Abstract
Novel view synthesis using neural radiance fields (NeRFs) for remote sensing images is important for various applications. Traditional methods often use implicit representations for modeling, which have slow rendering speeds and cannot directly obtain the structure of the 3D scene. Some studies have introduced explicit representations, such as point clouds and voxels, but this kind of method often produces holes when processing large-scale scenes from remote sensing images. In addition, NeRFs with explicit 3D expression are more susceptible to transient phenomena (shadows and dynamic objects) and even plane holes. In order to address these issues, we propose an improved method for synthesizing new views of remote sensing images based on Point-NeRF. Our main idea focuses on two aspects: filling in the spatial structure and reconstructing ray-marching rendering using shadow information. First, we introduce hole detection, conducting inverse projection to acquire candidate points that are adjusted during training to fill the holes. We also design incremental weights to reduce the probability of pruning the plane points. We introduce a geometrically consistent shadow model based on a point cloud to divide the radiance into albedo and irradiance, allowing the model to predict the albedo of each point, rather than directly predicting the radiance. Intuitively, our proposed method uses a sparse point cloud generated with traditional methods for initialization and then builds the dense radiance field. We evaluate our method on the LEVIR_NVS data set, demonstrating its superior performance compared to state-of-the-art methods. Overall, our work provides a promising approach for synthesizing new viewpoints of remote sensing images.
1. Introduction
Due to the ability to capture global features on a larger geographical scale, remote sensing images have advantages in the context of road extraction [1,2,3,4], urban planning [5], and object detection [6], whereas ground-based images often lack global information. With continuous advancements in aerial and satellite photography technologies, obtaining high-resolution remote sensing images has become much easier, allowing for the accurate identification of large structures, roads, rivers, and other man-made features, even for dynamic scenes. However, due to the limitation of the satellite camera’s angle and frequency, the image quantity for a specific area is often insufficient. Consequently, synthesizing novel views based on existing images has gradually become a mainstream data augmentation approach. Rendered images can help to enhance intelligence-gathering capabilities within target areas. Thus, the synthesis of remote sensing novel view images has attracted more and more attention.
Recently, NeRFs (neural radiance fields) [7] have been proposed to organically combine image-based 3D reconstruction and novel view synthesis. Unlike explicit 3D representation techniques, such as point clouds [8], volumes [9,10], or meshes [11], NeRFs employ an implicit representation method [12] to store 3D scenes within neural network weights. For each ray in an image, NeRF performs positional sampling and decodes the feature embedding, thus obtaining the radiance and volume density of each sampling point. Next, a ray-marching algorithm [13] is used to determine the color (RGB) and transparency of the specific pixel that the ray projects onto the image. With the color value as the ground truth, NeRF achieves simultaneous new view rendering and 3D structure optimization using radiance information. However, the implicit 3D representation lacks interpretability, and the efficiency of rendering ray by ray is too low for high-resolution remote sensing images. Moreover, the capture method of remote sensing images is different from standard close-range cameras, which creates larger distances between the targets and the camera. DoNeRFs [14] address this challenge by acquiring real-depth information and focusing on important samples around the object’s surface; however, obtaining accurate depth information is very difficult for remote sensing images. To this end, ImMPI [15] introduces implicit representation of 3D scenes using multi-plane images (MPIs) and performs novel view synthesis on remote sensing images. It also includes the LEVIR_NVS dataset, which comprises multi-scene and multi-view remote sensing data captured by drones. Despite this, NeRF and its variants (based on implicit 3D representations) still produce ineffective sampling in large blank areas [16], which not only reduces the overall performance efficiency but also causes rendering artifacts in some regions.
When compared to implicit expression, explicit 3D scene expression (e.g., point clouds and voxels) is more intuitive and is easier to combine with existing 3D application technologies [17,18,19]. Point-NeRF [20] first uses a point cloud as the skeleton of the neural radiation field to build a volume-rendering framework. Point-NeRF implements an effective algorithm to query adjacent points, based on which the point features located on rays can be calculated through adjacent point aggregation, with the radiance and transparency then decoded. Point-NeRF first uses MVSNet [21] to initialize the point cloud to fill the neural radiance field and then uses the VGG [22] model to extract feature vectors at each pixel position. During training, the model parameters, feature vectors, and confidence of each neural point are optimized synchronously. It is worth mentioning that Point-NeRF also introduces point cloud pruning and growing operations, dynamically encrypting neural clouds. Thus, Point-NeRF can process external point clouds, such as the photogrammetry point clouds generated by COLMAP [23].
However, directly applying Point-NeRF to the tasks of novel view synthesis from remote sensing images is challenging. At larger geographic scales, the original point cloud settings make it difficult to describe the whole scene and may result in large holes in the reconstruction results, which are mainly distributed in planar areas (such as straight roads and roofs), as shown in Figure 1. We believe that there are two main reasons for this: (1) the spatial density of the flat area is relatively low, and (2) the homogenization of a flat texture leads to poor optimization effects based on color values, causing the points on the plane to have low confidence and are, therefore, easily merged by pruning. We have also observed that these holes are mainly concentrated on buildings and roads in urban areas, whereas the quality of the mountains is quite good (as is shown in Figure 2). Thus, point cloud-based NeRF may be better at depicting continuous terrain rather than rapidly changing urban landscapes, which requires more structural prior knowledge and processing. On the other hand, Point-NeRF finds it difficult to render shadows that are closely related to 3D structures (examples in Figure 3), which inevitably results in the unpredictability of a scene.
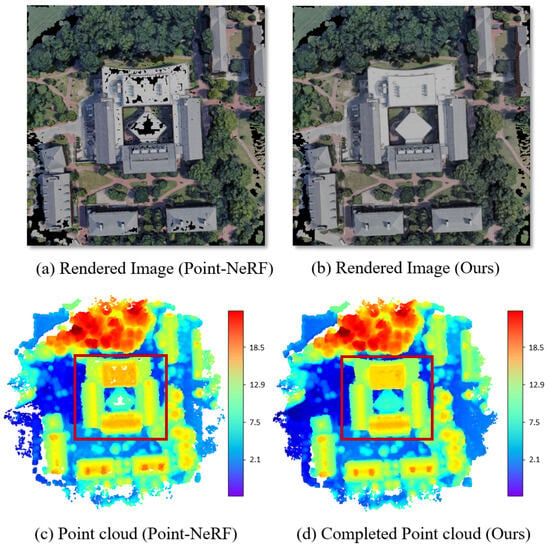
Figure 1.
The main idea and effect of our method. A neural radiance field constructed from a point cloud often generates holes in the planes during the rendering of remote sensing images (a,c). We introduce a new neural point cloud completion method based on Point-NeRF, effectively addressing this issue (b,d). In order to eliminate the influence of different coordinate systems, the color band corresponds to the absolute elevation range of the neural point cloud; that is, if the z values of the lowest and highest points are and , respectively, the corresponding range of the color band is [0, ].
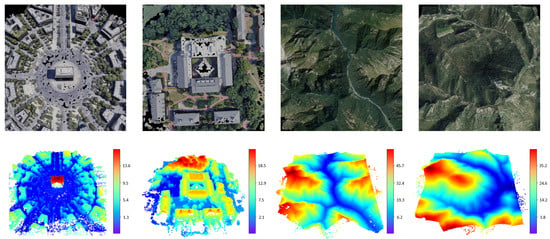
Figure 2.
Different effects when Point-NeRF reconstructs urban scenes and mountains. The first row contains the rendered images, and the second row contains the neural point clouds.

Figure 3.
The problem with Point-NeRF in reconstructing an area in shadow. Point-NeRF has difficulty dealing with shadows, especially those in shadow areas caused by sunlight.
Some studies have utilized NeRF to reconstruct digital surface models (DSMs) from remote sensing images, mainly focusing on the consideration of shadows. S-NeRF [24] reconsiders the radiance and rewrites it as the product of the albedo and irradiance, instead of directly estimating the whole radiance, as per the original NeRF. The albedo only relates to the location of the points and the scene information stored in the model, which is generated by an additional layer after the density network. Irradiance is a weighted sum of direct light from the sun and ambient light from the sky, both calculated by special modules based on solar direction. S-NeRF provides the basic idea for processing shadows—that is, splitting the original radiance and modeling the solar rays—based on the assumption that the difference between the location of the shadow and other locations is whether it can receive sunlight. Based on S-NeRF, Sat-NeRF [25] introduces an embedding vector to describe the characteristics of transient objects that cannot be captured by changes in illumination between different image frames. It also incorporates an uncertainty output to indicate whether a pixel belongs to a transient object. This approach partially decouples the features of shadows and transient objects. The iterative version, EO-NeRF [26], makes more intuitive use of the relationship between the solar ray and the spatial structure. It queries the position of the surface point through the camera ray and then determines whether the point is in the shadow region according to the radiance transmittance of the last term from the solar direction. Eo-NeRF [26] completely separates shadows and transient objects and adds two new learnable affine transform feature-embedding vectors to characterize the structural differences between images in different phases. This provides a new idea for our research.
Based on the above research, we adopt three methods to improve the current shortcomings of Point-NeRF. First, we utilize COLMAP to initialize the point cloud structure [23] using an existing projection matrix to obtain an initial 3D point cloud, instead of using the built-in MVSNet [21], which is then fed into the main model for optimization. In order to address the holes, we propose a new neural point-growing method, which is shown in Figure 4. Our main idea focuses on two aspects: filling in the spatial structure and reconstructing the ray-marching rendering using shadow information. First, we introduce hole detection and conduct inverse projection to acquire the candidate points that are adjusted during training to fill the holes. These 3D points are located in the light made up of the void point and the optical center, which will gradually converge to the correct position during training. We also design incremental weights to reduce the probability of pruning the plane points. Then, we introduce a geometrically consistent shadow model based on a point cloud to divide the radiance into albedo and irradiance according to the shadow information, allowing the model to decode more shadow-aware features. The neural point cloud is continuously optimized. After performing the above steps, we obtain an encrypted point cloud. Due to the introduction of shadow factors, we name the proposed method “shadow-aware Point-NeRF” (SA-Point-NeRF). Our method effectively compensates for the shortcomings of Point-NeRF, and experiments conducted on the LEVIR_NVS data set demonstrate the superiority of the proposed method over other state-of-the-art methods.
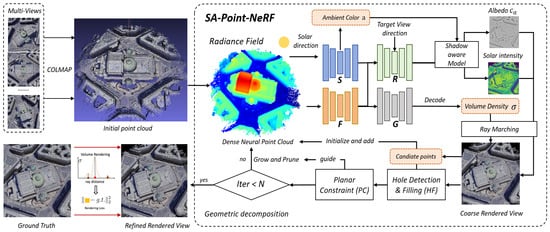
Figure 4.
The main workflow of our method. We first employ COLMAP to generate a sparse point cloud and initialize the radiance field. Subsequently, we decompose the radiance into albedo and irradiance, optimizing the original ray-marching algorithm using a shadow model with structural consistency to obtain shadow-invariant features. Following this, we perform hole detection and filling on the rendered views, and we introduce a new planar confidence parameter to reduce the probability of pruning the planar points. Finally, the model is optimized by calculating the loss between the rendered radiance and the ground truth.
The contributions of this work can be summarized as follows:
- To the best of our knowledge, we are the first to apply Point-NeRF to the novel view synthesis of remote sensing images.
- We propose a new neural point-growing method, which detects holes in the rendered image and calculates some alternative 3D points through inverse projection. This method can effectively make up for the plane points being pruned by mistake.
- We design a shadow model based on point cloud geometric consistency to deal with the holes in the shadow areas, which is useful for the perception of shadows.
- Our method was tested on the LEVIR_NVS data set and performed better than state-of-the-art methods.
2. Method
2.1. Preliminary
2.1.1. Neural Radiance Field
The original neural radiance field (NeRF) [7] is essentially a continuous function, , that stores the geometric structure and appearance of a 3D scene. In the simplest form, NeRF takes a set of 3D coordinates, , as input, and optionally, an appended view direction, , to predict the RGB color, , and a non-negative scalar volume density, , from that viewing angle, , which can be formulated as
When training, NeRF takes the input view image and camera poses to encode Equation (1). Specifically, in each view, the origin of the camera light, , and pixel points constitute a ray, , and a multi-layer perceptron (MLP) estimates the state of each point in the ray, summing them to obtain the final color value, . Each ray, , can be represented as :
The rendered color, , is obtained by aggregating the states of the entire ray. Each ray is discretized into N 3D points, and each 3D point, , is moved by a certain step between the near boundary, , and the far boundary, , linearly, according to the formula . The contribution of each point to is determined by the opacity, , and transmittance, .
where is the distance between adjacent samples. All these factors are taken in the interval and only rely on the volume density, . The opacity, , will increase with , and it denotes the probability that belongs to a non-transparent surface. The transmittance, , represents the probability of the ray reaching without hitting an obstruction. Thus, the depth, , can be calculated in a similar way as in Equation (2).
In the NeRF model, the MLP is responsible for estimating the most difficult volume density, , and the radiance, , of ; thus, the RGB value, , can be calculated using the ray-marching algorithm described above. Then, the model is optimized by calculating the error between the rendered color, , and the ground image pixel color, :
where is a batch of randomly selected rays during training.
2.1.2. Point-Based Neural Radiance Field
The radiation field used by NeRF is implicitly included in the MLP model, whereas Point-NeRF [20] uses a point cloud that includes M neural points as the skeleton. In this explicit representation, each point, , is assigned a neural embedding, , and a confidence, , which are used to encode the radiation information and determine whether it is near the surface. The radiance field based on the neural point cloud can be expressed as
As the radiance field is discretized, Point-NeRF aggregates the features of K neighborhood points when estimating the volume density, , of a point, x, and the view-independent radiance, r.
Specifically, Point-NeRF first uses an MLP model, F, to encode the relationship between the existing neighbor points, , and the position, x, to be solved, generating relative features, .
Then, the view-dependent radiance at x is solved by another MLP, R, after the inverse distance-weighted aggregation of the relative neighborhood features:
For the volume density, , Point-NeRF first uses a new model, G, to directly calculate the density, , of each neighbor point according to . Then, it obtains the aggregated using inverse distance-weighted summation.
Here, adjusts the probability that the neural points are located on the surface; thus, the model can better converge to the real scene structure.
2.2. Overview
2.2.1. Main Workflow
We first define the outputs of our method. Then, we introduce the hole detection and filling method, which searches for points (i.e., black pixels) that are not rendered by any light on the generated image. Possible alternative points are then found using inverse projection. We initialize these points with feature embedding and put them into the neural point cloud for training. In this process, in order to reduce the unreasonable pruning of planar points, we introduce incremental weights to guide the regression of the volume density. Finally, we introduce a structural consistency shadow model based on a point cloud, which splits the radiance of Point-NeRF into albedo and irradiance regression, guiding volume rendering by judging whether a point is in a shadow. Thus, the model can produce shadow-aware features and reduce the rendering holes in shadow areas.
2.2.2. Module Function
Due to the discrete expression of radiance fields, the modules in Point-NeRF focus on aggregating neighborhood features instead of facing the whole ray. Therefore, taking the 3D point x as input, Point-NeRF first queries the neighborhood points from the point cloud to obtain the adjacent features, . Then, using the feature encoding module, (MLP in Figure 4), it completes the calculation of the relative features, , between x and these points. Then, the relative features and view direction, , are input into (MLP in Figure 4) to regress the albedo, , as is view-dependent. The calculation of the volume density, , requires (MLP in Figure 4) to apply all the relative features. Finally, the ambient color is calculated by (MLP in Figure 4) from the perspective of the solar direction, . The ambient color, albedo, and volume density all eventually contribute to the ray color, according to the ray-marching algorithm.
2.3. Problem Definition
The expanded neural radiance field of SA-Point-NeRF is
Here, we expand the definition of the surface confidence, , in Point-NeRF to describe the structural information in more detail by adding a parameter, . During training, determines whether the current point is on a plane, and this is calculated using the point density, .
Based on the above, the outputs of SA-Point-NeRF can be expressed as
The inputs of Equation (14) include the 3D point coordinates, ; solar direction vector, ; current view direction, ; and neighborhood points, . The outputs are as follows:
- : Volume density at location ;
- : Albedo RGB vector, only related to the spatial coordinate, ;
- : Ambient color of the sky according to the solar direction, ;
- : Confidence of whether the point is near the surface;
- : Confidence of whether the point belongs to a plane.
SA-Point-NeRF uses the output to render the color, , of a ray, , as follows:
where denotes the total irradiance and is defined as , with defined in Equation (19).
2.4. Hole Detection and Filling
During training, we also introduce hole detection to find the corresponding candidate 3D coordinates. We only need to find the black pixels in the rendered image, ; that is, . The pixel coordinates in the holes are denoted as , the intrinsic matrix is denoted as , the rotation matrix is denoted as , the corresponding world coordinate is denoted as , and the depth is denoted as z. Using these, we can build the inverse projection:
However, the depth cannot be determined using Equation (16). Thus, we chose the average depth, z, of the current point cloud to be , such that and can be calculated. Although these points may not be on the surface, they are still located on the ray with holes, satisfying the projection equation. During the continuous optimization carried out by Point-NeRF, these points are gradually adjusted to the appropriate position.
2.5. Incremental Weight of Planar Information
We added the parameter , indicating the probability of the point being on a plane. Unlike the original surface confidence, , which is independent, is obtained by aggregating neighborhood information because the planar point should share the relationship between neighborhood points. Specifically, when we use F to encode the features, we also make it judge whether the point has common conditions to become a plane point among the neighborhood points. That is, F outputs both the relative features, , and planar confidence, .
Then, the surface confidence, , and planar confidence, , are used in the volume density regression. We consider that if the current point is on the surface, will contribute more weight to the volume density, , and then the model will pay more attention to such a point, reducing the probability of pruning.
2.6. Structural Consistency Shadow Model
We introduce a sunlight model and a sky ambient color model to determine whether a point is in a shadow. Instead of directly estimating the radiance of x, we decomposed it into albedo and irradiance items. For this purpose, we added an albedo component, , to each neural point, , which is decoded during per-point processing in Equation (8). Then, we decomposed the irradiance into direct solar radiance and sky ambient color, . The direct solar radiance, , is calculated based on a point cloud-based structural consistency method, and the ambient color values are computed by a specialized model according to the solar direction, . Considering that both the direct solar ray, , and ambient colors, , affect the entire scene, we conducted the process only in the ray-marching algorithm, instead of embedding it into per-point attribution. As shown in Figure 5, we adopted the idea of the structural consistency shadow model in EO-NeRF, where the transmittance, T, of the last point in the solar ray, , represents the shadow condition of the surface point, . Unlike EO-NeRF, in our research, the surface is characterized using a discrete point cloud method, and the model automatically aggregates the features of neighboring points to generate the attribution. We can determine the surface point, , using Equation (4) along the view direction, , and then place the point in the solar direction, . Similarly, the transmittance, T, of this point can be calculated using Equation (3). If the transmittance is 0, it means that the point in the solar ray, , is already occluded (i.e., the shadow area). If not, it means that the solar ray can reach its current position. For simplicity, we do not need to consider the changes in transient objects in our study without setting any transient object parameters. We denote the step of the surface point as , and the irradiance, , is defined as
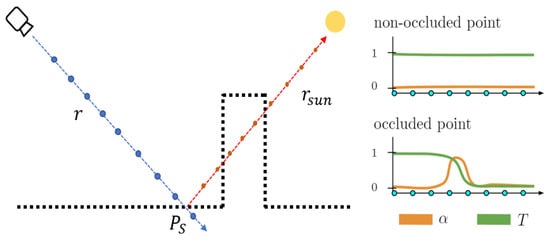
Figure 5.
Structural consistency shadow model based on point clouds.
Meanwhile, the radiance decoder, R, in the original Point-NeRF also changes to predict the view-dependent albedo vector, , which is formulated as
2.7. Loss Function
SA-Point-NeRF mainly uses three loss functions for optimization. The core loss function is still the radiance regression, , described by Equation (5). As our method only alters the calculation of the radiation but still outputs the rendered image, Equation (5) does not need to be modified. As we do not process transient objects, we continue to use the loss functions of Point-NeRF, including the rendering loss between the rendered color and image pixel and the sparse loss of surface confidence. In order to enhance the effect of planar confidence, we also designed sparse loss following the processing method of in Point-NeRF:
The sparse loss function will force the planar confidences, and , to be close to either zero or one; thus, the pruning technique can handle the planar points more carefully. In the per-scene optimization stage, we adopted the final loss, which combines the rendering loss and the sparsity loss:
where we use and for all our experiments according to the Point-NeRF setting.
3. Results
3.1. Datasets
We used the LEVIR_NVS data set [15] as the novel view synthesis benchmark. All the images were taken by drones, with flight heights of around 100 m. LEVIR_NVS contains 16 scenes with 21 multi-view images at a resolution of 512 × 512 pixels. There was some rotation between the images to ensure sufficient overlap. The 11 odd-numbered images in each scene acted as the training set, and the remaining 10 images were used as the test set.
3.2. Quality Assessment Metrics
Novel view synthesis methods based on NeRF are usually evaluated using the PSNR (peak signal-to-noise ratio), SSIM (structural similarity index measure), and LPIPS (learned perceptual image patch similarity). Given the synthesized new view, I, and the ground truth image, G, the PSNR is
The SSIM describes the structural similarity between images and quantifies this by introducing brightness and contrast. The SSIM ranges from 0 to 1, with larger values indicating greater image similarity. The SSIM is calculated as follows:
where and are the means of I and G, which indicate the brightness, and the contrast is estimated according to the variances and . is the covariance of I and G, which is used to estimate the structural similarity. and are two constants, which are set as 0.01 and 0.02, respectively.
The LPIPS is a kind of perception loss that considers whether the two images are similar, and the feature distance in the high-level space should also be small. The LPIPS can be calculated as
where and are the l layer features of I and G at the pixel position . The output feature is often obtained using the pre-training weights of the VGG network.
3.3. Implementation Details
All experiments in this paper share the same configuration with Point-NeRF [20]. We utilized the Adam optimizer with an initial learning rate of 5 × 10−4. The experimental platform used a Tesla v100 graphics card with 32 GB of memory. The total number of iterations was 200,000, and point cloud growth and pruning were performed every 10,000 iterations.
3.4. Performance Comparison
We compared our proposed method with four existing methods: NeRF [7], NeRF++ [27], ImMPI [15], and our baseline Point-NeRF [20]. The visual comparisons for the training and test sets are shown in Figure 6 and Figure 7, respectively. We also demonstrate the neural point cloud structure for the corresponding scenes. The red boxes represent comparisons between our method and ImMPI, showing that our method can reduce artifacts at the edges of the image. The yellow boxes represent comparisons between our method and the baseline, Point-NeRF. We found that NeRF [7] and NeRF++ [27] performed well on the training views but exhibited serious artifacts on the test views, indicating poor generalization. Point-NeRF [20] maintained relatively consistent performance across both the training and test sets due to stable, explicit 3D scene modeling. However, it suffered from holes in flat planes and shadows when faced with remote sensing imagery, meaning that Point-NeRF was outperformed by ImMPI. Our method effectively filled these holes and improved shadow processing, thereby achieving a more detailed perception.
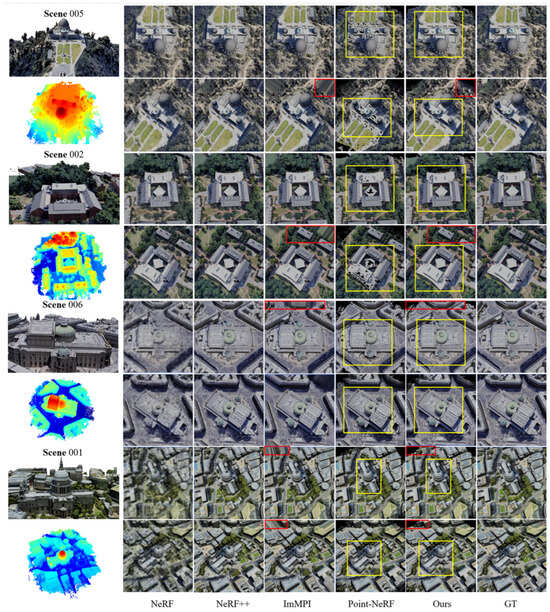
Figure 6.
Qualitative comparison of training set images. These images were used during training and were rendered using the corresponding camera poses. The neural point cloud structure of each scene is demonstrated on the left. The red boxes represent comparisons between our method and ImMPI, and the yellow boxes represent comparisons between our method and the baseline, Point-NeRF.

Figure 7.
Qualitative comparison of test set images. The views in these images had not been seen by the models in the pre-training and optimization process. These images were used during training and were rendered using the corresponding camera poses. The neural point cloud structure of each scene is shown on the left. The red boxes represent comparisons between our method and ImMPI, and the yellow boxes represent comparisons between our method and the baseline, Point-NeRF.
In Table 1, we show the results of our quantitative comparison, mainly in relation to ImMPI and our baseline, Point-NeRF. First, due to the presence of holes, the performance of Point-NeRF was completely insufficient, resulting in PSNRs lower by 5.51 and 5.25 compared to ImMPI. However, it surpassed ImMPI by 0.027 in terms of the SSIM, indicating that the images rendered by explicit 3D scene representation have a more refined structure compared to the output of ImMPI. Our method significantly outperformed Point-NeRF across the 16 scenes. We achieved PSNRs that were 6.12/5.99 higher than those of Point-NeRF (training and test sets, respectively) and LPIPS values that were 0.040/0.036 lower. Thanks to the treatment of filling holes and shadows, our method maintained the advantage of Point-NeRF in terms of the SSIM, indicating that our approach can improve the quality of rendered images while preserving the integrity of spatial structural information.

Table 1.
Quality assessment metrics of the training/test views for different methods.
4. Discussion
We now provide a detailed discussion of the innovative points of this study. First, we conduct ablation experiments on each sub-component to demonstrate the effectiveness of the method. Second, we compare the rendering efficiency consumption of the proposed method with that of other classical algorithms. Then, we separately analyze the structural consistency shadow model, the planar constraint, and inverse-projection hole-filling.
4.1. Ablation Study
We conducted ablation studies on the LEVIR_NEVS training set, as shown in Table 2. Initially, we found that all individual aspects of the proposed innovative points contributed to the overall improvement. When using the structural consistency shadow model (SC) alone, the model achieved gains of 2.81, 0.015, and −0.018 in terms of the PSNR, SSIM, and LPIPS, respectively. Meanwhile, the gains achieved using the planar constraint (PC) and inverse-projection hole-filling (HF) alone were 2.75, 0.13, and −0.001, and 1.66, 0.008, and 0.005, respectively. In the subsequent sections, we analyze these individual components in detail. Furthermore, we observed that combining these methods did not cause interference. The combination of HF and PC contributed the most to model performance, with gains of 4.59, 0.41, and 0.04. This indicates that our method can effectively address the issues present in a 3D scene structure.
Table 2.
Ablation study of sub-components.
4.2. Efficiency in Optimization and Rendering
We compared the optimization time and runtime speed of the proposed method against ImMPI, NeRF, NeRF++, and Point-NeRF. As shown in Table 3, our method outperformed NeRF and NeRF++ in terms of rendering speed and optimization duration when considering images of the same size (512 × 512). Although our method was not as fast as ImMPI in terms of rendering speed, it did not require a pre-training time of up to 21 h. For cross-scene problems, we only needed approximately 5 min to generate an initial point cloud based on COLMAP [23]. Therefore, our method demonstrates better efficiency in addressing cross-scene problems.
Table 3.
Quantitative comparison of optimization durations and rendering speeds between different methods.
4.3. Effectiveness of Structural Consistency Shadow Model
During the rendering process, we attached two modules to output the albedo, , and solar intensity, , of the rendering points, as shown in Figure 8. The brighter the color, the higher the albedo and solar intensity values. We use two different color maps (gray and viridis) for distinction. We do not show the ambient light, as it is uniform and position-independent. As rendering is based on a 3D point cloud structure, some holes appear around the edges. However, hole-filling is not the strength of the shadow model. In the second and third rows, we can see that the structural consistency of light and shadow effectively identifies the shadow and processes the holes within it. For instance, in the input image in the first column of Figure 8, there are many holes inside the shadow of the central building. However, after correction using radiometric information, the point cloud has been supplemented. Similarly, in the input image in the second column, there are many holes within the shadow under the eaves, which, after correction, have been reduced. Our method not only achieves good perception in lower elevation areas but also performs well in downtown scenarios (as shown in the sixth column of Figure 8), helping to remove the missing parts caused by the shadowing of tall buildings.
4.4. Effectiveness of Planar Constraint and Hole-Filling
Plane constraint (PC) and hole-filling (HF), which use inverse-projection techniques, both aim to reduce failures in flat areas. For intuitive display, we selected three planar areas from the data set for demonstration: the roundabout in Scene 0 (Area #1), the square in Scene 5 (Area #2), and the factory roof in Scene 14 (Area #3). First, we show the results of both methods in Figure 9. From left to right are the images of the sampled areas, the results predicted using the original Point-NeRF model equipped with the PC/HF method, and finally, the effects of the proposed method. It is evident that the large areas of holes were significantly reduced with the addition of the PC method, and the incorporation of the HF method suppressed the presence of discrete holes. The combined use of these two methods led to the best enhancement in the model’s performance.

Figure 8.
Albedo and solar intensity information calculated by the model. From top to bottom are the input images, albedo, and solar intensity. The ambient light is not shown because it is uniform and position-independent.
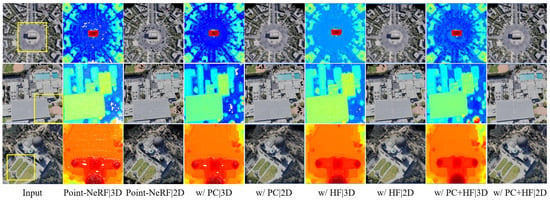
Figure 9.
Qualitative effects of plane constraint (PC) and hole-filling (HF). We selected three planar areas: the roundabout in Scene 0 (Area #1), the square in Scene 5 (Area #2), and the factory roof in Scene 14 (Area #3). Each area is marked with the yellow rectangles. From left to right are the images of the sampled areas, the rendered (2D) and neural point (3D) results predicted using the original Point-NeRF model equipped with the PC/HF method, and finally, the effects of the proposed method.
Subsequently, we analyzed the properties of the point clouds within these three areas. As shown in Table 4, we defined the 3D scene boundaries based on inverse projection using Equation (16) and then extracted all the points within the generated neural point cloud. We counted the number of points and calculated the mean and variance of the z coordinate. These properties are presented at different training timestamps. In order to further compare the performance of Point-NeRF with the attached PC and HF methods, we also analyzed the data for each situation, along with the results generated by the traditional COLMAP [23] method. While the point cloud produced by COLMAP was relatively sparse, it could also reflect the overall properties of the area. The basic Point-NeRF progressively densified the original sparse point cloud, acquiring a 3D structure close to the real scene. However, as demonstrated in Figure 9, the rendered images that relied on these neural points suffered from many holes. After incorporating the PC and HF methods, the number of produced points at the three training timestamps was much higher. Taking Area #1 as an example, the growth rate of the point cloud quantity was 14% for the PC method, 29% after adding the HF method, and 56% with the combined use of both methods at 150,000 iterations. Similar trends were also observed in the other two scenes, indicating that our methods are capable of detecting the hole areas and, thus, can perform filling. However, increasing the number of points was not the ultimate goal. From the comparison of the statistical measures between the Point-NeRF and COLMAP point clouds, we observed that the COLMAP point clouds had a higher mean z coordinate, whereas those of Point-NeRF exhibited approximately a 5–15 m deviation, and the values from COLMAP were relatively stable. We also observed that our method adhered closely to the mean and variance of the point clouds produced by COLMAP after HF and PC processing. Taking Area #2 as an example, the z-mean value of the point cloud for this area generated by Point-NeRF was −36.77, with a variance of 12.93. After processing using our method, the mean was −32.27 and the variance was 10.29, closer to the results produced by COLMAP, thereby reflecting that the output of the neural point cloud aligned more with the actual structure. Of course, we do not rule out the possibility that the points may not be perfectly flat (for instance, there might be some inclination), but the reduction in variance indeed indicates that the elevation component of the points (in the world coordinate system) is gradually becoming consistent.
Table 4.
Quantitative comparison of local planar area attribution.
5. Conclusions
We have proposed an improved method to address the limitations of Point-NeRF in remote sensing image novel view synthesis tasks. This method tackles the problems of severe plane point loss and challenging hole processing in shadow areas by introducing plane constraint confidence handling, hole detection and filling, and a structural consistency shadow model to aid Point-NeRF in rendering. Specifically, the plane constraint confidence incorporates the original surface confidence to reduce the probability of plane points being pruned. Hole detection and filling incorporate 2D detection and inverse projection during training to identify holes and provide candidate spatial points for subsequent optimization. The shadow model, based on structural consistency, decomposes the radiance of object surfaces into albedo and irradiance, allowing the model to avoid directly predicting radiance and possess more reasonable physical properties. The experimental results demonstrate that our method can outperform the classical ImMPI algorithm in 2D novel viewpoint synthesis tasks.
In the 2D novel viewpoint synthesis task, our method achieved PSNRs of 26.95/26.93, SSIMs of 0.894/0.890, and LPIPSs of 0.170/0.176 for the training and test sets, respectively, on the LEVIR_NVS benchmark data set. Our method also generated a more accurate neural point cloud representation of the ground’s structural distribution. In subsequent research, we plan to incorporate more types of data, such as airborne LiDAR point clouds, for joint processing. We also aim to develop more efficient algorithms.
Author Contributions
Conceptualization, L.L. (Li Li), Z.W. and Z.Z.; methodology, L.L. (Li Li), Z.W., Z.Z. and Z.J.; software, Z.W. and Z.J.; validation, Z.W., Y.Z. and Y.Y.; formal analysis, Y.Z, L.L. (Lei Li) and L.Z.; investigation, Z.W., Z.Z., Y.Y. and L.L. (Lei Li); data curation, Z.Z., Z.J., Y.Y., L.L. (Lei Li) and L.Z.; writing—original draft preparation, L.L. (Li Li), Z.W., Z.J. and L.Z.; writing—review and editing, L.L. (Li Li), Z.W., Z.Z., Z.J., L.L. (Lei Li) and L.Z.; visualization, Y.Z. and Z.Z.; supervision, Y.Z. and Z.Z.; project administration, Y.Z.; funding acquisition, Y.Z. and Y.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China under grant 42071340 and the Program of Song Shan Laboratory (included in the management of Major Science and Technology of Henan Province) under grant 2211000211000-01 and 2211000211000-02.
Data Availability Statement
The data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. (Engl. Ed.) 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Chen, Z.; Deng, L.; Luo, Y.; Li, D.; Junior, J.M.; Gonçalves, W.N.; Nurunnabi, A.A.M.; Li, J.; Wang, C.; Li, D. Road extraction in remote sensing data: A survey. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102833. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road extraction from high-resolution remote sensing imagery using deep learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Zhang, L.; Lan, M.; Zhang, J.; Tao, D. Stagewise unsupervised domain adaptation with adversarial self-training for road segmentation of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Scheuer, S.; Kremer, P.; Mascarenhas, A.; Kraemer, R.; et al. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning representations and generative models for 3d point clouds. In Proceedings of the International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; pp. 40–49. [Google Scholar]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and multi-view cnns for object classification on 3d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5648–5656. [Google Scholar]
- Liu, L.; Gu, J.; Zaw Lin, K.; Chua, T.S.; Theobalt, C. Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 2020, 33, 15651–15663. [Google Scholar]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Cagliari, Italy, 26–28 June 2006; Volume 7, p. 4. [Google Scholar]
- Chen, Z.; Zhang, H. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5939–5948. [Google Scholar]
- Levoy, M.; Hanrahan, P. Light field rendering. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2; Association for Computing Machinery: New York, NY, USA, 2023; pp. 441–452. [Google Scholar]
- Neff, T.; Stadlbauer, P.; Parger, M.; Kurz, A.; Mueller, J.H.; Chaitanya, C.R.A.; Kaplanyan, A.; Steinberger, M. DONeRF: Towards Real-Time Rendering of Compact Neural Radiance Fields using Depth Oracle Networks. Comput. Graph. Forum 2021, 40, 45–59. [Google Scholar] [CrossRef]
- Wu, Y.; Zou, Z.; Shi, Z. Remote sensing novel view synthesis with implicit multiplane representations. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Lv, J.; Guo, J.; Zhang, Y.; Zhao, X.; Lei, B. Neural Radiance Fields for High-Resolution Remote Sensing Novel View Synthesis. Remote Sens. 2023, 15, 3920. [Google Scholar] [CrossRef]
- Li, X.; Li, C.; Tong, Z.; Lim, A.; Yuan, J.; Wu, Y.; Tang, J.; Huang, R. Campus3d: A photogrammetry point cloud benchmark for hierarchical understanding of outdoor scene. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 238–246. [Google Scholar]
- Iman Zolanvari, S.; Ruano, S.; Rana, A.; Cummins, A.; da Silva, R.E.; Rahbar, M.; Smolic, A. DublinCity: Annotated LiDAR point cloud and its applications. arXiv 2019, arXiv:1909.03613. [Google Scholar]
- Yang, G.; Xue, F.; Zhang, Q.; Xie, K.; Fu, C.W.; Huang, H. UrbanBIS: A Large-Scale Benchmark for Fine-Grained Urban Building Instance Segmentation. In ACM SIGGRAPH 2023 Conference Proceedings; Association for Computing Machinery: New York, NY, USA, 2023; pp. 1–11. [Google Scholar]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-nerf: Point-based neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5438–5448. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Derksen, D.; Izzo, D. Shadow Neural Radiance Fields for Multi-View Satellite Photogrammetry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 1152–1161. [Google Scholar]
- Marí, R.; Facciolo, G.; Ehret, T. Sat-NeRF: Learning Multi-View Satellite Photogrammetry with Transient Objects and Shadow Modeling Using RPC Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 19–20 June 2022; pp. 1311–1321. [Google Scholar]
- Marí, R.; Facciolo, G.; Ehret, T. Multi-Date Earth Observation NeRF: The Detail Is in the Shadows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Vancouver, BC, Canada, 18–22 June 2023; pp. 2035–2045. [Google Scholar]
- Zhang, K.; Riegler, G.; Snavely, N.; Koltun, V. NeRF++: Analyzing and Improving Neural Radiance Fields. Clin. Orthop. Relat. Res. 2020. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).