1. Introduction
Unmanned Aerial Vehicles (UAVs) are autonomous platforms controlled via remote commands or preprogrammed instructions [
1]. Due to their compact size, ease of operation, and high mobility, UAVs are increasingly deployed across military reconnaissance, urban planning, agriculture, and disaster management [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12]. However, the aerial perspective of UAV imaging introduces challenges such as small object scale, blurred boundaries, and severe occlusions, leading to high false and missed detection rates [
13]. These issues significantly reduce the performance of object detection algorithms in real-time, high-precision applications. Furthermore, due to limited onboard computing and memory, deploying heavy detection models on UAVs remains impractical [
14].
Deep learning has accelerated progress in object detection, driving innovation across computer vision and autonomous systems [
15,
16,
17,
18,
19]. Existing methods are broadly categorized into two-stage and one-stage detectors. Two-stage algorithms, such as R-CNN and Fast R-CNN [
20], first generate region proposals and then classify and regress object locations. Cui et al. [
21] improved Faster R-CNN with deformable convolutions, hybrid attention, and Soft-NMS to enhance UAV detection accuracy. Butler et al. [
22] extended Mask R-CNN with a non-volume integral branch to address scale variations, while Zhang et al. [
23] proposed MS-FRCNN with ResNet50, FPNs (Feature Pyramid Networks), and attention modules for improved forest fire small target detection. Despite their high accuracy, the complexity of two-stage pipelines limits their applicability in real-time UAV operations.
One-stage detectors such as RetinaNet [
24], CenterNet [
25], SSD [
26], and especially the YOLO series [
27], provide faster inference and have attracted significant research attention. Cao et al. [
28] proposed YOLOv5s-MSES with a small-target layer and multi-scale attention fusion to reduce false detections. Duan et al. [
29] enhanced YOLOv8s by introducing a small-object detection head, Inner-WIoU loss, and cross-spatial attention for better feature aggregation. Luo et al. [
30] developed YOLOD with HardSwish/Mish activation, EIoU loss, and adaptive spatial fusion for UAV images. Zhang et al. [
31] introduced HSP-YOLOv8, improving mAP@0.5 by 11% on the Visdrone2019 dataset through structural optimization. Another study by Luo et al. [
32] proposed asymmetric convolution modules, enhanced attention, and EIoU-NMS, achieving strong performance across multiple datasets.
Although deep learning-based target detection technology has made significant progress, existing methods still face many severe challenges in the scenario of small target detection in UAV aerial images, which severely restrict the improvement of detection performance.
Small target detection is one of the core challenges of UAV aerial image detection. Since drones usually shoot at higher altitudes, ground objects occupy very few pixels in the image, often only a few to a dozen pixels. This makes the object lack sufficient spatial information and texture details in the low-level feature map, which makes it difficult for the detection model to accurately extract and distinguish different categories of small objects. Shang et al. [
33] improved the detection performance of small targets in aerial images by applying a small target detection layer to the YOLOv5 model. Zhang et al. [
34] improved the YOLOv8n model and enhanced the feature fusion ability by introducing a bidirectional feature pyramid network (BiFPN), achieving more accurate recognition and positioning of small target objects. Qin et al. [
35] optimized the FPN structure of the YOLOv7 model and added a small target detection layer to enhance the network’s ability to detect small targets.
Fuzzy boundaries and severe occlusion problems are also common in UAV aerial image target detection tasks. On the one hand, the high-altitude overlook angle and weather factors may cause the edges of objects to be blurred, which increases the difficulty of accurately locating the bounding box. On the other hand, in dense scenes, it is very common for objects to block each other, and only a small part of some targets may be exposed, which makes them difficult for the model to reliably identify and locate based on the limited visible area. Wang et al. [
36] improved the RTDETR model by combining the HiLo attention mechanism with the in-scale feature interaction module and integrating it into the hybrid encoder to enhance the focus of the model on dense targets and reduce the missed detection rate and false detection rate. Chang et al. [
37] improved the YOLOv5s model by adding a coordinated attention mechanism after the convolution operation to improve the model detection accuracy of small targets under image blurring.
Complex background and similarity between classes also make detection difficult. UAV aerial images usually contain broad scenes with rich and complex background elements. At the same time, different categories of targets may have similarities in appearance, shape or color, which makes the model prone to confusion, especially when the target size is small, and this distinction is more difficult. Xiong et al. [
38] optimized the spatial attention module in the YOLOv5 model to enhance the representation of small target features while suppressing background interference. Yang et al. [
39] used the EMA attention mechanism in YOLOv8 to construct a new C2f-E module in the feature extraction network, grouped channel dimensions into multiple sub-features, and reshaped some channel dimensions into batch dimensions to maximize the feature information of small targets. Zhang et al. [
40] adopted two-layer routing attention (BRA) in the feature extraction stage of the YOLOv10 model to effectively reduce background interference.
While these efforts have advanced small object detection from UAV aerial images, challenges remain in terms of efficient cross-scale feature fusion and keeping the model lightweight. Many existing models improve accuracy by integrating complex modules or advanced feature fusion strategies, but this often leads to a large increase in computational complexity and model size, making it incompatible with the limited airborne resources of UAVs. Conversely, attempts at model compression sometimes sacrifice detection accuracy, especially for small objects in complex scenes. Meanwhile, YOLOv8s, while effective in real-time detection, still struggles to handle complex scenarios involving multi-scale variability and small object localization. To address these issues, this paper proposes an improvement of YOLOv8s for UAVs through four main contributions:
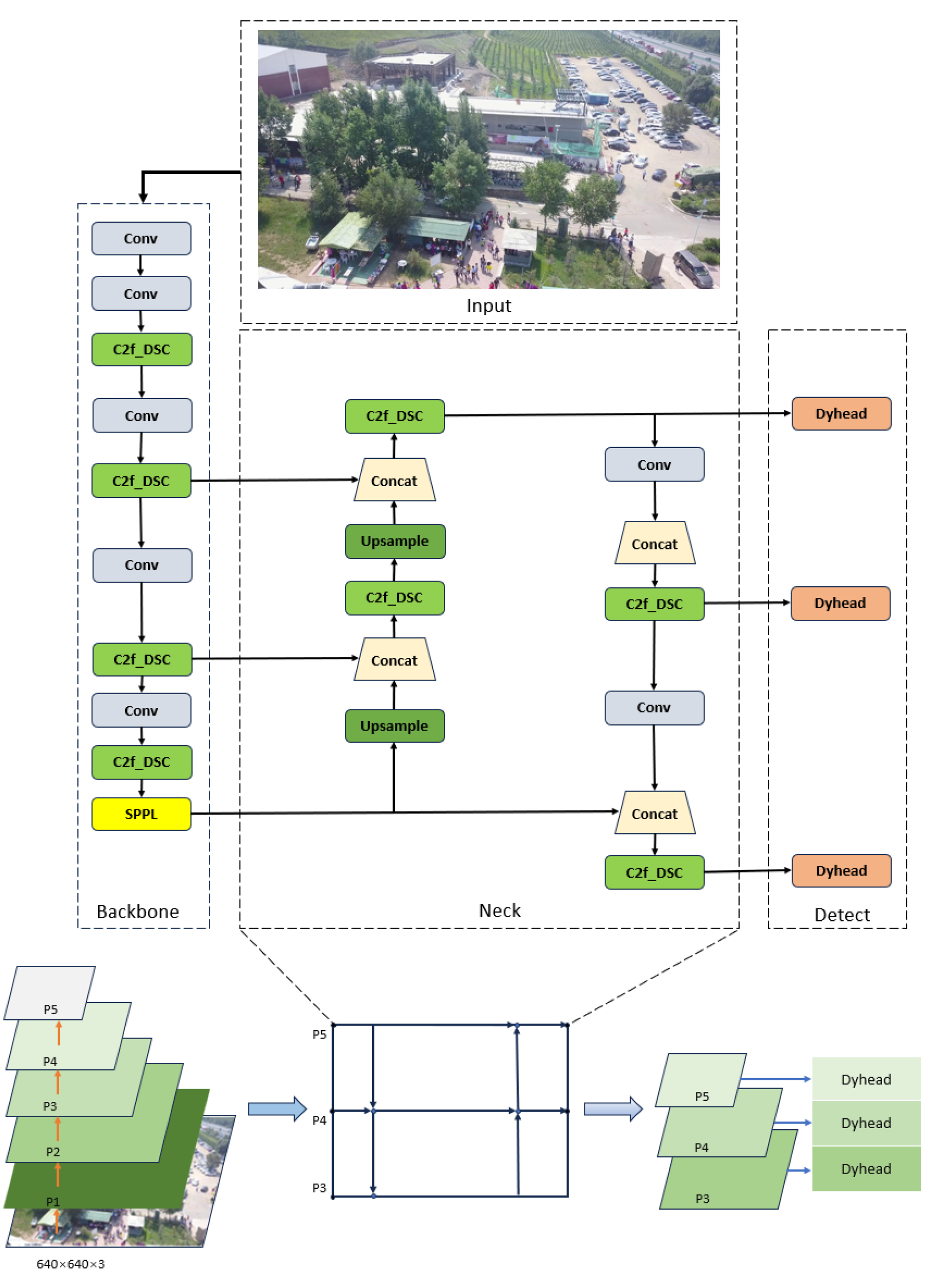
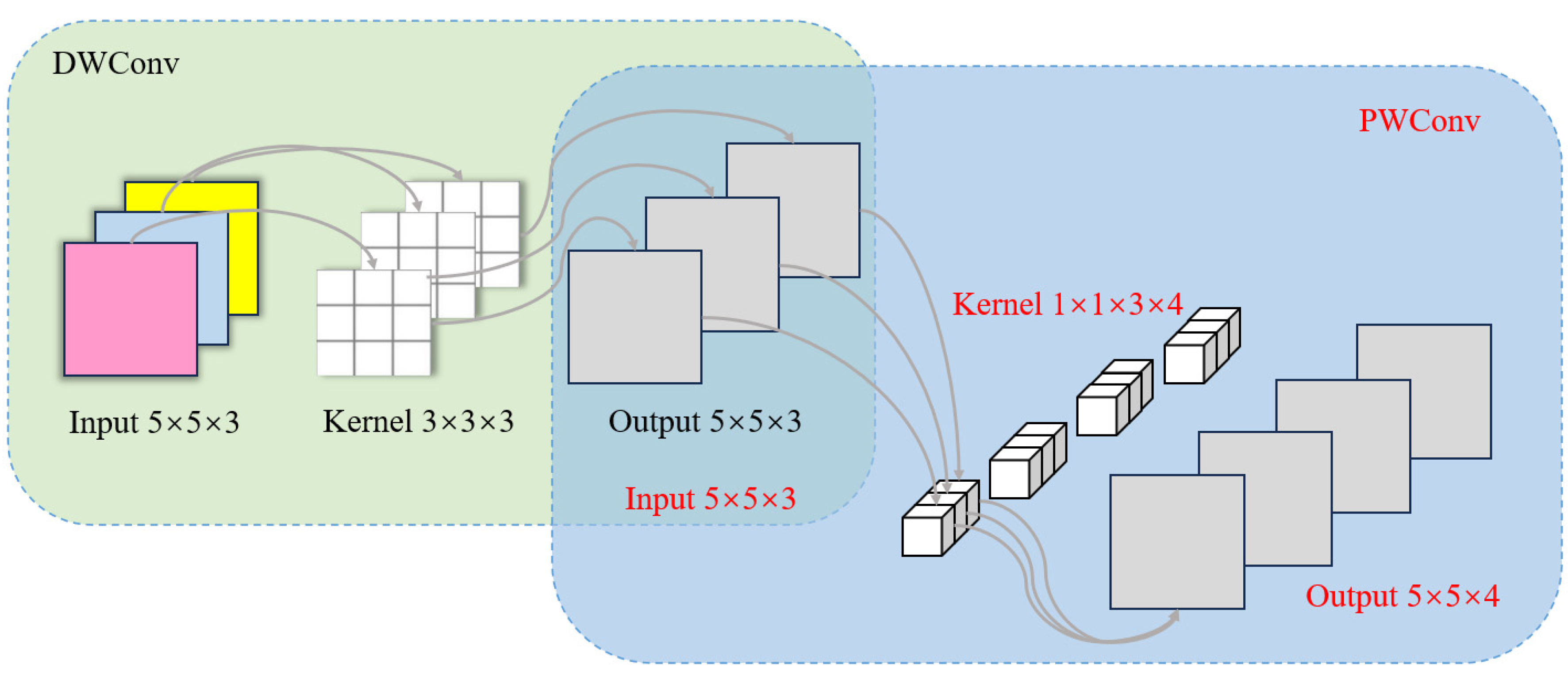
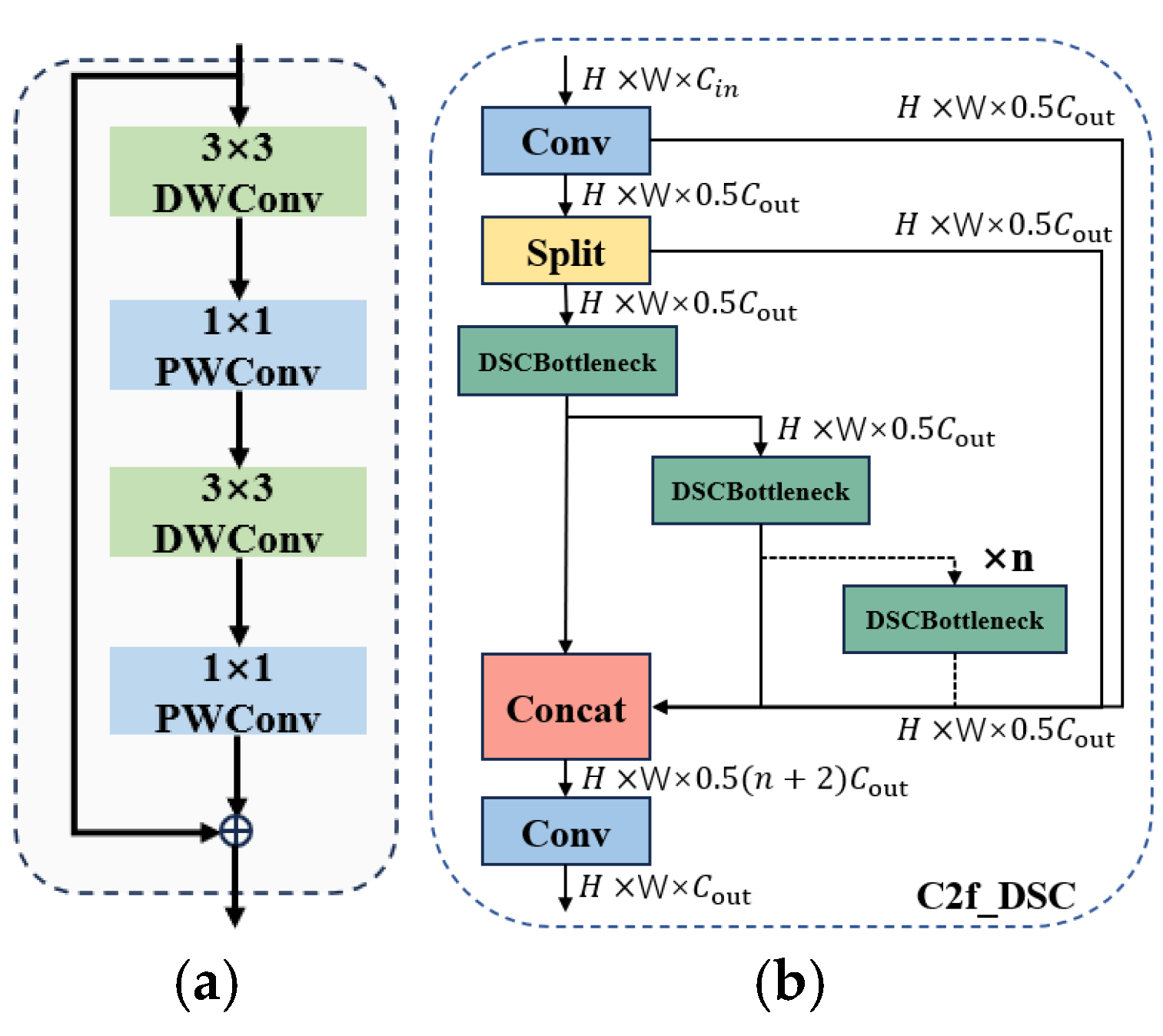
The C2f_DSC design: By introducing deep separable convolution and point-by-point convolution to build a double separation convolution block (DSC), and using DSC to replace the Bottleneck structure of the C2f module, C2f_DSC can effectively reduce the amount of parameters, calculations, and memory accesses, while enhancing feature expression capabilities and improving inference computation efficiency, especially for UAV aerial photography small target detection tasks.
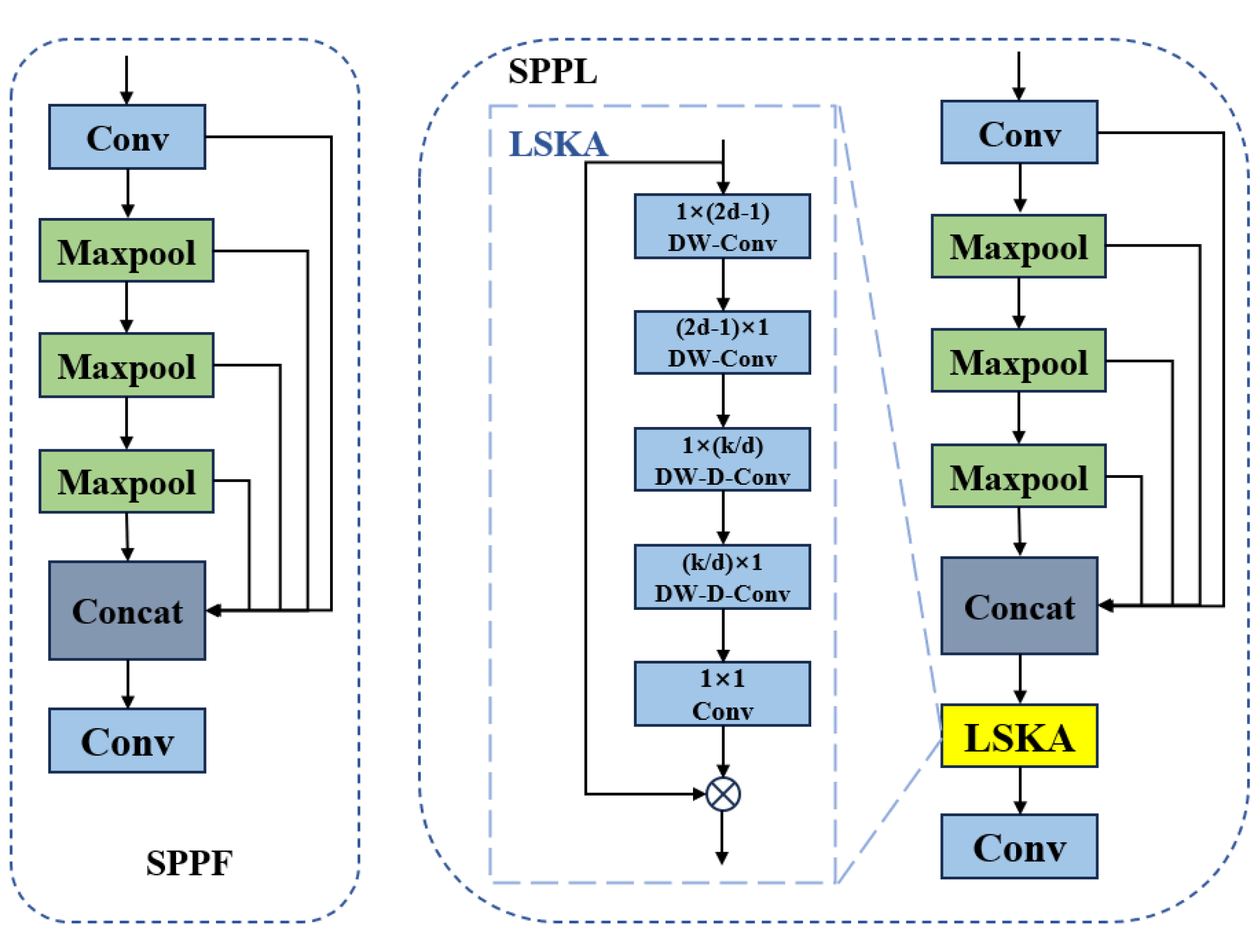
The SPPL module: By combining the multi-scale feature extraction capability of SPPF with the long-distance dependency capture and self-attention mechanism of LSKA, the diversity and flexibility of feature extraction are improved, and the model’s ability to detect targets at various scales is enhanced, making it more suitable for handling multi-scale target detection tasks.
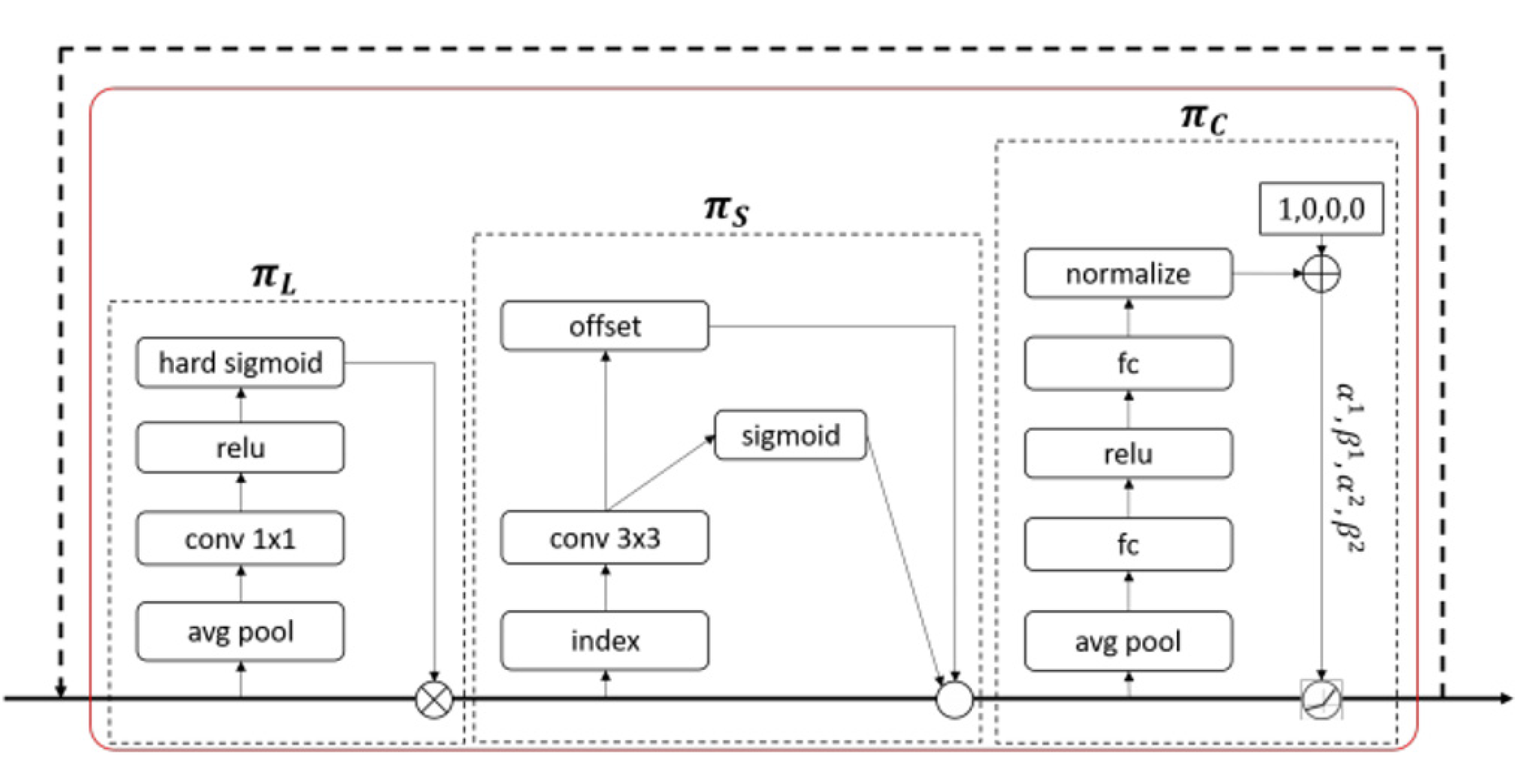
The integration of DyHead: Dyhead is used to replace the head part of the original model, which aims to solve the shortcomings of the traditional target detection model in feature fusion and dynamic adjustment. By introducing dynamic weight allocation and adaptive feature fusion mechanism, Dyhead can capture and utilize multi-scale feature information more effectively, which improves the accuracy of target detection, especially for small-sized and complex background targets.
The WIPIoU loss: Three loss functions of Wise-IoU, MPDIoU, and Inner-IoU are combined, and the WIPIoU loss function is proposed, which improves the regression accuracy of bounding box, enables the model to accurately locate the target, and accelerates the convergence speed of the model.
The rest of this paper is arranged as follows:
Section 2 describes the technical details of network model improvement;
Section 3 shows and analyzes the experimental results; finally,
Section 4 summarizes the research work.
3. Results and Analysis
3.1. Experimental Datasets
This study utilizes the VisDrone2019 dataset, curated by the AISKYEYE team from the Machine Learning and Data Mining Laboratory at Tianjin University [
51]. Captured via UAVs across diverse scenes, weather conditions, and lighting environments, the dataset comprises over 2.6 million manually annotated bounding boxes, ensuring high annotation accuracy, rich object categories, and comprehensive occlusion scenarios. It includes 10,209 drone-captured images, partitioned into 6471 for training, 548 for validation, and 3190 for testing. The training set contains 353,550 annotated objects, with approximately 50% affected by occlusion—142,873 partially occluded and 33,804 severely occluded. Ten categories of small objects are labeled, making the dataset particularly well-suited for small object detection and recognition research. Representative examples are shown in
Figure 7.
3.2. Experiment Environment
Experiments were conducted on a desktop equipped with an Intel
® Core™ i5-14400F processor, 16 GB RAM, NVIDIA GeForce RTX 3050 GPU, and Windows 11 (64-bit). The deep learning environment was configured with Python 3.8.19, PyTorch 1.13.1, and CUDA 11.7. Model training employed stochastic gradient descent (SGD) for parameter optimization. Key hyperparameter settings are summarized in
Table 1.
3.3. Evaluation Metrics
A total of five evaluation metrics are employed in order to provide a comprehensive assessment of the detection model. These include precision, recall, parameter count, computational complexity, and mean average precision (mAP). The equations for these metrics are as follows:
TP represents the number of positive samples correctly predicted as positive by the model, FP represents the number of negative samples incorrectly predicted as positive by the model, and FN represents the number of positive samples incorrectly predicted as negative by the model. P refers to the ratio of correctly predicted positive samples among all samples predicted to be positive; R refers to the ratio of correctly predicted positive samples among all actual positive samples. AP represents the area under the Precision–Recall (P-R) curve, while mAP denotes the average of AP for each category.
3.4. Analysis of the Influence of C2f_DSC Module on Model Performance
Although the C2f_DSC module theoretically enhances feature extraction while reducing the parameter count, its practical impact on performance remains uncertain, particularly when applied to deep network structures. To evaluate the optimal integration point within the YOLOv8s architecture, four experimental configurations were tested, as summarized in
Table 2. Replacing only the backbone’s C2f module led to a slight accuracy gain (49.8%→50.3%), a minor decrease in recall (38.4%→38.1%), and notable reductions in parameters (14%) and FLOPs (19%), with a marginal increase in mAP@0.5 (+0.1%). Modifying only the neck module resulted in decreased accuracy (49.8%→48.6%) and recall (38.4%→37.4%), but with a 20% parameter and 28% FLOPs reduction, while mAP@0.5 slightly declined (−0.1%). When both backbone and neck modules were replaced, accuracy and recall further declined (49.8%→47.4%, 38.4%→37.7%), though parameter count and FLOPs dropped significantly by 34% and 47%, respectively, with a mAP@0.5 decrease of 0.2%. These results suggest that while C2f_DSC enhances computational efficiency, performance improvements do not scale linearly with the extent of replacement. Given its highest cost-efficiency, this study adopts C2f_DSC throughout the network.
3.5. Comparison of Loss Functions
In this chapter, we perform quantitative contrast experiments on several loss functions: CIoU, Inner-IoU, GIoU, SIoU, ShapeIoU, DIoU, and WIPIoU. The experimental results are shown in
Table 3.
By comparing the experimental results, we find that the model accuracy, recall, and mAP@0.5 using the WIPIoU loss function are all superior to other loss functions. The accuracy of the model using WIPIoU loss function is significantly improved, which shows that the model reduces false detection and missed detection when identifying small targets, and improves the detection accuracy. The performance of the WIPIoU loss function in terms of recall rate is also very good, indicating that the model can effectively identify more real targets and reduce missed detection, which is particularly important for UAV small target detection in practical applications.
3.6. Comparison of Different Network Detection Heads
To further evaluate the performance of the DyHead detection head, comparative experiments were conducted under identical conditions by integrating DyHead, EfficientHead, SEAMHead, and MultiSEAMHead into the YOLOv8s framework. The results, presented in
Table 4, show that the DyHead-enhanced model achieved the highest overall performance, with an accuracy of 51.5%, recall of 44.9%, and mAP@0.5 of 44.7%. While EfficientHead, SEAMHead, and MultiSEAMHead yielded improvements in select metrics, none matched the comprehensive effectiveness of DyHead. Moreover, DyHead introduces only a marginal increase in model parameters. Therefore, DyHead is identified as the most effective enhancement strategy among those tested.
3.7. Visual Analysis of the Model Before and After Improvement
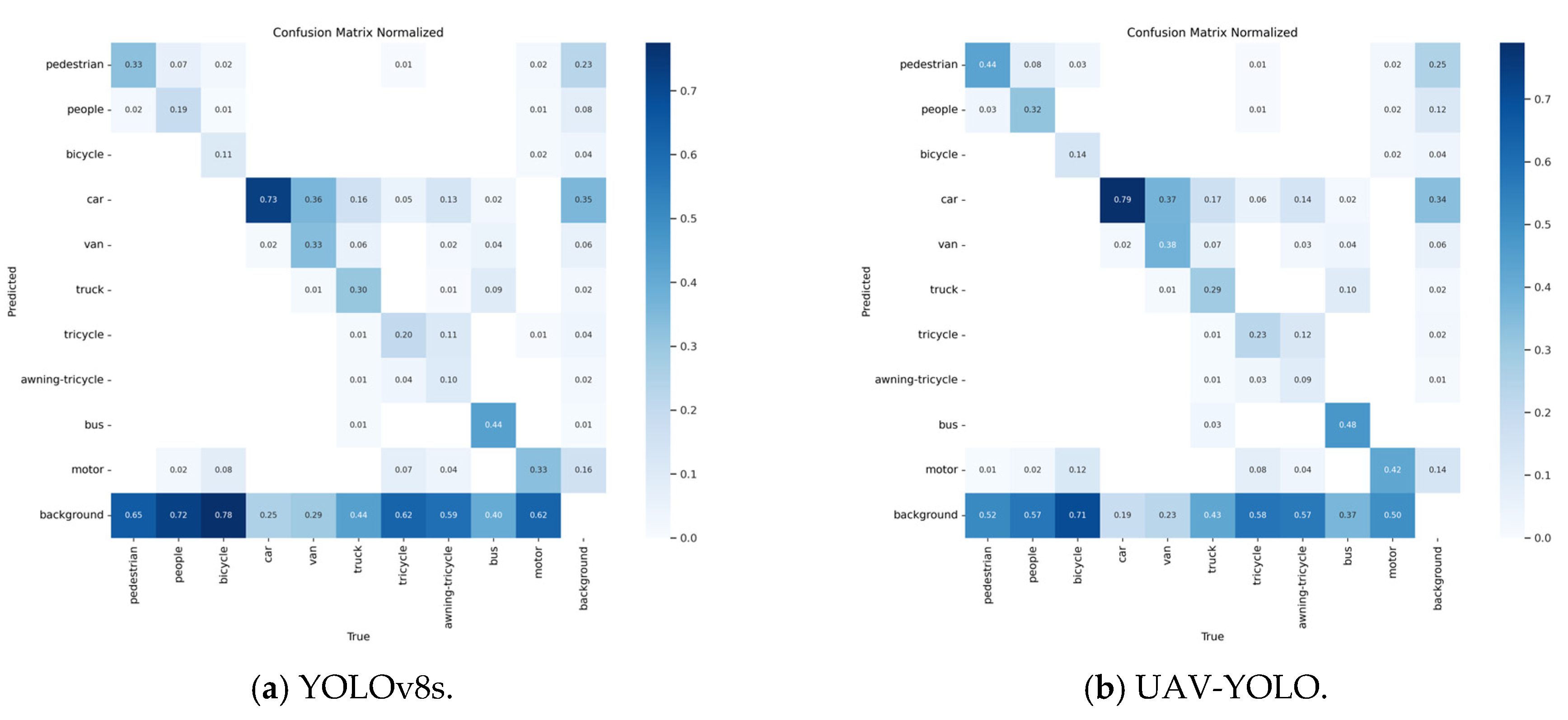
We further evaluate the detection ability of the trained model through the confusion matrix. The confusion matrix is shown in
Figure 8. It can be seen from the confusion matrix that the improved model can reflect higher classification accuracy and a more balanced classification performance in UAV aerial images.
To evaluate the validity and accuracy of the UAV-YOLO model, comparative experiments were performed using the benchmark model YOLOv8s and the UAV-YOLO model, performed using several different scenarios involving the VisDrone2019 dataset.
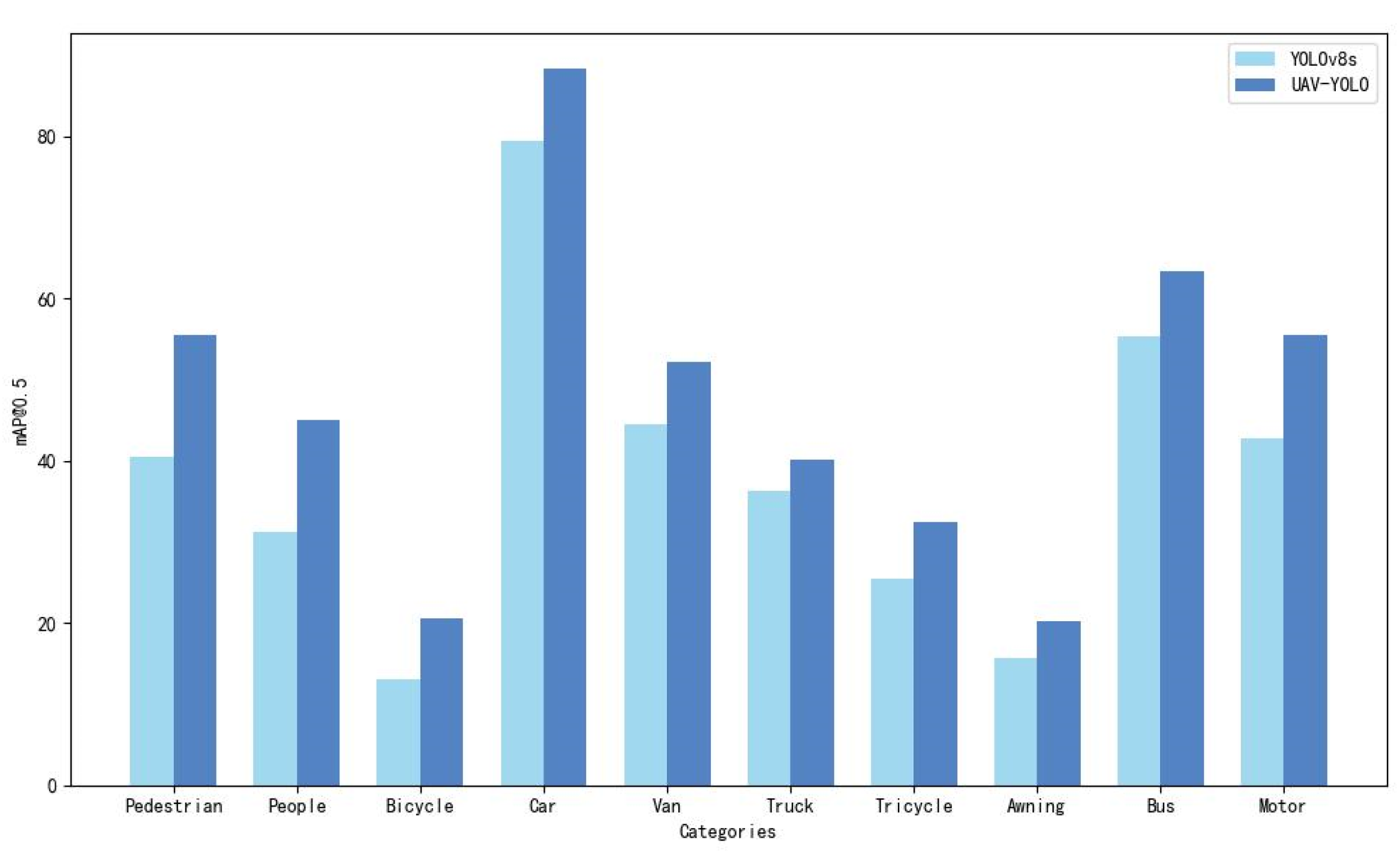
Table 5 and
Table 6 provide detailed comparisons of performance indicators and detection accuracies for all categories before and after model improvement. The mAP@0.5 of UAV-YOLO was significantly improved by 8.9% compared to YOLOv8s. The parameter amount of UAV-YOLO is 8.5 × 106, which is 23.4% less than the benchmark model, and the model calculation amount is 16.9 FLOPs, which is 40.7% less than the benchmark model, demonstrating excellent performance. In addition,
Figure 9 more intuitively shows the comparison of the recognition accuracy of the YOLOv8s and UAV-YOLO models for all categories on the VisDrone2019 dataset.
Figure 10 provides a more intuitive diagram of the test results. In high-exposure scenes, as shown in
Figure 10a,b, the UAV-YOLO model shows significant advantages in detecting small objects. Compared with the benchmark model YOLOv8s, UAV-YOLO can detect and locate different targets more accurately, while YOLOv8s may cause missed detection and false detection by identifying signs as motorcycles and not identifying people on the bridge, etc. In the dense target scene, as shown in
Figure 10c,d, UAV-YOLO successfully identified motorcycles and pedestrians that the YOLOv8s model failed to identify. In the night scene, as shown in
Figure 10e,f, UAV-YOLO maintains excellent detection performance and successfully identifies more cars, pedestrians and motorcycles, while the YOLOv8s model mistakenly identifies motorcycles as bicycles. The ability of the UAV-YOLO model to accurately locate objects in low light conditions further verifies its robustness to illumination changes, providing reliable support for night surveillance and target detection tasks. In multi-scale scenarios, as shown in
Figure 10g,h, UAV-YOLO shows excellent performance when detecting distant or incoming and exiting vehicles. It is worth noting that in the lower right corner of the image, UAV-YOLO can more accurately distinguish different vehicle types.
3.8. Ablation Experiment
Given its balance between detection accuracy and speed, YOLOv8s was selected as the baseline model for optimizing small object detection in UAV imagery. To assess the proposed enhancements, nine improved configurations were designed and evaluated under consistent training conditions.
Table 7 outlines the modifications, while
Table 8 presents the corresponding results on the VisDrone2019 dataset, with optimal values highlighted in bold. The experimental results demonstrate that the best performance is achieved when all four improvements are applied simultaneously, effectively enhancing the extraction and utilization of small object features while simplifying the model architecture.
In single-module ablation studies, replacing the C2f module with the proposed C2f_DSC module reduced the computational load and parameter count by 40.7% and 23.4%, respectively, with only a marginal mAP@0.5 drop of 0.2%, indicating substantial efficiency gains with minimal accuracy loss. Substituting SPPF with the SPPL module slightly increased complexity but improved mAP@0.5 by 1.8%, validating its effectiveness in feature fusion. Integrating DyHead significantly boosted mAP@0.5 by 6.3% with only minor overhead. Additionally, replacing the CIoU loss function with the proposed WIPIoU yielded a 2.0% mAP@0.5 gain without increasing model complexity, confirming its robustness.
Combined ablation experiments revealed synergistic effects among the modules. Simultaneously incorporating C2f_DSC, SPPL, and DyHead raised mAP@0.5 to 45.4%, with parameter and FLOPs counts of 8.5 M and 16.9, respectively, demonstrating strong complementarity in performance and compactness. Replacing DyHead with WIPIoU under the same conditions further improved mAP@0.5 to 46.4%. In contrast, combining DyHead, SPPL, and WIPIoU yielded a lower mAP@0.5 of 42.6%, with substantially higher parameters (12.4 M) and FLOPs (30.3), indicating the dominant influence of the C2f_DSC module in maintaining lightweight efficiency.
Overall, the optimized UAV-YOLO model achieves a 23.4% reduction in parameters and a 40.7% reduction in computational load while maintaining high detection accuracy. These results confirm the effectiveness of the proposed improvements in achieving a favorable balance between model compactness, computational efficiency, and detection performance for UAV-based small object detection.
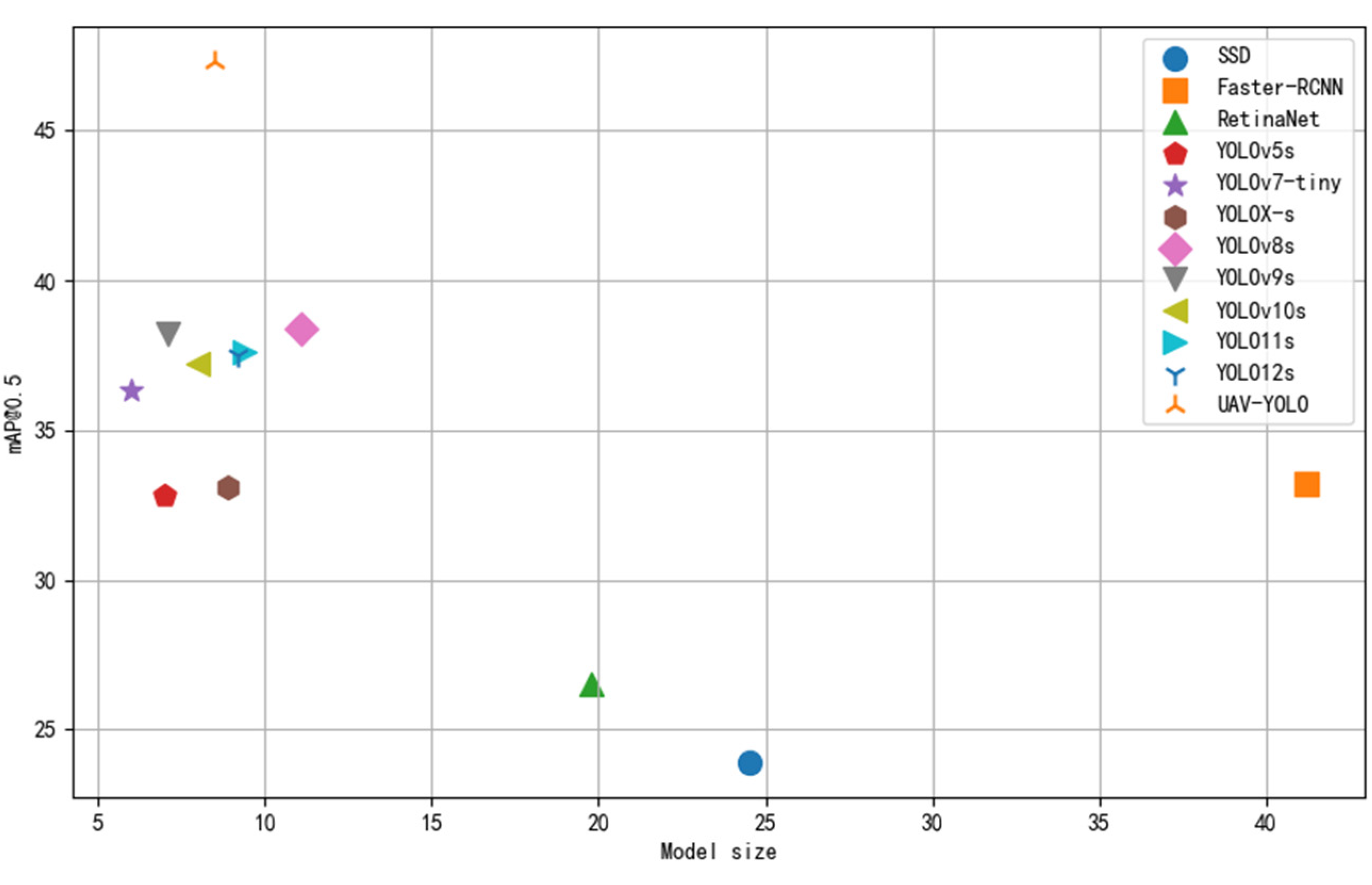
3.9. Comparative Analysis with Other Models
To comprehensively assess the performance of UAV-YOLO in UAV-based small object detection, it was compared with several mainstream object detection models, including Faster R-CNN, SSD, RetinaNet, YOLOv5s, YOLOv7-tiny, YOLOX-s, YOLOv8s, YOLOv9s, YOLOv10s, YOLO11s, and YOLO12s.
Table 9 summarizes the comparative results across key metrics such as parameter count, computational complexity, accuracy, recall, and mAP@0.5, with optimal values highlighted in bold. A visual comparison is provided in
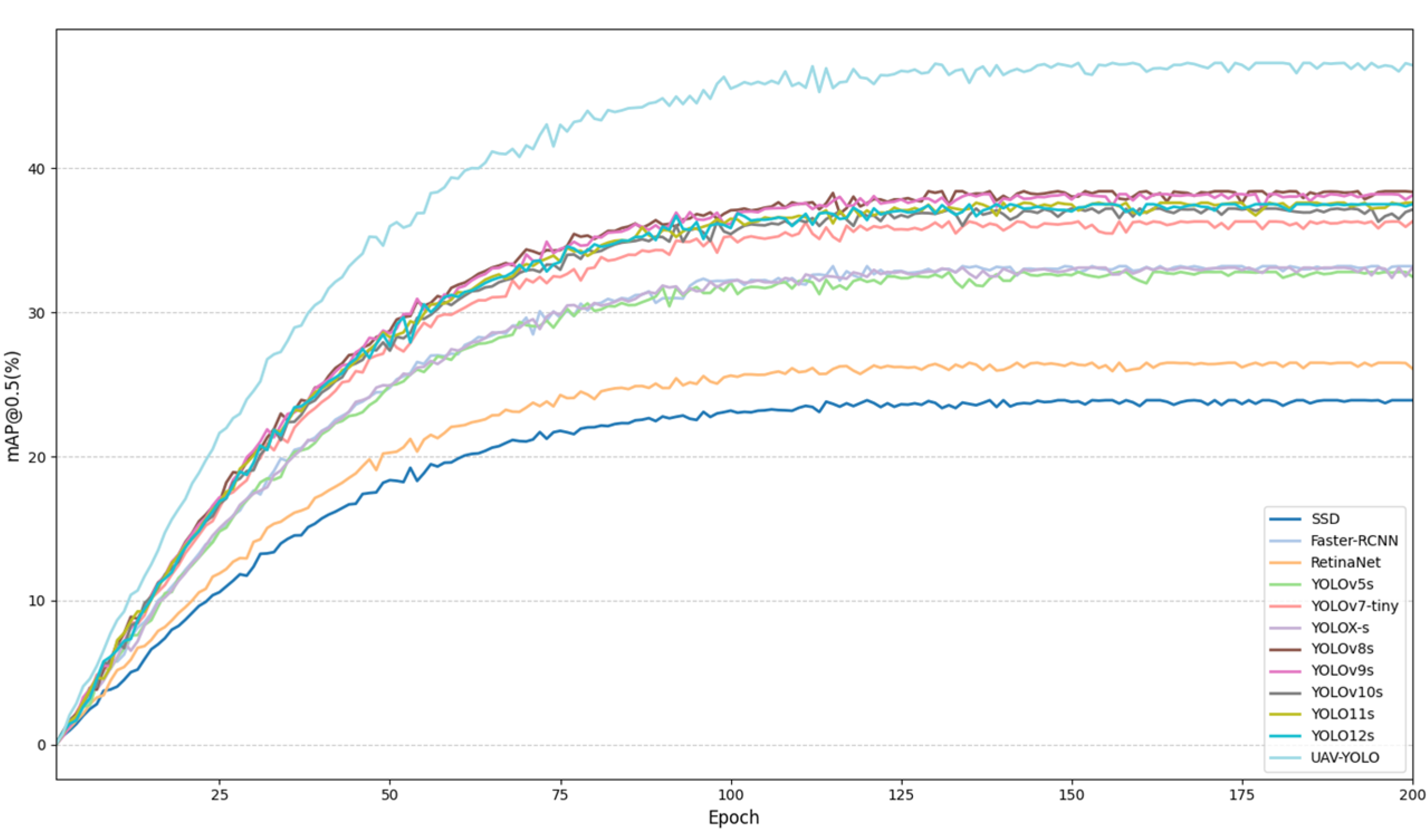
Figure 11 and
Figure 12, presenting the dynamic change curve of the mAP@0.5 index of each model on the Visdrone2019 dataset with the growth of training rounds.
As shown in
Table 10, SSD and RetinaNet incur high computational costs and parameter counts but yield low mAP@0.5 values (23.9% and 26.5%, respectively), indicating insufficient feature extraction capabilities for small objects. Although Faster R-CNN exhibits the highest resource demands, its detection performance remains limited (mAP@0.5 = 33.2%). YOLOv5s and YOLOX-s are more efficient in terms of resources, but their detection accuracy is similarly constrained, with mAP@0.5 values of 32.8% and 33.1%, respectively. In contrast, advanced YOLO variants (YOLOv7-tiny, YOLOv8s, YOLOv9s [
52], YOLOv10s [
53], YOLO11s [
54], and YOLO12s) achieve better performance, with mAP@0.5 ranging from 36.3% to 38.4%.
UAV-YOLO achieves a mAP@0.5 of 47.3%, with accuracy and recall of 58.7% and 45.2%, respectively. Compared with the YOLOv8s baseline, it reduces parameter count and computational complexity by 23.4% and 40.7%, respectively. These improvements result from integrating specialized modules for small object detection, enhancing feature extraction in complex UAV scenarios. Although its complexity is slightly higher, this trade-off is justified by the significant accuracy gains. Overall, UAV-YOLO demonstrates an optimal balance between detection accuracy, computational efficiency, and real-time performance, making it well-suited for high-precision small object detection tasks in resource-constrained UAV environments.
3.10. Generalization Experiment
In order to further verify the superiority and versatility of the proposed algorithm in this study, this chapter uses DIOR [
55], RSOD and NWPU VHR-10 [
56] datasets for verification. The experimental results of the YOLOv8s and UAV-YOLO models are shown in
Table 9,
Table 11 and
Table 12, respectively.
The UAV-YOLO model proposed in this study exhibits significant performance improvement when applied to DIOR, RSOD, and NWPU VHR-10. Compared with the benchmark model YOLOv8s, UAV-YOLO achieved 78.5%, 97.5%, and 92.7% on the average accuracy mean (mAP), while YOLOv8s achieved 69.2%, 90.7%, and 89.8%, respectively. This result shows that UAV-YOLO has better processing capabilities when dealing with challenges such as small targets, occlusion and dense distribution, and it performs better in UAV aerial image detection. In order to demonstrate this advantage more intuitively,
Figure 13,
Figure 14 and
Figure 15 shows some images detected by the YOLOv8s and UAV-YOLO models on three datasets, respectively, further confirming the superiority of the UAV-YOLO model.
4. Conclusions
In this study, we present UAV-YOLO, an enhanced small object detection model based on YOLOv8s, which is specifically designed for UAV aerial imagery. To reduce model complexity and facilitate the potential deployment on edge devices, the original C2f modules are replaced with the C2f_DSC modules, which adopt depthwise separable and pointwise convolutions. This modification effectively enhances spatial feature extraction and fusion while significantly reducing parameters, computation, and memory access, thereby improving inference efficiency. These effects are particularly beneficial for UAV-based small object detection.
To further improve detection accuracy, we introduce a novel SPPL module that integrates the multi-scale feature extraction capability of SPPF with the long-range dependency modeling and self-attention mechanism of LSKA. This structure enables more effective detection of targets across varying scales and strengthens the model’s adaptability to complex multi-scale environments. In addition, the detection head is replaced with DyHead, which employs dynamic weight allocation and adaptive feature fusion to capture multi-scale information more effectively. This enhancement significantly boosts detection performance for small objects in cluttered scenes. Moreover, we adopt the WIPIoU loss function, which integrates several losses to replace the original CIoU loss. WIPIoU introduces auxiliary boundaries to improve robustness against low-quality annotations, while also enhancing generalization and convergence speed through the synergistic effects of the combined losses, ultimately improving small target detection accuracy. Experimental results for the VisDrone2019 dataset show that UAV-YOLO achieves a mAP@0.5 of 47.3%, representing an 8.9% improvement over the baseline YOLOv8s model, and consistently outperforms other mainstream detectors. The model demonstrates strong generalization capability and performs reliably across diverse scenes, including those with complex backgrounds and varying target scales.
Although UAV-YOLO has demonstrated superior performance in a variety of scenarios, its model’s ability to extract small target features may decline in extreme environments such as extreme weather or severe lighting changes. Public datasets such as VisDrone and DIOR based on current experiments are not comprehensive enough for labeling small targets in specific fields such as ocean monitoring and forest fires, which may affect the model’s generalization ability in professional scenarios.
In future work, Active Disturbance Rejection Control (ADRC) [
57] could be incorporated to enhance real-time control robustness and deployed on actual UAV platforms to further validate the model’s performance in real-world scenarios. Additionally, the integration of UAV–UGV cooperative navigation could be explored, wherein the UAV provides path planning and navigational guidance for the UGV to execute precision agricultural tasks [
58]. Furthermore, the adoption of digital twin technology and synthetic data generation may significantly improve the robustness and accuracy of the UAV-YOLO model under extreme environmental conditions, enabling more reliable performance in diverse field applications [
59,
60]. Moreover, the integration of multimodal technologies could further enhance the model’s adaptability and detection performance across complex environments [
61,
62].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}