1. Introduction
While natural hazards cause large-scale damages and disruptions around the continents, their effects are felt most severely in least-developed environments, such as the Sahel [
1]. Between 1960 and 2020, natural hazards afflicted almost 300 million people in the Sahel, where hydrological hazards were the most dominant, and floods were a prime example. These hydrological hazards include floods, storm surges, tsunamis, and other water-related phenomena that risk human life, property, and the environment. These hazards are defined as natural events caused by the occurrence, movement, and distribution of surface and subsurface freshwater and saltwater [
2]. In the region, these hazards constituted 41.8% of all reported natural disasters [
3].
In addition, the affected areas often lack robust infrastructure, early warning systems, and adequate response capabilities to disasters. These are typically tied to a scarcity of financial resources, which may result in a significant loss of life and property [
4]. In the Sahel region, this lack of resources has been intensified by the increasing frequency and intensity of extreme rainfall over the past 30 years [
5,
6].
Many previous studies have reported variations in rainfall characteristics across the Sahel region, with significant differences between its eastern and western sections. Additionally, analyses of not only ground-based but also satellite-based rainfall data indicate a clear trend towards more frequent and intense extreme rainfall events since the early 2000s [
6,
7,
8,
9,
10]. In this regard, floods are a significant threat to Sahel communities, especially given the fact that many of them are settled in areas with limited urban planning and lack of drainage facilities, which make them highly vulnerable to floods [
11,
12,
13]. In addition, the combined impacts of climate change and the intensification of urbanization due to demographic growth are expected to increase flooding risks in the coming years [
12,
13].
To cope with the growing threat of natural disasters, the United Nations Sustainable Development Goals (SDGs) established a framework for building resilience, defined by the UN’s General Assembly (A/RES/76/203) as “the ability of a living being, material, mechanism, or system not to succumb or break under a disturbance or adverse situation, and/or to recover its initial state when that disturbance or situation no longer exists”. This framework includes specific indicators focused on mitigating natural disasters’ impacts, with indicator 13.1.1 being the one which measures the number of deaths, missing persons, and directly affected individuals due to disasters per 100,000 population. This indicator is integrated within target 13.1, which calls for urgent actions against climate-related hazards and natural disasters. Indicator 13.1.1 also quantifies the disaster-induced human impact, highlighting the most vulnerable populations and regions worldwide. In this line, as a standardized metric, it also enables an international comparison and assessment of trends, ensuring continuous improvement in disaster mitigation, adaptation, and development of response efforts.
However, despite the critical importance of such an indicator, there is a notable lack of official data providers and standardized methodologies for assessing the resilience of populated areas to natural hazards. This gap significantly hinders efforts to develop effective resilience-building strategies [
14,
15].
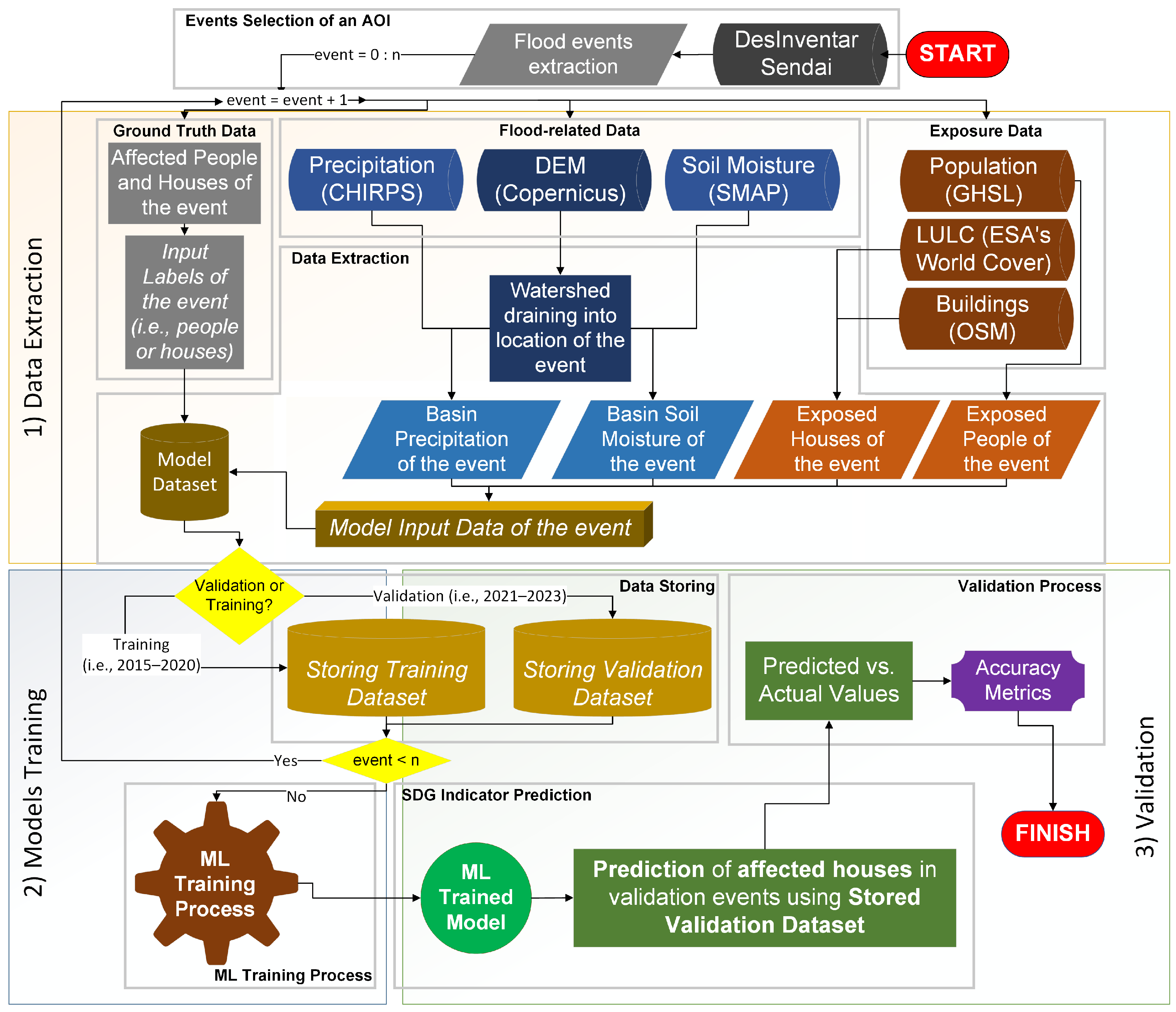
In this regard, EO and geospatial technologies, combined with local data, are indispensable tools for estimating the resilience of specific communities to particular hazards [
16]. These technologies offer essential detailed, timely, and accurate data for monitoring and responding to disaster risks [
17]. In this context, previous studies have combined satellite data with local information to assess flood resilience comprehensively. Cian et al. (2021) [
18] aggregated socioeconomic conditions, physical exposure, and adaptive capacities by integrating EO data with census information to map a multi-temporal flood vulnerability index in Northeast Italy. Additionally, hydrologic models remain fundamental in flood estimation, particularly when integrated with geospatial technologies [
19] while Hu et al. (2017) [
20] applied GIS-based methods for flood risk assessments in suburban areas, combining multi-dimensional impact factors within a GIS environment to enhance resilience estimation. Machine learning (ML)-based frameworks also play a crucial role in flood estimation [
21,
22]; by integrating historical flood data with socioeconomic and environmental indicators, it is possible to estimate the community’s resilience to this events. Abdel-Mooty et al. (2022) [
23] developed a two-stage ML-based framework synthesizing resilience indices to predict community responses to future flood hazards. This approach relied on historical flood records and climate data to train ML algorithms.
Recent advances in deep learning have significantly improved real-time flood mapping and damage detection capabilities. CNN-based models such as U-Net have shown strong performance when identifying flooded areas from satellite imagery [
24,
25]. Thus, datasets like FloodNet [
26] and applications of deep neural networks for real-time flood mapping [
27] are increasingly shaping emergency response strategies. However, these approaches rely on dense ground truth data, which are unavailable in the Sahel region. Unlike these methods, the presented study prioritizes predictive estimation of infrastructure impact (e.g., number of affected houses) based on pre-event meteorological and exposure data. This makes it suitable for data-constrained settings and long-term SDG monitoring.
The critical importance of fostering community resilience to mitigate the impacts of flooding has been emphasized by numerous researchers [
28,
29,
30]. This issue is particularly severe in developing countries where rapid and low-quality urbanization, coupled with increasing flood impacts and associated uncertainties, poses significant challenges driven by complex social and environmental threats [
31,
32,
33]. In this regard, the present study aims to address the existing knowledge gap concerning standardized methodologies for assessing the resilience of populated areas to natural hazards (i.e., specifically floods) by introducing an integrated approach that combines regional ecological stratification, multi-source geospatial data, and machine learning to estimate the number of houses affected by flooding. While individual components such as data fusion and machine learning are well established, the novelty of this approach lies in their operational integration for predictive flood impact estimation, specifically linked to SDG indicator 13.1.1. The use of ecoregion-based stratification enables context-specific modeling of flood impacts, enhancing accuracy in heterogeneous environments, a feature not previously operationalized in regional-scale applications. This measure, therefore, provides a replicable framework for estimating SDG 13.1.1 in regions prone to extreme events like the Sahel, where data constraints often limit conventional monitoring methods.
2. Study Area
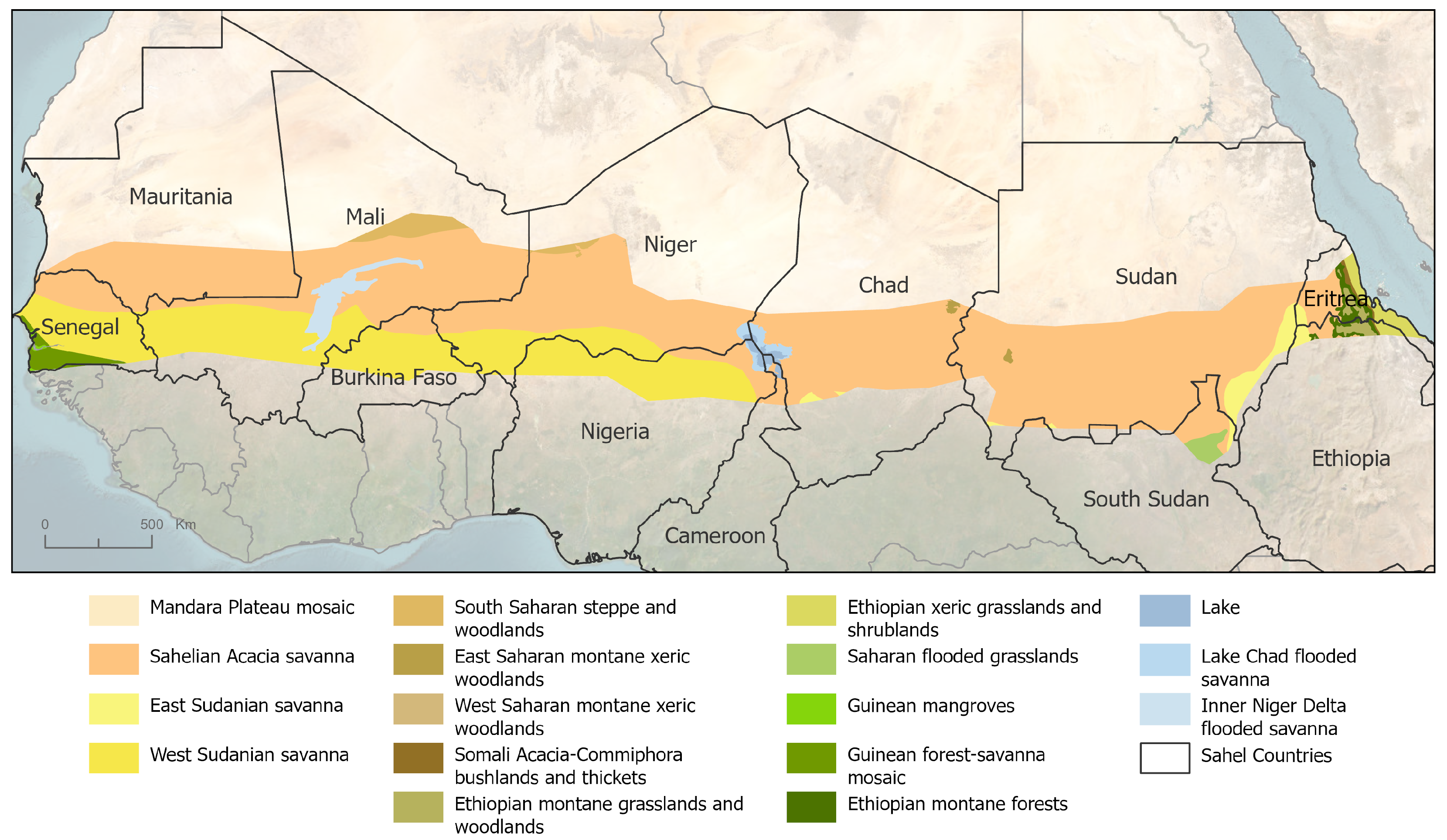
The Sahel region is a hot semi-arid area located just south of the Sahara Desert and north of the Sudanian savanna. It covers several countries, including Senegal, Mauritania, Mali, Burkina Faso, Niger, Nigeria, Chad, and Sudan (
Figure 1). This region has a long, dry, and shorter rainy season, which spans approximately 8–9 months and 3–4 months, respectively [
34]. In addition, rainfall distribution varies across the Sahel region, with higher precipitation in the southern areas when compared to the northern zones [
35]. Lastly, recent studies have highlighted increased extreme rainfall over the past few years [
7].
The Sahel encompasses a diverse array of terrestrial ecoregions [
36], each presenting unique ecological characteristics and challenges, which have been considered while developing the proposed methodology (see
Section 4).
Table 1 provides a detailed breakdown of the ecoregions, the area they cover, and the total number of recorded flood events used in the study. This summary offers an overview of the spatial distribution of flood occurrences across different ecoregions.
Figure 1.
Map of the Sahel region and its ecoregions, based on [
37].
Figure 1.
Map of the Sahel region and its ecoregions, based on [
37].
Flood events have been documented across 91.3% of the Sahel, with the Sahelian Acacia savanna and West Sudanian savanna hosting most of these records. This reflects their extensive geographic coverage within the region and their susceptibility to flooding due to varying climatic and ecological conditions. These factors highlight the importance of tailoring methodologies to the unique characteristics of each ecoregion to enhance the results.
6. Discussion
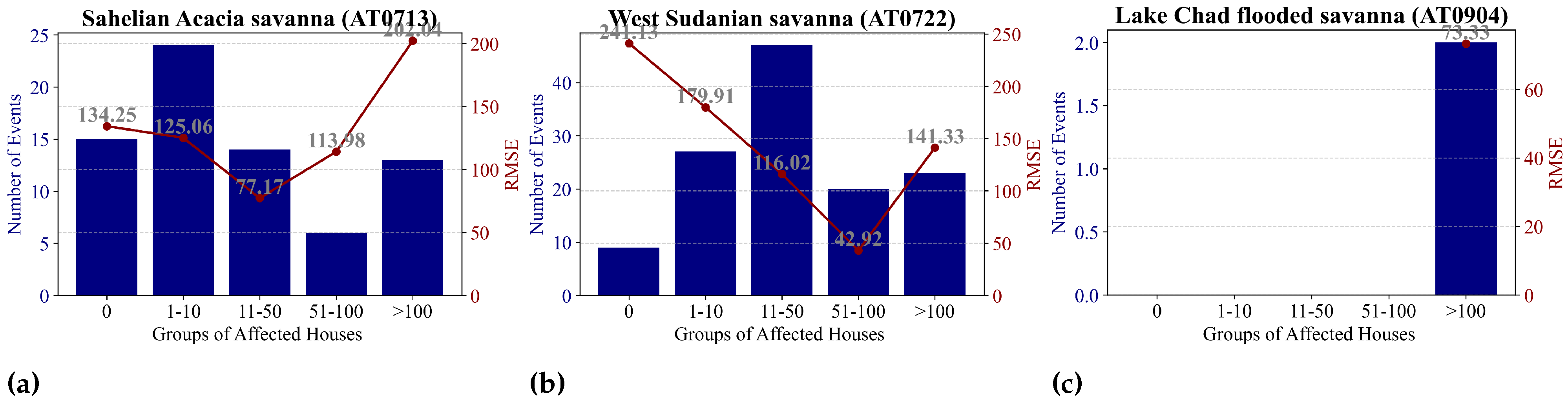
The results of this study offer critical insights into the performance of an algorithm for estimating the number of houses affected by flood events across different ecoregions within the Sahel. The observed variability in prediction accuracy, characterized by discrepancies between predicted and actual outputs, aligns with prior research that highlights the challenges of modeling complex and dynamic flood phenomena, particularly in data-scarce regions such as the Sahelian and West Sudanian savannas [
54]. Studies have shown that landscape heterogeneity, floodplain complexity, and inconsistent data availability often increase prediction errors, as seen in the high RMSE values reported in these regions. The Lake Chad flooded savanna, demonstrating the highest prediction accuracy, underscores the impact of simplified conditions or limited validation datasets. While the RMSE of 73.33 suggests robust algorithm performance, this result should be interpreted cautiously. The limited number of events in this ecoregion (only two) may not adequately reflect the range of flood scenarios, potentially inflating the perceived accuracy. This region’s relatively homogeneous landscape and flat floodplain conditions may also simplify the flood modeling process, as fewer environmental variables introduce uncertainty. Nonetheless, this result highlights the potential benefits of focused datasets in improving predictive reliability when applied in regions with consistent environmental characteristics. Comparatively, the Sahelian Acacia savanna and West Sudanian savanna exhibited more pronounced errors, with RMSE values of 136.84 and 130.84, respectively. This finding suggests that the models struggle to accurately capture the nuances of larger-scale flood events, consistent with hypotheses from earlier studies that emphasise the importance of detailed topographic and hydrologic data for flood prediction in complex terrains. The higher variability in these regions may arise from their more heterogeneous landscapes, characterized by a mixture of dry lands, variable soil infiltration rates, and complex hydrological pathways. This aligns with findings from prior studies that highlight the role of terrain complexity and data quality in influencing flood prediction accuracy [
55].
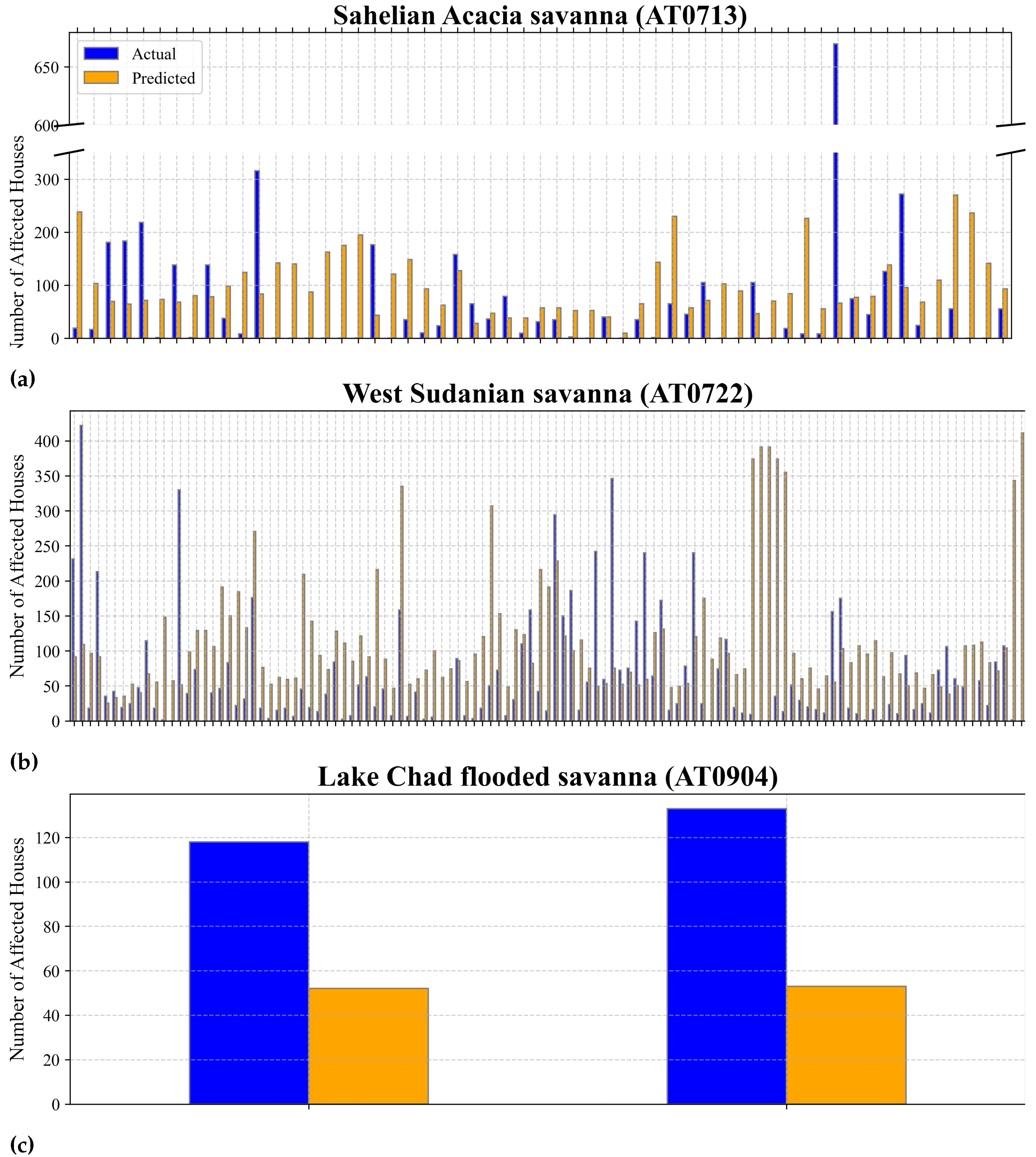
The analysis of affected houses reveals a clear trend: the prediction accuracy of the algorithm is closely linked to the scale of the flood impact, with accuracy decreasing as the scale of impact increases. Smaller-scale flood events, such as those affecting 11–50 houses, were predicted with relatively low RMSE values, particularly in the Sahelian Acacia savanna (RMSE = 77.17) and West Sudanian savanna (RMSE = 42.92 for events impacting 51–100 houses). These findings align with the observed bias in the training dataset, where moderate-impact events (11–100 affected houses) were better represented, particularly in regions like AT0722 and AT0713. Conversely, the algorithm exhibited significant underperformance for extreme flood events, with RMSE values exceeding 200 when the number of affected houses surpassed 100, likely due to their sparse representation in the training data (e.g., only 60 cases in AT0713 and 79 cases in AT0722 for events >100 houses). This emphasizes the accuracy dependency on the similarity between the predicted events and the distribution of events used in training, with models performing best for scenarios resembling the most frequent and moderately impactful floods within the training dataset. Additionally, fixed aggregation windows may also limit the ability of the algorithm to capture delayed hydrological responses or longer-term flood generation processes since flood dynamics are often shaped by both immediate and antecedent hydrological conditions, which can vary substantially across regions and years [
5].
The consistent patterns of overestimation and underestimation observed in certain regions, particularly in the Sahelian Acacia savanna, suggest the presence of systemic biases in the predictive models. A notable example is the substantial discrepancy in an event where the number of affected houses was 670, but the algorithm estimated only 66, highlighting a severe underestimation issue. This underperformance is likely exacerbated by the scarcity of extreme events (e.g., those affecting >600 houses) in the training dataset, with only eight such cases in AT0713, six in AT0722, and none in AT0904. The lack of sufficient training data for large-scale floods impedes the ability of the algorithm to predict high-impact events, which deviate significantly from the more frequent, moderate-impact scenarios that dominate the training set.
The findings reveal that, despite some variability, the algorithm demonstrates a robust ability to estimate the percentage of affected houses when considering the total number of exposed houses in each location across different ecoregions, which is a key achievement of this research. The percentage differences between predicted and actual values in all three ecoregions are close to zero, indicating satisfactory overall accuracy. Notably, the Lake Chad flooded savanna (AT0904) exhibits a narrow IQR, reflecting consistent predictions, though the limited sample size likely influences this consistency. In contrast, the Sahelian Acacia savanna (AT0713) and West Sudanian savanna (AT0722) regions show more significant variability, with wider IQRs due to the larger number of validation events. While these regions experience a slight trend of overestimating affected houses, the differences are generally modest, ranging between 2% and 3% of under- and overestimation, respectively, even for large-scale events involving extensive numbers of houses. This ability to accurately predict the percentage of affected houses holds significant practical implications, especially in improving resilience to floods in the Sahel and surrounding regions, where extreme rainfall and flooding events are becoming increasingly frequent. By providing reliable estimates of the proportion of houses affected, authorities can better anticipate the potential number of impacted individuals and initiate timely mitigation measures. This predictive capability enables more effective planning for disaster response, resource allocation, and long-term adaptation strategies, ultimately reducing the adverse impacts of floods on vulnerable communities.
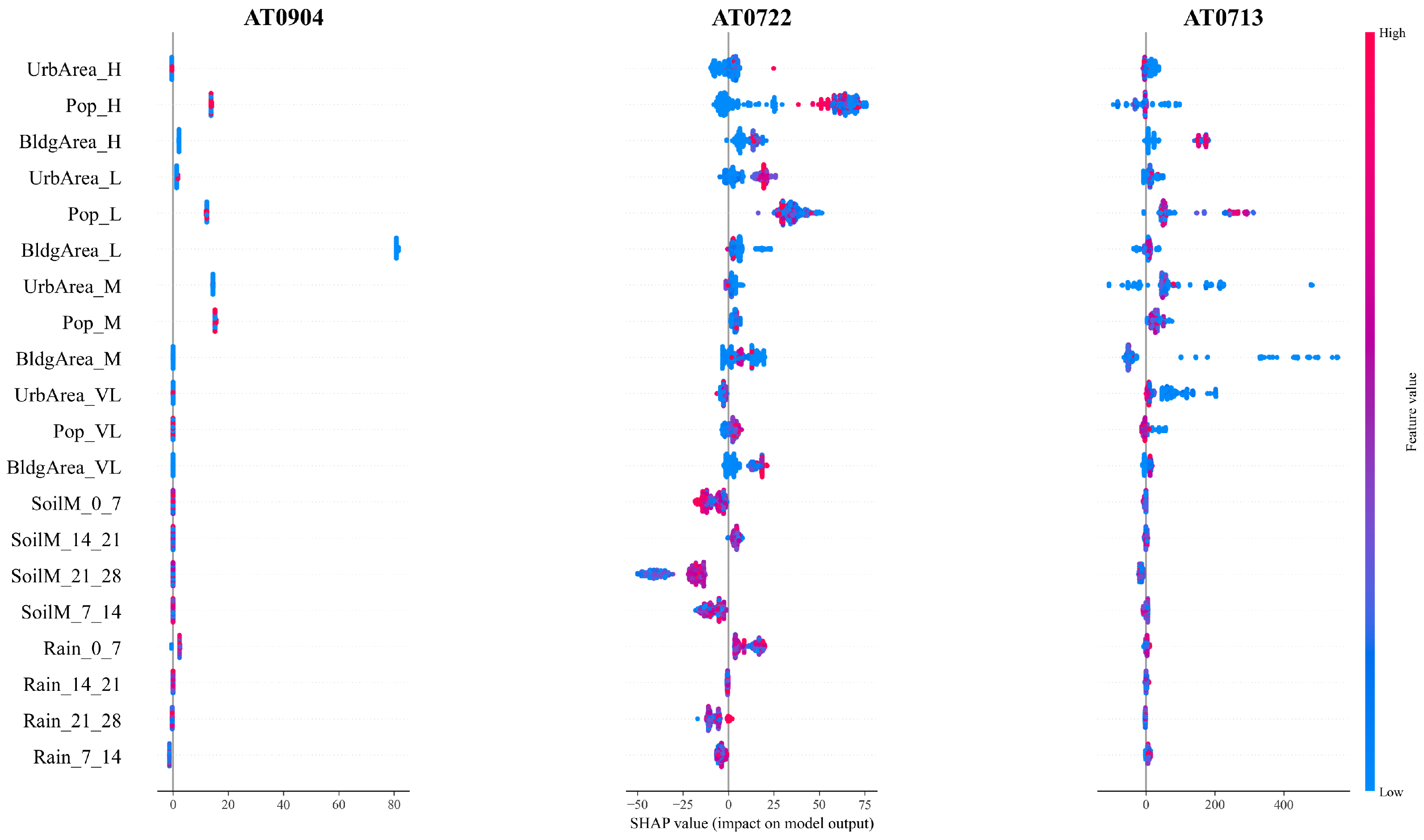
In order to improve interpretability and transparency of model behavior, SHAP values were also employed to decompose the contribution of each input to individual predictions. These results corroborate the variable importance rankings derived from the random forest algorithm while enabling a more granular assessment of local feature effects. Notably, the SHAP analysis highlights the heterogeneous influence of predictor variables across ecoregions, reinforcing the importance of regionally adaptive modeling strategies. The inclusion of SHAP values aligns with best practices in explainable machine learning and enhances the transparency and policy relevance of the model, particularly in the context of decision-making for flood risk mitigation. Nevertheless, the current approach has not yet been validated on out-of-sample regions, and no direct comparison has been made with physically based hydrodynamic models such as LISFLOOD [
56]. Such models require detailed hydraulic and structural data that are currently unavailable for the Sahel. Future research should consider hybrid approaches and cross-validation with physical models to enhance robustness and assess generalizability under varying geographic and hydrological conditions.
On the other hand, the analysis of input variable importance further reinforces the need for high-quality input data tailored to regional conditions to improve predictive accuracy and guide future model enhancements. Across all three ecoregions, soil moisture and rainfall data emerged as the most influential predictors, highlighting the central role of meteorological and hydrological conditions in shaping flood impacts. Pre-event soil moisture levels in the Lake Chad flooded savanna were particularly critical, likely due to the flat terrain’s propensity to exacerbate flooding under saturated conditions [
57]. Similarly, in the West Sudanian savanna, building area and infrastructure metrics were highly significant, reflecting the vulnerability of human settlements in flood-prone zones. These findings demonstrate the reliance of the algorithm on specific input variables and emphasize the importance of integrating diverse and reliable data sources. However, several critical variables such as building materials, detailed elevation data, and drainage infrastructure were not included due to their unavailability at the required spatial resolution or coverage across the study area [
58].
To further quantify prediction reliability, 95% confidence intervals for the mean prediction error were computed via bootstrap resampling (10,000 iterations). These intervals provide a quantitative measure of uncertainty and highlight the variability in accuracy across ecoregions. The Sahelian Acacia savanna (AT0713) and West Sudanian savanna (AT0722) showed wider confidence bounds, indicating greater uncertainty due to complex terrain and more diverse event samples. Conversely, the Lake Chad flooded savanna (AT0904) exhibited a narrow interval, reflecting lower observed error given the inflated confidence due to the limited validation sample.
In line with the methodological direction of the present study, related work by Marín-García et al. (2023) [
59] employed decision tree algorithms to classify building damage levels resulting from riverine floods in the Andalusia (Spain). Their approach, which relied on a relatively limited dataset and environmental predictors, achieved a classification accuracy of 81.09% (±13.77%) across three predefined damage categories. Such work illustrates the growing emphasis on operationally feasible methods in flood impact assessment where data are lacking. Against this backdrop, the RMSE values reported in the present study (ranging from 73 to 137) may be considered consistent with expectations, underscoring the reliability and suitability of the algorithm for application in regions characterized by limited observational records and heterogeneous infrastructure data, such as the Sahel.
Although the random forest algorithm was selected due to its established performance with limited and imbalanced datasets, its resilience to overfitting, and its ability to provide interpretable outputs through variable importance measures [
52], it is recognized that alternative modeling techniques such as XGBoost, support vector machines, or deep learning models may offer advantages under different conditions. However, these methods typically require larger datasets to perform effectively. In particular, deep learning approaches have shown considerable potential in flood prediction when applied to large-scale and high-frequency datasets [
60], which are not available in the Sahel. XGBoost, although effective in other flood susceptibility assessments also benefits from larger training data [
61]. Given the data-scarce nature of the current study area, random forest was deemed the most appropriate method. Nonetheless, future research should explore these alternatives as more extensive and detailed datasets become available, to assess potential improvements.
Finally, the methodology developed in this study is readily adaptable to other data-scarce, flood-prone regions beyond the Sahel. Its reliance on globally available datasets such as CHIRPS for precipitation, SMAP for soil moisture, GHSL for population, and OpenStreetMap for exposure ensures broad applicability. By recalibrating the algorithm using locally observed flood events and tailoring the ecological stratification to reflect regional hydrological and environmental conditions, this framework can be extended to diverse contexts including parts of Southeast Asia, Central America, and East Africa. Such an adaptation would allow local authorities in similarly vulnerable regions to utilize low-cost and open-access data for flood resilience planning and the effective monitoring of SDG Indicator 13.1.1.
7. Conclusions
This study provides insights into the performance of predictive models for estimating the number of houses affected by flood events across distinct ecoregions in the Sahel. While the results reveal a satisfactory level of accuracy overall when considering the total number of exposed houses in each location, with percentage differences between predicted and actual values close to zero in most cases, the variability in prediction accuracy across regions and scales underscores key challenges. Smaller-scale floods were generally predicted with higher accuracy, reflecting biases in the training dataset, favoring moderate-impact events. However, the algorithm struggled with extreme flood events, particularly those affecting over 600 houses, due to their under-representation in the training data.
Additionally, the ability of the algorithm to accurately estimate the percentage of affected houses has significant practical implications. Reliable percentage predictions enable authorities to better anticipate the number of affected individuals, facilitating more efficient disaster response, resource allocation, and mitigation planning. As extreme rainfall and flood events are expected to become more frequent in the Sahel, this capability will enhance regional resilience.
In addition, the analysis of input variable importance underscores the central role of high-quality, region-specific data in improving model performance. Meteorological and hydrological variables, particularly soil moisture and rainfall, emerged as the most influential predictors, while infrastructure metrics were significant in densely populated regions. Notably, the accurate prediction of the number of affected houses can serve as a critical SDG indicator, aligning with global objectives to enhance climate resilience and mitigate the impacts of disasters.
Finally, future research should focus on overcoming key data limitations and tailoring models to specific regional contexts. The current study relied on openly available datasets, which, while enabling broad applicability, constrained the inclusion of critical variables such as building materials, drainage infrastructure, and high-resolution elevation data. Modeling choices were guided by the nature of the available data, with random forest preferred for its interpretability and suitability for small, imbalanced datasets; however, comparative evaluation with alternative algorithms remains a priority for future research. Furthermore, the geographic focus on the Sahel, though highly relevant, constrains the assessment of generalizability beyond this region. To address these challenges, future work should explore cross-regional validation, incorporate finer-grained socio-environmental inputs, and consider simulating synthetic extreme scenarios to compensate for the under-representation of high-impact events in historical records. These efforts will enhance predictive accuracy and support broader objectives of building resilience, protecting livelihoods, and reducing community vulnerability to increasingly severe flood events.

 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}