1. Introduction
Wildlife is an essential component of natural ecosystems, playing a crucial role in regulating and balancing these ecosystems. Furthermore, it actively participates in the Earth’s carbon cycle, contributing to the stability of ecosystems, species diversity, and the overall health of the carbon cycle [
1]. Unfortunately, due to the exponential growth in the human population and the excessive pursuit of economic development, natural resources have been excessively exploited. Additionally, human social activities have expanded into the natural environment, leading to rapid and significant changes in the Earth’s ecosystem [
2]. Consequently, the diversity of wildlife is declining at an unprecedented rate, with some species facing extinction [
3]. Therefore, it is imperative to enhance the protection and management of wildlife.
Detecting and identifying wildlife is a crucial aspect of wildlife protection and management. It not only improves our understanding of the current status of wildlife species and populations but also provides valuable information about changes in the natural ecological environment, as evident through the survival of wildlife observed during the detection process [
4].
Traditional wildlife detection and identification methods rely on wildlife conservation rangers collaborating with taxonomic experts [
5]. These methods, including direct observation and capture–recapture, are currently widely used. However, they have drawbacks such as being time-consuming, costly, and requiring specialized taxonomic experts to ensure reliable identification results. Additionally, conducting traditional wildlife surveys faces obstacles like the remoteness of some wildlife habitats and the presence of aggressive and potentially dangerous animals that make close observation difficult [
6]. Comparatively, wildlife identification using GPS collars and environmental DNA sampling is less expensive and poses less risk than manual census methods [
7]. However, these approaches have limitations. They cover smaller areas and allow for the surveying of fewer wildlife species. Moreover, the use of GPS collars can cause harm to the animals themselves.
Advances in machine vision and monitoring equipment have shed new light on wildlife identification and detection [
8]. Monitoring equipment, including visible and infrared cameras, can collect vast amounts of wildlife image data without requiring a human presence [
9]. Deep learning techniques, as the primary method used in target recognition, which is the most researched field in machine vision, can be utilized to extract the features of target wildlife using a large amount of image data, thereby recognizing the species of wildlife [
10]. With the continuous improvement of large-scale image datasets and device arithmetic power, the superiority of deep learning has been recognized [
11]. Deep convolutional neural networks have been more and more widely used in wildlife detection and identification by virtue of its excellent feature extraction ability [
12], which can be broadly classified into two kinds. The first is a two-stage deep learning model based on region suggestions, including Fast-RCNN, Mask-RCNN and Faster-RCNN, etc. The second is a single-stage deep learning model, with the most representative being the You Only Look Once (YOLO) deep learning model [
13]. Each of these two models has its own strengths and excels in different tasks.
Fast R-CNN is a new rapid target detection model proposed by Ross Girshcik et al. from Microsoft Research [
14]. This model generates a region of interest for potential targets by processing images through convolution and maximum pooling layers to propose features. It then compares the extracted feature vectors and ultimately identifies the most probable target region. This method represents a significant advancement in terms of speed and accuracy when compared to models like VGG16 and SPPNet. To enhance the accuracy of Fast R-CNN, Shaoqing Ren and colleagues proposed integrating a fully convolutional network called the Region Proposal Network into Fast R-CNN [
15]. This addition aims to produce high-quality regions of interest through end-to-end training while sharing convolutional features with the baseline network to decrease the network’s computational cost. In experiments, Faster R-CNN demonstrated a considerable enhancement in detection frame rate and accuracy compared to the backbone network, making it more suitable for target detection tasks.
Alekss Vecvanags et al. utilized RetinaNet and Faster R-CNN models as the backbone network in monitoring wildlife activity in hoofed species [
16]. The models were compared with the YOLO model, and experiments showed that Faster R-CNN has a faster detection speed compared to RetinaNet. However, as a two-stage model, the average detection speed is still not as efficient as the single-stage YOLO model. Despite this, the YOLO model does not perform as well as Faster R-CNN in small target detection. Each model has its own set of advantages.
Mohamad Ziad Altobel and colleagues successfully remotely monitored wild tigers using the Faster R-CNN model applied to the ATRW dataset for tiger detection [
17]. After comparing the results with the MobileNet and YOLOv3 models, it was found that the Faster R-CNN model had a significant advantage in terms of accuracy. Jinbang Peng et al. utilized Faster R-CNN for detecting wildlife targets in UAV images. The purpose was to address the challenge posed by the smaller and more scattered distribution of wildlife targets in such images [
18]. The experimental findings indicated that Faster R-CNN outperformed other methods in terms of suppressing image background and detecting targets quickly. It is evident that Fast R-CNN and Faster R-CNN outperform backbone networks like VGG in target detection, being both quicker and more precise. However, thorough research and experiments have revealed that there still exists a noticeable gap in detection speed between Fast R-CNN and the YOLO model. Despite its complex background suppression capabilities and unmatched detection accuracy, Fast R-CNN falls short in terms of detection speed when compared to the YOLO model.
Mask R-CNN is an advanced model that builds upon the strengths of Faster R-CNN, as proposed by Kaiming He et al. It is a highly adaptable framework for target instance segmentation, effectively detecting targets within images [
19]. In comparison to Faster R-CNN, the increase in computational cost with Mask R-CNN is minimal. However, it achieves greater accuracy in the task of instance segmentation, resulting in more precise target detection. Jiaxi Tang et al. proposed a two-stage model based on the Mask R-CNN model for detecting wildlife targets captured by trap cameras [
20]. In the first stage, few-shot object detection is used to identify the species and initially describe the target contour. In the second stage, the feature extraction module of Mask R-CNN is utilized to carry out contour approximation. An experiment proved that the method achieves good results in fast contour outlining of wildlife, and it performs better in terms of FPS and mAP50 metrics compared to the Mask R-CNN and PANet models.
Yasmin M. Kassim et al. have proposed a fast detection algorithm for small targets in infrared video based on migration learning to solve the problem of small targets being difficult to recognize in natural M.G. thermal imaging [
21]. The algorithm utilizes Mask R-CNN and DAF processes, and the experimental results show that the method achieves better accuracy in target detection at higher frame rates.
Timm Haucke and others proposed the D-MASK-R-CNN model for recognizing wild animal images with added depth information, achieving instance segmentation of wild animal targets [
22]. It is evident that Mask R-CNN outperforms Fast R-CNN in terms of target detection accuracy and target contour approximation. However, they perform similarly in terms of detection speed. In the context of wildlife target detection in complex field environments, high detection accuracy is crucial, but equally important is the need for fast detection speeds.
The YOLO algorithm, proposed in 2016 by Joseph Redmon et al., is a one-stage target detection algorithm [
23]. This algorithm converts the problem of target localization into a regression problem. Moreover, the algorithm offers the advantages of speed and flexibility, creating conditions for enhanced image processing [
24]. After undergoing several iterations, the YOLO model has been further improved. YOLOv5, being the fifth version of the YOLO series and also the model with the most recent updates, is an efficient and accurate target monitoring algorithm. Its performance in terms of speed, capacity, and accuracy has witnessed significant improvements. The YOLOv5 model group consists of five sub-models. Among these, the YOLOv5s model stands out for having the shallowest network depth and width, the fewest parameters, and a faster inference speed compared to other models, except for the edge device-specific variants [
25]. The other models expand upon and enhance the YOLOv5s model by increasing the network depth and width, resulting in improved accuracy. However, this increased complexity also leads to higher hardware requirements for computing devices [
26]. Compared to two-stage deep learning models like Fast R-CNN, the YOLO series of models do not require target extraction based on candidate frames for recognition results. Instead, detection results are obtained directly through image computation. The emergence of the YOLO model and its variants has significantly improved the speed of detection and has also shown high accuracy [
27].
William Andrew et al. proposed an offline automatic detection model based on the YOLOv2 model in order to realize an unmanned aircraft platform capable of wildlife recognition and reasoning, and demonstrated that the YOLO model has some potential for application in wildlife detection through a small-scale experiment in a farm environment [
28]. Runchen Wei et al. used the YOLOv3 deep learning model as the base model for Northeast tiger recognition and adopted channel pruning and knowledge distillation to lighten the model. The experimental results showed that although the model accuracy decreased, the model size and computation amount were greatly reduced, and the comprehensive performance was better than the previous target detection model [
29]. Arunabha M. Roy et al. designed a deep learning model for endangered wildlife identification based on the YOLOv4 model and introduced a residual module in the backbone network for enhancing the feature extraction capability, which outperformed the mainstream deep learning models at a certain detection rate [
30]. The YOLOv5 target detection algorithm is known for its fast detection speed and light weight, making it ideal for improving the efficiency of image data processing. However, using the YOLOv5 network directly to detect targets in complex environments can lead to high leakage and false detection rates.
To address this issue, Mingyu Zhang et al. proposed an enhanced animal detection model based on the YOLOv5s model by introducing the GSConv module, which combines deep convolution, standard convolution, and hybrid channels, thus realizing the improvement of classification detection accuracy in the presence of improved model detection speed [
31]. Similarly, Ding Ma et al. developed the YOLO-Animal model by incorporating the YOLOv5s model and integrating the weighted bi-directional feature pyramid network and attention module. This fusion with the YOLOv5s network significantly enhanced the detection accuracy for small and fuzzy targets of wild animals [
32]. YOLOv5s has achieved improved results in various tasks due to its light weight.
Kaixuan Liu et al. developed an algorithm specifically for quickly identifying the rice fertility period. Building upon the lightweight nature of YOLOv5s [
33], the backbone network was replaced with MobileNetV3 to enhance the model’s detection speed. Additionally, the feature extraction network was replaced with GSConv to reduce the computational costs, and a lightweight Neck network was constructed to decrease the complexity of the model while preserving accuracy. Xinfa Wang et al. also utilized the YOLOv5 model to enhance it for detecting small targets in tomatoes in agriculture [
34]. MobileNetV3 was introduced instead of the backbone network to improve efficiency. A small target detection layer was added during small target detection to enhance accuracy, resulting in significant improvements in both accuracy and detection speed based on experimental results. These advanced studies highlight that YOLOv5s, as an outstanding lightweight model structure, can effectively accommodate rapid target detection tasks. There is potential for further improvement in terms of lightweight design, and by refining the feature extraction method, detection accuracy can be enhanced while maintaining detection speed. This makes YOLOv5s more suitable for detecting wildlife targets in complex forest environments.
In addition to the more popular single-stage and two-stage models such as YOLO and Fast R-CNN, there are also other models that have shown excellent performance in wildlife target detection tasks. For example, Lei Liu et al. addressed the issue of accurately recognizing wildlife targets by proposing the Temporal-SE-ResNet50 network [
35]. This network not only utilizes ResNet50 to extract image features but also incorporates a residual multilayer perceptron to capture temporal features. By fusing these features, the model’s accuracy in recognizing animal categories is significantly improved, as demonstrated by experiments showing a notable enhancement in accuracy compared to models like ResNet50 and VGG16. While this approach has achieved impressive results, it is more suitable for recognizing data collected by trap cameras, due to its large model scale and challenges in meeting real-time detection demands after two-stage coding.
In summary, the YOLO series model has more evident advantages in detection speed and model scale compared with a series of two-stage models like Fast R-CNN due to its concise structure. However, there are still deficiencies in detection accuracy. It can be observed that by integrating the feature extraction mechanisms of models with higher detection accuracy, such as the attention mechanism, with the YOLO backbone network, there is potential to enhance detection accuracy while maintaining fast detection speeds.
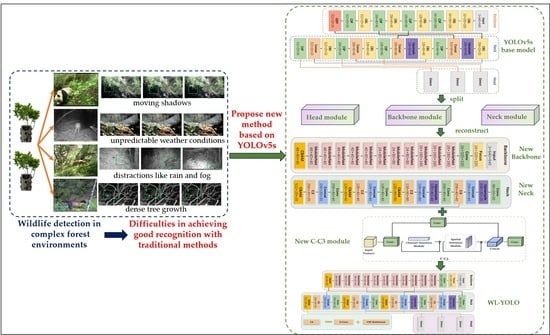
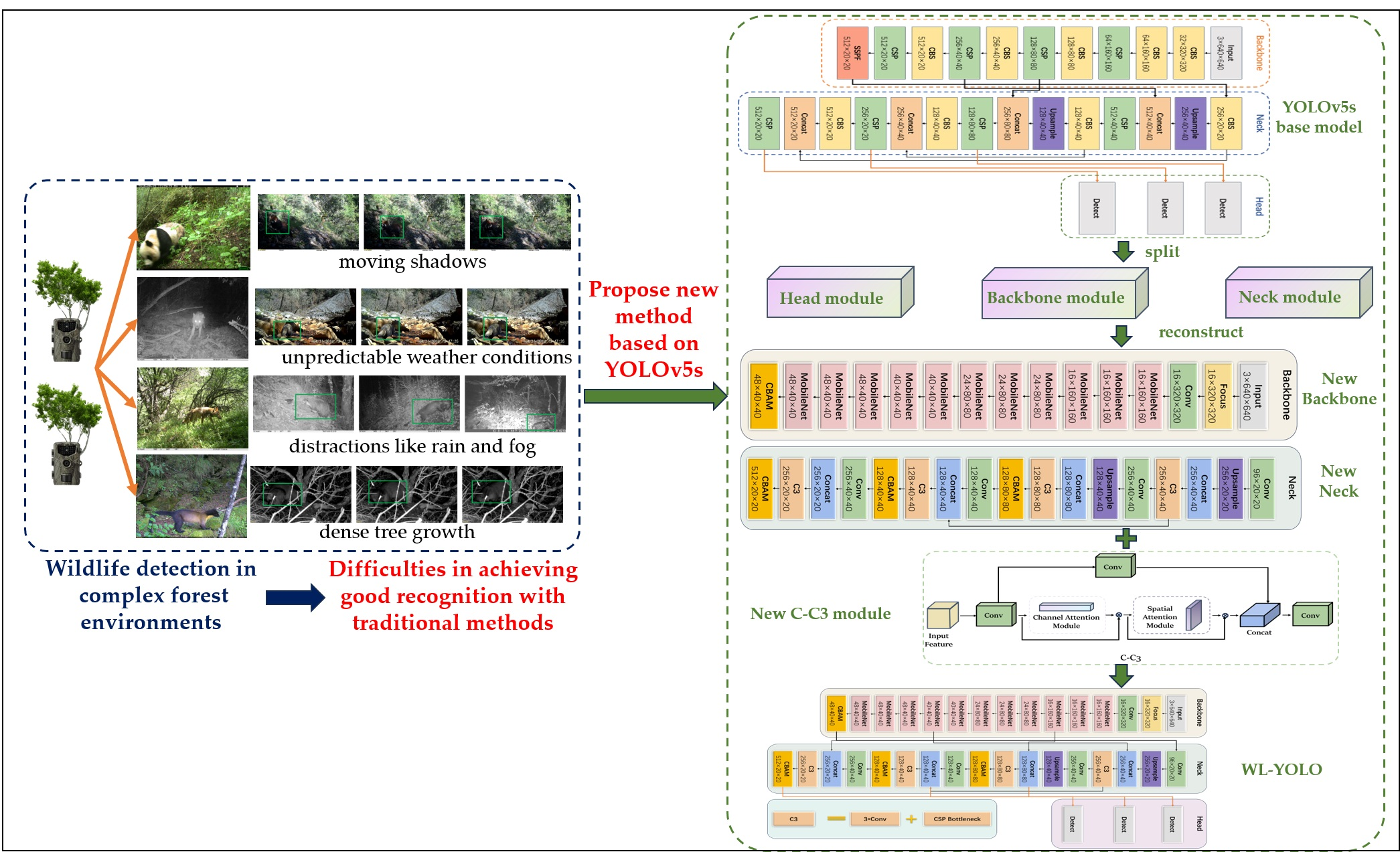
Unlike conventional target recognition, wildlife recognition in complex forest environments is a challenge. This is due to several factors, such as dense tree growth, unpredictable weather conditions, moving shadows, and distractions like rain and fog [
36]. Additionally, the natural camouflage of wild animals further complicates their identification in these environments (
Figure 1) [
37]. As depicted in
Figure 1, the targets within the green boxes are the wildlife targets that must be identified. Each row in
Figure 1 represents a different situation in which a target is affected, including factors such as light, weather, and more. Therefore, the primary challenge lies in developing models that can efficiently and accurately detect and recognize animals against complex backgrounds.
To address the aforementioned challenges, this study utilized public parks and ecological reserves in China as the study area. We focused on gathering data on approximately 14 species of wildlife as our research objectives. In order to achieve real-time and accurate detection of wildlife in intricate forest environments, we introduced the WL-YOLO model, an enhanced version of the YOLOv5s detection model. By deploying the model on both the server-side and mobile-side, real-time monitoring can be achieved through surveillance cameras in national parks and by field workers using mobile devices, respectively. The main contributions of this article are as follows:
- (1)
In the WL-YOLO model, we have integrated the MobileNetV3 module to reduce the model parameters and improve the real-time detection speed, achieving a 44.73% reduction in the number of parameters compared to the YOLOv5m model.
- (2)
Additionally, we have introduced the CBAM attention mechanism, which combines spatial and channel aspects with the feature extraction module to participate in end-to-end training. This attention mechanism has a better target focusing effect compared to mechanisms that solely focus on the channel.
- (3)
We have enhanced the scale of the model’s anchor frame, which is used for detecting targets. This improvement enables the model to better concentrate its attention on elusive wildlife targets. Compared to the unimproved YOLOv5 model, this model has a superior ability to focus on small targets and detect hidden targets in complex environments.
In comparison to two-stage models like Fast R-CNN, the WL-YOLO model boasts a smaller number of parameters, faster detection speed, and, simultaneously, better accuracy.
This article is organized as follows:
Section 2 presents the wildlife dataset we collected and used, as well as the designed wildlife detection and identification model. In
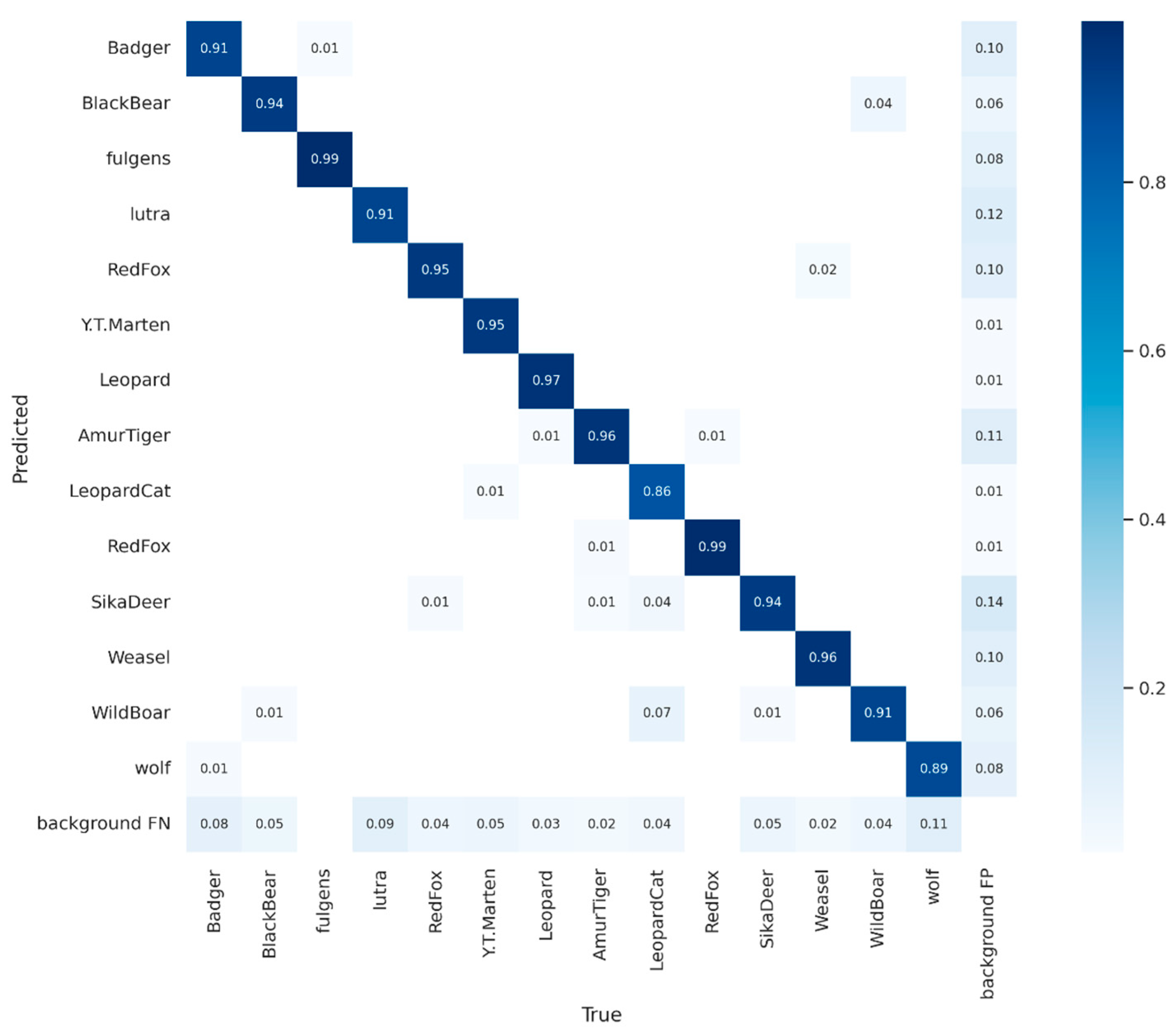
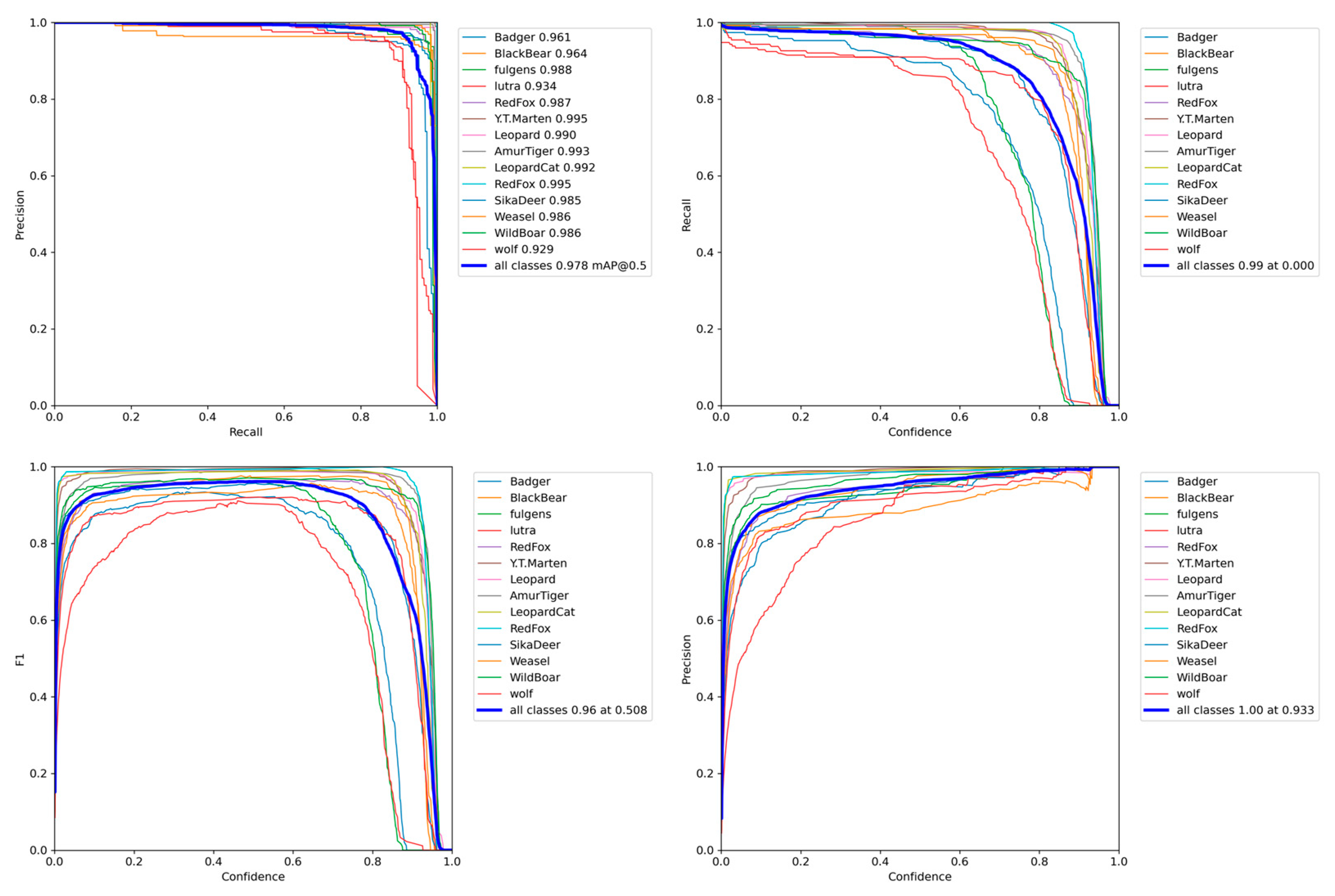
Section 3, the experimental results of the model are evaluated and analyzed.
Section 4 provides a summary and generalization of the wildlife detection and identification model for complex forest environments, presented in conjunction with the experimental results. This section also highlights the advantages and limitations of the model.
2. Materials and Methods
2.1. Study Area and Sample Plots
The wildlife image data collected and used in this paper are all from national parks as well as ecological reserve areas within China, including the Giant Panda National Park, Northeast Tiger and Leopard National Park, Three-River-Source National Park, Xishuangbanna National Nature Reserve of Yunnan, Gongga Mountain National Nature Reserve and other areas. The main focus of this paper is the study area, which primarily encompasses the Giant Panda National Park and the Northeast Tiger and Leopard National Park. This region boasts a diverse range of wildlife and a complex ecological environment, covering an expansive area of 170,840 square kilometers. Notable examples of the key national wildlife found here include the Amur tiger, the Amur leopard, the giant panda, the golden monkey, and the red panda. The specific location of the study area is depicted in
Figure 2.
To maximize the collection of wildlife image data, we employed infrared and visible infrared trap cameras. These cameras enabled us to capture an extensive array of images, featuring diverse wildlife species set against complex backgrounds. The infrared cameras and visible light cameras we used to collect data were primarily distributed in the Giant Panda National Park and Northeast Tiger and Leopard National Park. We used trap cameras to minimize the impact on wildlife and prevent damage to the equipment by animals. Our staff regularly collected the memory cards from the equipment and transmitted the data. In areas with good communication, we deployed infrared cameras with 4G communication capability for real-time data transmission and identification.
The dataset used for the experiments consisted of 14 main categories: badger, black bear, red panda, otter, red fox, marten, leopard, Amur tiger, leopard cat, Sika deer, weasel, wild boar, and wolf.
Figure 3 displays representative images from the training dataset used in this paper. The dataset comprises a total of 14,000 image data, with 1000 images per category. Each category includes 500 visible image data and 500 infrared image data. Additionally, a small amount of video data has been included to test the model. This means that the video data is converted frame-by-frame into image data to be input into the model in order to test its target detection effect at higher frame rates. To ensure the dataset’s versatility and diversity, we included images that exhibit various characteristics such as limited or full light, high or low visibility, high levels of occlusion, and complex backgrounds, among others. Furthermore, the dataset encompasses variations in terms of image resolution, orientation, and grayscale. The subsequent section provides a more detailed description of these specific aspects of variation.
2.2. General Methodology
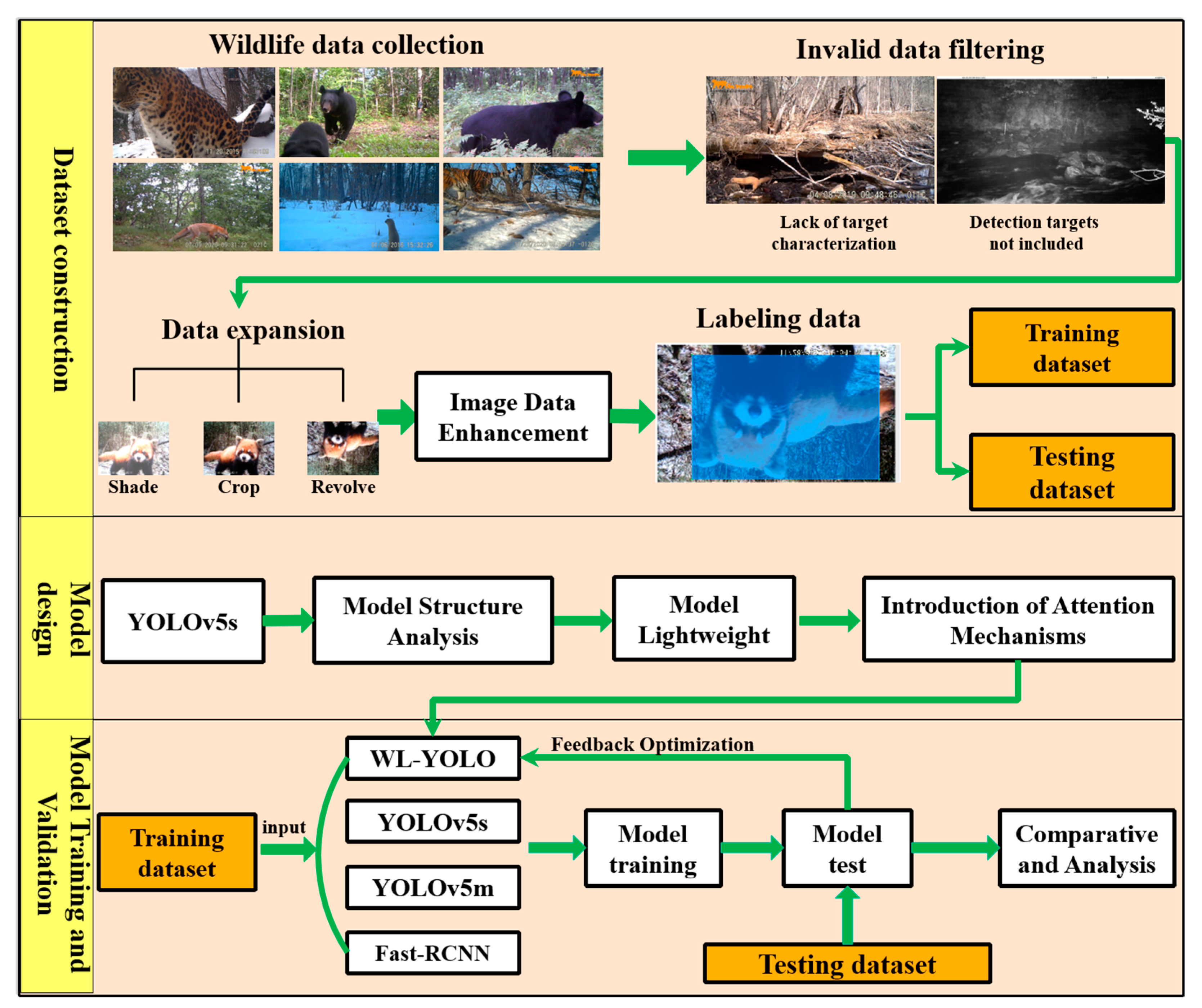
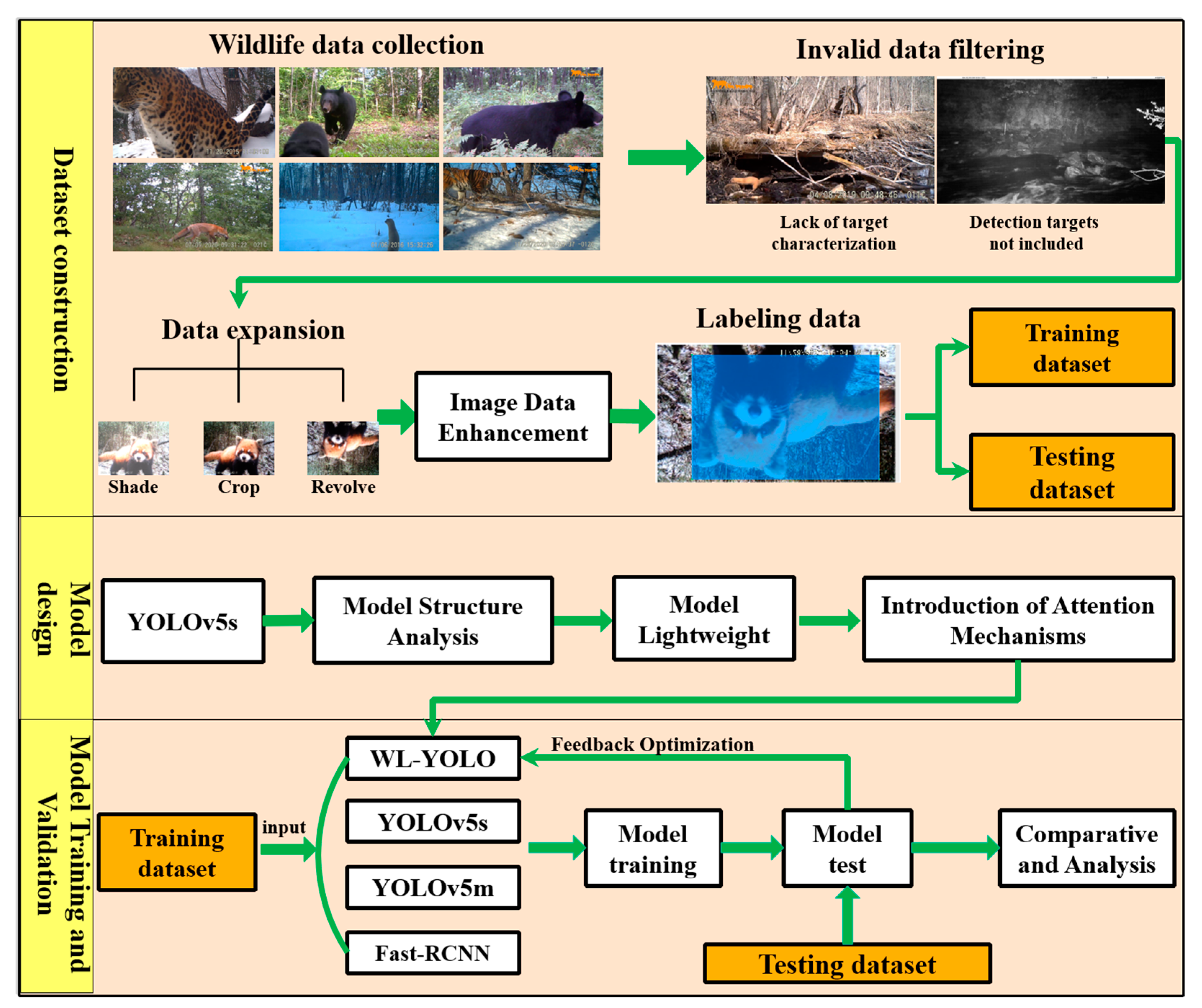
Our proposed method includes the following main steps: first, the collected wildlife image data is preprocessed. This involves filtering out irrelevant data, converting the data to a uniform format, and performing other necessary operations. This is performed to create a strong foundation for accurately annotating the images. As the number of images captured for each animal species may vary, the dataset was augmented using various methods.
The goal was to ensure that there are at least 1000 images available for each species of animal and achieve a balanced amount of image data for all animals. Furthermore, we aimed to improve the quality of the image data by implementing deep learning algorithms specifically designed for low-quality images. To accomplish this, we utilized the YOLOv5s model as the foundation, retaining the Darknet53 feature extraction structure. Additionally, we redesigned both the detection head and the feature extraction module of the model’s backbone network, resulting in the creation of the WL-YOLO wildlife detection model. To train, validate, and compare the performance of the WL-YOLO and other models such as YOLOv5s, YOLOv5m, and Fast-RCNN, we fed the training dataset, test dataset, and validation dataset into each model. The overall technical route is illustrated in
Figure 4.
2.3. Dataset Construction
The process of constructing a wildlife dataset mainly involves acquiring data, preprocessing it, augmenting it, enhancing data quality, converting data formats, and labeling data. Due to the natural conditions of the complex forest environment and the limitations of the data acquisition equipment, the collected wildlife data often include a large number of aerial data and fuzzy images. These factors adversely affect the effectiveness of the model. Therefore, the first step in constructing the dataset is to clean the dataset by removing extraneous data and filtering out images that do not have the desired characteristics.
Limited by the points of wildlife infestation, the frequency of infestation may differ. Consequently, the number of wildlife images captured by our surveillance equipment for each category may also differ. However, the balance of data for each category directly influences the effectiveness of the model. To address this, we have ensured that the amount of wildlife images for all categories in the model is approximately 1000 pieces of data. Various methods, including image rotation, panning, cropping, changes in lighting and darkness, and changes to gray scale, have been employed to generate multiple representations of the same image and augment the dataset.
Different kinds of wildlife image data were collected using various acquisition equipment. As a result, the sizes of wildlife image data in the dataset are not uniform. The dataset contains images of different resolutions, such as 1920 × 1080, 647 × 657, 474 × 392, and others. However, our model requires a fixed input size. If the image is too large or too small, it will impact the model’s ability to read the image features and affect the overall performance of the model.
To address this issue, we decided to compress all of the original images to a standardized size of 224 × 224 pixels before performing image quality enhancement. In this process, we first rescaled the shorter side of each image to ensure it matches a fixed length. Then, we utilized the center cropping technique to crop the images to the same length. This approach helps to maintain the efficiency and accuracy of our work. Furthermore, in order to ensure uniformity across the dataset, we adjusted the width and height of all image data to a consistent size.
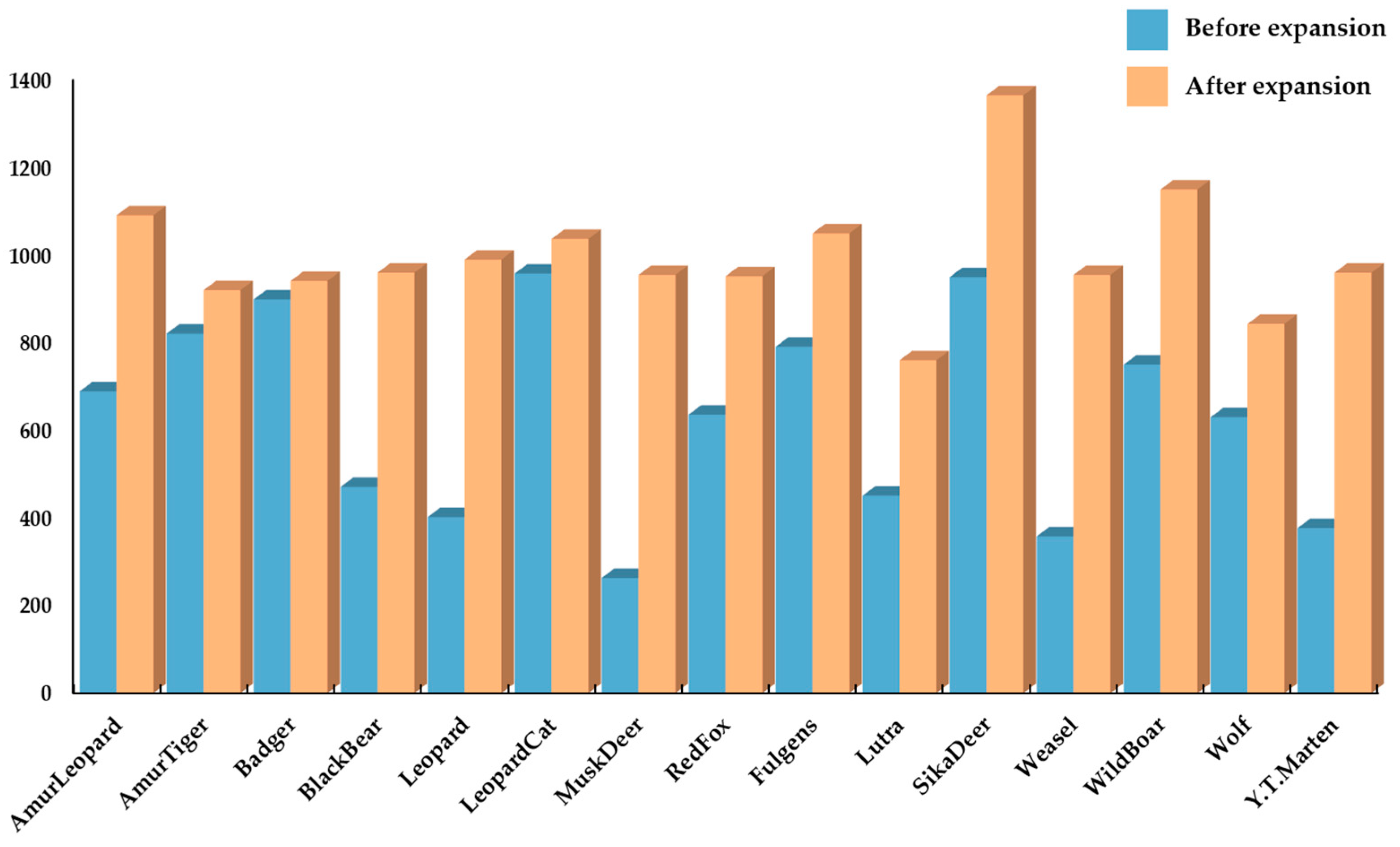
Due to the sparse survival of certain animal species, it becomes challenging to collect a large amount of image data. However, deep learning algorithms require a sufficient number of samples. Using augmented image methods excessively for quantity expansion can result in the repetition of image features, which leads to overfitting models [
38].
Therefore, for this specific part of the image data, we have designed an image quality enhancement method based on deep learning techniques in order to enhance the fuzzy images. We utilized the torch vision library provided by the PyTorch deep learning framework for image quality enhancement. This method generates similar but not identical training samples by enhancing the image quality [
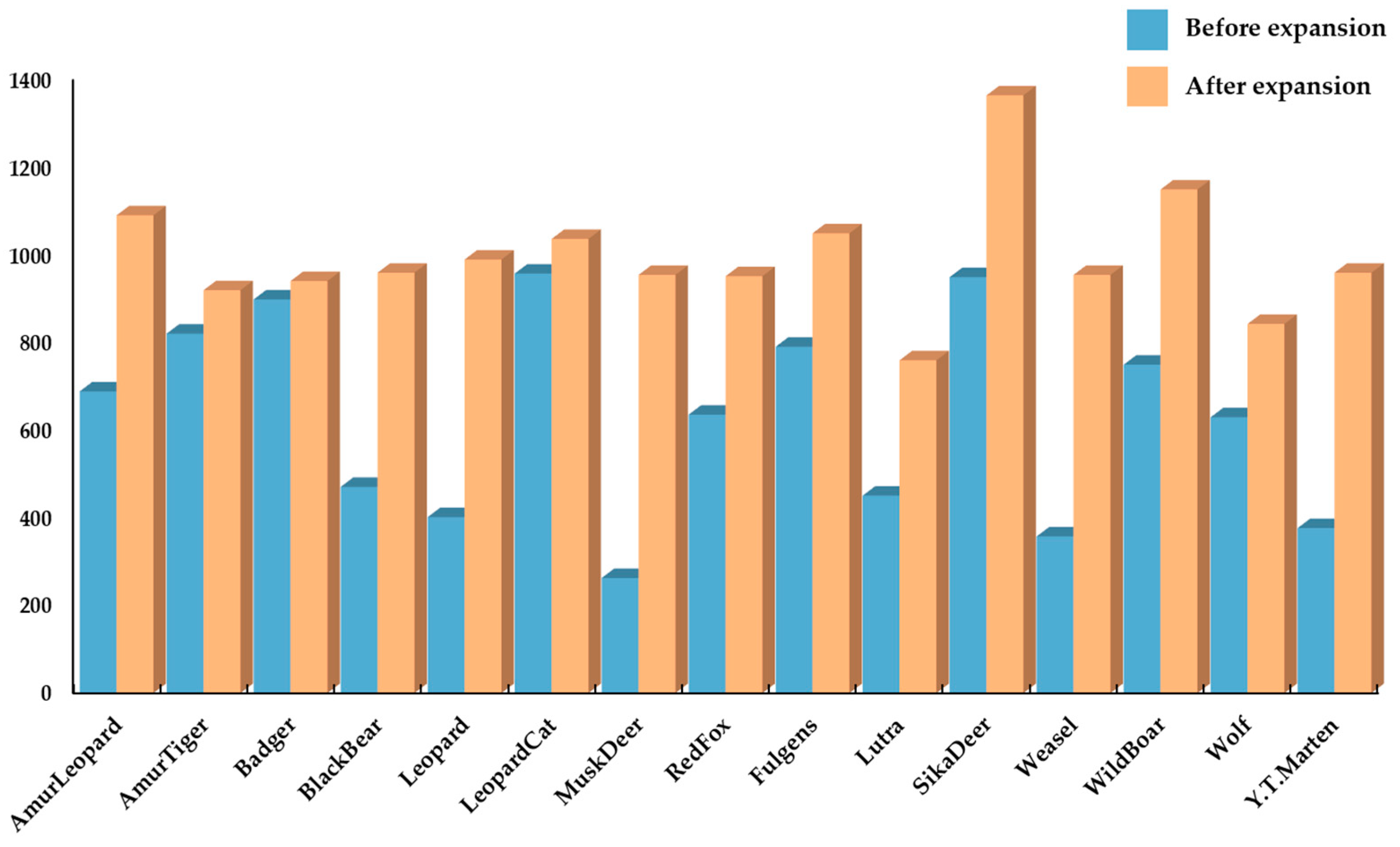
39]. This helps in expanding the size of the training set. Additionally, it reduces the model’s reliance on specific attributes, thus improving the model’s ability to generalize. A comparison of the number of images for each type of animal before and after data expansion and enhancement is shown in
Figure 5. It can be observed that the amount of image data for each type of wildlife is well-balanced after the implementation of data expansion and enhancement techniques, thereby meeting the dataset quality standards required for model training and validation. To introduce a certain level of error in the image data and also ensure its experimental value, as well as to prevent overfitting to some extent, we applied a suitable amount of Gaussian noise to the obtained image data.
By performing a series of operations, such as data cleaning, data expansion, and data enhancement, on the dataset, we obtained the dataset that was used for model training. Next, we needed to label the dataset. For the annotation process, we utilized the LabelImg (v1.8.2) software to annotate the images with the wildlife category name and the relative position of the wildlife target in each image. Traditional manual annotation methods require significant human and material resources, which is why we adopted active learning methods to accurately annotate 30% of the dataset manually. Additionally, we employed the “Human-in-the-loop” interactive framework to automatically annotate the remaining data [
40], effectively reducing the amount of manual data annotation required.
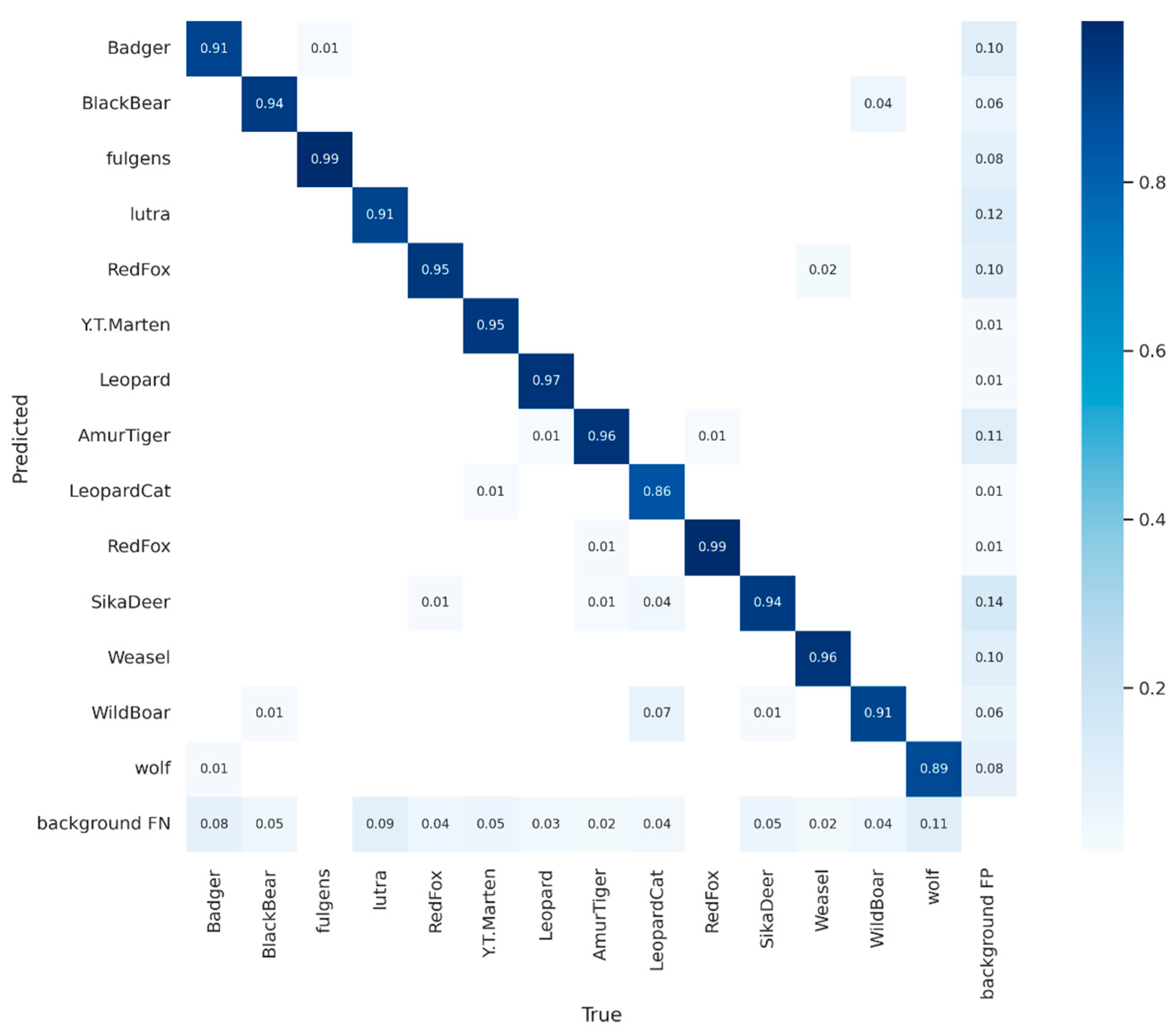
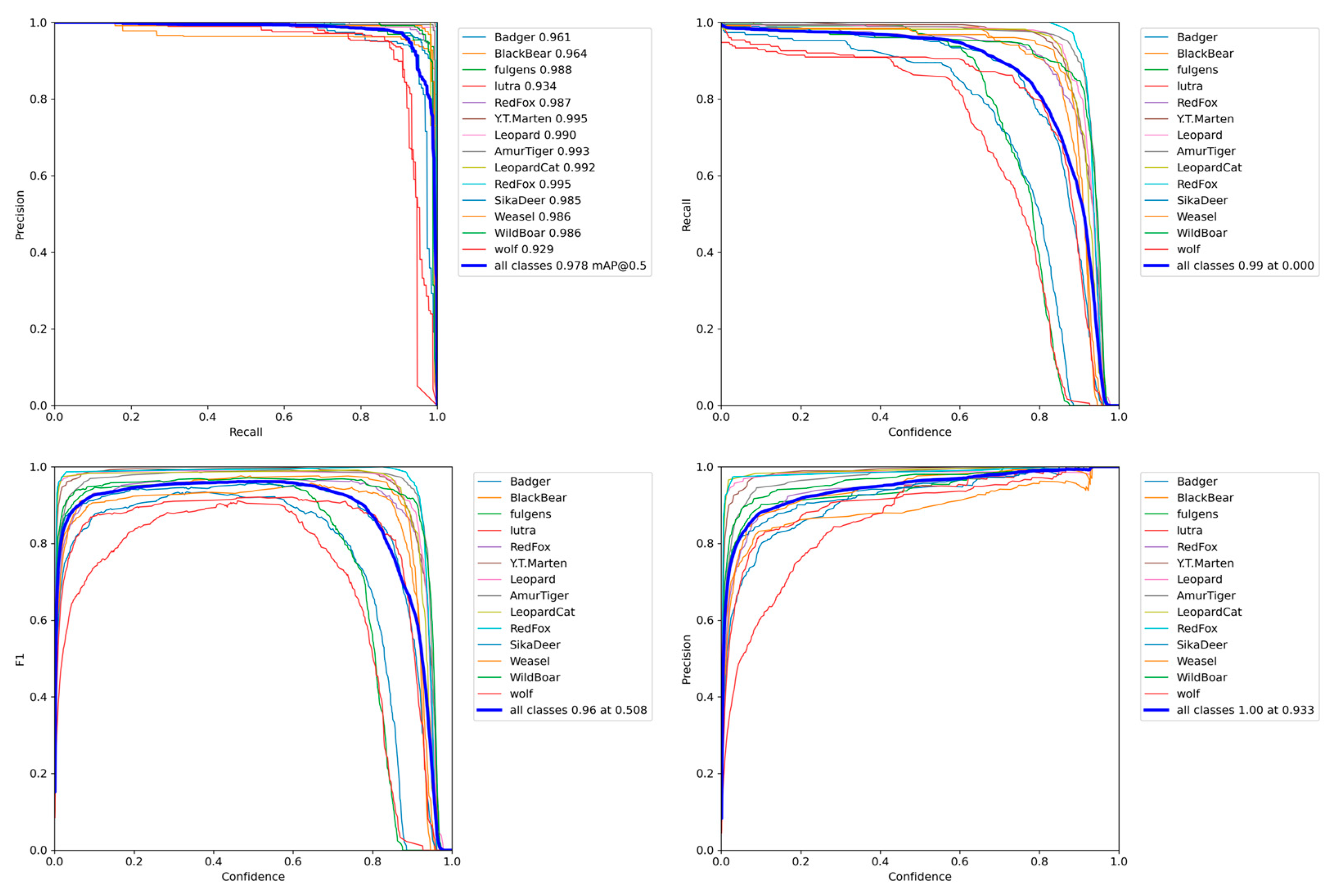
After labeling all of the image data, we divided the dataset into a training set and a test set with a 7:3 ratio. Additionally, we included a portion of video data that were not part of the dataset as the model validation data. This allowed us to effectively compare the performance of different models.
2.4. WL-YOLO
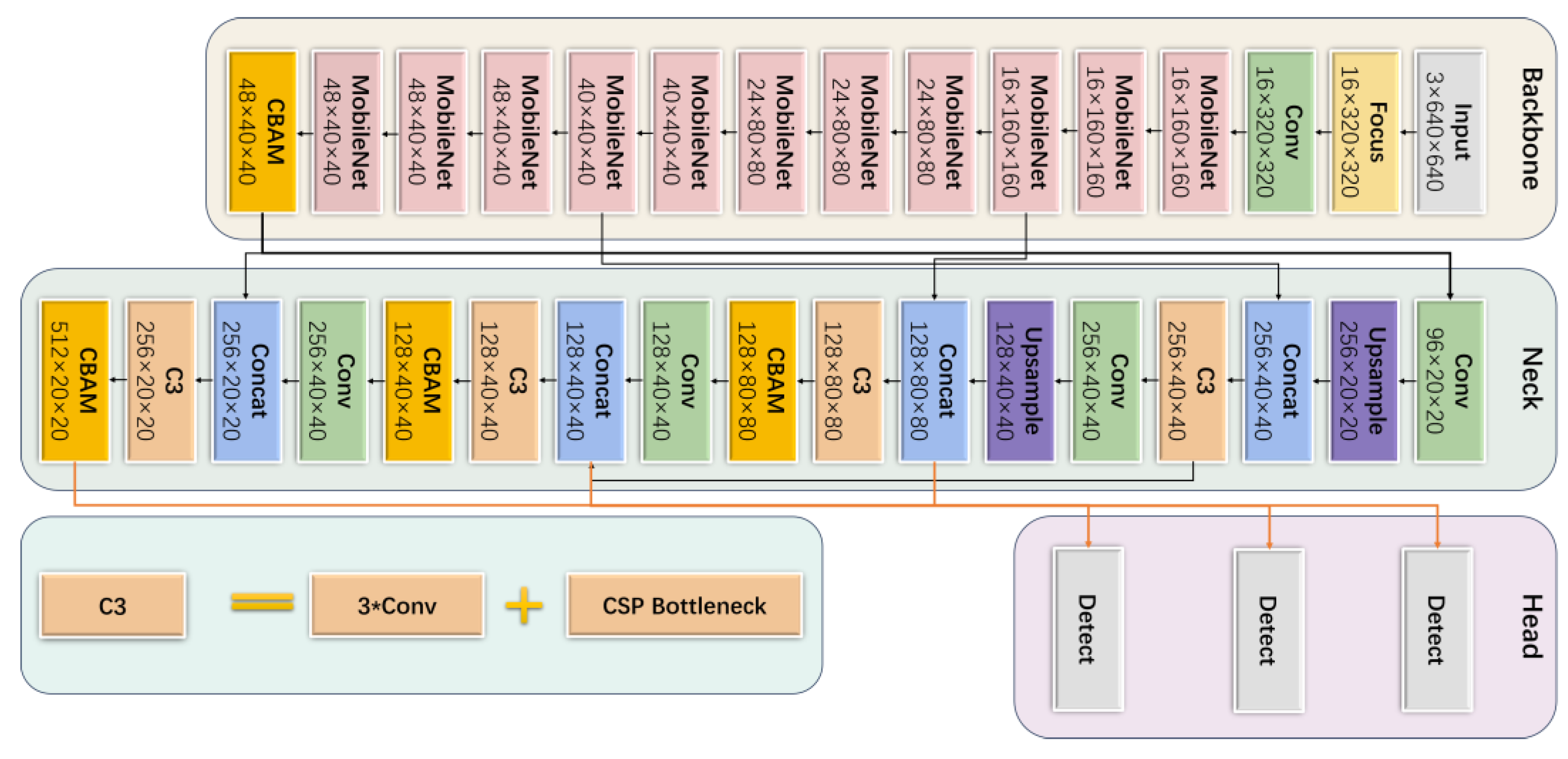
To address the practical challenges associated with detecting wildlife targets in complex field environments, this study suggests leveraging YOLOv5s for rapid target detection. The focus is on improving accuracy and reducing the likelihood of omission and misdetection of wildlife targets in challenging environments, ultimately introducing a new method and structure for enhanced detection capabilities. In this work, we have designed the WL-YOLO model for detecting and recognizing wildlife in complex forest environments. The WL-YOLO model has been developed using the YOLOv5s model as a foundation but with specific modifications to suit our needs.
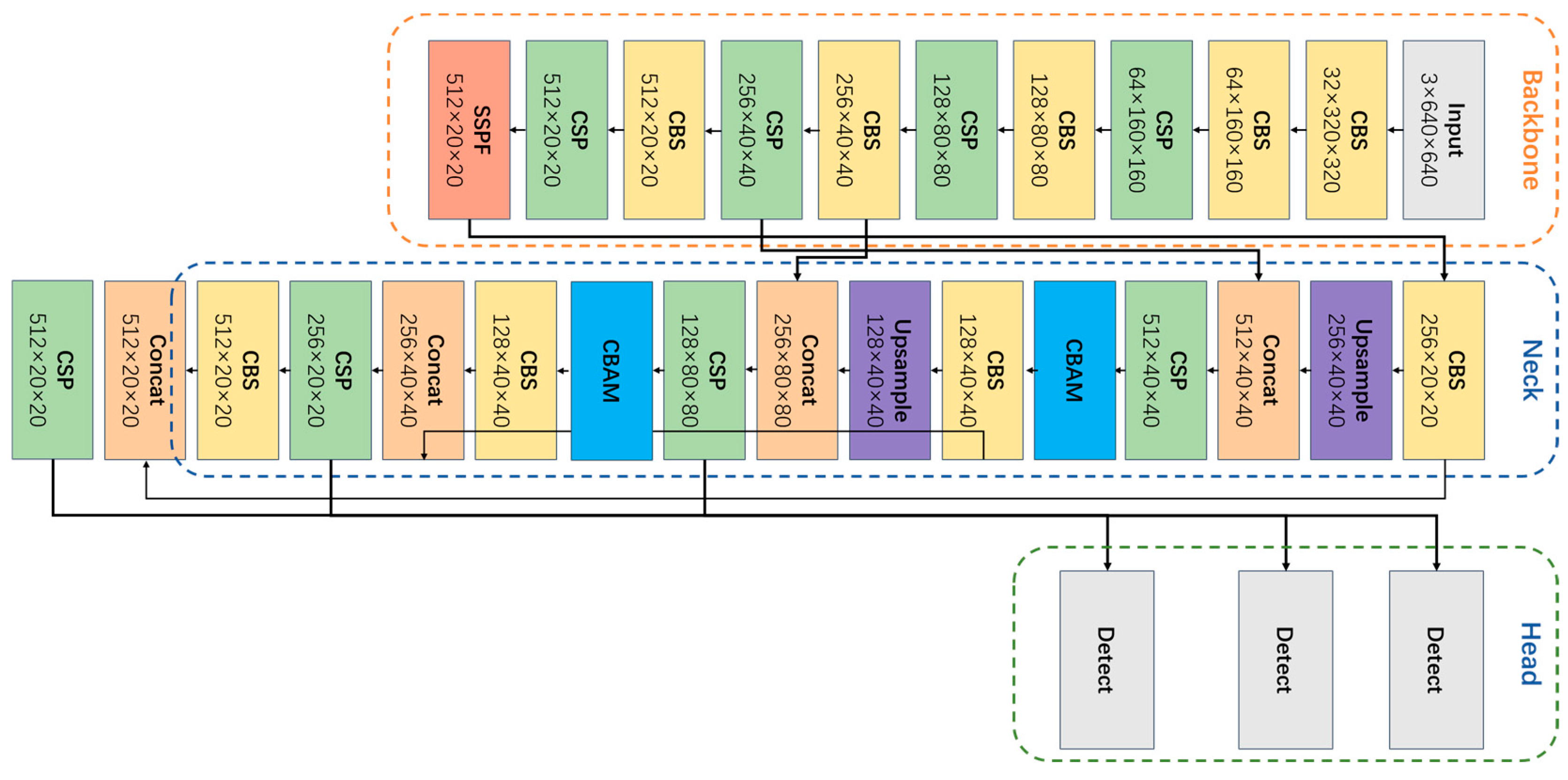
The architecture of the YOLOv5s model is depicted in
Figure 6. The YOLOv5s model network structure mainly consists of input, neck, backbone, and head modules [
41]. The Input module primarily utilizes the mosaic method to enhance the input data. The mosaic method generates new images by randomly cropping, combining, splicing, and scaling the existing images. This data enhancement technique improves the model’s generalization ability and overall performance [
32]. The backbone is the core structure of the YOLOv5 model. It consists of Focus, Conv, C3, and SPP, and is responsible for extracting features from multi-scale images. Compared to other models, the C3 module effectively reduces the repetition of gradient information during network information transmission [
42]. By adjusting the number and depth of C3 modules, the total number of parameters in the model can be controlled.
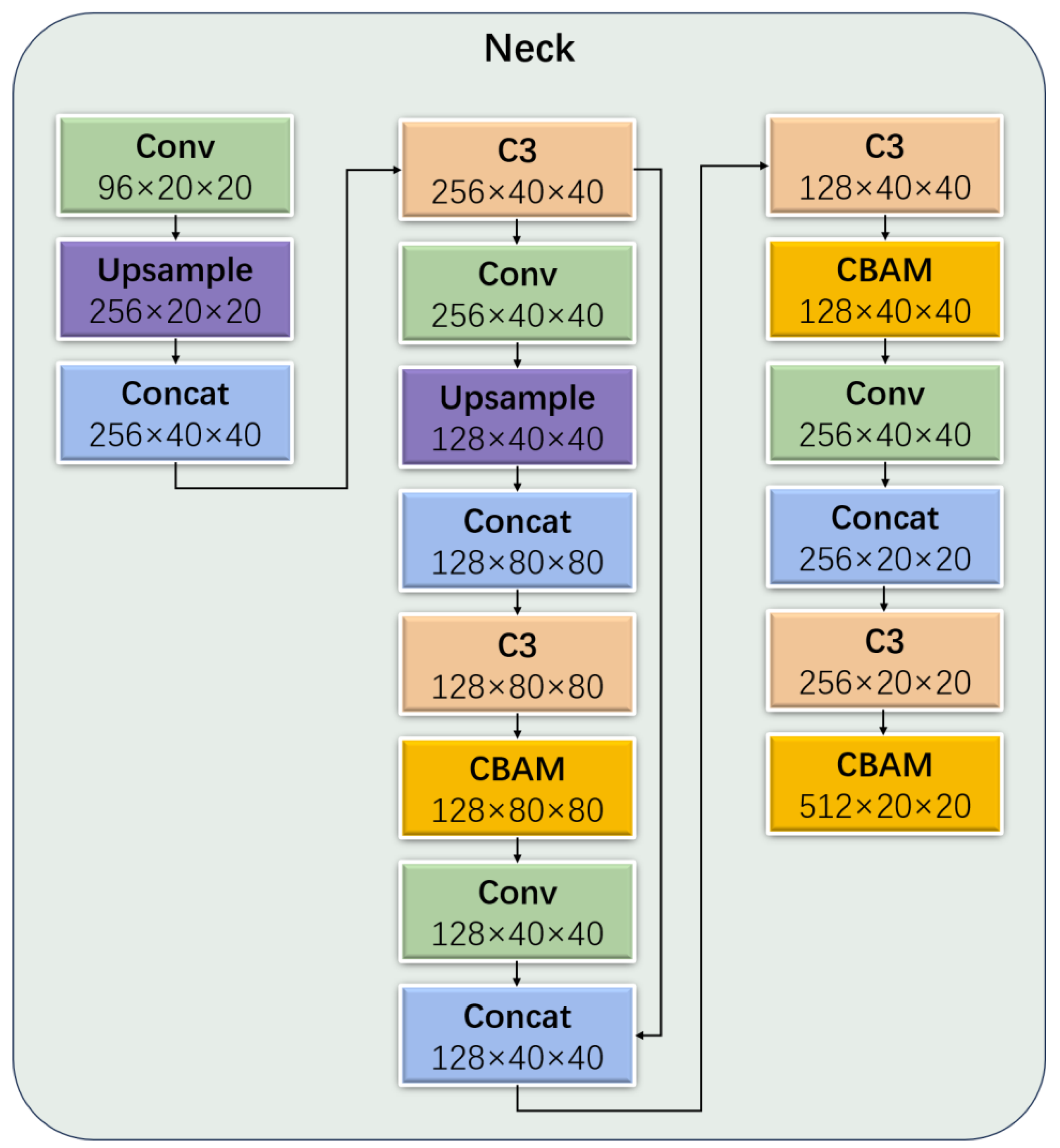
The neck network is primarily structured by SPPF and PANet. It consists of a series of feature layers that fuse image features. By combining feature maps of various sizes generated by the backbone network, the neck network obtains more contextual information. This process increases the sensory field of the model and reduces information loss.
The head serves as the terminal of the model and is responsible for detecting images with different scales. It corresponds to the three different sizes of feature maps in the neck network.
The difference between YOLOv5s and several other derived models lies in the fact that depth_multiple and width_multiple are unique to YOLOv5s and do not include repetitive modules [
43]. These exclusive features contribute to its faster computation and more efficient models. Additionally, the YOLOv5s model incorporates the innovative SPP (Spatial Pyramid) Pooling module into its backbone [
44]. This module effectively combines feature maps of various sizes to create a comprehensive global feature description. As a result, the model becomes highly resilient to challenges such as small objects, occlusion, and changes in illumination. These characteristics make YOLOv5s an ideal choice for wildlife identification tasks, particularly in intricate forest environments. In summary, the YOLOv5s model is highly suitable for rapidly monitoring and identifying wildlife targets in complex forest environments.
As the number of parameters in YOLOv5’s model decreases, the low-level features are less mapped and the receptive field is smaller. This leads to a reduction in its deep feature extraction ability. Additionally, due to the complexity of the wildlife target environment, the model struggles to suppress invalid information such as background effectively. As a result, YOLOv5s model faces challenges in achieving better results in recognition accuracy. Moreover, YOLOv5s is not a top performer in terms of accuracy among the YOLOv5 series models. The gap becomes even more evident when compared to the two-stage model with higher detection accuracy. To address these limitations, we propose the WL-YOLO model, which enhances the model in three key areas: backbone, neck, and head:
- (1)
To minimize redundancy in model parameters and enhance computational speed, we have opted to utilize the lightweight network MobileNetV3 for the backbone structure instead of the base network’s combination of Conv and C3 modules.
- (2)
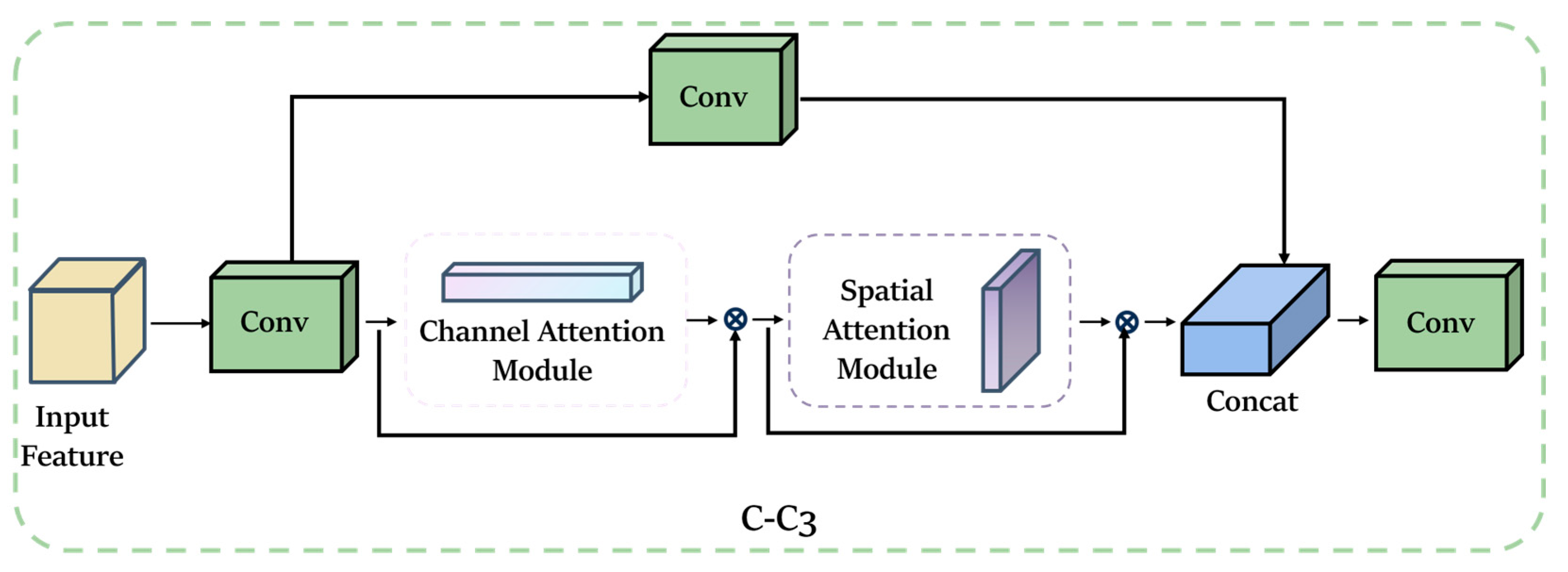
In order to enhance the model’s ability to focus on small targets in complex environments and effectively ignore complex backgrounds, we have designed a novel C-C3 module. This module integrates an attention mechanism into the neck component of the model, replacing the original C3 module.
Based on our enhanced model, we offer a real-time detection algorithm that is specifically designed for wildlife in intricate forest environments. This algorithm aims to greatly enhance detection accuracy while also ensuring efficiency in detection.
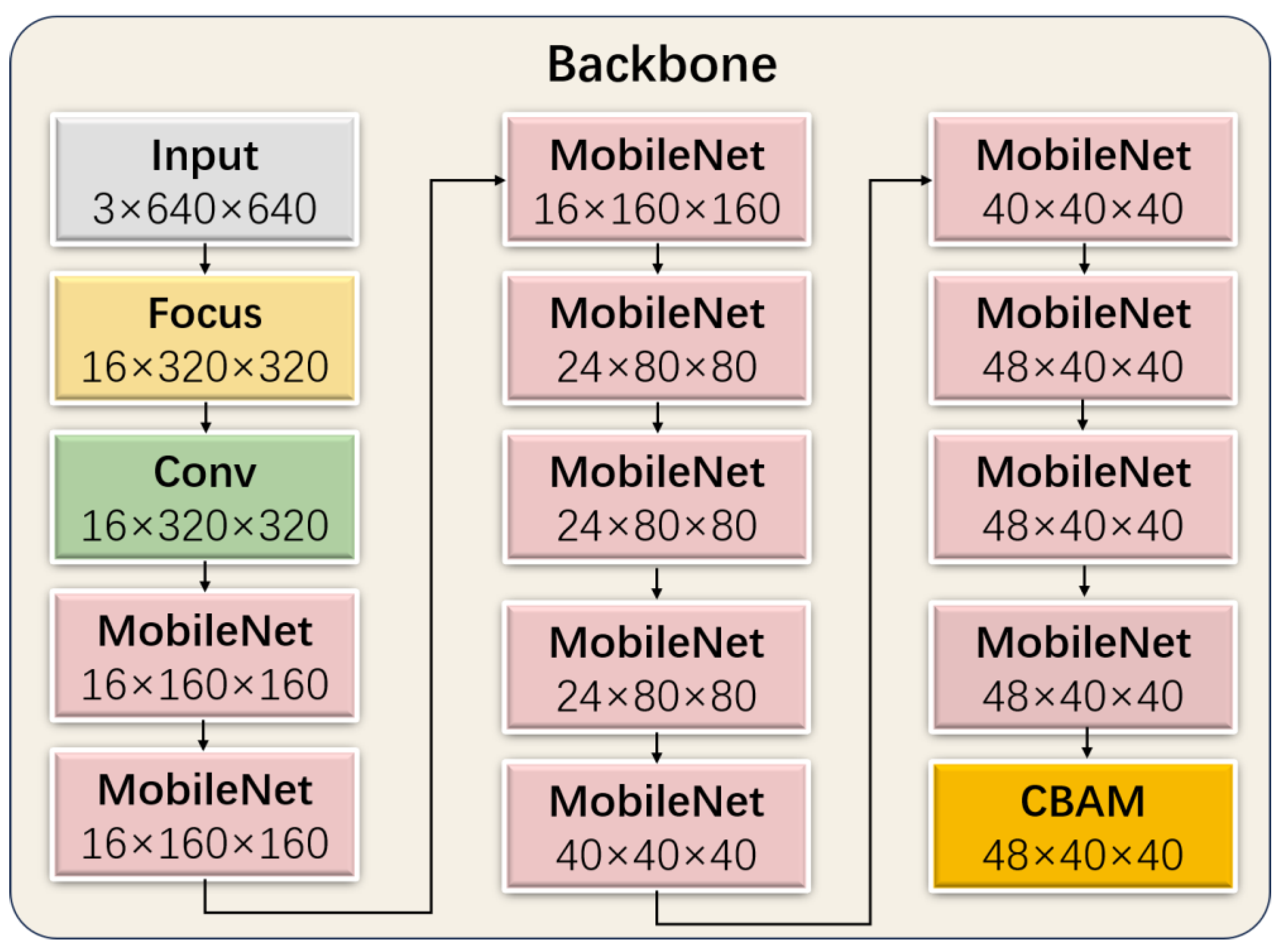
In the backbone structure design of WL-YOLO, we introduced a lightweight network called MobileNetV3 to address the issues of excessive model parameters in YOLOv5s, which leads to slow recognition, high complexity, and poor real-time performance. The MobileNet family of networks is a convolutional network proposed by the Google team for mobile devices [
45]. It is designed to address the limitations of both memory and arithmetic power. MobileNet suggests the utilization of deeply separable convolutional layers instead of traditional convolutional layers. This approach helps in reducing computational requirements and the model size. MobileNetV3 combines the deeply separable convolution from MobileNetV1 with the inverted residual structure featuring linear bottlenecks from MobileNetV2 [
46]. It also incorporates a network search algorithm with a superimposed SE Attention Mechanism module and a hard-Swish activation function. This combination aims to decrease computational complexity while maintaining model accuracy intact.
We employed the deeply separable convolutional network in the MobileNetV3 model to minimize redundancy in the feature maps generated by the backbone structure during feature extraction. Similar to traditional convolution operations, the Depth Separable Convolution breaks down a complete convolution operation into two components: Depthwise Convolution and Pointwise Convolution [
47].
Each convolution kernel of Depthwise Convolution is responsible for one channel of the input data, which undergoes the first convolution operation. Unlike conventional convolution, Depthwise Convolution is performed entirely on the two-dimensional plane. The number of convolution kernels is exactly the same as the number of channels in the previous layer [
48], resulting in N feature maps produced from an N-channel image. However, this operation method does not effectively utilize the feature information from different channels at the same spatial location due to the independent convolution operation of each channel. Therefore, it is necessary to generate new feature maps by combining the N feature maps using Pointwise Convolution. The operation process is illustrated in
Figure 7. Pointwise Convolution is mainly responsible for the weighted combination of feature maps generated by Depthwise Convolution in the depth direction [
49]. The size of the convolution kernel is 1 × 1 ×
N, the number of convolution kernels determines the number of output feature maps, and its computational process is shown in
Figure 7. When the size of the input feature map is
Dk ×
Dk ×
M, the size of the convolution kernel is
DF ×
DF ×
M, and the number of convolution kernels is
N. When a convolution operation is performed for each point in the corresponding feature map spatial location, a single convolution requires a total of
Dk ×
Dk ×
DF ×
DF ×
M operations because the feature map spatial dimension contains a total of
Dk ×
Dk points, and the amount of computation to perform a convolution operation on each point is the same as the size of the convolution kernel, i.e.,
DF ×
DF ×
M. Therefore, the total amount of computation, C1, is shown in Formula (1) for the ordinary convolution of
N channels:
And for deeply separable convolution, the total computation C2 is:
Compared to ordinary convolution, the ratio of depth-separable convolution to ordinary convolution is shown in Formula (3). This clearly demonstrates that the computational efficiency of depth-separable convolution is significantly better than that of ordinary convolution:
However, the high efficiency of deep separable convolution comes at the expense of low accuracy. To address this concern, the squeeze and extraction (SE) attention mechanism module has been introduced into the MobilieNetV3 module. This module comprises a pooling layer, two fully connected layers, and a hard sigmoid activation function [
50]. The original model utilizes sigmoid and swish functions as activation functions:
The sigmoid and swish activation functions have been replaced with the hard-sigmoid and hard-swish activation functions, as shown in Formula (8). In comparison to h-swish, h-sigmoid has a lower computational and derivation complexity:
The SE module within the module pools information from the channels, generates weights for each feature channel, and then multiplies these weights with the input feature mapping elements to obtain the final feature mapping [
51].
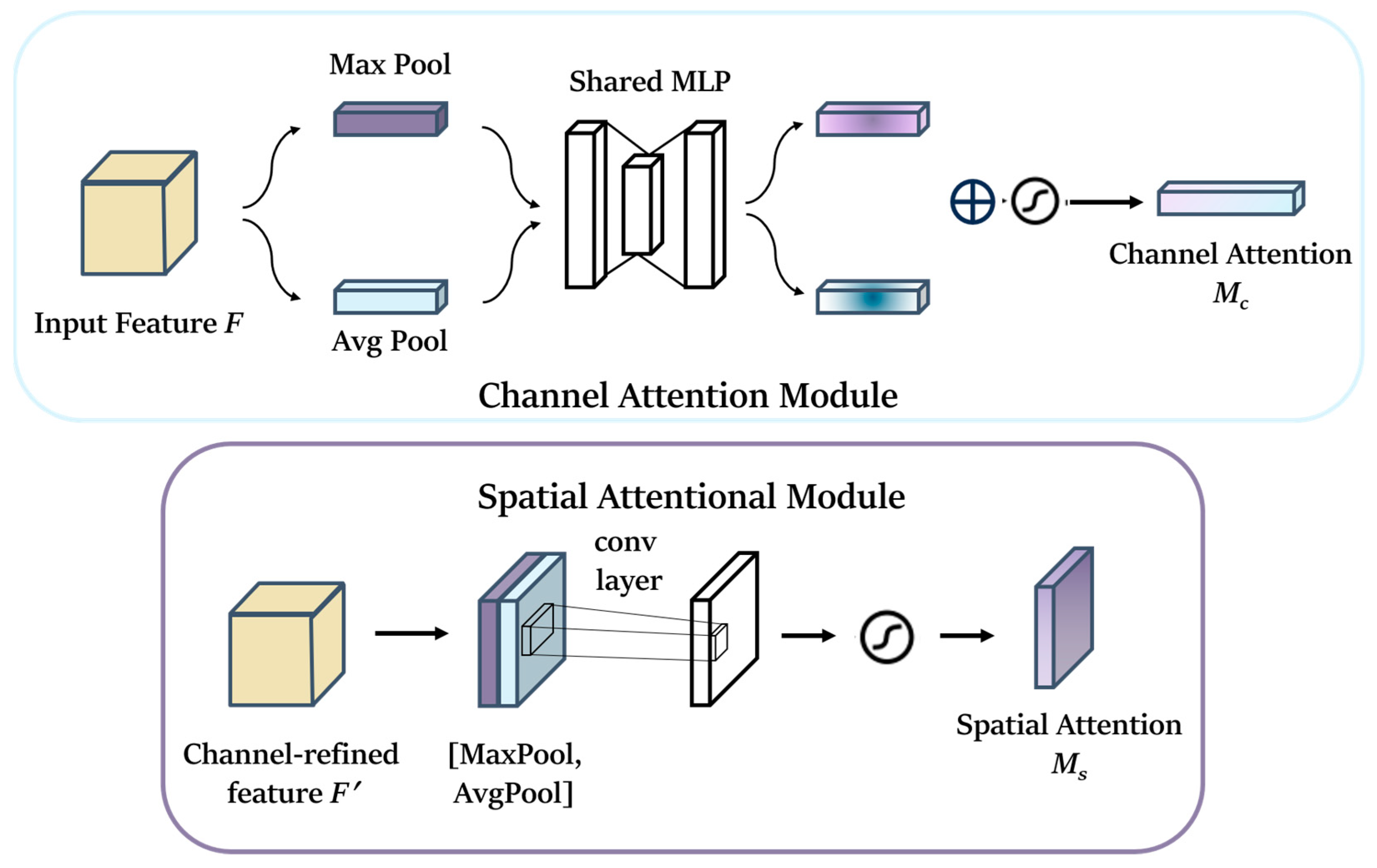
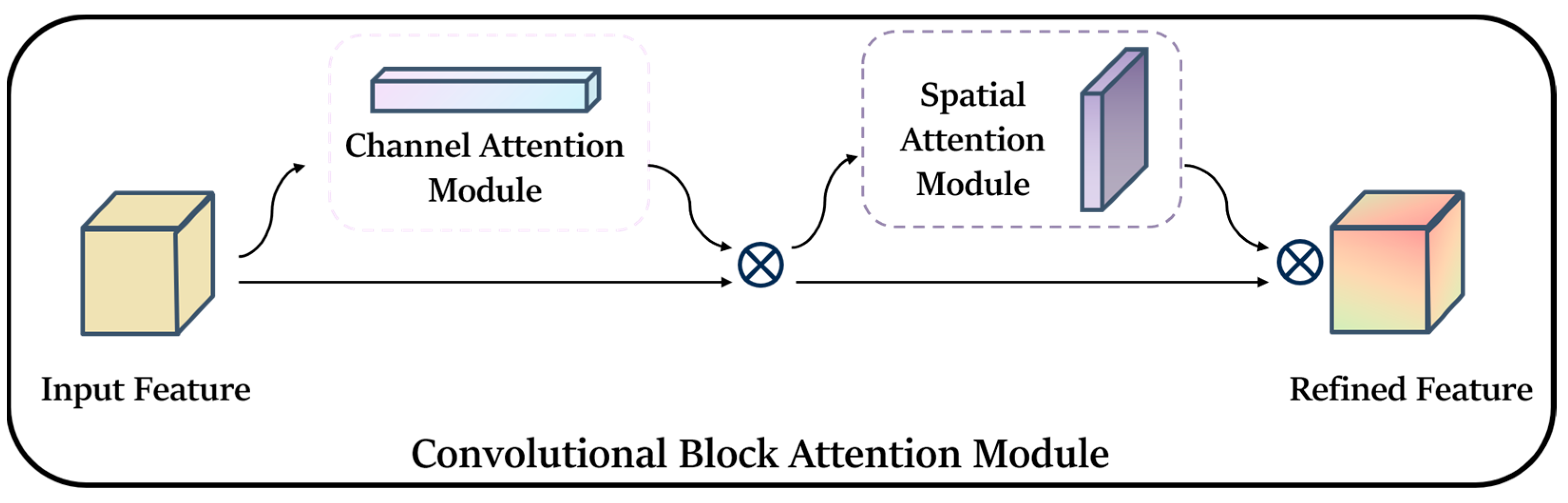
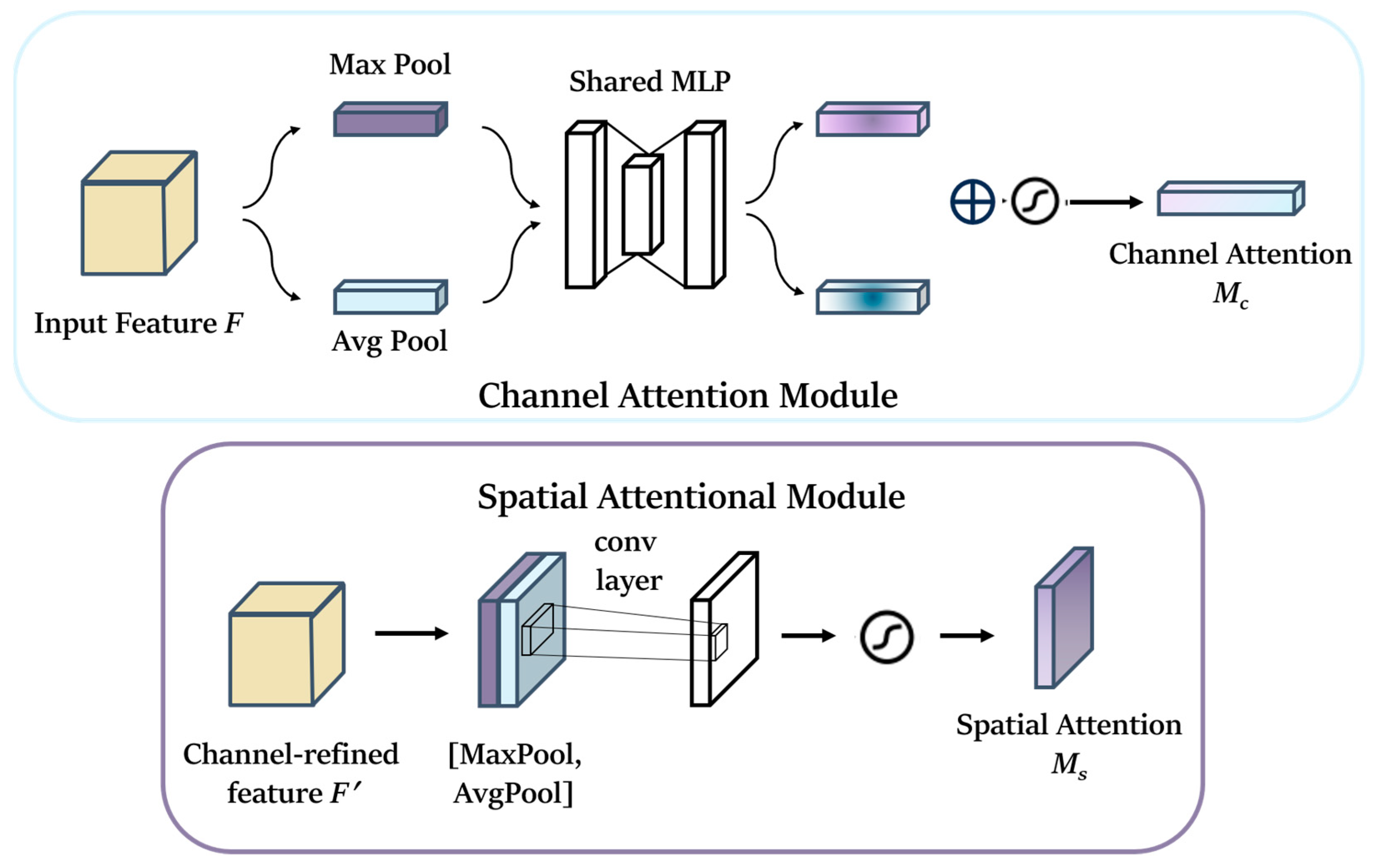
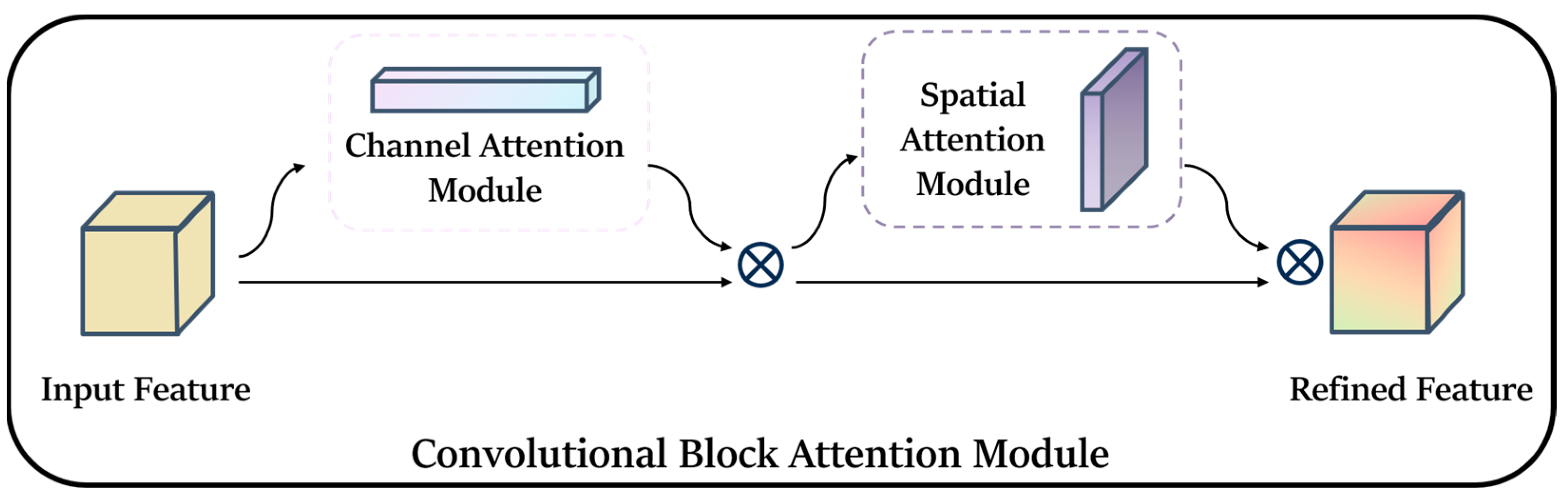
In the backbone, we utilize one convolutional module and eleven MobileNetV3 modules, which significantly decrease the parameter count and computational complexity of the backbone. However, because of the extensive usage of MobileNetV3, although the SE module can help suppress irrelevant features to some extent, it remains ineffective. Therefore, prior to feeding the feature map into the neck part, we have introduced CBAM (Convolution Block Attention Module) to enhance the feature representation of the target amidst complex environments. CBAM is an efficient and lightweight attention mechanism feed-forward convolutional neural network that primarily consists of channel attention and spatial attention machines [
52]. Firstly, the global average and global maximum in spatial dimension are performed on the feature layer input from MobileNet. This process obtains a rough global perceptual feature map by utilizing Global Average Pooling and Global Max Pooling [
30]. Based on the results of these two Pooling operations, the correlation between multiple channels is constructed using a shared fully connected layer. Finally, the results processed by the shared fully connected layer are fused and transmitted to the sigmoid activation function module [
53]. The overall structure of CBAM is shown in
Figure 8.
When an intermediate feature mapping map
F ϵ
RC ×
H ×
W exists as an input, CBAM derives a one-dimensional channel attention map
Mc ϵ
RC × 1 × 1 and a two-dimensional spatial attention map
Ms ϵ
R1 ×
H ×
W according to the sequence, as shown in the two feature maps in the above figure, and the whole process can be summarized as Formula (9):
where ⊗ denotes the product of elements, i.e., the process of multiplying the corresponding elements of two matrices to obtain a new matrix, in which the attention values are propagated, with the values of the channel attention being propagated along the spatial dimension, and the values of the spatial attention being propagated along the channel dimension, with
F′ representing the final input.
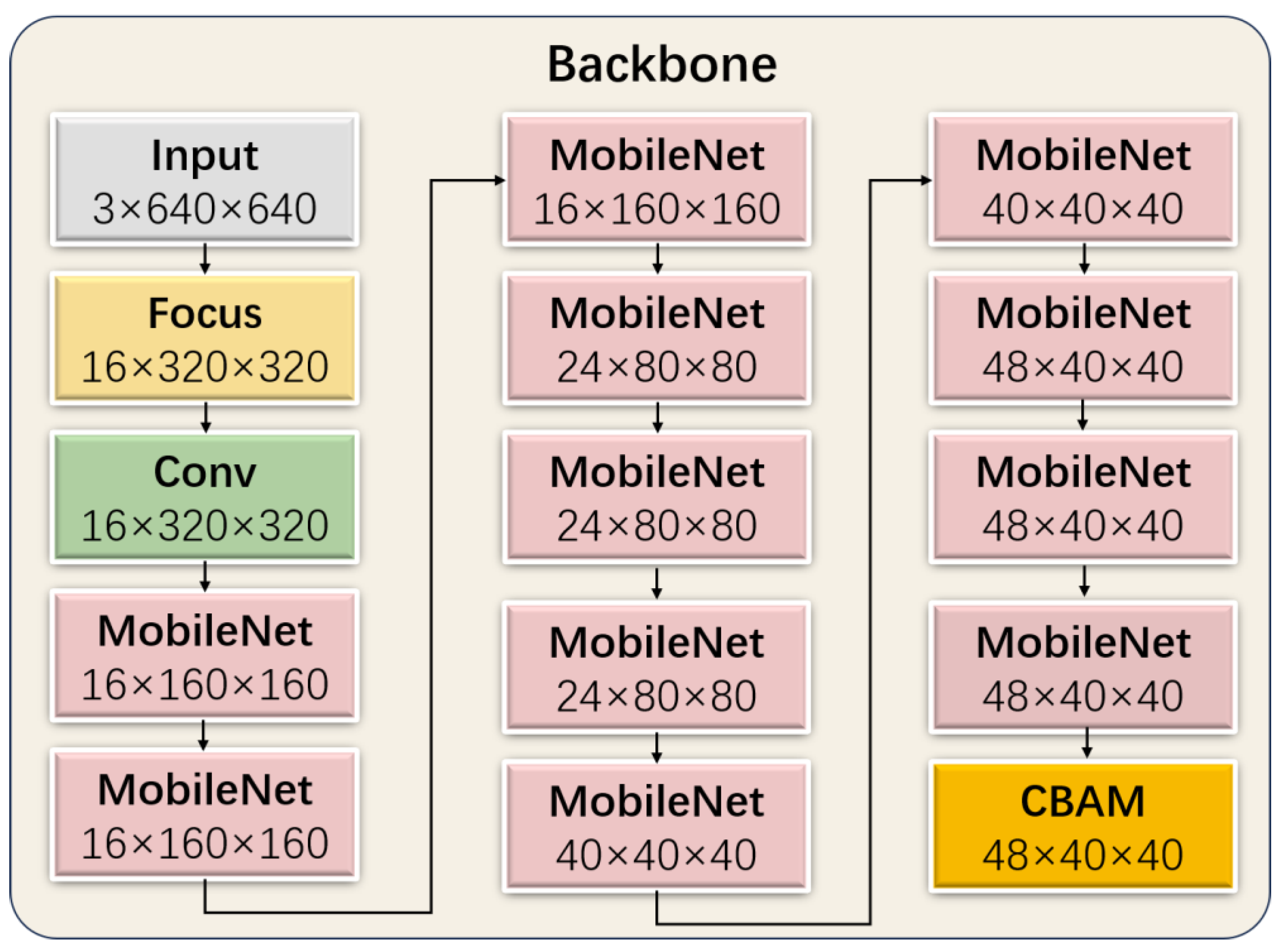
In the backbone module of WL-YOLO, we utilize the MobileNet module and convolution module to enhance the backbone module. Additionally, we employ CBAM to significantly decrease the number of parameters without compromising accuracy. By incorporating CBAM at the end of the backbone part, all of the generated feature maps are passed to CBAM, granting CBAM a global field of view. The structure of the backbone is depicted in
Figure 9.
Similar to the backbone module, we have reconstructed the feature extraction unit in the neck part of WL-YOLO. We have incorporated the CBAM attention mechanism with the objective of achieving attentional learning at each layer of the feature map as it passes through the neck part. This allows the attention mechanism to focus on each local feature. The overall structure of the neck network is illustrated in
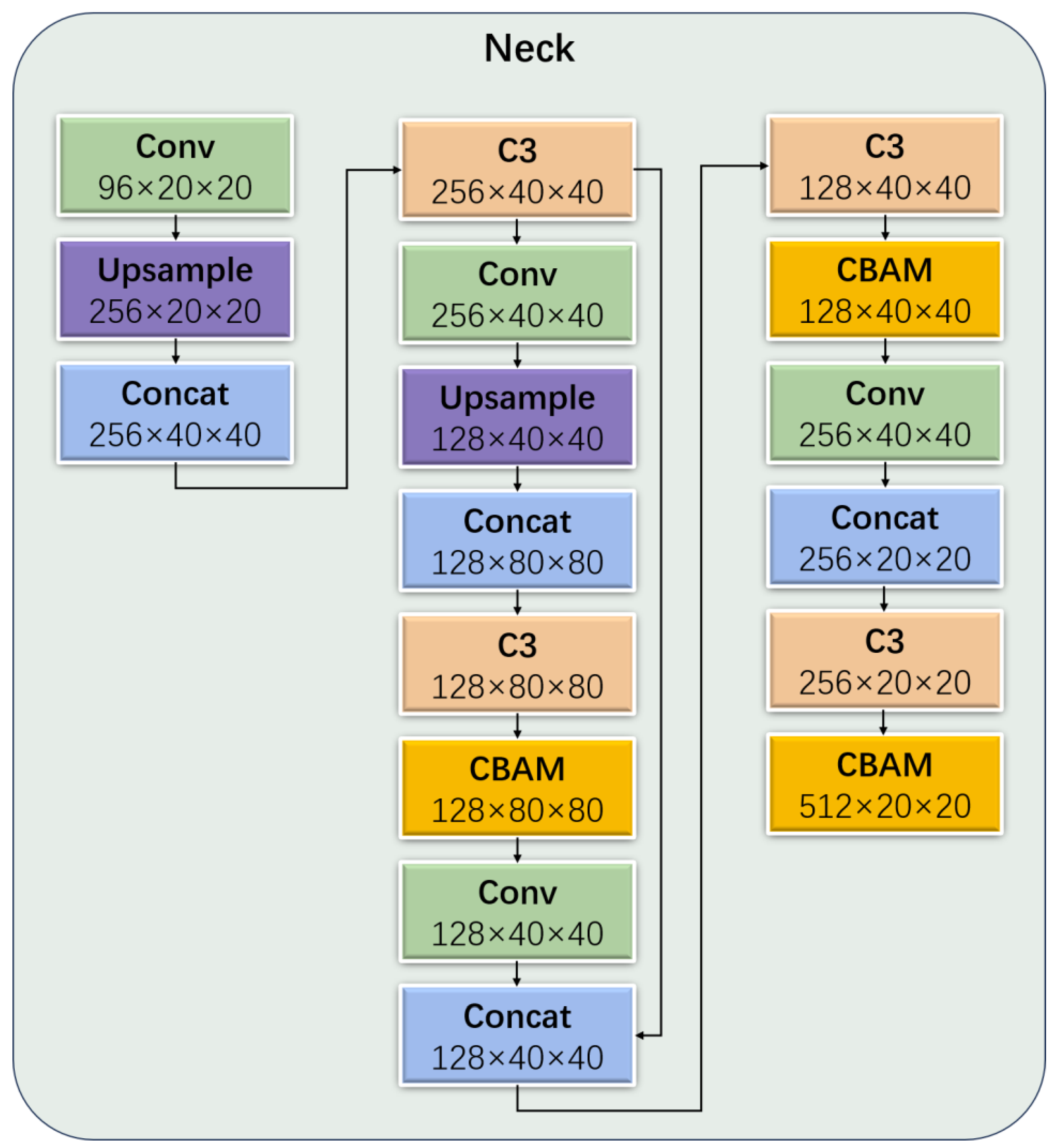
Figure 10.
The neck part of the native model utilizes the C3 module to reduce the computational cost by imposing a bottleneck module after convolution, followed by reorganization. Although this effectively reduces the computational cost, it also results in feature loss. Therefore, in the neck part, we suggest replacing the previous bottleneck module with a C-C3 module based on the attentional mechanism. This modification enhances the attention capability of the mechanism without incurring additional computational costs. The structure of the C-C3 module is depicted in
Figure 11.
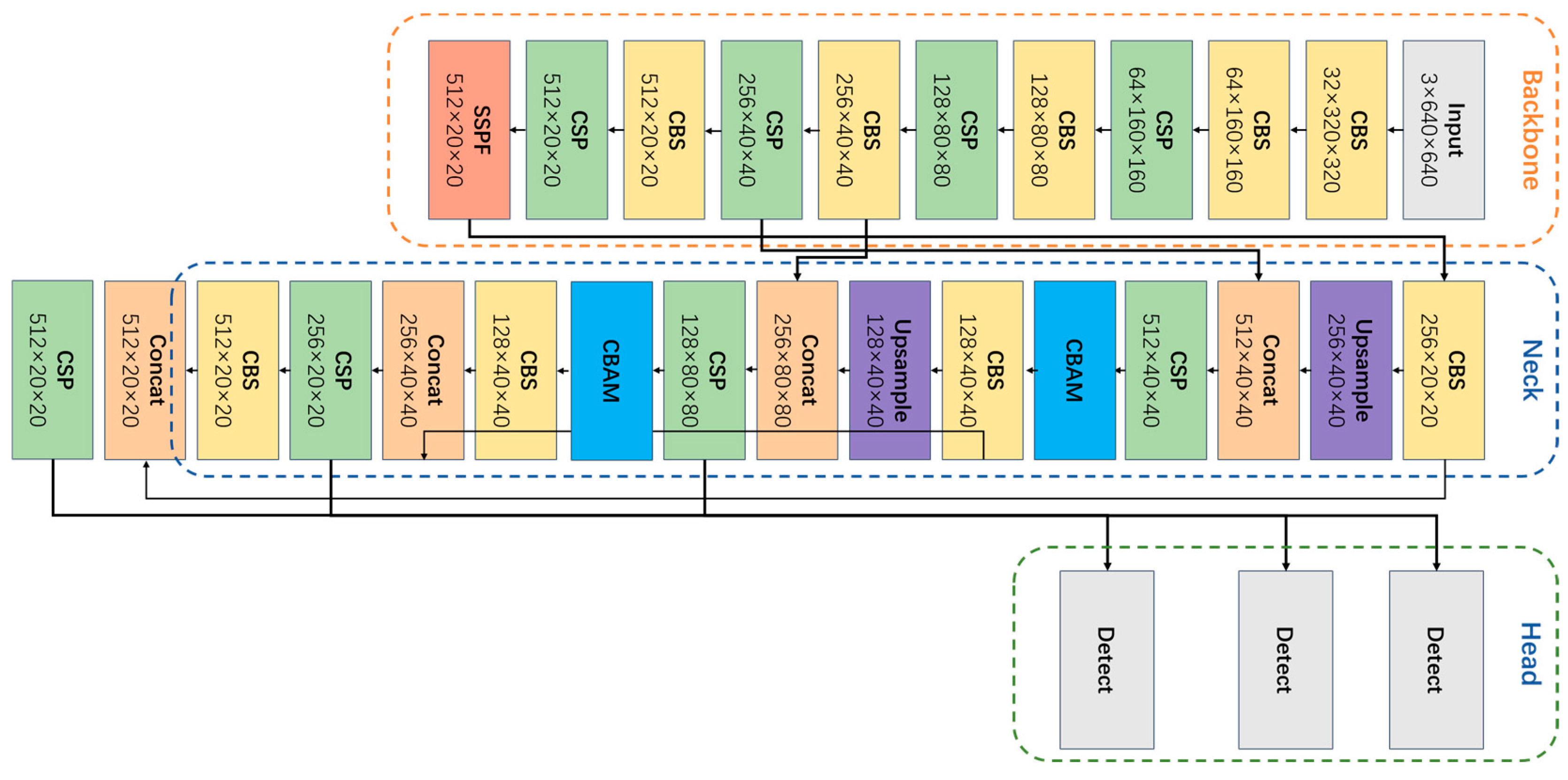
The overall structure of the model studied in this paper is shown in
Figure 12. First, we used Mosaic to enhance the input image. Then, the resulting enhanced graph was used as the input to the model. After modeling the image data, the first layer performed a convolution operation using a 6×6 size convolution kernel, which is equivalent to the Focus module of the original model. The output of this layer is then passed to the backbone module. In the backbone module, all of the convolution operations are replaced by DP in the MobileNetV3 module. The neck module is responsible for feature fusion, and it uses the C-C3 module to extract key features. Before the final prediction output image is produced, NMS is used to eliminate the redundant prediction anchor frames.
2.5. Experimental Environment and Parameters
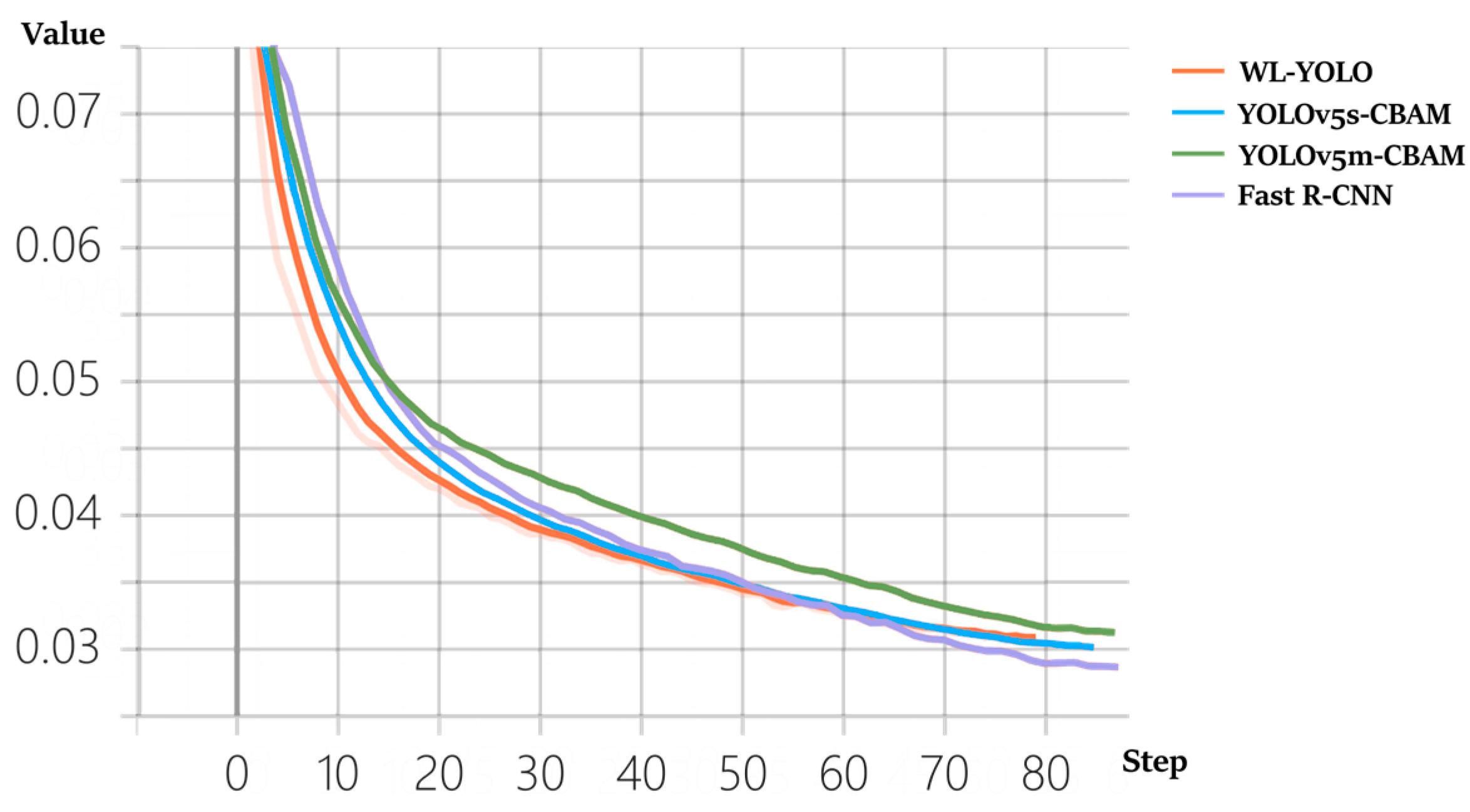
The experimental session of this study was conducted using the PyTorch framework on a remote server running Linux. The server was equipped with an Intel(R) Xeon(R) Gold 6330 CPU @ 2.00 GHz, 80 GB of RAM, and an NVIDIA GeForce RTX 3090 (24 GB) graphics card. Utilizing a GPU instead of a CPU for deep learning model training can significantly reduce the training time. The experimental environment was configured with a CUDA 11.3 parallel computing framework and CUDNN 8.2 deep neural network acceleration library. The input image size was set to 640 × 640, the batch size was set to 16, the learning rate was set to 0.001, and the training step size was set to 80. In order to avoid differences in the model validation results due to the change of equipment, the training and testing of the model as well as the validation were performed on the same remote server (provided by AutoDL) to save time and avoid discrepancies. The detailed environment configuration is shown in
Table 1 and the training parameter settings are shown in
Table 2.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}