
A Renovated Framework of a Convolution Neural Network with Transformer for Detecting Surface Changes from High-Resolution Remote-Sensing Images

 , ,
, , 
Abstract
1. Introduction
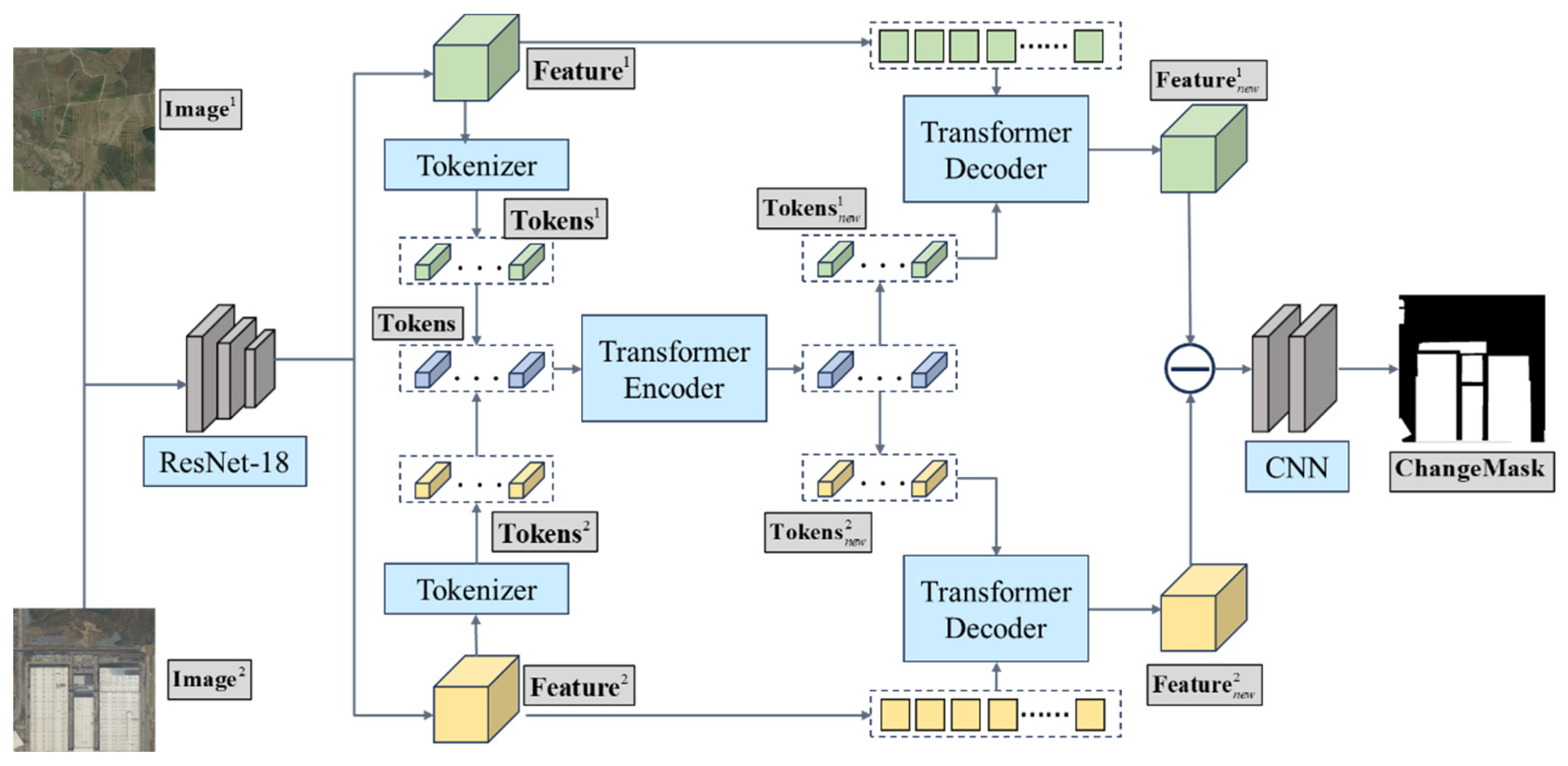
2. Methodology
| Algorithm 1. The overall architecture of the ResNet18+Transformer deep learning model for change detection |
| 1: Input::: 2: Load pretrained ResNet-18 network and feature extraction 3: 4: 5: function Tokenizer() 6: 7: 8: 9: end function 10: function TransformerEncoder(Tokens) 11: Initialize Transformer encoder layers 12: 13: 14: 15: end function 16: function TransformerDecoder() 17: Initialize Transformer decoder layers 18: 19: 20: 21: 22: end function 23: function PredictionHead() 24: Initialize decoding layers 25: 26: 27: 28: 29: end function |
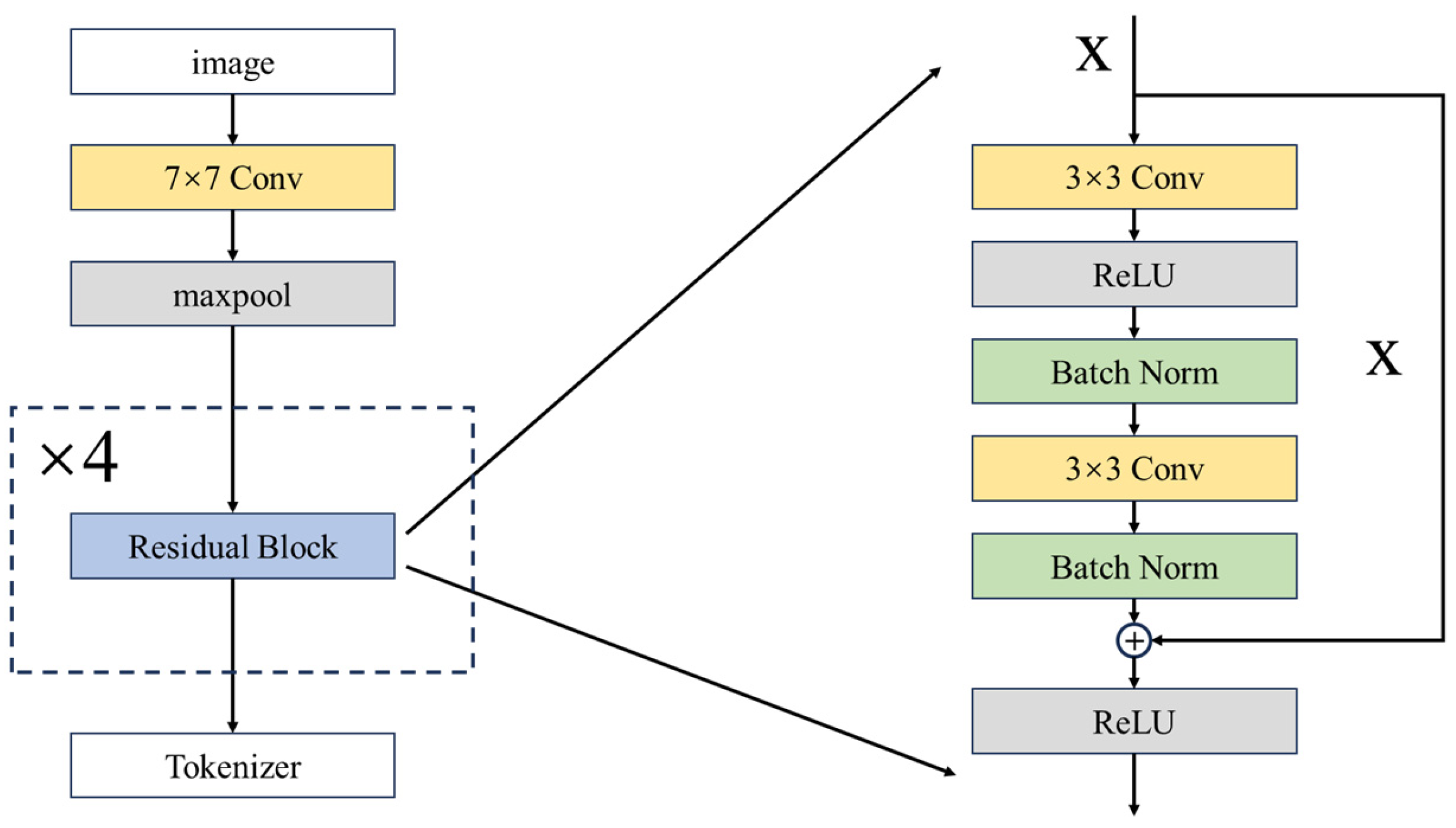
2.1. Initial Feature Extraction
2.2. Transformer-Based Network
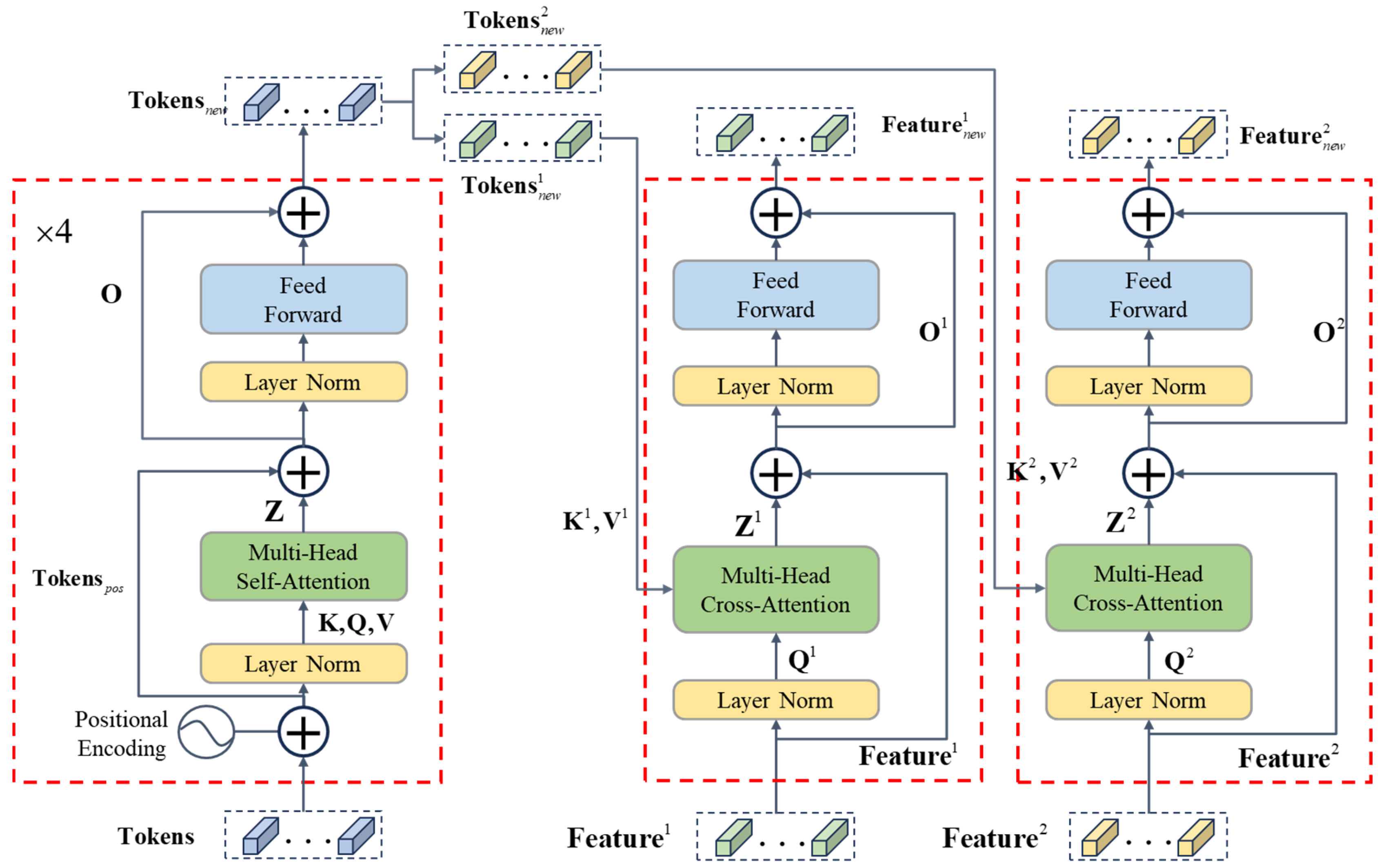
2.2.1. Tokenizer
2.2.2. Transformer Encoder
2.2.3. Transformer Decoder
2.3. Prediction Head
2.4. Performance Evaluation
2.5. Image Preprocessing Toolkit
3. Demonstration Case
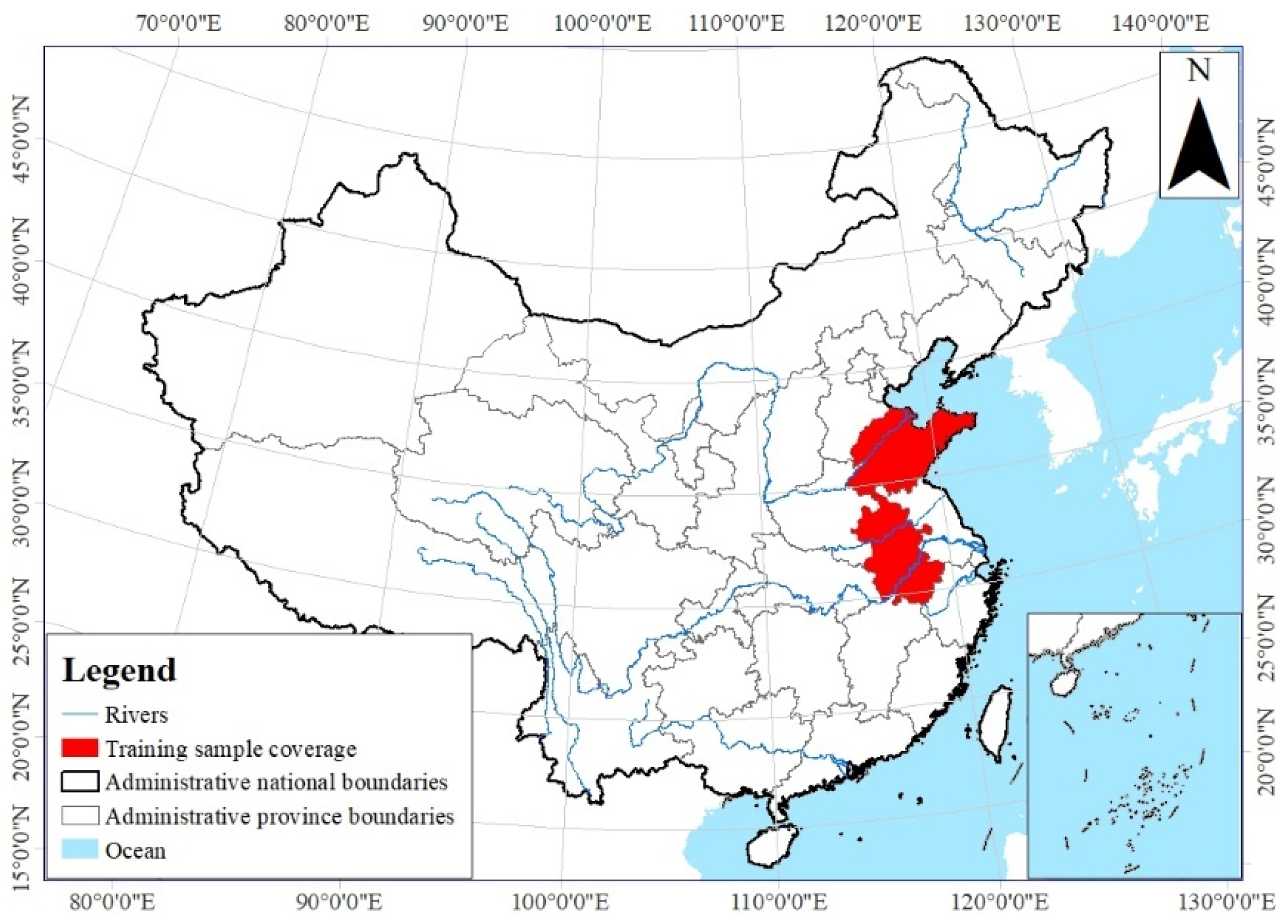
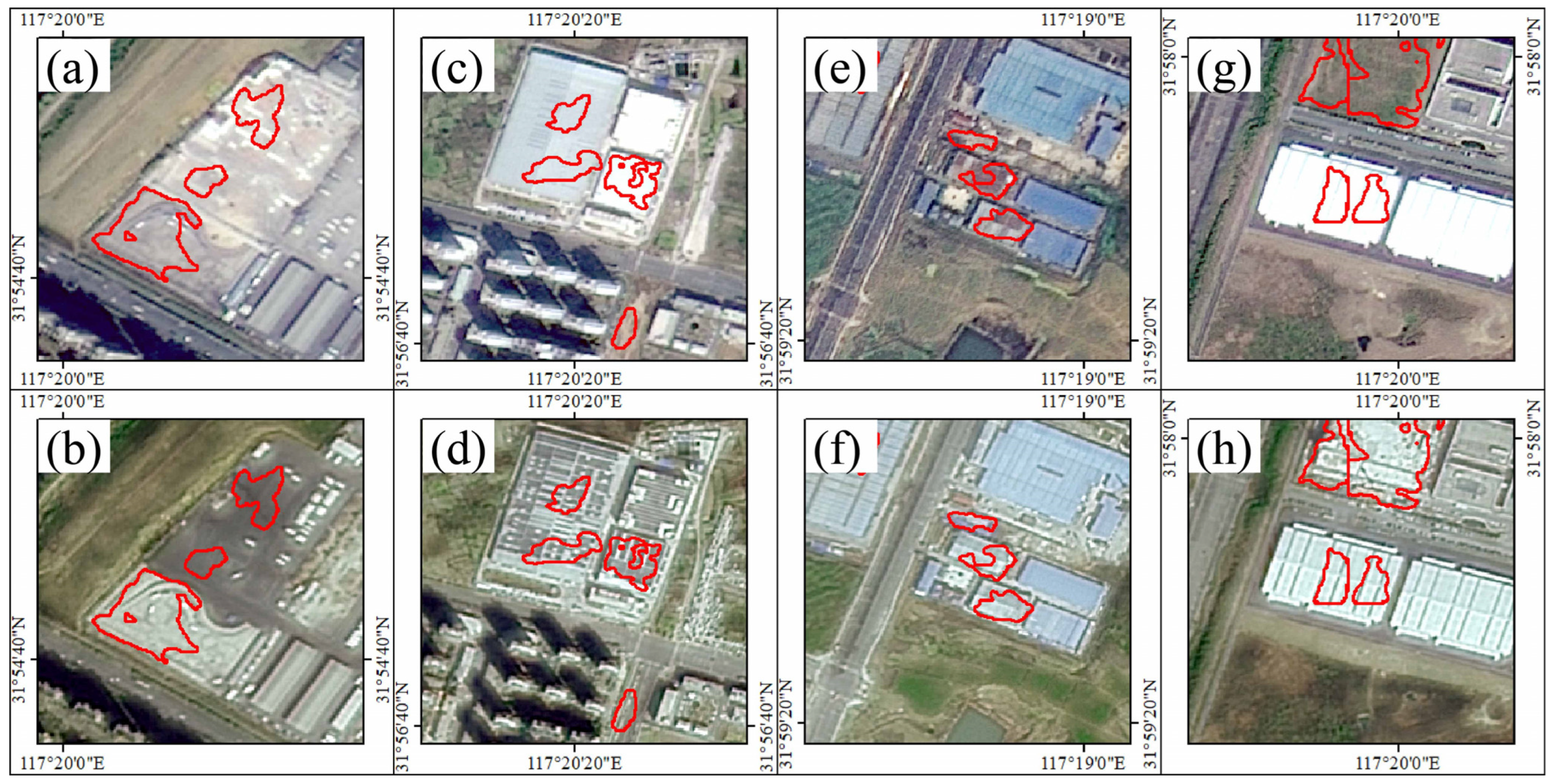
3.1. Data Collection and Processing
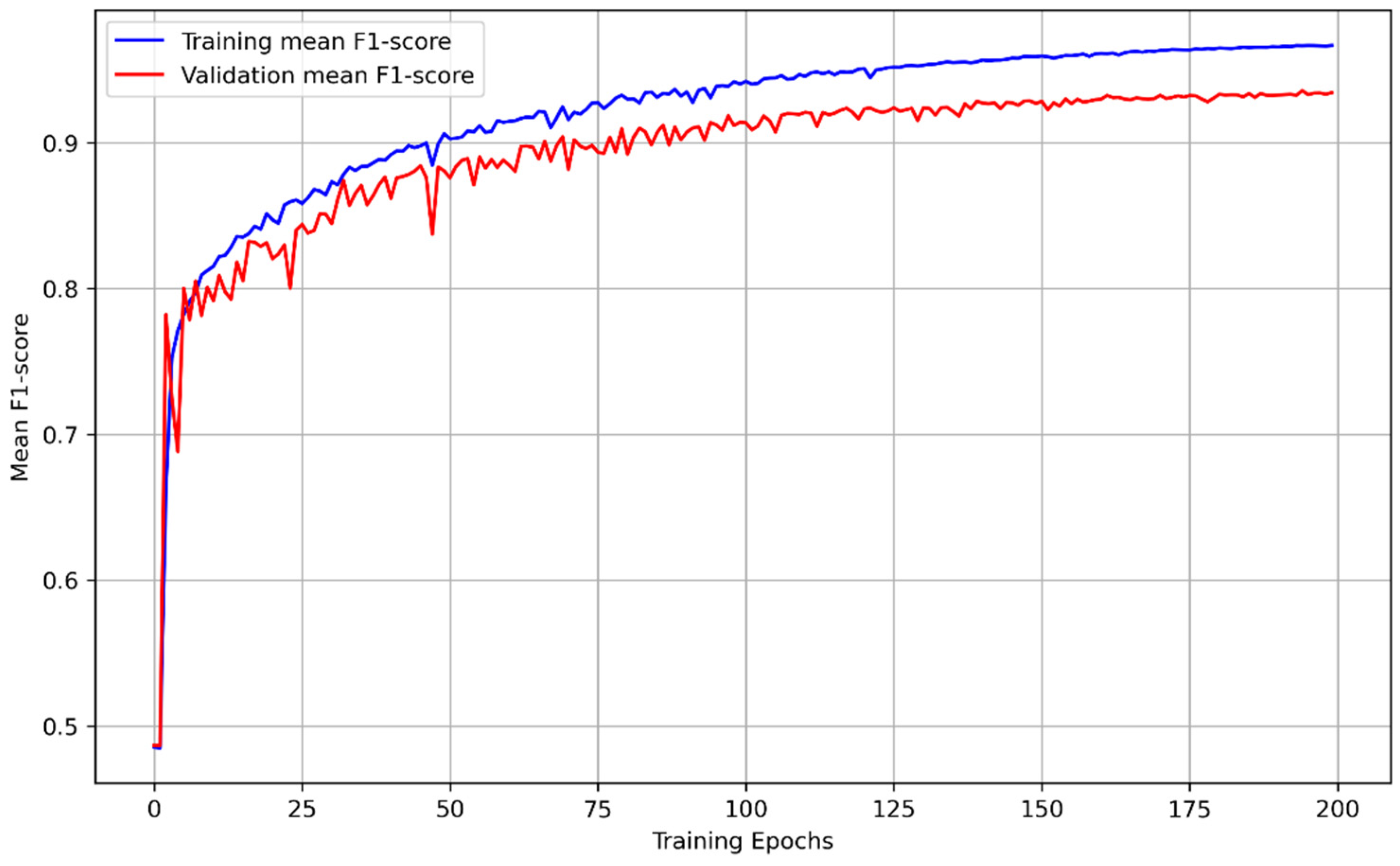
3.2. Training Result of the Proposed Framework
4. Discussion
4.1. Performance Evaluation
4.2. Application of ResNet18+Transformer Model
5. Conclusions
- (1)
- Compared to fully convolutional neural networks, incorporating attention mechanisms can achieve better results since CNNs usually ignore the global information, resulting in limited handling with high-level semantic features at the global level.
- (2)
- Among attention networks, the Vision Transformer structure outperforms the pure multi-head attention since its unit structure can add a feed-forward network based on the self-attention mechanism to achieve channel-dimensional information interaction.
- (3)
- The proposed model outperforms both the convolution-based model and attention-based models in terms of Overall Accuracy, F1-score, and IoU since it combines the great capability of CNN on image feature extraction, and the ability to obtain global semantic information from the attention mechanism. It presents a significant improvement in the balance between identifying the positive samples and avoiding false positives in complex image change detection.
- (4)
- The proposed structure shows better extrapolation and robustness in handling complex images in practical applications with an approximately 80% accuracy in detecting changes in new testing sets (i.e., Yaohai District in 2022 and 2023).
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, H.; Wang, Z. Human activities and natural geographical environment and their interactive effects on sudden geologic hazard: A perspective of macro-scale and spatial statistical analysis. Appl. Geogr. 2022, 143, 102711. [Google Scholar] [CrossRef]
- Gill, J.C.; Malamud, B.D. Anthropogenic processes, natural hazards, and interactions in a multi-hazard framework. Earth-Sci. Rev. 2017, 166, 246–269. [Google Scholar] [CrossRef]
- Rahmati, O.; Golkarian, A.; Biggs, T.; Keesstra, S.; Mohammadi, F.; Daliakopoulos, I.N. Land subsidence hazard modeling: Machine learning to identify predictors and the role of human activities. J. Environ. Manag. 2019, 236, 466–480. [Google Scholar] [CrossRef] [PubMed]
- Shine, K.P.; de Forster, P.M. The effect of human activity on radiative forcing of climate change: A review of recent developments. Glob. Planet. Chang. 1999, 20, 205–225. [Google Scholar] [CrossRef]
- Trenberth, K.E. Climate change caused by human activities is happening and it already has major consequences. J. Energy Nat. Resour. Law 2018, 36, 463–481. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, Y.; Wan, J.; Yang, Z.; Zhang, X. Analysis of human activity impact on flash floods in China from 1950 to 2015. Sustainability 2020, 13, 217. [Google Scholar] [CrossRef]
- Wang, F.; Mu, X.; Li, R.; Fleskens, L.; Stringer, L.C.; Ritsema, C.J. Co-evolution of soil and water conservation policy and human–environment linkages in the Yellow River Basin since 1949. Sci. Total Environ. 2015, 508, 166–177. [Google Scholar] [CrossRef] [PubMed]
- Xitao, H.; Siyu, C.; Yu, Z.; Han, Z.; Xiaofeng, Y.; Pengtao, J.; Liyuan, X. Study on Dynamic Monitoring Technology of Soil and Water Conservation in Construction Projects using Multi-source Remote Sensing Information. J. Phys. Conf. Ser. 2021, 1848, 012055. [Google Scholar] [CrossRef]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef]
- Bovolo, F.; Bruzzone, L.; Marconcini, M. A Novel Approach to Unsupervised Change Detection Based on a Semisupervised SVM and a Similarity Measure. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2070–2082. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Soille, P.; Vogt, P. Morphological segmentation of binary patterns. Pattern Recognit. Lett. 2009, 30, 456–459. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004; pp. 506–513. [Google Scholar]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2014; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, G.; Chen, K.; Yan, M.; Sun, X. Triplet-based semantic relation learning for aerial remote sensing image change detection. IEEE Geosci. Remote Sens. Lett. 2018, 16, 266–270. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, W. A Feature Difference Convolutional Neural Network-Based Change Detection Method. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7232–7246. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Kalinaki, K.; Malik, O.A.; Ching Lai, D.T. FCD-AttResU-Net: An improved forest change detection in Sentinel-2 satellite images using attention residual U-Net. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103453. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y. SUACDNet: Attentional change detection network based on siamese U-shaped structure. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Wang, X.; Yan, X.; Tan, K.; Pan, C.; Ding, J.; Liu, Z.; Dong, X. Double U-Net (W-Net): A change detection network with two heads for remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103456. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, M.; Lin, S.; Li, Y.; Wang, H. Deep Self-Representation Learning Framework for Hyperspectral Anomaly Detection. IEEE Trans. Instrum. Meas. 2024, 73, 5002016. [Google Scholar] [CrossRef]
- Lin, S.; Zhang, M.; Cheng, X.; Shi, L.; Gamba, P.; Wang, H. Dynamic Low-Rank and Sparse Priors Constrained Deep Autoencoders for Hyperspectral Anomaly Detection. IEEE Trans. Instrum. Meas. 2024, 73, 2500518. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical Remote Sensing Image Change Detection Based on Attention Mechanism and Image Difference. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7296–7307. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid Feature-Based Attention-Guided Siamese Network for Remote Sensing Orthoimagery Building Change Detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef]
- Yin, H.; Weng, L.; Li, Y.; Xia, M.; Hu, K.; Lin, H.; Qian, M. Attention-guided siamese networks for change detection in high resolution remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103206. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Cui, F.; Jiang, J. MTSCD-Net: A network based on multi-task learning for semantic change detection of bitemporal remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103294. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5402711. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, H.; Xuan, Y. A Spatial Pattern Extraction and Recognition Toolbox Supporting Machine Learning Applications on Large Hydroclimatic Datasets. Remote Sens. 2022, 14, 3823. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ho, Y.; Wookey, S. The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling. IEEE Access 2019, 8, 4806–4813. [Google Scholar] [CrossRef]
- Monard, M.C.; Batista, G. Learning with skewed class distributions. Adv. Log. Artif. Intell. Robot. 2002, 85, 173–180. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Province | District/County | Number of Changing Samples | Administrative District Area of the District/County(km2) |
|---|---|---|---|
| Anhui Province | San-Shan District | 49 | 289.33 |
| Shou County | 36 | 2949.76 | |
| Yi-Jiang District | 87 | 168.61 | |
| Da-Tong District | 94 | 304.02 | |
| Hua-Shan District | 115 | 181.12 | |
| Ying-Jiang District | 150 | 202.02 | |
| Lang-Ya District | 221 | 225.32 | |
| Feng-Yang County | 267 | 1936.02 | |
| Bo-Wang District | 74 | 338.79 | |
| Shu-Shan District | 557 | 651.75 | |
| Chang-Feng County | 343 | 1838.69 | |
| Lu-Jiang County | 187 | 2343.57 | |
| Chao-Hu City | 216 | 2030.39 | |
| Jing-Hu District | 50 | 115.18 | |
| Jiu-Jiang District | 233 | 870.48 | |
| Wu-Hu County | 235 | 649.28 | |
| Fan-Chang County | 198 | 629.55 | |
| Nan-Ling County | 127 | 1260.65 | |
| Shandong Province | He-Kou District | 149 | 1850.09 |
| Guang-Rao County | 151 | 1147.82 | |
| Wei-Cheng District | 201 | 287.50 | |
| Han-Ting District | 341 | 1253.83 | |
| Tai-Shan District | 144 | 339.65 | |
| Dong-Ping County | 66 | 1338.56 | |
| Mou-Ping District | 85 | 1508.46 |
| Overall Accuracy | F1-Score | IoU | Precision | Recall | |
|---|---|---|---|---|---|
| Training set | 0.99269 | 0.93719 | 0.88181 | 0.93913 | 0.93526 |
| Validation set | 0.98779 | 0.87812 | 0.78272 | 0.91710 | 0.84232 |
| Test set | 0.98764 | 0.86378 | 0.76022 | 0.91482 | 0.81813 |
| Model | Structure | Explanation |
|---|---|---|
| Bitemporal-FCN [27] | A bitemporal fully convolutional neural network with ResNet-18 | CNN is firstly trained for learning the deep features of the images. Transfer learning is implemented to compose a two-channel network with shared weights to generate the change mask |
| STANet-BAM [38] | Metric-based Siamese FCN-based method embedded by a basic spatial–temporal attention module (BAM) with ResNet-18 | BAM is designed to facilitate the network in capturing the spatial–temporal dependency between any two positions and computing the positional response through a weighted sum of features across all spatial and temporal positions |
| STANet-PAM [38] | Metric-based Siamese FCN-based method embedded by pyramid spatial–temporal attention module (PAM) with ResNet-18 | Same network as STANet-BAM but the attention module is replaced by PAM |
| SNUNet [48] | Fundamental structure is an UNet++ but combining the Siamese network and NestedUNet [49] | Channel attention is applied to the features at each level of the decoder. Deep supervision is employed to enhance the discrimination capability of intermediate features |
| ResNet18+Transformer | CNN embedded by a renovated Transformer with ResNet-18 | The network is designed by incorporating a renovated Transformer structure based on the Bitemporal-FCN network structure |
| Model | Overall Accuracy | F1-Score | IoU | Precision | Recall |
|---|---|---|---|---|---|
| Bitemporal-FCN | 0.98156 | 0.79285 | 0.65680 | 0.95889 | 0.67583 |
| STANet-BAM | 0.983 | 0.839 | 0.654 | 0.836 | 0.841 |
| STANet-PAM | 0.981 | 0.822 | 0.698 | 0.817 | 0.833 |
| SNUNet | 0.9871 | 0.8567 | 0.7495 | 0.8839 | 0.8313 |
| ResNet18+Transformer | 0.98779 | 0.87812 | 0.78272 | 0.91710 | 0.84232 |
| Model | Overall Accuracy | F1-Score | IoU | Precision | Recall |
|---|---|---|---|---|---|
| Bitemporal-FCN | 0.98182 | 0.77651 | 0.63467 | 0.94436 | 0.65933 |
| STANet-BAM | 0.985 | 0.846 | 0.733 | 0.836 | 0.856 |
| STANet-PAM | 0.983 | 0.822 | 0.698 | 0.807 | 0.838 |
| SNUNet | 0.9867 | 0.8561 | 0.7485 | 0.8880 | 0.8265 |
| ResNet18+Transformer | 0.98764 | 0.86378 | 0.76022 | 0.91482 | 0.81813 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, S.; Wang, H.; Su, Y.; Li, Q.; Sun, T.; Liu, C.; Li, Y.; Cheng, D. A Renovated Framework of a Convolution Neural Network with Transformer for Detecting Surface Changes from High-Resolution Remote-Sensing Images. Remote Sens. 2024, 16, 1169. https://doi.org/10.3390/rs16071169
Yao S, Wang H, Su Y, Li Q, Sun T, Liu C, Li Y, Cheng D. A Renovated Framework of a Convolution Neural Network with Transformer for Detecting Surface Changes from High-Resolution Remote-Sensing Images. Remote Sensing. 2024; 16(7):1169. https://doi.org/10.3390/rs16071169
Chicago/Turabian StyleYao, Shunyu, Han Wang, Yalu Su, Qing Li, Tao Sun, Changjun Liu, Yao Li, and Deqiang Cheng. 2024. "A Renovated Framework of a Convolution Neural Network with Transformer for Detecting Surface Changes from High-Resolution Remote-Sensing Images" Remote Sensing 16, no. 7: 1169. https://doi.org/10.3390/rs16071169
APA StyleYao, S., Wang, H., Su, Y., Li, Q., Sun, T., Liu, C., Li, Y., & Cheng, D. (2024). A Renovated Framework of a Convolution Neural Network with Transformer for Detecting Surface Changes from High-Resolution Remote-Sensing Images. Remote Sensing, 16(7), 1169. https://doi.org/10.3390/rs16071169