1. Introduction
Synthetic Aperture Radar (SAR), as an important means of remote sensing, is widely used in many fields such as military reconnaissance, ocean monitoring, disaster assessment, etc., because of its ability to work all-weather and all-day without being limited by weather conditions. With the rapid development of SAR imaging technology of drones, satellites and other platforms, a huge amount of SAR image data is constantly generated, and how to efficiently and accurately extract useful information from these data has become an urgent problem to be solved. Object detection in SAR images is one of the key technologies that significantly enhances the practical value of SAR systems. In recent years, deep learning-based object detection methods have provided new approaches to SAR image interpretation. The existing research primarily follows two paradigms: CNN-based detection methods [
1,
2,
3] and Transformer-based methods [
4,
5,
6].
Recent advancements in CNN-based SAR object detection showcase substantial progress driven by innovations addressing core challenges, with research systematically evolving along several interconnected directions. To mitigate the critical issue of domain shifts between SAR and optical data or across different SAR sensors, cross-domain adaptation and knowledge transfer have emerged as pivotal strategies: Zhou et al. [
7] leverage the latent similarities between optical and SAR images for domain-adaptive few-shot ship detection, while Luo et al. [
8] propose a semi-supervised framework fusing optical and limited SAR data to counteract shifts at image, instance, and feature levels. Huang et al. [
9] further reduce reliance on annotated SAR data through pixel-instance information transfer, and Chen et al. [
10] achieve unsupervised detection via cross-modal distribution alignment and pseudo-label refinement. Concurrently, overcoming the challenges posed by multi-scale objects and small targets has spurred significant innovation in feature representation. Sun et al. [
11] introduce a multi-scale dynamic feature fusion network enhanced by MSLK-Blocks, DFF-Blocks, and GPD loss for superior elliptical ship detection, and Zhang et al. [
12] employ a dynamic feature discrimination module (DFDM) and center-aware calibration module (CACM) with bidirectional aggregation to counter cross-sensor degradation. Liu et al. [
13] develop a Subpixel Feature Pyramid Network (SFPN) preserving fine details. Furthermore, strategies to amplify discriminative features prominently utilize attention mechanisms. Ma et al. [
14] integrate bidirectional coordinate attention and multi-resolution fusion into CenterNet for small ship detection, and Chen et al. [
15] apply Incentive Attention Feature Fusion (IAFF) to align scattering characteristics with semantics. In response to data scarcity and open-world complexities, few-shot, open-set, and semi-supervised methodologies are advancing. Zhao et al. [
16] utilize context-aware Gaussian flow representations to alleviate foreground–background imbalance, and Xiao et al. [
17] enhance open-set generalization via global context modeling. Semi-supervised approaches, such as Chen et al.’s [
18] teacher–student framework (SMDC-SSOD) with cross-scale consistency and Yang et al.’s [
19] fuzzy-evaluation guided adaptive data selection effectively minimize annotation burdens. These interrelated advances collectively demonstrate developments in the field in terms of robust domain adaptation, complex multi-scale modeling, and efficient learning paradigms, driving higher accuracy in SAR target detection in complex scenarios.
Transformer-based methods achieve remarkable breakthroughs in SAR object detection, with innovations systematically progressing across three dimensions—model architecture, noise robustness, and semantic optimization—collectively enhancing accuracy for objects in complex scenarios. In architectural design, hybrid approaches dominate to leverage complementary strengths. Yang et al. [
20] combine CNNs’ local feature extraction with Swin Transformer’s global modeling for multi-scale ship detection, and Li et al. [
21] propose GL-DETR, adopting global-to-local processing to boost small-object accuracy. Zhou et al. [
22] enhance YOLOv7 with Swin Transformer through PS-FPN modules and mix-attention strategies, while multi-scale frameworks by Chen et al. [
23] and Feng et al. [
24] significantly improve cross-scale fusion and orientation adaptability through window-based Swin Transformers and rotation-aware DETR modules. To address the critical challenge of speckle noise and data scarcity, advanced denoising and adaptation strategies have emerged. Liu et al. [
25] develop MD-DETR with multi-level denoising to suppress noise interference, and Chen et al. [
23] integrate embedded denoising modules for low-SNR robustness. Cross-domain gaps are mitigated by semi-supervised frameworks leveraging optical-to-SAR transfer [
8] and domain-adaptive Transformers with pseudo-label refinement [
26]. For handling geometric variations and semantic ambiguity, innovative attention mechanisms provide solutions. Lin et al. [
27] incorporate deformable attention modules to address shape-scale diversity in ships, while Chen et al. [
28] propose anchor-free SAD-Det using adaptive Transformer features to minimize background interference in oriented detection. Future directions emphasize leveraging large-scale pre-trained models [
29] and datasets (e.g., SARDet-100K [
30]) to enhance generalization and scalability. Collectively, Transformer-based SAR detection demonstrates transformative potential through synergistic architectural innovation, noise-robust modeling, and geometry-aware optimization, establishing new paradigms for handling real-world complexity while pointing toward efficient, generalizable solutions.
Although modern object detection algorithms are being designed with increasing sophistication and substantially higher accuracy, their GPU-oriented architectures typically involve excessive parameterization (e.g., >100 M trainable weights) and prohibitive computational complexity (often exceeding 200 GB Floating-point Operations (GFLOPs) per inference), rendering them impractical for resource-constrained platforms. This limitation becomes particularly critical in SAR image analysis scenarios such as military reconnaissance and disaster assessment, where latency-sensitive object detection must be performed on embedded systems with strict power budgets (<10 W), including drones, nanosatellites, and portable devices. The inference latency of traditional deep models on edge TPUs is greater than 500 milliseconds, which cannot meet the real-time processing requirements. Therefore, it is urgent to research and develop lightweight SAR object detection algorithms, which can not only improve processing speed and energy efficiency but also better adapt to the needs of embedded platforms. The question of how to achieve a lightweight model while ensuring detection performance has become one of the key challenges in the field of SAR image object detection.
Recent lightweight studies focus on optimizing existing frameworks [
31,
32,
33]. Gao et al. [
34] design a lightweight network for multi-band SAR vehicle detection to improve accuracy in complex scenarios, and Wang et al. [
35] propose SAFN, combining attention-guided fusion and lightweight modules (LGA-FasterNet and DA-BFNet) to reduce parameters while enhancing ship detection. Huo et al. [
36] introduce GSE-ships, integrating GhostMSENet and ECIoU loss to lower computational burden by 7.97% while boosting accuracy, and Guan et al. [
37] enhances YOLOv8 with a Shuffle Re-parameterization module and hybrid attention to improve small SAR ship detection. Knowledge distillation techniques leverage to bridge performance gaps between large and lightweight models. Chen et al. [
38] propose DPKD for precise localization knowledge transfer, reducing the performance gap in SAR detection, and Zhang et al. [
39] incorporate attention selection modules and lightweight multi-scale pyramids into RTMDet, enhancing near-shore ship detection. Attention mechanisms, such as the Multi-Scale Coordinate Attention in MSSD-Net [
40] and Shuffle Attention in SHIP-YOLO [
41], are critical in balancing feature extraction and computational costs. FPGA-based implementations and edge-device adaptations accelerate real-time SAR detection. Huang et al. [
42] deploy lightweight SAR ship detection on FPGAs, significantly reducing processing time, and Fang et al. [
43] propose a hybrid FPGA-YOLOv5s architecture for low-power, high-precision small object detection. Addressing scale and orientation variability, Meng et al. [
44] propose LSR-Det with adaptive feature pyramids and lightweight rotation heads for efficient multi-scale ship detection, and Tian et al. [
45] achieve 98.8% mAP on SSDD using YOLO-MSD, which integrates DPK-Net and BSAM modules for multi-scale adaptability. Zhu et al. [
46] introduce DSENet for weak-supervised arbitrary-oriented detection, eliminating reliance on rotated bounding box annotations. Integrated applications demonstrate practical viability. Yasir et al.’s [
47] YOLOv8n-based tracker with knowledge distillation and C-BIoU tracking, and Luo et al.’s [
41] SHIP-YOLO with ghost convolutions and Wise-IoU, enhance real-time maritime monitoring. Rahman et al. [
48] optimize lightweight CNNs for SAR classification in resource-limited environments, while Zhang et al. [
49] deploy APDNet for edge-based person detection with minimal accuracy loss. These advancements collectively address the trade-off between detection accuracy and computational efficiency, enabling practical deployment in satellite, UAV, and edge-device scenarios while maintaining robustness against SAR-specific challenges such as noise, scale variation, and complex backgrounds.
However, these approaches exhibit notable limitations in real-time SAR image interpretation: (1) The lightweight architecture design (e.g., channel compression and depth reduction) degrades feature map resolution and weakens cross-channel information interaction, leading to insufficient feature representation in complex scenarios (e.g., dense objects and multi-scale interference). (2) Existing methods primarily optimize inference speed for GPU platforms, whereas their deployment efficiency on edge devices remains suboptimal due to limited computational parallelism and scarce on-chip memory resources.
Therefore, it is necessary to design a lightweight model that balances real-time performance and object detection accuracy while being easy to deploy on edge platforms. This paper addresses the SAR image object detection problem from a more balanced perspective, significantly reducing the number of parameters and improving detection accuracy. The main contributions of this paper are summarized as follows:
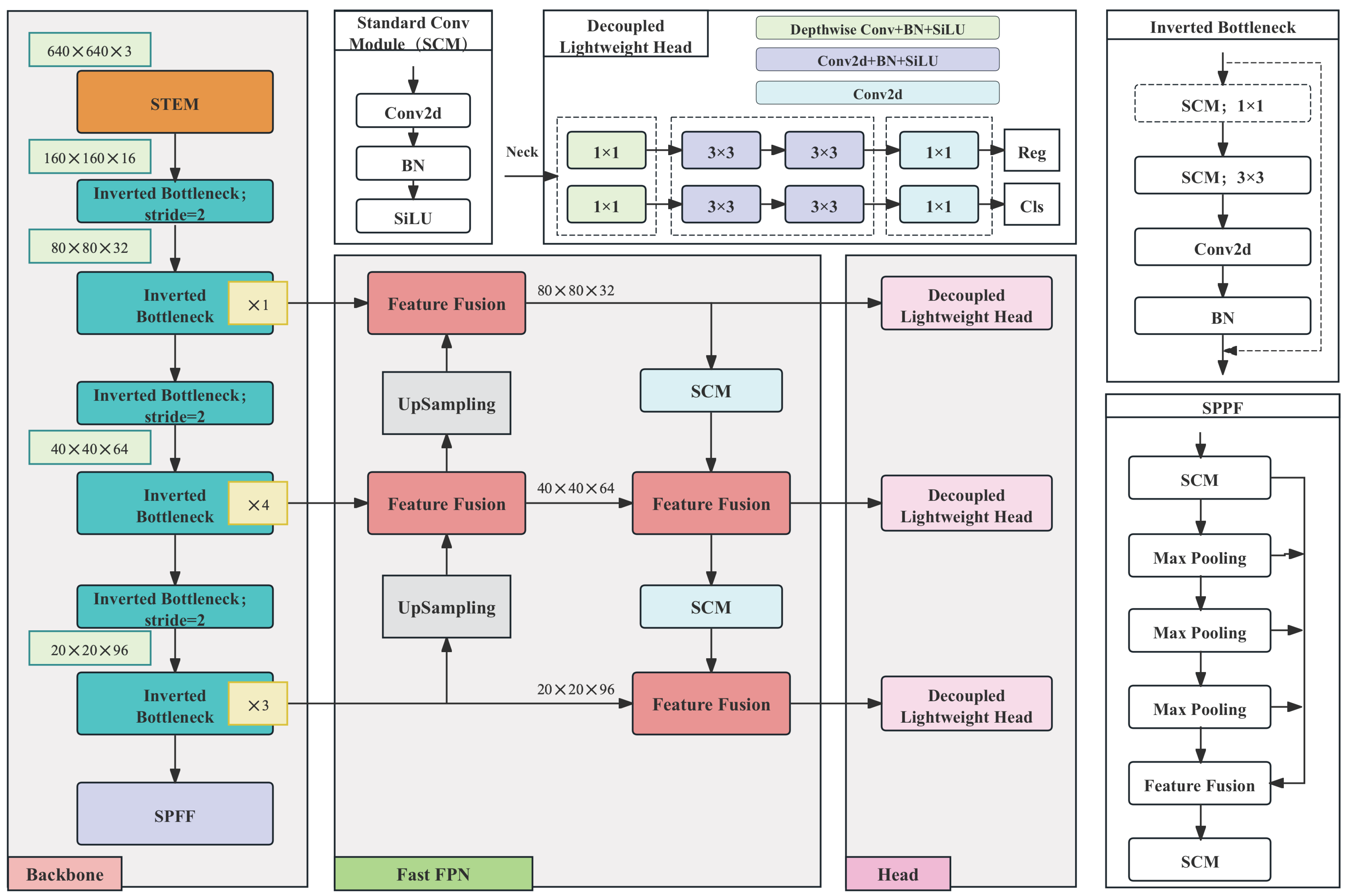
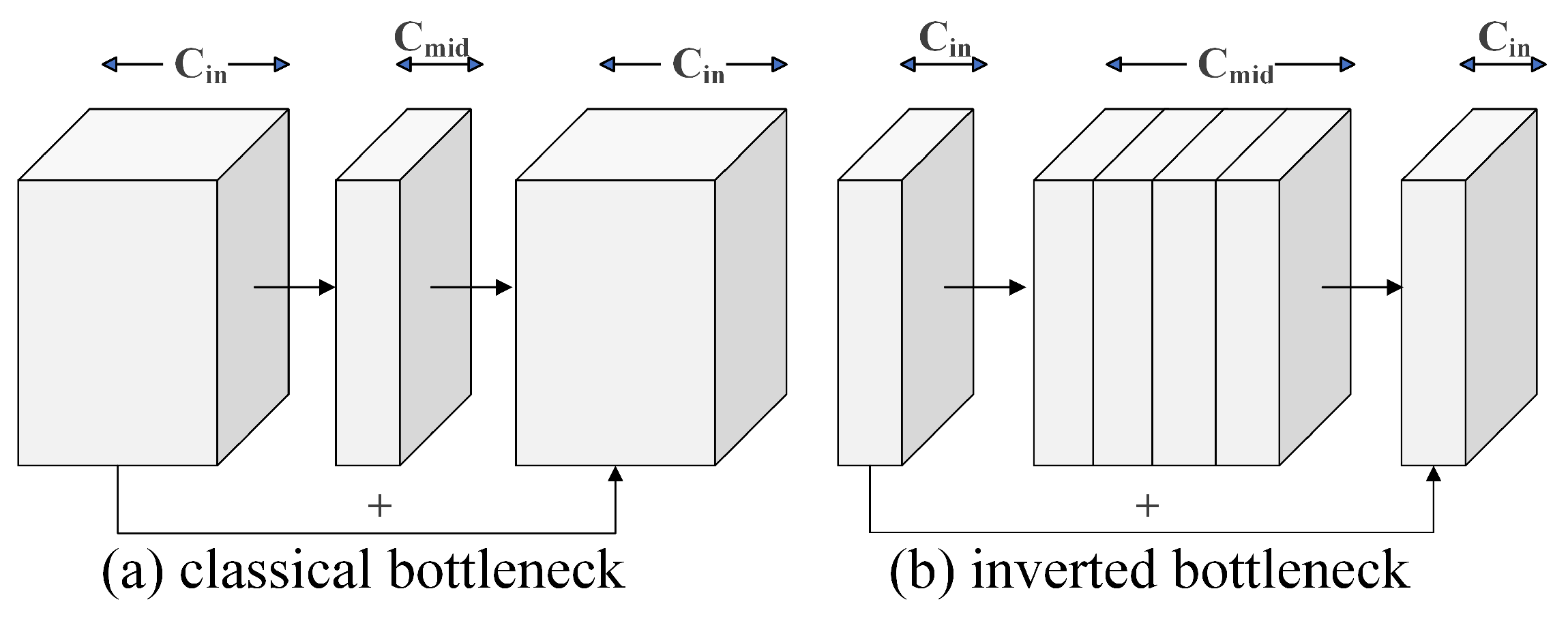
1. The efficient backbone feature extraction network leverages inverted bottlenecks and information bottlenecks, achieving an optimal balance between feature extraction capability and computational resource consumption. This design provides enhanced flexibility for real-time SAR image-processing tasks.
2. The core idea of the proposed fast pyramid architecture network is to facilitate rapid multi-scale feature sharing, aiming to accelerate the detection process by reducing the demand for computational resources. By optimizing the information flow and minimizing intermediate computations, P4 is adopted as the primary fusion node to efficiently aggregate complementary information from both low-level and high-level layers, enhancing the feature representation capability in complex backgrounds.
3. We introduce a decoupled network-in-network detection head, specifically designed to provide fast and lightweight computations required for classification and regression tasks. This design enhances the model’s expressive power while effectively alleviating computational burdens, ensuring robust detection performance even in resource-constrained environments.
4. Discussion
Analysis of Experimental Results. The proposed edge-optimized lightweight YOLO method achieved a detection accuracy of 87.7% mAP50 and 54.0% mAP50-95 on the SARDet-100K dataset, while requiring only 4.4 GFLOPs of computational load and 1.9 M parameters, significantly outperforming YOLOv10n (87.4% mAP50, 6.7 GFLOPs) and YOLOv8n (85.1% mAP50, 8.7 GFLOPs). The P4-driven Fast Feature Pyramid Network reduced the computational cost of the neck by 34.8% while maintaining multi-scale feature fusion capabilities. The decoupled detection head adopted a point convolution network structure, reducing the computational load by 44.4% compared to the traditional dual-branch design, with only a 0.1% drop in accuracy. Deployment tests on edge devices demonstrated real-time performance, achieving 34.2 FPS on Jetson TX2 and 30.7 FPS on Huawei Atlas DK 310. As shown in
Figure 4, the model exhibited excellent detection performance for vehicles (recall rate 0.98) and ports (0.95) but showed noticeable deficiencies in identifying bridges (0.71) and oil tanks (0.66), primarily due to their slender structures or high similarity to the background, leading to feature confusion.
Potential Limitations. The method performed weakly in detecting bridges and oil tanks, with AP scores of only 0.754 and 0.703, indicating limited feature extraction capability for targets with special structures. Although the depthwise separable convolution used in the inverted bottleneck layer significantly reduced the computational load, its channel-wise operation characteristic lowered parallel efficiency, resulting in slightly lower FPS compared to YOLOv5n (34.2 vs. 38.1 FPS). Despite the optimization of multi-scale fusion by FFPN, missed detections still occurred for extremely small targets. Current experiments were only validated on two edge devices, and further evaluation on more heterogeneous hardware (e.g., FPGA and DSP) is needed to assess generalizability.
Practical Application. The lightweight nature of the method (1.9 M parameters) makes it highly suitable for UAV-mounted SAR systems, enabling real-time ship/aircraft detection. Combined with the low-power (8 W) feature of Ascend chips, it can support real-time ship tracking on satellites. In the field of remote sensing reconnaissance, the model’s real-time performance can meet the demand for rapid target identification in complex environments.
Future Research. The follow-up work will focus on two aspects: first, continuing to validate performance across different embedded devices while researching universal quantization and pruning techniques to further reduce computational load and improve detection speed; second, leveraging incremental learning and few-shot learning techniques to enhance the model’s detection capability for imbalanced class distributions and unknown incremental categories, thereby improving the robustness of long-term deployment.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}