Abstract
Real-time object detection is critical for unmanned aerial vehicles (UAVs) performing various tasks. However, efficiently deploying detection models on UAV platforms with limited storage and computational resources remains a significant challenge. To address this issue, we propose ELNet, an efficient and lightweight object detection model based on YOLOv12n. First, based on an analysis of UAV image characteristics, we strategically remove two A2C2f modules from YOLOv12n and adjust the size and number of detection heads. Second, we propose a novel lightweight detection head, EPGHead, to alleviate the computational burden introduced by adding the large-scale detection head. In addition, since YOLOv12n employs standard convolution for downsampling, which is inefficient for extracting UAV image features, we design a novel downsampling module, EDown, to further reduce model size and enable more efficient feature extraction. Finally, to improve detection in UAV imagery with dense, small, and scale-varying objects, we propose DIMB-C3k2, an enhanced module built upon C3k2, which boosts feature extraction under complex conditions. Compared with YOLOv12n, ELNet achieves an 88.5% reduction in parameter count and a 52.3% decrease in FLOPs, while increasing mAP50 by 1.2% on the VisDrone dataset and 0.8% on the HIT-UAV dataset, reaching 94.7% mAP50 on HIT-UAV. Furthermore, the model achieves a frame rate of 682 FPS, highlighting its superior computational efficiency without sacrificing detection accuracy.
1. Introduction
Object detection based on remote sensing imagery holds significant importance across a wide range of practical fields, including military reconnaissance [1], disaster search and rescue [2,3], traffic monitoring [4,5,6], road planning [7], and routine surveillance [8]. As computer vision technologies advance, UAVs have become an efficient tool for acquiring remote sensing imagery. Thanks to their small physical footprint, adaptable flight altitudes, strong stealth capabilities, rapid data collection, and minimal operating expenses [9], UAVs are widely used in civilian and military fields. Consequently, significant research attention has been drawn to object detection using UAV imagery.
In recent years, methodologies for object detection have generally been divided into two major branches: conventional techniques and those grounded in deep learning frameworks. Conventional techniques mainly depend on handcrafted features, sliding window mechanisms, and traditional classification models. However, due to their limited representational capacity, they often struggle to handle object scale and appearance variations. The sliding window mechanism also incurs high computational overhead and low detection efficiency. In contrast, deep learning-based approaches demonstrate substantial advantages in terms of accuracy and generalization [10]. Benefiting from training on large-scale datasets, these models can learn hierarchical feature representations [11], which significantly outperform handcrafted features used in traditional methods. Moreover, deep learning-based approaches have experienced rapid development [12,13,14] and can be broadly categorized into convolutional neural network (CNN)-based and Transformer-based frameworks.
CNN-based methods are generally categorized into two-stage and single-stage detectors. Two-stage methods generate region proposals followed by classification and regression, with notable examples including Faster RCNN [15], Fast RCNN [16], and RCNN [17], which are well-suited for high-precision applications [18,19]. Conversely, one-stage methods, such as SSD [20] and the YOLO series [21,22,23,24,25,26], directly predict object categories and bounding boxes without requiring proposal generation, resulting in faster detection speeds. This advantage makes them highly compatible with resource-constrained UAV platforms. Notably, the YOLO series has undergone extensive optimization and delivers outstanding performance in real-time object detection tasks [27].
Unlike CNN-based methods, Transformer-based frameworks model global feature dependencies through self-attention mechanisms [28], exhibiting notable advancements in capturing long-range interactions. DETR exemplifies representative Transformer-based object detectors [29], along with its enhanced successors like Deformable DETR [30] and DINO [31]. For example, RT-DETR [32,33,34] facilitates end-to-end object detection by eliminating the need for region proposals and post-processing, simplifying the detection pipeline. Transformer-based frameworks exhibit improved adaptability in complex environments and long-distance detection, critical for UAV imagery.
However, the computational complexity of self-attention remains a barrier for deployment on resource-constrained UAV platforms. To overcome this, hybrid architectures combining CNNs and self-attention have been proposed. For example, T2T-ViT [35] effectively reduces the number of parameters in the ViT model [28] by incorporating architectural design principles from CNNs. Swin Transformer [36], on the other hand, introduces a shifted window attention mechanism. This approach achieves linear computational complexity with respect to image size and helps lower inference latency. Furthermore, YOLOv12 [26] integrates a region attention module to improve detection accuracy without compromising the efficiency of the YOLO framework.
Although these models achieve promising results in object detection, UAV imagery poses unique challenges due to differences in viewpoint and imaging conditions. These challenges include dense object distribution, complex backgrounds, significant scale variations, and small object sizes (often less than 32 × 32 pixels [37]). Additionally, the limited computational resources available on UAV platforms demand lightweight and efficient models. Therefore, developing an object detector that balances accuracy and model compactness is both urgent and critical.
Overall, to harness the complementary strengths of CNNs and self-attention mechanisms, we propose an efficient and lightweight network called ELNet. Based on the YOLOv12 framework, the model is specifically optimized to enhance the detection of small objects in UAV imagery. Firstly, based on the characteristics of the UAV dataset, we modify the overall structure of YOLOv12n by removing two A2C2f modules from the backbone and neck, and adjusting the sizes and number of detection heads. These modifications result in a more lightweight model with improved detection performance. Second, we aim to reduce the computational burden caused by the large-scale detection head. To this end, we design a novel convolutional module, partial group convolution (PGConv), and a lightweight detection head, EPGHead. By employing EPGHead, the computational burden of the model is significantly reduced, and the detection speed is improved. Third, we note that YOLOv12 adopts standard convolution operations for feature downsampling. However, standard convolution is less efficient in capturing fine-grained features and imposes more significant computational overhead, making it suboptimal for lightweight models. To overcome this limitation, we propose an efficient downsampling module, EDown, which leverages depthwise separable convolution and max pooling. With the introduction of EDown for downsampling, the model size is further optimized, and the feature extraction capability is significantly enhanced. Finally, to address the challenges of small object detection and significant scale variations in UAV imagery, we propose a dynamic inception mixer block (DIMB) and design the DIMB-C3k2. When integrated into the backbone, this module significantly improves the model’s ability to extract discriminative features in complex background scenarios.
The main contributions of this paper are summarized as follows:
- We present ELNet, an efficient and lightweight small object detection model designed for UAV imagery, striking an optimal trade-off between detection accuracy and real-time processing efficiency, all within a compact architectural framework.
- We introduce a novel partial group convolution (PGConv) and a lightweight detection head (EPGHead), which jointly reduce computational complexity while ensuring stability.
- We design a lightweight downsampling module (EDown) based on depthwise separable convolution and max pooling, effectively reducing the model size while enhancing detection performance.
- We propose the dynamic inception mixer block (DIMB) and integrate it into the redesigned DIMB-C3k2 module, which enhances the network’s feature extraction capability for small objects and varying scales in UAV imagery.
2. Related Works
2.1. CNN-Based Remote Sensing Object Detection
Convolutional neural network (CNN)-based object detectors are typically divided into two-stage and single-stage frameworks. Considering the limited computational resources of edge devices such as UAV platforms and the requirement for real-time inference, single-stage models, particularly the YOLO series [21,22,23,24,25,26], are more widely adopted for remote sensing imagery. For instance, BiFA-YOLO [38] introduces a bidirectional feature aggregation module that successfully tackles the difficulties of extracting objects at multiple scales and in dense formations within SAR images. ECAP-YOLO [39] improves detection performance in aerial imagery containing small objects and visually similar backgrounds by modifying the detection head architecture. Hu et al. [40] observed that the YOLO framework insufficiently captures global–local feature relationships and accordingly proposed PAG-YOLO to overcome this limitation. Overall, the YOLO framework offers a favorable balance between accuracy and efficiency in remote sensing object detection. Accordingly, YOLOv12 [26] is adopted as the baseline for its balance of accuracy and speed. Furthermore, object enhancements are applied to adapt the model to UAV-specific challenges, including handling complex backgrounds, detecting small objects, and operating within limited computational resources.
2.2. Self-Attention-Based Remote Sensing Object Detection
Introducing models such as DETR [29] and RT-DETR [32] has sparked growing interest in applying self-attention mechanisms to object detection. Transformer-based architectures have subsequently gained rapid traction in remote sensing applications. For example, OEGR-DETR [41] incorporates orientation-enhancement techniques to better capture rotational features in remote sensing images. MCG-RTDETR [42] effectively tackles issues such as intricate backgrounds and significant occlusions in UAV imagery by integrating deformable convolutions and context-guided downsampling modules into the RT-DETR framework, achieving significant performance improvements. AgeDETR [43], designed for space-based object monitoring, enhances the backbone with multi-scale attention and introduces an attention-guided module, leading to notable gains in recognition accuracy. These studies demonstrate the advantages of Transformer-based architectures in remote sensing object detection. As a result, recent research has increasingly explored hybrid architectures that combine the strengths of CNNs and self-attention, as exemplified by the Swin Transformer [36] and the enhanced YOLOv12 model proposed in this work.
2.3. Model Lightweighting Techniques
Model size and computational complexity are critical considerations, particularly for deployment on resource-constrained platforms such as UAVs. Lightweighting strategies generally fall into two main categories: model pruning and convolutional operation optimization. Model pruning reduces computational cost by eliminating redundant parameters based on predefined criteria [44]. In terms of convolutional optimization, architectures such as MobileNet [45], GhostNet [46], and ShuffleNet [47] employ depthwise separable or group convolutions to improve computational efficiency. However, Chen et al. [48] noted that while depthwise convolutions reduce parameter count, they may increase memory access overhead, potentially hindering inference speed. Partial convolution operations have been proposed as more efficient alternatives to address this issue. Therefore, it is essential to employ convolutional optimization techniques in this work to enhance object detection performance in UAV imagery.
2.4. Lightweight and Small Object Detection in UAV Remote Sensing Imagery
Recent advancements in UAV-based remote sensing have emphasized the development of lightweight architectures and enhanced detection performance for small objects. Ni et al. [49] proposed an improved YOLOv8s model tailored for UAV images, integrating coordinate attention and lightweight modules to bolster small-scale target perception. Yu et al. [50] introduced a full-scale detection framework leveraging deformable convolutions and multi-scale contextual feature optimization, achieving improved accuracy but still demanding considerable computational resources. Wu et al. [51] developed EUAVDet, a lightweight detector specifically designed for edge computing platforms. While EUAVDet balances speed and accuracy effectively, it does not fully address the optimization of model depth and convolutional overhead. Similarly, Wang et al. [52] designed a lightweight algorithm for UAV imagery by integrating attention mechanisms, but the inference speed remains limited under high-resolution inputs due to its complex neck design.
In contrast, our proposed ELNet achieves a smaller model size, reduced FLOPs, and higher inference speed. Specifically, ELNet introduces a dynamic inception mixer block (DIMB) and an efficient partial group detection head (EPGHead), facilitating efficient feature extraction while maintaining high accuracy in small object detection. These advantages render ELNet more suitable for deployment on UAV platforms with constrained computational capacities.
3. Proposed Methods
This chapter provides a comprehensive overview of the proposed ELNet. Section 3.1 presents an overview of the ELNet architecture. The EPGHead, EDown, and DIMB-C3k2 modules within ELNet are described in detail in Section 3.2, Section 3.3, and Section 3.4, respectively.
3.1. Overall Architecture
YOLOv12 [26], as an advanced YOLO framework, further enhances the performance of YOLO models in real-time object detection tasks by incorporating attention mechanisms. Nevertheless, the integration of attention mechanisms still introduces a non-negligible computational burden. As a result, the inference speed of YOLOv12 remains lower than that of CNN-based counterparts such as YOLOv11. To address this issue, our work builds upon YOLOv12n. It further explores lightweight and efficient architectural enhancements to improve its deployment feasibility in UAV-based object detection. Figure 1 illustrates the overall architecture of ELNet. Building upon YOLOv12n, ELNet incorporates a series of architectural adjustments to better accommodate UAV-based object detection.
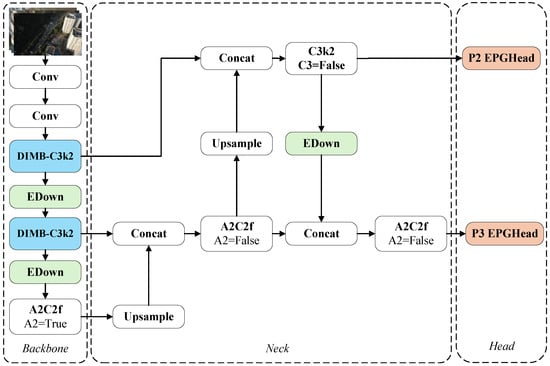
Figure 1.
Overall architecture of ELNet. First, the backbone and neck are streamlined by removing one A2C2f module from each, effectively reducing redundancy. In addition, the size and number of detection heads are adjusted, and the EPGHead is introduced to lower computational complexity. The EDown module is then incorporated to optimize the downsampling process. Furthermore, the original C3k2 structure is substituted by DIMB-C3k2, enhancing the backbone’s feature representation capability. P2 and P3 represent detection heads with output resolutions of and , respectively.
Experimental results indicate that small objects constitute the majority of samples in UAV imagery. Meanwhile, our experimental results also indicate that the (P5) detection head in YOLOv12n contributes minimally to the overall performance. Therefore, we first modified the architecture of YOLOv12n by adjusting the detection head resolutions to 160 × 160 (P2) and 80 × 80 (P3), better suited for detecting small objects. Additionally, due to the reduced detection heads, we pruned the A2C2f modules in both the backbone and neck for efficiency. The revised connection scheme is illustrated in Figure 1. These changes boost accuracy and cut parameters, ensuring efficient detection.
Moreover, to reduce the overhead caused by adding the P2 detection head, we propose a lightweight detection head named EPGHead. EPGHead reduces computational cost by leveraging shared feature maps and improves detection speed by replacing DWConv with the more efficient partial group convolution (PGConv).
In addition, we observe that YOLOv12n still employs standard convolution for downsampling. Compared to efficient alternatives such as DWConv and GhostConv [46], standard convolution is less effective in fine-grained feature extraction and incurs higher computational costs, making it less suitable for lightweight applications. We designed a more efficient downsampling module, EDown, to address this issue by integrating max pooling and depthwise separable convolutions.
Finally, UAV imagery presents significant challenges due to dense object distribution, complex backgrounds, significant scale variations, and small object sizes, making it difficult for standard convolution to extract informative features. We propose a dynamic inception mixer module, termed DIMB-C3k2. This module integrates convolutional kernels of various sizes and shapes with a dynamic weighting mechanism, enabling the network to effectively capture small object features in cluttered scenes.
3.2. Efficient Partial Group Detection Head
As illustrated in Figure 2a, we propose the EPGHead to mitigate the increased computational burden introduced by the P2 detection head. Experimental studies [25] have shown that, compared with the classification task, the regression task exhibits higher learning difficulty. Accordingly, YOLOv12 adopts a decoupled detection head to learn and predict features for classification and regression tasks separately. Although this design improves detection performance, it nearly doubles the computational cost compared with the shared-head structure, making it unsuitable for resource-constrained devices. Inspired by the findings of YOLOX [53], we revisit the design of detection heads in object detection networks. YOLOX demonstrated that decoupled detection heads can improve accuracy. However, this improvement comes at the cost of increased computational load and parameter complexity. To maintain a lightweight architecture suitable for deployment on resource-constrained UAV platforms, our proposed ELNet adopts a coupled detection head. Additionally, prior research [48] indicates that although DWConv offers improved computational efficiency, it results in a higher memory access frequency than standard convolution. Consequently, despite a smaller model size, detection speed does not improve significantly. Therefore, we replace DWConv with PGConv, and the corresponding derivation is presented below.
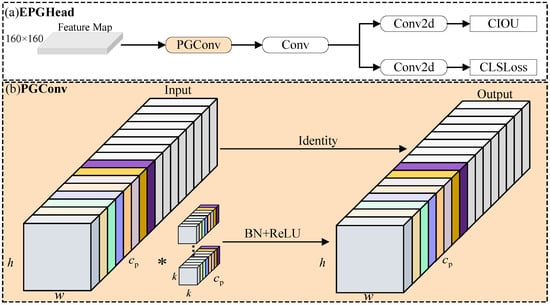
Figure 2.
Architecture of EPGHead. (a) The detailed structure of the detection head, where the feature map corresponds to the P2 layer. The structure of the P3 detection head is similar. (b) The design of the partial group convolution (PGConv) operation, in which ∗ denotes the selected partial channels involved in the grouped convolution with the convolutional kernel. BN and ReLU represent batch normalization and the activation function, respectively. The matching colors in the input/output feature maps and the convolution kernel signify that the convolution is applied only to corresponding channel groups. This visualization demonstrates that a specific partition of the kernel operates exclusively on its corresponding partition of the input channels.
According to the study by Chen et al. [48], for an input tensor , the theoretical computational cost of depthwise convolution (DWConv) is , which is substantially lower than the standard convolutional cost of . However, such operations often suffer from noticeable accuracy degradation. A common mitigation strategy is to increase the number of channels , which may introduce elevated memory access overhead and lead to reduced inference speed on hardware platforms.
To approximate the memory access cost (MAC), simplified models assuming uniform memory access and latency are often used. Based on this theoretical approximation, the MAC for depthwise separable convolution can be estimated as follows:
For standard convolution, the corresponding MAC is
Here, C, H, W, and k denote the number of channels, the height and width of the input tensor, and the kernel size, respectively.
Although DWConv significantly reduces FLOPs, the increase in channel count () may lead to cache inefficiency or memory bottlenecks on real-world hardware, diminishing the expected speedup [48].
To alleviate this issue, partial convolution is introduced, in which standard convolution is selectively applied to a subset of consecutive channels, significantly reducing both computational and memory access costs. The approximate MAC is
When , the MAC is roughly halved compared to full convolution.
Building upon this, we further propose a lightweight partial group convolution strategy, as illustrated in Figure 2b. Grouped convolution has been shown to improve both computational efficiency and data locality, and is therefore widely used in lightweight networks. The computational cost for our proposed grouped partial convolution is given by
When the group size , the cost is only of standard convolution. Furthermore, combining this operation with batch normalization and activation functions (e.g., ReLU) facilitates gradient propagation and enhances training stability. It should be noted that all MAC estimations are theoretical and serve as approximations to compare relative efficiency. Actual inference speed is influenced by hardware-dependent factors such as memory hierarchy, cache line alignment, and bandwidth utilization.
3.3. Efficient Downsample Module
Since the introduction of max pooling operations in convolutional neural networks, they have effectively been widely adopted in deep learning models to reduce parameters and computational complexity [54]. Despite their efficiency in downscaling feature maps, max pooling operations often discard fine-grained spatial information, limiting the model’s representational capacity. In contrast, depthwise separable convolutions offer a favorable trade-off by reducing computational cost while better preserving local features. To further reduce model complexity while enhancing feature extraction performance, we propose an efficient downsampling module termed EDown, as illustrated in Figure 3.
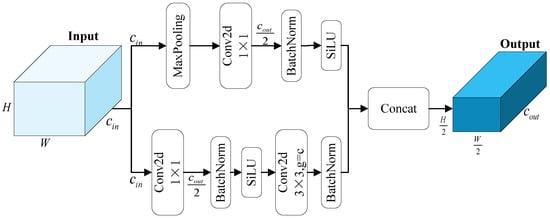
Figure 3.
Architecture of the EDown module.
Given an input feature map , the EDown module employs a dual-branch design to extract features more efficiently. The first branch (upper path) primarily utilizes max pooling to downsample the input while retaining the dominant structural information. Its computational process is formulated as follows:
Here, Conv2d denotes a convolution used to adjust the number of feature channels, while batch normalization (BN) and the SiLU (Sigmoid Linear Unit) activation function enhance model convergence and optimization. This branch captures coarse but structurally significant features with minimal computational overhead.
The second branch (lower path) enhances detail preservation by applying depthwise separable convolution after a lightweight transformation:
This branch first uses a Conv2d to reduce the channel dimension, followed by BN and activation to strengthen feature expressiveness. Downsampling is achieved via depthwise separable convolution, effectively capturing fine-grained details while reducing computation. Inspired by the SCDown module proposed in YOLOv10 [25], we apply only batch normalization after the depthwise convolution. This design choice helps eliminate redundant nonlinear transformations, thereby preserving smoother information flow and enhancing feature continuity. Moreover, batch normalization alone [55] has been shown to stabilize training, reduce internal covariate shift, and facilitate gradient propagation in deep networks. Finally, both branch outputs are concatenated along the channels:
Combining the strengths of max pooling and depthwise convolution, the EDown module enhances feature expressiveness, offering a more effective downsampling strategy for lightweight detection models.
3.4. DIMB-C3k2 Feature Extraction Module
The structural comparison between C3k2 and DIMB-C3k2 is shown in Figure 4. In UAV imagery, object scale and orientation often vary significantly, posing challenges for traditional stacked convolutions used in modules such as C3k and bottleneck. These conventional approaches rely on static kernels, which may be insufficient for capturing multi-scale and transformation-variant features under complex backgrounds. To address this limitation, we propose the dynamic inception mixer block (DIMB), an enhanced feature extraction module designed to improve adaptability and representation capability. The detailed structure of the DIMB is illustrated in Figure 5.
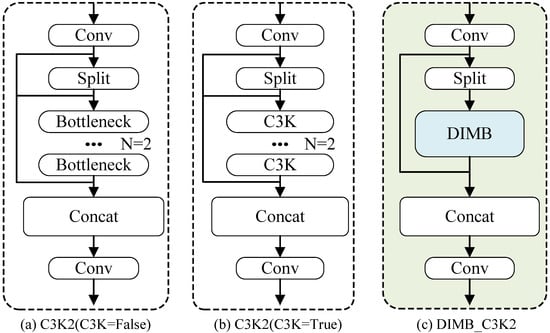
Figure 4.
A comparative analysis of the C3k2 and DIMB-C3k2 modules is presented. (a) The structure of the C3k2 module without the C3k block, and (b) the structure of the C3k2 module with the C3k block, where both the bottleneck and C3k blocks are primarily composed of stacked convolutional layers. (c) The detailed architecture of the proposed DIMB-C3k2 module.
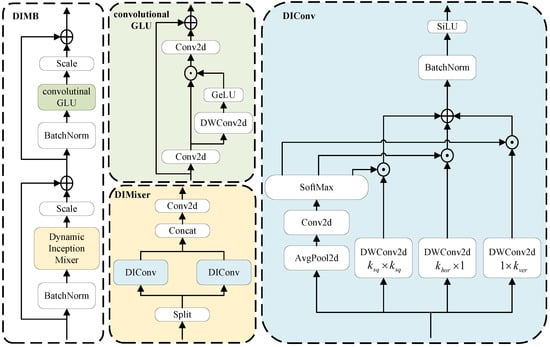
Figure 5.
Detailed architecture diagram of the DIMB module. Here, ⊕ denotes matrix addition, ⊙ represents element-wise multiplication, and GeLU is the activation function. The symbols , , and indicate the kernel sizes of the square, horizontal, and vertical convolutions, respectively.
The DIMB module consists of three components: dynamic inception convolution (DIConv), dynamic inception mixer (DIMixer), and a residual cross-layer connection structure designed to enhance feature propagation. This design is inspired by the MetaFormer architecture [56], which emphasizes the importance of token mixing and residual pathways for efficient information flow.
The DIConv module shares a conceptual similarity with the recent InceptionNeXt [57], as both leverage multiple depthwise convolutional kernels (e.g., square, horizontal, and vertical) to extract diverse spatial features. However, there are fundamental differences. InceptionNeXt statically splits input channels and assigns each split to a specific convolutional branch, which may constrain the flexibility of feature learning. In contrast, DIConv applies all convolution branches to the full input feature map and introduces a dynamic weighting mechanism to adaptively aggregate features.
Specifically, the processing of input features by DIConv includes two stages: multi-scale feature extraction and dynamic weight generation. All input channels are processed by each convolutional branch (square, horizontal, and vertical), and the outputs are fused via input-conditioned weights generated by a lightweight attention module. This allows the model to adaptively emphasize appropriate spatial features based on content, rather than relying on fixed channel partitions.The formula for multi-scale feature extraction is defined as follows:
where represents square convolution, denotes horizontal convolution, and refers to vertical convolution. The relationship between the square convolution kernel and the two asymmetric convolution kernels is given by
Additionally, to further enhance the model’s adaptability, DIConv adopts a dynamic kernel weighting (DKW) mechanism, which enables the network to allocate kernel weights adaptively based on the specific needs of the input feature maps. The particular formula for weight computation is given as follows:
The input feature is first processed by global average pooling to generate the feature vector , followed by a convolution to expand the channel dimension from C to , corresponding to the square, horizontal, and vertical convolutions. The result is normalized using a softmax function to yield the dynamic weight tensor W.
Let , where each is extracted from the first, second, and third slices of W, respectively. Then the output of DIConv is calculated as follows:
Here, denotes the element-wise multiplication between the dynamic weight and the output feature from the corresponding convolution branch. The weighted results are summed and refined by batch normalization and the SiLU activation function to improve feature representation.
Furthermore, we propose the DIMixer module based on DIConv to enhance cross-scale feature fusion and information sharing. The mathematical formulation of DIMixer is as follows:
In the DIMixer module, the input feature is first split into two feature tensors with the shape . These two tensors are then fed into DIConv modules with different convolutional kernel sizes for feature extraction. Finally, the outputs of the DIConv modules are fused using a concatenation operation followed by a convolution to produce the final output .
Building upon DIMixer, we propose the final feature extraction module DIMB based on the MetaFormer architecture [56] to enable more effective feature mixing and learning. As illustrated in Figure 5, DIMB employs DIMixer in the token mixer component, while the channel MLP adopts the convolutionalGLU structure from TransNeXt [58]. In addition, two trainable scale layers are introduced to adjust the feature fusion ratios finely. The detailed computation process is as follows:
Here, and correspond to the two scale layers, both initialized to 0.01. In contrast to the Layer Normalization (LayerNorm) used in TransNeXt [58], batch normalization (BN) is employed here to normalize the incoming features. Moreover, cross-hierarchical connections are utilized to promote feature fusion effectively. The detailed computational formula for the convolutionalGLU module is provided below:
In the above formulation, the input feature is first processed with a convolution to reshape it to . The feature is then split into and . Among them, serves as a gating unit for dynamic feature selection, while is further processed with depthwise separable convolution to extract features, yielding . The resulting and are then multiplied element-wise to obtain a weighted feature tensor . Finally, a residual connection is applied with , resulting in the final output .
Overall, DIMB effectively addresses the limitations of a conventional CNN in handling complex backgrounds, significant scale variations, and small object sizes. The proposed module enhances network adaptability and flexibility through dynamic kernel selection, cross-scale information fusion, and optimized computation strategies.
4. Experiments and Results
4.1. Datasets
To assess the effectiveness and generalization ability of the proposed model, experiments are conducted on two publicly available UAV-based datasets: VisDrone2019 [59] and HIT-UAV [60].
The VisDrone2019 dataset, a widely adopted benchmark for object detection and recognition tasks, is composed of two parts: 261,908 video frames and 10,209 high-resolution still images. The still images, which are specifically used for object detection tasks, are captured by UAVs under diverse conditions, including variations in altitude, weather, and lighting. They cover a wide range of scenes, such as urban streets, residential neighborhoods, and industrial areas. According to the official dataset split, the 10,209 images are divided into 6471 for training, 548 for validation, and 3190 for testing. The dataset includes 10 annotated object categories: pedestrian, people, bicycle, car, van, truck, tricycle, awning-tricycle, bus, and motor. Representative sample images are presented in Figure 6.

Figure 6.
VisDrone2019 dataset samples.
The HIT-UAV dataset is employed as an additional evaluation benchmark to assess the generalization performance further. In contrast to conventional optical imagery, HIT-UAV provides infrared aerial images, which enhance robustness to lighting and weather variations. The HIT-UAV dataset consists of 2898 infrared photos, and is labeled initially into five categories: people, cars, bicycles, other vehicles, and DontCare. The DontCare category is excluded for experimental purposes, and the cars and other vehicles categories are merged into a single cars class. The dataset is split into training, validation, and test sets at a 7:1:2 ratio, corresponding to 1859 images for training, 266 for validation, and 532 for testing. Representative samples are shown in Figure 7.

Figure 7.
HIT-UAV dataset samples.
A statistical analysis of the annotations in both datasets reveals that small objects constitute a substantial proportion of all labeled instances, as shown in Table 1. This finding highlights the crucial role of small object feature extraction in improving UAV-based object detection. Accordingly, enhancing small object detection is a central objective in the design of our proposed model.

Table 1.
Different dataset distributions. Here, small refers to objects with pixel sizes ranging from 0 to , medium refers to sizes from to , and large represents objects larger than pixels.
4.2. Experimental Environment and Parameter Setup
Table 2 summarizes the hardware and software configurations employed during the experiments in detail. All experiments are conducted on a Linux-based system equipped with an Intel(R) Xeon(R) Gold 5418Y CPU and an NVIDIA RTX 4090 GPU (24 GB VRAM). The software environment uses Python 3.10 and PyTorch 2.2.2.
Table 2.
Experimental hardware and software configurations.
The hyperparameter configuration adopted for model training is provided in Table 3. During training, the Mosaic data augmentation technique is applied to improve the model’s generalization ability. This study employs the Stochastic Gradient Descent (SGD) optimizer with an initial learning rate of 0.01, a momentum factor of 0.937, and a weight decay coefficient of 0.0005. The training process is conducted over 300 epochs using a batch size of 16 and an input image resolution of 640 × 640. Finally, Binary Cross-Entropy (BCE) loss is adopted for classification, whereas CIoU and DFL are used for bounding box regression.
Table 3.
Training hyperparameters.
4.3. Evaluation Indicators
To comprehensively evaluate the effectiveness of the proposed model, several key performance metrics are employed in this study, including precision (P), recall (R), mean average precision (mAP), and Frames Per Second (FPS). The following are the definitions and their corresponding formulas:
In the above equations, TP (True Positives), FP (False Positives), and FN (False Negatives) represent correctly detected objects, incorrectly detected objects, and missed detections, respectively. Among these metrics, mAP is a key indicator, comprehensively reflecting the overall detection performance across all object categories. Specifically, is the mean average precision at a 50% IoU threshold. In contrast, represents the mean of mAP values calculated at IoU thresholds between 50% and 95%, with increments of 5%. The symbol j denotes the index of the IoU threshold used to compute the mean average precision, ranging from 0.50 to 0.95 in steps of 0.05.
FPS evaluates inference speed, where N is the number of images and T is the total time. All inference experiments are conducted on a single GPU, ensuring a fair comparison of detection speeds before and after model optimization. In addition, the number of parameters and Floating-Point Operations (FLOPs) are critical indicators of the model’s computational efficiency and lightweight design.
These metrics comprehensively assess the trade-off between detection accuracy and computational complexity, offering valuable insights into the model’s suitability for deployment in resource-constrained environments.
4.4. Exploration of Detection Head Scale and Quantity Optimization
In the YOLO series of model frameworks, to accommodate objects of varying scales, the detection heads P3, P4, and P5 target objects of varying sizes, from small to large. However, statistical analysis of the UAV dataset reveals that most objects are smaller than or equal to pixels. Therefore, this section explores modifications to the number and size of detection heads based on the distribution of object sizes in UAV imagery.
As shown in Table 4, removing the P5 detection head for large objects results in only a slight performance drop, with mAP50 decreasing by just 0.1% (from 27.2% to 27.1%) and mAP50:95 remaining unchanged at 15.1%. This indicates that the impact on overall detection performance is negligible. One reason for this limited impact is that the VisDrone2019 dataset mainly consists of small and medium-sized objects, with large objects appearing less frequently. Therefore, the P5 head contributes minimally to the overall accuracy in this specific UAV-based scenario. Furthermore, removing the P5 detection head and its associated feature extraction modules leads to a substantial reduction in model size (from 2.6 M to 1.8 M parameters) and computation (from 6.5 G to 5.7 G FLOPs). These gains demonstrate the effectiveness of this strategy in creating a lightweight model suitable for deployment on resource-constrained UAV platforms.
Table 4.
Experimental results of detection head size and quantity adjustment.
To further investigate the impact of detection head scale, we introduce an additional larger detection head at (P2) for evaluation. The results demonstrate a significant improvement in detection performance. Specifically, mAP50 and mAP50:95 increase by 1.3% and 0.8%, respectively. However, including a large-scale detection head also leads to a notable increase in computational cost. To strike a more favorable balance between accuracy and efficiency, the P4 detection head is removed. The experiments show that using only the P2 and P3 detection heads substantially reduces model parameters. The parameter count is reduced to only 24% of the original YOLOv12n, while both mAP50 and mAP50:95 are notably improved. More importantly, the increase in computational cost remains within an acceptable range compared to the P2–P4 configuration.
In summary, we first restructure the YOLOv12n architecture in this experiment. By reducing feature extraction modules and adjusting the number and size of detection heads, we develop a baseline model named YOLOv12n-lite. Subsequent experiments are conducted based on YOLOv12n-lite.
4.5. Hyperparameter Experiment Results of the EPGHead Module
During the design of the EPGHead module, our primary focus is to effectively reduce the computational burden while minimizing the impact on detection performance. To this end, a systematic hyperparameter comparison experiment is conducted, based on YOLOv12n-lite. Table 5 provides a summary of the experimental results.
Table 5.
Experimental results of the comparison between different hyperparameter settings in the EPGHead module.
This study focuses explicitly on adjusting in partial convolution and g in grouped convolution, where the first value in each parenthetical pair represents and the second denotes g. The experimental findings indicate that as and g gradually increase, the number of model parameters consistently decreases, with only a marginal impact on overall detection performance. Notably, the computational cost remains nearly unchanged across different configurations. A particularly promising configuration is observed when , where denotes half the number of input channels, and . This setting results in only a 0.6% reduction in mAP50, indicating minimal degradation in detection accuracy. However, further increasing and g leads to a more pronounced decline in detection performance.
4.6. The Experiment on EDown Quantity and Performance Comparison with Different Modules
To replace the traditional downsampling operations in YOLOv12n, the proposed EDown module is applied as extensively as possible. We conduct experiments to assess how varying the number of EDown blocks affects model performance, as summarized in Table 6.
Table 6.
Experimental results with varying number of EDown modules.
In these experiments, the EDown module is sequentially integrated into the model from the top layers of the neck downward. Experimental results indicate that adding more EDown modules leads to a notable reduction in model size. At the same time, it also improves detection performance. Optimal performance is obtained by using two or three EDown modules. However, when the fourth downsampling module (corresponding to the second layer of the backbone) is replaced, a noticeable drop in detection performance is observed. Therefore, ELNet ultimately adopts the configuration with three EDown modules, as illustrated in Figure 1.
In order to assess the impact of the proposed EDown module more thoroughly, we conduct comparative experiments by replacing it with the downsampling modules from YOLOv9 [24] and YOLOv10 [25] at the same positions. The detailed results are summarized in Table 7. The results demonstrate that EDown significantly reduces both computational cost and model complexity. Specifically, compared with the original model, EDown achieves a 10.1% reduction in FLOPs and a 29.1% decrease in the number of parameters. Additionally, precision (P) increases by 1.0%, recall (R) improves by 0.6%, and mAP50 is enhanced by 0.3%, with EDown achieving the highest mAP50:95 among all evaluated configurations. The comparison with ADown from YOLOv9 and SCDown from YOLOv10 confirms that EDown reduces computational overhead. It also achieves superior detection accuracy, indicating enhanced feature extraction capabilities.
Table 7.
Experimental results of the comparison between different downsampling modules.
Additionally, heatmap visualizations are employed to compare the attention regions generated by different downsampling modules, as illustrated in Figure 8. The heatmap analysis reveals that ADown and SCDown exhibit greater sensitivity to environmental background features, with attention regions often dispersed in irrelevant areas. In contrast, EDown concentrates more effectively on objects while suppressing background interference, thereby validating its superior ability to extract and emphasize salient features in complex environments.

Figure 8.
Visualization of feature extraction for different downsampling modules.
4.7. Comparison Experiments of Multi-Scale Feature Extraction Modules
To validate the effectiveness of the proposed DIMB, we conduct a series of comparative experiments, as shown in Table 8. These experiments are based on YOLOv12n-lite, incorporating modifications to evaluate the performance of different multi-scale feature extraction modules. Specifically, the second and third rows, Inception-C3K2 and metaInception-C3K2, respectively, replace the proposed DIMB and DIConv modules with multi-scale feature extraction structures from InceptionNeXt [57]. The experimental results demonstrate that compared with the Inception-based modules, DIMB achieves the most significant improvements in both mAP50 and mAP50:95. This confirms the effectiveness of multi-scale structures in UAV image feature extraction and further highlights the superiority of the proposed DIMB module. To more intuitively illustrate the enhanced feature extraction capability of the DIMB-C3K2 module, we generate a receptive field comparison heatmap [61], as shown in Figure 9. A broader distribution in the heatmap indicates a larger receptive field at the corresponding layer. A larger receptive field is generally more beneficial for learning the features of small objects in UAV imagery [62]. The comparison clearly shows that the receptive field of the backbone network increases significantly after integrating the DIMB module. This further validates the effectiveness and superiority of the proposed module.
Table 8.
Comparative experimental results of different multi-scale modules based on YOLOv12n-lite.
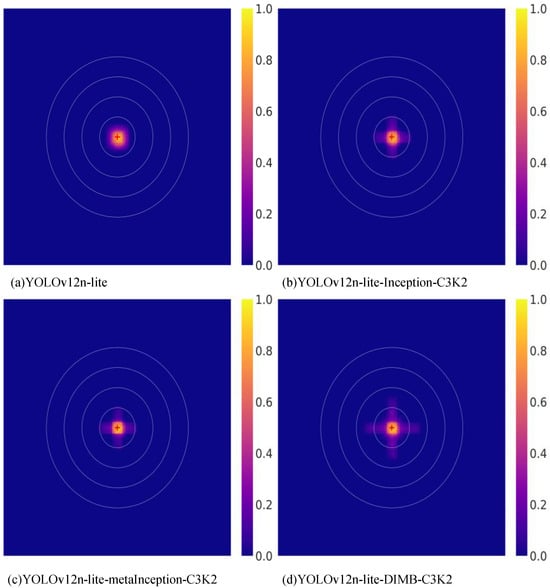
Figure 9.
Visualization heatmaps of receptive field sizes for different multi-scale feature extraction modules. (a) Shows the receptive field size in the fifth layer of the YOLOv12n-lite backbone without any multi-scale module added. (b) Illustrates the receptive field size when the DIMB module is replaced with the Inception feature extraction module. (c) Presents the receptive field size when the DIConv module is replaced with the Inception feature extraction module. (d) Shows the receptive field size when using the DIMB-C3K2 module.
4.8. Ablation Experiments
An ablation study on VisDrone2019 validates module effectiveness (see Table 9). Optimizing YOLOv12n to YOLOv12n-lite significantly reduces the model’s parameter count, from 2.6 M to 0.6 M, only 23.1% of the original model’s size. Meanwhile, YOLOv12n-lite demonstrates improvements in recall (R), mAP50, and mAP50:95, with respective increases of 1.2%, 1.0%, and 0.6%. However, the computational burden increases due to using the P2 detection head. A novel lightweight detection head, EPGHead, is introduced to balance detection performance and computational efficiency. Experimental results indicate that with EPGHead, the FLOPs is reduced from 7.9 G to 4.0 G (a 55.7% reduction), while mAP50 remains 0.4% higher than that of the original YOLOv12n, demonstrating its effectiveness.
Table 9.
Ablation experiment results.
Furthermore, an efficient downsampling module, EDown, is proposed to optimize the model’s downsampling process further. As shown in Table 9, the implementation of EDown decreases the FLOPs from 7.9 G to 7.1 G, while improving mAP50 to 28.4%, further validating its effectiveness. When EPGHead and EDown are combined, the model’s parameter count and FLOPs are reduced to 11.5% and 49.2% of the original YOLOv12n, respectively. This makes the model highly suitable for deployment on resource-constrained edge devices like UAVs.
To enhance the model’s feature extraction capability for UAV imagery, a dynamic inception mixer module (DIMB-C3k2) is introduced. Experimental results indicate that this module greatly enhances detection capabilities and improves adaptability to complex scenarios, with minimal impact on model parameters and computational cost. The results demonstrate that the proposed approach effectively reduces computational overhead, boosting accuracy and enabling efficient real-time UAV detection.
An analysis is conducted on the HIT-UAV dataset to visually compare the detection performance of YOLOv12n and the improved ELNet. The confusion matrices for both models are presented in Figure 10. As observed from the confusion matrices, ELNet exhibits a lower misclassification rate across all categories than YOLOv12n. Notably, significant improvements in classification accuracy are achieved for the person, car, and bicycle categories. These results suggest that ELNet exhibits improved object differentiation in complex scenes, confirming its effectiveness and robustness in UAV-based object detection.
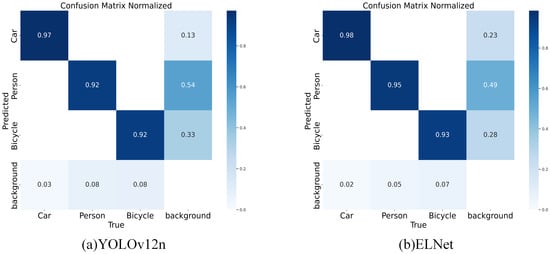
Figure 10.
Comparison of confusion matrices.
4.9. Comparison Experiment with Other Models
To evaluate the effectiveness of ELNet, we conduct comprehensive comparisons against recent lightweight object detectors on the VisDrone2019 and HIT-UAV datasets. Specifically, we compare with YOLOv5n to YOLOv12n and RT-DETR-R18, covering both lightweight and high-performance baselines. All models are trained and evaluated under identical conditions for fairness, using an input resolution of 640 × 640, a batch size of 16, and consistent training schedules. All models are implemented and trained under the same Ultralytics framework to ensure consistency in training protocols and evaluation metrics. As shown in Table 10, ELNet achieves the highest detection performance among recent YOLO-based lightweight models, with 28.4% mAP50 and 15.5% mAP50:95. It maintains a strong balance between accuracy and efficiency. ELNet contains only 0.3 M parameters and requires 3.1 G FLOPs, which is significantly lower than YOLOv12n (2.6 M parameters and 6.5 G FLOPs). Additionally, ELNet achieves an inference speed of 682 FPS (batch size = 8), demonstrating its suitability for real-time, resource-constrained UAV applications. Although its detection accuracy is slightly lower than RT-DETR-R18, a significantly larger model, ELNet’s parameter count and FLOPs are only 1.5% and 5.4% of those of RT-DETR-R18, respectively. These results validate that ELNet offers excellent trade-offs in terms of detection performance, model compactness, and computational efficiency.
Table 10.
Performance comparison of various models on the VisDrone2019 dataset. Note: all FPS values are measured on an NVIDIA RTX 4090 GPU with an input resolution of 640 × 640 and a batch size of 8 (bs = 8).
In order to assess the generalization ability of ELNet, additional comparative experiments are performed on the HIT-UAV dataset, with results summarized in Table 11. As observed, ELNet achieves 94.7% mAP50 and 60.5% mAP50:95, demonstrating superior detection performance. This further confirms its robust detection capability and strong generalization performance. To provide a more comprehensive evaluation, we further include two recently proposed lightweight UAV detection models, G-YOLO [63] and LRI-YOLO [64], both specifically designed for aerial detection tasks. As shown in Table 11, although G-YOLO and LRI-YOLO maintain compact architectures with parameter counts of 0.8 M and 1.6 M, respectively, their detection performance is inferior to that of ELNet. In particular, ELNet achieves the best trade-off between accuracy and efficiency, obtaining the highest mAP50 (94.7%) and mAP50:95 (60.5%) while maintaining the smallest model size (0.3 M parameters and 3.1 GFLOPs). These results further highlight the effectiveness and competitiveness of ELNet in efficient and lightweight UAV object detection scenarios. To provide a more precise comparison between ELNet and other models, a performance scatter plot based on mAP50 and the number of parameters is presented in Figure 11.
Table 11.
Performance comparison of various models on the HIT-UAV dataset.
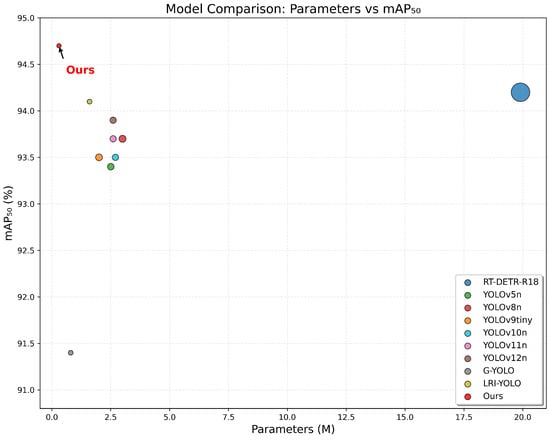
Figure 11.
Model detection performance comparison scatter plot. The x-axis represents the model parameter size, while the y-axis denotes the mAP50 score. The size of each scatter point is proportional to the corresponding model’s FLOPs.
Overall, the experimental results on both datasets demonstrate that ELNet achieves higher detection accuracy while maintaining extremely low computational costs. This is primarily attributed to the proposed lightweight network architecture and optimization strategies, which enable efficient deployment in UAVs. Compared to existing lightweight YOLO models, ELNet reduces the parameter count to 11.5% of YOLOv12n, yet still achieves the highest mAP50 and mAP50:95 scores. With an inference speed of 682 FPS, substantially higher than YOLOv12n’s 570 FPS, ELNet further enhances real-time detection capabilities. In conclusion, ELNet demonstrates excellent detection accuracy. It also offers high computational efficiency and fast inference speed. These advantages make it an up-and-coming solution for real-time UAV-based object detection.
4.10. Visualization Analysis
To provide a clearer illustration of the performance improvements achieved by ELNet, we conduct a comparative visualization analysis of the detection results from YOLOv11n, YOLOv12n, and ELNet. Specifically, we select images from the VisDrone2019 dataset, which feature varying perspectives, illumination conditions, and complex backgrounds. The results are displayed in Figure 12 for reference. The cyan bounding boxes indicate detected vehicles, and the purple bounding boxes represent detected motorcycles. We magnify key regions where discrepancies are observed to facilitate a more precise detection performance comparison across different models. The enlarged results show that, compared with YOLOv11n and YOLOv12n, ELNet demonstrates enhanced detection capabilities under varying angles, lighting conditions, and complex backgrounds, with a notable improvement in minimizing missed detections. This further validates ELNet’s superiority in small-object detection within complex environments, providing an effective real-time UAV-based object detection solution.

Figure 12.
Visualization of detection results on the VisDrone2019 dataset.
Furthermore, a comparative evaluation on the HIT-UAV dataset is conducted to assess the generalization ability of the model, with results shown in Figure 13. We select samples from multiple perspectives to analyze detection performance on the HIT-UAV dataset. In Figure 13, cyan bounding boxes denote the detected person category, blue bounding boxes represent car, and white bounding boxes indicate bicycle. To provide a more intuitive comparison, we again magnify key regions exhibiting discrepancies in detection. As observed in the top row of Figure 13, YOLOv11n and YOLOv12n exhibit redundant and missed detections in certain regions. Both models show varying degrees of missed detections in the second and third rows. In contrast, ELNet, which integrates an improved large-scale detection head and the DIMB-C3k2 module, demonstrates superior adaptability in small-object detection, effectively mitigating missed detections.

Figure 13.
Visualization of detection results on the HIT-UAV dataset.
The comparative visualization across diverse scenarios, illumination conditions, background complexities, and infrared images further substantiates ELNet’s advanced performance and robustness in UAV-based object detection. Experimental results indicate that ELNet exhibits stronger detection capabilities in challenging environments and maintains stability across different datasets.
5. Conclusions
In this study, we streamline YOLOv12n’s feature extraction modules to meet UAV task requirements. The original detection heads P3, P4, and P5 are replaced with P2 and P3 to better adapt to UAV-specific data characteristics. However, the P2 detection head also introduces increased computational costs. We design a lightweight detection head called EPGHead to address this issue, significantly reducing computational overhead and improving inference speed. Moreover, YOLOv12n initially employs standard convolution for downsampling. However, this method proves less efficient in extracting fine-grained features and results in higher computational costs, rendering it unsuitable for real-time, lightweight applications. To this end, we propose a novel downsampling module, EDown, which incorporates max pooling and depthwise separable convolution to enhance model compactness and feature extraction capability. Finally, to tackle challenges such as dense object distribution, complex backgrounds, significant scale variations, and small object sizes commonly found in UAV imagery, we enhance the C3k2 module and introduce DIMB-C3k2. DIMB’s multi-scale convolution and dynamic weighting improve the detection of small and scale-varying objects.
Experiments conducted on the VisDrone2019 and HIT-UAV datasets validate the effectiveness of ELNet. Compared with YOLOv12n, ELNet achieves an 88.5% reduction in parameters and a 52.3% decrease in FLOPs, while increasing mAP50 by 1.2% and 0.8%, respectively. Notably, ELNet achieves an mAP50 of 94.7% on the HIT-UAV dataset, demonstrating its superior detection and generalization ability. Moreover, ELNet reaches an inference speed of 682 FPS on an RTX 4090 GPU with batch size = 8, which ensures fair comparison with other models and confirms its potential for real-time object detection tasks.
In conclusion, ELNet is an effective solution for real-time small object detection in UAVs. Although current experiments are conducted on a high-end GPU, ELNet is specifically designed with low computational cost (0.3 M parameters and 3.1 G FLOPs), making it highly suitable for deployment on embedded platforms such as the NVIDIA Jetson series. Future work will focus on refining the network architecture, enhancing detection accuracy, and exploring hardware-specific optimizations and deployment strategies to further improve performance in resource-constrained environments.
Author Contributions
Conceptualization, H.L. and J.M.; data curation, H.L.; formal analysis, H.L.; funding acquisition, J.Z.; investigation, H.L.; methodology, H.L.; project administration, J.Z.; resources, H.L.; software, H.L.; supervision, J.Z.; validation, H.L.; visualization, H.L.; writing—original draft, H.L. and J.M.; writing—review and editing, H.L., J.M. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
Frontier Research Fund of the Institute of Optics and Electronics, China Academy of Sciences under Grant number C24K003.
Data Availability Statement
Relevant data can be obtained by contacting the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yue, M.; Zhang, L.; Huang, J.; Zhang, H. Lightweight and efficient tiny-object detection based on improved YOLOv8n for UAV aerial images. Drones 2024, 8, 276. [Google Scholar] [CrossRef]
- Cao, S.; Deng, J.; Luo, J.; Li, Z.; Hu, J.; Peng, Z. Local convergence index-based infrared small target detection against complex scenes. Remote Sens. 2023, 15, 1464. [Google Scholar] [CrossRef]
- Fan, X.; Li, H.; Chen, Y.; Dong, D. UAV Swarm Search Path Planning Method Based on Probability of Containment. Drones 2024, 8, 132. [Google Scholar] [CrossRef]
- Oh, D.; Han, J. Smart search system of autonomous flight UAVs for disaster rescue. Sensors 2021, 21, 6810. [Google Scholar] [CrossRef]
- Qiu, Z.; Bai, H.; Chen, T. Special vehicle detection from UAV perspective via YOLO-GNS based deep learning network. Drones 2023, 7, 117. [Google Scholar] [CrossRef]
- Niu, C.; Song, Y.; Zhao, X. SE-Lightweight YOLO: Higher accuracy in YOLO detection for vehicle inspection. Appl. Sci. 2023, 13, 13052. [Google Scholar] [CrossRef]
- Shokouhifar, M.; Hasanvand, M.; Moharamkhani, E.; Werner, F. Ensemble Heuristic–Metaheuristic Feature Fusion Learning for Heart Disease Diagnosis Using Tabular Data. Algorithms 2024, 17, 34. [Google Scholar] [CrossRef]
- Patel, T.; Guo, B.H.; van der Walt, J.D.; Zou, Y. Effective motion sensors and deep learning techniques for unmanned ground vehicle (UGV)-based automated pavement layer change detection in road construction. Buildings 2022, 13, 5. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Wang, Y.; Tian, Y.; Liu, J.; Xu, Y. Multi-stage multi-scale local feature fusion for infrared small target detection. Remote Sens. 2023, 15, 4506. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. pp. 740–755. [Google Scholar]
- Chang, Y.; Li, D.; Gao, Y.; Su, Y.; Jia, X. An improved YOLO model for UAV fuzzy small target image detection. Appl. Sci. 2023, 13, 5409. [Google Scholar] [CrossRef]
- Wu, A.; Deng, C. TIB: Detecting unknown objects via two-stream information bottleneck. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Wu, A.; Deng, C.; Liu, W. Unsupervised out-of-distribution object detection via PCA-driven dynamic prototype enhancement. IEEE Trans. Image Process. 2024, 33, 2431–2446. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural. Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. Uav-yolo: Small object detection on unmanned aerial vehicle perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Ghamisi, P.; Li, W.; Tao, R. MsRi-CCF: Multi-scale and rotation-insensitive convolutional channel features for geospatial object detection. Remote Sens. 2018, 10, 1990. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. Yolo-based uav technology: A review of the research and its applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Lv, W.; Zhao, Y.; Chang, Q.; Huang, K.; Wang, G.; Liu, Y. Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer. arXiv 2024, arXiv:2407.17140. [Google Scholar]
- Wang, S.; Xia, C.; Lv, F.; Shi, Y. RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision. arXiv 2024, arXiv:2409.08475. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Seth, A.; James, A.; Kuantama, E.; Mukhopadhyay, S.; Han, R. Drone high-rise aerial delivery with vertical grid screening. Drones 2023, 7, 300. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. BiFA-YOLO: A novel YOLO-based method for arbitrary-oriented ship detection in high-resolution SAR images. Remote Sens. 2021, 13, 4209. [Google Scholar] [CrossRef]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient channel attention pyramid YOLO for small object detection in aerial image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Shi, T.; Zhang, W.; Cui, Y.; Zhao, S. PAG-YOLO: A portable attention-guided YOLO network for small ship detection. Remote Sens. 2021, 13, 3059. [Google Scholar] [CrossRef]
- Feng, Y.; You, Y.; Tian, J.; Meng, G. OEGR-DETR: A novel detection transformer based on orientation enhancement and group relations for SAR object detection. Remote Sens. 2023, 16, 106. [Google Scholar] [CrossRef]
- Yu, C.; Shin, Y. MCG-RTDETR: Multi-convolution and context-guided network with cascaded group attention for object detection in unmanned aerial vehicle imagery. Remote Sens. 2024, 16, 3169. [Google Scholar] [CrossRef]
- Wang, X.; Xi, B.; Xu, H.; Zheng, T.; Xue, C. AgeDETR: Attention-Guided Efficient DETR for Space Target Detection. Remote Sens. 2024, 16, 3452. [Google Scholar] [CrossRef]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Ni, J.; Zhu, S.; Tang, G.; Ke, C.; Wang, T. A small-object detection model based on improved YOLOv8s for UAV image scenarios. Remote Sens. 2024, 16, 2465. [Google Scholar] [CrossRef]
- Yu, W.; Zhang, J.; Liu, D.; Xi, Y.; Wu, Y. An Effective and Lightweight Full-Scale Target Detection Network for UAV Images Based on Deformable Convolutions and Multi-Scale Contextual Feature Optimization. Remote Sens. 2024, 16, 2944. [Google Scholar] [CrossRef]
- Wu, W.; Liu, A.; Hu, J.; Mo, Y.; Xiang, S.; Duan, P.; Liang, Q. EUAVDet: An efficient and lightweight object detector for UAV aerial images with an edge-based computing platform. Drones 2024, 8, 261. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, F.; Zhang, Y.; Liu, Y.; Cheng, T. Lightweight object detection algorithm for uav aerial imagery. Sensors 2023, 23, 5786. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. Inceptionnext: When inception meets convnext. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5672–5683. [Google Scholar]
- Shi, D. Transnext: Robust foveal visual perception for vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17773–17783. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Suo, J.; Wang, T.; Zhang, X.; Chen, H.; Zhou, W.; Shi, W. HIT-UAV: A high-altitude infrared thermal dataset for Unmanned Aerial Vehicle-based object detection. Sci. Data 2023, 10, 227. [Google Scholar] [CrossRef] [PubMed]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Zhao, X.; Zhang, W.; Xia, Y.; Zhang, H.; Zheng, C.; Ma, J.; Zhang, Z. G-YOLO: A Lightweight Infrared Aerial Remote Sensing Target Detection Model for UAVs Based on YOLOv8. Drones 2024, 8, 495. [Google Scholar] [CrossRef]
- Ding, B.; Zhang, Y.; Ma, S. A Lightweight Real-Time Infrared Object Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones 2024, 8, 479. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).