
RSNet: Compact-Align Detection Head Embedded Lightweight Network for Small Object Detection in Remote Sensing



Abstract
1. Introduction
- 1.
- We propose the Compact-Align Detection Head (CADH), a lightweight detection head tailored for small object detection in remote sensing imagery. Our method dynamically adjusts feature processing to accommodate objects of varying sizes and scales, ensuring accurate localization while minimizing computational overhead. By combining adaptive feature alignment with a compact architecture, CADH achieves high detection precision and is well-suited for real-time applications in resource-constrained environments.
- 2.
- We introduce ADown, an optimized downsampling module that balances computational efficiency and feature preservation. By integrating preprocessing, channel splitting, and feature fusion, ADown reduces computation while retaining both global semantics and fine-grained details, achieving compact yet expressive feature representations.
- 3.
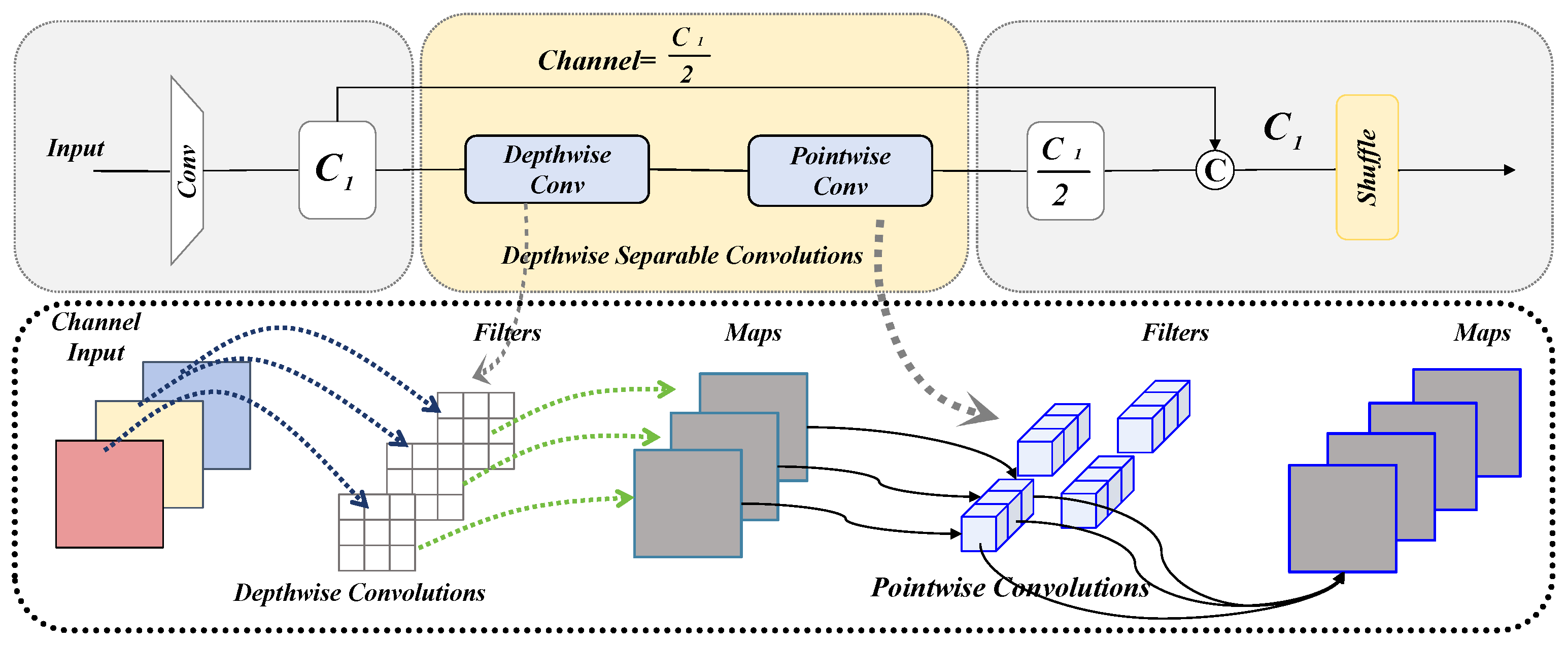
- To address the limited cross-channel interactions in depthwise separable convolution, we integrate GSConv, which combines deep and pointwise convolutions. This design enhances feature extraction by improving both efficiency and representation capacity, enabling accurate detection with reduced computational cost.
- 4.
- We designed a K-fold cross-validation strategy to obtain stable and statistically representative performance evaluations and to assess the robustness of the model under different data partition conditions. By conducting multiple rounds of data partitioning and training across different folds, this strategy effectively reduces the evaluation bias caused by a single partition scheme and improves the reliability of the experimental results.
2. Related Work
2.1. Traditional Object Detection Methods: Foundations and Limitations
2.2. Advancements in Object Detection Algorithms
2.3. Object Detection Techniques in Remote Sensing Imagery
2.4. Lightweight Networks for Remote Sensing and Small Object Detection
3. Methods
3.1. Baseline Detection Framework
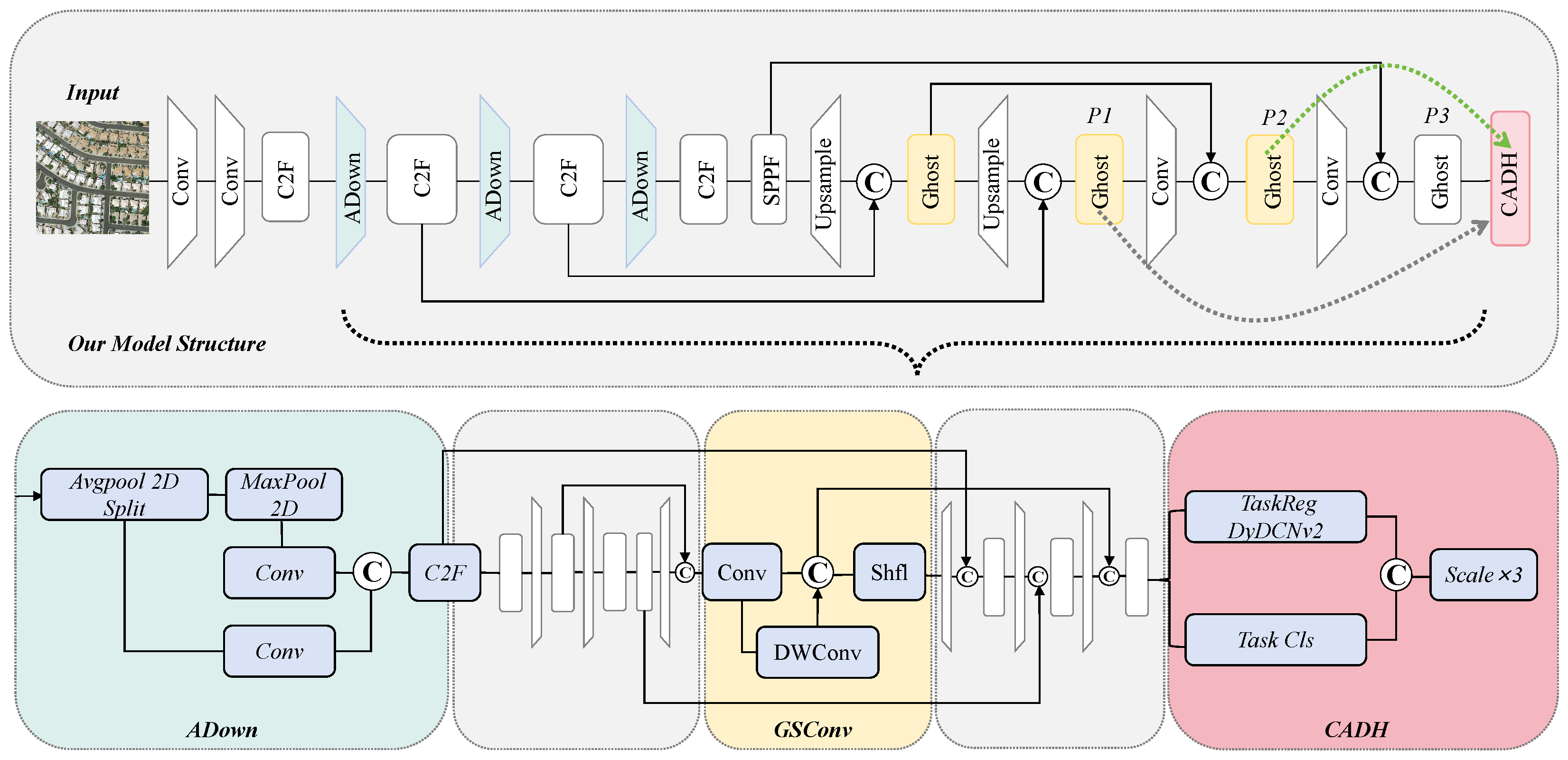
3.2. RSNet
3.2.1. Input
3.2.2. Backbone
3.2.3. Head
3.3. Compact-Align Detection Head (CADH)
| Algorithm 1: Forward Pass of Compact-Align Detection Head (CADH) |
Input: Feature map F from backbone Output: Detection output O ; //Shared Feature Extraction
; //Task Decomposition
; //Regression Alignment
; //Classification Refinement
; //Final Output
|
3.4. GSConv: A Lightweight Hybrid Convolution with Feature Shuffle
3.5. Adaptive Downsampling Module (ADown)
3.6. Embedded Deployment and Optimization
4. Experimental Validation
4.1. Dataset and Experimental Configuration
4.1.1. DOTA Dataset
4.1.2. NWPU VHR-10 Dataset
4.1.3. Technical Environment
4.1.4. Model Training Configuration
4.1.5. Training Hyperparameters
4.2. Criteria for Evaluating Detection Performance
4.2.1. Detection Accuracy
4.2.2. Computational Complexity
4.2.3. Parameter Count
4.3. Relative Performance Evaluation of Enhanced Algorithms
4.4. Ablation Experiment Analysis
4.5. Cross-Validation Results
4.5.1. Model Validation Technique
4.5.2. Data Partitioning and Validation Procedure
4.5.3. Cross-Validation Metrics
4.5.4. Result Analysis
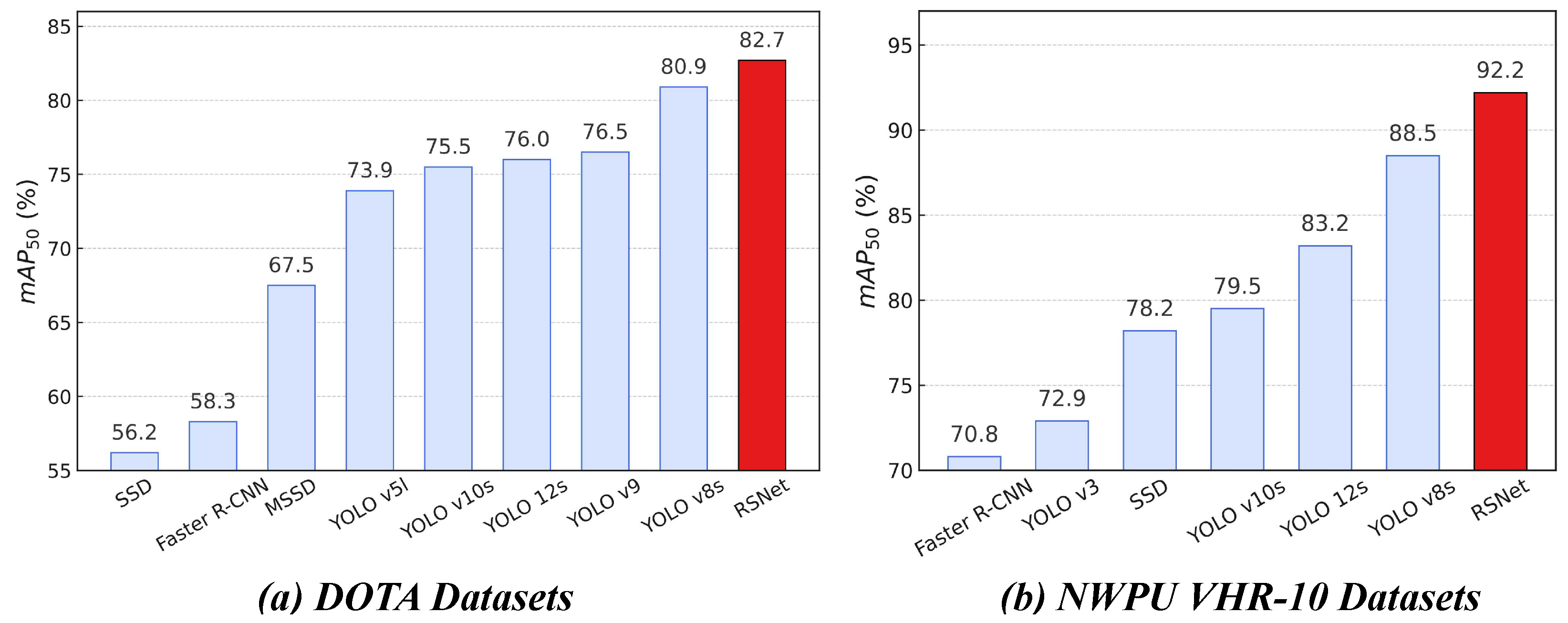
4.6. Benchmarking Against Leading Algorithms
4.7. Feature Map Visualization and Analysis
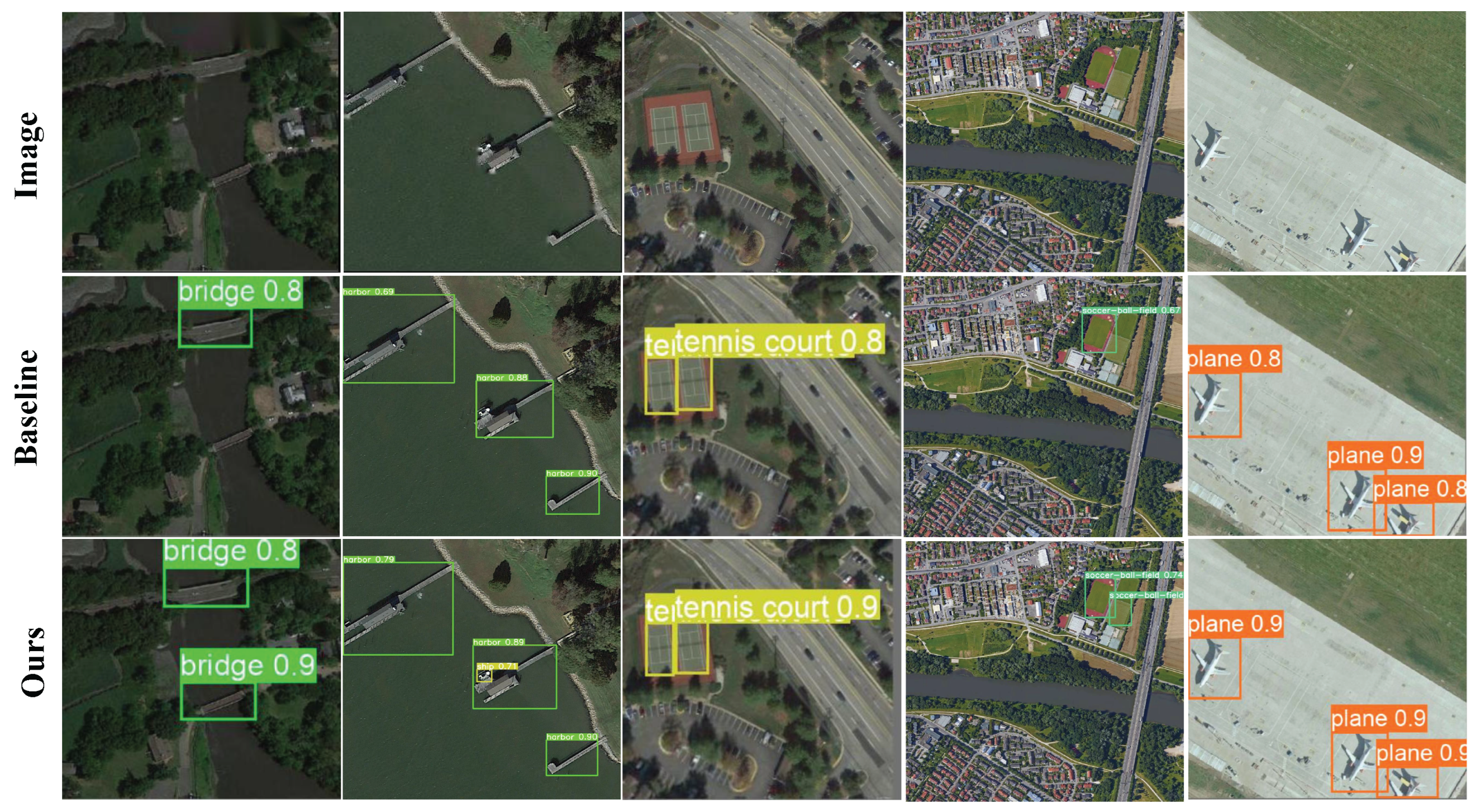
4.8. Experimental Results in a Visual Format
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CADH | Compact-Align Detection Head |
| GSConv | lightweight hybrid convolution with feature shuffle |
| ADown | adaptive downsampling module |
| CNN | Convolutional Neural Network |
| mAP | mean Average Precision |
| AP | Average Precision |
| IoU | Intersection over Union |
| P | Precision |
| R | Recall |
| TPs | True Positives |
| FPs | False Positives |
| FN | False Negatives |
| GFLOPs | Giga Floating-point Operations Per Second |
| FPS | Frame Per Second |
References
- Wang, Y.; Shao, Z.; Lu, T.; Wu, C.; Wang, J. Remote Sensing Image Super-Resolution via Multiscale Enhancement Network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Huang, S.; Lin, C.; Jiang, X.; Qu, Z. BRSTD: Bio-Inspired Remote Sensing Tiny Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Xu, Q.; Shi, Y.; Yuan, X.; Zhu, X.X. Universal Domain Adaptation for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4700515. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Wang, L.; Zhang, C. Land cover classification from remote sensing images based on multi-scale fully convolutional network. Geo-Spat. Inf. Sci. 2022, 25, 278–294. [Google Scholar] [CrossRef]
- Shi, J.; Liu, W.; Shan, H.; Li, E.; Li, X.; Zhang, L. Remote Sensing Scene Classification Based on Multibranch Fusion Attention Network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Liang, D.; Zhang, J.W.; Tang, Y.P.; Huang, S.J. MUS-CDB: Mixed Uncertainty Sampling with Class Distribution Balancing for Active Annotation in Aerial Object Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, F.; Liu, Q.; Zhang, H.; Zhang, Z.; Yang, L. Improved Architecture and Training Strategies of YOLOv7 for Remote Sensing Image Object Detection. Remote Sens. 2024, 16, 3321. [Google Scholar] [CrossRef]
- Zhu, Y.; Pan, Y.; Zhang, D.; Wu, H.; Zhao, C. A Deep Learning Method for Cultivated Land Parcels’ (CLPs) Delineation From High-Resolution Remote Sensing Images with High-Generalization Capability. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–25. [Google Scholar] [CrossRef]
- Han, T.; Dong, Q.; Wang, X.; Sun, L. BED-YOLO: An Enhanced YOLOv8 for High-Precision Real-Time Bearing Defect Detection. IEEE Trans. Instrum. Meas. 2024, 73, 1–13. [Google Scholar] [CrossRef]
- Cheng, A.; Xiao, J.; Li, Y.; Sun, Y.; Ren, Y.; Liu, J. Enhancing Remote Sensing Object Detection with K-CBST YOLO: Integrating CBAM and Swin-Transformer. Remote Sens. 2024, 16, 2885. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001. [CrossRef]
- Wan, D.; Lu, R.; Wang, S.; Shen, S.; Xu, T.; Lang, X. YOLO-HR: Improved YOLOv5 for Object Detection in High-Resolution Optical Remote Sensing Images. Remote Sens. 2023, 15, 614. [Google Scholar] [CrossRef]
- Shin, Y.; Shin, H.; Ok, J.; Back, M.; Youn, J.; Kim, S. DCEF2-YOLO: Aerial Detection YOLO with Deformable Convolution–Efficient Feature Fusion for Small Target Detection. Remote Sens. 2024, 16, 1071. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, Z.; Yan, G.; Wang, Y.; Hu, B. Faster and Lightweight: An Improved YOLOv5 Object Detector for Remote Sensing Images. Remote Sens. 2023, 15, 4974. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar] [CrossRef]
- Seo, M.; Lee, H.; Jeon, Y.; Seo, J. Self-Pair: Synthesizing Changes from Single Source for Object Change Detection in Remote Sensing Imagery. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 6363–6372. [Google Scholar] [CrossRef]
- Lang, K.; Yang, M.; Wang, H.; Wang, H.; Wang, Z.; Zhang, J.; Shen, H. Improved One-Stage Detectors with Neck Attention Block for Object Detection in Remote Sensing. Remote Sens. 2022, 14, 5805. [Google Scholar] [CrossRef]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Bayrak, O.C.; Erdem, F.; Uzar, M. Deep learning based aerial imagery classification for tree species identification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, XLVIII-M-1-2023, 471–476. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, L.; Wang, Q.; Wang, N.; Wang, D.; Wang, X.; Zheng, Q.; Hou, X.; Ouyang, G. A Lightweight and High-Accuracy Deep Learning Method for Grassland Grazing Livestock Detection Using UAV Imagery. Remote Sens. 2023, 15, 1593. [Google Scholar] [CrossRef]
- Gu, L.; Fang, Q.; Wang, Z.; Popov, E.; Dong, G. Learning Lightweight and Superior Detectors with Feature Distillation for Onboard Remote Sensing Object Detection. Remote Sens. 2023, 15, 370. [Google Scholar] [CrossRef]
- Liu, S.; Shao, F.; Chu, W.; Dai, J.; Zhang, H. An Improved YOLOv8-Based Lightweight Attention Mechanism for Cross-Scale Feature Fusion. Remote Sens. 2025, 17, 1044. [Google Scholar] [CrossRef]
- Zhang, J.; Lei, J.; Xie, W.; Li, Y.; Yang, G.; Jia, X. Guided Hybrid Quantization for Object Detection in Remote Sensing Imagery via One-to-One Self-Teaching. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5614815. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, M.; Wang, Y.; Zhu, Y.; Zhang, Z. Object Detection in High Resolution Remote Sensing Imagery Based on Convolutional Neural Networks with Suitable Object Scale Features. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2104–2114. [Google Scholar] [CrossRef]
- Bai, P.; Xia, Y.; Feng, J. Composite Perception and Multiscale Fusion Network for Arbitrary-Oriented Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5645916. [Google Scholar] [CrossRef]
- Lin, Q.; Chen, N.; Huang, H.; Zhu, D.; Fu, G.; Chen, C.; Yu, Y. Attention-Based Mean-Max Balance Assignment for Oriented Object Detection in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–15. [Google Scholar] [CrossRef]
- Yang, Y.; Dai, J.; Wang, Y.; Chen, Y. FM-RTDETR: Small Object Detection Algorithm Based on Enhanced Feature Fusion with Mamba. IEEE Signal Process. Lett. 2025, 32, 1570–1574. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for Small Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the Computer Vision—ECCV 2024: 18th European Conference, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Proceedings of the Computer Vision—ACCV 2018, Perth, Australia, 2–6 December 2018; Jawahar, C.V., Li, H., Mori, G., Schindler, K., Eds.; Springer: Cham, Switzerland, 2019; pp. 150–165. [Google Scholar]
- Zhou, Q.; Yu, C.; Wang, Z.; Wang, F. D2Q-DETR: Decoupling and Dynamic Queries for Oriented Object Detection with Transformers. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- He, X.; Liang, K.; Zhang, W.; Li, F.; Jiang, Z.; Zuo, Z.; Tan, X. DETR-ORD: An Improved DETR Detector for Oriented Remote Sensing Object Detection with Feature Reconstruction and Dynamic Query. Remote Sens. 2024, 16, 3516. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-Merged Single-Shot Detection for Multiscale Objects in Large-Scale Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3377–3390. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equation | Pseudocode | Description |
|---|---|---|
| Shared feature representation | ||
| Global context feature | ||
| Classification-specific feature | ||
| Aligned regression feature | ||
| Class probability map | ||
| Refined classification feature | ||
| O | Final detection output |
| Dataset | 10–50 pixels | 50–300 pixels | Above 300 pixels |
|---|---|---|---|
| NWPU VHR-10 | 0.15 | 0.83 | 0.02 |
| DOTA | 0.57 | 0.41 | 0.02 |
| Training Hyperparameter | Selected Configuration |
|---|---|
| Number of Epochs | 200 |
| Image Dimensions | 640 × 640 |
| Batch Size | 16 |
| Data Augmentation Method | Mosaic |
| Hyperparameter | Setup |
|---|---|
| Optimizer | SGD |
| Initial Learning Rate (Lr0) | 0.01 |
| Final Learning Rate (Lrf) | 0.01 |
| Momentum | 0.937 |
| Weight Decay Coefficient | 0.0005 |
| Image Scale | 0.5 |
| Image Flip Left-Right | 0.5 |
| Image Translation | 0.1 |
| Mosaic | 1.0 |
| Module | Dataset | Par. (M) | GFLOPs | P (%) | R (%) | mAP@50 (%) |
|---|---|---|---|---|---|---|
| YOLOv8s | DOTA | 11.12 | 28.5 | 86.1 | 75.7 | 80.9 |
| RSNet | DOTA | 6.49 | 24.6 | 89.6 | 77.3 | 82.7 |
| YOLOv8s | NWPU | 11.12 | 28.5 | 91.4 | 81.9 | 88.5 |
| RSNet | NWPU | 6.49 | 24.6 | 91.6 | 86.7 | 92.2 |
| Model | Parameter | FPS (Jetson Nano) | GFLOPs |
|---|---|---|---|
| baseline | 11.12 | 18.4 | 28.4 |
| RSnet | 6.49 | 72.6 | 24.6 |
| Dataset | Model | ADown | GSConv | CADH | Parameters (M) | GFLOPs | P (%) | R (%) | mAP50 (%) |
|---|---|---|---|---|---|---|---|---|---|
| DOTA | YOLOv8s | 11.12 | 28.5 | 86.1 | 75.7 | 80.9 | |||
| DOTA | +Adown | ✓ | 9.48 | 25.7 | 88.6 | 73.7 | 81.3 | ||
| DOTA | +GSConv | ✓ | 5.92 | 16.1 | 86.6 | 75.3 | 80.5 | ||
| DOTA | +CADH | ✓ | 8.87 | 33.0 | 88.1 | 76.7 | 82.2 | ||
| DOTA | +GSConv+CADH | ✓ | ✓ | 4.53 | 10.9 | 87.0 | 76.3 | 81.6 | |
| DOTA | RSNet | ✓ | ✓ | ✓ | 6.49 | 24.6 | 89.6 | 77.3 | 82.7 |
| NWPU | YOLOv8s | 11.12 | 28.5 | 91.4 | 81.9 | 88.5 | |||
| NWPU | +ADown | ✓ | 9.48 | 25.7 | 90.1 | 81.2 | 89.8 | ||
| NWPU | +GSConv | ✓ | 5.92 | 16.1 | 91.3 | 80.0 | 88.0 | ||
| NWPU | +CADH | ✓ | 8.87 | 33.0 | 89.5 | 87.3 | 91.9 | ||
| NWPU | +GSConv+CADH | ✓ | ✓ | 4.53 | 10.9 | 91.3 | 86.1 | 91.6 | |
| NWPU | RSNet | ✓ | ✓ | ✓ | 6.49 | 24.6 | 91.6 | 86.7 | 92.2 |
| Fold | mAP50 (%) | P (%) | R (%) | GFLOPs | Para. (M) |
|---|---|---|---|---|---|
| 1 | 82.4 | 87.4 | 77.4 | 24.6 | 6.49 |
| 2 | 82.9 | 86.1 | 78.8 | 24.6 | 6.49 |
| 3 | 82.7 | 86.6 | 79.1 | 24.6 | 6.49 |
| 4 | 82.5 | 87.1 | 77.1 | 24.6 | 6.49 |
| 5 | 82.5 | 86.3 | 78.3 | 24.6 | 6.49 |
| Average | 82.6 | 86.7 | 78.1 | 24.6 | 6.49 |
| Model | DOTA | NWPU | One-Stage | Two-Stage | Precision (%) | Recall (%) | mAP50 (%) | Params |
|---|---|---|---|---|---|---|---|---|
| SCRDet [43] | ✓ | ✓ | 75.4 | 84.2 | 71.7 | – | ||
| ICN [44] | ✓ | ✓ | 72.5 | 83.0 | 77.7 | — | ||
| Faster R-CNN | ✓ | ✓ | 62.6 | 76.7 | 58.3 | 107.8 | ||
| FADet | ✓ | ✓ | 75.4 | 88.2 | 78.6 | – | ||
| SSD | ✓ | ✓ | 59.6 | 68.4 | 56.2 | 90.7 | ||
| RT-DETR [23] | ✓ | ✓ | — | — | 68.1 | 32.8 | ||
| D2Q-DETR [45] | ✓ | ✓ | — | — | 78.8 | – | ||
| DETR-ORD [46] | ✓ | ✓ | — | — | 72.1 | – | ||
| YOLO v3 | ✓ | ✓ | 60.9 | 69.0 | 57.1 | 60.4 | ||
| YOLO v5l | ✓ | ✓ | 81.5 | 69.1 | 73.9 | 45.5 | ||
| YOLO v7 | ✓ | ✓ | 77.9 | 71.7 | 75.5 | 51.1 | ||
| YOLO v8s | ✓ | ✓ | 86.1 | 75.7 | 80.9 | 11.12 | ||
| YOLO v9 | ✓ | ✓ | 79.6 | 72.0 | 76.5 | 61.8 | ||
| YOLO v10s | ✓ | ✓ | 78.4 | 72.7 | 75.5 | 8.04 | ||
| YOLO 12s | ✓ | ✓ | 84.2 | 69.5 | 76.0 | 9.23 | ||
| FFCA-YOLO [36] | ✓ | ✓ | 84.4 | 75.1 | 81.5 | 7.12 | ||
| FMSSD [47] | ✓ | ✓ | 72.4 | 82.1 | 67.5 | 61.3 | ||
| RSNet (Ours) | ✓ | ✓ | 89.6 | 77.3 | 82.7 | 6.49 | ||
| Faster R-CNN | ✓ | ✓ | 76.4 | 86.4 | 70.8 | 60.77 | ||
| FPN | ✓ | ✓ | 88.3 | 85.2 | 90.2 | 50.7 | ||
| SSD | ✓ | ✓ | 79.1 | 90.2 | 78.2 | 90.7 | ||
| YOLO v3 | ✓ | ✓ | 72.3 | 73.6 | 72.9 | 60.4 | ||
| YOLO v4 | ✓ | ✓ | 86.9 | 87.8 | 89.7 | 64.4 | ||
| YOLO v7 | ✓ | ✓ | 90.3 | 88.6 | 91.1 | 36.9 | ||
| YOLO v7-tiny | ✓ | ✓ | 88.1 | 84.4 | 88.4 | 6.2 | ||
| YOLO v8s | ✓ | ✓ | 91.4 | 81.9 | 88.5 | 11.12 | ||
| YOLO v10s | ✓ | ✓ | 75.7 | 73.3 | 79.5 | 8.04 | ||
| YOLO 12s | ✓ | ✓ | 85.1 | 77.1 | 83.2 | 9.23 | ||
| RSNet (Ours) | ✓ | ✓ | 91.6 | 86.7 | 92.2 | 6.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Q.; Han, T.; Wu, G.; Qiao, B.; Sun, L. RSNet: Compact-Align Detection Head Embedded Lightweight Network for Small Object Detection in Remote Sensing. Remote Sens. 2025, 17, 1965. https://doi.org/10.3390/rs17121965
Dong Q, Han T, Wu G, Qiao B, Sun L. RSNet: Compact-Align Detection Head Embedded Lightweight Network for Small Object Detection in Remote Sensing. Remote Sensing. 2025; 17(12):1965. https://doi.org/10.3390/rs17121965
Chicago/Turabian StyleDong, Qing, Tianxin Han, Gang Wu, Baiyou Qiao, and Lina Sun. 2025. "RSNet: Compact-Align Detection Head Embedded Lightweight Network for Small Object Detection in Remote Sensing" Remote Sensing 17, no. 12: 1965. https://doi.org/10.3390/rs17121965
APA StyleDong, Q., Han, T., Wu, G., Qiao, B., & Sun, L. (2025). RSNet: Compact-Align Detection Head Embedded Lightweight Network for Small Object Detection in Remote Sensing. Remote Sensing, 17(12), 1965. https://doi.org/10.3390/rs17121965