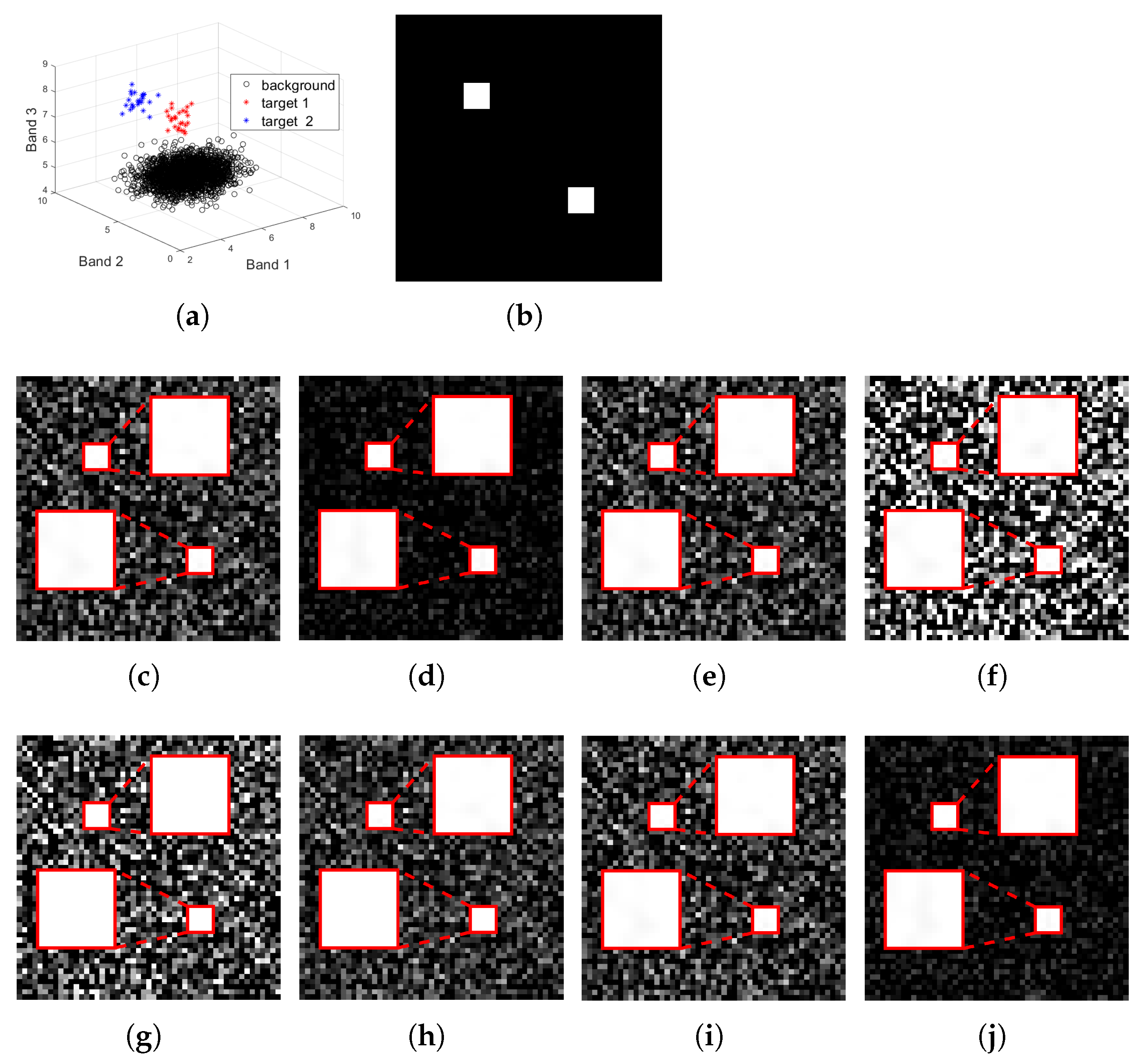
Figure 1.
Target detection results for the simulated data with a size of : (a): the distribution of the simulation image in three-dimensional spectral space, where the background pixels are marked in a black circle, and the targets are marked with red and blue asterisks; (b): the groundtruth image for the target and ; the detection result of (c) MTCEM where , (d) MTMF where , (e) MTR1 where , and (f) MTR2 where , (g) SCEM, (h) WTACEM, and (i) RMTCEM, respectively; (j): the detection result of MTCE ().
Figure 1.
Target detection results for the simulated data with a size of : (a): the distribution of the simulation image in three-dimensional spectral space, where the background pixels are marked in a black circle, and the targets are marked with red and blue asterisks; (b): the groundtruth image for the target and ; the detection result of (c) MTCEM where , (d) MTMF where , (e) MTR1 where , and (f) MTR2 where , (g) SCEM, (h) WTACEM, and (i) RMTCEM, respectively; (j): the detection result of MTCE ().
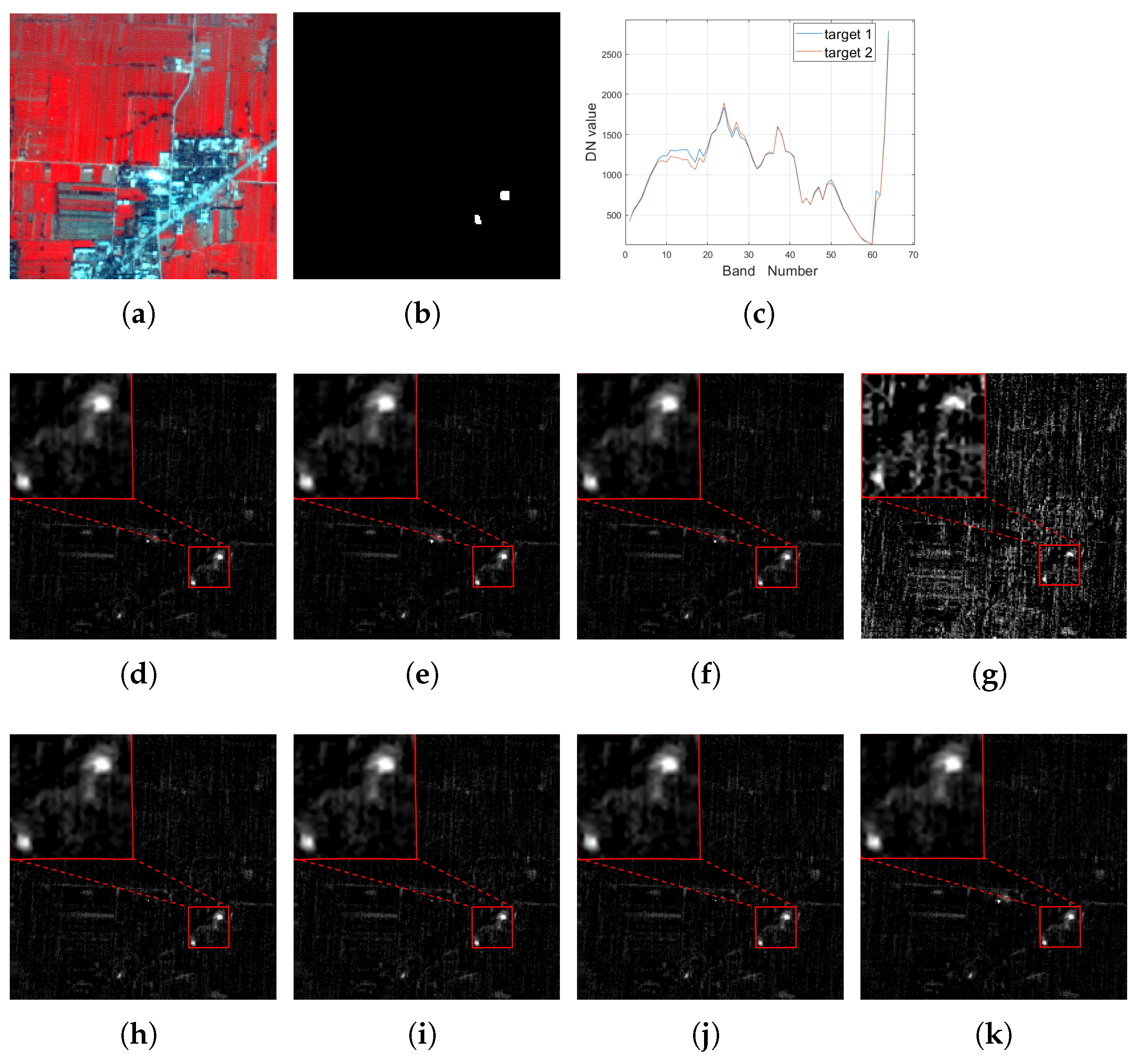
Figure 2.
For the Xi’an data, (a): the false color image (R: 750.6 nm, G: 559.6 nm, B: 510.1 nm); (b) the groundtruth image for the target of interest; (c): the spectrum curve for the target of interest; the detection result of (d) MTCEM where , (e) MTMF where , (f) MTR1 where , and (g) MTR2 where using (h) SCEM, (i) WTACEM, and (j) RMTCEM, respectively. (k): The detection result of MTCE ().
Figure 2.
For the Xi’an data, (a): the false color image (R: 750.6 nm, G: 559.6 nm, B: 510.1 nm); (b) the groundtruth image for the target of interest; (c): the spectrum curve for the target of interest; the detection result of (d) MTCEM where , (e) MTMF where , (f) MTR1 where , and (g) MTR2 where using (h) SCEM, (i) WTACEM, and (j) RMTCEM, respectively. (k): The detection result of MTCE ().
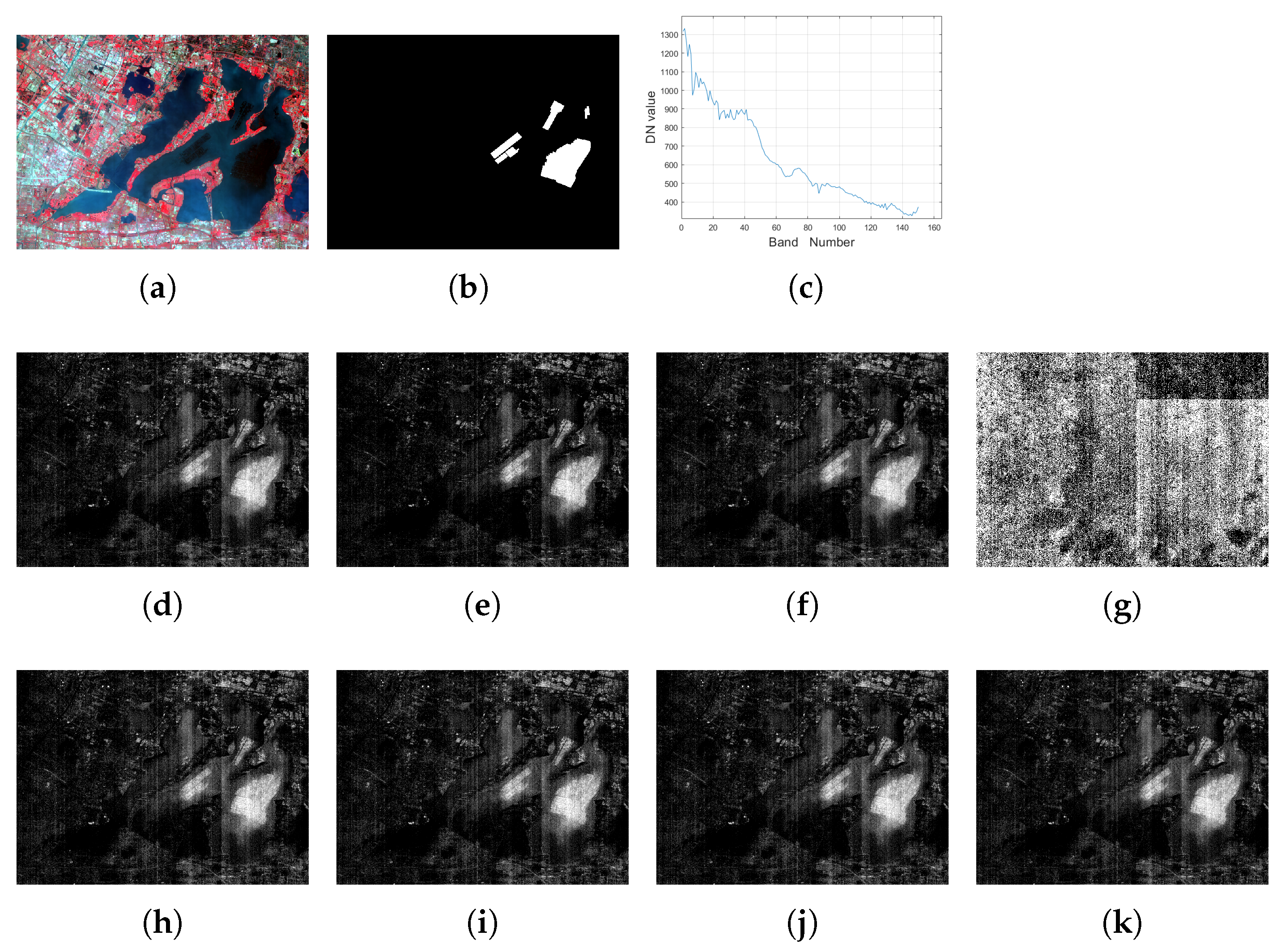
Figure 3.
For the YCLake data, (a): the false color image (R: 860.88 nm, G: 651.31 nm, B: 548.66 nm); (b) the groundtruth image for the target of interest; (c): the spectrum curve for the target of interest; the detection result with setting of (d) MTCEM where , (e) MTMF where , (f) MTR1 where , and (g) MTR2 where , (h) SCEM, (i) WTACEM, and (j) RMTCEM, respectively. (k): The detection result of MTCE ().
Figure 3.
For the YCLake data, (a): the false color image (R: 860.88 nm, G: 651.31 nm, B: 548.66 nm); (b) the groundtruth image for the target of interest; (c): the spectrum curve for the target of interest; the detection result with setting of (d) MTCEM where , (e) MTMF where , (f) MTR1 where , and (g) MTR2 where , (h) SCEM, (i) WTACEM, and (j) RMTCEM, respectively. (k): The detection result of MTCE ().
Figure 4.
Time consumption curve as a function of (a) the number of bands L; (b) the number of target p.
Figure 4.
Time consumption curve as a function of (a) the number of bands L; (b) the number of target p.
Table 1.
Notational conventions adopted in this article.
Table 1.
Notational conventions adopted in this article.
| Symbol | Description | Symbol | Description |
|---|
| L | The number of bands | N | The number of pixels |
| The number of selected target spectrum | | Target sample matrix |
| Dataset | | Mean vector of data |
| Correlation matrix of | | Covariance matrix of |
| Best data origin | | Projection detector varying with |
| Detection result output | | p-dimensional all-one vector |
Table 2.
Relation between the aforementioned algorithms and the generalized MTCE one.
Table 2.
Relation between the aforementioned algorithms and the generalized MTCE one.
| u | p | | u | p |
|---|
| | | | | |
| | | | | |
| variable | | | variable | |
Table 3.
Computational complexity comparison of MTCE, MTCEM and MTMF, where L, N, p represents the number of the bands, total pixels, and target samples, respectively.
Table 3.
Computational complexity comparison of MTCE, MTCEM and MTMF, where L, N, p represents the number of the bands, total pixels, and target samples, respectively.
| |
|---|
| . |
| . |
| . |
Table 4.
Illustration of the confusion matrix of a binary classification.
Table 4.
Illustration of the confusion matrix of a binary classification.
| | Target | Non-Target |
|---|
| Hypothesized Target | True positive (TP) | False positive (FP) |
| Hypothesized Non-target | False negative (FN) | True negative (TN) |
Table 5.
Quantitative comparison of the average output energy (denoted ) and four quantitative metrics, including AUC, OA, F-score (denoted ), and Kappa coefficient (denoted ), of different algorithms (including MTCEM, MTMF, MTR1, MTR2, and MTCE) for the simulated data. “-” means that their energy metric is not computed for a fair comparison. Bold numbers indicate the highest values in each row.
Table 5.
Quantitative comparison of the average output energy (denoted ) and four quantitative metrics, including AUC, OA, F-score (denoted ), and Kappa coefficient (denoted ), of different algorithms (including MTCEM, MTMF, MTR1, MTR2, and MTCE) for the simulated data. “-” means that their energy metric is not computed for a fair comparison. Bold numbers indicate the highest values in each row.
| Metrics | | | | | | | | |
|---|
| 0.1241 | 0.0385 | 0.1237 | 0.5414 | - | - | - | 0.0370 |
| 0.9966 | 0.9996 | 0.9966 | 0.8641 | 0.9987 | 0.9988 | 0.9966 | 0.9996 |
| 0.9650 | 1.0000 | 0.9800 | 0.9210 | 0.9850 | 0.9950 | 0.9700 | 1.0000 |
| 0.9346 | 1.0000 | 0.9615 | 0.9259 | 0.9703 | 0.9901 | 0.9434 | 1.0000 |
| 0.9108 | 1.0000 | 0.9481 | 0.8420 | 0.9603 | 0.9868 | 0.9231 | 1.0000 |
Table 6.
Quantitative comparison of the average output energy (denoted ) and four quantitative metrics, including AUC, OA, F-score (denoted ), and Kappa coefficient (denoted ), of different algorithms (including MTCEM, MTMF, MTR1, MTR2, and MTCE) for the hyperspectral Xian data. “-” means that their energy metric is not computed for a fair comparison. Bold numbers indicate the highest values in each row.
Table 6.
Quantitative comparison of the average output energy (denoted ) and four quantitative metrics, including AUC, OA, F-score (denoted ), and Kappa coefficient (denoted ), of different algorithms (including MTCEM, MTMF, MTR1, MTR2, and MTCE) for the hyperspectral Xian data. “-” means that their energy metric is not computed for a fair comparison. Bold numbers indicate the highest values in each row.
| Metrics | | | | | | | | |
|---|
| 4.387 | 4.297 | 5.177 | 68.7 | - | - | - | 4.278 |
| 0.9581 | 0.9594 | 0.9533 | 0.7967 | 0.9498 | 0.9519 | 0.9581 | 0.9594 |
| 0.9276 | 0.9211 | 0.9046 | 0.7510 | 0.9243 | 0.9145 | 0.9243 | 0.9441 |
| 0.8659 | 0.8554 | 0.8284 | 0.7511 | 0.8589 | 0.8434 | 0.8606 | 0.8931 |
| 0.8659 | 0.8554 | 0.8284 | 0.5020 | 0.8589 | 0.8434 | 0.8606 | 0.8931 |
Table 7.
The quantitative comparison of the average output energy (denoted E) and four quantitative metrics, including AUC, OA, F-score (denoted ), and Kappa coefficient (denoted ), of different algorithms (including MTCEM, MTMF, MTR1, MTR2, and MTCE) for the hyperspectral YCLake data. “-” means that their energy metric is not computed for a fair comparison. Bold numbers indicate the highest values in each row.
Table 7.
The quantitative comparison of the average output energy (denoted E) and four quantitative metrics, including AUC, OA, F-score (denoted ), and Kappa coefficient (denoted ), of different algorithms (including MTCEM, MTMF, MTR1, MTR2, and MTCE) for the hyperspectral YCLake data. “-” means that their energy metric is not computed for a fair comparison. Bold numbers indicate the highest values in each row.
| p | | | | | | | | | |
|---|
| 51 | | 0.0689 | 0.0731 | 0.0689 | | - | - | - | 0.0681 |
| 0.9811 | 0.9824 | 0.9811 | 0.5636 | 0.9811 | 0.9811 | 0.9811 | 0.9824 |
| 0.9382 | 0.9386 | 0.9398 | 0.5248 | 0.9385 | 0.9396 | 0.9372 | 0.9372 |
| 0.8828 | 0.8841 | 0.8856 | 0.3907 | 0.8833 | 0.8852 | 0.8811 | 0.8817 |
| 0.8410 | 0.8425 | 0.8449 | 0.0772 | 0.8417 | 0.8444 | 0.8386 | 0.8391 |
| 510 | | 0.0638 | 0.0665 | 0.0638 | | - | - | - | 0.0623 |
| 0.9591 | 0.9628 | 0.9591 | 0.5458 | 0.9612 | 0.8133 | 0.9591 | 0.9628 |
| 0.8943 | 0.9007 | 0.8930 | 0.5052 | 0.8966 | 0.7341 | 0.8925 | 0.9023 |
| 0.8092 | 0.8189 | 0.8073 | 0.3851 | 0.8133 | 0.5874 | 0.8066 | 0.8212 |
| 0.7370 | 0.7512 | 0.7343 | 0.0617 | 0.7427 | 0.4054 | 0.7332 | 0.7547 |
Table 8.
Time consumption comparison of MTCEM, MTMF, SCEM, WTACEM, RMTCEM, and MTCE for the different datasets used in the subsections A, B, and C, where L, N, p represents the number of bands, pixels, and target samples, respectively.
Table 8.
Time consumption comparison of MTCEM, MTMF, SCEM, WTACEM, RMTCEM, and MTCE for the different datasets used in the subsections A, B, and C, where L, N, p represents the number of bands, pixels, and target samples, respectively.
| Data | L | p | N | Time (s) |
|---|
|
MTCEM
|
MTMF
|
SCEM
|
WTACEM
|
RMTCEM
|
MTCE
|
|---|
| 3 | 2 | 2601 | 0.0008 | 0.0042 | 0.0051 | 0.0009 | 0.0099 | 0.0111 |
| 64 | 2 | 40,000 | 0.0047 | 0.0119 | 0.0135 | 0.0118 | 0.0436 | 0.0456 |
| 200 | 1 | 479,144 | 0.1808 | 0.3208 | 0.2066 | 0.1920 | 0.5015 | 1.0526 |
| 200 | 10 | 479,144 | 0.1581 | 0.3454 | 0.5794 | 0.5572 | 2.1545 | 1.0881 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}