
Multimodal Features Alignment for Vision–Language Object Tracking


Abstract
1. Introduction
- A novelty multimodal features alignment network (MFA) for vision–language visual tracking is proposed, which is used in modeling a semantic relationship between visual features and annotated language descriptions to generate fusion features. Experiments are conducted on three natural-language-annotated datasets, and our tracker exhibits a good performance compared to that of a state-of-the-art tracker.
- Weighted fusion features are used as input to the tracking procedure instead of traditional resized images. The fused feature map is divided into multiple grids with distributed weights. To the best of our knowledge, this is the first study to use fusion feature maps instead of traditional search images for a tracking network.
- The proposed loss function minimizes the cross-modality discrepancy between visual and natural language features, reflecting the effectiveness of the fusion in the tracking procedure.
2. Related Work
2.1. Visual Object Tracking
2.2. Vision–Language Fusion Model
2.3. Vision–Language Object Tracking
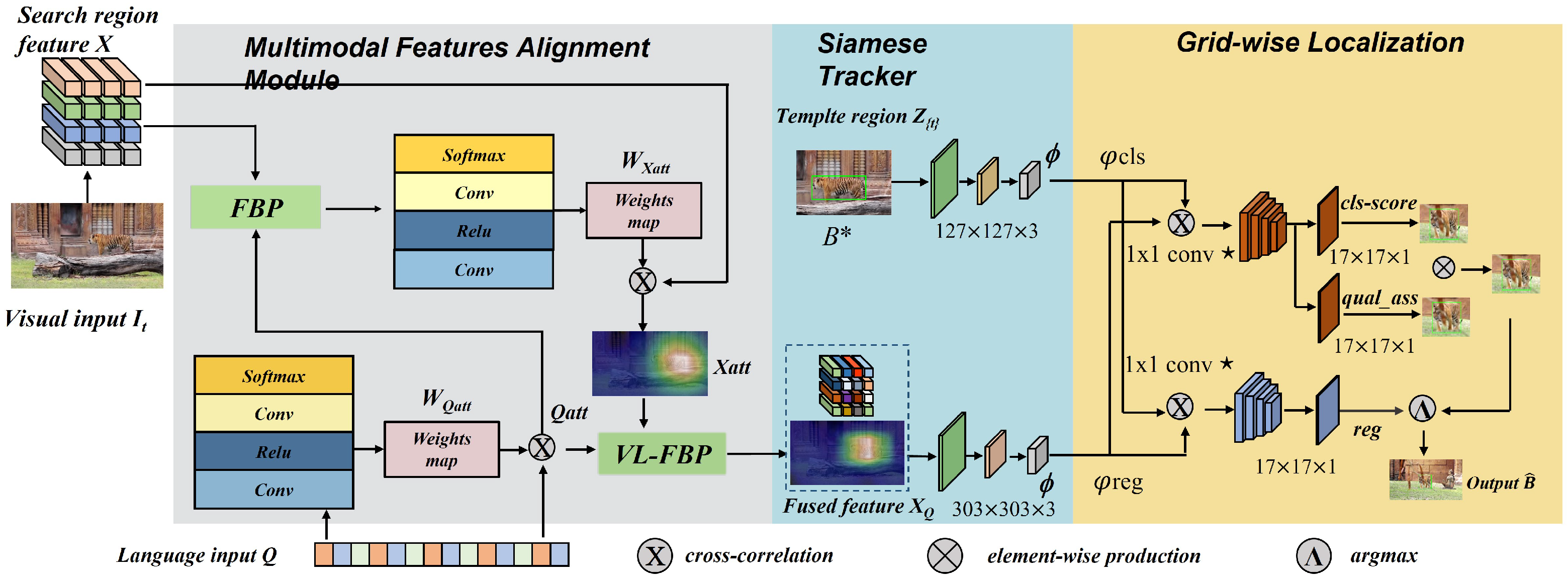
3. Methods
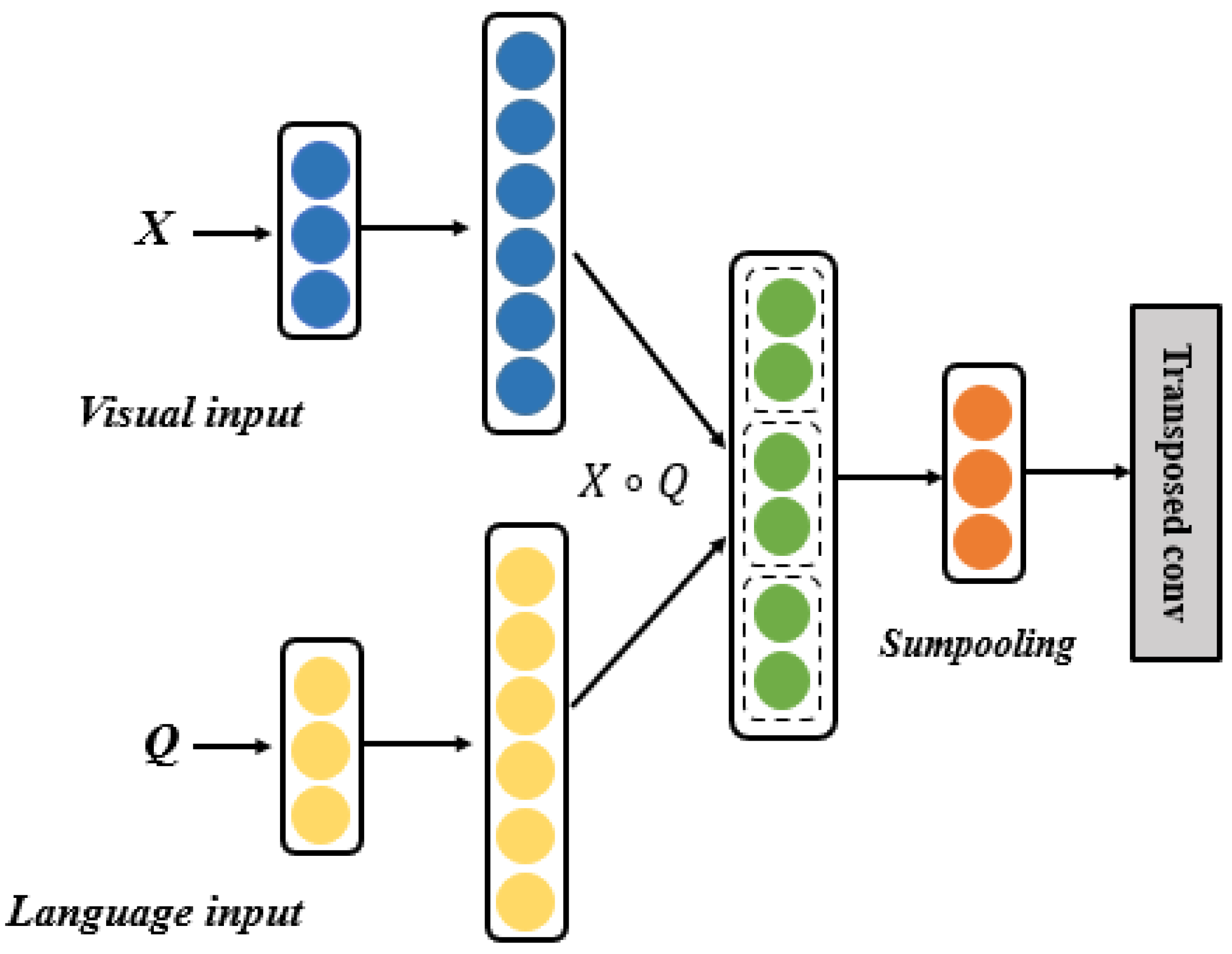
3.1. Vision–Language Feature Factorized Bilinear Module
| Algorithm 1: Curriculum training for the tracker. |
 |
3.2. Vision–Language Feature Co-Attention Module
3.3. Prediction Head
| Algorithm 2: Inference of the proposed tracker. |
 |
3.4. Loss Function
4. Experiments
4.1. Datasets and Metrics
4.1.1. Datasets
4.1.2. Metrics
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Trackers
4.4. Ablation Study
4.4.1. Attribute Analysis
4.4.2. Component-Wise Ablation Analysis
4.4.3. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the ECCV Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Jiang, M.; Guo, S.; Luo, H.; Yao, Y.; Cui, G. A Robust Target Tracking Method for Crowded Indoor Environments Using mmWave Radar. Remote Sens. 2023, 15, 2425. [Google Scholar] [CrossRef]
- Han, G.; Su, J.; Liu, Y.; Zhao, Y.; Kwong, S. Multi-Stage Visual Tracking with Siamese Anchor-Free Proposal Network. IEEE Trans. Multimed. 2023, 25, 430–442. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, X.; Wang, D.; Lu, H.; Ruan, X. Transformer vision-language tracking via proxy token guided cross-modal fusion. Pattern Recognit. Lett. 2023, 168, 10–16. [Google Scholar] [CrossRef]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1571–1580. [Google Scholar] [CrossRef]
- Scribano, C.; Sapienza, D.; Franchini, G.; Verucchi, M.; Bertogna, M. All You Can Embed: Natural Language based Vehicle Retrieval with Spatio-Temporal Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Online, 19–25 June 2021; pp. 4248–4257. [Google Scholar]
- Dong, X.; Shen, J.; Wang, W.; Shao, L.; Ling, H.; Porikli, F. Dynamical Hyperparameter Optimization via Deep Reinforcement Learning in Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1515–1529. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Shen, J.; Porikli, F.; Luo, J.; Shao, L. Adaptive Siamese Tracking with a Compact Latent Network. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8049–8062. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Li, C.; Yang, R.; Zhang, T.; Tang, J.; Luo, B. Describe and attend to track: Learning natural language guided structural representation and visual attention for object tracking. arXiv 2018, arXiv:1811.10014. [Google Scholar]
- Wang, X.; Shu, X.; Zhang, Z.; Jiang, B.; Wang, Y.; Tian, Y.; Wu, F. Towards More Flexible and Accurate Object Tracking with Natural Language: Algorithms and Benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 13763–13773. [Google Scholar]
- Feng, Q.; Ablavsky, V.; Bai, Q.; Sclaroff, S. Siamese Natural Language Tracker: Tracking by Natural Language Descriptions with Siamese Trackers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 5851–5860. [Google Scholar]
- Yang, Z.; Kumar, T.; Chen, T.; Su, J.; Luo, J. Grounding-Tracking-Integration. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3433–3443. [Google Scholar] [CrossRef]
- Feng, Q.; Ablavsky, V.; Bai, Q.; Li, G.; Sclaroff, S. Real-time Visual Object Tracking with Natural Language Description. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2019; pp. 689–698. [Google Scholar]
- Feng, Q.; Ablavsky, V.; Bai, Q.; Sclaroff, S. Robust Visual Object Tracking with Natural Language Region Proposal Network. arXiv 2019, arXiv:1912.02048. [Google Scholar]
- Liu, G.; He, J.; Li, P.; Zhong, S.; Li, H.; He, G. Unified Transformer with Cross-Modal Mixture Experts for Remote-Sensing Visual Question Answering. Remote Sens. 2023, 15, 4682. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, J.; Xiang, C.; Fan, J.; Tao, D. Beyond Bilinear: Generalized Multimodal Factorized High-Order Pooling for Visual Question Answering. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 5947–5959. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, F.; Liu, C.; Tian, Q.; Qu, H. ACTNet: A Dual-Attention Adapter with a CNN-Transformer Network for the Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2023, 15, 2363. [Google Scholar] [CrossRef]
- Zhang, W.; Yu, J.; Zhao, W.; Ran, C. DMRFNet: Deep Multimodal Reasoning and Fusion for Visual Question Answering and explanation generation. Inf. Fusion 2021, 72, 70–79. [Google Scholar] [CrossRef]
- Li, Z.; Tao, R.; Gavves, E.; Snoek, C.G.; Smeulders, A.W. Tracking by natural language specification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6495–6503. [Google Scholar]
- Hu, D.; Lu, X.; Li, X. Multimodal Learning via Exploring Deep Semantic Similarity. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Yu, Z.; Yu, J.; Fan, J.; Tao, D. Multi-modal Factorized Bilinear Pooling with Co-attention Learning for Visual Question Answering. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1839–1848. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV Tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3086–3092. [Google Scholar]
- Sosnovik, I.; Moskalev, A.; Smeulders, A.W.M. Scale Equivariance Improves Siamese Tracking. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2764–2773. [Google Scholar]
- Su, Z.; Wan, G.; Zhang, W.; Guo, N.; Wu, Y.; Liu, J.; Cong, D.; Jia, Y.; Wei, Z. An Integrated Detection and Multi-Object Tracking Pipeline for Satellite Video Analysis of Maritime and Aerial Objects. Remote Sens. 2024, 16, 724. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4586–4595. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4655–4664. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Van Gool, L.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6181–6190. [Google Scholar] [CrossRef]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning Spatio-Temporal Transformer for Visual Tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10428–10437. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 8122–8131. [Google Scholar]
- Ye, B.; Chang, H.; Ma, B.; Shan, S. Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Guo, M.; Zhang, Z.; Fan, H.; Jing, L.; Lyu, Y.; Li, B.; Hu, W. Learning target-aware representation for visual tracking via informative interactions. arXiv 2022, arXiv:2201.02526. [Google Scholar]
- Dai, K.; Zhang, Y.; Wang, D.; Li, J.; Lu, H.; Yang, X. High-Performance Long-Term Tracking with Meta-Updater. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6297–6306. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef]
- Roy, D.; Li, Y.; Jian, T.; Tian, P.; Roy Chowdhury, K.; Ioannidis, S. Multi-modality Sensing and Data Fusion for Multi-vehicle Detection. IEEE Trans. Multimed. 2022, 25, 2280–2295. [Google Scholar] [CrossRef]
- Schwartz, I.; Schwing, A.G.; Hazan, T. High-Order Attention Models for Visual Question Answering. arXiv 2017, arXiv:1711.04323. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Jiang, D.; Zhou, M. Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal pretraining. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019. [Google Scholar]
- Kim, K.; Park, S. AOBERT: All-modalities-in-One BERT for multimodal sentiment analysis. Inf. Fusion 2022, 92, 37–45. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Guo, M.; Zhang, Z.; Fan, H.; Jing, L. Divert more attention to vision-language tracking. Adv. Neural Inf. Process. Syst. 2022, 35, 4446–4460. [Google Scholar]
- Zhou, L.; Zhou, Z.; Mao, K.; He, Z. Joint Visual Grounding and Tracking with Natural Language Specification. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 23151–23160. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Ye, Y.; Yu, G. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. arXiv 2019, arXiv:1911.06188. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2016, 123, 32–73. [Google Scholar] [CrossRef]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. LaSOT: A High-Quality Benchmark for Large-Scale Single Object Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5369–5378. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Danelljan, M.; Van Gool, L.; Timofte, R. Probabilistic Regression for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7181–7190. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition |
|---|---|
| t | Frame index. |
| The t-th frame image from a video. | |
| Feature of search region at frame step. t | |
| The NL description of target. | |
| The weight matrix of a linguistic feature. | |
| The weight matrix of a visual feature conditioned by a linguistic feature. | |
| Linguistic attentional feature from embedding of . | |
| Visual attentional feature of , conditioned. | |
| Fused feature. | |
| The visual template region. | |
| Set of similarities between and . | |
| Set of region features for bounding boxes. | |
| Bounding boxes candidate chosen by the model. | |
| Bounding boxes predicted by the tracker at time t. | |
| General output of bilinear pooling model. | |
| ⋆ | Depth-wise cross-correlation layers. |
| Convolutional layers. | |
| Siamese convolutional neural network. |
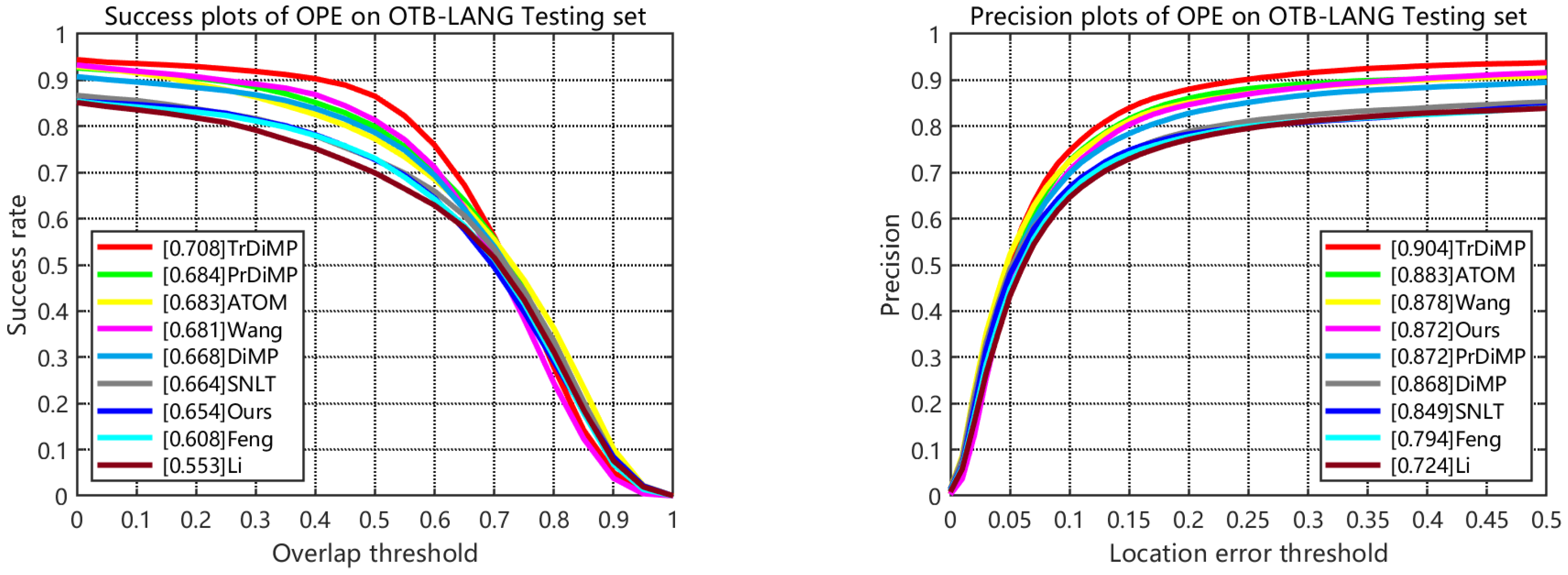
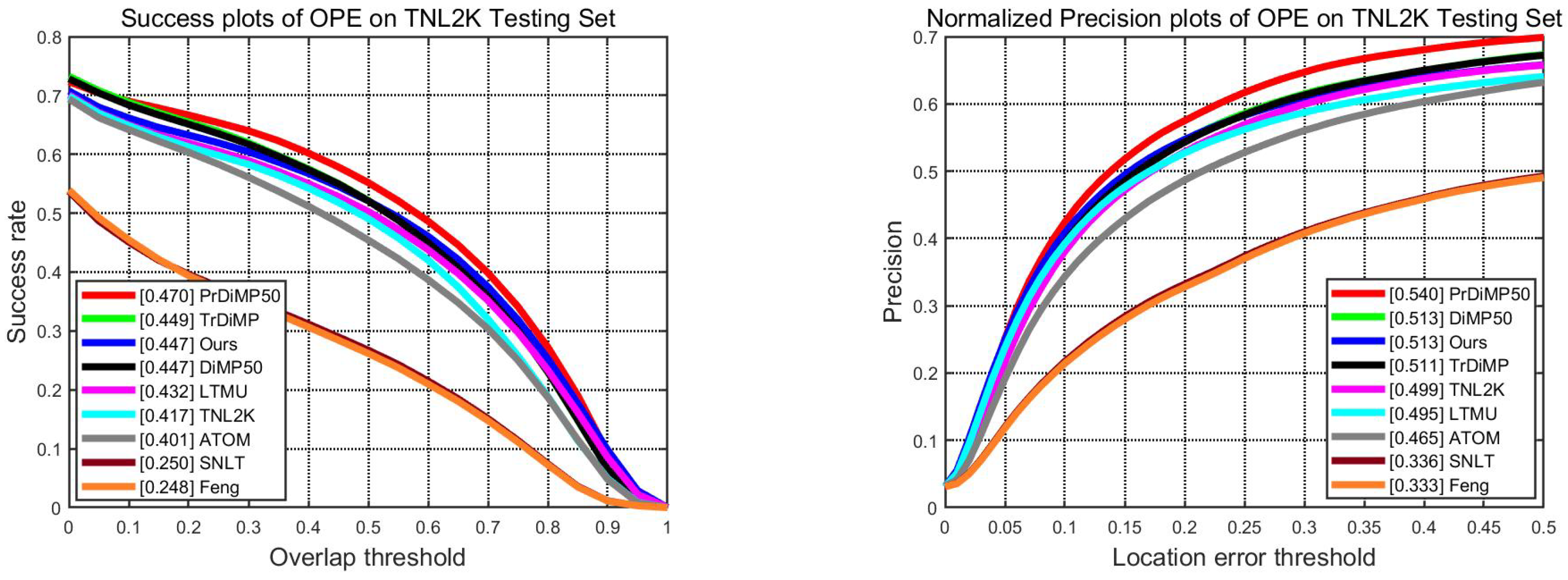
| Algorithm | Initialize | OTB-LANG [22] | LaSOT [49] | TNL2K [13] | Fps |
|---|---|---|---|---|---|
| AUC|P | AUC|P | AUC| | |||
| ATOM [29] | BBox | 0.683|0.883 | 0.521|0.522 | 0.401|0.465 | 30 |
| DiMP50 [30] | BBox | 0.668|0.868 | 0.572|0.561 | 0.447|0.513 | 40 |
| PrDiMP50 [52] | BBox | 0.684|0.872 | 0.603|0.609 | 0.470|0.540 | 30 |
| TrDiMP [8] | BBox | 0.708|0.904 | 0.643|0.663 | 0.449|0.511 | 26 |
| LTMU [35] | BBox | - | - | 0.432|0.495 | 15 |
| STARK [31] | BBox | 0.696|0.914 | 0.671|0.770 | - | 30 |
| TransT [32] | BBox | 0.698|0.887 | 0.649|0.738 | - | 50 |
| OSTrack-256 [33] | BBox | - | 0.691|0.752 | - | 105 |
| TransInMo [34] | BBox | - | 0.657|0.707 | 0.520|0.527 | 67 |
| Li [1] | NL | 0.553|0.724 | - | - | 21 |
| Feng [16] | BBox + NL | 0.608|0.794 | 0.352|0.353 | 0.248|0.333 | 30 |
| SNLT [14] | BBox + NL | 0.664|0.849 | 0.539|0.558 | 0.250|0.336 | 50 |
| TNL2K [13] | BBox + NL | 0.681|0.878 | 0.508|0.548 | 0.417|0.499 | 12 |
| Ours | BBox + NL | 0.654|0.872 | 0.553|0.556 | 0.447|0.513 | 37 |
| Attributes | Definition |
|---|---|
| CM | Abrupt motion of the camera. |
| ROT | Target object rotates in the video. |
| DEF | The target is deformable. |
| FOC | Target is fully occluded. |
| IV | Illumination variation. |
| OV | The target completely leaves the video sequence. |
| POC | Partially occluded. |
| VC | Viewpoint change. |
| SV | Scale variation. |
| BC | Background clutter. |
| MB | Motion Blur. |
| ARC | The ratio of bounding box aspect ratio is outside the range . |
| LR | Low resolution. |
| FM | The motion of the target is larger than the size of its bounding box. |
| AS | Influence of adversarial samples. |
| TC | Two targets with similar intensity cross each other. |
| MS | Video contain both color and thermal images. |
| Index | FBP | Co-Att | BBox | AUC | P |
|---|---|---|---|---|---|
| ➀ | ✓ | ✓ | - | 0.519 | 0.517 |
| ➁ | - | ✓ | ✓ | 0.483 | 0.506 |
| ➂ | ✓ | - | ✓ | 0.415 | 0.428 |
| ➃ | ✓ | ✓ | ✓ | 0.553 | 0.556 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, P.; Xiao, G.; Liu, J. Multimodal Features Alignment for Vision–Language Object Tracking. Remote Sens. 2024, 16, 1168. https://doi.org/10.3390/rs16071168
Ye P, Xiao G, Liu J. Multimodal Features Alignment for Vision–Language Object Tracking. Remote Sensing. 2024; 16(7):1168. https://doi.org/10.3390/rs16071168
Chicago/Turabian StyleYe, Ping, Gang Xiao, and Jun Liu. 2024. "Multimodal Features Alignment for Vision–Language Object Tracking" Remote Sensing 16, no. 7: 1168. https://doi.org/10.3390/rs16071168
APA StyleYe, P., Xiao, G., & Liu, J. (2024). Multimodal Features Alignment for Vision–Language Object Tracking. Remote Sensing, 16(7), 1168. https://doi.org/10.3390/rs16071168