

Exploring Uncertainty-Based Self-Prompt for Test-Time Adaptation Semantic Segmentation in Remote Sensing Images


Abstract
1. Introduction
- We propose a self-prompted test-time adaptation method based on uncertainty, which does not require any prior knowledge, and effectively directs the model’s attention to domain gap adaptation. At the same time, our method effectively improves the anti-forgetting ability and maintains effective performance over multiple rounds of continuous adaptation.
- Our proposed method surpasses six previous online TTA methods and one continuous TTA semantic segmentation method, demonstrating its effectiveness in cross-domain learning.
2. Related Work
2.1. Road Scene Semantic Segmentation
2.2. Domain Adaptation
2.3. Test-Time Adaptation
2.4. Visual Domain Prompt
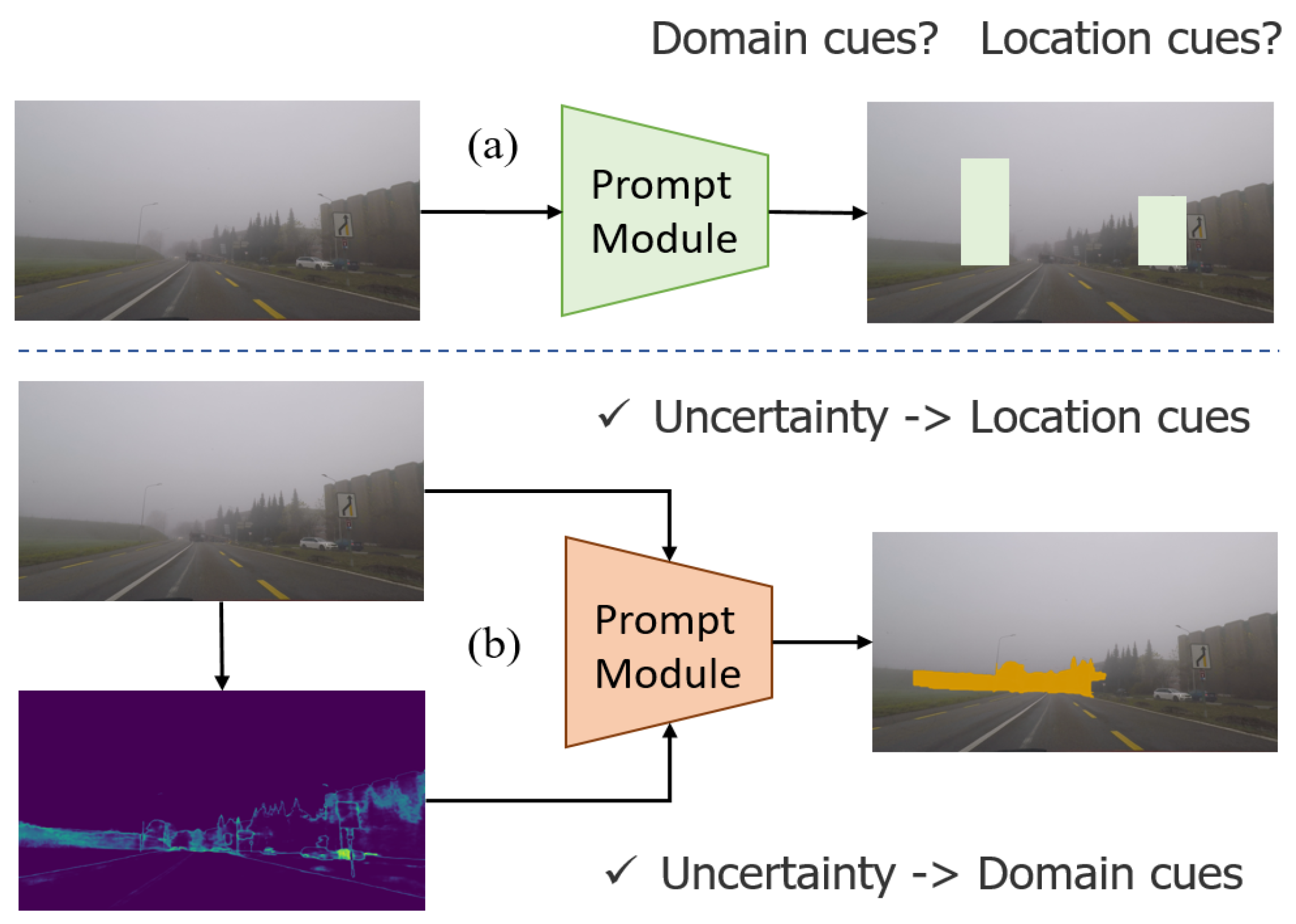
3. Method
3.1. Preliminaries
3.1.1. Test-Time Adaptation (TTA)
3.1.2. Visual Domain Prompt
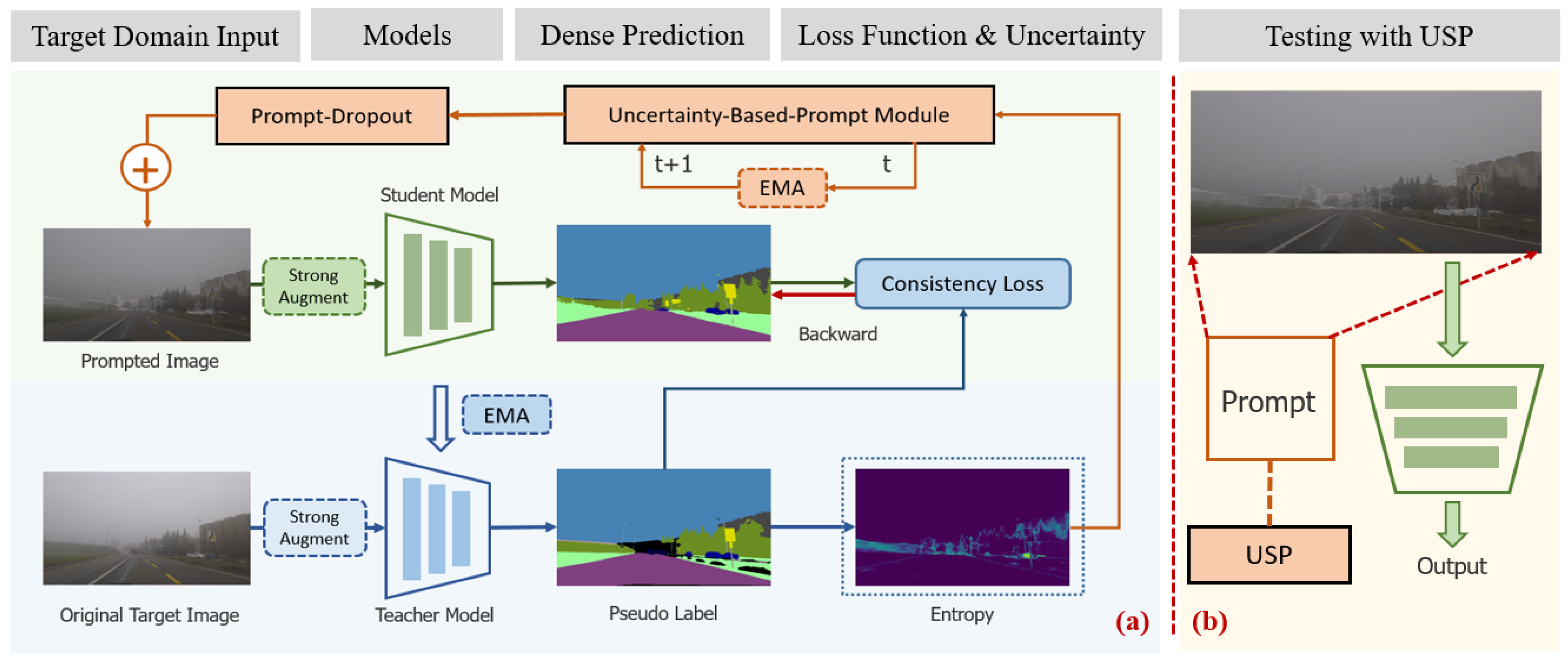
3.2. Overview
3.3. Uncertainty Prompted and Dropout
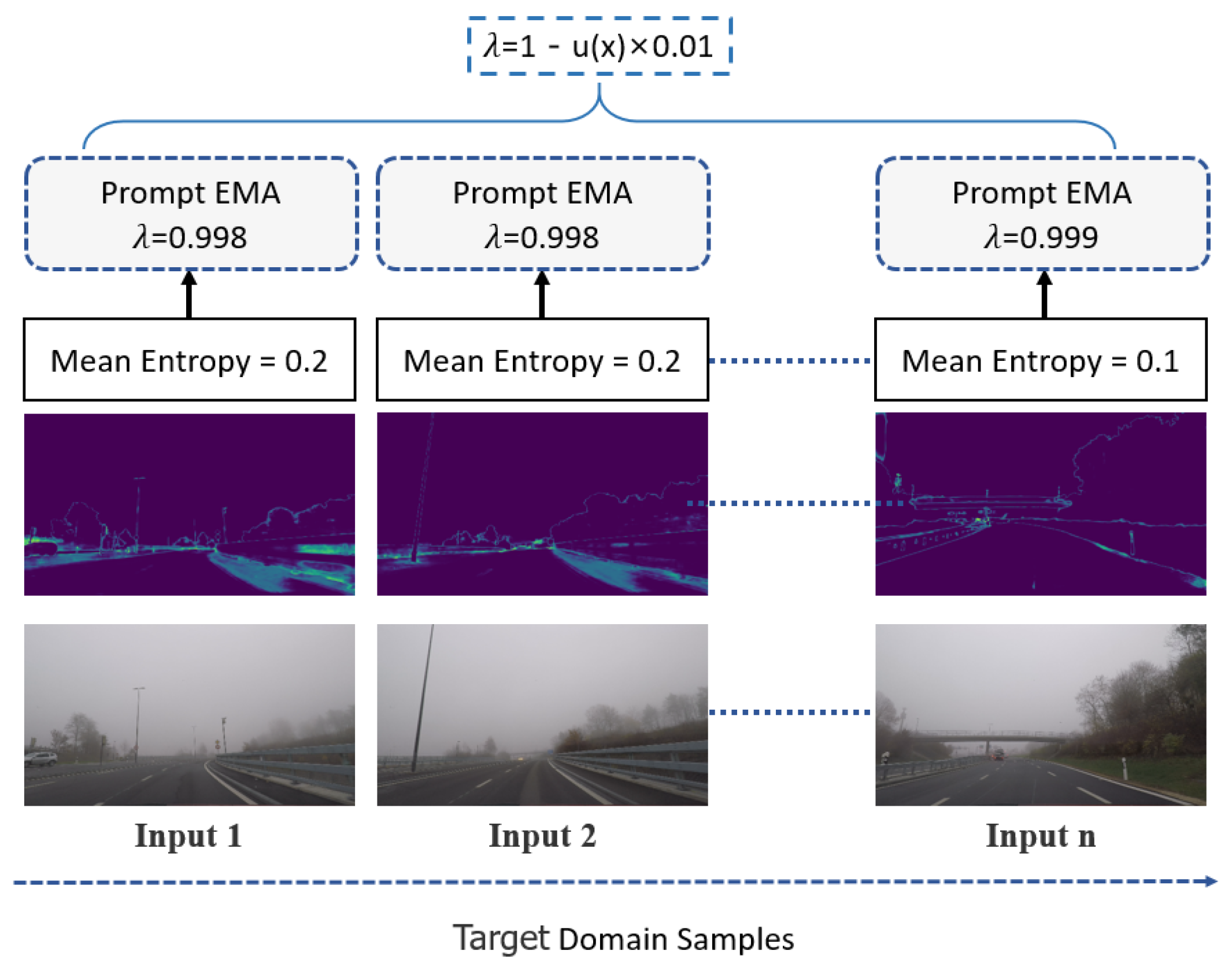
3.4. Domain Prompt Updating
3.5. Loss Function
4. Results
4.1. Task Settings
4.1.1. TTA and CTTA
4.1.2. Cityscapes-to-ACDC
4.1.3. Citsycapes-to-(Foggy and Rainy) Citsycapes
4.2. Dataset and Metrics
4.3. Experiment Workflow
4.4. Implementation Details
4.5. Performance Comparison
4.5.1. Cityscapes-to-ACDC TTA
4.5.2. Citsycapes-to-(Foggy and Rainy) Citsycapes TTA
4.5.3. Cityscapes-to-ACDC CTTA
5. Discussion
5.1. Effectiveness of Each Component
5.2. How Does Prompt Architecture Affect the Performance?
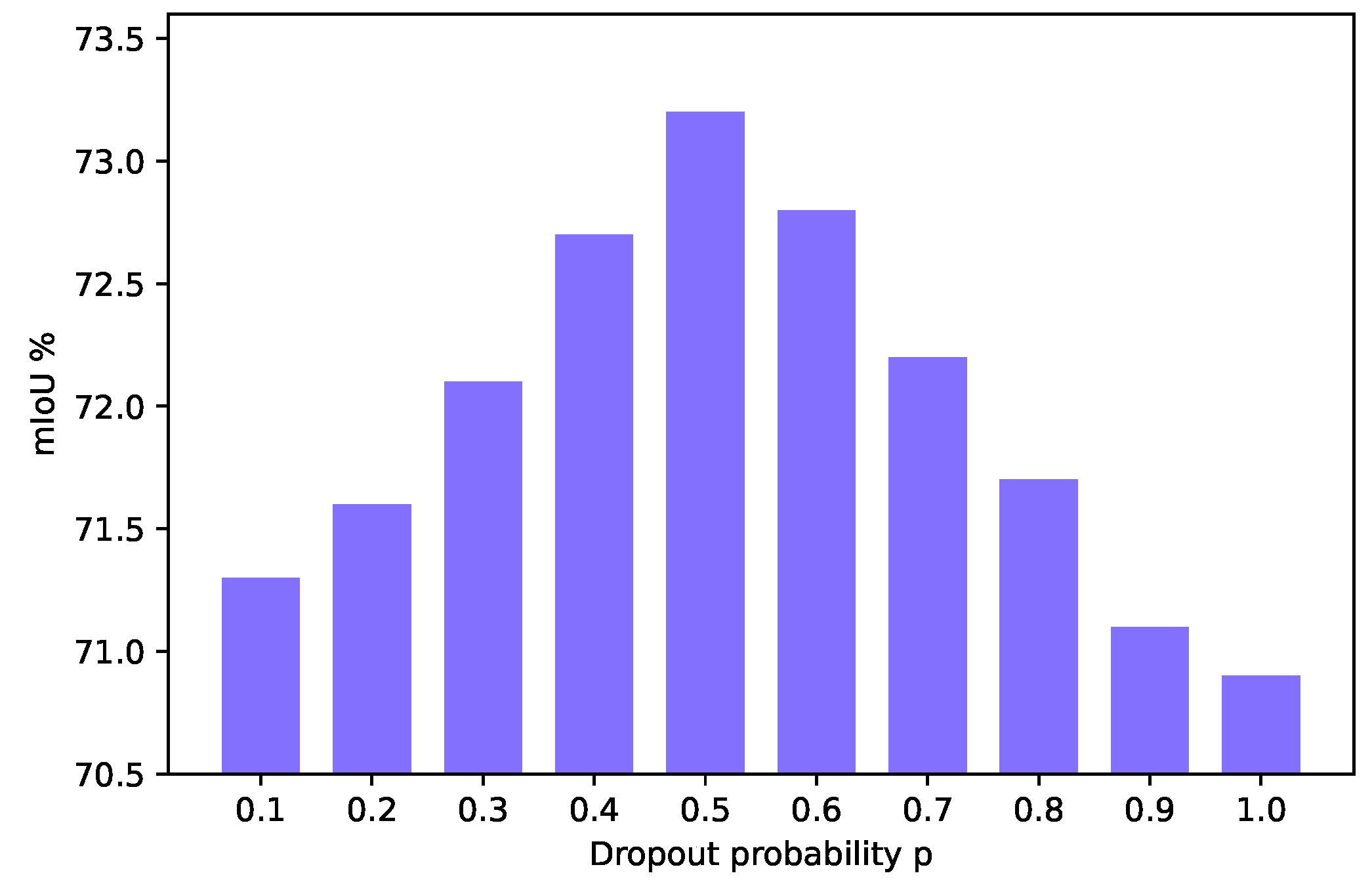
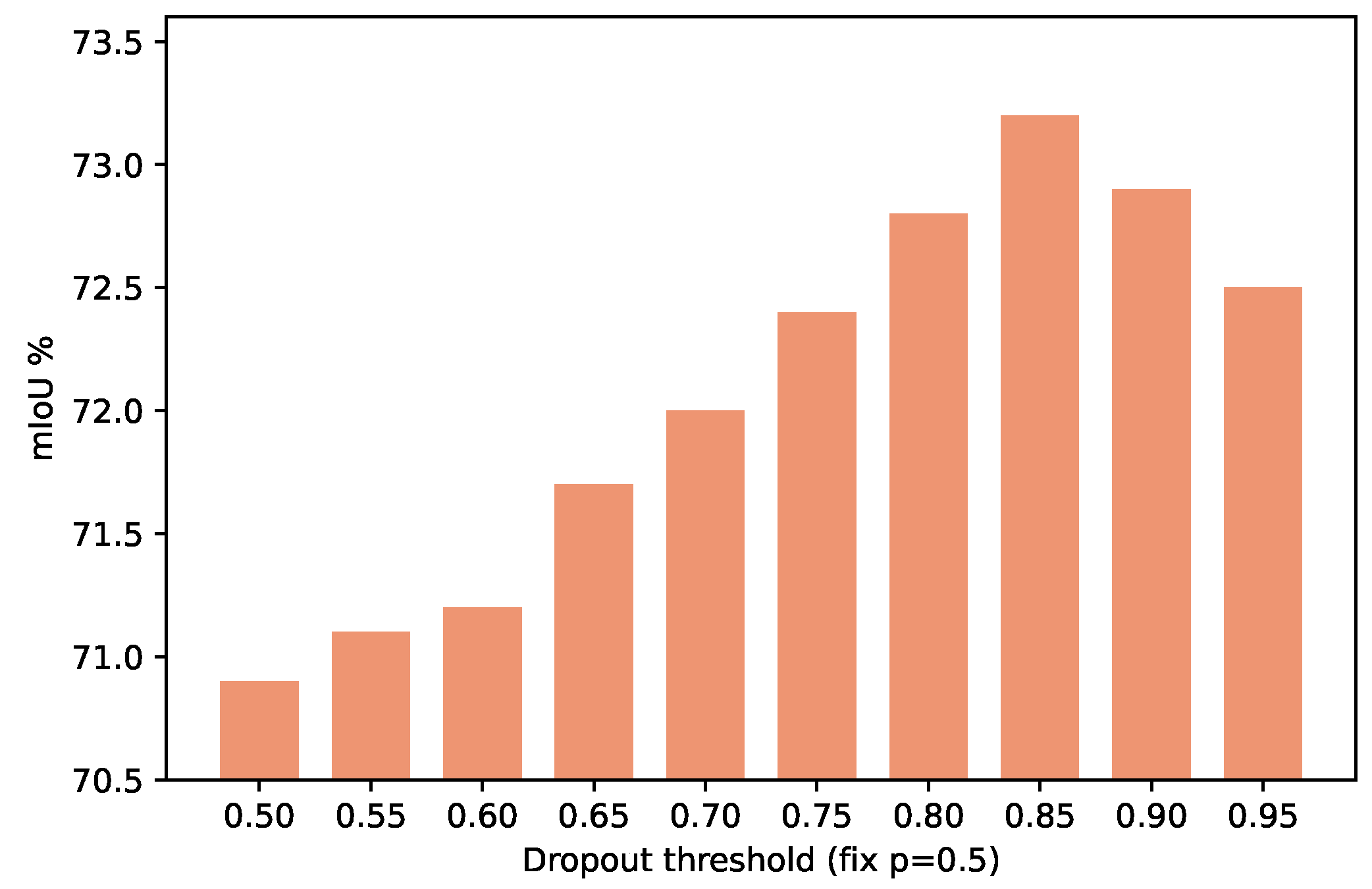
5.3. How Do the Hyper-Parameters Affect the Performance
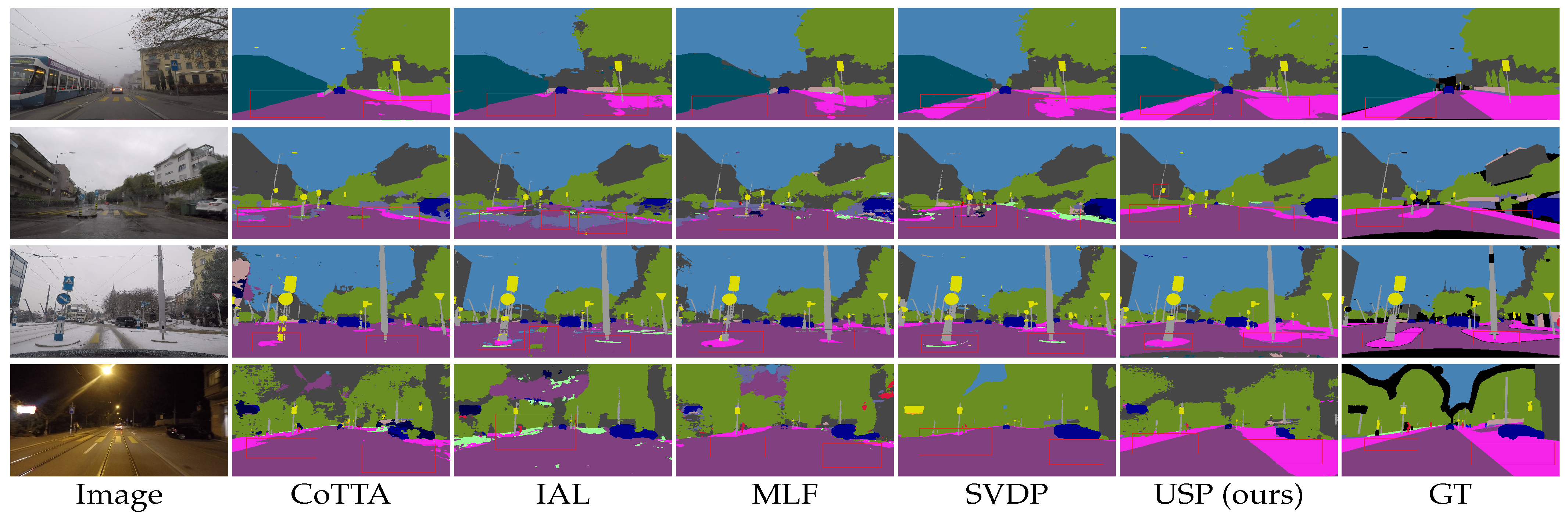
5.4. The Visual Effect of Prompt
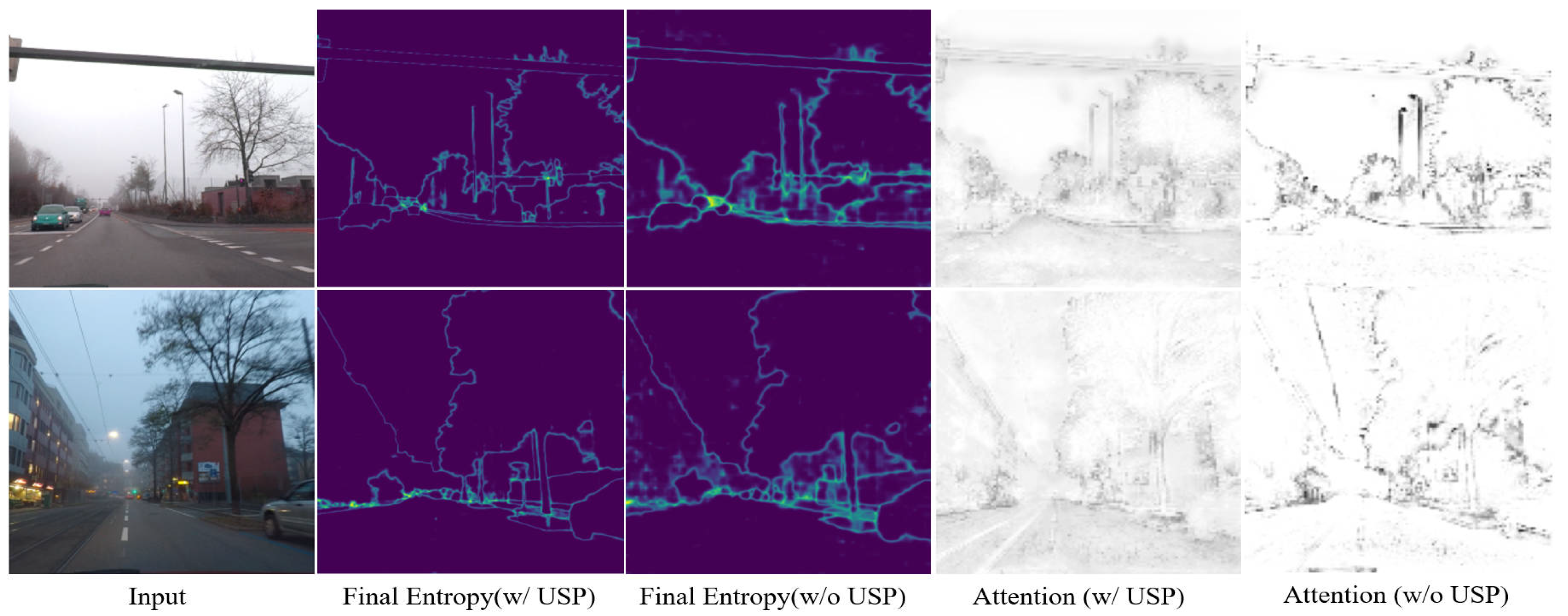
5.5. Attention and Specific Performance Affected by USP
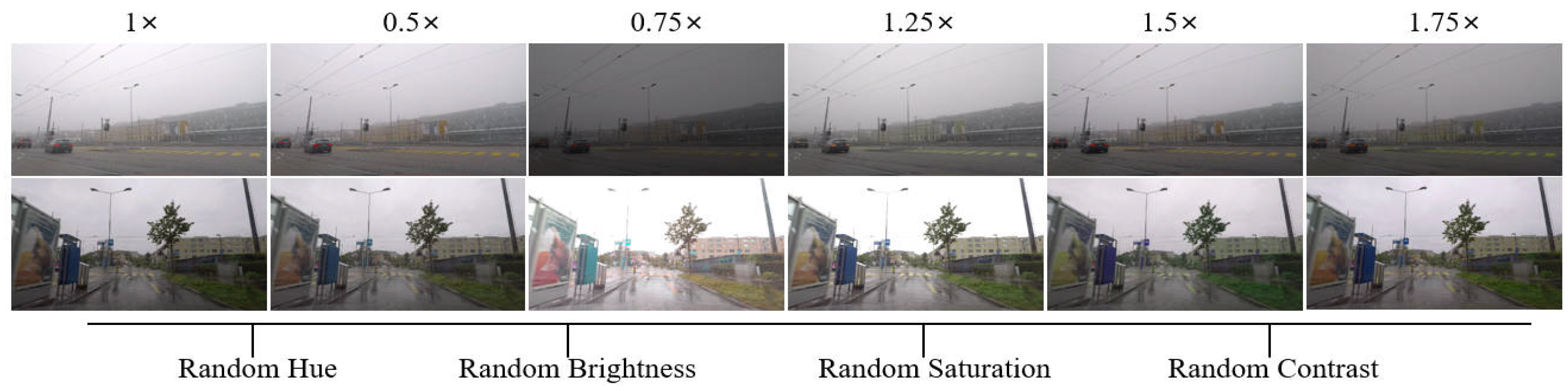
5.6. The Impact of Augmentation
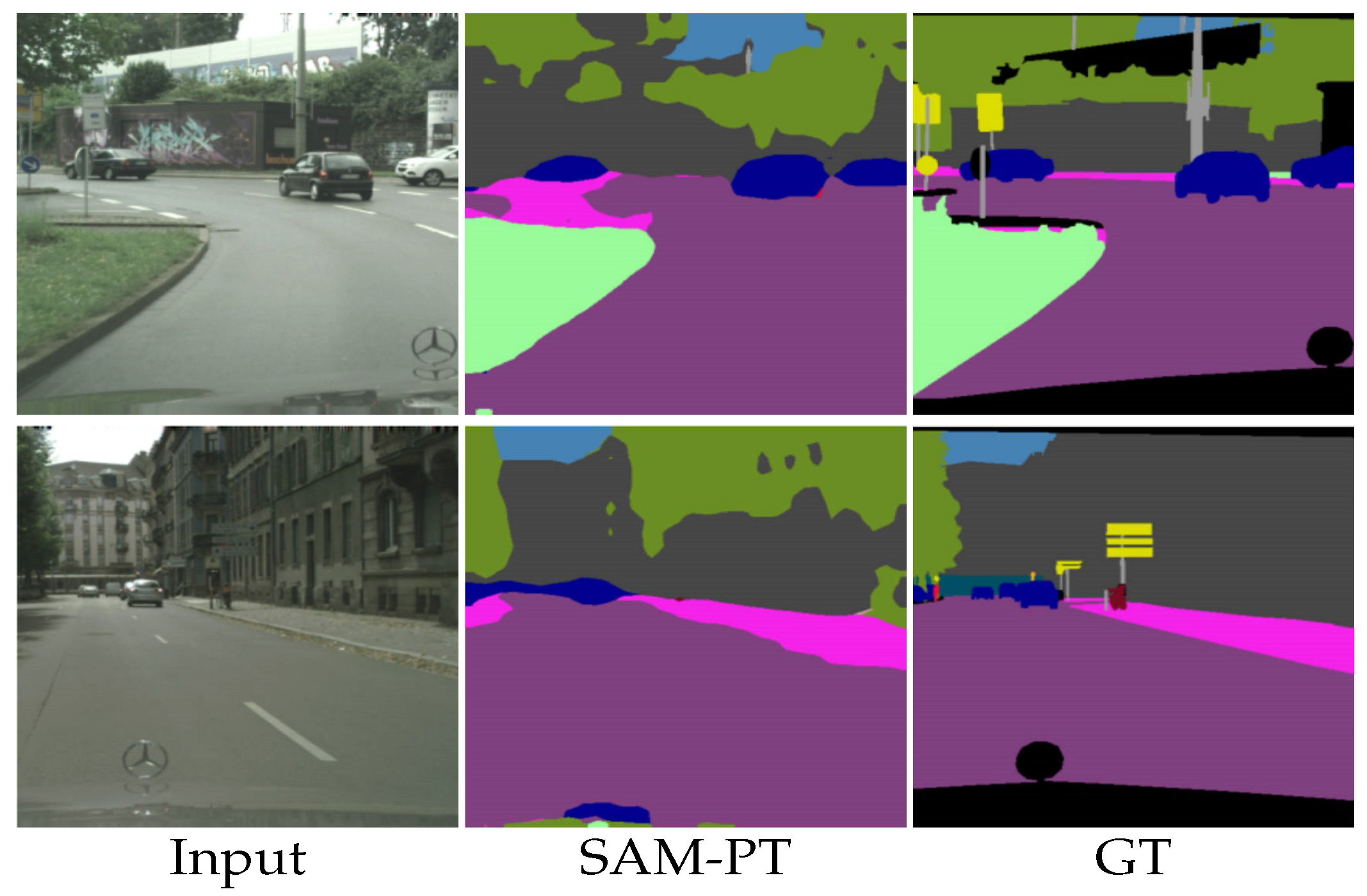
5.7. The Case against Prompt-Tuning Large Models
5.8. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Nomenclature | |||
| DA | Domain Adaptation | DPU | Domain Prompt Updating |
| DG | Domain Generalization | USP | Uncertainty-based Self-Prompt |
| TTA | Test-Time Adaptation | VPT | Visual Prompt Tuning |
| CTTA | Continual Test-Time Adaptation | GT | Ground Truth |
| VDP | Visual Domain Prompt | ACDC | Adverse Condition Datasets with Correspondence |
References
- Zhu, H.; Yuen, K.V.; Mihaylova, L.; Leung, H. Overview of Environment Perception for Intelligent Vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2584–2601. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A Survey of Deep Learning Applications to Autonomous Vehicle Control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 712–733. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Zhang, J.; Pu, J.; Chen, J.; Fu, H.; Tao, Y.; Wang, S.; Chen, Q.; Xiao, Y.; Chen, S.; Cheng, Y.; et al. DSiV: Data Science for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2023, 8, 2628–2634. [Google Scholar] [CrossRef]
- Ranft, B.; Stiller, C. The Role of Machine Vision for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2016, 1, 8–19. [Google Scholar] [CrossRef]
- Muhammad, K.; Hussain, T.; Ullah, H.; Ser, J.D.; Rezaei, M.; Kumar, N.; Hijji, M.; Bellavista, P.; de Albuquerque, V.H.C. Vision-Based Semantic Segmentation in Scene Understanding for Autonomous Driving: Recent Achievements, Challenges, and Outlooks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22694–22715. [Google Scholar] [CrossRef]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Dai, D.; Gool, L.V. Dark Model Adaptation: Semantic Image Segmentation from Daytime to Nighttime. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Sakaridis, C.; Dai, D.; Gool, L.V. ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10765–10775. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9924–9935. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2517–2526. [Google Scholar]
- Li, Y.; Yuan, L.; Vasconcelos, N. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6936–6945. [Google Scholar]
- Zou, Y.; Yu, Z.; Liu, X.; Kumar, B.V.; Wang, J. Confidence Regularized Self-Training. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1379–1389. [Google Scholar]
- Ma, X.; Wang, Z.; Zhan, Y.; Zheng, Y.; Wang, Z.; Dai, D.; Lin, C.W. Both style and fog matter: Cumulative domain adaptation for semantic foggy scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18922–18931. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. HRDA: Context-aware high-resolution domain-adaptive semantic segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 372–391. [Google Scholar]
- Hoyer, L.; Dai, D.; Wang, H.; Gool, L.V. MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation. arXiv 2023, arXiv:2212.01322. [Google Scholar]
- Muandet, K.; Balduzzi, D.; Schölkopf, B. Domain generalization via invariant feature representation. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 10–18. [Google Scholar]
- Li, B.; Wu, F.; Lim, S.N.; Belongie, S.; Weinberger, K.Q. On feature normalization and data augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12383–12392. [Google Scholar]
- Yin, D.; Gontijo Lopes, R.; Shlens, J.; Cubuk, E.D.; Gilmer, J. A fourier perspective on model robustness in computer vision. In Advances in Neural Information Processing Systems; MiT and Morgan Kaufmann: San Francisco, CA, USA, 2019; Volume 32. [Google Scholar]
- Ashukha, A.; Lyzhov, A.; Molchanov, D.; Vetrov, D. Pitfalls of in-domain uncertainty estimation and ensembling in deep learning. arXiv 2020, arXiv:2002.06470. [Google Scholar]
- Lyzhov, A.; Molchanova, Y.; Ashukha, A.; Molchanov, D.; Vetrov, D. Greedy policy search: A simple baseline for learnable test-time augmentation. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020; pp. 1308–1317. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 969–977. [Google Scholar]
- Liang, J.; He, R.; Tan, T. A Comprehensive Survey on Test-Time Adaptation under Distribution Shifts. arXiv 2023, arXiv:2303.15361. [Google Scholar]
- Mummadi, C.K.; Hutmacher, R.; Rambach, K.; Levinkov, E.; Brox, T.; Metzen, J.H. Test-Time Adaptation to Distribution Shift by Confidence Maximization and Input Transformation. arXiv 2021, arXiv:2106.14999. [Google Scholar]
- Wang, D.; Shelhamer, E.; Liu, S.; Olshausen, B.; Darrell, T. Tent: Fully Test-time Adaptation by Entropy Minimization. arXiv 2021, arXiv:2006.10726. [Google Scholar]
- Liang, J.; Hu, D.; Feng, J. Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020. JMLR.org, ICML’20. [Google Scholar]
- Liu, Y.; Zhang, W.; Wang, J. Source-Free Domain Adaptation for Semantic Segmentation. arXiv 2021, arXiv:2103.16372. [Google Scholar]
- Ye, M.; Zhang, J.; Ouyang, J.; Yuan, D. Source Data-Free Unsupervised Domain Adaptation for Semantic Segmentation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; Association for Computing Machinery: New York, NY, USA, 2021. MM ’21. pp. 2233–2242. [Google Scholar] [CrossRef]
- Wang, Q.; Fink, O.; Van Gool, L.; Dai, D. Continual test-time domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7201–7211. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37, Lille, France, 7–9 July 2015; JMLR.org, ICML’15. pp. 448–456. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Information Processing Systems; MiT and Morgan Kaufmann: San Francisco, CA, USA, 2017; Volume 30. [Google Scholar]
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Wang, X.; Wang, W.; Cao, Y.; Shen, C.; Huang, T. Images speak in images: A generalist painter for in-context visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6830–6839. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 709–727. [Google Scholar]
- Gan, Y.; Bai, Y.; Lou, Y.; Ma, X.; Zhang, R.; Shi, N.; Luo, L. Decorate the newcomers: Visual domain prompt for continual test time adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 7595–7603. [Google Scholar]
- Gao, Y.; Shi, X.; Zhu, Y.; Wang, H.; Tang, Z.; Zhou, X.; Li, M.; Metaxas, D.N. Visual prompt tuning for test-time domain adaptation. arXiv 2022, arXiv:2210.04831. [Google Scholar]
- Ge, C.; Huang, R.; Xie, M.; Lai, Z.; Song, S.; Li, S.; Huang, G. Domain adaptation via prompt learning. arXiv 2022, arXiv:2202.06687. [Google Scholar] [CrossRef] [PubMed]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Dai, Y.; Li, C.; Su, X.; Liu, H.; Li, J. Multi-Scale Depthwise Separable Convolution for Semantic Segmentation in Street–Road Scenes. Remote Sens. 2023, 15, 2649. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual attention deep fusion semantic segmentation networks of large-scale satellite remote-sensing images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]
- Hehn, T.; Kooij, J.; Gavrila, D. Fast and Compact Image Segmentation Using Instance Stixels. IEEE Trans. Intell. Veh. 2022, 7, 45–56. [Google Scholar] [CrossRef]
- Ni, P.; Li, X.; Kong, D.; Yin, X. Scene-Adaptive 3D Semantic Segmentation Based on Multi-Level Boundary-Semantic-Enhancement for Intelligent Vehicles. IEEE Trans. Intell. Veh. 2023, 9, 1722–1732. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, Y.; Jiang, Z.; Pei, Y.; Zheng, B.; Zheng, L.; Fu, Z. Multi-Pooling Context Network for Image Semantic Segmentation. Remote Sens. 2023, 15, 2800. [Google Scholar] [CrossRef]
- Sun, Q.; Chao, J.; Lin, W.; Xu, Z.; Chen, W.; He, N. Learn to Few-Shot Segment Remote Sensing Images from Irrelevant Data. Remote Sens. 2023, 15, 4937. [Google Scholar] [CrossRef]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 102–118. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. arXiv 2017, arXiv:1711.03213. [Google Scholar]
- Chang, W.L.; Wang, H.P.; Peng, W.H.; Chiu, W.C. All about structure: Adapting structural information across domains for boosting semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1900–1909. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12414–12424. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Michieli, U.; Biasetton, M.; Agresti, G.; Zanuttigh, P. Adversarial Learning and Self-Teaching Techniques for Domain Adaptation in Semantic Segmentation. IEEE Trans. Intell. Veh. 2020, 5, 508–518. [Google Scholar] [CrossRef]
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar]
- Huang, J.; Guan, D.; Xiao, A.; Lu, S. Model Adaptation: Historical Contrastive Learning for Unsupervised Domain Adaptation without Source Data. arXiv 2022, arXiv:2110.03374. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. arXiv 2017, arXiv:1611.07725. [Google Scholar]
- Bar, A.; Gandelsman, Y.; Darrell, T.; Globerson, A.; Efros, A. Visual prompting via image inpainting. Adv. Neural Inf. Process. Syst. 2022, 35, 25005–25017. [Google Scholar]
- Yang, S.; Wu, J.; Liu, J.; Li, X.; Zhang, Q.; Pan, M.; Pan, M.; Zhang, S. Exploring Sparse Visual Prompt for Cross-domain Semantic Segmentation. arXiv 2023, arXiv:2303.09792. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Romera, E.; Álvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Chen, B.; Gong, C.; Yang, J. Importance-Aware Semantic Segmentation for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2019, 20, 137–148. [Google Scholar] [CrossRef]
- Fan, J.; Wang, F.; Chu, H.; Hu, X.; Cheng, Y.; Gao, B. MLFNet: Multi-Level Fusion Network for Real-Time Semantic Segmentation of Autonomous Driving. IEEE Trans. Intell. Veh. 2023, 8, 756–767. [Google Scholar] [CrossRef]
- Chen, C.; Wang, C.; Liu, B.; He, C.; Cong, L.; Wan, S. Edge Intelligence Empowered Vehicle Detection and Image Segmentation for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 13023–13034. [Google Scholar] [CrossRef]
- Contributors, M. MMSegmentation: Openmmlab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 22 January 2024).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, X.; Zhang, X.; Cao, Y.; Wang, W.; Shen, C.; Huang, T. SegGPT: Segmenting Everything In Context. arXiv 2023, arXiv:2304.03284. [Google Scholar]
- Wang, Z.; Zhang, Y.; Ma, X.; Yu, Y.; Zhang, Z.; Jiang, Z.; Cheng, B. Semantic Segmentation of Foggy Scenes Based on Progressive Domain Gap Decoupling 2023. Available online: https://www.techrxiv.org/doi/full/10.36227/techrxiv.22682161.v1 (accessed on 22 January 2024).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Scenario | Labelled Images | Number of Label Used | Experiment Purpose |
|---|---|---|---|---|
| Cityscapes | Autonomous Driving in clear scene | 2975(train)/500(val) | 2975(for train source) | not involved in testing |
| Foggy Cityscapes | Autonomous Driving in synthetic foggy scene | 2975(train)/500(val) | 0(TTA)/2975(for evaluation) | Test the performance of TTA |
| Rainy Cityscapes | Autonomous Driving in synthetic rainy scene | 2975(train)/500(val) | 0(TTA)/2975(for evaluation) | Test the performance of TTA |
| ACDC-Fog | Autonomous Driving in real foggy scene | 400(train)/100(val) | 0(TTA)/400(for evaluation) | Test the performance of TTA |
| ACDC-Rain | Autonomous Driving in real rainy scene | 400(train)/100(val) | 0(TTA)/400(for evaluation) | Test the performance of TTA |
| ACDC-Night | Autonomous Driving in real nighttime scene | 400(train)/106(val) | 0(TTA)/400(for evaluation) | Test the performance of TTA |
| ACDC-Snow | Autonomous Driving in real snowy scene | 400(train)/100(val) | 0(TTA)/400(for evaluation) | Test the performance of TTA |
| Test-Time Adaptation | Source2Fog | Source2Night | Source2Rain | Source2Snow | Mean-mIoU↑ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | REF | mIoU↑ | mAcc↑ | mIoU↑ | mAcc↑ | mIoU↑ | mAcc↑ | mIoU↑ | mAcc↑ | |
| ERFNet | TITS2018 [67] | 61.3 | 71.1 | 28.4 | 41.6 | 47.6 | 61.0 | 51.8 | 62.7 | 47.3 |
| IAL | TITS2019 [68] | 64.0 | 74.8 | 34.5 | 46.3 | 52.8 | 67.2 | 54.0 | 66.4 | 51.3 |
| SegFormer | NeurIPS2021 [57] | 69.1 | 79.4 | 40.3 | 55.6 | 59.7 | 74.4 | 57.8 | 69.9 | 56.7 |
| TENT | ICLR2021 [28] | 69.0 | 79.5 | 40.3 | 55.5 | 59.9 | 73.2 | 57.7 | 69.7 | 56.7 |
| CoTTA | CVPR2022 [32] | 70.9 | 80.2 | 41.2 | 55.5 | 62.6 | 75.4 | 59.8 | 70.7 | 58.6 |
| MLFNet | TIV2023 [69] | 68.4 | 77.3 | 39.2 | 54.1 | 60.8 | 72.3 | 56.3 | 68.2 | 56.2 |
| EIE | TITS2023 [70] | 70.2 | 79.1 | 40.5 | 55.0 | 60.2 | 72.1 | 58.6 | 70.3 | 57.4 |
| DePT | ICLR2023 [41] | 71.0 | 80.2 | 40.9 | 55.8 | 61.3 | 74.4 | 59.5 | 70.0 | 58.2 |
| VDP | AAAI2023 [40] | 70.9 | 80.3 | 41.2 | 55.6 | 62.3 | 75.5 | 59.7 | 70.7 | 58.5 |
| SVDP | ICCV2023 [64] | 72.5 | 81.4 | 45.3 | 58.9 | 65.7 | 76.7 | 62.2 | 72.4 | 61.4 |
| USP | Ours | 73.2 | 82.1 | 44.9 | 59.4 | 66.4 | 77.0 | 63.2 | 72.8 | 61.9 |
| Time | t————————————————————————————————> | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Round | 1 | 2 | 3 | Mean | Gain | |||||||||||||
| Method | REF | Fog | Night | Rain | Snow | Mean | Fog | Night | Rain | Snow | Mean | Fog | Night | Rain | Snow | Mean | ||
| ERFNet | TITS2018 [67] | 61.2 | 28.4 | 47.5 | 51.8 | 47.2 | 61.2 | 28.4 | 47.5 | 51.8 | 47.2 | 61.2 | 28.4 | 47.5 | 51.8 | 47.2 | 47.2 | - |
| IAL | TITS2019 [68] | 64.0 | 34.4 | 52.8 | 54.0 | 51.3 | 64.0 | 34.4 | 52.8 | 54.0 | 51.3 | 64.0 | 34.4 | 52.8 | 54.0 | 51.3 | 51.3 | - |
| MLFNet | TIV2023 [69] | 68.4 | 39.3 | 60.9 | 56.3 | 56.2 | 68.4 | 39.3 | 60.9 | 56.3 | 56.2 | 68.4 | 39.3 | 60.9 | 56.3 | 56.2 | 56.2 | - |
| EIE | TITS2023 [70] | 70.1 | 40.3 | 60.3 | 58.5 | 57.3 | 70.1 | 40.3 | 60.3 | 58.5 | 57.3 | 70.1 | 40.3 | 60.3 | 58.5 | 57.3 | 57.3 | - |
| SegFormer | NeurIPS2021 [57] | 69.1 | 40.3 | 59.7 | 57.8 | 56.7 | 69.1 | 40.3 | 59.7 | 57.8 | 56.7 | 69.1 | 40.3 | 59.7 | 57.8 | 56.7 | 56.7 | - |
| TENT | ICLR2021 [28] | 69.0 | 40.2 | 60.1 | 57.3 | 56.7 | 68.3 | 39.0 | 60.1 | 56.3 | 55.9 | 67.5 | 37.8 | 59.6 | 55.0 | 55.0 | 55.7 | -1.0 |
| CoTTA | CVPR2022 [32] | 70.9 | 41.2 | 62.4 | 59.7 | 58.6 | 70.9 | 41.1 | 62.6 | 59.7 | 58.6 | 70.9 | 41.0 | 62.7 | 59.7 | 58.6 | 58.6 | +1.9 |
| DePT | ICLR2023 [41] | 71.0 | 40.8 | 58.2 | 56.8 | 56.5 | 68.2 | 40.0 | 55.4 | 53.7 | 54.3 | 66.4 | 38.0 | 47.3 | 47.2 | 49.7 | 53.4 | -3.3 |
| VDP | AAAI2023 [40] | 70.5 | 41.1 | 62.1 | 59.5 | 58.3 | 70.4 | 41.1 | 62.2 | 59.4 | 58.2 | 70.4 | 41.0 | 62.2 | 59.4 | 58.2 | 58.2 | +1.5 |
| SVDP | ICCV2023 [64] | 72.5 | 45.9 | 67.0 | 64.1 | 62.4 | 72.2 | 44.8 | 67.3 | 64.1 | 62.1 | 72.0 | 44.5 | 67.6 | 64.2 | 62.1 | 62.2 | +5.5 |
| USP | Ours | 74.2 | 44.6 | 67.4 | 64.5 | 62.7 | 74.1 | 44.6 | 67.3 | 64.2 | 62.5 | 74.1 | 44.6 | 67.0 | 63.8 | 62.3 | 62.5 | +5.8 |
| Sky | Road | Build | Veget. | Train | Car | Terrain | Truck | S.walk | Rider | Tr.Sing | Tr.Light | Bus | M.Bike | Wall | Person | Pole | Bike | Fence | mIoU | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S2Fog | w/o USP | 98.1 | 90.6 | 88.3 | 84.3 | 82.6 | 89.4 | 73.5 | 77.9 | 80.4 | 76.9 | 79.3 | 69.4 | 78.6 | 55.8 | 60.1 | 59.9 | 49.3 | 30.3 | 23.3 | 70.9 |
| w/ USP | 98.8 | 93.5 | 87.2 | 81.4 | 88.9 | 92.6 | 77.4 | 80.1 | 79.5 | 81.2 | 80.1 | 75.2 | 77.1 | 56.9 | 63.4 | 60.2 | 44.7 | 40.8 | 32.5 | 73.2 | |
| S2Night | w/o USP | 37.9 | 76.4 | 68.3 | 65.7 | 32.9 | 72.1 | 38.4 | 15.3 | 50.3 | 20.3 | 56.7 | 35.4 | 42.9 | 26.4 | 6.60 | 54.4 | 38.3 | 33.8 | 10.2 | 41.2 |
| w/ USP | 44.6 | 75.1 | 79.2 | 48.3 | 50.3 | 68.9 | 41.2 | 26.4 | 50.1 | 25.2 | 37.0 | 15.8 | 40.3 | 31.5 | 29.4 | 55.9 | 37.1 | 47.6 | 18.3 | 44.9 | |
| S2Rain | w/o USP | 96.4 | 83.1 | 85.4 | 92.6 | 76.5 | 84.3 | 41.8 | 65.9 | 45.4 | 22.1 | 67.3 | 62.4 | 58.7 | 49.7 | 44.7 | 57.7 | 52.1 | 56.3 | 47.5 | 62.6 |
| w/ USP | 97.9 | 88.2 | 90.4 | 91.0 | 79.4 | 88.9 | 43.0 | 61.0 | 55.4 | 45.3 | 62.1 | 62.4 | 82.3 | 42.8 | 60.3 | 58.9 | 51.8 | 57.0 | 41.0 | 66.3 | |
| S2Snow | w/o USP | 94.7 | 81.3 | 83.7 | 89.4 | 78.3 | 87.8 | 10.3 | 54.9 | 49.8 | 43.1 | 64.2 | 65.4 | 51.9 | 37.5 | 35.3 | 64.1 | 47.0 | 57.1 | 40.8 | 59.8 |
| w/ USP | 96.9 | 84.1 | 84.2 | 85.3 | 87.1 | 88.9 | 25.6 | 53.5 | 37.4 | 55.3 | 62.4 | 70.3 | 74.1 | 39.2 | 28.5 | 61.6 | 51.3 | 61.7 | 53.2 | 63.2 |
| Foggy | SegFormer | TENT | CoTTA | DePT | VDP | SVDP | USP |
|---|---|---|---|---|---|---|---|
| mIoU | 69.2 | 69.3 | 72.1 | 71.9 | 71.8 | 74.5 | 76.2 |
| mAcc | 79.1 | 79.0 | 79.4 | 80.2 | 80.0 | 82.3 | 84.3 |
| Rainy | SegFormer | TENT | CoTTA | DePT | VDP | SVDP | USP |
| mIoU | 58.4 | 58.7 | 62.4 | 61.2 | 63.7 | 65.3 | 65.3 |
| mAcc | 71.5 | 71.4 | 74.0 | 72.4 | 73.1 | 75.6 | 77.7 |
| TS 1 | USP 2 | DPU 3 | P-Drop 4 | mIoU | mAcc | |
|---|---|---|---|---|---|---|
| 69.1 | 79.4 | |||||
| ✓ | 69.4 | 79.6 | ||||
| ✓ | ✓ | 72.4 | 81.2 | |||
| ✓ | ✓ | ✓ | 72.9 | 81.2 | ||
| ✓ | ✓ | ✓ | 73.0 | 81.8 | ||
| ✓ | ✓ | ✓ | ✓ | 73.2 | 82.1 |
| Prompt Module City-to-ACDC(fog) TTA | Architecture | |||
|---|---|---|---|---|
| Prompt|S | Prompt|M | Prompt|L | Prompt|H | |
| Encoder | ||||
| Decoder | ||||
| mIoU | 73.9 | 73.2 | 73.2 | 73.8 |
| mAcc | 81.4 | 82.1 | 82.0 | 81.8 |
| Augmentation | TTA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Configuation | M-S 1 | R.H 2 | R.B 3 | R.S 4 | R.C 5 | Fog | Night | Rain | Snow |
| ✓ | 70.9 | 41.2 | 62.6 | 59.8 | |||||
| ✓ | 71.4 | 41.9 | 63.0 | 61.1 | |||||
| ✓ | 71.2 | 42.3 | 62.8 | 60.3 | |||||
| ✓ | 71.5 | 42.1 | 63.1 | 61.5 | |||||
| ✓ | 71.8 | 42.0 | 62.9 | 60.7 | |||||
| ✓ | ✓ | ✓ | ✓ | ✓ | 73.2 | 44.9 | 66.4 | 63.2 | |
| SegFormer-Based | SAM-PT 1 | SAM-FT 2 | |
|---|---|---|---|
| Memory (Bs = 1, GB) | 6–8 | 15–20 | |
| Speed (FPS) | 6–7 | 1–2 | |
| mIoU (City|40,000 3) | 80.2 | 18.3 | 16.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhang, Y.; Zhang, Z.; Jiang, Z.; Yu, Y.; Li, L.; Zhang, L. Exploring Uncertainty-Based Self-Prompt for Test-Time Adaptation Semantic Segmentation in Remote Sensing Images. Remote Sens. 2024, 16, 1239. https://doi.org/10.3390/rs16071239
Wang Z, Zhang Y, Zhang Z, Jiang Z, Yu Y, Li L, Zhang L. Exploring Uncertainty-Based Self-Prompt for Test-Time Adaptation Semantic Segmentation in Remote Sensing Images. Remote Sensing. 2024; 16(7):1239. https://doi.org/10.3390/rs16071239
Chicago/Turabian StyleWang, Ziquan, Yongsheng Zhang, Zhenchao Zhang, Zhipeng Jiang, Ying Yu, Lei Li, and Lei Zhang. 2024. "Exploring Uncertainty-Based Self-Prompt for Test-Time Adaptation Semantic Segmentation in Remote Sensing Images" Remote Sensing 16, no. 7: 1239. https://doi.org/10.3390/rs16071239
APA StyleWang, Z., Zhang, Y., Zhang, Z., Jiang, Z., Yu, Y., Li, L., & Zhang, L. (2024). Exploring Uncertainty-Based Self-Prompt for Test-Time Adaptation Semantic Segmentation in Remote Sensing Images. Remote Sensing, 16(7), 1239. https://doi.org/10.3390/rs16071239