1. Introduction
Hyperspectral remote sensing is a multidimensional information acquisition technology that integrates imaging technology and spectral technology, simultaneously detecting two-dimensional spatial information and one-dimensional spectral information of the feature target, so as to obtain hyperspectral images (HSIs) with high spectral resolution and many bands. HSIs can reflect nearly continuous spectral characteristic curves of the feature, containing rich spatial and spectral information, and is a comprehensive carrier of various information. The use of hyperspectral data spectral unity and the characteristics of a wide range of band coverage can greatly improve its ability to distinguish the identification of feature classes [
1]; thus, hyperspectral remote sensing technology has been widely applied to the refinement of agriculture [
2,
3], military applications [
4,
5], environmental monitoring [
6,
7] and other aspects.
Hyperspectral image classification (HIC) is the foundation of various hyperspectral applications. The main goal of HIC is to adjudicate the pixels in an image so as to achieve the automatic identification of feature classes for other sectors. From classical machine learning theories, such as SVM [
8] and KNN [
9], to deep neural networks (DNNs), deep learning model frameworks represented by convolutional neural networks have been widely used for HIC and have achieved remarkable success. Before 2012, deep learning algorithms based on neural networks had not been popularized due to the large scale of computing parameters and insufficient hardware to support such large-scale parameter operations. However, 2012 was an epochal year in which AlexNet [
10] made a major breakthrough in the ImageNet competition held by Google, and deep learning algorithms based on convolutional neural networks (CNNs)-based deep learning algorithms began to be emphasized, and deep learning algorithms about CNNs, such as VGG (16/19) [
10], ResNet [
11], etc., have been continuously proposed and applied to the fields of image categorization, target detection, and image style conversion. With the continuous development of CNNs, HIC algorithms based on convolutional neural networks have gradually become one of the research hotspots. Hu et al. [
12] proposed a five-layer convolutional neural network for hyperspectral image classification and achieved good classification results. Yue et al. [
13] introduced the spatial and spectral information in the hyperspectral image into the CNN model after fusion, which further improved the classification effect. Zhao et al. [
14] extracted the spectral and spatial relationship information of neighboring pixel pairs by using the twin neural network and utilized the Softmax loss function to achieve classification. Wu et al. [
15] used 1D-CNN and 2D-CNN to extract spectral and spatial features, respectively; however, when using 1D-CNN for spectral feature learning, a large number of convolution kernels are required in the face of the high number of bands in HSI, which results in excessive computation and likely overfitting. To alleviate this problem, Chen et al. [
16] made the first attempt to use training sample chunks to train CNNs for deep feature extraction and the classification of HSIs. Thanks to the powerful automatic feature extraction capability of CNNs, many deep CNN models based on training sample chunks for extracting spectral–patial joint features have been proposed [
17,
18,
19,
20]. Roy et al. [
21] proposed HybridSN networks based on 3D-CNN and 2D-CNN, where 3D-CNN is used to extract spectral–stereo spatial information, and 2D-CNN is further used to extract the planar spatial information. However, HybridSN does not fully consider the rich spectral and spatial information of HSI itself, and there is still room for improvement in the extraction and utilization of spatial and spectral information of HSIs. Zhang et al. [
22] proposed a differential region convolutional neural network (DRCNN)-based approach that uses different image blocks within the neighborhood of the target pixel as the input to the CNN, where the input data are effectively reinforced. Roy et al. [
23] used attention-based adaptive spectral–spatial kernel residual network (A2S2K-ResNet) to mine more discriminative joint spectral–spatial features. Pu et al. [
24] used convolutional kernel-adaptive rotation to extract features in different orientations of an object. Yang et al. [
25] proposed a supervised change detection method based on deep concatenated semantic segmentation network to process the data efficiently. Scheibenreif et al. [
26] used self-supervised mask image reconstruction to advance the transformer model for hyperspectral remote sensing images.
Due to the special data characteristics of HSIs, there are still several challenges in building network models using convolutional neural networks [
27,
28]: (1) The spectral dimension of HSI has hundreds of band values, and the information between bands has redundancy, resulting in high data dimensionality and, therefore, rich spectral information. However, when the number of available labeled samples is limited, this high dimensionality characteristic of the data will introduce the curse of dimensionality problem (usually also becomes Hughes phenomenon), i.e., with the increase in the number of bands involved in the operation, the classification accuracy increases and then decreases. (2) The high cost of HSI sample labeling leads to insufficient labeled samples, which lead to the model overfitting phenomenon, resulting in low generalization performance. (3) Due to the role of convolutional kernel and pooling layer, as the network continues to deepen, it will cause unavoidable feature loss, insufficient feature extraction, and other problems.
Based on the above problems, researchers must consider both the rich spectral and spatial information extraction of HSI when designing network models. However, pure 3D-CNN is not widely used due to its huge computational volume. The computational resources consumed are huge; therefore, pure 3D-CNN is not widely used. Moreover, pure 2D-CNN is not widely used in the field of HIC due to its inability to deal with spectral dimensional data information; in other words, pure 2D-CNN restricts itself to spatial information features, and thus, pure 2D-CNN cannot shine in the field of HIC. To sum up, researchers considered combining 2D-CNN and 3D-CNN and used 3D-CNN’s powerful computational ability as a spectral spatial information feature extractor and 2D-CNN as a pure spatial feature extractor. From this, the 3D-2D-CNN structure came into being. Roy constructed a classification model for hyperspectral images using 3D-2D-CNN in HyBridSN, but he ignored the fact that the 3D-2D-CNN structure was not a good choice for classification. Roy used 3D-2D-CNN structure in HyBridSN to complete the construction of hyperspectral image classification models, but he neglected one point, that is, the continuous stacking of convolutional blocks will inevitably lead to the loss of feature information, which is an inherent defect of the convolutional computation and so can not be avoided. In addition, the model’s ability to extract salient features is insufficient, which leads to the unsatisfactory performance of the model in small samples. Feng et al. [
29]. proposed R-HyBridSN, which is based on HyBridSN, and uses the so-called depth-separable convolution and residual convolution blocks to optimize HyBridSN to a certain extent but the model’s ability to extract salient features of HSI is still insufficient. The saliency feature extraction abilities are still insufficient, and the large number of 3D-CNN leads to the significant consumption of computational resources by the model. However, from another point of view, we cannot deny that the 3D-2D-CNN architecture is more advantageous for HIC. Zhang et al. [
30] proposed a DPCMF model that has a dense pyramid connection structure with a two-branch structure, which effectively alleviates the performance degradation caused by the feature loss, but the DPCMF uses the 3D convolutional block as the model. However, DPCMF uses 3D convolutional blocks as the base component of the model, which leads to a very large number of computational resources being consumed by the model. Secondly, HSI data contain very complex spectral and spatial information, and the simple two-branch structure of DPCMF directly fuses the high-level feature maps generated by the two branches and then classifies them, which leads to the lack of extraction of complex features for HSI; however, there are not enough parameters to fit the complex data distributions, and the results obtained are not satisfactory. However, it is undeniable that the two-branch structure has a unique advantage for the HIC task; that is, each branch of the two-branch structure can use different network structures and parameters to capture the spatial and spectral features of the input HSI data.
How can the advantages of the 3D-2D-CNN architecture be better exploited under small sample conditions? How can we effectively mitigate the problem of insufficient model feature extraction capabilities and feature loss caused by deepening network hierarchy? Generally speaking, as the network continues to deepen, the extracted features will gradually transform form low-level features to high-level features; however, under the objective conditions of the CNN limitations, it will cause a certain degree of feature loss, and also lead to model training difficulties, gradient disappearance, and other problems. The traditional residual connection and dense connection can alleviate the above problems but the effect is always unsatisfactory; the reason is that the model in the process of training is not the same attention to the attention to the features. In order to solve this problem, the attention mechanism has gradually become a hotspot for the application of HIC, ref. [
31] proposed a dense CNN network based on feedback attention, and ref. [
32] proposed a convolutional block-based attention module (CBAM) [
33] for a dual-branch multiple attention mechanism network (DBMA). Although these methods have better results, they are not targeted to solve the problems of feature loss and insufficient feature extraction, especially in the case of limited samples, the feature loss has a very large impact on the HIC effect, and could not obtain satisfactory classification results.
Aiming at the problems of missing features and insufficient ability to extract features in the feature extraction process of CNN models, we propose a high-precision HIC model with two-branch multiscale feature aggregation and multiple attention mechanisms inspired by the two-branch structure and attention mechanisms. The model extracts multiscale spatial–spectral feature information using a joint spatial–spectral branch and a spectral branch, respectively. The original HSI processing dimensionality reduction is performed using FA (factor analysis), where significant spectral information is preserved, while the rest of the redundant information and noise are removed. In the two-branch dense connection mechanism, each branch consists of different convolutional blocks that are densely connected to form a dense pyramid connection. In the joint spatial–spectral feature extraction process, the dense pyramid convolution is used to extract the multiscale spatial–spectral feature information in the sample; in the spectral branch, the dense pyramid convolution layer is used to extract the spectral features. Subsequently, the two-branch feature maps are fused and fed to the spatial feature extractor. During the construction of the spatial feature extractor, we propose a new efficient channel–spatial block attention nodule (ECBAM) to enhance the model’s ability to extract salient features; we propose a deep feature fusion strategy high–low deep feature fusion strategy (HLDFF), specifically to enhance the spatial feature learning ability via inverse convolution. Finally, the obtained feature maps are input into the classifier to obtain the classification results. The three main contributions of this paper are as follows:
- (1)
In order to alleviate the problem of insufficient feature missing, a two-branch multiscale feature aggregation with multiple attention mechanism is proposed as a HIC model, which extracts multiscale joint spatial–spectral feature information fusion to obtain hyperspectral feature maps by using dense pyramidal joint spatial–spectral feature extraction branches and inter-spectral feature extraction branches, respectively.
- (2)
In order to enhance the level of attention to significant features during spatial feature extraction, an efficient channel–spatial block attention module (ECBAM) is proposed to enhance the expressiveness of salient spatial information.
- (3)
In the process of spatial feature extraction, a high–low deep feature fusion strategy (HLDFF) is proposed to implement up-sampling of the high-level feature maps and cleverly fuse them with the low-level feature maps to obtain richer feature representations.
The rest of the paper is organized as follows:
Section 2 presents the concrete implementation of the proposed model.
Section 3 presents and analyses the experimental results,
Section 4 discusses the experimental results.
Section 5 summarizes the conclusions of the paper and gives directions for future research.
2. Materials and Methods
2.1. Overall Framework
Figure 1 shows the overall design framework of the FHDANet network. The hyperspectral image can be regarded as a high-dimensional data cube, assuming that the spatial dimension of the original hyperspectral data cube is
, and the number of spectral bands is
, it can be denoted as
. The hyperspectral data cube is downscaled using factor analysis (FA), where significant spectral information is retained while the rest of the redundant information and noise are removed, and the overall computation and the number of model parameters are also reduced. The number of spectral bands after FA downscaling is noted as
, and the hyperspectral image can be denoted as
, which is sliced into
patches with the dimensions of
, where
is the predefined neighbourhood size, the patch category is determined by the category of the central image element, and the patch contains not only the spectral information of the image element to be classified but also the spatial information of the image element within a certain distance around it, and each patch can be denoted as
, and the FHDANet takes
as input.
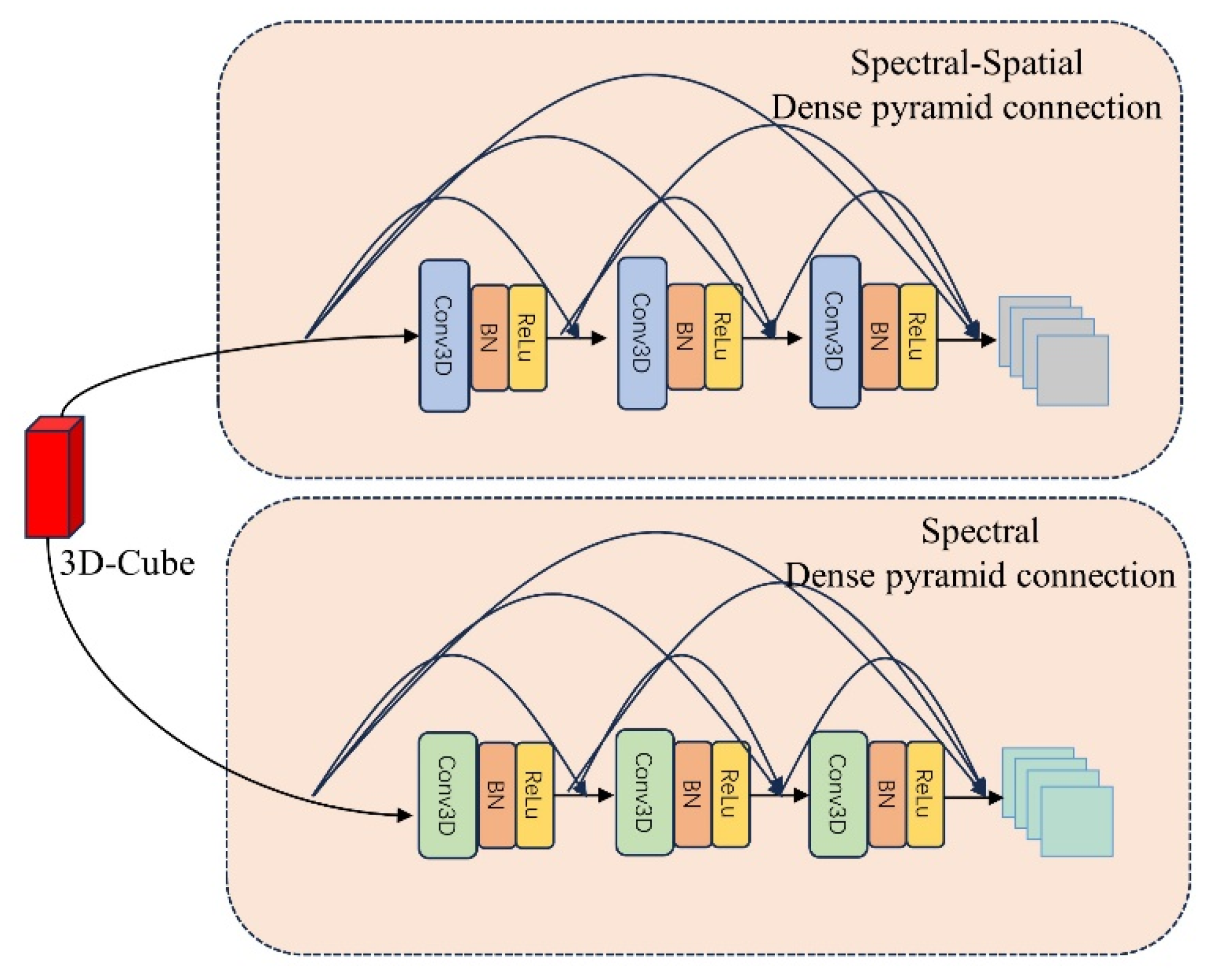
The two-branch dense pyramid structure is a densely connected block composed of 3D-CNNs, and the first branch is the joint spatial–spectrum feature extraction branch, which employs 3D-CNNs with convolutional kernel sizes of , and , respectively, for the joint extraction of multiscale spatial–spectrum information. In this case, dense connections are used to alleviate the gradient vanishing problem, enhance feature propagation, and greatly enhance feature reuse. The second branch is the inter-spectral feature extractor, which also consists of densely connected blocks of 3D-CNN, and differs from the first branch in that its convolutional kernel sizes are , , and in that order, and the focus of the feature extraction is changed from the previous mixed spectral and spatial extraction to the extraction and learning of the spectral information, and the feature maps generated in this branch are fused with those generated from joint spatial–spectral feature extraction The feature maps generated by this branch will be fused with the feature maps generated by spatial–spectrum joint feature extraction.
Let us return to the feature map generated by the first branch. Traditional HyBridSN, including other improved versions, performs feature extraction and learning through a hybrid 3D-2D-CNN, in which spatial and spectral feature learning is performed in the 3D-CNN stage, and spatial correlation learning is performed in the 2D-CNN stage. In the FHDANet proposed in this paper, a branching structure is introduced to make full use of the powerful computational capability of 3D convolution to carry out spatial and spectral feature learning in the spatial–spectrum joint branch and spectral feature learning in the inter-spectrum branch, and finally, the generated feature maps are fused, and the resulting new feature maps serve as input feature maps for the spatial extractor. Adopting the branching structure allows the spectral features to be further extracted and learnt, which is beneficial in the case of small samples, and combined with the dense connectivity mechanism, feature reuse can be well performed.
We introduce an improved efficient channel–spatial block attention module (ECBAM) in the spatial feature extraction stage to efficiently allocate computational resources and enhance the learning of salient spatial features. In addition, we propose a high–low deep feature fusion strategy (HLDFF). HLDFF involves the deconvolution of high-level feature maps generated after convolutional kernel sizes of , and in that order, up-sampling them to the same size as the low-level feature maps, and then splicing the two feature maps together channel-by-channel to obtain a richer representation of the features, thus enhancing feature reuse. Finally, the fully connected layer is used as a classifier to complete the classification task.
2.2. Dense Two-Branch Structure
Given that HSI is a 3D cubic structure with spatial–spectral binding, in 3D convolution, the 3D convolution kernel can be moved in all 3 directions (height, width, and channel of the image). At each position, the multiplication and addition of elements provide a number. Since the filter slides in 3D space, the output digits are also arranged in 3D space, and then the 3D data are output. HSI contains rich one-dimensional spectral information and two-dimensional spatial information; therefore, we adopted 3D-CNN as the convolution module and utilized its excellent computational power as the base building block of the two-branch dense pyramid structure.
In Equation (1), , , and represent the length, width, and number of spectral bands of the 3D convolution kernel, respectively. represents the weights of the kernel that is connected to the th feature cube of the layer; is the activation function.
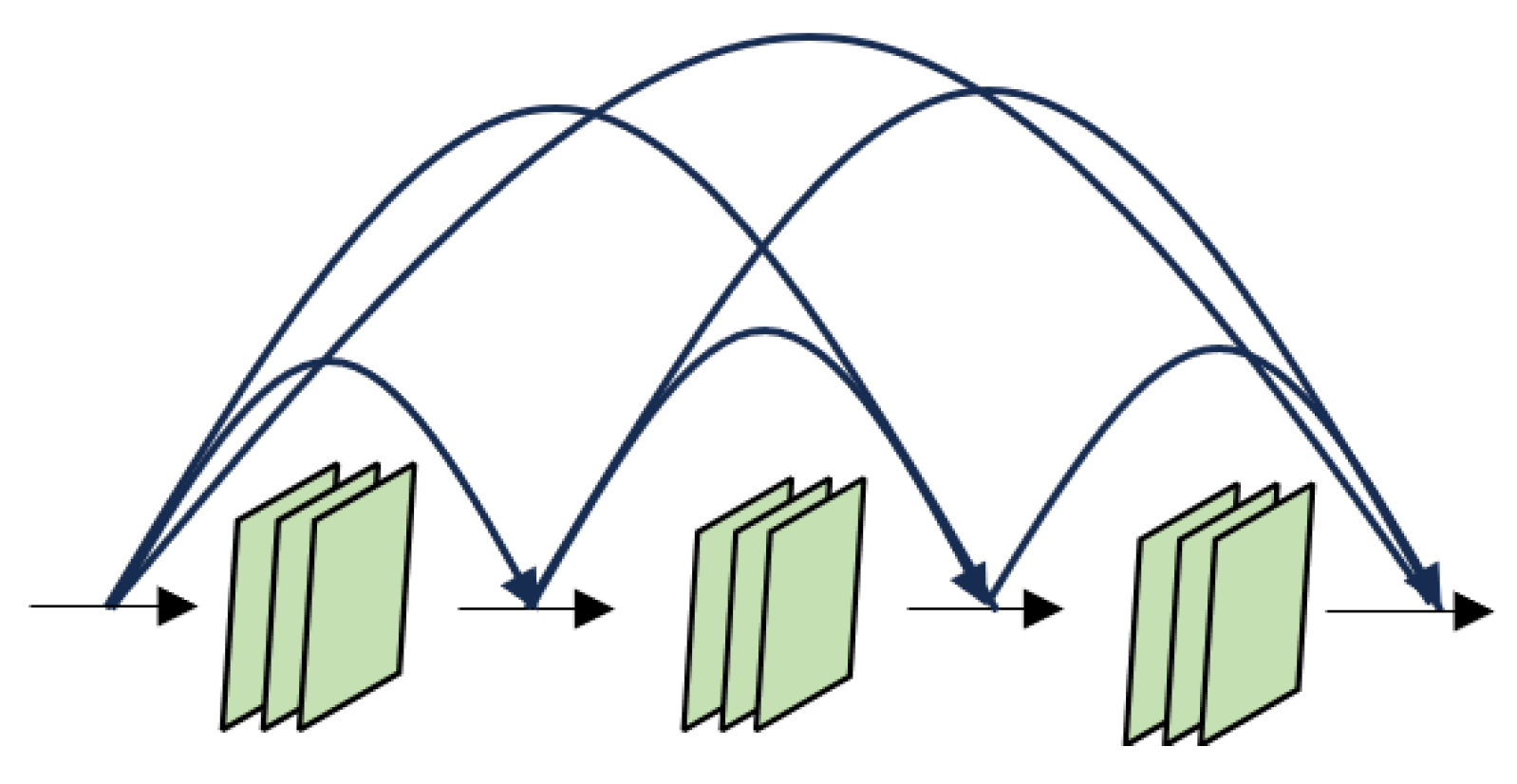
Here, we briefly introduce dense connectivity. DenseNet’s [
34] dense connectivity uses feature maps connected in the channel dimension, where each layer is connected to the outputs of all previous layers and serves as an input to the next layer. For a network with
layers, it contains
connections. Our proposed FHDANet contains two feature feature extractors with a dense pyramid structure, the spatial–spectrum joint dense pyramid feature extractor and the inter-spectrum dense pyramid feature extractor, each of which contains six dense connections, and its feature mapping expression is shown in Equation (2). Introducing the dense connection mechanism into the model makes the model pay more attention to feature reuse and information sharing, enhances the gradient flow, and can substantially improve the performance and generalization ability of the model, although there is a slight loss in computational efficiency. In this paper, we combine the dense connection with 3D-CNN for the construction of dense pyramid structure, which is shown in
Figure 2.
In Equation (2), denotes the output of layer . Layer receives the feature mapping of the previous layers, and is defined as a composite function of three consecutive operations: Batch normalization (BN), linear rectification unit (ReLU), and 3D convolution.
In the traditional dense connection, researchers mostly default to using the same size of convolutional kernel for feature extraction; however, they ignore an important issue, i.e., the scale problem, and are unable to extract multiscale feature information, which leads to the insufficient feature extraction capability of the model, even though the use of dense connection largely enhances the feature multiplexing but still can not cover up the problem of insufficient feature extraction capabilities. In this paper, we adopted the dense golden tower connection combined with the double branch structure to alleviate the problem of insufficient feature extraction ability of the traditional dense connection.
During the dual branch building process, since the size of the output feature maps of each layer varies, the output feature maps of each layer are subjected to maximal pooling to adapt the size of the densely connected feature maps to fit. The spatial–spectrum joint dense pyramid branch, using convolution kernels of size
,
,
in order, uses maximum adaptive pooling for the feature map size of each layer to fit the feature map splicing of each layer to complete the dense connection. The first branch network architecture is shown in
Table 1.
The inter-spectral dense pyramid branch uses convolution kernels of size 7 × 1 × 1, 5 × 1 × 1, and 3 × 1 × 1 in order, which is consistent with the principle used in the first branch, with maximum adaptive pooling for the feature map size at each layer. The second branch network architecture is shown in
Table 2. A schematic diagram of a dense two-branch pyramid connection is shown in
Figure 3.
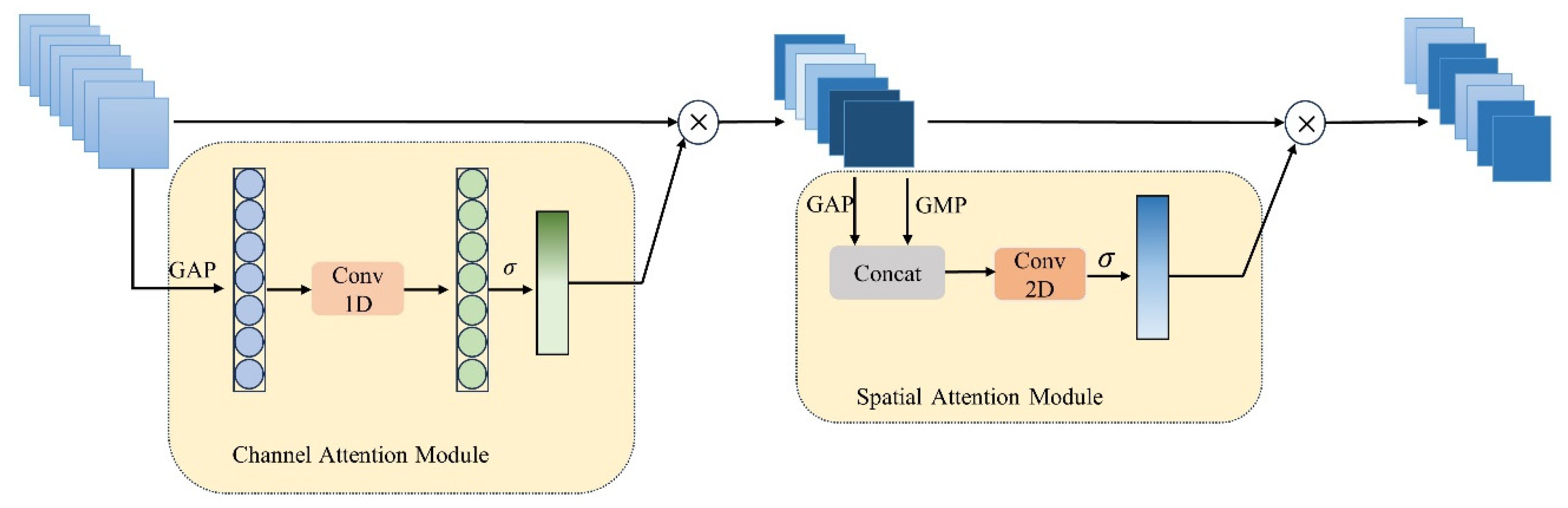
2.3. ECBAM Module
In the spatial feature extraction process, we propose an efficient channel–spatial block attention module (ECBAM) focusing on feature extraction for spatial categories of interest while ignoring the influence of background as much as possible. The development of existing mainstream attention modules is centered around two broad aspects: (1) enhanced feature aggregation and (2) the combination of channel and spatial attention. We note that traditional CBAM is divided into two sub-modules, channel, and spatial attention. In the channel attention module, the input feature maps need to be subjected to global maximum pooling and global mean pooling, and subsequently fed into a two-layer neural network, assuming that the number of neurons in the first layer is
M/r, and the number of neurons in the second layer is
M, the channel attention module performs dimensionality reduction of the original input feature maps. Wang et al. [
35] demonstrated, with a large number of experiments in ECA-Net, that dimensionality reduction has a negative effect on the learning ability of the model. Despite the fact it reduces the complexity of the model, it will inevitably lead to information loss, and we should try our best to avoid dimensionality reduction when designing the attention module, and he proposed a local cross-channel interactive attention module ECAM. We are inspired by ECAM and, in this paper, we present the ECBAM attention module on the basis of CBAM.
ECBAM consists of two separate sub-modules: the channel attention module and the spatial attention module. In the channel attention module, the convolutional features are aggregated using GAP. We believe that the cross-channel information capturing ability of convolution is very strong; therefore, we used the traditional fully connected layer and instead performed one-dimensional convolution with the convolution kernel size set to 3. Subsequently, the output feature maps are multiplied by the Sigmoid activation function, and finally, the output feature maps are multiplied by the input feature maps to obtain the output feature maps
of the channel attention module, as shown in Equation (3). The second module of ECBAM, the spatial attention module, is introduced next. We take the feature maps
generated by the channel attention as the input feature maps
of this module. The spatial attention module first performs the channel-based global maximum pooling and global mean pooling to connect the respective outputs by the channel dimensions, performs the convolution operation with a convolution kernel of 7, and finally multiplies the output feature maps with the input feature maps
to generate the final feature maps
. The whole process is shown in
Figure 4.
where
is the input feature map,
is the activation function Sigmoid,
is the 1D-CNN with the convolution kernel size of 3, and
is global mean pooling.
where
is the input feature map,
is global maximum pooling, and
is the 2D-CNN with the convolution kernel size of 7.
2.4. HLDFF Strategy
In order to solve the problem of missing features, in the spatial feature extraction stage, we propose a spatial feature extractor based on the deep feature fusion strategy (HLDFF), which can generate richer and deeper feature representations and enhance the reusability of features in order to improve model performance and generalization ability. In HLDFF, we cleverly use deconvolution to up-sample the high-level feature maps. Deconvolution can greatly recover the spatial feature information lost in the spatial feature extraction process and enhance the feature detail expression ability, so that the resulting high-level feature maps have high spatial accuracy while maintaining rich semantic information. Deconvolution is a special forward convolution process. In this process, the size of the input image is first enlarged by complementing 0 according to a certain ratio, followed by forward convolution.
As shown in
Table 3, we use 2D-CNN with convolutional kernel sizes of 7 × 7, 5 × 5, and 3 × 3, and then the extracted high-level feature maps were deconvolutional expanded to the same size as the input low-level feature maps, and then channel-level connectivity was carried out, i.e., the fusion of up-sampled high-level feature maps and low-level feature maps, which not only makes full use of the rich semantic information of high-level feature maps but also combines the fine-grained features of low-level feature maps to construct a more comprehensive and fine-grained feature representation. This fusion process not only makes full use of the rich semantic information of the high-level feature maps but also combines the fine-grained features of the low-level feature maps so as to construct a more comprehensive and fine-grained feature representation. This feature fusion strategy not only enhances the reusability of the features but also improves the ability of the model to capture and utilize the spatial features, which alleviates the problem of spatial feature loss.
2.5. Classifier Construction
We use two fully connected layers and Softmax classification loss function for classifier construction, in which the first fully connected layer has the largest number of parameters, and the number of nodes in the last fully connected layer is the same as the number of categories corresponding to the given dataset. In addition, in order to effectively deal with model overfitting due to the large number of model parameters and small number of training samples, Dropout is used to achieve regularization effect to a certain extent to alleviate the occurrence of overfitting; ReLU is chosen as the nonlinear activation function; and BN layers are added after each convolutional layer to make the training easier and accelerate the convergence.
4. Discussion
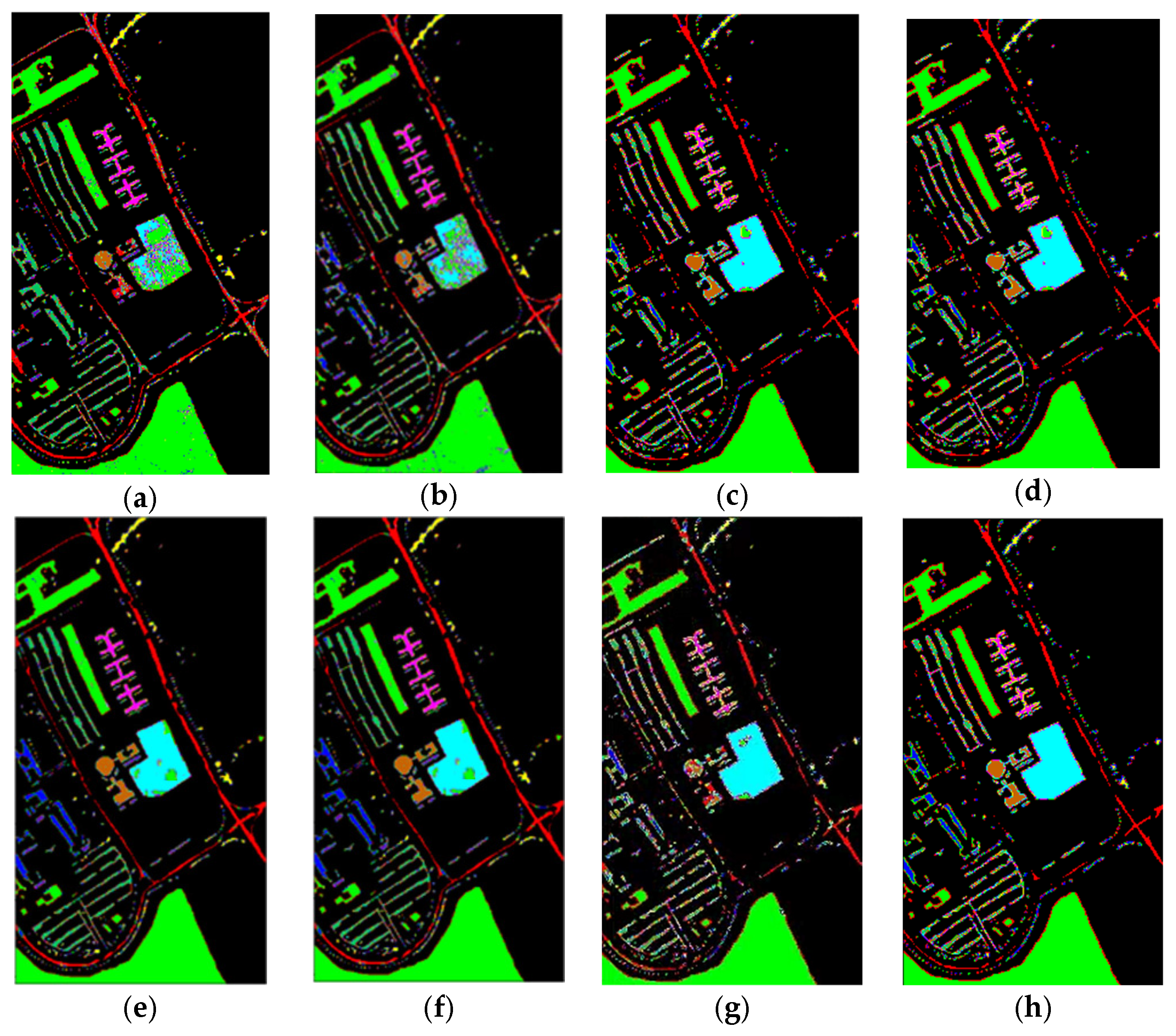
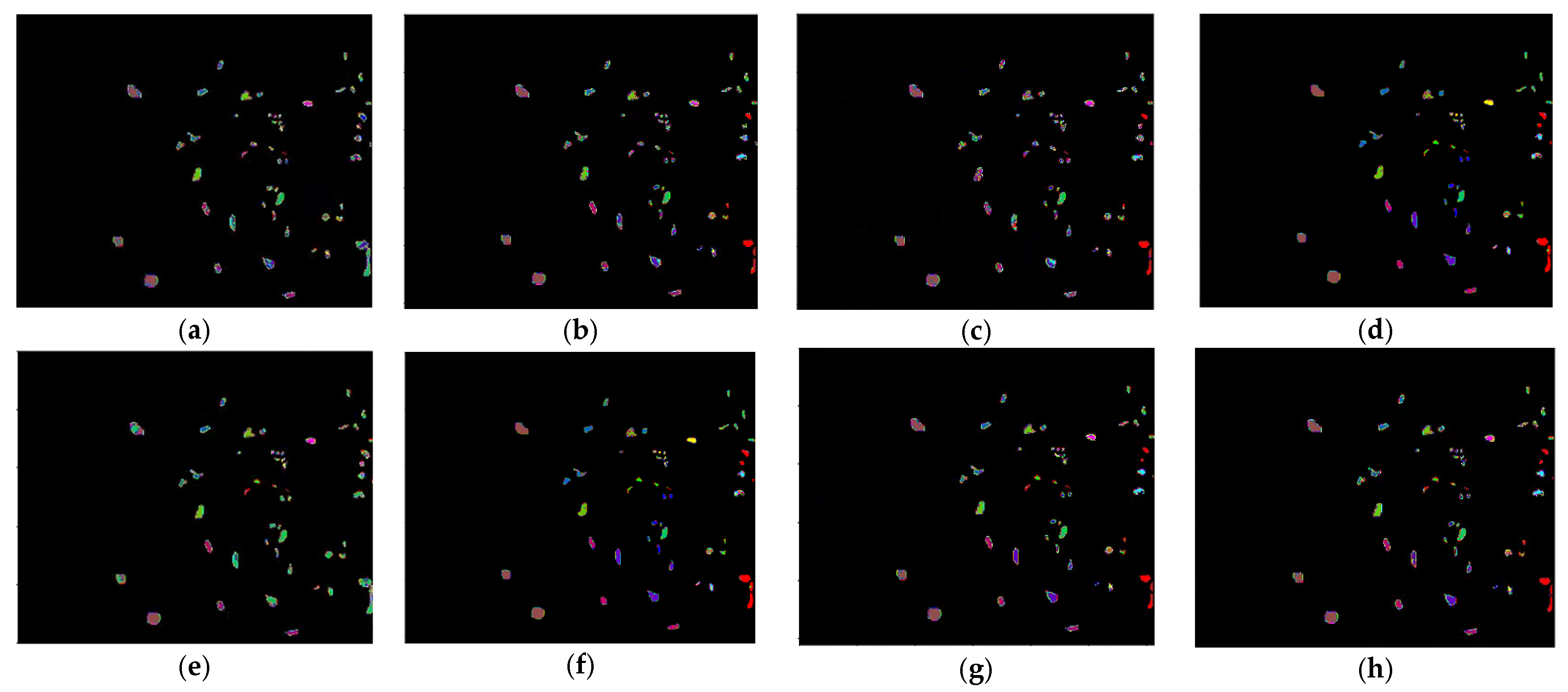
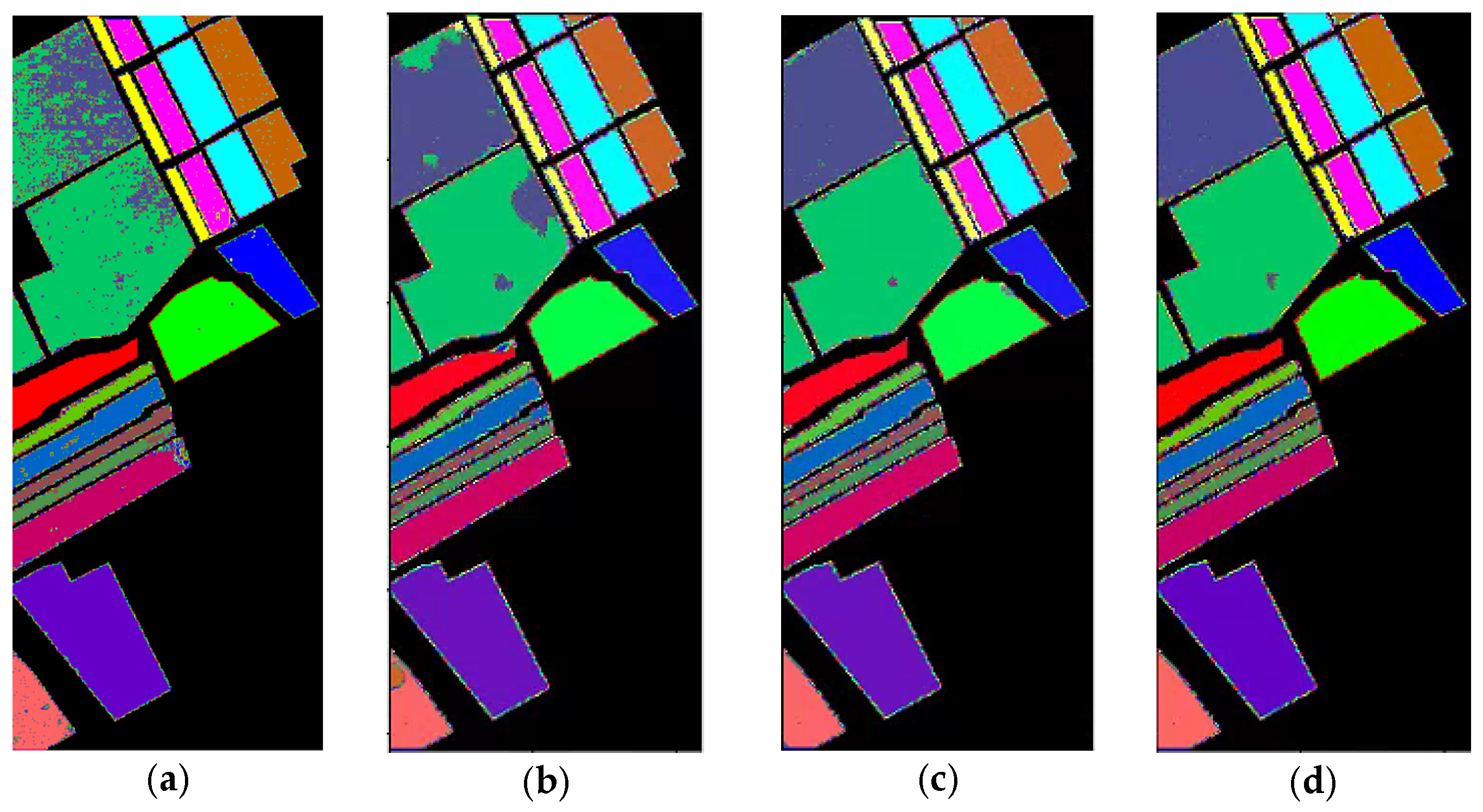
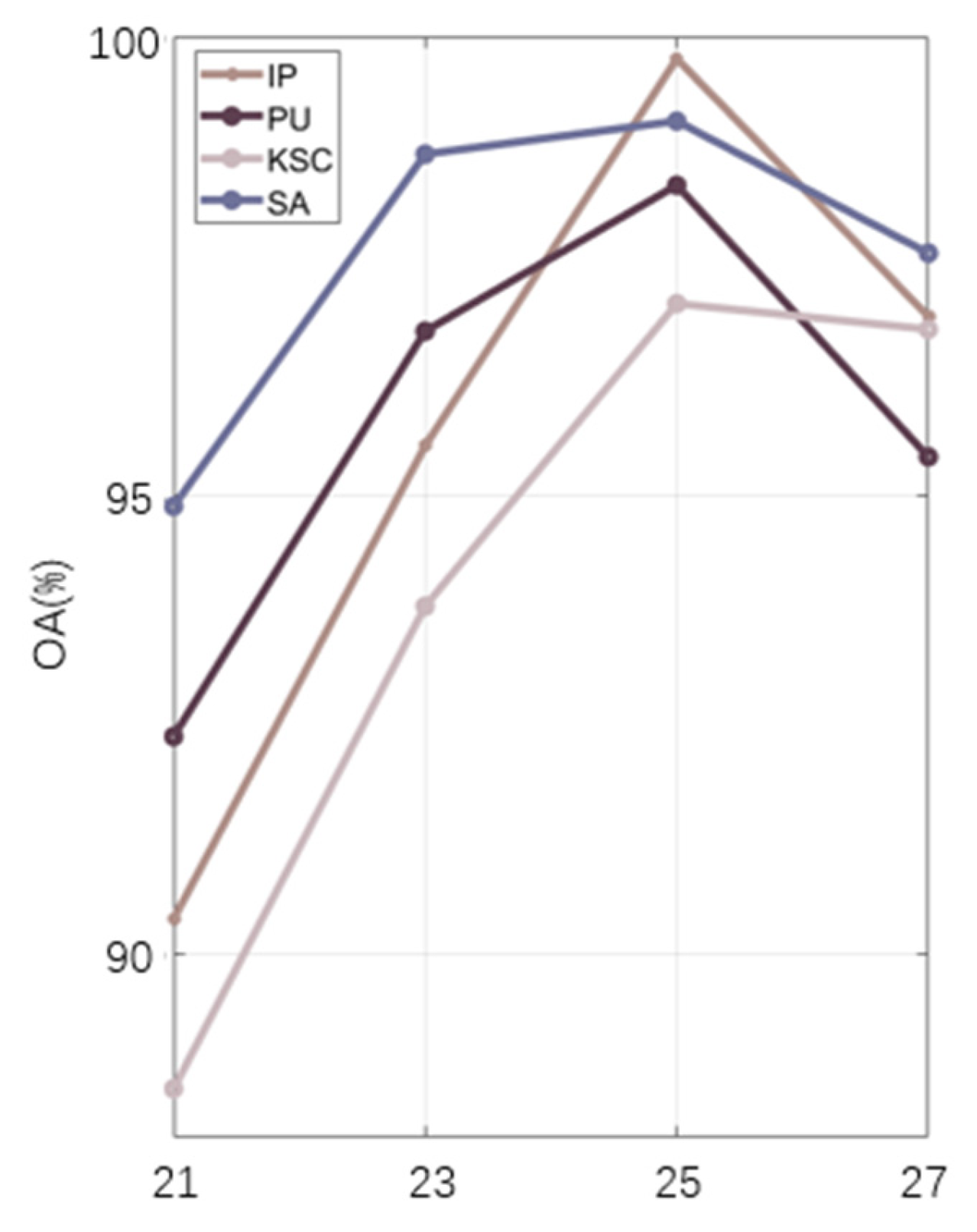
In this paper, we propose a hyperspectral image classification model FHDANet based on a dense two-branch structure. In FHDANet, we propose a new spatial–channel attention module ECBAM and a spatial feature extractor based on a deep feature fusion strategy (HLDFF). In the model, we adopt a dense two-branch connection structure for the construction of the joint spatial–spectral feature extractor and the inter-spectral feature extractor, which alleviates the problems of feature loss and insufficient feature extraction caused by the use of traditional methods, increases the feature reuse, and better obtains the spatial–spectral context information. In order to better cope with the problems of “same object, different spectrum” and “different object, same spectrum”, we adopt multiscale pyramid connection to carry out multiscale feature extraction so as to better combine the spatial feature information. Meanwhile, in the process of constructing the spatial feature extractor, we innovatively propose HLDFF to further enhance the feature reuse, and HLDFF can generate richer and deeper feature expressions through the clever use of deconvolution to enhance the feature reuse, in order to improve the model performance and generalization ability. In addition, we propose the ECBAM attention module, which uses the global mean pooling kernel 1DCNN for feature aggregation, directly avoiding the feature loss caused by the dimensionality reduction in the traditional attention module. Meanwhile, in order to better mitigate the effects of “same object, different spectrum” and “different object, same spectrum”, we use ECBAM to maintain the model’s sensitivity to salient features so as to better incorporate spatial contextual information and improve classification accuracy. The above experiments on the four datasets demonstrate that FHDANet possesses excellent classification performance. The six deep learning-based classification models, SSRN, A2SK2-ResNet, HyBridSN, SSGDL, RSSDL, and LANet, which were compared, all share a common defect, that is, they fail to consider the problems of feature loss and insufficient feature extraction ability well and ignore feature reuse to a certain extent. In the case of sufficient training samples, these problems can be masked, but when in the condition of few training samples, the limitations of these methods are exposed. In addition to this, each comparison model has its shortcomings, which will be analyzed in detail for the overall classification performance in the following. Looking at the model as a whole, the modular design allows for good scalability, specifically by performing operations such as adding or replacing new network layers, meaning that loss functions or optimizers can be changed relatively easy.
As shown in
Figure 9,
Figure 10,
Figure 11 and
Figure 12 and
Table 4,
Table 5,
Table 6 and
Table 7, in A2S2K-ResNet, a large amount of labeled data are required, the limitations of the model are exposed under small sample conditions, and the risk of overfitting is greatly increased, so its accuracy is much smaller than that of the FHDANet proposed in this paper on all four datasets, with gaps of 5.41%, 5.14%, 0.23%, and 2.24%, respectively. The network structure of SSRN is more complex. This leads to similar drawbacks as those seen in A2S2K-ResNet, i.e., a large amount of labeled data are required, which would otherwise lead to the risk of overfitting, but due to the large number of spectral residual blocks and spatial residual blocks inside the model, the model not only mitigates the risk of gradient vanishing and overfitting but also achieves feature reuse to a certain degree, which mitigates the problem of feature loss, and thus, the average OA of the four datasets reaches 91.13%. Although HyBridSN attaches importance to multiscale feature extraction and distinguishes between spatial and spatial–spectral information extraction, it ignores the problem of feature loss, and thus, performs better in the experiments, and the OA even reaches 98.57% in the SA dataset, which confirms that multiscale feature information extraction is beneficial to the model in terms of improving the generalization ability, and thus, the overall classification performance. In SSGDL and RSSGL, since they are actually global feature extraction frameworks, and despite the fact that they have slightly greater accuracy than several other comparison algorithms, they have high computational costs, involve large FLOP values, and are not effective overall. In LANet, the classification effect is not as good as that of FHDANet in this paper due to the fact that it does not consider the joint multiscale spatial–spectral information. From the ablation experiments, as shown in
Table 8, the addition of the ECBAM module can better ensure the model’s saliency feature extraction ability, thus enhancing the model’s generalization ability. As shown in
Figure 9,
Figure 10,
Figure 11 and
Figure 12 and
Table 4,
Table 5,
Table 6 and
Table 7, we can see that when the model is trained and tested using four different datasets, we find that both in terms of the classification accuracy of individual categories and the overall classification accuracy, our proposed FHDANet model is significantly improved compared with previous deep learning algorithms, which shows that the model is highly robust in relation to different datasets.
Let us go back to the two-branch dense concatenation mechanism. Dense concatenation not only improves the reusability of features but, more importantly, it alleviates the problem of gradient vanishing as the model depth deepens. As shown in the figure, the parameter sharing between different layers of the dense concatenation greatly reduces the amount of parameter training in terms of the network but undeniably increases the amount of gradient information that needs to be computed, which leads to an increase in the value of the model’s FLOPs, which is intuitively manifested as an increase in the training time of the model. However, we can reduce the number of convolutional layers by means of dense connectivity, making the depth of the network considerably lower, and from this point of view, dense connectivity can be considered as an indispensable and fundamental mechanism to improve the generalization of the model, at least as far as FHDANet is concerned.
5. Conclusions
In this paper, we propose a highly accurate two-branch multiscale feature aggregation and multiple attention mechanism for hyperspectral image classification model FHDANet. The model achieves high efficiency extraction of spatial–spectral and inter-spectral feature information by using dense two-branch pyramid connection, which largely reduces feature loss and strengthens the model’s ability to extract contextual information; we propose a channel–space attention module, ECBAM, which greatly improves the extraction capability of the model for salient features. A spatial information extraction module based on the deep feature fusion strategy HLDFF is proposed, which fully strengthens the feature reuse capability and mitigates the feature loss problem brought about by the deepening of the model. Experiments were carried out on four representative datasets, and the experiments proved that FHDANet has excellent classification performance under the condition of small samples, which is better than other comparative experiments.
However, our proposed model still has some shortcomings. First, as far as the dimensionality reduction in the preprocessing step of the HSI is concerned, we used FA to perform dimensionality reduction on the HSI in order to reduce the computational complexity of the model. However, no matter how dimensionality reduction is used, it will lead to the unavoidable loss of information in the original HSI, which is a source loss and we cannot recover it by means of dense joining, residual joining, and inverse convolution, etc. Therefore, the model’s future development should be optimized in the direction of full-band feature extraction. Specifically, we should try our best to solve the problem caused by Hughes phenomenon, i.e., the phenomenon that classification accuracy increases and then decreases with the increase in the number of bands involved in the operation. Secondly, the proposed model is a 3D-2D-CNN model based on dense two-branch pyramid connection, which can effectively improve the classification performance and obtain high-precision classification results; however, the large number of floating-point operations leads to an increase in the training time of the model, which makes the model less computationally efficient.
In addition, under small sample conditions, we should think that, in addition to deepening the depth of the network and using feature reuse, there is a more direct way to cope with the phenomenon of low classification accuracy brought about by the use of small samples, and this research method is how to give full play to and make use of the value of a large number of unlabeled samples under the condition of given labeled samples so as to enable the classification model to fully exert its potential to obtain optimal generalization performance, which is also commonly known as semi-supervised algorithm research. This is also commonly known as semi-supervised algorithm research. The optimization direction of the model should be toward semi-supervision to take advantage of the large amount of unlabeled data because simply deepening the network and performing feature reuse will make the model consume a huge amount of computational resources; however, using semi-supervised methods can take advantage of the large amount of unlabeled samples; specifically, we do not need to overemphasize feature reuse in the design of the network. Firstly, a small number of labeled samples are used for the model. First, the model is pre-trained using a small number of labeled samples; second, the model is used to generate pseudo-labels for the unlabeled samples, and then the model is co-trained using both labeled and pseudo-labeled samples. This classification model based on pseudo-label generation can make full use of the feature information in hyperspectral data to a great extent, while saving computational resources to a certain extent. Overall, the future optimization direction of the model should be towards full-waveband and semi-supervised direction so as to further improve the robustness and generalization ability of the model.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}