
Extraction of Levees from Paddy Fields Based on the SE-CBAM UNet Model and Remote Sensing Images

Abstract

1. Introduction
2. Materials and Methods
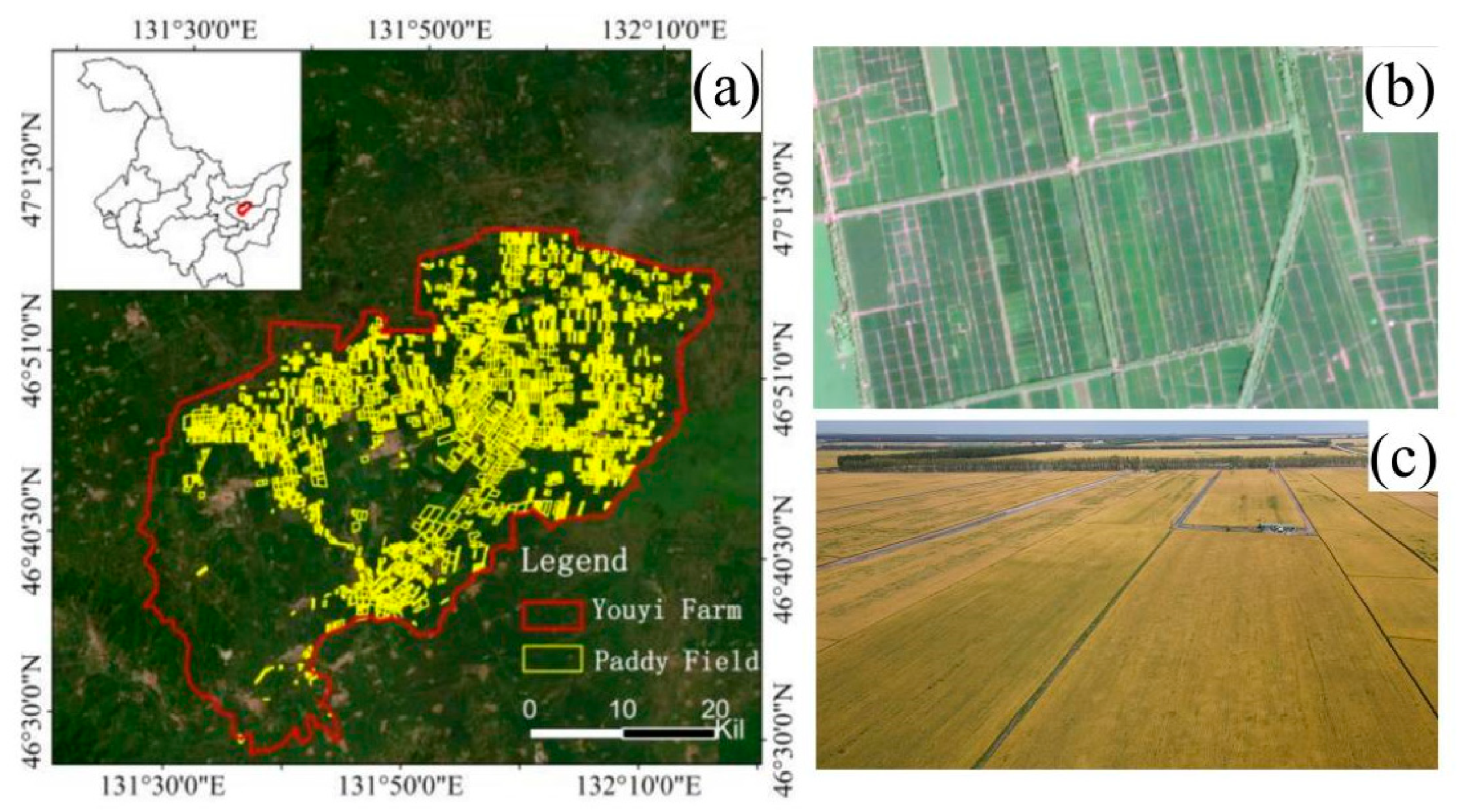
2.1. Study Areas and Datasets
2.1.1. Data Acquisition and Preprocessing
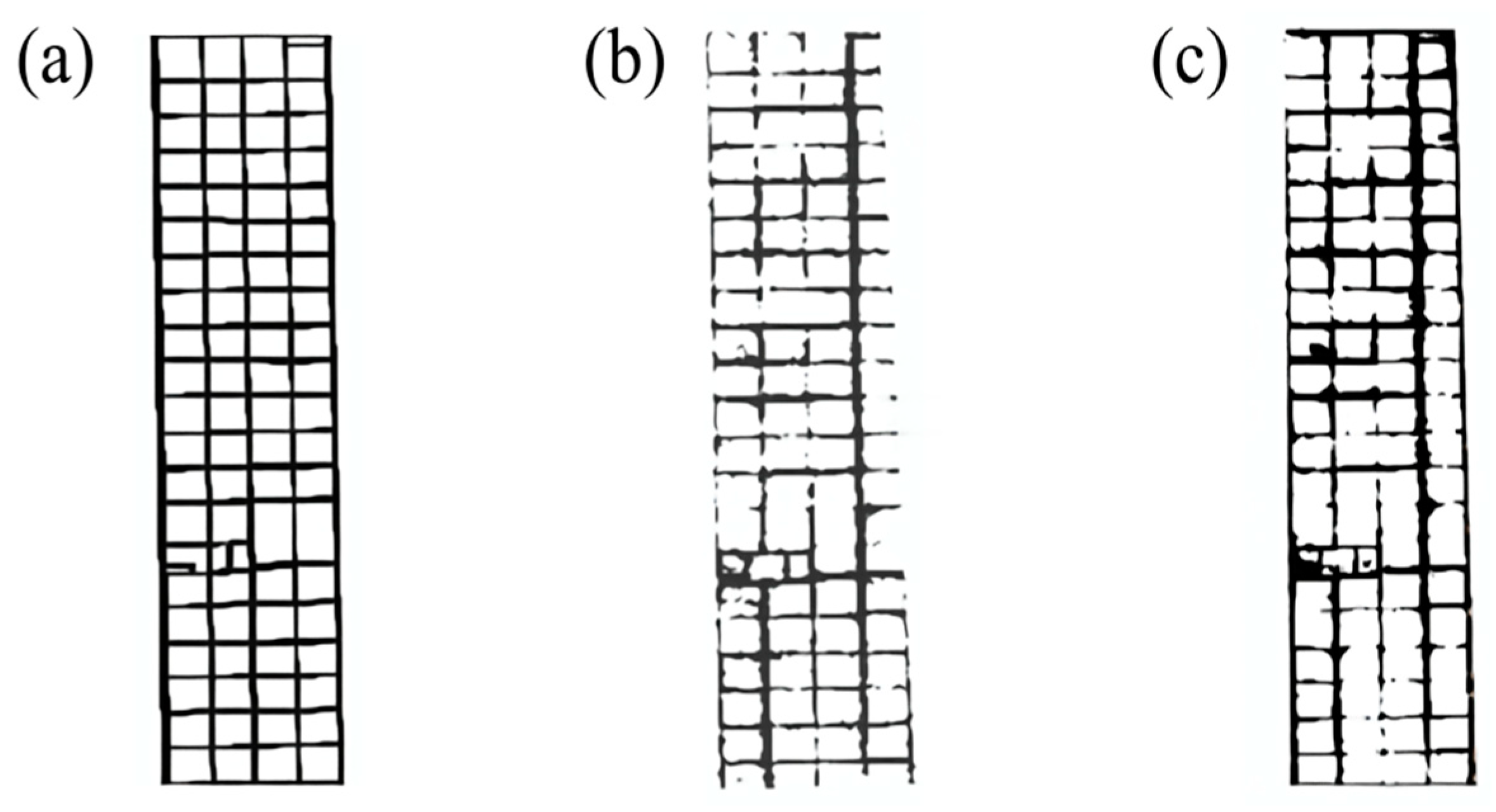
2.1.2. Labeled Dataset Construction
2.1.3. Construction of the Training and Testing Dataset
2.2. UNet Network Model
2.3. Attention Mechanism
2.3.1. Squeeze and Excitation
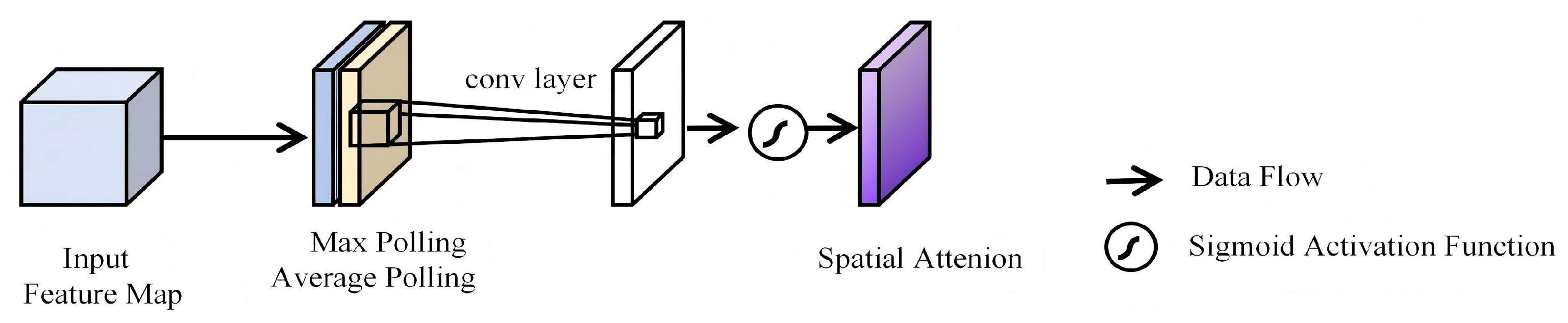
2.3.2. Convolutional Block Attention Module
2.4. SCA-UNet Model Construction
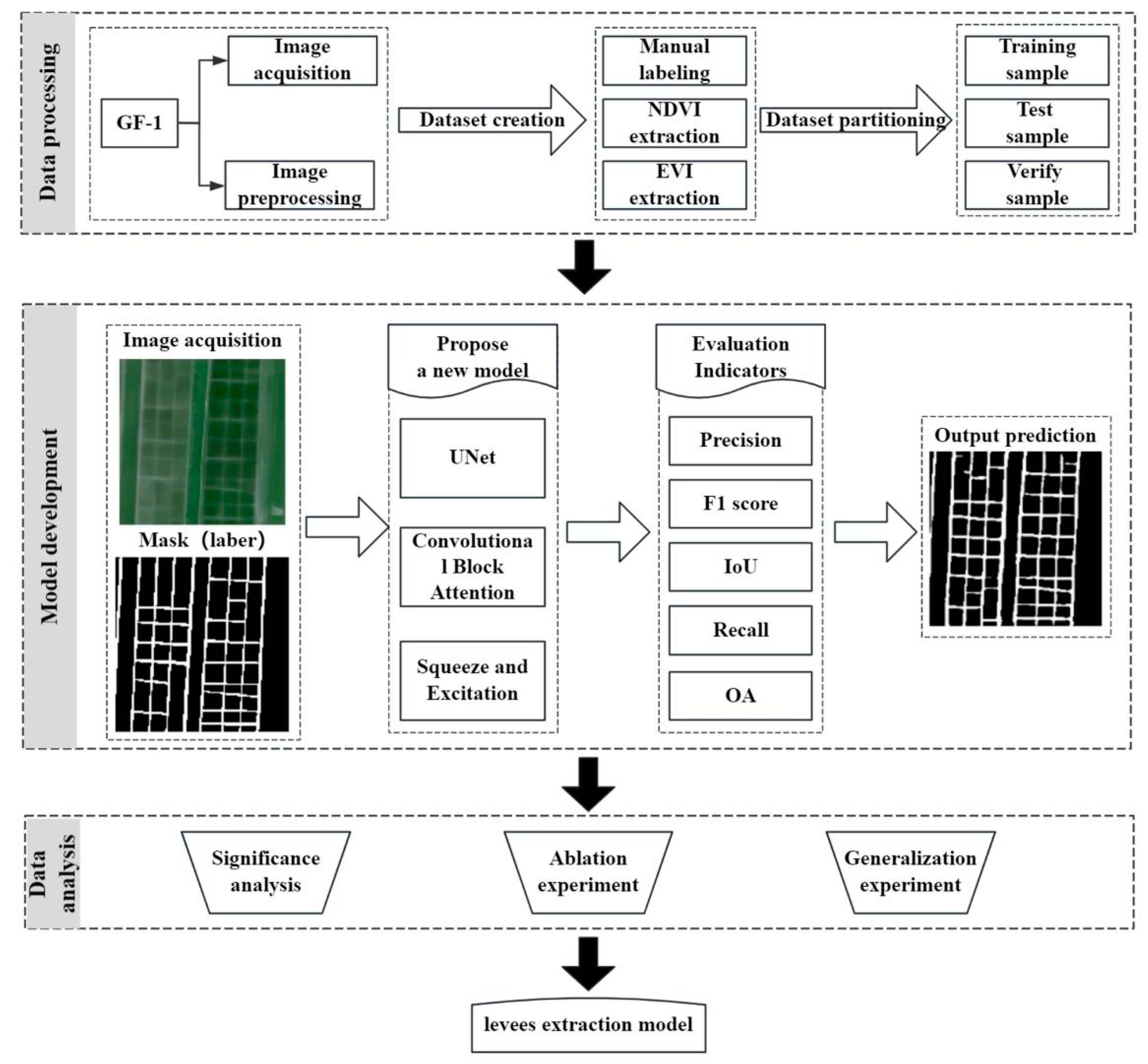
2.5. Technological Processes
- (1)
- Data Collection and Preprocessing: High-resolution remote sensing images from the Gaofen-1 satellite were collected. The acquired data were preprocessed to create a labeled dataset using three methods: manual labeling, NDVI extraction, and EVI extraction.
- (2)
- Model Construction: A model optimized for levee extraction was constructed by integrating the SE and CBAM dual-attention mechanisms into the UNet model, based on remote sensing data, to enhance model performance.
- (3)
- Accuracy Assessment and Result Analysis: Significance analysis of the extraction results is a crucial method for evaluating the reliability and effectiveness of the experimental outcomes. Ablation experiments are a key component in verifying model effectiveness. Generalization experiments can validate the model’s performance on data outside the training distribution.
3. Results
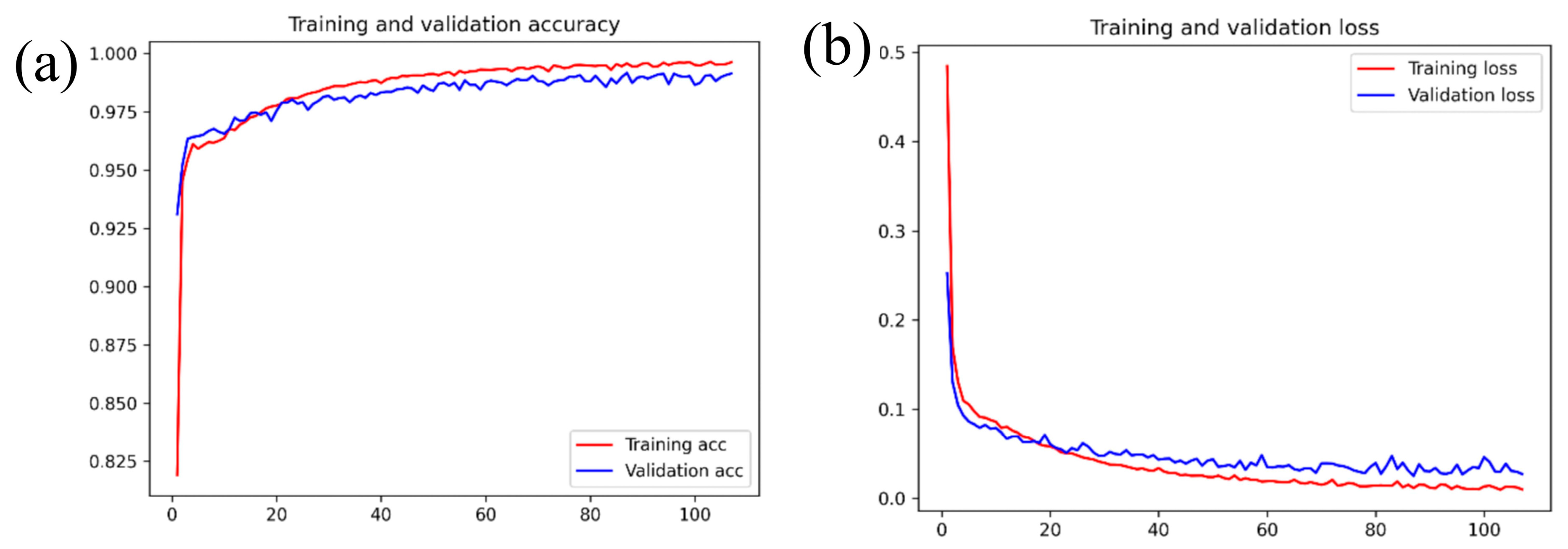
3.1. Experimental Environment and Parameter Settings
3.1.1. Experimental Settings
3.1.2. Model Comparison
3.1.3. Evaluation Criteria
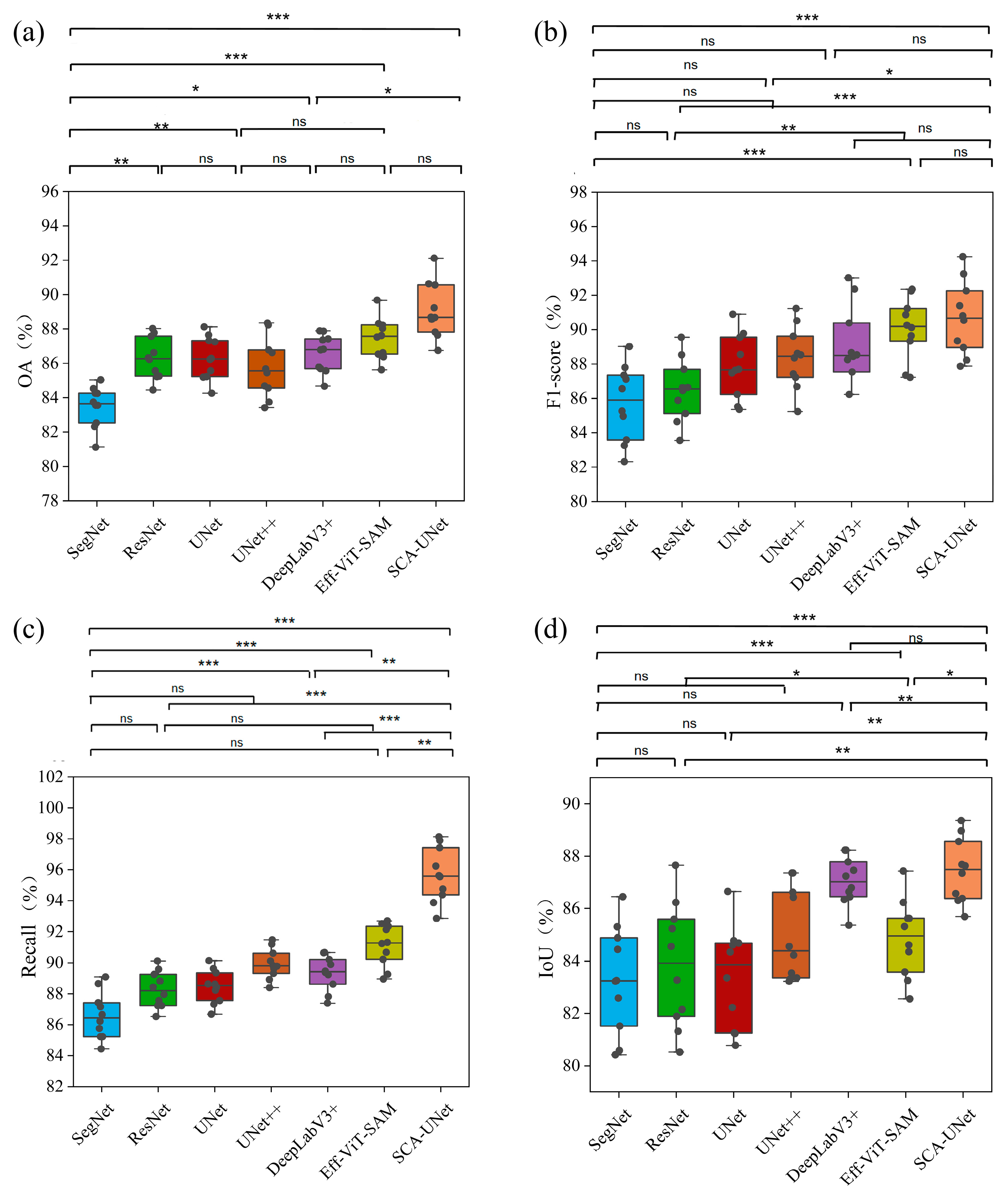
3.2. Comparison Experiment
3.3. Significance Analysis of Experimental Results
3.4. Ablation Experiment
3.5. Generalization Experiment
4. Discussion
4.1. Analysis of Method Performance Advantages and Disadvantages
4.2. Connections with Existing Research
4.3. Limitations and Future Prospects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, X.; Xu, Y.; Huang, P.; Yuan, D.; Song, C.; Wang, Y.; Cui, Y.; Luo, Y. Identifying Changes and Their Drivers in Paddy Fields of Northeast China: Past and Future. Agriculture 2024, 14, 1956. [Google Scholar] [CrossRef]
- Somashekar, K.S.; Moinuddin; Belagalla, N.; Srinatha, T.N.; Abhishek, G.J.; Kumar, V.; Tiwari, A. Revolutionizing Agriculture: Innovative Techniques, Applications, and Future Prospects in Precision Farming. J. Sci. Res. Rep. 2024, 30, 405–419. [Google Scholar]
- Wang, S.G.; Wu, S.K.; Wang, X.S.; Li, Z.L. A Canny operator road edge detection method based on color features. J. Phys. Conf. Ser. 2020, 1629, 012018. [Google Scholar] [CrossRef]
- Rana, D.; Dalai, S. Review on traditional methods of edge detection to morphological based techniques. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 5915–5920. [Google Scholar]
- Shi, G.; Suo, J. Remote sensing image edge-detection based on improved Canny operator. In Proceedings of the 2016 8th IEEE International Conference on Communication Software and Networks (ICCSN), Beijing, China, 4–6 June 2016; pp. 652–656. [Google Scholar]
- Xu, L.; Ming, D.; Du, T.; Chen, Y.; Dong, D.; Zhou, C. Delineation of cultivated land parcels based on deep convolutional networks and geographical thematic scene division of remotely sensed images. Comput. Electron. Agric. 2022, 192, 106611. [Google Scholar] [CrossRef]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation Based on Visual Foundation Model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4701117. [Google Scholar] [CrossRef]
- Yan, Z.; Li, J.; Li, X.; Zhou, R.; Zhang, W.; Feng, Y.; Diao, W.; Fu, K.; Sun, X. RingMO-SAM: A foundation model for segment anything in multimodal remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5625716. [Google Scholar] [CrossRef]
- Li, X.; Su, J.; Yue, Z.; Duan, F. Adaptive Multi-ROI Agricultural Robot Navigation Line Extraction Based on Image Semantic Segmentation. Sensors 2022, 22, 7707. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, L.; Jiang, T.; Gao, F. MDE-UNet: A multitask deformable UNet combined enhancement network for farmland boundary segmentation. IEEE Geosci. Remote Sens. Lett. 2023, 20, 3001305. [Google Scholar] [CrossRef]
- Kaur, S.; Madaan, S. A hybrid unet based approach for crop classification using sentinel-1b synthetic aperture radar images. Multimed. Tools Appl. 2025, 84, 4223–4252. [Google Scholar] [CrossRef]
- Meyarian, A.; Yuan, X.; Liang, L.; Wang, W.; Gu, L. Gradient convolutional neural network for classification of agricultural fields with contour levee. Remote Sens. 2021, 43, 75–94. [Google Scholar] [CrossRef]
- Dale, D.S.; Liang, L.; Zhong, L.; Reba, M.L.; Runkle, B.R. Deep learning solutions for mapping contour levee rice production systems from very high resolution imagery. Comput. Electron. Agric. 2023, 211, 107954. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 53. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Lecture Notes in Computer Science, Proceedings of the 15th European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Ge, Z.; Cao, G.; Shi, H.; Zhang, Y.; Li, X.; Fu, P. Compound multiscale weak dense network with hybrid attention for hyperspectral image classification. Remote Sens. 2021, 13, 3305. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.K.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Bai, X.; Guo, L.; Huo, H.; Zhang, J.; Zhang, Y.; Li, Z.L. Rse-net: Road-shape enhanced neural network for road extraction in high resolution remote sensing image. Int. J. Remote Sens. 2023, 45, 7339–7360. [Google Scholar] [CrossRef]
- Wang, J.; Lv, P.; Wang, H.; Shi, C. SAR-U-Net: Squeeze-and-excitation block and atrous spatial pyramid pooling based residual U-Net for automatic liver segmentation in computed tomography. Comput. Methods Programs Biomed. 2021, 208, 106268. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Xu, Q.; Liang, H.; Wei, Z.; Zhang, Y.; Lu, X.; Li, F.; Wei, N.; Zhang, S.; Yuan, H.; Liu, S.; et al. Assessing climate change impacts on crop yields and exploring adaptation strategies in Northeast China. Earth’s Future 2024, 12, e2023EF004063. [Google Scholar] [CrossRef]
- Chen, H.; Meng, F.; Yu, Z.; Tan, Y. Spatial–temporal characteristics and influencing factors of farmland expansion in different agricultural regions of Heilongjiang Province, China. Land Use Policy 2022, 115, 106007. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Liu, Z. Effects of climate change on paddy expansion and potential adaption strategies for sustainable agriculture development across Northeast China. Appl. Geogr. 2022, 141, 102667. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, F.; Yang, S. Fusion of multispectral and panchromatic images via spatial weighted neighbor embedding. Remote Sens. 2019, 11, 557. [Google Scholar] [CrossRef]
- Yin, Q.; Liu, M.; Cheng, J.; Ke, Y.; Chen, X. Mapping Paddy Rice Planting Area in Northeastern China Using Spatiotemporal Data Fusion and Phenology-Based Method. Remote Sens. 2019, 11, 1699. [Google Scholar] [CrossRef]
- Duan, J.; Wang, H.; Yang, Y.; Cheng, M.; Li, D. Rice Growth Parameter Estimation Based on Remote Satellite and Unmanned Aerial Vehicle Image Fusion. Agriculture 2025, 15, 1026. [Google Scholar] [CrossRef]
- Zhang, G.; Xiao, X.; Biradar, C.M.; Dong, J.; Qin, Y.; Menarguez, M.A.; Zhou, Y.; Zhang, Y.; Jin, C.; Wang, J.; et al. Spatiotemporal patterns of paddy rice croplands in China and India from 2000 to 2015. Sci. Total Environ. 2017, 579, 82–92. [Google Scholar] [CrossRef]
- Zhang, M.; Lin, H.; Wang, G.; Sun, H.; Fu, J. Mapping paddy rice using a convolutional neural network (CNN) with Landsat 8 datasets in the Dongting Lake Area, China. Remote Sens. 2018, 10, 1840. [Google Scholar] [CrossRef]
- de la Rosa, F.L.; Gómez-Sirvent, J.L.; Sánchez-Reolid, R.; Morales, R.; Fernández-Caballero, A. Geometric transformation-based data augmentation on defect classification of segmented images of semiconductor materials using a ResNet50 convolutional neural network. Expert Syst. Appl. 2022, 206, 117731. [Google Scholar] [CrossRef]
- Shao, G.; Wang, Y.; Han, W. Estimation method of leaf area index for summer maize using UAV-based multispectral remote sensing. Smart Agric. 2020, 2, 118–128. [Google Scholar]
- Hu, Q.; Ma, L.; Zhao, J. DeepGraph: A PyCharm tool for visualizing and understanding deep learning models. In Proceedings of the 2018 25th Asia-Pacific Software Engineering Conference (APSEC), Nara, Japan, 4–7 December 2018; pp. 628–632. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Lecture Notes in Computer Science, Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Yan, C.; Fan, X.; Fan, J.; Wang, N. Improved U-Net remote sensing classification algorithm based on multi-feature fusion perception. Remote Sens. 2022, 14, 1118. [Google Scholar] [CrossRef]
- Wang, Y. AMSA-UNet: An Asymmetric Multiple Scales U-net Based on Self-attention for Deblurring. arXiv 2024, arXiv:2406.09015. [Google Scholar]
- Kim, D.; Kim, J.; Kim, J. Elastic exponential linear units for convolutional neural networks. Neurocomputing 2020, 406, 253–266. [Google Scholar] [CrossRef]
- He, J.; Li, L.; Xu, J.; Zheng, C. ReLU deep neural networks and linear finite elements. arXiv 2018, arXiv:1807.03973. [Google Scholar]
- Yin, M.; Chen, Z.; Zhang, C. A CNN-transformer network combining CBAM for change detection in high-resolution remote sensing images. Remote Sens. 2023, 15, 2406. [Google Scholar] [CrossRef]
- Rajendran, T.; Valsalan, P.; Amutharaj, J.; Jenifer, M.; Rinesh, S.; Charlyn, P.L.G. Hyperspectral image classification model using squeeze and excitation network with deep learning. Comput. Intell. Neurosci. 2022, 2022, 9430779. [Google Scholar]
- Gu, J.; Sun, X.; Zhang, Y.; Fu, K.; Wang, L. Deep residual squeeze and excitation network for remote sensing image super-resolution. Remote Sens. 2019, 11, 1817. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Wang, W.; Tan, X.; Zhang, P.; Wang, X. A CBAM based multiscale transformer fusion approach for remote sensing image change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6817–6825. [Google Scholar] [CrossRef]
- Alshawi, R.; Hoque, M.T.; Ferdaus, M.M.; Abdelguerfi, M.; Niles, K.; Prathak, K.; Tom, J.; Klein, J.; Mousa, M.; Lopez, J.J. Dual attention u-net with feature infusion: Pushing the boundaries of multiclass defect segmentation. arXiv 2023, arXiv:2312.14053. [Google Scholar]
- Amin, S.U.; Abbas, M.S.; Kim, B.; Jung, Y.; Seo, S. Enhanced anomaly detection in pandemic surveillance videos: An attention approach with EfficientNet-B0 and CBAM integration. IEEE Access 2024, 12, 162697–162712. [Google Scholar] [CrossRef]
- Van Horn, B.M., II.; Nguyen, Q. Hands-On Application Development with PyCharm: Build Applications Like a Pro with the Ultimate Python Development Tool; Packt Publishing Ltd.: Birmingham, UK, 2023. [Google Scholar]
- Hunt, J. Python Virtual Environments. In A Beginner’s Guide to Python 3 Programming; Springer International Publishing: Cham, Switzerland, 2023; pp. 469–486. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Lecture Notes in Computer Science, Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 801–818. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road segmentation of remotely-sensed images using deep convolutional neural networks with landscape metrics and conditional random fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef]
- Zhang, Z.; Cai, H.; Han, S. EfficientViT-SAM: Accelerated Segment Anything Model Without Accuracy Loss. arXiv 2024, arXiv:2402.05008. [Google Scholar]
- Trigka, M.; Dritsas, E. A Comprehensive Survey of Machine Learning Techniques and Models for Object Detection. Sensors 2025, 25, 214. [Google Scholar] [CrossRef] [PubMed]
- Alshehri, M.; Ouadou, A.; Scott, G.J. Deep transformer-based network deforestation detection in the Brazilian Amazon using sentinel-2 imagery. IEEE Geosci. Remote Sens. Lett. 2024, 21, 2502705. [Google Scholar] [CrossRef]
- Li, L.; Jiang, Y.; Shen, X.; Li, D. Long-term assessment and analysis of the radiometric quality of standard data products for Chinese Gaofen-1/2/6/7 optical remote sensing satellites. Remote Sens. Environ. 2024, 308, 114169. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Z.; Luo, H.; Yang, H.; Wang, B.; Jiang, Y.; Liu, Y.; Wu, Y. GF-2 Remote Sensing-Based Winter Wheat Extraction with Multitask Learning Vision Transformer. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 12454–12469. [Google Scholar] [CrossRef]
- Liu, Y.; Li, H.; Hu, C.; Luo, S.; Luo, Y.; Chen, C.W. Learning to aggregate multi-scale context for instance segmentation in remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 595–609. [Google Scholar] [CrossRef]
- Zhou, L.; Liu, S.; Zheng, W. Automatic analysis of transverse musculoskeletal ultrasound images based on the multi-task learning model. Entropy 2023, 25, 662. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Y.; Xu, J.; Lu, H.; Heng, P.-A.; Lam, W. Unveiling the generalization power of fine-tuned large language models. arXiv 2024, arXiv:2403.09162. [Google Scholar]
- Solopov, M.; Chechekhina, E.; Kavelina, A.; Akopian, G.; Turchin, V.; Popandopulo, A.; Filimonov, D.; Ishchenko, R. Comparative Study of Deep Transfer Learning Models for Semantic Segmentation of Human Mesenchymal Stem Cell Micrographs. Int. J. Mol. Sci. 2025, 26, 2338. [Google Scholar] [CrossRef]
- Höge, M.; Wöhling, T.; Nowak, W. A primer for model selection: The decisive role of model complexity. Water Resour. Res. 2018, 54, 1688–1715. [Google Scholar] [CrossRef]
- Alsabhan, W.; Alotaiby, T. Automatic building extraction on satellite images using UNet and ResNet50. Comput. Intell. Neurosci. 2022, 2022, 5008854. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Qin, Y.; Liu, X.; Wang, H.; Zhao, J. An improved DeepLabv3+ lightweight network for remote-sensing image semantic segmentation. Complex Intell. Syst. 2024, 10, 2839–2849. [Google Scholar] [CrossRef]
- Ryhede Bengtsson, B.; Bengs, J. Accelerated Segmentation with Mixed-Precision Quantization of EfficientViT-SAM. Master’s Thesis, Lund University, Lund, Sweden, 2024. [Google Scholar]
- Haroon, Z.; Cheema, M.J.M.; Saleem, S.; Amin, M.; Anjum, M.N.; Tahir, M.N.; Hussain, S.; Zahid, U.; Khan, F. Potential of precise fertilization through adoption of management zones strategy to enhance wheat production. Land 2023, 12, 540. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Initialized learning rate | 0.00001 |
| Early Stopping | 20 |
| Epoch | 100 |
| Batch size | 14 |
| Pixel | 256 × 256 |
| Optimizer | Adam |
| Mothod | OA/% | F1-Score/% | IoU/% | Precision/% | Recall/% |
|---|---|---|---|---|---|
| SegNet | 85.04 | 89.02 | 86.45 | 92.79 | 89.09 |
| ResNet | 88.02 | 89.56 | 87.65 | 93.54 | 90.12 |
| UNet | 88.12 | 90.9 | 86.65 | 94.64 | 90.14 |
| UNet++ | 88.35 | 91.23 | 87.36 | 95.69 | 91.49 |
| DeepLabV3+ | 87.89 | 93.02 | 88.23 | 96.21 | 90.67 |
| EfficientViT-SAM | 89.68 | 92.35 | 87.43 | 98.23 | 92.69 |
| Ours | 92.12 | 94.25 | 89.36 | 98.13 | 92.67 |
| Model | OA | F1 Score | Recall | IoU | Shapiro-Wilk |
|---|---|---|---|---|---|
| SegNet | 0.834 ± 0.011 | 0.857 ± 0.021 | 0.865 ± 0.015 | 0.824 ± 0.032 | 0.781 |
| ResNet | 0.863 ± 0.012 | 0.864 ± 0.018 | 0.882 ± 0.016 | 0.834 ± 0.029 | 0.873 |
| UNet | 0.863 ± 0.025 | 0.878 ± 0.018 | 0.884 ± 0.017 | 0.848 ± 0.012 | 0.959 |
| UNet++ | 0.857 ± 0.017 | 0.883 ± 0.018 | 0.889 ± 0.009 | 0.850 ± 0.017 | 0.924 |
| DeepLabV3+ | 0.865 ± 0.011 | 0.892 ± 0.021 | 0.893 ± 0.011 | 0.856 ± 0.013 | 0.507 |
| EfficientViT-SAM | 0.872 ± 0.013 | 0.890 ± 0.018 | 0.910 ± 0.017 | 0.845 ± 0.016 | 0.483 |
| Ours | 0.884 ± 0.021 | 0.906 ± 0.023 | 0.916 ± 0.042 | 0.875 ± 0.016 | 0.376 |
| Model | Mean Difference ± Standard Error | 95%CI | p-Value |
|---|---|---|---|
| SegNet | 4.968 ± 0.064 | [4.84, 5.09] | p < 0.001 |
| ResNet | 4.217 ± 0.33 | [2.22, 6.22] | p < 0.05 |
| UNet | 2.82 ± 0.281 | [2.27, 3.37] | p < 0.001 |
| UNet++ | 2.344 ± 0.33 | [1.70, 2.99] | p < 0.05 |
| DeepLabV3+ | 1.451 ± 0.015 | [1.42, 1.48] | p < 0.0001 |
| EfficientViT-SAM | 1.403 ± 0.013 | [1.37, 1.42] | p < 0.05 |
| Model | OA/% | F1-Score/% | IoU/% | Precision/% | Recall/% |
|---|---|---|---|---|---|
| UNet | 88.12 | 90.09 | 86.65 | 94.64 | 90.14 |
| SE-UNet | 87.82 | 92.88 | 86.71 | 94.89 | 89.77 |
| CBAM-UNet | 88.05 | 92.90 | 86.75 | 94.71 | 91.44 |
| SCA-UNet | 92.12 | 94.25 | 89.36 | 98.13 | 92.67 |
| Metrics | Mean (%) | SD (%) |
|---|---|---|
| OA | 90.47 | 1.47 |
| F1-score | 90.69 | 2.02 |
| IoU | 87.18 | 1.61 |
| Precision | 95.18 | 2.39 |
| Recall | 95.13 | 2.32 |
| Model | OA (%) | Parameters (106) | FLOPS (109) |
|---|---|---|---|
| SegNet | 85.04 | 23.02 | 28.4 |
| ResNet | 88.02 | 25.60 | 3.8 |
| UNet | 88.12 | 33.89 | 65.3 |
| UNet++ | 88.35 | 45.89 | 150.29 |
| DeepLabV3+ | 87.89 | 26.89 | 25.3 |
| EfficientViT-SAM | 89.68 | 34.8 | 69 |
| Ours | 92.12 | 31.3 | 67.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ai, H.; Zhu, X.; Han, Y.; Ma, S.; Wang, Y.; Ma, Y.; Qin, C.; Han, X.; Yang, Y.; Zhang, X. Extraction of Levees from Paddy Fields Based on the SE-CBAM UNet Model and Remote Sensing Images. Remote Sens. 2025, 17, 1871. https://doi.org/10.3390/rs17111871
Ai H, Zhu X, Han Y, Ma S, Wang Y, Ma Y, Qin C, Han X, Yang Y, Zhang X. Extraction of Levees from Paddy Fields Based on the SE-CBAM UNet Model and Remote Sensing Images. Remote Sensing. 2025; 17(11):1871. https://doi.org/10.3390/rs17111871
Chicago/Turabian StyleAi, Hongfu, Xiaomeng Zhu, Yongqi Han, Shinai Ma, Yiang Wang, Yihan Ma, Chuan Qin, Xinyi Han, Yaxin Yang, and Xinle Zhang. 2025. "Extraction of Levees from Paddy Fields Based on the SE-CBAM UNet Model and Remote Sensing Images" Remote Sensing 17, no. 11: 1871. https://doi.org/10.3390/rs17111871
APA StyleAi, H., Zhu, X., Han, Y., Ma, S., Wang, Y., Ma, Y., Qin, C., Han, X., Yang, Y., & Zhang, X. (2025). Extraction of Levees from Paddy Fields Based on the SE-CBAM UNet Model and Remote Sensing Images. Remote Sensing, 17(11), 1871. https://doi.org/10.3390/rs17111871