
Underwater Acoustic Nonlinear Blind Ship Noise Separation Using Recurrent Attention Neural Networks

 , ,
, ,  , and
, and 
Abstract
1. Introduction
2. Materials and Methods
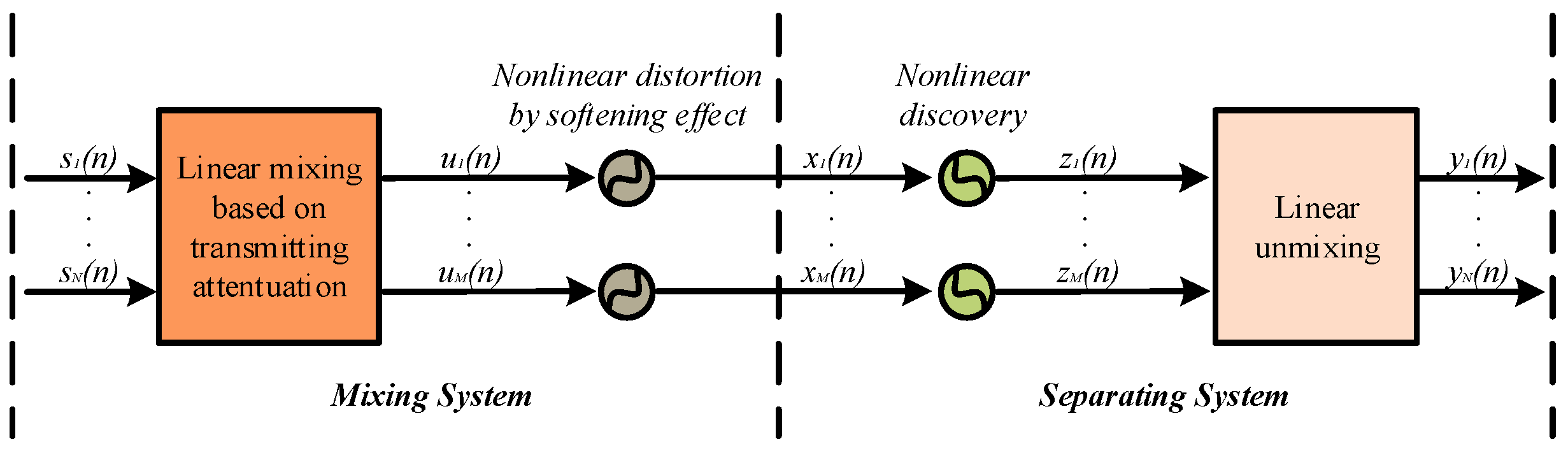
2.1. Nonlinear Underwater Acoustic Channel Model
2.2. Nonlinear Mixing Model in BSS
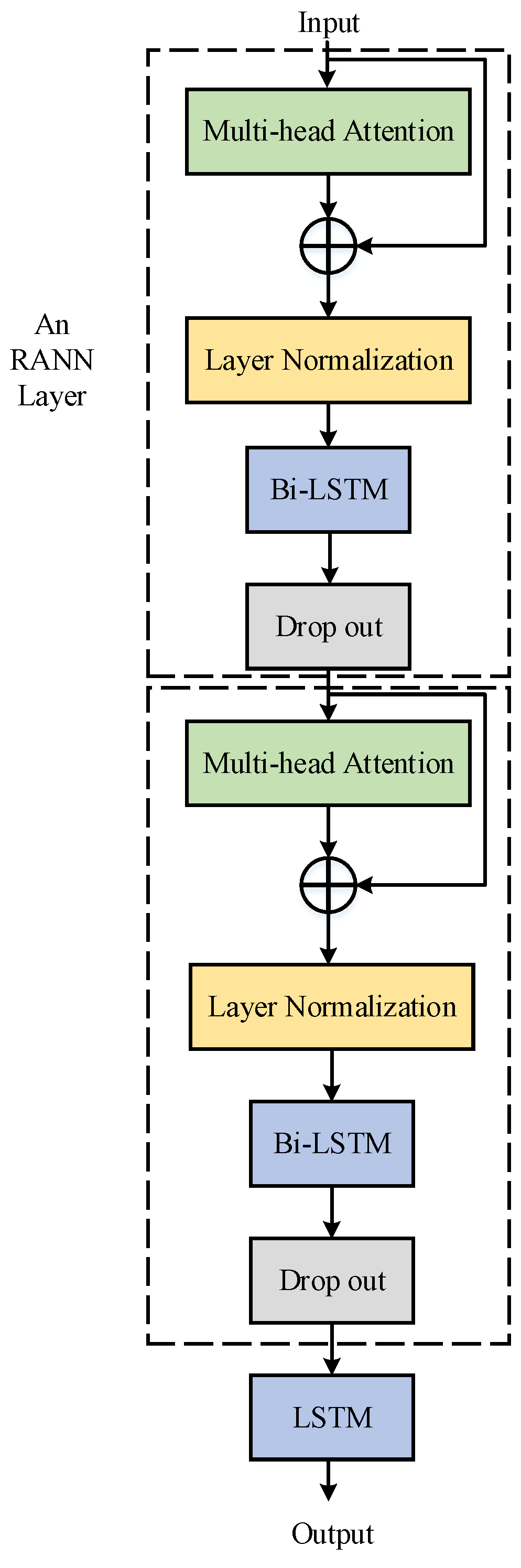
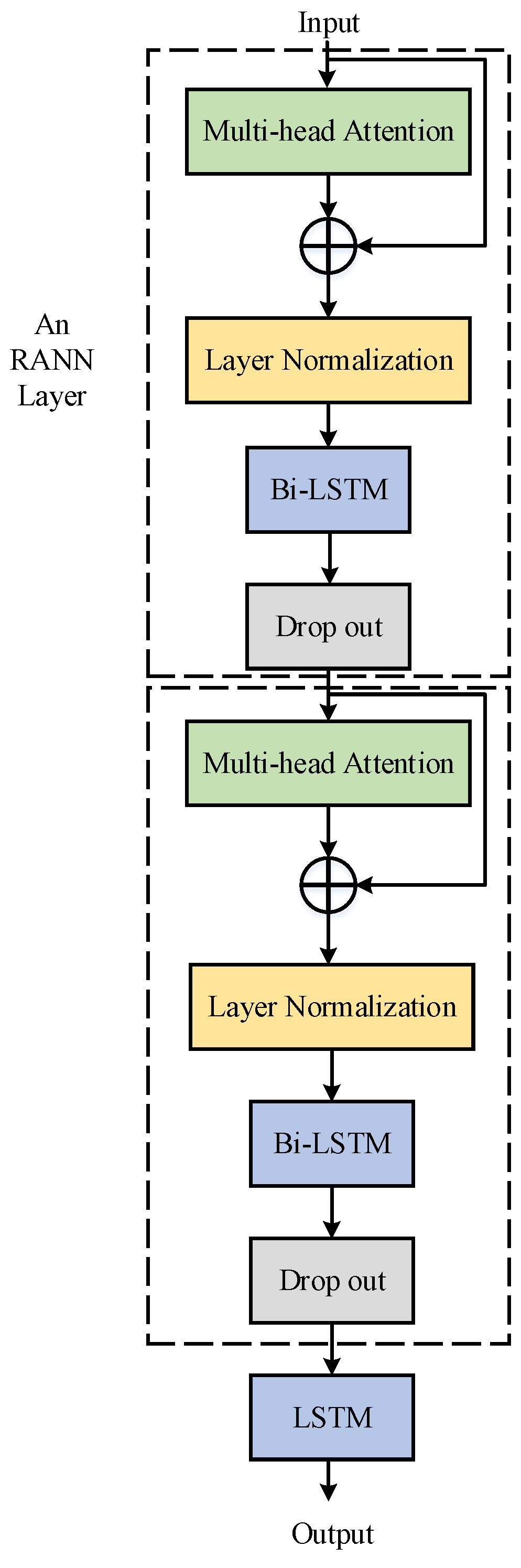
2.3. Recurrent Attention Neural Networks
3. Simulation Configuration
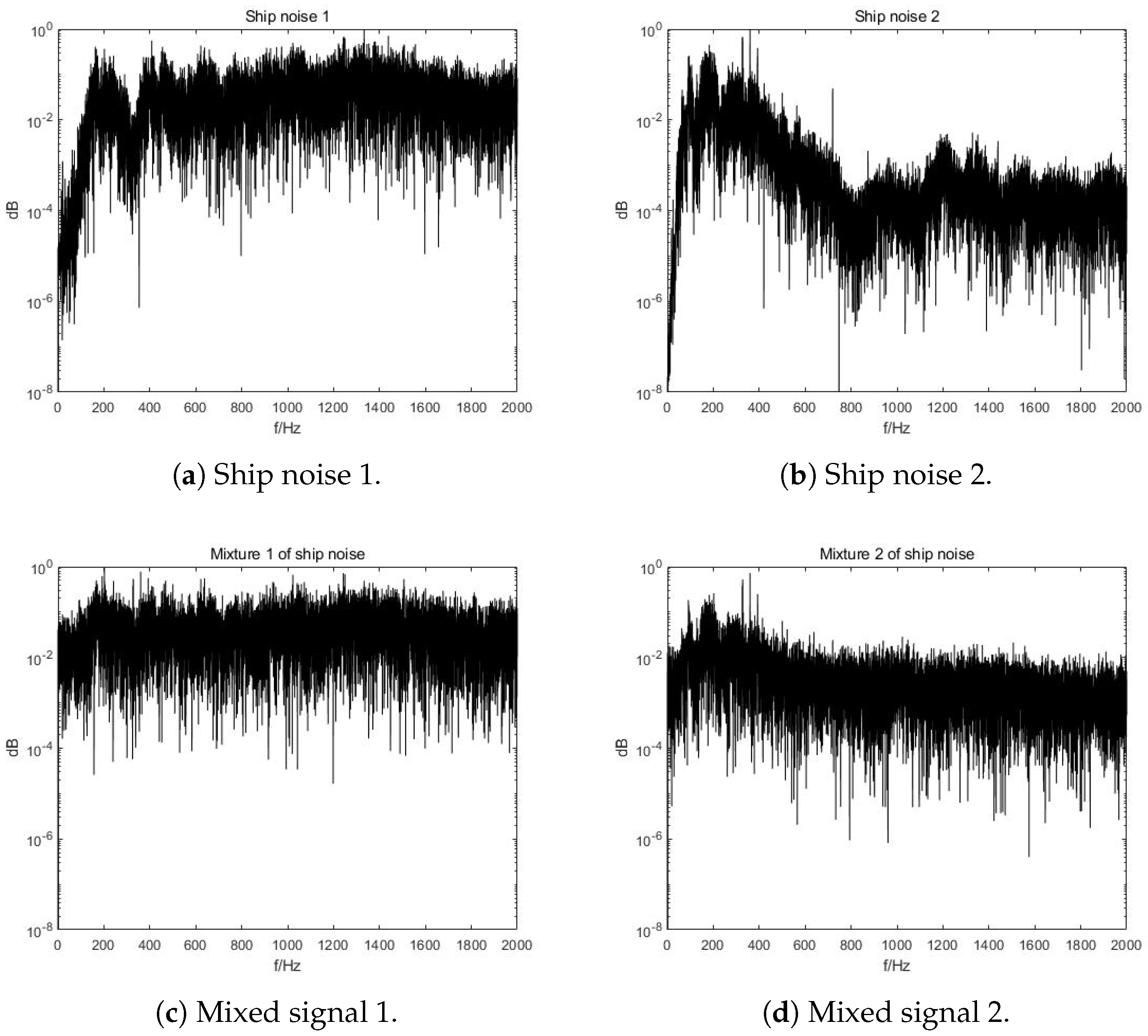
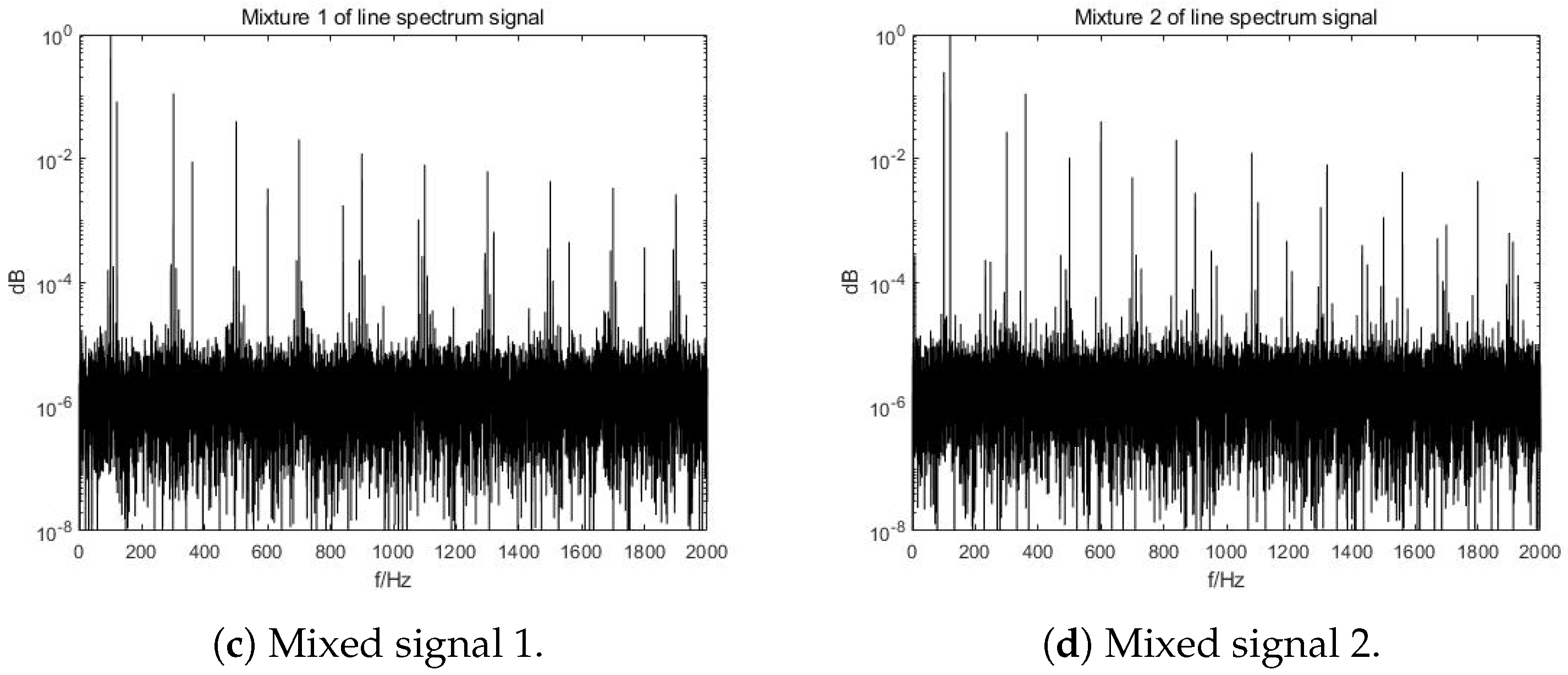
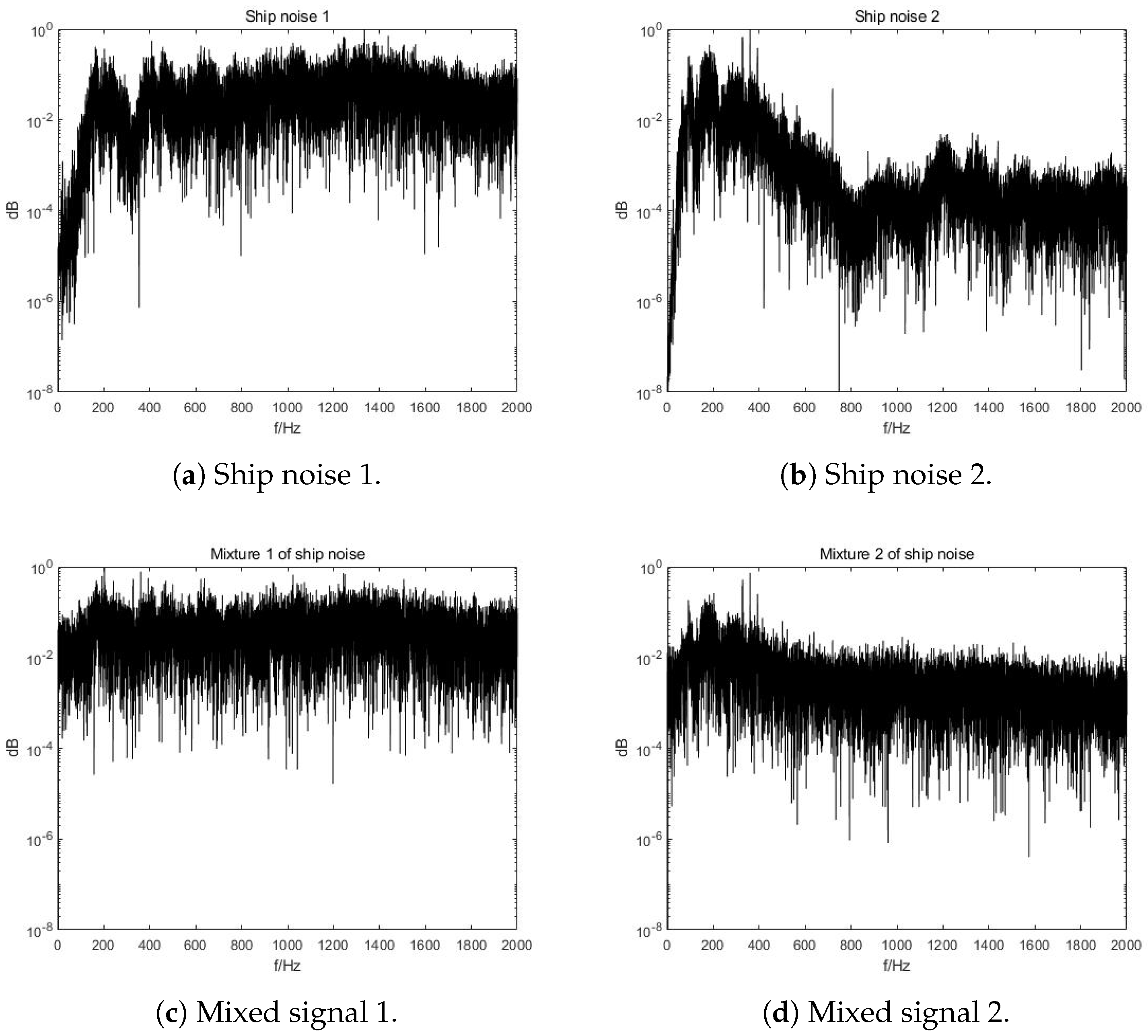
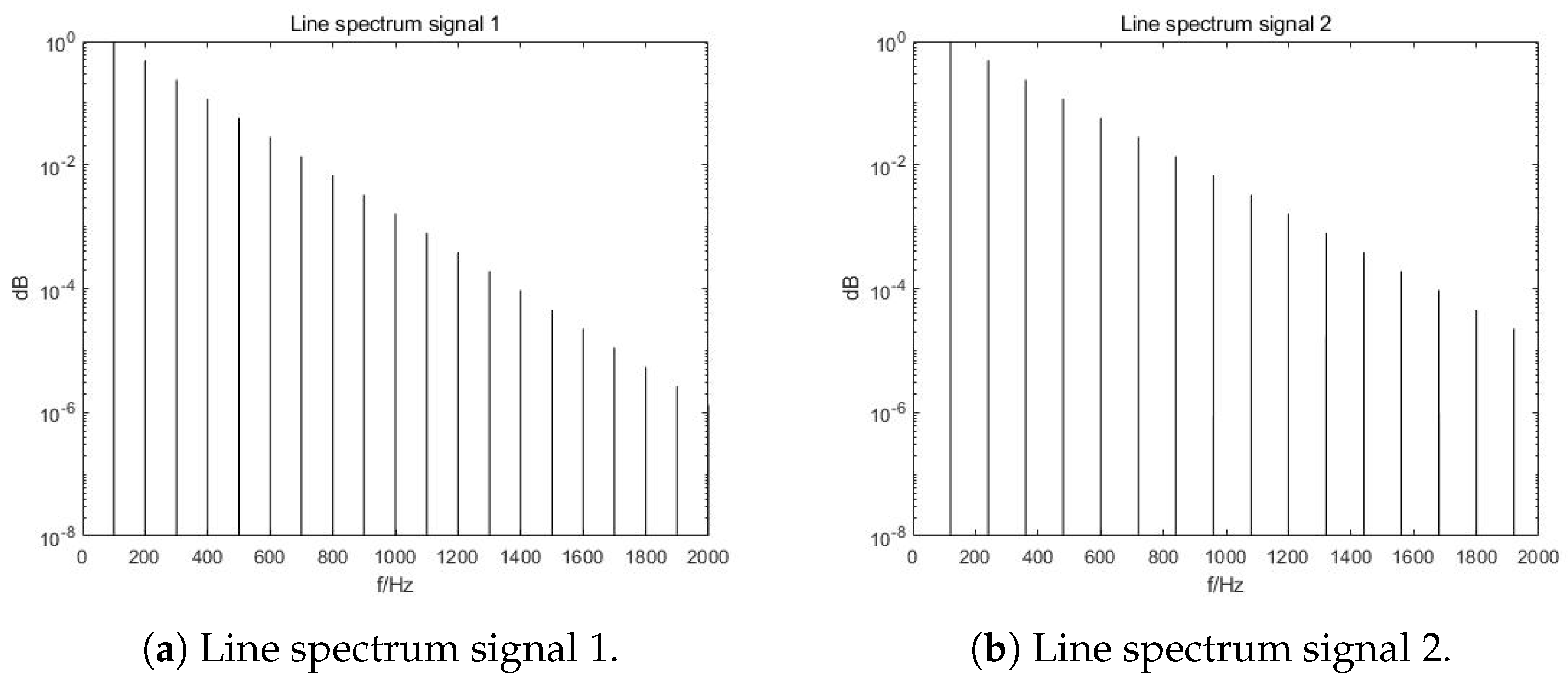
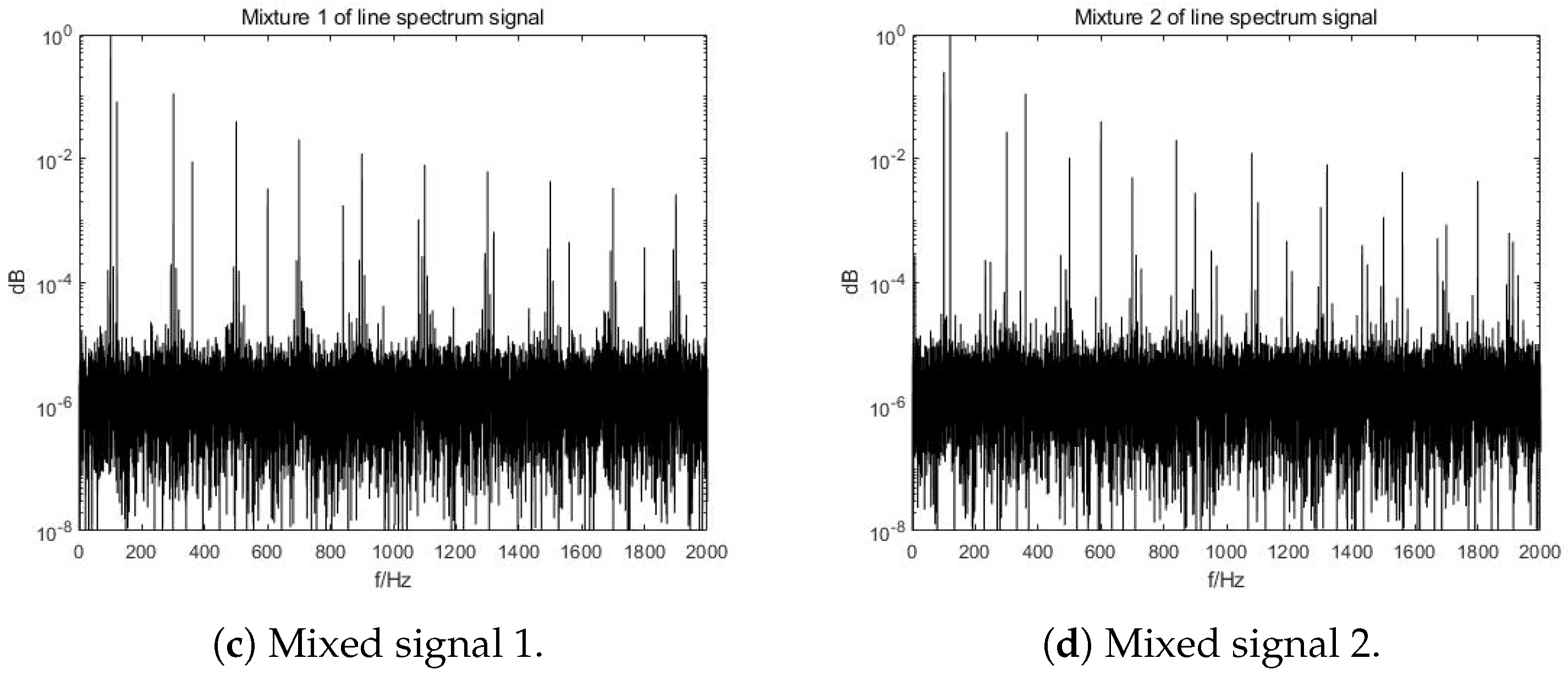
3.1. Original Signals, Distortion and Mixtures
3.2. Configuration and Referred Networks
4. Results and Discussion
4.1. Metrics of Results
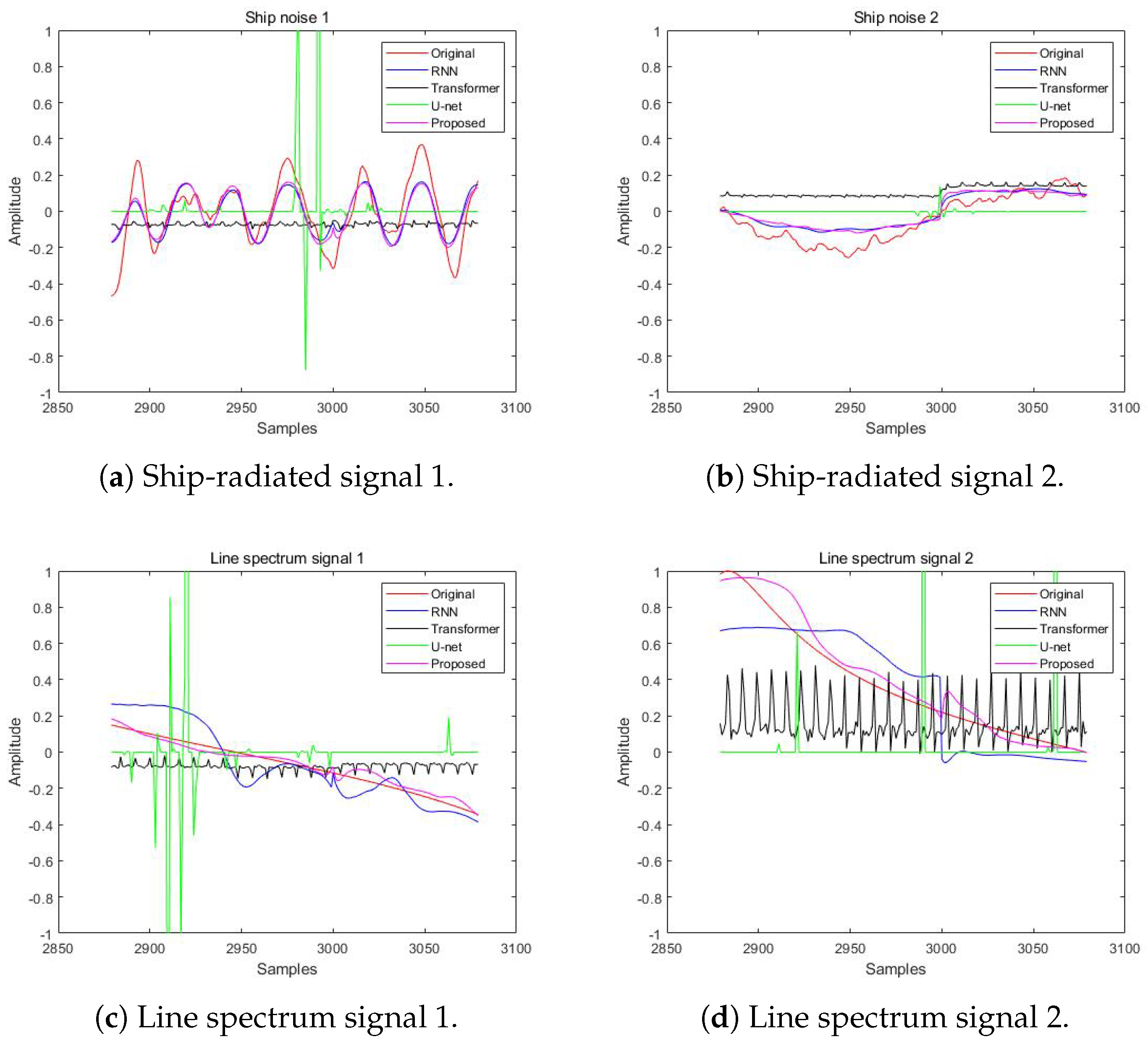
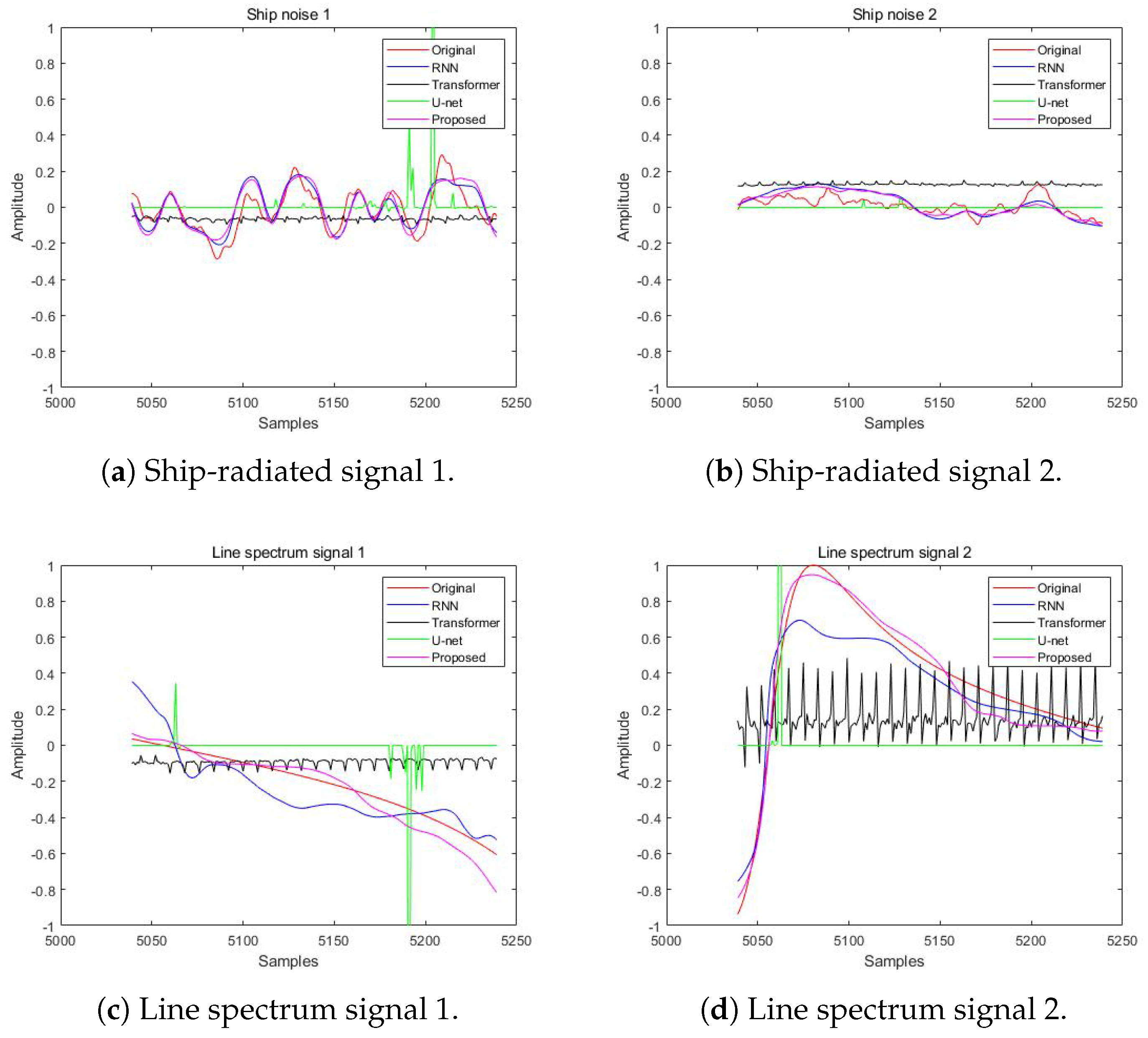
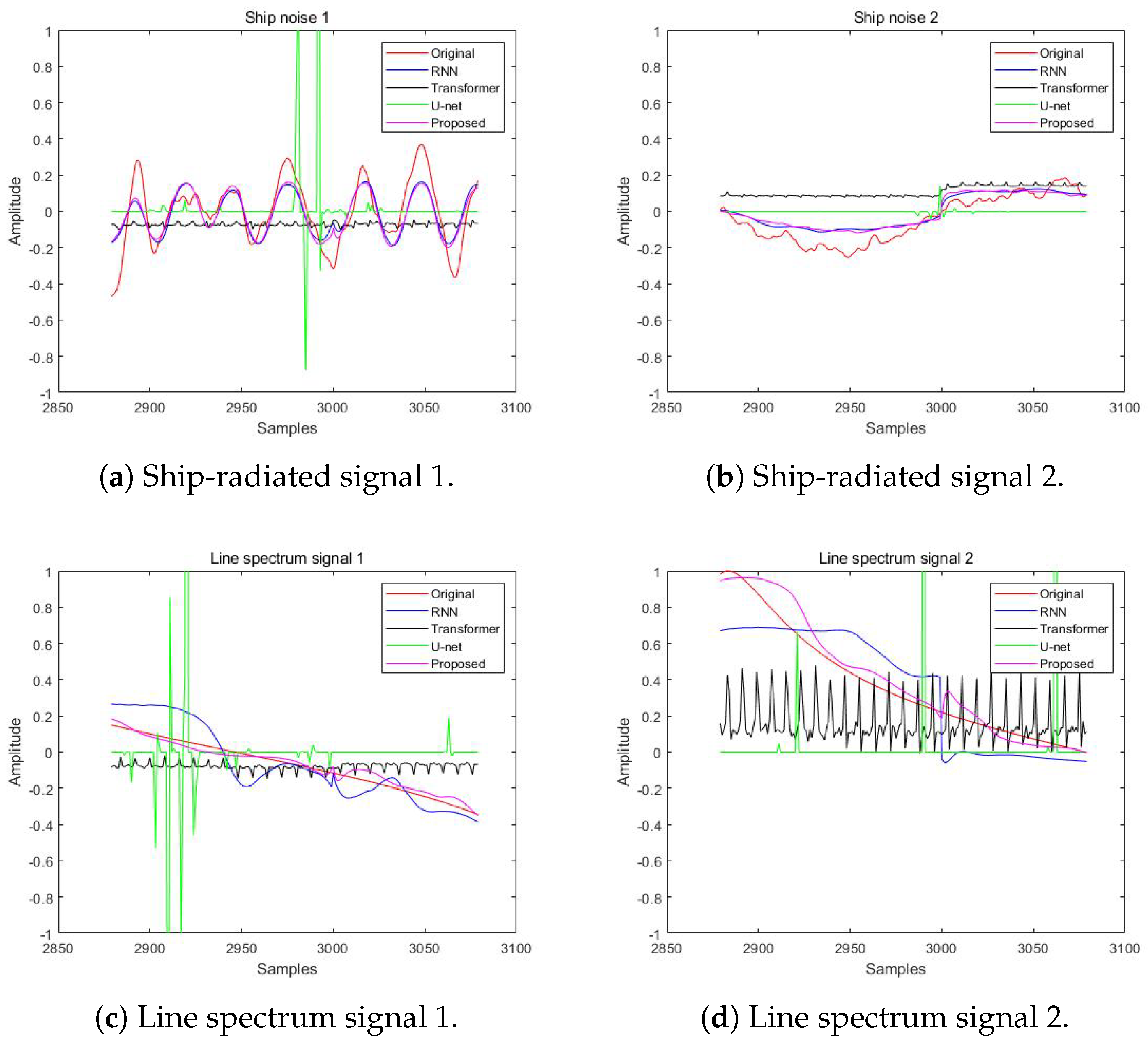
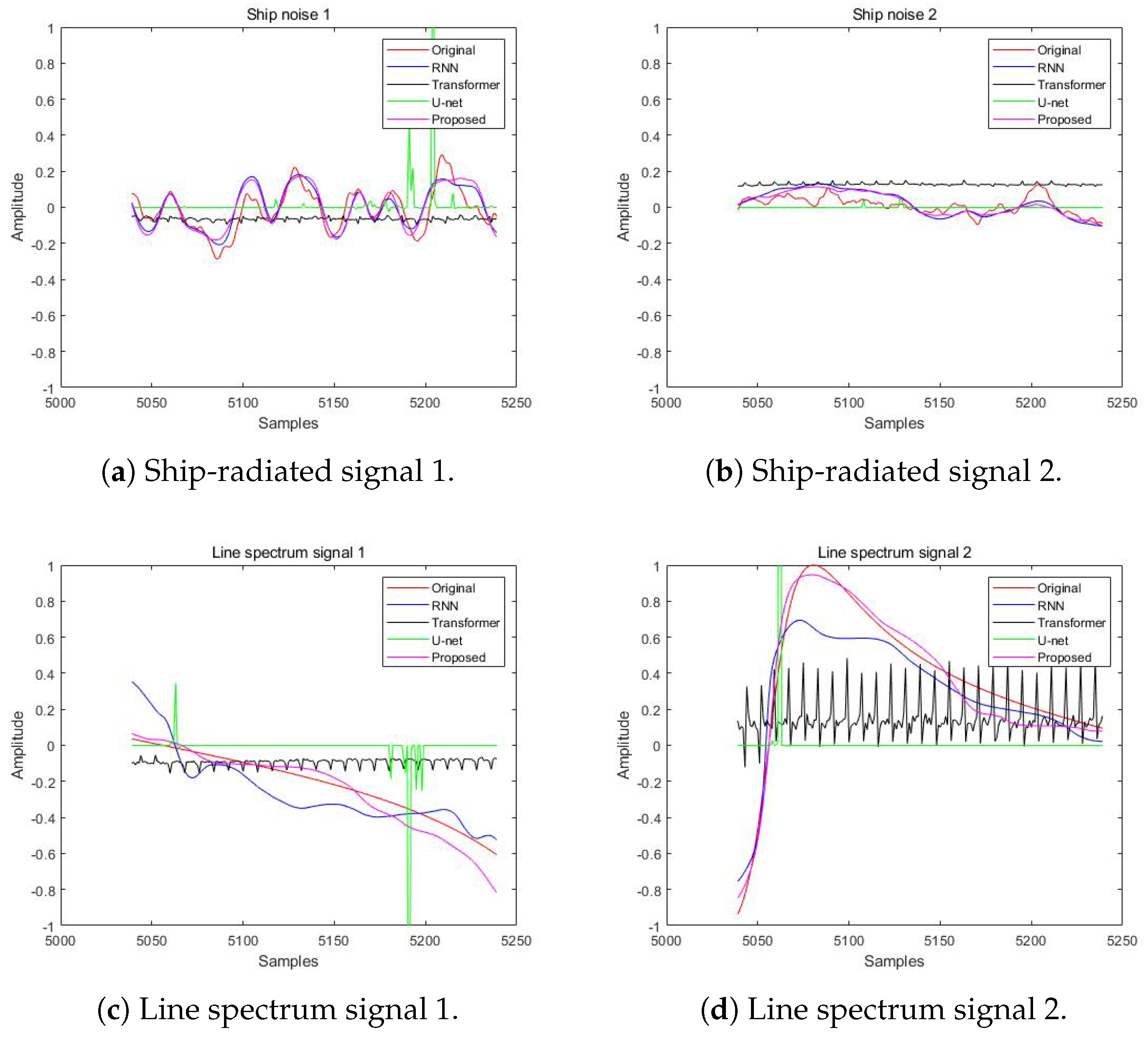
4.2. Separated Waveforms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SAS | Synthetic Aperture Sonar |
| BSS | Blind Source Separation |
| NMF | Non-Negative Matrix Factorization |
| FastICA | Fast Independent Component Analysis |
| MIMO | Multi-Input Multi-Output |
| OFDM | Orthogonal Frequency Division Modulation |
| IoUT | Internet of Underwater Things |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| RANN | Recurrent Attention Neural Network |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| PAM | Passive Acoustic Monitoring |
| BMI | Blind Mixture Identification |
| PCA | Principal Component Analysis |
| PNL | Post-Nonlinear |
| MSE | Mean Square Error |
| SDR | Signal-to-Distortion Ratio |
References
- Yin, F.; Li, C.; Wang, H.; Nie, L.; Zhang, Y.; Liu, C.; Yang, F. Weak Underwater Acoustic Target Detection and Enhancement with BM-SEED Algorithm. J. Mar. Sci. Eng. 2023, 11, 357. [Google Scholar] [CrossRef]
- Yin, F.; Li, C.; Wang, H.; Zhou, S.; Nie, L.; Zhang, Y.; Yin, H. A Robust Denoised Algorithm Based on Hessian-Sparse Deconvolution for Passive Underwater Acoustic Detection. J. Mar. Sci. Eng. 2023, 11, 2028. [Google Scholar] [CrossRef]
- Chu, H.; Li, C.; Wang, H.; Wang, J.; Tai, Y.; Zhang, Y.; Yang, F.; Benezeth, Y. A deep-learning based high-gain method for underwater acoustic signal detection in intensity fluctuation environments. Appl. Acoust. 2023, 211, 109513. [Google Scholar] [CrossRef]
- Zhou, M.; Wang, J.; Feng, X.; Sun, H.; Qi, J.; Lin, R. Neural-Network-Based Equalization and Detection for Underwater Acoustic Orthogonal Frequency Division Multiplexing Communications: A Low-Complexity Approach. Remote Sens. 2023, 15, 3796. [Google Scholar] [CrossRef]
- Yonglin, Z.; Chao, L.; Haibin, W.; Jun, W.; Fan, Y.; Fabrice, M. Deep learning aided OFDM receiver for underwater acoustic communications. Appl. Acoust. 2022, 187, 108515. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Y.; Wang, C.; Ouyang, D.; Huang, Y. A-OMP: An Adaptive OMP Algorithm for Underwater Acoustic OFDM Channel Estimation. IEEE Wirel. Commun. Lett. 2021, 10, 1761–1765. [Google Scholar] [CrossRef]
- Atanackovic, L.; Lampe, L.; Diamant, R. Deep-Learning Based Ship-Radiated Noise Suppression for Underwater Acoustic OFDM Systems. In Proceedings of the Global Oceans 2020: Singapore—U.S. Gulf Coast, Biloxi, MS, USA, 5–30 October 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Li, P.; Zhang, X.G.; Zhang, X.Y.; Liu, Y. Vertical array signal recovery method based on normalized virtual time reversal mirror. J. Phys. Conf. Ser. 2023, 2486, 012070. [Google Scholar] [CrossRef]
- Yuqing, Y.; Peng, X.; Nikos, D. Underwater localization with binary measurements: From compressed sensing to deep unfolding. Digit. Signal Process. 2023, 133, 103867. [Google Scholar] [CrossRef]
- Zonglong, B. Sparse Bayesian learning for sparse signal recovery using l1/2-norm. Appl. Acoust. 2023, 207, 109340. [Google Scholar] [CrossRef]
- Zhu, J.H.; Fan, C.Y.; Song, Y.P.; Huang, X.T.; Zhang, B.B.; Ma, Y.X. Coordination of Complementary Sets for Low Doppler-Induced Sidelobes. Remote Sens. 2022, 14, 1549. [Google Scholar] [CrossRef]
- Zhu, J.H.; Song, Y.P.; Jiang, N.; Xie, Z.; Fan, C.Y.; Huang, X.T. Enhanced Doppler Resolution and Sidelobe Suppression Performance for Golay Complementary Waveforms. Remote Sens. 2023, 15, 2452. [Google Scholar] [CrossRef]
- Xie, Z.; Xu, Z.; Han, S.; Zhu, J.; Huang, X. Modulus Constrained Minimax Radar Code Design Against Target Interpulse Fluctuation. IEEE Trans. Veh. Technol. 2023, 72, 13671–13676. [Google Scholar] [CrossRef]
- Zhang, X.B.; Wu, H.R.; Sun, H.X.; Ying, W.W. Multireceiver SAS Imagery Based on Monostatic Conversion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10835–10853. [Google Scholar] [CrossRef]
- Zhang, X.B.; Yang, P.X.; Zhou, M.Z. Multireceiver SAS Imagery With Generalized PCA. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1502205. [Google Scholar] [CrossRef]
- Cherry, E.C. Some experiments on the recognition of speech, with one and with two ears. J. Acoust. Soc. Am. 1953, 25, 975–979. [Google Scholar] [CrossRef]
- Zhang, W.; Tait, A.; Huang, C.; Ferreira de Lima, T.; Bilodeau, S.; Blow, E.C.; Jha, A.; Shastri, B.J.; Prucnal, P. Broadband physical layer cognitive radio with an integrated photonic processor for blind source separation. Nat. Commun. 2023, 14, 1107. [Google Scholar] [CrossRef] [PubMed]
- Kumari, R.; Mustafi, A. The spatial frequency domain designated watermarking framework uses linear blind source separation for intelligent visual signal processing. Front. Neurorobot. 2022, 16, 1054481. [Google Scholar] [CrossRef] [PubMed]
- Erdogan, A.T. An Information Maximization Based Blind Source Separation Approach for Dependent and Independent Sources. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4378–4382. [Google Scholar] [CrossRef]
- Boccuto, A.; Gerace, I.; Giorgetti, V.; Valenti, G. A Blind Source Separation Technique for Document Restoration Based on Image Discrete Derivative. In International Conference on Computational Science and Its Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 445–461. [Google Scholar]
- Martin, G.; Hooper, A.; Wright, T.J.; Selvakumaran, S. Blind Source Separation for MT-InSAR Analysis with Structural Health Monitoring Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7605–7618. [Google Scholar] [CrossRef]
- Yao, H.; Wang, H.; Zhang, Z.; Xu, Y.; Juergen, K. A stochastic nonlinear differential propagation model for underwater acoustic propagation: Theory and solution. Chaos Solitons Fractals 2021, 150, 111105. [Google Scholar]
- Naman, H.A.; Abdelkareem, A.E. Variable direction-based self-interference full-duplex channel model for underwater acoustic communication systems. Int. J. Commun. Syst. 2022, 35, e5096. [Google Scholar] [CrossRef]
- Shen, L.; Henson, B.; Zakharov, Y.; Mitchell, P. Digital Self-Interference Cancellation for Full-Duplex Underwater Acoustic Systems. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 192–196. [Google Scholar] [CrossRef]
- Yang, S.; Deane, G.B.; Preisig, J.C.; Sevüktekin, N.C.; Choi, J.W.; Singer, A.C. On the Reusability of Postexperimental Field Data for Underwater Acoustic Communications R&D. IEEE J. Ocean. Eng. 2019, 44, 912–931. [Google Scholar] [CrossRef]
- Ma, X.; Raza, W.; Wu, Z.; Bilal, M.; Zhou, Z.; Ali, A. A Nonlinear Distortion Removal Based on Deep Neural Network for Underwater Acoustic OFDM Communication with the Mitigation of Peak to Average Power Ratio. Appl. Sci. 2020, 10, 4986. [Google Scholar] [CrossRef]
- Campo-Valera, M.; Rodríguez-Rodríguez, I.; Rodríguez, J.V.; Herrera-Fernández, L.J. Proof of Concept of the Use of the Parametric Effect in Two Media with Application to Underwater Acoustic Communications. Electronics 2023, 12, 3459. [Google Scholar] [CrossRef]
- Yao, H.; Wang, H.; Xu, Y.; Juergen, K. A recurrent plot based stochastic nonlinear ray propagation model for underwater signal propagation. New J. Phys. 2020, 22, 063025. [Google Scholar]
- Cheng, Y.; Shi, J.; Deng, A. Effective Nonlinearity Parameter and Acoustic Propagation Oscillation Behavior in Medium of Water Containing Distributed Bubbles. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 345–350. [Google Scholar]
- Yu, J.; Yang, D.; Shi, J. Influence of softening effect of bubble water on cavity resonance. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 351–355. [Google Scholar]
- Li, J.; Yang, D.; Chen, G. Study on the acoustic scattering characteristics of the parametric array in the wake field of underwater cylindrical structures. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 340–344. [Google Scholar]
- Li, D.; Wu, M.; Yu, L.; Han, J.; Zhang, H. Single-channel blind source separation of underwater acoustic signals using improved NMF and FastICA. Front. Mar. Sci. 2023, 9, 1097003. [Google Scholar] [CrossRef]
- Khosravy, M.; Gupta, N.; Dey, N.; Crespo, R.G. Underwater IoT network by blind MIMO OFDM transceiver based on probabilistic Stone’s blind source separation. ACM Trans. Sens. Netw. (TOSN) 2022, 18, 1–27. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Zhou, A.; Ren, K.; Song, J. Underwater acoustic source separation with deep Bi-LSTM networks. In Proceedings of the 2021 4th International Conference on Information Communication and Signal Processing (ICICSP), Shanghai, China, 24–26 September 2021; pp. 254–258. [Google Scholar] [CrossRef]
- Chen, J.; Liu, C.; Xie, J.; An, J.; Huang, N. Time–Frequency Mask-Aware Bidirectional LSTM: A Deep Learning Approach for Underwater Acoustic Signal Separation. Sensors 2022, 22, 5598. [Google Scholar] [CrossRef]
- Hadi, F.I.M.A.; Ramli, D.A.; Azhar, A.S. Passive Acoustic Monitoring (PAM) of Snapping Shrimp Sound Based on Blind Source Separation (BSS) Technique. In Proceedings of the 11th International Conference on Robotics, Vision, Signal Processing and Power Applications: Enhancing Research and Innovation through the Fourth Industrial Revolution; Springer: Berlin/Heidelberg, Germany, 2022; pp. 605–611. [Google Scholar]
- Hadi, F.I.M.; Ramli, D.A.; Hassan, N. Spiny Lobster Sound Identification Based on Blind Source Separation (BSS) for Passive Acoustic Monitoring (PAM). Procedia Comput. Sci. 2021, 192, 4493–4502. [Google Scholar] [CrossRef]
- Deville, Y.; Faury, G.; Achard, V.; Briottet, X. An NMF-based method for jointly handling mixture nonlinearity and intraclass variability in hyperspectral blind source separation. Digit. Signal Process. 2023, 133, 103838. [Google Scholar] [CrossRef]
- Isomura, T.; Toyoizumi, T. On the achievability of blind source separation for high-dimensional nonlinear source mixtures. Neural Comput. 2021, 33, 1433–1468. [Google Scholar] [CrossRef]
- Moraes, C.P.; Fantinato, D.G.; Neves, A. Epanechnikov kernel for PDF estimation applied to equalization and blind source separation. Signal Process. 2021, 189, 108251. [Google Scholar] [CrossRef]
- He, J.; Chen, W.; Song, Y. Single channel blind source separation under deep recurrent neural network. Wirel. Pers. Commun. 2020, 115, 1277–1289. [Google Scholar] [CrossRef]
- Zamani, H.; Razavikia, S.; Otroshi-Shahreza, H.; Amini, A. Separation of Nonlinearly Mixed Sources Using End-to-End Deep Neural Networks. IEEE Signal Process. Lett. 2020, 27, 101–105. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 1–11. [Google Scholar]
- Ansari, S.; Alnajjar, K.A.; Khater, T.; Mahmoud, S.; Hussain, A. A Robust Hybrid Neural Network Architecture for Blind Source Separation of Speech Signals Exploiting Deep Learning. IEEE Access 2023, 11, 100414–100437. [Google Scholar] [CrossRef]
- Herzog, A.; Chetupalli, S.R.; Habets, E.A.P. AmbiSep: Ambisonic-to-Ambisonic Reverberant Speech Separation Using Transformer Networks. In Proceedings of the 2022 International Workshop on Acoustic Signal Enhancement (IWAENC), Bamberg, Germany, 5–8 September 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Qian, J.; Liu, X.; Yu, Y.; Li, W. Stripe-Transformer: Deep stripe feature learning for music source separation. EURASIP J. Audio Speech Music. Process. 2023, 2023, 2. [Google Scholar] [CrossRef]
- Wang, J.; Liu, H.; Ying, H.; Qiu, C.; Li, J.; Anwar, M.S. Attention-based neural network for end-to-end music separation. CAAI Trans. Intell. Technol. 2023, 8, 355–363. [Google Scholar] [CrossRef]
- Reddy, P.; Wisdom, S.; Greff, K.; Hershey, J.R.; Kipf, T. AudioSlots: A slot-centric generative model for audio separation. arXiv 2023, arXiv:2305.05591. [Google Scholar]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Grondin, F.; Bronzi, M. Exploring Self-Attention Mechanisms for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2169–2180. [Google Scholar] [CrossRef]
- Melissaris, T.; Schenke, S.; Van Terwisga, T.J. Cavitation erosion risk assessment for a marine propeller behind a Ro–Ro container vessel. Phys. Fluids 2023, 35, 013342. [Google Scholar] [CrossRef]
- Abbasia, A.A.; Viviania, M.; Bertetta, D.; Delucchia, M.; Ricottic, R.; Tania, G. Experimental Analysis of Cavitation Erosion on Blade Root of Controlable Pitch Propeller. In Proceedings of the 20th International Conference on Ship & Maritime Research, Genoa, La Spazia, Italy, 15–17 June 2022; pp. 254–262. [Google Scholar]
- Wang, Y.; Zhang, H.; Huang, W. Fast ship radiated noise recognition using three-dimensional mel-spectrograms with an additive attention based transformer. Front. Mar. Sci. 2023, 1–15. [Google Scholar] [CrossRef]
- Pu, X.; Yi, P.; Chen, K.; Ma, Z.; Zhao, D.; Ren, Y. EEGDnet: Fusing non-local and local self-similarity for EEG signal denoising with transformer. Comput. Biol. Med. 2022, 151, 106248:1–106248:9. [Google Scholar] [CrossRef] [PubMed]
- Woo, B.J.; Kim, H.Y.; Kim, J.; Kim, N.S. Speech separation based on dptnet with sparse attention. In Proceedings of the 2021 7th IEEE International Conference on Network Intelligence and Digital Content (IC-NIDC), Beijing, China, 17–19 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 339–343. [Google Scholar]
- Liu, Y.; Xu, X.; Tu, W.; Yang, Y.; Xiao, L. Improving Acoustic Echo Cancellation by Mixing Speech Local and Global Features with Transformer. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Yin, J.; Liu, A.; Li, C.; Qian, R.; Chen, X. A GAN Guided Parallel CNN and Transformer Network for EEG Denoising. IEEE J. Biomed. Health Inform. 2023, 1–12, Early Access. [Google Scholar] [CrossRef] [PubMed]
- Ji, W.; Yan, G.; Li, J.; Piao, Y.; Yao, S.; Zhang, M.; Cheng, L.; Lu, H. DMRA: Depth-induced multi-scale recurrent attention network for RGB-D saliency detection. IEEE Trans. Image Process. 2022, 31, 2321–2336. [Google Scholar] [CrossRef] [PubMed]
- Reza, S.; Ferreira, M.C.; Machado, J.J.M.; Tavares, J.M.R. A multi-head attention-based transformer model for traffic flow forecasting with a comparative analysis to recurrent neural networks. Expert Syst. Appl. 2022, 202, 117275. [Google Scholar] [CrossRef]
- Geng, X.; He, X.; Xu, L.; Yu, J. Graph correlated attention recurrent neural network for multivariate time series forecasting. Inf. Sci. 2022, 606, 126–142. [Google Scholar] [CrossRef]
- De Maissin, A.; Vallée, R.; Flamant, M.; Fondain-Bossiere, M.; Le Berre, C.; Coutrot, A.; Normand, N.; Mouchère, H.; Coudol, S.; Trang, C.; et al. Multi-expert annotation of Crohn’s disease images of the small bowel for automatic detection using a convolutional recurrent attention neural network. Endosc. Int. Open 2021, 9, E1136–E1144. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Gao, X.; Lu, W.; He, L.; Li, J. Beyond vision: A multimodal recurrent attention convolutional neural network for unified image aesthetic prediction tasks. IEEE Trans. Multimed. 2020, 23, 611–623. [Google Scholar] [CrossRef]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Yu, J.; Yang, D.; Shi, J.; Zhang, J.; Fu, X. Nonlinear sound field under bubble softening effect. J. Harbin Eng. Univ. 2023, 44, 1433–1444. [Google Scholar]
- Deville, Y.; Duarte, L.T.; Hosseini, S. Nonlinear Blind Source Separation and Blind Mixture Identification: Methods for Bilinear, Linear-Quadratic and Polynomial Mixtures; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Moraes, C.P.; Saldanha, J.; Neves, A.; Fantinato, D.G.; Attux, R.; Duarte, L.T. An SOS-Based Algorithm for Source Separation in Nonlinear Mixtures. In Proceedings of the 2021 IEEE Statistical Signal Processing Workshop (SSP), Rio de Janeiro, Brazil, 11–14 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 156–160. [Google Scholar]
- Wang, H.; Guo, L. Research of Modulation Feature Extraction from Ship-Radiated Noise. Proc. J. Phys. Conf. Ser. 2020, 1631, 012130. [Google Scholar] [CrossRef]
- Peng, C.; Yang, L.; Jiang, X.; Song, Y. Design of a ship radiated noise model and its application to feature extraction based on winger’s higher-order spectrum. In Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; IEEE: Piscataway, NJ, USA, 2019; Volume 1, pp. 582–587. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cao, Y.; Zhang, H.; Qin, Y.; Zhu, H.; Cao, J.; Ma, N. Joint Denoising Blind Source Separation Algorithmfor Anti-jamming. In Proceedings of the 2021 4th International Conference on Information Communication and Signal Processing (ICICSP), Shanghai, China, 24–26 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 27–35. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Parameters |
|---|---|
| RNN | 0.3 M |
| Transformer | 24 K |
| U-net | 3.4 M |
| RANN (1 layer) | 1.1 M |
| Proposed RANN (2 layers) | 2.1 M |
| RANN (3 layers) | 3.2 M |
| RANN (4 layers) | 4.2 M |
| Network | MSE | SDR (dB) | |
|---|---|---|---|
| RNN | 0.007 | 0.817 | 4.495 |
| Transformer | 0.037 | 0.001 | −2.947 |
| U-net | 0.053 | 0.006 | −4.453 |
| RANN (1 layer) | 0.007 | 0.830 | 4.492 |
| Proposed RANN (2 layers) | 0.006 | 0.840 | 4.651 |
| RANN (3 layers) | 0.006 | 0.842 | 4.674 |
| RANN (4 layers) | 0.006 | 0.843 | 4.684 |
| Network | MSE | SDR (dB) | |
|---|---|---|---|
| RNN | 0.035 | 0.929 | 8.621 |
| Transformer | 0.311 | 0.015 | −0.842 |
| U-net | 0.504 | −0.002 | −2.939 |
| RANN (1 layer) | 0.020 | 0.967 | 11.003 |
| Proposed RANN (2 layers) | 0.014 | 0.981 | 12.699 |
| RANN (3 layers) | 0.013 | 0.987 | 12.850 |
| RANN (4 layers) | 0.012 | 0.992 | 12.922 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, R.; Feng, X.; Wang, J.; Sun, H.; Zhou, M.; Esmaiel, H. Underwater Acoustic Nonlinear Blind Ship Noise Separation Using Recurrent Attention Neural Networks. Remote Sens. 2024, 16, 653. https://doi.org/10.3390/rs16040653
Song R, Feng X, Wang J, Sun H, Zhou M, Esmaiel H. Underwater Acoustic Nonlinear Blind Ship Noise Separation Using Recurrent Attention Neural Networks. Remote Sensing. 2024; 16(4):653. https://doi.org/10.3390/rs16040653
Chicago/Turabian StyleSong, Ruiping, Xiao Feng, Junfeng Wang, Haixin Sun, Mingzhang Zhou, and Hamada Esmaiel. 2024. "Underwater Acoustic Nonlinear Blind Ship Noise Separation Using Recurrent Attention Neural Networks" Remote Sensing 16, no. 4: 653. https://doi.org/10.3390/rs16040653
APA StyleSong, R., Feng, X., Wang, J., Sun, H., Zhou, M., & Esmaiel, H. (2024). Underwater Acoustic Nonlinear Blind Ship Noise Separation Using Recurrent Attention Neural Networks. Remote Sensing, 16(4), 653. https://doi.org/10.3390/rs16040653