
Automatic Detection of Landslide Surface Cracks from UAV Images Using Improved U-Network


Abstract
1. Introduction
2. Methodology
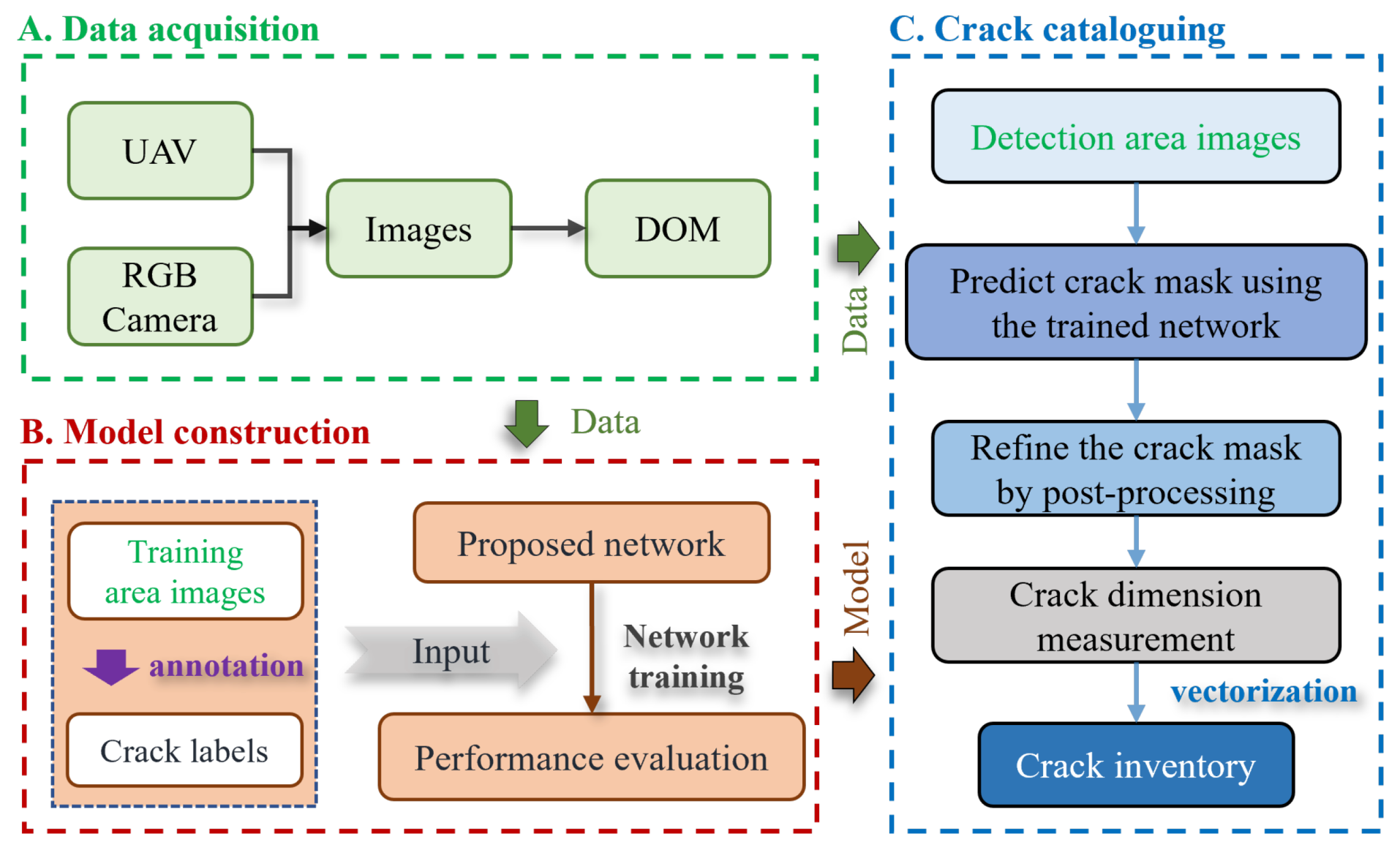
2.1. Pipeline of Landslide Surface Crack Detection
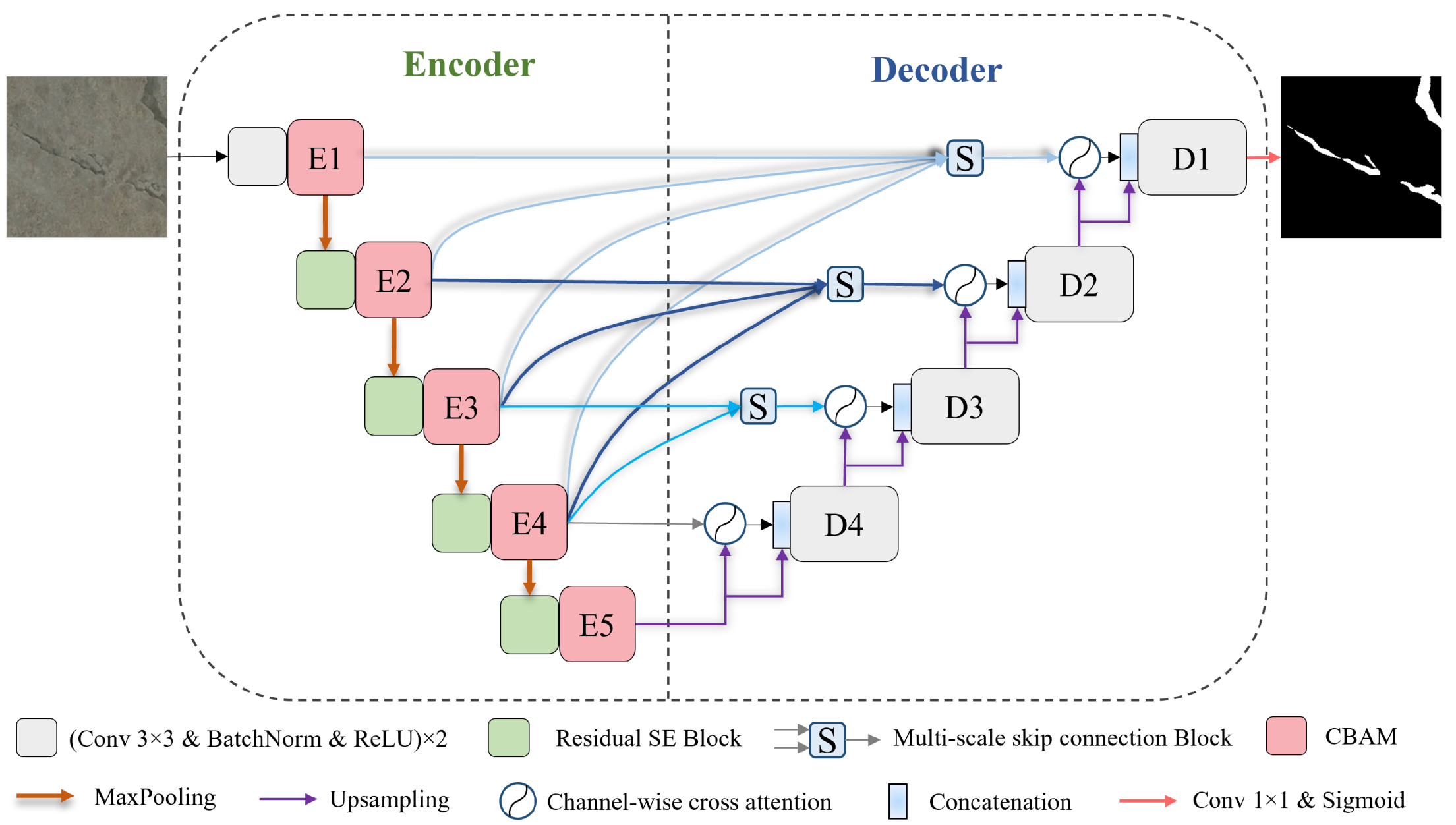
2.2. Proposed Crack Segmentation Network Architecture
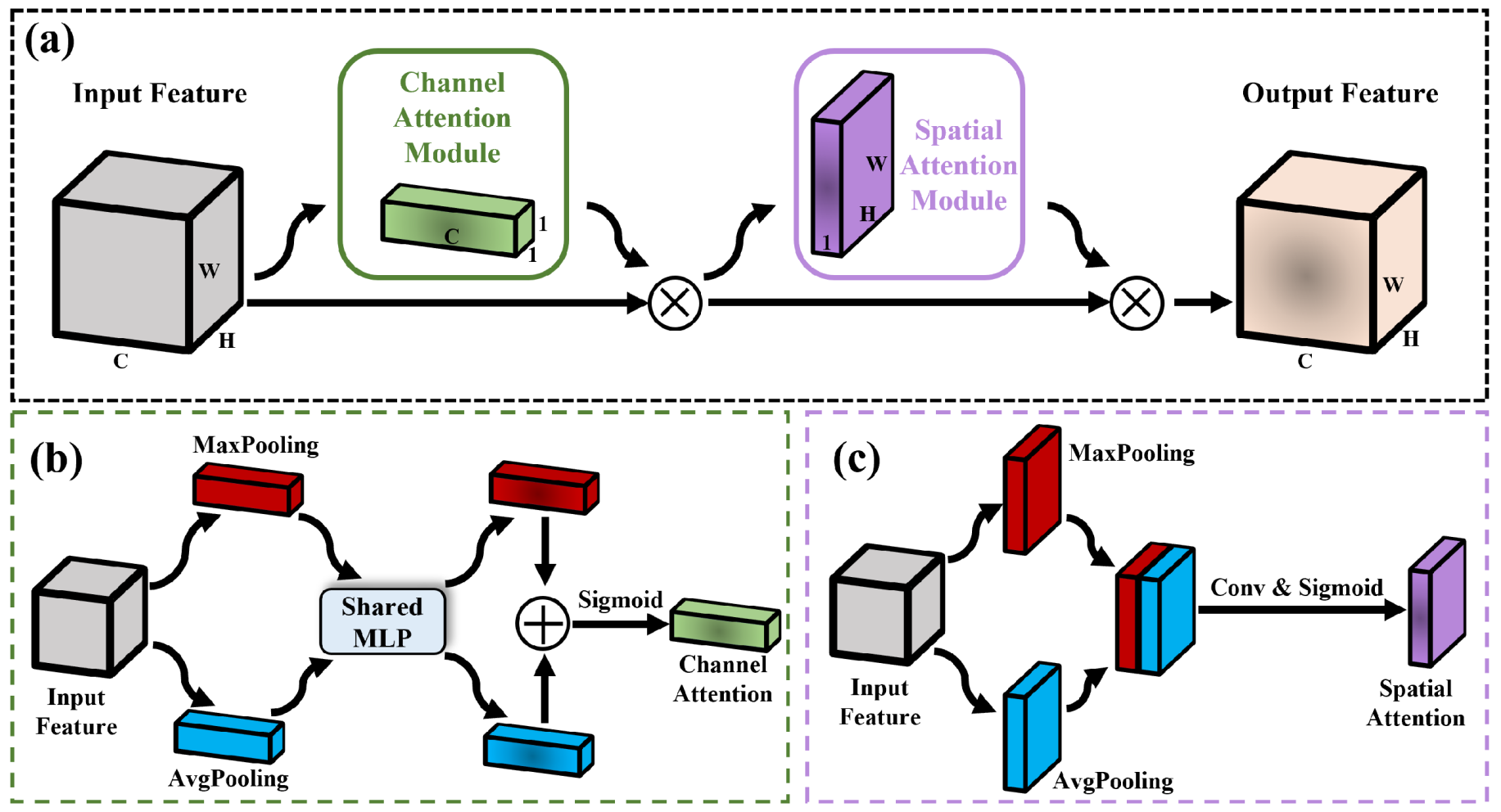
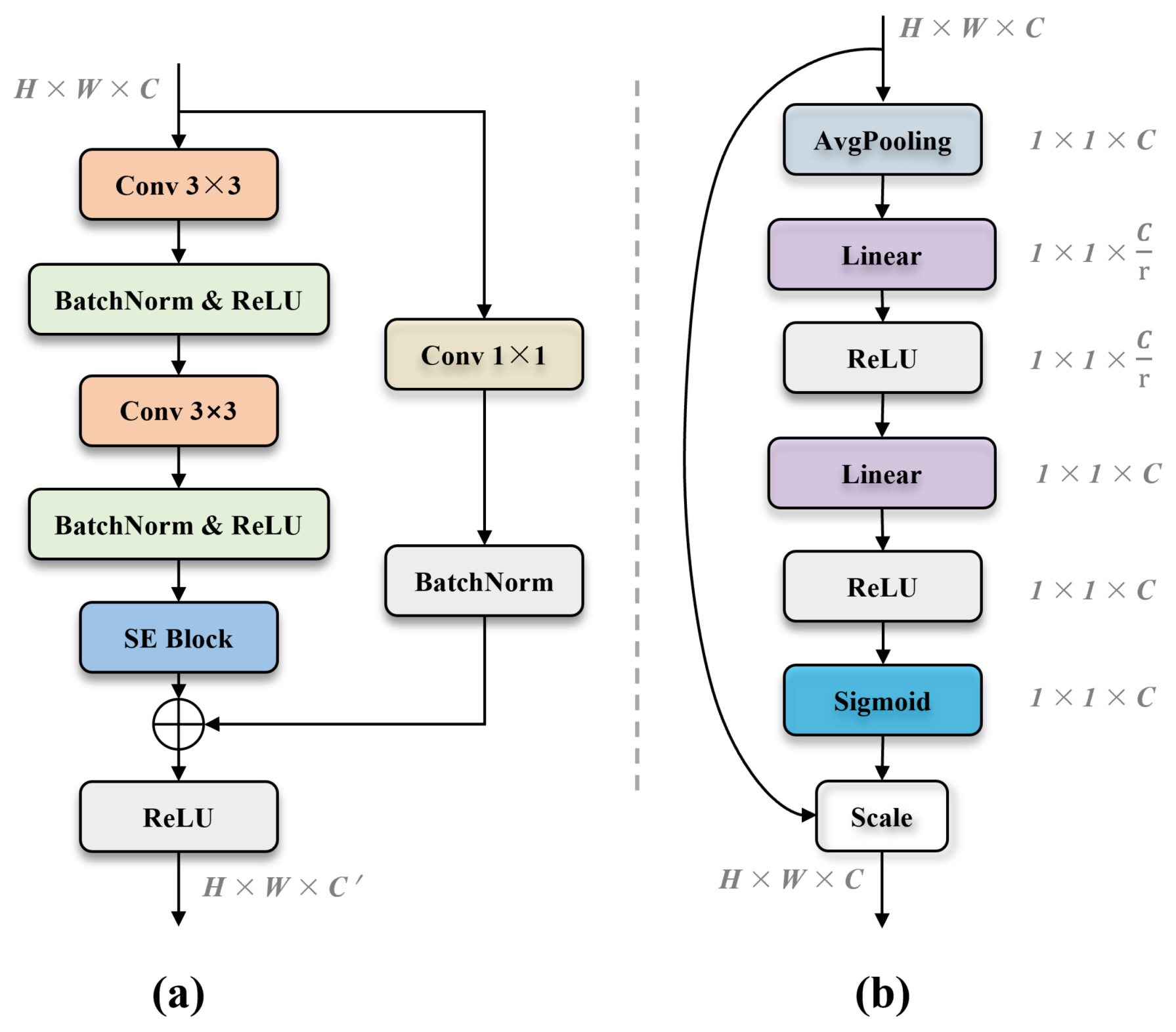
2.2.1. Enhanced Feature Extraction Encoder
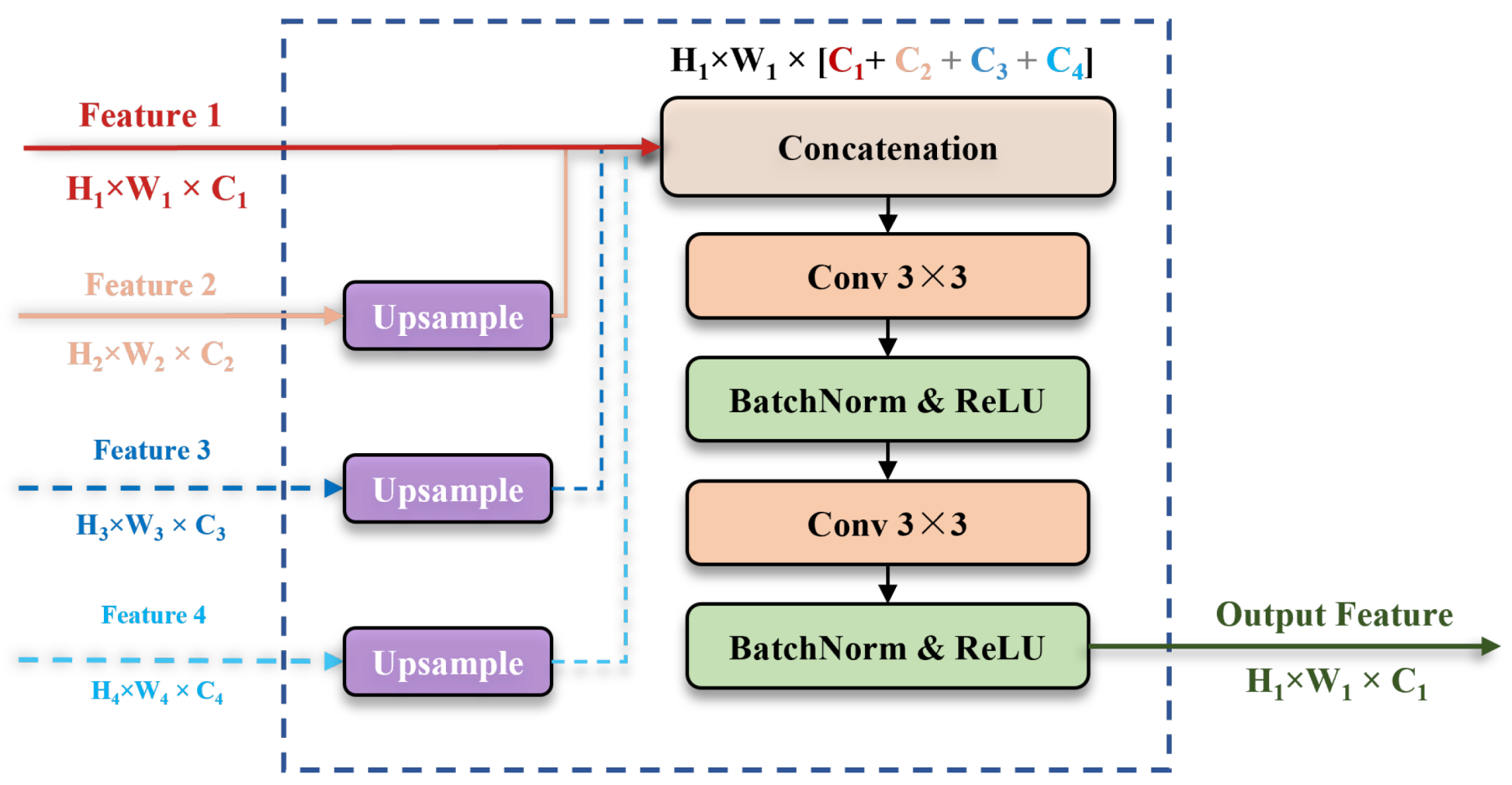
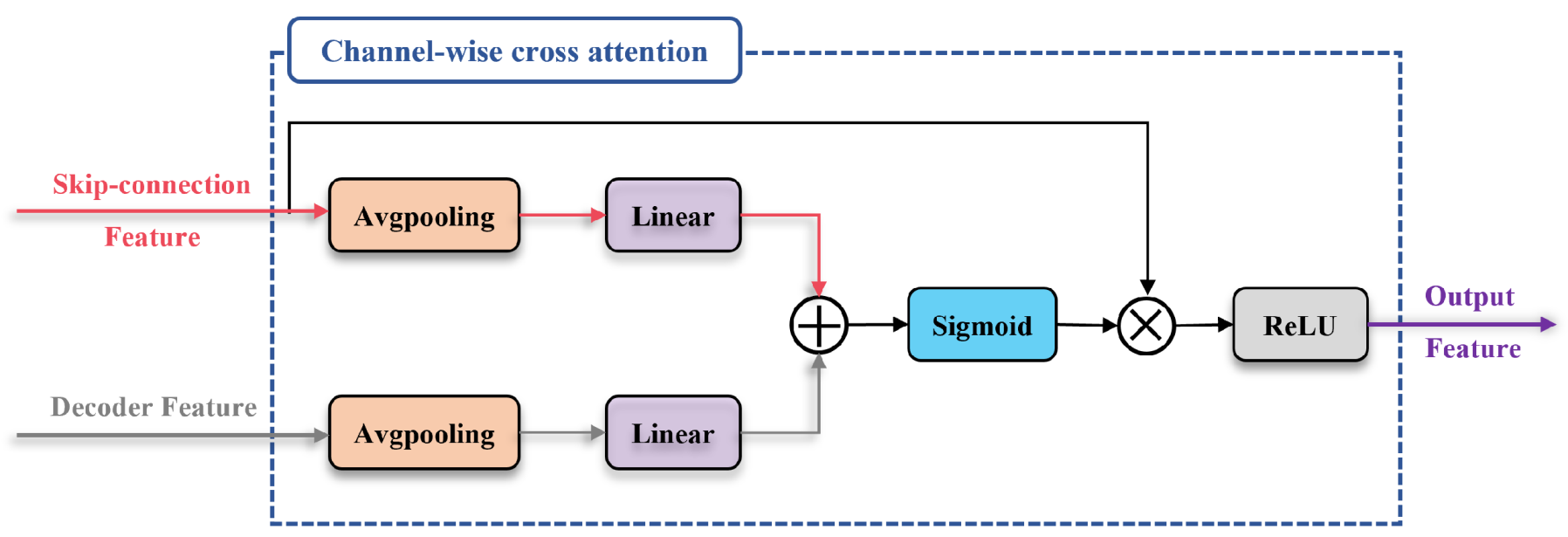
2.2.2. Enhanced Feature Reconstruction Decoder
2.2.3. Loss Function
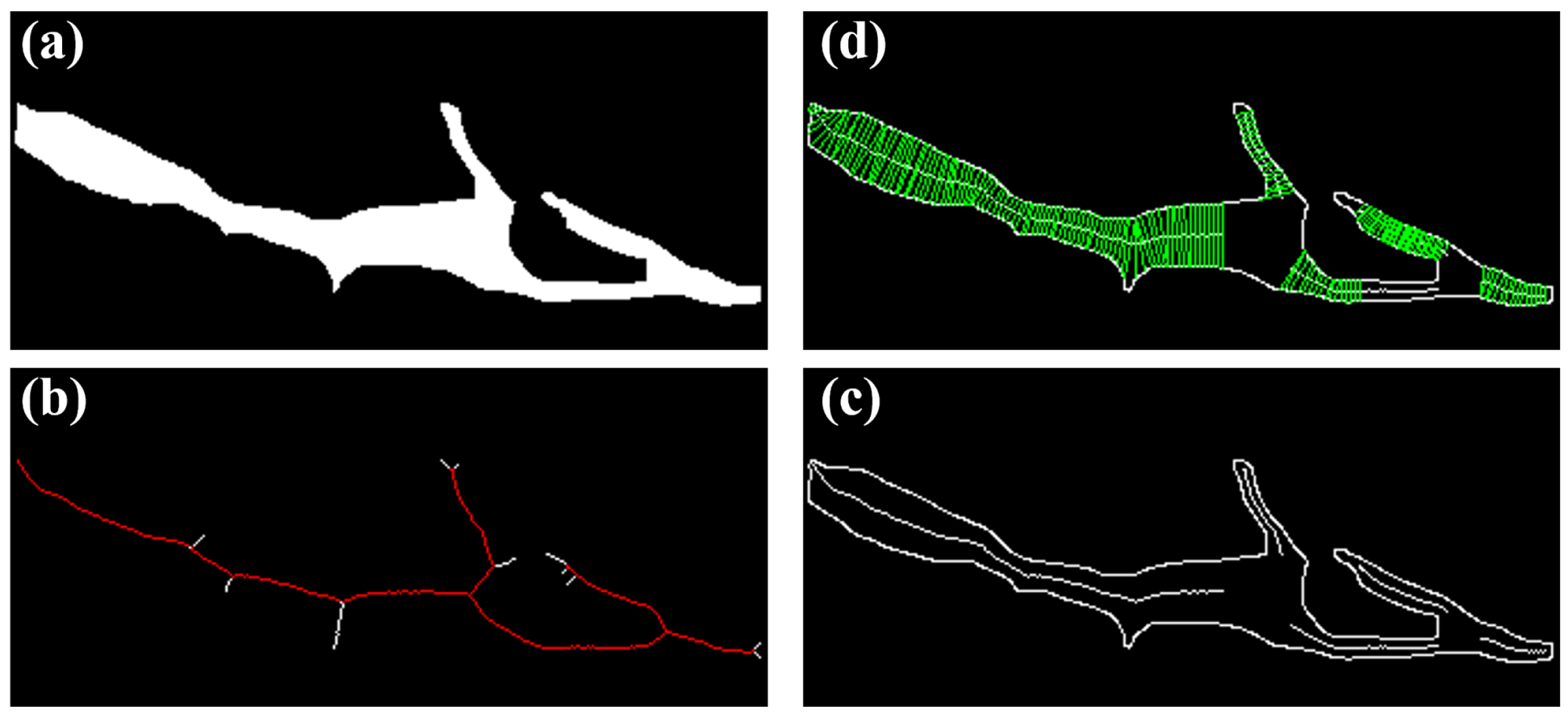
2.3. Crack Mask Post-Processing and Cataloging
3. Experiments and Results
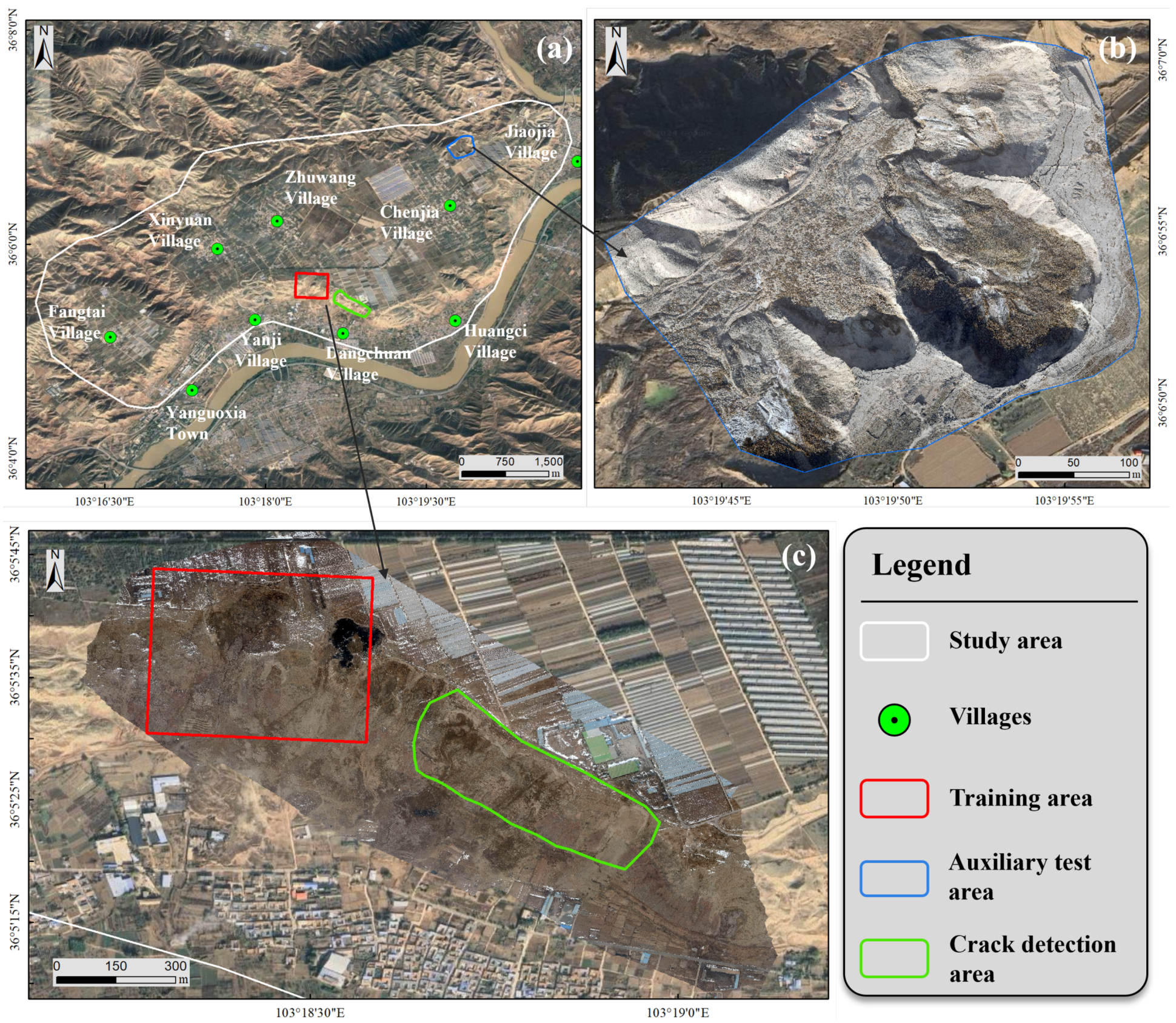
3.1. Study Area and Dataset Preparation
3.2. Evaluation Metrics and Experimental Settings
3.3. Crack Segmentation Performance Analysis
3.3.1. Comparison Between IEDSSNet and Other Methods
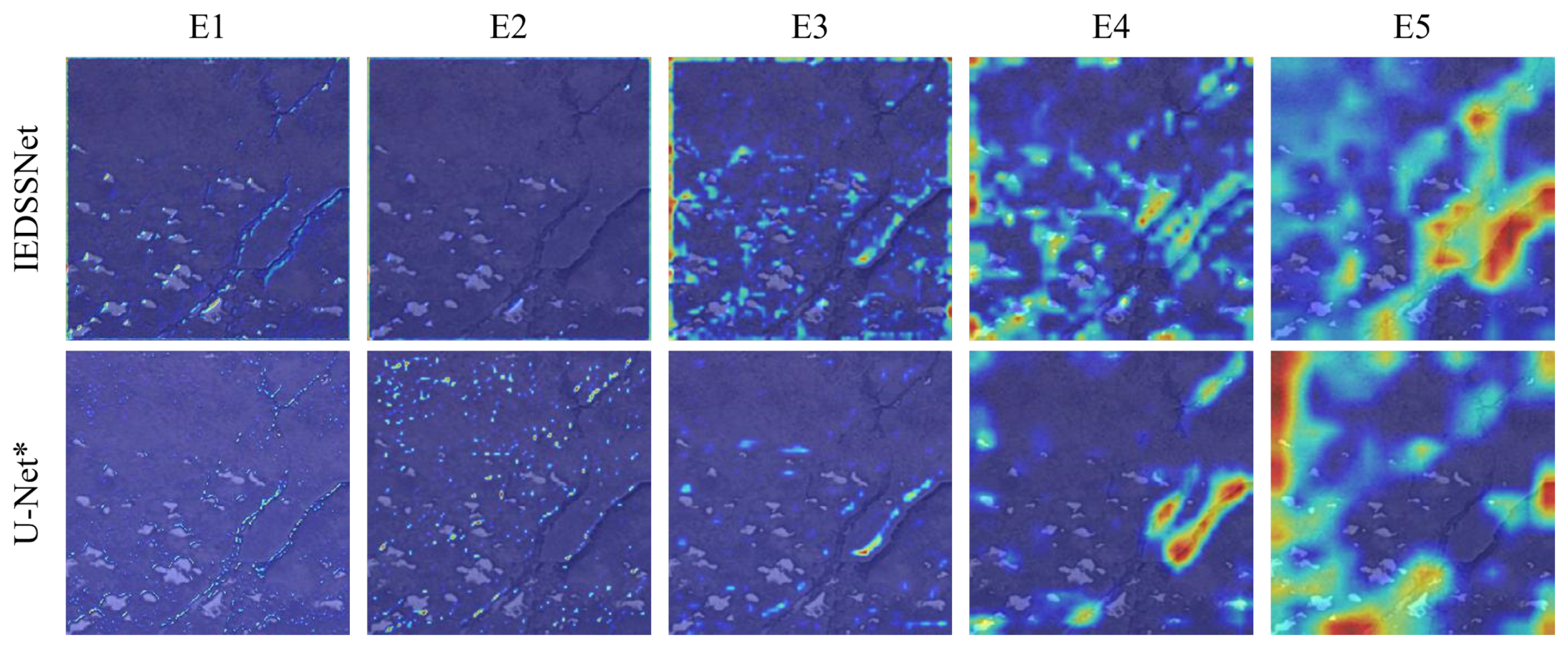
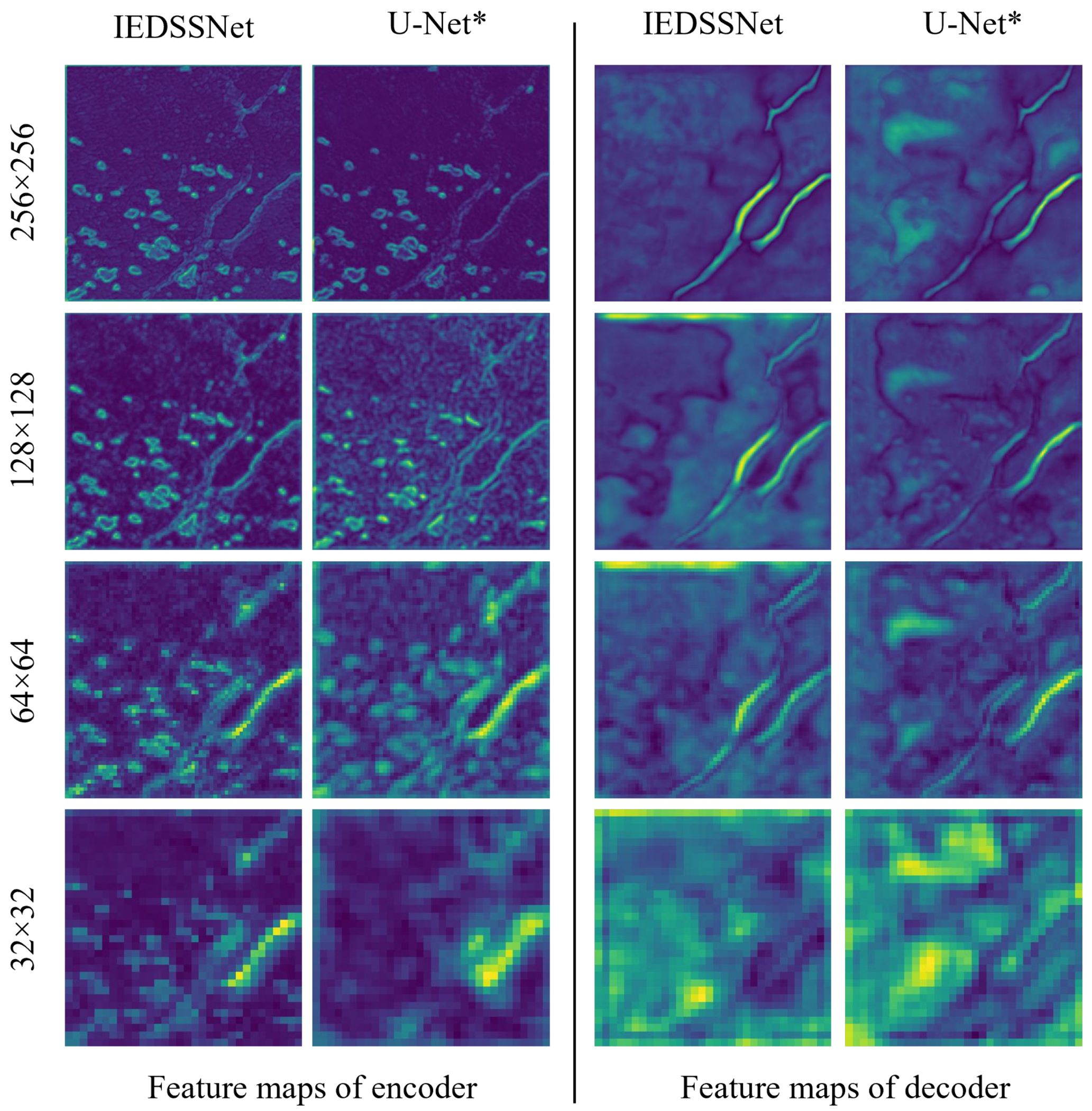
3.3.2. Improvement Analysis of IEDSSNet
3.4. Post-Processing and Cataloging Results
4. Discussion
4.1. Efficiency of Crack Detection
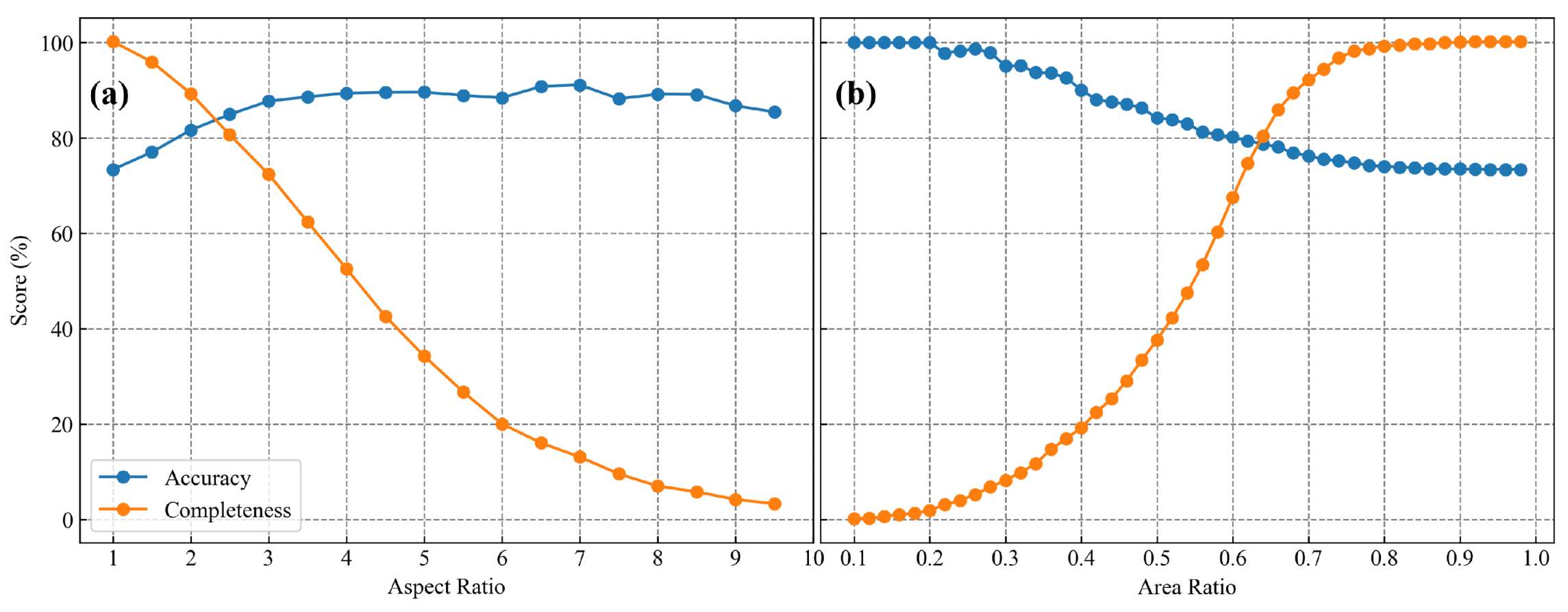
4.2. Impact of Post-Processing Thresholds
4.3. Limitations and Future Work
5. Conclusions
- (1)
- The proposed IEDSSNet outperforms other mainstream semantic segmentation networks on the Heifangtai landslide surface crack dataset, with IoU, recall, precision, and F1 scores reaching 69.65%, 80.77%, 83.49%, and 82.11%, respectively. Despite performance degradation under significant illumination variations, it maintains optimal performance with demonstrated generalization capability.
- (2)
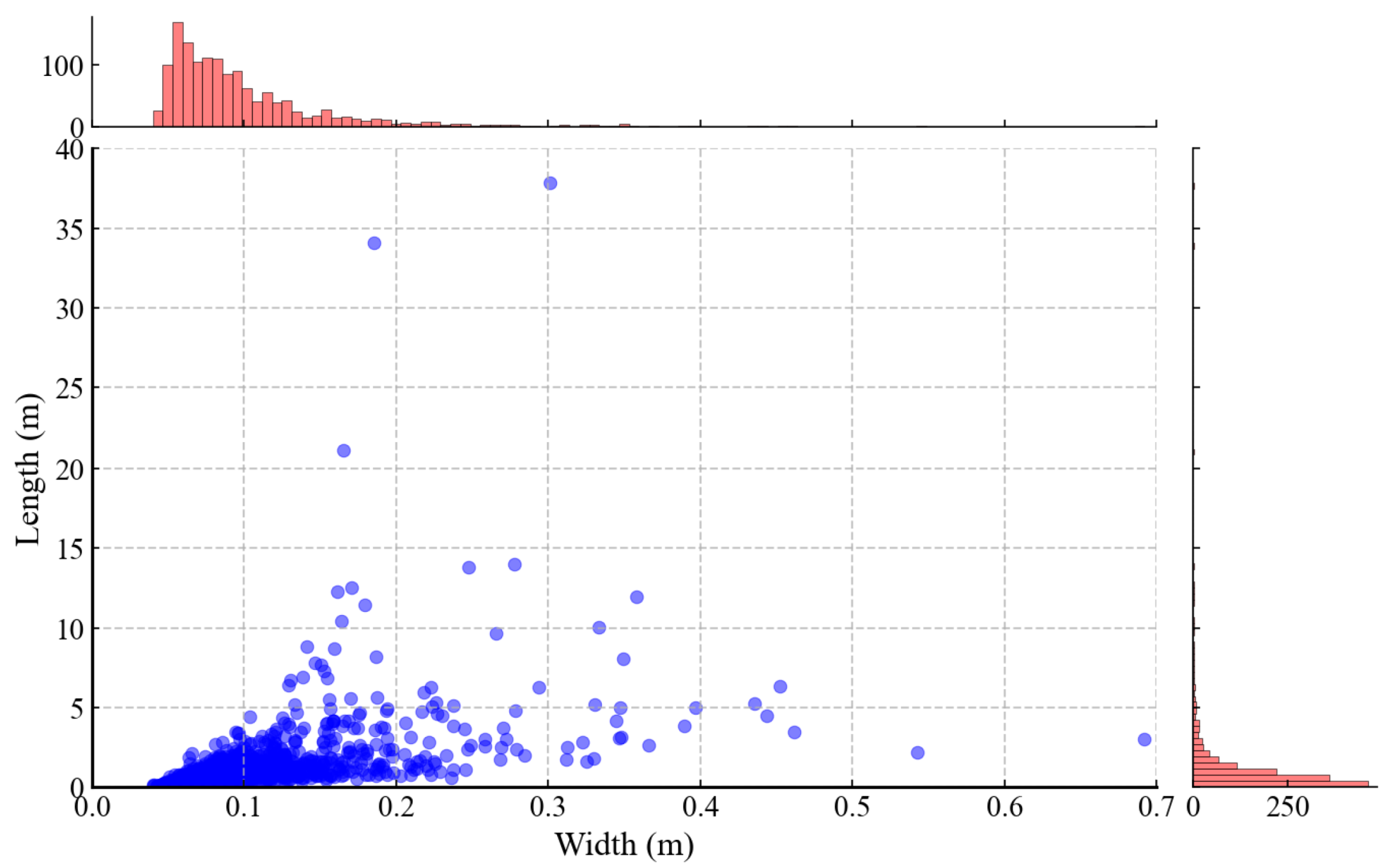
- Closing operation and connected-component analysis can effectively suppress false positives. A total of 1658 cracks were automatically cataloged, with a cataloging accuracy of 85.22% following manual inspection. These cracks are predominantly distributed along rear and lateral edges of landslides, with crack widths generally below 0.2 m and lengths concentrated within 5 m.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gariano, S.L.; Guzzetti, F. Landslides in a changing climate. Earth-Sci. Rev. 2016, 162, 227–252. [Google Scholar] [CrossRef]
- Xu, H.; Shu, B.; Zhang, Q.; Du, Y.; Zhang, J.; We, T.; Xiong, G.; Dai, X.; Wang, L. Site selection for landslide GNSS monitoring stations using InSAR and UAV photogrammetry with analytical hierarchy process. Landslides 2024, 21, 791–805. [Google Scholar] [CrossRef]
- Xu, H.; Zhang, Q.; Wang, L.; Shu, B.; Du, Y.; Huang, G. Intelligent site selection method for UAV-dropped GNSS landslide monitoring equipment. Acta Geod. Cartogr. Sin. 2024, 53, 1140. [Google Scholar]
- Wang, H.; Nie, D.; Tuo, X.; Zhong, Y. Research on crack monitoring at the trailing edge of landslides based on image processing. Landslides 2020, 17, 985–1007. [Google Scholar] [CrossRef]
- Al-Rawabdeh, A.; He, F.; Moussa, A.; El-Sheimy, N.; Habib, A. Using an unmanned aerial vehicle-based digital imaging system to derive a 3D point cloud for landslide scarp recognition. Remote Sens. 2016, 8, 95. [Google Scholar] [CrossRef]
- Deng, B.; Xu, Q.; Dong, X.; Ju, Y.; Hu, W. Automatic Detection of Deformation Cracks in Slopes Fused with Point Cloud and Digital Image. Geomat. Inf. Sci. Wuhan Univ. 2023, 48, 1296–1311. [Google Scholar]
- Deng, B.; Xu, Q.; Dong, X.; Li, W.; Wu, M.; Ju, Y.; He, Q. Automatic Method for Detecting Deformation Cracks in Landslides Based on Multidimensional Information Fusion. Remote Sens. 2024, 16, 4075. [Google Scholar] [CrossRef]
- Fu, H.; Meng, D.; Li, W.; Wang, Y. Bridge crack semantic segmentation based on improved Deeplabv3+. J. Mar. Sci. Eng. 2021, 9, 671. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, S.; Li, X.; Li, G.; Li, X. Lightweight bridge crack detection method based on segnet and bottleneck depth-separable convolution with residuals. IEEE Access 2021, 9, 161649–161668. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. Deepcrack: Learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 2018, 28, 1498–1512. [Google Scholar] [CrossRef]
- Han, C.; Ma, T.; Huyan, J.; Huang, X.; Zhang, Y. CrackW-Net: A novel pavement crack image segmentation convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 22135–22144. [Google Scholar] [CrossRef]
- Lau, S.L.; Chong, E.K.; Yang, X.; Wang, X. Automated pavement crack segmentation using u-net-based convolutional neural network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Loverdos, D.; Sarhosis, V. Automatic image-based brick segmentation and crack detection of masonry walls using machine learning. Autom. Constr. 2022, 140, 104389. [Google Scholar] [CrossRef]
- Chen, K.; Reichard, G.; Xu, X.; Akanmu, A. Automated crack segmentation in close-range building façade inspection images using deep learning techniques. J. Build. Eng. 2021, 43, 102913. [Google Scholar] [CrossRef]
- Zhou, S.; Canchila, C.; Song, W. Deep learning-based crack segmentation for civil infrastructure: Data types, architectures, and benchmarked performance. Autom. Constr. 2023, 146, 104678. [Google Scholar] [CrossRef]
- Yuan, Y.; Ge, Z.; Su, X.; Guo, X.; Suo, T.; Liu, Y.; Yu, Q. Crack length measurement using convolutional neural networks and image processing. Sensors 2021, 21, 5894. [Google Scholar] [CrossRef]
- Xu, J.J.; Zhang, H.; Tang, C.S.; Cheng, Q.; Liu, B.; Shi, B. Automatic soil desiccation crack recognition using deep learning. Geotechnique 2022, 72, 337–349. [Google Scholar] [CrossRef]
- Pham, M.V.; Ha, Y.S.; Kim, Y.T. Automatic detection and measurement of ground crack propagation using deep learning networks and an image processing technique. Measurement 2023, 215, 112832. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S.; Li, X.; Yuan, Z.; Shen, C. Earthquake crack detection from aerial images using a deformable convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4412012. [Google Scholar] [CrossRef]
- Tao, T.; Han, K.; Yao, X.; Chen, X.; Wu, Z.; Yao, C.; Tian, X.; Zhou, Z.; Ren, K. Identification of ground fissure development in a semi-desert aeolian sand area induced from coal mining: Utilizing UAV images and deep learning techniques. Remote Sens. 2024, 16, 1046. [Google Scholar] [CrossRef]
- Sandric, I.; Chitu, Z.; Ilinca, V.; Irimia, R. Using high-resolution UAV imagery and artificial intelligence to detect and map landslide cracks automatically. Landslides 2024, 21, 2535–2543. [Google Scholar] [CrossRef]
- Cheng, Z.; Gong, W.; Jaboyedoff, M.; Chen, J.; Derron, M.H.; Zhao, F. Landslide Identification in UAV Images Through Recognition of Landslide Boundaries and Ground Surface Cracks. Remote Sens. 2025, 17, 1900. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. Uctransnet: Rethinking the skip connections in u-net from a channel-wise perspective with transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2441–2449. [Google Scholar]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, K.; Sun, M.; Han, T.X.; Yuan, X.; Guo, L.; Liu, T. Residual networks of residual networks: Multilevel residual networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1303–1314. [Google Scholar] [CrossRef]
- Ates, G.C.; Mohan, P.; Celik, E. Dual cross-attention for medical image segmentation. Eng. Appl. Artif. Intell. 2023, 126, 107139. [Google Scholar] [CrossRef]
- Wazir, S.; Fraz, M.M. HistoSeg: Quick attention with multi-loss function for multi-structure segmentation in digital histology images. In Proceedings of the 2022 12th International Conference on Pattern Recognition Systems (ICPRS), Saint-Etienne, France, 7–10 June 2022; pp. 1–7. [Google Scholar]
- Blum, H. Biological shape and visual science (Part I). J. Theor. Biol. 1973, 38, 205–287. [Google Scholar] [CrossRef]
- Bai, X.; Latecki, L.J. Discrete skeleton evolution. In Proceedings of the Energy Minimization Methods in Computer Vision and Pattern Recognition: 6th International Conference, EMMCVPR 2007, Ezhou, China, 27–29 August 2007; Proceedings 6. Springer: Berlin/Heidelberg, Germany, 2007; pp. 362–374. [Google Scholar]
- Ong, J.C.; Ismadi, M.Z.P.; Wang, X. A hybrid method for pavement crack width measurement. Measurement 2022, 197, 111260. [Google Scholar] [CrossRef]
- Zhang, Q.; Bai, Z.; Huang, G.; Kong, J.; Du, Y.; Wang, D.; Jing, C.; Xie, W. Innovative landslide disaster monitoring: Unmanned aerial vehicle-deployed GNSS technology. Geomat. Nat. Hazards Risk 2024, 15, 2366374. [Google Scholar] [CrossRef]
- Huang, G.; Wang, D.; Du, Y.; Zhang, Q.; Bai, Z.; Wang, C. Deformation feature extraction for GNSS landslide monitoring series based on robust adaptive sliding-window algorithm. Front. Earth Sci. 2022, 10, 884500. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.; Wu, J.U. 3+: A full-scale connected UNet for medical image segmentation. arXiv 2020, arXiv:2004.08790. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Wang, G.; Cheng, G.; Zhou, P.; Han, J. Cross-level attentive feature aggregation for change detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 6051–6062. [Google Scholar] [CrossRef]
- Inoue, Y.; Nagayoshi, H. Weakly-supervised crack detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 12050–12061. [Google Scholar] [CrossRef]
- Kaiser, S.; Boike, J.; Grosse, G.; Langer, M. The Potential of UAV Imagery for the Detection of Rapid Permafrost Degradation: Assessing the Impacts on Critical Arctic Infrastructure. Remote Sens. 2022, 14, 6107. [Google Scholar] [CrossRef]
- Xu, J.J.; Zhang, H.; Tang, C.S.; Cheng, Q.; Tian, B.-G.; Liu, B.; Shi, B. Automatic soil crack recognition under uneven illumination condition with the application of artificial intelligence. Eng. Geol. 2022, 296, 106495. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Samples | Source | Augmentation | Resolution |
|---|---|---|---|---|
| Training set | 1152 | Training area | Yes | 2 cm/pixel |
| Primary test set | 48 | Training area | No | 2 cm/pixel |
| Auxiliary test set | 111 | Auxiliary test area | No | 1.5 cm/pixel |
| Network | IOU (%) | Recall (%) | Precision (%) | F1 Score (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| U-Net | 65.02 | 76.53 | 81.20 | 78.80 | 31.03 | 54.65 |
| Attention U-Net | 66.10 | 77.10 | 82.24 | 79.59 | 34.88 | 66.57 |
| U-Net++ | 64.47 | 75.93 | 81.03 | 78.40 | 36.63 | 138.60 |
| U-Net3+ | 65.36 | 78.84 | 79.27 | 79.06 | 16.35 | 170.95 |
| PSPNet | 53.74 | 73.28 | 66.84 | 69.91 | 46.58 | 25.89 |
| UCTransNet | 65.43 | 77.03 | 81.29 | 79.10 | 78.83 | 36.23 |
| Deeplabv3+ | 64.98 | 80.49 | 77.13 | 78.77 | 59.34 | 22.24 |
| DeepCrack | 60.78 | 70.29 | 81.79 | 75.61 | 30.91 | 137.06 |
| Crack-CADNet | 66.23 | 77.95 | 81.51 | 79.69 | 20.17 | 15.38 |
| IEDSSNet | 69.65 | 80.77 | 83.49 | 82.11 | 18.82 | 99.20 |
| Network | IOU (%) | Recall (%) | Precision (%) | F1 Score (%) |
|---|---|---|---|---|
| U-Net | 58.50 | 79.70 | 68.74 | 73.82 |
| Attention U-Net | 53.30 | 73.32 | 66.13 | 69.54 |
| U-Net++ | 56.00 | 73.22 | 70.43 | 71.80 |
| U-Net3+ | 54.84 | 92.39 | 57.44 | 70.84 |
| PSPNet | 45.94 | 57.97 | 68.88 | 62.96 |
| UCTransNet | 60.84 | 77.68 | 73.72 | 75.65 |
| Deeplabv3+ | 58.05 | 88.13 | 62.98 | 73.46 |
| DeepCrack | 64.62 | 89.30 | 70.05 | 78.51 |
| Crack-CADNet | 52.89 | 72.79 | 65.92 | 69.18 |
| IEDSSNet | 65.59 | 84.17 | 74.82 | 79.21 |
| Network | IOU (%) | Recall (%) | Precision (%) | F1 Score (%) |
|---|---|---|---|---|
| U-Net* | 64.54 (+0.00) | 76.13 (+0.00) | 80.92 (+0.00) | 78.45 (+0.00) |
| RSE | 68.63 (+4.09) | 80.60 (+4.47) | 82.22 (+1.30) | 81.40 (+2.95) |
| CBAM | 67.14 (+2.60) | 78.68 (+2.55) | 82.07 (+1.15) | 80.34 (+1.89) |
| MSC | 67.18 (+2.64) | 81.52 (+5.39) | 79.25 (−1.67) | 80.37 (+1.92) |
| CCA | 67.46 (+2.92) | 78.98 (+2.85) | 82.22 (+1.30) | 80.57 (+2.12) |
| RSE+MSC | 67.26 (+2.72) | 79.36 (+3.23) | 81.52 (+0.60) | 80.42 (+1.97) |
| RSE+CCA | 66.96 (+2.42) | 82.78 (+6.65) | 77.80 (−3.12) | 80.21 (+1.76) |
| RSE+CBAM | 67.00 (+2.46) | 78.34 (+2.21) | 82.23 (+1.31) | 80.24 (+1.79) |
| CBAM+MSC | 67.45 (+2.91) | 79.49 (+3.36) | 81.66 (+0.74) | 80.56 (+2.11) |
| CBAM+CCA | 68.63 (+4.09) | 80.78 (+4.65) | 82.02 (+1.10) | 81.39 (+2.94) |
| MSC+CCA | 67.52 (+2.98) | 81.63 (+5.50) | 79.62 (−1.30) | 80.61 (+2.16) |
| RSE+CBAM+MSC | 68.53 (+3.99) | 84.59 (+8.46) | 78.30 (-2.62) | 81.32 (+2.87) |
| RSE+CBAM+CCA | 67.40 (+2.86) | 78.38 (+2.25) | 82.79 (+1.87) | 80.52 (+2.07) |
| CBAM+MSC+CCA | 67.20 (+2.66) | 78.00 (+1.87) | 82.90 (+1.98) | 80.38 (+1.93) |
| RSE+MSC+CCA | 66.50 (+1.96) | 79.72 (+3.59) | 80.04 (−0.88) | 79.88 (+1.43) |
| IEDSSNet | 69.65 (+5.11) | 80.77 (+4.64) | 83.49 (+2.57) | 82.11 (+3.66) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Wang, L.; Shu, B.; Zhang, Q.; Li, X. Automatic Detection of Landslide Surface Cracks from UAV Images Using Improved U-Network. Remote Sens. 2025, 17, 2150. https://doi.org/10.3390/rs17132150
Xu H, Wang L, Shu B, Zhang Q, Li X. Automatic Detection of Landslide Surface Cracks from UAV Images Using Improved U-Network. Remote Sensing. 2025; 17(13):2150. https://doi.org/10.3390/rs17132150
Chicago/Turabian StyleXu, Hao, Li Wang, Bao Shu, Qin Zhang, and Xinrui Li. 2025. "Automatic Detection of Landslide Surface Cracks from UAV Images Using Improved U-Network" Remote Sensing 17, no. 13: 2150. https://doi.org/10.3390/rs17132150
APA StyleXu, H., Wang, L., Shu, B., Zhang, Q., & Li, X. (2025). Automatic Detection of Landslide Surface Cracks from UAV Images Using Improved U-Network. Remote Sensing, 17(13), 2150. https://doi.org/10.3390/rs17132150