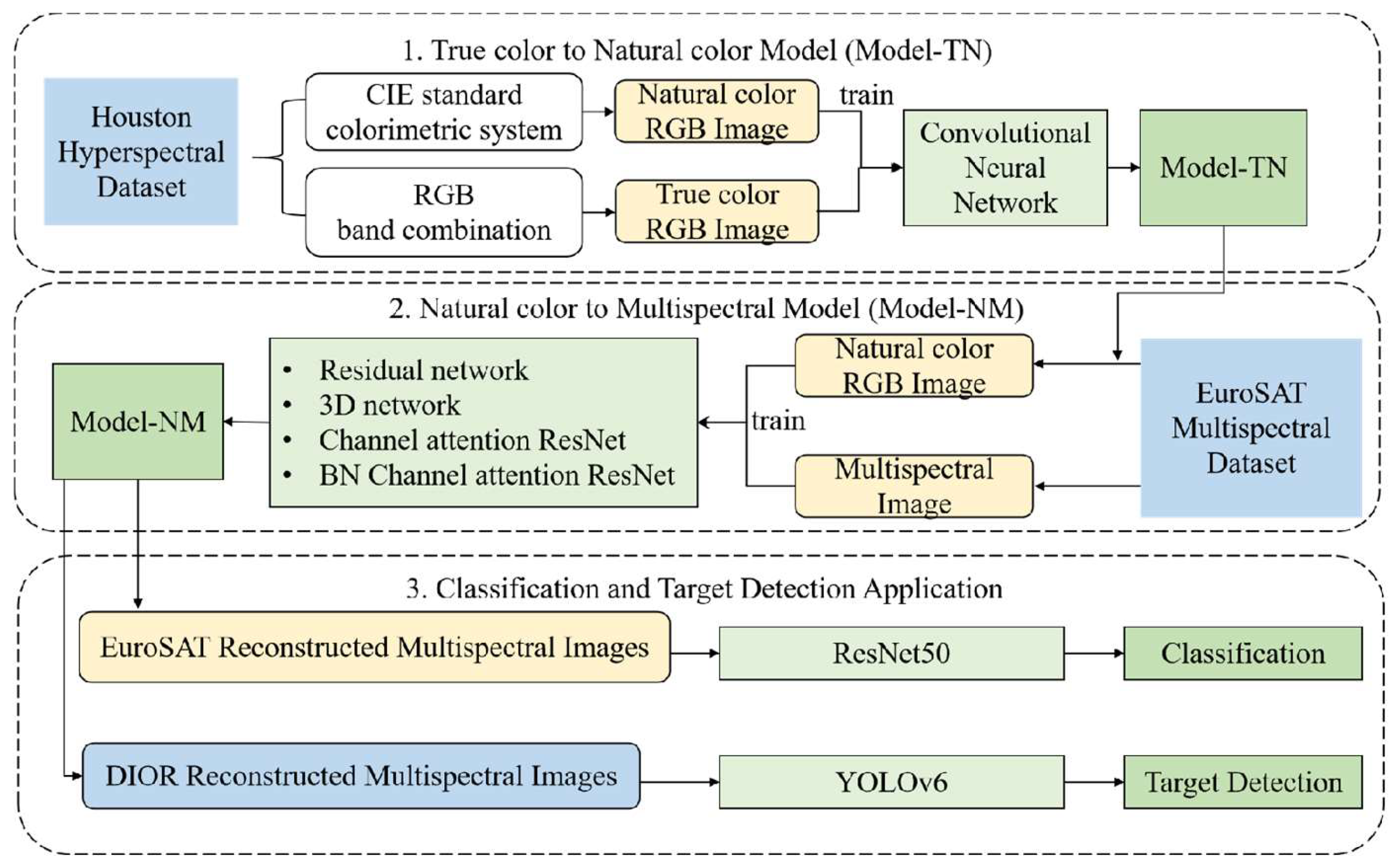
The flowchart of the multispectral image reconstruction algorithm and subsequent applications is shown in
Figure 4. This paper first addresses the issue of lacking insufficient paired multispectral and natural color images by combining the design of a novel deep learning model (i.e., Model-TN) based on the Houston hyperspectral dataset, and standard colorimetric systems theory. Then, we propose a multispectral reconstruction model (i.e., Model-NM) using the residual network integrated with channel attention mechanisms for the reconstruction of multispectral images. Finally, the effectiveness of the Model-NM is further verified, by applying the reconstructed multispectral images to image classification and object detection. Relevant methods are introduced in detail as follows.
2.2.1. True to Natural Color RGB Method Model-TN
Firstly, the ncRGB images corresponding to the hyperspectral images were generated using the Houston hyperspectral image dataset and the CIE tristimulus curves. The tristimulus curves of the CIE standard colorimetric system theory, also known as the CIE color matching function (CMF), can convert images to the corresponding CIE color space [
25,
26,
27,
28,
29]. Additionally, the hyperspectral image reflectance at different wavelengths and the spectral power distribution of the corresponding light source were also used, by which the ncRGB images were generated from the hyperspectral reflectance images. The specific operation process is shown in
Figure 5.
where
X,
Y, and
Z are the response values of the CIE XYZ color space, as a function of wavelength
λ, object reflectance
S(
λ), the spectral power distribution of the light source
I(
λ), three-stimulus curves
N, and proportionality factor
K.
,
, and
are tristimulus values. The parameter
N can normalize the response values, and
K serves as a proportionality factor, typically set to 100. After obtaining
X,
Y, and
Z through weighted summation, the corresponding conversion matrix is selected based on the color spaces before and after conversion and the light source, as shown in
Table 2. Then,
X,
Y, and
Z are converted to the corresponding color space using the conversion matrix, as illustrated in (5), and the numerical values of M and M
−1 are given as (6) and (7), respectively.
Finally, a Gamma correction converted the response values (ranging from 0 to 1) to the RGB color space using a segmented nonlinear function, such as the one represented in (8), for correction. In simpler cases, Formula (9) can be used instead. Then, the R, G, and B values are clipped to [0, 1] and stored as 8bit integers (0–255) to be correctly displayed on the screen.
In this paper, the CIE 1964 XYZ CMF was selected, where the spectral power distribution of the standard daylight source D65 was utilized. The Houston hyperspectral images were employed to generate the corresponding ncRGB images. Because the spectrum of the hyperspectral image is not continuous, appropriate CMF values were selected based on the wavelength of each hyperspectral image channel. The CMF wavelengths range from 400 nm to 700 nm, with an interval of 10 nm. For each channel, the wavelength closest to that of the CMF was chosen from the hyperspectral image. Since the wavelengths of the hyperspectral image channels are discontinuous, the rectangular method was used to solve the integral as shown in Formulas (10)–(13):
where
is the interval of the wavelength of the CMF (
= 10), and the other parameters have the same physical meaning as the parameters of the Formulas (1)–(4).
First, normalize the hyperspectral data to [0, 1] according to the data storage format of Houston Hyperspectral Dataset. After converting hyperspectral image data into XYZ color space values, the conversion matrix is transformed from XYZ to sRGB color space. Then, a gamma correction was applied to make the image more consistent with human vision to obtain an ncRGB image. After applying the transfer function and gamma correction, the R, G, and B values are clipped to [0, 1] and stored as 8bit integers (0–255).
Finally, ncRGB images and tcRGB images generated from the Houston hyperspectral dataset as float32 tensors in the 0–1 range were employed to train the Model-TN for converting tcRGB images into ncRGB images. The CNN was employed to train Model-TN, and the model structure employed during training is illustrated in
Figure 6. The first convolutional layer performs preliminary feature extraction from the 3-channel image data, converting it into 64-channel feature maps. Next, a convolution activation layer further extracts feature information while maintaining the channel number of the feature map. Finally, a convolutional layer can transform the 64-channel feature map into a 3-channel ncRGB image.
Houston true and natural color image pairs were trimmed to a same size of 64 × 64 pixels for model training and validation. Two-thirds of the images were allocated to the training set, while one-third were reserved for the verification set. The experiments were conducted using Python 3.9, with the deep learning framework based on Pytorch 2.3. The hardware configuration includes an Intel Core i5-13490F processor (Intel Corporation, Santa Clara, CA, USA, sourced from China), an NVIDIA GeForce RTX 4060 Ti GPU (PC Partner, Singapore, sourced from China), and a 32 GB CPU memory. The loss function used the mean relative absolute error (MRAE), where the batch size was set to 1. We selected the Adamax optimizeris, and the learning rate was set to 0.001 to avoid a divisor of zero. The learning rate was multiplied by 0.98 every 200 epochs until the loss function stopped decreasing over a span of 200 epochs. To obtain the best training model parameter of the Model-TN, we select the MRAE as the loss. Meanwhile, the MRAE and Root Mean Square Error (RMSE) are used to evaluate the accuracy of the Model-TN, which are defined as follows:
where
represents the number of image pixels, and
and
refer to the pixel value of the ground truth and the reconstructed result, respectively.
2.2.2. Multispectral Reconstruction Method Model-NM
Considering the high-performance of the deep learning method, the residual network was selected as the basic method of the multispectral image reconstruction model-NM. The gradient of the backpropagation of the residual network [
30] consists of two parts, the identity mapping of x with the gradient of 1 and the gradient of multilayer traditional neural network mapping. When a specific layer in the network converges to an optimal state, the local gradient vanishes, inhibiting backpropagation of the error signal to earlier layers. Consequently, parameters that should remain stable continue to be updated, potentially increasing the overall model error. Particularly, we incorporated a shortcut connection, which can allow the gradient value to remain at 1 when the optimal solution for a layer is reached. This allows deeper gradients to be effectively transferred to the shallower layers, enabling the weight parameters of the shallow-layer network to be effectively trained and avoiding the problem of gradient disappearance.
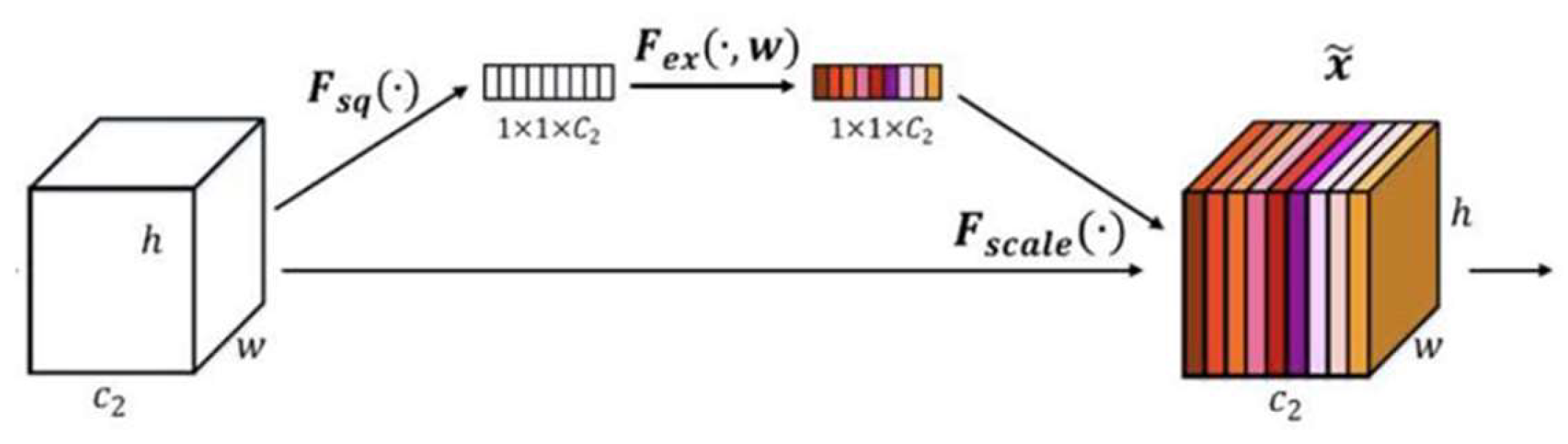
Based on the residual network model, the channel attention mechanism using Squeeze-and-Excitation (SE) block is innovatively added to enhance the focus on the differences between channels during model training, which consists of two primary steps as shown in
Figure 7. The first step is compression. The pooling of the feature map with a size of
h × w × c can result in the information of each channel being compressed into a single value, thereby generating a global compressed feature with a size of 1 × 1 ×
c. The second step is excitation. The global compressed features obtained from the first step were further processed through a structure consisting of a fully connected layer, another fully connected layer (i.e., the ReLU activation layer), and a Sigmoid layer. This process yields the weights for each channel in the feature map, which were then used to weight the original feature map, resulting in a processed feature map. The first fully connected layer compresses
c channels into
c/r channels to reduce the computational load, and then the second fully connected layer restores the number of channels to c channels through a ReLU nonlinear activation layer. Finally, the normalized weights were obtained by activating the Sigmoid function. r is the ratio of compression, and it is not possible to use both the ReLU nonlinear activation function and the Sigmoid function if only one fully connected layer is used.
Figure 8 shows the overall structure of the channel attention residual network model, Model-NM, proposed in this paper. The input data is an image as float32 tensors in the 0–1 range with a height of 64 pixels, a width of 64 pixels, and 3 channels for RGB (red, green, and blue). The reconstructed multispectral images contain five bands. So, the output data is an image with a height of 64 pixels, a width of 64 pixels, and 5 channels for blue, green, red, red edge, and near-infrared. These five bands and their wavelengths respectively correspond to b02, b03, b04, b05, and b08 in the EuroSAT dataset as listed in
Table 1.
The specific operation process is as follows. The network first processes the 64 × 64 × 3 RGB input through an initial 3 × 3 convolution (3 to 64 channels) with a ReLU activation. The feature map then passes through three consecutive residual blocks, where each block contains the following parts: (1) two 3 × 3 convolutional layers (64 to 64 channels) with a ReLU activation; (2) an identity skip connection; and (3) element-wise addition followed by a ReLU.
Critically, after the residual blocks but before the SE module, the network applies an intermediate 3 × 3 convolutional layer (64 to 64 channels) with a ReLU activation to further refine feature representations.
The processed features then enter the Squeeze-and-Excitation (SE) module (compression ratio r = 16), which dynamically recalibrates channel weights through the following processes: (1) global average pooling to generate channel-wise statistics; (2) two fully connected layers (64 to 4 to 64) with ReLU and Sigmoid activation, respectively; and (3) channel-wise multiplication with the input feature map. Finally, a 3 × 3 convolution projects the 64-channel features to 5 output bands (B02/B03/B04/B05/B08), preserving the 64 × 64 spatial resolution throughout the network via symmetric padding.
EuroSAT multispectral images in five bands mentioned above and corresponding ncRGB images generated through the Model-TN introduced in
Section 3.1 were collected as training image paeqirs. Data for categories 1–7 and 9 (N = 21,000 images) (see
Figure 2a–g,i) were used for training, where 2/3 of data were composed of training sets while 1/3 of the total were used as validation sets. Additionally, image pairs for the other two categories (i.e.,
Figure 2h,j) were used to test the accuracy and generalization ability of the Model-NM.
The programming language Python 3.9 was employed, with the deep learning framework based on PyTorch 2.3. The hardware configurations include an Intel Core i5-13490F processor (Intel Corporation, US CA Santa Clara, sourced from China), an NVIDIA GeForce RTX 4060 Ti GPU (PC Partner, Singapore, sourced from China), and 32 GB of CPU memory. The loss function employed is the MRAE, and the batch size was set to 16. The optimizer used was Adamax, with a learning rate of 0.001. The exponential decay rates were set to 0.9 and 0.999 to prevent the denominator from approaching zero. The learning rate was multiplied by 0.98 every 200 epochs until the loss function ceased to decrease over a span of 200 epochs.
Similarly to the training process of the Model-TN, we also select MRAE as the loss to train the Model-NM. In addition, the MRAE, RMSE, and Spectral Information Divergence (SID) are employed to evaluate the accuracy of the Model-NM with a formula as follows:
where
,
, and
refer to the same meaning as formulas (14) and (15).
2.2.3. Image Classification Method
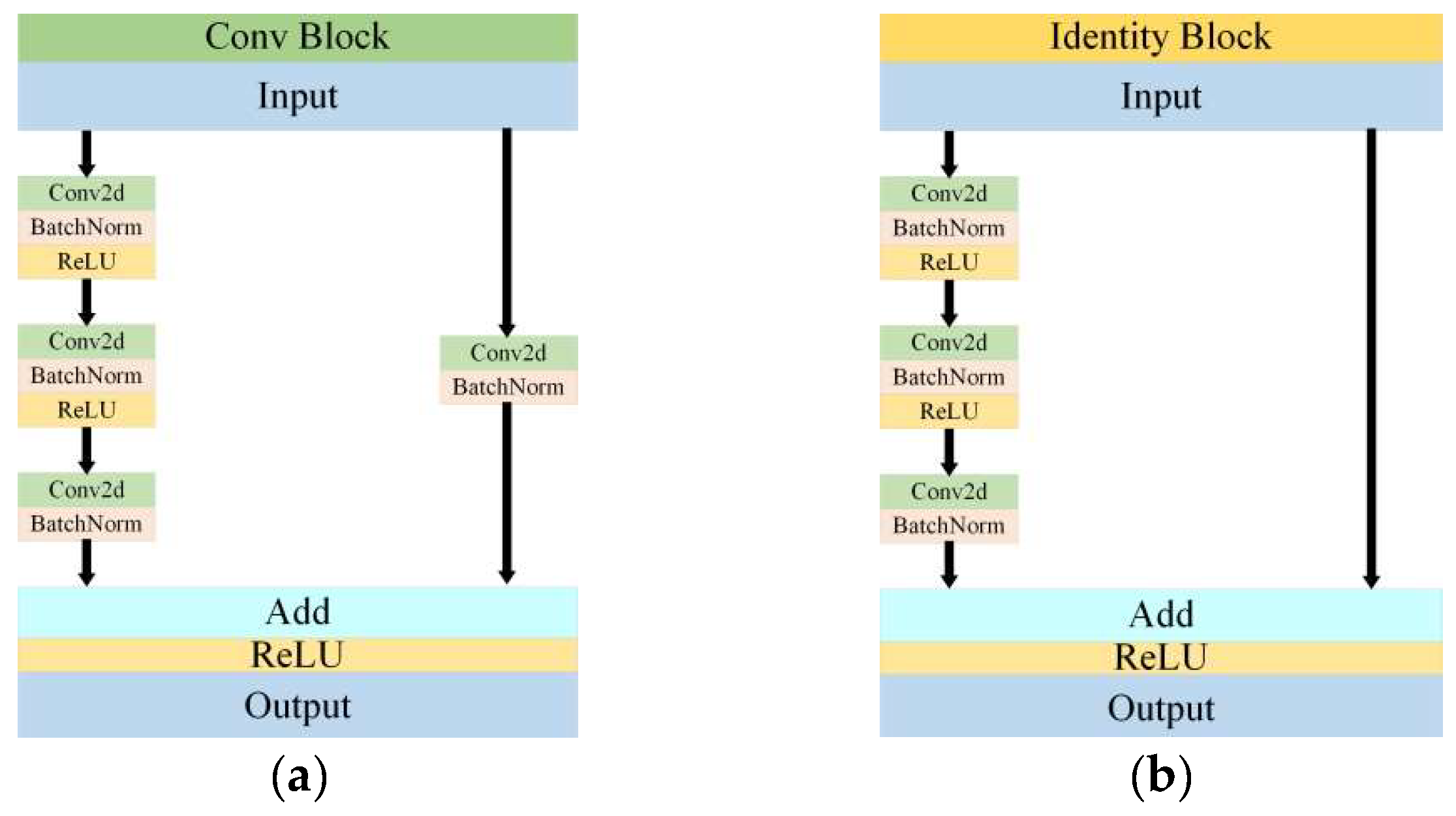
The classical network model ResNet50 was employed for image classification, which consists of two fundamental blocks including the Conv Block and the Identity Block as illustrated in
Figure 9. The Conv Block alters the input and output dimensions to prepare for the subsequent use in the Identity Block. It should be noted that the Conv Blocks cannot be used in series. In contrast, the Identity Block maintains the same input and output dimensions and can be used in series, which allows for a deeper network and the extraction of more complex features.
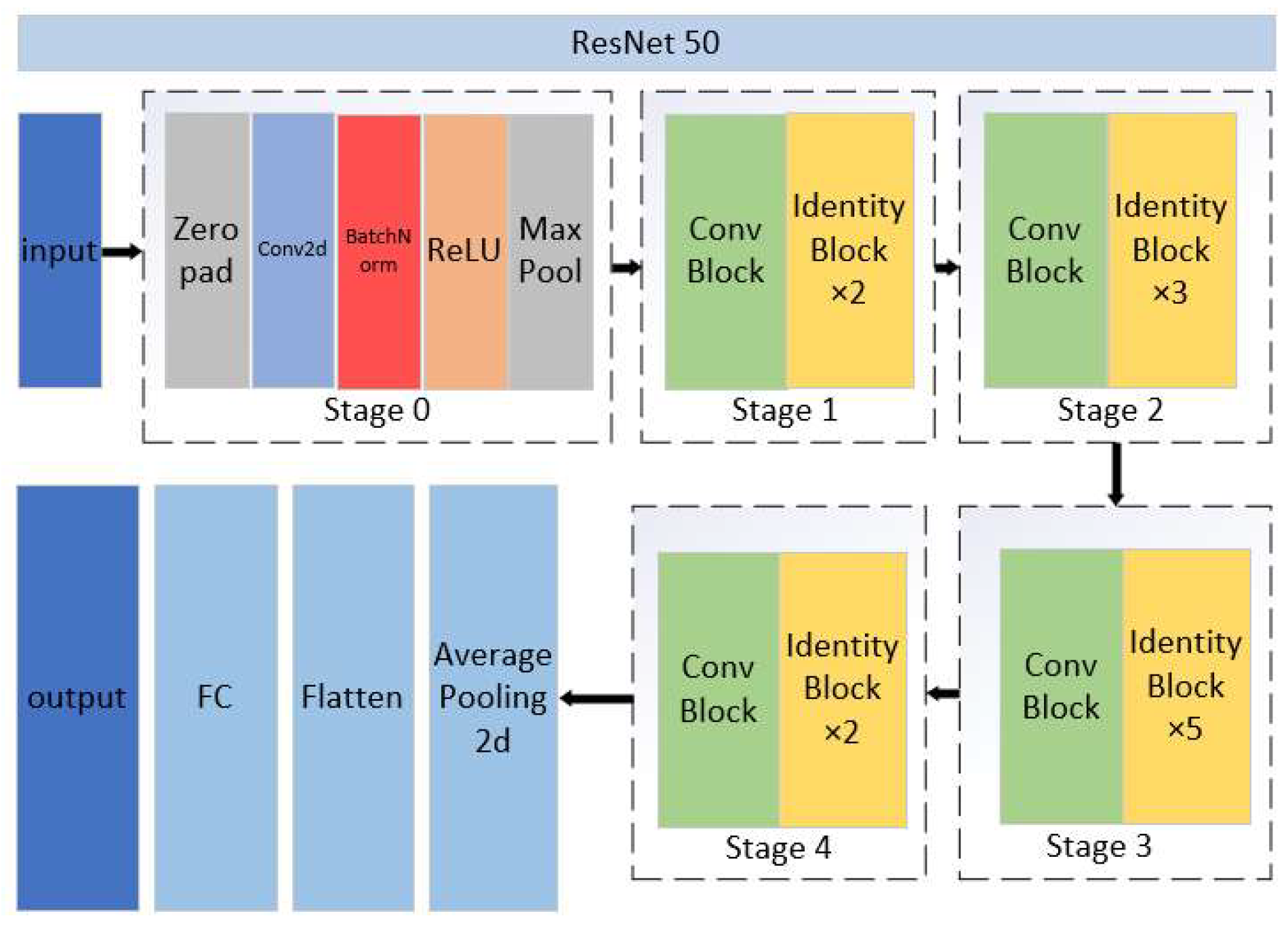
Figure 10 illustrates the main structure of ResNet50, which consists of five stages. Stage 0 serves as the preprocessing stage, where the data are adjusted into suitable forms for training and initial feature extraction from the images. Stages 1–4 share a similar structure and function, where a Conv Block is followed by several Identity blocks. Specifically, Stages 1–4 connect Identity blocks 2, 3, 5, and 2 after the Conv Block, respectively. This design aims to deepen the network and enhance the extraction of deep features from the images. Finally, the extracted information is pooled and fully connected to classify the images. The CNN was also used to train the image classification model, which can reduce memory usage in the deep network. By using three key operations including local receptive fields, weight sharing, and pooling layers, it can effectively decrease the number of network parameters and help mitigate the overfitting problem of the model.
Based on the ResNet50 model, this paper modified stage 0 to adjust the height, width, and channel size of the input images. This adjustment allows the model to adapt to the multispectral images of the EuroSAT dataset, the generated ncRGB image, and the reconstructed multispectral image.
Categorical cross entropy (i.e., Equation (17)) was used as the Loss function for training the classification model, where represents the number of target object classes and is the number of samples. represents the true value of the sample belonging to the class. If the sample belongs to the class, then , otherwise 0. represents the probability of predicting the sample to be class .
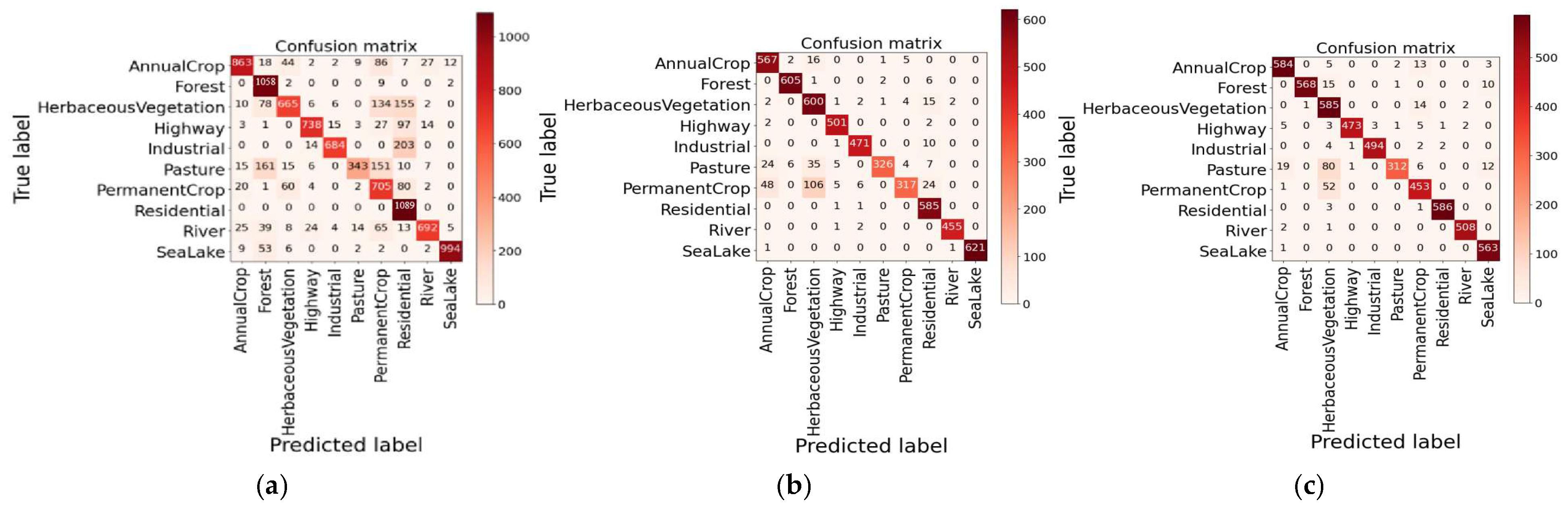
The precision, recall, and overall accuracy are selected to evaluate classification accuracy as shown in Formulas (18)–(21), which are defined based on the confusion matrix given in Equation (22).
represents the number of samples of Class
predicted to be Class
.
represents the total number of Class
samples, and
refers to the total number of samples predicted as Class
.
2.2.4. Target Detection Method
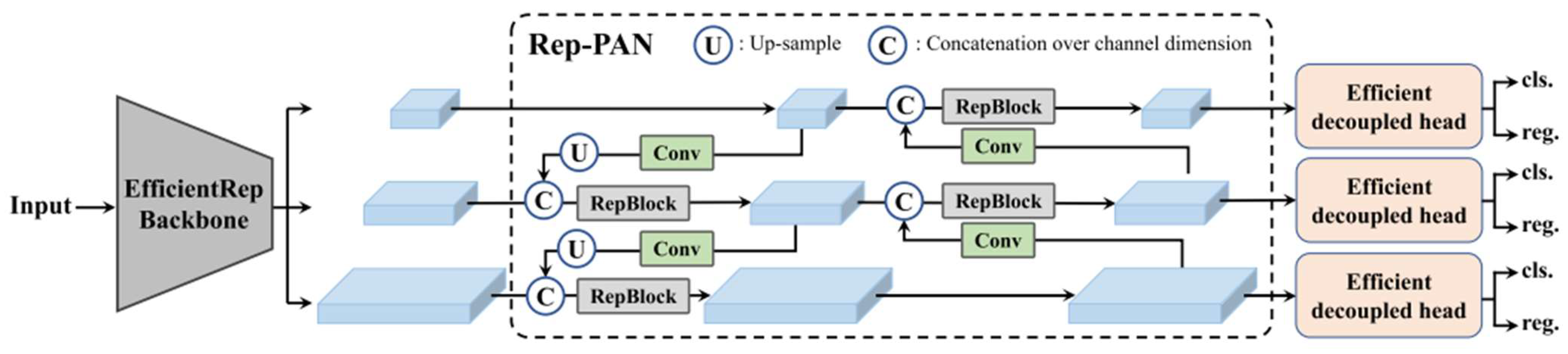
The target detection method employs the YOLOv6 algorithm [
31], which consists of three main components: the backbone network, the neck, and the head, as shown in
Figure 11. The backbone network primarily determines the model’s feature representation capability. The neck aggregates low-level physical features with high-level semantic features and constructs pyramidal feature mappings across all levels. The head comprises multiple convolutional layers that predict the final detection results based on the multi-level features assembled by the neck. In the YOLOv6 algorithm, these components are referred to as EfficientRep, EfficientRep-PAN, and Efficient Decoupled Head, respectively.
The RGB image of the DIOR dataset was applied to the multispectral image reconstruction model, Model-NM, to generate the reconstructed multispectral image of the DIOR dataset. In this paper, based on YOLOv6 algorithm, the reconstructed multispectral image of the DIOR dataset and the original RGB image were, respectively, identified, and the differences in target recognition results were compared. The input layer of the model was changed from 3 layers to 5 layers when the object detection of the reconstructed multispectral image was carried out.
The Intersection over Union (
IoU) loss (i.e.,
) and Classification Binary Cross Entropy Loss (i.e.,
) were selected to train the target detection model, and we used average precision (i.e., AP) and mean AP (i.e., mAP) to evaluate target detection accuracy. The number of batches was set to 20. Their Formulas (23)–(26) are as follows.
In Equation (23), represents the ratio of the overlapping area to the total area between the ground truth box and the predicted box. refers to the Euclidean distance between the center points of the ground truth box and the predicted box, and is the diagonal distance of the smallest enclosing box that fully contains both the ground truth and predicted boxes. represents the aspect ratio between the ground truth box and the predicted box, and is the weight balancing parameter. In Equation (24), represents the number of samples, and and are the round truth labels and the model predictions, respectively.
In Equations (25) and (26), represents the number of horizontal ordinate points on the precision recall curve after interpolation. represents the recall value corresponding to the horizontal ordinate points in ascending order, and represents precision corresponding to the . mAP at the of 0.5 (hereafter mAP(0.5)) is used, as well as the average value of mAP at the ranging from 0.5 to 0.95 with a step of 0.05 (hereafter mAP(0.5–0.95)).
The experiment used Python 3.9 for programming, with the deep learning framework based on PyTorch 2.4. The hardware consists of an Intel Core i5-10200H processor (Intel Corporation, Santa Clara, CA, USA, sourced from China), an NVIDIA GeForce GTX 1650 GPU (NVIDIA, Santa Clara, CA, USA, sourced from China), and 16 GB of CPU memory.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}