1. Introduction
As the rapid expansion of urban areas continues worldwide, timely and accurate mapping of land cover dynamics provides vital information for sustainable development and management [
1,
2,
3]. Compared to traditional ground-based surveys, remote sensing enables efficient large-area coverage at flexible repeated intervals [
4]. In recent years, the number of remote sensing satellites has surged dramatically, providing massive geographic imagery for almost every corner of the Earth’s surface [
5,
6]. In extracting urban land cover information from remote sensing data, researchers often consider spatial resolution more important than spectral resolution [
7,
8]. This is because spatial resolution can reflect the shape and texture features of objects, for example, roads and buildings have similar spectral features but different shape and texture features [
9,
10,
11], which can be used to distinguish these two types of objects. However, compared to the mixed effects of medium-low spatial resolution sensors, the increased within-scene spectral variability of high spatial resolution sensors may reduce the pixel-based classification accuracy of conventional approaches [
12].
To address this challenge, object-based image analysis (OBIA) techniques emerged as a promising alternative in a timely manner [
13]. OBIA first utilizes the multiscale characteristics of different geo-objects in high-resolution imagery to segment an image into a series of adjacent homogeneous regions (i.e., segments) of pixel sets, then fully exploits spectral, textural, shape, semantic, and other features, mining the spatial dimensions (distance, pattern, neighborhood, and topology) of segments to further aggregate them into objects to ensure classification accuracy [
14]. In this process, the most basic processing unit is the segment rather than the pixel, thus avoiding the “salt-and-pepper” phenomenon of pixel-based methods. OBIA has gained rapid recognition in the remote sensing field, marked by a focus on object semantics explored through fixed or emerging ontologies, as well as the need for interoperability between OBIA approaches and geographic information systems (GIS) along with spatial modeling frameworks [
15,
16,
17]. The above advantages have made the OBIA method gradually evolve into a new paradigm for high-resolution remote sensing and spatial analysis [
13]. Traditional machine learning classification models based on object-based methods usually take the statistical summary of all pixels in a segment as input. However, with the increase in image resolution, the spectral heterogeneity within objects and the homogeneity between objects are both increasing, which makes such summarization inevitably carry noise, thus eventually leading to misclassification [
18,
19]. To overcome this problem, it is necessary to introduce additional morphological and textural information of segments into the classification process [
20,
21]. However, these feature engineering methods typically rely on prior human knowledge, which often introduces subjectivity into the process [
22].
In recent years, deep learning technology has made breakthrough progress in the field of computer vision [
23]. In particular, convolutional neural networks (CNNs) can automatically extract high-level features from image patches through a series of convolutional and pooling layers and have demonstrated excellent representation and classification capabilities for object shape, texture, and context information [
24,
25]. These methods thus avoid the tedious and time-consuming hand-crafted feature engineering required in traditional remote sensing image analysis methods [
26]. Therefore, it is necessary to combine object-based image analysis with deep learning methods to take advantage of each. Initially, CNNs were applied to remote sensing image scene classification, where rectangular patches cropped from images were fed into the CNNs, which then output an image-level label [
27,
28,
29]. In full-resolution remote sensing mapping, however, densely overlapping patches are used pixel by pixel, which inevitably leads to extremely redundant computation [
30]. To address this issue, CNNs with objects as the basic processing units can better preserve the boundaries of geographical entities, reduce computational cost, and improve processing efficiency [
30]. However, in remote sensing images, the distribution range of the central target area to be classified may be relatively small while background information occupies larger areas. Therefore, classification is inevitably affected by heterogeneous content, which leads to the wrong classification of regions of interest into background categories [
28]. Currently, the common strategy is to use an ensemble of models with different input scales to suppress heterogeneity and enhance feature representation capability for the central region. However, these methods require comprehensive consideration of inter-model scale combinations, parameter relations, and sample distributions [
31,
32,
33,
34], and it is thus relatively complex to apply them in practice.
Fully convolutional networks (FCNs) can achieve dense pixel-level prediction and are not affected by the content heterogeneity of image patches [
35]. Therefore, FCNs and their extensions have been gradually introduced into remote sensing semantic segmentation [
30,
34]. The main difference between CNNs and fully convolutional networks (FCNs) is that FCNs replace the fully connected layers in CNNs with convolutional layers [
35]. This enables FCNs to take images of arbitrary sizes as input and generate correspondingly sized output segmentation maps, thereby achieving dense pixel-level prediction. Representative FCN models include SegNet [
36], U-Net [
37], Deeplab series [
38,
39,
40], PSPNet [
41], DenseASPP [
42], DANet [
43], OCNet [
44], and, more recently, UNet++ [
45] and Auto-DeepLab [
46]. These FCNs are commonly pre-trained on large-scale natural image datasets like ImageNet, then finetuned on remote sensing images to mitigate overfitting caused by limited labeled training samples [
47,
48]. Multiscale feature integration through pyramid pooling modules [
41] or encoder–decoder structures [
37] helps FCNs capture both local details and global context. Conditional random fields (CRFs) can further refine object boundaries as a post-processing step [
39]. Atrous/dilated convolutions maintain large receptive fields without losing resolution [
38]. Attention mechanisms focus models on informative regions and reduce confusion due to irrelevant features [
49]. However, several issues remain to be addressed for remote sensing FCN segmentation, such as large intra-class variance, small inter-class differences, and the lack of sufficient annotated samples.
FCNs can achieve high classification accuracy owing to abundant labeled samples and powerful computational capabilities. However, in some practical applications, it is difficult to obtain large amounts of labeled data samples. To address this issue, transfer learning provides an effective solution. The idea of transfer learning is to use publicly available pre-trained neural networks containing massive generic data as a basis, then fine-tune them on a small amount of data samples from a specific domain to alleviate overfitting caused by limited labeled training samples, thereby obtaining a well-performing neural network model [
50,
51]. However, most of the above methods were tested on RGB public datasets [
50,
51]. There are fewer specific applications on multispectral remote sensing images, which differ from natural images in terms of indistinct target boundaries, large variances in similar target sizes, small inter-class differences, large intra-class differences, and distribution differences between source domain datasets and target domain datasets. These differences make it difficult to directly transfer models pre-trained on natural images to remote sensing image segmentation tasks [
52]. In addition, when there are more categories in the test dataset to be segmented than in the training dataset, transfer learning methods cannot achieve good segmentation accuracy [
53].
Compared to relying on pre-trained models, models trained from scratch can better adapt to multiband target datasets. Semi-supervised learning, by reducing annotation costs, has become an effective implementation of this training paradigm. It complements a small labeled dataset with a large number of unlabeled images to improve model generalization. The main categories of semi-supervised learning include self-training, consistency regularization, generative models, graph-based methods, and, more recently, adversarial training [
54,
55,
56,
57]. Self-training is one of the earliest and most widely used semi-supervised learning strategies due to its simplicity [
58]. It first trains a model on limited labeled data, then uses the model to generate pseudo-labels for unlabeled images. The unlabeled images with pseudo-labels are combined with the labeled set to retrain the model. Increasing the amount of data can prevent overfitting caused by limited data samples. Consistency regularization enforces consistent model predictions when unlabeled data are perturbed through noise injection, image flipping, cropping, etc. [
59].
These semi-supervised techniques have been integrated with deep convolutional neural networks and applied to remote sensing image segmentation tasks. For example, Staeger et al. proposed a self-training method by predicting pseudo-labels from an FCN ensemble [
60]. French et al. applied strong data augmentation as consistency regularization for iterative self-training [
59]. Souly et al. used GANs to generate additional labeled data from unlabeled images [
57]. Recent works have incorporated spatial–contextual information in graph structures as well [
61,
62]. More recent semi-supervised segmentation methods also include co-training, where two models provide complementary supervision for each other [
63]. Curriculum learning gradually incorporates unlabeled data from easy to hard based on prediction confidence [
64]. Hybrid methods combine self-training, consistency regularization, and adversarial training for improved performance [
65]. Despite promising results on benchmarks like ISPRS Potsdam and Vaihingen, several issues remain to be addressed [
66]. Some methods have attempted semantic segmentation of remote sensing images, but most are based on binary semantic segmentation with few categories and large inter-class differences [
26]. Meanwhile, they experience problems of complex training, large computational demands, and high memory usage, and false pseudo-labeling can easily mislead self-training. Despite its potential, limited research has been done on few-shot semi-supervised learning, which remains an active area of research for reducing annotation efforts in remote sensing image segmentation.
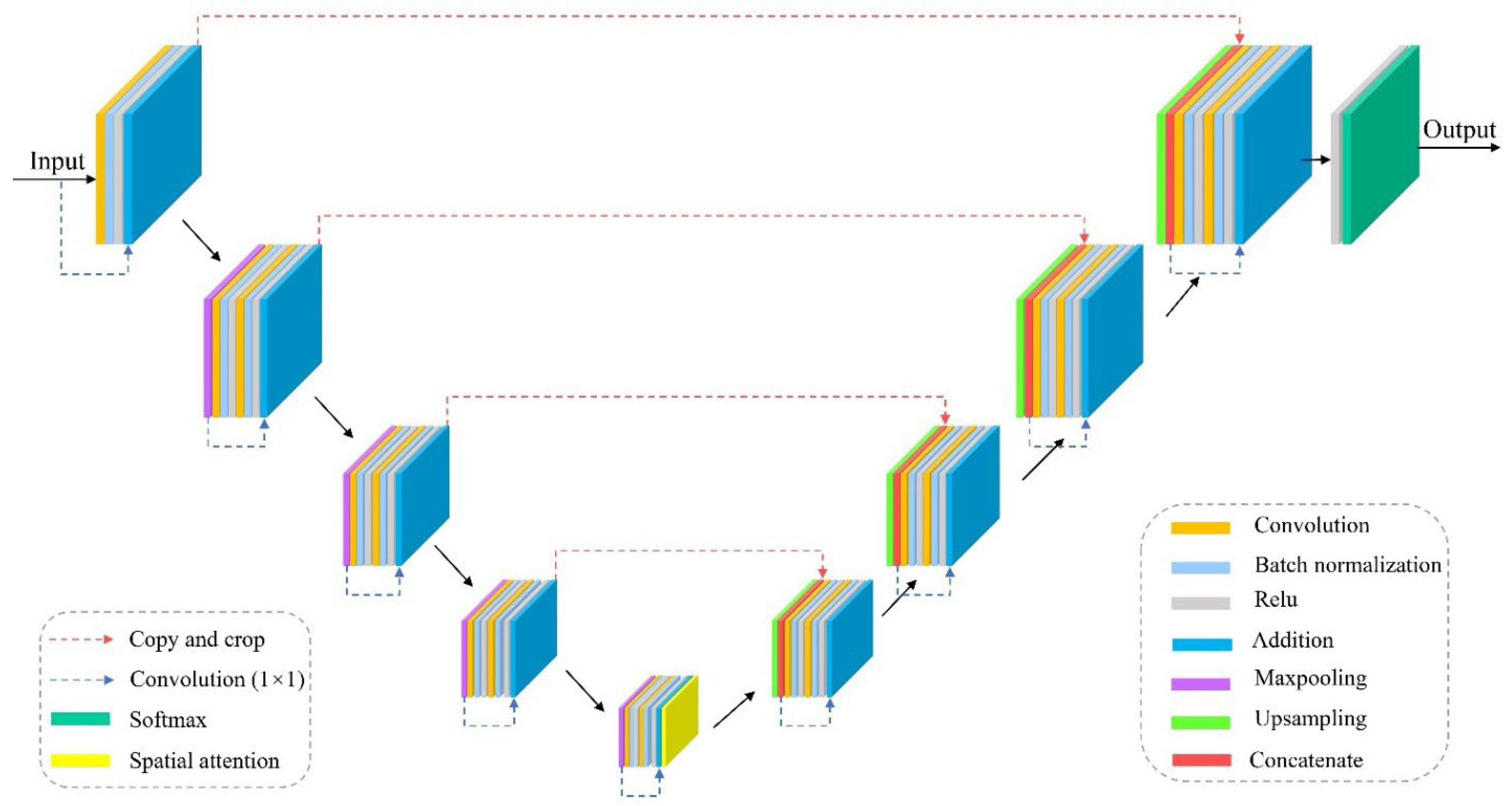
To provide a single-model approach that can work with limited samples, this paper proposes a from-scratch-trained, object-based, semi-supervised spatial attention residual UNet (OS-ARU) for urban land cover classification of multiband high-resolution remote sensing imagery. First, segments obtained via multiscale segmentation serve as a bridge to assign known sample point categories to the segments they fall in to train the model. Then, the similarity between segments of known and unknown categories is compared based on the mean probability distribution over classes from model predictions, and unknown segments obtain pseudo-labels via label propagation. Finally, the model is retrained on the original sample set augmented with pseudo-annotation information. With such an algorithm, OS-ARU can be trained using sample sets based on sparse pixels. Therefore, it is not adversely affected by image content heterogeneity, thus simplifying its implementation and usage as a single model. Ablation experiments further demonstrate that the spatial attention and residual components bring complementary gains individually, with only slight performance drops when removed separately. Experimental results show that OS-ARU achieves the highest overall classification metrics compared to other benchmark methods and is not very sensitive to input scales. In summary, the contributions of our work are as follows:
- (1)
A selective categorical focal loss function with label smoothing adapted for FCNs trained on incompletely annotated sample sets.
- (2)
Object-based classification executed with a single FCN model, OS-ARU, without relying on other models to suppress heterogeneity.
- (3)
A procedure of training FCNs using sparse pixel sample points and generating pseudo-labels, then retraining the model on the sample set augmented with pseudo-category information.
4. Discussion
In land cover classification of high-resolution remote sensing imagery in urban areas, several key challenges exist. Firstly, high intra-class heterogeneity and inter-class homogeneity are present due to the high resolution [
94]. Secondly, highly imbalanced distributions of classes can bias classifiers towards majority categories [
95]. Thirdly, pixel-based spectrum classification often results in salt-and-pepper noise. Lastly, high-quality manual annotation samples are relatively scarce, with the annotation process being time-consuming and expensive [
96]. The combined effects of these issues have made semantic segmentation of high-resolution remote sensing imagery an active research focus and persistent challenge. Therefore, a two-iteration OS-ARU method is proposed for urban land cover classification using high-resolution remote sensing images. It optimizes the model training process of forward and backward propagation by utilizing the selective categorical focal loss function with label smoothing. Selective parameters are introduced to handle labeled and unlabeled data, while the label-smoothed focal loss function can effectively reduce the weights of easy samples and increase the model’s attention to hard samples.
The OS-ARU method has the following four differences from previous research works [
28,
30]: (1) on the basis of the UNet framework, residual modules and spatial attention modules are incorporated to more comprehensively and sufficiently extract features from a sparse training sample set through two iterations of training; (2) it trains the semi-supervised model from scratch instead of fine-tuning a pre-trained model, thus avoiding transfer issues caused by domain differences in pre-trained models, and is not limited by the input bands of pre-trained models, which facilitates further analysis, diagnosis, and improvement of the model; (3) a selective categorical focal loss function with label smoothing can improve model classification accuracy for imbalanced datasets compared to the cross entropy loss function; (4) it calculates the similarity of an unknown category segment to segments of known categories, rather than just the central segment of a known category in the patch, to generate pseudo-labels through label propagation.
The proposed OS-ARU overcomes the common challenge of inconsistency between the regular patch inputs of CNNs and the irregular shapes of object segments obtained by segmentation methods. Traditional CNN approaches employ additional models to mitigate the negative effects of this heterogeneity, resulting in increased complexity and potential instability. Our proposed OS-ARU generates per-pixel class labels, obviating the need for explicit heterogeneity suppression and effectively isolating different content types. Through the pseudo-label propagation algorithm, the category information of the training samples is augmented, and the accuracy of the model trained with both true and pseudo-labels greatly improves during the second iteration of training. This highlights the efficacy of making reasonable assumptions about unlabeled segments to regularize the learning process. The residual connections alleviate gradient vanishing issues, facilitating convergence of deep neural networks to mine representative features [
69,
70]. Meanwhile, the spatial attention mechanism further strengthens classification capability by guiding the network to focus on discriminative object regions. This prevents distraction due to irrelevant background information. Moreover, one important thing that should be discussed is why the residual module plays a more significant role than the spatial attention module in enhancing the OS-ARU’s performance. This can be attributed to the potential noise introduced by the pseudo-labeled samples, which may have different impacts on the attention module and the residual module. Since the training set includes both true and pseudo-labeled samples, focusing attention on certain areas may inadvertently amplify incorrect category information from the pseudo-labels, leading the model to learn noisy representations. In contrast, the residual module aids in propagating and preserving information across layers, mitigating the impact of noisy pseudo-labels on the learned features. Additionally, the optimal scale of the OS-ARU method is larger than that of CNNs, and the model performance is insensitive to scale variations near the optimum. Although operating on local patches, the large receptive field provided by the deep network layers can sufficiently capture global object structure. By extracting features encompassing entire segments, the OS-ARU can make accurate predictions even for fragmented inputs.
The semi-supervised classification results are within 2% difference from those of the fully supervised approach, despite utilizing only a fraction of labeled samples. In scenarios where annotation is difficult to obtain or limited labeled data are available, semi-supervised methods present a viable alternative to supervised learning. While supervised classification generally produces better outcomes with abundant training data, the comparable semi-supervised performance of the proposed method with scarce labels highlights its potential. By leveraging unlabeled data through reasonable assumptions, semi-supervised learning strikes a balance between labeling effort and model accuracy. Deep learning exhibits a certain degree of fault tolerance when trained with pseudo-labels containing errors in semi-supervised learning. This is attributable to several aspects. Firstly, deep learning models have sufficient model capacity to absorb a moderate amount of label noise. Secondly, by learning feature representations from a large number of parameters, deep learning models can offset the adverse effects of erroneous labels by capturing valid features from correct labels. Finally, a small proportion of incorrect labels can act as a means of regularization to prevent overfitting, thereby improving generalization to unseen data. While inadequate label errors do not completely invalidate deep learning models, this demonstrates their tolerance for imperfectly accurate or ambiguous sample labels, enabling applications with such characteristics. Nevertheless, the ratio of label errors must be controlled, as excessive errors can disrupt model training.
While the proposed OS-ARU achieves promising performance for remote sensing image classification with sparse labeling, it still exhibits confusion, to a certain degree, between classes with high internal variability, such as trees and cars. Some limitations exist. The reliance on multiscale segmentation can propagate errors to pseudo-labels if the segmentation quality is low for certain complex classes. The simple feature similarity heuristic for pseudo-label generation could also be enhanced. In addition, tuning classification thresholding requires more robust validation. To address these issues, future work may explore incorporating more advanced segmentation techniques, optimizing pseudo-label generation with consistency regularization, and adopting adaptive thresholding approaches. There is also room to enhance the computational efficiency and reduce the training time. Overall, by improving segmentation, pseudo-labeling, and thresholding components, the framework can further boost classification accuracy and robustness.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}