
Integrated Framework for Unsupervised Building Segmentation with Segment Anything Model-Based Pseudo-Labeling and Weakly Supervised Learning


Abstract
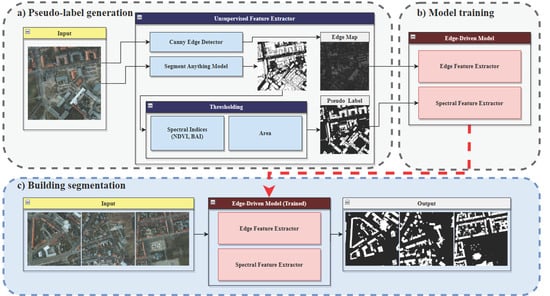
1. Introduction
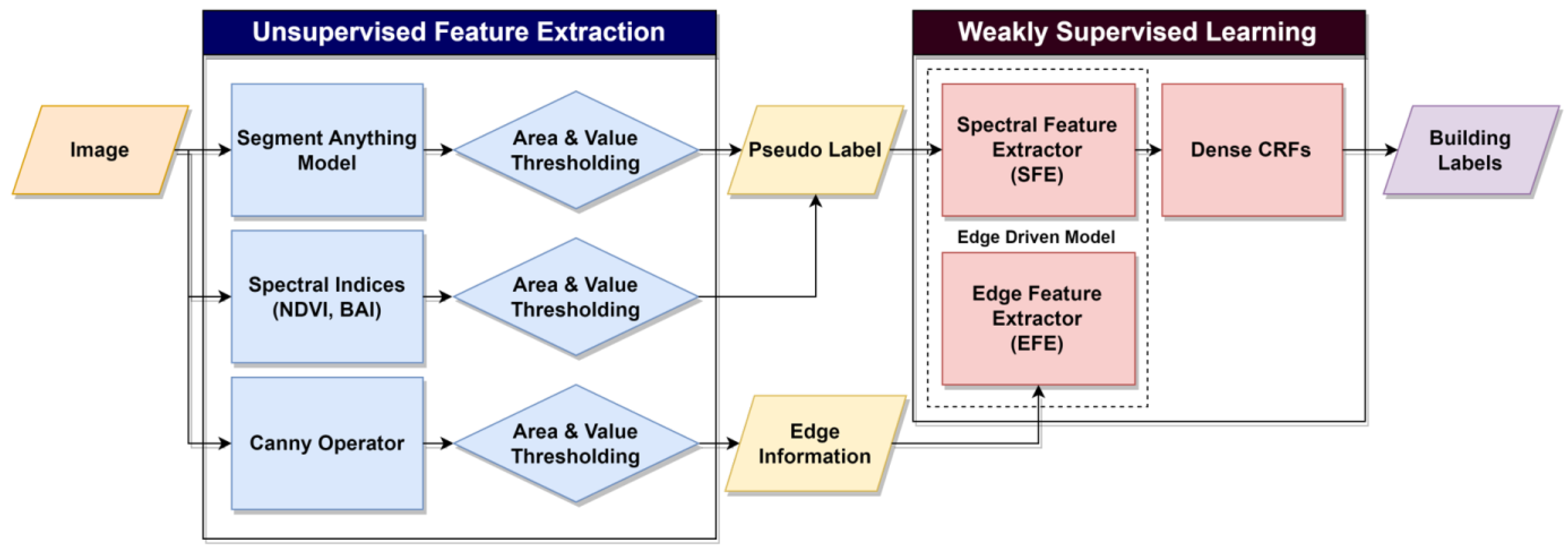
2. Materials and Methods
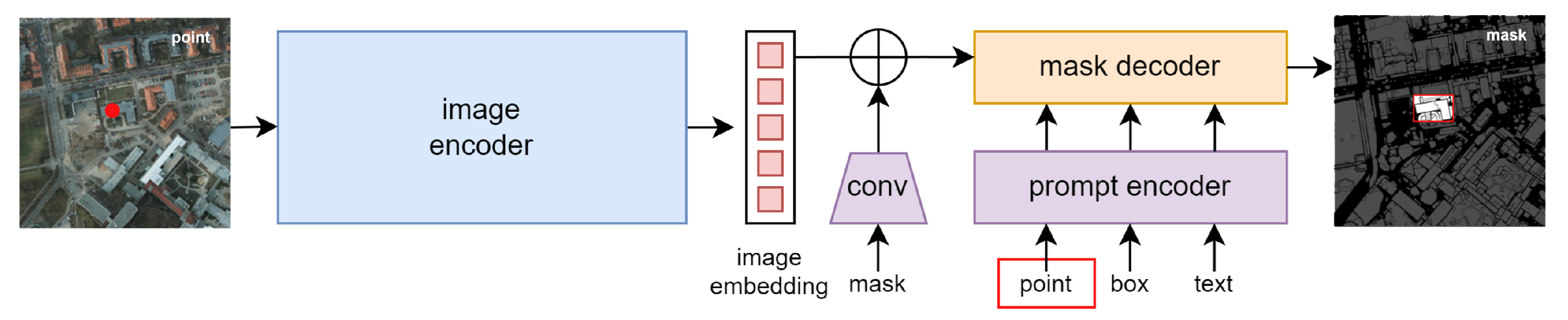
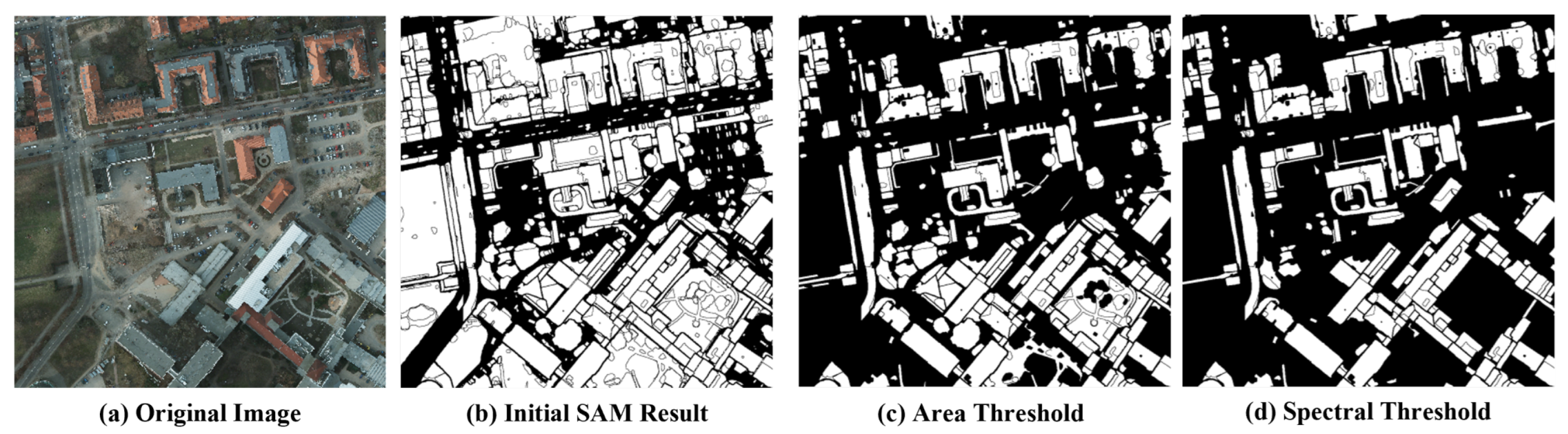
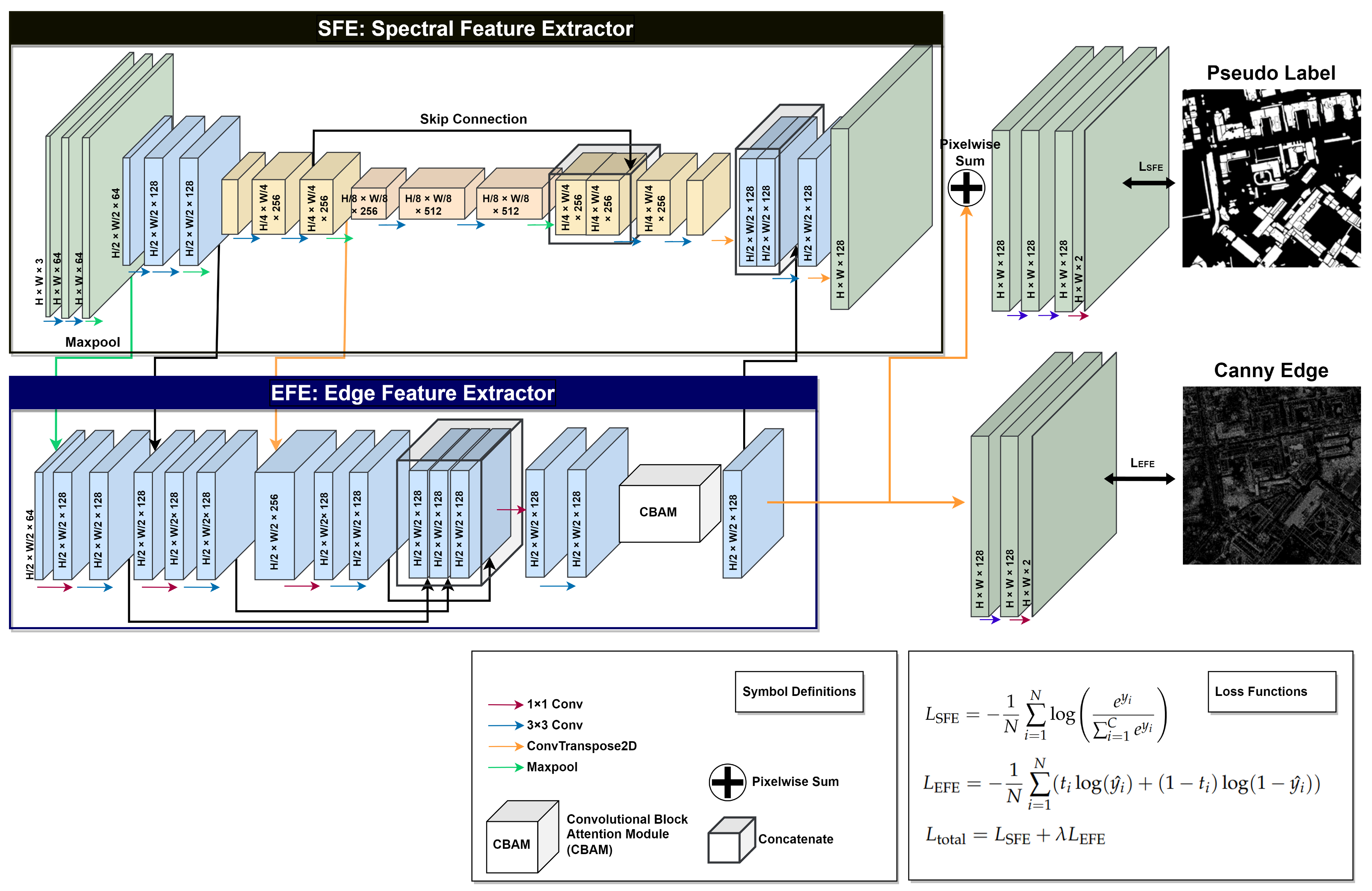
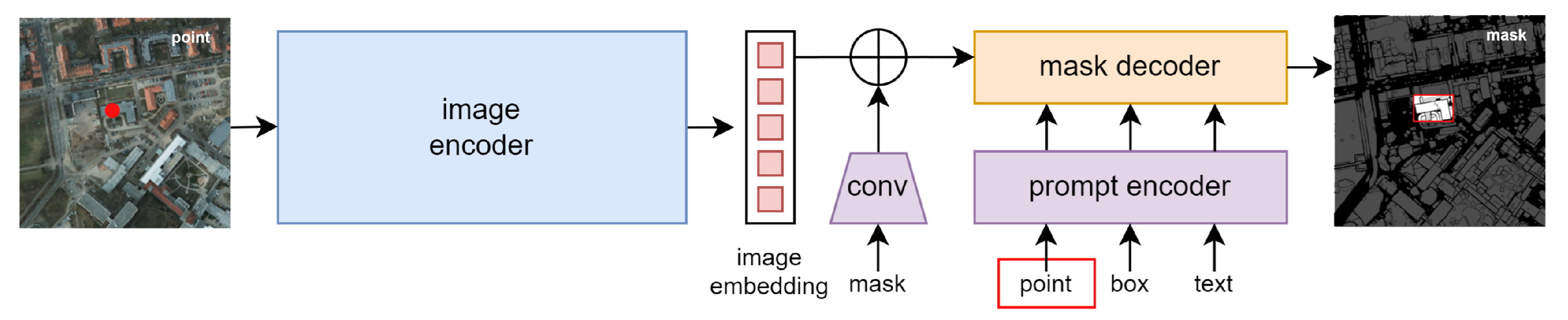
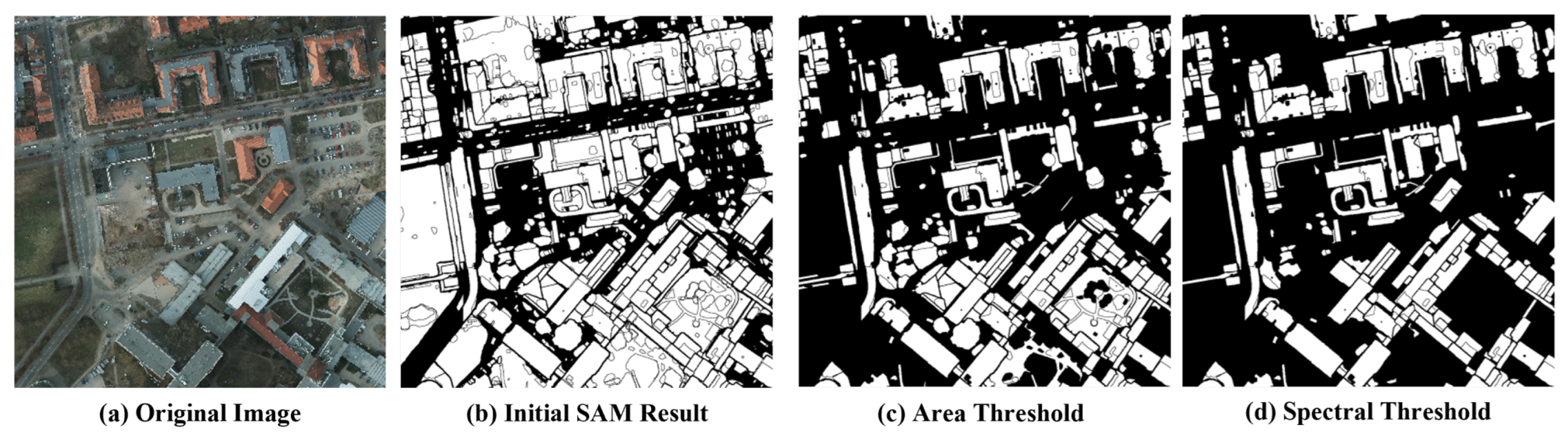
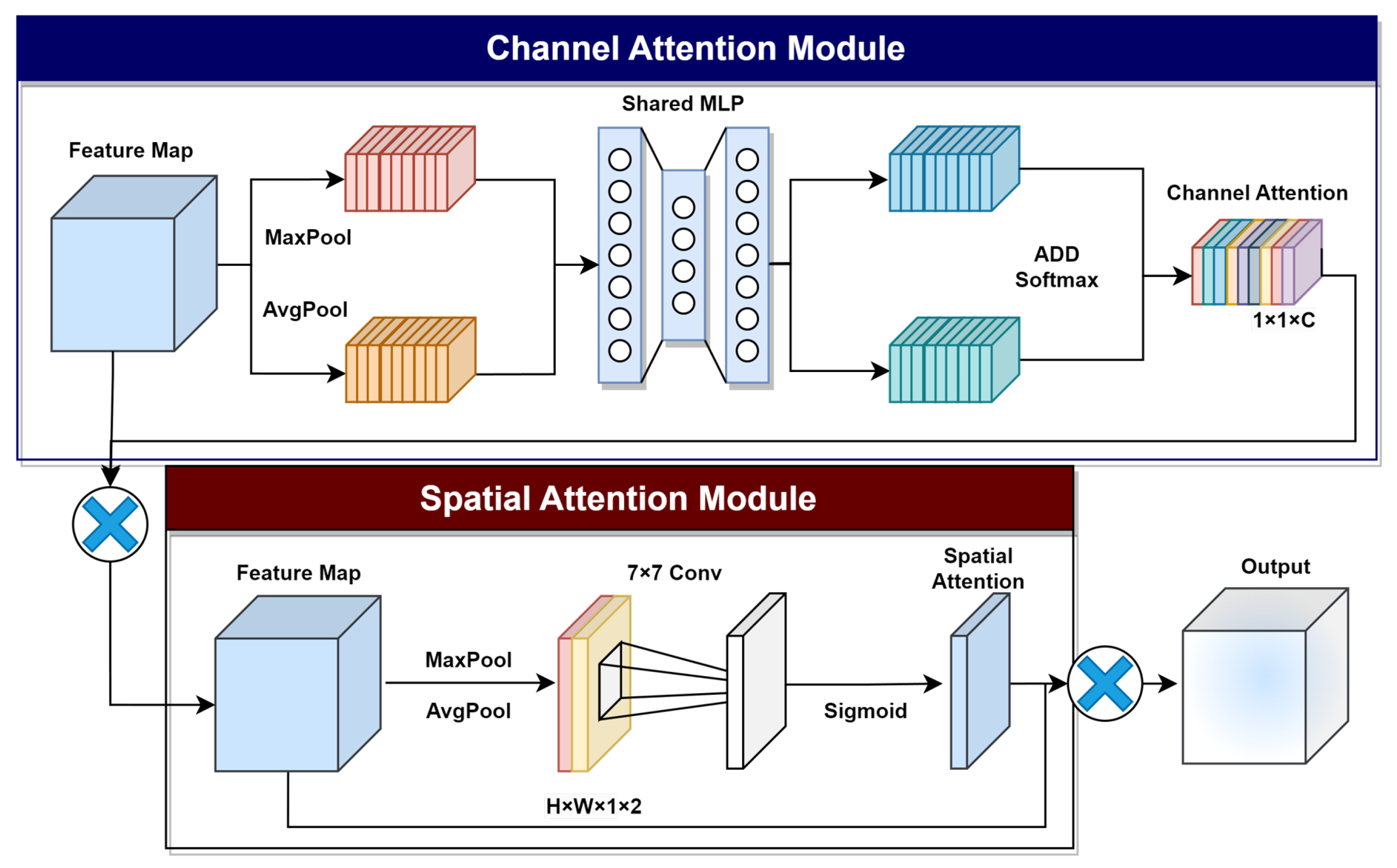
2.1. Unsupervised Feature Extractor
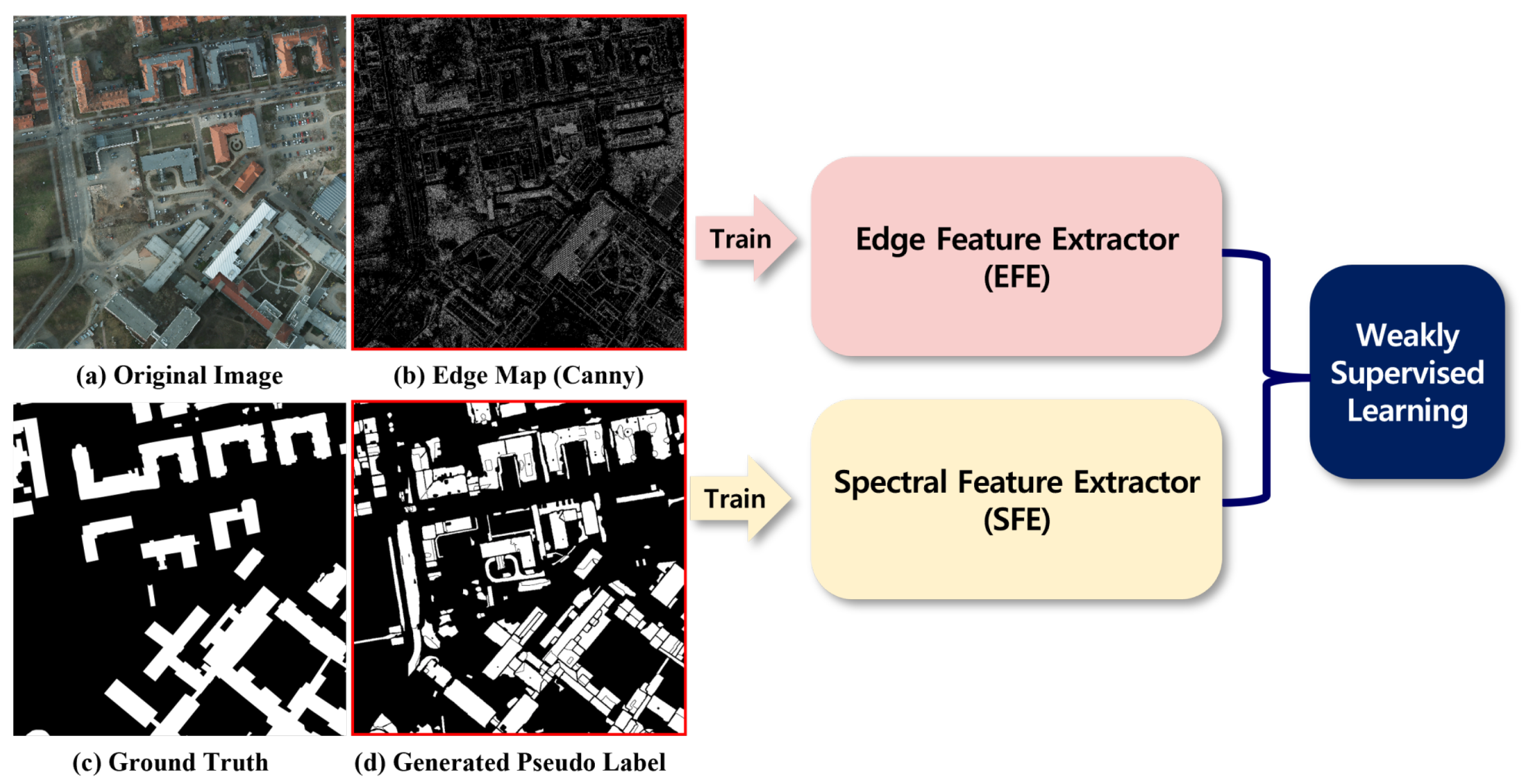
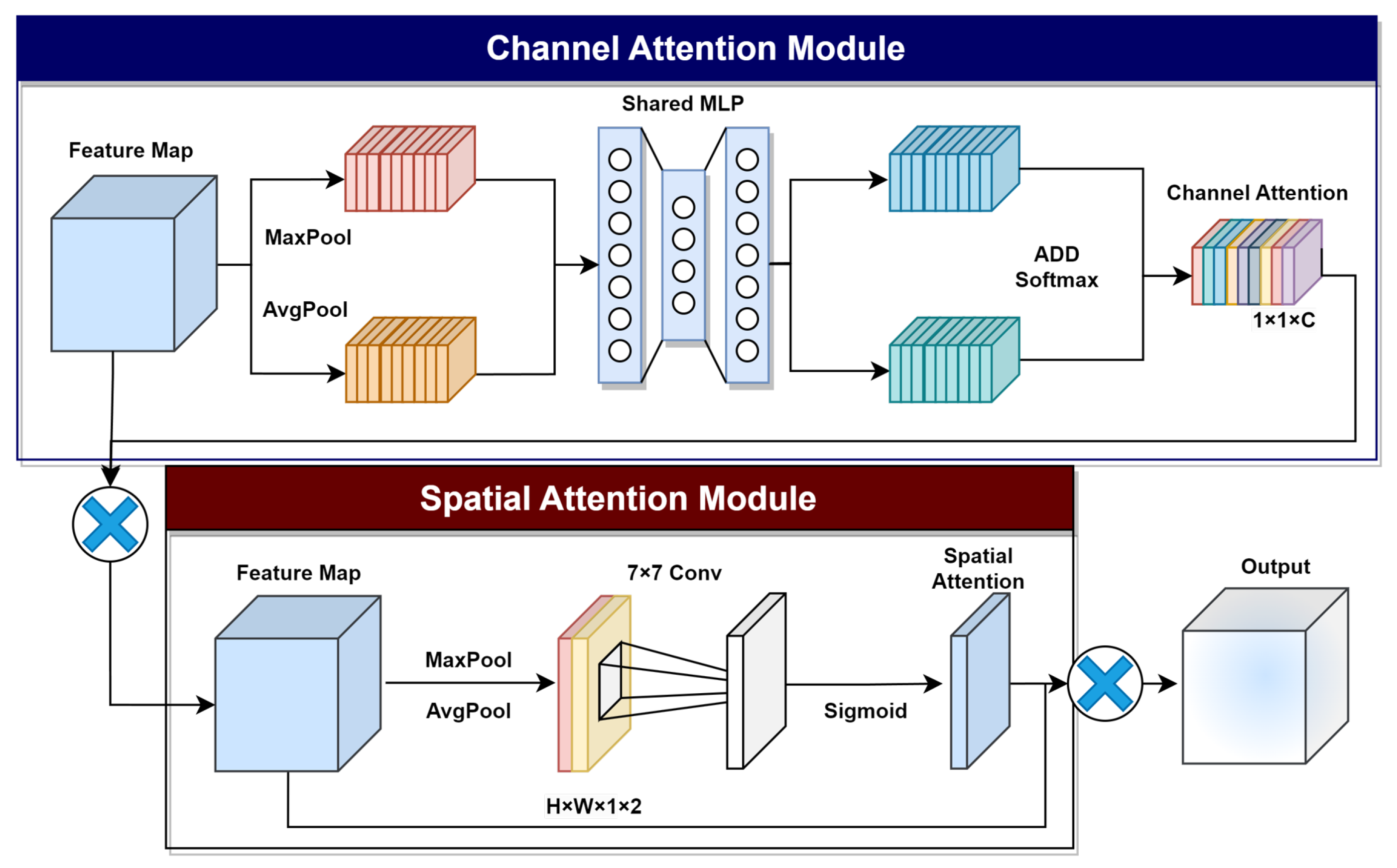
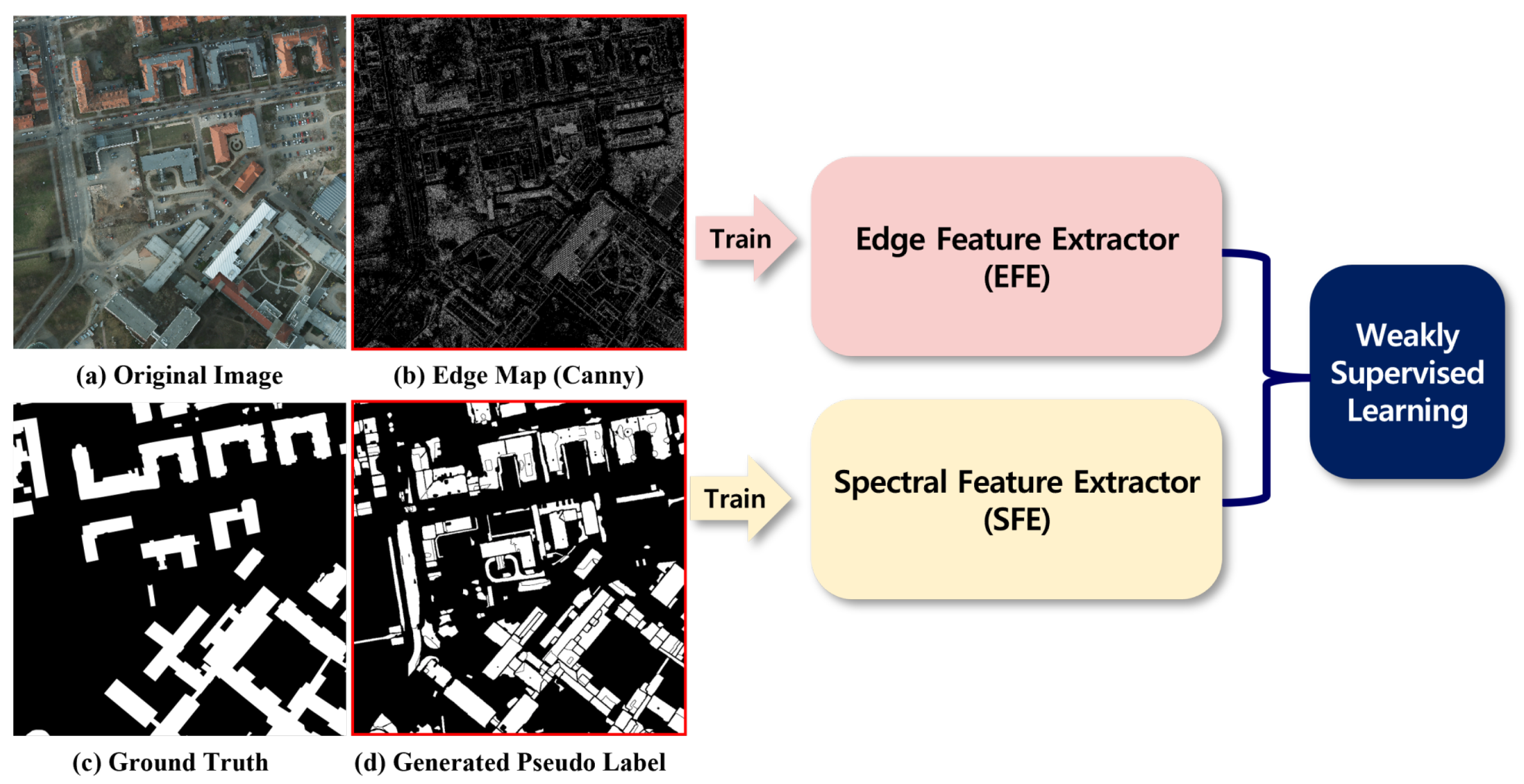
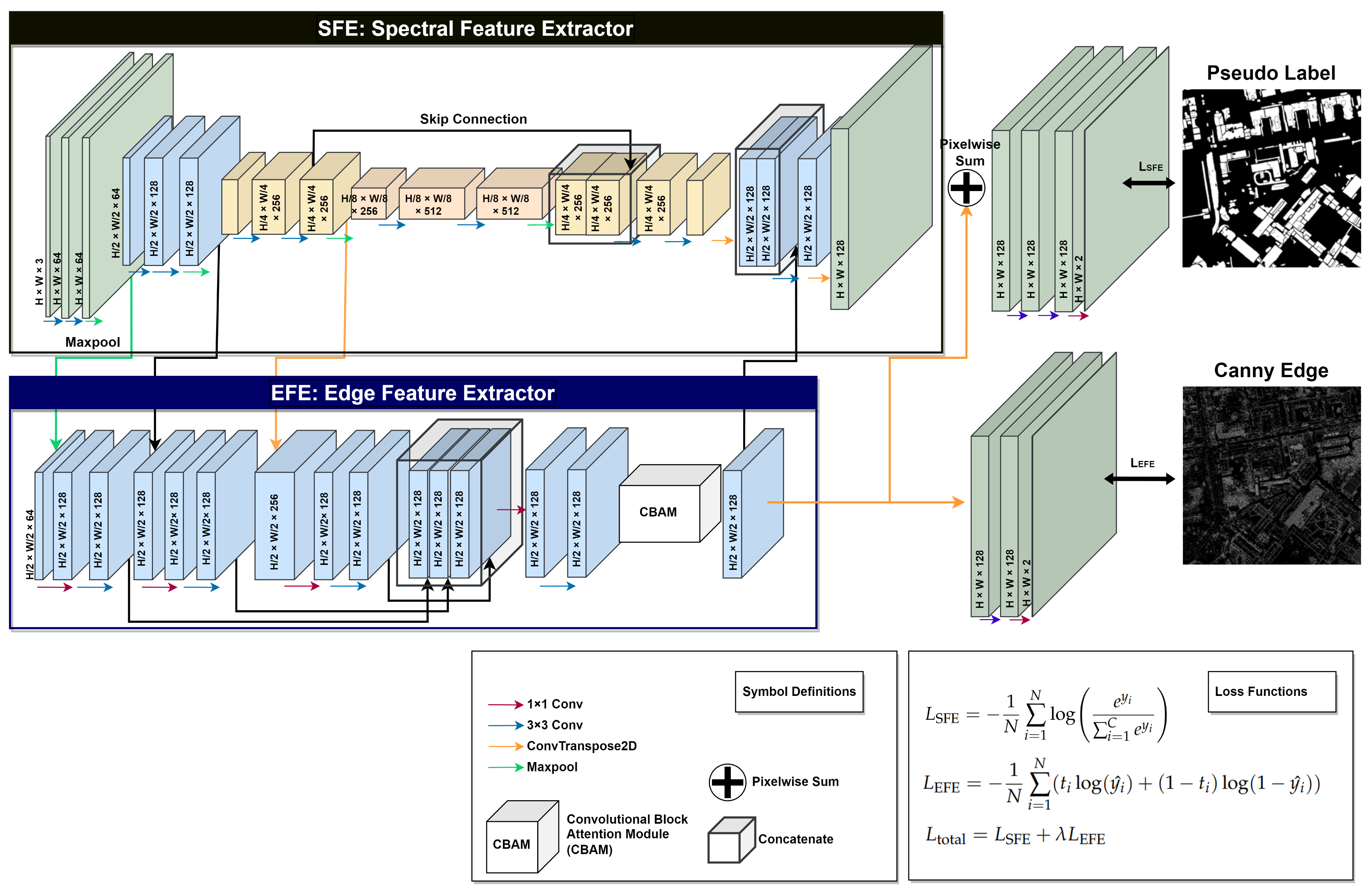
2.2. Weakly Supervised Learning
3. Experiments
3.1. Datasets
3.2. Evaluation
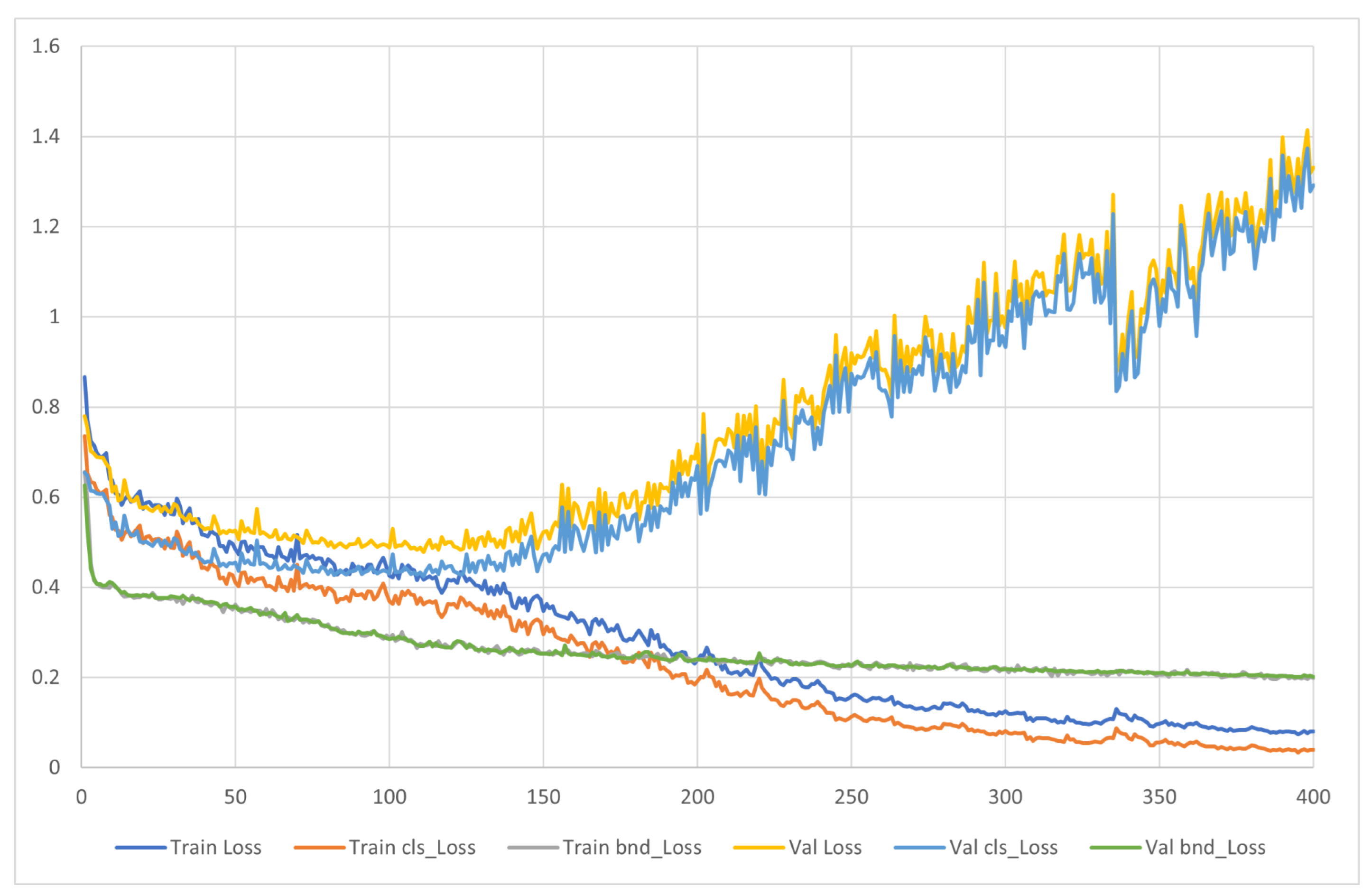
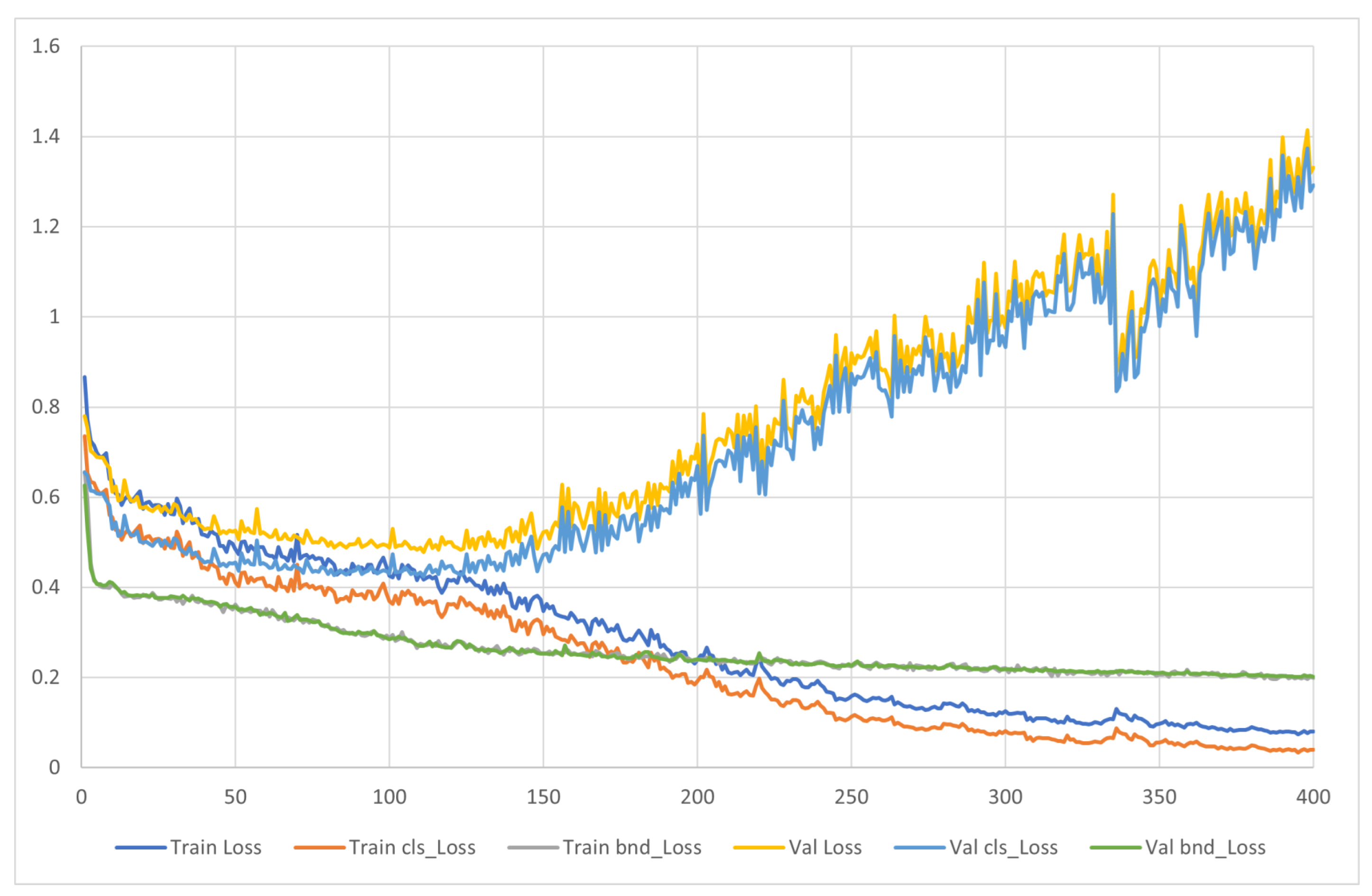
3.3. Training and Validation
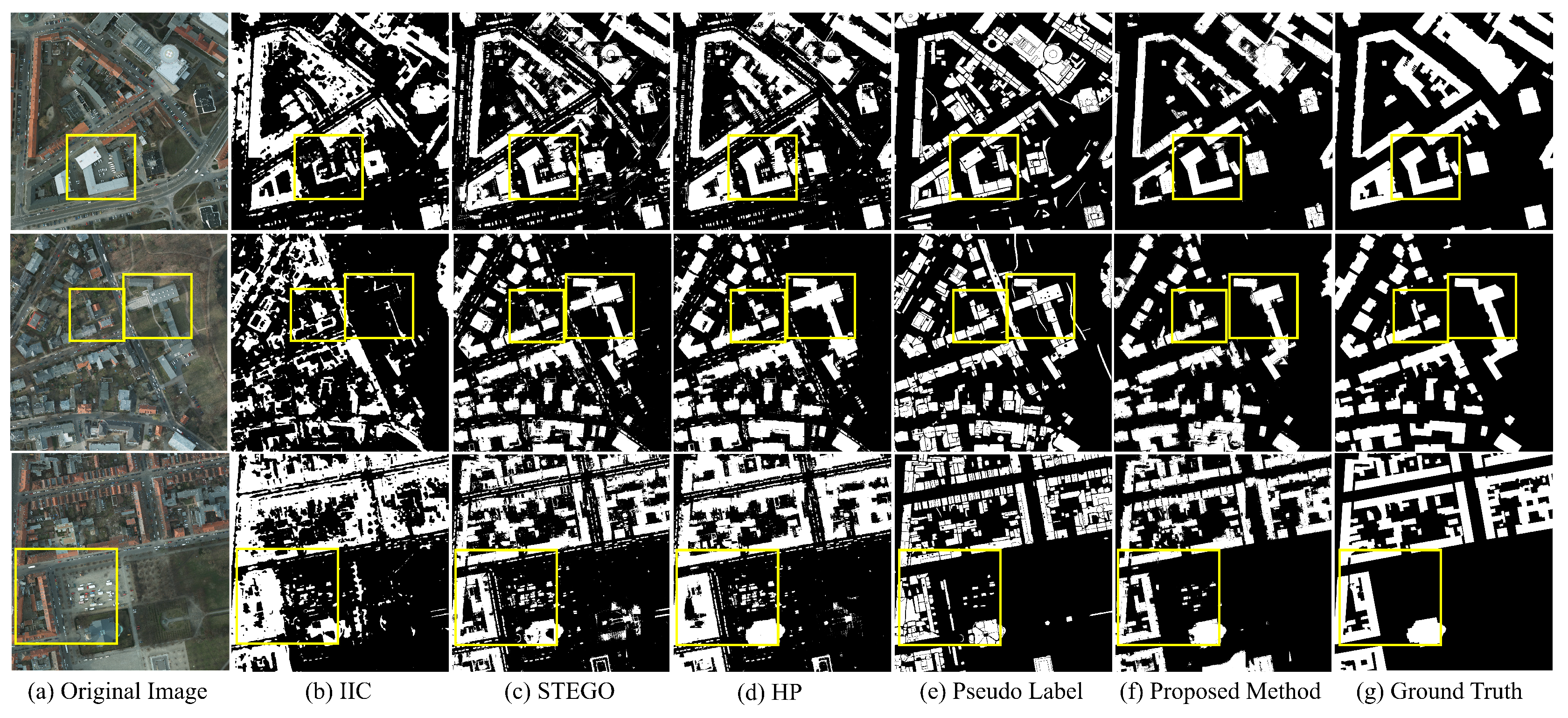
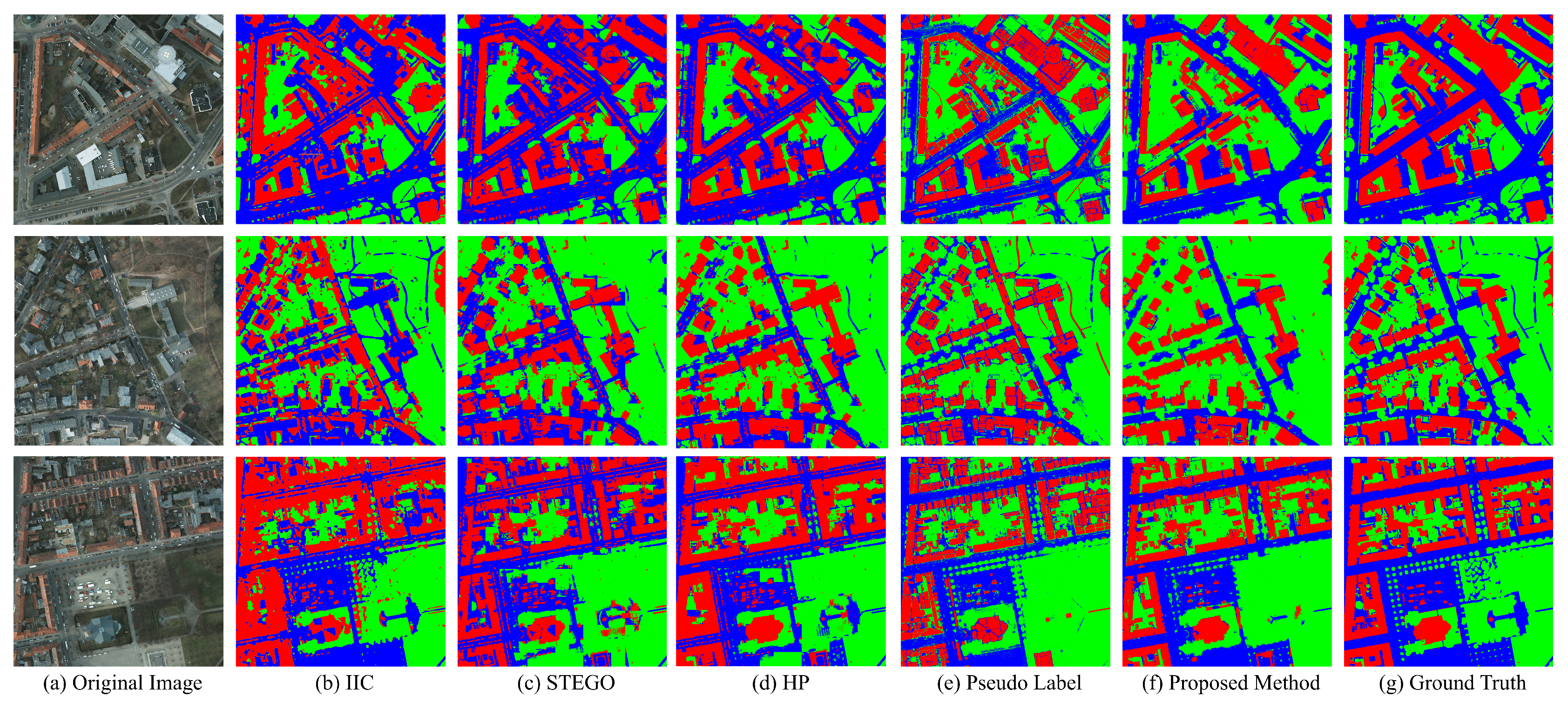
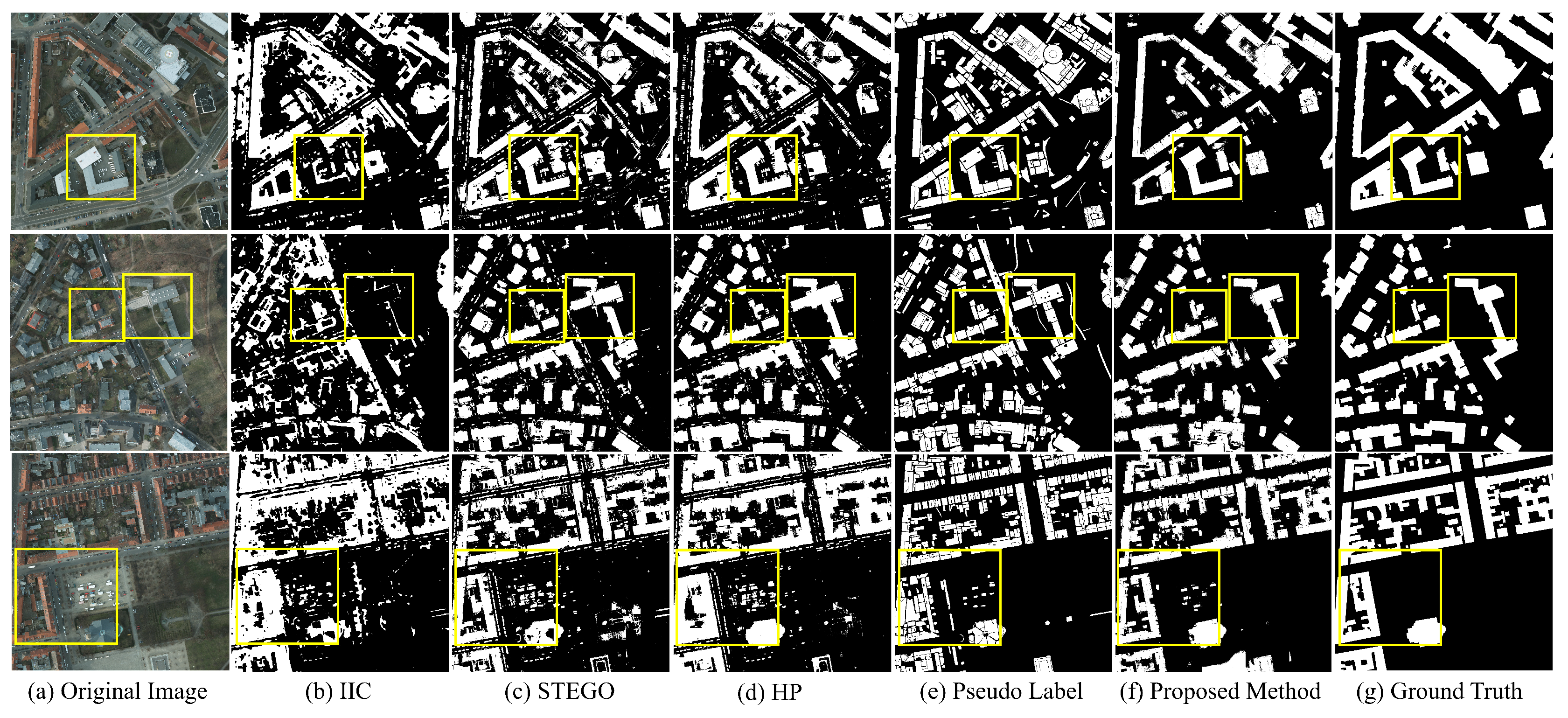
3.4. Experimental Results
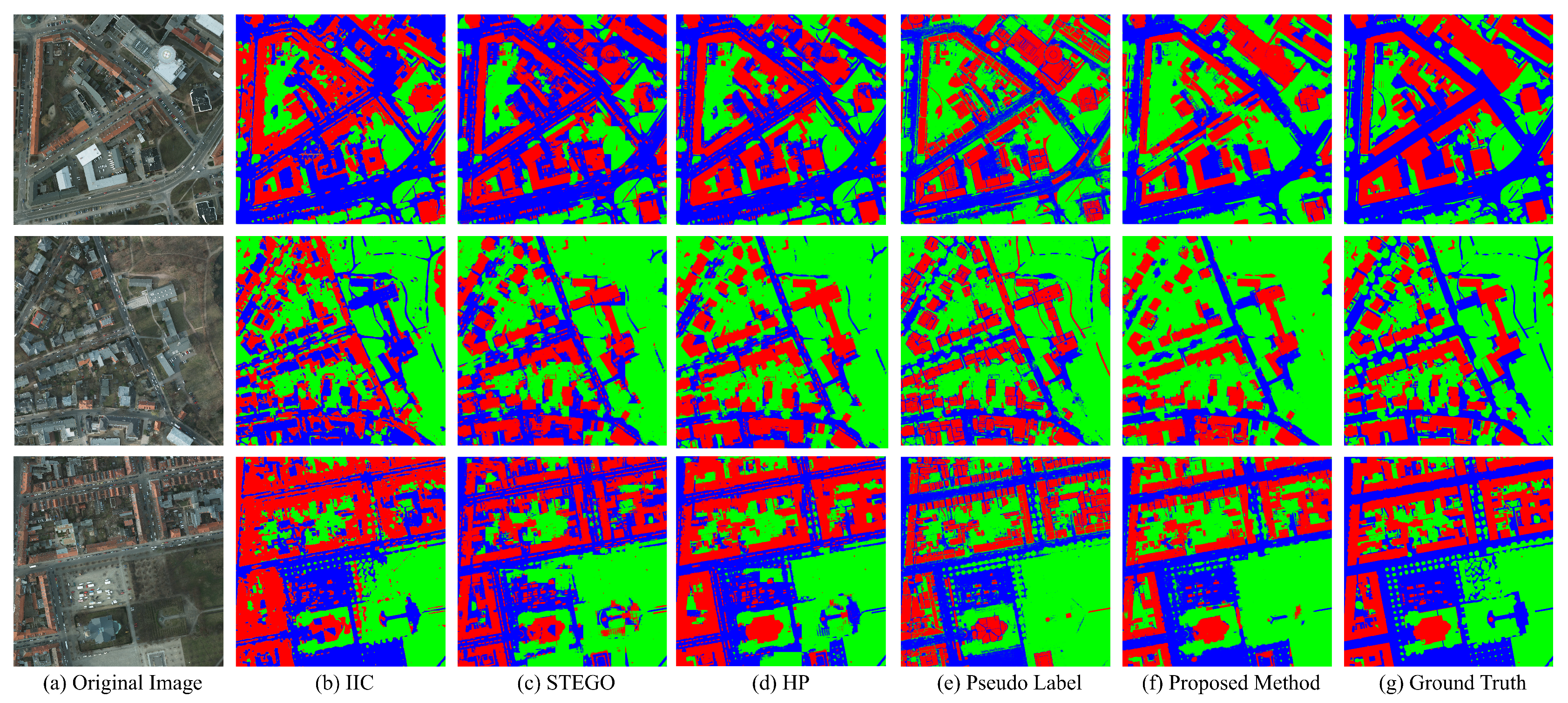
3.4.1. Unsupervised Models
3.4.2. Supervised Models
4. Discussion
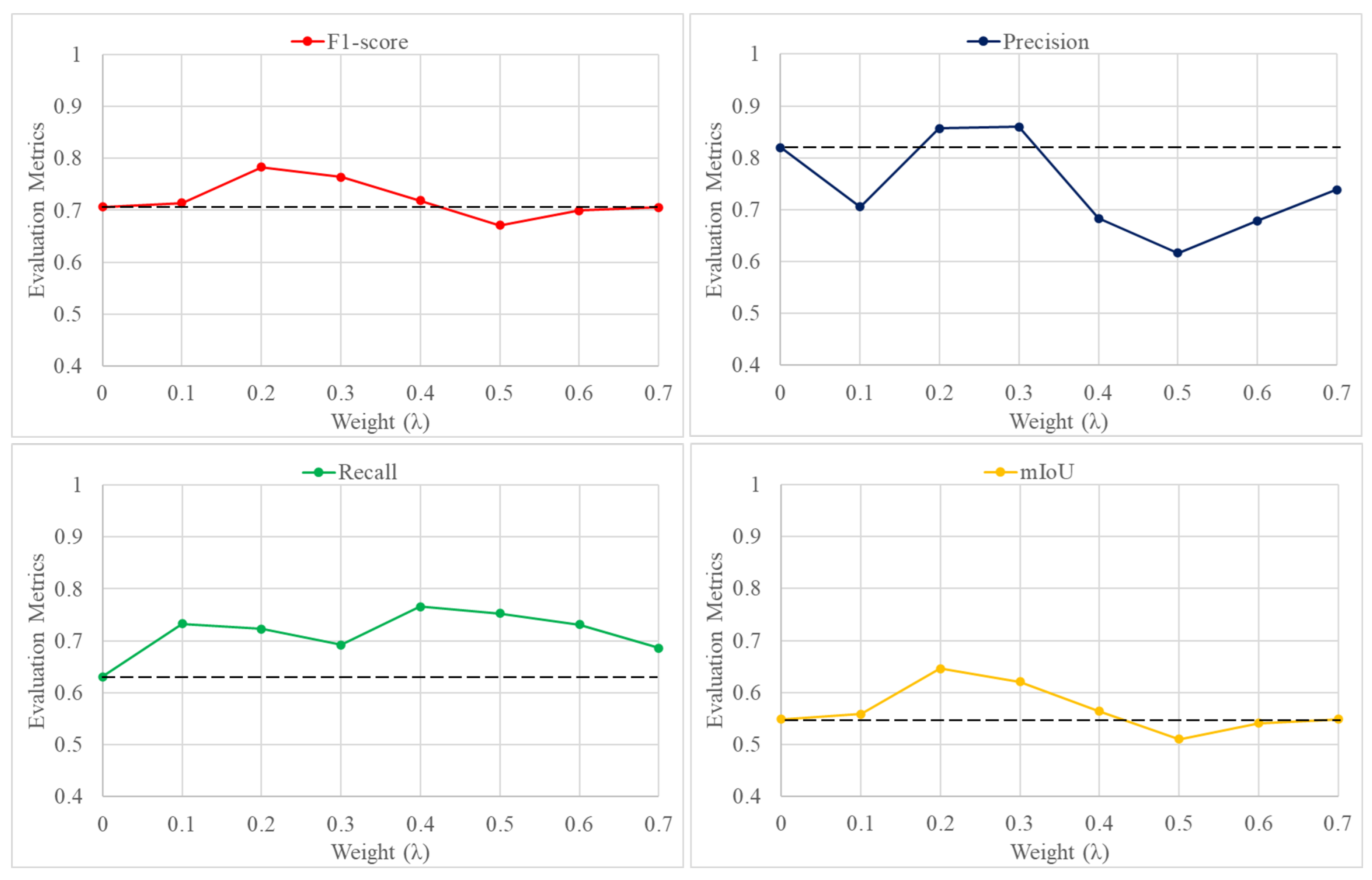
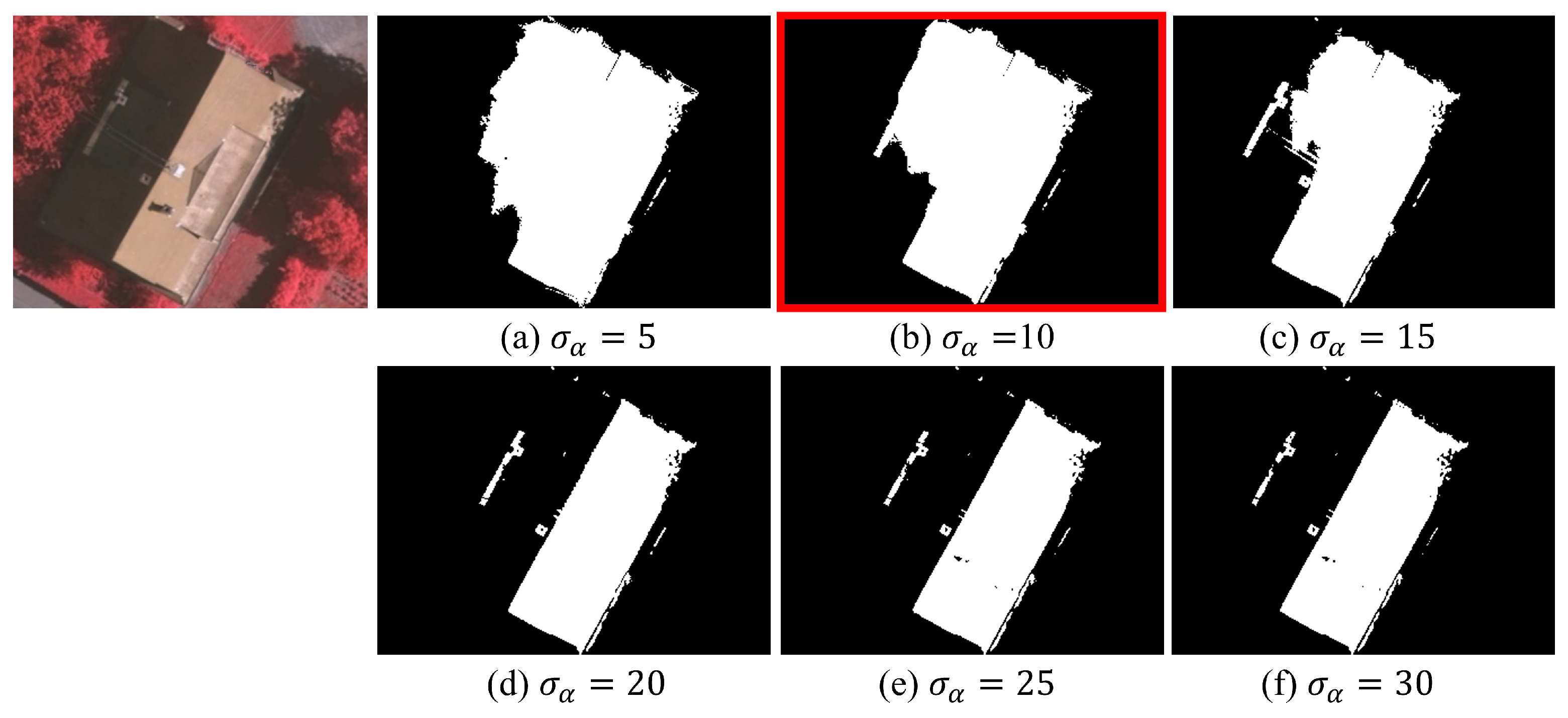
4.1. Effects of Edge Information
4.2. Further Application
4.3. Model Parameters
4.4. Research Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mayer, H. Automatic object extraction from aerial imagery—A survey focusing on buildings. Comput. Vis. Image Underst. 1999, 74, 138–149. [Google Scholar] [CrossRef]
- Ahmadi, S.; Zoej, M.V.; Ebadi, H.; Moghaddam, H.A.; Mohammadzadeh, A. Automatic urban building boundary extraction from high resolution aerial images using an innovative model of active contours. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 150–157. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Gerke, M.; Wegner, J.D. ISPRS Semantic Labeling Contest; ISPRS: Leopoldshöhe, Germany, 2014; Volume 1. [Google Scholar]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. Spacenet: A remote sensing dataset and challenge series. arXiv 2018, arXiv:1807.01232. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Ji, X.; Henriques, J.F.; Vedaldi, A. Invariant information clustering for unsupervised image classification and segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9865–9874. [Google Scholar]
- Hamilton, M.; Zhang, Z.; Hariharan, B.; Snavely, N.; Freeman, W.T. Unsupervised semantic segmentation by distilling feature correspondences. arXiv 2022, arXiv:2203.08414. [Google Scholar]
- Seong, H.S.; Moon, W.; Lee, S.; Heo, J.P. Leveraging Hidden Positives for Unsupervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 19540–19549. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Shen, W.; Peng, Z.; Wang, X.; Wang, H.; Cen, J.; Jiang, D.; Xie, L.; Yang, X.; Tian, Q. A survey on label-efficient deep image segmentation: Bridging the gap between weak supervision and dense prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9284–9305. [Google Scholar] [CrossRef]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Li, Z.; Zhang, X.; Xiao, P.; Zheng, Z. On the effectiveness of weakly supervised semantic segmentation for building extraction from high-resolution remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3266–3281. [Google Scholar] [CrossRef]
- Vernaza, P.; Chandraker, M. Learning random-walk label propagation for weakly-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7158–7166. [Google Scholar]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Box-driven class-wise region masking and filling rate guided loss for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3136–3145. [Google Scholar]
- Cheng, T.; Wang, X.; Chen, S.; Zhang, Q.; Liu, W. Boxteacher: Exploring high-quality pseudo labels for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 3145–3154. [Google Scholar]
- Chen, H.; Cheng, L.; Zhuang, Q.; Zhang, K.; Li, N.; Liu, L.; Duan, Z. Structure-aware weakly supervised network for building extraction from remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Xu, L.; Clausi, D.A.; Li, F.; Wong, A. Weakly supervised classification of remotely sensed imagery using label constraint and edge penalty. IEEE Trans. Geosci. Remote Sens. 2016, 55, 1424–1436. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 1–26 July 2016; pp. 2921–2929. [Google Scholar]
- Obukhov, A.; Georgoulis, S.; Dai, D.; Van Gool, L. Gated CRF loss for weakly supervised semantic image segmentation. arXiv 2019, arXiv:1906.04651. [Google Scholar]
- Zhang, J.; Yu, X.; Li, A.; Song, P.; Liu, B.; Dai, Y. Weakly-supervised salient object detection via scribble annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12546–12555. [Google Scholar]
- Lee, S.; Lee, M.; Lee, J.; Shim, H. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5495–5505. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Ren, S.; Luzi, F.; Lahrichi, S.; Kassaw, K.; Collins, L.M.; Bradbury, K.; Malof, J.M. Segment anything, from space? arXiv 2023, arXiv:2304.13000. [Google Scholar]
- Bradbury, K.; Saboo, R.; L Johnson, T.; Malof, J.M.; Devarajan, A.; Zhang, W.; M Collins, L.; G Newell, R. Distributed solar photovoltaic array location and extent dataset for remote sensing object identification. Sci. Data 2016, 3, 160106. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An end-to-end cloud detection algorithm for Landsat 8 imagery. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019; pp. 1029–1032. [Google Scholar]
- Aung, H.L.; Uzkent, B.; Burke, M.; Lobell, D.; Ermon, S. Farm parcel delineation using spatio-temporal convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 76–77. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Thenkabail, P.S. Remotely Sensed Data Characterization, Classification, and Accuracies; CRC Press: Boca Raton, FL, USA, 2015; Volume 1, p. 7. [Google Scholar]
- Cheng, H.D.; Jiang, X.H.; Sun, Y.; Wang, J. Color image segmentation: Advances and prospects. Pattern Recognit. 2001, 34, 2259–2281. [Google Scholar] [CrossRef]
- Xiao, C.; Qin, R.; Huang, X. Treetop detection using convolutional neural networks trained through automatically generated pseudo labels. Int. J. Remote Sens. 2020, 41, 3010–3030. [Google Scholar] [CrossRef]
- Mhangara, P.; Odindi, J.; Kleyn, L.; Remas, H. Road Extraction Using Object Oriented Classification. Vis. Tech. Available online: https://www.researchgate.net/profile/John-Odindi/publication/267856733_Road_extraction_using_object_oriented_classification/links/55b9fec108aed621de09550a/Road-extraction-using-object-oriented-classification.pdf (accessed on 5 December 2023).
- Ma, X.; Li, B.; Zhang, Y.; Yan, M. The Canny Edge Detection and Its Improvement. In Proceedings of the Artificial Intelligence and Computational Intelligence, Chengdu, China, 26–28 October 2012; Lei, J., Wang, F.L., Deng, H., Miao, D., Eds.; Springer: Berlin/Heidelberg, Germnay, 2012; pp. 50–58. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Zhou, T.; Fu, H.; Sun, C.; Wang, S. Shadow detection and compensation from remote sensing images under complex urban conditions. Remote Sens. 2021, 13, 699. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Models | f1-Score | Precision | Recall | IoU |
|---|---|---|---|---|---|
| Potsdam | IIC | 0.4587 | 0.4315 | 0.5110 | 0.3013 |
| STEGO | 0.7557 | 0.7775 | 0.7408 | 0.6122 | |
| HP | 0.7771 | 0.8063 | 0.7532 | 0.6390 | |
| Pseudo-Label | 0.7363 | 0.7273 | 0.7548 | 0.5850 | |
| Proposed Method | 0.7829 | 0.8569 | 0.7231 | 0.6463 |
| Dataset | Models | f1-Score | Precision | Recall | IoU |
|---|---|---|---|---|---|
| Vaihingen | IIC | 0.4042 | 0.3793 | 0.4422 | 0.2618 |
| STEGO | 0.7330 | 0.7068 | 0.7613 | 0.5741 | |
| HP | 0.7567 | 0.7709 | 0.7430 | 0.6226 | |
| Pseudo-Label | 0.7108 | 0.7066 | 0.7156 | 0.5504 | |
| Proposed Method | 0.7779 | 0.8242 | 0.7483 | 0.6453 |
| Methods | Models | f1-Score | Precision | Recall | IoU |
|---|---|---|---|---|---|
| Potsdam | DeepLabV3+ | 0.8344 | 0.8371 | 0.8444 | 0.7216 |
| ResUNet | 0.8504 | 0.8687 | 0.8381 | 0.7427 | |
| U-Net | 0.8228 | 0.8333 | 0.8363 | 0.7088 | |
| MANet | 0.8540 | 0.8601 | 0.8536 | 0.7481 | |
| Proposed Method | 0.8512 | 0.9072 | 0.8080 | 0.7442 |
| Methods | Models | f1-Score | Precision | Recall | IoU |
|---|---|---|---|---|---|
| Vaihingen | DeepLabV3+ | 0.8241 | 0.8204 | 0.8487 | 0.7016 |
| ResUNet | 0.8335 | 0.8286 | 0.8381 | 0.7142 | |
| U-Net | 0.8183 | 0.8139 | 0.8357 | 0.6953 | |
| MANet | 0.8415 | 0.8257 | 0.8583 | 0.7262 | |
| Proposed Method | 0.8435 | 0.8632 | 0.8242 | 0.7295 |
| Weight | ||||||||
|---|---|---|---|---|---|---|---|---|
| Metrics | 0.0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 |
| f1-score | 0.7065 | 0.7138 | 0.7828 | 0.7641 | 0.7186 | 0.6714 | 0.6998 | 0.7055 |
| Precision | 0.8196 | 0.7057 | 0.8569 | 0.8595 | 0.6832 | 0.6169 | 0.6789 | 0.7387 |
| Recall | 0.6306 | 0.7326 | 0.7531 | 0.6922 | 0.7659 | 0.7529 | 0.7313 | 0.6863 |
| IoU | 0.5488 | 0.5583 | 0.6563 | 0.6207 | 0.5638 | 0.5099 | 0.5412 | 0.5484 |
| f1-Score | IoU | ||||||
|---|---|---|---|---|---|---|---|
| Methods | Models | Bldg. | Veg. | Road. | Bldg. | Veg. | Road. |
| Unsupervised | IIC | 0.4587 | 0.8237 | 0.5789 | 0.3013 | 0.7021 | 0.4112 |
| STEGO | 0.7557 | 0.8007 | 0.7144 | 0.6122 | 0.6759 | 0.5570 | |
| HP | 0.7771 | 0.8461 | 0.7928 | 0.6390 | 0.7030 | 0.6578 | |
| Pseudo-Label | 0.7363 | 0.7762 | 0.6640 | 0.5850 | 0.6455 | 0.5012 | |
| Proposed Method | 0.7829 | 0.8108 | 0.7222 | 0.6464 | 0.6887 | 0.5677 | |
| Methods | Models | Parameter | Trainable | Running Time (h) | Inference Time (ms) |
|---|---|---|---|---|---|
| Supervised | DeepLabV3+ | 41 M | 41 M | 0.78 | 9.81 |
| ResUNet | 31 M | 31 M | 0.85 | 17.70 | |
| U-Net | 23 M | 23 M | 0.80 | 16.19 | |
| MANet | 36 M | 36 M | 0.61 | 12.76 | |
| Unsupervised | STEGO | 49 M | 27 M | 2.36 | 41.10 |
| IIC | 4 M | 4 M | 0.48 | 22.36 | |
| HP | 87 M | 9.8 M | 1.92 | 107.13 | |
| Proposed Method | 8 M | 8 M | 0.52 | 23.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Kim, Y. Integrated Framework for Unsupervised Building Segmentation with Segment Anything Model-Based Pseudo-Labeling and Weakly Supervised Learning. Remote Sens. 2024, 16, 526. https://doi.org/10.3390/rs16030526
Kim J, Kim Y. Integrated Framework for Unsupervised Building Segmentation with Segment Anything Model-Based Pseudo-Labeling and Weakly Supervised Learning. Remote Sensing. 2024; 16(3):526. https://doi.org/10.3390/rs16030526
Chicago/Turabian StyleKim, Jiyong, and Yongil Kim. 2024. "Integrated Framework for Unsupervised Building Segmentation with Segment Anything Model-Based Pseudo-Labeling and Weakly Supervised Learning" Remote Sensing 16, no. 3: 526. https://doi.org/10.3390/rs16030526
APA StyleKim, J., & Kim, Y. (2024). Integrated Framework for Unsupervised Building Segmentation with Segment Anything Model-Based Pseudo-Labeling and Weakly Supervised Learning. Remote Sensing, 16(3), 526. https://doi.org/10.3390/rs16030526