1. Introduction
The digital surface model (DSM) serves as the cornerstone for three-dimensional (3D) reconstruction, capturing authentic ground undulations and finding applications in various fields, including change monitoring and urban planning [
1,
2]. The stereo matching of remote sensing satellite image pairs plays a pivotal role in the DSM production process [
3]. Compared to the direct acquisition of DSM by light detection and ranging [
4], dense stereo matching methods offer advantages such as lower cost and higher automation, making them widely applicable for recovering 3D information from imagery. Using two remote sensing images taken by the same camera from different viewpoints, epipolar rectification is used to create left and right stereo images [
5]. This process ensures that each pixel and its corresponding pixel are aligned on the same row in both images. The disparity is then calculated as the difference between the column numbers of the corresponding pixels. The goal of stereo matching is to produce a disparity map that is converted to a depth map using geometric relationships to recover elevation information. The accuracy of the disparity map derived from stereo matching significantly affects the accuracy of the resulting DSM. Therefore, improving the accuracy of stereo matching technology has become a major research focus.
Through years of dedicated research, traditional stereo matching technology has evolved from local and global matching [
6,
7] to semi-global matching [
8,
9]. This evolution has improved matching accuracy and achieved breakthroughs in matching speed. However, traditional methods suffer from inherent shortcomings such as a large number of parameters and insufficient processing power for complex scenes [
10]. These limitations are particularly apparent in optical satellite imagery, where traditional methods struggle due to the long baseline and large coverage area. In recent years, stereo matching using deep learning technology has made steady progress and achieved remarkable results. Early approaches in this field replace certain steps within traditional methods with deep learning techniques [
11,
12,
13]. A notable example is [
14], which uses the convolutional neural networks (CNNs) with shared weights for feature extraction and cosine similarity to compute the probability of matching between two image blocks. While these methods have made remarkable progress over traditional approaches, they still face inherent challenges in pathological regions, such as textureless areas, occluded regions and repetitive patterns. Therefore, there is an urgent need to develop end-to-end stereo matching networks that use deep learning techniques at all stages. Such approaches can seamlessly integrate global information into the network to optimize matching results.
The process of end-to-end stereo matching networks can be divided into several modules, broadly categorized as 3D cost volume, four-dimensional (4D) cost volume and hybrid 3D-4D cost volume, based on different methods of cost volume construction [
10]. Some networks [
15,
16] use conditional random fields to build a recurrent neural network for 3D cost volume regularization. Ref. [
17] is an early adopter, introducing appropriate operators to construct the 3D cost volume and inspiring subsequent architectures [
18,
19,
20]. In [
21], the network uses input images to construct residuals to optimize initial disparity estimation, demonstrating remarkable performance in both training results and speed of operation.
While the 3D cost volume is highly efficient, it suffers from the elimination of the feature dimension, resulting in a final performance that is not as robust as that achieved with the 4D cost volume. In [
22], disparity features are represented by 4D cost volumes and consolidated using 3D CNNs. A notable breakthrough in disparity estimation is introduced by incorporating soft argmin into the regression process. Building upon these foundations, many end-to-end models have been introduced. For example, pyramid stereo matching network (PSMNet) [
23] integrates spatial pyramid pooling layers into the network to enhance its ability to exploit contextual information. It also uses stacked multiple hourglass networks for cost volume regularization. StereoNet [
24] is recognized as the first real-time stereo matching network. It performs initial disparity estimation in low-resolution cost volumes and introduces a reference image in the final step to generate residuals. This process ensures that the up-sampling phase recovers high-frequency detail and produces an edge-preserved disparity map. While these methods produce excellent results, the extensive use of 3D CNN parameters for aggregation increases computational complexity and lengthens training time. To address this challenge, several networks have introduced innovations [
25]. For example, a practical deep stereo network [
26] compresses the features of the associated left and right images before cost aggregation to reduce memory requirements. Previous studies detailing these innovations are summarized in
Table 1.
In summary, existing stereo matching methods are not tailored for optical satellite imagery. Complex networks have high hardware requirements, making them unsuitable for processing large areas of optical imagery. On the other hand, simple networks struggle to handle the rich content and wide disparity range of optical imagery, presenting additional challenges. Traditional approaches, such as cropping images into smaller blocks to reduce memory consumption, can compromise image integrity and affect training results. Therefore, a balance must be struck between minimizing training time and maintaining effectiveness when handling optical satellite imagery.
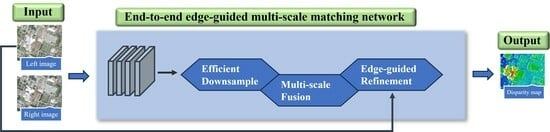
To address the challenge of dense matching in large and complex scenarios of optical satellite imagery, this paper introduces an end-to-end edge-guided multi-scale matching network, guided by the insights provided in
Table 1. The main contributions of this paper are as follows:
In feature extraction, we first use cascaded small convolutional filters and residual blocks to learn features at the original resolution. This ensures that the high-frequency information in the image is fully captured. Subsequently, the size is reduced to one-fourth of the original image to reduce computational complexity.
We use an efficient down-sampling operation to extract pyramid features at different scales, simultaneously increasing the number of channels while decreasing the resolution. This approach minimizes the loss of information during the down-sampling process and better preserves the extracted feature information.
We construct 4D cost volumes based on features extracted at different scales and design a top–down cost volume fusion module. Within this module, we incorporate the Squeeze-and-Excitation (SE) block, which recalibrates channels based on feature importance to provide more accurate feature information through multi-scale fusion.
We introduce a disparity refinement module where the left image is trained to generate a guidance map. This guidance map is then fed into a trainable guided filtering layer along with a low-resolution disparity map. The result is a refinement process that enhances finer edges when up-sampling from the low-resolution disparity map to the original resolution.
This paper is organized as follows:
Section 2 introduces the specific architecture of the proposed network.
Section 3 provides a detailed description of the experimental materials. Results and analysis are presented in
Section 4. Finally, discussions and conclusions are given in
Section 5.
2. Methods
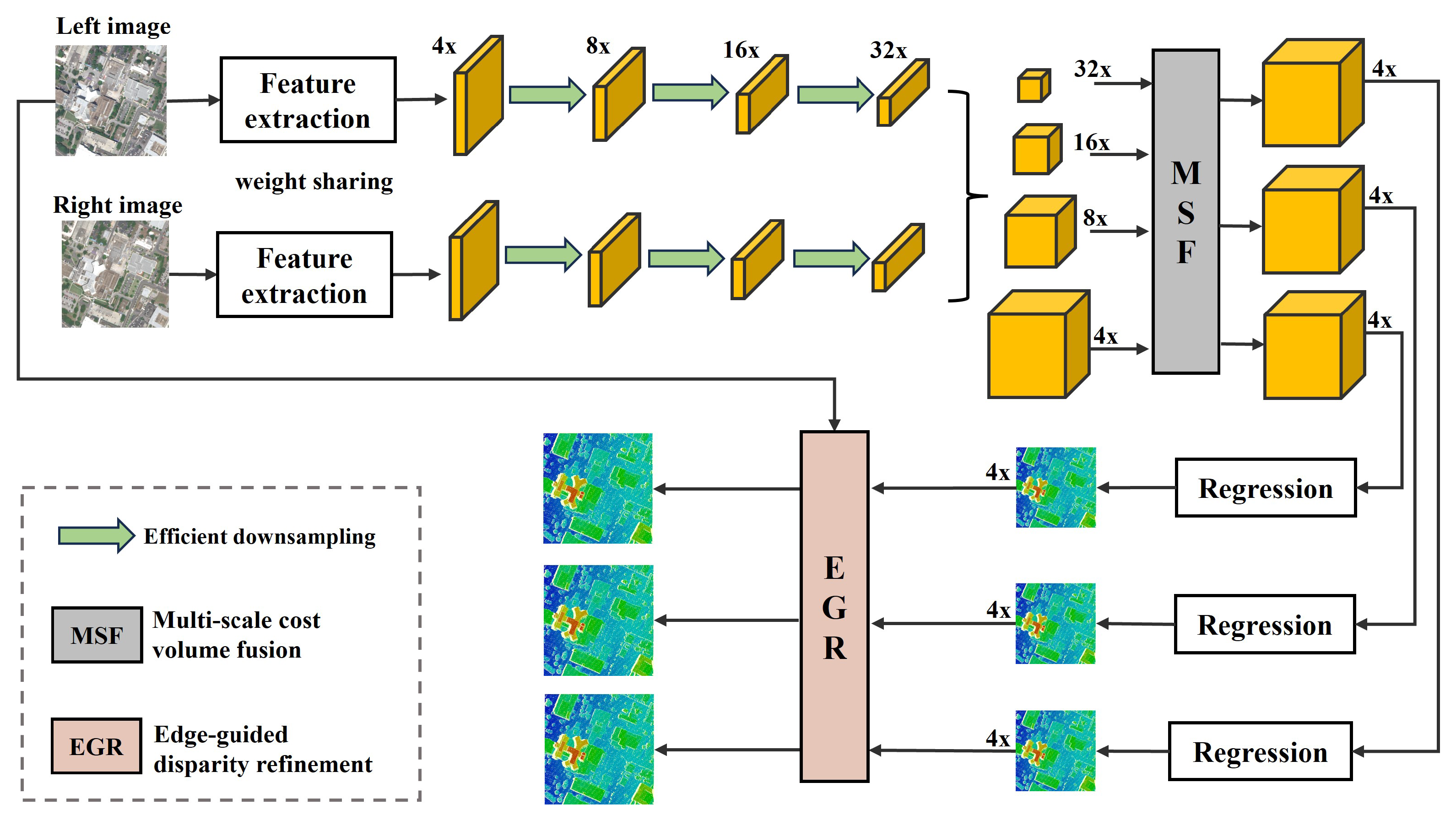
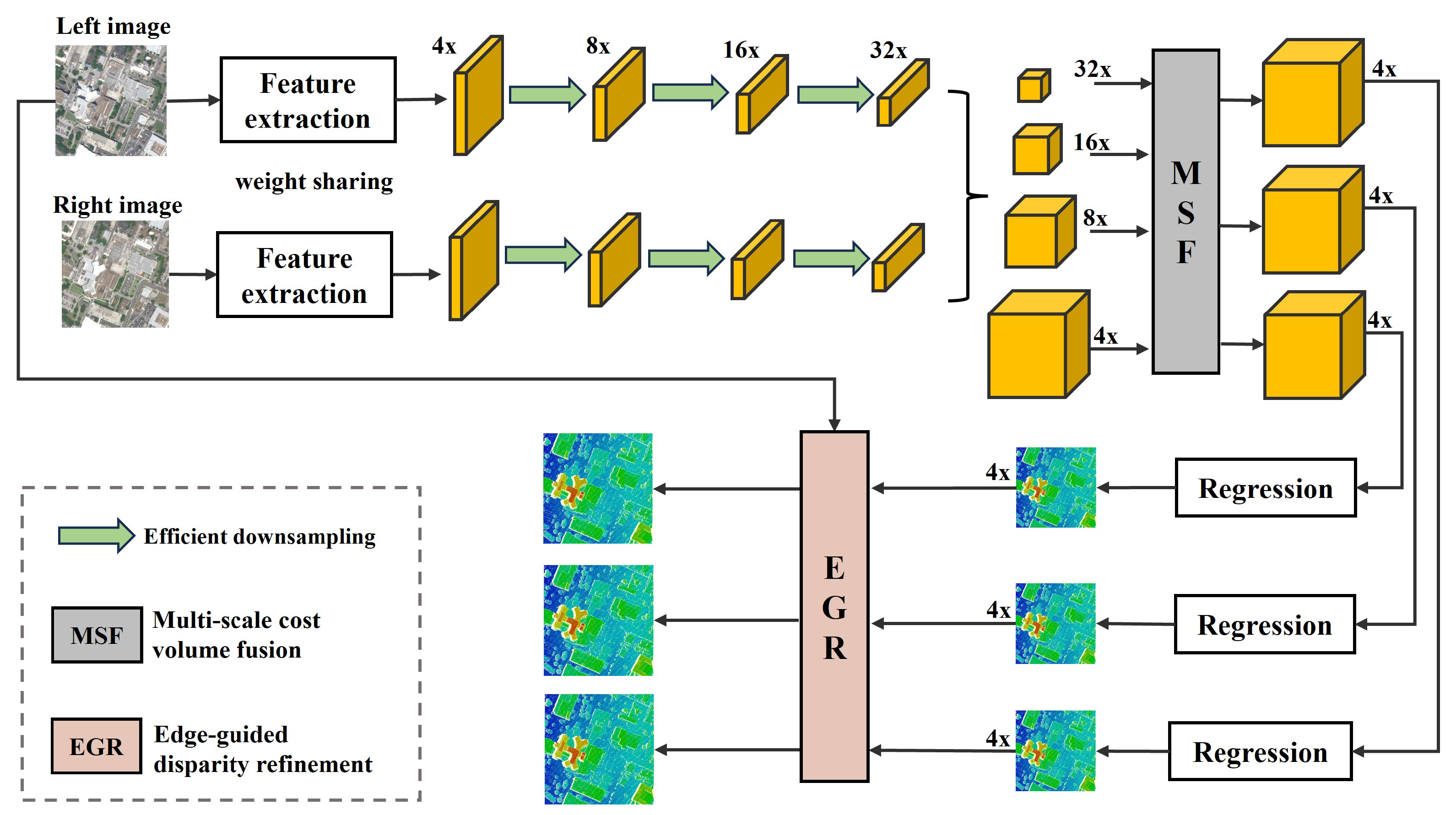
Considering the characteristics of high-resolution optical satellite stereo image pairs, we opt for the 4D cost volume to ensure the accuracy of the results and propose an edge-guided multi-scale matching network. The whole network architecture consists of five modules: feature extraction, cost volume construction, cost volume aggregation, disparity regression and disparity refinement. The structure of the EGMS-Net is shown in
Figure 1. In the first step, multi-scale pyramid features are extracted from the input image pair using a feature extraction network with shared weights and efficient down-sampling networks. Next, 4D cost volumes are constructed separately at multiple scales, and a multi-scale cost volume fusion network aggregates the cost volumes from top to bottom using a 3D CNN. In the disparity regression, soft argmin is used to estimate the disparity. To optimize the low-resolution disparity maps generated due to memory and speed limitations, we use fast trainable guided filters and introduce the left image as a reference image to restore the original resolution disparity map. The details and specific implementation processes for each part are presented in the following subsections.
2.1. Feature Extraction with Efficient Down-Sampling
Feature extraction serves as the initial phase in the network, which is critical for retrieving localised information from each pixel (image block) to ensure accurate matching. Many networks choose to reduce the resolution initially to reduce the computational cost. For example, PSMNet and StereoNet use convolutional kernels with a stride of 2 to reduce the resolution of the feature map by half and 1/8 of the original resolution, respectively. These networks are tailored for ground scenes with many textureless regions, where resolution reduction is necessary to ensure feature extraction from a large receptive field. However, unlike ground scenes, optical satellite imagery contains a wide variety of features, including small and dense buildings. Reducing resolution at the outset risks losing fine detail. Therefore, we use three small convolutions for feature extraction at the original size to minimise the loss of information due to resolution reduction.
We also increase the number of channels from 32 to 64, a common operation in networks [
23,
24,
27]. This increase helps to extract richer feature representations, fully capturing high-frequency signals and increasing the expressiveness of the model. Once sufficient high-frequency information is obtained, two residual blocks [
28] with a stride of 2 are used to reduce the resolution of the feature map to 1/4 of the original, allowing for faster training. Multiple residual blocks are then used to further extract features at lower resolutions and increase network depth. This results in a larger receptive field, allowing more features to be captured from similar pixels, especially in textureless regions. The feature extraction architecture is outlined in
Table 2. In this part, we use a Siamese network to share weights, allowing both input images to generate their own feature maps.
Satellite images contain a wide variety of objects of different sizes. To capture the detail and hold more information, we construct pyramid features with different scales and receptive fields [
27]. The low-resolution feature maps are tailored to resolve the interference of textureless areas while maintaining a compact arrangement of feature vectors. Conversely, the high-resolution feature maps are designed to recover fine local features of objects.
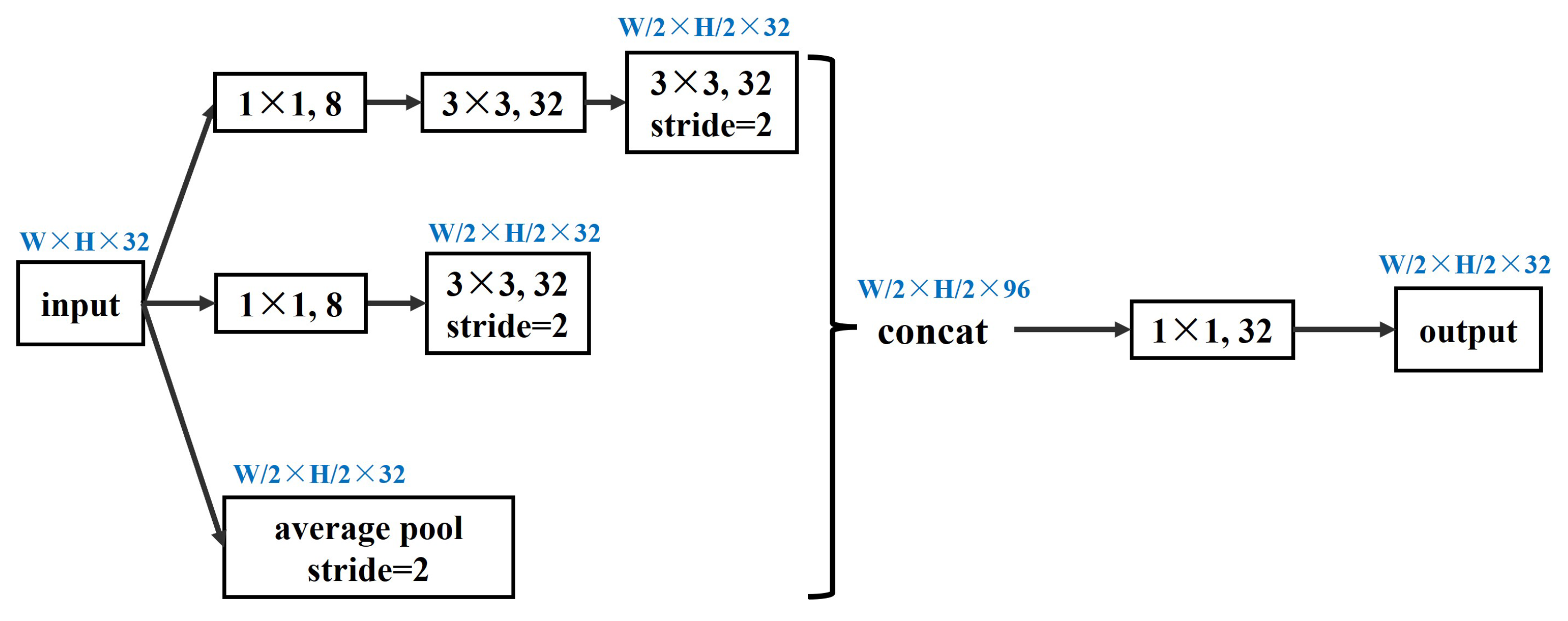
To capture features of different scales, many stereo matching networks use pooling layers to reduce the size of feature maps. The principle outlined in [
29] emphasizes that, as the network deepens, the size of the feature maps should gradually decrease to avoid excessive feature reduction, which can lead to information loss. To address this, it is advisable to increase the number of channels before merging layers to avoid rendering bottlenecks. In our approach, we use a more efficient down-sampling scheme, as shown in
Figure 2. We use (
) kernels to compress feature channels, which increases network complexity without compromising accuracy. We also replace large filters (
) with two small convolutional filters (
) and concatenate features from different receptive fields. This reduces computational complexity and speeds up training. The final output feature map sizes are 1/4, 1/8, 1/16 and 1/32 of the input image size, respectively.
2.2. Four-Dimensional Cost Volumes Construction
After obtaining multi-scale left and right feature maps through the feature extraction module, it is crucial to fuse them to generate the corresponding matching cost volume. This process allows for the exploration of potential match points within a specified disparity range. A 3D cost volume can be constructed by calculating L1, L2 or a correlation distance between the left feature map and the corresponding right feature map [
20,
30,
31]. In this way, the dimension of the feature channel (C) is compressed and the generated volume has only three dimensions: height (H), width (W) and disparity (D). Using this method can improve the training speed by reducing the number of parameters. However, it reduces the complexity and generalizability of the network, which is not suitable for optical satellite imagery.
We decided to retain the feature channel information and fully exploit the multi-scale features extracted in the previous step. Accordingly, we construct 4D cost volumes independently in four scales, where the dimensions are height (H), width (W), disparity (D) and feature channels (C). The procedure is illustrated in
Figure 3. We construct cost volumes by computing the absolute differences between the features of the left image and the corresponding features of the right image at different disparities. This approach is similar to the result obtained by directly concatenating two vectors [
24], but it reduces the number of channels by half, resulting in a more efficient use of computational memory.
Many networks typically set the disparity range between non-negative values when constructing volumes, but remote sensing datasets may have negative disparity ranges. To account for this and ensure realism, we follow the guidelines outlined in [
32] to include the case of negative disparity in the process. It is worth noting that, when the disparity is
, the correspondence between potential matching points
and
in the left and right feature maps becomes
. The final size of the cost volumes is
, where
.
2.3. Multi-Scale Cost Volume Fusion
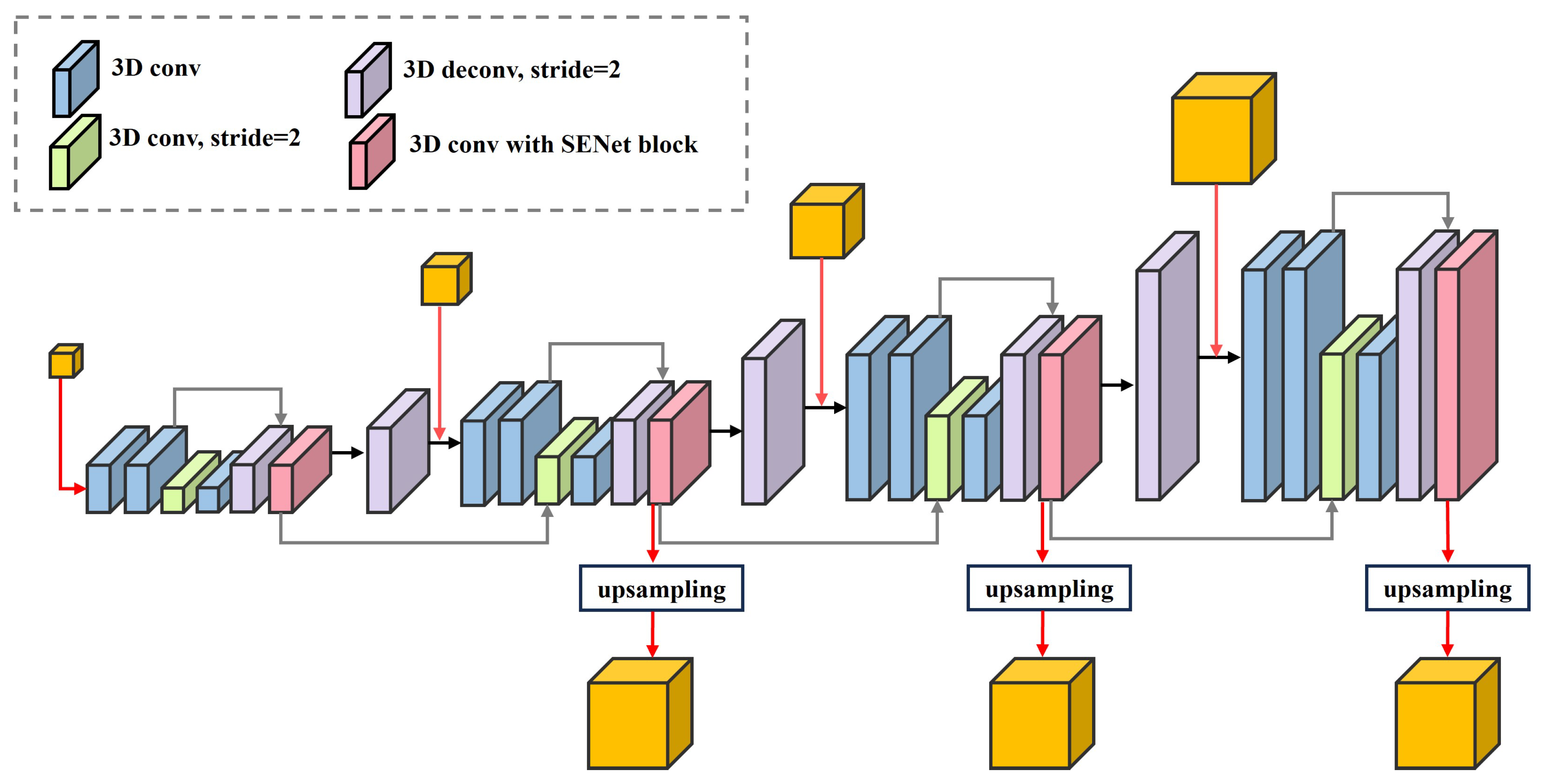
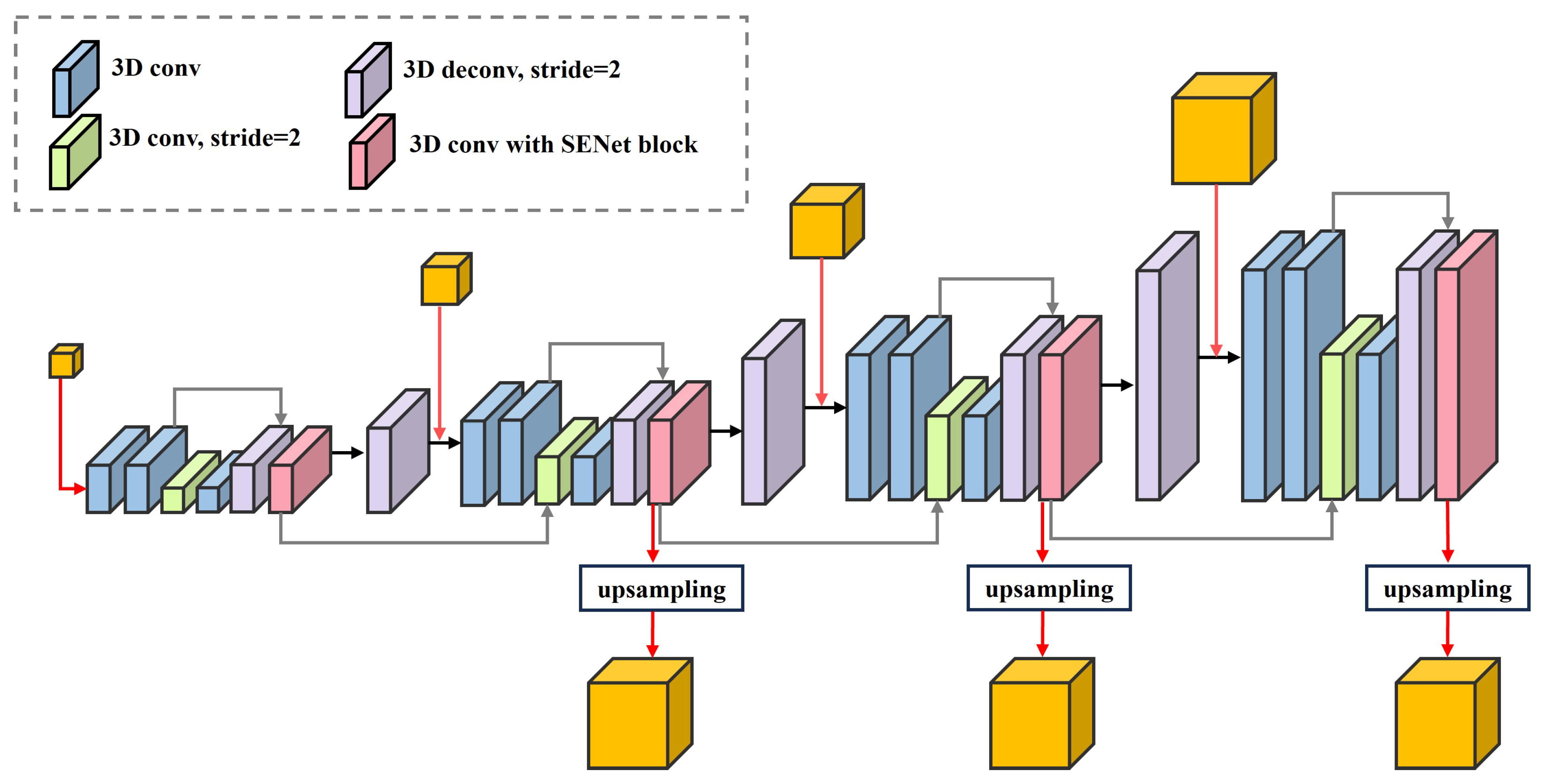
The 4D feature volumes require 3D convolution to learn regularized aggregation functions over three dimensions: height, width and disparity. We use 3D convolution to construct a stacked hourglass structure integrated with a volume pyramid pool to generate features. The architecture shown in
Figure 4 is specifically designed to aggregate multi-scale features from top to bottom.
Starting with the lowest resolution cost volume, a 3D convolution kernel with a stride of 2 is used to down-sample. After capturing smaller-scale features, transposed convolution is used to restore scale and generate the processed cost volume at that resolution. The transposed convolution operation is also used to up-sample to a higher resolution, gradually contributing to the initial cost volume at the same resolution. At the same time, as indicated by the gray arrow in
Figure 4, the cost volumes are summed at the same resolution. Each 3D convolution layer is followed by batch normalization (BN) [
33] and rectified linear unit (ReLU) activation. When a cost volume addition is encountered, the addition operation is performed first, followed by activation.
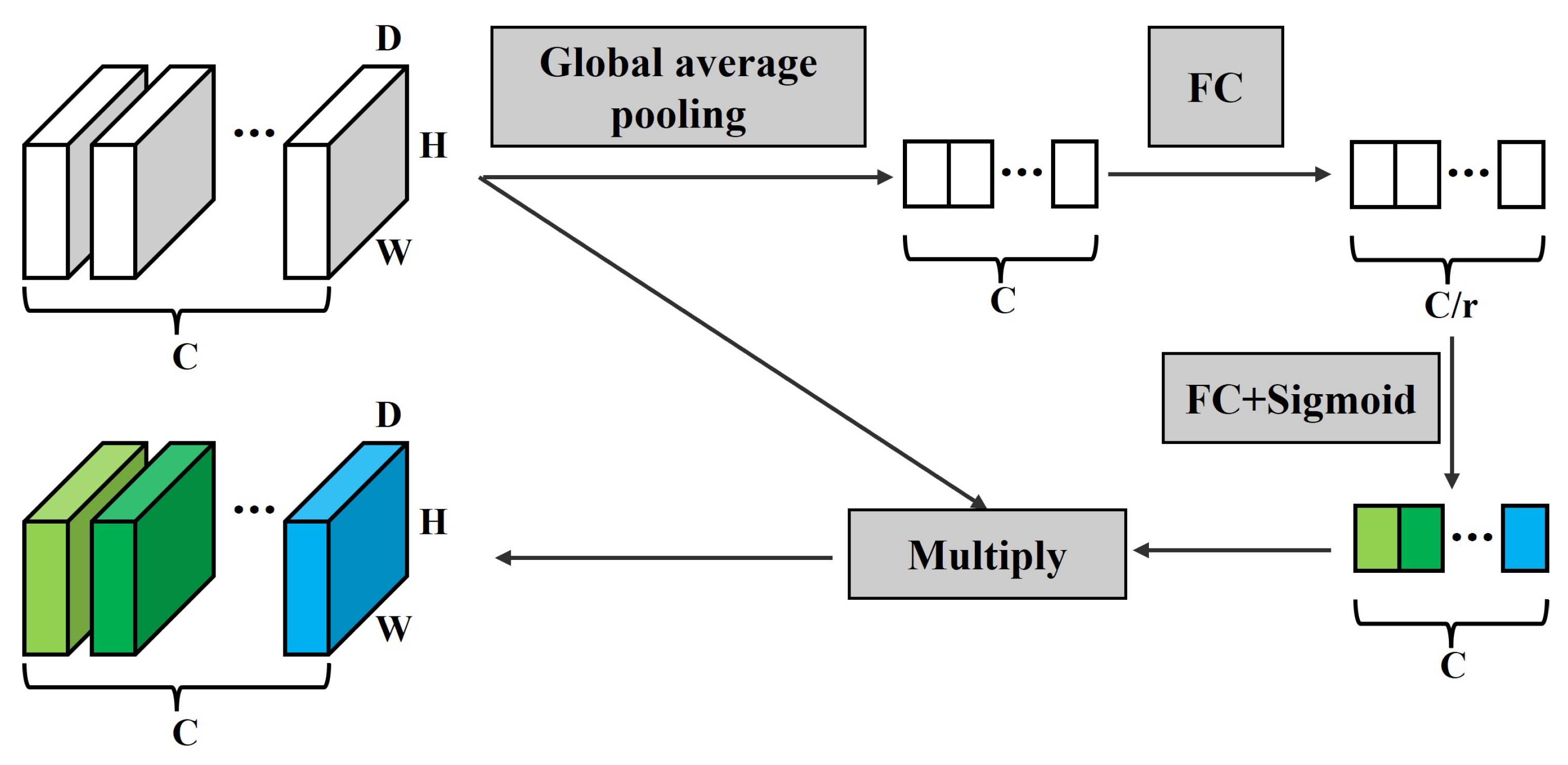
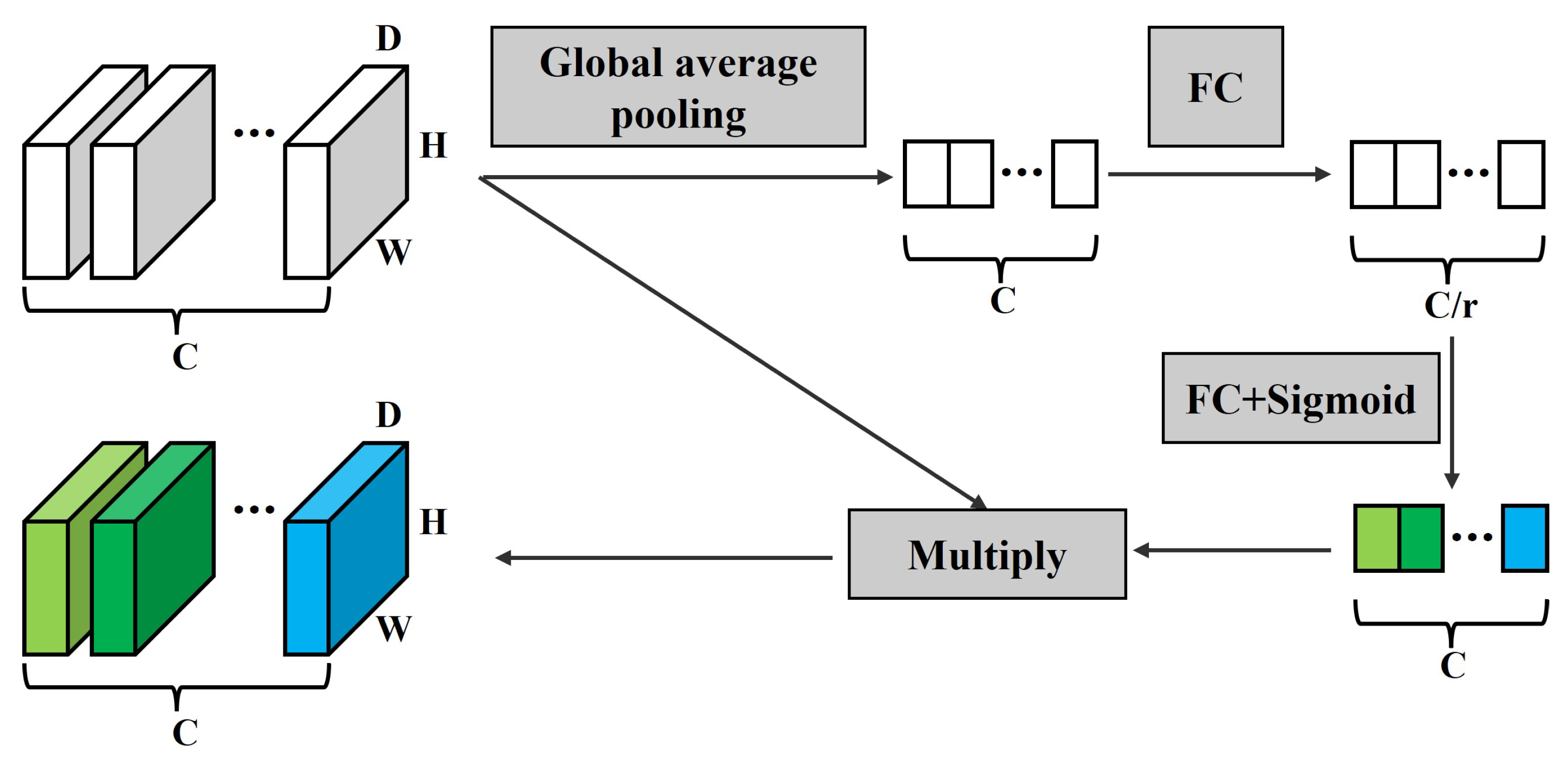
We integrate the attention mechanism during the final convolution of the cost volume at each scale, using the SE block [
34]. While the original SE block is designed for 3D feature volumes, we extend it to the 4D feature volume. The implementation process is shown in
Figure 5. The feature compression process begins with global average pooling, which consolidates the cost volume of
in each feature channel into a single real number. Subsequently, two fully connected layers are employed to generate weights for each feature channel. The parameter
r acts as a scaling factor to reduce the number of channels. Different activation functions are applied to increase the non-linearity of the network. Finally, the weights obtained are multiplied by their corresponding channels, completing the recalibration of the original channels and generating the output. This step evaluates the importance of features in different channels.
Due to the excessively low resolution at the 1/32 scale, the fused contextual information is limited. Up-sampling to the original resolution during disparity refinement in
Section 2.5 results in significant loss of content, which hinders effective restoration of detail. Therefore, we choose not to pass the cost volume at this resolution to subsequent processing steps. Instead, we up-sample the cost volumes at 1/8 and 1/16 resolutions to 1/4 resolution, followed by two convolution operations, resulting in three aggregated cost volumes of equal size.
2.4. Disparity Regression
After the multi-scale aggregation of the cost volumes, it is essential to compress the feature channels to 1 before proceeding with the disparity regression. We adopt the widely used disparity regression method proposed in [
22]. This method uses softmax to normalize the cost values for each disparity
d, and then uses the normalized probability values to weight the disparities within the disparity range. The final result is a floating-point number that represents the predicted disparity at the subpixel level, thereby improving disparity accuracy. The approach is implemented using Equation (
1).
where
represents the predicted disparity and
denotes softmax, the variable
in the cost volume stores the matching cost for a candidate disparity value
d. A larger matching cost indicates a less favourable match, so it is necessary to take a negative value to obtain smaller probability values through the softmax operation.
2.5. Edge-Guided Disparity Refinement
Typically, in most networks, the first step is to estimate low-resolution disparity maps using stereo disparity computation. Interpolation methods are then used to up-sample the maps to full resolution. However, the up-sampling process has inherent limitations that inevitably result in the loss of fine detail. Commonly used linear interpolation methods include nearest neighbor interpolation and bilinear interpolation. These methods use the same kernel during interpolation and do not consider the location of the pixel. In edge regions where there are significant variations in disparity, maintaining clear edges after interpolation becomes a challenge, especially if the disparities do not conform to smoothness assumptions. It is therefore common to introduce additional information into the network to restore the content and texture of the original images. The guided filter [
35] is an edge-preserving filter commonly used in traditional methods. By using an input image as a guidance map, it preserves edge details during filtering and finds application in classic tasks such as denoising and detail enhancement. Building upon this, a joint up-sampling guided filter layer is proposed in [
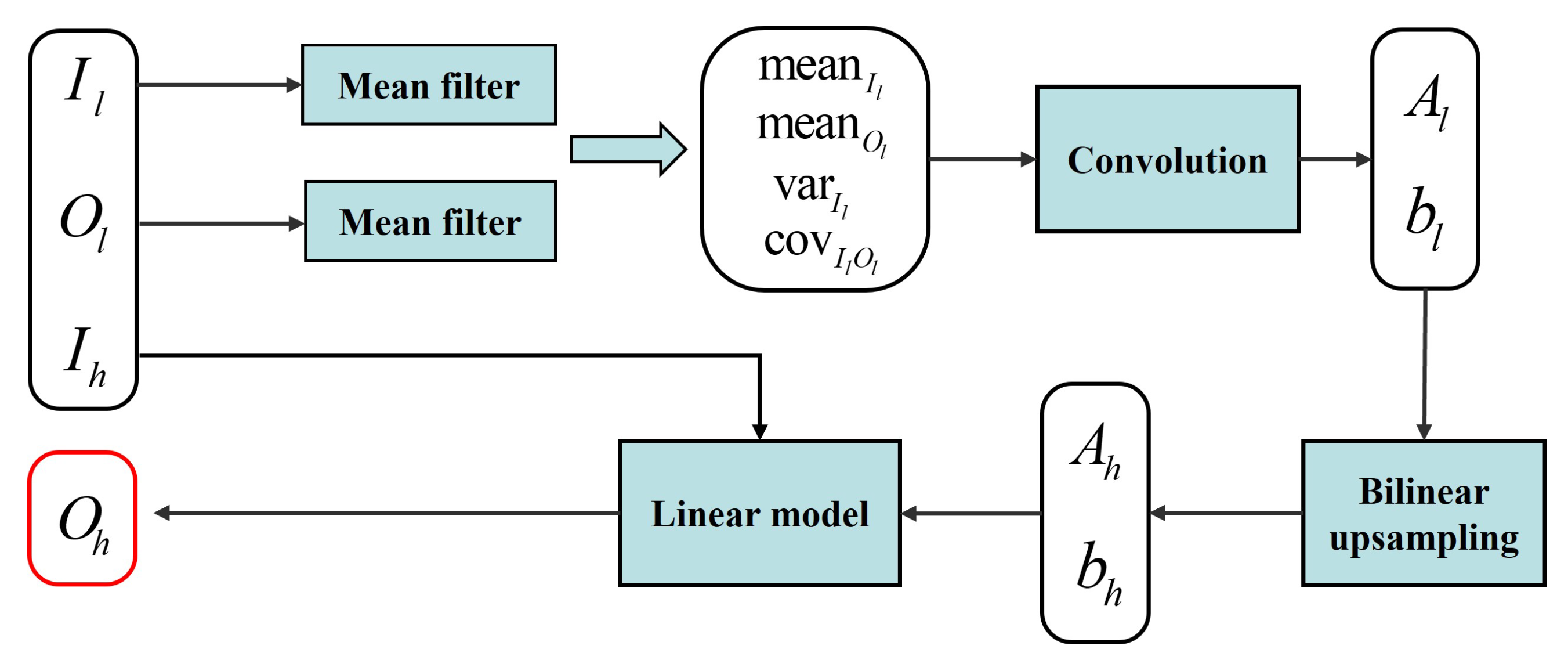
36], where the original guided filter is transformed into a convolutional block with learnable parameters. This construction allows for a seamless integration with the CNN, optimizing the whole system through end-to-end training.
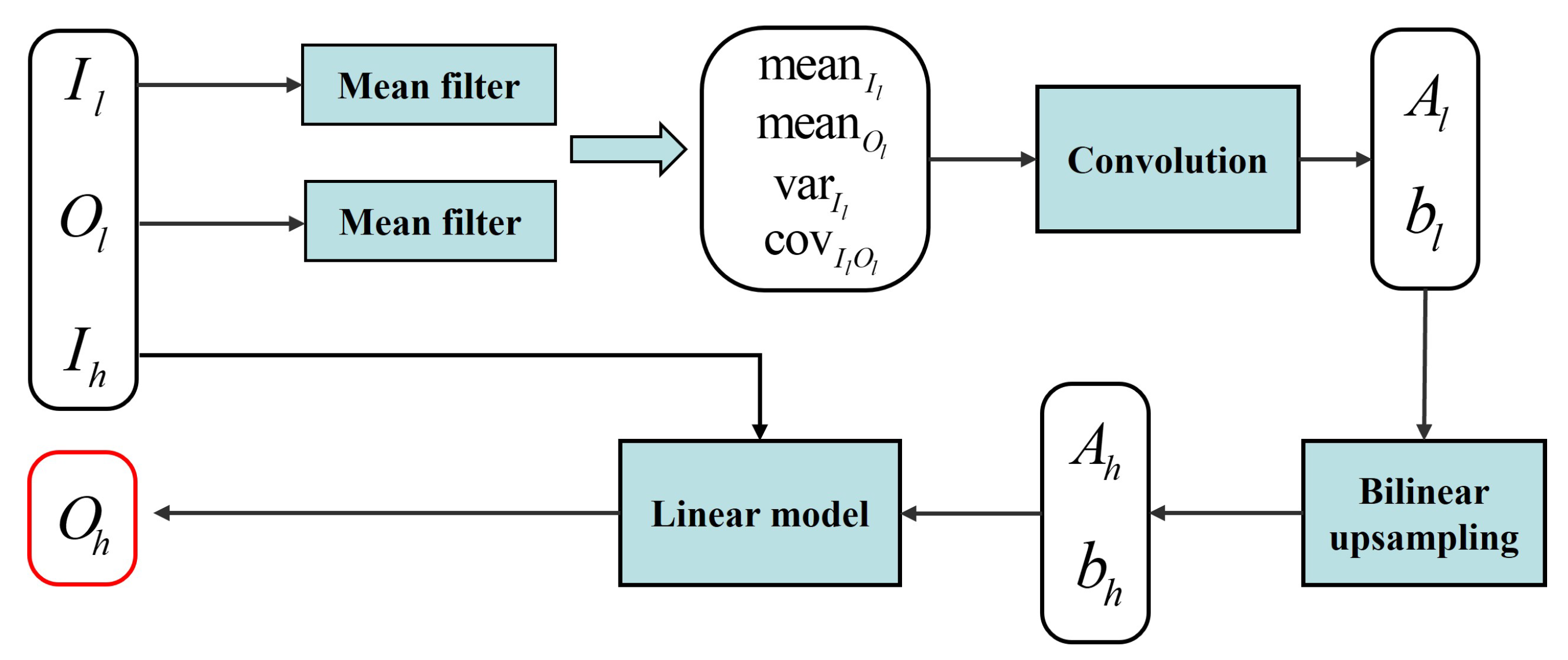
The image
obtained by the traditional guided filter can be represented by:
where
represents the guidance map, and
and
can be calculated from the initial image to be filtered using relevant formulas derived by deduction. The fast end-to-end trainable guided filter replaces traditional formulas with convolutional networks when solving for
and
. This substitution allows it to learn more accurate values. The overall structure is shown in
Figure 6. The process starts by applying a mean filter to the input low-resolution guidance map and the low-resolution disparity map. This gives the mean values of the low-resolution guidance map, the mean values of the low-resolution disparity map, the cross-correlation and the auto-correlation from Equation (
3).
To reduce computational complexity and increase efficiency,
and
are learned from the low-resolution images. The convolution module here consists of three cascaded convolutions with a kernel size of 1 and 32 channels. The first two convolutions are followed by BN and ReLU layers. After obtaining
and
, they are further up-sampled to high resolution. Finally,
,
and the input high-resolution guidance map
are substituted into Equation (
2) and the filtered high-resolution disparity map is obtained by linear model.
We extend the fast end-to-end trainable guided filter and integrate it into our model to improve the matching performance, especially at the edges of the terrain. The left image is chosen as the reference image and the necessary features are trained to generate the guidance map, as shown in
Figure 7. Given our goal of refining the disparity map during the up-sampling process, the guidance map derived from the trained left image should prioritize edge details with notable disparity variations. The feature extraction module consists of four
convolutional layers. Each convolutional layer is followed by a BN layer and a ReLU layer. The resulting high-resolution guidance map
is down-sampled to 1/4 of the original resolution. Subsequently, it is separately input, along with the high-resolution guidance map and the low-resolution disparity map, into three guided filters. Finally, three high-resolution disparity maps are generated as output. It is essential to note that, once the disparity map has been restored to its original resolution, the disparity values need to be scaled up accordingly.
2.6. Loss
We compute different disparity maps at multiple scales, based upon which we calculate the loss function for back-propagation. Due to the aggregation process in the previous step, the high-resolution cost volume incorporates prior information from the low-resolution cost volume, enabling the generation of more refined disparity maps. In addition, the process of up-sampling to the original image size can result in the loss of fine detail. Higher-resolution disparity maps are more likely to produce accurate results than their lower-resolution counterparts. Therefore, we define the total loss as the weighted sum of the losses obtained at each scale:
where
represents the loss of the disparity map computed from the cost volume at the lowest resolution (1/16),
represents the loss of disparity map computed from the cost volume at 1/8 resolution, and correspondingly,
represents the loss of the disparity map obtained from the cost volume at the highest resolution (1/4). The variables
,
and
denote the weighting coefficients for each loss, and their magnitudes depend on the resolution of the cost volumes. The loss function for the disparity map at a single resolution is defined as:
where
N is the number of valid pixels. When constructing optical image datasets, the ground truth disparity maps often contain some void points. Therefore, when calculating the loss function, it is necessary to exclude these void points and only consider the loss for valid disparities.
represents the ground truth, and
represents the predicted value.
can be expressed as:
5. Discussions
5.1. Significance Test
To make our experimental results more credible, we perform significance tests on the US3D dataset. Given the long training time, all three models are trained five times with different random seeds, ensuring that the remaining parameters are kept constant. Each of the three methods ultimately produces five results. We test EGMS-Net against PSMNet and StereoNet, respectively. Given the small sample size, we do not expect the difference between the two models to follow a normal distribution, so we use the Mann–Whitney U test in non-parametric form.
Table 8 shows the test results of our method with PSMNet and StereoNet, respectively.
The null hypothesis (H0) states that the metrics of EGMS-Net are not significantly different from those of PSMNet and StereoNet. This implies that the performance of EGMS-Net is similar to that of PSMNet and StereoNet. On the other hand, the alternative hypothesis (H1) states that the metrics of EGMS-Net are significantly different from the metrics of PSMNet and StereoNet. These hypotheses would guide the statistical analysis to determine whether EGMS-Net has superior performance compared to PSMNet and StereoNet based on the defined metrics.
Based on the results presented in
Table 8, where the
p-values for all metrics are less than the significance level of 0.05, the null hypothesis (H0) is rejected. Therefore, the alternative hypothesis (H1) is accepted, indicating that EGMS-Net does indeed differ from PSMNet and StereoNet on these metrics. Judging from the combined data, the metrics of EGMS-Net are smaller than those of the other two networks. This indicates that EGMS-Net achieves better results compared to PSMNet and StereoNet in terms of the defined performance indicators.
5.2. Ablation Study
To verify the effectiveness of each component of the network on the results, we perform a detailed ablation study on US3D. We do not change any of the parameter settings during the experiment, including the learning rate and the weights in the loss function. The network is retrained after removing the corresponding components. The results are recorded in
Table 9.
“High-resolution” means that high-resolution feature extraction is not performed at the beginning. Following the other networks, we first reduce the resolution to one-fourth and then perform feature learning. It can be seen that, after this change, the EPE increases by 0.062 pixels and D1-2 and D1-1 also increase. This suggests that learning features at the original size of the input image in the feature extraction module positively contributes to the overall performance of the network.
“Efficient down-sampling” means that we do not use efficient down-sampling, but simply use the normal bilinear down-sampling operation to obtain multi-scale features. As expected, the EPE increases by 0.026 pixels. In addition, although the bilinear down-sampling is simpler, the running time has increased instead. This suggests that this part achieves the goal of improving the efficiency of the network.
“Multi-scale aggregation” means that we do not use multi-scale aggregation, but only acquire the feature maps at 1/32 resolution through efficient down-sampling, and then perform the subsequent aggregation operation. The superiority of multi-scale has been demonstrated in numerous papers. As can be seen from
Table 9, the results without multi-scale aggregation are significantly worse, although the running time is reduced.
“Trainable guided filter” means that we do not use the final disparity refinement module, but use bilinear up-sampling to bring the disparity map back to its original size. It can be seen that, although the network becomes simpler when this module is removed, the running time does not decrease, but rather increases. The results of other metrics also become worse. The trainable guided filter is an effective way to increase the matching accuracy.
6. Conclusions
This study presents an end-to-end edge-guided multi-scale matching network. The network performs fine feature extraction at the original resolution and constructs feature maps at different scales through efficient down-sampling. Top–down 4D cost volume aggregation is then performed by a feature aggregation module using SE blocks. Finally, a disparity refinement module is used to train the left image to generate the guidance map, while a trainable guided filter ensures accurate edge details when returning to original resolution. In our experiments, EGMS-Net successfully reduces EPE and D1 compared to PSMNet and StereoNet, achieving EPE values of 1.515 pixels and 2.495 pixels on the two test datasets. The primary objective of reducing network running time while maintaining the quality of the disparity map is achieved. EGMS-Net provides notable improvements in challenging regions such as occluded and textureless areas in optical images, particularly in regions of significant disparity variation where it produces sharper edges. Furthermore, the ablation study shows that the four design choices we implemented contribute significantly to the performance of the network.
In future research, we aim to further improve the accuracy of the network, especially in scenarios with larger viewpoints and more occlusions, while at the same time improving its ability to generalize to different datasets. In addition, we recognize the need to address the longer running time of EGMS-Net compared to StereoNet, which warrants further optimization. Furthermore, extending the applicability of the network to lower resolution satellite imagery, such as ZY-3, is an interesting challenge that we plan to investigate.
This study validates the feasibility of using deep learning techniques to construct dense matching networks for optical images. It shows that a favorable balance between processing speed and result accuracy can be achieved, particularly for large format optical images. In addition, the improvements made in EGMS-Net hold promise for application to other computer vision tasks. For example, efficient down-sampling operations can be used to preserve information when generating multi-scale feature maps. If the visualization results need to improve resolution or keep edges sharp, a reference map can be introduced and a trainable guided filter can be added at the end of the network to optimize the final results.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}