3.1. Mathematical Principles of RFI
Common RFI can be divided into narrowband interference and wideband interference, with the latter further categorized into chirp-modulated wideband interference and sinusoidal-modulated wideband interference. Narrowband interference can be represented as follows:
where
,
, and
are sequentially represented as carrier frequency, the amplitude of the
n-th interference signal, and the frequency offset of the
n-th interference signal, which is the number of interference signals. The chirp modulation interference can be represented as follows:
where
and
are sequentially represented as the amplitude of the
n-th interference signal, and the chirp rate of the
n-th interference signal. The sinusoidal modulation interference can be represented as follows:
where
,
, and
are sequentially represented as the amplitude of the
n-th interference signal, carrier frequency, modulation coefficient of the
n-th interference signal, and modulation frequency of the
n-th interference signal.
According to the Bessel formula, sinusoidal modulated broadband interference can be expressed as follows:
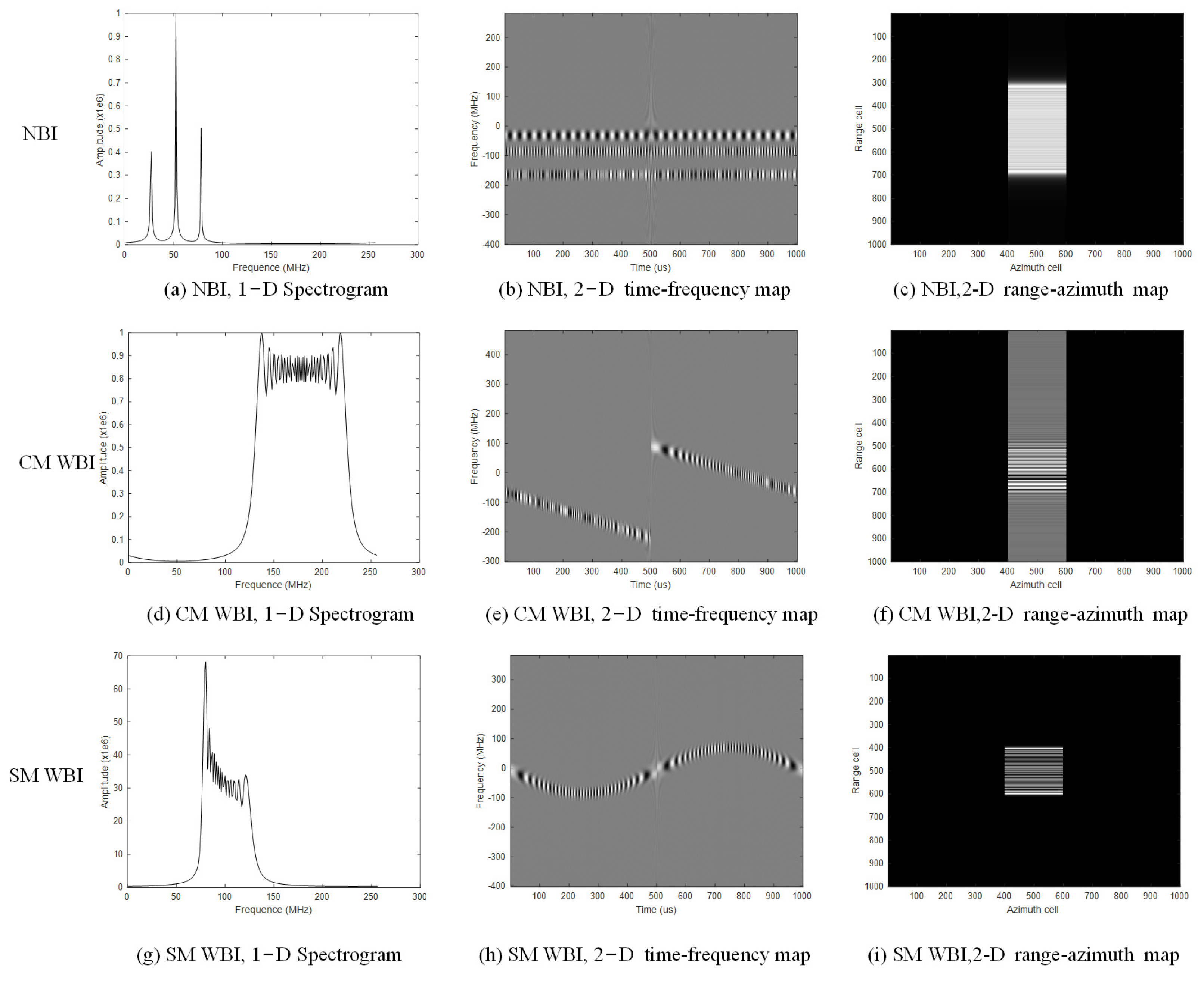
According to Equation (4), sinusoidal modulated broadband interference is composed of a series of narrowband interferences, approximating a specific form of chirp modulated broadband interference. The spectrum and time-frequency graphs of the interference signals are illustrated in
Figure 3. Each row represents a type of interference paradigm, where the first row represents narrowband interference, the second row represents chirp modulation interference, and the third row represents sinusoidal modulation interference. Each column represents a representation dimension of the interference signal, with the first column depicting the interference spectrum, the second column displaying the time-frequency map of the interference, and the third column displaying the interfered SAR images.
To simplify the analysis, the radio frequency interference signal can be unified and represented as follows:
where
is tuning rate,
is the bandwidth of interference; when
is large, the interference signal is a broadband signal, and when
is small, the interference signal is a narrowband signal.
The range matched filter is given by the following:
After performing range-matched filtering, RFI can be expressed as follows:
According to Equation (7), after matched filtering, the interference signal is also a wideband signal, which appears as a block-like coverage.
3.2. RFI Suppression Pipeline
The RFI suppression pipeline is schematically represented in
Figure 4, where the interference image undergoes Fourier transformation and is subsequently divided into two paths. One path involves the amplitude spectrum, which passes through two cascaded networks to suppress interference, while the other path concerns the phase spectrum, which remains unchanged or has slight adjustments. Following the processing of both paths, the results are recombined and undergo inverse Fourier transformation to reconstruct the azimuth-range image. The specific details are as follows.
As SAR images are like visual data, visual image inpainting methods based on neural networks are becoming more and more popular for suppressing SAR RFI. In this framework, the image inpainting model based on maximum posterior probability can be formulated as follows:
where
X and
Y represent the disturbed image and inpainting image, respectively; log(
P(
X/
Y)) denotes the loss function and
is the prior information of
X. Equation (8) can be compactly expressed as follows:
From Equation (9), one can see that with more prior information, higher performance can be achieved while using the same model. In fact, the motivation of most famous deep neural networks is to mine the prior information of the data to be dealt with.
Using Equations (6) and (7) from
Section 3.1, the relationship between frequency and time is as follows:
According to Equations (10) and (11), both the target signal and RFI signal appear as linear functions over time, leading to global characteristics in the time-frequency domain. We state that this is an obvious prior information that can help us achieve better performance of RFI suppression.
Prior1. Both the interference signal and the target signal hold global features.
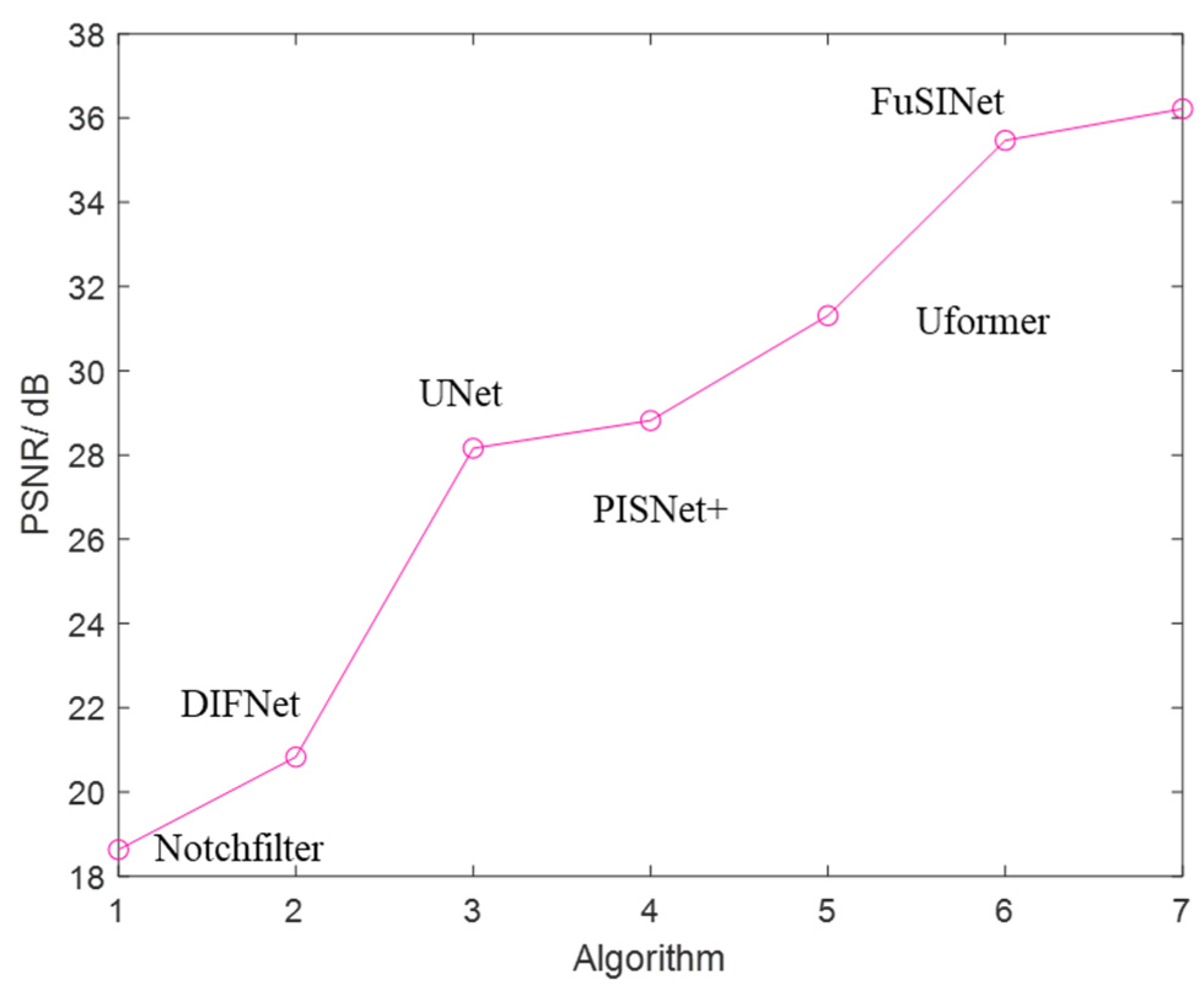
Prior1 guides us to seek a network that can capture global feature information to achieve interference suppression. In the prosperous field of deep learning with various network models, adjusting existing models is a better choice compared to designing a delicate neural network from scratch since it can also achieve very good results in most cases. Based on this, we choose U-Transformer (Uformer) with an attention mechanism and the ability to capture fine texture information as the backbone network.
The cornerstone of transformer-based methods is the attention mechanism which allows for parallel computation of the similarity between every interested token or query token and other tokens without limitations on distance. Here, a token usually refers to the linear mapping (embedding by matrix) of image patches in the time-frequency diagram. By visualizing and analyzing the output content of various layers of deep neural networks, there is increasing evidence that transformer-based image inpainting can generate content for the damaged areas that do not have semantic conflicts with the entire image. The crucial semantics mainly refer to edge contours or geometric structures within the damaged areas, which are often referred to as latent patterns in high-level image processing tasks such as classification, recognition, segmentation, and more. Therefore, to generate desirable undistorted content for the interfered area, we need to extract patterns of the original image content from undisturbed areas that are below the interfered areas.
It is assumed that
and
are sets of
Z1 +
Z2 distinct patterns embranced in the training data set, where
and
come from clean and RFI regions of disturbed SAR images, respectively. Since
is beneficial to reconstructing the damaged SAR image, we call
train-related pattern. Accordingly,
is a train-unrelated pattern due to he negative effect on reconstruction. A token used to train a Transformer can be represented as
where superscript
and subscript
indicate that the
kth token is extracted from
nth training sample;
is gaussian noise
iid for different
i and
n;
and
denote the minimum and mean fraction of train-related patterns, respectively. Ref. [
55] states the following theorem.
Theorem 1. For a self-attention-based transformer whose attention block is followed by a feed-forward network, as long as the number of neurons m is large enough that for constant , the mini-batch size . Then, afterthe number of iterations, the trained model achieves zero generalization error with a sufficiently large probability. c1 and c2 are some constants related to the characteristics of the dataset. and indicate that increases at least or in the order of , respectively. From Theorem 1, the sample complex N = TB can be a reduced scale with or . On the other hand, while N = TB remains unchanged, lower or means higher generalization. Recalling Equation (13), minor or can be achieved by decreasing weighting the pattern exhibited by RFI. Thus, we can conclude the following prior information of Transformer-based RFI suppression method.
Prior2. Variable interference components have a negative contribution to image inpainting.
A deeper foundation of Prior2 is the interference energy usually significantly higher than the target energy. The structure of the interference is the most prominent feature observed in a damaged training TF image patch, as seen in
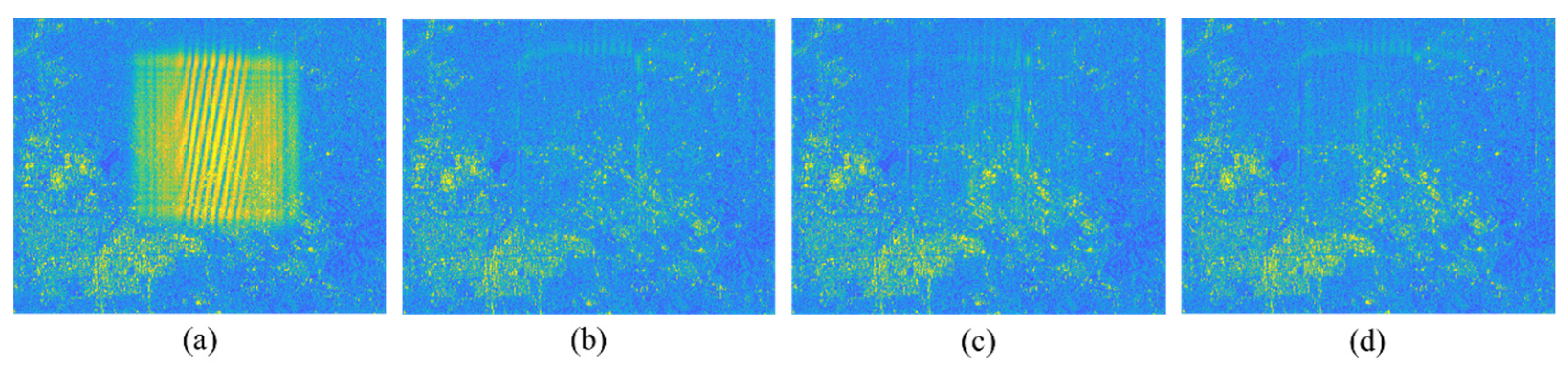
Figure 3b,e,h. To enhance the dominance of clean TF image patterns and achieve a desired transformer, a straightforward approach is to reduce the intensity of RF interference. Fortunately, numerous methods for RFI elimination in the TF domain have been proposed, and even relatively inexpensive methods can effectively remove most of the interference energy, such as segment networks and so on.
Based on Prior1 and Prior2, we fused the Uformer model inspired by Prior1 and the segment networks model inspired by Prior2 to create a new network architecture, called FuSINet, to improve SAR RFI suppression performance in the time-frequency domain. The proposed FuSINet is shown in
Figure 4, and the whole process is given in Algorithm 1. Firstly, if there are SAR echoes, we locate the corresponding interfered echoes by disturbed SAR images; if there are no SAR echoes, we convert the SAR images into SAR echoes by inverse imaging algorithm. Secondly, STFT pulse-by-pulse is performed in a one-dimensional range profile. Thirdly, the short-time magnitude spectra are passed through a cascade CNN formed segment network, followed by a Uformer. Meanwhile, the short-time phase spectrum is slightly adjusted through the pipeline. Fourthly, ISTFT is performed pulse-by-pulse based on the repaired magnitude spectra and the adjusted phase spectrum. Finally, a clean SAR image is obtained from echoes with the RFI suppressed.
| Algorithm 1. The whole process of RFI suppression pipeline based on FuSINet. |
| 1. Detect RFI in SAR images; |
| 2. If there are SAR echoes: |
| Locate interference echoes; |
| Else: |
| Convert interfered images into echoes; |
| 3. Perform STFT pulse-by-pulse; |
| 4. Repair time-frequency map by FuSINet; |
| 5. Perform ISTFT pulse-by-pulse; |
| 6. Convert SAR echoes into SAR images. |
| end |
Remark 1. In our method, the segment network will detect RFI in the time-frequency domain as much as possible, while the Uformer aims to restore hidden target information in the interference region under the action of the attention mechanism and skip connection. Furthermore, these two purposes are achieved simultaneously by fusing their loss functions into a single one. This is significantly different from traditional CNN-based methods that directly inpaint the interference region on the original interfered image. Traditional methods not only fail to match the patterns in a larger range of the interference region but also often suffer from strong RFI effects, making it difficult to significantly improve performance.
3.3. FuSINet
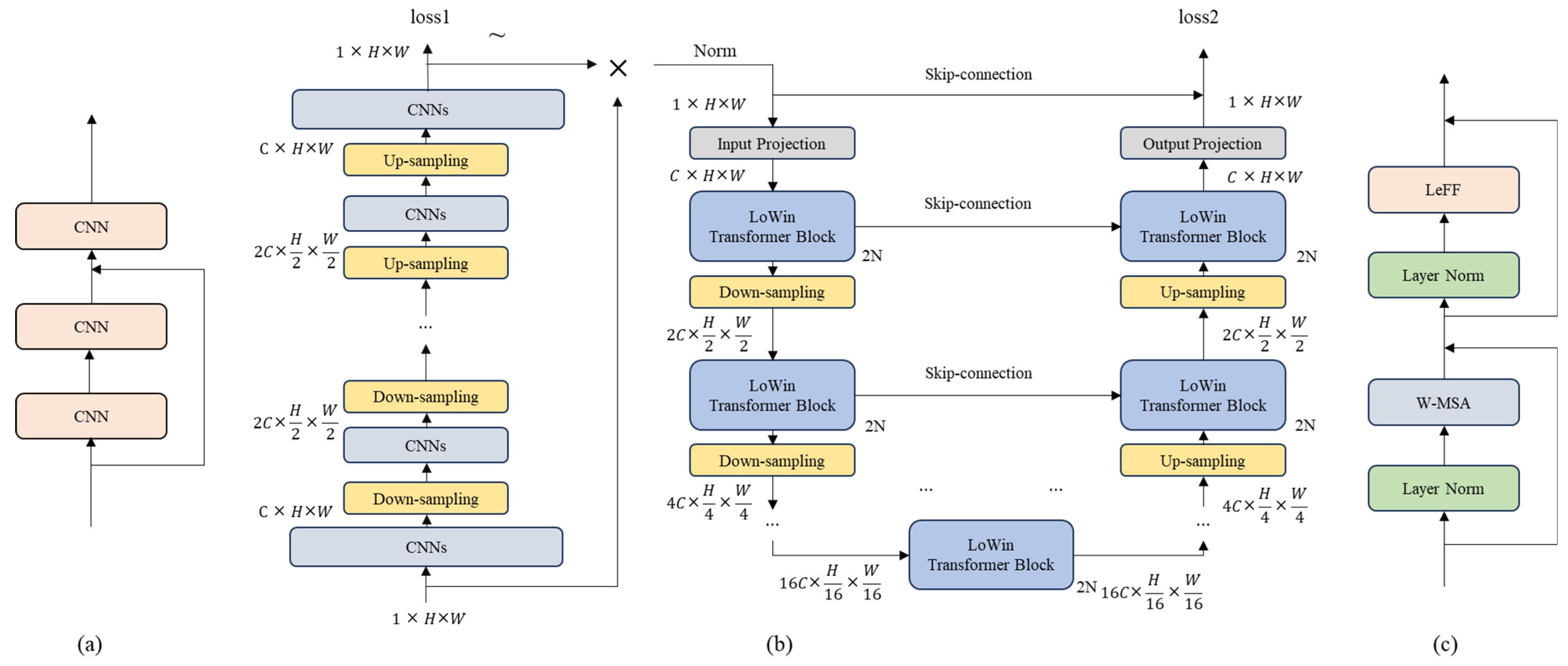
The proposed FuSINet is illustrated in
Figure 5,
Figure 5a is the structure of CNNs,
Figure 5b shows the overall network diagram, and
Figure 5b depicts the LoWin Transformer block. In
Figure 5b, the network consists of two parts. The first part is a cascaded CNN, and the second part is a Uformer network. The first part only requires segmenting the interfered region, so we only built a simple CNN-based network. The second part aims to repair the image, so we built a Uformer network.
The network is constructed by fusing a segment and inpainting a network. In the first part, the network consists of an encoder and a decoder, both composed of multiple CNN layers. Each encoder layer reduces the image size and increases the number of channels, while each decoder layer increases the image size and decreases the number of channels.
In the first part, the encoder consists of
L encoding layers, each encoding layer is composed of CNNs and a down-sampling layer, and the down-sampling layer reduces the length and width of the input data by half while doubling the number of channels. Each encoding layer can be represented as follows:
The decoder consists of
L decoding layers. Each decoding layer is composed of an up-sampling layer and CNNs. The up-sampling layer, composed of convolutional layers, increases the feature resolution while reducing the number of channels. Each decoding layer can be represented as follows:
In the second part, like all autoencoders, the Uformer consists of an encoder and a decode, and skip connections are added between the encoder and decoder because the skip connections often show good performance in low-dimensional visual tasks. Additionally, two layers of LoWin Transformer blocks are added at the bottom of the U-shaped structure to further extract information and capture longer-range dependencies. In FuSINet, the input of the second part network consists of two parts. The first part is the raw input, and the second part is the output of the first part network. In this case, the input of the second part network can be represented as follows:
where
is the regularization function,
is the matrix of the first stage network, and
is the raw input.
The encoder consists of an input projection layer and
L encoding layers. Each encoding layer is composed of 2
N LoWin Transformer blocks and a down-sampling layer. The input projection layer is composed of convolutional layers and is responsible for extracting low-level features, denoted as
, where
C represents the number of channels. The two LoWin Transformer blocks within an encoding layer are designed by shift-windows to achieve global interaction, as shown in
Figure 6. The down-sampling layer reduces the length and width of the input data by half while doubling the number of channels to increase the receptive field. Due to the reduction in image size, a larger field of view can be felt under the same patch. Given an input
, the output feature map of the
l-th encoding layer can be represented as
. Each encoding layer can be represented as follows:
The decoder consists of an output projection layer and L decoding layers. Each decoding layer is composed of an up-sampling layer and 2N LoWin Transformer blocks. The up-sampling layer, composed of convolutional layers, increases the feature resolution while reducing the number of channels. The up-sampling features, along with the features from the corresponding encoding layer, are passed through the LoWin Transformer block. After
L decoding layers, the features obtained by the decoder are restored to the original image by an output projection layer. Each decoding layer can be represented as follows:
The proposed local attention windows have limited receptive fields, so in order to increase the receptive field, a double-layer LoWin Transformer block is employed, and the shift-windows between the two LoWin Transformer blocks are shown in
Figure 6. The first layer represents the receptive field of the first LoWin Transformer block, where each differently colored block represents an attention window. The second layer represents the receptive field of the second LoWin Transformer block. Compared to the first layer, the second layer shifts the entire image by half of the window length along both dimensions. As a result, a single window in the second layer contains all four colors from the first layer, meaning the second layer’s receptive field includes all four independent regions from the first layer. Theoretically, with these two layers of LoWin Transformer blocks, global information interaction can be achieved.
The LoWin Transformer Block consists of W-MSA (Window-based Multi-head Self-Attention) and FFN (Feed-Forward Network). This module has the following advantages: 1. Compared to the standard Transformer, it significantly reduces computational costs. The standard Transformer computes global self-attention across the entire image, resulting in high computational costs. In contrast, the proposed method uses non-overlapping local window attention modules, which greatly reduces the computational costs. 2. This module can better capture both global and local information. W-MSA captures long-range information, while FFN captures local information.
The LoWin Transformer module can be represented as follows:
Unlike the global self-attention in the standard Transformer, the non-overlapping local window self-attention mechanism efficiently reduces computational complexity. We first split
into non-overlapping blocks of size
M ×
M, resulting in the input to W-MSA as
. Next, we perform self-attention operations on each window. The computation process of the
k-th head can be described as follows:
All the results of the heads are concatenated and linearly projected to obtain the final result. Inspired by the Swin Transformer, we also introduce relative position encoding
B in the attention module. Therefore, the attention calculation process can be represented as follows:
Compared to global self-attention, the computational complexity of a single W-MSA is reduced from to , where M is the window size, which is generally much smaller than H and W. Since this network contains a large number of multi-head W-MSA blocks, the final computational complexity is significantly reduced.
The standard Transformer has limited capability to capture local contextual information. Considering the importance of neighboring pixels in image tasks, to further enhance the capture of local information, we add a feed-forward network (FFN) after W-SMA. The FFN consists of three convolutional layers.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}