
Multi-Scale Feature Mixed Attention Network for Cloud and Snow Segmentation in Remote Sensing Images


Abstract
1. Introduction
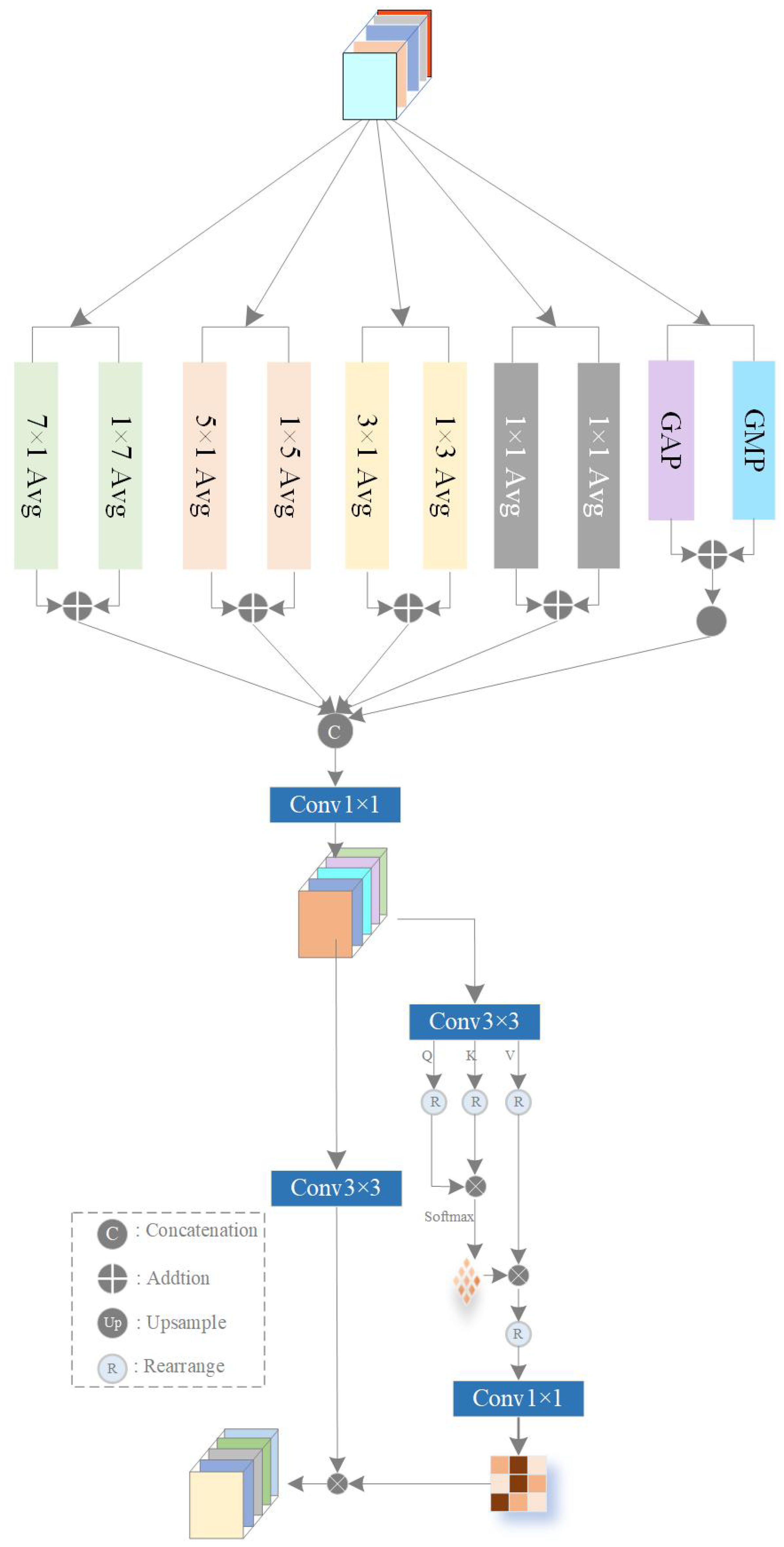
- Design of the Multi-scale Pooling Feature Perception (MPFP): This module integrates multi-scale strip pooling operations with a self-attention mechanism to enhance global context modeling. By capturing dependencies and structural characteristics of cloud and snow across varying scales, it improve the identification accuracy and reduces misclassification.
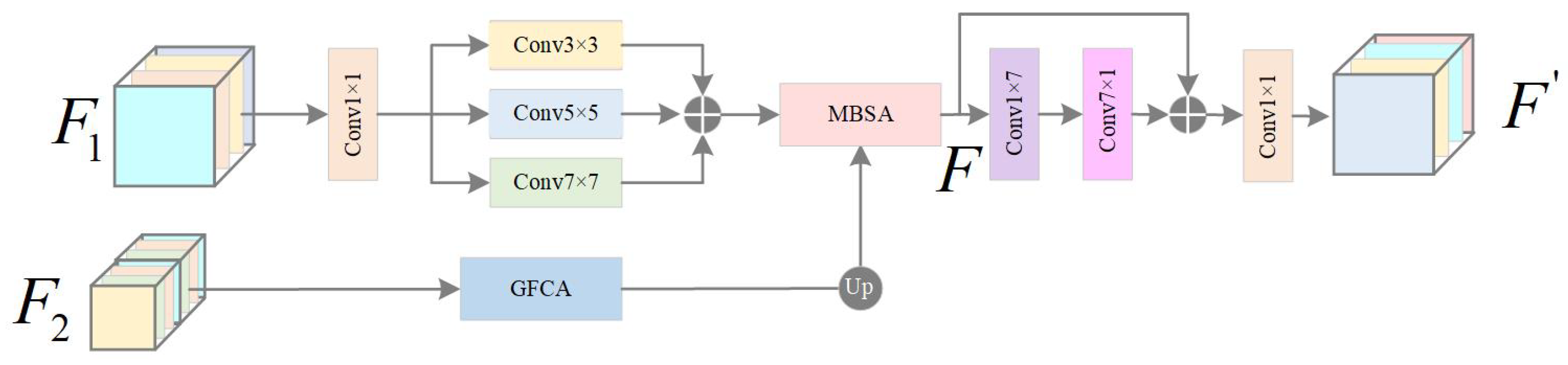
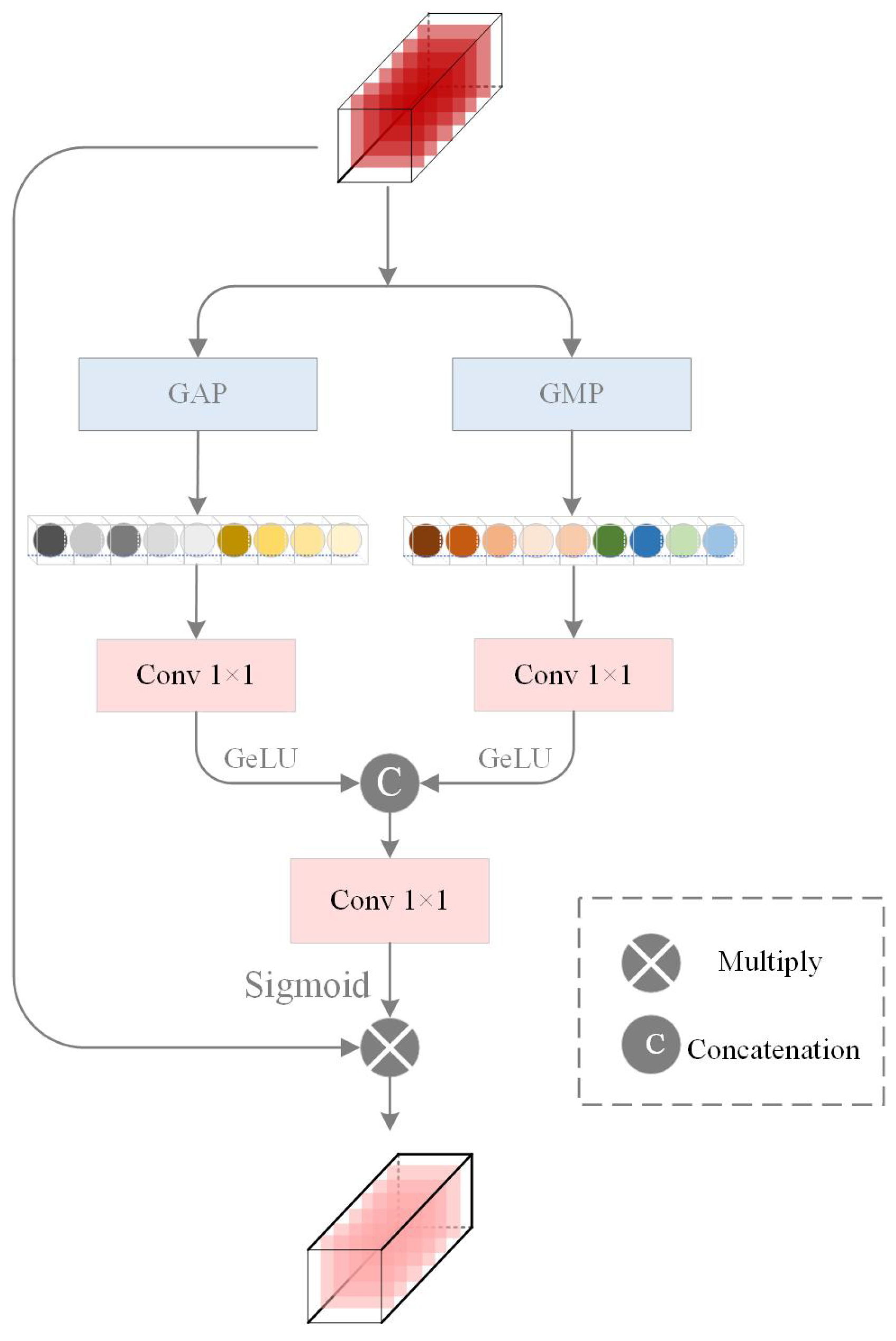
- Proposal of the Bilateral Feature Mixed Attention Module (BFMA): This module combines spatial and channel attention to address the irregular morphology of cloud and snow. In order to preserve the edge features and avoid the loss of edge features of target classification caused by direct global pooling, Global Feature Channel Attention (GFCA) sets two branches to use global average pooling and global maximum pooling respectively, which can extract richer global features, and the Multi-Branch Spatial Aggregation (MBSA) refines boundary details through multi-kernel convolutions. This dual attention framework significantly enhances segmentation accuracy in regions with spectral confusion and complex spatial distributions.
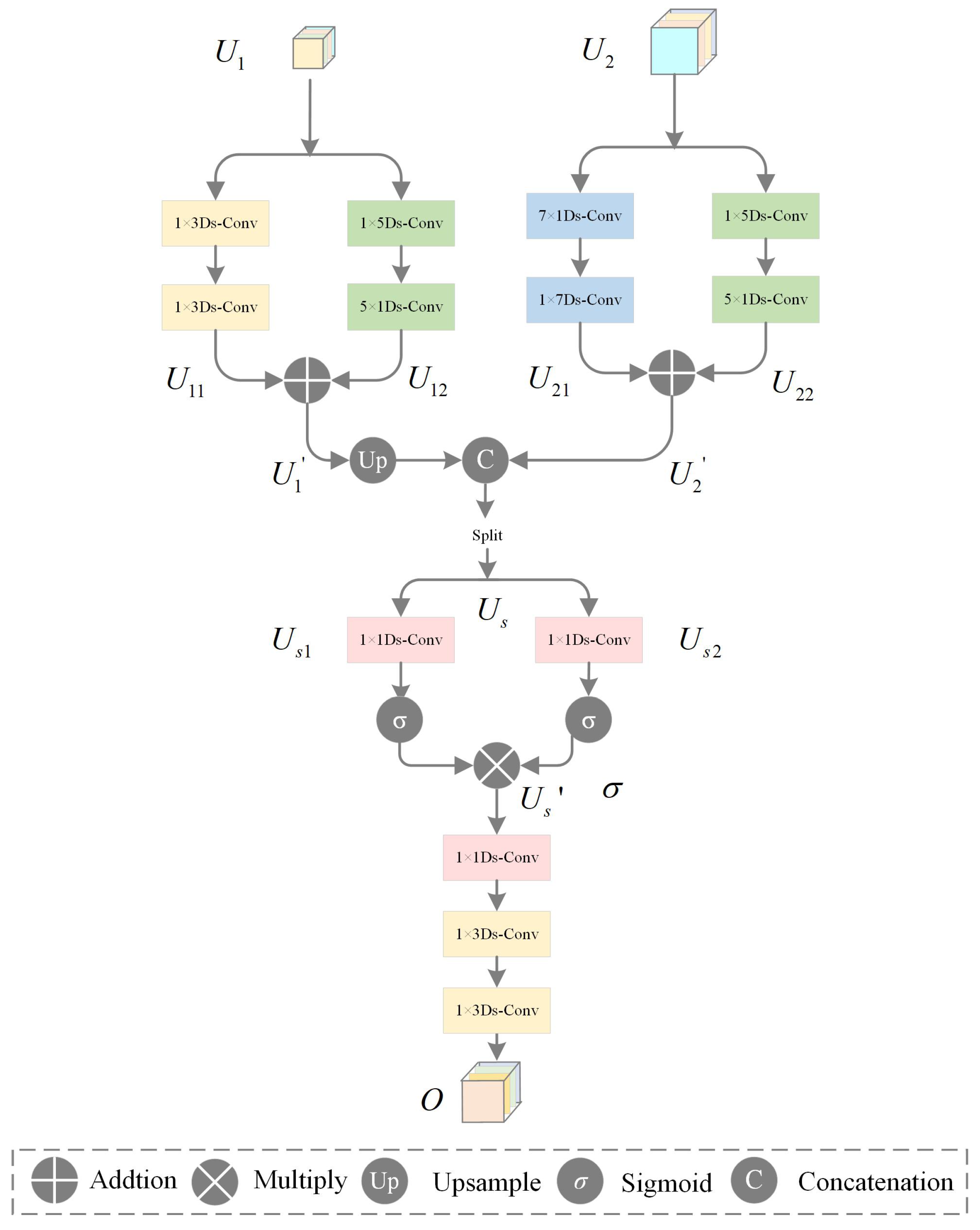
- Develop the Multi-scale Feature Convolution Fusion Module (MFCF): To mitigate edge blurring caused by scale mismatches, this module employs directional strip convolutions (e.g., 1 × 7, 7 × 1) to fuse multi-scale features. By leveraging elongated kernels aligned with cloud/snow textures, it effectively restores fine-grained boundary details and improves segmentation robustness, thus getting superior performance in recovering tortuous and irregular cloud/snow edges compared to conventional square convolutions.
2. Methodology
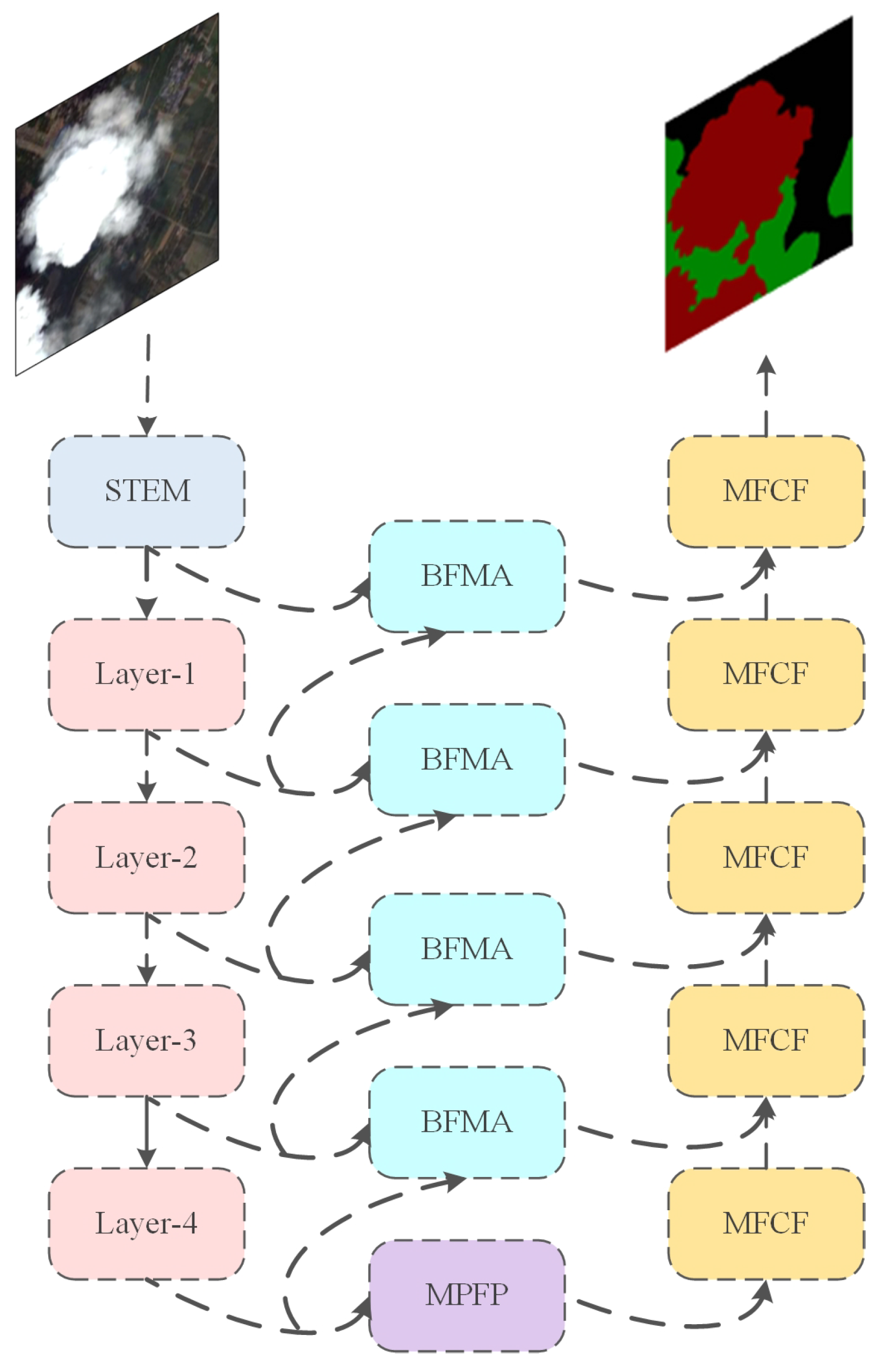
2.1. Framework
2.2. Backbone
2.3. Multi-Scale Pooling Feature Perception Module (MPFP)
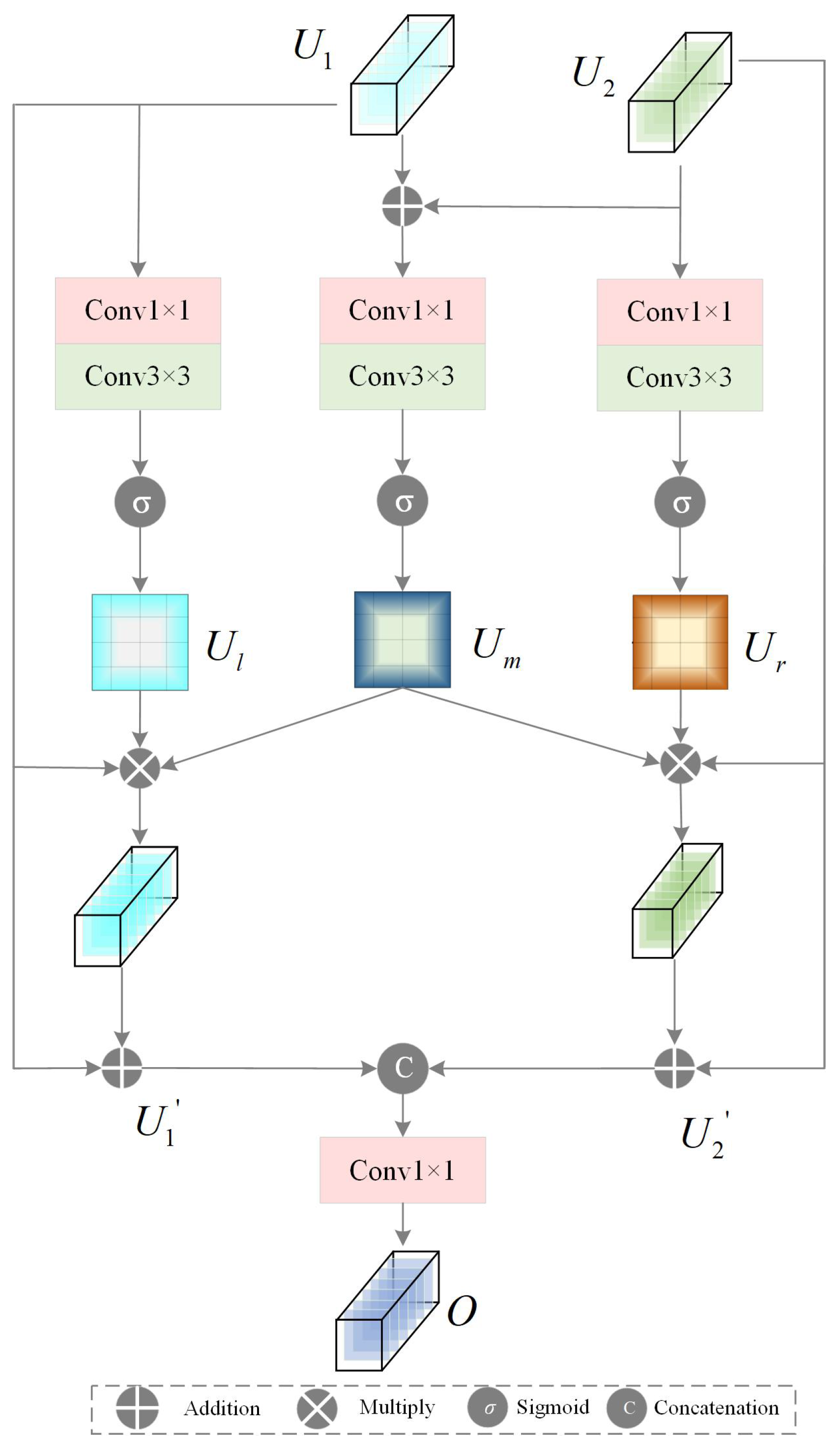
2.4. Bilateral Feature Mixed Attention Module (BFMA)
2.4.1. GFCA Module
2.4.2. MBSA Module
2.5. Multi-Scale Feature Convolution Fusion Module (MFCF)
3. Experiments
3.1. Dataset
3.1.1. The CSWV Dataset
3.1.2. The HRC_WHU Dataset
3.2. Experimental Parameter Setting
3.3. Metrics
3.4. Ablation Studies
- MPFP Module: According to the experimental results, after integrating the MPFP module into the deepest layer of the model, the segmentation metric MIoU improved by 0.63%. The experimental results demonstrate that the effective extraction of semantic information from the deepest layer guided the network in making a preliminary judgment on cloud and snow, as can be seen from the heatmap (C). However, as the deep semantic information is mixed with a significant amount of noise interference, there are some misclassifications and missed detections of cloud and snow. More modules need to be introduced into the network to improve the discrimination of details;
- BFMA Module: We introduced Multi-Branch Spatial Aggregation (MBSA) and Global Feature Channel Attention (GFCA) through the BFMA module. After integrating the BFMA module, the MIoU improved by 0.46%. From the heatmaps, it is evident that from (C) to (B), the misclassifications and missed detections of the main cloud and snow areas were significantly reduced, and the interference from noisy elements was suppressed. This allows for better detection of cloud and snow, effectively verifying that this module can fuse bilateral features and focus better on cloud and snow targets in the spatial domain;
- MFCF Module: The experimental results intuitively show that after integrating the MFCF module into the network, the model’s MIoU improved by 0.39%. It can be seen that compared to simple feature concatenation, MFCF can effectively fuse multi-scale features. From the heatmaps, it is also evident that from (B) to (A), with the addition of the MFCF module, the boundaries of cloud and snow became clearer and more distinct. This effectively restores the edge details of cloud and snow, verifying that strip convolution is highly sensitive to linear and edge features and can effectively extract the boundary features of cloud and snow, resulting in more accurate segmentation. Therefore, adding the MFCF module is effective for the cloud and snow segmentation task. It not only fuses multi-scale features effectively but also restores the edge information of classification targets well.
3.5. Comparative Experiments
3.6. Generalization Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lu, X.; Wang, X.; Xie, G.; Cui, C.; Wang, J. Snow depth retrieval based on passive microwave remote sensing. J. Arid Land Resour. Environ. 2012, 26, 108–112. (In Chinese) [Google Scholar]
- Li, H.; Xiao, P.; Feng, X.; Lin, J.; Wang, Z.; Man, W. Snow depth inversion method based on repeat-track InSAR. J. Glaciol. Geocryol. 2014, 36, 517–526. (In Chinese) [Google Scholar]
- Braaten, J.D.; Cohen, W.B.; Yang, Z. Automated cloud and cloud shadow identification in Landsat MSS imagery for temperate ecosystems. Remote Sens. Environ. 2015, 169, 128–138. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef]
- Tapakis, R.; Charalambides, A.G. Equipment and methodologies for cloud detection and classification: A review. Sol. Energy 2013, 95, 392–430. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel-2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Jiang, B.; Li, X.; Chong, H.; Wu, Y.; Li, Y.; Jia, J.; Wang, S.; Wang, J.; Chen, X. A deep-learning reconstruction method for remote sensing images with large thick cloud cover. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103079. [Google Scholar] [CrossRef]
- Zou, X.C.; Li, K.; Xing, J.L.; Zhang, Y.; Wang, S.Y.; Jin, L.; Tao, P. DiffCR: A fast conditional diffusion framework for cloud removal from optical satellite images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5612014. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Feng, J. Deep forest. Nat. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef] [PubMed]
- Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H.; Qian, M. Multiscale location attention network for building and water segmentation of remote sensing image. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–19. [Google Scholar] [CrossRef]
- Chen, K.; Xia, M.; Lin, H.; Qian, M. Multiscale attention feature aggregation network for cloud and cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial cross attention meets CNN: Bibranch fusion network for change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 21–32. [Google Scholar] [CrossRef]
- Yin, H.; Weng, L.; Li, Y.; Xia, M.; Hu, K.; Lin, H.; Qian, M. Attention-guided siamese networks for change detection in high resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103206. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Guo, J.; Yang, J.; Yue, H.; Tan, H.; Hou, C.; Li, K. CDnetV2: CNN-based cloud detection for remote sensing imagery with cloud-snow coexistence. IEEE Trans. Geosci. Remote Sens. 2020, 59, 700–713. [Google Scholar] [CrossRef]
- Du, H.; Li, K.; Guo, J.; Zhang, J.; Yang, J. Cloud and snow detection from remote sensing imagery based on convolutional neural network. In Optoelectronic Imaging and Multimedia Technology VI; SPIE: Bellingham, WA, USA, 2019; Volume 11187, pp. 260–266. [Google Scholar]
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Fang, Z.; Ji, W.; Wang, X.; Li, L.; Li, Y. Automatic cloud and snow detection for GF-1 and PRSS-1 remote sensing images. J. Appl. Remote Sens. 2021, 15, 024516. [Google Scholar] [CrossRef]
- Wu, X.; Shi, Z.; Zou, Z. A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection. ISPRS J. Photogramm. Remote Sens. 2021, 174, 87–104. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CVT: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6798–6807. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Zhang, G.; Gao, X.; Yang, Y.; Wang, M.; Ran, S. Controllably deep supervision and multi-scale feature fusion network for cloud and snow detection based on medium-and high-resolution imagery dataset. Remote Sens. 2021, 13, 4805. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1857–1866. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Structure | Feature Map Size |
|---|---|---|
| Stem | conv, stride 2 | |
| 3 × 3 Max pool | stride 2 | |
| L1 | ||
| L2 | ||
| L3 | ||
| (Dilated conv) | ||
| L4 | ||
| (Dilated conv) |
| Confusion Matrix | Predicted Value | ||
|---|---|---|---|
| Positive | Negative | ||
| True Value | Positive | TP (True Positive) | FN (False Negative) |
| Negative | FP (False Positive) | TN (True Negative) | |
| Method | MIoU (%) |
|---|---|
| Backbone | 87.69 |
| Backbone + MPFP | 88.32 (0.63 ↑) |
| Backbone + MPFP + BFMA | 88.78 (0.46 ↑) |
| Backbone + MPFP + BFMA + MFCF | 89.17 (0.39 ↑) |
| Method | PA (%) | MPA (%) | F1 (%) | MIoU (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| CvT | 89.92 | 88.47 | 88.27 | 78.87 | 0.82 | 5.73 |
| DeepLabV3Plus | 91.47 | 90.36 | 89.93 | 81.93 | 7.83 | 6.03 |
| HRNet | 91.63 | 90.58 | 90.51 | 82.82 | 65.85 | 23.31 |
| SegNet | 91.76 | 91.41 | 90.85 | 83.32 | 29.48 | 42.52 |
| BiSeNetV2 | 91.88 | 91.53 | 90.93 | 84.83 | 3.62 | 3.20 |
| DABNet | 91.91 | 91.68 | 90.77 | 85.47 | 0.752 | 1.27 |
| FCN8s | 92.07 | 91.72 | 91.55 | 86.55 | 18.64 | 20.06 |
| ACFNet | 92.54 | 92.27 | 91.73 | 86.53 | 89.97 | 99.32 |
| PSPNet | 92.71 | 92.57 | 91.86 | 87.46 | 49.07 | 46.07 |
| PAN | 92.82 | 93.93 | 92.67 | 87.67 | 23.65 | 5.37 |
| DFN | 93.52 | 93.86 | 92.79 | 87.49 | 42.53 | 10.51 |
| CSDNet | 93.66 | 93.33 | 93.28 | 88.28 | 8.66 | 21.90 |
| UNet | 93.98 | 94.35 | 93.61 | 88.44 | 13.41 | 30.94 |
| MFMANet | 95.12 | 94.69 | 94.34 | 89.17 | 25.39 | 34.78 |
| Method | PA (%) | MPA (%) | F1 (%) | MIoU (%) |
|---|---|---|---|---|
| CvT | 93.50 | 93.36 | 92.27 | 87.47 |
| FCN8s | 94.27 | 94.21 | 93.53 | 89.83 |
| HRNet | 94.29 | 94.93 | 93.02 | 88.50 |
| UNet | 94.34 | 94.32 | 93.47 | 88.96 |
| PAN | 94.37 | 94.23 | 93.12 | 88.72 |
| BiSeNetV2 | 94.45 | 94.29 | 93.27 | 89.03 |
| DABNet | 94.47 | 94.31 | 93.36 | 89.17 |
| DeepLabV3Plus | 94.50 | 94.68 | 93.45 | 89.51 |
| ACFNet | 94.52 | 94.70 | 93.52 | 89.53 |
| PSPNet | 94.55 | 94.77 | 93.57 | 89.46 |
| SegNet | 94.59 | 94.93 | 93.59 | 89.67 |
| DFN | 94.72 | 94.86 | 93.63 | 90.19 |
| CSDNet | 94.86 | 95.03 | 93.80 | 90.54 |
| ACFNet | 95.09 | 94.91 | 93.76 | 90.59 |
| MFMANet | 95.22 | 94.88 | 94.27 | 91.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Chen, J.; Liao, Z.; Shi, F. Multi-Scale Feature Mixed Attention Network for Cloud and Snow Segmentation in Remote Sensing Images. Remote Sens. 2025, 17, 1872. https://doi.org/10.3390/rs17111872
Zhao L, Chen J, Liao Z, Shi F. Multi-Scale Feature Mixed Attention Network for Cloud and Snow Segmentation in Remote Sensing Images. Remote Sensing. 2025; 17(11):1872. https://doi.org/10.3390/rs17111872
Chicago/Turabian StyleZhao, Liling, Junyu Chen, Zichen Liao, and Feng Shi. 2025. "Multi-Scale Feature Mixed Attention Network for Cloud and Snow Segmentation in Remote Sensing Images" Remote Sensing 17, no. 11: 1872. https://doi.org/10.3390/rs17111872
APA StyleZhao, L., Chen, J., Liao, Z., & Shi, F. (2025). Multi-Scale Feature Mixed Attention Network for Cloud and Snow Segmentation in Remote Sensing Images. Remote Sensing, 17(11), 1872. https://doi.org/10.3390/rs17111872