
AFRNet: Anchor-Free Object Detection Using Roadside LiDAR in Urban Scenes


Abstract

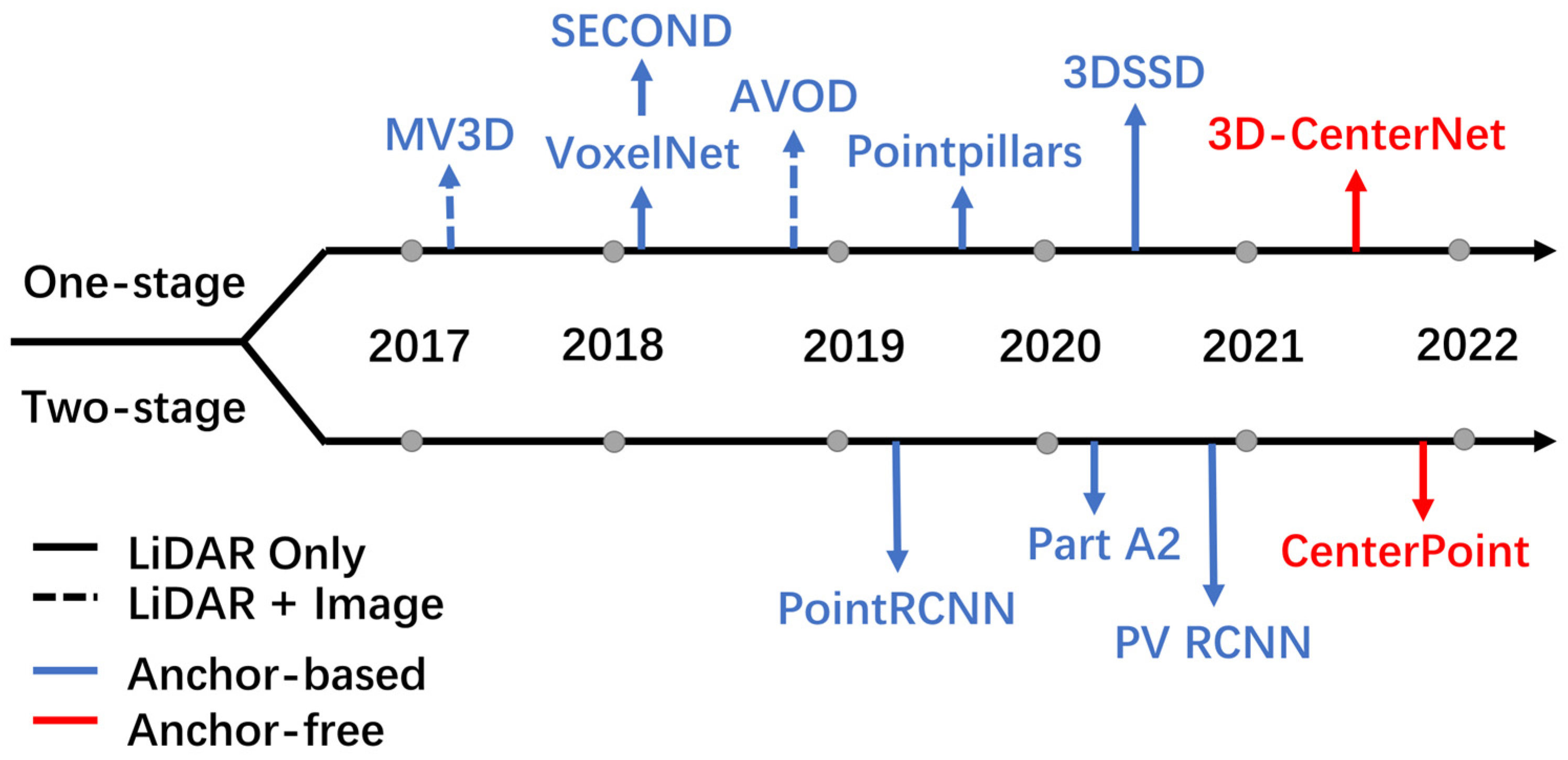
1. Introduction
- (1)
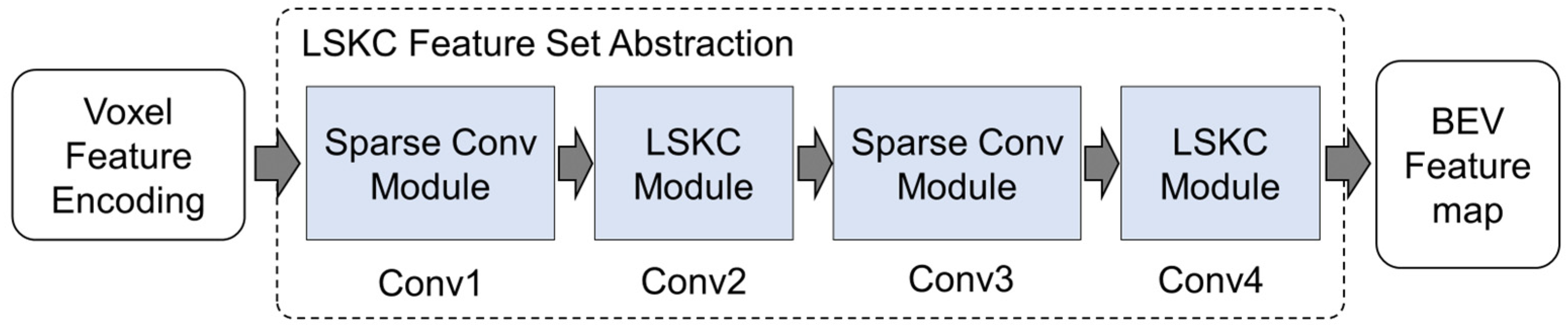
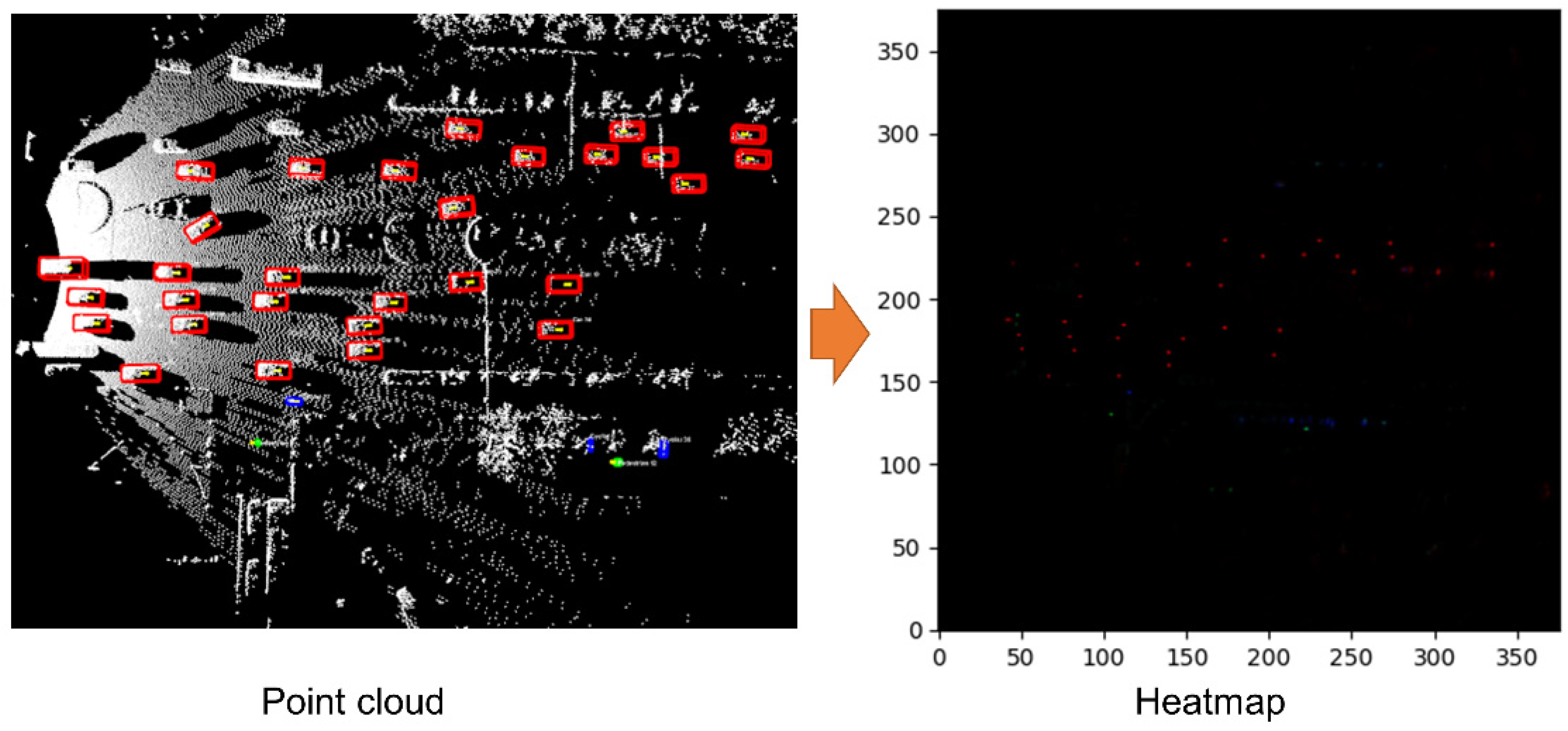
- A centerpoint-based roadside LiDAR detection network, AFRNet, is proposed. It efficiently encodes input data features, and voxelizes disordered point clouds. The voxel data is continuously computed through 3D and 2D convolutional layers, resulting in fast and high-quality point cloud encoding. We also utilize the heatmap to implement centerpoint-based detection. The heatmap head achieves high performance for the feature map of 3D point cloud data.
- (2)
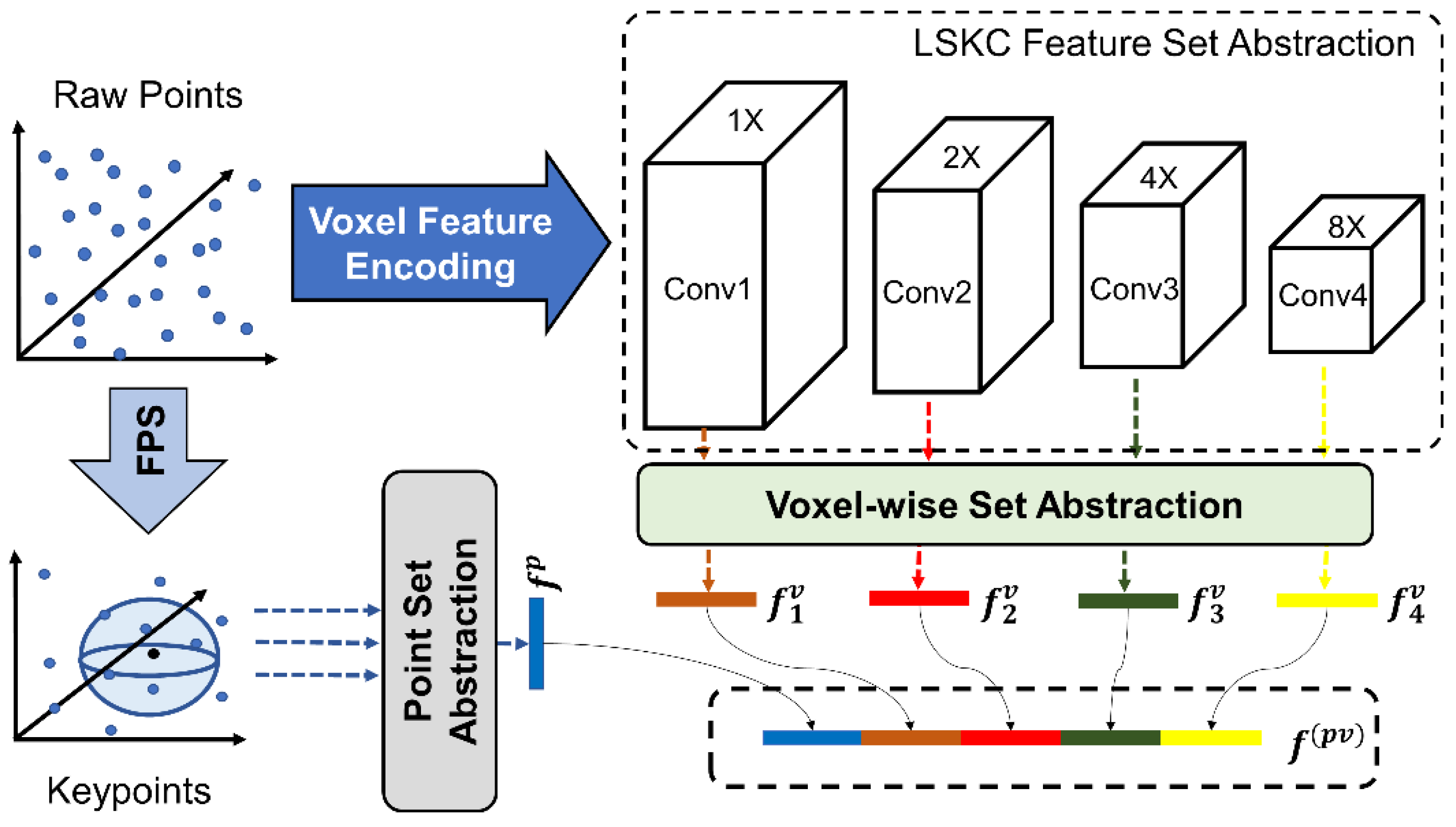
- A 3D feature extraction backbone is designed based on the LSKC feature set abstraction module to expand the sensory field. Additionally, a CBAM attention mechanism is incorporated into the backbone to enhance the network’s feature processing capabilities. It can distinguish the features of different objects by their importance, thus making the network more focused on the features of the objects we set as targets.
- (3)
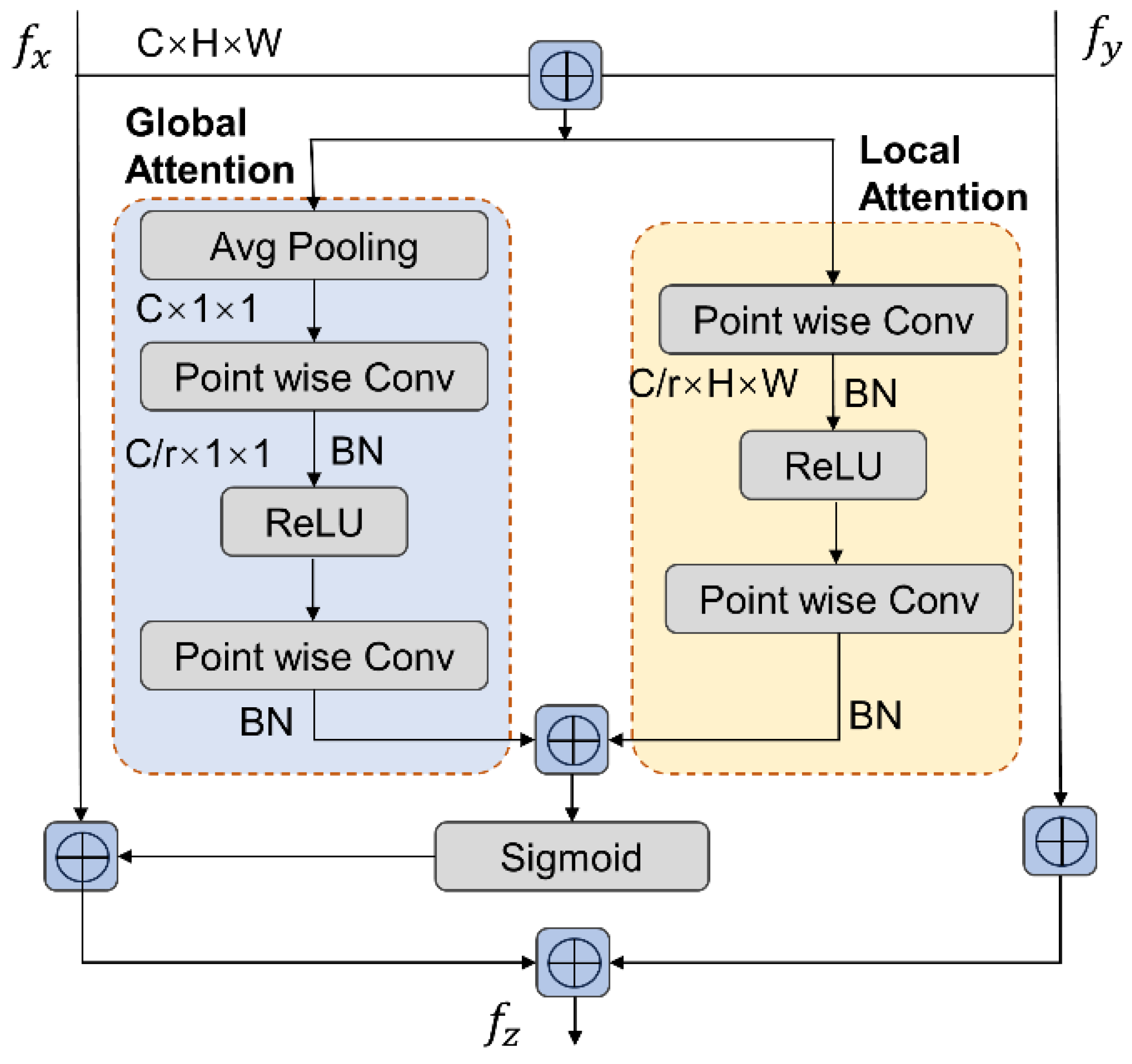
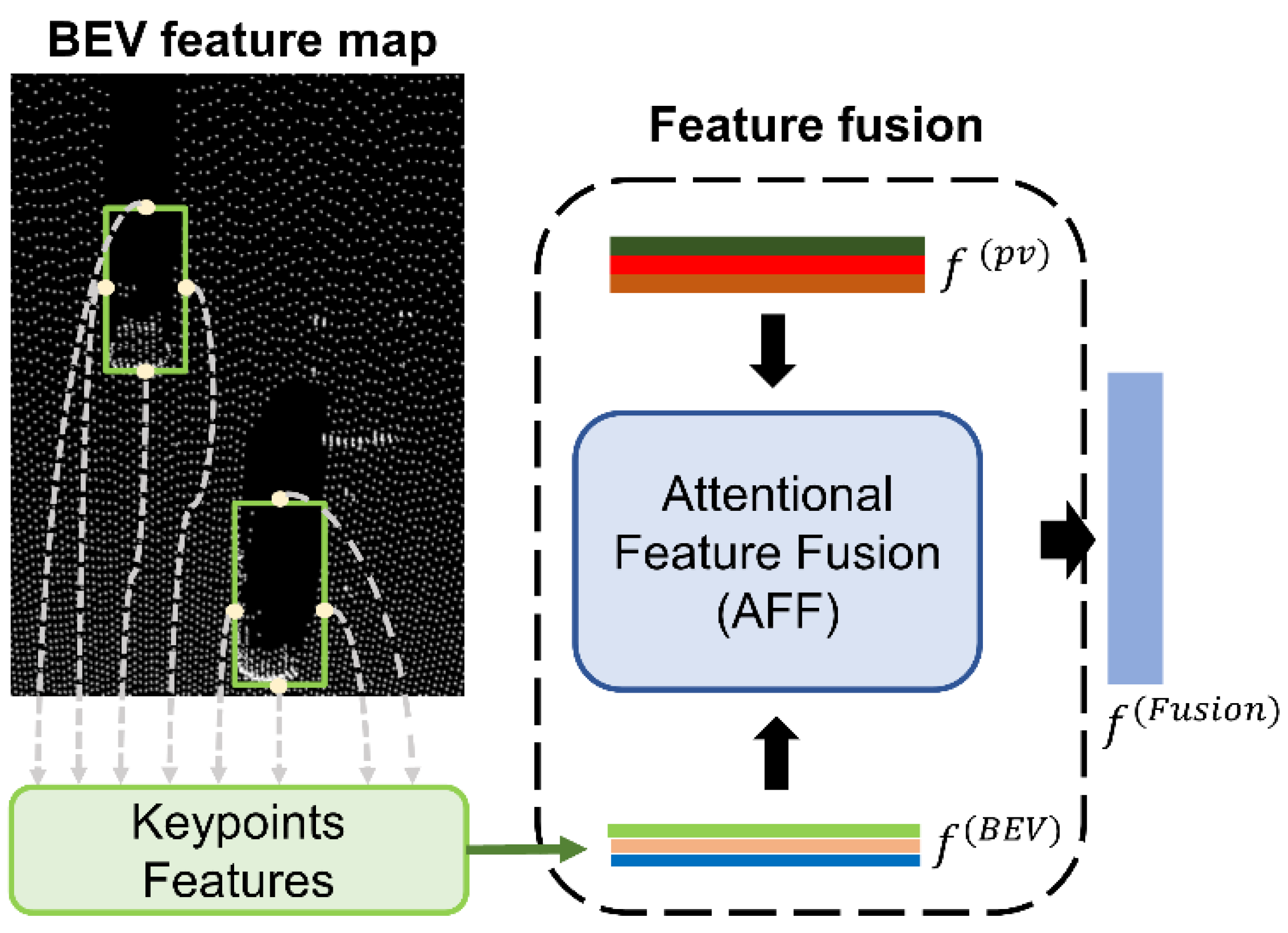
- We designed a attention feature fusion refinement module. This module fuses raw point features, voxel features, features on BEV maps, and key point features into fusion features. This module not only solves the problem of insufficient richness of features used in general unanchored algorithms, but also compensates for the underutilization of spatial location information in point-based detection.
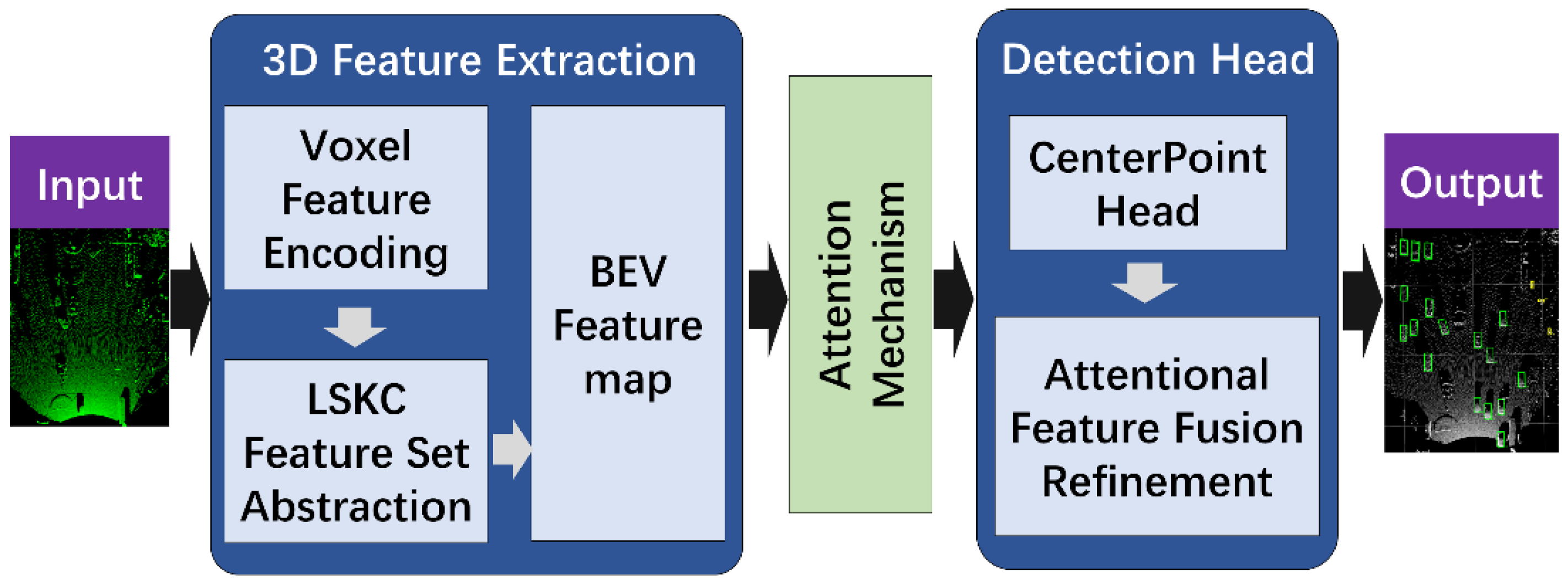
2. Materials and Methods
2.1. Dataset
2.2. Method
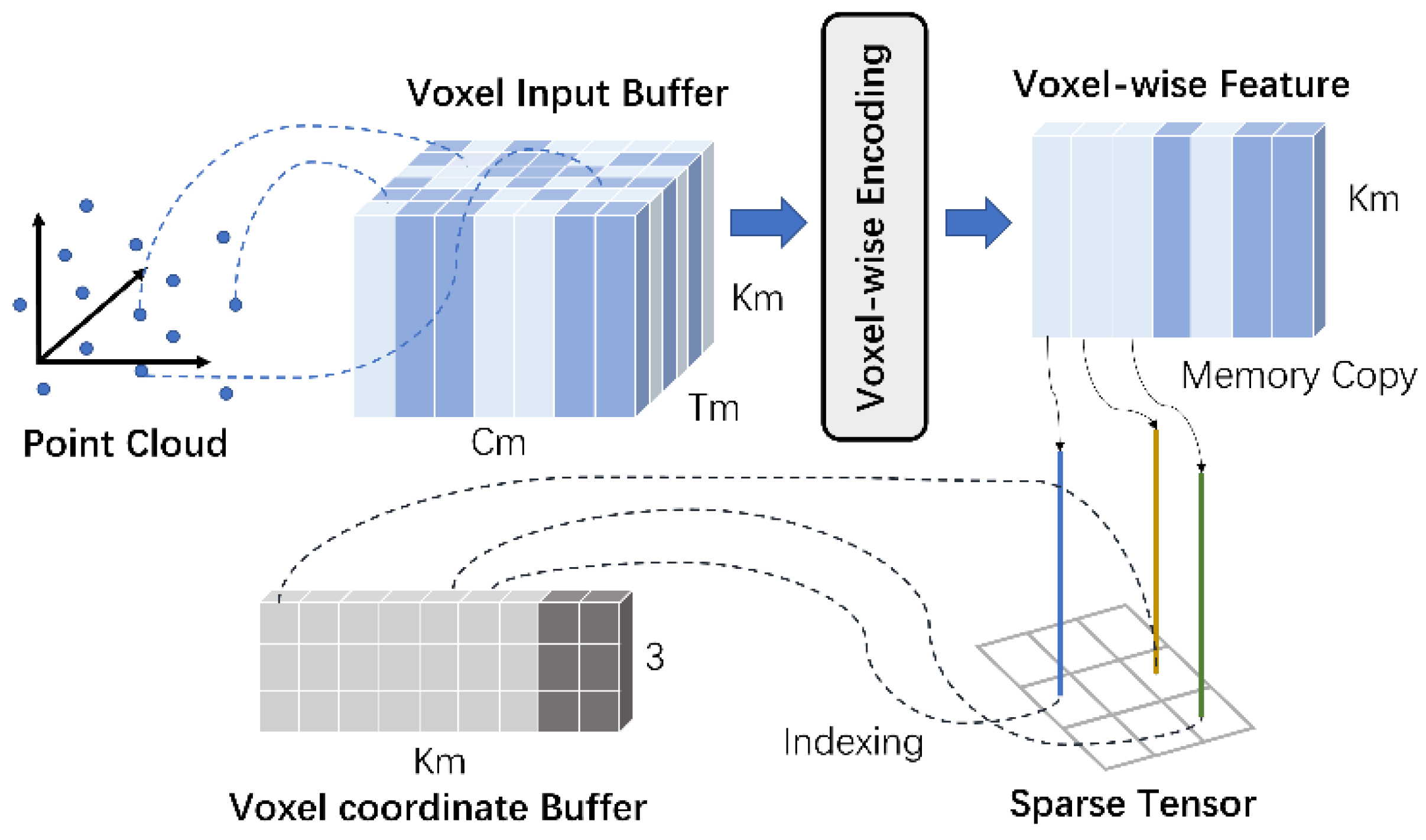
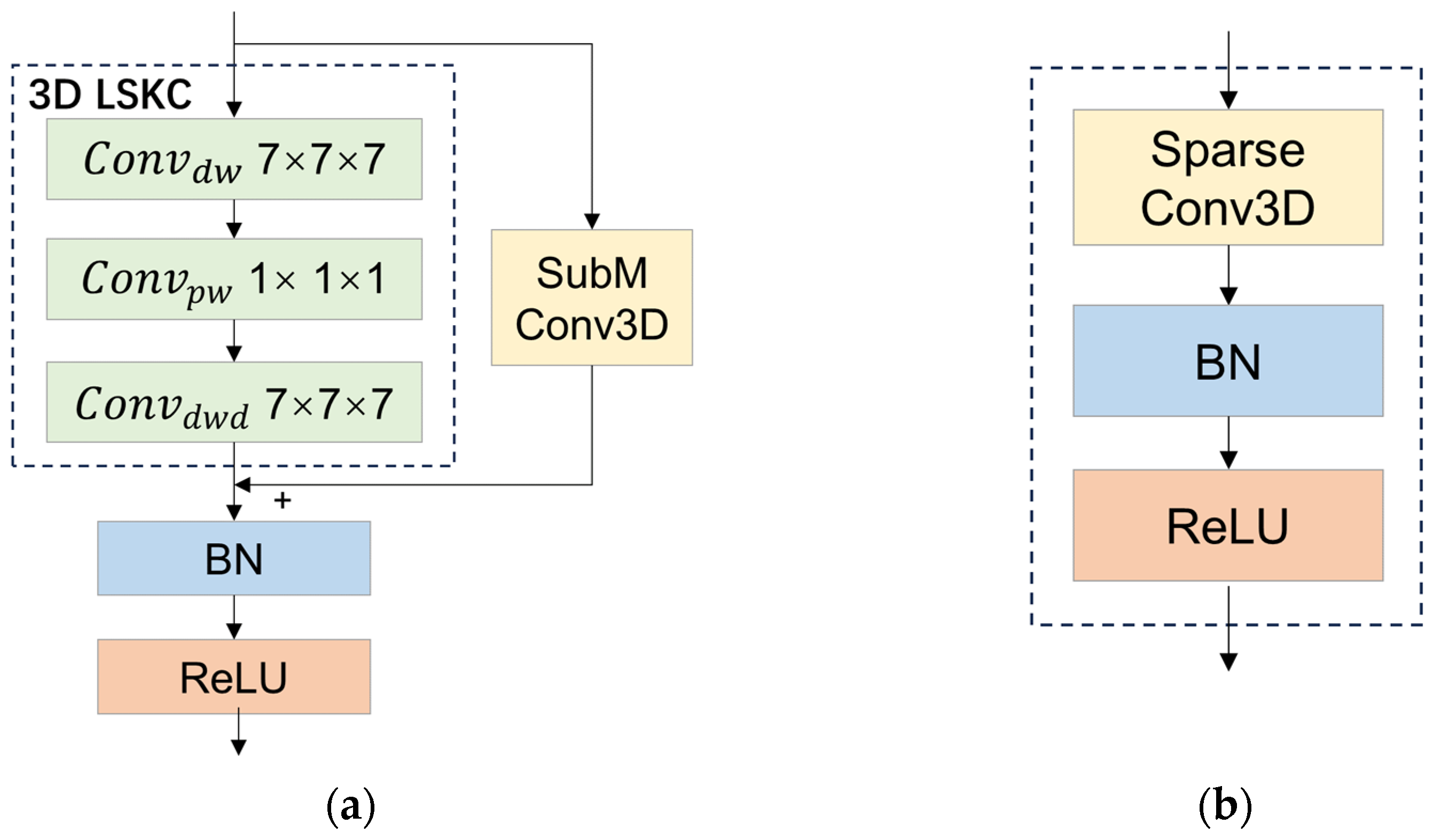
2.2.1. 3D Feature Extraction with LSKC
2.2.2. Feature Extraction with Attention
2.2.3. Detection Head
- Grid offset: the target centerpoint was mapped onto a gridded feature map [46]. To compensate for the loss of accuracy during projection, this head needed to predict a deviation value to correct it.
- Height above ground: in order to construct a 3D bounding box and locate objects in 3D space, it was necessary to compensate for the lack of Z-axis based height information in the height compression.
- Bounding box size and orientation: the size of the bounding box was the 3D size of the entire object box , which could be predicted from the heatmap and the height information. For direction prediction, the and of the deflection angle were used as continuous regression targets.
- : The coordinates of the prediction center points are set to be [23]. The coordinates of the actual center points corresponding to the ground-truth are . The difference is , where , , and the loss calculation formula is as follows:
- : The length, the width and the height of the prediction box are set to be , the length, the width and the height of the ground-truth bounding box are set to be [34]. The difference to be and the loss calculation formula is as follows:
- Orientation regression loss: The deflection angle is , which is also calculated using the smooth L1 loss function [14].
2.2.4. Attentional Feature Fusion Refinement Module
3. Results
3.1. Visualization Results and Analysis
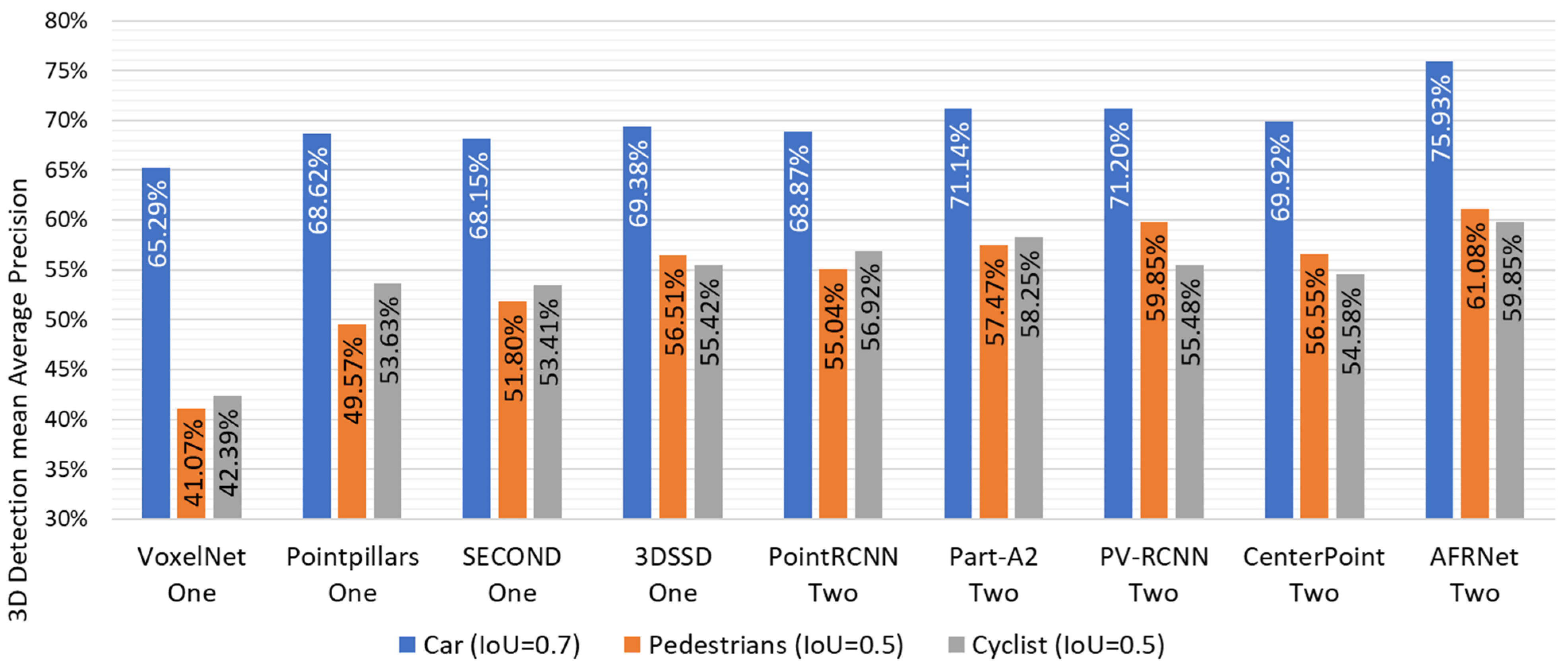
3.2. Detection Experiment
3.3. Ablation Experiment
4. Discussion
- The LSKC provides an increased convolutional receptive field, leading to improved contextual understanding, target localization for thermal maps, and detection accuracy for large-sized targets such as cars. In addition, LSKC has a detection accuracy advantage over smaller convolutional kernels when processing large clouds of scene point clouds collected by roadside lidar in the DAIR-V2X dataset.
- The AFRNet method is a lightweight two-stage network. Our method achieves performance levels comparable to those of one-stage networks in terms of reasoning time, and surpasses the majority of two-stage networks. Therefore, based on our analysis, we conclude that AFRNet is an agile network with the ability to rapidly identify and detect objects in urban scenes.
- CBAM embedded in the backbone network can deduce attention weights from both spatial and channel dimensions in turn, then adaptively adjust the features. The focus of attention in the network layer is on the target object we set with CBAM. Most importantly, with the help of an attention mechanism, AFRNet achieves a significant improvement in detection accuracy for small, easily overlooked goals such as pedestrians.
- Implementing the feature fusion module leads to a significant improvement in network detection accuracy. The usage of comprehensive and diverse feature information has proven advantageous in identifying challenging objects, and fusion features can represent the characteristics of multiple object types. Multidimensional and multilevel spatial features are ideal for representing the 3D structure of point cloud objects. This approach enhances the contrasts between various object types, which in turn enables the network to accurately identify targets and produce precise prediction results.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Menenti, M. Challenges and Opportunities in Lidar Remote Sensing. Front. Remote Sen. 2021, 2, 641723. [Google Scholar] [CrossRef]
- Li, F.; Yigitcanlar, T.; Nepal, M.; Nguyen, K.; Dur, F. Machine Learning and Remote Sensing Integration for Leveraging Urban Sustainability: A Review and Framework. Sustain. Cities Soc. 2023, 96, 104653. [Google Scholar] [CrossRef]
- Ballouch, Z.; Hajji, R.; Kharroubi, A.; Poux, F.; Billen, R. Investigating Prior-Level Fusion Approaches for Enriched Semantic Segmentation of Urban LiDAR Point Clouds. Remote Sens. 2024, 16, 329. [Google Scholar] [CrossRef]
- Li, W.; Zhan, L.; Min, W.; Zou, Y.; Huang, Z.; Wen, C. Semantic Segmentation of Point Cloud with Novel Neural Radiation Field Convolution. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6501705. [Google Scholar] [CrossRef]
- Diab, A.; Kashef, R.; Shaker, A. Deep Learning for LiDAR Point Cloud Classification in Remote Sensing. Sensors 2022, 22, 7868. [Google Scholar] [CrossRef] [PubMed]
- Zaboli, M.; Rastiveis, H.; Hosseiny, B.; Shokri, D.; Sarasua, W.A.; Homayouni, S. D-Net: A Density-Based Convolutional Neural Network for Mobile LiDAR Point Clouds Classification in Urban Areas. Remote Sens. 2023, 15, 2317. [Google Scholar] [CrossRef]
- Yan, Y.; Wang, Z.; Xu, C.; Su, N. GEOP-Net: Shape Reconstruction of Buildings from LiDAR Point Clouds. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6502005. [Google Scholar] [CrossRef]
- Yuan, Q.; Mohd Shafri, H.Z. Multi-Modal Feature Fusion Network with Adaptive Center Point Detector for Building Instance Extraction. Remote Sens. 2022, 14, 4920. [Google Scholar] [CrossRef]
- Xiao, Y.; Liu, Y.; Luan, K.; Cheng, Y.; Chen, X.; Lu, H. Deep LiDAR-Radar-Visual Fusion for Object Detection in Urban Environments. Remote Sens. 2023, 15, 4433. [Google Scholar] [CrossRef]
- Kim, J.; Yi, K. Lidar Object Perception Framework for Urban Autonomous Driving: Detection and State Tracking Based on Convolutional Gated Recurrent Unit and Statistical Approach. IEEE Veh. Technol. Mag. 2023, 18, 60–68. [Google Scholar] [CrossRef]
- Unal, G. Visual Target Detection and Tracking based on Kalman Filter. J. Aeronaut. Space Technol. 2021, 14, 251–259. [Google Scholar]
- Bai, Z.; Wu, G.; Qi, X.; Liu, Y.; Oguchi, K.; Barth, M.J. Infrastructure-based Object Detection and Tracking for Cooperative Driving Automation: A Survey. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 2022; pp. 1366–1373. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end Learning for Point Cloud based 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-based 3D Single Stage Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11040–11048. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel Transformer for 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3164–3173. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- McCrae, S.; Zakhor, A. 3D Object Detection for Autonomous Driving using Temporal LiDAR Data. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 September 2020; pp. 2661–2665. [Google Scholar]
- Wang, Z.; Bao, C.; Cao, J.; Hao, Q. AOGC: Anchor-Free Oriented Object Detection Based on Gaussian Centerness. Remote Sens. 2023, 15, 4690. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, Y.; Zhang, W.; Zheng, C.; Zhang, Z. YOLO-ViT-Based Method for Unmanned Aerial Vehicle Infrared Vehicle Target Detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A Survey on 3D Object Detection Methods for Autonomous Driving Applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Law, H.; Deng, J. Cornernet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. FCOS3D: Fully Convolutional One-stage Monocular 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 913–922. [Google Scholar]
- Wang, Q.; Chen, J.; Deng, J.; Zhang, X. 3D-CenterNet: 3D Object Detection Network for Point Clouds with Center Estimation Priority. Pattern Recogn. 2021, 115, 107884. [Google Scholar] [CrossRef]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3D Object Detection and Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Yang, C.; He, L.; Zhuang, H.; Wang, C.; Yang, M. Pseudo-Anchors: Robust Semantic Features for Lidar Mapping in Highly Dynamic Scenarios. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1619–1630. [Google Scholar] [CrossRef]
- Vanian, V.; Zamanakos, G.; Pratikakis, I. Improving Performance of Deep Learning Models for 3D Point Cloud Semantic Segmentation via Attention Mechanisms. Comput. Graph. 2022, 106, 277–287. [Google Scholar] [CrossRef]
- Chen, B.; Li, P.; Sun, C.; Wang, D.; Yang, G.; Lu, H. Multi Attention Module for Visual Tracking. Pattern Recogn. 2019, 87, 80–93. [Google Scholar] [CrossRef]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J. Dair-v2x: A Large-scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Ye, X.; Shu, M.; Li, H.; Shi, Y.; Li, Y.; Wang, G.; Tan, X.; Ding, E. Rope3d: The Roadside Perception Dataset for Autonomous Driving and Monocular 3D Object Detection Task. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 21341–21350. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 1201–1209. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3D Object Detector for Point Cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1951–1960. [Google Scholar]
- Li, Y.; Qi, X.; Chen, Y.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Voxel field Fusion for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1120–1129. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. Adv. Neural Inf. Process. Syst. 2017, 30, 690. [Google Scholar]
- Zeng, T.; Luo, F.; Guo, T.; Gong, X.; Xue, J.; Li, H. Recurrent Residual Dual Attention Network for Airborne Laser Scanning Point Cloud Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5702614. [Google Scholar] [CrossRef]
- Shi, H.; Hou, D.; Li, X. Center-Aware 3D Object Detection with Attention Mechanism Based on Roadside LiDAR. Sustainability 2023, 15, 2628. [Google Scholar] [CrossRef]
- Liu, Y.; Mishra, N.; Sieb, M.; Shentu, Y.; Abbeel, P.; Chen, X. Autoregressive Uncertainty Modeling for 3D Bounding Box Prediction. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23 October 2022; pp. 673–694. [Google Scholar]
- Zhao, X.; Liu, Z.; Hu, R.; Huang, K. 3D Object Detection using Scale Invariant and Feature Reweighting Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9267–9274. [Google Scholar]
- Kiyak, E.; Unal, G. Small Aircraft Detection using Deep Learning. Aircr. Eng. Aerosp. Technol. 2021, 93, 671–681. [Google Scholar] [CrossRef]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Online, 5–9 February 2021; pp. 3560–3569. [Google Scholar]
- Wu, W.; Zhang, Y.; Wang, D.; Lei, Y. SK-Net: Deep Learning on Point Cloud via End-to-end Discovery of Spatial Keypoints. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 6422–6429. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. Resnest: Split-attention Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2736–2746. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep Sensor Fusion for 3D Bounding box Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 244–253. [Google Scholar]
- Chen, G.; Wang, F.; Qu, S.; Chen, K.; Yu, J.; Liu, X.; Xiong, L.; Knoll, A. Pseudo-image and Sparse Points: Vehicle Detection with 2D LiDAR Revisited by Deep Learning-based Methods. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7699–7711. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum Pointnets for 3D Object Detection from RGB-D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Method | Anchor | Model Size | Speed |
|---|---|---|---|---|
| One | VoxelNet | Based | 132.0 M | 714.50 ms |
| PointPillars | Based | 58.1 M | 79.69 ms | |
| SECOND | Based | 64.0 M | 114.39 ms | |
| 3DSSD | Free | 98.2 M | 115.48 ms | |
| Two | PointRCNN | Based | 48.7 M | 183.04 ms |
| PartA2 | Based | 766.1 M | 201.97 ms | |
| PV-RCNN | Based | 157.7 M | 250.48 ms | |
| CenterPoint | Free | 26.7 M | 119.88 ms | |
| AFRNet | Free | 120.4 M | 157.29 ms |
| LSKC Feature Extraction | Attention Mechanism | 3D Detection (mAP) | ||
|---|---|---|---|---|
| Car (IoU = 0.7) | Pedestrian (IoU = 0.5) | Cyclist (IoU = 0.5) | ||
| × | × | 72.18 | 58.82 | 56.23 |
| × | √ | 72.98 | 60.24 | 57.15 |
| √ | × | 75.71 | 59.43 | 58.91 |
| √ | √ | 75.93 | 61.08 | 59.85 |
| 3D Detection (mAP) | |||||
|---|---|---|---|---|---|
| Car (IoU = 0.7) | Pedestrian (IoU = 0.5) | Cyclist (IoU = 0.5) | |||
| √ | × | × | 73.27 | 57.57 | 56.74 |
| × | √ | × | 75.73 | 61.03 | 55.01 |
| × | × | √ | 75.93 | 61.08 | 59.85 |
| Method | Model Size | Speed |
|---|---|---|
| CenterPoint | 26.7 M | 119.88 ms |
| LSKC only | 50.1 M | 139.20 ms |
| CBAM only | 26.9 M | 128.38 ms |
| Attention feature fusion only | 96.7 M | 132.15 ms |
| AFRNet | 120.4 M | 157.29 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Lan, J.; Li, M. AFRNet: Anchor-Free Object Detection Using Roadside LiDAR in Urban Scenes. Remote Sens. 2024, 16, 782. https://doi.org/10.3390/rs16050782
Wang L, Lan J, Li M. AFRNet: Anchor-Free Object Detection Using Roadside LiDAR in Urban Scenes. Remote Sensing. 2024; 16(5):782. https://doi.org/10.3390/rs16050782
Chicago/Turabian StyleWang, Luyang, Jinhui Lan, and Min Li. 2024. "AFRNet: Anchor-Free Object Detection Using Roadside LiDAR in Urban Scenes" Remote Sensing 16, no. 5: 782. https://doi.org/10.3390/rs16050782
APA StyleWang, L., Lan, J., & Li, M. (2024). AFRNet: Anchor-Free Object Detection Using Roadside LiDAR in Urban Scenes. Remote Sensing, 16(5), 782. https://doi.org/10.3390/rs16050782