
A CFAR-Enhanced Ship Detector for SAR Images Based on YOLOv5s


Abstract

1. Introduction
- (1)
- Aiming at the complex backgrounds encountered in SAR images, we propose an end-to-end network structure based on a single-stage object detection algorithm. This network achieves high ship detection accuracy while maintaining a fast speed. We incorporate handcrafted feature extraction and attention mechanisms into the network, ensuring the effectiveness of ship detection in SAR images.
- (2)
- We design a sub-net that supervises feature extraction in the main network, helping our model learn more handcrafted features and highlighting the differences between ships and backgrounds, thereby overcoming the challenges of ship detection in complex backgrounds.
2. Related Work
2.1. Handcraft Feature-Based Methods
2.2. Deep Learning-Based Methods
2.3. Fusion-Based Methods
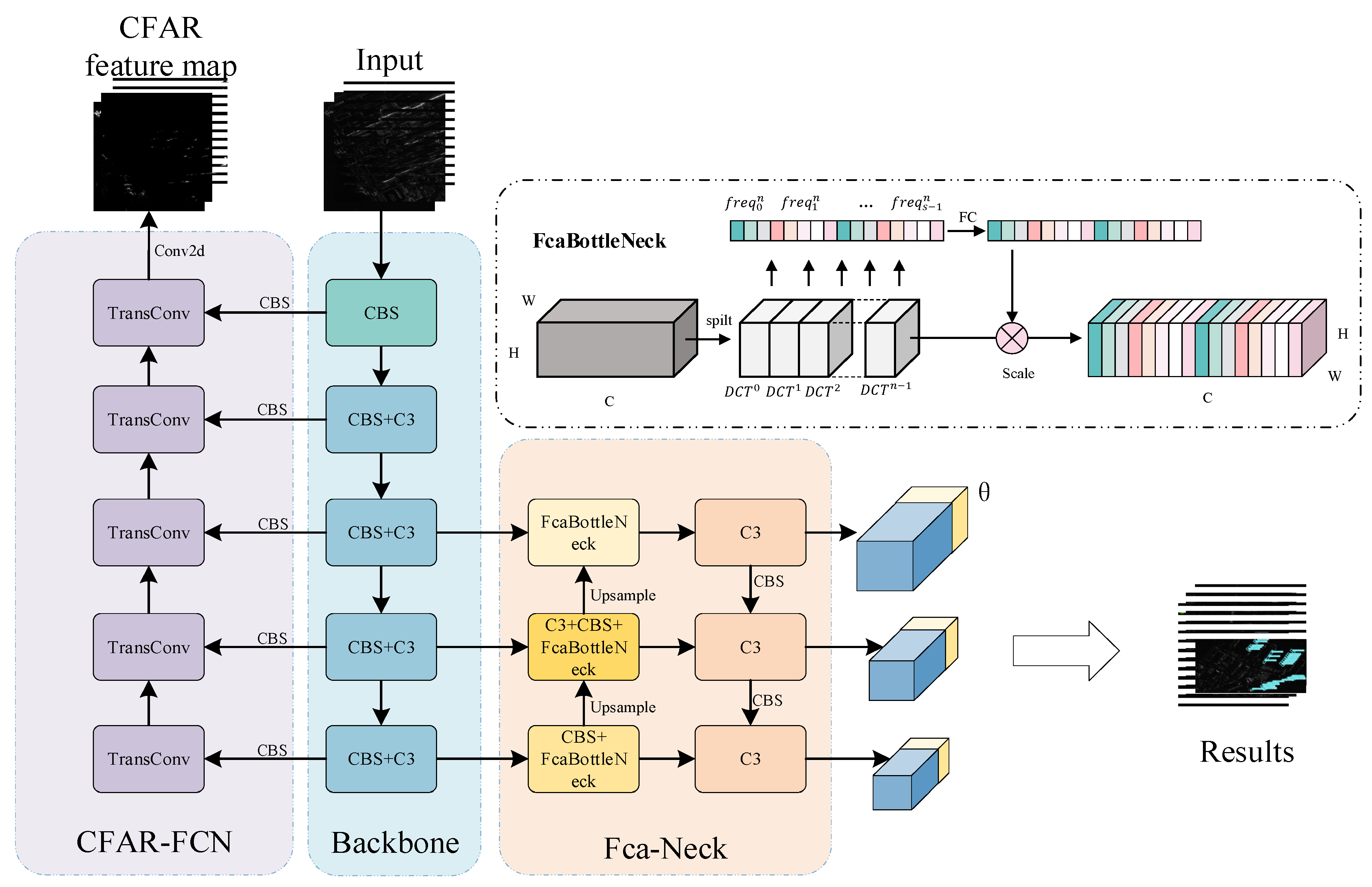
3. Method
3.1. The Overall Framework
3.2. CFAR-FCN
3.3. Fca-Neck
3.4. Loss Function
4. Experiments and Analysis
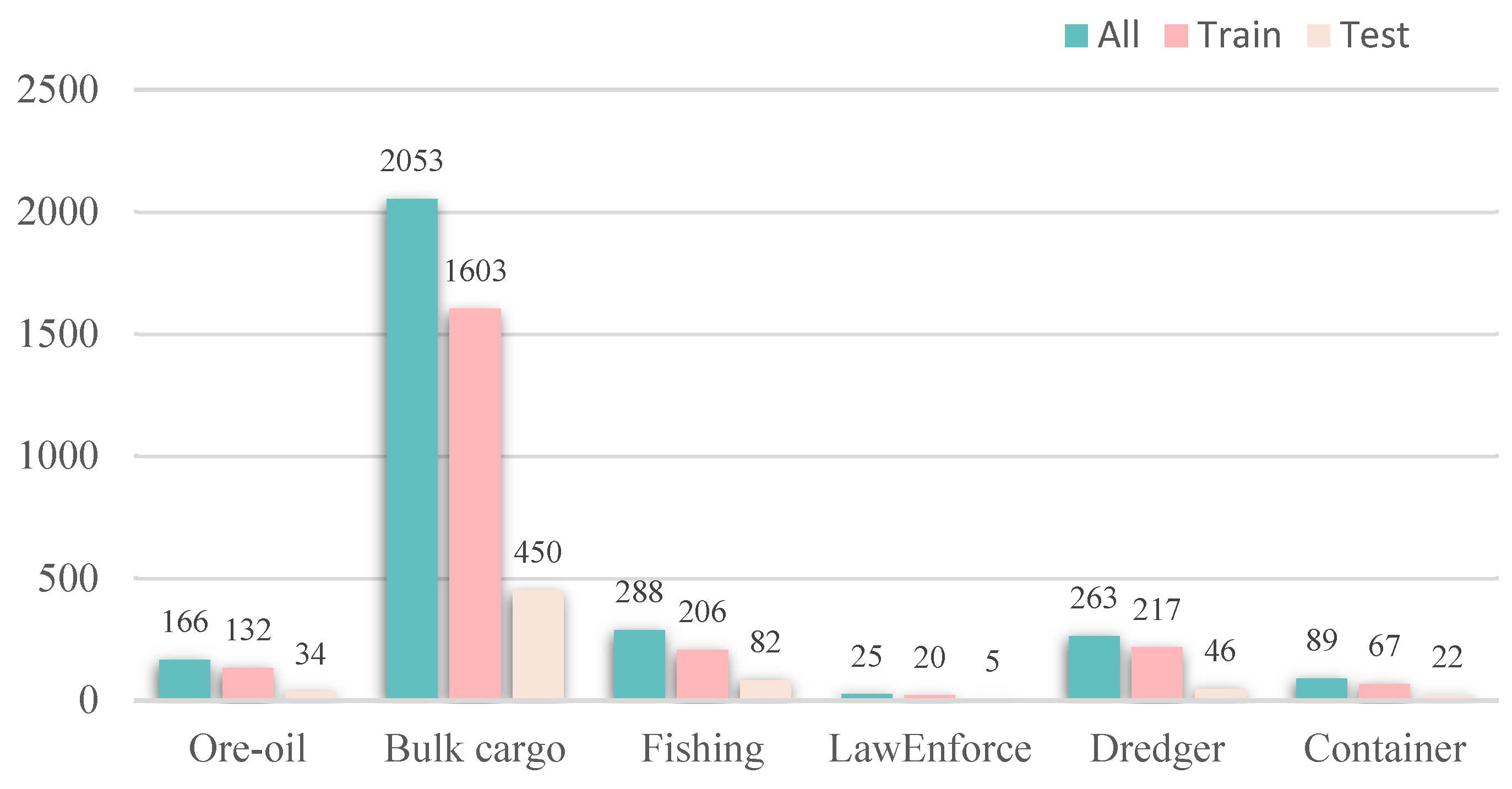
4.1. Dataset and Experimental Settings
4.1.1. Dataset
4.1.2. Implementation
4.1.3. Metrics
4.2. Experimental Results
4.2.1. Quantitative Analysis of Results
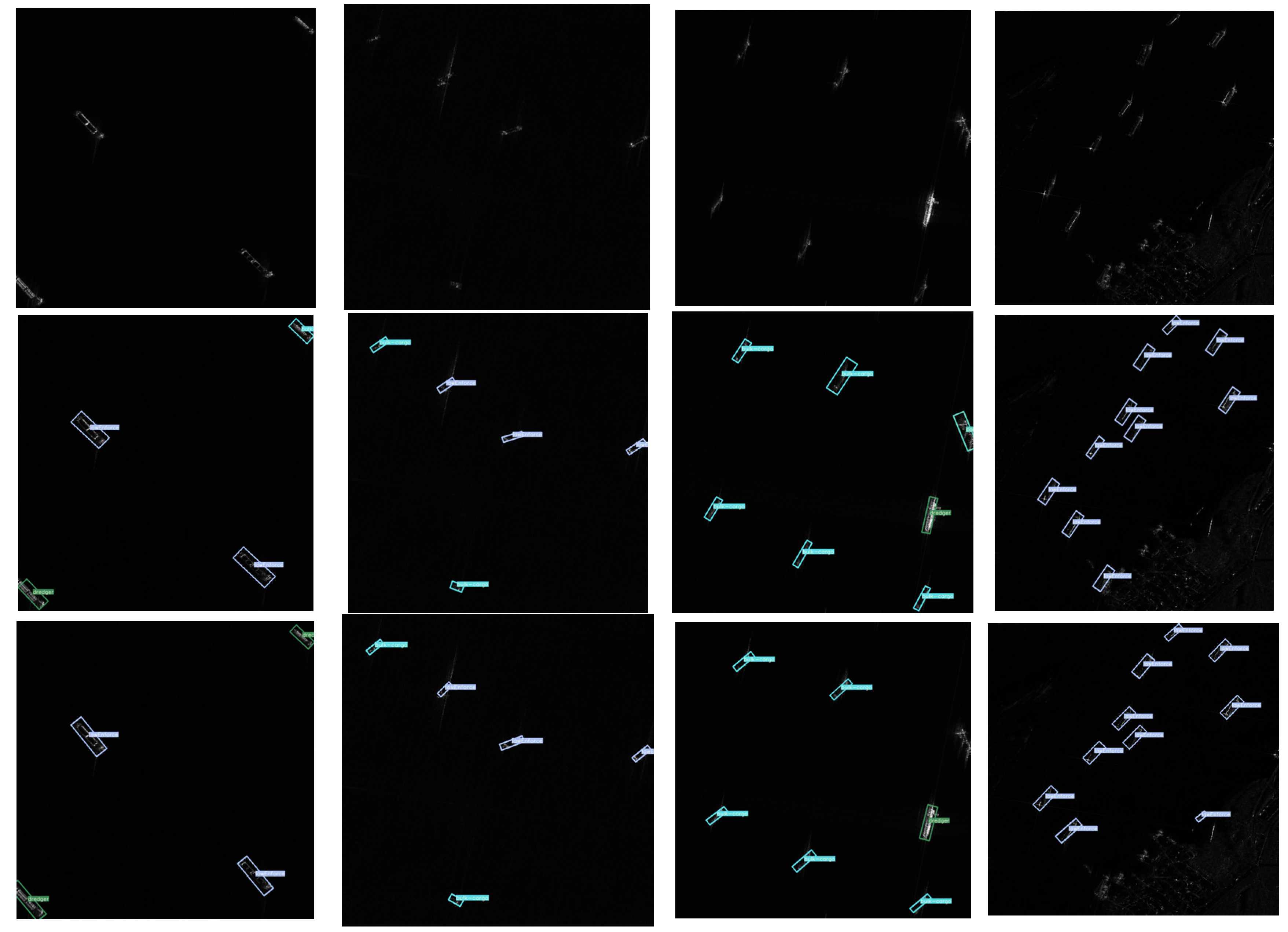
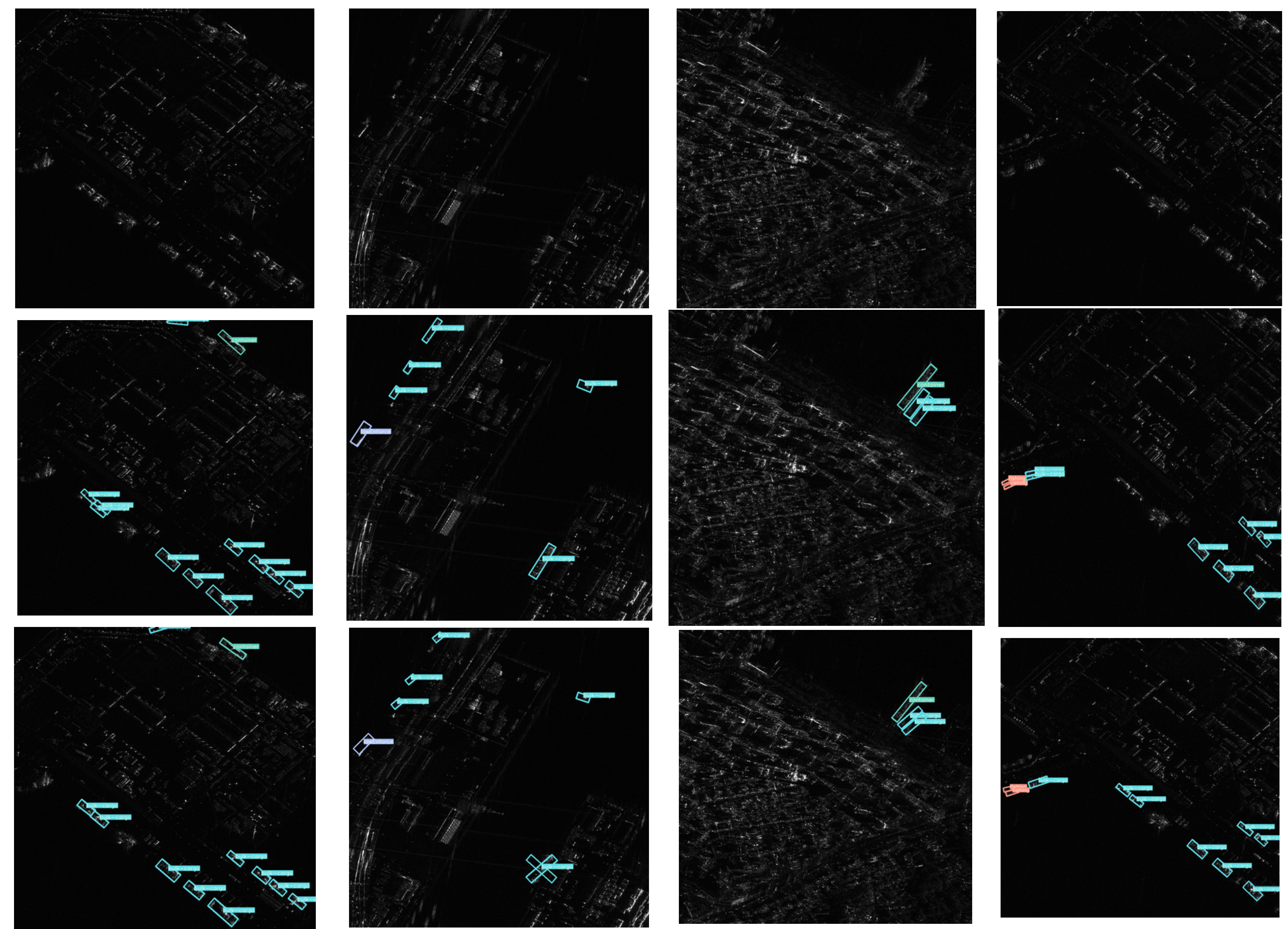
4.2.2. Qualitative Analysis of Results
4.2.3. Ablation Experiments
- Effectiveness of CFAR-FCN
- Effectiveness of Fca-Neck
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Depthwise Separable Convolution Neural Network for High-Speed SAR Ship Detection. Remote Sens. 2019, 11, 2483. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. High-Speed Ship Detection in SAR Images Based on a Grid Convolutional Neural Network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, R.; Xu, K.; Wang, J.; Sun, W. R-CNN-Based Ship Detection from High Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef]
- Wang, X.; Li, G.; Plaza, A.; He, Y. Ship Detection in SAR Images by Aggregating Densities of Fisher Vectors: Extension to a Global Perspective. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5206613. [Google Scholar] [CrossRef]
- Wackerman, C.C.; Friedman, K.S.; Pichel, W.G.; Clemente-Colón, P.; Li, X. Automatic Detection of Ships in RADARSAT-1 SAR Imagery. Can. J. Remote Sens. 2001, 27, 568–577. [Google Scholar] [CrossRef]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An Adaptive and Fast CFAR Algorithm Based on Automatic Censoring for Target Detection in High-Resolution SAR Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1685–1697. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A Novel Quad Feature Pyramid Network for SAR Ship Detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, X.; Zhang, T.; Xu, X.; Zeng, T. RBFA-Net: A Rotated Balanced Feature-Aligned Network for Rotated SAR Ship Detection and Classification. Remote Sens. 2022, 14, 3345. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Z.; Yu, W.; Truong, T.-K. A Cascade Coupled Convolutional Neural Network Guided Visual Attention Method for Ship Detection from SAR Images. IEEE Access 2018, 6, 50693–50708. [Google Scholar] [CrossRef]
- Joseph, R.; Ali, F. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. FcaNet: Frequency Channel Attention Networks. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Adil, M.; Buono, A.; Nunziata, F.; Ferrentino, E.; Velotto, D.; Migliaccio, M. On the Effects of the Incidence Angle on the L-Band Multi-Polarisation Scattering of a Small Ship. Remote Sens. 2022, 14, 5813. [Google Scholar] [CrossRef]
- Marino, A. A Notch Filter for Ship Detection with Polarimetric SAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1219–1232. [Google Scholar] [CrossRef]
- Ferrara, G.; Migliaccio, M.; Nunziata, F.; Sorrentino, A. Generalized-K (GK)-Based Observation of Metallic Objects at Sea in Full-Resolution Synthetic Aperture Radar (SAR) Data: A Multipolarization Study. IEEE J. Ocean. Eng. 2011, 36, 195–204. [Google Scholar] [CrossRef]
- He, C.; Tu, M.; Xiong, D.; Tu, F.; Liao, M. Adaptive Component Selection-Based Discriminative Model for Object Detection in High-Resolution SAR Imagery. ISPRS Int. J. Geo-Inf. 2018, 7, 72. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Yang, K.; Zou, H. A Bilateral CFAR Algorithm for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1536–1540. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Neural Inf. Process. Syst. 2016, 29, 1–9. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I. European Conference on Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. ISBN 978-3-319-46448-0. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S.; Wang, J.; Li, J.; Su, H.; Zhou, Y. Balance Scene Learning Mechanism for Offshore and Inshore Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4004905. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. ShipDeNet-20: An only 20 convolution layers and< 1-MB lightweight SAR ship detector. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1234–1238. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction From High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Injection of Traditional Hand-Crafted Features into Modern CNN-Based Models for SAR Ship Classification: What, Why, Where, and How. Remote Sens. 2021, 13, 2091. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. A polarization fusion network with geometric feature embedding for SAR ship classification. Pattern Recognit. 2022, 123, 108365. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Zhao, W.; Wang, X.; Li, G.; He, Y. Frequency-Adaptive Learning for SAR Ship Detection in Clutter Scenes. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5215514. [Google Scholar] [CrossRef]
- Ai, J.; Tian, R.; Luo, Q.; Jin, J.; Tang, B. Multi-Scale Rotation-Invariant Haar-Like Feature Integrated CNN-Based Ship Detection Algorithm of Multiple-Target Environment in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10070–10087. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X.; Zhan, X.; Wang, C.; Ahmad, I.; Zhou, Y.; Pan, D.; et al. HOG-ShipCLSNet: A Novel Deep Learning Network with HOG Feature Fusion for SAR Ship Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–22. [Google Scholar] [CrossRef]
- Zhang, X.; Huo, C.; Xu, N.; Jiang, H.; Cao, Y.; Ni, L.; Pan, C. Multitask Learning for Ship Detection From Synthetic Aperture Radar Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8048–8062. [Google Scholar] [CrossRef]
- Zhang, G.; Li, Z.; Li, X.; Yin, C.; Shi, Z. A Novel Salient Feature Fusion Method for Ship Detection in Synthetic Aperture Radar Images. IEEE Access 2020, 8, 215904–215914. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete Cosine Transform. IEEE Trans. Comput. 1974, C-23, 90–93. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- Lei, S.; Lu, D.; Qiu, X.; Ding, C. SRSDD-v1.0: A High-Resolution SAR Rotation Ship Detection Dataset. Remote Sens. 2021, 13, 5104. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Computer Vision—ECCV 2018. Part XIV, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 765–781. ISBN 9783030012632. [Google Scholar]
- Yi, J.; Wu, P.; Liu, B.; Huang, Q.; Qu, H.; Metaxas, D. Oriented Object Detection in Aerial Images with Box Boundary-Aware Vectors. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3163–3171. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of Images | 666 |
| Waveband | C |
| Image Size | 1024 × 1024 |
| Image Mode | Spotlight Mode |
| Polarization | HH, VV |
| Resolution (m) | 1 |
| Ship Classes | 6 |
| Position | Nanjing, Hongkong, Zhoushan, Macao, Yokohama |
| Project | Model/Parameter |
|---|---|
| CPU | Intel® Core™ 7-10875H |
| RAM | 16 GB |
| GPU | GeForce RTx 2060 Mobile |
| SYSTEM | Ubuntu22.4 |
| CODE | Python3.8 |
| FRAMEWORK | CUDA11.7/torch 1.13 |
| Model | Category | Precision (%) | Recall (%) | mAP | F1 | FPS | Model (M) |
|---|---|---|---|---|---|---|---|
| FR-O [37] | Two-stage | 57.12 | 49.66 | 53.93 | 53.13 | 8.09 | 315 |
| ROI [37,41] | Two-stage | 59.31 | 51.22 | 54.38 | 54.97 | 7.75 | 421 |
| Gliding Vertex [37,42] | Two-stage | 57.75 | 53.95 | 51.50 | 55.79 | 7.58 | 315 |
| O-RCNN [37,38] | Two-stage | 64.01 | 57.61 | 56.23 | 60.64 | 8.38 | 315 |
| R-RetinaNet [37] | One-stage | 53.52 | 12.55 | 32.73 | 20.33 | 10.53 | 277 |
| R3Det [37,43] | One-stage | 58.06 | 15.41 | 39.12 | 24.36 | 7.69 | 468 |
| BBAVectors [37,39] | One-stage | 50.08 | 34.56 | 45.33 | 40.90 | 3.26 | 829 |
| R-FCOS [37,40] | One-stage | 60.56 | 18.42 | 49.49 | 28.25 | 10.15 | 244 |
| our method | One-stage | 68.04 | 60.25 | 61.07 | 63.91 | 56.18 | 18.51 * |
| Model | Precision (%) | Recall (%) | mAP | F1 | FPS | Param(M) | Model (M) |
|---|---|---|---|---|---|---|---|
| YOLOv5s + CFAR + low | 68.04 | 60.25 | 61.07 * | 63.91 | 56.18 | 9.52 | 18.51 |
| YOLOv5s + CFAR | 69.84 | 56.65 | 57.56 | 62.56 | 60.98 | 8.98 | 17.48 |
| YOLOv5s + low | 67.21 | 58.06 | 56.49 | 62.3 | 78.74 | 7.84 | 15.7 |
| YOLOv5s | 68.57 | 56.34 | 52.04 | 61.86 | 84.75 | 7.51 | 14.67 |
| Model | Precision (%) | Recall (%) | mAP | F1 | FPS | Param (M) | Model (M) |
|---|---|---|---|---|---|---|---|
| YOLOv5s + CFAR | 69.84 | 56.65 | 57.56 * | 62.56 | 60.98 | 8.98 | 17.48 |
| YOLOv5s + shipseg | 65.86 | 55.56 | 40.09 | 60.27 | 63.69 | 8.98 | 17.48 |
| YOLOv5s | 68.57 | 56.34 | 52.04 | 61.86 | 84.75 | 7.51 | 14.67 |
| Model | Precision (%) | Recall (%) | mAP | F1 | FPS | Param (M) | Model (M) |
|---|---|---|---|---|---|---|---|
| YOLOv5s + low | 67.21 | 58.06 | 56.49 * | 62.3 | 78.74 | 7.84 | 15.7 |
| YOLOv5s + top | 63.44 | 58.37 | 55.4 | 60.8 | 80.0 | 7.84 | 15.7 |
| YOLOv5s + bot | 67.11 | 55.87 | 53.26 | 60.97 | 78.13 | 7.84 | 15.7 |
| YOLOv5s | 68.57 | 56.34 | 52.04 | 61.86 | 84.75 | 7.51 | 14.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, X.; Zhang, S.; Wang, J.; Yao, T.; Tang, Y. A CFAR-Enhanced Ship Detector for SAR Images Based on YOLOv5s. Remote Sens. 2024, 16, 733. https://doi.org/10.3390/rs16050733
Wen X, Zhang S, Wang J, Yao T, Tang Y. A CFAR-Enhanced Ship Detector for SAR Images Based on YOLOv5s. Remote Sensing. 2024; 16(5):733. https://doi.org/10.3390/rs16050733
Chicago/Turabian StyleWen, Xue, Shaoming Zhang, Jianmei Wang, Tangjun Yao, and Yan Tang. 2024. "A CFAR-Enhanced Ship Detector for SAR Images Based on YOLOv5s" Remote Sensing 16, no. 5: 733. https://doi.org/10.3390/rs16050733
APA StyleWen, X., Zhang, S., Wang, J., Yao, T., & Tang, Y. (2024). A CFAR-Enhanced Ship Detector for SAR Images Based on YOLOv5s. Remote Sensing, 16(5), 733. https://doi.org/10.3390/rs16050733