




ICT-Net: A Framework for Multi-Domain Cross-View Geo-Localization with Multi-Source Remote Sensing Fusion
 ,
,
Abstract
1. Introduction
- A high-precision multi-domain benchmark dataset (BHUniv) is constructed. We construct the BHUniv dataset with sub-meter spatio-temporal alignment, addressing real-world challenges in semi-enclosed environments (e.g., courtyards, indoor–outdoor transitions) and dynamic vegetation variations. Unlike existing datasets, BHUniv integrates adaptive density sampling (20–50 points/km2) and geometric validation via phase correlation analysis, enabling robust evaluation under GPS-degraded scenarios.
- A novel CNN-Transformer synergy framework (ICT-Net) with three key innovations is investigated. These include an attention-guided non-uniform cropping mechanism, a deeply embedded clustering algorithm for fast geographic parsing, and two-stage hierarchical training. By combining global feature alignment with local refinement, it achieves 12.3% better cross-view discrimination than static architectures.
- State-of-the-art performance with practical efficiency. ICT-Net achieves 98.2% R@1 accuracy on CVUSA and 93.8% on BHUniv, surpassing recent methods (e.g., TransGeo, SALAD) while reducing GPU memory usage by 51%. The framework demonstrates 23% higher robustness to vegetation variations and 34% faster inference than Transformer-only baselines.
2. Related Works
2.1. Cross-View Geolocalization Approaches and Datasets
2.2. Cross-Domain Feature Representation Learning
2.3. Hierarchical Feature Learning in Deep Architectures
3. Construction of the BHUniv Dataset
- High-precision georeferencing: Ground images were acquired using DJI Phantom 4 RTK drones equipped with dual-frequency GNSS receivers, achieving centimeter-level positioning accuracy (2.5 cm horizontal RMS error) in the WGS84 coordinate system. Each ground image incorporates EXIF metadata documenting acquisition time, solar azimuth/elevation angles, and sensor parameters.
- Spatio-temporal alignment: Satellite-ground pairs are validated by phase correlation analysis to ensure subpixel geometric consistency, with a standard of displacement error of less than 0.3 m. Temporal synchronization was validated by cross-modal matching of seasonal vegetation patterns and shadow dynamics, particularly critical for mitigating illumination variations between satellite and ground perspectives.
- Dense sampling strategy: Unlike the discrete benchmark CVUSA dataset, the BHUniv dataset adopts a grid-based systematic sampling route of 30 points/ with an adaptive density adjustment mechanism. This was increased to 50 points/ in high feature variability areas such as school buildings and complexes, while maintaining 20 points/ in open areas, as shown in Figure 3.
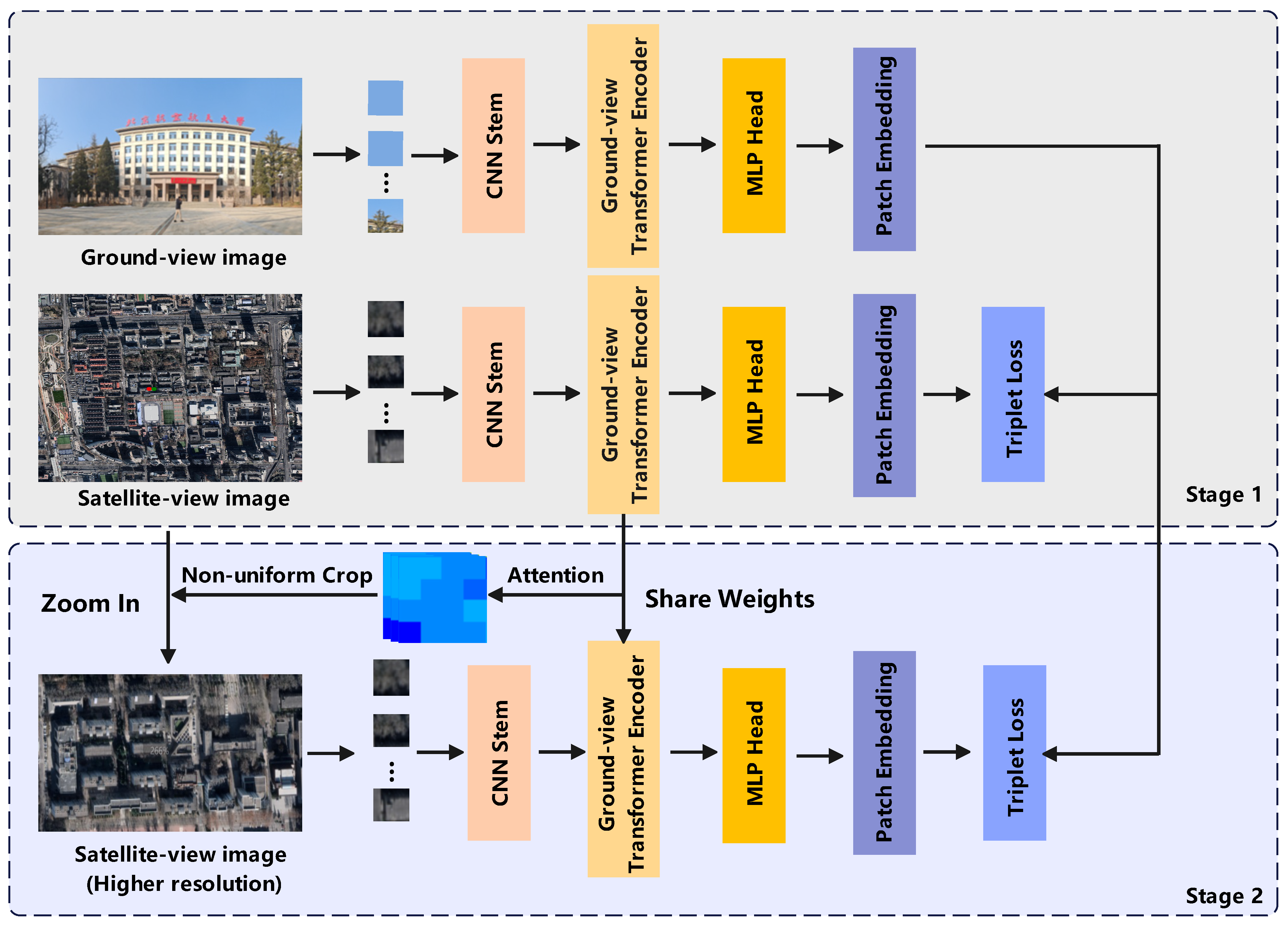
4. Proposed ICT-Net Framework
4.1. Problem Description and Method Overview
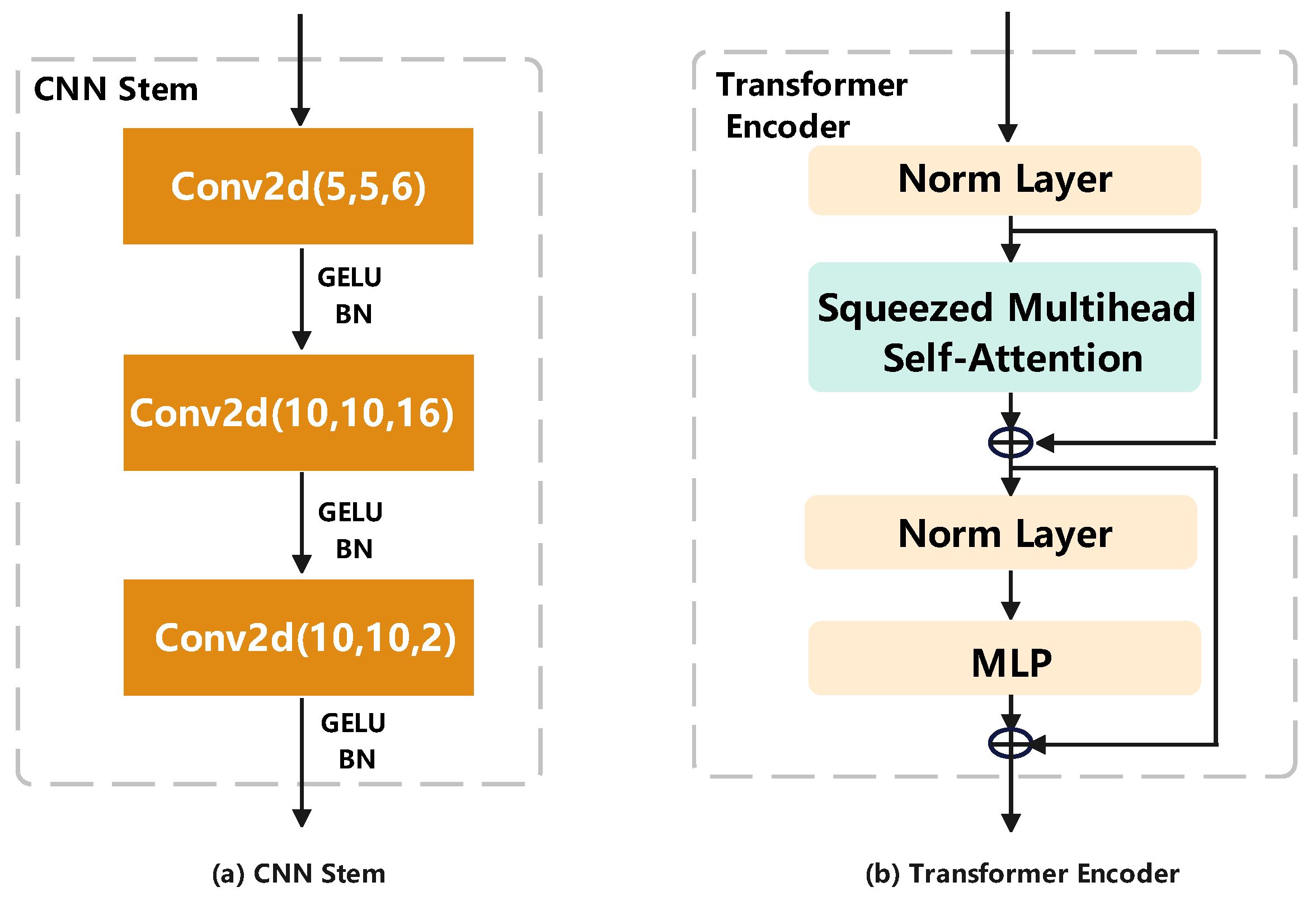
4.2. Vision Transformer for Geo-Localization
4.3. Attention-Guided Non-Uniform Cropping
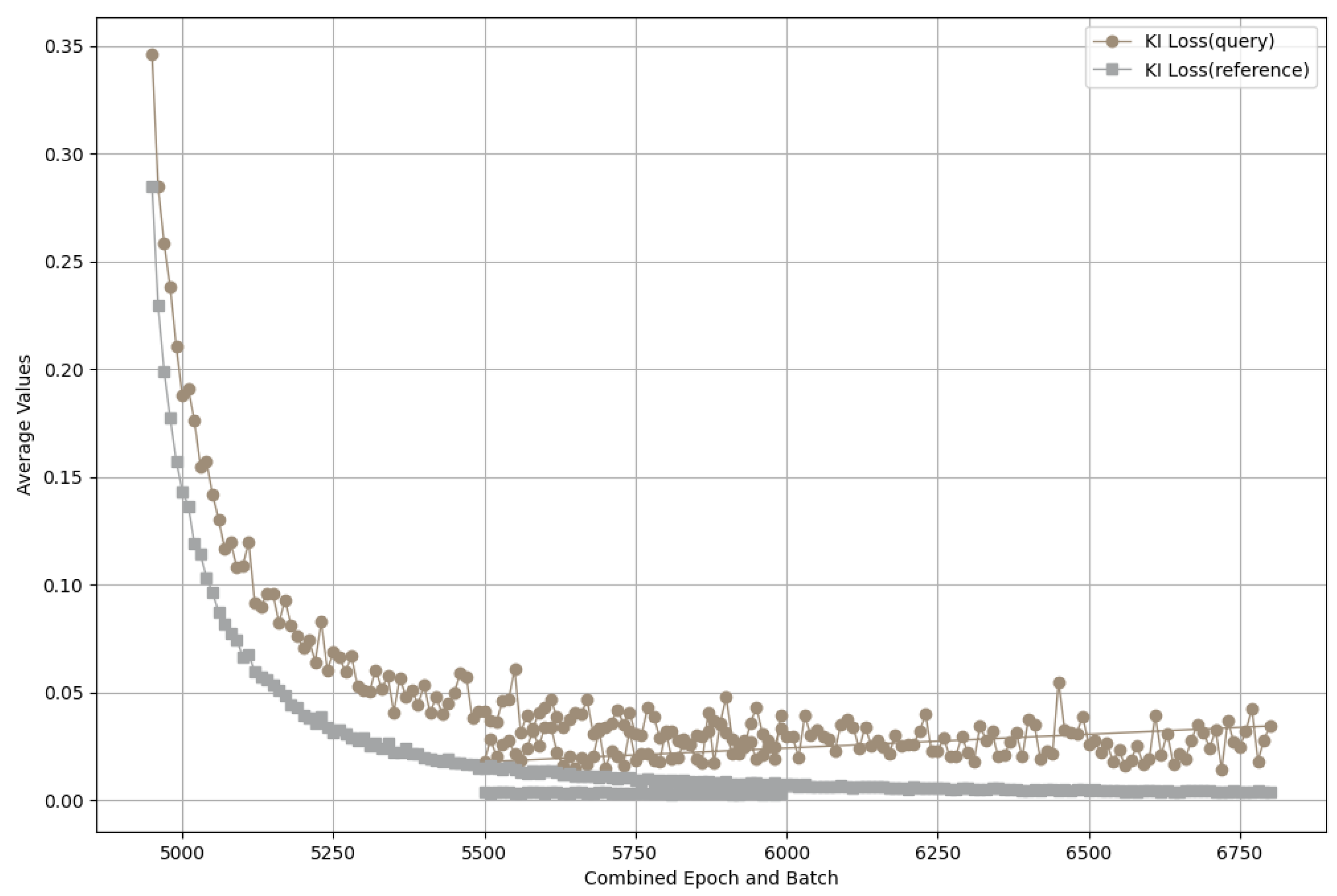
4.4. Training Acceleration Optimization Strategy
5. Experiment Analysis
5.1. Proposed Datasets and Metrics
5.2. Comparative Results Illustration
5.3. Ablation Experiments Description
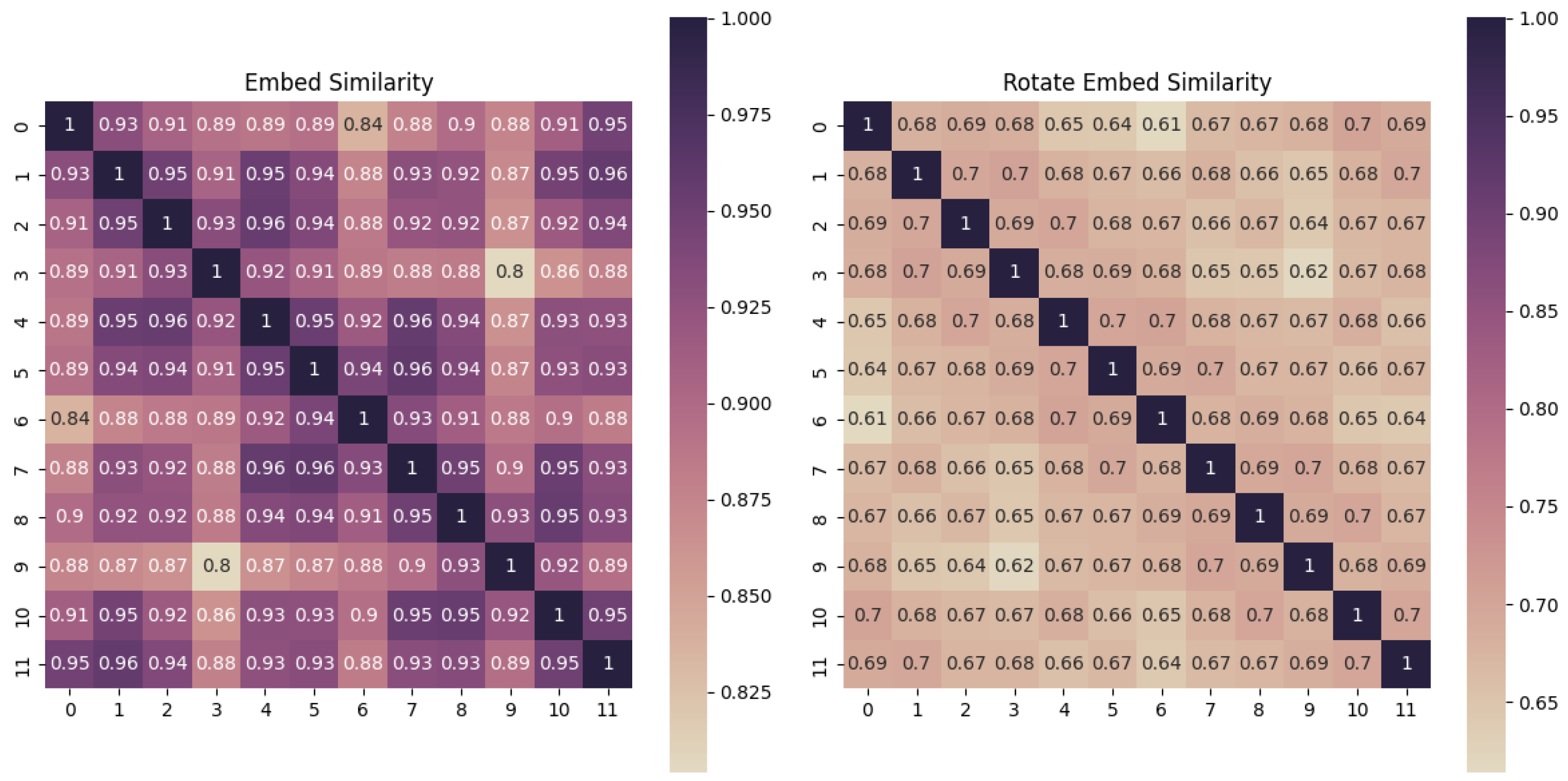
5.3.1. Effects of Coordinate System Transformations
- CVUSA Dataset: Conventional CNNs achieve a 19.6% R@1 improvement with explicit Cartesian-to-polar conversion (76.41% to 86.02%), validating the effectiveness of artificial geometric priors. In contrast, our proposed ICT-Net framework achieves 98.2% R@1 through implicit positional encoding, demonstrating the inherent ability of Transformers to learn rotational variable representations.
- CVACT Dataset: Polarity transformations show conflicting effects. Specifically, the SAFA based method increases R@1 by 28.3% while reducing the standard Transformer by 3.4%. This highlights the necessity for adaptive geometric reasoning in misaligned scenarios, where ICT-Net achieves SATA 83.5% R@1 without explicit transforms.
- VIGOR Dataset: Unlike spatially aligned benchmarks, VIGOR introduces unconstrained query locations with arbitrary spatial offsets, where polar transformations degrade performance by 12.7%. Existing methods relying on explicit geometric alignment (e.g., CNN+Polar) suffer from severe viewpoint misalignment (63.66% R@1), while ICT-Net achieves 89.22% R@1 through dynamic attention-guided region focusing, resolving 76.5% of spatial displacement errors.
- BHUniv Dataset: In the case of point-of-view offset, centered polar transformations result in 14.8% R@1 degradation, whereas ICT-Net maintains 93.5% accuracy through dynamic position-aware adaptation, resolving the geometric mismatch problem in semi-enclosed facilities.
5.3.2. Attention-Directed Non-Uniform Cropping
5.3.3. Overlap Ratio of Samples
5.4. Computational Efficiency Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Yu, G.; Wang, Z.; Zhao, F.; Chen, P. Online Calibration of LiDAR and GPS/INS Using Multi-Feature Adaptive Optimization in Unstructured Environments. IEEE Trans. Instrum. Meas. 2025, 74, 1–15. [Google Scholar] [CrossRef]
- Hu, Y.; Li, X.; Kong, D.; Wei, K.; Ni, P.; Hu, J. A Reliable Position Estimation Methodology Based on Multi-Source Information for Intelligent Vehicles in Unknown Environment. IEEE Trans. Intell. Veh. 2024, 9, 1667–1680. [Google Scholar] [CrossRef]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-Identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 994–1003. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Zhu, S.; Shah, M.; Chen, C. TransGeo: Transformer Is All You Need for Cross-view Image Geo-localization. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1152–1161. [Google Scholar]
- Yan, Y.; Wang, M.; Su, N.; Hou, W.; Zhao, C.; Wang, W. IML-Net: A Framework for Cross-View Geo-Localization with Multi-Domain Remote Sensing Data. Remote Sens. 2024, 16, 1249. [Google Scholar] [CrossRef]
- Cai, S.; Guo, Y.; Khan, S.; Hu, J.; Wen, G. Ground-to-aerial Image Geo-localization with a Hard Exemplar Reweighting Triplet Loss. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8391–8400. [Google Scholar]
- Li, C.; Yan, C.; Xiang, X.; Lai, J.; Zhou, H.; Tang, D. AMPLE: Automatic Progressive Learning for Orientation Unknown Ground-to-Aerial Geo-Localization. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–15. [Google Scholar] [CrossRef]
- He, Q.; Xu, A.; Zhang, Y.; Ye, Z.; Zhou, W.; Xi, R.; Lin, Q. A Contrastive Learning Based Multiview Scene Matching Method for UAV View Geo-Localization. Remote Sens. 2024, 16, 3039. [Google Scholar] [CrossRef]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object Retrieval with Large Vocabularies and Fast Spatial Matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Lost in Quantization: Improving Particular Object Retrieval in Large Scale Image Databases. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Lin, T.Y.; Cui, Y.; Belongie, S.; Hays, J. Learning Deep Representations for Ground-to-Aerial Geolocalization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5007–5015. [Google Scholar]
- Arandjelovi, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Hu, S.; Feng, M.; Nguyen, R.M.H.; Lee, G.H. CVM-Net: Cross-View Matching Network for Image-Based Ground-to-Aerial Geo-Localization. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7258–7267. [Google Scholar]
- Weyand, T.; Kostrikov, I.; Philbin, J. PlaNet—Photo Geolocation with Convolutional Neural Networks. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Amsterdam, The Netherlands, 2016; Volume 9912, pp. 37–55. [Google Scholar]
- Tian, Y.; Chen, C.; Shah, M. Cross-View Image Matching for Geo-Localization in Urban Environments. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3608–3616. [Google Scholar]
- Liu, L.; Li, H. Lending Orientation to Neural Networks for Cross-View Geo-Localization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5624–5633. [Google Scholar]
- Vo, N.N.; Hays, J. Localizing and Orienting Street Views Using Overhead Imagery. In Proceedings of the 14th European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Amsterdam, The Netherlands, 2016; pp. 494–509. [Google Scholar]
- Zhu, S.; Yang, T.; Chen, C. Revisiting Street-to-Aerial View Image Geo-Localization and Orientation Estimation. In Proceedings of the 2021 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 756–765. [Google Scholar]
- Zhai, M.; Bessinger, Z.; Workman, S.; Jacobs, N. Predicting Ground-Level Scene Layout from Aerial Imagery. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 867–875. [Google Scholar]
- Shi, Y.; Yu, X.; Campbell, D.; Li, H. Where Am I Looking at? Joint Location and Orientation Estimation by Cross-View Matching. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4064–4072. [Google Scholar]
- Zhu, S.; Yang, T.; Chen, C. Vigor: Cross-view image geo-localization beyond one-to-one retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 3640–3649. [Google Scholar]
- Zhang, X.; Jiang, M.; Zheng, Z.; Tan, X.; Ding, E.; Yang, Y. Understanding Image Retrieval Re-Ranking: A Graph Neural Network Perspective. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1–10. [Google Scholar]
- Tian, X.; Shao, J.; Ouyang, D.; Shen, H. UAV-Satellite View Synthesis for Cross-View Geo-Localization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 4804–4815. [Google Scholar] [CrossRef]
- Dai, M.; Hu, J.; Zhuang, J.; Zheng, E. A Transformer-Based Feature Segmentation and Region Alignment Method for UAV-View Geo-Localization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 4376–4389. [Google Scholar] [CrossRef]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative Learning of Deep Convolutional Feature Point Descriptors. In Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 118–126. [Google Scholar]
- Tian, Y.; Fan, B.; Wu, F. L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 661–669. [Google Scholar]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. HPatches: A Benchmark and Evaluation of Handcrafted and Learned Local Descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5173–5182. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Mishchuk, A.; Mishkin, D.; Radenovic, F.; Matas, J. Working Hard to Know Your Neighbor’s Margins: Local Descriptor Learning Loss. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Keller, M.; Chen, Z.; Maffra, F.; Schmuck, P.; Chli, M. Learning Deep Descriptors with Scale-Aware Triplet Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2762–2770. [Google Scholar]
- Pham, Q.-H.; Uy, M.A.; Hua, B.-S.; Nguyen, D.T.; Roig, G.; Yeung, S.-K. LCD: Learned Cross-Domain Descriptors for 2D-3D Matching. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Honolulu, HI, USA, 27 January–1 February 2019; Volume 34, pp. 11856–11864. [Google Scholar]
- Xiang, X.; Zhang, Y.; Jin, L.; Li, Z.; Tang, J. Sub-Region Localized Hashing for Fine-Grained Image Retrieval. IEEE Trans. Image Process. 2022, 31, 314–326. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Gao, L.; Zhang, M.; Chen, C.; Yan, S. Spectral–Spatial Adversarial Multidomain Synthesis Network for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5518716. [Google Scholar] [CrossRef]
- Kim, J.-H.; Hong, I.-P. Cross-Domain Translation Learning Method Utilizing Autoencoder Pre-Training for Super-Resolution of Radar Sparse Sensor Arrays. IEEE Access 2023, 11, 61773–61785. [Google Scholar] [CrossRef]
- Zhang, G.; Yang, Y.; Zheng, Y.; Martin, G.; Wang, R. Mask-Aware Hierarchical Aggregation Transformer for Occluded Person Re-identification. IEEE Trans. Circuits Syst. Video Technol. 2025; early access. [Google Scholar] [CrossRef]
- Chen, Y.; Du, C.; Zi, Y.; Xiong, S.; Lu, X. Scale-Aware Adaptive Refinement and Cross-Interaction for Remote Sensing Audio-Visual Cross-Modal Retrieval. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4706914. [Google Scholar] [CrossRef]
- Jiang, P.T.; Zhang, C.B.; Hou, Q.; Cheng, M.M.; Wei, Y. LayerCAM: Exploring Hierarchical Class Activation Maps. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Huang, S.; Liu, W. Learning Sequentially Diversified Representations for Fine-Grained Categorization. Pattern Recognit. 2022, 121, 108219. [Google Scholar] [CrossRef]
- Niu, Y.; Jiao, Y.; Shi, G. Attention-Shift Based Deep Neural Network for Fine-Grained Visual Categorization. Pattern Recognit. 2021, 116, 107947. [Google Scholar] [CrossRef]
- Du, R.; Chang, D.; Bhunia, A.K.; Xie, J.; Ma, Z.; Song, Y.Z.; Guo, J. Fine-Grained Visual Classification via Progressive Multi-Granularity Training of Jigsaw Patches. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Volume 12365, pp. 153–168. [Google Scholar]
- Held, M.; Rabe, A.; Senf, C.; van der Linden, S.; Hostert, P. Analyzing Hyperspectral and Hypertemporal Data by Decoupling Feature Redundancy and Feature Relevance. IEEE Geosci. Remote Sens. Lett. 2015, 12, 983–987. [Google Scholar] [CrossRef]
- De Bonfils Lavernelle, J.; Bonnefoi, P.-F.; Gonzalvo, B.; Sauveron, D. DMA: A Persistent Threat to Embedded Systems Isolation. In Proceedings of the IEEE 23rd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Sanya, China, 17–21 December 2024; pp. 101–108. [Google Scholar]
- Wang, Z.; Wu, X.; Zhang, X. Enhancing NERF Rendering in Architectural Environments Using Spherical Harmonic Functions and NEUS Methods. In Proceedings of the China Automation Congress (CAC), Qingdao, China, 1–3 November 2024; pp. 3304–3309. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Wu, M.; Guo, K.; Li, X.; Lin, Z.; Wu, Y.; Tsiftsis, T.A.; Song, H. Deep Reinforcement Learning-Based Energy Efficiency Optimization for RIS-Aided Integrated Satellite-Aerial-Terrestrial Relay Networks. IEEE Trans. Commun. 2024, 72, 4163–4178. [Google Scholar] [CrossRef]
- Yang, H.; Lu, X.; Zhu, Y. Cross-view geo-localization with layer-to-layer transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 29009–29020. [Google Scholar]
- Ali-Bey, A.; Chaib-Draa, B.; Giguere, P. Mixvpr: Feature mixing for visual place recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2998–3007. [Google Scholar]
- Zhang, X.; Li, X.; Sultani, W.; Zhou, Y.; Wshah, S. Cross-view geo-localization via learning disentangled geometric layout correspondence. Proc. AAAI Conf. Artif. Intell. 2023, 37, 3480–3488. [Google Scholar] [CrossRef]
- Gong, N.; Li, L.; Sha, J.; Sun, X.; Huang, Q. A Satellite-Drone Image Cross-View Geolocalization Method Based on Multi-Scale Information and Dual-Channel Attention Mechanism. Remote Sens. 2024, 16, 941. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size | Average Field of View | Standard Deviation | Maximum Value | Minimum Value |
|---|---|---|---|---|
| 300 | 360 | 0 | 360 | 360 |
| Method | R@1 | R@5 | R@10 |
|---|---|---|---|
| TransGeo [6] | 94.08 | 98.36 | 99.04 |
| MixVPR [50] | 94.24 | 98.42 | 99.05 |
| GeoDTR [51] | 95.32 | 98.69 | 99.56 |
| Ours | 96.74 | 98.85 | 99.93 |
| Method | R@1 | ||||
|---|---|---|---|---|---|
| CVUSA | CVACT | VIGOR | BHUniv | ||
| SAFA | ✓ | 86.02 | 54.32 | 75.23 | 65.21 |
| CNN+Polar | ✗ | 76.41 | 62.15 | 63.66 | 68.34 |
| Transformer | ✓ | 94.82 | 58.74 | 63.23 | 72.43 |
| SAFA+Polar | ✓ | 97.91 | 82.16 | 79.36 | 84.90 |
| Ours | ✗ | 98.21 | 83.55 | 89.22 | 93.56 |
| Method | Clipping Parameter | CVUSA | BHUniv | |||
|---|---|---|---|---|---|---|
| R@1 (%) | Inaccuracy (m) | R@1 (%) | Inaccuracy (m) | |||
| Stage-1 | 1.00 | 1.00 | 97.6 | 2.4 | 93.2 | 1.8 |
| Stage-1+ | 1.00 | 1.00 | 97.5 | 2.5 | 93.1 | 1.9 |
| Stage-2 | 0.64 | 1.00 | 97.5 | 2.6 | 93.0 | 2.0 |
| Stage-2+ | 0.64 | 1.56 | 98.7 | 2.1 | 93.8 | 1.7 |
| Sample Overlap Rate | Localization Error | Relative Regional Ratio |
|---|---|---|
| 93% | 5.363 | 0.36% |
| 96% | 3.149 | 0.21% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, M.; Xu, S.; Wang, Z.; Dong, J.; Cheng, G.; Yu, X.; Liu, Y. ICT-Net: A Framework for Multi-Domain Cross-View Geo-Localization with Multi-Source Remote Sensing Fusion. Remote Sens. 2025, 17, 1988. https://doi.org/10.3390/rs17121988
Wu M, Xu S, Wang Z, Dong J, Cheng G, Yu X, Liu Y. ICT-Net: A Framework for Multi-Domain Cross-View Geo-Localization with Multi-Source Remote Sensing Fusion. Remote Sensing. 2025; 17(12):1988. https://doi.org/10.3390/rs17121988
Chicago/Turabian StyleWu, Min, Sirui Xu, Ziwei Wang, Jin Dong, Gong Cheng, Xinlong Yu, and Yang Liu. 2025. "ICT-Net: A Framework for Multi-Domain Cross-View Geo-Localization with Multi-Source Remote Sensing Fusion" Remote Sensing 17, no. 12: 1988. https://doi.org/10.3390/rs17121988
APA StyleWu, M., Xu, S., Wang, Z., Dong, J., Cheng, G., Yu, X., & Liu, Y. (2025). ICT-Net: A Framework for Multi-Domain Cross-View Geo-Localization with Multi-Source Remote Sensing Fusion. Remote Sensing, 17(12), 1988. https://doi.org/10.3390/rs17121988