
A Multi-Hyperspectral Image Collaborative Mapping Model Based on Adaptive Learning for Fine Classification

Abstract
1. Introduction
- An adaptive learning-based mapping model is proposed for precise reconstruction and fine classification of HSIs. We innovatively design an adaptive learning module and a self-attention block and felicitously combine them with the image fusion and spectral resolution module, with the aim of enhancing model generalization capabilities and significantly achieving high quality and reconstruction precision.
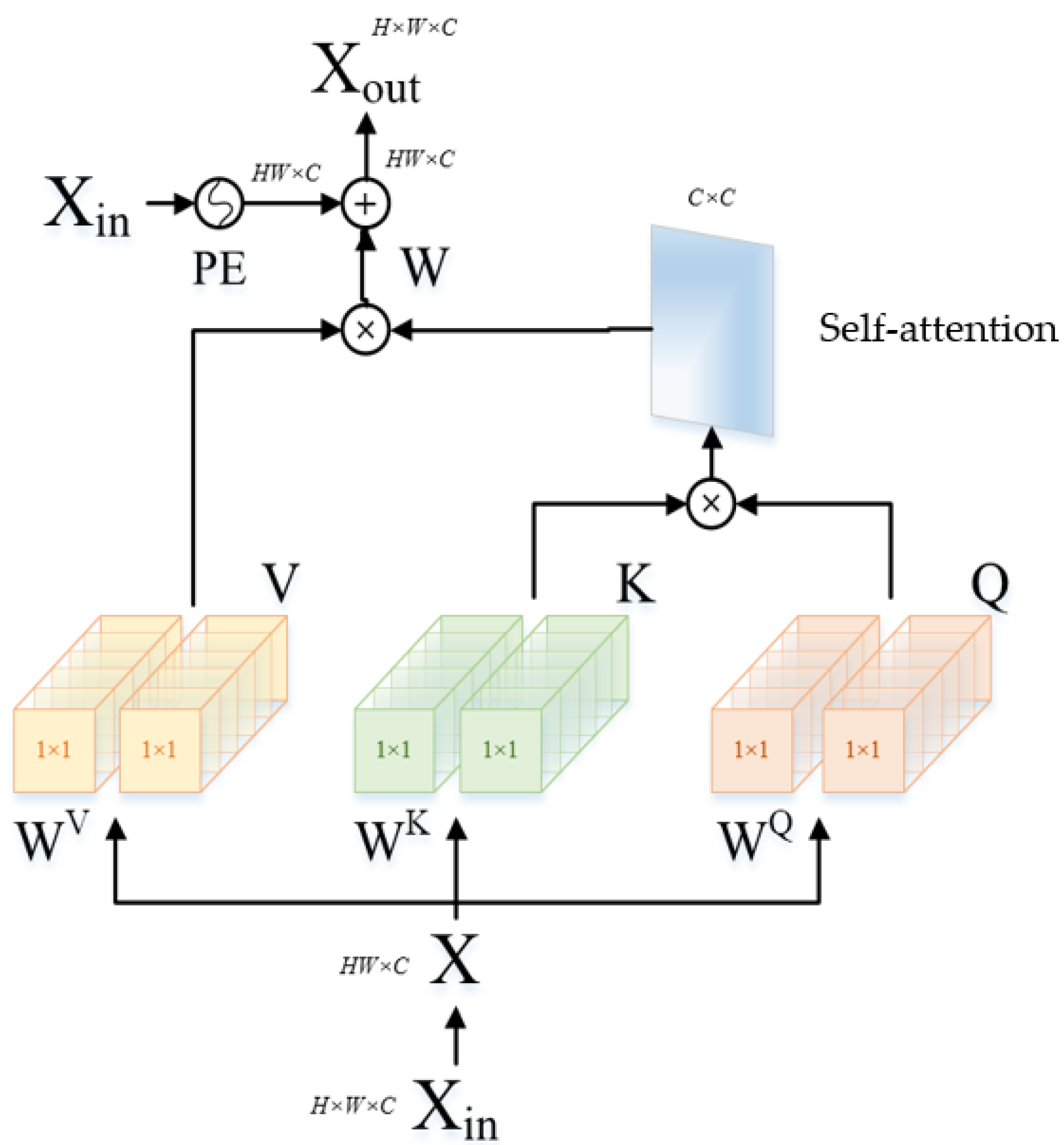
- A self-attention block is innovatively constructed in a spectral super-resolution network to allow the network’s attention to focus on the parts related to the current task, thereby capturing non-local self-similarity and spectral correlation. Moreover, we innovatively design a self-learning network into image reconstruction so as to increase the a priori spectral response function and learn the unknown spatial degradation function. And thus adjust the network structure and parameters dynamically and improve the performance of the model in processing spectral super-resolution tasks.
2. Related Works
2.1. Spectral Super-Resolution Based on Dictionary Learning
2.2. Spectral Super-Resolution Based on Deep Learning
2.3. Attention Mechanism
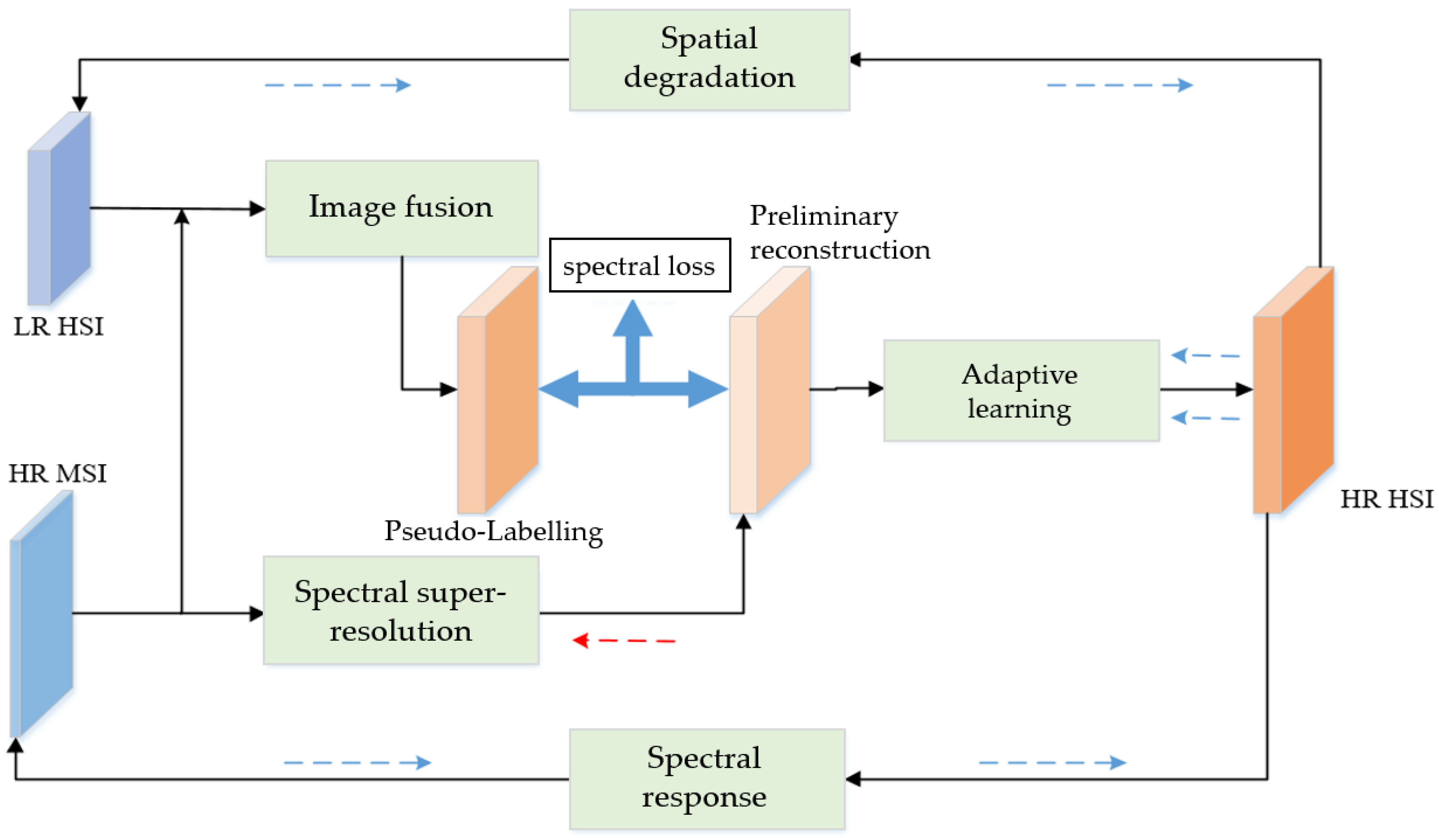
3. Proposed Method
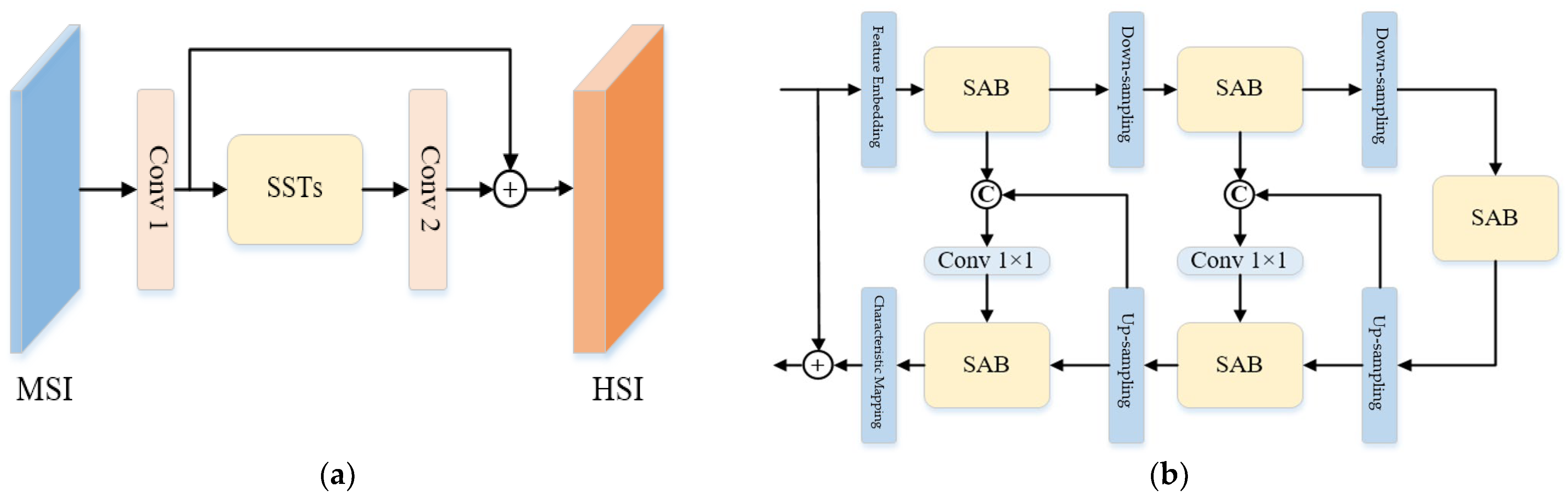
3.1. Network Structure
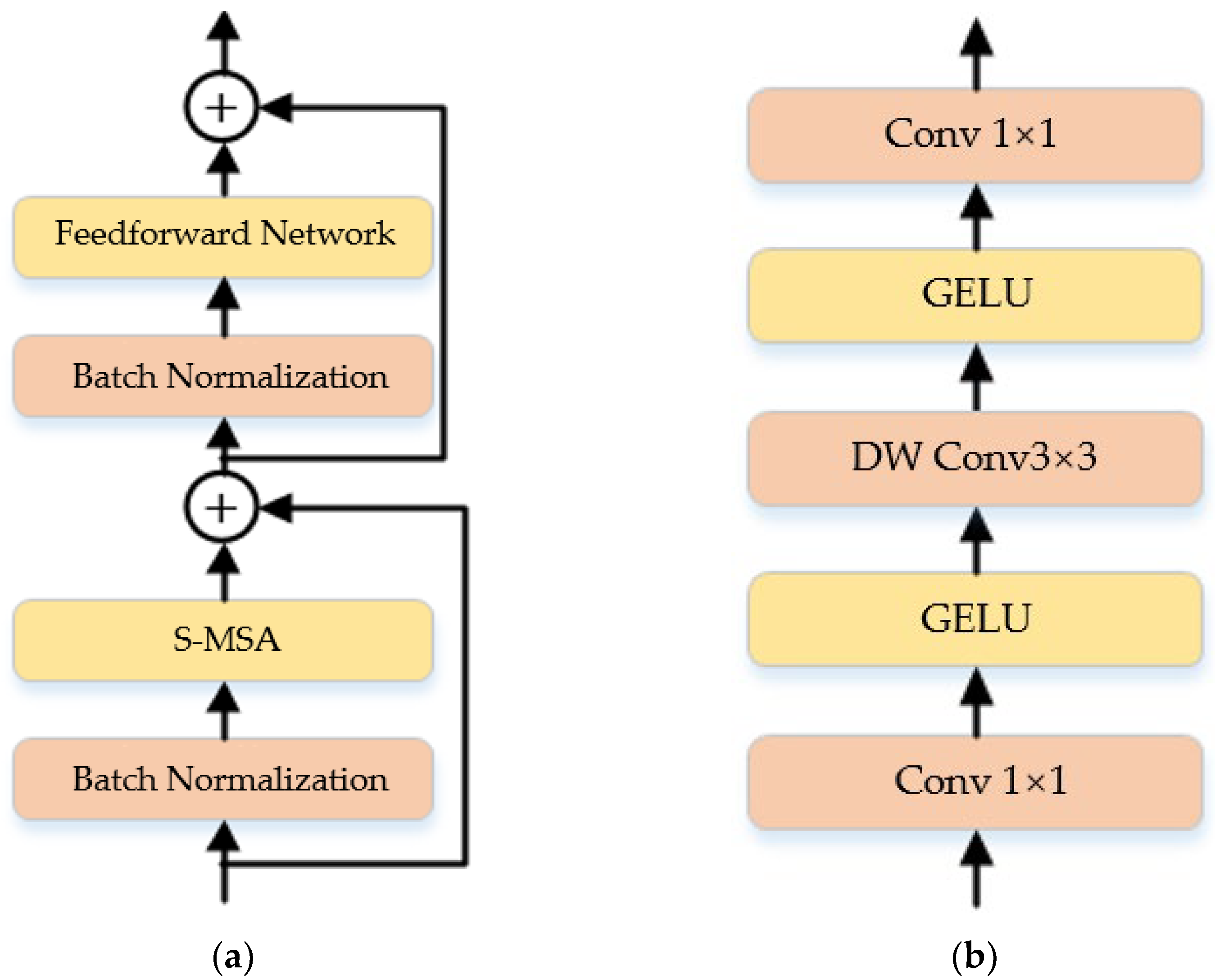
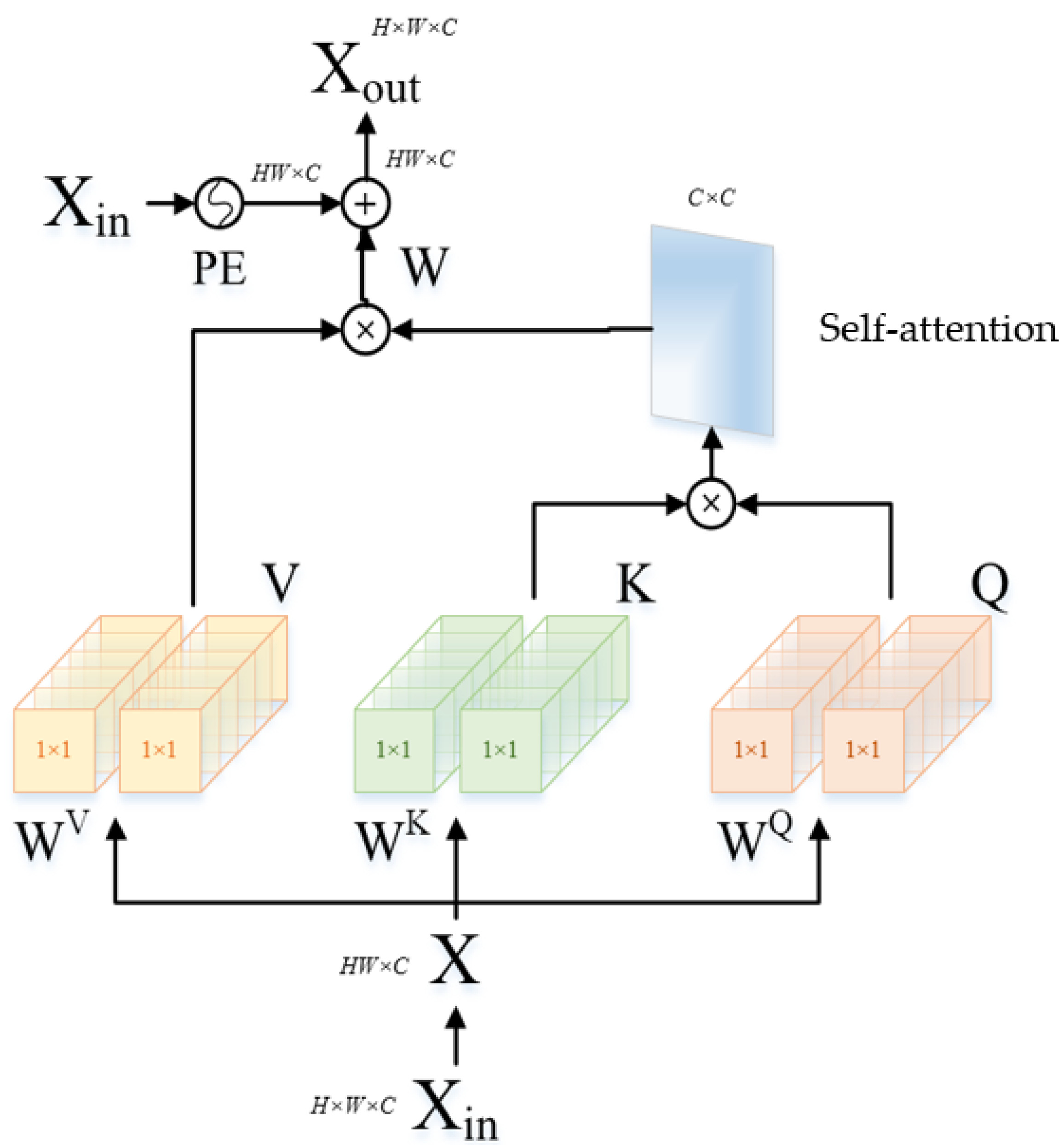
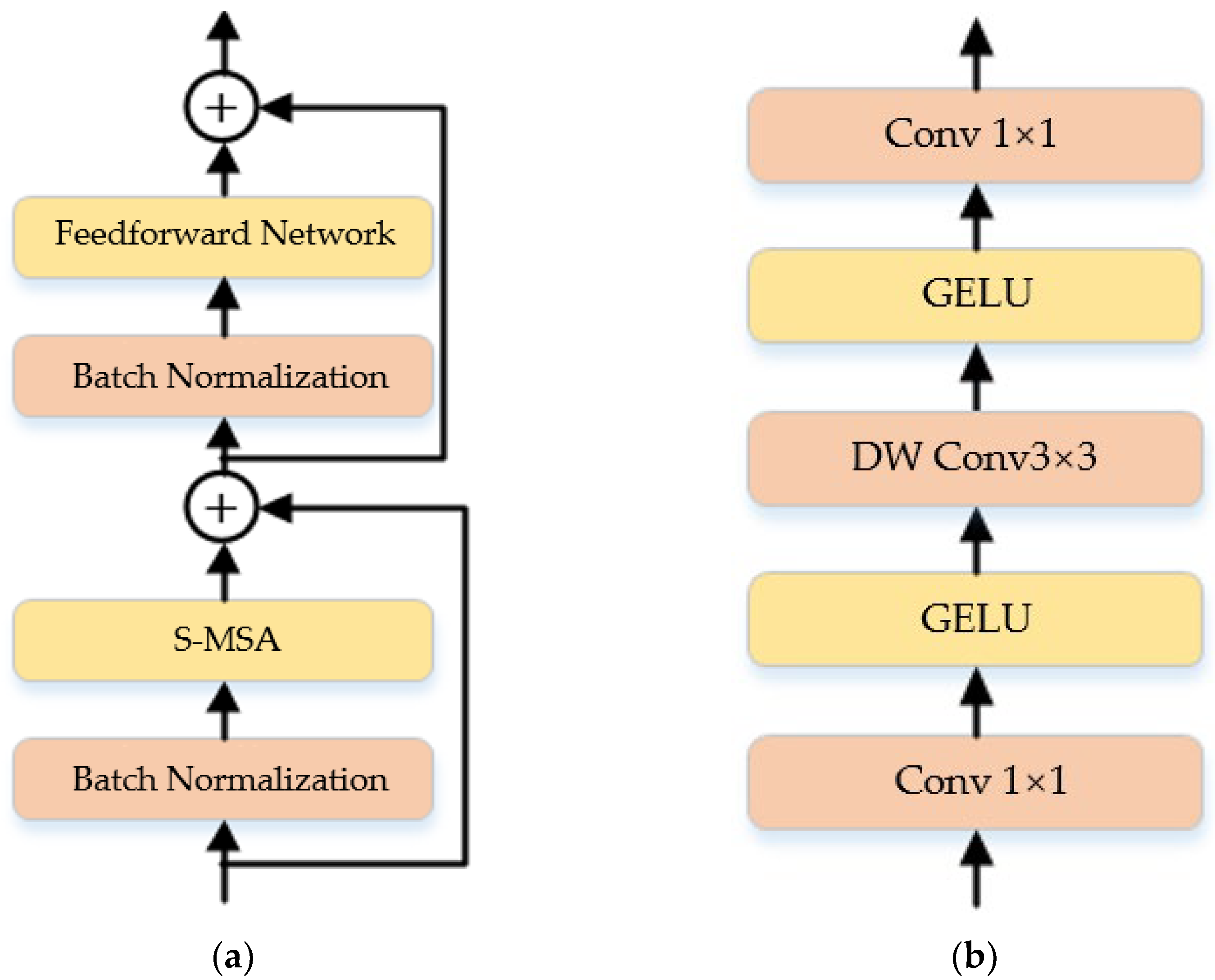
3.2. Spectral Super-Resolution Network Based on Self-Attention Mechanism
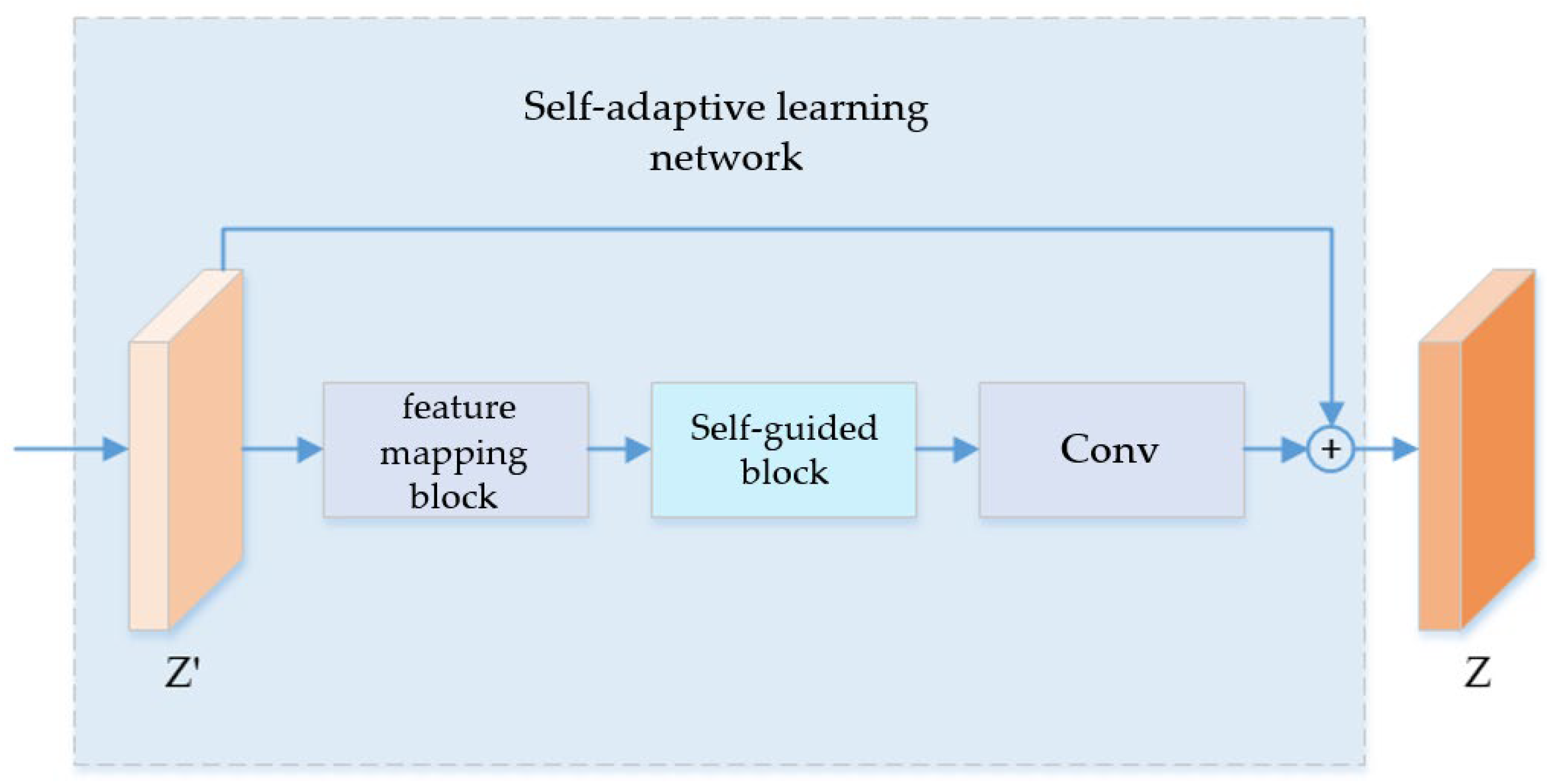
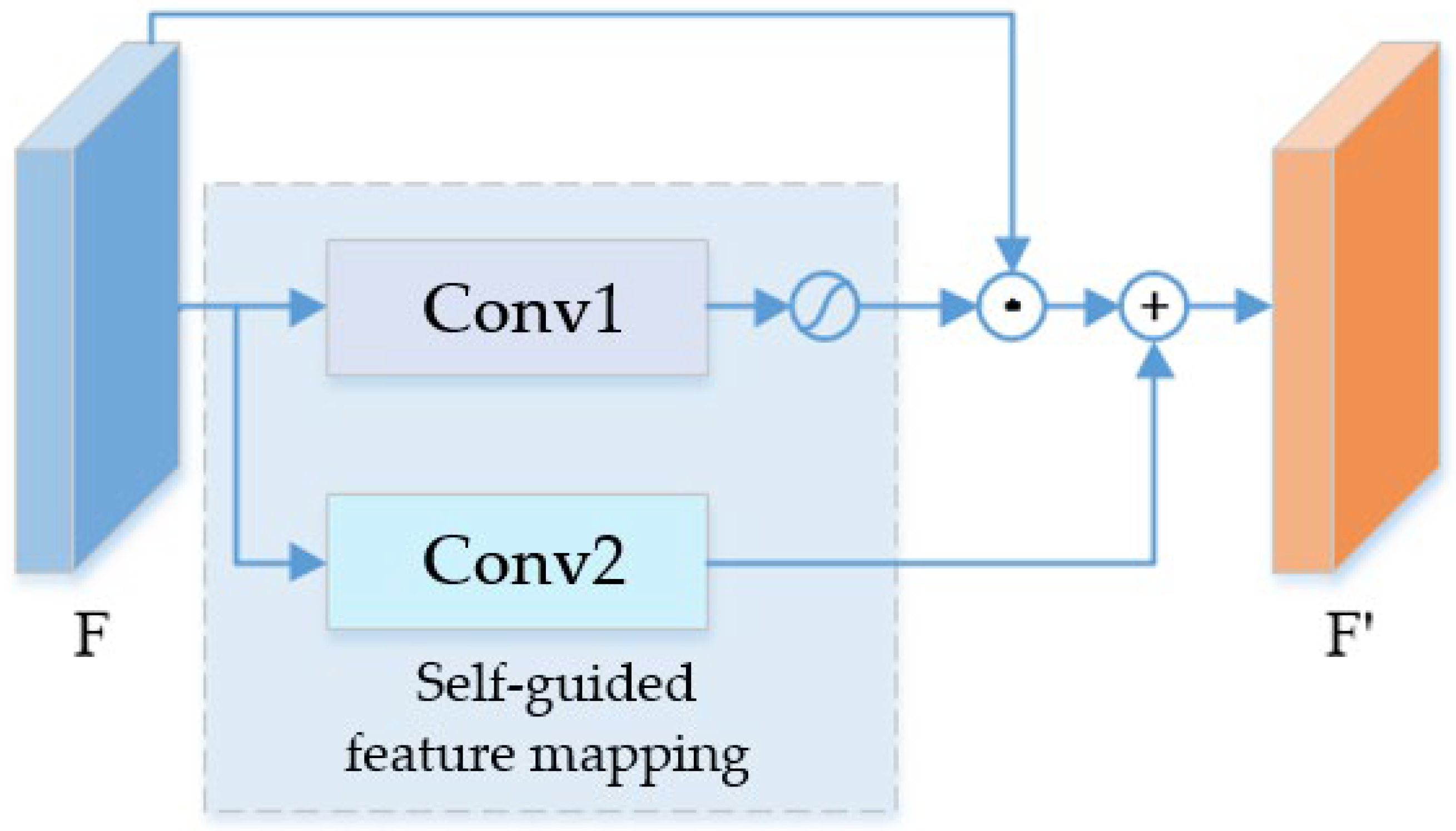
3.3. Adaptive Learning Network
4. Experimental Datasets and Evaluation Indicators
4.1. Experimental Datasets
- (1)
- The Houston data were acquired by the ITRES CASI-1500 sensor (ITRES, Calgary, AB, Canada). The raw image data size is 349 × 1905, and the data have a total of 144 bands, covering the spectral range of 364–1046 nm. As shown in Figure 7, 71, 39, and 16 bands are selected for false-color display. Moreover, Figure 7b,c show the training set and test set labels. And the number of labels for class training sets and test sets during the classification of Houston data is listed in Table 2.
- (2)
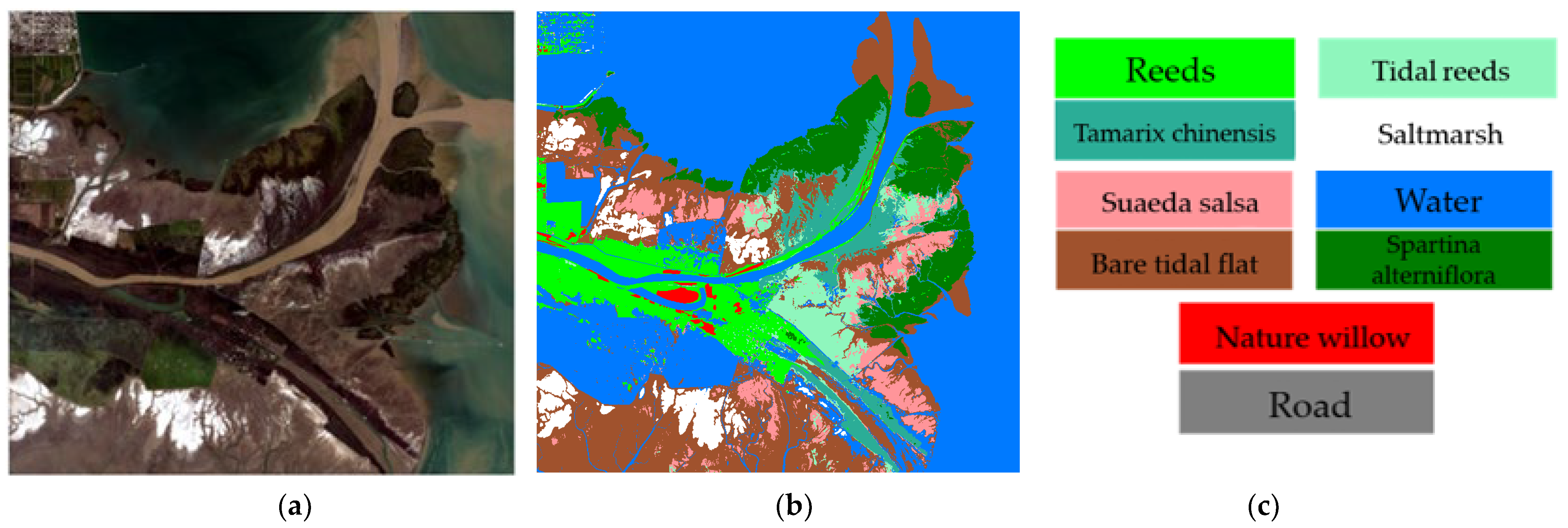
- The hyperspectral and multispectral data of GF-YR were acquired by the Gaofen-5 and Gaofen-1 satellites, respectively. The multispectral camera on the Gaofen-1 satellite (GF-1) can provide multispectral data. The data have four different bands, with the range of 450–520 nm, 520–590 nm, 630–690 nm, and 770–890 nm, respectively. Moreover, the Gaofen-5 satellite (GF-5) has the highest spectral resolution among the national Gaofen major projects. It was officially launched in 2019 with six payloads, including a full-band spectral imager with a spatial resolution of 30 m. Moreover, the imaging spectrum covers 400~2500 nm, including a total of 330 bands, and the visible spectral resolution is 5 nm. In reality, it has retained 295 bands after removing bad bands by preprocessing the satellite data. Figure 8 shows the image of GF-5, and 56, 39, and 25 bands are selected for false-color display of the HSI image. Figure 8c introduces a schematic representation of the category labels, which lists the features corresponding to each color. Furthermore, Table 3 shows the number of various labels of GF-YR data.
4.2. Evaluation Indicators
- PSNR was used to measure the distortion after compression. Higher PSNR values indicate smaller image distortion, and indicate a higher image similarity. Generally, a PSNR value above 30 indicates fine image quality.where is a real HSI, represents the reconstructed HSI. , , and represent the number of bands, height, and width of the image, respectively.
- SAM determines the spectral similarity by calculating the angle of spectrum vectors between the reconstructed image and the real HS image, so as to quantify the spectral information retention of each pixel. Closer SAM values to zero indicate less spectral distortion, manifesting a higher level of spectral similarity.where represents the inner product of the vector, and represents the module of the vector.
- The similarity of the overall structure between the real HS image and the reconstructed image was evaluated by SSIM. Closer SSIM values to one indicate higher image similarity.where , represent the mean of and , respectively. Moreover, , represent the variance of and , respectively. And are constants, avoiding the denominator tending to a zero value to make the calculation more stable. Default , is the range of pixel values in the image.
- is used to measure the spectral distortion of the reconstructed image. The closer the value is to zero, the smaller the spectral distortion.where represents the reconstructed image, represents the average of pixels in the image . represents the LR-HSI.
- is used to measure the degree of spatial information loss of the image. Closer to zero leads to less spatial loss of the image.where is a HR-MSI. And is a multispectral image after the down-sampling of , which has the same spatial resolution as .
- QNR measures the global quality of the image. If QNR is close to one, the image quality is higher. The calculation method is calculated as follows:
5. Results and Analysis
5.1. Data Preprocessing
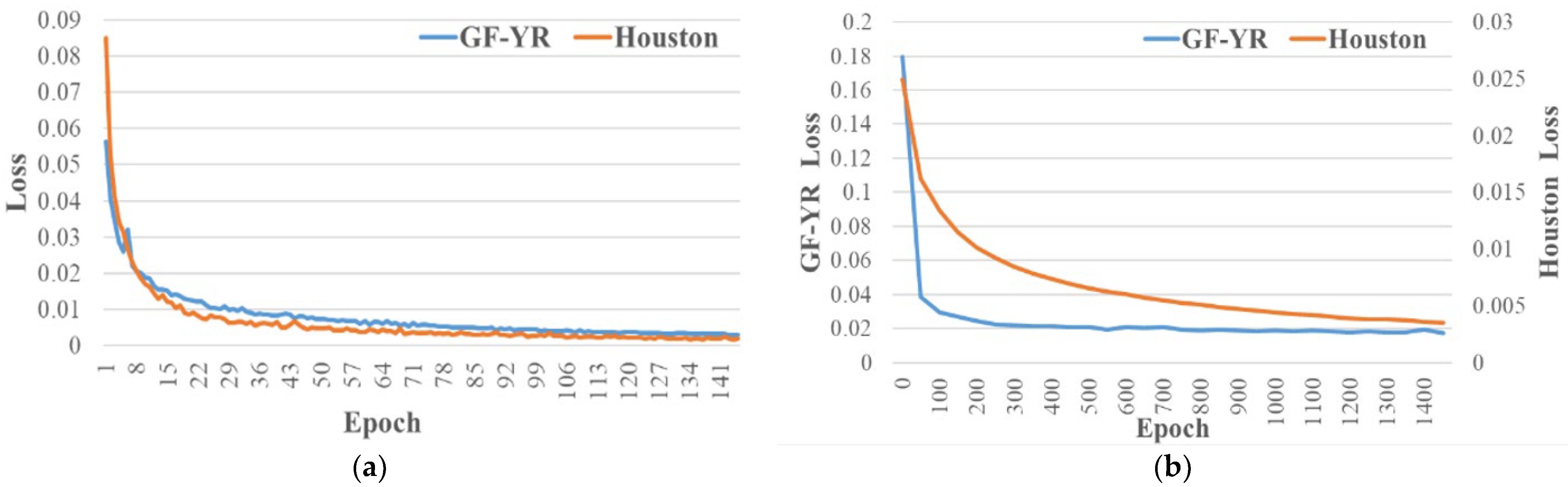
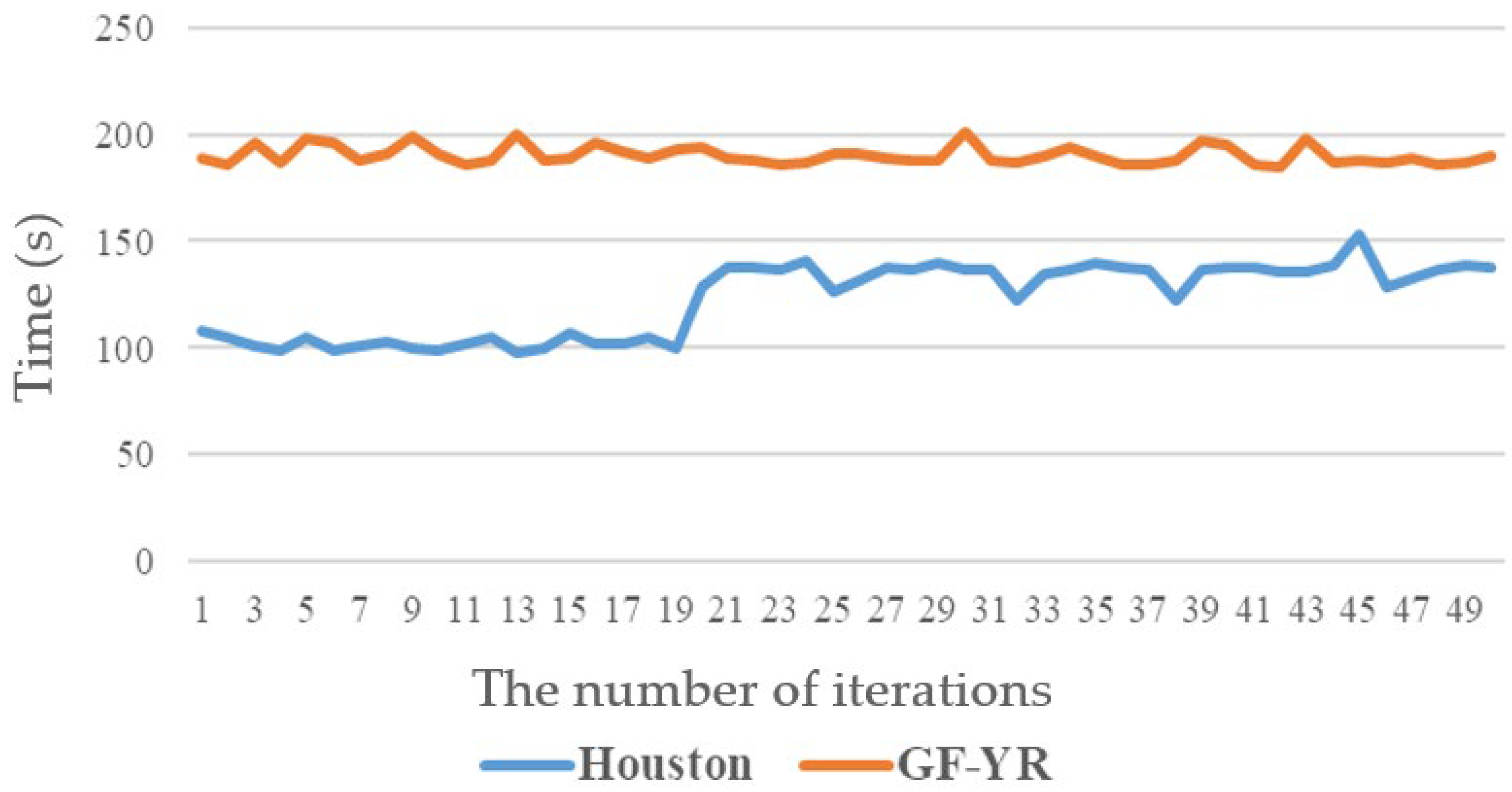
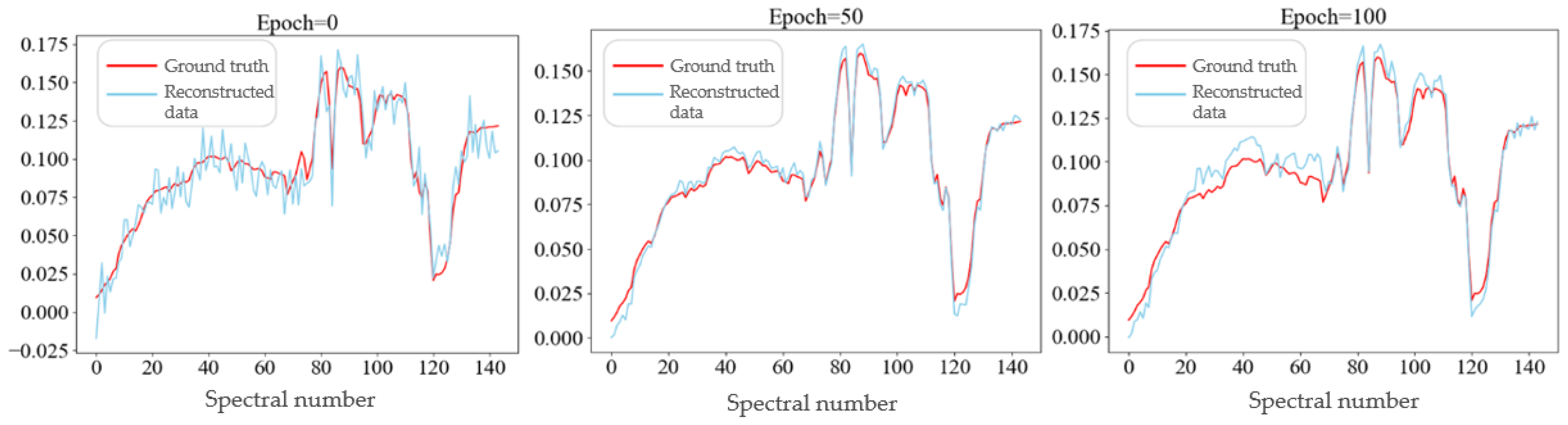
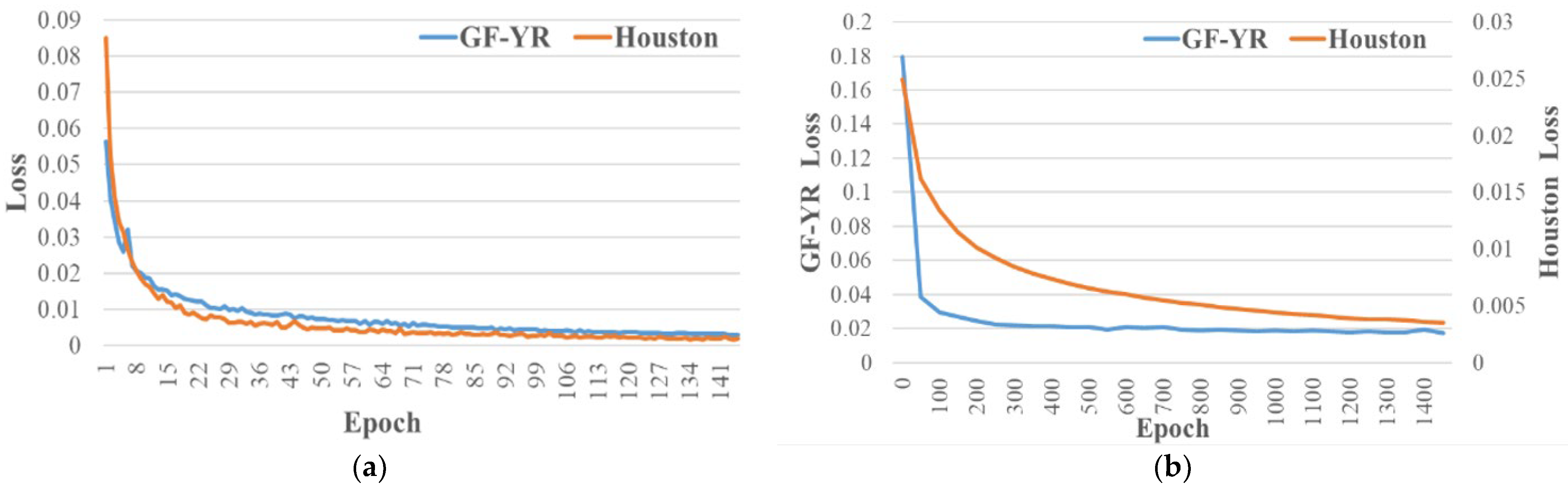
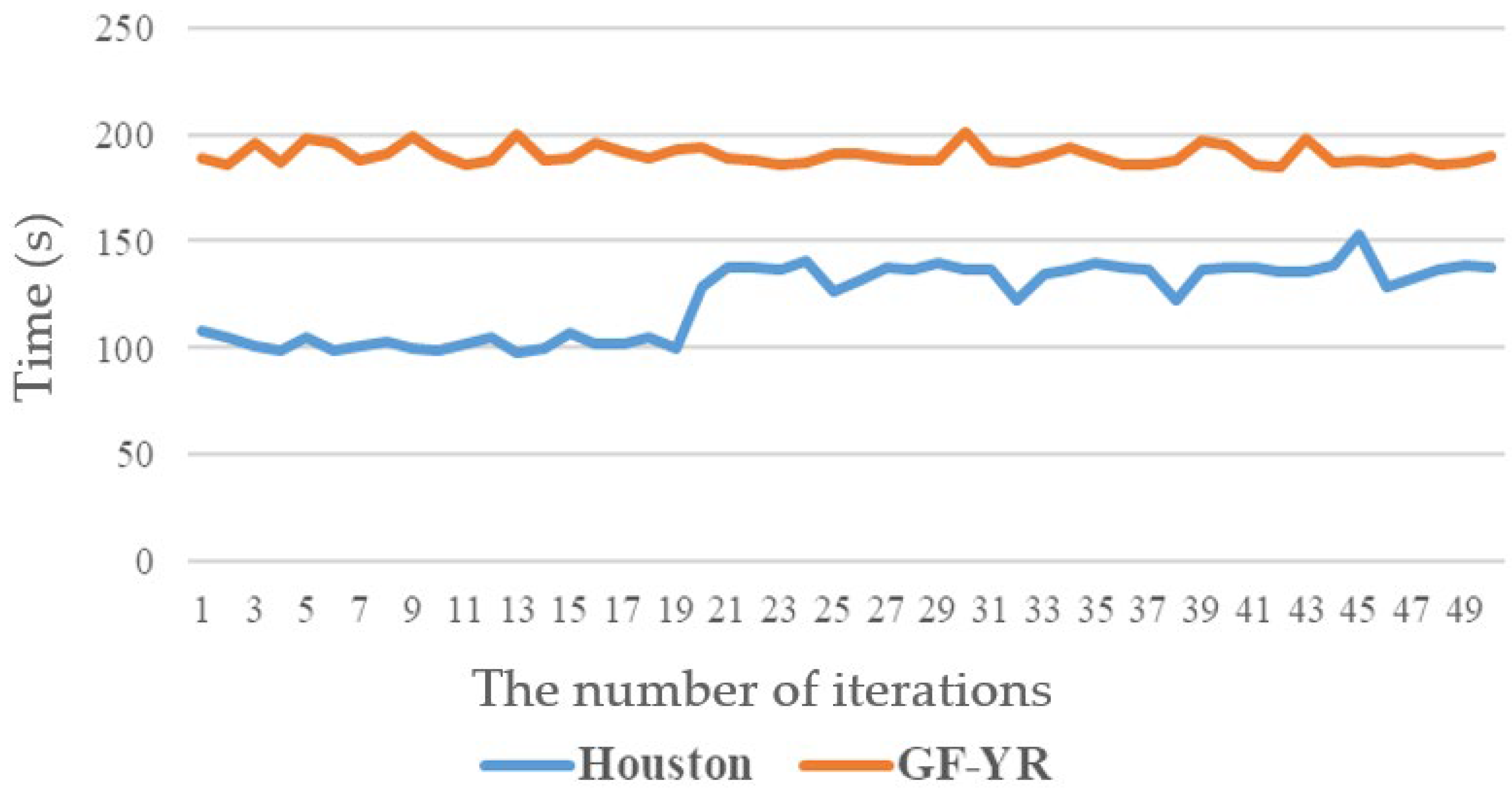
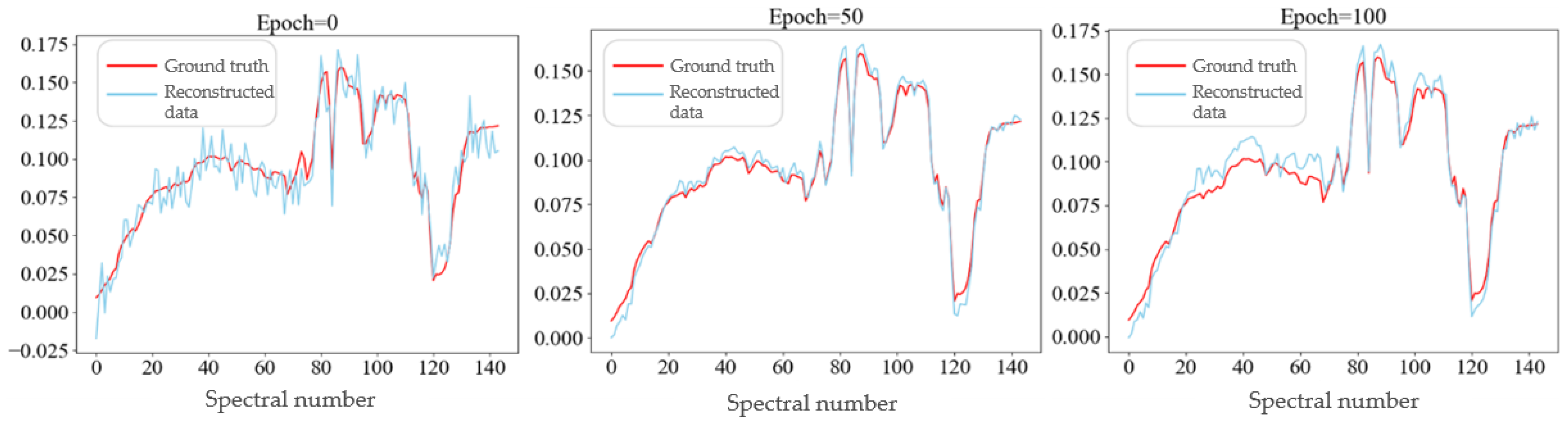
5.2. Analysis of the Training Process
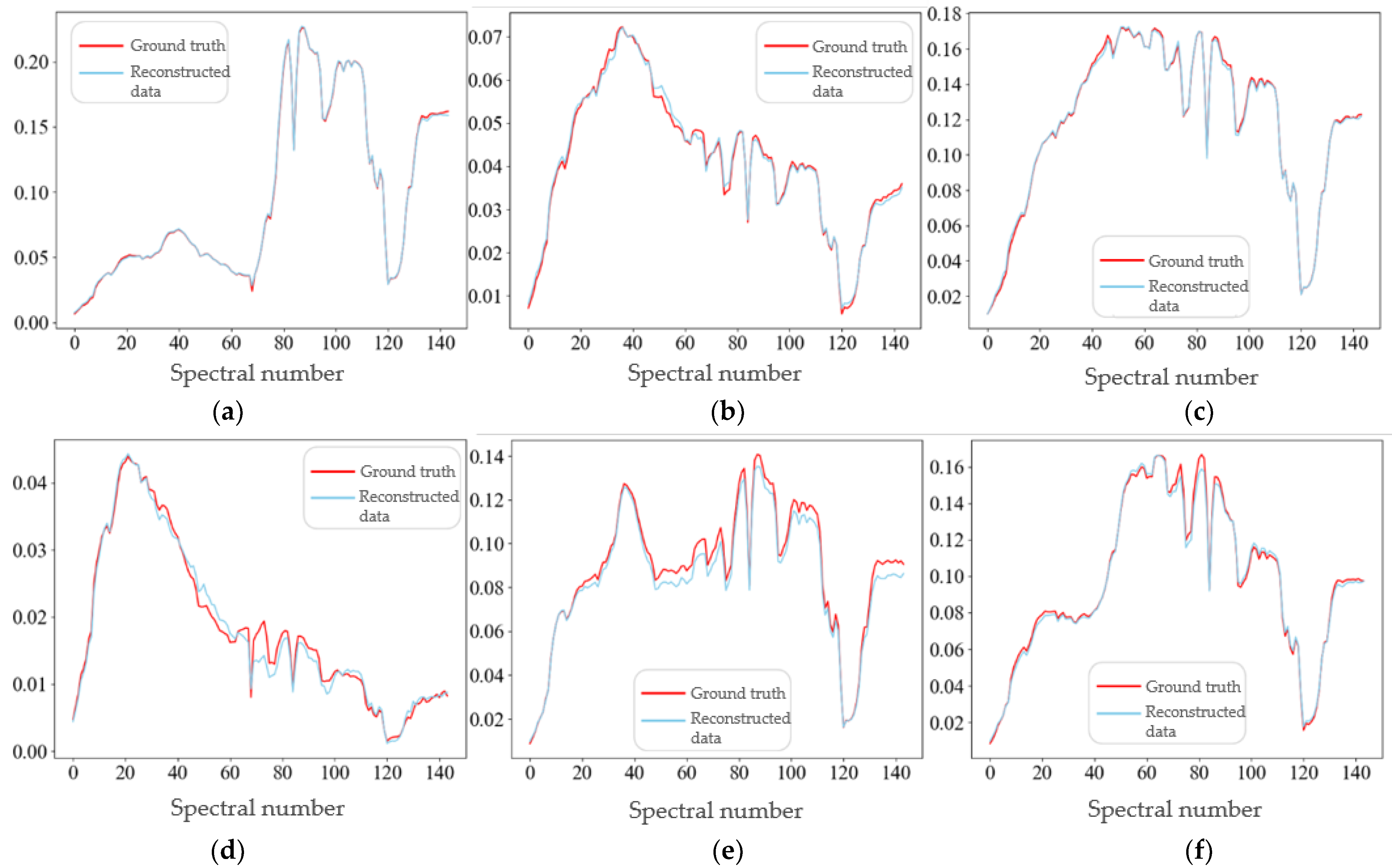
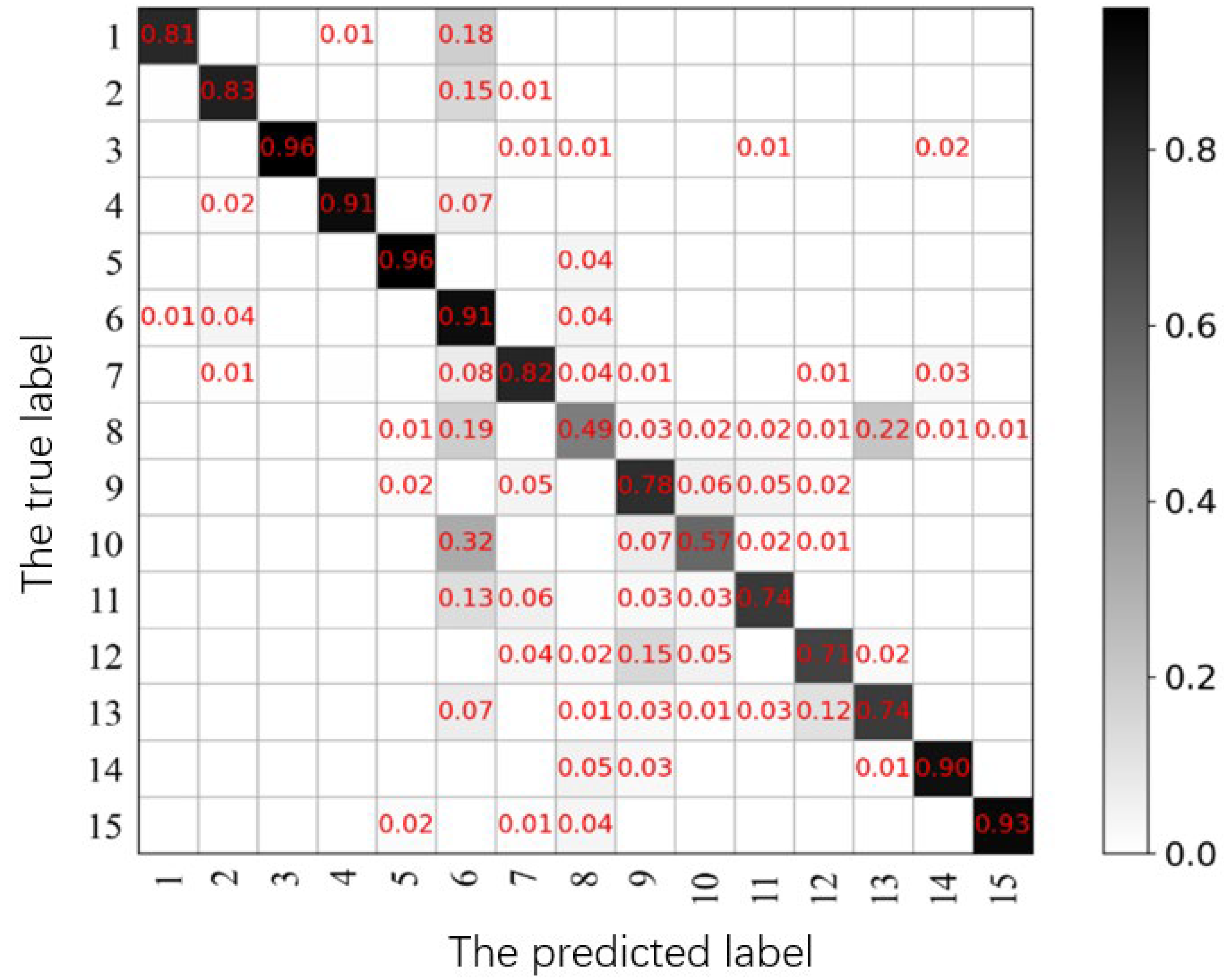
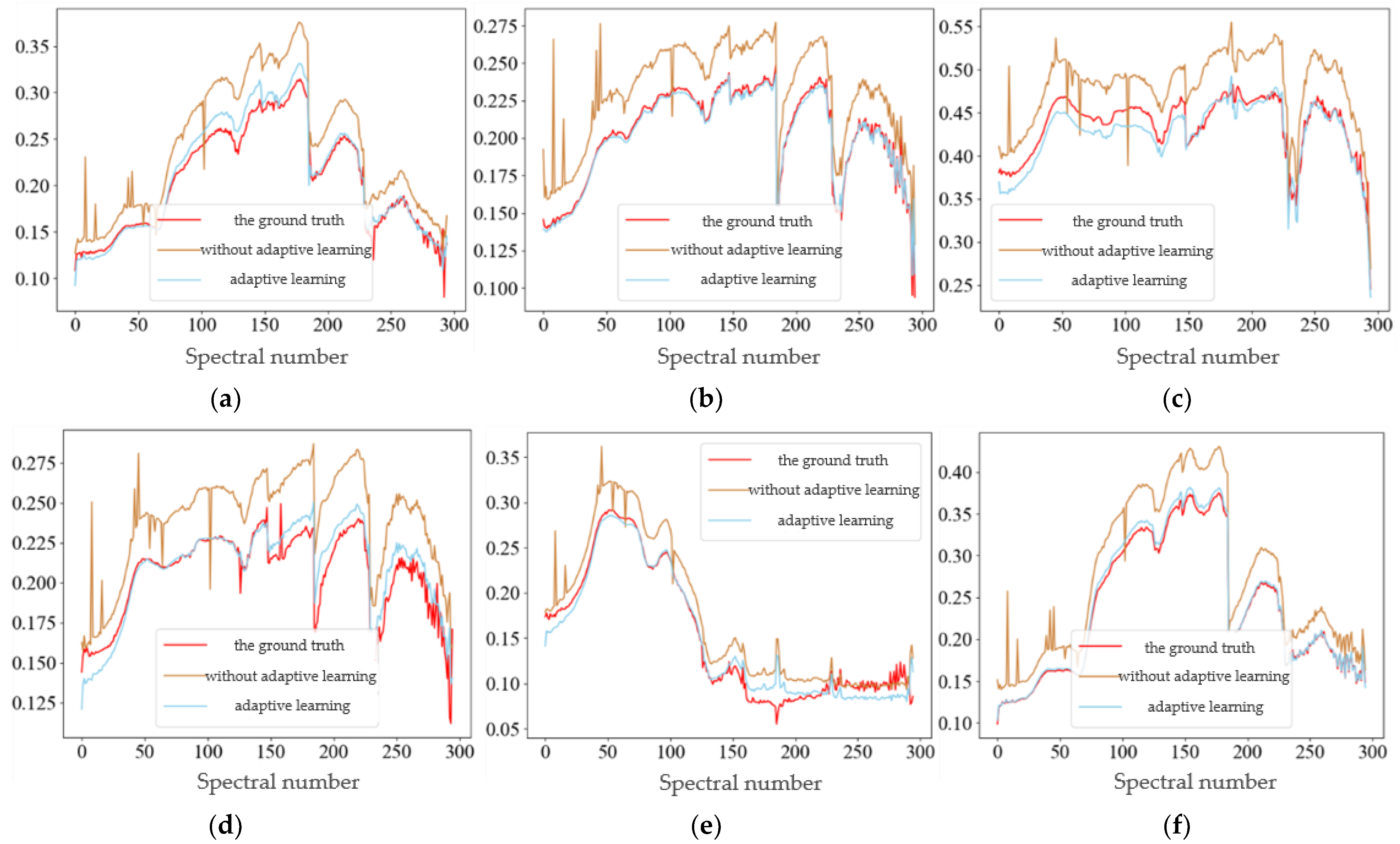
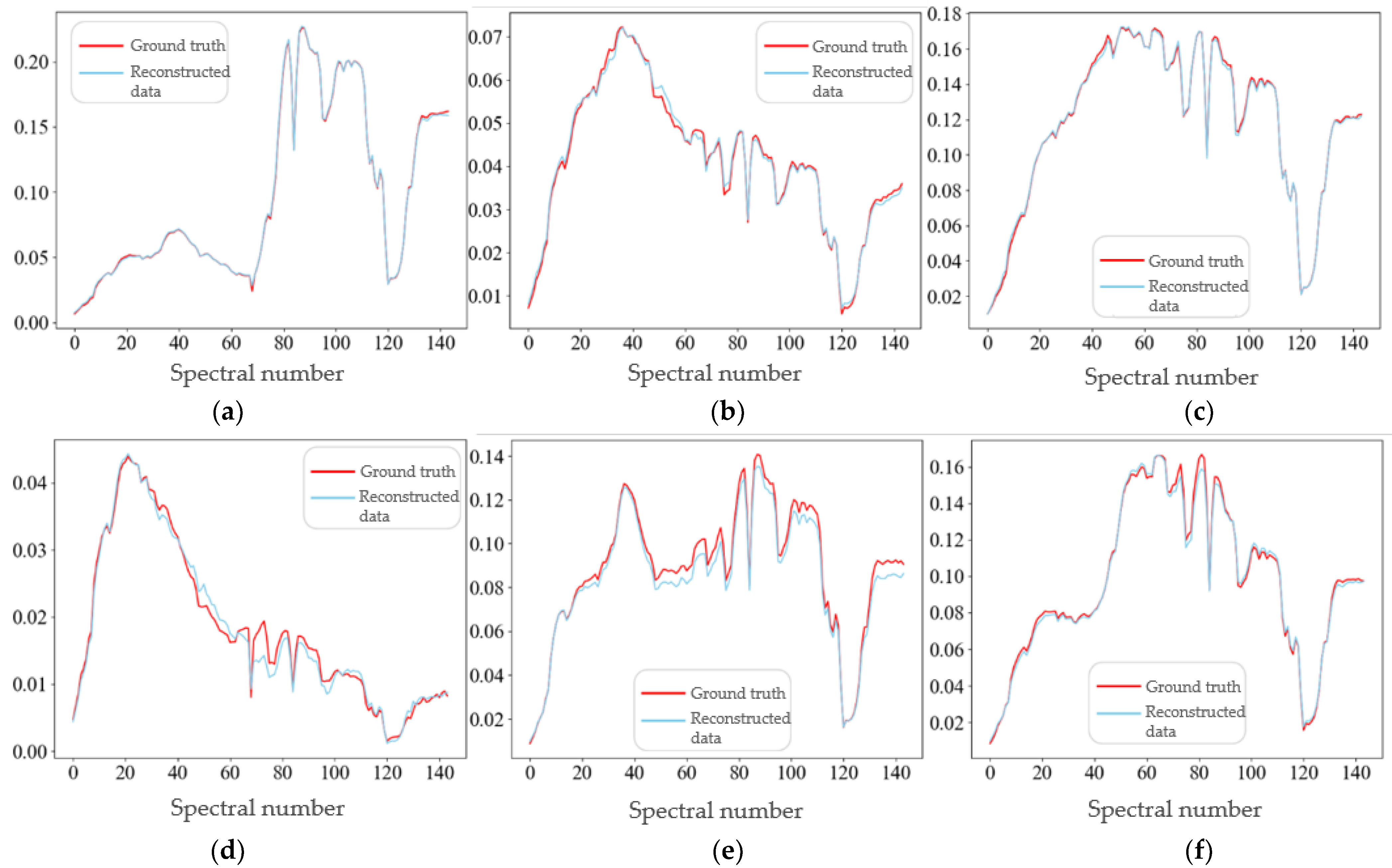
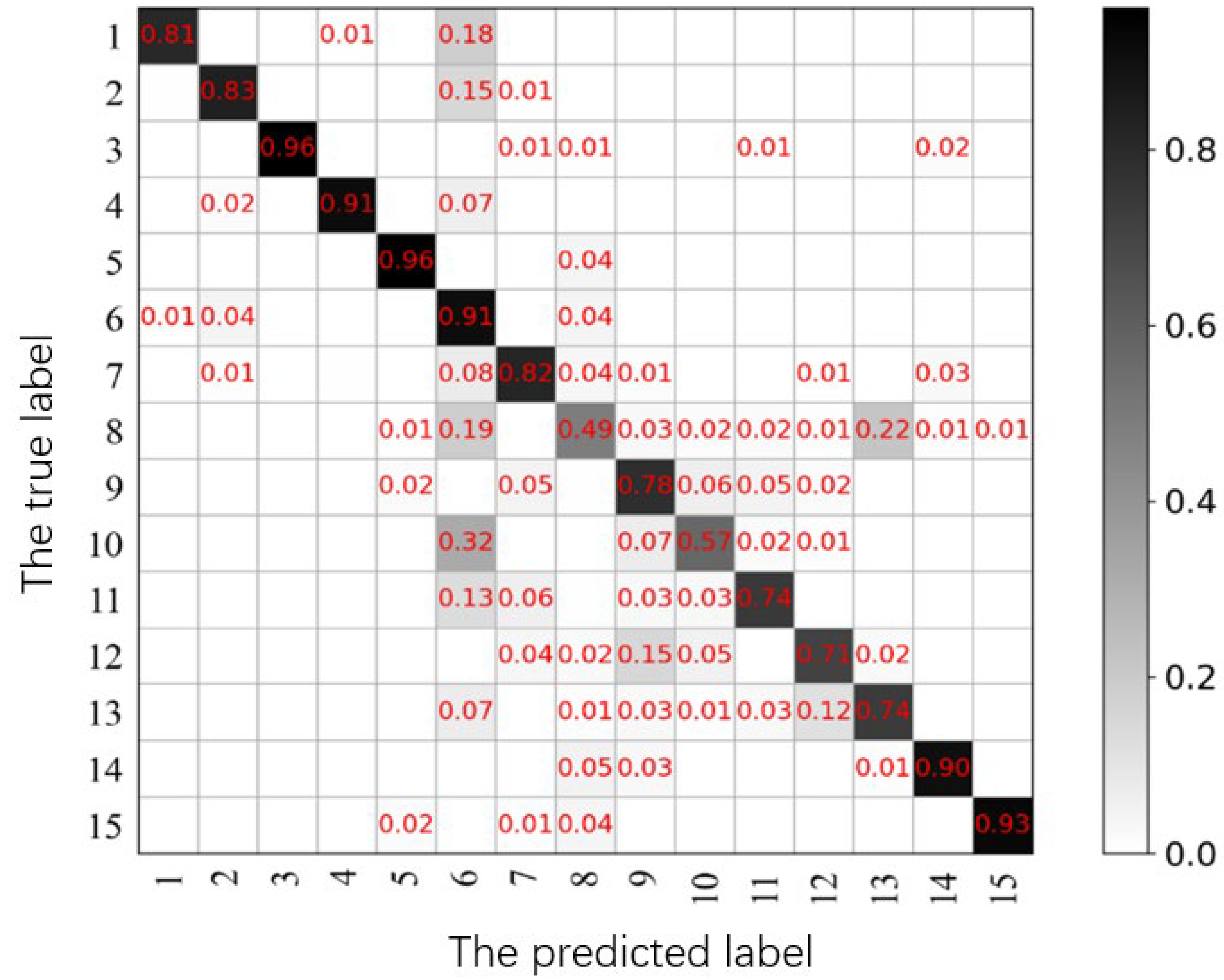
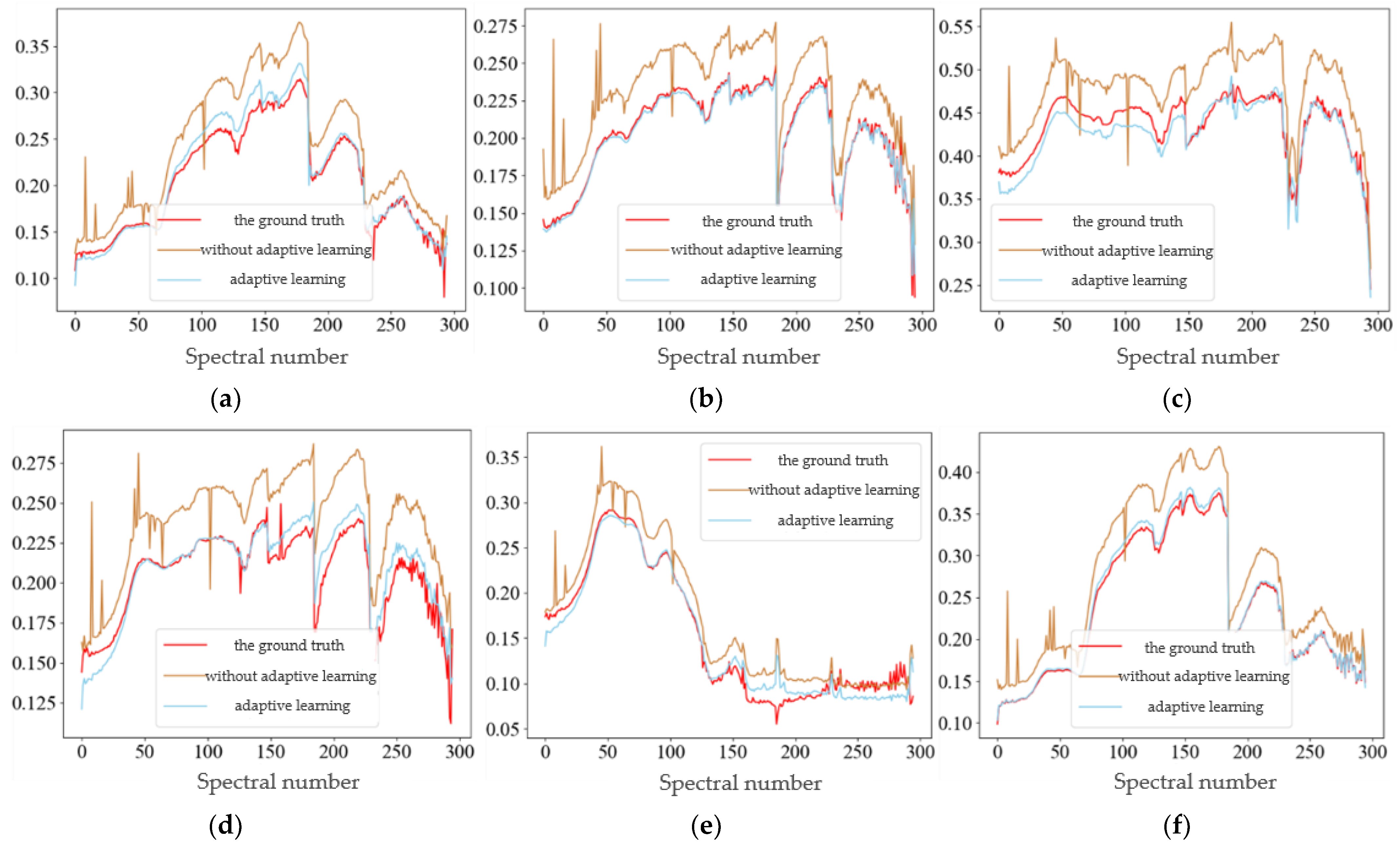
5.3. Comparative Experiment and Analysis
5.4. Ablation Experiments on Partial Network Structures
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, M.; Luo, Q.; Liu, S. Application of Hyperspectral Imaging Technology in Quality Inspection of Agricultural Products. In Proceedings of the 2022 International Conference on Computers, Information Processing and Advanced Education (CIPAE), Ottawa, ON, Canada, 26–28 August 2022; pp. 369–372. [Google Scholar]
- Rayhana, R.; Ma, Z.; Liu, Z.; Xiao, G.; Ruan, Y.; Sangha, J.S. A Review on Plant Disease Detection Using Hyperspectral Imaging. IEEE Trans. AgriFood Electron. 2023, 1, 108–134. [Google Scholar] [CrossRef]
- Tang, X.-J.; Liu, X.; Yan, P.-F.; Li, B.-X.; Qi, H.-Y.; Huang, F. An MLP Network Based on Residual Learning for Rice Hyperspectral Data Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6007405. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, S.; Guan, K. Advancing Airborne Hyperspectral Data Processing and Applications for Sustainable Agriculture Using RTM-Based Machine Learning. In Proceedings of the IGARSS 2023, 2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 1269–1272. [Google Scholar]
- Oudijk, A.E.; Hasler, O.; Øveraas, H.; Marty, S.; Williamson, D.R.; Svendsen, T.; Berg, S.; Birkeland, R.; Halvorsen, D.O.; Bakken, S.; et al. Campaign For Hyperspectral Data Validation In North Atlantic Coastal Waters. In Proceedings of the 2022 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), Rome, Italy, 13–16 September 2022; pp. 1–5. [Google Scholar]
- Rocha, A.D.; Groen, T.A.; Skidmore, A.K.; Willemen, L. Role of Sampling Design when Predicting Spatially Dependent Ecological Data With Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2021, 59, 663–674. [Google Scholar] [CrossRef]
- Guo, T.; Luo, F.; Guo, J.; Duan, Y.; Huang, X.; Shi, G. Hyperspectral Target Detection With Target Prior Augmentation and Background Suppression-Based Multidetector Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 1765–1780. [Google Scholar] [CrossRef]
- Qi, J.; Gong, Z.; Xue, W.; Liu, X.; Yao, A.; Zhong, P. An Unmixing-Based Network for Underwater Target Detection From Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5470–5487. [Google Scholar] [CrossRef]
- Sun, L.; Ma, Z.; Zhang, Y. ABLAL: Adaptive Background Latent Space Adversarial Learning Algorithm for Hyperspectral Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 411–427. [Google Scholar] [CrossRef]
- Wang, S.; Feng, W.; Quan, Y.; Bao, W.; Dauphin, G.; Gao, L.; Zhong, X.; Xing, M. Subfeature Ensemble-Based Hyperspectral Anomaly Detection Algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5943–5952. [Google Scholar] [CrossRef]
- Bai, W.; Zhang, P.; Liu, H.; Zhang, W.; Qi, C.; Ma, G.; Li, G. A Fast Piecewise-Defined Neural Network Method to Retrieve Temperature and Humidity Profile for the Vertical Atmospheric Sounding System of FengYun-3E Satellite. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4100910. [Google Scholar] [CrossRef]
- Fiscante, N.; Addabbo, P.; Biondi, F.; Giunta, G.; Orlando, D. Unsupervised Sparse Unmixing of Atmospheric Trace Gases From Hyperspectral Satellite Data. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6006405. [Google Scholar] [CrossRef]
- Wang, J.; Li, C. Development and Prospect of Hyperspectral Imager and Its Application. Chin. J. Space Sci. 2021, 41, 22–33. [Google Scholar] [CrossRef]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural RGB images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 19–34. [Google Scholar]
- Wu, J.; Aeschbacher, J.; Timofte, R. In Defense of Shallow Learned Spectral Reconstruction from RGB Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 471–479. [Google Scholar]
- Yokoya, N.; Heiden, U.; Bachmann, M. Spectral Enhancement of Multispectral Imagery Using Partially Overlapped Hyperspectral Data and Sparse Signal Representation. In Proceedings of the Whispers 2018, Amsterdam, The Netherlands, 24–26 September 2018. [Google Scholar]
- Fotiadou, K.; Tsagkatakis, G.; Tsakalides, P. Spectral Super Resolution of Hyperspectral Images via Coupled Dictionary Learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2777–2797. [Google Scholar] [CrossRef]
- Gao, L.; Hong, D.; Yao, J.; Zhang, B.; Gamba, P.; Chanussot, J. Spectral Superresolution of Multispectral Imagery With Joint Sparse and Low-Rank Learning. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2269–2280. [Google Scholar] [CrossRef]
- Han, X.; Yu, J.; Luo, J.; Sun, W. Reconstruction From Multispectral to Hyperspectral Image Using Spectral Library-Based Dictionary Learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1325–1335. [Google Scholar] [CrossRef]
- Liu, T.; Gu, Y.; Jia, X. Class-guided coupled dictionary learning for multispectral-hyperspectral remote sensing image collaborative classification. Sci. China Technol. Sci. 2022, 65, 744–758. [Google Scholar] [CrossRef]
- Liu, T.; Gu, Y.; Yu, W.; Jia, X.; Chanussot, J. Separable Coupled Dictionary Learning for Large-Scene Precise Classification of Multispectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5542214. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, L.; Li, J.; Wei, W.; Zhang, Y. Accurate Spectral Super-Resolution from Single RGB Image Using Multi-scale CNN. In Pattern Recognition and Computer Vision, In Proceedings of the First Chinese Conference, PRCV 2018, Guangzhou, China, 23–26 November 2018; Lecture Notes in Computer Science; Lai, J.-H., Liu, C.-L., Chen, X., Zhou, J., Tan, T., Zheng, N., Zha, H., Eds.; Springer: Cham, Switzerland, 2018; pp. 206–217. [Google Scholar]
- Han, X.; Zhang, H.; Xue, J.-H.; Sun, W. A Spectral–Spatial Jointed Spectral Super-Resolution and Its Application to HJ-1A Satellite Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5505905. [Google Scholar] [CrossRef]
- Hu, X.; Cai, Y.; Lin, J.; Wang, H.; Yuan, X.; Zhang, Y.; Timofte, R.; Van Gool, L. Hdnet: High-resolution dual-domain learning for spectral compressive imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17542–17551. [Google Scholar]
- Li, J.; Du, S.; Song, R.; Wu, C.; Li, Y.; Du, Q. HASIC-Net: Hybrid Attentional Convolutional Neural Network With Structure Information Consistency for Spectral Super-Resolution of RGB Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522515. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-Stage Progressive Image Restoration. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14816–14826. [Google Scholar]
- Li, J.; Du, S.; Wu, C.; Leng, Y.; Song, R.; Li, Y. DRCR Net: Dense Residual Channel Re-calibration Network with Non-local Purification for Spectral Super Resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 1258–1267. [Google Scholar]
- He, J.; Yuan, Q.; Li, J.; Xiao, Y.; Liu, X.; Zou, Y. DsTer: A dense spectral transformer for remote sensing spectral super-resolution. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102773. [Google Scholar] [CrossRef]
- Li, T.; Liu, T.; Li, X.; Gu, Y.; Wang, Y.; Chen, Y. Multi-sensor Multispectral Reconstruction Framework Based on Projection and Reconstruction. Sci. China Inf. Sci. 2024, 67, 132303. [Google Scholar] [CrossRef]
- Li, T.; Gu, Y. Progressive Spatial–Spectral Joint Network for Hyperspectral Image Reconstruction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5507414. [Google Scholar] [CrossRef]
- Li, T.; Liu, T.; Wang, Y.; Li, X.; Gu, Y. Spectral Reconstruction Network From Multispectral Images to Hyperspectral Images: A Multitemporal Case. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5535016. [Google Scholar] [CrossRef]
- Du, D.; Gu, Y.; Liu, T.; Li, X. Spectral Reconstruction From Satellite Multispectral Imagery Using Convolution and Transformer Joint Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5515015. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF-tailored Multiscale Fusion of High-resolution MS and Pan Imagery. Photogramm. Eng. Remote Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | HSI or MSI | Source | Image Size | Number of Bands | Spatial Resolution |
|---|---|---|---|---|---|
| Houston | HSI | CASI | 171 × 951 | 144 | 5 m |
| MSI | simulate | 342 × 1902 | 4 | 2.5 m | |
| GF-YR | HSI | GF5 | 734 × 763 | 295 | 30 m |
| MSI | GF1 | 1468 × 1526 | 4 | 15 m |
| Labels | Categories | Number of Training Labels | Number of Testing Labels |
|---|---|---|---|
| 1 | Grass healthy | 537 | 699 |
| 2 | Grass stressed | 61 | 1154 |
| 3 | Synthetic Grass | 340 | 357 |
| 4 | Tree | 209 | 1035 |
| 5 | Soil | 74 | 1168 |
| 6 | Water | 22 | 303 |
| 7 | Residential buildings | 52 | 1203 |
| 8 | Commercial | 320 | 924 |
| 9 | Road | 76 | 1149 |
| 10 | Highway | 279 | 948 |
| 11 | Railway | 33 | 1185 |
| 12 | Parking lot 1 | 329 | 904 |
| 13 | Parking lot 2 | 20 | 449 |
| 14 | Tennis Court | 665 | 162 |
| 15 | Running Track | 279 | 381 |
| Labels | Categories | Number of Global Labels |
|---|---|---|
| 1 | Reeds | 171,779 |
| 2 | Tamarix chinensis | 104,809 |
| 3 | Tidal reeds | 83,161 |
| 4 | Saltmarsh | 76,206 |
| 5 | Suaeda salsa | 102,579 |
| 6 | Naked tidal flat | 436,015 |
| 7 | Water | 1,066,570 |
| 8 | Spartina alterniflora | 180,186 |
| 9 | Nature willow | 13,492 |
| 10 | Road | 5371 |
| PSNR | SAM (°) | SSIM | OA | DS | Dλ | QNR | |
|---|---|---|---|---|---|---|---|
| Proposed | 43.5576 | 1.2894 | 0.9996 | 0.7653 | 0.0170 | 0.0074 | 0.9756 |
| J-SLoL [18] | 35.0719 | 5.5209 | 0.9699 | 0.6764 | 0.0374 | 0.0622 | 0.9027 |
| MPRNet [26] | 34.6842 | 4.2354 | 0.9541 | 0.6896 | 0.0694 | 0.0781 | 0.8579 |
| CGCDL [20] | 35.5778 | 4.7765 | 0.9977 | 0.6907 | 0.0364 | 0.1106 | 0.8570 |
| MSSNet [22] | 31.2342 | 3.0510 | 0.9367 | 0.6975 | 0.0518 | 0.1174 | 0.8367 |
| OA | DS | Dλ | QNR | |
|---|---|---|---|---|
| Proposed | 0.8251 | 0.0471 | 0.0549 | 0.9004 |
| J-SLoL [18] | 0.7815 | 0.1218 | 0.1667 | 0.7317 |
| MPRNet [26] | 0.7726 | 0.1496 | 0.1238 | 0.7451 |
| CGCDL [20] | 0.8636 | 0.1803 | 0.1772 | 0.6744 |
| MSSNet [22] | 0.7842 | 0.1121 | 0.1614 | 0.7451 |
| Methods | PSNR | SAM (°) | SSIM | OA | DS | Dλ | QNR |
|---|---|---|---|---|---|---|---|
| w/o adaptation | 40.9896 | 1.3752 | 0.9997 | 0.7480 | 0.0164 | 0.0094 | 0.9741 |
| w/o fusion | 36.6576 | 3.2535 | 0.9538 | 0.7644 | 0.0331 | 0.0345 | 0.9315 |
| Proposed | 43.5576 | 1.2894 | 0.9996 | 0.7653 | 0.0170 | 0.0074 | 0.9756 |
| Methods | OA | DS | Dλ | QNR |
|---|---|---|---|---|
| w/o adaptation | 0.8150 | 0.0736 | 0.0552 | 0.8752 |
| w/o fusion | 0.8077 | 0.1726 | 0.1259 | 0.7232 |
| Proposed | 0.8251 | 0.0471 | 0.0549 | 0.9004 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liu, Z.; Zhang, X.; Liu, T. A Multi-Hyperspectral Image Collaborative Mapping Model Based on Adaptive Learning for Fine Classification. Remote Sens. 2024, 16, 1384. https://doi.org/10.3390/rs16081384
Zhang X, Liu Z, Zhang X, Liu T. A Multi-Hyperspectral Image Collaborative Mapping Model Based on Adaptive Learning for Fine Classification. Remote Sensing. 2024; 16(8):1384. https://doi.org/10.3390/rs16081384
Chicago/Turabian StyleZhang, Xiangrong, Zitong Liu, Xianhao Zhang, and Tianzhu Liu. 2024. "A Multi-Hyperspectral Image Collaborative Mapping Model Based on Adaptive Learning for Fine Classification" Remote Sensing 16, no. 8: 1384. https://doi.org/10.3390/rs16081384
APA StyleZhang, X., Liu, Z., Zhang, X., & Liu, T. (2024). A Multi-Hyperspectral Image Collaborative Mapping Model Based on Adaptive Learning for Fine Classification. Remote Sensing, 16(8), 1384. https://doi.org/10.3390/rs16081384