
OITrack: Multi-Object Tracking for Small Targets in Satellite Video via Online Trajectory Completion and Iterative Expansion over Union


Abstract
1. Introduction
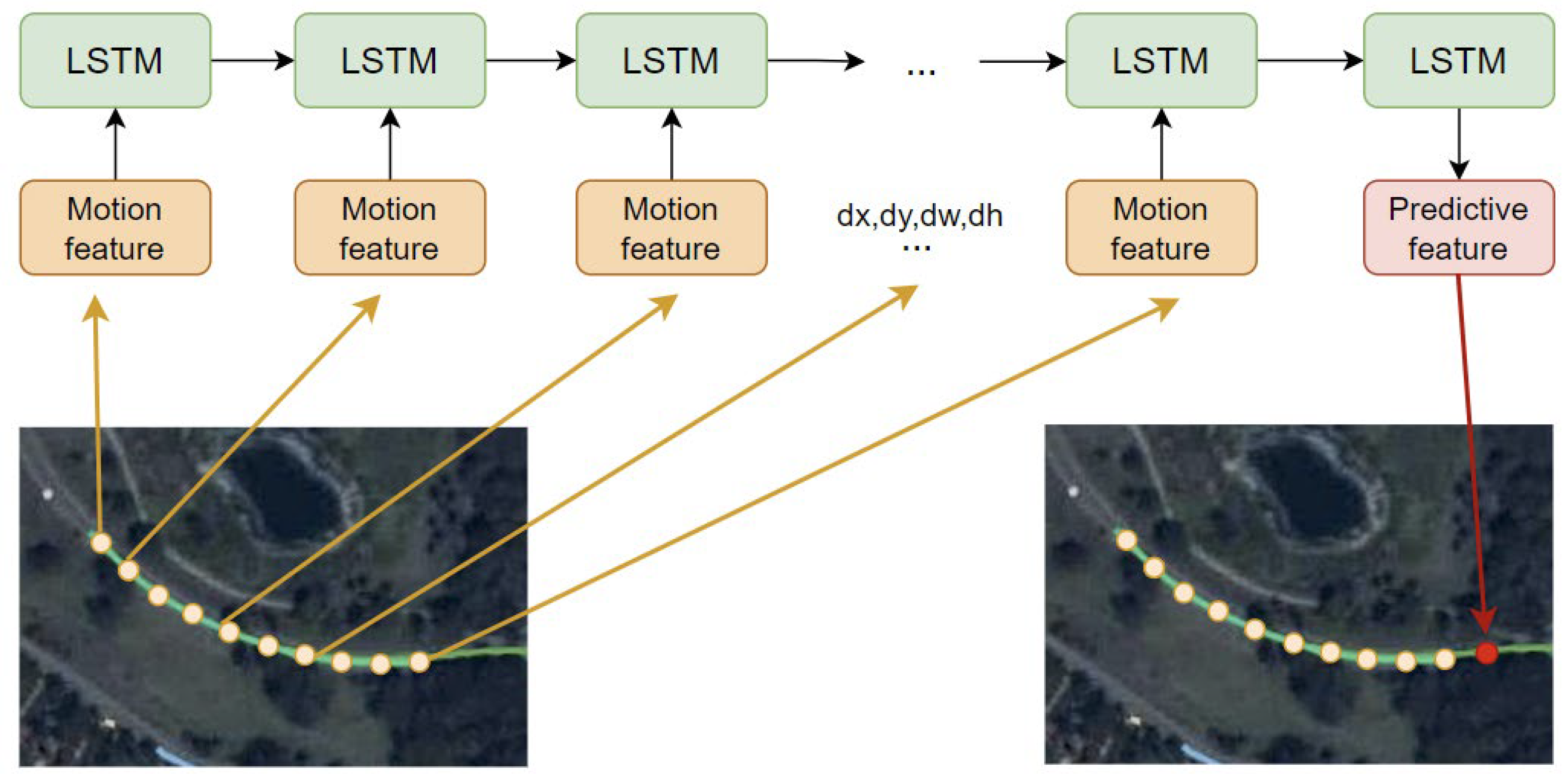
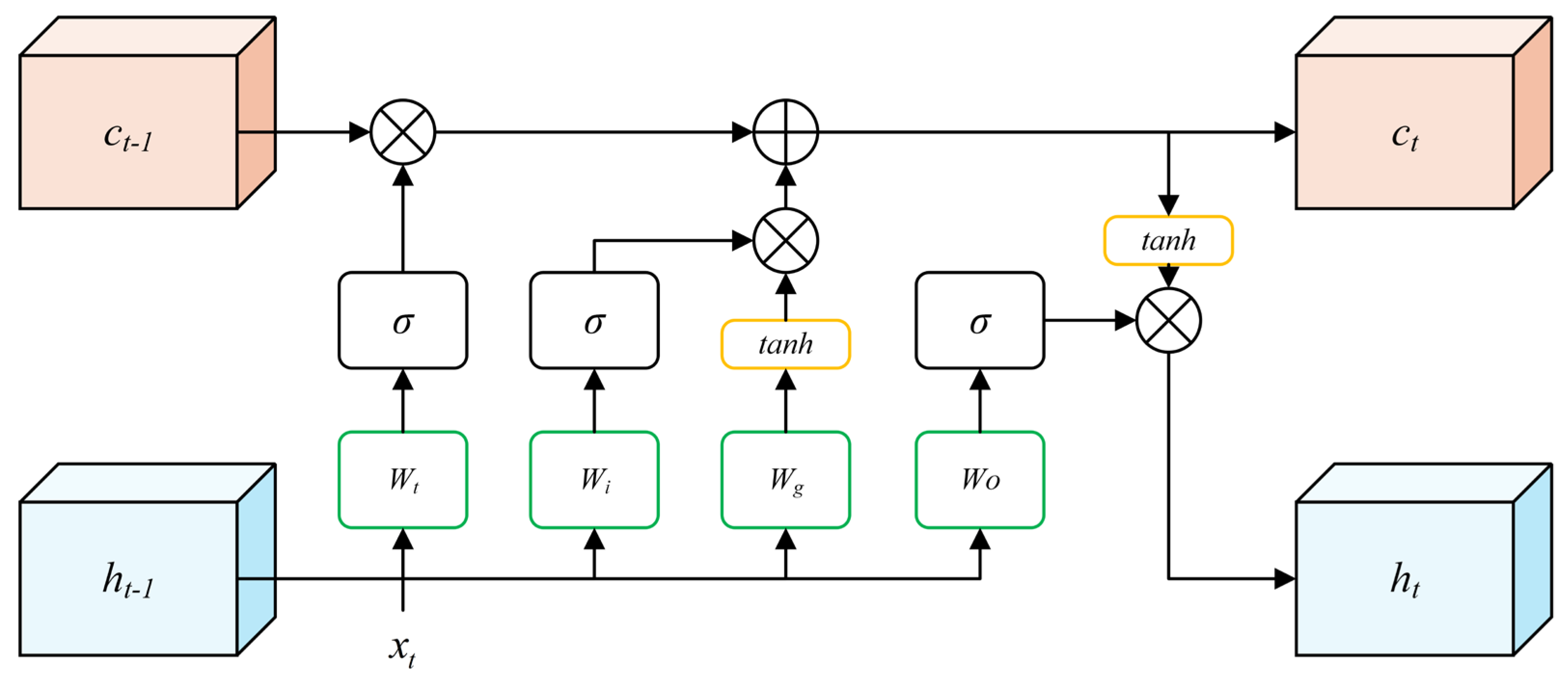
- Trajectory Completion Module (TCM): We propose a novel trajectory completion method based on Long Short-Term Memory (LSTM) networks and an adaptive Kalman Filter. This module effectively compensates for missed detections, reducing target loss caused by detector failures and improving tracking continuity.
- Adaptive Kalman Filter (AKF): Unlike the traditional Kalman Filter, which assumes a fixed observation noise, our method dynamically adjusts observation noise based on detection confidence, enhancing tracking robustness.
- Iterative Extended Intersection over Union (I-EIoU) Strategy: We propose an enhanced target matching strategy that significantly reduces identity switches and false negatives in small-object tracking.
2. Related Work
2.1. Traditional Multi-Object Tracking Methods
2.2. DBT Method
2.3. JDT Method
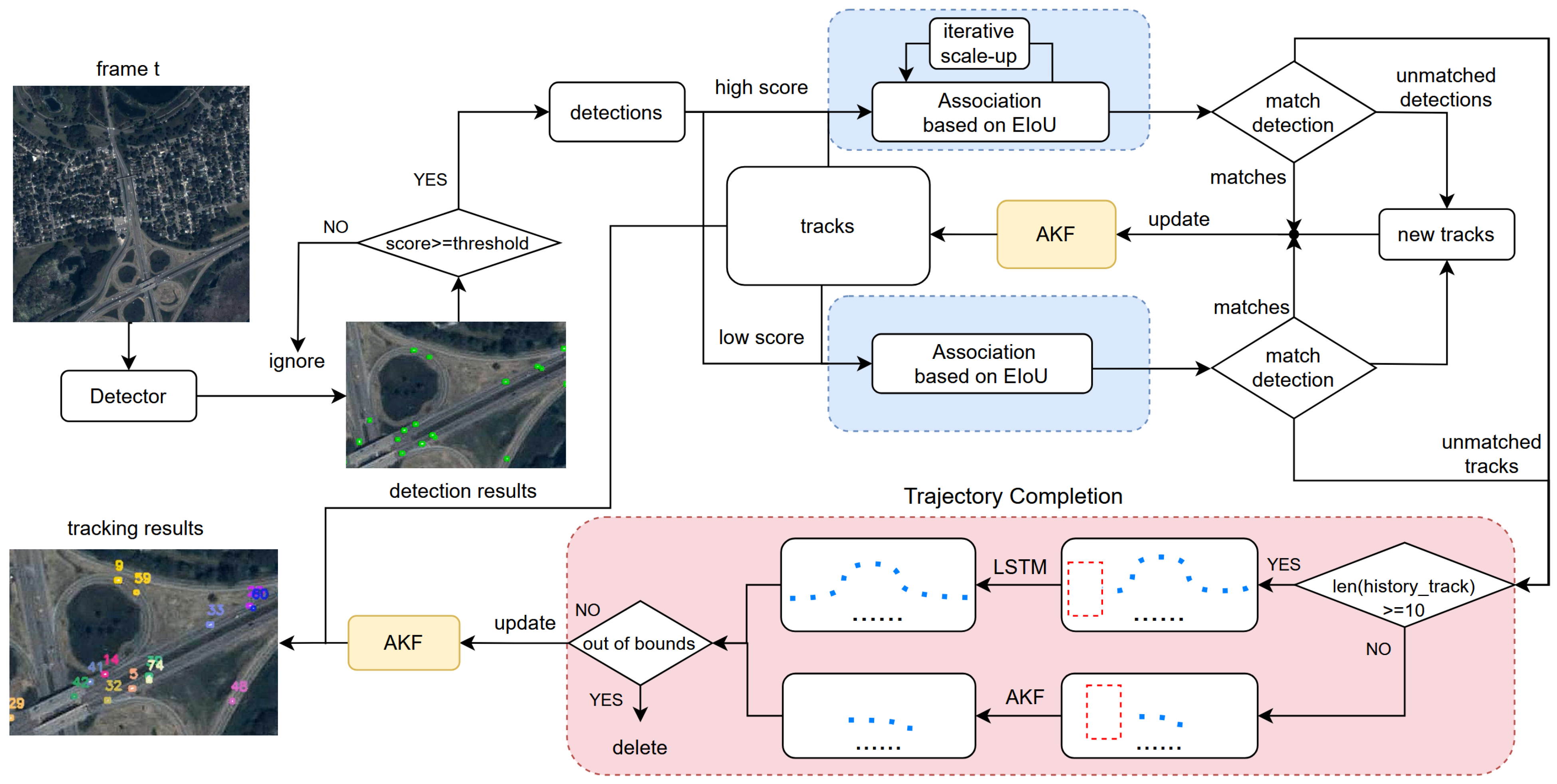
3. Methods
3.1. Trajectory Completion Module
| Algorithm 1: Trajectory Completion Module |
| Input: Detection results format: , convert to center and size: ; Historical trajectory of the target: ; Detection result of the current frame; Output: Completed trajectory information: ; Data: Initialize Kalman Filter and LSTM model ; Initialize the completed trajectory set ; Initialize Kalman filter state ; for to do if Historical trajectory is less than 10 frames then Use Kalman filter to update trajectory: Complete the current state of the target; end else Use LSTM model for trajectory completion; Input historical trajectory ; LSTM predicts the current trajectory ; Feed LSTM-completed trajectory into Kalman filter: end Perform boundary check for the target; ; if Target is out of bounds then Delete historical trajectory information for the target, stop updating it; end else Add the completed trajectory to the completed trajectory set: ; end end return Updated completed trajectory ; |
3.2. Adaptive Kalman Filter
3.3. Iterative Extension IoU
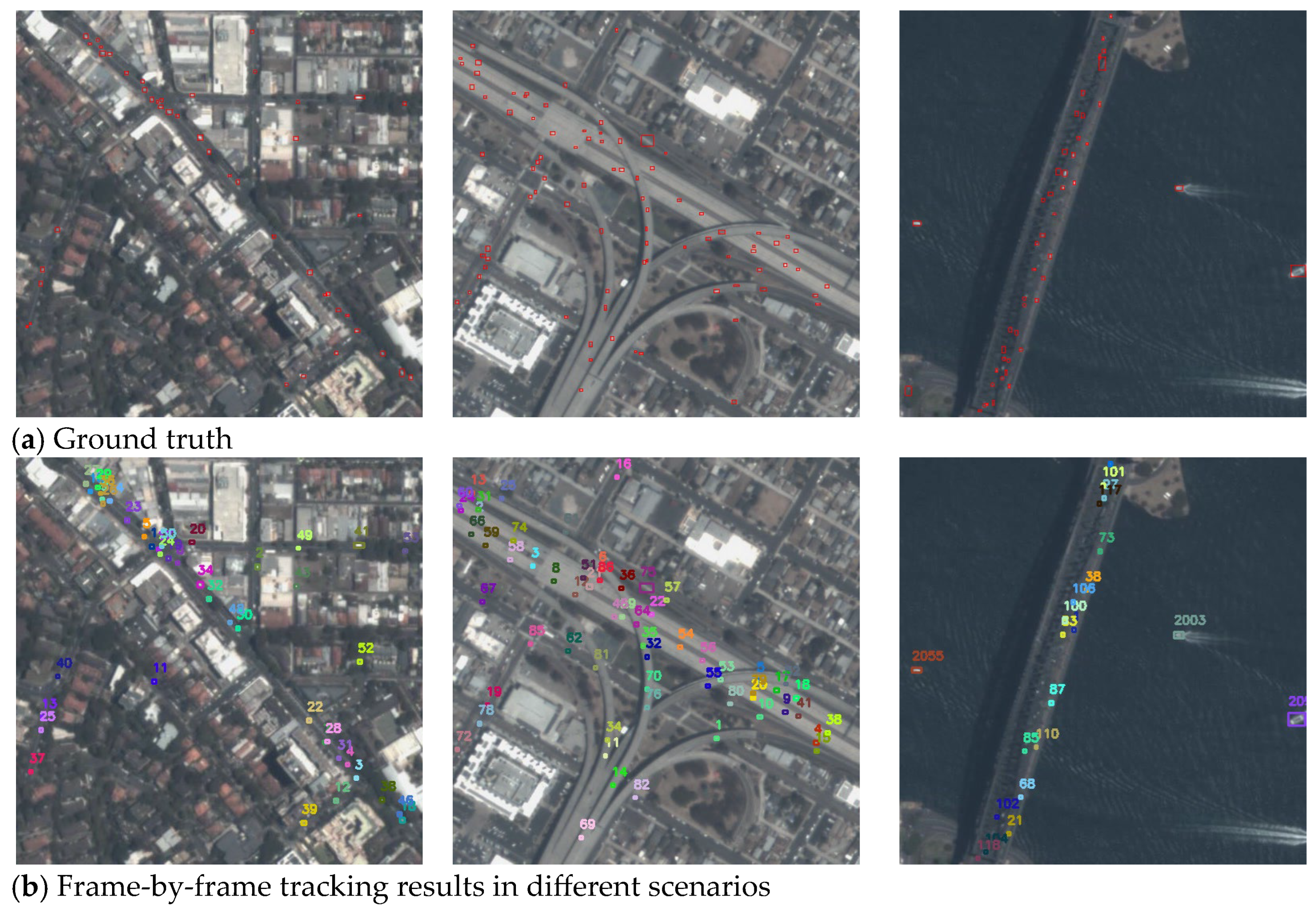
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Experimental Setup
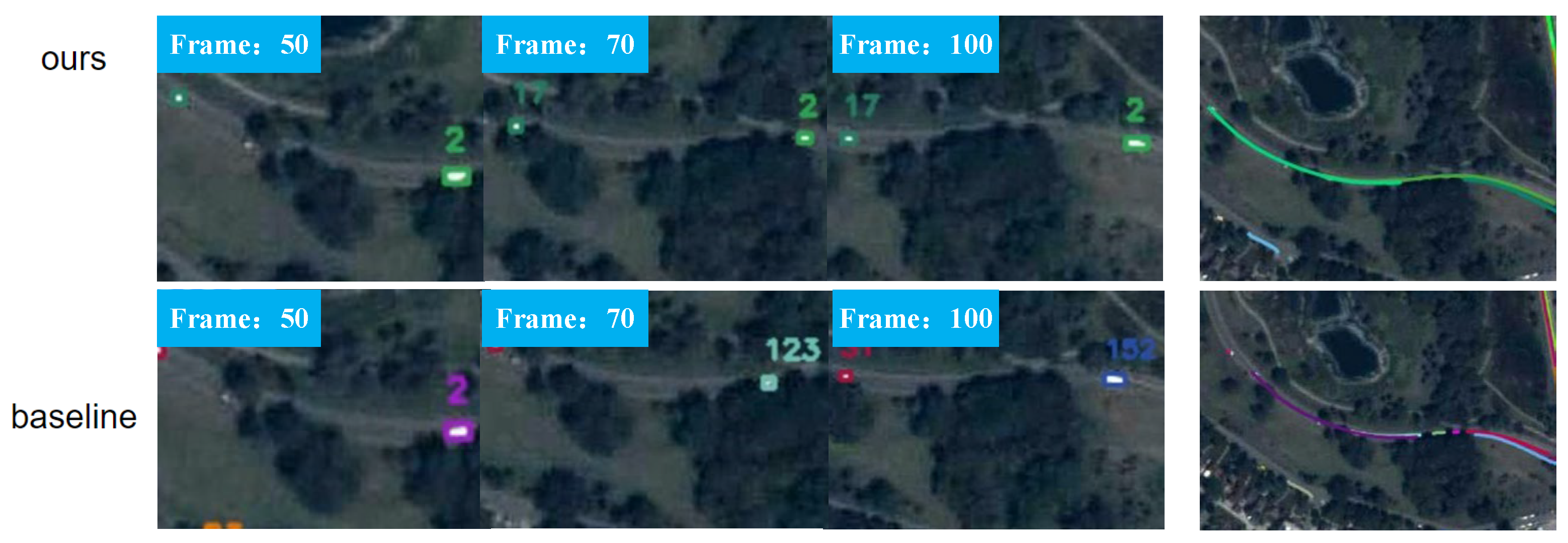
4.3. Comparison with Existing Methods
4.4. Ablation Experiments
4.4.1. Effectiveness of the TCM
4.4.2. Effectiveness of the AKF
4.4.3. Effectiveness of the I-EIoU
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bauk, S.; Kapidani, N.; Lukšić, Ž.; Rodrigues, F.; Sousa, L. Review of Unmanned Aerial Systems for the Use as Maritime Surveillance Assets. In Proceedings of the 2020 24th International Conference on Information Technology (IT), Zabljak, Montenegro, 18–22 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, Z.; Zhang, Y. UAV-based forest fire detection and tracking using image processing techniques. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; pp. 639–643. [Google Scholar] [CrossRef]
- Liu, Y.; Liao, Y.; Lin, C.; Yang, X.; Jia, Y.; Liu, Y. Object Tracking in Satellite Videos Based on Correlation Filter with Multi-Feature Fusion and Motion Trajectory Compensation. Remote Sens. 2022, 14, 777. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Huang, Z.; Cheng, X.; Feng, J.; Jiao, L. Bidirectional Multiple Object Tracking Based on Trajectory Criteria in Satellite Videos. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5603714. [Google Scholar] [CrossRef]
- Li, Y.; Liao, X.; Yuan, Q.; Jin, X.; Liu, Y.; He, J. Advancing Multi-object Tracking for Small Vehicles in Satellite Videos: A More Focused and Continuous Approach. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5631519. [Google Scholar] [CrossRef]
- Mahler, R. Statistical Multisource Multitarget Information Fusion; Artech House: Boston, MA, USA, 2007; pp. 1255–1259. [Google Scholar]
- Lin, S.; Vo, B.; Nordholm, S. Measurement driven birth model for the generalized labeled multi-Bernoulli filter. In Proceedings of the 2016 International Conference on Control, Automation and Information Sciences (ICCAIS), Ansan, Republic of Korea, 27–29 October 2016; pp. 94–99. [Google Scholar] [CrossRef]
- Reuter, S.; Meissner, D.; Wilking, B.; Dietmayer, K. Cardinality balanced multi-target multi-Bernoulli filtering using adaptive birth distributions. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013; pp. 1608–1615. [Google Scholar]
- Vo, B.; Vo, B.; Cantoni, A. The Cardinalized Probability Hypothesis Density Filter for Linear Gaussian Multi-Target Models. In Proceedings of the 2006 40th Annual Conference on Information Sciences and Systems, Ansan, Republic of Korea, 22–24 March 2006; pp. 681–686. [Google Scholar] [CrossRef]
- Vo, B.; Vo, B.; Hoang, H. An Efficient Implementation of the Generalized Labeled Multi-Bernoulli Filter. IEEE Trans. Signal Process. 2017, 65, 1975–1987. [Google Scholar] [CrossRef]
- Fu, Z.; Feng, P.; Angelini, F.; Chambers, J.; Naqvi, S. Particle PHD Filter Based Multiple Human Tracking Using Online Group-Structured Dictionary Learning. IEEE Access 2018, 6, 14764–14778. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE international conference on image processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef]
- Kalman, R. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the Computer Visio—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–21. [Google Scholar] [CrossRef]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 9686–9696. [Google Scholar] [CrossRef]
- Aharon, N.; Orfaig, R.; Bobrovsky, B. Bot-sort: Robust associations multi-pedestrain tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Feng, J.; Zeng, D.; Jia, X.; Zhang, X.; Li, J.; Liang, Y.; Jiao, L. Cross-frame keypoint-based and spatial motion information-guided networks for moving vehicle detection and tracking in satellite videos. ISPRS J. Photogramm. 2021, 177, 116–130. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar] [CrossRef]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple People Tracking by Lifted Multicut and Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3701–3710. [Google Scholar] [CrossRef]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. StrongSORT: Make DeepSORT Great Again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Xiao, C.; Yin, Q.; Ying, X.; Li, R.; Wu, S.; Li, M.; Liu, L.; An, W.; Chen, Z. DSFNet: Dynamic and Static Fusion Network for Moving Object Detection in Satellite Videos. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3510405. [Google Scholar] [CrossRef]
- Zhang, J.; Jia, X.; Hu, J.; Tan, K. Satellite Multi-Vehicle Tracking under Inconsistent Detection Conditions by Bilevel K-Shortest Paths Optimization. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, ACT, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Sommer, L.; Krüger, W.; Teutsch, M. Appearance and Motion Based Persistent Multiple Object Tracking in Wide Area Motion Imagery. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 3871–3881. [Google Scholar] [CrossRef]
- Wu, S.; Xiao, C.; Wang, Y.; Yang, J.; An, W. Sparsity-Aware Global Channel Pruning for Infrared Small-target Detection Networks. IEEE Trans. Geosci. Remote. Sens. 2025, 63, 5615011. [Google Scholar] [CrossRef]
- Xiao, C.; An, W.; Zhang, Y.; Su, Z.; Li, M.; Sheng, W.; Pietikäinen, M.; Liu, L. Highly Efficient and Unsupervised Framework for Moving Object Detection in Satellite Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 11532–11539. [Google Scholar] [CrossRef]
- Wu, J.; Su, X.; Yuan, Q.; Shen, H.; Zhang, L. Multivehicle Object Tracking in Satellite Video Enhanced by Slow Features and Motion Features. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5616426. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V. Tracking objects as points. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2016; pp. 474–490. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Li, B.; Fu, K. Multi-object tracking in satellite videos with graph-based multitask modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619513. [Google Scholar] [CrossRef]
- Kong, L.; Yan, Z.; Zhang, Y.; Diao, W.; Zhu, Z.; Wang, L. CFTracker: Multi-object tracking with cross-frame connections in satellite videos. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5611214. [Google Scholar] [CrossRef]
- Liang, C.; Zhang, Z.; Zhou, X.; Li, B.; Zhu, S.; Hu, W. Rethinking the competition between detection and ReID in multi-object tracking. IEEE Trans. Image Process. 2022, 31, 3182–3196. [Google Scholar] [CrossRef]
- Zhang, H.; Wen, S.; Wei, Z.; Chen, Z. High-Resolution Feature Generator for Small-Ship Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5617011. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for Small Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Hou, Q.; Wang, Z.; Tan, F.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust Infrared Small Target Detection Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7000805. [Google Scholar] [CrossRef]
- Du, Y.; Wan, J.; Zhao, Y.; Zhang, B.; Tong, Z.; Dong, J. GIAOTracker: A comprehensive framework for MCMOT with global information and optimizing strategies in VisDrone. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2809–2819. [Google Scholar] [CrossRef]
- Huang, H.; Yang, C.; Sun, J.; Kim, P.; Kim, K.; Lee, K.; Huang, C.; Hwang, J. Iterative Scale-Up ExpansionIoU and Deep Features Association for Multi-Object Tracking in Sports. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 1–6 January 2024; pp. 163–172. [Google Scholar] [CrossRef]
- Yin, Q.; Hu, Q.; Liu, H.; Zhang, F.; Wang, Y.; Lin, Z.; An, W.; Guo, Y. Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5612518. [Google Scholar] [CrossRef]
- Li, S.; Zhou, Z.; Zhao, M.; Yang, J.; Guo, W.; Lv, Y.; Kou, L.; Wang, H.; Gu, Y. A Multitask Benchmark Dataset for Satellite Video: Object Detection, Tracking, and Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5611021. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MOTA (%) ↑ | IDF1 (%) ↑ | MT ↑ | ML ↓ | FP ↓ | FN ↓ | IDs ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|
| ByteTrack [14] | 37.5 | 56.8 | 108 | 484 | 1393 | 69,048 | 149 | 14.7 |
| OCSORT [15] | 49.3 | 66.3 | 178 | 256 | 4634 | 44,118 | 848 | 10.4 |
| StrongSORT [21] | 35.4 | 42.6 | 170 | 260 | 7173 | 46,444 | 14,970 | 9.5 |
| FairMOT [28] | −0.1 | 6.0 | 5 | 824 | 1543 | 119,635 | 52 | 11.6 |
| DSFNet [22] | 47.6 | 66.1 | 190 | 256 | 6360 | 41,996 | 506 | 3.1 |
| SMTNet [17] | 47.5 | 59.5 | 143 | 366 | 1217 | 55,938 | 548 | 18.4 |
| CFTracker [31] | 33.3 | 38.3 | 149 | 288 | 8056 | 52,784 | 6476 | 5.0 |
| TGraM [30] | −2.1 | 23.1 | 20 | 627 | 9207 | 100,979 | 1894 | 16.4 |
| OITrack (ours) | 51.7 | 67.5 | 296 | 163 | 15,079 | 29,170 | 889 | 1.8 |
| Method | MOTA (%) ↑ | IDF1 (%) ↑ | MT ↑ | ML ↓ | FP ↓ | FN ↓ | IDs ↓ |
|---|---|---|---|---|---|---|---|
| ByteTrack [14] | 27.9 | 43.3 | 534 | 2153 | 3660 | 244,072 | 102 |
| FairMOT [28] | 8.5 | 18.5 | 102 | 2417 | 9529 | 291,156 | 13,895 |
| SMTNet [17] | 27.1 | 45.3 | 368 | 735 | 73,022 | 172,994 | 4808 |
| OCSORT [15] | 29.0 | 43.9 | 469 | 1958 | 6155 | 237,226 | 707 |
| TGraM [30] | 4.8 | 12.1 | 57 | 2668 | 8117 | 309,047 | 10,307 |
| DSFNet [22] | 48.1 | 63.9 | 1121 | 1073 | 12,719 | 165,022 | 694 |
| OITrack(ours) | 49.7 | 65.2 | 1853 | 580 | 15,375 | 148,643 | 837 |
| Baseline | TCM | AKF | I-EIoU | MOTA (%) ↑ | IDF1 (%) ↑ | MT ↑ | ML ↓ | FP ↓ | FN ↓ | IDs ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| √ | 47.7 | 64.0 | 190 | 248 | 6353 | 41,996 | 511 | 3.0 | |||
| √ | √ | 50.5 | 65.1 | 289 | 163 | 15,553 | 29,644 | 1111 | 1.9 | ||
| √ | √ | √ | 50.8 | 65.3 | 292 | 163 | 15,417 | 29,507 | 1094 | 1.9 | |
| √ | √ | √ | √ | 51.7 | 67.5 | 296 | 163 | 15,079 | 29,170 | 889 | 1.8 |
| Hidden Size | MOTA (%) ↑ | IDF1 (%) ↑ | MT ↑ | ML ↓ | FP ↓ | FN ↓ | IDs ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|
| 64 | 50.5 | 65.1 | 289 | 163 | 15,553 | 29,644 | 1111 | 1.9 |
| 128 | 50.6 | 65.1 | 293 | 161 | 15,540 | 29,628 | 1104 | 0.8 |
| Backbone | Motion Modeling | MOTA (%) ↑ | IDF1 (%) ↑ |
|---|---|---|---|
| DLA-34 | GRU | 49.0 | 63.2 |
| LSTM | 50.1 | 64.4 | |
| LSTM + KF | 50.6 | 65.1 |
| KF | AKF | MOTA (%) ↑ | IDF1 (%) ↑ | MT ↑ | ML ↓ | FP ↓ | FN ↓ | IDs ↓ |
|---|---|---|---|---|---|---|---|---|
| √ | 51.4 | 67.10 | 292 | 168 | 15,144 | 29,310 | 907 | |
| √ | 51.7 | 67.50 | 296 | 163 | 15,079 | 29,170 | 889 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, W.; Wang, X.; An, W.; Xiao, C.; Yin, Q.; Zhang, G. OITrack: Multi-Object Tracking for Small Targets in Satellite Video via Online Trajectory Completion and Iterative Expansion over Union. Remote Sens. 2025, 17, 2042. https://doi.org/10.3390/rs17122042
Lu W, Wang X, An W, Xiao C, Yin Q, Zhang G. OITrack: Multi-Object Tracking for Small Targets in Satellite Video via Online Trajectory Completion and Iterative Expansion over Union. Remote Sensing. 2025; 17(12):2042. https://doi.org/10.3390/rs17122042
Chicago/Turabian StyleLu, Weishan, Xueying Wang, Wei An, Chao Xiao, Qian Yin, and Guoliang Zhang. 2025. "OITrack: Multi-Object Tracking for Small Targets in Satellite Video via Online Trajectory Completion and Iterative Expansion over Union" Remote Sensing 17, no. 12: 2042. https://doi.org/10.3390/rs17122042
APA StyleLu, W., Wang, X., An, W., Xiao, C., Yin, Q., & Zhang, G. (2025). OITrack: Multi-Object Tracking for Small Targets in Satellite Video via Online Trajectory Completion and Iterative Expansion over Union. Remote Sensing, 17(12), 2042. https://doi.org/10.3390/rs17122042