
Synthetic Data for Sentinel-2 Semantic Segmentation



Abstract

1. Introduction
- -
- In practical scenarios, specific classes may be essential for the intended task, yet no dataset comprehensively encompasses these classes.
- -
- The presence of inaccuracies within these datasets potentially impedes the efficiency of the optimization process throughout the training phase (Figure 1).
- -
- The geographical coverage of these datasets may not align with the target region for segmentation, exemplifying a well-documented issue of generalization.

- Introduction of a novel simulation methodology to rapidly create segmentation datasets with minimal human intervention, involving the construction of synthetic scenes from real image samples.
- Training of a model solely on simulated data, which eliminates the need for further fine-tuning on real datasets.
- Demonstration of our model’s impressive generalization capabilities on unseen test data across diverse regions, despite training on limited samples from one area.
2. Materials and Methods
2.1. Summarized Methodology
2.2. Classes Choice
2.3. Sample Collection
2.3.1. Google Earth Engine
2.3.2. The Sentinel Imagery
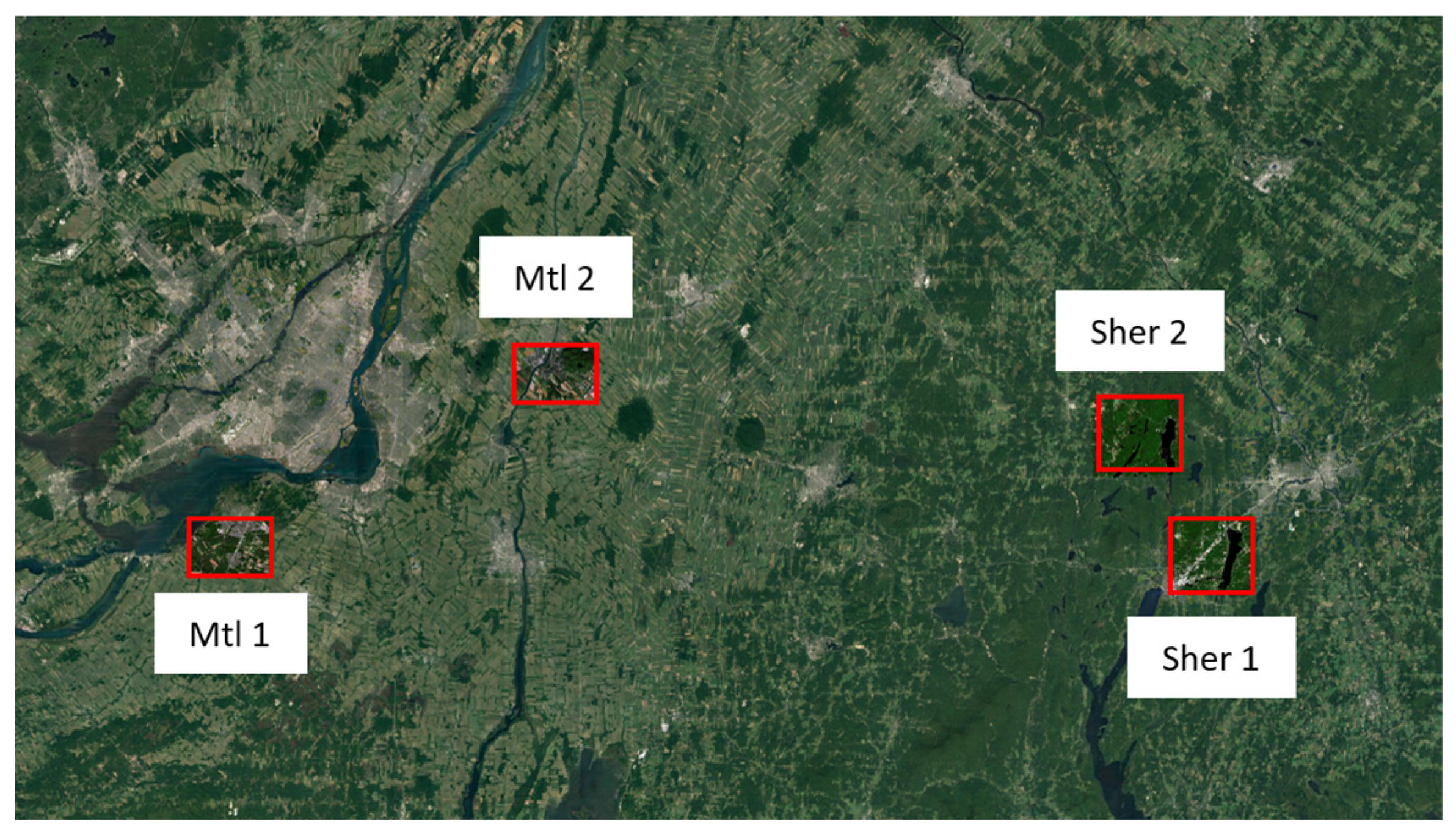
2.3.3. Study Sites
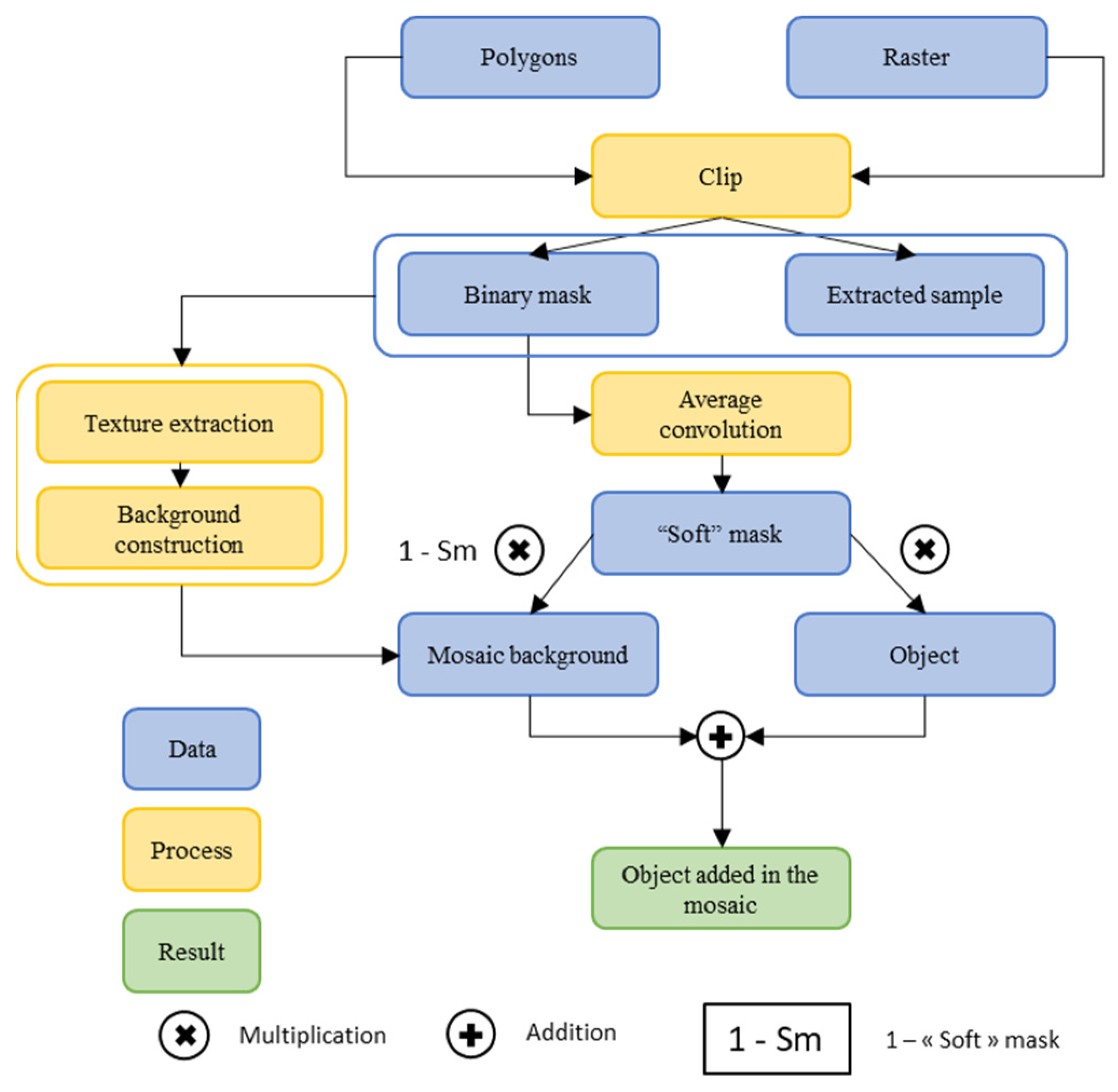
2.4. Scene Simulations
- -
- Creation of a binary mask that allows for cutting the background.
- -
- Application of a 3 × 3 “average” type convolution on the binary mask to obtain mixing proportions on the object’s boundaries (Figure 10a), called a “soft” mask hereafter.
- -
- Cutting the background with softening of the edges (Figure 10b).
- -
- Softening of the edges for the object to be added (Figure 10c).
- -
- Sum of the sample and the background mosaic weighted by the filtered mask (Figure 10d).
- -
- The ground truth is the mask used to “paste” the sample.



3. Results and Discussion
3.1. Results on Validation Datasets
3.1.1. Architecture Choice
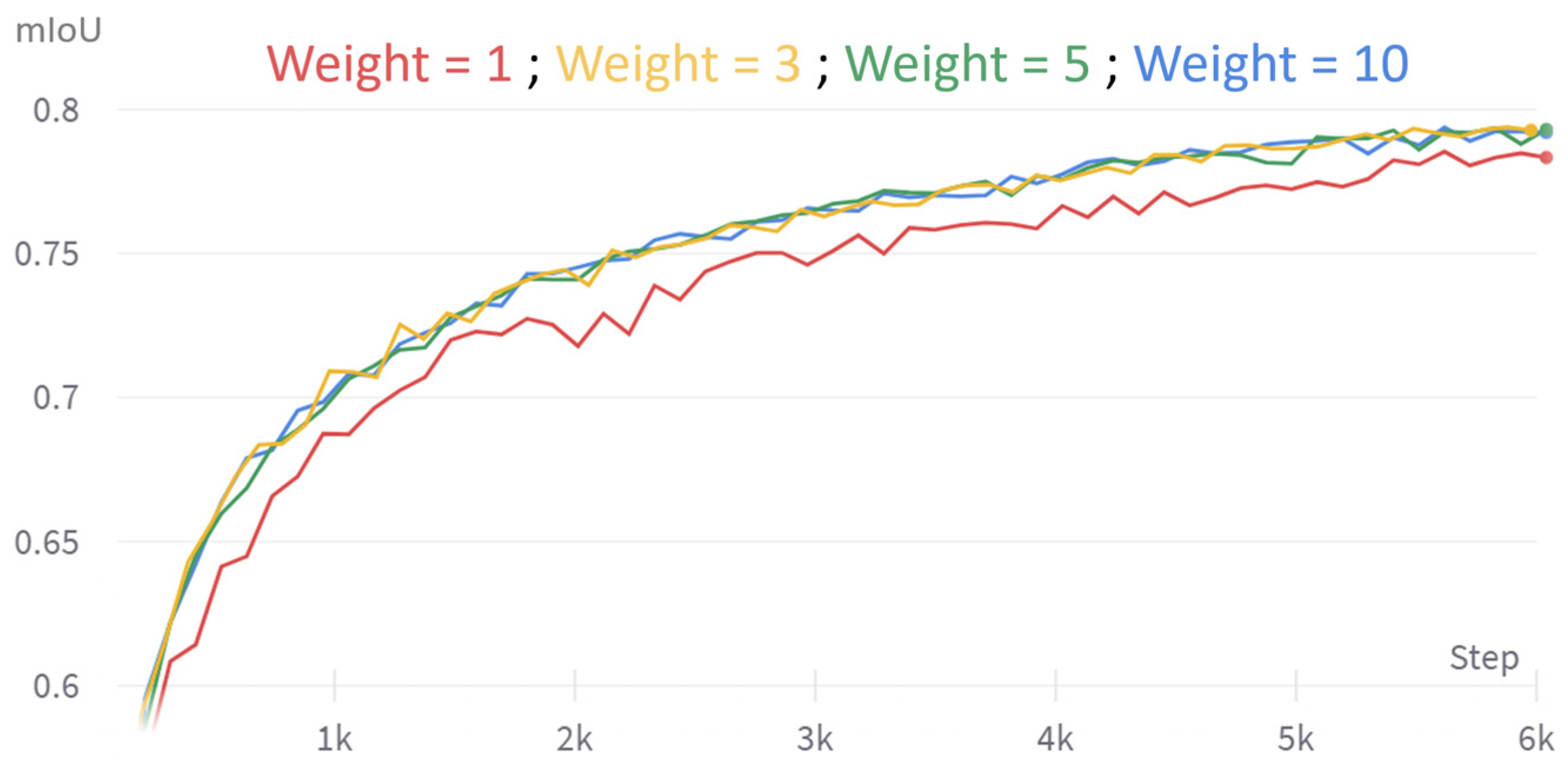
3.1.2. General Training Rules
3.2. Results on Test Data
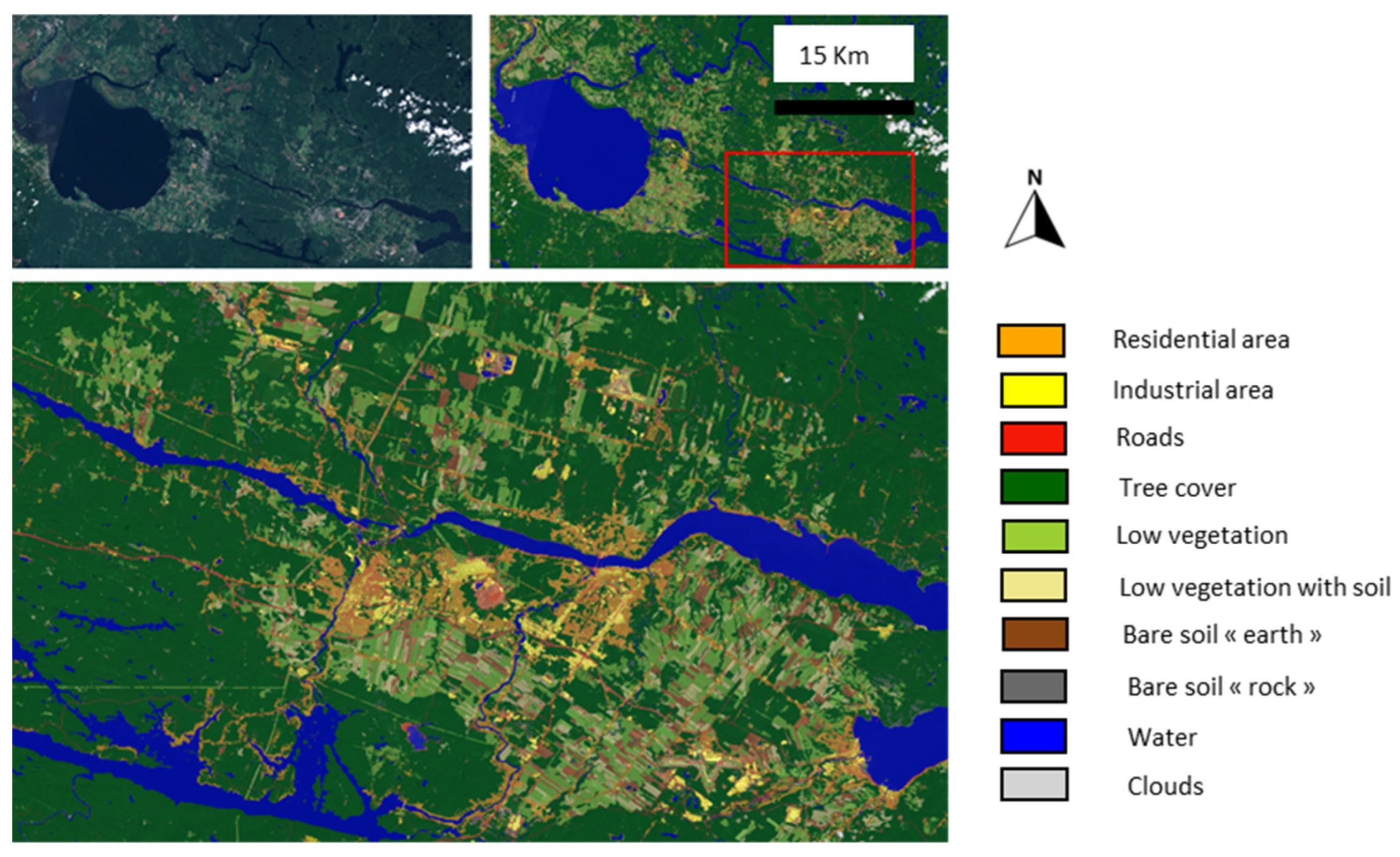
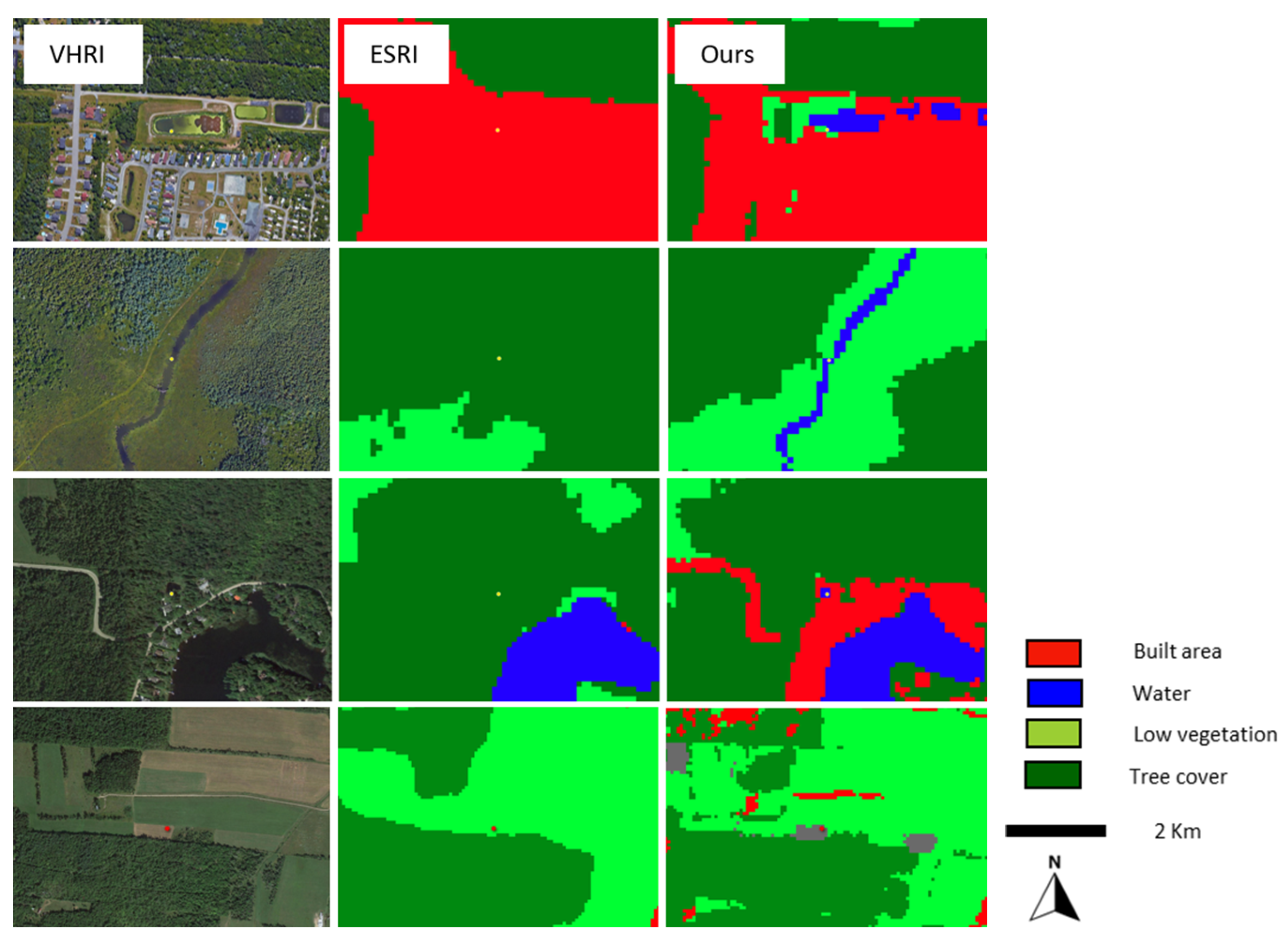
3.2.1. General Overview
- -
- Water–Forest Confusion: There was an inconsistent distinction between water and forests. For example, some small lakes were not correctly segmented while others were. This inconsistency lacks an apparent human-observable reason, making it a challenging anomaly to interpret. Different noises on dark waters could be an explanation.
- -
- Waterways as Roads: Some waterways were mistakenly classified as roads. This could be attributed to radiometric differences, perhaps due to variations in sun elevation and seasonal drying patterns that make some watercourses resemble elongated ground structures.
- -
- Shadows as Water: Shadows (from clouds, buildings, trees…) in some images were incorrectly classified as water. Given that the elevation in these images is lower compared to the data’s source images, it is plausible that intense shadows could be misinterpreted as water bodies.
3.2.2. General Comparison with Two Other 10 m Products
3.2.3. Quantitative Evaluation
- -
- Our results are accessible online for those who wish to delve deeper.
- -
- The primary objective of this paper is not to advocate the superiority of our classification, but rather to underline the efficacy and potential of our simulation approach in producing high-quality semantic segmentation.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Minnett, P.J.; Alvera-Azcárate, A.; Chin, T.; Corlett, G.; Gentemann, C.; Karagali, I.; Li, X.; Marsouin, A.; Marullo, S.; Maturi, E.; et al. Half a century of satellite remote sensing of sea-surface temperature. Remote Sens. Environ. 2019, 233, 111366. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, J.; Liang, S.; Chai, L.; Wang, D.; Liu, J. Estimation of 1-km all-weather remotely sensed land surface temperature based on reconstructed spatial-seamless satellite passive microwave brightness temperature and thermal infrared data. ISPRS J. Photogramm. Remote Sens. 2020, 167, 321–344. [Google Scholar] [CrossRef]
- Hussain, S.; Karuppannan, S. Land use/land cover changes and their impact on land surface temperature using remote sensing technique in district Khanewal, Punjab Pakistan. Geol. Ecol. Landsc. 2023, 7, 46–58. [Google Scholar] [CrossRef]
- Kim, J.-M.; Kim, S.-W.; Sohn, B.-J.; Kim, H.-C.; Lee, S.-M.; Kwon, Y.-J.; Shi, H.; Pnyushkov, A.V. Estimation of summer pan-Arctic ice draft from satellite passive microwave observations. Remote Sens. Environ. 2023, 295, 113662. [Google Scholar] [CrossRef]
- Rivera-Marin, D.; Dash, J.; Ogutu, B. The use of remote sensing for desertification studies: A review. J. Arid Environ. 2022, 206, 104829. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Kerle, N.; Pasolli, E.; Arsanjani, J.J. Post-Disaster Building Database Updating Using Automated Deep Learning: An Integration of Pre-Disaster OpenStreetMap and Multi-Temporal Satellite Data. Remote Sens. 2019, 11, 2427. [Google Scholar] [CrossRef]
- Higuchi, A. Toward More Integrated Utilizations of Geostationary Satellite Data for Disaster Management and Risk Mitigation. Remote Sens. 2021, 13, 1553. [Google Scholar] [CrossRef]
- Segarra, J.; Buchaillot, M.L.; Araus, J.L.; Kefauver, S.C. Remote Sensing for Precision Agriculture: Sentinel-2 Improved Features and Applications. Agronomy 2020, 10, 641. [Google Scholar] [CrossRef]
- Gao, F.; Zhang, X. Mapping Crop Phenology in Near Real-Time Using Satellite Remote Sensing: Challenges and Opportunities. J. Remote Sens. 2021, 2021, 8379391. [Google Scholar] [CrossRef]
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Scheuer, S.; Kremer, P.; Mascarenhas, A.; Kraemer, R.; et al. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Bai, H.; Li, Z.; Guo, H.; Chen, H.; Luo, P. Urban Green Space Planning Based on Remote Sensing and Geographic Information Systems. Remote Sens. 2022, 14, 4213. [Google Scholar] [CrossRef]
- Nagy, A.; Szabó, A.; Adeniyi, O.D.; Tamás, J. Wheat Yield Forecasting for the Tisza River Catchment Using Landsat 8 NDVI and SAVI Time Series and Reported Crop Statistics. Agronomy 2021, 11, 652. [Google Scholar] [CrossRef]
- Clabaut, É.; Lemelin, M.; Germain, M.; Williamson, M.-C.; Brassard, É. A Deep Learning Approach to the Detection of Gossans in the Canadian Arctic. Remote Sens. 2020, 12, 3123. [Google Scholar] [CrossRef]
- Siebels, K.; Goita, K.; Germain, M. Estimation of Mineral Abundance from Hyperspectral Data Using a New Supervised Neighbor-Band Ratio Unmixing Approach. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6754–6766. [Google Scholar] [CrossRef]
- Chirico, R.; Mondillo, N.; Laukamp, C.; Mormone, A.; Di Martire, D.; Novellino, A.; Balassone, G. Mapping hydrothermal and supergene alteration zones associated with carbonate-hosted Zn-Pb deposits by using PRISMA satellite imagery supported by field-based hyperspectral data, mineralogical and geochemical analysis. Ore Geol. Rev. 2023, 152, 105244. [Google Scholar] [CrossRef]
- Gemusse, U.; Cardoso-Fernandes, J.; Lima, A.; Teodoro, A. Identification of pegmatites zones in Muiane and Naipa (Mozambique) from Sentinel-2 images, using band combinations, band ratios, PCA and supervised classification. Remote Sens. Appl. Soc. Environ. 2023, 32, 101022. [Google Scholar] [CrossRef]
- Lemenkova, P. Evaluating land cover types from Landsat TM using SAGA GIS for vegetation mapping based on ISODATA and K-means clustering. Acta Agric. Serbica 2021, 26, 159–165. [Google Scholar] [CrossRef]
- Saikrishna, M.; Sivakumar, V.L. A Detailed Analogy between Estimated Pre-flood area using ISOdata Classification and K-means Classification on Sentinel 2A data in Cuddalore District, Tamil Nadu, India. Int. J. Mech. Eng. 2022, 7, 1007. [Google Scholar]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W. Building Segmentation of Aerial Images in Urban Areas with Deep Convolutional Neural Networks. In Advances in Remote Sensing and Geo Informatics Applications; El-Askary, H.M., Lee, S., Heggy, E., Pradhan, B., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 61–64. [Google Scholar] [CrossRef]
- Li, M.; Wu, P.; Wang, B.; Park, H.; Hui, Y.; Yanlan, W. A Deep Learning Method of Water Body Extraction from High Resolution Remote Sensing Images with Multisensors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3120–3132. [Google Scholar] [CrossRef]
- Yuan, K.; Zhuang, X.; Schaefer, G.; Feng, J.; Guan, L.; Fang, H. Deep-Learning-Based Multispectral Satellite Image Segmentation for Water Body Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7422–7434. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-Supervised Visual Feature Learning with Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. Int. Conf. Mach. Learn. 2020, 119, 1597–1607. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Wu, Y.; Zeng, D.; Wang, Z.; Shi, Y.; Hu, J. Distributed Contrastive Learning for Medical Image Segmentation. Med. Image Anal. 2022, 81, 102564. [Google Scholar] [CrossRef]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and Local Contrastive Self-Supervised Learning for Semantic Segmentation of HR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Chen, Y.; Wei, C.; Wang, D.; Ji, C.; Li, B. Semi-Supervised Contrastive Learning for Few-Shot Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 4254. [Google Scholar] [CrossRef]
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-Aware Self-Supervised Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10161–10170. [Google Scholar] [CrossRef]
- Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.-G.; Lee, S.-W.; Fidler, S.; Urtasun, R.; Yuille, A. The Role of Context for Object Detection and Semantic Segmentation in the Wild. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 891–898. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Audebert, N.; Boulch, A.; Saux, B.L.; Lefèvre, S. Distance transform regression for spatially-aware deep semantic segmentation. Comput. Vis. Image Underst. 2019, 189, 102809. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. BigEarthNet: A Large-Scale Benchmark Archive for Remote Sensing Image Understanding. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5901–5904. [Google Scholar] [CrossRef]
- Seale, C.; Redfern, T.; Sentinel, P.C. 2021. Available online: https://openmldata.ukho.gov.uk/ (accessed on 17 January 2024).
- Wang, D.; Zhang, J.; Du, B.; Xu, M.; Liu, L.; Tao, D.; Zhang, L. SAMRS: Scaling-up Remote Sensing Segmentation Dataset with Segment Anything Model. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Hurl, B.; Czarnecki, K.; Waslander, S. Precise Synthetic Image and LiDAR (PreSIL) Dataset for Autonomous Vehicle Perception. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2522–2529. [Google Scholar] [CrossRef]
- Talwar, D.; Guruswamy, S.; Ravipati, N.; Eirinaki, M. Evaluating Validity of Synthetic Data in Perception Tasks for Autonomous Vehicles. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence Testing (AITest), Oxford, UK, 3–6 August 2020; pp. 73–80. [Google Scholar] [CrossRef]
- De La Pena, J.; Bergasa, L.M.; Antunes, M.; Arango, F.; Gomez-Huelamo, C.; Lopez-Guillen, E. AD PerDevKit: An Autonomous Driving Perception Development Kit using CARLA simulator and ROS. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 4095–4100. [Google Scholar] [CrossRef]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for Data: Ground Truth from Computer Games. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar] [CrossRef]
- World Cover. Available online: https://esa-worldcover.org/en (accessed on 1 October 2023).
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar] [CrossRef]
- Hapke, B. Bidirectional reflectance spectroscopy: 1. Theory. J. Geophys. Res. 1981, 86, 3039–3054. [Google Scholar] [CrossRef]
- Shkuratov, Y.; Starukhina, L.; Hoffmann, H.; Arnold, G. A Model of Spectral Albedo of Particulate Surfaces: Implications for Optical Properties of the Moon. Icarus 1999, 137, 235–246. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-Wise Perspective with Transformer. AAAI 2022, 36, 2441–2449. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
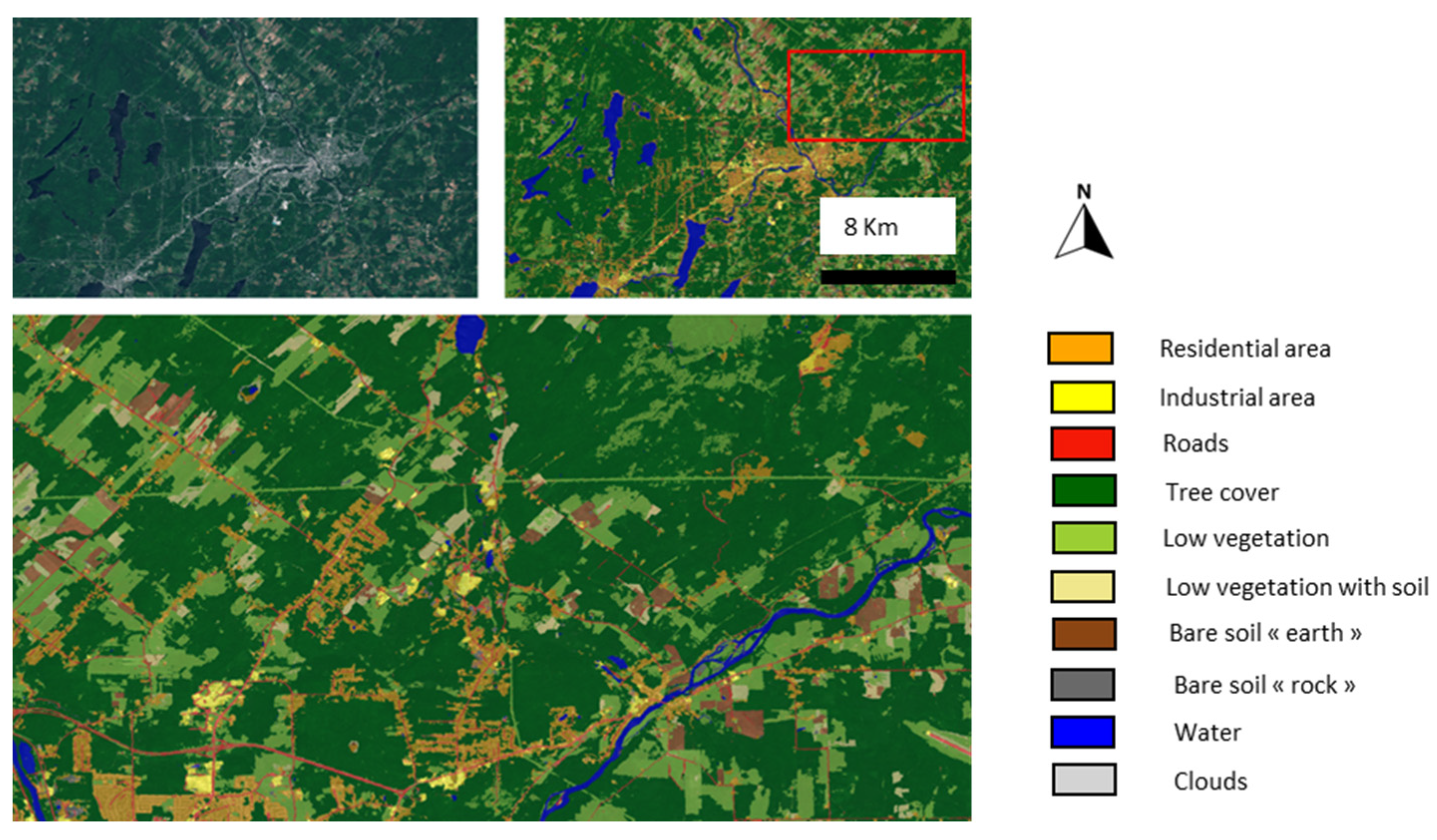
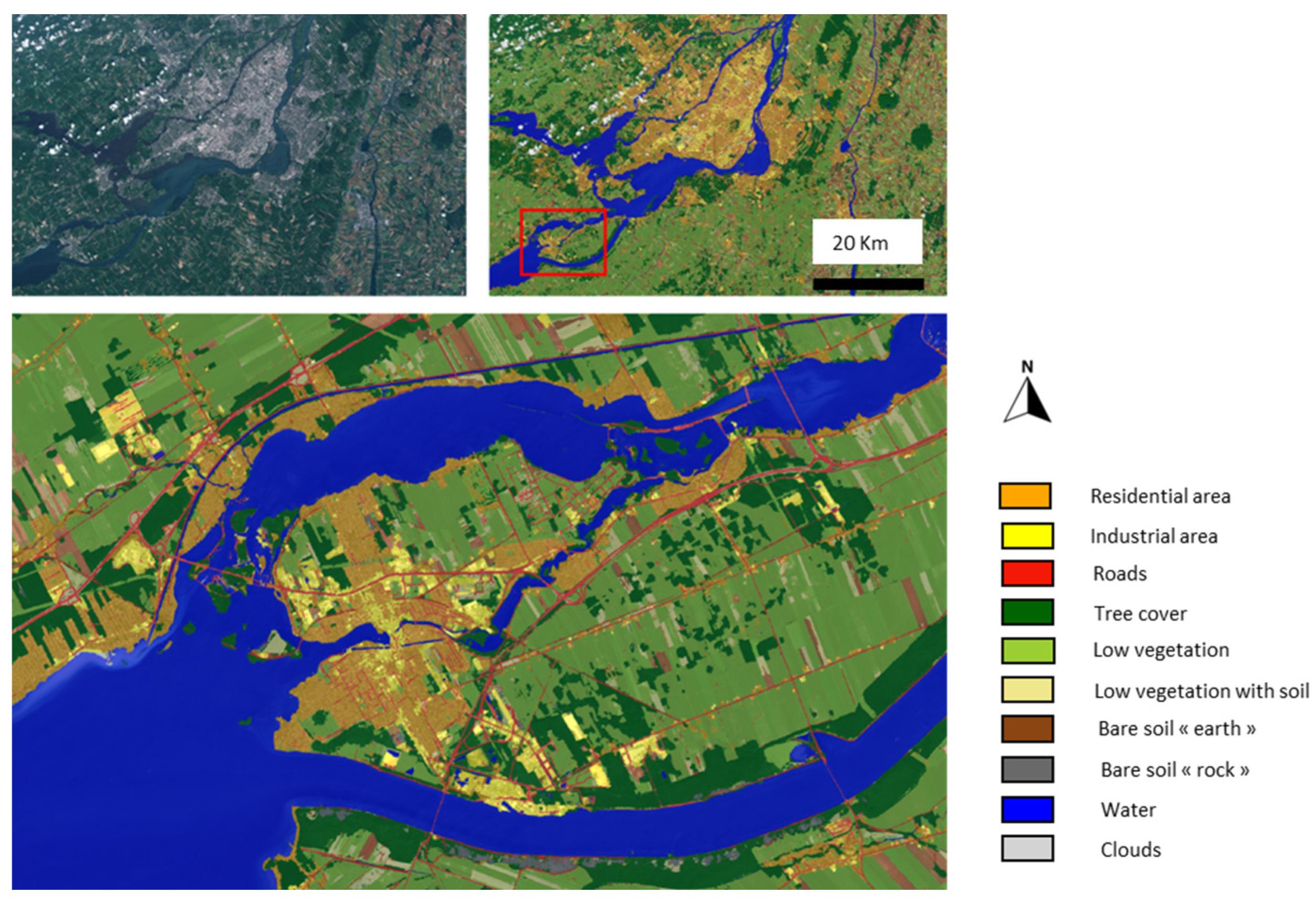
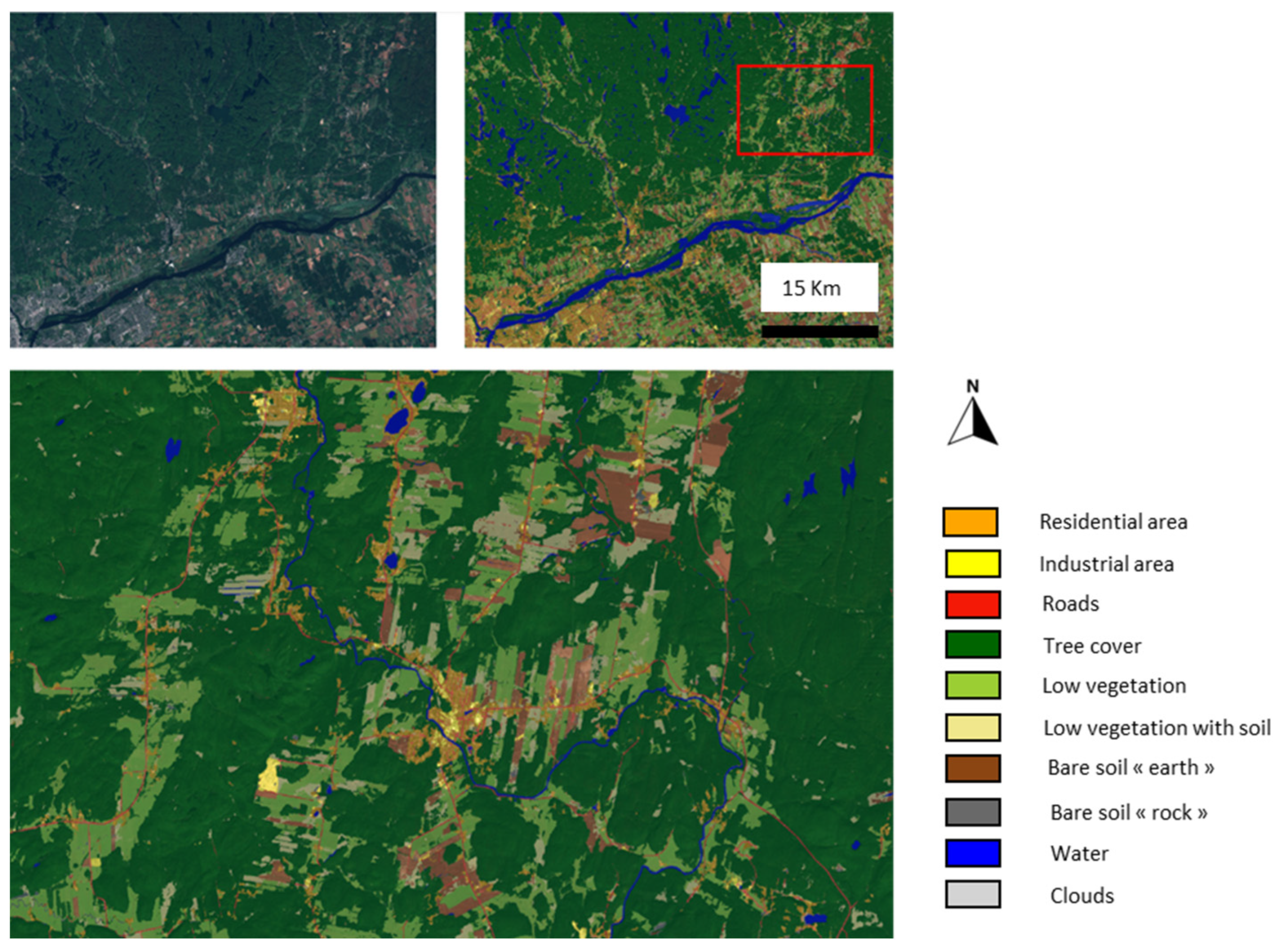
| Classes | Identification | Associated Confusions |
|---|---|---|
| Residential Areas | Urbanized areas with a high presence of “single-family” type homes have a particular texture, presenting a mix of buildings and both low and high vegetation. | The strong presence of vegetation might cause confusion with vegetation intermittently interspersed with bare soil. The road network within these zones is very hard to distinguish. |
| Commercial/and or Industrial Areas | These zones feature large-sized buildings with very little vegetation. One often finds large parking areas or storage yards. | These zones are hard to differentiate from very large residential buildings (boundary between ground cover/use). The road network can “disappear” amidst these zones. |
| Roads | Roads are comparable to bare soil but have a unique linear structure. | They are very hard to discern in urban areas. It will most likely not be possible to differentiate highways/roads/paths/lanes… |
| Tree Cover | Does not fit the definition of a forest. Here, the dense vegetative cover is segmented, presenting a distinct texture indicating a high density of trees. | Confusion with forests is rare. Mistakes generally arise from misinterpreted shadows. |
| Low Vegetation | Represents all low and dense vegetation presenting a smooth appearance reminiscent of grass cover. | Generally, few confusions. This class will contain numerous crops (land use). |
| Low Vegetation with Soil | Represents all low and not so dense vegetation that partially reveals bare soil. Often crops in early growth or vacant lots. | Generally, few confusions. This class will contain numerous crops (land use). |
| Bare Soil “earth type” | Surface without vegetation, usually brown in color. The texture can be uniform or present a furrowed appearance. | This class will likely group fields before vegetation growth and also recently cleared lands. The distinction is about “land use.” |
| Bare Soil “rock type” | Consistent bedrock with a smooth appearance, often in a natural context. | There could be numerous confusions with excavations (construction, mines, earthworks…). Distinguishing among rock/crushed stone/asphalt might be problematic. |
| Permanent Water Bodies | Often a smooth and dark surface, which might have glints. | It is recognized that water can be easily confused with shadows (very low reflectance). Furthermore, “agitated” water (streams, dam outlets) appears white and becomes very hard to identify as water. |
| Clouds | Large objects with an extremely high reflectance, often with diffuse boundaries. | Generally, very well segmented. “Transparent” clouds, which let the ground be discerned, are hard to map and deceive the model by significantly altering the radiometry. |
| Sher 1 | Sher 2 | Mtl 1 | Mtl 2 | |
|---|---|---|---|---|
| Forests | 0.996 | 0.998 | 0.978 | 0.989 |
| Water | 0.999 | 0.996 | 0.991 | 0.983 |
| Low Vegetation | 0.950 | 0.947 | 0.995 | 0.967 |
| Low Vegetation/soil | 0.928 | 0.958 | 0.842 | 0.879 |
| Soil | 0.962 | 0.965 | 0.928 | 0.906 |
| Rocky outcrop | N/A | N/A | N/A | 0.020 |
| Roads | 0.972 | 0.924 | 0.980 | 0.967 |
| Residential Areas | 0.897 | 0.815 | 0.926 | 0.946 |
| Industrial Areas | 0.661 | N/A | 0.756 | 0.737 |
| Clouds | N/A | N/A | N/A | N/A |
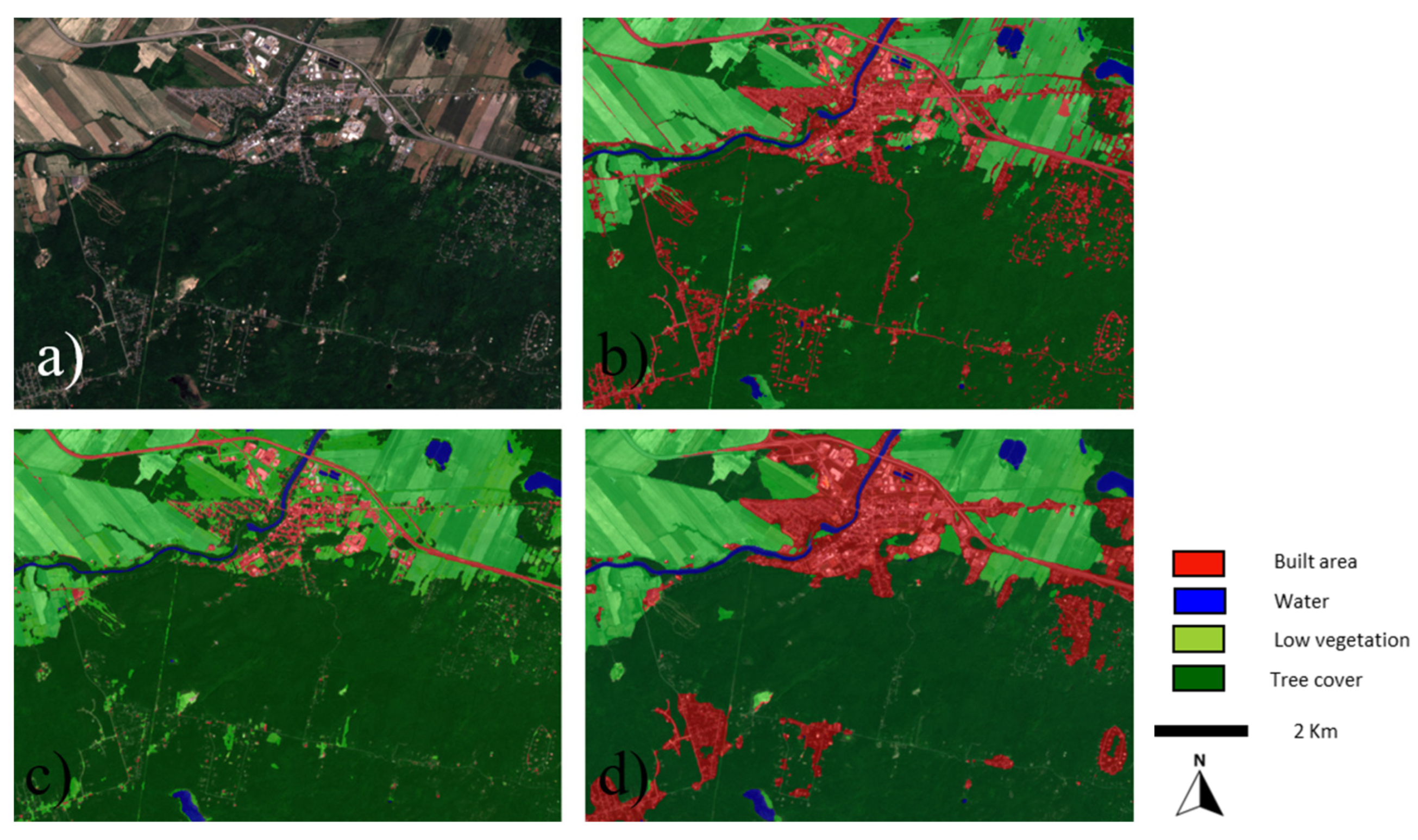
| ESRI | Ours | Undetermined | |
|---|---|---|---|
| Sherbrooke 1 | 14 | 68 | 18 |
| Sherbrooke 2 | 12 | 72 | 16 |
| Montreal 1 | 29 | 58 | 13 |
| Montreal 2 | 37 | 47 | 16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Clabaut, É.; Foucher, S.; Bouroubi, Y.; Germain, M. Synthetic Data for Sentinel-2 Semantic Segmentation. Remote Sens. 2024, 16, 818. https://doi.org/10.3390/rs16050818
Clabaut É, Foucher S, Bouroubi Y, Germain M. Synthetic Data for Sentinel-2 Semantic Segmentation. Remote Sensing. 2024; 16(5):818. https://doi.org/10.3390/rs16050818
Chicago/Turabian StyleClabaut, Étienne, Samuel Foucher, Yacine Bouroubi, and Mickaël Germain. 2024. "Synthetic Data for Sentinel-2 Semantic Segmentation" Remote Sensing 16, no. 5: 818. https://doi.org/10.3390/rs16050818
APA StyleClabaut, É., Foucher, S., Bouroubi, Y., & Germain, M. (2024). Synthetic Data for Sentinel-2 Semantic Segmentation. Remote Sensing, 16(5), 818. https://doi.org/10.3390/rs16050818