
TreeDetector: Using Deep Learning for the Localization and Reconstruction of Urban Trees from High-Resolution Remote Sensing Images



Abstract
1. Introduction
- Incorporating object detection methods firstly and combining them with semantic segmentation for tree localization tasks, dividing the detection targets into easily detectable individual trees, shrub units, and challenging tree clusters, achieving the highest accuracy in individual tree detection;
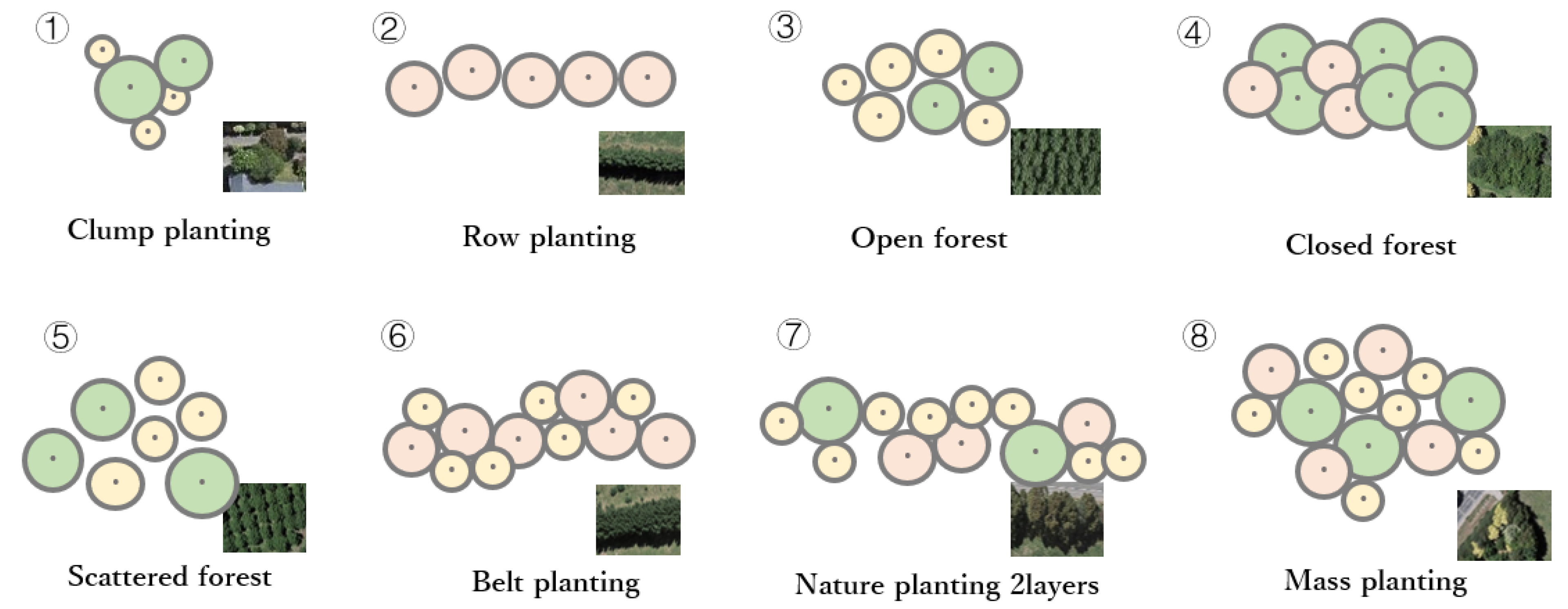
- Developing a planting rule algorithm based on forest characteristics to more realistically represent the distribution of tree clusters;
- Designing a city region partition algorithm that automatically divides the urban space into four categories;
- Estimating the positions, radii, heights, and other information of trees from satellite images and utilizing this information in three-dimensional reconstruction to create more realistic models of urban trees compared to previous methods.
2. Materials
2.1. Traditional Methods for Obtaining Tree Information
2.2. Application of Deep Learning in Tree Information Retrieval
2.3. Application of Procedural Generation in Tree Distribution
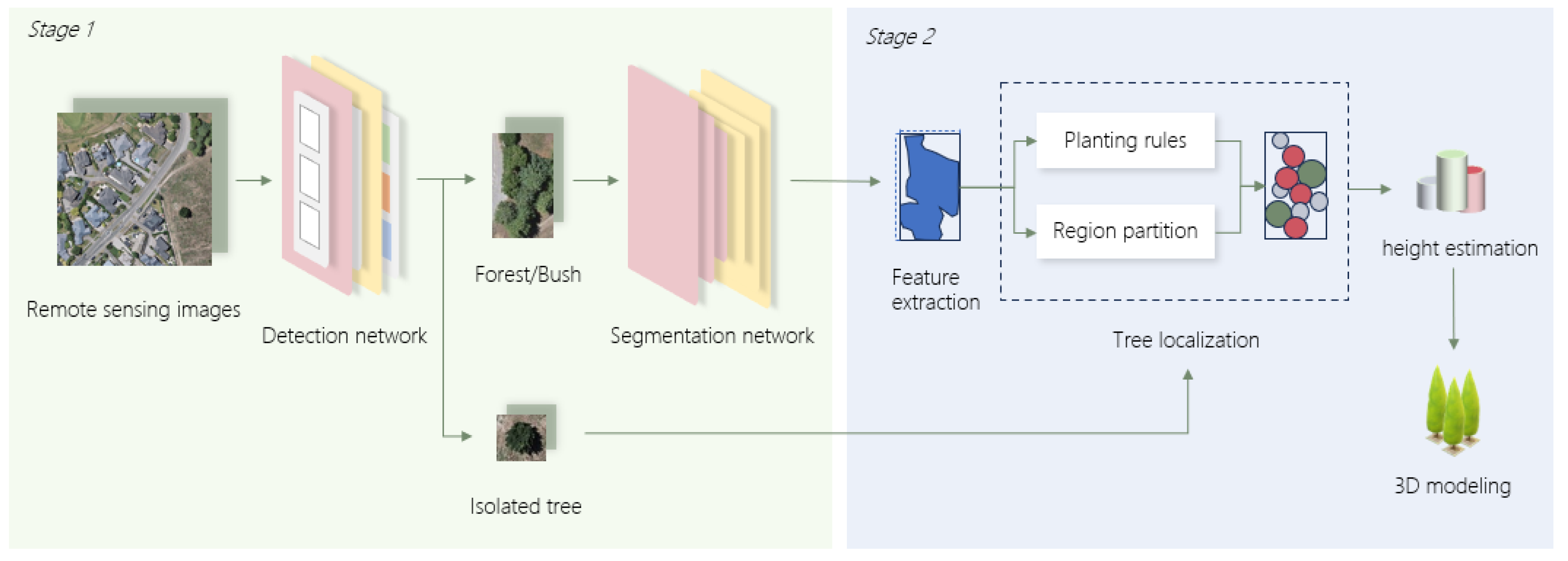
3. Methods
3.1. Definition of Tree Units
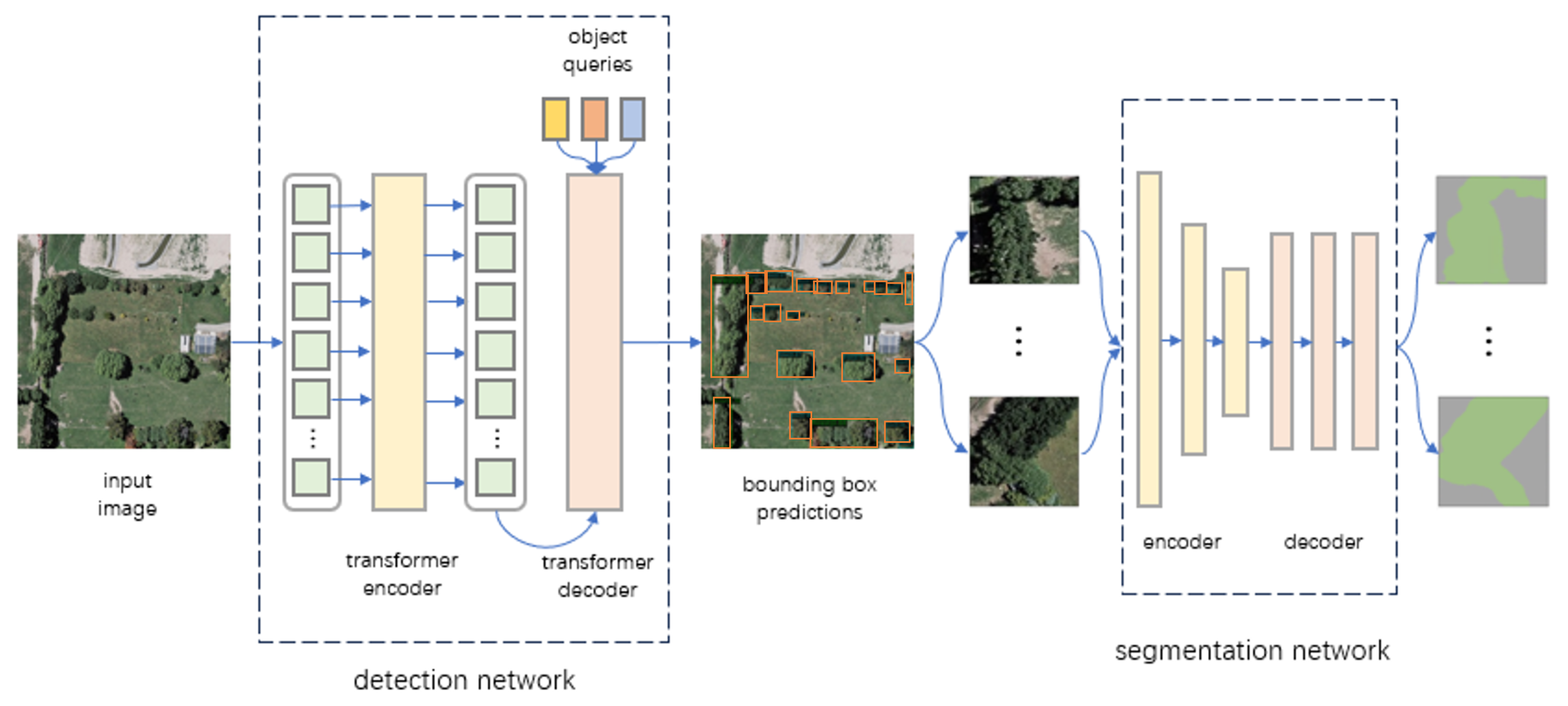
3.2. Deep Learning Network Treedetector
3.2.1. Detection Network
3.2.2. Segmentation Network
3.3. Procedural Tree Distribution Localization
3.3.1. Feature Extraction
3.3.2. Region Partition
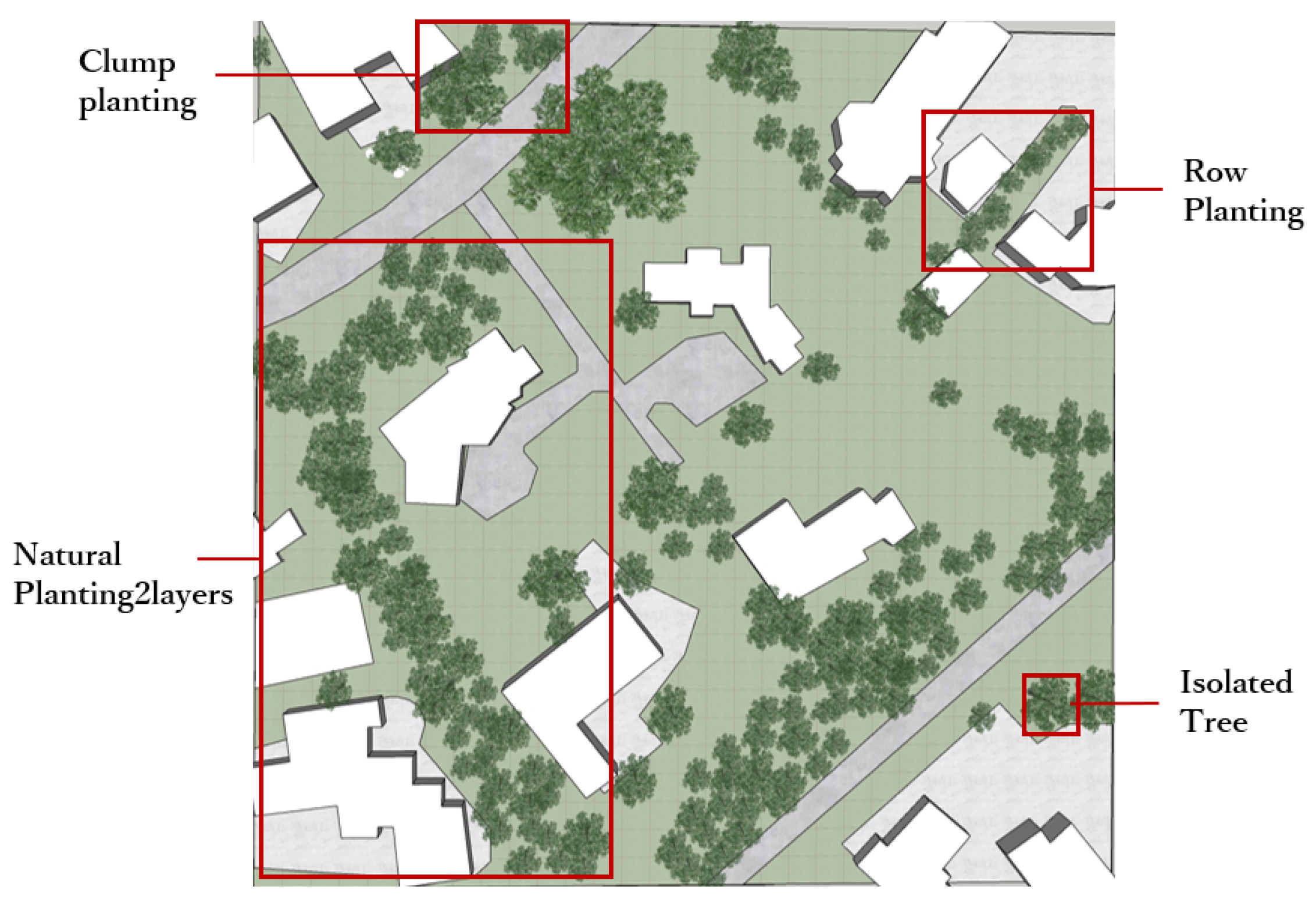
3.3.3. Planting Rules
3.3.4. Height Estimation
4. Results
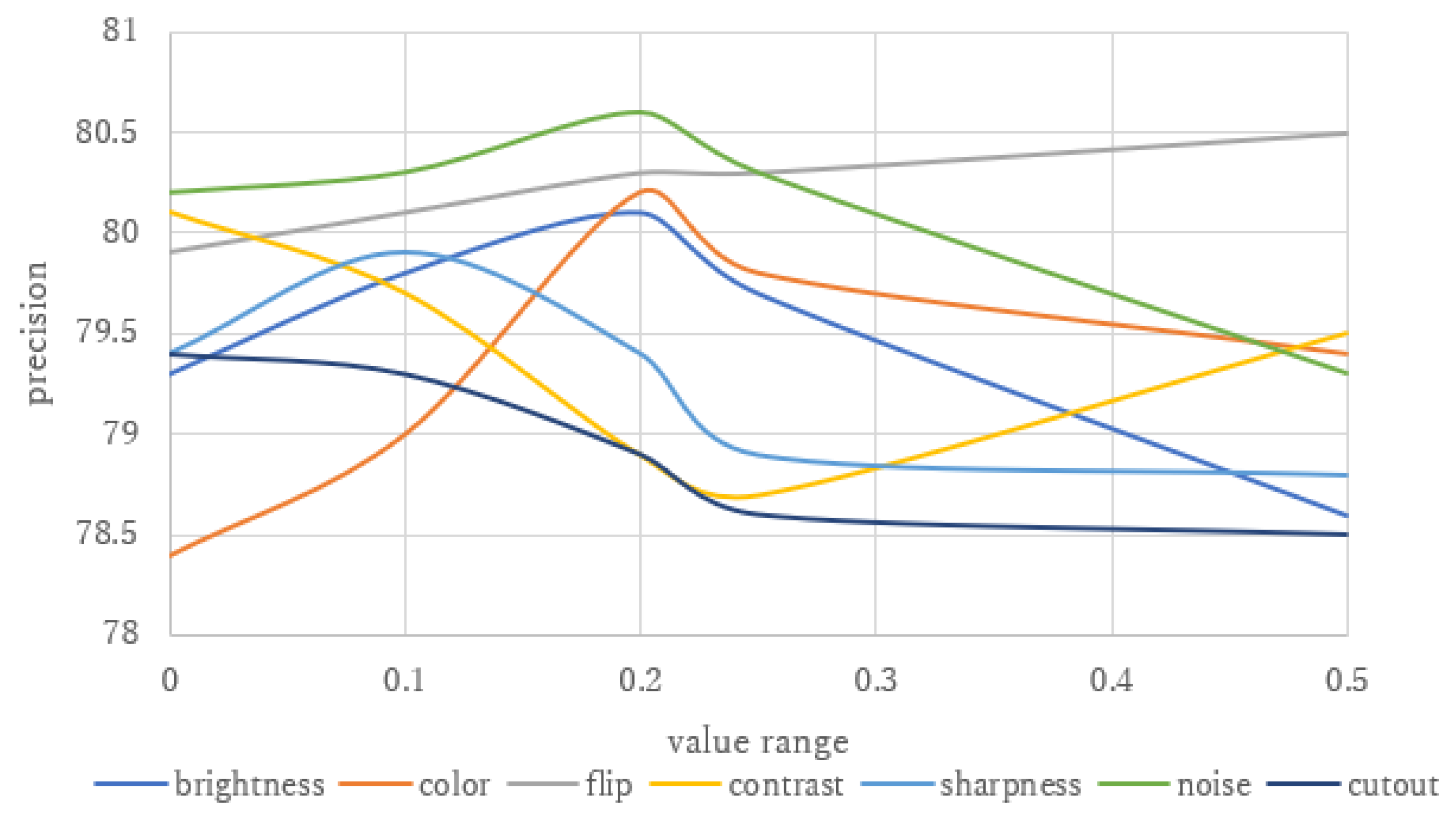
4.1. Experimental Setup
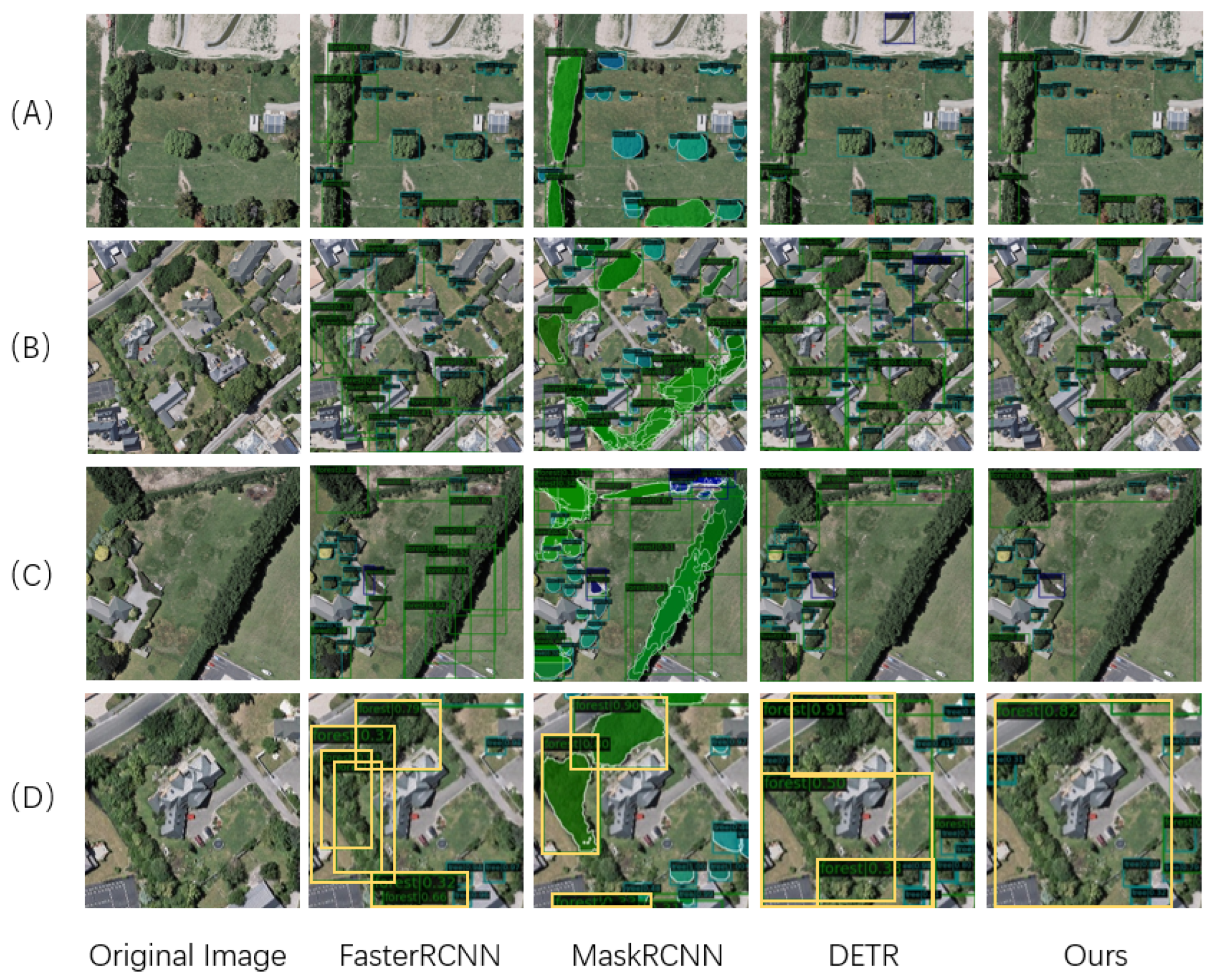
4.2. Comparison of Detection Results
4.3. Single-Tree Detection
4.4. The Impact of Planting Rules
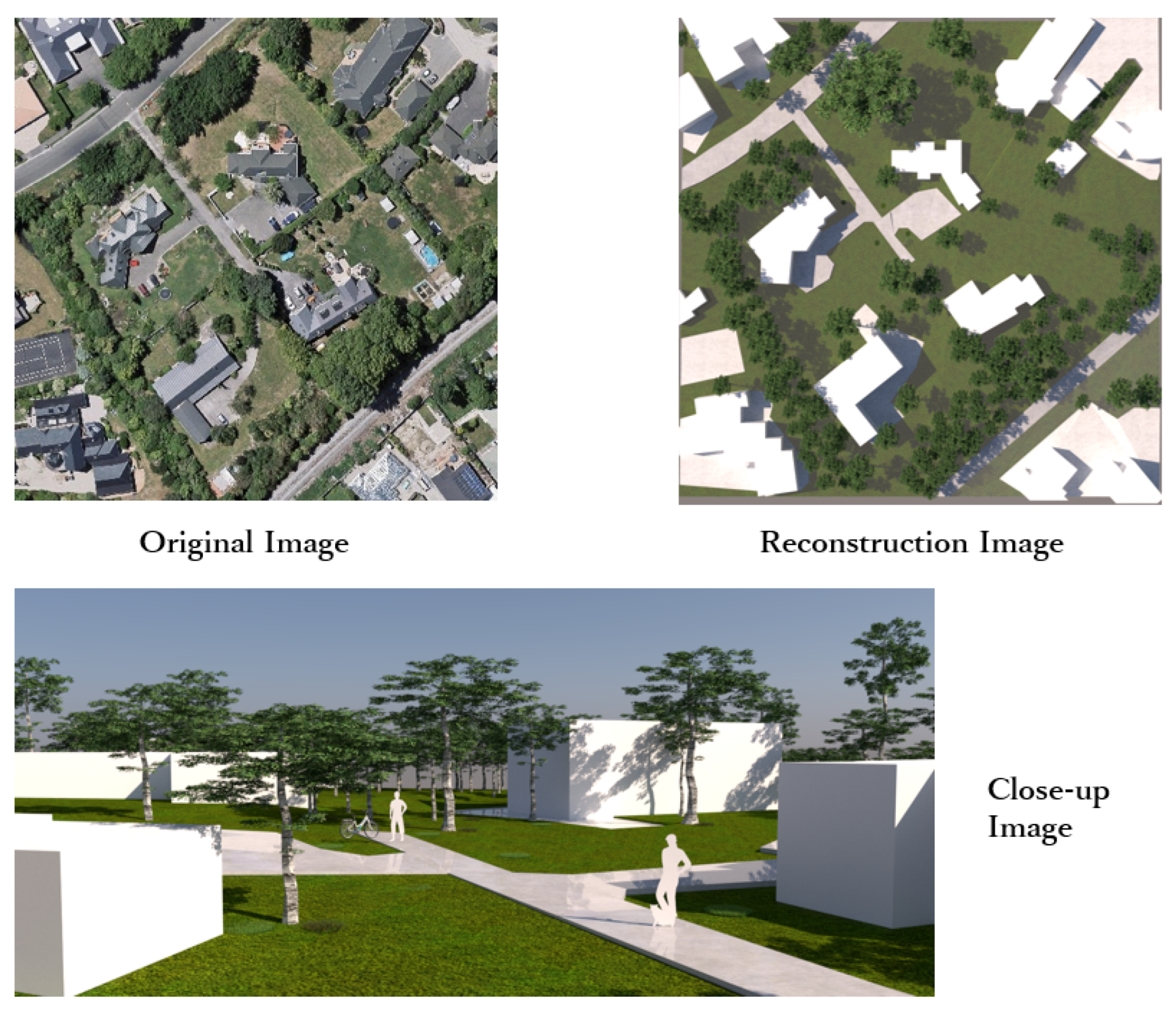
4.5. Visualization Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Global Forest Resources Assessment 2020—Key Findings. Available online: https://doi.org/10.4060/ca8753en (accessed on 21 July 2020).
- Guldin, R.W. Forest science and forest policy in the Americas: Building bridges to a sustainable future. For. Policy Econ. 2003, 5, 329–337. [Google Scholar] [CrossRef]
- Cao, S.; Sun, G.; Zhang, Z. Greening China naturally. Ambio 2011, 40, 828–831. [Google Scholar] [CrossRef]
- Oldfield, E.E.; Felson, A.J.; Auyeung, D.S.N.; Crowther, T.W.; Sonti, N.F.; Harada, Y.; Maynard, D.S.; Sokol, N.W.; Ashton, M.S.; Warren, R.J., II; et al. Growing the urban forest: Tree performance in response to biotic and abiotic land management. Restor. Ecol. 2015, 23, 707–718. [Google Scholar] [CrossRef]
- Turner, W.; Rondinini, C.; Pettorelli, N.; Mora, B.; Leidner, A.K.; Szantoi, Z.; Buchanan, G.; Dech, S.; Dwyer, J.; Herold, M.; et al. Free and open-access satellite data are key to biodiversity conservation. Biol. Conserv. 2015, 182, 173–176. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Fox, J.C.; Ades, P.K.; Bi, H. Stochastic structure and individual-tree growth models. For. Ecol. Manag. 2001, 154, 261–276. [Google Scholar] [CrossRef]
- Rohner, B.; Waldner, P.; Lischke, H.; Ferretti, M.; Thürig, E. Predicting individual-tree growth of central European tree species as a function of site, stand, management, nutrient, and climate effects. Eur. J. For. Res. 2018, 137, 29–44. [Google Scholar] [CrossRef]
- Brandt, M.; Tucker, C.J.; Kariryaa, A.; Rasmussen, K.; Abel, C.; Small, J.; Chave, J.; Rasmussen, L.V.; Hiernaux, P.; Diouf, A.A.; et al. An unexpectedly large count of trees in the West African Sahara and Sahel. Nature 2020, 587, 78–82. [Google Scholar] [CrossRef]
- Freudenberg, M.; Magdon, P.; Nölke, N. Individual tree crown delineation in high-resolution remote sensing images based on U-Net. Neural Comput. Appl. 2022, 34, 22197–22207. [Google Scholar] [CrossRef]
- Niese, T.; Pirk, S.; Albrecht, M.; Benes, B.; Deussen, O. Procedural Urban Forestry. ACM Trans. Graph. 2022, 41, 1–18. [Google Scholar] [CrossRef]
- Firoze, A.; Benes, B.; Aliaga, D. Urban tree generator: Spatio-temporal and generative deep learning for urban tree localization and modeling. Vis. Comput. 2022, 38, 3327–3339. [Google Scholar] [CrossRef]
- Lu, J. Planting Design, 1st ed.; China Architecture & Building Press: Beijing, China, 2008; pp. 62–87. [Google Scholar]
- Crowther, T.W.; Glick, H.B.; Covey, K.R.; Bettigole, C.; Maynard, D.S.; Thomas, S.M.; Smith, J.R.; Hintler, G.; Duguid, M.C.; Amatulli, G.; et al. Mapping tree density at a global scale. Nature 2015, 525, 201–205. [Google Scholar] [CrossRef]
- Nowak, D.J.; Crane, D.E.; Stevens, J.C.; Hoehn, R.E.; Walton, J.T.; Bond, J. A ground-based method of assessing urban forest structure and ecosystem services. Arboric. Urban For. 2008, 34, 347–358. [Google Scholar] [CrossRef]
- Edson, C.; Wing, M.G. Airborne Light Detection and Ranging (LiDAR) for individual tree stem location, height, and biomass measurements. Remote Sens. 2011, 3, 2494–2528. [Google Scholar] [CrossRef]
- Wang, L. A Multi-scale Approach for Delineating Individual Tree Crowns with Very High Resolution Imagery. Photogramm. Eng. Remote Sens. 2010, 76, 371–378. [Google Scholar] [CrossRef]
- Martins, J.; Junior, J.M.; Menezes, G.; Pistori, H.; Sant, D.; Gonçalves, W. Image Segmentation and Classification with SLIC Superpixel and Convolutional Neural Network in Forest Context. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July 2019. [Google Scholar]
- Culvenor, D.S. TIDA: An algorithm for the delineation of tree crowns in high spatial resolution remotely sensed imagery. Comput. Geosci. 2002, 28, 33–44. [Google Scholar] [CrossRef]
- Ghasemi, M.; Latifi, H.; Pourhashemi, M. A Novel Method for Detecting and Delineating Coppice Trees in UAV Images to Monitor Tree Decline. Remote Sens. 2022, 14, 5910. [Google Scholar] [CrossRef]
- Sivanandam, P.; Lucieer, A. Tree Detection and Species Classification in a Mixed Species Forest Using Unoccupied Aircraft System (UAS) RGB and Multispectral Imagery. Remote Sens. 2022, 14, 4963. [Google Scholar] [CrossRef]
- Onishi, M.; Ise, T. Explainable identification and mapping of trees using UAV RGB image and deep learning. Sci. Rep. 2021, 11, 903. [Google Scholar] [CrossRef]
- Firoze, A.; Wingren, C.; Yeh, R.A.; Benes, B.; Aliaga, D. Tree Instance Segmentation with Temporal Contour Graph. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Guo, J.; Xu, Q.; Zeng, Y.; Liu, Z.; Zhu, X.X. Nationwide urban tree canopy mapping and coverage assessment in Brazil from high-resolution remote sensing images using deep learning. ISPRS J. Photogramm. Remote Sens. 2023, 198, 1–15. [Google Scholar] [CrossRef]
- Liu, T.; Yao, L.; Qin, J.; Lu, J.; Lu, N.; Zhou, C. A Deep Neural Network for the Estimation of Tree Density Based on High-Spatial Resolution Image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4403811. [Google Scholar] [CrossRef]
- Li, S.; Brandt, M.; Fensholt, R.; Kariryaa, A.; Igel, C.; Gieseke, F.; Nord-Larsen, T.; Oehmcke, S.; Carlsen, A.H.; Junttila, S.; et al. Deep learning enables image-based tree counting, crown segmentation, and height prediction at national scale. PNAS Nexus 2023, 2, 76. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Mou, Y.; Liu, S.; Yanrong, M.; Zelin, L.; Peng, L.; Wenhua, X.; Xiaolu, Z.; Changhui, P. Detecting and mapping tree crowns based on convolutional neural network and Google Earth images. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102764. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 25 March 2021. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23 August 2020. [Google Scholar]
- Demir, I.; Aliaga, D.G.; Benes, B. Proceduralization of buildings at city scale. In Proceedings of the 2014 2nd International Conference on 3D Vision, Washington, DC, USA, 8–11 December 2014. [Google Scholar]
- Kelly, T.; Femiani, J.; Wonka, P.; Mitra, N.J. BigSUR: Large-scale structured urban reconstruction. ACM Trans. Graph. 2017, 36, 204. [Google Scholar] [CrossRef]
- Roglà, P.O.; Pelechano, G.N.; Patow, G.A. Procedural semantic cities. In Proceedings of the CEIG 2017: XXVII Spanish Computer Graphics Conference, Sevilla, Spain, 28–30 June 2017. [Google Scholar]
- Beneš, B.; Massih, M.A.; Jarvis, P.; Aliaga, D.G.; Vanegas, C.A. Urban ecosystem design. In Proceedings of the Symposium on Interactive 3D Graphics and Games, San Francisco, CA, USA, 18–20 February 2011. [Google Scholar]
- Benes, B.; Zhou, X.; Chang, P.; Cani, M.P.R. Urban Brush: Intuitive and Controllable Urban Layout Editing. In Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology, New York, NY, USA, 10 October 2021. [Google Scholar]
- Hao, Z.; Lin, L.; Post, C.J.; Yu, K.; Liu, J.; Lin, L.; Chen, Y.; Mikhailova, E.A. Automated tree-crown and height detection in a young forest plantation using mask region-based convolutional neural network (Mask R-CNN). ISPRS J. Photogramm. Remote Sens. 2021, 178, 112–123. [Google Scholar] [CrossRef]
- Guirado, E.; Blanco-Sacristan, J.; Rodriguez-Caballero, E.; Tabik, S.; Alcaraz-Segura, D.; Martínez-Valderrama, J.; Cabello, J. Mask R-CNN and OBIA fusion improves the segmentation of scattered vegetation in very high-resolution optical sensors. Sensors 2021, 21, 320. [Google Scholar] [CrossRef] [PubMed]
- Blum, J. Urban Forests: Ecosystem Services and Management, 1st ed.; Apple Academic Press: New York, NY, USA, 2017; pp. 234–236. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Bourne, K.S.; Conway, T.M. The influence of land use type and municipal context on urban tree species diversity. Urban Ecosyst. 2014, 17, 329–348. [Google Scholar] [CrossRef]
- Hiernaux, P.; Issoufou, H.B.A.; Igel, C.; Kariryaa, A.; Kourouma, M.; Chave, J.; Mougin, E.; Savadogo, P. Allometric equations to estimate the dry mass of Sahel woody plants mapped with very-high resolution satellite imagery. For. Ecol. Manag. 2023, 529, 120653. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tree | Forest/Bush | ||
|---|---|---|---|
| Symbol | Meaning | Symbol | Meaning |
| i | identifier | d | canopy offset |
| o | center point | a | canopy area |
| w | canopy width | p | perimeter-area ratio |
| h | canopy height | r | aspect ratio |
| m | translocation identifier | v | canopy contour |
| Hyperparameter | ||||
|---|---|---|---|---|
| <20 | <30 | >20 | <15 | |
| <20 | <30 | <15 | <15 | |
| >50 | >40 | <10 | <10 | |
| >50 | >30 | >15 | >20 |
| Methods | AP (Tree) | AP (Forest) | AP (Bush) | AP (All) | AR (All) | Time (s) |
|---|---|---|---|---|---|---|
| FasterRCNN | 0.485 | 0.506 | 0.271 | 0.540 | 0.622 | 23 |
| MaskRCNN in [27] | 0.481 | 0.520 | 0.245 | 0.532 | 0.620 | 29 |
| DETR | 0.481 | 0.544 | 0.219 | 0.539 | 0.631 | 24 |
| Ours (deformable DETR) | 0.509 (0.562) | 0.565 (0.626) | 0.272 | 0.569 | 0.689 | 24 |
| Methods | Acc [%] | Recall [%] |
|---|---|---|
| FasterRCNN | 80.7 | 89.7 |
| MaskRCNN in [27] | 75.2 | 82.8 |
| DETR | 49.4 | 85.0 |
| Ours (deformable DETR) | 82.3 | 90.5 |
| Methods | Farmland | Residential | Grassland | Industrial |
|---|---|---|---|---|
| Random | 127.56% | 116.78% | 119.37% | 82.36% |
| Ours | 108.87% | 91.70% | 86.67% | 77.24% |
| Planting Rules | Mean | Standard Deviation |
|---|---|---|
| Clump planting | 8.144 | 2.117 |
| Row planting | 8.224 | 0.990 |
| Belt planting | 8.185 | 1.050 |
| Nature planting 2layers | 7.881 | 1.453 |
| Closed forest | 8.677 | 0.859 |
| Mass planting | 7.567 | 1.017 |
| Open forest | 7.234 | 1.531 |
| Scattered forest | 6.875 | 1.623 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, H.; Sun, Q.; Fang, C.; Sun, L.; Su, R. TreeDetector: Using Deep Learning for the Localization and Reconstruction of Urban Trees from High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 524. https://doi.org/10.3390/rs16030524
Gong H, Sun Q, Fang C, Sun L, Su R. TreeDetector: Using Deep Learning for the Localization and Reconstruction of Urban Trees from High-Resolution Remote Sensing Images. Remote Sensing. 2024; 16(3):524. https://doi.org/10.3390/rs16030524
Chicago/Turabian StyleGong, Haoyu, Qian Sun, Chenrong Fang, Le Sun, and Ran Su. 2024. "TreeDetector: Using Deep Learning for the Localization and Reconstruction of Urban Trees from High-Resolution Remote Sensing Images" Remote Sensing 16, no. 3: 524. https://doi.org/10.3390/rs16030524
APA StyleGong, H., Sun, Q., Fang, C., Sun, L., & Su, R. (2024). TreeDetector: Using Deep Learning for the Localization and Reconstruction of Urban Trees from High-Resolution Remote Sensing Images. Remote Sensing, 16(3), 524. https://doi.org/10.3390/rs16030524