1. Introduction
Images captured under adverse weather conditions, such as haze, are significantly degraded due to the presence of atmospheric scattering, which leads to color distortion, reduced saturation, and loss of fine texture details. These degradations pose substantial challenges to the performance of high-level computer vision tasks, including image classification, semantic segmentation, object detection, and target tracking, as the quality of the input imagery is a critical factor. Consequently, image dehazing has emerged as a vital pre-processing step in computer vision pipelines.
Existing dehazing techniques can be broadly categorized into three groups: image enhancement-based methods, methods grounded in physical models and prior knowledge, and deep learning-based approaches [
1,
2].
Image enhancement-based methods aim to improve image quality by reducing haze effects and enhancing contrast, without explicitly modeling the imaging process. Representative methods include Retinex-based enhancement [
3], histogram equalization [
4], and wavelet transform techniques [
5]. Although these methods are computationally efficient, they typically fail to address the underlying causes of haze formation, often resulting in dehazed images that lack visual naturalness and robustness under varying haze conditions.
Physical model-based dehazing approaches utilize prior knowledge or constraints derived from the atmospheric scattering model (ASM) [
6,
7] to estimate scene transmission and atmospheric light. A seminal work in this domain is the dark channel prior (DCP) introduced by He et al. [
8], which estimates transmission maps using the dark channel assumption. Zhu et al. [
9] proposed the color attenuation prior (CAP), which exploits statistical correlations among brightness, saturation, and haze concentration. Meng et al. [
10] introduced the boundary constraint and contextual regularization (BCCR) method to refine transmission estimation. Despite their effectiveness, these methods often suffer from limitations such as inaccurate parameter estimation and limited generalizability due to reliance on hand-crafted priors.
In contrast, deep learning-based dehazing methods leverage large-scale datasets to learn data-driven mappings from hazy to clear images. Cai et al. [
11] proposed DehazeNet, a CNN-based model for estimating transmission maps. Li et al. [
12] designed AOD-Net by integrating transmittance and atmospheric light into a unified variable to simplify the estimation process. Subsequent models, such as GCANet [
13], FFANet [
14], and FD-GAN [
15], introduced innovations in context aggregation, attention mechanisms, and frequency-domain priors. More recently, AECR-Net [
16] employed contrastive learning for feature regularization, while gUNet [
17] introduced residual gating into the U-Net architecture. C2PNet [
18] incorporated a dual-branch design and contrastive curriculum learning. DeHamer [
19] addressed modality inconsistency between CNNs and Transformers via a modulation matrix and 3D positional encoding. Finally, DehazeFormer [
20] fused the Swin Transformer [
21] and U-Net [
22] architectures with improvements in normalization, activation, and spatial feature aggregation. Despite these advances, most methods exhibit limited effectiveness when dealing with non-homogeneous haze, a common characteristic in real-world scenarios, especially in UAV imagery.
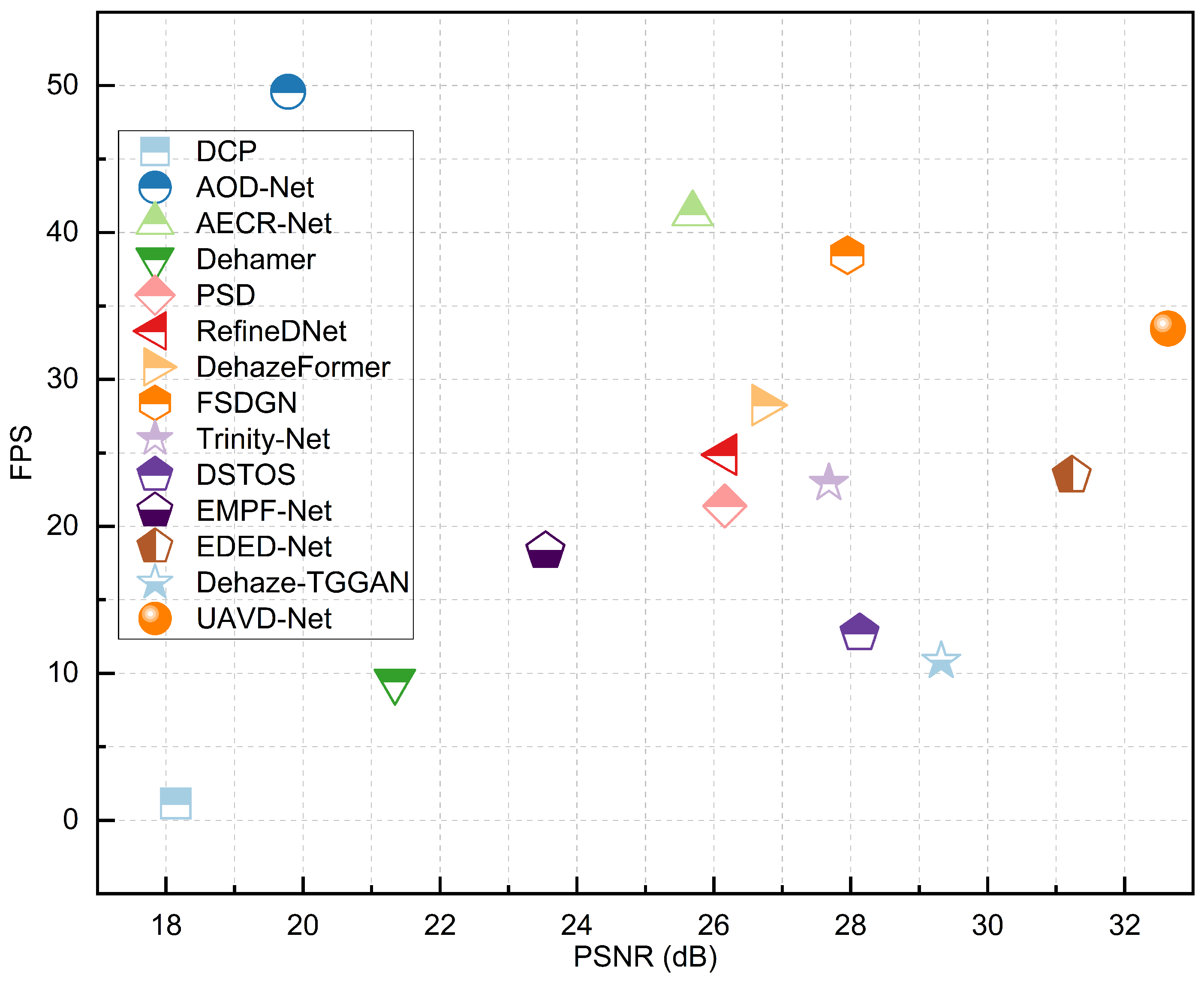
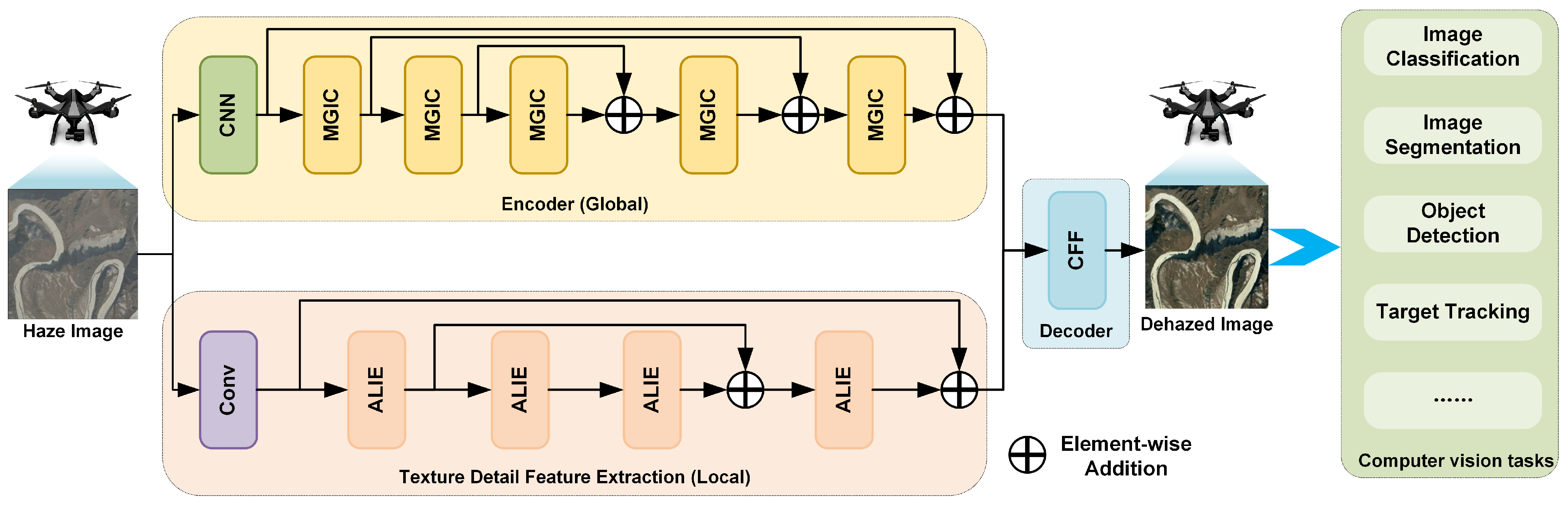
To address these challenges, we propose a novel dehazing method for UAV remote sensing images based on the collaborative integration of global and local features. Unlike methods that rely on the atmospheric scattering model, our approach learns the direct mapping from hazy to haze-free images using deep neural networks. It effectively mitigates issues such as residual local haze and incomplete haze removal, while exhibiting strong capabilities in restoring fine details and color fidelity in both synthetic and real-world datasets. A comparative overview of the performance of our method against state-of-the-art techniques is illustrated in
Figure 1. In terms of dehazing accuracy, the proposed method, UAVD-Net, achieves the highest PSNR, demonstrating its superior performance in image restoration. Furthermore, UAVD-Net ranks fourth in efficiency, indicating that it not only delivers high-precision dehazing results but also maintains competitive computational efficiency. These results collectively validate the method’s effectiveness in achieving a favorable balance between accuracy and efficiency.
The specific contributions of this work are as follows:
We propose a multi-layer global information capturing module (MGIC) that extracts and fuses global feature layer-by-layer to enhance the model’s capacity to understand complex scenes and improve dehazing accuracy.
We propose an adaptive local information enhancement module (ALIE) that effectively acquires and enhances texture detail information in the image and improve dehazing accuracy.
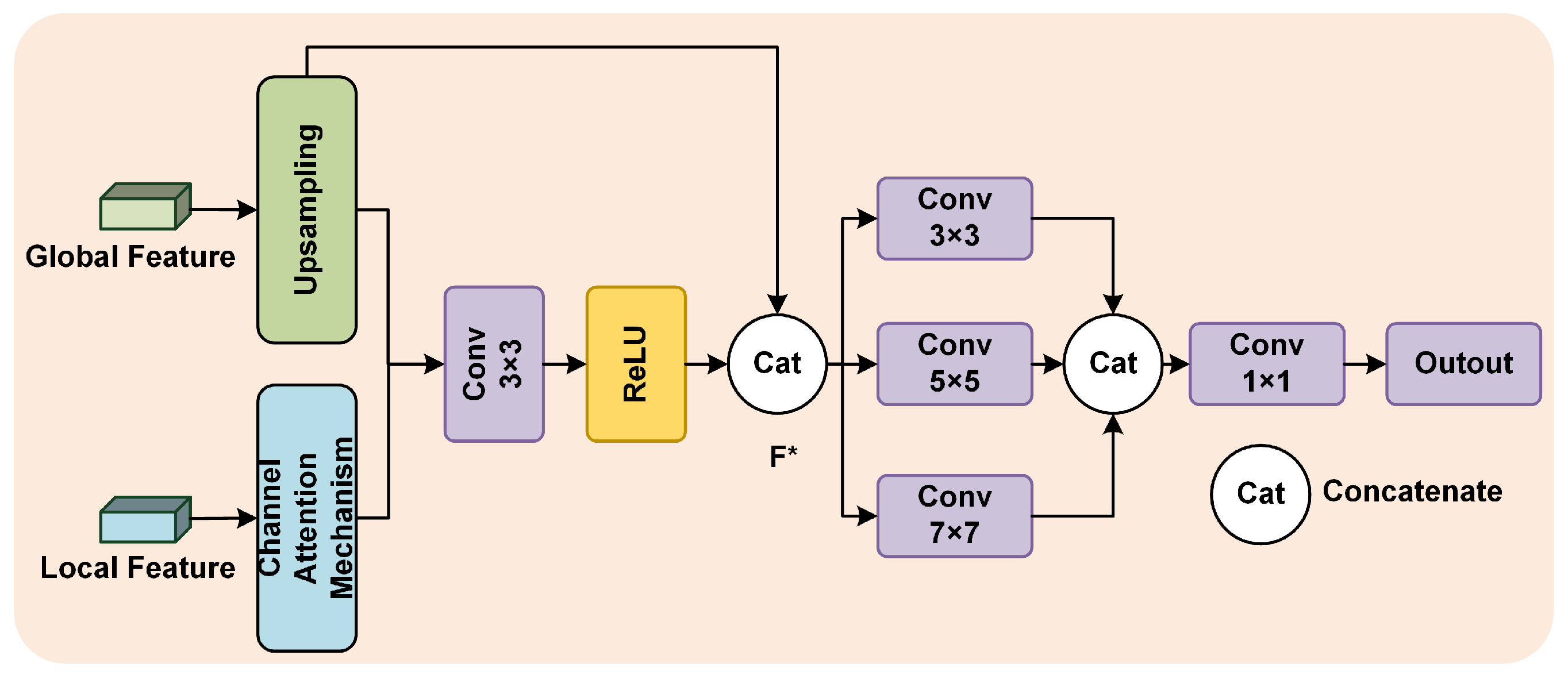
We propose a cross-channel feature fusion module (CFF) that fuses global and local information through a cross-channel mechanism to preserve the overall structure of the image and enhance local detail clarity, resulting in natural and clear dehazed images.
Our proposed UAVD-Net is an end-to-end network that does not require post-processing. Extensive experiments on the UAV [
23], RICE-I [
24], RS-Haze [
20], SateHaze1k [
25], and HyperDehazing [
26] datasets consistently demonstrate its superior performance and robustness across various dehazing scenarios.
The structure of the subsequent sections of this paper is outlined as follows:
Section 2 provides an overview of pertinent prior research.
Section 3 elaborates on the methodology proposed for image dehazing.
Section 4 showcases and scrutinizes the experimental outcomes. A discussion of the balance between accuracy and real-time performance is given in
Section 5. Concluding the paper,
Section 6 presents the final thoughts and reflections.
4. Experimental and Results Analysis
To comprehensively validate the effectiveness of our proposed method, we carried out a comprehensive series of experiments. First, we provide a detailed description of the key elements of the experiments, including the datasets used, the evaluation metrics, the state-of-the-art methods for comparison, and the specific experimental parameters. We conducted ablation experiments to dissect each sub-module of the proposed method, demonstrating their individual contributions to overall performance. Additionally, we performed a comparative analysis of our method against existing state-of-the-art methods, both qualitatively and quantitatively. To further validate the feasibility of our method in real-world applications, we conducted computational complexity comparisons using the NVIDIA Jetson Xavier NX, an edge computing platform, to assess its performance in meeting the computational requirements of a UAV platform. Finally, we carried out object detection experiments in hazy weather conditions to verify that the proposed method can sustain efficient object detection performance under adverse environmental conditions.
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets
In this paper, we test and evaluate the performance of our method using both real and synthetic datasets. The real-world datasets include UAV [
23] and RICE-I [
24], while the synthetic datasets consist of RS-Haze [
20], SateHaze1k [
25], and HyperDehazing [
26]. The UAV dataset is a real-world benchmark comprising 150 remote sensing hazy images captured by unmanned aerial vehicles. The RICE-I dataset contains 500 pairs of images, each pair consisting of one image with clouds and one without, with a resolution of 512 × 512 pixels. The RS-Haze dataset comprises 54,000 image pairs, with 51,300 pairs designated for training and the remaining 2700 pairs for testing. This dataset features remote sensing images with relatively monotonous scenes but highly inhomogeneous haze. The SateHaze1k dataset includes 1200 pairs of synthetic aperture radar (SAR) and visible spectral remote sensing images, each with varying levels of haze, alongside corresponding ground truth images. The dataset is categorized into three degrees of haze—thin, medium, and dense—with each category containing 400 image pairs.
4.1.2. Evaluation Metrics
To evaluate the quality of dehazed images, we employ several key metrics, including the structural similarity index (SSIM) [
46], peak signal-to-noise ratio (PSNR) [
47], and learned perceptual image patch similarity (LPIPS) [
48]. SSIM is a perceptual metric that assesses image quality by measuring the similarity between the dehazed image and the original image in terms of luminance, contrast, and structure. A higher SSIM value indicates that the dehazed image retains more structural and visual similarities to the original, enhancing its perceptual accuracy. PSNR is another critical metric that quantifies the ratio between the maximum possible signal power and the power of corrupting noise that affects its fidelity. In the context of image dehazing, a higher PSNR value signifies that the dehazed image exhibits less distortion and noise, closely resembling the real image. Additionally, LPIPS is a deep learning-based metric that evaluates perceptual similarity by comparing the high-level feature representations of two images. Unlike traditional pixel-wise comparisons, LPIPS considers the perceived visual quality, with a lower LPIPS score indicating that the dehazed image is perceptually closer to the original, capturing finer details and textures. Collectively, higher SSIM and PSNR values, along with a lower LPIPS score, demonstrate that the dehazed image is more similar to the real, haze-free image, indicating superior dehazing performance. The determination of SSIM is given in Equation (
15) and of PSNR is given in Equation (
16).
where
x and
y represent the two images to be compared;
and
denote the means of the two images, respectively;
and
are the variances of the two images, respectively; and
and
are constants introduced to prevent division by zero.
is the maximum possible pixel value in the image and
is the mean square error.
denotes the image resolution.
4.2. State-of-the-Art Methods
To thoroughly evaluate the dehazing performance of the algorithms proposed in this paper, we conducted a comprehensive comparison with a diverse set of state-of-the-art methods. We carefully selected a variety of dehazing algorithms, including DCP (PAMI’2010) [
8], AOD-Net (ICCV’2017) [
12], AECR-Net (CVPR’2021) [
16], Dehamer (CVPR’2022) [
19], PSD (CVPR’2021) [
49], RefineDNet (TIP’2021) [
50], DehazeFormer (TIP’2023) [
20], FSDGN (ECCV’2022) [
51], Trinity-Net (TGRS’2023) [
52], DSTOS (GRSL’2023) [
23], EMPF-Net (TGRS’2023) [
53], EDED-Net (RS’2024) [
54], and Dehaze-TGGAN (TGRS’2024) [
55]. These algorithms were chosen to represent a wide range of methodologies, allowing us to critically analyze and benchmark the effectiveness of our proposed method against a broad array of existing solutions. This comparison not only highlights the strengths and potential advantages of our algorithm but also provides valuable insights into their relative performance across various scenarios and challenging conditions.
4.3. Experimental Implementation
During the training process, the input images are uniformly cropped to a resolution of 512 × 512 pixels. To balance computational efficiency with accurate gradient estimation, the model is optimized using the Adam optimizer, with a batch size of 16. The initial learning rate is set to , and training is conducted over 100 epochs. To prevent overfitting and enhance model performance, the learning rate is halved every 25 epochs. This study employs the PyTorch 0.12.0 deep learning framework for model training, with all experiments performed on an NVIDIA RTX 4090 GPU (24GB).
4.4. Ablation Study
An ablation study is conducted to assess the importance of different components or features in the model. To verify the effectiveness of the proposed module and loss function, we perform ablation experiments on the real-world UAV dataset and the synthesis RS-Haze dataset. The experimental results are presented in
Table 1.
4.4.1. MGIC
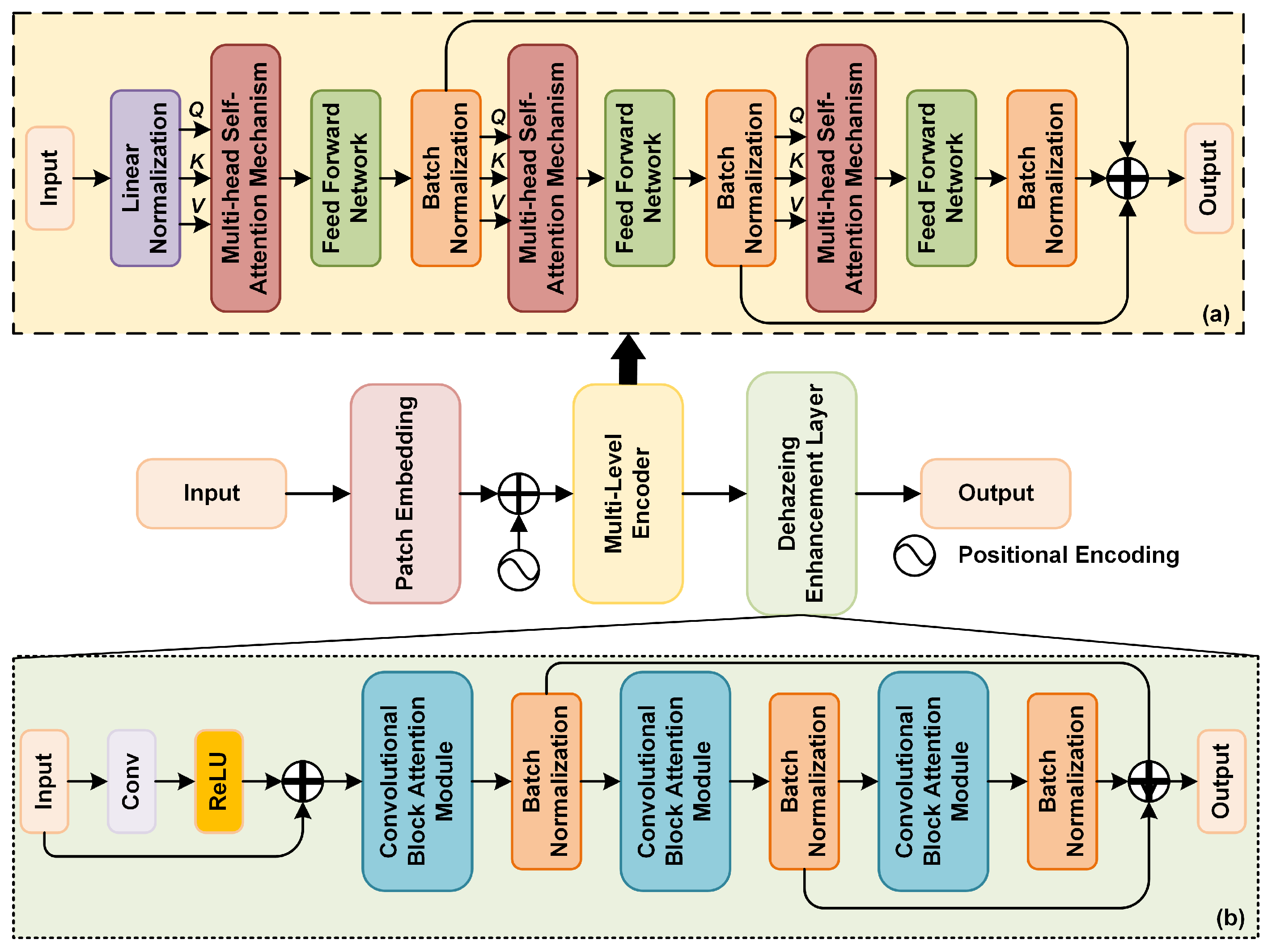
When the MGIC module is integrated into the baseline network, the UAV dataset shows an improvement in SSIM and PSNR by 0.0841 and 4.87 dB, respectively, while LPIPS decreases by 0.1461. Similarly, on the RS-Haze dataset, SSIM and PSNR improve by 0.0999 and 4.98 dB, with LPIPS decreasing by 0.1667. This improvement is attributed to the MGIC module’s ability to enhance image quality post-dehazing by combining multiple layers of the Transformer encoder, skip connections, and low-frequency information. This combination helps to preserve and refine both global and local information in the image.
4.4.2. ALIE
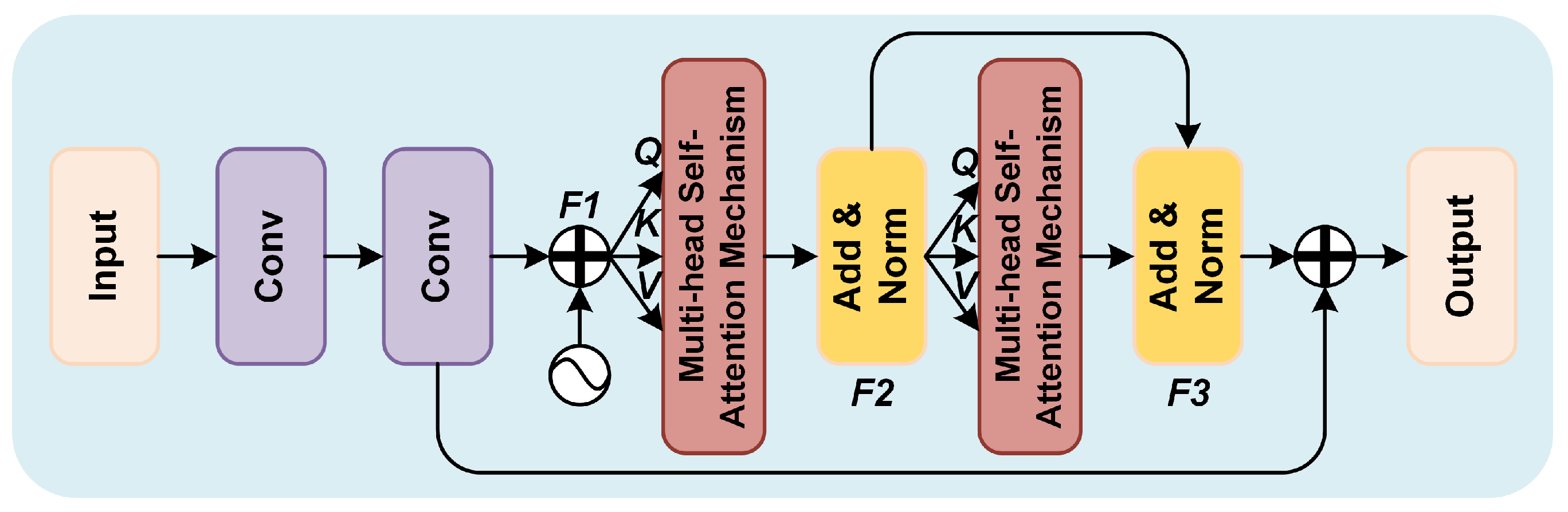
The integration of the ALIE module with MGIC demonstrates significant improvements in image quality metrics across both real and synthetic datasets. Experimental results on the UAV real-world dataset and the RS-Haze synthetic dataset reveal notable increases in SSIM and PSNR, alongside decreases in LPIPS. Specifically, on the UAV dataset, SSIM, PSNR, and LPIPS values reached 0.8759, 27.14, and 0.2194, respectively. On the RS-Haze dataset, these values were 0.9169, 28.41, and 0.1930, respectively. These findings indicate that the ALIE module effectively captures high-frequency information and efficiently extracts local fine features, thereby enhancing detail preservation and overall dehazing performance.
4.4.3. CFF
Combining the CFF module with both the MGIC and ALIE modules results in substantial improvements across all three metrics on both datasets. The CFF module replaces the conventional concatenation-based feature fusion with a cross-channel attention mechanism, which dynamically adjusts the weight allocation between channels. This approach ensures that low-frequency and high-frequency information are effectively complemented during fusion, leading to dehazed images that exhibit both global clarity and rich detail retention.
4.4.4.
We employed a hybrid loss function that integrates structural similarity index (SSIM) loss, perceptual loss, and adversarial loss. Utilizing this combined loss function, we achieved an SSIM of 0.9351, a PSNR of 32.63 dB, and an LPIPS of 0.1734 on the UAV dataset, and an SSIM of 0.9411, a PSNR of 33.53 dB, and an LPIPS of 0.1575 on the RS-Haze dataset. These results demonstrate that the proposed hybrid loss function significantly enhances the network’s performance in dehazing tasks. By effectively integrating structural similarity, perceptual quality, and adversarial aspects, the hybrid loss function markedly improves the visual quality and detail retention of the dehazed images.
4.5. Quantitative Experiments
In order to comprehensively verify the effectiveness of the proposed method in the image dehazing task, we conducted extensive comparison experiments on both real and synthetic datasets to ensure the applicability and robustness of the methods across multiple scenarios. The experimental results are shown in
Table 2 and
Table 3.
4.5.1. Real-World Datasets
As shown in
Table 2, we conducted quantitative experiments on the real-world datasets UAV and RICE-I to comprehensively evaluate the image dehazing performance of each method. The experimental results indicate that DCP has the weakest performance across all three metrics—SSIM, PSNR, and LPIPS—on both datasets. In contrast, AECR-Net surpasses AOD-Net, Dehamer, and PSD but still falls short of RefineDNet, DehazeFormer, and DSTOS. However, EMPF-Net outperforms these methods in all three metrics, achieving a PSNR of 23.54 dB, SSIM of 0.8439, and LPIPS of 0.3123, representing the best results among them. Additionally, Dehaze-TGGAN and EDED-Net exhibit strong competitiveness, securing the third and second best results, respectively. Most notably, our proposed UAVD-Net achieves optimal results on both the UAV and RICE-I datasets. Specifically, UAVD-Net records PSNR, SSIM, and LPIPS values of 32.63 dB, 0.9351, and 0.1734 on the UAV dataset, and 32.05 dB, 0.9309, and 0.1828 on the RICE-I dataset, respectively. These results are significantly superior to those of the other methods, which fully demonstrates the excellent performance and robustness of our proposed method across various scenarios, showcasing its strong dehazing capabilities.
4.5.2. Synthetic Datasets
As shown in
Table 3, to thoroughly assess the dehazing capabilities of various methods, we conducted quantitative evaluations on two synthetic datasets: RS-Haze and StateHaze1K. The comparison spans three key metrics—PSNR, SSIM, and LPIPS—offering a comprehensive performance profile. Among the evaluated methods, DCP consistently ranks at the bottom across all metrics and datasets. AECR-Net delivers noticeable improvements over AOD-Net, Dehamer, and PSD, yet it is still outperformed by more advanced approaches such as RefineDNet, DehazeFormer, and DSTOS. EMPF-Net emerges as a strong contender, surpassing these methods with scores of 25.84 dB in PSNR, 0.8874 in SSIM, and 0.2288 in LPIPS. Dehaze-TGGAN and EDED-Net also demonstrate competitive results, securing third and second places, respectively. Most significantly, our proposed UAVD-Net achieves the highest performance across all benchmarks. On the RS-Haze dataset, it records a PSNR of 33.53 dB, an SSIM of 0.9411, and a notably low LPIPS of 0.1575. On StateHaze1K, it further improves to 34.23 dB in PSNR, 0.9593 in SSIM, and 0.1465 in LPIPS. These scores not only outperform all other methods by a substantial margin but also highlight the robustness and superior generalization ability of UAVD-Net under complex synthetic hazy conditions.
To evaluate its robustness and generality, we conducted dehazing experiments on the hyperspectral dataset: HyperDehazing, and the experimental results are shown in
Table 4. As this dataset is a synthetic dataset, its dehazing effect is better than that of the real dataset. Specifically. UAVD-Net achieves the best performance across all three evaluation metrics, with a PSNR of 37.83, SSIM of 0.9672, and LPIPS of 0.1376, ranking first among all compared methods. These results demonstrate its significant advantage in image quality restoration. Following closely, EDED-Net also exhibits strong performance, achieving a PSNR of 36.91 and an LPIPS of 0.1791, indicating its competitiveness particularly in terms of structural and perceptual consistency. Dehaze-TGGAN obtains the second-highest SSIM value of 0.9349, though it performs slightly worse in PSNR and LPIPS compared to the top-ranking methods. In contrast, traditional approaches such as DCP and earlier deep networks like AOD-Net exhibit notably lower performance, suggesting that recent advances in network architecture and training strategies have led to substantial improvements in dehazing capability under complex scenarios. Overall, UAVD-Net demonstrates superior performance across multiple key metrics, confirming its effectiveness and robustness in single image dehazing tasks.
4.6. Qualitative Experiments
The primary goal of image dehazing is to enhance image clarity and visibility. To intuitively demonstrate the effectiveness of various dehazing algorithms, we conduct visualization experiments on both real-world and synthetic datasets, with the results presented in
Figure 7,
Figure 8,
Figure 9 and
Figure 10.
For the real-world datasets UAV and RICE-I (
Figure 7 and
Figure 8), notable differences in dehazing performance are observed across methods. The DCP algorithm produces darker images with severe highlight distortions. AOD-Net and DehazeFormer leave noticeable residual haze, particularly in the UAV dataset, while RefineDNet, AOD-Net, and EMPF-Net introduce visual artifacts. In contrast, our proposed method achieves a more balanced restoration, effectively removing haze while preserving natural color tones, resulting in more visually pleasing and realistic images.
For the synthetic datasets RS-Haze and SateHaze1k (
Figure 9 and
Figure 10), the DCP algorithm again results in overly dark images with substantial haze retention. While EDED-Net reduces some haze, it introduces noticeable color artifacts, leading to uneven visual quality. The PSD algorithm struggles with haze removal in township scenes and introduces unrealistic colors in river and mountain scenes. Dehaze-TGGAN, although enhancing certain details, leads to over-restoration and suboptimal results. In comparison, our method demonstrates superior detail recovery, effectively preserving color and contrast, and generating dehazed images that more closely resemble the original scene, thus providing a more natural and authentic visual experience.
4.7. Complexity Experiment
Complexity is also a crucial factor in evaluating algorithm performance. To evaluate the complexity of our proposed method and the comparison method, we conducted experiments on the UAV and RICE-I datasets. The metrics used include the number of parameters and FPS (Frames Per Second). The number of parameters represents the total count of tunable parameters in a model, with a higher count indicating the model’s capability to fit more complex data patterns. FPS measures the number of image frames processed per second, reflecting the real-time processing capability of the system; a higher FPS value indicates better responsiveness and accuracy. The results of the complexity experiments are presented in
Table 5 and
Figure 11.
The complexity experiments were conducted on a NVIDIA Jetson Xavier NX edge computing device, processing images of size 512 × 512. As shown in
Table 5 and
Figure 11, AOD-Net has the smallest number of parameters and the highest FPS, with values of 49.59 and 48.12 for the two datasets. AECR-Net shows the second-best performance, with 2.61M parameters and FPS values of 41.28 and 40.56. In contrast, Dehamer, with its more complex architecture, has the largest number of parameters (67M) and the lowest FPS, with results of 9.45 and 9.12. The method proposed in this paper achieves the fourth-best FPS, with values of 33.46 and 32.91, but has a higher number of parameters compared to AOD-Net, AECR-Net, and FSDGN. This indicates that our method provides a balance between accuracy and complexity, effectively meeting the real-time requirements of UAV computing platforms.
4.8. Experiment of Object Detection
Object detection in hazy weather is a prominent focus of current research. To test the object detection performance of the proposed method after dehazing, we used the haze synthesis method in [
20] to add haze to the UAV object detection datasets VisDrone 2019 [
56] and AU-AIR [
57]. After dehazing the remote sensing images, we tested the object detection performance using Yolov5s [
58]. Object detection performance was evaluated using three metrics: precision (P), recall (R), and mean average precision (mAP). The results of the object detection experiments are presented in
Table 6.
As shown in
Table 6, the object detection accuracy of DCP+Yolov5s is the lowest on the VisionDrone 2019 dataset, with the P-value, R-value, and mAP recorded at 63.94%, 45.40%, and 46.73%, respectively. This result suggests that while the DCP algorithm is capable of image dehazing, the quality of the processed images is insufficient, thereby negatively impacting object detection. In contrast, RefineDNet+Yolov5s achieves the highest detection accuracy on the same dataset, indicating that RefineDNet’s dehazing process produces superior image quality compared to other methods, significantly enhancing target detection performance. Notably, our proposed UAVD-Net method shows a substantial improvement in object detection accuracy, with the P-value, R-value, and mAP reaching 80.23%, 71.71%, and 71.45%, respectively. This result strongly supports the effectiveness of the UAVD-Net dehazing algorithm in improving image clarity and enhancing object features, further validating its superiority in complex environments. These findings demonstrate that UAVD-Net not only effectively enhances visual image quality but also significantly boosts object detection accuracy, underscoring its potential and advantages in practical applications.
As shown in
Table 6, FSDGN+Yolov5s records the lowest object detection accuracy on the AU-AIR dataset, with the P-value, R-value, and mAP at 75.27%, 60.46%, and 61.63%, respectively, suggesting that the FSDGN algorithm’s dehazing performance is insufficient, thereby impacting detection accuracy. In contrast, EDED-Net+Yolov5s achieves the highest detection accuracy, demonstrating superior image quality post-dehazing and significantly enhancing detection performance. Notably, our proposed UAVD-Net method shows a marked improvement in object detection accuracy, with the P-value, R-value, and mAP reaching 82.29%, 73.05%, and 73.46%, respectively. These results indicate that the UAVD-Net algorithm excels not only in enhancing image clarity and object features but also in significantly improving object detection accuracy, underscoring its superiority and potential for practical application in complex environments.
5. Discussion
Although the proposed model demonstrates superior dehazing performance compared to existing lightweight networks, it inevitably incurs a moderate computational overhead due to the incorporation of hierarchical Transformer blocks and multi-scale feature fusion. Specifically, the model comprises 16.3 million parameters and achieves a processing speed of 33.46 FPS on a single NVIDIA 2080Ti GPU, outperforming many current Transformer-based approaches in terms of efficiency. Nevertheless, it remains comparatively heavier than ultra-lightweight models such as AOD-Net (0.3M parameters, 49.59 FPS) and AECR-Net (2.61M parameters, 41.28 FPS).
This trade-off underscores a key design principle: prioritizing restoration quality while ensuring real-time inference capability on general-purpose GPUs. The proposed model is particularly well suited for applications demanding high visual fidelity, such as autonomous driving and UAV-based surveillance in adverse weather conditions. However, for deployment on resource-constrained edge devices, further model optimization is essential. In future work, we intend to investigate techniques such as network pruning, quantization, and knowledge distillation to develop a more lightweight variant of the model. Moreover, we are exploring dynamic inference strategies that adjust computational load based on haze severity, thereby enabling adaptable deployment across diverse hardware platforms. This balance between performance and complexity lays a solid foundation for both the model’s current applicability and its future scalability.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}