
MFA-SCDNet: A Semantic Change Detection Network for Visible and Infrared Image Pairs


Abstract
1. Introduction
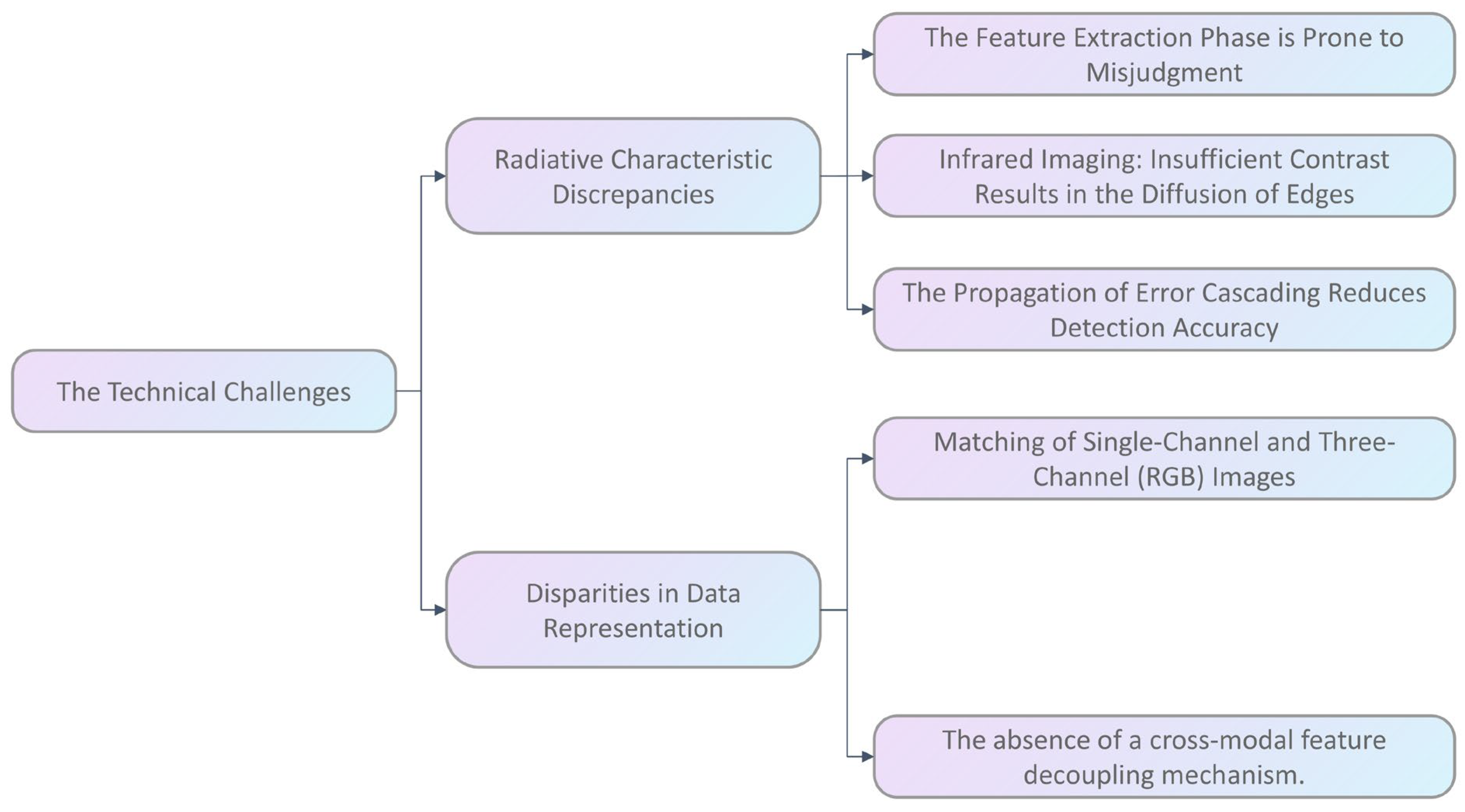
- The inherent divergence in radiometric characteristics between infrared and visible spectral domains introduces significant challenges for cross-modal SCD. Even when imaging identical targets within co-registered scenes, sensor-specific feature discrepancies emerge: visible sensors capture high-resolution texture patterns under adequate illumination, whereas infrared detectors record thermal emission profiles with inherent low contrast and edge diffusion effects. This modality gap frequently induces neural networks to misinterpret sensor-specific artifacts as genuine semantic changes during feature extraction, ultimately compromising change detection accuracy through cascading error propagation.
- The distinct sensing mechanisms between optical and infrared modalities produce fundamentally divergent data representations: visible sensors encode tricolor spectral signatures (RGB channels) through photon reflection, while infrared detectors capture monochromatic thermal intensity profiles corresponding to target emissivity. This representational dichotomy creates asymmetric feature spaces, with visible imagery containing multispectral signatures versus infrared’s thermodynamic characteristics. Current SCD architectures exhibit insufficient cross-modal feature decoupling mechanisms, leading to asymmetric feature learning that preferentially weights photometric patterns while attenuating critical thermal discriminators during multimodal fusion processes.
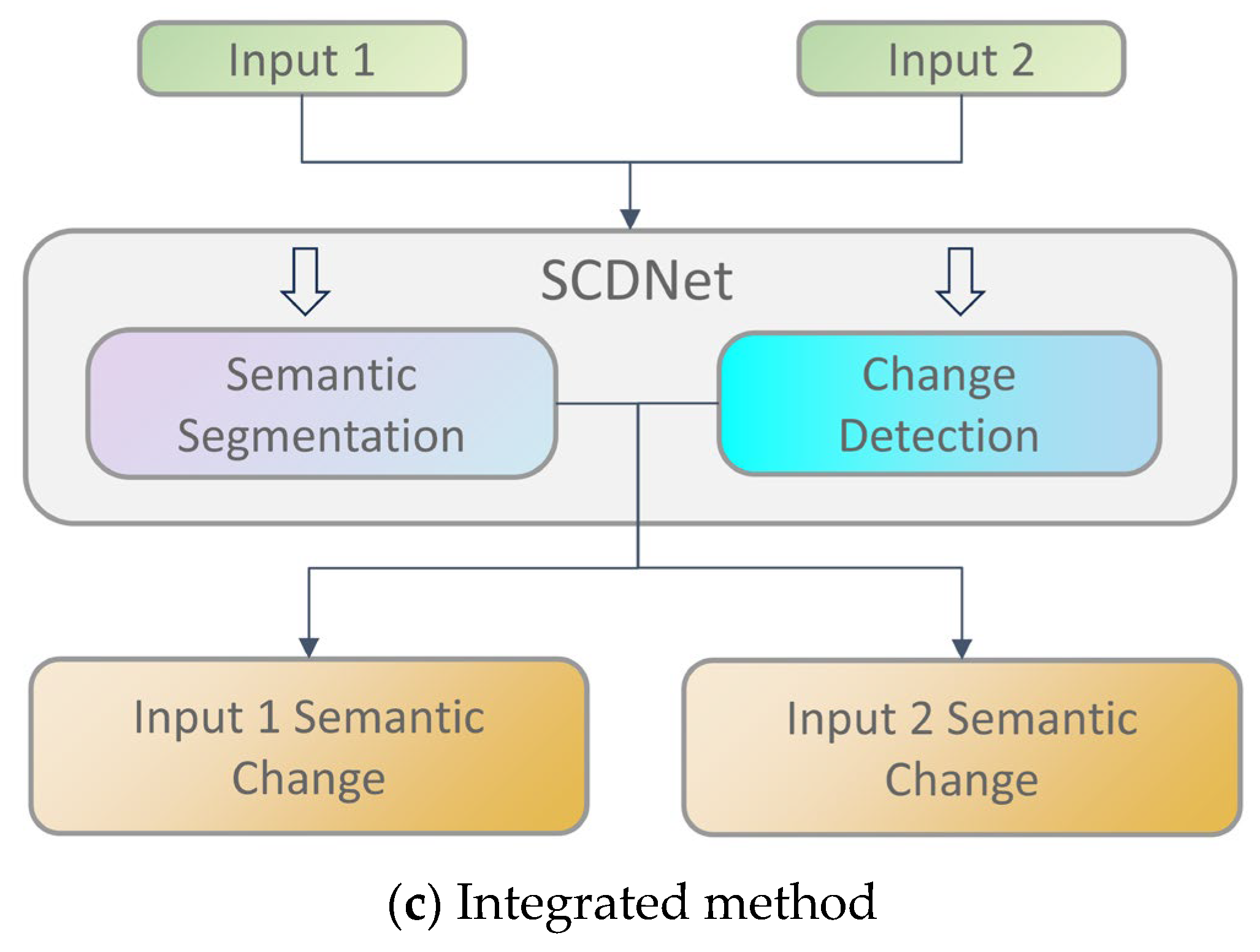
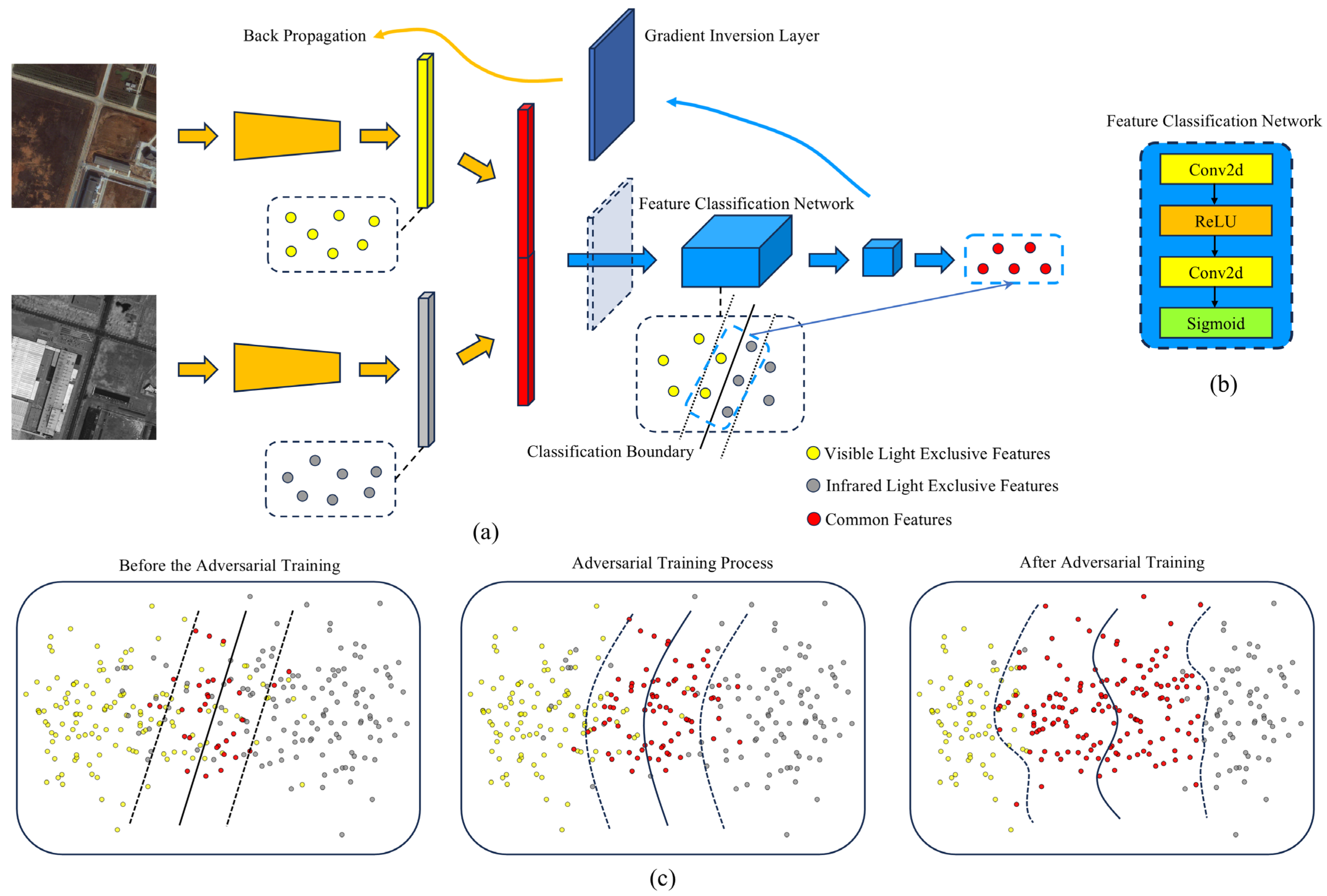
- We propose a cross-modal SCD network, MFA-SCDNet, which utilizes adversarial training tasks to filter features from heterogeneous images. This approach extracts common features that are minimally affected by modal changes in both visible light and infrared images for effective change information detection. Furthermore, we combine the change information with semantic information to obtain semantic change results.
- To address the distinct frequency requirements of change detection (high-frequency edge variations) and semantic recognition (low-frequency semantic information), we designed an infrared feature enhancement module. This component extracts and integrates both high-frequency and low-frequency components from infrared imagery, generating an enhanced representation optimized for downstream semantic feature extraction and change detection.
- We propose a multi-task loss function that integrates cross-entropy loss for semantic segmentation, weighted focal loss for change detection, and a shared feature loss from adversarial training. This approach aims to avoid error accumulation caused by independent task processing in traditional methods, enabling end-to-end optimization.
2. Related Work
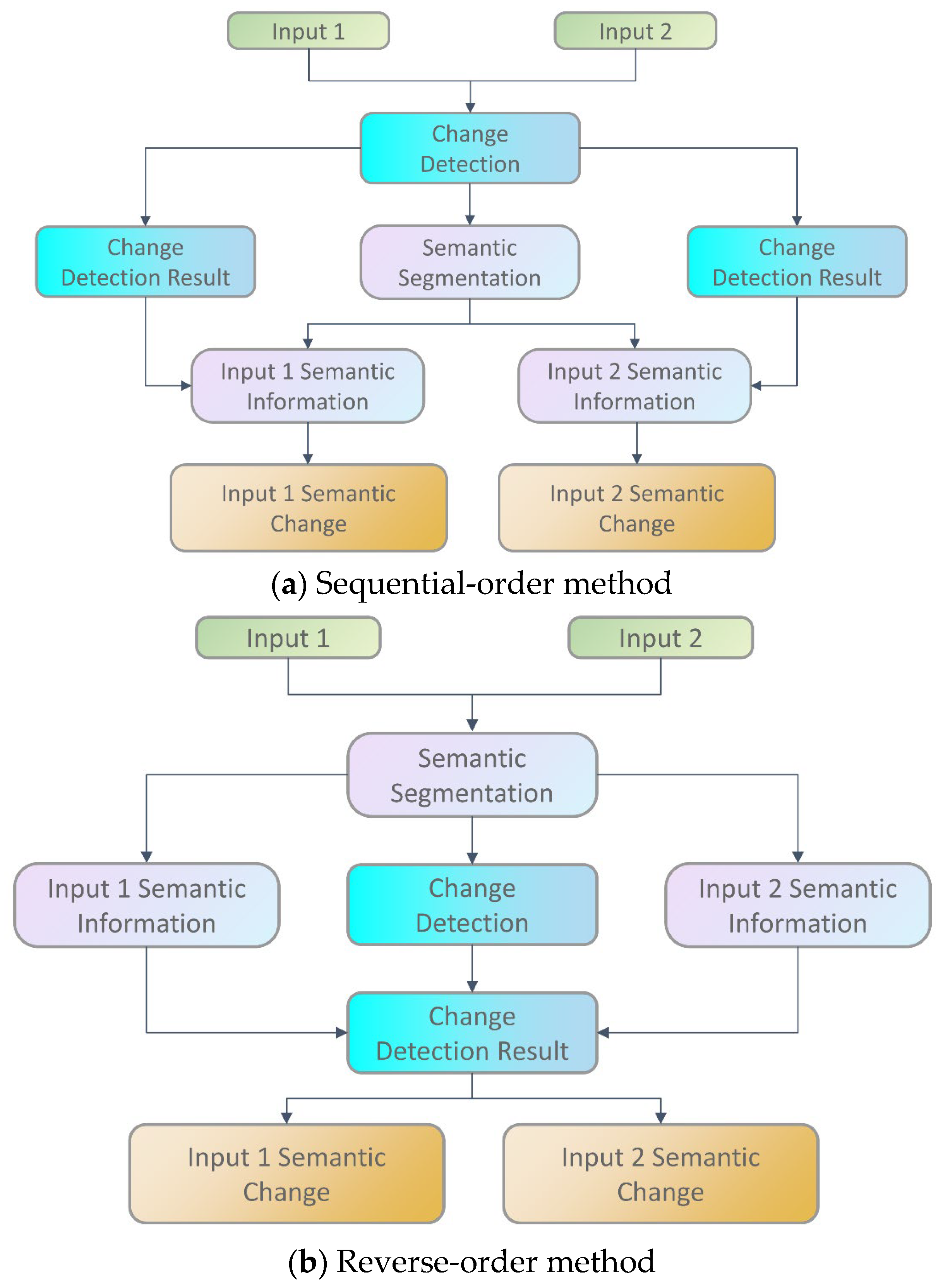
2.1. Two-Stage Framework: Change Detection Followed by Semantic Classification
2.2. Cross-Modal Comparison via Bitemporal Semantic Segmentation
2.3. End-to-End Multi-Task Learning for Joint Semantic and Change Detection
3. Methodology
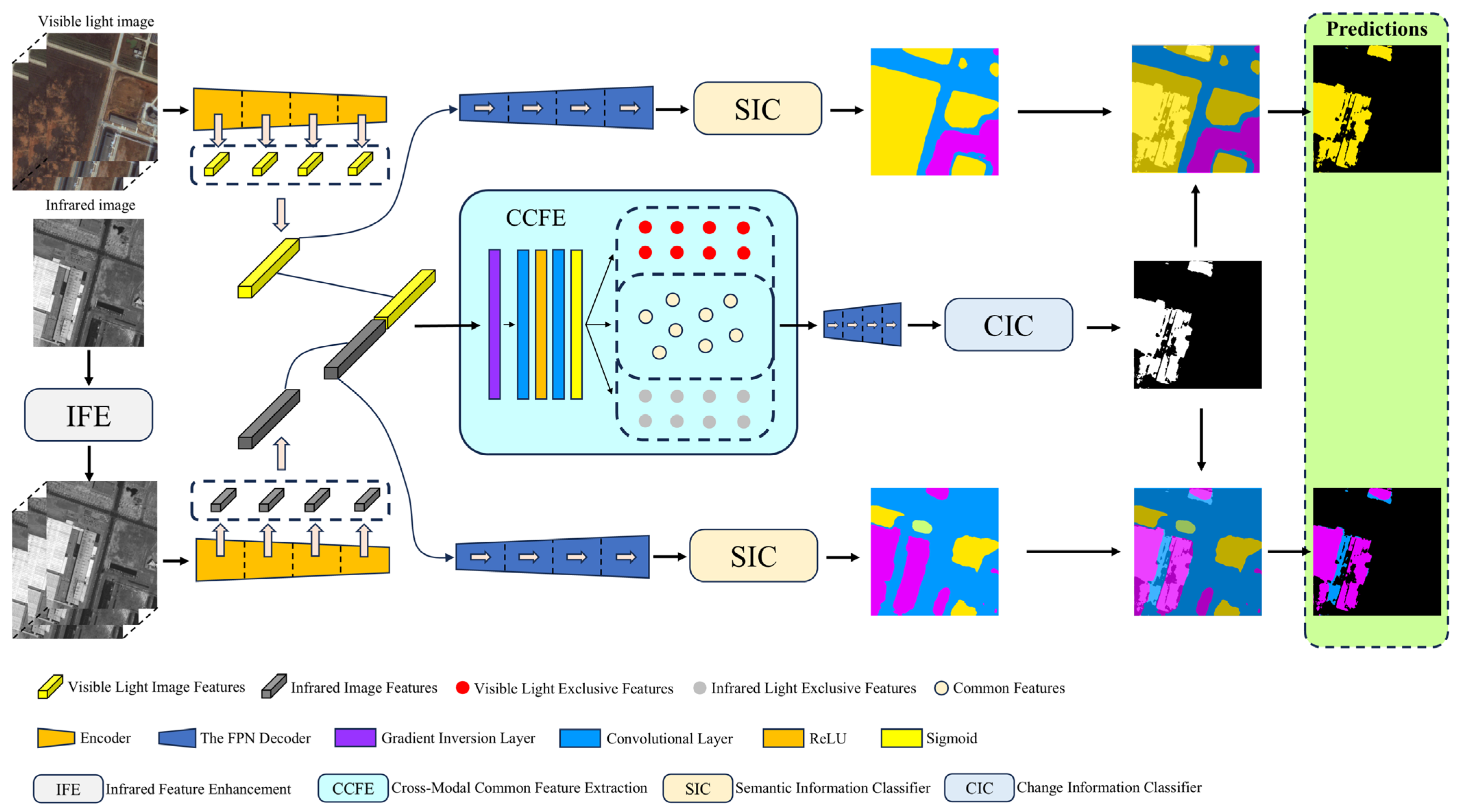
3.1. Overall Structure of the Network
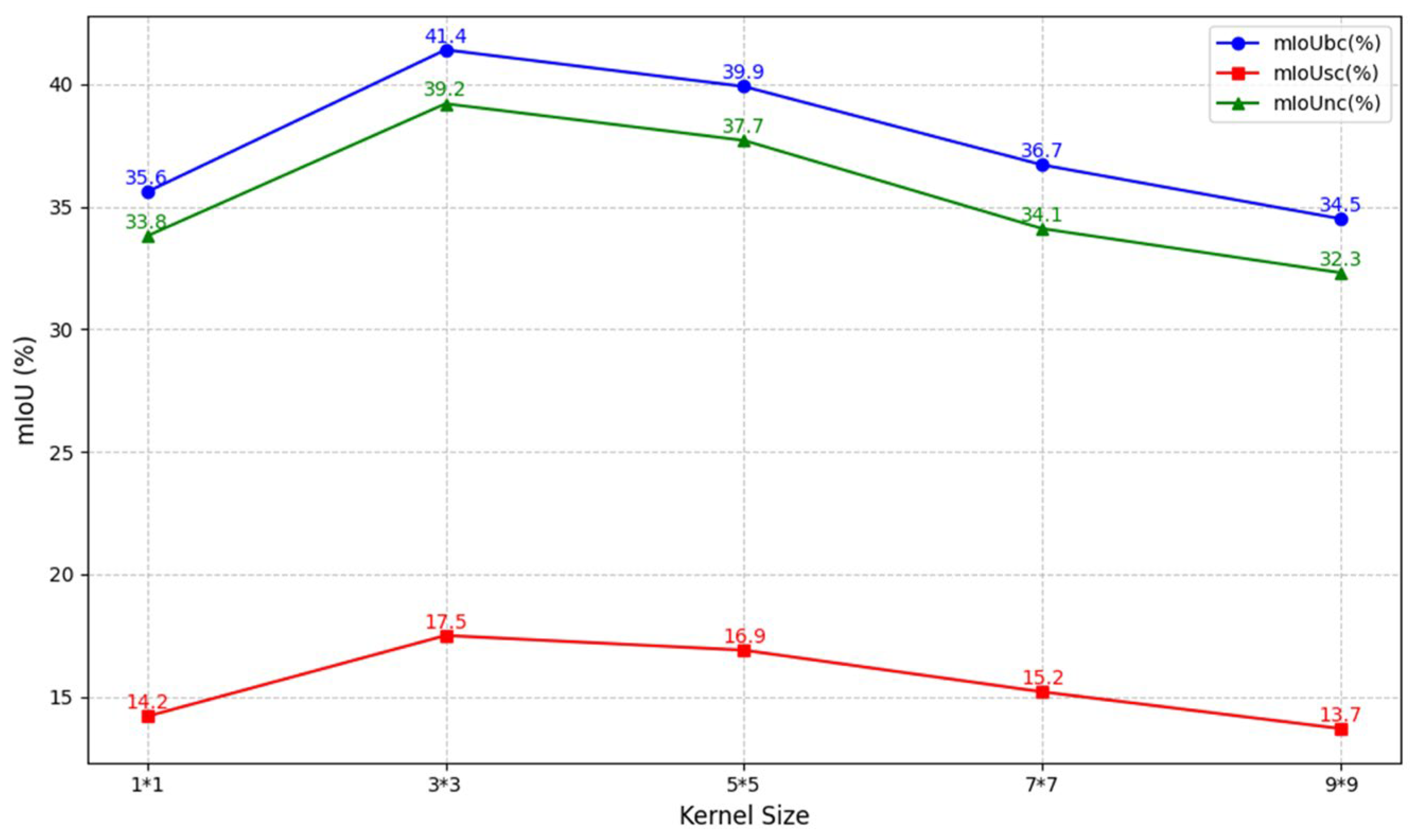
3.2. Infrared Feature Enhancement (IFE)
3.3. Encoder and Decoder
3.4. Cross-Modal Common Feature Extraction (CCFE)
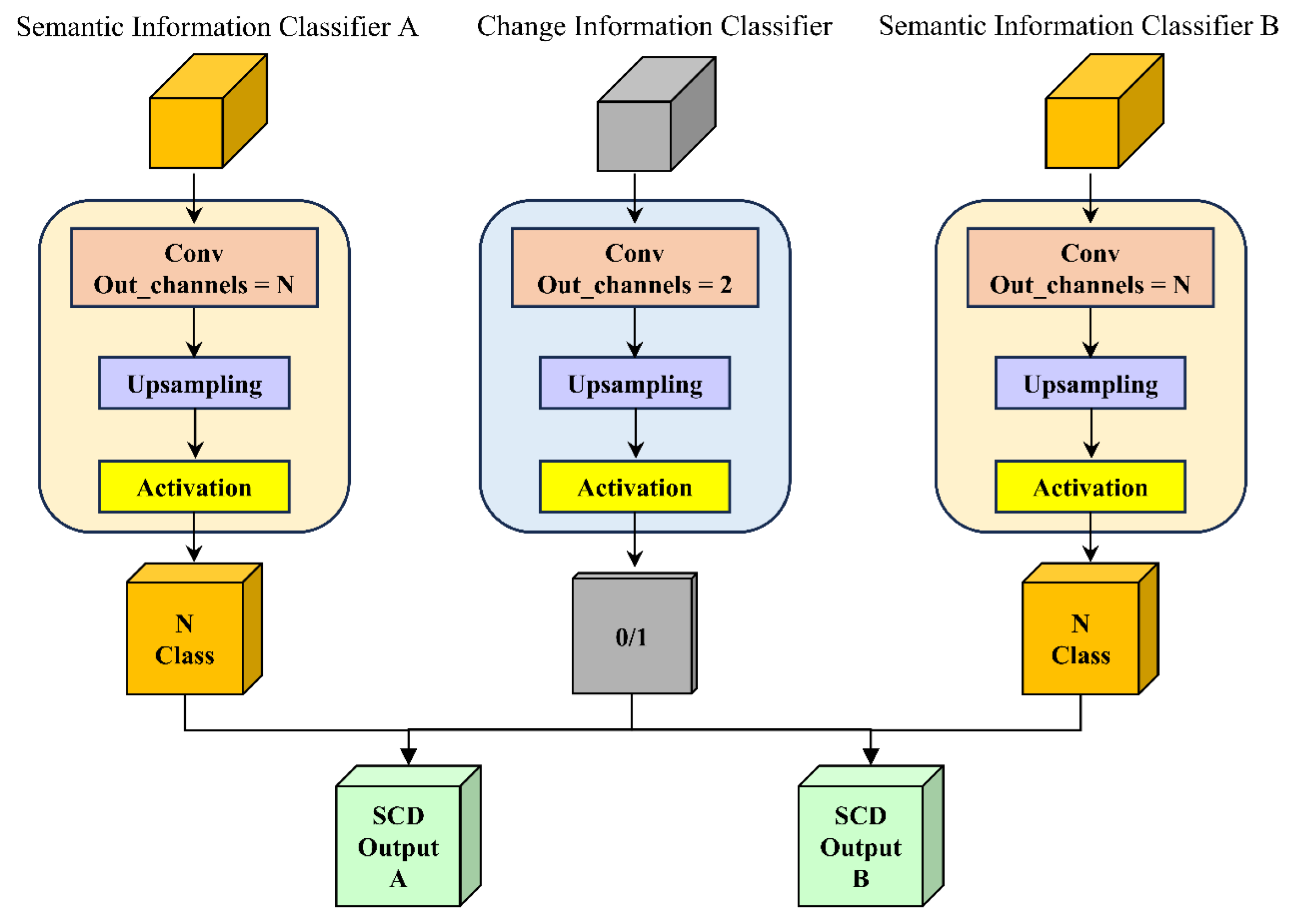
3.5. Information Classifier
3.6. Loss Functions
4. Results
4.1. Experiments Settings
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Benchmark Methods
- ClearSCD: This network simulates the dependency relationship between semantics and variations, incorporating multiple innovative modules to enhance model performance [5].
- MTL: By merging the outputs of multiple encoders, this approach addresses the issue of how multi-task networks manage feature interactions among sub-tasks in SCD [8].
- SCanNet: The network jointly considers spatiotemporal dependencies to enhance the accuracy of SCD and introduces a semantic learning scheme to guide the learning of semantic variations [55].
- SCD-SAM: The introduction of the Segment Anything Module (SAM) aims to enhance SCD in high-resolution remote sensing images [56].
- The CdSC model employs a twin-vision transformer network to address the issue of high consistency reliance within dual-temporal feature spaces in traditional SCD architectures. This dependency often leads to false positives or missed detections in the identification of change regions [57].
- HRSCD.str4: This model features a distinct encoder–decoder architecture for BCD and semantic segmentation, which facilitates the direct transfer of semantic features to the CD branch through skip connections, thereby enabling information sharing [39].
4.2. Experiments on the HanYang Series Dataset
4.2.1. Results and Analysis of Binary Change Detection
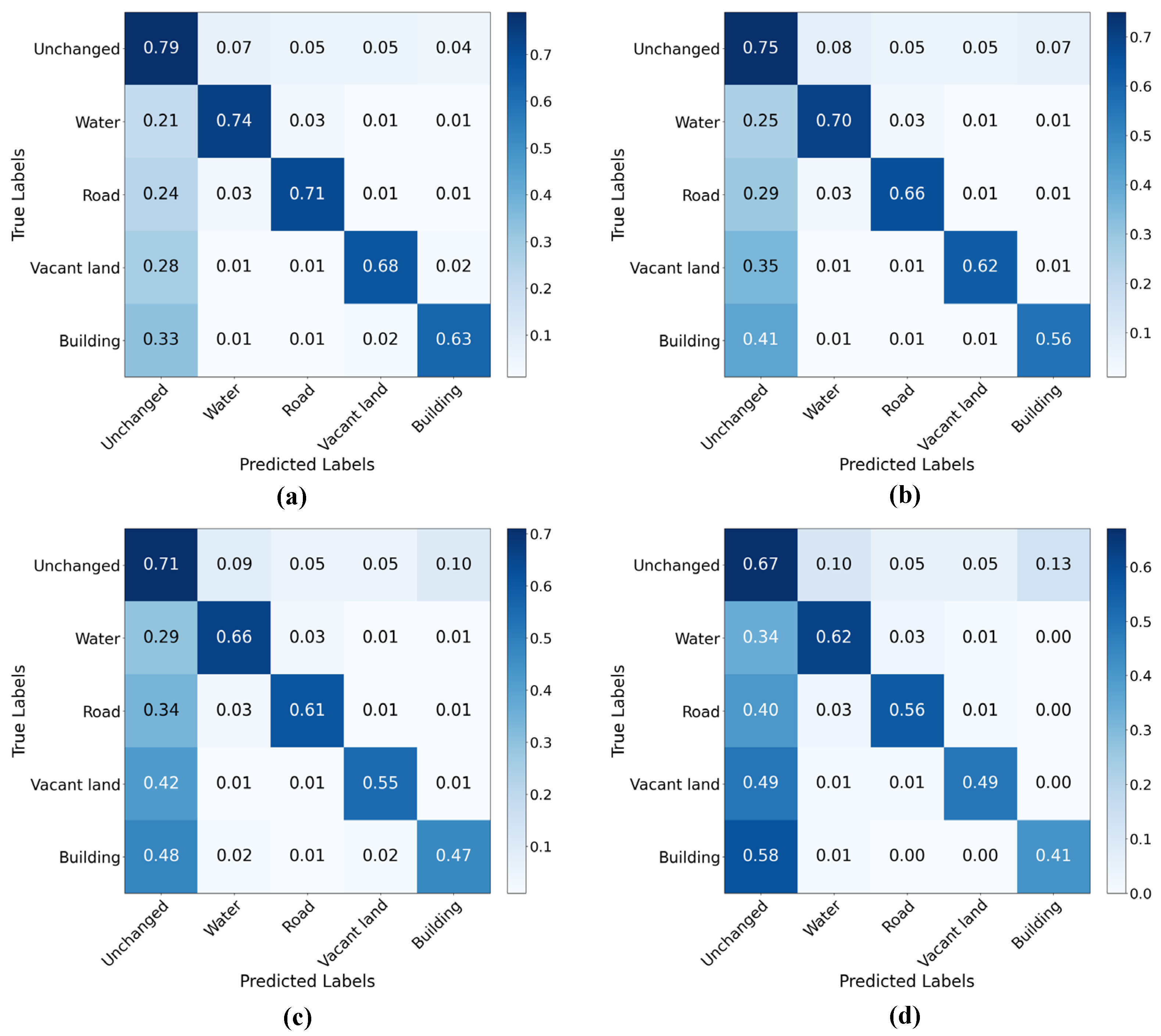
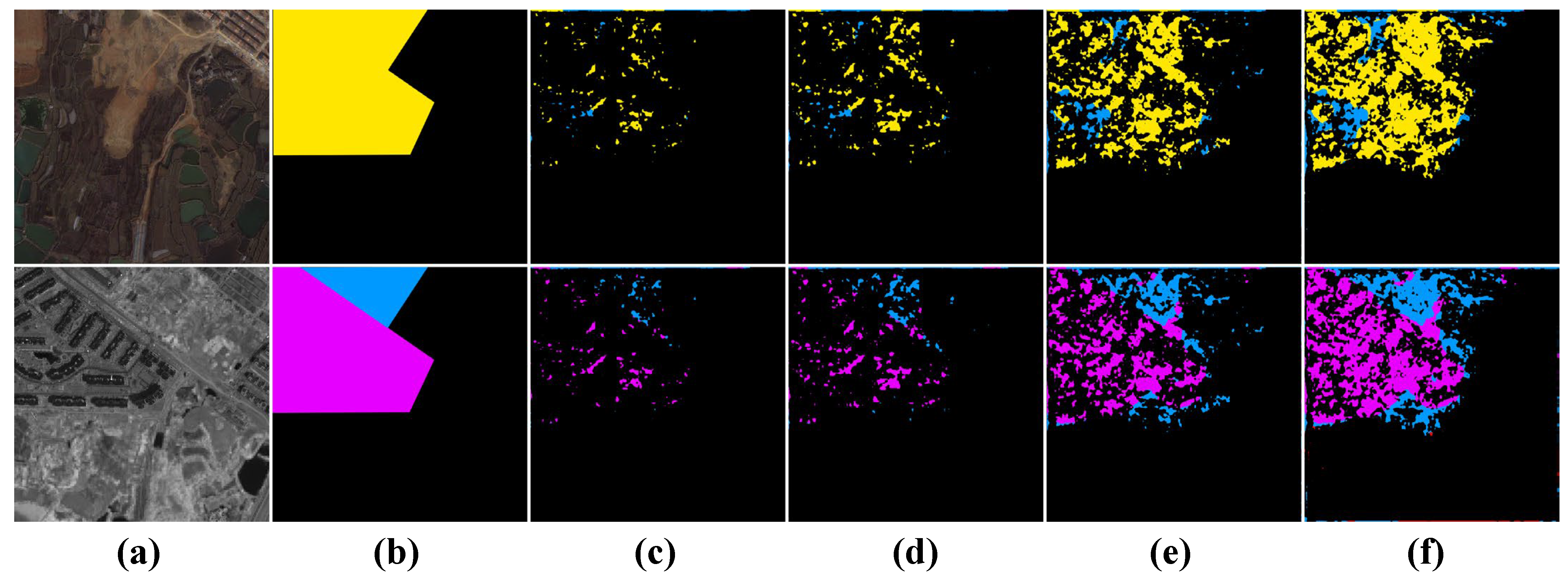
4.2.2. Results and Analysis of SCD
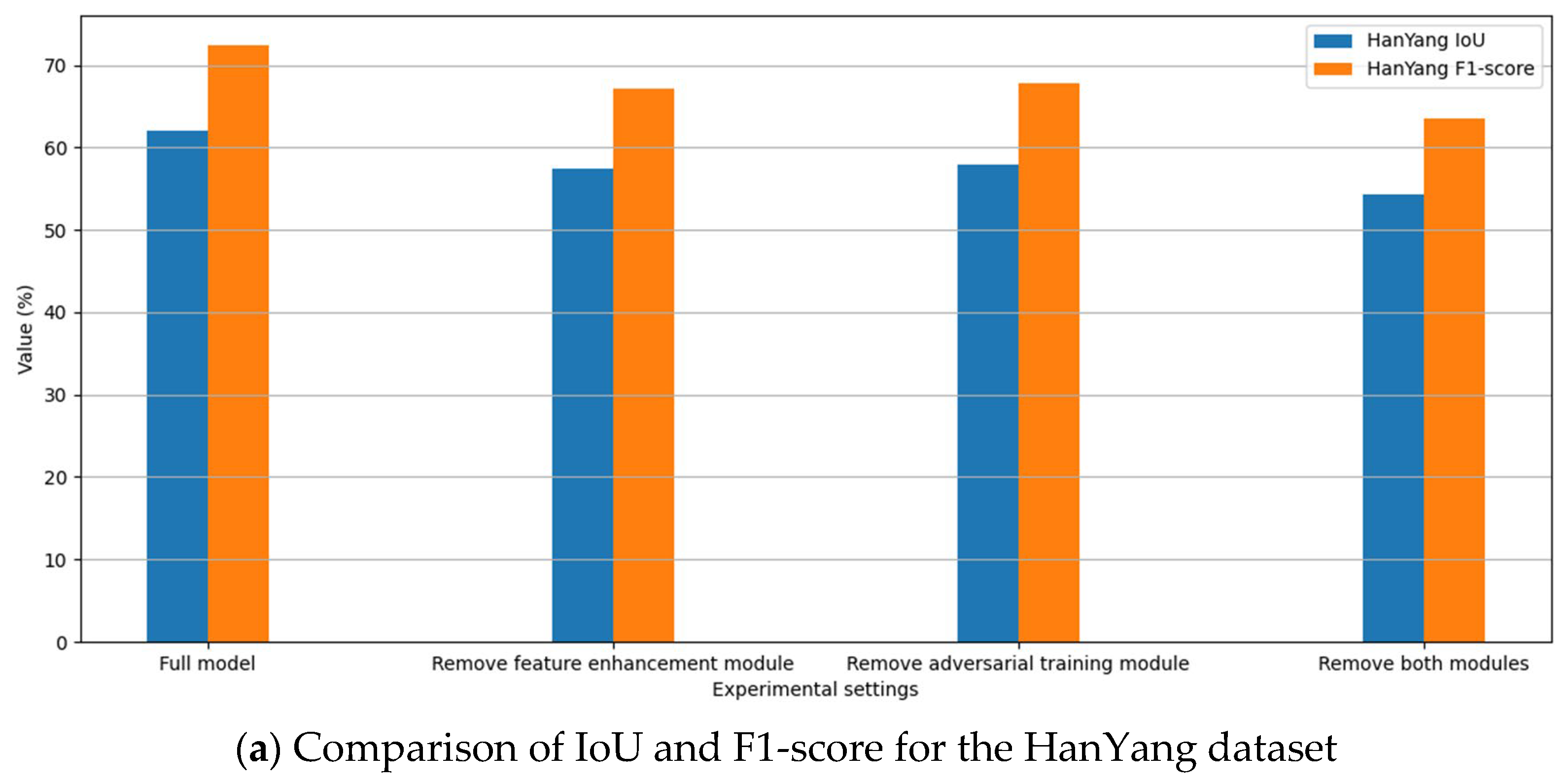
4.2.3. Ablation Studies
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SCD | Semantic Change Detection |
| BCD | Binary Change Detection |
| IFE | Infrared feature enhancement |
| CCFE | Linear dichroism |
References
- He, J.; Jiang, X.; Hao, Z.; Zhu, M.; Gao, W.; Liu, S. LPHOG: A Line Feature and Point Feature Combined Rotation Invariant Method for Heterologous Image Registration. Remote Sens. 2023, 15, 4548. [Google Scholar] [CrossRef]
- Zhu, X.; Yang, Z.; Zoubir, T. Research on the Matching Algorithm for Heterologous Image After Deformation in the Same Scene. Discret. Contin. Dyn. Syst. 2019, 12, 1281–1296. [Google Scholar]
- Jiang, C.; Ren, H.; Yang, H.; Huo, H.; Zhu, P.; Yao, Z.; Li, J.; Sun, M.; Yang, S. M2FNet: Multi-Modal Fusion Network for Object Detection from Visible and Thermal Infrared Images. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103918. [Google Scholar] [CrossRef]
- Hou, Z.; Li, X.; Yang, C.; Ma, S.; Yu, W.; Wang, Y. Dual-Branch Network Object Detection Algorithm Based on Dual-Modality Fusion of Visible and Infrared Images. Multimed. Syst. 2024, 30, 333. [Google Scholar] [CrossRef]
- Tang, K.; Xu, F.; Chen, X.; Dong, Q.; Yuan, Y.; Chen, J. The ClearSCD Model: Comprehensively Leveraging Semantics and Change Relationships for Semantic Change Detection in High Spatial Resolution Remote Sensing Imagery. ISPRS-J. Photogramm. Remote Sens. 2024, 211, 299–317. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, M.; Gong, M.; Zhang, Q.; Jiang, F.; Zheng, H.; Lu, D. Commonality Feature Representation Learning for Unsupervised Multimodal Change Detection. IEEE Trans. Image Process. 2025, 34, 1219–1233. [Google Scholar] [CrossRef]
- Wu, Y.; Li, J.H.; Yuan, Y.Z.; Qin, A.K.; Miao, Q.G.; Gong, M.G. Commonality Autoencoder: Learning Common Features for Change Detection from Heterogeneous Images. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4257–4270. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wang, X.; Fang, S.; Zhao, J.; Yang, S.; Li, W. A Decoder-Focused Multitask Network for Semantic Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5609115. [Google Scholar] [CrossRef]
- Han, Y.; Zheng, C.; Liu, X.; Tian, Y.; Dong, Z. Burned Area and Burn Severity Mapping with a Transformer-Based Change Detection Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 13866–13880. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, X.; Weng, Q. A Multi-Scale Weakly Supervised Learning Method with Adaptive Online Noise Correction for High-Resolution Change Detection of Built-Up Areas. Remote Sens. Environ. 2023, 297, 113779. [Google Scholar] [CrossRef]
- Chantharaj, S.; Pornratthanapong, K.; Chitsinpchayakun, P.; Panboonyuen, T.; Vateekul, P.; Lawavirojwong, S.; Srestasathiern, P.; Jitkajornwanich, K. Semantic Segmentation on Medium-Resolution Satellite Images Using Deep Convolutional Networks with Remote Sensing Derived Indices. In Proceedings of the 15th International Joint Conference on Computer Science and Software Engineering (JCSSE), Nakhonpathom, Thailand, 11–13 July 2018. [Google Scholar]
- Cao, Y.; Feng, W.; Quan, Y.; Bao, W.; Dauphin, G.; Ren, A.; Yuan, X.; Xing, M. Forest Disaster Detection Method Based on Ensemble Spatial-Spectral Genetic Algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7375–7390. [Google Scholar] [CrossRef]
- Han, T.; Tang, Y.; Chen, Y.; Zou, B.; Feng, H. Global Structure Graph Mapping for Multimodal Change Detection. Int. J. Digit. Earth 2024, 17, 2347457. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, L.; Zhang, L. A Scene Change Detection Framework for Multi-Temporal Very High Resolution Remote Sensing Images. Signal Process. 2016, 124, 184–197. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, L.; Du, B. Kernel Slow Feature Analysis for Scene Change Detection. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2367–2384. [Google Scholar] [CrossRef]
- Lal, A.; Anouncia, S. Modernizing the Multi-Temporal Multispectral Remotely Sensed Image Change Detection for Global Maxima Through Binary Particle Swarm Optimization. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 95–103. [Google Scholar] [CrossRef]
- Kusetogullari, H.; Yavariabdi, A.; Celik, T. Unsupervised Change Detection in Multitemporal Multispectral Satellite Images Using Parallel Particle Swarm Optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2151–2164. [Google Scholar] [CrossRef]
- Qu, J.; Yang, P.; Dong, W.; Zhang, X.; Li, Y. A Semi-Supervised Multiscale Convolutional Sparse Coding-Guided Deep Interpretable Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5531314. [Google Scholar] [CrossRef]
- Yao, F.; Wang, Y. Tracking Urban Geo-Topics Based on Dynamic Topic Model. Comput. Environ. Urban Syst. 2020, 79, 101419. [Google Scholar] [CrossRef]
- Lv, P.; Cheng, P.; Ma, C.; Zhong, Y. A Semi-Supervised Semantic and Spatial Change Detail Retention Network for Semantic Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4416516. [Google Scholar] [CrossRef]
- Niu, Y.; Guo, H.; Lu, J.; Ding, L.; Yu, D. SMNet: Symmetric Multi-Task Network for Semantic Change Detection in Remote Sensing Images Based on CNN and Transformer. Remote Sens. 2023, 15, 949. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, Y.; Zhang, L. Semantic Change Detection Based on Supervised Contrastive Learning for High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5649720. [Google Scholar] [CrossRef]
- Ji, Z.; Wang, X.; Wang, Z.; Li, G. An Enhanced and Unsupervised Siamese Network with Superpixel-Guided Learning for Change Detection in Heterogeneous Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19451–19466. [Google Scholar] [CrossRef]
- Li, W.; Wang, X.; Li, G.; Geng, B.C.; Varshney, P.K. A Copula-Guided In-Model Interpretable Neural Network for Change Detection in Heterogeneous Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4700817. [Google Scholar] [CrossRef]
- Han, P.; Ma, C.; Li, Q.; Leng, P.; Bu, S.; Li, K. Aerial Image Change Detection Using Dual Regions of Interest Networks. Neurocomputing 2019, 349, 190–201. [Google Scholar] [CrossRef]
- Kwan, C.; Larkin, J. Detection of Small Moving Objects in Long Range Infrared Videos from a Change Detection Perspective. Photonics 2021, 8, 394. [Google Scholar] [CrossRef]
- Mirka, B.; Stow, D.; Paulus, G.; Loerch, A.C.; Coulter, L.L.; An, L.; Lewison, R.L.; Pflüger, L.S. Evaluation of Thermal Infrared Imaging from Uninhabited Aerial Vehicles for Arboreal Wildlife Surveillance. Environ. Monit. Assess. 2022, 194, 512. [Google Scholar] [CrossRef]
- Bian, L.; Cao, F.; Zhao, H.; Xiang, F.; Sun, H.; Wang, M.; Li, L. Self-Powered Perovskite/Si Bipolar Response Photodetector for Visible and Near-Infrared Dual-Band Imaging and Secure Optical Communication. Laser Photon. Rev. 2024, 19, 1. [Google Scholar] [CrossRef]
- Kurban, T. Fusion of Remotely Sensed Infrared and Visible Images Using Shearlet Transform and Backtracking Search Algorithm. Int. J. Remote Sens. 2021, 42, 5087–5104. [Google Scholar] [CrossRef]
- Fang, H.; Wei, Y.; Luo, H.; Hu, Q. Detection of Building Shadow in Remote Sensing Imagery of Urban Areas with Fine Spatial Resolution Based on Saturation and Near-Infrared Information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2695–2706. [Google Scholar] [CrossRef]
- Wang, R.; Wu, H.; Qiu, H.; Wang, F.; Liu, X.; Cheng, X. A Difference Enhanced Neural Network for Semantic Change Detection of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5509205. [Google Scholar] [CrossRef]
- Xiang, S.; Wang, M.; Jiang, X.; Xie, G.; Zhang, Z.; Tang, P. Dual-Task Semantic Change Detection for Remote Sensing Images Using the Generative Change Field Module. Remote Sens. 2021, 13, 3336. [Google Scholar] [CrossRef]
- Feng, H.; Dai, X.; Chai, L.; Su, B.; Zhang, T.; Xiao, C. Landsat Data-Driven Identification of Surface Soil Freeze and Thaw States: A Comparison of Various Target Detection and Semantic Segmentation Models. Int. J. Digit. Earth 2024, 17, 2413889. [Google Scholar] [CrossRef]
- Khoshboresh-Masouleh, M.; Shah-Hosseini, R. Development and Evaluation of a Deep Learning Model for Real-Time Ground Vehicle Semantic Segmentation from UAV-Based Thermal Infrared Imagery. ISPRS-J. Photogramm. Remote Sens. 2019, 155, 172–186. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, X.; Bao, L.; Yin, H.; Jiang, Q.; Zhang, J. AGFNet: Adaptive Gated Fusion Network for RGB-T Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2025, 26, 6477–6492. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Tian, S.; Ma, A.; Zhang, L. ChangeMask: Deep Multi-Task Encoder-Transformer-Decoder Architecture for Semantic Change Detection. ISPRS-J. Photogramm. Remote Sens. 2022, 183, 228–239. [Google Scholar] [CrossRef]
- Zheng, D.; Wu, Z.; Liu, J.; Xu, Y.; Hung, C.; Wei, Z. Explicit Change-Relation Learning for Change Detection in VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6005005. [Google Scholar] [CrossRef]
- Prasad, J.V.D.; Sreelatha, M.; SuvarnaVani, K. Semantic Land Cover Change Detection Using HarDNet and Dual Path Coronet. Int. J. Remote Sens. 2023, 44, 7857–7875. [Google Scholar] [CrossRef]
- Daudt, R.; Le Saux, B.; Boulch, A.; Gousseau, Y. Multitask Learning for Large-Scale Semantic Change Detection. Comput. Vis. Image Underst. 2019, 187, 102783. [Google Scholar] [CrossRef]
- He, L.; Zhang, M.; Li, Y.; Zhang, J.; Luo, S.; Li, S.; Zhang, X. Change-Guided Similarity Pyramid Network for Semantic Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5637917. [Google Scholar] [CrossRef]
- Jiang, X.; Huang, B.; Zhao, Y. Spatiotemporal Image Fusion with Spectrally Preserved Pre-Prediction: Tackling Complex Land-Cover Changes. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5406114. [Google Scholar] [CrossRef]
- Singh, S.; Tiwari, R.; Sood, V.; Gusain, H.; Prashar, S. Image Fusion of Ku-Band-Based SCATSAT-1 and MODIS Data for Cloud-Free Change Detection Over Western Himalayas. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4302514. [Google Scholar] [CrossRef]
- Benson, I.M.; Helser, T.E.; Barnett, B.K. Fourier Transform Near Infrared Spectroscopy of Otoliths Coupled with Deep Learning Improves Age Prediction for Long-Lived Northern Rockfish. Fish. Res. 2024, 278, 107116. [Google Scholar] [CrossRef]
- Zhang, L.; Ding, X.; Hou, R. Classification Modeling Method for Near-Infrared Spectroscopy of Tobacco Based on Multimodal Convolution Neural Networks. J. Anal. Methods Chem. 2020, 2020, 9652470. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Q.; Chen, L.; Zhang, X.; Yin, Y. Cascaded Cross-Modal Alignment for Visible-Infrared Person Re-Identification. Knowledge-Based Syst. 2024, 305, 112585. [Google Scholar] [CrossRef]
- Yuan, M.; Shi, X.; Wang, N.; Wang, Y.; Wei, X. Improving RGB-Infrared Object Detection with Cascade Alignment-Guided Transformer. Inf. Fusion 2024, 105, 102246. [Google Scholar] [CrossRef]
- Gonzalez, C.; Horrocks, T.; Wedge, D.; Holden, E.; Hackman, N.; Green, T. Anomaly Detection in Fourier Transform Infrared Spectroscopy of Geological Specimens Using Variational Autoencoders. Ore Geol. Rev. 2023, 158, 105478. [Google Scholar] [CrossRef]
- Ma, N.; Peng, Y.; Wang, S. On-Line Hyperspectral Anomaly Detection with Hypothesis Test Based Model Learning. Infrared Phys. Technol. 2019, 97, 15–24. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Zhang, C.; Kuang, G. Multimodal Semantic Consistency-Based Fusion Architecture Search for Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4412414. [Google Scholar] [CrossRef]
- Liao, M.; Tian, S.; Wei, B.; Zhang, Y.; Zou, W.; Li, X. Class-Balanced Sampling and Discriminative Stylization for Domain Generalization Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2024, 26, 2596–2608. [Google Scholar] [CrossRef]
- Zhang, C.; Li, H.; Feng, Z.; He, S. Joint coupled dictionaries-based visible-infrared image fusion method via texture preservation structure in sparse domain. Comput. Vis. Image Underst. 2023, 235, 103781. [Google Scholar] [CrossRef]
- Wan, D.; Lu, R.; Hu, B.; Yin, J.; Shen, S.; Xu, T.; Lang, X. YOLO-MIF: Improved YOLOv8 with Multi-Information Fusion for Object Detection in Gray-Scale Images. Adv. Eng. Inform. 2024, 62, 102709. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Tian, H.; Feng, Z.; Liang, R. Asymptotic Feature Pyramid Network for Labeling Pixels and Regions. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7820–7829. [Google Scholar] [CrossRef]
- Tian, S.; Zhong, Y.; Zheng, Z.; Ma, A.; Tan, X.; Zhang, L. Large-scale deep learning based binary and semantic change detection in ultra high resolution remote sensing imagery: From benchmark datasets to urban application. ISPRS-J. Photogramm. Remote Sens. 2022, 193, 164–186. [Google Scholar] [CrossRef]
- Ding, L.; Zhang, J.; Guo, H.; Zhang, K.; Liu, B.; Bruzzone, L. Joint Spatio-Temporal Modeling for Semantic Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5610814. [Google Scholar] [CrossRef]
- Cheng, Y.; Yang, W.; Li, Y.; Xu, W.; Chang, L.; Li, R. Remote Sensing Semantic Change Detection Based on the Visual Foundation Model. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Athens, Greece, 7–12 July 2024. [Google Scholar]
- Wang, Q.; Jing, W.; Chi, K.; Yuan, Y. Cross-Difference Semantic Consistency Network for Semantic Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4406312. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | HanYang Dataset | |
|---|---|---|
| IoU (%) | F1-Score (%) | |
| SCanNet | 59.5 | 69.6 |
| ClearSCD | 58.8 | 68.1 |
| CdSC | 57.3 | 66.5 |
| SCD-SAM | 56.9 | 66.1 |
| MTL | 56.2 | 65.8 |
| HRSCD.str4 | 53.5 | 62.2 |
| MFA-SCDNet | 62.1 | 72.4 |
| Methods | mIoUbc | mIoUsc | mIoUnc |
|---|---|---|---|
| SCanNet | 39.2 | 16.4 | 37.8 |
| ClearSCD | 38.9 | 16.2 | 36.3 |
| CdSC | 37.4 | 15.5 | 35.5 |
| SCD-SAM | 37.3 | 15.4 | 35.3 |
| MTL | 37.2 | 15.1 | 35.1 |
| HRSCD.str4 | 36.1 | 14.5 | 33.8 |
| MFA-SCDNet | 41.2 | 17.5 | 39.2 |
| Experiment Serial Number | IFE | CCFE |
|---|---|---|
| 1 | √ | √ |
| 2 | √ | |
| 3 | √ | |
| 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Gong, J.; Wen, J.; Wang, Z. MFA-SCDNet: A Semantic Change Detection Network for Visible and Infrared Image Pairs. Remote Sens. 2025, 17, 2011. https://doi.org/10.3390/rs17122011
Li X, Gong J, Wen J, Wang Z. MFA-SCDNet: A Semantic Change Detection Network for Visible and Infrared Image Pairs. Remote Sensing. 2025; 17(12):2011. https://doi.org/10.3390/rs17122011
Chicago/Turabian StyleLi, Xingyu, Jiulu Gong, Jianxiong Wen, and Zepeng Wang. 2025. "MFA-SCDNet: A Semantic Change Detection Network for Visible and Infrared Image Pairs" Remote Sensing 17, no. 12: 2011. https://doi.org/10.3390/rs17122011
APA StyleLi, X., Gong, J., Wen, J., & Wang, Z. (2025). MFA-SCDNet: A Semantic Change Detection Network for Visible and Infrared Image Pairs. Remote Sensing, 17(12), 2011. https://doi.org/10.3390/rs17122011