
AECA-FBMamba: A Framework with Adaptive Environment Channel Alignment and Mamba Bridging Semantics and Details





Abstract
1. Introduction
- We propose AECA-FBMamba, a novel feature enhancement framework for weakly supervised land cover mapping that improves the input feature robustness and enables smooth feature transformation through an integrated architecture.
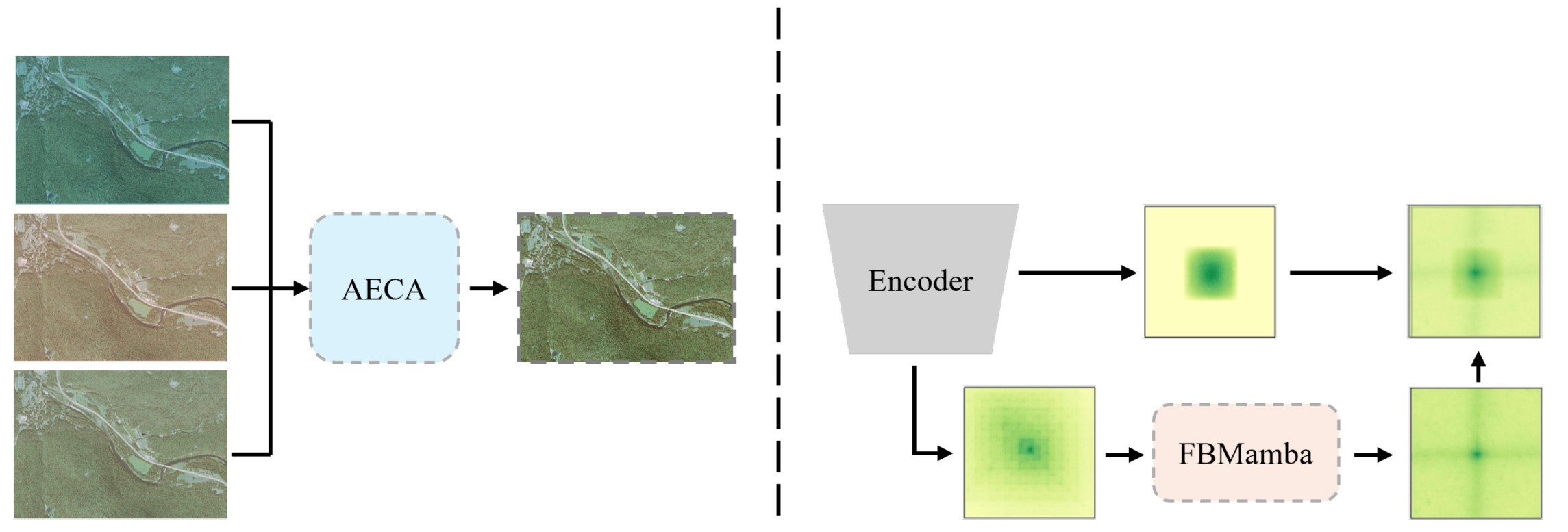
- The introduced AECA module enhances feature extraction by capturing gradient variations across different color spaces and establishing inter-channel correlations through grouped channel attention, significantly improving the model robustness when processing cross-modal data.
- Our FBMamba module effectively bridges global and local features by leveraging Mamba’s unique receptive field (as an intermediate between Transformers and CNNs). This architecture enables smooth feature transitions, allowing deep-level features to progressively evolve from semantic relationships to local details.
- Comprehensive evaluations on two datasets demonstrate our method’s superiority. Using a ViT-B backbone, we achieve a 65.3 mIoU on the Chesapeake Bay dataset (surpassing the previous SOTA under identical conditions) and set new SOTA benchmarks across multiple weakly supervised scales on the Poland dataset.
2. Materials and Methods
2.1. Materials
2.1.1. Chesapeake Bay Dataset
- The HR images (1 m/pixel) are from the U.S. Department of Agriculture’s National Agriculture Imagery Program (NAIP). The photos contain four bands of red, green, blue, and near-infrared [37].
- The LR historical annotations (30 m/pixel) are from the USGS’s National Land Cover Database (NLCD) [38], including 16 land cover classes.
- The ground truths (1 m/pixel) are from the Chesapeake Bay Conservancy Land Cover (CCLC) project.
2.1.2. Poland Dataset
- The HR images (0.25 m and 0.5 m/pixel) are from the LandCover.ai [39] dataset. The images contain three bands of red, green, and blue.
- The HR ground truths are from the OpenEarthMap [44] dataset with five land cover classes.
2.2. Methods
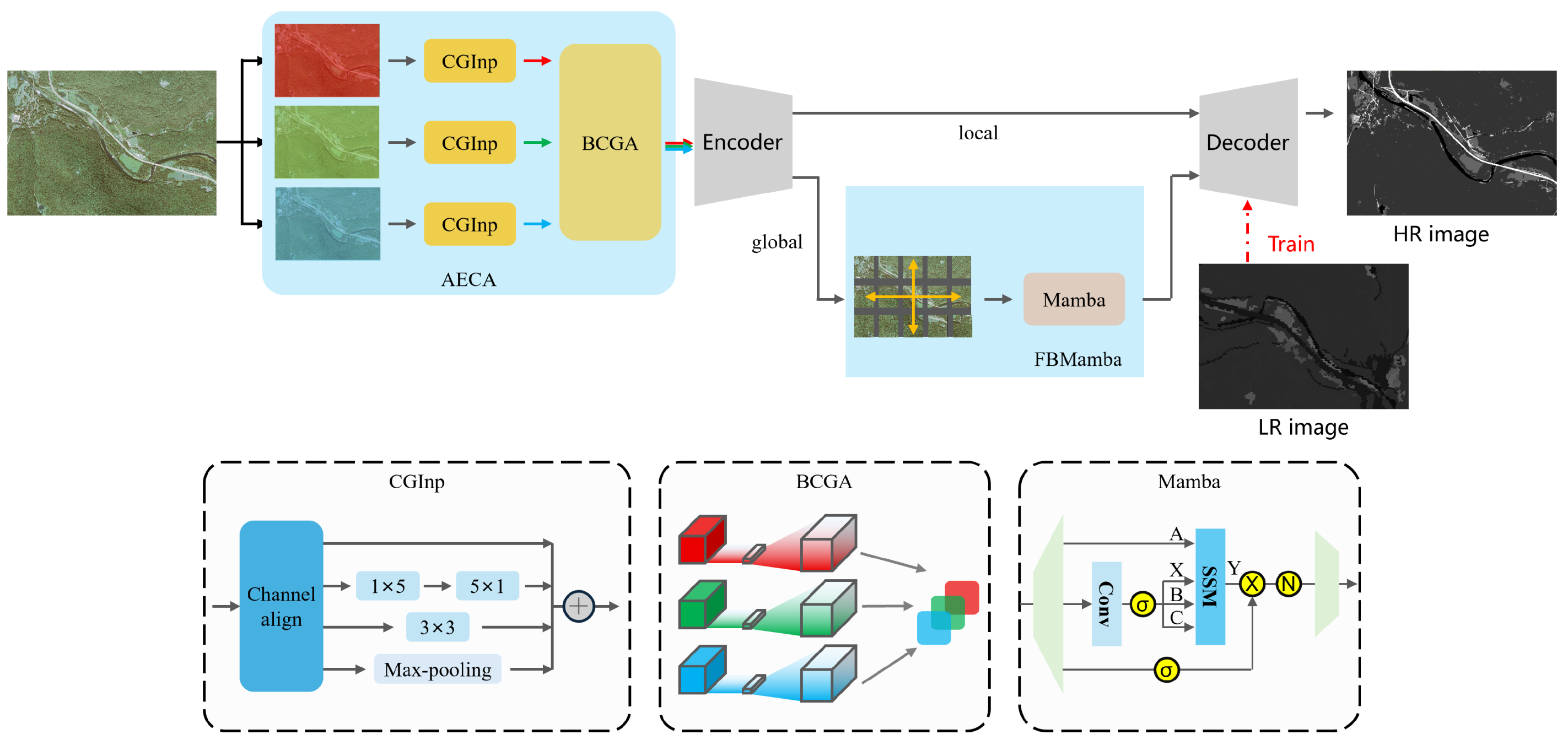
2.2.1. Overall Architecture
2.2.2. Adaptive Environment Channel Alignment (AECA) Module
- Multi-scale feature preservation: Inherits the Inception module’s fundamental strength in capturing hierarchical visual patterns while adding channel isolation capabilities.
- Enhanced feature diversity: Implicit regularization through grouped convolutions increases feature variation while reducing overfitting risks.
- Channel independence: The decoupled architecture allows flexible input channel configuration without cross-channel parameter interference.
2.2.3. Feature Bridging Mamba (FBMamba) Block
2.2.4. Evaluation Method
2.2.5. Experimental Settings
3. Results
3.1. Ablation Study
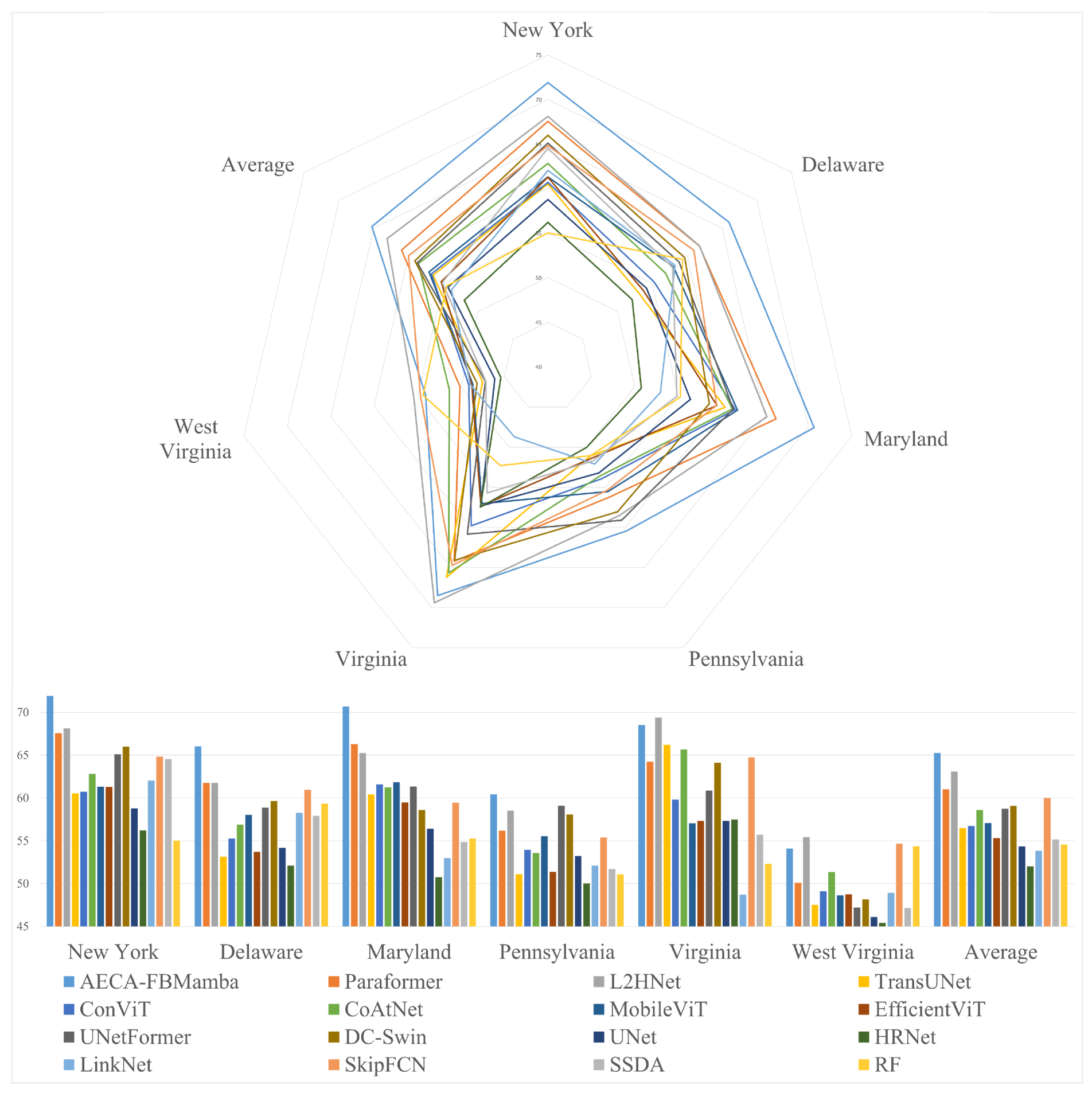
3.2. Comparison with Other Models
4. Discussion
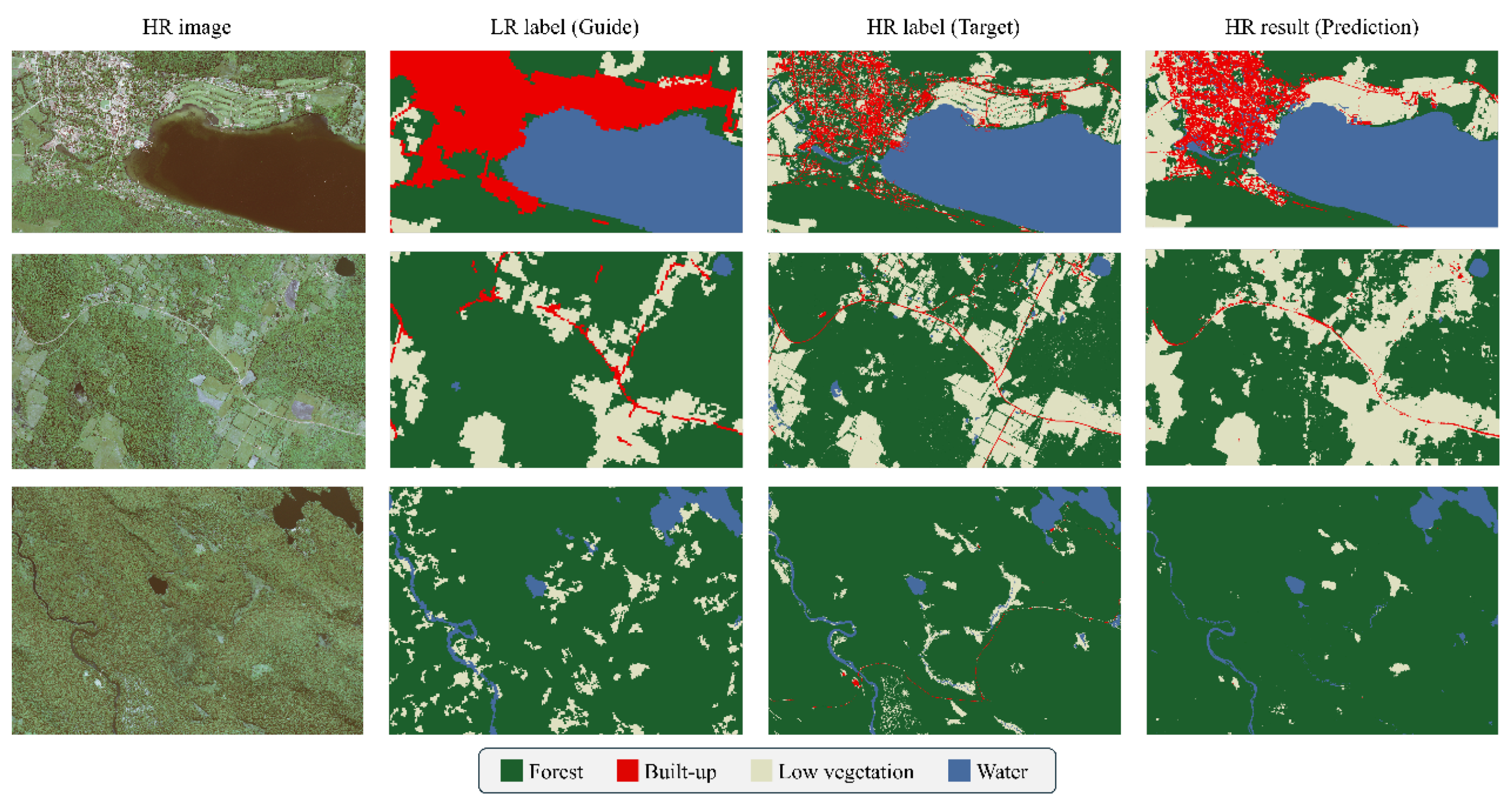
4.1. Reducing the Focus on Details Benefits Weakly Supervised Training
Decoder-Side Modification Analysis
4.2. Synergistic Integration of Transformer and Mamba
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cihlar, J. Land cover mapping of large areas from satellites: Status and research priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef]
- Robinson, C.; Hou, L.; Malkin, K.; Soobitsky, R.; Czawlytko, J.; Dilkina, B.; Jojic, N. Large Scale High-Resolution Land Cover Mapping With Multi-Resolution Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12718–12727. [Google Scholar] [CrossRef]
- Girard, N.; Smirnov, D.; Solomon, J.; Tarabalka, Y. Polygonal Building Extraction by Frame Field Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5887–5896. [Google Scholar] [CrossRef]
- Li, Z.; Lu, F.; Zhang, H.; Tu, L.; Li, J.; Huang, X.; Robinson, C.; Malkin, K.; Jojic, N.; Ghamisi, P.; et al. The Outcome of the 2021 IEEE GRSS Data Fusion Contest - Track MSD: Multitemporal Semantic Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1643–1655. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Janga, B.; Asamani, G.P.; Sun, Z.; Cristea, N. A Review of Practical AI for Remote Sensing in Earth Sciences. Remote Sens. 2023, 15, 4112. [Google Scholar] [CrossRef]
- Friedl, M.; Brodley, C. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. Support Vector Machines for Land Cover Mapping from Remote Sensor Imagery; Springer Remote Sensing/Photogrammetry; Springer: Dordrecht, The Netherlands, 2015; pp. 265–279. [Google Scholar] [CrossRef]
- Luo, M.; Ji, S. Cross-spatiotemporal land-cover classification from VHR remote sensing images with deep learning based domain adaptation. ISPRS J. Photogramm. Remote Sens. 2022, 191, 105–128. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Chen, K.; Zou, Z.; Shi, Z. Building Extraction from Remote Sensing Images with Sparse Token Transformers. Remote Sens. 2021, 13, 4441. [Google Scholar] [CrossRef]
- Li, J.; He, W.; Cao, W.; Zhang, L.; Zhang, H. UANet: An Uncertainty-Aware Network for Building Extraction From Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5608513. [Google Scholar] [CrossRef]
- Sun, Z.; Zhou, W.; Ding, C.; Xia, M. Multi-Resolution Transformer Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2022, 11, 165. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Cai, H.; Li, J.; Hu, M.; Gan, C.; Han, S. EfficientViT: Lightweight Multi-Scale Attention for High-Resolution Dense Prediction. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 17256–17267. [Google Scholar] [CrossRef]
- d’Ascoli, S.; Touvron, H.; Leavitt, M.L.; Morcos, A.S.; Biroli, G.; Sagun, L. ConViT: Improving vision transformers with soft convolutional inductive biases*. J. Stat. Mech. Theory Exp. 2022, 2022, 114005. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Wu, Q.; Osco, L.P. samgeo: A Python package for segmenting geospatial data with the Segment Anything Model (SAM). J. Open Source Softw. 2023, 8, 5663. [Google Scholar] [CrossRef]
- Osco, L.P.; Wu, Q.; de Lemos, E.L.; Gonçalves, W.N.; Ramos, A.P.M.; Li, J.; Marcato, J. The Segment Anything Model (SAM) for remote sensing applications: From zero to one shot. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103540. [Google Scholar] [CrossRef]
- Li, Z.; He, W.; Li, J.; Lu, F.; Zhang, H. Learning without Exact Guidance: Updating Large-Scale High-Resolution Land Cover Maps from Low-Resolution Historical Labels. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 17–21 June 2024; pp. 27717–27727. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, X. A coarse-to-fine weakly supervised learning method for green plastic cover segmentation using high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2022, 188, 157–176. [Google Scholar] [CrossRef]
- Malkin, K.; Robinson, C.; Hou, L.; Jojic, N. Label super-resolution networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Chen, Y.; Zhang, G.; Cui, H.; Li, X.; Hou, S.; Ma, J.; Li, Z.; Li, H.; Wang, H. A novel weakly supervised semantic segmentation framework to improve the resolution of land cover product. ISPRS J. Photogramm. Remote Sens. 2023, 196, 73–92. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, H.; Lu, F.; Xue, R.; Yang, G.; Zhang, L. Breaking the resolution barrier: A low-to-high network for large-scale high-resolution land-cover mapping using low-resolution labels. ISPRS J. Photogramm. Remote Sens. 2022, 192, 244–267. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Kirillov, A.; Girshick, R.; He, K.; Dollar, P.; Soc, I.C. Panoptic Feature Pyramid Networks. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6392–6401. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Zhu, K.; Xiong, N.N.; Lu, M. A Survey of Weakly-supervised Semantic Segmentation. In Proceedings of the 2023 IEEE 9th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), New York, NY, USA, 6–8 May 2023; pp. 10–15. [Google Scholar] [CrossRef]
- Vincenzi, S.; Porrello, A.; Buzzega, P.; Cipriano, M.; Fronte, P.; Cuccu, R.; Ippoliti, C.; Conte, A.; Calderara, S. The color out of space: Learning self-supervised representations for earth observation imagery. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2020; pp. 3034–3041. [Google Scholar]
- Yang, Z.; Cao, S.; Aibin, M. Beyond sRGB: Optimizing Object Detection with Diverse Color Spaces for Precise Wildfire Risk Assessment. Remote Sens. 2025, 17, 1503. [Google Scholar] [CrossRef]
- Yang, H.; Kong, J.; Hu, H.; Du, Y.; Gao, M.; Chen, F. A Review of Remote Sensing for Water Quality Retrieval: Progress and Challenges. Remote Sens. 2022, 14, 1770. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Vanderbilt, B.C.; Ramezan, C.A. Land Cover Classification and Feature Extraction from National Agriculture Imagery Program (NAIP) Orthoimagery: A Review. Photogramm. Eng. Remote Sens. 2017, 83, 737–747. [Google Scholar] [CrossRef]
- Wickham, J.; Stehman, S.V.; Sorenson, D.G.; Gass, L.; Dewitz, J.A. Thematic accuracy assessment of the NLCD 2016 land cover for the conterminous United States. Remote Sens. Environ. 2021, 257, 112357. [Google Scholar] [CrossRef]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Dziedzic, T.; Zambrzycka, A. LandCover.ai: Dataset for Automatic Mapping of Buildings, Woodlands, Water and Roads from Aerial Imagery. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef]
- Van De Kerchove, R.; Zanaga, D.; Keersmaecker, W.; Souverijns, N.; Wevers, J.; Brockmann, C.; Grosu, A.; Paccini, A.; Cartus, O.; Santoro, M.; et al. ESA WorldCover: Global land cover mapping at 10 m resolution for 2020 based on Sentinel-1 and 2 data. In Proceedings of the AGU Fall Meeting Abstracts, New Orleans, LA, USA, 13–17 December 2021; Volume 2021, pp. GC45I–0915. [Google Scholar]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30 m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Xia, J.; Yokoya, N.; Adriano, B.; Broni-Bediako, C. OpenEarthMap: A Benchmark Dataset for Global High-Resolution Land Cover Mapping. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 6243–6253. [Google Scholar] [CrossRef]
- Prativadibhayankaram, S.; Panda, M.P.; Seiler, J.; Richter, T.; Sparenberg, H.; Foessel, S.; Kaup, A. A study on the effect of color spaces in learned image compression. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; pp. 3744–3750. [Google Scholar]
- Qian, X.; Su, C.; Wang, S.; Xu, Z.; Zhang, X. A Texture-Considerate Convolutional Neural Network Approach for Color Consistency in Remote Sensing Imagery. Remote Sens. 2024, 16, 3269. [Google Scholar] [CrossRef]
- Yan, Q.; Feng, Y.; Zhang, C.; Wang, P.; Wu, P.; Dong, W.; Sun, J.; Zhang, Y. You only need one color space: An efficient network for low-light image enhancement. arXiv 2024, arXiv:2402.05809. [Google Scholar]
- Atoum, Y.; Ye, M.; Ren, L.; Tai, Y.; Liu, X. Color-wise Attention Network for Low-light Image Enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2130–2139. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2024, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. VMamba: Visual State Space Model. arXiv 2024, arXiv:2401.10166. [Google Scholar] [CrossRef]
- Wang, C.; Tsepa, O.; Ma, J.; Wang, B. Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces. arXiv 2024, arXiv:2402.00789. [Google Scholar]
- Ma, J.; Li, F.; Wang, B. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv 2024, arXiv:2401.04722. [Google Scholar]
- Dao, T.; Gu, A. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. arXiv 2024, arXiv:2405.21060. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5– 9 October 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. arXiv 2020, arXiv:1908.07919. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 192–1924. [Google Scholar] [CrossRef]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Li, Z.; Lu, F.; Zhang, H.; Yang, G.; Zhang, L. Change cross-detection based on label improvements and multi-model fusion for multi-temporal remote sensing images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2054–2057. [Google Scholar]
- Ahmed, S.; Al Arafat, A.; Rizve, M.N.; Hossain, R.; Guo, Z.; Rakin, A.S. SSDA: Secure Source-Free Domain Adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 19180–19190. [Google Scholar]
- Oh, Y.; Kim, B.; Ham, B. Background-Aware Pooling and Noise-Aware Loss for Weakly-Supervised Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6909–6918. [Google Scholar] [CrossRef]
- Tang, M.; Djelouah, A.; Perazzi, F.; Boykov, Y.; Schroers, C. Normalized Cut Loss for Weakly-Supervised CNN Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1818–1827. [Google Scholar] [CrossRef]
- Ke, T.W.; Hwang, J.J.; Yu, S.X. Universal Weakly Supervised Segmentation by Pixel-to-Segment Contrastive Learning. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Zhang, B.; Xiao, J.; Jiao, J.; Wei, Y.; Zhao, Y. Affinity Attention Graph Neural Network for Weakly Supervised Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8082–8096. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Box-Driven Class-Wise Region Masking and Filling Rate Guided Loss for Weakly Supervised Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3131–3140. [Google Scholar] [CrossRef]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for remote sensing image semantic segmentation. arXiv 2024, arXiv:2405.10530. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Los Alamitos, CA, USA, 27 October–2 November 2019; pp. 1911–1920. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Base Annotation | HR Annotation | LR Annotation |
|---|---|---|
| Built-up | Roads Buildings Barren | Developed open space Developed low Developed medium Developed high |
| Tree canopy | Tree canopy | Deciduous forest Evergreen forest Mixed forest Woody wetland |
| Low vegetation | Low vegetation | Barren land Shrub/scrub Grassland Pasture/hay Cultivated crops Herbaceous wetlands Herbaceous wetlands |
| Water | Water | Open water |
| Base Annotation | OpenEarthMap [44] | FROM GLC10 [40] | ESA GLC10 [41] | ESRI GLC10 [42] | GLC FCS30 [43] |
|---|---|---|---|---|---|
| Built-up | Developed space Road | Impervious | Built-up | Built area | Impervious surfaces |
| Tree canopy | Tree | Forest | Tree cover Mangroves | Trees Flooded vegetation | Forest |
| Low vegetation | Bareland Rangeland Agriculture land | Cropland Grass Shrub Bareland | Shrubland Grassland Cropland Moss and lichen Herbaceous wetland Bare/sparse vegetation | Crops Bare ground Rangeland | Cropland Shrubland Grassland Wetlands Bare areas |
| Water | Water | Water | Permanent water bodies | Water | Water body |
| Kernel Size | Stride | Output Feature Size | Channel | Group Number |
|---|---|---|---|---|
| 1 | 64 | 64 | ||
| 1 | 64 | 1 | ||
| 1, 2 | 64 | 64 | ||
| 2, 1 | 64 | 64 | ||
| Max-Pooling | 1 | 64 | 1 |
| Chunk Size | mIoU | mAcc | Acc | Water IoU | Built-Up IoU | Low Vegetation IoU | Tree IoU |
|---|---|---|---|---|---|---|---|
| 0 | 67.55 | 79.68 | 87.69 | 85.06 | 28.71 | 72.93 | 83.50 |
| 7 | 68.90 | 79.73 | 87.69 | 85.22 | 28.13 | 75.43 | 86.83 |
| 14 | 70.14 | 79.51 | 89.63 | 85.16 | 28.90 | 78.32 | 88.20 |
| 28 | 70.19 | 79.58 | 90.08 | 86.24 | 29.53 | 77.43 | 87.56 |
| Channel Name | mIoU | mAcc | Acc | Water IoU | Built-Up IoU | Low Vegetation IoU | Tree IoU |
|---|---|---|---|---|---|---|---|
| AECA | 69.57 | 81.17 | 89.08 | 88.09 | 29.00 | 75.81 | 85.37 |
| - Red (R) | 69.13 | 80.84 | 88.76 | 87.53 | 28.73 | 75.24 | 85.00 |
| - Green (G) | 69.04 | 80.77 | 88.73 | 87.48 | 28.91 | 75.07 | 84.68 |
| - Blue (B) | 69.12 | 80.85 | 88.79 | 87.37 | 28.88 | 75.19 | 85.02 |
| - Near-infrared (NIR) | 68.32 | 80.10 | 88.35 | 85.94 | 28.83 | 74.26 | 84.25 |
| Baseline | 67.55 | 79.68 | 87.69 | 85.06 | 28.71 | 72.93 | 83.50 |
| Method | mParams | GFLOPs | FPS | mIoU | mAcc | Acc | Water IoU | Built-Up IoU | Low Vegetation IoU | Tree IoU |
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 145.40 | 143.72 | 15.42 | 67.55 | 79.68 | 87.69 | 85.06 | 28.71 | 72.93 | 83.50 |
| + AECA | 143.05 | 116.24 | 17.76 | 69.57 | 81.17 | 89.08 | 88.09 | 29.00 | 75.81 | 85.37 |
| + FBMamba | 151.22 | 102.94 | 20.22 | 70.19 | 79.58 | 90.08 | 86.24 | 29.53 | 77.43 | 87.56 |
| Ours | 151.55 | 117.89 | 17.38 | 71.91 | 84.70 | 89.64 | 89.64 | 38.68 | 76.36 | 85.94 |
| Method | Delaware | New York | Maryland | Pennsylvania | Virginia | West Virginia | Average |
|---|---|---|---|---|---|---|---|
| AECA-FBMamba | 66.02 | 71.91 | 70.66 | 60.43 | 68.50 | 54.09 | 65.27 |
| Paraformer [25] | 61.76 | 67.55 | 66.28 | 56.17 | 64.22 | 50.10 | 61.01 |
| L2HNet [29] | 61.77 | 68.12 | 65.24 | 58.52 | 69.39 | 55.43 | 63.08 |
| TransUNet [12] | 53.15 | 60.53 | 60.42 | 51.08 | 66.21 | 47.52 | 56.49 |
| ConViT [20] | 55.26 | 60.71 | 61.58 | 53.94 | 59.80 | 49.11 | 56.73 |
| CoAtNet [60] | 56.89 | 62.83 | 61.25 | 53.57 | 65.67 | 51.34 | 58.59 |
| MobileViT [21] | 58.03 | 61.32 | 61.84 | 55.53 | 57.04 | 48.64 | 57.07 |
| EfficientViT [19] | 53.72 | 61.28 | 59.48 | 51.38 | 57.34 | 48.76 | 55.33 |
| UNetFormer [11] | 58.85 | 65.11 | 61.34 | 59.10 | 60.84 | 47.20 | 58.74 |
| DC-Swin [18] | 59.65 | 65.99 | 58.60 | 58.06 | 64.11 | 48.15 | 59.09 |
| UNet [57] | 54.16 | 58.79 | 56.42 | 53.21 | 57.34 | 46.11 | 54.34 |
| HRNet [58] | 52.11 | 56.21 | 50.76 | 50.03 | 57.48 | 45.42 | 52.00 |
| LinkNet [59] | 58.27 | 62.05 | 52.96 | 52.11 | 48.71 | 48.93 | 53.84 |
| SkipFCN [61] | 60.97 | 64.83 | 59.44 | 55.37 | 64.72 | 54.66 | 60.00 |
| SSDA [62] | 57.91 | 64.54 | 54.85 | 51.71 | 55.71 | 47.15 | 55.15 |
| RF [8] | 59.35 | 55.03 | 55.26 | 51.07 | 52.29 | 54.36 | 54.56 |
| mIoU (%) of Different Methods | |||||||
|---|---|---|---|---|---|---|---|
| Max Gap | LR Annotation | AECA-FBMamba | Paraformer [25] | L2HNet [29] | TransUNet [12] | HRNet [58] | SkipFCN [61] |
| FEOM_CLC10 | 56.96 | 53.49 | 50.15 | 38.44 | 43.66 | 27.14 | |
| 40× | ESA_GLC10 | 55.55 | 52.14 | 52.13 | 35.58 | 49.81 | 28.34 |
| Esri_GLC10 | 55.44 | 52.05 | 50.78 | 26.20 | 41.46 | 23.67 | |
| 120× | GLC_FCS30 | 49.71 | 46.42 | 43.62 | 26.20 | 41.46 | 23.67 |
| Method | mIoU | mAcc | Acc | Water IoU | Built-Up IoU | Low Vegetation IoU | Tree IoU |
|---|---|---|---|---|---|---|---|
| Baseline | 67.55 | 79.68 | 87.69 | 85.06 | 28.71 | 72.93 | 83.50 |
| + CGA [68] | 64.07 | 78.05 | 82.19 | 81.38 | 34.90 | 65.85 | 74.17 |
| + MSAA [69] | 65.81 | 76.05 | 89.05 | 85.92 | 14.90 | 75.73 | 86.71 |
| + DA [12] | 61.88 | 69.00 | 89.67 | 84.22 | 12.47 | 76.10 | 87.20 |
| + RPLinear block [29] | 66.46 | 76.08 | 88.57 | 80.97 | 24.15 | 75.57 | 85.16 |
| ViT Num | FBMamba Num | mParams | GFLOPs | FPS | mIoU | mAcc | Acc |
|---|---|---|---|---|---|---|---|
| 12 | 0 | 145.40 | 143.72 | 15.42 | 67.55 | 79.68 | 89.69 |
| 12 | 1 | 151.55 | 117.89 | 17.38 | 71.91 | 84.70 | 89.64 |
| 12 | 2 | 160.06 | 119.54 | 17.11 | 71.75 | 82.03 | 89.80 |
| 11 | 1 | 144.47 | 116.44 | 17.57 | 70.61 | 79.69 | 89.70 |
| 11 | 2 | 152.97 | 118.09 | 17.37 | 67.80 | 79.11 | 89.53 |
| 10 | 1 | 137.38 | 114.99 | 17.92 | 67.00 | 79.98 | 89.83 |
| 10 | 2 | 145.88 | 116.64 | 17.75 | 61.33 | 69.66 | 89.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, X.; Zhang, W.; Li, Z.; Zhang, N.; Chai, X. AECA-FBMamba: A Framework with Adaptive Environment Channel Alignment and Mamba Bridging Semantics and Details. Remote Sens. 2025, 17, 1935. https://doi.org/10.3390/rs17111935
Chai X, Zhang W, Li Z, Zhang N, Chai X. AECA-FBMamba: A Framework with Adaptive Environment Channel Alignment and Mamba Bridging Semantics and Details. Remote Sensing. 2025; 17(11):1935. https://doi.org/10.3390/rs17111935
Chicago/Turabian StyleChai, Xin, Wenrong Zhang, Zhaoxin Li, Ning Zhang, and Xiujuan Chai. 2025. "AECA-FBMamba: A Framework with Adaptive Environment Channel Alignment and Mamba Bridging Semantics and Details" Remote Sensing 17, no. 11: 1935. https://doi.org/10.3390/rs17111935
APA StyleChai, X., Zhang, W., Li, Z., Zhang, N., & Chai, X. (2025). AECA-FBMamba: A Framework with Adaptive Environment Channel Alignment and Mamba Bridging Semantics and Details. Remote Sensing, 17(11), 1935. https://doi.org/10.3390/rs17111935