test Set Number |
|---|---|---|
| Bulk | 1614 | 403 |
| Container | 1424 | 355 |
| Tanker | 2130 | 532 |
| Attack | Type | Settings |
|---|---|---|
| FGSM | Gradient-based | eps = () () |
| BIM | Gradient-based | eps = () () iteration = 50 stride = 0.001 |
| PGD | Gradient-based | eps = () () iteration = 50 stride = 0.001 |
| DeepFool | Gradient-based | eps = () () iteration = 50 |
| C&W | Optimization-based | eps = () iteration = 100 |
| FMN | Optimization-based | eps = () () iteration = 20 |
| Standard Training | Adversarial Training | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | |
| Clean | 98.93 | 98.27 | 99.01 | 99.051 | 97.07 | 98.23 | 97.94 | 99.01 | 99.05 | 96.90 |
| FGSM | 34.35 | 9.24 | 13.17 | 18.02 | 50.76 | 86.64 | 85.07 | 83.26 | 89.73 | 82.06 |
| BIM | 26.39 | 7.17 | 8.62 | 6.59 | 27.38 | 84.04 | 82.30 | 79.29 | 85.77 | 71.21 |
| PGD | 26.31 | 7.26 | 8.62 | 6.76 | 27.67 | 84.08 | 82.39 | 79.42 | 85.86 | 71.29 |
| DeepFool | 26.39 | 5.85 | 7.05 | 11.75 | 43.34 | 84.45 | 82.47 | 81.77 | 88.04 | 78.55 |
| FMN | 29.64 | 7.09 | 8.53 | 7.25 | 32.21 | 83.54 | 81.89 | 79.87 | 85.32 | 72.12 |
| Standard Training | Adversarial Training | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | |
| Clean | 98.93 | 98.27 | 99.01 | 99.05 | 97.07 | 98.23 | 97.94 | 99.01 | 99.05 | 96.90 |
| FGSM | 15.13 | 6.39 | 10.26 | 8.82 | 44.04 | 64.20 | 65.40 | 63.62 | 80.66 | 73.03 |
| BIM | 6.76 | 3.87 | 3.95 | 1.03 | 18.76 | 51.38 | 56.70 | 51.21 | 61.60 | 51.87 |
| PGD | 6.76 | 4.04 | 4.00 | 1.15 | 19.05 | 51.42 | 56.78 | 51.17 | 61.64 | 51.87 |
| DeepFool | 7.05 | 3.17 | 2.63 | 3.91 | 35.21 | 55.79 | 58.06 | 55.79 | 75.54 | 66.68 |
| C&W | 22.14 | 8.20 | 8.16 | 6.47 | 32.16 | 64.37 | 67.91 | 64.12 | 71.58 | 62.39 |
| FMN | 15.17 | 5.77 | 5.73 | 6.93 | 40.49 | 61.94 | 63.92 | 60.86 | 75.75 | 69.32 |
| Standard Training | Adversarial Training | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | |
| Clean | 83.25 | 79.61 | 79.22 | 81.00 | 82.32 | 83.10 | 79.38 | 78.99 | 82.79 | 82.79 |
| FGSM | 56.58 | 41.00 | 31.00 | 27.59 | 24.26 | 78.45 | 71.93 | 72.40 | 74.72 | 76.12 |
| BIM | 52.71 | 31.08 | 22.32 | 12.09 | 11.24 | 77.67 | 70.23 | 70.23 | 71.86 | 75.27 |
| PGD | 52.86 | 31.00 | 22.40 | 12.09 | 11.24 | 77.67 | 70.23 | 70.23 | 71.86 | 75.27 |
| DeepFool | 46.04 | 26.58 | 17.05 | 15.50 | 11.62 | 71.93 | 63.79 | 63.79 | 67.28 | 71.08 |
| FMN | 44.96 | 22.17 | 13.87 | 1.16 | 6.74 | 71.63 | 62.71 | 61.78 | 64.88 | 71.08 |
| Standard Training | Adversarial Training | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | ACN | VGG11 | VGG16 | ResNet18 | ResNet101 | |
| Clean | 83.25 | 79.61 | 79.22 | 81.00 | 82.32 | 83.10 | 79.38 | 78.99 | 82.79 | 82.79 |
| FGSM | 47.98 | 33.41 | 28.99 | 31.78 | 38.76 | 66.04 | 61.16 | 62.09 | 64.03 | 64.96 |
| BIM | 38.60 | 20.62 | 17.20 | 12.24 | 11.70 | 61.86 | 54.41 | 58.60 | 51.24 | 47.36 |
| PGD | 38.68 | 20.62 | 17.28 | 12.24 | 11.78 | 61.86 | 54.41 | 58.52 | 51.47 | 47.36 |
| DeepFool | 34.41 | 15.96 | 10.23 | 16.35 | 21.47 | 55.50 | 48.68 | 49.76 | 51.93 | 55.96 |
| C&W | 46.66 | 32.55 | 29.22 | 18.68 | 19.38 | 63.79 | 56.43 | 60.31 | 55.58 | 56.66 |
| FMN | 36.82 | 17.59 | 13.02 | 14.34 | 17.21 | 56.43 | 50.00 | 50.93 | 53.48 | 54.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, T.; Zhang, L.; Guo, W.; Zhang, Z.; Datcu, M. Analyzing the Adversarial Robustness and Interpretability of Deep SAR Classification Models: A Comprehensive Examination of Their Reliability. Remote Sens. 2025, 17, 1943. https://doi.org/10.3390/rs17111943
Chen T, Zhang L, Guo W, Zhang Z, Datcu M. Analyzing the Adversarial Robustness and Interpretability of Deep SAR Classification Models: A Comprehensive Examination of Their Reliability. Remote Sensing. 2025; 17(11):1943. https://doi.org/10.3390/rs17111943
Chicago/Turabian StyleChen, Tianrui, Limeng Zhang, Weiwei Guo, Zenghui Zhang, and Mihai Datcu. 2025. "Analyzing the Adversarial Robustness and Interpretability of Deep SAR Classification Models: A Comprehensive Examination of Their Reliability" Remote Sensing 17, no. 11: 1943. https://doi.org/10.3390/rs17111943
APA StyleChen, T., Zhang, L., Guo, W., Zhang, Z., & Datcu, M. (2025). Analyzing the Adversarial Robustness and Interpretability of Deep SAR Classification Models: A Comprehensive Examination of Their Reliability. Remote Sensing, 17(11), 1943. https://doi.org/10.3390/rs17111943