
Multi-Branch Attention Fusion Network for Cloud and Cloud Shadow Segmentation


Abstract
1. Introduction
- We designed a multi-branch attention fusion module (MAFM), increasing the positional information of feature maps. The multi-branch aggregation attention (MAA) in the MAFM fully fuses local and global information, enhancing the boundary segmentation capability and the detection capability of small targets.
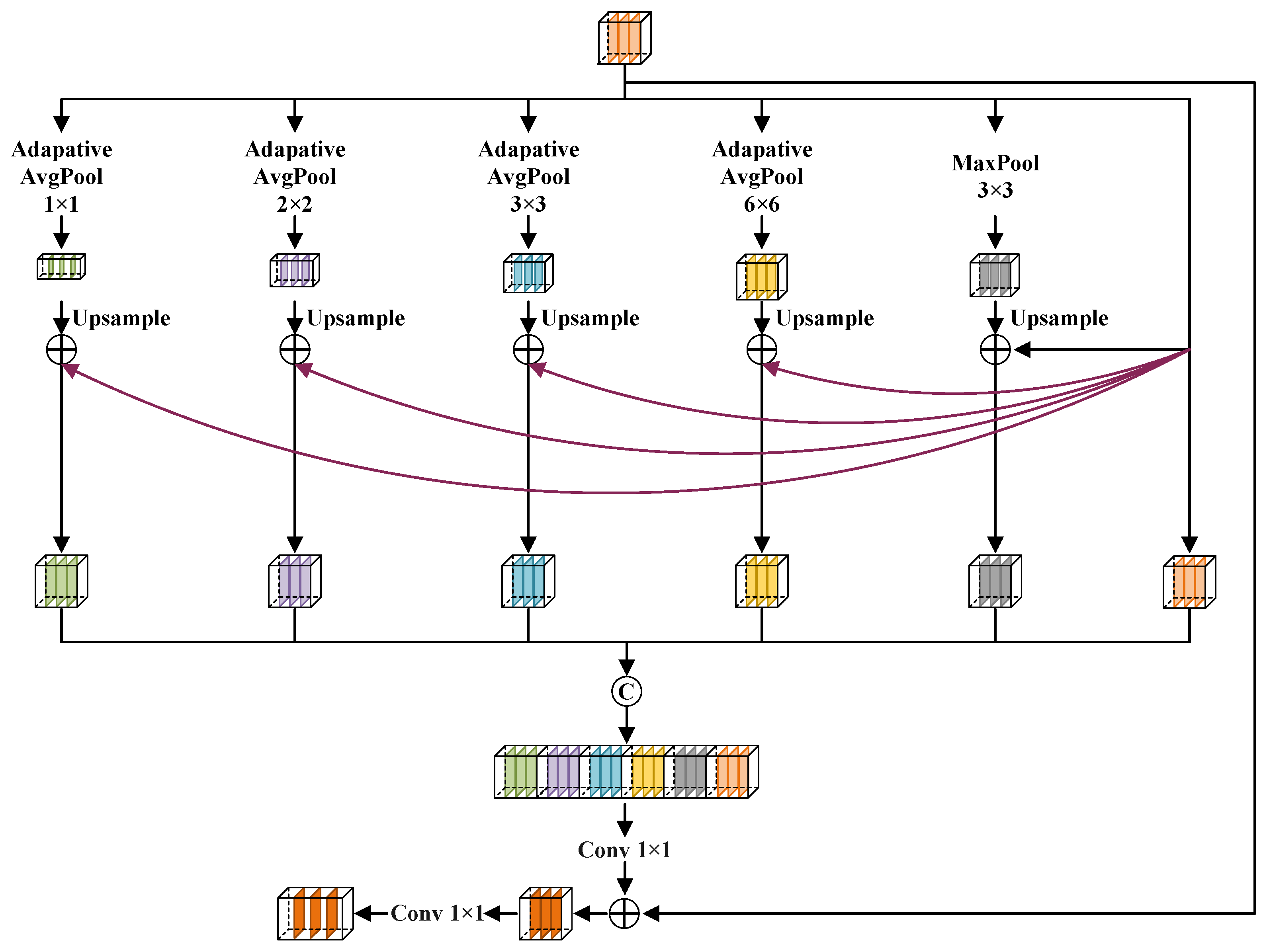
- To enhance the detection capability of small targets, we designed an information deep aggregation module (IDAM), which performs multi-scale deep feature extraction, thereby increasing the network’s sensitivity to small targets.
- In the decoder, we introduced a recovery guided module (RGM), which adjusts the attention distribution of feature maps in the spatial dimension, enhancing the network’s focus on boundary information and enabling finer boundary segmentation.
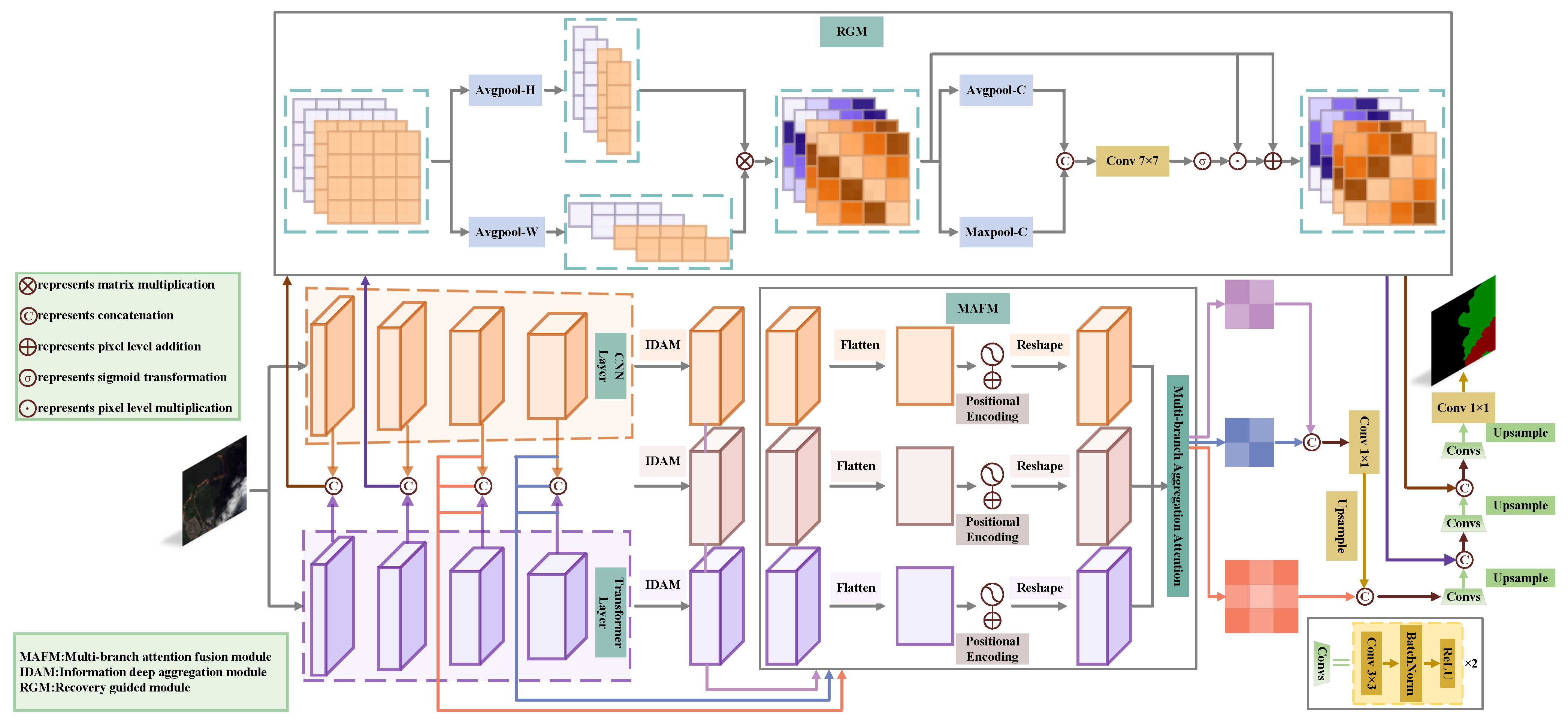
2. Methodology
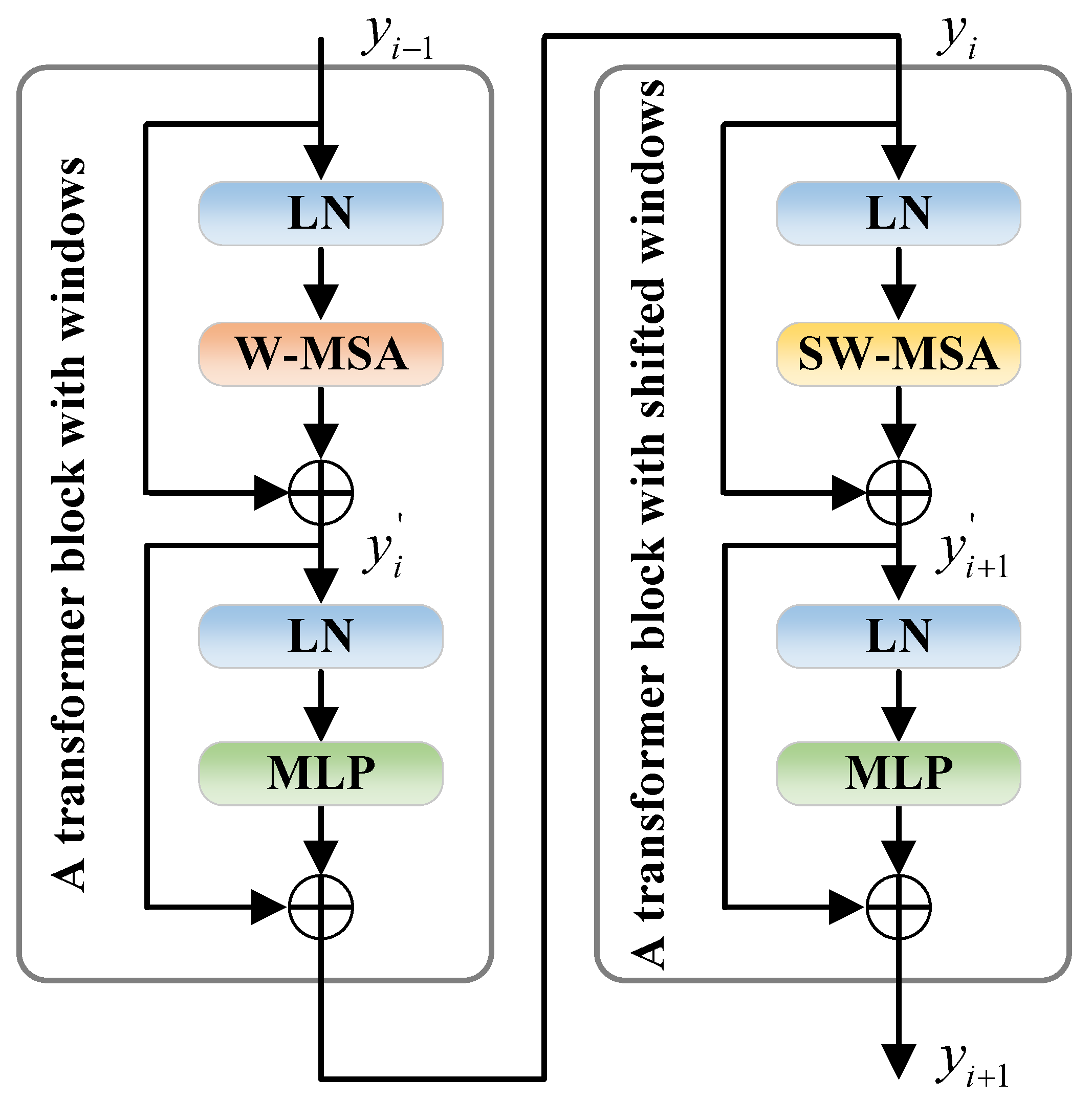
2.1. Backbone
2.2. Multi-Branch Attention Fusion Module
2.3. Information Deep Aggregation Module
2.4. Recovery Guided Module
3. Experiments
3.1. Datasets
3.1.1. Cloud and Cloud Shadow Dataset
3.1.2. HRC-WHU Dataset
3.1.3. SPARCS Dataset
3.2. Experimental Details
3.3. Network Backbone Selection
3.4. Network Fusion Experiment
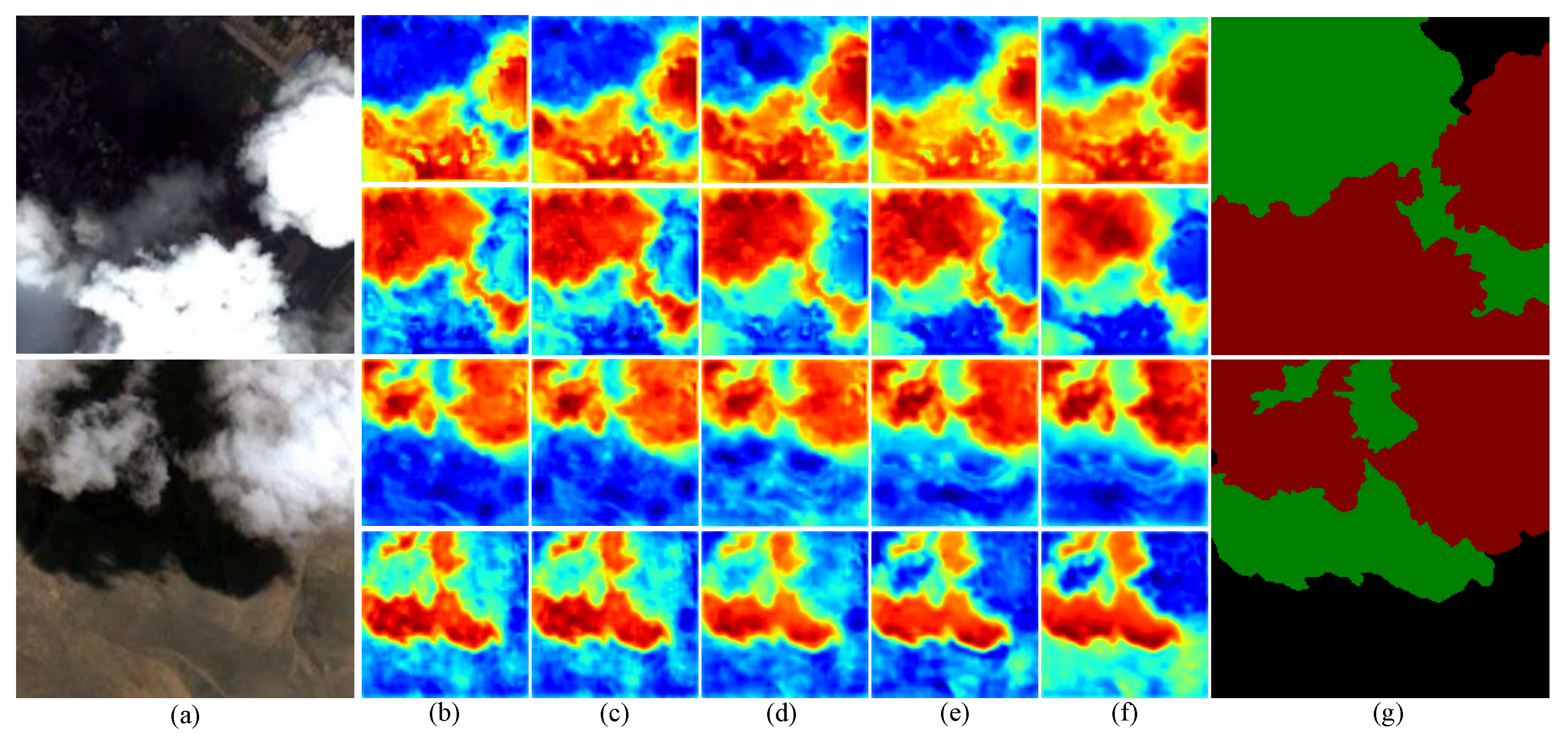
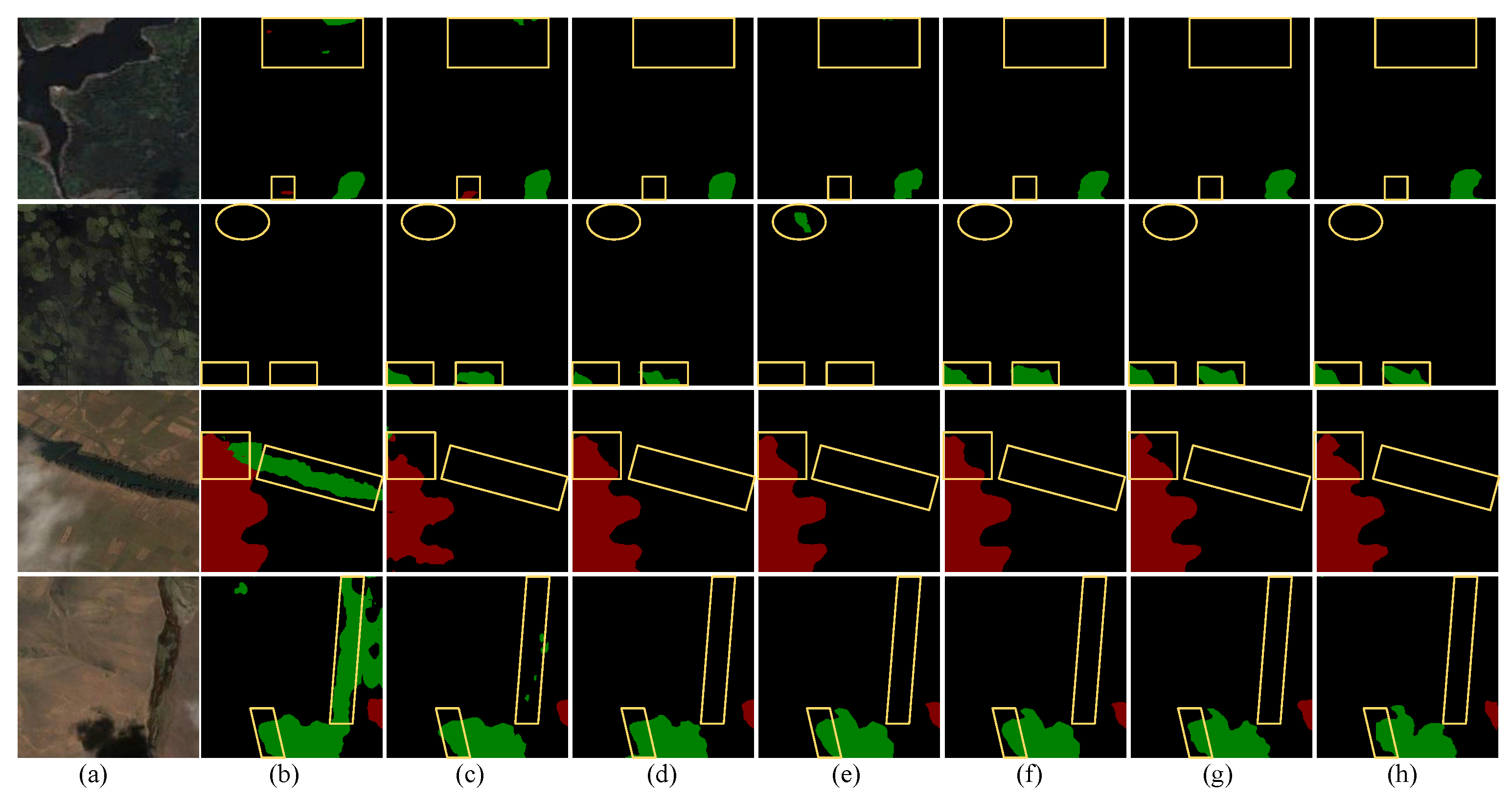
3.5. Ablation Experiments on Cloud and Cloud Shadow Dataset
- Ablation for Swin: To enhance global modelling capabilities, we introduced a Swin transformer based on the ResNet50 architecture. Table 4 indicates that MIoU is 0.41% higher than that of the simple ResNet50, which adequately demonstrates that it can strengthen the performance of our model to extract global information utilizing the Swin transformer.
- Ablation for MAFM: To improve the boundary segmentation of clouds and their shadows, as well as the detection capability of small objects, we introduced MAFM. The MAFM enhances the positional information of feature maps. Its MMA allows deep features at the same level to guide each other, fully fusing fine and rough features. Table 4 indicates that the introduction of the MAFM improves the MIoU by 1.10%, which demonstrates the MAFM is effective in the semantic segmentation of clouds and their shadows.
- Ablation for IDAM: To further enhance the localization capability for small target clouds and cloud shadows, we introduced IDAM to extract deep features at multiple scales and supplement high semantic information, thus increasing sensitivity to small targets. Table 4 indicates that the introduction of IDAM can improve the MIoU by 0.57%.
- Ablation for RGM: Fine boundary segmentation has always been a major challenge in the segmentation of clouds and their shadows. To address this issue, we added the RGM based on the UNet decoder. The RGM can focus the model on important information in the feature map, enhancing the model’s focus on complex boundary features. As shown in Table 4, the introduction of the RGM improves the MIoU by 0.39%, which sufficiently demonstrates that the RGM effectively facilitates the refinement of segmentation boundaries.
3.6. Comparative Experiments on Different Datasets
3.6.1. Comparison Test on Cloud and Cloud Shadow Dataset
3.6.2. Generalization Experiment of HRC-WHU Dataset
3.6.3. Generalization Experiment of SPARCS Dataset
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Manolakis, D.G.; Shaw, G.A.; Keshava, N. Comparative analysis of hyperspectral adaptive matched filter detectors. In Proceedings of the Algorithms for Multispectral, Hyperspectral, and Ultraspectral Imagery VI, Orlando, FL, USA, 24–26 April 2000; SPIE: Bellingham, WA, USA, 2000; Volume 4049, pp. 2–17. [Google Scholar]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Cloud/shadow detection based on spectral indices for multi/hyperspectral optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 235–253. [Google Scholar] [CrossRef]
- Kegelmeyer, W., Jr. Extraction of Cloud Statistics from Whole Sky Imaging Cameras; Technical Report; Sandia National Lab. (SNL-CA): Livermore, CA, USA, 1994. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y. SUACDNet: Attentional change detection network based on siamese U-shaped structure. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25, Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Nice, France, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Gu, J.; Kwon, H.; Wang, D.; Ye, W.; Li, M.; Chen, Y.H.; Lai, L.; Chandra, V.; Pan, D.Z. Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12094–12103. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-HRNet: A Lightweight High-Resolution Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10440–10450. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Dong, R.; Pan, X.; Li, F. DenseU-net-based semantic segmentation of small objects in urban remote sensing images. IEEE Access 2019, 7, 65347–65356. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Jiang, J.; Han, Z.; Deng, S.; Li, Z.; Fang, T.; Huo, H.; Li, Q.; Liu, M. Adaptive Effective Receptive Field Convolution for Semantic Segmentation of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3532–3546. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-branch network for cloud and cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Gu, G.; Weng, L.; Xia, M.; Hu, K.; Lin, H. Muti-path Muti-scale Attention Network for Cloud and Cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5404215. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Huang, Y. Da-transformer: Distance-aware transformer. arXiv 2020, arXiv:2010.06925. [Google Scholar]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial cross attention meets CNN: Bibranch fusion network for change detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 21–32. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Chaman, A.; Dokmanic, I. Truly shift-invariant convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3773–3783. [Google Scholar]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, 10–14 July 2017; pp. 601–604. [Google Scholar]
- Ha, S.; Yun, J.M.; Choi, S. Multi-modal convolutional neural networks for activity recognition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Kowloon Tong, Hong Kong, 9–12 October 2015; pp. 3017–3022. [Google Scholar]
- Hu, K.; Zhang, D.; Xia, M. CDUNet: Cloud detection UNet for remote sensing imagery. Remote Sens. 2021, 13, 4533. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep learning based cloud detection for medium and high resolution remote sensing images of different sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. Cgnet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. Mpvit: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7287–7296. [Google Scholar]
- Illingworth, A.; Hogan, R.; O’connor, E.; Bouniol, D.; Brooks, M.; Delanoë, J.; Donovan, D.; Eastment, J.; Gaussiat, N.; Goddard, J.; et al. Cloudnet: Continuous evaluation of cloud profiles in seven operational models using ground-based observations. Bull. Am. Meteorol. Soc. 2007, 88, 883–898. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- KO, M.A.; Poruran, S. OCR-nets: Variants of pre-trained CNN for Urdu handwritten character recognition via transfer learning. Procedia Comput. Sci. 2020, 171, 2294–2301. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | (%) | MIoU (%) |
|---|---|---|
| PVT + ResNet34 | 92.78 | 92.76 |
| PVT + ResNet50 | 92.86 | 92.91 |
| CVT + ResNet34 | 92.97 | 92.56 |
| CVT + ResNet50 | 93.09 | 92.71 |
| Swin + ResNet34 | 94.28 | 93.47 |
| Swin + ResNet50 (ours) | 95.18 | 93.67 |
| Method | (%) | MIoU (%) |
|---|---|---|
| Concat | 95.18 | 93.67 |
| + | 93.70 | 93.13 |
| ⊙ | 93.85 | 93.23 |
| Method | (%) | MIoU (%) |
|---|---|---|
| (1) + (2) | 95.18 | 93.67 |
| (1) + (2) + (3) | 93.69 | 93.03 |
| (1) + (2) + (3) + (4) | 93.42 | 92.90 |
| Method | (%) | MIoU (%) |
|---|---|---|
| ResNet50 | 90.55 | 91.20 |
| ResNet50 + Swin | 91.20 | 91.61 (0.41↑) |
| ResNet50 + Swin + MAFM | 93.09 | 92.71 (1.10↑) |
| ResNet50 + Swin + MAFM + IDAM | 93.85 | 93.28 (0.57↑) |
| ResNet50 + Swin + MAFM + IDAM + RGM | 95.18 | 93.67 (0.39↑) |
| Cloud | Cloud Shadow | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | P (%) | R (%) | (%) | P (%) | R (%) | (%) | PA (%) | MPA (%) | MIoU (%) | Time (ms) |
| Unet [11] | 95.28 | 92.82 | 90.73 | 91.84 | 92.37 | 88.73 | 95.28 | 94.43 | 89.16 | 3.12 |
| PVT [22] | 94.90 | 94.36 | 92.02 | 91.63 | 93.14 | 89.34 | 95.63 | 94.48 | 89.83 | 30.10 |
| CGNet [36] | 93.90 | 95.47 | 92.60 | 92.76 | 92.62 | 89.38 | 95.72 | 94.61 | 90.08 | 7.42 |
| CVT [23] | 93.91 | 96.05 | 93.15 | 93.45 | 92.62 | 89.71 | 95.93 | 94.90 | 90.54 | 16.54 |
| Mpvit [37] | 96.62 | 93.55 | 92.04 | 94.04 | 92.47 | 89.84 | 96.02 | 95.65 | 90.77 | 37.48 |
| CloudNet [38] | 94.58 | 95.51 | 92.97 | 92.20 | 94.69 | 91.04 | 96.09 | 94.81 | 90.89 | 5.30 |
| DeepLabV3 [39] | 94.21 | 95.97 | 93.22 | 94.02 | 93.29 | 90.61 | 96.17 | 95.23 | 91.09 | 7.20 |
| BiseNetv2 [40] | 94.76 | 96.05 | 93.56 | 93.82 | 93.27 | 90.49 | 96.23 | 95.33 | 91.23 | 8.30 |
| CMT [41] | 93.15 | 93.99 | 90.85 | 97.46 | 97.06 | 95.85 | 96.25 | 95.26 | 91.26 | 16.52 |
| SwinUNet [42] | 94.91 | 96.37 | 93.95 | 94.17 | 92.61 | 90.03 | 96.33 | 95.50 | 91.36 | 16.07 |
| HRVit [14] | 92.29 | 94.72 | 91.12 | 97.92 | 96.77 | 95.79 | 96.38 | 95.09 | 91.48 | 57.41 |
| PSPNet [12] | 94.77 | 95.99 | 93.51 | 95.09 | 92.82 | 90.64 | 96.35 | 95.71 | 91.52 | 6.80 |
| PAN [43] | 95.80 | 95.76 | 93.79 | 95.61 | 92.00 | 90.10 | 96.44 | 96.10 | 91.69 | 9.87 |
| HRNet [15] | 94.76 | 96.65 | 94.13 | 94.29 | 93.96 | 91.36 | 97.82 | 95.62 | 91.92 | 41.48 |
| DBNet [24] | 96.22 | 95.66 | 93.90 | 92.87 | 95.63 | 92.24 | 97.83 | 95.64 | 92.18 | 29.37 |
| OCRNet [44] | 95.87 | 96.15 | 94.20 | 94.44 | 94.38 | 91.83 | 96.74 | 95.99 | 92.36 | 40.25 |
| CDUNet [32] | 95.04 | 93.67 | 91.44 | 97.94 | 97.39 | 96.40 | 96.84 | 96.05 | 92.57 | 32.15 |
| MAFNet(ours) | 96.21 | 96.95 | 95.13 | 95.79 | 95.33 | 93.37 | 97.31 | 96.70 | 93.67 | 19.33 |
| Model | PA (%) | MPA (%) | R (%) | (%) | MIoU (%) |
|---|---|---|---|---|---|
| BiseNetv2 | 96.72 | 94.65 | 95.96 | 93.44 | 91.12 |
| DeepLabV3 | 96.96 | 95.85 | 95.57 | 93.67 | 91.87 |
| CGNet | 97.05 | 95.47 | 96.13 | 94.01 | 92.02 |
| CMT | 97.27 | 95.49 | 96.71 | 94.55 | 92.26 |
| PAN | 97.22 | 95.71 | 96.39 | 94.37 | 92.47 |
| Unet | 97.29 | 95.59 | 96.68 | 94.58 | 92.61 |
| CloudNet | 97.43 | 96.21 | 96.50 | 94.72 | 93.04 |
| HRVit | 97.48 | 96.06 | 96.76 | 94.89 | 93.13 |
| PVT | 97.49 | 96.54 | 96.36 | 94.76 | 93.21 |
| PSPNet | 97.54 | 96.17 | 96.81 | 95.00 | 93.28 |
| Mpvit | 97.58 | 96.75 | 96.43 | 94.92 | 93.47 |
| SwinUNet | 97.68 | 96.61 | 96.81 | 95.22 | 93.69 |
| HRNet | 97.71 | 96.38 | 97.10 | 95.38 | 93.74 |
| CVT | 97.75 | 96.65 | 96.96 | 95.38 | 93.86 |
| OCRNet | 97.84 | 96.45 | 97.38 | 97.72 | 94.05 |
| DBNet | 97.96 | 97.06 | 97.36 | 98.01 | 94.43 |
| CDUNet | 98.15 | 97.17 | 97.57 | 96.22 | 94.91 |
| MAFNet (ours) | 98.59 | 97.81 | 98.19 | 97.13 | 96.10 |
| Class Pixel Accuracy | Comprehensive Metric | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Cloud (%) | Cloud Shadow (%) | Water (%) | Snow (%) | Land (%) | Shadow over Water (%) | Flood (%) | F1 (%) | MIoU (%) |
| Unet | 92.75 | 66.40 | 86.52 | 94.59 | 93.46 | 39.51 | 91.03 | 77.62 | 71.58 |
| BiseNetv2 | 89.65 | 67.76 | 86.21 | 94.24 | 95.79 | 46.98 | 88.79 | 78.56 | 73.27 |
| CloudNet | 88.23 | 68.02 | 88.35 | 94.27 | 96.43 | 41.63 | 89.74 | 78.88 | 73.54 |
| CGNet | 72.10 | 90.10 | 93.11 | 95.95 | 50.19 | 91.59 | 85.63 | 79.45 | 74.67 |
| CVT | 86.72 | 73.07 | 90.90 | 95.75 | 96.62 | 47.78 | 92.94 | 80.47 | 75.56 |
| PVT | 90.21 | 74.22 | 92.03 | 94.70 | 96.52 | 51.33 | 91.82 | 81.63 | 77.00 |
| HRVit | 91.29 | 75.99 | 86.31 | 95.08 | 96.56 | 58.00 | 94.16 | 81.75 | 77.34 |
| PAN | 91.22 | 72.99 | 89.29 | 94.39 | 96.25 | 66.59 | 91.50 | 81.64 | 77.35 |
| SwinUNet | 91.94 | 75.42 | 91.08 | 95.00 | 95.89 | 60.22 | 89.67 | 81.94 | 77.55 |
| HRNet | 91.35 | 75.58 | 87.56 | 95.61 | 96.60 | 63.19 | 93.16 | 81.98 | 77.78 |
| CMT | 91.33 | 75.56 | 87.61 | 95.59 | 96.69 | 63.17 | 93.19 | 82.09 | 77.90 |
| PSPNet | 91.30 | 74.29 | 90.78 | 94.69 | 96.51 | 55.56 | 94.10 | 82.65 | 78.09 |
| Mpvit | 91.38 | 74.98 | 93.32 | 96.59 | 96.80 | 51.31 | 92.34 | 82.73 | 78.24 |
| DBNet | 91.78 | 75.11 | 91.22 | 96.79 | 96.42 | 63.11 | 90.99 | 82.89 | 78.67 |
| DeepLabV3 | 92.31 | 75.47 | 90.18 | 94.96 | 96.79 | 57.64 | 93.06 | 83.33 | 78.80 |
| OCRNet | 92.14 | 75.57 | 92.25 | 95.05 | 96.60 | 61.04 | 94.15 | 83.52 | 79.29 |
| CDUNet | 90.31 | 79.24 | 92.95 | 94.72 | 96.89 | 62.89 | 93.90 | 83.72 | 79.68 |
| MAFNet (ours) | 92.25 | 80.87 | 91.64 | 96.99 | 97.11 | 61.26 | 93.85 | 84.95 | 80.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, H.; Gu, G.; Liu, Y.; Lin, H.; Xu, Y. Multi-Branch Attention Fusion Network for Cloud and Cloud Shadow Segmentation. Remote Sens. 2024, 16, 2308. https://doi.org/10.3390/rs16132308
Gu H, Gu G, Liu Y, Lin H, Xu Y. Multi-Branch Attention Fusion Network for Cloud and Cloud Shadow Segmentation. Remote Sensing. 2024; 16(13):2308. https://doi.org/10.3390/rs16132308
Chicago/Turabian StyleGu, Hongde, Guowei Gu, Yi Liu, Haifeng Lin, and Yao Xu. 2024. "Multi-Branch Attention Fusion Network for Cloud and Cloud Shadow Segmentation" Remote Sensing 16, no. 13: 2308. https://doi.org/10.3390/rs16132308
APA StyleGu, H., Gu, G., Liu, Y., Lin, H., & Xu, Y. (2024). Multi-Branch Attention Fusion Network for Cloud and Cloud Shadow Segmentation. Remote Sensing, 16(13), 2308. https://doi.org/10.3390/rs16132308