
Feature-Guided Instance Mining and Task-Aligned Focal Loss for Weakly Supervised Object Detection in Remote Sensing Images



Abstract

1. Introduction
- 1.
- A novel FGSIM strategy is proposed to address the challenge where current models often detect salient objects while overlooking inconspicuous ones due to their reliance on selecting the top-scoring proposal as the seed instance. The FGSIM first selects high-scoring proposals as initial seed instances and then expands this set by mining additional seed instances based on a feature similarity measure. Furthermore, a contrastive loss is introduced to establish a reliable similarity threshold for FGSIM by leveraging the consistent feature representations of instances within the same category.
- 2.
- A TAF loss is proposed to address inconsistencies between the classification and regression branches. The TAF loss utilizes localization and classification difficulty scores as weights for the regression and classification losses, respectively. Thus, minimizing the TAF loss enables the synchronous optimization of classification and regression.
2. Related Work
2.1. Weakly Supervised Deep Detection Network
2.2. Online Instance Classifier Refinement
2.3. Bounding Box Regression Branch
2.4. Other WSOD Models
3. Proposed Method
3.1. Overview
3.2. Feature-Guided Seed Instance Mining Strategy
3.3. Contrastive Loss
3.4. Task-Aligned Focal Loss
3.5. Overall Training Loss
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
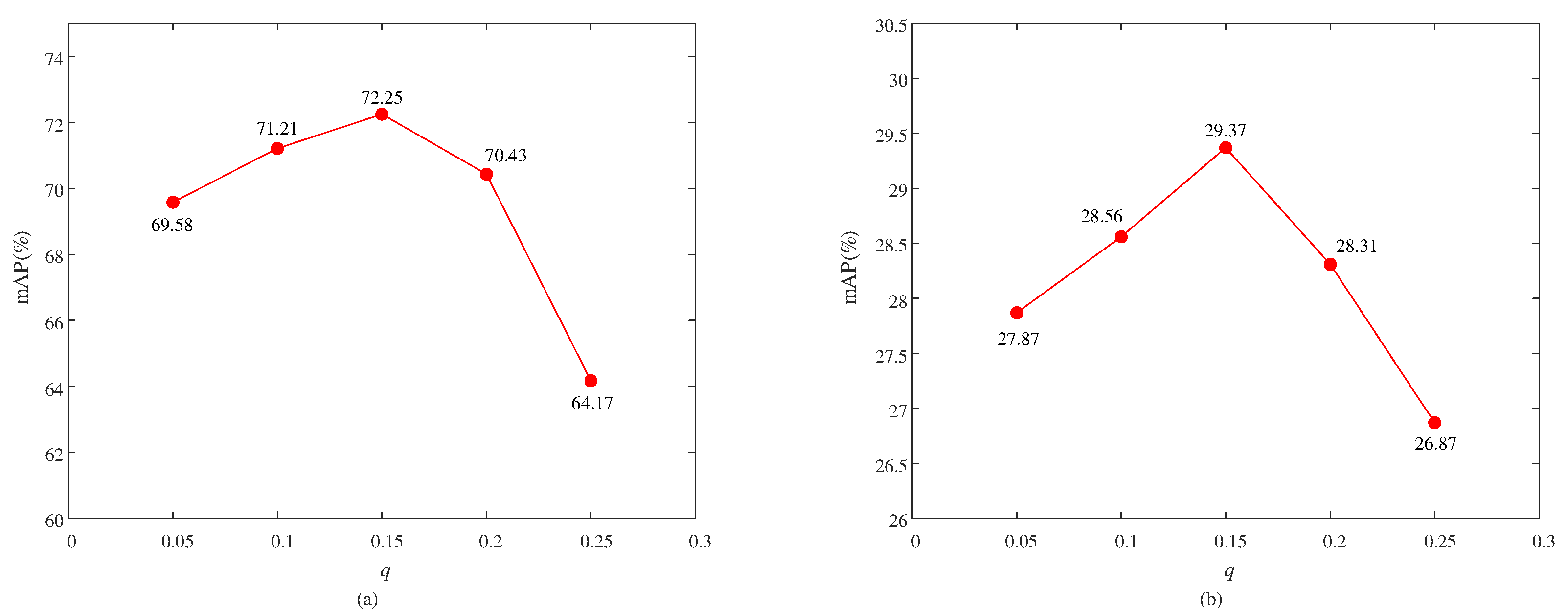
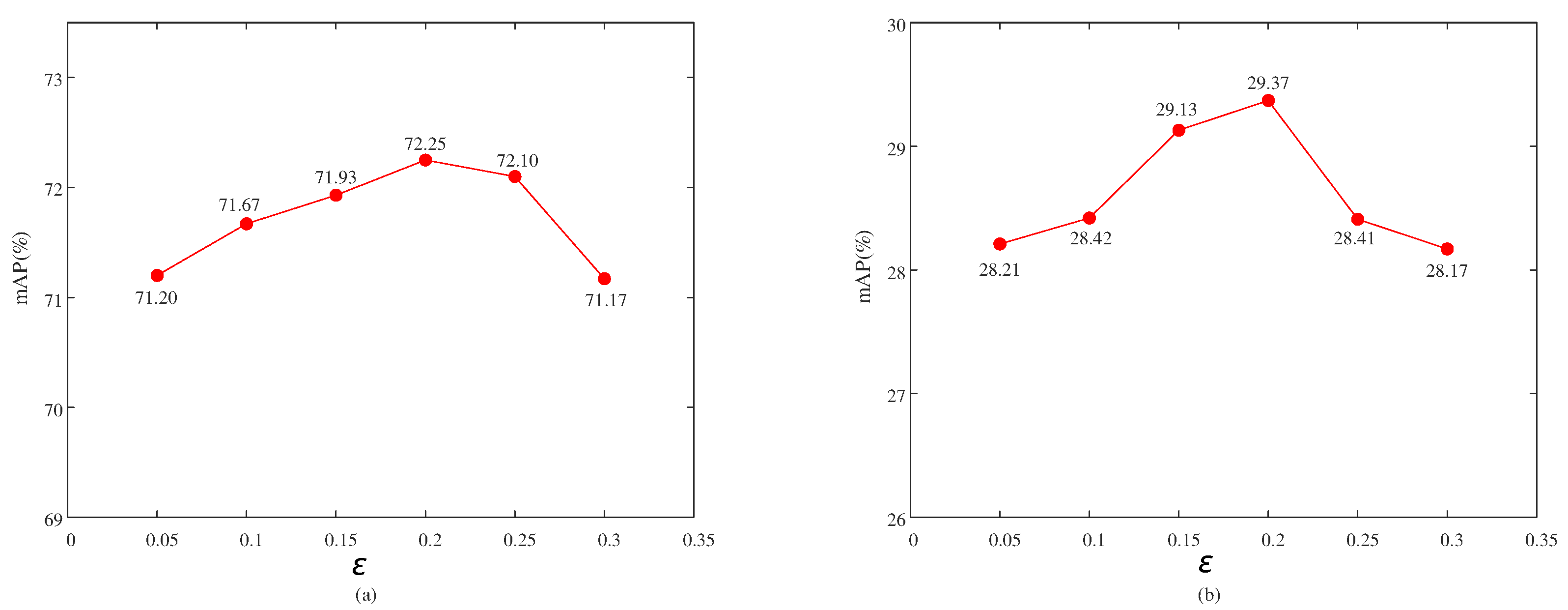
4.3. Parameter Analysis
4.4. Ablation Study
4.4.1. Quantitative Ablation Study
4.4.2. Subjective Ablation Study
4.5. Quantitative Comparison with Popular Methods
4.6. Subjective Evaluation
4.7. Performance on Natural Images
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| WSOD | Weakly Supervised Object Detection |
| RSI | Remote Sensing Image |
| TAF | Task-aligned Focal |
| FGSIM | Feature-guided Seed Instance Mining |
| WSDDN | Weakly Supervised Deep Detection Network |
| OICR | Online Instance Classifier Refinement |
| BBR | Bounding Box Regression |
| RoI | Region of Interest |
| NMS | Non-Maximum Suppression |
References
- Șerban, R.D.; Șerban, M.; He, R.; Jin, H.; Li, Y.; Li, X.; Wang, X.; Li, G. 46-Year (1973–2019) Permafrost Landscape Changes in the Hola Basin, Northeast China Using Machine Learning and Object-Oriented Classification. Remote Sens. 2021, 13, 910. [Google Scholar] [CrossRef]
- Li, W.; Yu, Y.; Meng, F.; Duan, J.; Zhang, X. A image fusion and U-Net approach to improving crop planting structure multi-category classification in irrigated area. J. Intell. Fuzzy Syst. 2023, 45, 185–198. [Google Scholar] [CrossRef]
- Chen, Q.; Huang, M.; Wang, H. A Feature Discretization Method for Classification of High-Resolution Remote Sensing Images in Coastal Areas. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8584–8598. [Google Scholar] [CrossRef]
- Maneepong, K.; Yamanotera, R.; Akiyama, Y.; Miyazaki, H.; Miyazawa, S.; Akiyama, C.M. Towards High-Resolution Population Mapping: Leveraging Open Data, Remote Sensing, and AI for Geospatial Analysis in Developing Country Cities—A Case Study of Bangkok. Remote Sens. 2025, 17, 1204. [Google Scholar] [CrossRef]
- Somanath, S.; Naserentin, V.; Eleftheriou, O.; Sjölie, D.; Wästberg, B.S.; Logg, A. Towards Urban Digital Twins: A Workflow for Procedural Visualization Using Geospatial Data. Remote Sens. 2024, 16, 1939. [Google Scholar] [CrossRef]
- Tian, T.; Pan, M.; Zhang, F.; Cong, W.; Han, X.; Zhang, J. A 3D GIS-based underground construction deformation display system. In Proceedings of the 2010 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Zeng, B.; Gao, S.; Xu, Y.; Zhang, Z.; Li, F.; Wang, C. Detection of Military Targets on Ground and Sea by UAVs with Low-Altitude Oblique Perspective. Remote Sens. 2024, 16, 1288. [Google Scholar] [CrossRef]
- Qian, X.; Lin, C.; Chen, Z.; Wang, W. SAM-Induced Pseudo Fully Supervised Learning for Weakly Supervised Object Detection in Remote Sensing Images. Remote Sens. 2024, 16, 1532. [Google Scholar] [CrossRef]
- Yao, X.; Feng, X.; Han, J.; Cheng, G.; Guo, L. Automatic weakly supervised object detection from high spatial resolution remote sensing images via dynamic curriculum learning. IEEE Trans. Geosci. Remote Sens. 2020, 59, 675–685. [Google Scholar] [CrossRef]
- Fasana, C.; Pasini, S.; Milani, F.; Fraternali, P. Weakly Supervised Object Detection for Remote Sensing Images: A Survey. Remote Sens. 2022, 14, 5362. [Google Scholar] [CrossRef]
- Qian, X.; Wu, B.; Cheng, G.; Yao, X.; Wang, W.; Han, J. Building a Bridge of Bounding Box Regression Between Oriented and Horizontal Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605209. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, S.; Zhang, S. CAW-YOLO: Cross-Layer Fusion and Weighted Receptive Field-Based YOLO for Small Object Detection in Remote Sensing. CMES-Comput. Model. Eng. Sci. 2024, 139, 3209–3231. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, Z.; Luo, H.; Qi, G.; Liu, Y.; Zuo, H.; Zhang, J.; Wei, Y. GCA2Net: Global-Consolidation and Angle-Adaptive Network for Oriented Object Detection in Aerial Imagery. Remote Sens. 2025, 17, 1077. [Google Scholar] [CrossRef]
- Shi, R.; Zhang, L.; Wang, G.; Jia, S.; Zhang, N.; Wang, C. GD-Det: Low-Data Object Detection in Foggy Scenarios for Unmanned Aerial Vehicle Imagery Using Re-Parameterization and Cross-Scale Gather-and-Distribute Mechanisms. Remote Sens. 2025, 17, 783. [Google Scholar] [CrossRef]
- Bilen, H.; Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2846–2854. [Google Scholar]
- Tang, P.; Wang, X.; Bai, X.; Liu, W. Multiple instance detection network with online instance classifier refinement. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2843–2851. [Google Scholar]
- Huang, Z.; Zou, Y.; Kumar, B.V.K.V.; Huang, D. Comprehensive Attention Self-Distillation for Weakly-Supervised Object Detection. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Newry, UK, 2020; Volume 33, pp. 16797–16807. [Google Scholar]
- Feng, X.; Han, J.; Yao, X.; Cheng, G. Progressive contextual instance refinement for weakly supervised object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8002–8012. [Google Scholar] [CrossRef]
- Feng, X.; Han, J.; Yao, X.; Cheng, G. TCANet: Triple Context-Aware Network for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6946–6955. [Google Scholar] [CrossRef]
- Feng, X.; Yao, X.; Cheng, G.; Han, J. Weakly Supervised Rotation-Invariant Aerial Object Detection Network. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14126–14135. [Google Scholar] [CrossRef]
- Wu, Z.; Wen, J.; Xu, Y.; Yang, J.; Zhang, D. Multiple Instance Detection Networks With Adaptive Instance Refinement. IEEE Trans. Multimed. 2023, 25, 267–279. [Google Scholar] [CrossRef]
- Huo, Y.; Qian, X.; Li, C.; Wang, W. Multiple Instance Complementary Detection and Difficulty Evaluation for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6006505. [Google Scholar] [CrossRef]
- Qian, X.; Li, C.; Wang, W.; Yao, X.; Cheng, G. Semantic segmentation guided pseudo label mining and instance re-detection for weakly supervised object detection in remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103301. [Google Scholar] [CrossRef]
- Ren, Z.; Yu, Z.; Yang, X.; Liu, M.Y.; Lee, Y.J.; Schwing, A.G.; Kautz, J. Instance-aware, context-focused, and memory-efficient weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10598–10607. [Google Scholar]
- Qian, X.; Wang, C.; Li, C.; Li, Z.; Zeng, L.; Wang, W.; Wu, Q. Multiscale Image Splitting Based Feature Enhancement and Instance Difficulty Aware Training for Weakly Supervised Object Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 7497–7506. [Google Scholar] [CrossRef]
- Seo, J.; Bae, W.; Sutherland, D.J.; Noh, J.; Kim, D. Object Discovery via Contrastive Learning for Weakly Supervised Object Detection. In Proceedings of the Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 312–329. [Google Scholar]
- Qian, X.; Wang, C.; Wang, W.; Yao, X.; Cheng, G. Complete and Invariant Instance Classifier Refinement for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5627713. [Google Scholar] [CrossRef]
- Chang, S.; Deng, Y.; Zhang, Y.; Zhao, Q.; Wang, R.; Zhang, K. An Advanced Scheme for Range Ambiguity Suppression of Spaceborne SAR Based on Blind Source Separation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5230112. [Google Scholar] [CrossRef]
- Qian, X.; Huo, Y.; Cheng, G.; Yao, X.; Li, K.; Ren, H.; Wang, W. Incorporating the Completeness and Difficulty of Proposals Into Weakly Supervised Object Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1902–1911. [Google Scholar] [CrossRef]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Liu, B.; Gao, Y.; Guo, N.; Ye, X.; Wan, F.; You, H.; Fan, D. Utilizing the Instability in Weakly Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Z.; Fu, Z.; Jiang, R.; Chen, Y.; Hua, X.S. SLV: Spatial Likelihood Voting for Weakly Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Feng, X.; Yao, X.; Shen, H.; Cheng, G.; Xiao, B.; Han, J. Learning an Invariant and Equivariant Network for Weakly Supervised Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11977–11992. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Tang, P.; Wang, X.; Bai, S.; Shen, W.; Bai, X.; Liu, W.; Yuille, A. PCL: Proposal Cluster Learning for Weakly Supervised Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 176–191. [Google Scholar] [CrossRef]
- Xing, P.; Huang, M.; Wang, C.; Cao, Y. High-Quality Instance Mining and Weight Re-Assigning for Weakly Supervised Object Detection in Remote Sensing Images. Electronics 2024, 13, 4753. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Chen, W.; Feng, X.; Yao, X.; Han, J. Self-Guided Proposal Generation for Weakly Supervised Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5625311. [Google Scholar] [CrossRef]
- Qian, X.; Huo, Y.; Cheng, G.; Gao, C.; Yao, X.; Wang, W. Mining High-Quality Pseudoinstance Soft Labels for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5607615. [Google Scholar] [CrossRef]
- Wang, B.; Zhao, Y.; Li, X. Multiple instance graph learning for weakly supervised remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5613112. [Google Scholar] [CrossRef]
- Hosang, J.; Benenson, R.; Schiele, B. Learning non-maximum suppression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4507–4515. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. arXiv 2021, arXiv:2004.11362. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Deselaers, T.; Alexe, B.; Ferrari, V. Weakly supervised localization and learning with generic knowledge. Int. J. Comput. Vis. 2012, 100, 275–293. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Conference Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Feng, X.; Yao, X.; Cheng, G.; Han, J.; Han, J. SAENet: Self-Supervised Adversarial and Equivariant Network for Weakly Supervised Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5610411. [Google Scholar] [CrossRef]
- Zheng, S.; Wu, Z.; Xu, Y.; Wei, Z. Weakly Supervised Object Detection for Remote Sensing Images via Progressive Image-Level and Instance-Level Feature Refinement. Remote Sens. 2024, 16, 1203. [Google Scholar] [CrossRef]
- Guo, C.; Ma, Z.; Zhao, Y.; Cao, C.; Jiang, Z.; Zhang, H. Multi-instance mining with dynamic localization for weakly supervised object detection in remote-sensing images. Int. J. Remote Sens. 2025, 46, 3487–3512. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Wan, F.; Wei, P.; Jiao, J.; Han, Z.; Ye, Q. Min-entropy latent model for weakly supervised object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1297–1306. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ConvNet | ||
|---|---|---|
| Conv2d (kernel 3, stride 1, padding 1)-64, ReLU Conv2d (kernel 3, stride 1, padding 1)-64, ReLU Max Pooling (kernel = 2. Stride 1, padding 0) | ||
| Conv2d (kernel 3, stride 1, padding 1)-128, ReLU Conv2d (kernel 3, stride 1, padding 1)-128, ReLU Max Pooling (kernel = 2. Stride 1, padding 0) | ||
| Conv2d (kernel 3, stride 1, padding 1)-256, ReLU Conv2d (kernel 3, stride 1, padding 1)-256, ReLU Conv2d (kernel 3, stride 1, padding 1)-256, ReLU Max Pooling (kernel = 2. Stride 1, padding 0) | ||
| Conv2d (kernel 3, stride 1, padding 1)-512, ReLU Conv2d (kernel 3, stride 1, padding 1)-512, ReLU Conv2d (kernel 3, stride 1, padding 1)-512, ReLU Max Pooling (kernel = 2. Stride 1, padding 0) | ||
| Conv2d (kernel 3, stride 1, padding 1)-512, ReLU Conv2d (kernel 3, stride 1, padding 1)-512, ReLU Conv2d (kernel 3, stride 1, padding 1)-512, ReLU | ||
| Region of Interest (RoI) Pooling FC-4096, ReLU, FC-4096, ReLU | ||
| WSDDN | OICR | BBR |
| FC-(number of classes), Softmax FC-(number of classes), Softmax | [FC-(number of classes + 1), Softmax] × B | [FC-((number of classes + 1) × 4)] × B |
| Baseline | FGSIM | TAF | NWPU VHR-10.v2 | |
|---|---|---|---|---|
| mAP | CorLoc | |||
| ✓ | 49.0 | 61.5 | ||
| ✓ | ✓ | 65.3 | 73.5 | |
| ✓ | ✓ | 61.7 | 72.9 | |
| ✓ | ✓ | ✓ | 72.5 | 78.6 |
| Method | Airplane | Ship | Storage Tank | Baseball Diamond | Tennis Court | Basketball Court | Ground Track Field | Harbor | Bridge | Vehicle | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN [34] | 90.9 | 90.6 | 89.3 | 47.3 | 100.0 | 85.9 | 84.9 | 88.2 | 80.3 | 69.8 | 82.7 |
| Faster R-CNN [49] | 90.9 | 86.3 | 90.5 | 98.2 | 89.7 | 69.6 | 100.0 | 80.1 | 61.5 | 78.1 | 84.5 |
| WSDDN [15] | 30.1 | 41.7 | 35.0 | 88.9 | 12.9 | 23.9 | 99.4 | 13.9 | 1.9 | 3.6 | 35.1 |
| OICR [16] | 13.7 | 67.4 | 57.2 | 55.2 | 13.6 | 39.7 | 92.8 | 0.2 | 1.8 | 3.7 | 34.5 |
| MIST [24] | 69.7 | 49.2 | 48.6 | 80.9 | 27.1 | 79.9 | 91.3 | 47.0 | 8.3 | 13.4 | 51.5 |
| DCL [9] | 72.7 | 74.3 | 37.1 | 82.6 | 36.9 | 42.3 | 84.0 | 39.6 | 16.8 | 35.0 | 52.1 |
| PCIR [18] | 90.8 | 78.8 | 36.4 | 90.8 | 22.6 | 52.2 | 88.5 | 42.4 | 11.7 | 35.5 | 55.0 |
| MIG [39] | 88.7 | 71.6 | 75.2 | 94.2 | 37.5 | 47.7 | 100.0 | 27.3 | 8.3 | 9.1 | 56.0 |
| TCA [19] | 89.4 | 78.2 | 78.4 | 90.8 | 35.3 | 50.4 | 90.9 | 42.4 | 4.1 | 28.3 | 58.8 |
| CDN [22] | 82.9 | 79.0 | 46.1 | 90.9 | 35.8 | 77.6 | 100.0 | 45.4 | 2.2 | 21.3 | 58.1 |
| SAE [50] | 82.9 | 74.5 | 50.2 | 96.7 | 55.7 | 72.9 | 100.0 | 36.5 | 6.3 | 31.9 | 60.7 |
| SPG [37] | 90.4 | 81.0 | 59.5 | 92.3 | 35.6 | 51.4 | 99.9 | 58.7 | 17.0 | 43.0 | 62.8 |
| PILM [38] | 87.6 | 81.0 | 57.3 | 94.0 | 36.4 | 80.4 | 100.0 | 56.9 | 9.8 | 35.6 | 63.8 |
| SGPM [23] | 90.7 | 79.9 | 69.3 | 97.5 | 41.6 | 77.5 | 100.0 | 44.4 | 17.2 | 33.5 | 65.2 |
| HQIM [36] | 90.8 | 80.5 | 73.4 | 96.6 | 47.4 | 78.9 | 100.0 | 43.9 | 18.4 | 33.5 | 66.2 |
| ILFR [51] | 90.8 | 81.6 | 56.6 | 91.7 | 51.9 | 69.5 | 100.0 | 53.4 | 16.3 | 40.5 | 65.2 |
| MIDL [52] | 90.1 | 65.3 | 67.4 | 90.9 | 50.2 | 62.8 | 99.8 | 33.2 | 16.7 | 42.3 | 61.9 |
| Ours | 90.8 | 81.4 | 72.9 | 94.7 | 56.4 | 81.8 | 100.0 | 68.7 | 15.3 | 62.7 | 72.5 |
| Method | Airplane | Ship | Storage Tank | Baseball Diamond | Tennis Court | Basketball Court | Ground Track Field | Harbor | Bridge | Vehicle | CorLoc |
|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN [15] | 22.3 | 36.8 | 40.0 | 92.5 | 18.0 | 24.2 | 99.3 | 14.8 | 1.7 | 2.9 | 35.2 |
| OICR [16] | 29.4 | 83.3 | 20.5 | 81.8 | 40.9 | 32.1 | 86.6 | 7.4 | 3.7 | 14.4 | 40.0 |
| MIST [24] | 90.2 | 82.5 | 80.3 | 98.6 | 48.5 | 87.4 | 98.3 | 66.5 | 14.6 | 35.8 | 70.3 |
| DCL [9] | - | - | - | - | - | - | - | - | - | - | 69.7 |
| PCIR [18] | 100.0 | 93.1 | 64.1 | 99.3 | 64.8 | 79.3 | 89.7 | 63.0 | 13.3 | 52.2 | 71.9 |
| MIG [39] | 97.8 | 90.3 | 87.2 | 98.7 | 54.9 | 64.2 | 100.0 | 74.1 | 13.0 | 21.6 | 70.2 |
| TCA [19] | 96.9 | 91.8 | 95.1 | 88.7 | 66.9 | 62.8 | 96.0 | 54.2 | 19.6 | 55.5 | 72.8 |
| CDN [22] | 96.5 | 81.3 | 67.1 | 95.3 | 66.9 | 86.3 | 100.0 | 74.2 | 10.3 | 46.5 | 72.4 |
| SAE [50] | 97.1 | 91.7 | 87.8 | 98.7 | 40.9 | 81.1 | 100.0 | 70.4 | 14.8 | 52.2 | 73.5 |
| SPG [37] | 98.1 | 92.7 | 70.1 | 99.7 | 51.9 | 80.1 | 96.2 | 72.4 | 13.0 | 60.0 | 73.4 |
| PILM [38] | 94.4 | 86.6 | 68.5 | 97.8 | 69.8 | 87.5 | 100.0 | 68.6 | 16.0 | 56.6 | 74.3 |
| SGPM [23] | 98.2 | 93.8 | 89.3 | 99.1 | 50.2 | 88.9 | 100.0 | 71.0 | 12.3 | 51.2 | 75.4 |
| HQIM [36] | 99.3 | 94.8 | 91.7 | 98.0 | 58.4 | 91.7 | 100.0 | 68.8 | 13.6 | 56.7 | 76.9 |
| ILFR [51] | 98.6 | 94.7 | 76.4 | 83.9 | 61.3 | 82.4 | 100.0 | 78.1 | 19.5 | 57.2 | 75.2 |
| Ours | 92.1 | 92.9 | 87.2 | 94.1 | 68.4 | 90.7 | 100.0 | 78.9 | 18.9 | 62.7 | 78.6 |
| Method | Airplane | Airport | Baseball Field | Basketball Court | Bridge | Chimney | Dam | Expressway Service Area | Expressway Toll Station | Golf Field | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN [34] | 44.2 | 66.8 | 67.0 | 60.5 | 15.6 | 72.3 | 52.0 | 65.9 | 44.8 | 72.1 | |
| Faster R-CNN [49] | 50.3 | 62.6 | 66.0 | 80.9 | 28.8 | 68.2 | 47.3 | 58.5 | 48.1 | 60.4 | |
| WSDDN [15] | 9.1 | 39.7 | 37.8 | 20.2 | 0.3 | 12.3 | 0.6 | 0.7 | 11.9 | 4.9 | |
| OICR [16] | 8.7 | 28.3 | 44.1 | 18.2 | 1.3 | 20.2 | 0.1 | 0.7 | 29.9 | 13.8 | |
| MIST [24] | 32.0 | 39.9 | 62.7 | 29.0 | 7.5 | 12.9 | 0.3 | 5.1 | 17.4 | 51.0 | |
| DCL [9] | 20.9 | 22.7 | 54.2 | 11.5 | 6.0 | 61.0 | 0.1 | 1.1 | 31.0 | 30.9 | |
| PCIR [18] | 30.4 | 36.1 | 54.2 | 26.6 | 9.1 | 58.6 | 0.2 | 9.7 | 36.2 | 32.6 | |
| MIG [39] | 22.2 | 52.6 | 62.8 | 25.8 | 8.5 | 67.4 | 0.7 | 8.9 | 28.7 | 57.3 | |
| TCA [19] | 25.1 | 30.8 | 62.9 | 40.0 | 4.1 | 67.8 | 8.1 | 23.8 | 29.9 | 22.3 | |
| CND [22] | 31.1 | 15.8 | 10.7 | 54.5 | 15.7 | 33.9 | 3.7 | 12.3 | 37.2 | 12.0 | |
| SAE [50] | 20.6 | 62.4 | 62.7 | 23.5 | 7.6 | 64.6 | 0.2 | 34.5 | 30.6 | 55.4 | |
| SPG [37] | 31.3 | 36.7 | 62.8 | 29.1 | 6.1 | 62.7 | 0.3 | 15.0 | 30.1 | 35.0 | |
| PILM [38] | 29.1 | 49.8 | 70.9 | 41.4 | 7.2 | 45.5 | 0.2 | 35.4 | 36.8 | 60.8 | |
| SGLM [23] | 39.1 | 64.6 | 64.4 | 26.9 | 6.3 | 62.3 | 0.9 | 12.2 | 26.3 | 55.3 | |
| HQIM [36] | 42.2 | 65.0 | 66.2 | 25.7 | 6.7 | 60.2 | 1.3 | 13.5 | 25.3 | 57.8 | |
| ILFR [51] | 32.9 | 70.5 | 63.2 | 45.7 | 0.2 | 69.7 | 0.2 | 12.4 | 39.4 | 56.4 | |
| MIDL [52] | 38.1 | 12.3 | 62.9 | 27.4 | 10.7 | 62.0 | 0.1 | 0.6 | 32.2 | 49.4 | |
| Ours | 37.5 | 62.7 | 60.9 | 30.2 | 9.2 | 63.4 | 1.9 | 16.8 | 37.6 | 54.7 | |
| Method | Ground track field | Harbor | Overpass | Ship | Stadium | Storage tank | Tennis court | Train station | Vehicle | Windmill | mAP |
| Fast R-CNN [34] | 62.9 | 46.2 | 38.0 | 32.1 | 71.0 | 35.0 | 58.3 | 37.9 | 19.2 | 38.1 | 50.0 |
| Faster R-CNN [34] | 67.0 | 43.9 | 46.9 | 58.5 | 52.4 | 42.4 | 79.5 | 48.0 | 34.8 | 65.4 | 55.5 |
| WSDDN [15] | 42.5 | 4.7 | 1.1 | 0.7 | 63.0 | 4.0 | 6.1 | 0.5 | 4.6 | 1.1 | 13.3 |
| OICR [16] | 57.4 | 10.7 | 11.1 | 9.1 | 59.3 | 7.1 | 0.7 | 0.1 | 9.1 | 0.4 | 16.5 |
| MIST [24] | 49.5 | 5.4 | 12.2 | 29.4 | 35.5 | 25.4 | 0.8 | 4.6 | 22.2 | 0.8 | 22.2 |
| DCL [9] | 56.5 | 5.1 | 2.7 | 9.1 | 63.7 | 9.1 | 10.4 | 0.0 | 7.3 | 0.8 | 20.2 |
| PCIR [18] | 58.5 | 8.6 | 21.6 | 12.1 | 64.3 | 9.1 | 13.6 | 0.3 | 9.1 | 7.5 | 24.9 |
| MIG [39] | 47.7 | 23.8 | 0.8 | 6.4 | 54.1 | 13.2 | 4.1 | 14.8 | 0.2 | 2.4 | 25.1 |
| TCA [19] | 53.9 | 24.8 | 11.1 | 9.1 | 46.4 | 13.7 | 31.0 | 1.5 | 9.1 | 1.0 | 25.8 |
| CDN [22] | 44.2 | 60.9 | 0.7 | 12.3 | 37.2 | 37.5 | 19.2 | 52.6 | 1.1 | 2.9 | 26.7 |
| SAE [50] | 52.7 | 17.6 | 6.9 | 9.1 | 51.6 | 15.4 | 1.7 | 14.4 | 1.4 | 9.2 | 27.1 |
| SPG [37] | 48.0 | 27.1 | 12.0 | 10.0 | 60.0 | 15.1 | 21.0 | 9.9 | 3.2 | 0.1 | 25.8 |
| PILM [38] | 48.5 | 14.0 | 25.1 | 18.5 | 48.9 | 11.7 | 11.9 | 3.5 | 11.3 | 1.7 | 28.6 |
| SGLM [23] | 60.6 | 9.4 | 23.1 | 13.4 | 57.4 | 17.7 | 1.5 | 14.0 | 11.5 | 3.5 | 28.5 |
| HQIM [36] | 61.4 | 10.4 | 20.4 | 14.1 | 58.6 | 18.9 | 2.2 | 13.6 | 10.0 | 4.7 | 28.9 |
| ILFR [51] | 55.3 | 16.6 | 0.6 | 9.1 | 54.8 | 18.1 | 11.0 | 16.1 | 9.1 | 1.1 | 29.1 |
| MIDL [52] | 64.7 | 7.4 | 29.0 | 9.1 | 53.8 | 11.3 | 57.0 | 7.7 | 1.6 | 0.5 | 27.3 |
| Our | 57.9 | 23.7 | 24.9 | 17.2 | 55.9 | 11.3 | 12.1 | 14.9 | 12.8 | 3.6 | 30.5 |
| Method | Airplane | Airport | Baseball Field | Basketball Court | Bridge | Chimney | Dam | Expressway Service Area | Expressway Toll Station | Golf Field | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN [15] | 5.7 | 59.9 | 94.2 | 55.9 | 4.9 | 23.4 | 1.0 | 6.8 | 44.5 | 12.8 | |
| OICR [16] | 16.0 | 51.5 | 94.8 | 55.8 | 3.6 | 23.9 | 0.0 | 4.8 | 56.7 | 22.4 | |
| MIST [24] | 91.6 | 53.2 | 93.5 | 66.3 | 10.8 | 30.7 | 1.5 | 14.3 | 35.2 | 47.5 | |
| DCL [9] | - | - | - | - | - | - | - | - | - | - | |
| PCIR [18] | 93.1 | 45.6 | 95.5 | 68.3 | 3.6 | 92.1 | 0.2 | 5.4 | 58.4 | 47.5 | |
| MIG [39] | 77.0 | 46.9 | 95.4 | 63.6 | 23.0 | 95.1 | 0.2 | 17.0 | 57.9 | 50.8 | |
| TCA [19] | 81.6 | 51.3 | 96.2 | 73.5 | 5.0 | 94.7 | 15.9 | 32.8 | 46.0 | 48.6 | |
| CDN [22] | 85.6 | 58.7 | 95.6 | 95.6 | 10.5 | 96.2 | 0.5 | 17.6 | 60.7 | 45.9 | |
| SAE [50] | 91.2 | 69.4 | 95.5 | 67.5 | 18.9 | 97.8 | 0.2 | 70.5 | 54.3 | 51.4 | |
| SPG [37] | 80.5 | 32.0 | 98.7 | 65.0 | 15.2 | 96.1 | 22.5 | 17.0 | 46.1 | 51.0 | |
| PILM [38] | 85.5 | 68.9 | 96.8 | 75.8 | 11.6 | 94.7 | 0.8 | 67.5 | 60.5 | 46.5 | |
| SGLM [23] | 92.2 | 58.3 | 97.8 | 74.2 | 16.2 | 95.2 | 0.3 | 51.3 | 56.2 | 52.3 | |
| HQIM [36] | 94.1 | 59.3 | 98.1 | 70.5 | 17.6 | 94.6 | 4.8 | 52.2 | 54.3 | 53.5 | |
| ILFR [51] | 88.3 | 69.1 | 98.8 | 69.4 | 19.9 | 97.8 | 0.3 | 24.7 | 56.2 | 54.4 | |
| Ours | 91.9 | 70.4 | 98.5 | 71.6 | 18.2 | 92.4 | 1.9 | 67.6 | 59.4 | 59.7 | |
| Method | Ground track field | Harbor | Overpass | Ship | Stadium | Storage tank | Tennis court | Train station | Vehicle | Windmill | CorLoc |
| WSDDN [15] | 89.9 | 5.5 | 10.0 | 23.0 | 98.5 | 79.6 | 15.1 | 3.5 | 11.6 | 3.2 | 32.4 |
| OICR [16] | 91.4 | 18.2 | 18.7 | 31.8 | 98.3 | 81.3 | 7.5 | 1.2 | 15.8 | 2.0 | 34.8 |
| MIST [24] | 87.1 | 38.6 | 23.4 | 50.7 | 80.5 | 89.2 | 22.4 | 11.5 | 22.2 | 2.4 | 43.6 |
| DCL [9] | - | - | - | - | - | - | - | - | - | - | 42.2 |
| PCIR [18] | 88.6 | 15.8 | 5.2 | 39.5 | 98.1 | 85.6 | 13.4 | 56.5 | 9.7 | 0.6 | 46.1 |
| MIG [39] | 89.4 | 42.1 | 19.8 | 37.9 | 97.9 | 80.7 | 13.8 | 10.3 | 10.5 | 6.9 | 46.8 |
| TCA [19] | 85.3 | 38.9 | 20.2 | 30.6 | 84.6 | 91.5 | 56.3 | 3.8 | 10.5 | 1.3 | 48.4 |
| CDN [22] | 90.6 | 51.5 | 17.4 | 45.7 | 89.7 | 72.0 | 11.3 | 10.6 | 17.9 | 6.5 | 47.9 |
| SAE [50] | 88.3 | 48.0 | 2.3 | 33.6 | 14.1 | 83.4 | 65.6 | 19.9 | 16.4 | 2.9 | 49.4 |
| SPG [37] | 89.2 | 49.5 | 22.0 | 35.2 | 98.6 | 90.0 | 32.6 | 12.7 | 10.0 | 2.3 | 48.3 |
| PILM [38] | 75.2 | 50.5 | 28.3 | 39.7 | 92.6 | 77.0 | 55.1 | 10.1 | 20.9 | 5.6 | 53.2 |
| SGLM [23] | 91.7 | 48.6 | 23.0 | 32.7 | 98.8 | 89.3 | 43.5 | 19.5 | 18.3 | 4.0 | 53.2 |
| HQIM [36] | 93.0 | 49.7 | 22.0 | 34.8 | 99.0 | 90.4 | 44.1 | 18.3 | 17.5 | 10.5 | 53.9 |
| ILFR [51] | 89.6 | 49.1 | 19.4 | 34.5 | 96.7 | 84.7 | 63.2 | 15.6 | 11.6 | 3.4 | 52.3 |
| Ours | 91.1 | 52.1 | 23.7 | 44.7 | 98.7 | 86.9 | 45.2 | 20.9 | 18.7 | 8.7 | 56.1 |
| Method | Aeroplane | Bicycle | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fast R-CNN [34] | 74.5 | 78.3 | 69.2 | 53.2 | 36.6 | 77.3 | 78.2 | 82.0 | 40.7 | 72.7 | |
| Faster R-CNN [49] | 70.0 | 80.6 | 70.1 | 57.3 | 49.9 | 78.2 | 80.4 | 82.0 | 52.2 | 75.3 | |
| WSDDN [15] | 39.4 | 50.1 | 31.5 | 16.3 | 12.6 | 64.5 | 42.8 | 42.6 | 10.1 | 35.7 | |
| OICR [16] | 58.0 | 62.4 | 31.1 | 19.4 | 13.0 | 65.1 | 62.2 | 28.4 | 24.8 | 44.7 | |
| PCL [35] | 54.4 | 69.0 | 39.3 | 19.2 | 15.7 | 62.9 | 64.4 | 30.0 | 25.1 | 52.5 | |
| MELM [54] | 55.6 | 66.9 | 34.2 | 29.1 | 16.4 | 68.8 | 68.1 | 43.0 | 25.0 | 65.6 | |
| Ours | 69.7 | 70.1 | 54.6 | 39.5 | 33.6 | 70.2 | 78.7 | 72.1 | 34.1 | 70.5 | |
| Method | Diningtable | Dog | Horse | Motorbike | Person | Pottedplant | Sheep | Sofa | Train | Tvmonitor | mAP |
| Fast R-CNN [34] | 67.9 | 79.6 | 79.2 | 73.0 | 69.0 | 30.1 | 65.4 | 70.2 | 75.8 | 65.8 | 66.9 |
| Faster R-CNN [49] | 67.2 | 80.3 | 79.8 | 75.0 | 76.3 | 39.1 | 68.3 | 67.3 | 81.1 | 67.6 | 69.9 |
| WSDDN [15] | 24.9 | 38.2 | 34.4 | 55.6 | 9.4 | 14.7 | 30.2 | 40.7 | 54.7 | 46.9 | 34.8 |
| OICR [16] | 30.6 | 25.3 | 37.8 | 65.5 | 15.7 | 24.1 | 41.7 | 46.9 | 64.3 | 62.6 | 41.2 |
| PCL [35] | 44.4 | 19.6 | 39.3 | 67.7 | 17.8 | 22.9 | 46.6 | 57.5 | 58.6 | 63.0 | 43.5 |
| MELM [54] | 45.3 | 53.2 | 49.6 | 68.6 | 2.0 | 25.4 | 52.5 | 56.8 | 62.1 | 57.1 | 47.3 |
| Ours | 45.9 | 64.5 | 63.1 | 75.7 | 31.8 | 27.9 | 59.2 | 61.5 | 69.8 | 68.9 | 58.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, J.; Wang, C.; Tan, X.; Zhang, M.; Wang, H. Feature-Guided Instance Mining and Task-Aligned Focal Loss for Weakly Supervised Object Detection in Remote Sensing Images. Remote Sens. 2025, 17, 1673. https://doi.org/10.3390/rs17101673
Tan J, Wang C, Tan X, Zhang M, Wang H. Feature-Guided Instance Mining and Task-Aligned Focal Loss for Weakly Supervised Object Detection in Remote Sensing Images. Remote Sensing. 2025; 17(10):1673. https://doi.org/10.3390/rs17101673
Chicago/Turabian StyleTan, Jinlin, Chenhao Wang, Xiaomin Tan, Min Zhang, and Hai Wang. 2025. "Feature-Guided Instance Mining and Task-Aligned Focal Loss for Weakly Supervised Object Detection in Remote Sensing Images" Remote Sensing 17, no. 10: 1673. https://doi.org/10.3390/rs17101673
APA StyleTan, J., Wang, C., Tan, X., Zhang, M., & Wang, H. (2025). Feature-Guided Instance Mining and Task-Aligned Focal Loss for Weakly Supervised Object Detection in Remote Sensing Images. Remote Sensing, 17(10), 1673. https://doi.org/10.3390/rs17101673