
Lightweight Infrared Small Target Detection Method Based on Linear Transformer

 ,
,
Abstract
1. Introduction
- 1.
- This paper proposes a method for infrared small target detection, IstdVit, which aims to address the “speed–accuracy” trade-off problem. It has a U-net architecture based on transformers, and it is a lightweight method.
- 2.
- This paper designs a multi-scale linear transformer (MLT) module. To improve the capability to distinguish small targets from the background, this paper introduces Mixed 2D rotational position encoding (RoPE) into the multi-scale linear transformer (MLT) to enhance spatial relative position modeling.
- 3.
- To address the demands of various small targets, the multi-scale parallel convolution processing strategy utilizing Dilated Convolution is proposed, followed by the introduction of the attention mechanism. The multi-scale features can combine their strengths to achieve a finer and more robust feature representation.
- 4.
- Experiments conducted on several datasets demonstrate that the proposed method outperforms other SOTA methods in the accuracy and speed metrics. Its mIoU increases by 11.07% in comparison with the ACM method. It reaches an MIoU of 70.22, Pd of 94.59, and Fa of 1.81 × 10−5 for the IRSTD-1K dataset.
2. Related Work
2.1. The Infrared Small Target Detection Datasets
2.2. The Infrared Small Target Detection Methods
3. Proposed Method
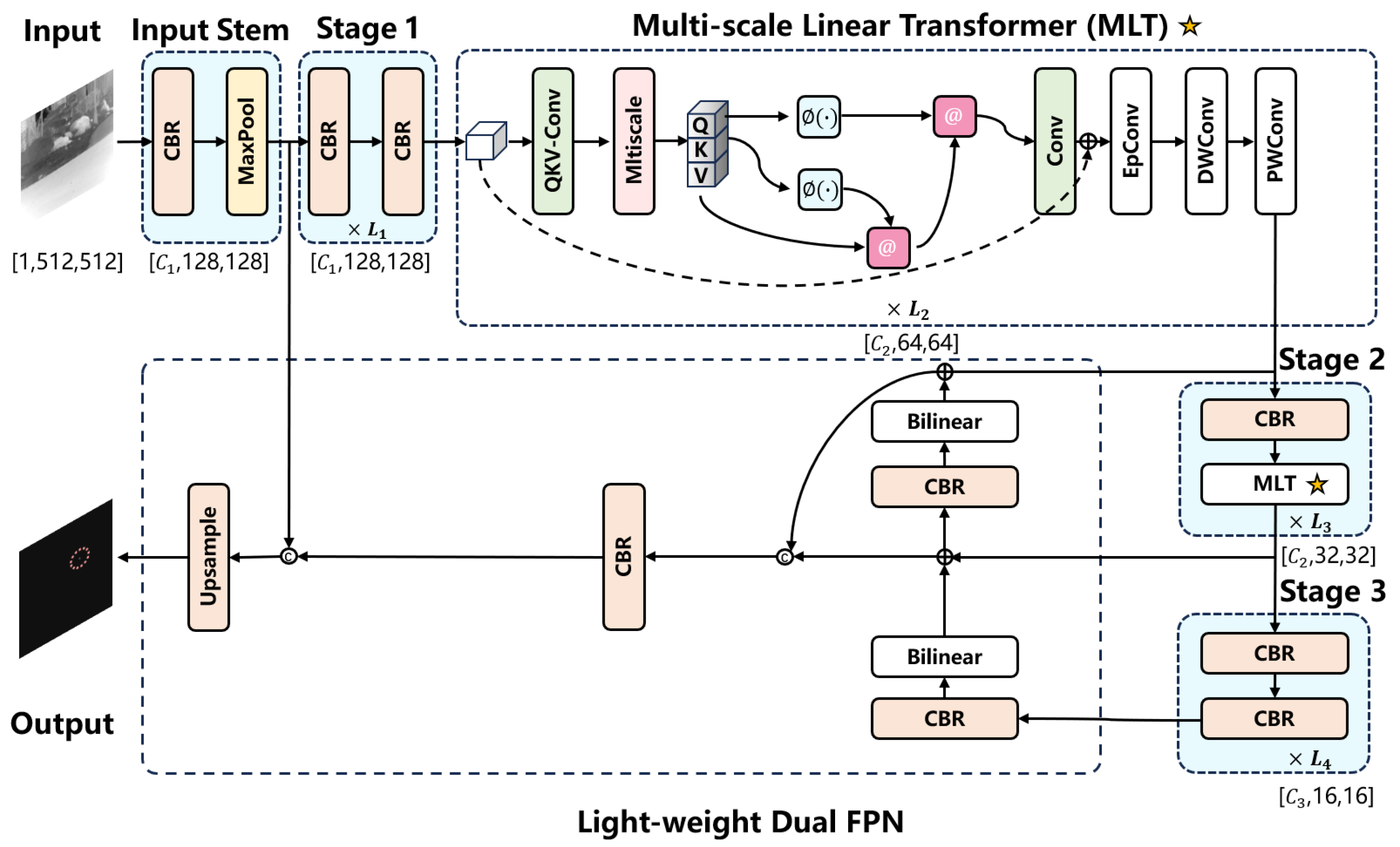
3.1. The Design of IstdVit Architecture
3.2. Multi-Scale Linear Transformer
3.2.1. The Original Transformer
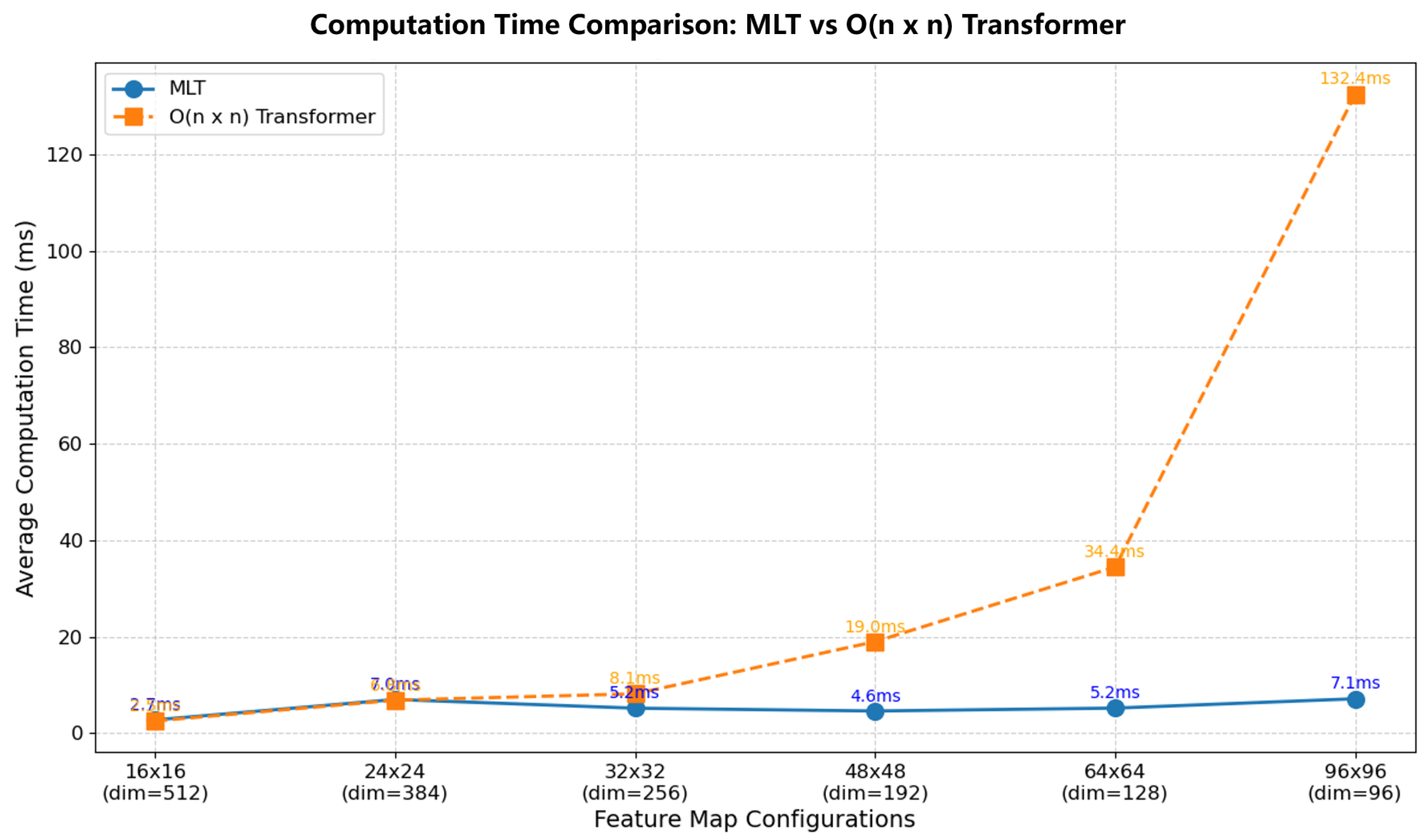
3.2.2. Design of Multi-Scale Linear Transformer
3.3. Evaluation Indicators
4. Results of the Experiments
4.1. Implementation Details
4.2. Quantitative Analysis
4.3. Ablation Study
4.4. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Mao, Q.; Liu, W.; Wang, J.; Wang, W.; Wang, B. Local information guided global integration for infrared small target detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 4425–4429. [Google Scholar]
- Zhang, Y.; Li, Z.; Siddique, A.; Azeem, A.; Chen, W.; Cao, D. Infrared Small Target Detection Based on Interpretation Weighted Sparse Method. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5001415. [Google Scholar] [CrossRef]
- Kou, R.; Wang, C.; Peng, Z.; Zhao, Z.; Chen, Y.; Han, J.; Huang, F.; Yu, Y.; Fu, Q. Infrared small target segmentation networks: A survey. Pattern Recognit. 2023, 143, 109788. [Google Scholar] [CrossRef]
- Chen, D.; Qin, F.; Ge, R.; Peng, Y.; Wang, C. ID-UNet: A densely connected UNet architecture for infrared small target segmentation. Alex. Eng. J. 2025, 110, 234–244. [Google Scholar] [CrossRef]
- Xin, B.; Li, Q.; Mao, Q.; Wang, J.; Wang, B. FBI-Net: Frequency Band Integration Network for Infrared Small Target Segmentation. In Proceedings of the 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; Volume 110, pp. 1–25. [Google Scholar]
- Gan, W.; Liu, Z.; Chen, C.L.P.; Zhang, T. Siamese labels auxiliary learning. Inf. Sci. 2023, 625, 314–326. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, K.; Wang, B.; Li, X. Hierarchical Multimodality Graph Reasoning for Remote Sensing Visual Question Answering. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5651312. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Volume 110, pp. 8509–8518. [Google Scholar]
- Wu, X.; Hong, D.; Chanussot, J. Uiu-net: U-net in u-net for infrared small object detection. IEEE Trans. Image. Process 2023, 32, 364–376. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Tan, F.; Xi, Y.; Zheng, H.; Li, N. ISTDU-net: Infrared small-target detection u-net. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7506205. [Google Scholar] [CrossRef]
- Sun, H.; Bai, J.; Yang, F.; Bai, X. Receptive-field and direction induced attention network for infrared dim small target detection with a large-scale dataset irdst. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5000513. [Google Scholar] [CrossRef]
- Hu, X.; Chen, C.L.P.; Zhang, T. Dynamic Broad Metric Learning. IEEE Trans. Artif. Intell. 2025, 1–14. [Google Scholar] [CrossRef]
- Li, S.; Zhang, T.; Chen, C.L.P. SIA-Net: Sparse Interactive Attention Network for Multimodal Emotion Recognition. IEEE Trans. Comput. Soc. Syst. 2024, 11, 6782–6794. [Google Scholar] [CrossRef]
- Li, C.; Wang, B.; Zheng, J.; Zhang, Y.; Chen, C.L.P. Unsigned Road Incidents Detection Using Improved RESNET From Driver-View Images. IEEE Trans. Artif. Intell. 2025, 6, 1203–1216. [Google Scholar] [CrossRef]
- Wang, B.; Li, C.; Zou, W.; Zheng, Q. Foreign Object Detection Network for Transmission Lines from Unmanned Aerial Vehicle Images. Drones 2024, 8, 361. [Google Scholar] [CrossRef]
- Cao, Z.; Lu, Y.; Xin, H.; Wang, R.; Nie, F.; Sebilo, M. Superpixel-Based Bipartite Graph Clustering Enriched with Spatial Information for Hyperspectral and LiDAR Data. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5505115. [Google Scholar] [CrossRef]
- Yuan, S.; Qin, H.; Yan, X.; Akhtar, N.; Mian, A. Sctransnet: Spatial-channel cross transformer network for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5002615. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. Isnet: Shape matters for infrared small target detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 867–876. [Google Scholar]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, R.; Zheng, B.; Wang, H.; Fu, Y. Infrared small target detection with scale and location sensitivity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 17490–17499. [Google Scholar]
- Zhang, M.; Yang, H.; Guo, J.; Li, Y.; Gao, X.; Zhang, J. Irprunedet: Efficient infrared small target detection via wavelet structure-regularized soft channel pruning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 7224–7232. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Attentional local contrast networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9813–9824. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, C.L.P.; Wu, M.; Zhang, T. SGB-Net: Scalable Graph Broad Network. IEEE Trans. Neural Netw. Learn. Syst. 2025, 1–15. [Google Scholar] [CrossRef]
- Li, S.; Zhang, T.; Chen, B.; Chen, C.P. MIA-Net: Multi-Modal Interactive Attention Network for Multi-Modal Affective Analysis. IEEE Trans. Affect. Comput. 2023, 14, 2796–2809. [Google Scholar] [CrossRef]
- Wu, T.; Li, B.; Luo, Y.; Wang, Y.; Xiao, C.; Liu, T.; Yang, J.; An, W.; Guo, Y. Mtu-net: Multilevel transunet for space-based infrared tiny ship detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5601015. [Google Scholar] [CrossRef]
- Liu, F.; Gao, C.; Chen, F.; Meng, D.; Zuo, W.; Gao, X. Infrared small and dim target detection with transformer under complex backgrounds. IEEE Trans. Image Process. 2023, 32, 12. [Google Scholar] [CrossRef]
- Yu, J.; Li, L.; Li, X.; Jiao, J.; Su, X.; Chen, F. Infrared moving small-target detection using strengthened spatial-temporal tri-layer local contrast method. Infrared Phys. Technol. 2024, 140, 105367. [Google Scholar] [CrossRef]
- Li, C.; Huang, Z.; Xie, X.; Li, W. Ist-transnet: Infrared small target detection based on transformer network. Infrared Phys. Technol. 2023, 132, 104723. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2103.13915. [Google Scholar]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Si, C.; Yu, W.; Zhou, P.; Zhou, Y.; Wang, X.; Yan, S. Inception transformer. arXiv 2022, arXiv:2205.12956. [Google Scholar]
- Park, N.; Kim, S. How do vision transformers work? In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022.
- Zhao, T.; Cao, J.; Hao, Q.; Bao, C.; Shi, M. Res-swintransformer with local contrast attention for infrared small target detection. Remote Sens. 2023, 15, 4387. [Google Scholar] [CrossRef]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. arXiv 2020, arXiv:2006.16236. [Google Scholar]
- Cai, H.; Li, J.; Hu, M.; Gan, C.; Han, S. Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 17302–17313. [Google Scholar]
- Heo, B.; Park, S.; Han, D.; Yun, S. Rotary position embedding for vision transformer. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Su, J.; Ahmed, M.; Lu, Y.; Pan, S.; Bo, W.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. arXiv 2023, arXiv:2104.09864. [Google Scholar] [CrossRef]
- Tom, V.T.; Peli, T.; Leung, M.; Bondaryk, J.E. Morphology-based algorithm for point target detection in infrared backgrounds. In Signal and Data Processing of Small Targets 1993: Volume 1954; SPIE: San Francisco, CA, USA, 1993; pp. 2–11. [Google Scholar]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Signal and Data Processing of Small Targets 1999: Volume 3809; SPIE: San Francisco, CA, USA, 1999; pp. 74–83. [Google Scholar]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared small target detection utilizing the multiscale relative local contrast measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Zhang, H.; Zhao, Q.; Zhang, X.; Li, N. Infrared small target detection based on the weighted strengthened local contrast measure. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1670–1674. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Liu, C.; Zhang, H.; Zhao, Q. A local contrast method for infrared small-target detection utilizing a tri-layer window. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1822–1826. [Google Scholar] [CrossRef]
- Moradi, S.; Moallem, P.; Sabahi, M.F. A false-alarm aware methodology to develop robust and efficient multi-scale infrared small target detection algorithm. Infrared Phys. Technol. 2018, 89, 387–397. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared small target detection via non-convex rank approximation minimization joint l2,1 norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y. Reweighted infrared patch-tensor model with both nonlocal and local priors for single-frame small target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, Z. Infrared small target detection based on partial sum of the tensor nuclear norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Venue | Params (M) | OPs (G) | |||
|---|---|---|---|---|---|---|
| RLCM | GRSL2018 | - | - | 14.62 | 65.66 | 1.79 |
| WSLCM | GRSL2021 | - | - | 0.98 | 70.03 | 1502.70 |
| TLLCM | GRSL2019 | - | - | 5.36 | 63.97 | 0.49 |
| MSLCM | IPT2018 | - | - | 5.34 | 59.93 | 0.54 |
| MSPCM | IPT2018 | - | - | 7.33 | 60.27 | 1.52 |
| NRAM | RS2018 | - | - | 15.24 | 70.68 | 1.69 |
| RIPT | JSTARS2018 | - | - | 14.10 | 77.55 | 2.83 |
| PSTNN | RS2019 | - | - | 24.57 | 71.99 | 3.52 |
| MSLSTIPT | RS2023 | - | - | 11.43 | 79.03 | 152.40 |
| ACM | WACV2021 | 0.41 | 2.65 | 59.15 | 90.57 | 2.04 |
| ALCNet | TGRS2021 | 0.44 | 2.19 | 61.59 | 89.56 | 1.44 |
| ISNet | CVPR2022 | 0.96 | >250.29 | 61.85 | 90.23 | 3.15 |
| RDIAN | TGRS2023 | 0.22 | 29.69 | 59.93 | 87.20 | 3.32 |
| DNA-Net | TIP2023 | 4.66 | 111.55 | 64.88 | 89.22 | 2.59 |
| ISTDU-Net | GRSL2022 | 2.82 | 63.66 | 65.71 | 90.57 | 1.37 |
| UIU-Net | TIP2023 | 50.54 | 434.93 | 65.69 | 91.25 | 1.34 |
| IRPruneDet | AAAI2024 | 0.18 | - | 64.54 | 91.74 | 1.60 |
| MSHNet | CVPR2024 | 4.06 | 48.39 | 67.87 | 92.86 | 0.88 |
| SCTransNet | TGRS2024 | 11.19 | 40.46 | 68.07 | 93.27 | 1.07 |
| MTUnet | TGRS2023 | - | - | 66.11 | 93.27 | 3.68 |
| LGGNet | ICASSP2024 | 4.30 | 42.00 | 65.01 | 90.57 | 1.55 |
| IstdVit | Ours | 2.92 | 2.89 | 70.22 | 94.59 | 1.81 |
| Method | Venue | Params (K) | OPs (G) | |||
|---|---|---|---|---|---|---|
| RLCM | GRSL2018 | - | - | 15.13 | 66.34 | 16.29 |
| WSLCM | GRSL2021 | - | - | 0.84 | 74.57 | 5239.16 |
| TLLCM | GRSL2019 | - | - | 7.05 | 62.01 | 4.61 |
| MSLCM | IPT2018 | - | - | 6.64 | 56.82 | 2.56 |
| MSPCM | IPT2018 | - | - | 5.85 | 55.86 | 11.59 |
| NRAM | RS2018 | - | - | 6.93 | 56.4 | 1.92 |
| RIPT | JSTARS2018 | - | - | 29.44 | 91.85 | 34.43 |
| PSTNN | RS2019 | - | - | 14.84 | 66.13 | 4.41 |
| MSLSTIPT | RS2023 | - | - | 8.34 | 47.39 | 8.81 |
| ACM | WACV2021 | 0.41 | 0.66 | 64.85 | 96.72 | 2.85 |
| ALCNet | TGRS2021 | 0.44 | 0.54 | 61.13 | 97.24 | 2.90 |
| ISNet | CVPR2022 | 0.96 | >62.57 | 81.23 | 97.77 | 0.63 |
| RDIAN | TGRS2023 | 0.22 | 7.42 | 82.41 | 98.83 | 1.36 |
| DNA-Net | TIP2023 | 4.66 | 27.88 | 89.81 | 98.90 | 0.64 |
| ISTDU-Net | GRSL2022 | 2.82 | 15.92 | 92.34 | 98.51 | 0.55 |
| UIU-Net | TIP2023 | 50.54 | 108.73 | 90.51 | 98.83 | 0.83 |
| MSHNet | CVPR2024 | 4.06 | 12.09 | 80.55 | 97.99 | 1.17 |
| SCTransNet | TGRS2024 | 11.19 | 20.24 | 94.09 | 98.62 | 0.42 |
| IstdVit | Ours | 2.92 | 0.73 | 93.67 | 99.31 | 0.02 |
| Method | Baseline | +Vanilla Transformer | +MLT | +RoPE |
|---|---|---|---|---|
| 66.73 | 69.52 | 69.44 | 70.22 | |
| 86.86 | 89.89 | 93.91 | 94.59 | |
| 1.71 | 1.64 | 2.11 | 1.81 | |
| Params (M) | 2.91 | 3.40 | 2.92 | 2.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Wang, Y.; Mao, Q.; Cao, J.; Zhang, H.; Zhang, L. Lightweight Infrared Small Target Detection Method Based on Linear Transformer. Remote Sens. 2025, 17, 2016. https://doi.org/10.3390/rs17122016
Wang B, Wang Y, Mao Q, Cao J, Zhang H, Zhang L. Lightweight Infrared Small Target Detection Method Based on Linear Transformer. Remote Sensing. 2025; 17(12):2016. https://doi.org/10.3390/rs17122016
Chicago/Turabian StyleWang, Bingshu, Yifan Wang, Qianchen Mao, Jingzhuo Cao, Han Zhang, and Laixian Zhang. 2025. "Lightweight Infrared Small Target Detection Method Based on Linear Transformer" Remote Sensing 17, no. 12: 2016. https://doi.org/10.3390/rs17122016
APA StyleWang, B., Wang, Y., Mao, Q., Cao, J., Zhang, H., & Zhang, L. (2025). Lightweight Infrared Small Target Detection Method Based on Linear Transformer. Remote Sensing, 17(12), 2016. https://doi.org/10.3390/rs17122016