
A Grid-Based Hierarchical Representation Method for Large-Scale Scenes Based on Three-Dimensional Gaussian Splatting

 ,
, 
Abstract
1. Introduction
2. Related Work
2.1. Three-Dimensional Modeling Using NeRF
2.2. Three-Dimensional Modeling Using 3DGS
2.3. Large-Scale 3D Scene Reconstruction
3. Preliminary
3.1. Three-Dimensional Gaussian Splatting
3.2. Hierarchy-GS
4. Methodology
4.1. Architecture Overview
4.2. Point Cloud Filtering
4.3. Grid-Based Scene Segmentation
4.3.1. Create Initial Grid
4.3.2. Grid Partitioning
4.3.3. Grid Merging
4.3.4. Choose the Camera
4.4. Evaluation Metrics
5. Experiments and Results
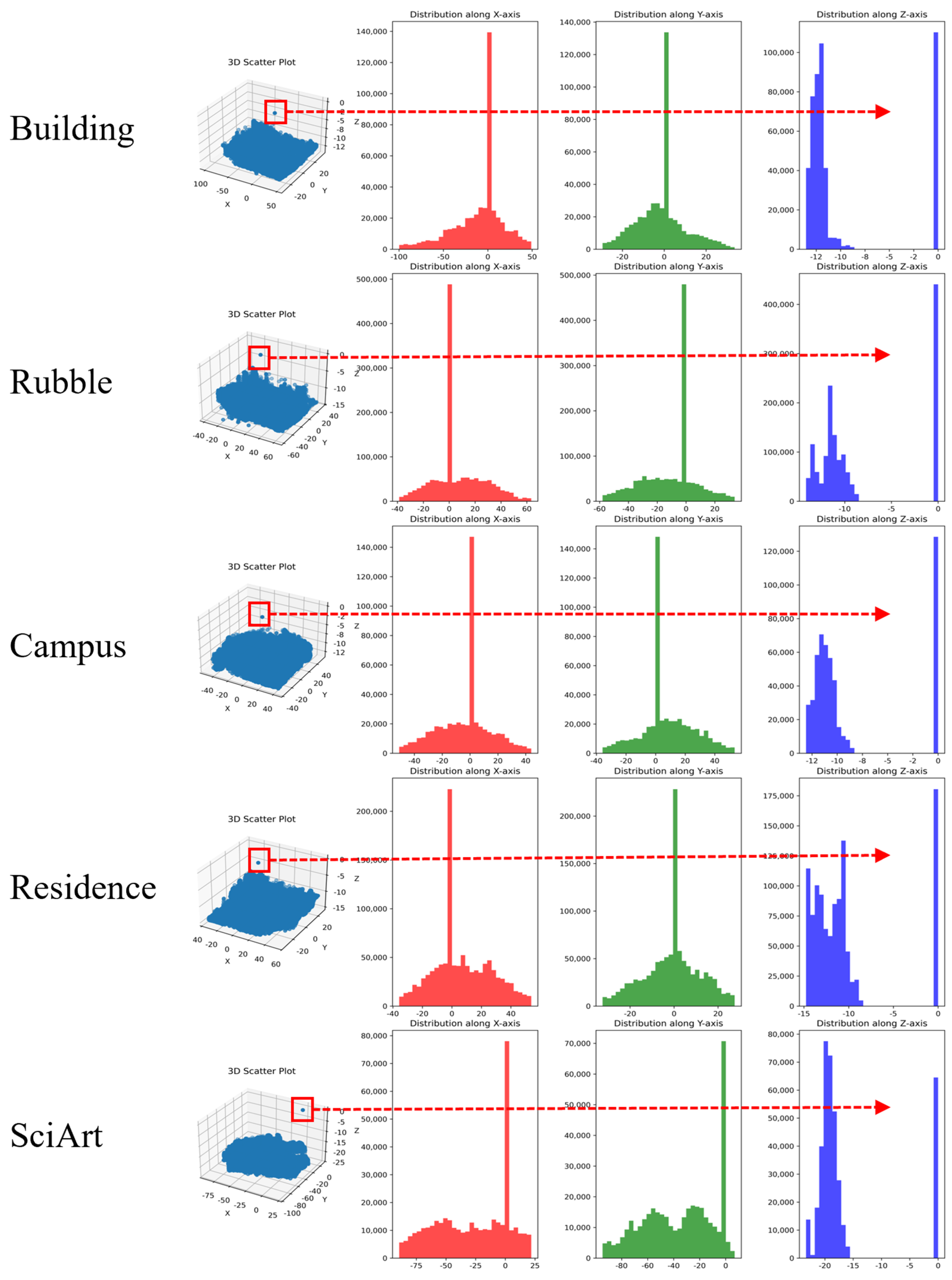
5.1. Data
5.1.1. Mill19
5.1.2. Urban Scene 3D
5.1.3. Self-Collected
5.2. Preprocessing
5.3. Training Details
5.4. Comparison with SOTA Implicit Methods
5.4.1. Single Block
5.4.2. Full Scene
6. Discussion
6.1. Importance of Filtering
6.2. Ablation Analysis
6.3. Shortcomings
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, H.; Zhang, Z.; Zhao, J.; Duan, H.; Ding, Y.; Xiao, X.; Yuan, J. Scene Reconstruction Techniques for Autonomous Driving: A Review of 3D Gaussian Splatting. Artif. Intell. Rev. 2024, 58, 30. [Google Scholar] [CrossRef]
- Cui, B.; Tao, W.; Zhao, H. High-Precision 3D Reconstruction for Small-to-Medium-Sized Objects Utilizing Line-Structured Light Scanning: A Review. Remote Sens. 2021, 13, 4457. [Google Scholar] [CrossRef]
- Chen, W.; Xu, H.; Zhou, Z.; Liu, Y.; Sun, B.; Kang, W.; Xie, X. CostFormer: Cost Transformer for Cost Aggregation in Multi-View Stereo. arXiv 2023, arXiv:2305.10320. [Google Scholar]
- Ding, Y.; Yuan, W.; Zhu, Q.; Zhang, H.; Liu, X.; Wang, Y.; Liu, X. TransMVSNet: Global Context-Aware Multi-View Stereo Network with Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8575–8584. [Google Scholar]
- Kato, H.; Ushiku, Y.; Harada, T. Neural 3D Mesh Renderer. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3907–3916. [Google Scholar]
- Berger, M.; Tagliasacchi, A.; Seversky, L.M.; Alliez, P.; Guennebaud, G.; Levine, J.A.; Sharf, A.; Silva, C.T. A Survey of Surface Reconstruction from Point Clouds. Comput. Graph. Forum 2017, 36, 301–329. [Google Scholar] [CrossRef]
- Häne, C.; Tulsiani, S.; Malik, J. Hierarchical Surface Prediction for 3D Object Reconstruction. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 412–420. [Google Scholar]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-Time 3D Reconstruction and Interaction Using a Moving Depth Camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16 October 2011; pp. 559–568. [Google Scholar]
- Fuentes Reyes, M.; d’Angelo, P.; Fraundorfer, F. Comparative Analysis of Deep Learning-Based Stereo Matching and Multi-View Stereo for Urban DSM Generation. Remote Sens. 2024, 17, 1. [Google Scholar] [CrossRef]
- Wang, T.; Gan, V.J.L. Enhancing 3D Reconstruction of Textureless Indoor Scenes with IndoReal Multi-View Stereo (MVS). Autom. Constr. 2024, 166, 105600. [Google Scholar] [CrossRef]
- Huang, H.; Yan, X.; Zheng, Y.; He, J.; Xu, L.; Qin, D. Multi-View Stereo Algorithms Based on Deep Learning: A Survey. Multimed. Tools Appl. 2024, 84, 2877–2908. [Google Scholar] [CrossRef]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4455–4465. [Google Scholar]
- Chen, Z.; Zhang, H. Learning Implicit Fields for Generative Shape Modeling. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5932–5941. [Google Scholar]
- Michalkiewicz, M.; Pontes, J.K.; Jack, D.; Baktashmotlagh, M.; Eriksson, A. Deep Level Sets: Implicit Surface Representations for 3D Shape Inference. arXiv 2019, arXiv:1901.06802. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. Commun. ACM 2022, 65, 99–106. [Google Scholar] [CrossRef]
- Kerbl, B.; Kopanas, G.; Leimkuehler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. 2023, 42, 139. [Google Scholar] [CrossRef]
- Chen, G.; Wang, W. A Survey on 3D Gaussian Splatting. arXiv 2024, arXiv:2401.03890. [Google Scholar]
- Barron, J.T.; Mildenhall, B.; Tancik, M.; Hedman, P.; Martin-Brualla, R.; Srinivasan, P.P. Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5835–5844. [Google Scholar]
- Cen, J.; Zhou, Z.; Fang, J.; Yang, C.; Shen, W.; Xie, L.; Jiang, D.; Zhang, X.; Tian, Q. Segment Anything in 3D with NeRFs. Adv. Neural Inf. Process. Syst. 2023, 36, 25971–25990. [Google Scholar]
- Chen, Z.; Funkhouser, T.; Hedman, P.; Tagliasacchi, A. MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2023; pp. 16569–16578. [Google Scholar]
- Deng, C. NeRDi: Single-View NeRF Synthesis with Language-Guided Diffusion as General Image Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Garbin, S.J.; Kowalski, M.; Johnson, M.; Shotton, J.; Valentin, J. FastNeRF: High-Fidelity Neural Rendering at 200FPS. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 14326–14335. [Google Scholar]
- Hu, T.; Liu, S.; Chen, Y.; Shen, T.; Jia, J. EfficientNeRF Efficient Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 11–15 June 2022; pp. 12902–12911. [Google Scholar]
- Jia, Z.; Wang, B.; Chen, C. Drone-NeRF: Efficient NeRF Based 3D Scene Reconstruction for Large-Scale Drone Survey. Image Vision. Comput. 2024, 143, 104920. [Google Scholar] [CrossRef]
- Johari, M.M.; Lepoittevin, Y.; Fleuret, F. GeoNeRF: Generalizing NeRF with Geometry Priors. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 18344–18347. [Google Scholar]
- Mari, R.; Facciolo, G.; Ehret, T. Sat-NeRF: Learning Multi-View Satellite Photogrammetry with Transient Objects and Shadow Modeling Using RPC Cameras. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 1310–1320. [Google Scholar]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-NeRF: Point-Based Neural Radiance Fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18–24 June 2022; pp. 5438–5448. [Google Scholar]
- Zhang, G.; Xue, C.; Zhang, R. SuperNeRF: High-Precision 3-D Reconstruction for Large-Scale Scenes. IEEE Trans. Geosci. Remote 2024, 62, 5635313. [Google Scholar] [CrossRef]
- Zhao, Q.; She, J.; Wan, Q. Progress in neural radiance field and its application in large-scale real-scene 3D visualization. Natl. Remote Bull. 2023, 28, 1242–1261. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, S.; Xie, W.; Chen, M.; Prisacariu, V.A. NeRF--: Neural Radiance Fields Without Known Camera Parameters. arXiv 2021, arXiv:2102.07064. [Google Scholar]
- Ma, L.; Li, X.; Liao, J.; Zhang, Q.; Wang, X.; Wang, J.; Sander, P.V. Deblur-NeRF: Neural Radiance Fields from Blurry Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12861–12870. [Google Scholar]
- Zeng, J.; Bao, C.; Chen, R.; Dong, Z.; Zhang, G.; Bao, H.; Cui, Z. Mirror-NeRF: Learning Neural Radiance Fields for Mirrors with Whitted-Style Ray Tracing. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 26 October 2023; pp. 4606–4615. [Google Scholar]
- Pumarola, A.; Corona, E.; Pons-Moll, G.; Moreno-Noguer, F. D-NeRF: Neural Radiance Fields for Dynamic Scenes. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10313–10322. [Google Scholar]
- Xu, H.; Alldieck, T.; Sminchisescu, C. H-NeRF: Neural Radiance Fields for Rendering and Temporal Reconstruction of Humans in Motion. Adv. Neural Inf. Process. Syst. 2021, 34, 14955–14966. [Google Scholar]
- Wang, C.; Chai, M.; He, M.; Chen, D.; Liao, J. CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3825–3834. [Google Scholar]
- Low, W.F.; Lee, G.H. Robust E-NeRF: NeRF from Sparse & Noisy Events under Non-Uniform Motion. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1 October 2023; pp. 18289–18300. [Google Scholar]
- Neff, T.; Stadlbauer, P.; Parger, M.; Kurz, A.; Mueller, J.H.; Chaitanya, C.R.A.; Kaplanyan, A.; Steinberger, M. DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields Using Depth Oracle Networks. Comput. Graph. Forum 2021, 40, 45–59. [Google Scholar] [CrossRef]
- Reiser, C.; Peng, S.; Liao, Y.; Geiger, A. KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 14315–14325. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Trans. Graph. (TOG) 2022, 41, 102. [Google Scholar] [CrossRef]
- Chen, A.; Xu, Z.; Zhao, F.; Zhang, X.; Xiang, F.; Yu, J.; Su, H. MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 14104–14113. [Google Scholar]
- Verbin, D.; Hedman, P.; Mildenhall, B.; Zickler, T.; Barron, J.T.; Srinivasan, P.P. Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 18–24 June 2022; pp. 5481–5490. [Google Scholar]
- Guo, Y.-C.; Kang, D.; Bao, L.; He, Y.; Zhang, S.-H. NeRFReN: Neural Radiance Fields with Reflections. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18388–18397. [Google Scholar]
- Bao, Y.; Ding, T.; Huo, J.; Liu, Y.; Li, Y.; Li, W.; Gao, Y.; Luo, J. 3D Gaussian Splatting: Survey, Technologies, Challenges, and Opportunities. In IEEE Transactions on Circuits and Systems for Video Technology; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Yan, Z.; Low, W.F.; Chen, Y.; Lee, G.H. Multi-Scale 3D Gaussian Splatting for Anti-Aliased Rendering. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16 June 2024; pp. 20923–20931. [Google Scholar]
- Lee, B.; Lee, H.; Sun, X.; Ali, U.; Park, E. Deblurring 3D Gaussian Splatting. In European Conference on Computer Vision; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 127–143. [Google Scholar]
- Yu, Z.; Chen, A.; Huang, B.; Sattler, T.; Geiger, A. Mip-Splatting: Alias-Free 3D Gaussian Splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Lin, Y.; Dai, Z.; Zhu, S.; Yao, Y. Gaussian-Flow: 4D Reconstruction with Dynamic 3D Gaussian Particle. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Chen, Y.; Chen, Z.; Zhang, C.; Wang, F.; Yang, X.; Wang, Y.; Cai, Z.; Yang, L.; Liu, H.; Lin, G. GaussianEditor: Swift and Controllable 3D Editing with Gaussian Splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Fang, J.; Wang, J.; Zhang, X.; Xie, L.; Tian, Q. GaussianEditor: Editing 3D Gaussians Delicately with Text Instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Ye, M.; Danelljan, M.; Yu, F.; Ke, L. Gaussian Grouping: Segment and Edit Anything in 3D Scenes. In European Conference on Computer Vision; Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 162–179. [Google Scholar]
- Li, Z.; Zheng, Z.; Wang, L.; Liu, Y. Animatable Gaussians: Learning Pose-Dependent Gaussian Maps for High-Fidelity Human Avatar Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Fan, Z.; Wang, K.; Wen, K.; Zhu, Z.; Xu, D.; Wang, Z. LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS. Adv. Neural Inf. Process. Syst. 2023, 37, 140138–140158. [Google Scholar]
- Jiang, Y.; Shen, Z.; Wang, P.; Su, Z.; Hong, Y.; Zhang, Y.; Yu, J.; Xu, L. HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Xie, Z.; Zhang, J.; Li, W.; Zhang, F.; Zhang, L. S-NeRF: Neural Radiance Fields for Street Views. arXiv 2023, arXiv:2303.00749. [Google Scholar]
- Wan, Q.; Guan, Y.; Zhao, Q.; Wen, X.; She, J. Constraining the Geometry of NeRFs for Accurate DSM Generation from Multi-View Satellite Images. ISPRS Int. J. Geo-Inf. 2024, 13, 243. [Google Scholar] [CrossRef]
- Turki, H.; Ramanan, D.; Satyanarayanan, M. Mega-NeRF: Scalable Construction of Large-Scale NeRFs for Virtual Fly- Throughs. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 12912–12921. [Google Scholar]
- Tancik, M.; Casser, V.; Yan, X.; Pradhan, S.; Mildenhall, B.P.; Srinivasan, P.; Barron, J.T.; Kretzschmar, H. Block-NeRF: Scalable Large Scene Neural View Synthesis. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 8238–8248. [Google Scholar]
- Lin, J.; Li, Z.; Tang, X.; Liu, J.; Liu, S.; Liu, J.; Lu, Y.; Wu, X.; Xu, S.; Yan, Y.; et al. VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16 June 2024; pp. 5166–5175. [Google Scholar]
- Ren, K.; Jiang, L.; Lu, T.; Yu, M.; Xu, L.; Ni, Z.; Dai, B. Octree-GS: Towards Consistent Real-Time Rendering with LOD-Structured 3D Gaussians. arXiv 2024, arXiv:2403.17898. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Lee, G.H. DoGaussian: Distributed-Oriented Gaussian Splatting for Large-Scale 3D Reconstruction Via Gaussian Consensus. Adv. Neural Inf. Process. Syst. 2024, 37, 34487–34512. [Google Scholar]
- Kerbl, B.; Meuleman, A.; Kopanas, G.; Wimmer, M.; Lanvin, A.; Drettakis, G. A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets. ACM Trans. Graph. 2024, 43, 62. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grid|Points | Building | Rubble | Campus | Residence | SciArt |
|---|---|---|---|---|---|
| Grid 0 | 8738 | 102,052 | 44,354 | 114,020 | 38,764 |
| Grid 1 | 59,739 | 720,013 | 99,433 | 410,024 | 64,313 |
| Grid 2 | 45,488 | 164,498 | 64,408 | 135,380 | 52,740 |
| Grid 3 | 108,314 | 201,176 | 40,313 | 79,331 | 40,785 |
| Grid 4 | 252,504 | 185,314 | 236,387 | 234,410 | 67,292 |
| Grid 5 | 11,003 | 73,592 | 34,348 | 117,398 | 119,335 |
| Max/Min | 28.9 | 9.78 | 6.88 | 5.17 | 3.08 |
| Mean | 80,964.33 | 241,107.5 | 86,540.5 | 181,760.5 | 63,871.5 |
| Std | 91,645.16 | 239,718.5 | 77,137.25 | 123,491.26 | 29,581.68 |
| Grid|Points | Building | Rubble | Campus | Residence | SciArt |
|---|---|---|---|---|---|
| Grid 0 | 8738 | 102,052 | 44,354 | 114,020 | 38,764 |
| Grid 1 | 59,739 | 141,656 | 49,717 | 104,188 | 32,157 |
| Grid 2 | 45,488 | 578,357 | 49,716 | 247,996 | 32,156 |
| Grid 3 | 54,158 | 164,498 | 64,408 | 57,840 | 52,740 |
| Grid 4 | 54,156 | 201,176 | 40,313 | 135,380 | 40,785 |
| Grid 5 | 54,410 | 185,314 | 152,091 | 79,331 | 33,647 |
| Grid 6 | 24,215 | 73,592 | 30,714 | 117,206 | 33,645 |
| Grid 7 | 133,025 | - | 53,582 | 117,204 | 40,675 |
| Grid 8 | 40,854 | - | 34,348 | 117,398 | 78,660 |
| Grid 9 | 11,003 | - | - | - | - |
| Max/Min | 15.22 | 7.86 | 4.95 | 4.29 | 2.45 |
| Mean | 48,578.6 | 206,663.57 | 57,693.67 | 121,173.67 | 42,581 |
| Std | 34,982.53 | 170,941.22 | 39,226.94 | 62,935.49 | 19,536.76 |
| Grid|Points | Building | Rubble | Campus | Residence | SciArt |
|---|---|---|---|---|---|
| Grid 0 | 113,965 | 243,708 | 143,787 | 218,208 | 103,077 |
| Grid 1 | 108,314 | 578,357 | 64,408 | 305,836 | 52,740 |
| Grid 2 | 78,625 | 164,498 | 40,313 | 135,380 | 108,077 |
| Grid 3 | 133,025 | 460,082 | 152,091 | 313,741 | 40,675 |
| Grid 4 | 51,857 | - | 118,644 | 117,398 | 78,660 |
| Max/Min | 2.57 | 3.52 | 3.77 | 2.67 | 2.66 |
| Mean | 97,157.2 | 361,661.25 | 103,848.6 | 218,112.6 | 76,645.8 |
| Std | 31,972.75 | 190,988.66 | 49,329.61 | 91,962.37 | 29,815.98 |
| Original Resolution | Sampling Resolution | Original Images | Colmap Images | |
|---|---|---|---|---|
| Rubble | 4608 × 3456 | 1152 × 864 | 1657 | 1657 |
| Building | 4608 × 3456 | 1152 × 864 | 1920 | 685 |
| Campus | 5472 × 3648 | 1368 × 912 | 2129 | 1290 |
| Residence | 5472 × 3648 | 1368 × 912 | 2582 | 2346 |
| SciArt | 5472 × 3648 | 1368 × 912 | 3620 | 668 |
| NJU | 5280 × 3956 | 1320 × 989 | 304 | 286 |
| CMCC-NanjingIDC | 5280 × 3956 | 1320 × 989 | 2520 | 2098 |
| Data | Building | Rubble | Campus | Residence | SciArt | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Metric | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM |
| 3DGS | 27.83 | 0.180 | 0.872 | 28.84 | 0.173 | 0.877 | 24.30 | 0.256 | 0.783 | 24.56 | 0.197 | 0.831 | 19.88 | 0.576 | 0.484 | |
| Octree-GS | 27.63 | 0.171 | 0.857 | 28.35 | 0.209 | 0.857 | 24.19 | 0.277 | 0.769 | 24.29 | 0.207 | 0.825 | 21.83 | 0.399 | 0.608 | |
| Hierarchy-GS | 27.36 | 0.184 | 0.870 | 27.28 | 0.238 | 0.837 | 24.78 | 0.346 | 0.766 | 23.72 | 0.247 | 0.799 | 22.14 | 0.387 | 0.611 | |
| Ours | 28.15 | 0.179 | 0.875 | 28.42 | 0.204 | 0.855 | 24.91 | 0.233 | 0.799 | 24.36 | 0.221 | 0.821 | 21.49 | 0.461 | 0.562 | |
| Building | Rubble | Campus | Residence | SciArt | |
|---|---|---|---|---|---|
| 3DGS | 18.8 GB | 19.7 GB | 22.6 GB | 22.8 GB | OOM |
| Octree-GS | 19.7 GB | 20.0 GB | 20.2 GB | 20.1 GB | 22.4 GB |
| Hierarchy-GS | 10.8 GB | 12.6 GB | 11.8 GB | 12.2 GB | 13.3 GB |
| Ours | 9.4 GB | 12.4 GB | 11.5 GB | 11.3 GB | 12.9 GB |
| Dataset | Building | Rubble | Camps | Residence | SciArt | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Metric | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM |
| Nerfacto-big | 15.70 | 0.465 | 0.325 | 18.38 | 0.452 | 0.440 | 18.05 | 0.537 | 0.463 | 16.46 | 0.405 | 0.464 | 17.31 | 0.758 | 0.363 | |
| Instant-NGP | 20.47 | 0.460 | 0.574 | 18.67 | 0.537 | 0.525 | 19.53 | 0.625 | 0.529 | 16.16 | 0.533 | 0.495 | 20.28 | 0.713 | 0.453 | |
| Hierarchy-GS | 26.28 | 0.210 | 0.836 | 26.73 | 0.246 | 0.830 | 23.62 | 0.364 | 0.731 | 21.47 | 0.282 | 0.702 | 20.05 | 0.426 | 0.558 | |
| Ours | 26.67 | 0.185 | 0.844 | 27.36 | 0.221 | 0.846 | 23.74 | 0.344 | 0.745 | 22.89 | 0.239 | 0.799 | 20.38 | 0.441 | 0.561 | |
| Model | Dataset | PSNR ↑ | LPIPS ↓ | SSIM ↑ |
|---|---|---|---|---|
| Complete | NJU | 27.58 | 0.161 | 0.904 |
| CMCC-NanjingIDC | 24.66 | 0.283 | 0.787 | |
| Rubble | 27.36 | 0.221 | 0.846 | |
| Remove Grid-based Scene Segmentation | NJU | 27.23 | 0.162 | 0.895 |
| CMCC-NanjingIDC | 24.59 | 0.291 | 0.779 | |
| Rubble | 26.81 | 0.247 | 0.831 | |
| Remove Point Cloud Filter | NJU | 27.12 | 0.166 | 0.897 |
| CMCC-NanjingIDC | 24.10 | 0.303 | 0.772 | |
| Rubble | 26.32 | 0.254 | 0.825 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, Y.; Wang, Z.; Zhang, S.; Han, J.; Wang, W.; Wang, S.; Zhu, Y.; Lv, Y.; Zhou, W.; She, J. A Grid-Based Hierarchical Representation Method for Large-Scale Scenes Based on Three-Dimensional Gaussian Splatting. Remote Sens. 2025, 17, 1801. https://doi.org/10.3390/rs17101801
Guan Y, Wang Z, Zhang S, Han J, Wang W, Wang S, Zhu Y, Lv Y, Zhou W, She J. A Grid-Based Hierarchical Representation Method for Large-Scale Scenes Based on Three-Dimensional Gaussian Splatting. Remote Sensing. 2025; 17(10):1801. https://doi.org/10.3390/rs17101801
Chicago/Turabian StyleGuan, Yuzheng, Zhao Wang, Shusheng Zhang, Jiakuan Han, Wei Wang, Shengli Wang, Yihu Zhu, Yan Lv, Wei Zhou, and Jiangfeng She. 2025. "A Grid-Based Hierarchical Representation Method for Large-Scale Scenes Based on Three-Dimensional Gaussian Splatting" Remote Sensing 17, no. 10: 1801. https://doi.org/10.3390/rs17101801
APA StyleGuan, Y., Wang, Z., Zhang, S., Han, J., Wang, W., Wang, S., Zhu, Y., Lv, Y., Zhou, W., & She, J. (2025). A Grid-Based Hierarchical Representation Method for Large-Scale Scenes Based on Three-Dimensional Gaussian Splatting. Remote Sensing, 17(10), 1801. https://doi.org/10.3390/rs17101801