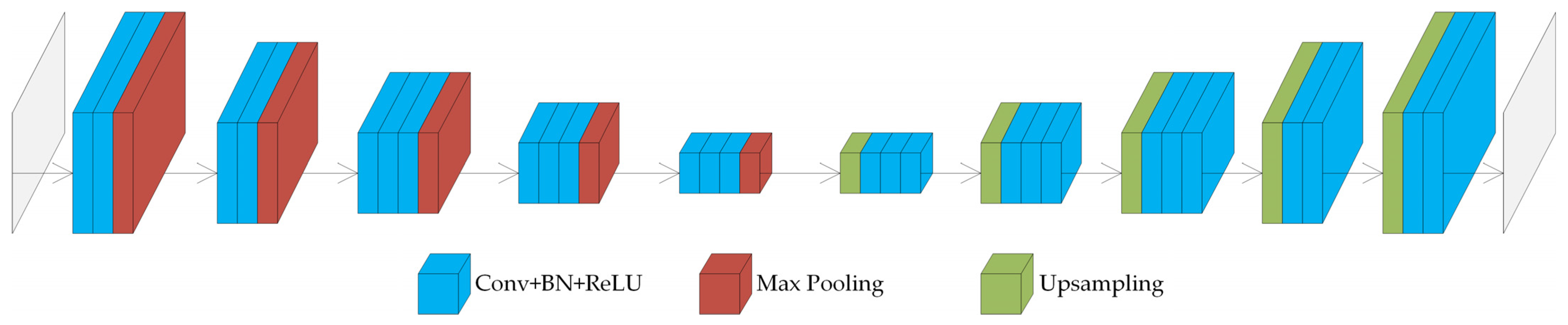
3.1. Comparative Experiment on the Placement of Coordinate Attention
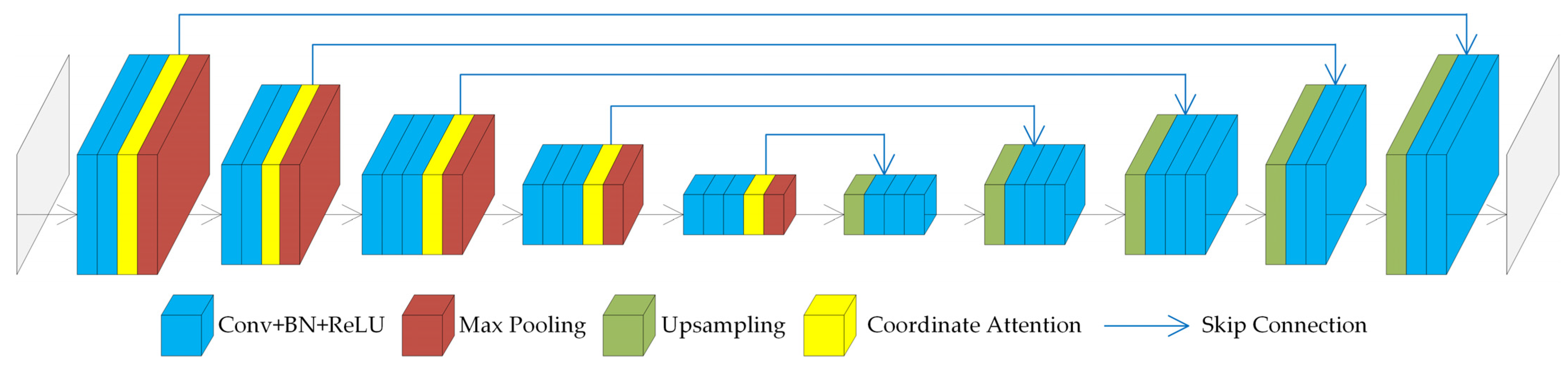
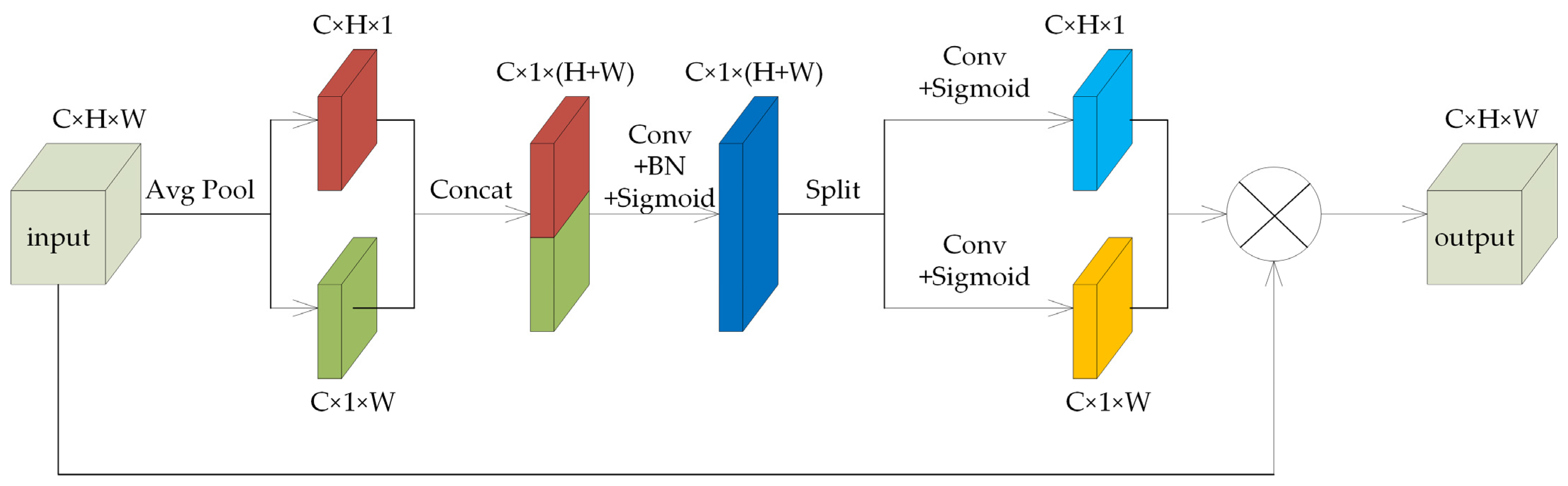
To determine the optimal position for adding the coordinate attention mechanism, experiments were conducted on networks with different configurations. (1) The coordinate attention mechanism was added after the convolution layer in each convolution block of the encoder, and the extracted feature maps were weighted. This network was temporarily named CSNet_v1. (2) The coordinate attention mechanism was added in the skip connection, where the shallow feature maps from the encoder were weighted and directly connected with the deep feature maps from the decoder. This network was temporarily named CSNet_v2. (3) The coordinate attention mechanism was added before the skip connection in the decoder, where the deep feature maps of the decoder were weighted and then directly connected with the shallow feature maps passed from the encoder. This network was temporarily named CSNet_v3. (4) The coordinate attention mechanism was added after the skip connection in the decoder, where the feature map obtained by connecting the deep and shallow feature maps was weighted. This network was temporarily named CSNet_v4. (5) The coordinate attention mechanism was added between the encoder and the decoder, specifically after the convolution layer in the last convolution block of the encoder. This network was temporarily named CSNet_v5.
In the coordinate attention structures of the different networks, the channel reduction ratio was set to 32, and the kernel size was set to 1. The experimental results for each network are shown in
Table 1.
From
Table 1, it can be observed that CSNet_v1 achieves the highest performance across all metrics, with Dice coefficient, mIoU, and OA values of 81.4%, 70.3%, and 90.5%, respectively, indicating that adding the coordinate attention structure after the convolution layers in the encoder is the optimal approach. The second-best performing network is CSNet_v2, with Dice coefficient, mIoU, and OA values of 79.7%, 68.1%, and 87.3%, respectively. CSNet_v3 and CSNet_v5 have OA values similar to CSNet_v2, but their Dice coefficient and mIoU are lower, suggesting that these networks perform worse in predicting small targets and small sample categories. The worst-performing network is CSNet_v4, with Dice coefficient, mIoU, and OA values that are similar to the original SegNet network. Therefore, this study adopted the coordinate attention addition method used in CSNet_v1.
3.2. Comparative Experiment of Different Networks
We first compared the inference speed of classical semantic segmentation networks with that of CSNet, as shown in
Table 2.
Although the inference speed of CSNet is slightly lower than that of SegNet, it is significantly faster than the other networks. Then, we conducted experiments using different networks on the Five-Billion-Pixels dataset. We quantitatively evaluated the models based on the Dice coefficient, mIoU, and overall accuracy (OA). The results are shown in
Table 3. The Precision and IoU for each class are shown in
Table 4 and
Table 5.
As shown in
Table 3, the CSNet network proposed in this study achieved an OA of 90.5%, higher than U-Net’s 86.0%, FCN’s 84.5%, DeepLabV3+’s 87.3%, SegNet’s 84.4%, and HRNet’s 66.5%, indicating that CSNet outperforms other networks in terms of overall segmentation capability for the dataset. Both mIoU and Dice coefficient are also higher than those of U-Net, FCN, DeepLabV3+, SegNet, and HRNet, demonstrating that CSNet excels in the segmentation of small objects and small sample categories compared to the other networks. Transformer-based networks excel in global modeling but exhibit relatively weak sensitivity to local textures. Given that the remote sensing images used in this experiment have a resolution of 256 × 256, the advantages of the Transformer’s self-attention mechanism are less pronounced, resulting in comparatively lower segmentation accuracy.
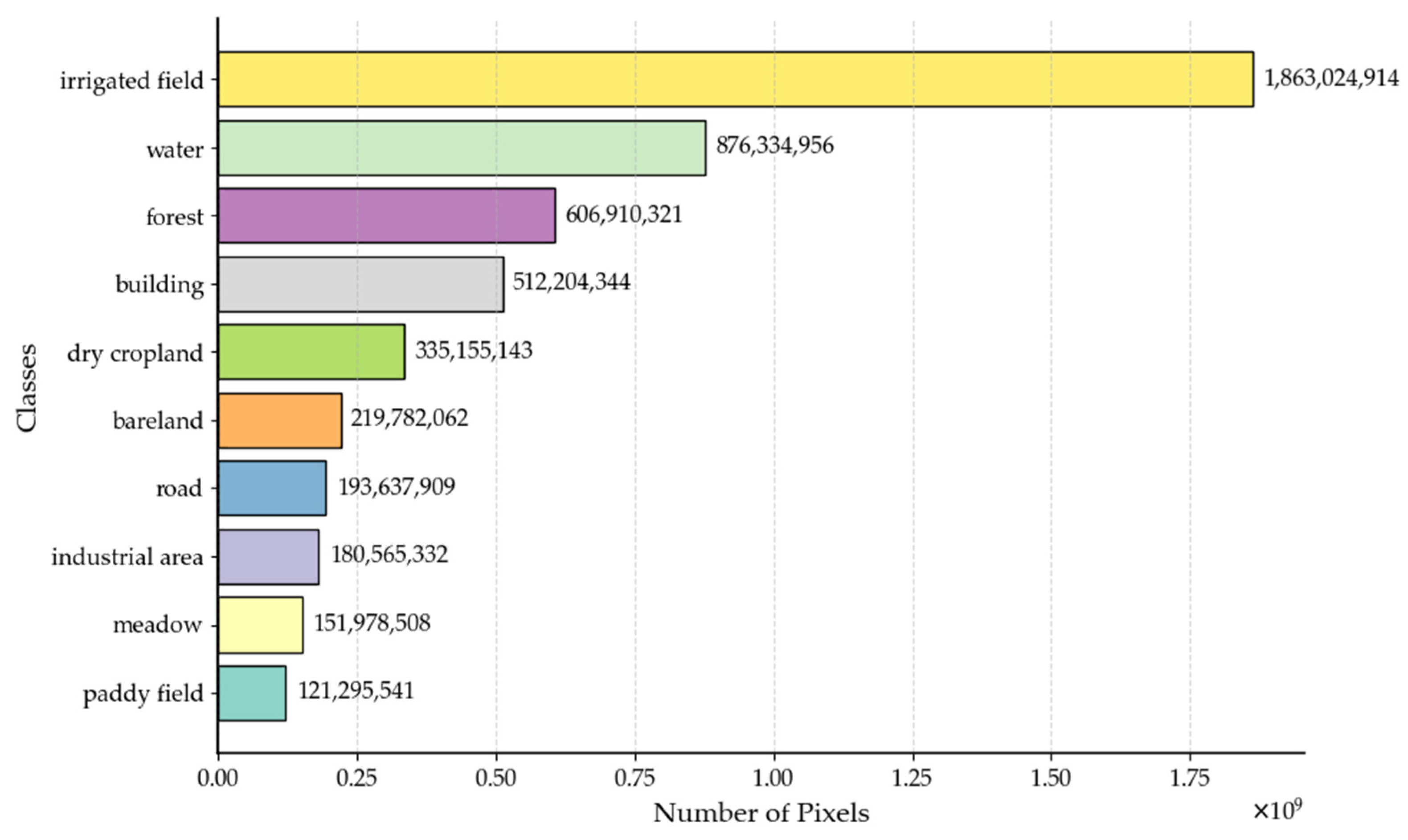
From the Precision results in Tabel 4, it can be observed that CSNet achieves the highest Precision in categories such as industrial area, irrigated field, and road. In most other categories, its Precision is very close to the best-performing network, with a maximum difference of only 3.5%. For categories like forest and meadow, CSNet’s Precision is 86.0% and 61.6%, respectively, which are slightly lower than DeepLabV3+’s Precision of 94.9% and 67.8%, but still higher than other networks.
From the IoU results in
Table 5, it can be observed that CSNet achieves the highest IoU in all categories except for forest, meadow and bareland, where it ranks second, only behind DeepLabV3+ or BiFormer. This indicates that for the vast majority of categories, CSNet demonstrates the strongest segmentation capability, particularly in accurately capturing boundary and spatial features.
For the small sample classes (bareland, road, industrial area, meadow, and paddy field), CSNet achieves either the highest or second-highest Precision scores. Regarding the small sample categories, CSNet attains the highest IoU for all classes except for meadow, where it achieves the second-highest IoU.
By comparing the classification results of different networks on selected samples from the test set, we further underscore the superior performance of the proposed CSNet. The visualization results indicate that CSNet not only achieves excellent classification performance across various land cover categories, but also demonstrates remarkable capability in preserving fine boundary details.
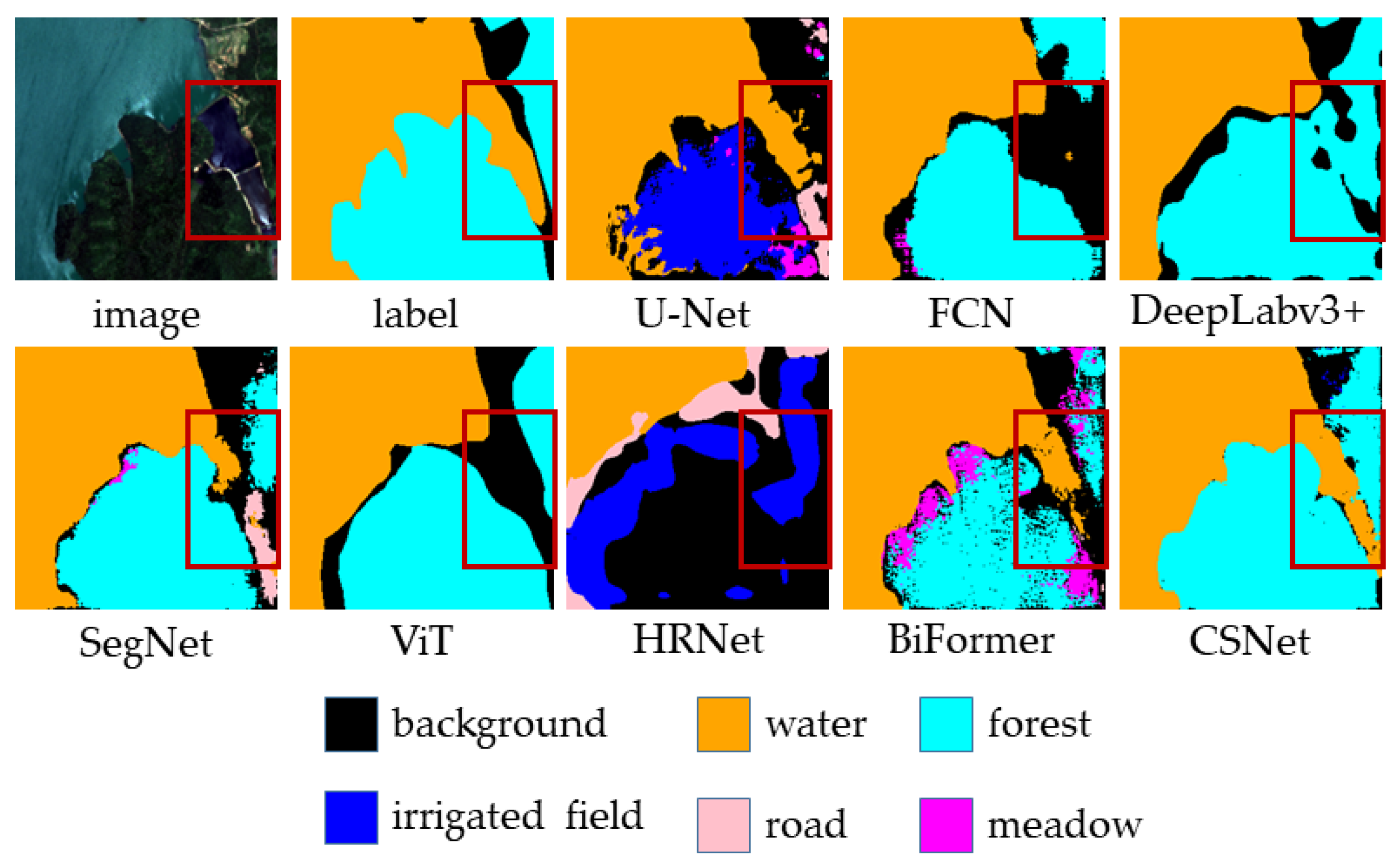
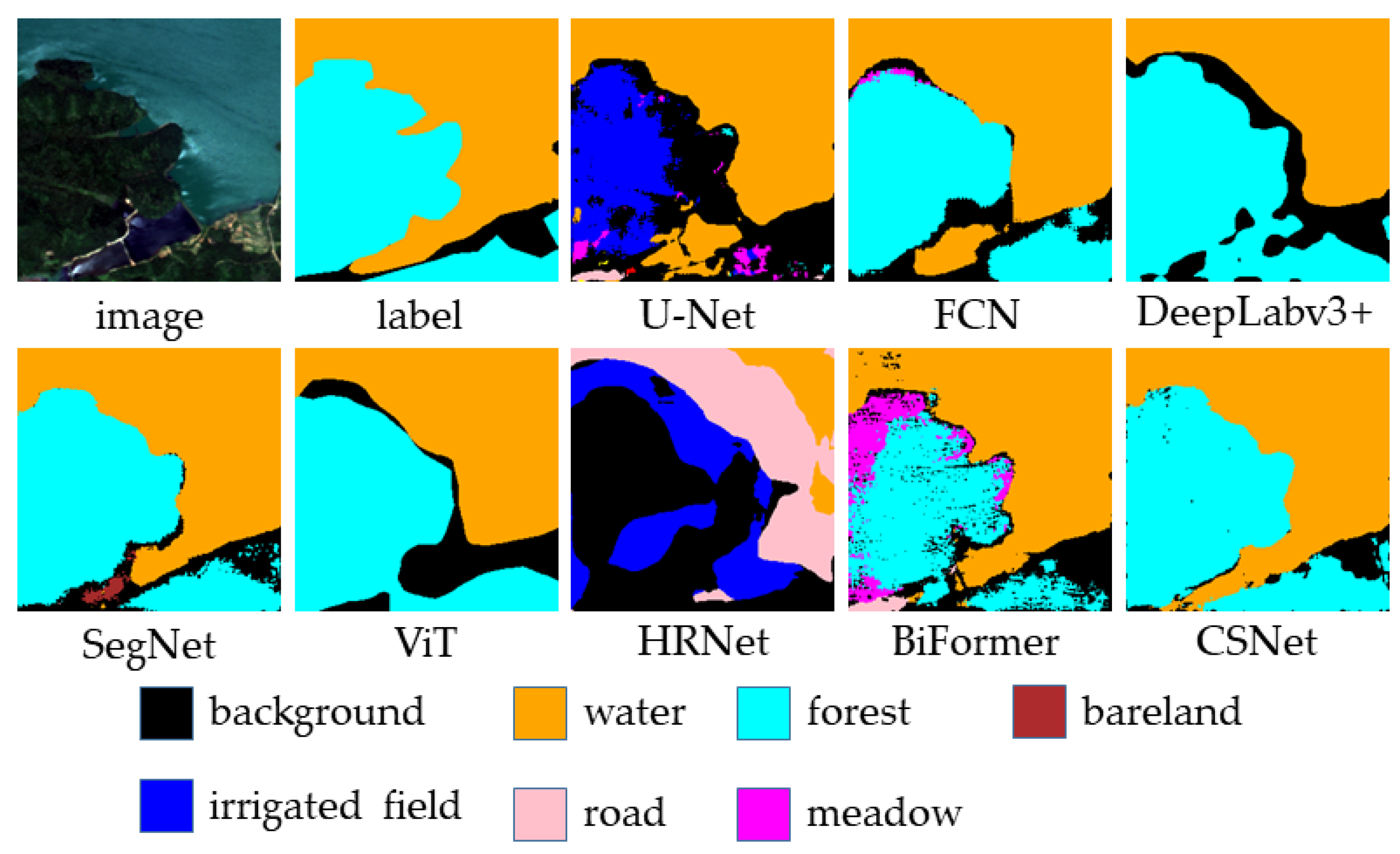
Figure 11 demonstrates the segmentation performance of different models on the water and forest categories. As seen in the figure, U-Net performs relatively well in segmenting the water category, but its segmentation ability for the forest category is poor, misclassifying most of the forest as irrigated field. FCN, DeepLabv3+, and SegNet show relatively poor segmentation performance for the water category and also struggle to accurately segment the forest category. In contrast, CSNet achieves the best segmentation results for both the water and forest categories. From a local structure perspective, there is a narrow water area on the right side of the image, which FCN, DeepLabv3+, and SegNet fail to segment. Although U-Net can segment part of it, the boundaries are blurred. This issue arises due to the skip connections present in U-Net, which help the model recover some of the structural details. CSNet, however, is able to segment this narrow water area more accurately. The combination of coordinate attention and skip connections in CSNet enables a more precise restoration of local structures in the image.
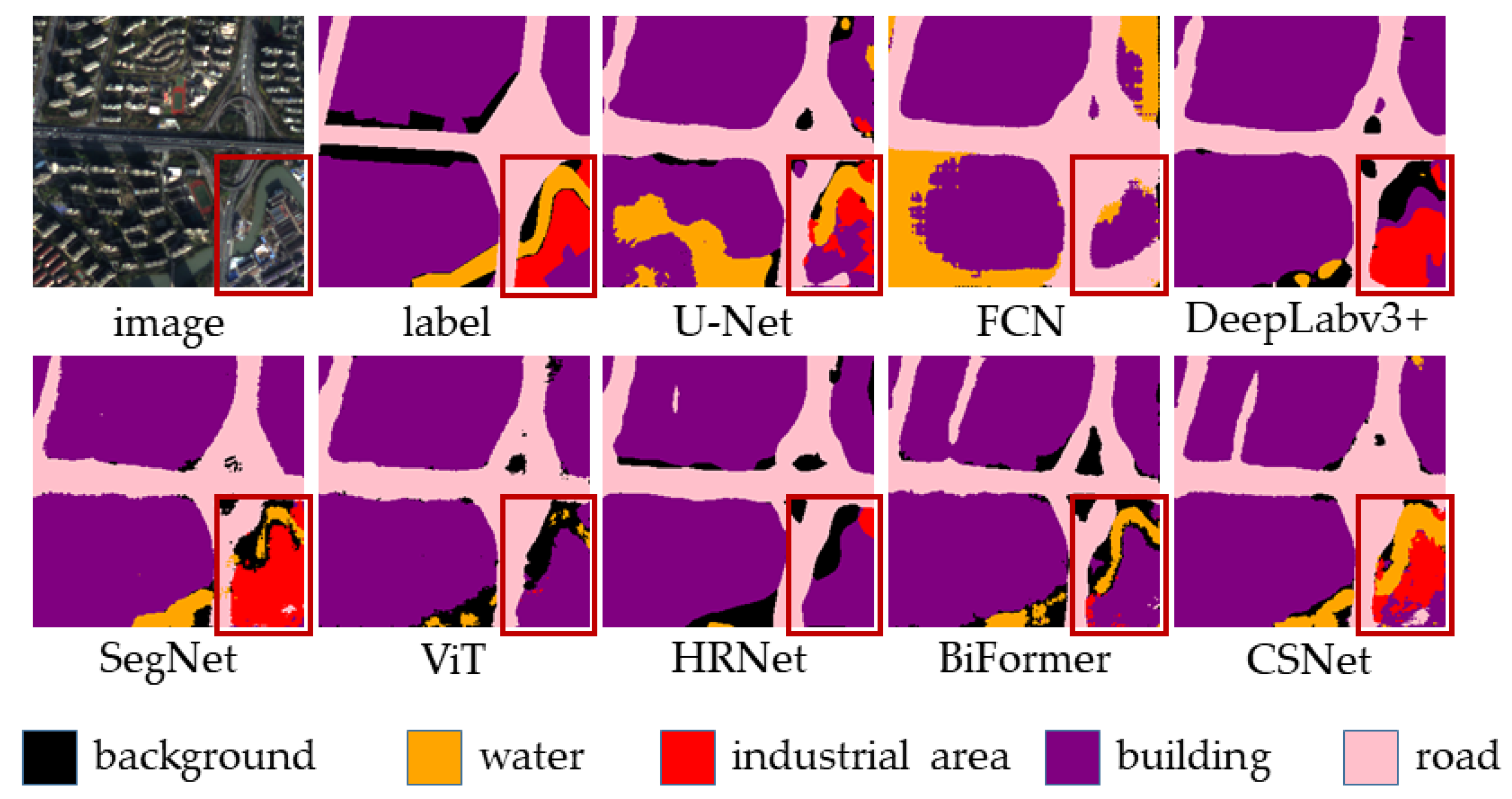
Figure 12 further demonstrates the segmentation performance of different models on local structures. In the bottom right corner of the image, there are three different land cover types: water, industrial area, and building. For this complex local structure, FCN, DeepLabv3+, and SegNet are unable to accurately segment it. U-Net can perform some segmentation of the water, but CSNet more accurately restores the location and spatial shape of all three land cover types.
The results indicate that by using skip connections, the model can fuse semantic information from different layers, helping to restore local structures. By employing the coordinate attention mechanism, CSNet can focus more on key areas of the image during feature extraction, improving the effectiveness of feature extraction and, consequently, enhancing the segmentation performance on local structures.
To further evaluate the generalization capability of the model, we conducted comparative experiments on the Vaihingen dataset. The Dice coefficient, mIoU, and overall accuracy obtained from the experiments are summarized in
Table 6.
It can be observed that CSNet still achieves the best performance on the Vaihingen dataset. Compared with SegNet, the Dice coefficient and mIoU are improved by 8.7% and 7.9%, respectively, while the overall accuracy increases by 2.8%.
To further validate the performance of CSNet and eliminate the influence of randomness, we conducted five experiments on the Five-Billion-Pixels dataset using CSNet and other comparative models with different random seeds. The overall accuracy for each experiment was recorded, and the results are summarized in
Table 7.
Based on the results of the five experiments, CSNet achieved a mean overall accuracy of 90.02% with a standard deviation of 0.36%. The 95% confidence interval was [89.58%, 90.46%]. A significance test was conducted against BiFormer, the best-performing baseline model, yielding a t-value of 7.12 and a p-value of 0.0002, indicating a statistically significant advantage of CSNet.
To assess the impact of geometric perturbations on CSNet, we applied small-scale translations (±10 pixels), slight rotations (±15°), and 90° rotations to the images in the Five-Billion-Pixels dataset. Comparative experiments between CSNet and other models were conducted under these conditions, and the results are presented in
Table 8.
Compared with other models, CSNet exhibits the smallest variation in mIoU, indicating its superior robustness to geometric perturbations.
Figure 13 presents the segmentation results of
Figure 11 after a 90° rotation. As shown in the figure, even after a 90° rotation, CSNet still achieves the best segmentation performance.
3.3. Ablation Experiment
To validate the effectiveness of skip connections and coordinate attention structures in the network, as well as the impact of different positions of coordinate attention addition on the model, ablation experiments were conducted. The experiments were performed on the original SegNet network, a SegNet network with coordinate attention structure added only in the encoder (SegNet + CA), a SegNet network with skip connections only (SegNet + SC), and the CSNet network. The experimental results are shown in
Table 9.
After adding the coordinate attention mechanism, the model’s Dice coefficient and mIoU increased by 3.1% and 4.2%, respectively, indicating that the model’s segmentation capability for small targets and small sample categories has improved. The overall accuracy (OA) increased by 4.5%, demonstrating that the model’s ability to segment the entire dataset has been enhanced. After adding skip connections, the model’s Dice coefficient and mIoU showed slight improvements, suggesting that the fusion of semantic information from different layers helps restore the spatial information of the image and improves the segmentation capability for small targets. OA increased by 2.2%, indicating an overall enhancement in the model’s segmentation ability. Compared to SegNet, CSNet achieved increases of 4.9%, 6.5%, and 6.1% in Dice coefficient, mIoU, and OA, respectively, demonstrating the model’s strong segmentation capability for various target categories.
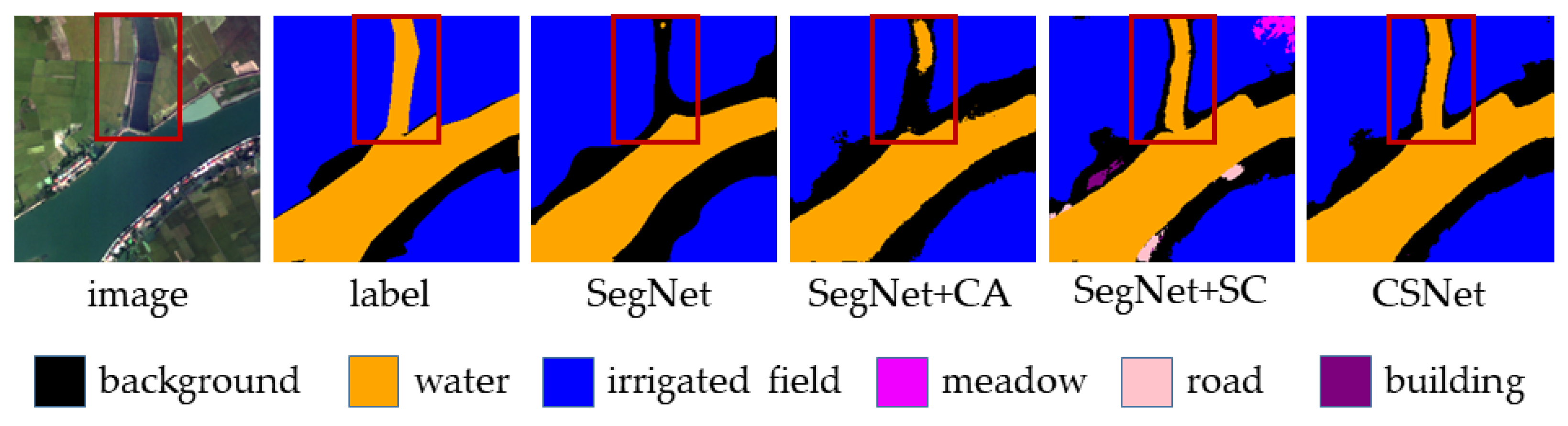
Figure 14 illustrates the segmentation results of different networks for the water and irrigated field classes in the ablation study. It can be observed that after adding skip connections, the model is able to segment the slender river structures, indicating that skip connections help restore the shape information of geographic features. However, the results with skip connections also show some instances of misclassification. Upon incorporating coordinate attention, the model eliminates these misclassifications and successfully segments water regions that SegNet failed to detect. Additionally, the segmentation of irrigated fields becomes more accurate, demonstrating that coordinate attention enhances the model’s ability to distinguish between different land cover types.
Figure 15 presents the segmentation results for paddy field and irrigated field in the ablation study across different network variants. Due to the spectral similarity between paddy field and irrigated field, SegNet misclassifies part of the paddy field as water. After incorporating skip connections, the boundary ambiguity is alleviated; however, the extent of misclassification becomes more severe. With the introduction of coordinate attention, the misclassification is significantly reduced, with almost no confusion observed. This indicates that the coordinate attention mechanism helps the model better distinguish between spectrally similar land cover types.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}