
An Open Benchmark Dataset for Forest Characterization from Sentinel-1 and -2 Time Series



Abstract
1. Introduction
1.1. Related Benchmark Datasets
1.2. Requirements on Training Data
1.3. Concept of the Wald5Dplus Benchmark Data Cube
2. Materials
2.1. Single-Tree Polygons
2.2. Sentinel-1/2 Time Series
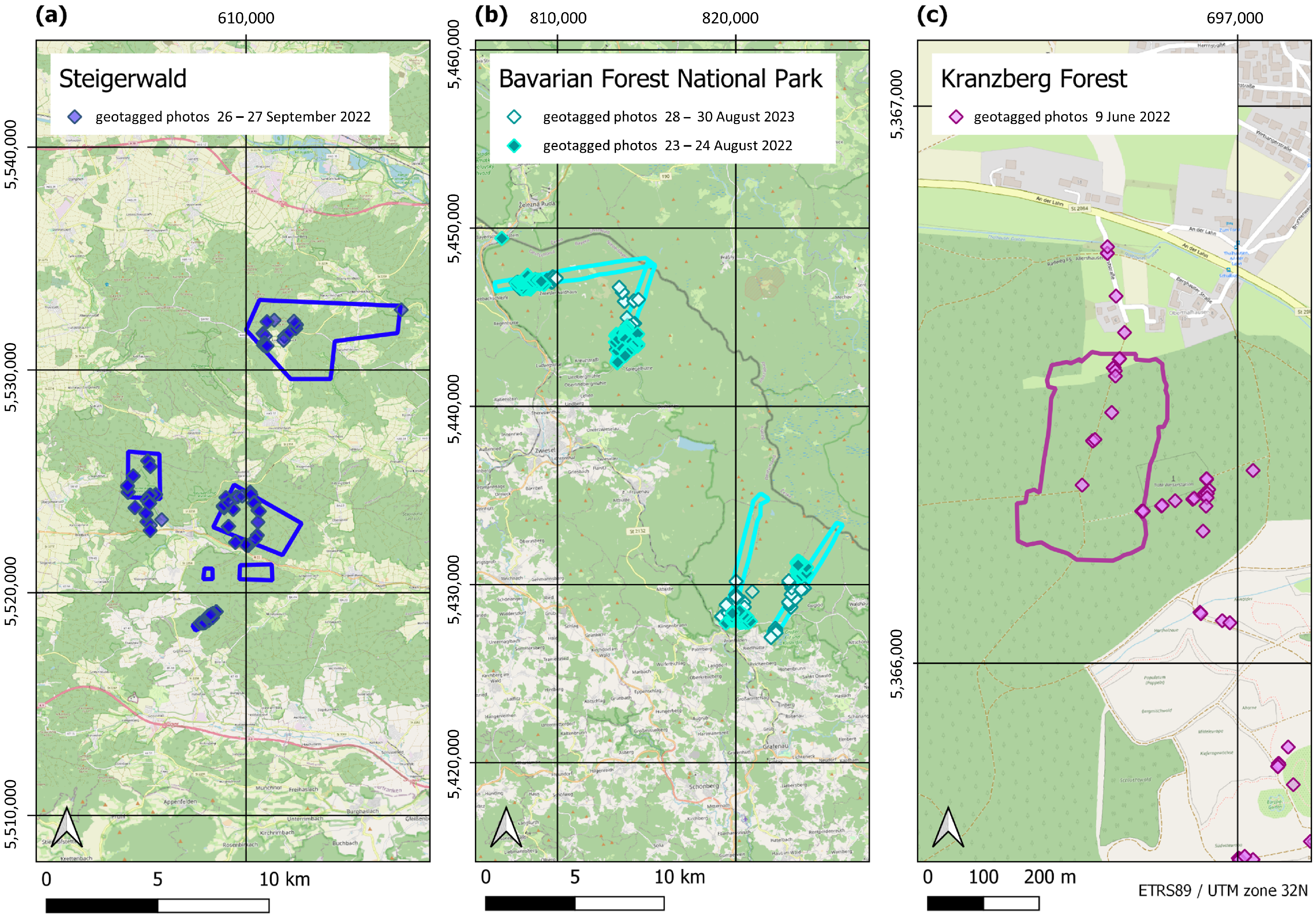
2.3. Ground Truth from Field Campaigns
3. Methodology
3.1. Generation of Labels from Single-Tree Polygons
3.2. Generation of Analysis-Ready Data Cube
- Sentinel-1 only 256 channels comprising 64 times 4 polarimetric Kennaugh elements;
- Sentinel-2 only 256 channels comprising 64 times 4 spectral Kennaugh-like elements;
- Sentinel-1 and -2 512 channels comprising 64 times 8 fused Kennaugh-like elements.
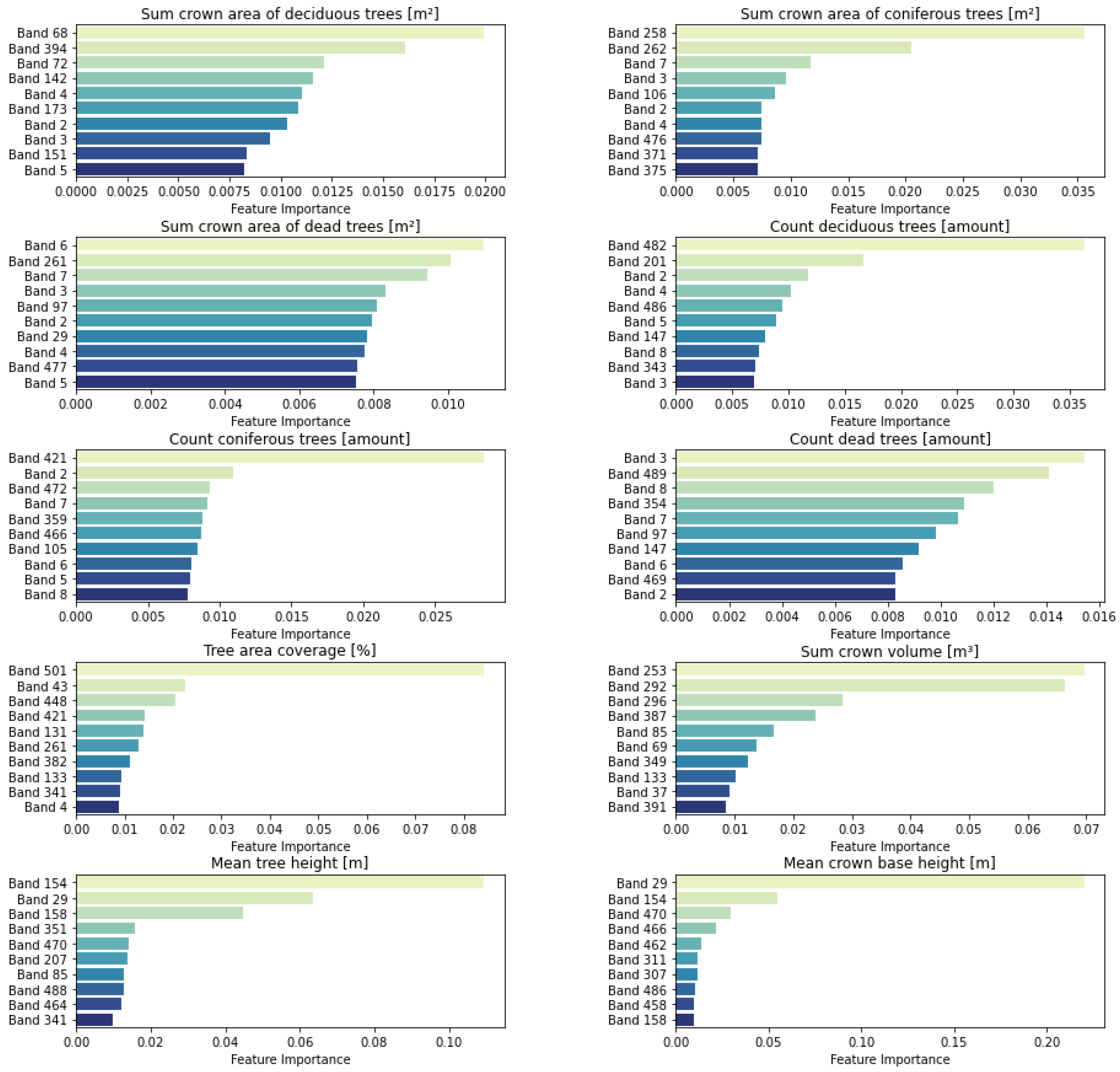
3.3. Forest Parameter Regression Analysis
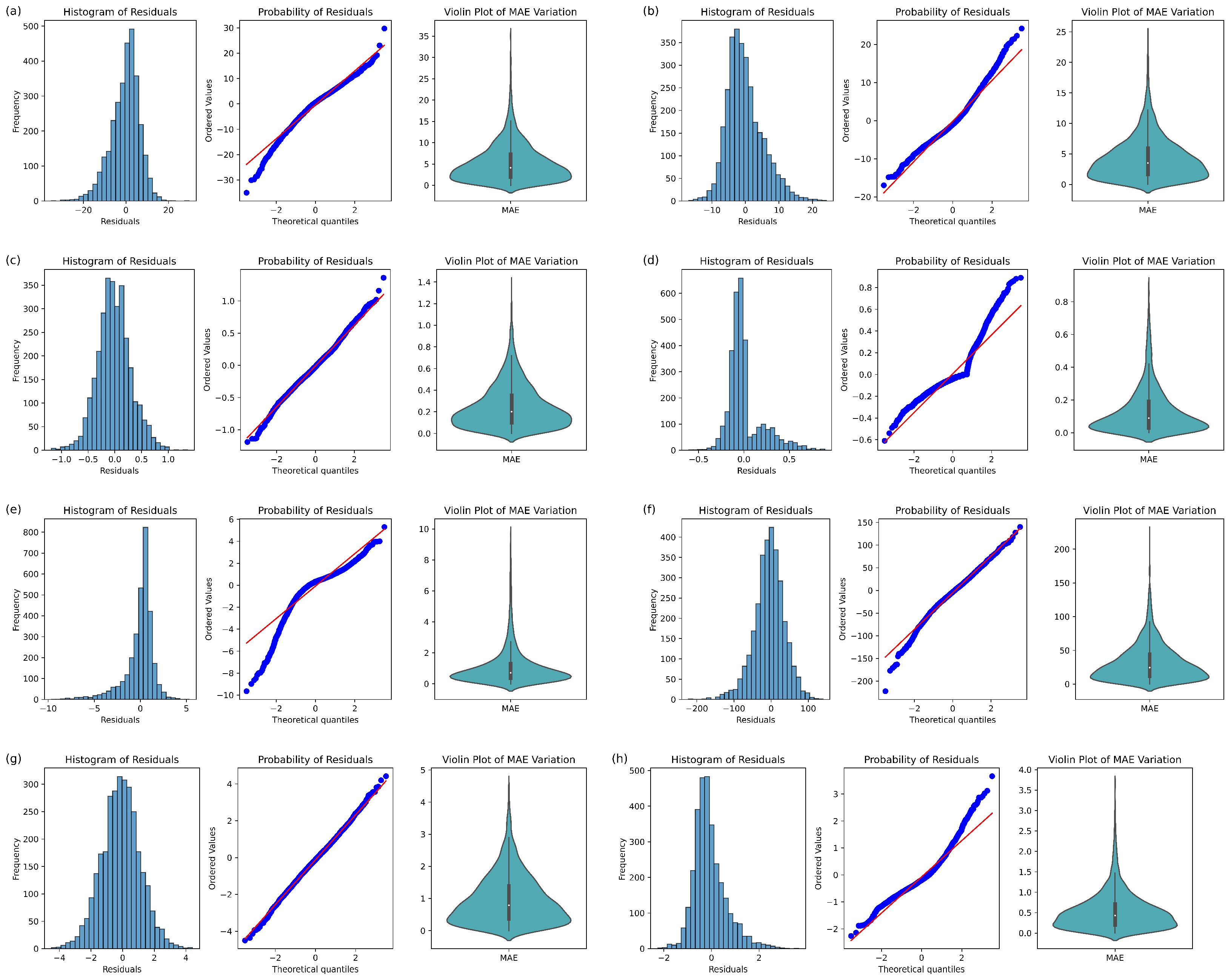
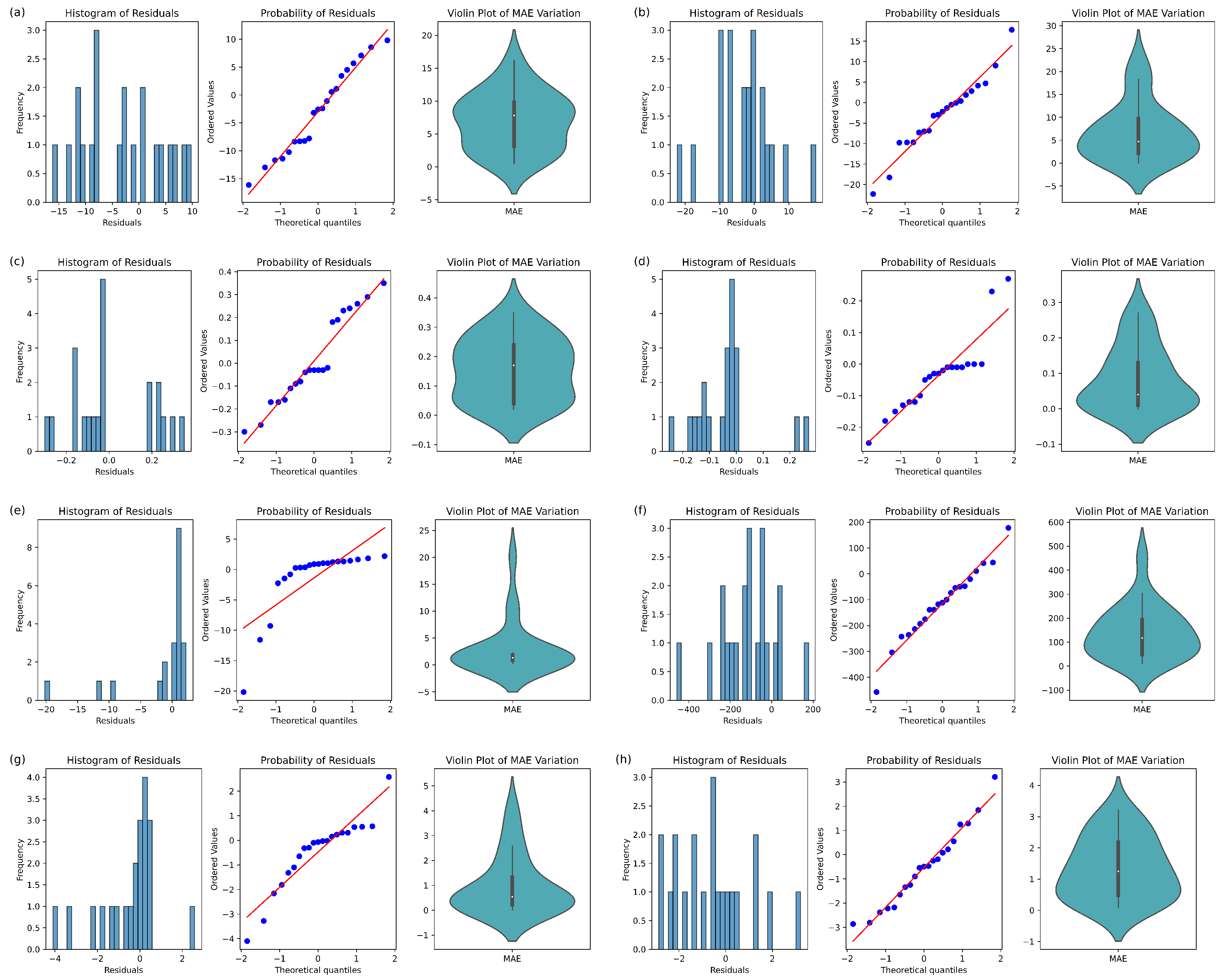
3.4. Comprehensive Quality Assurance
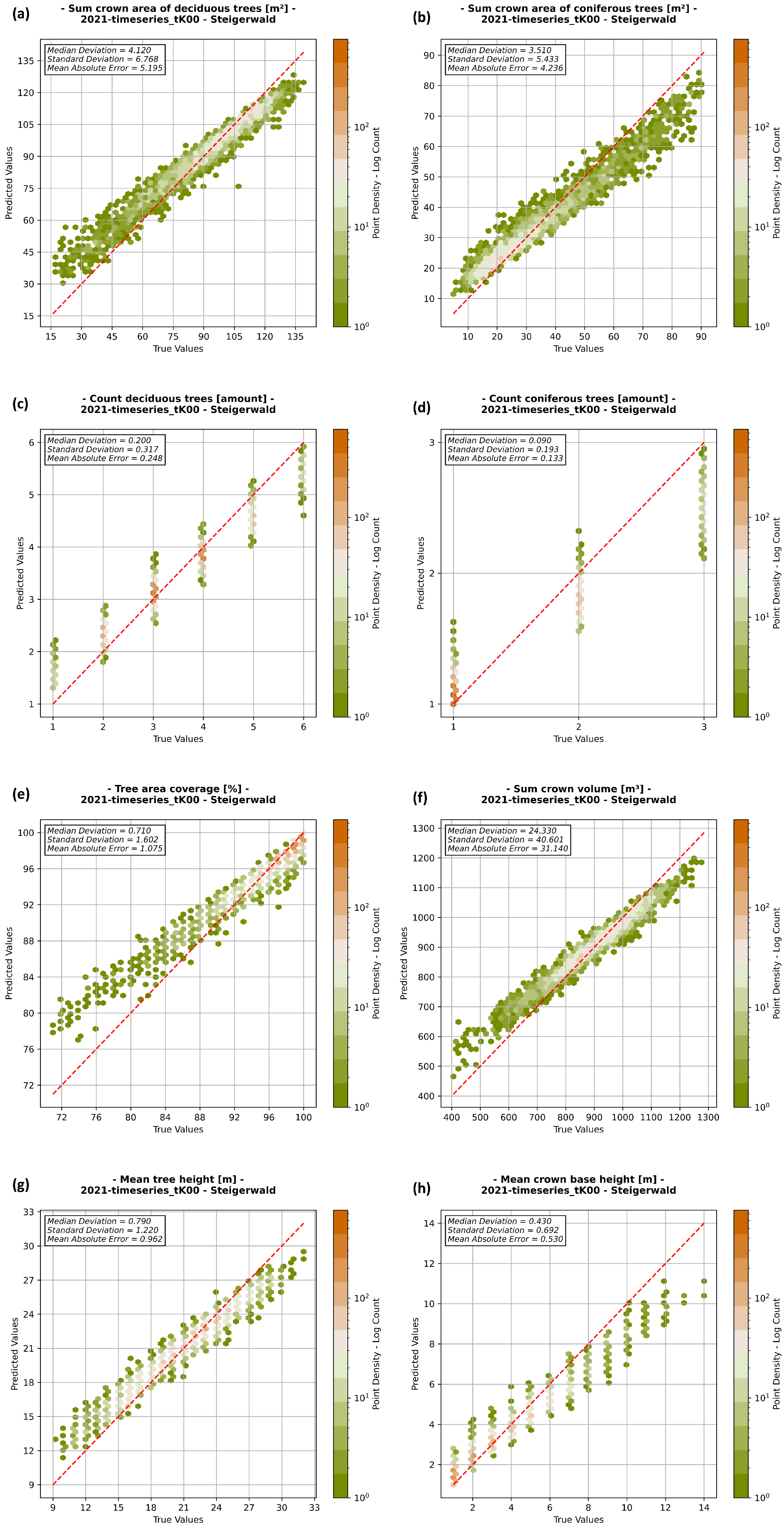
3.4.1. Accuracy of Regression
3.4.2. Transferability of Regression
3.4.3. Plausibility Analysis by Ground Truth
4. Results
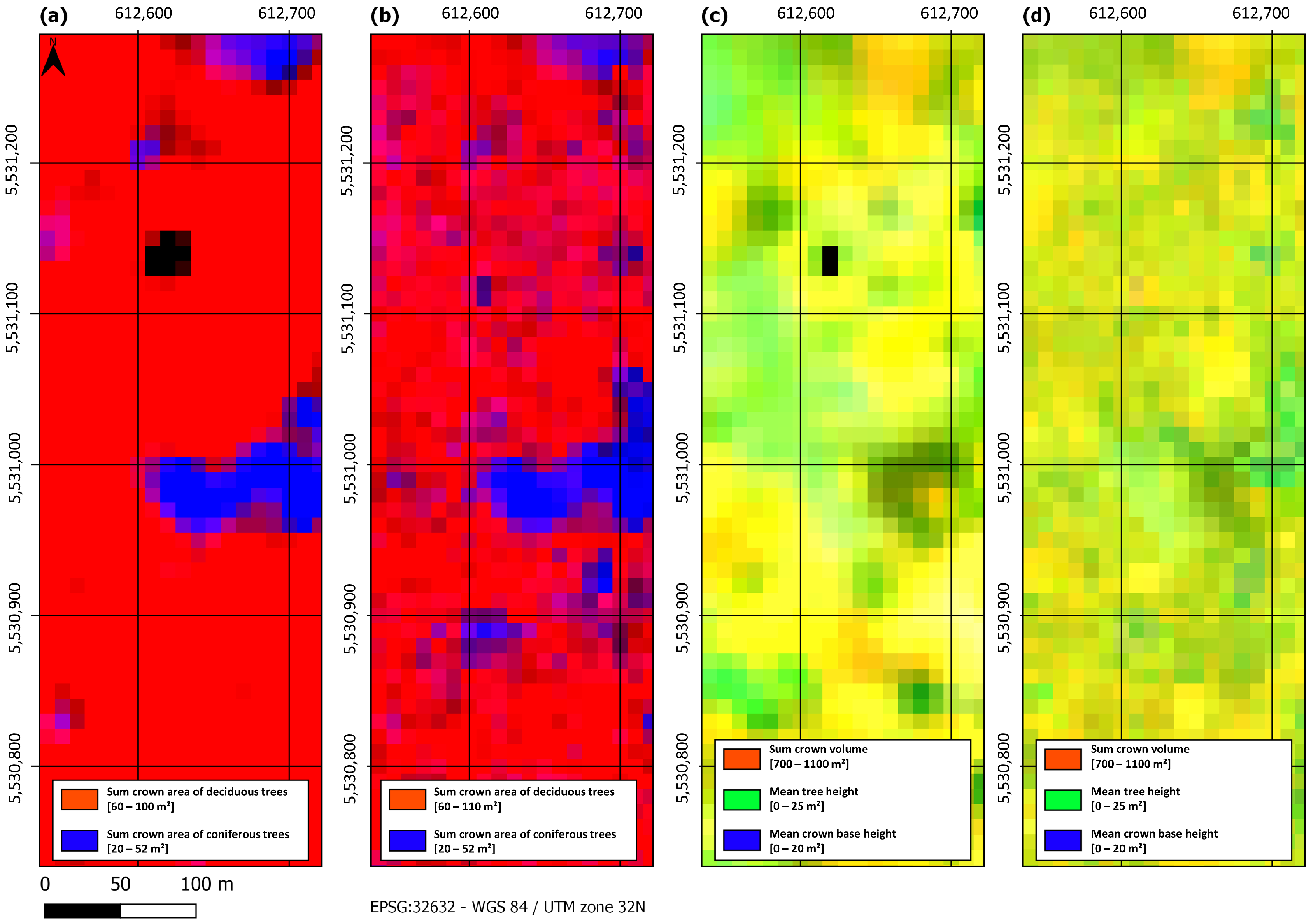
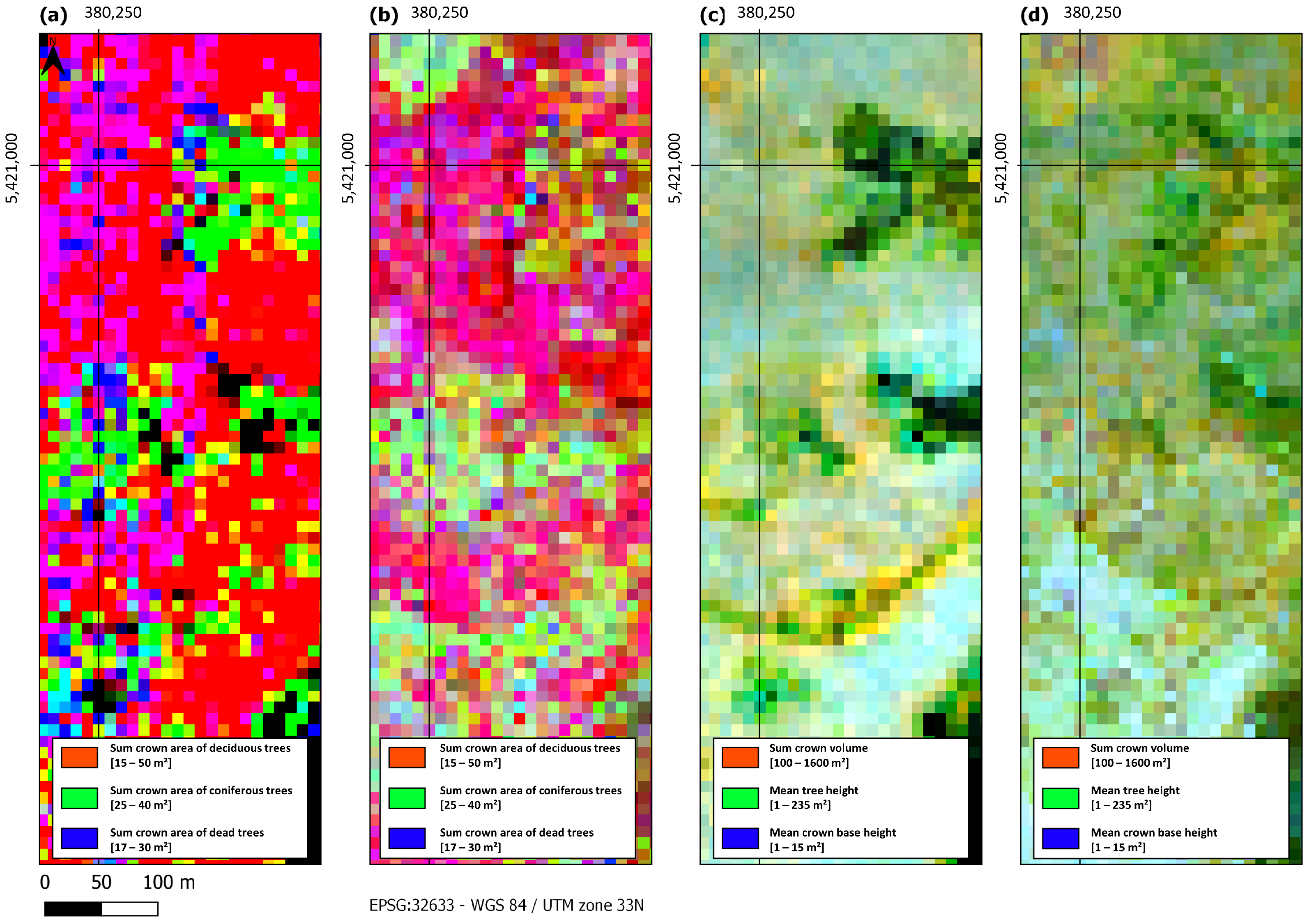
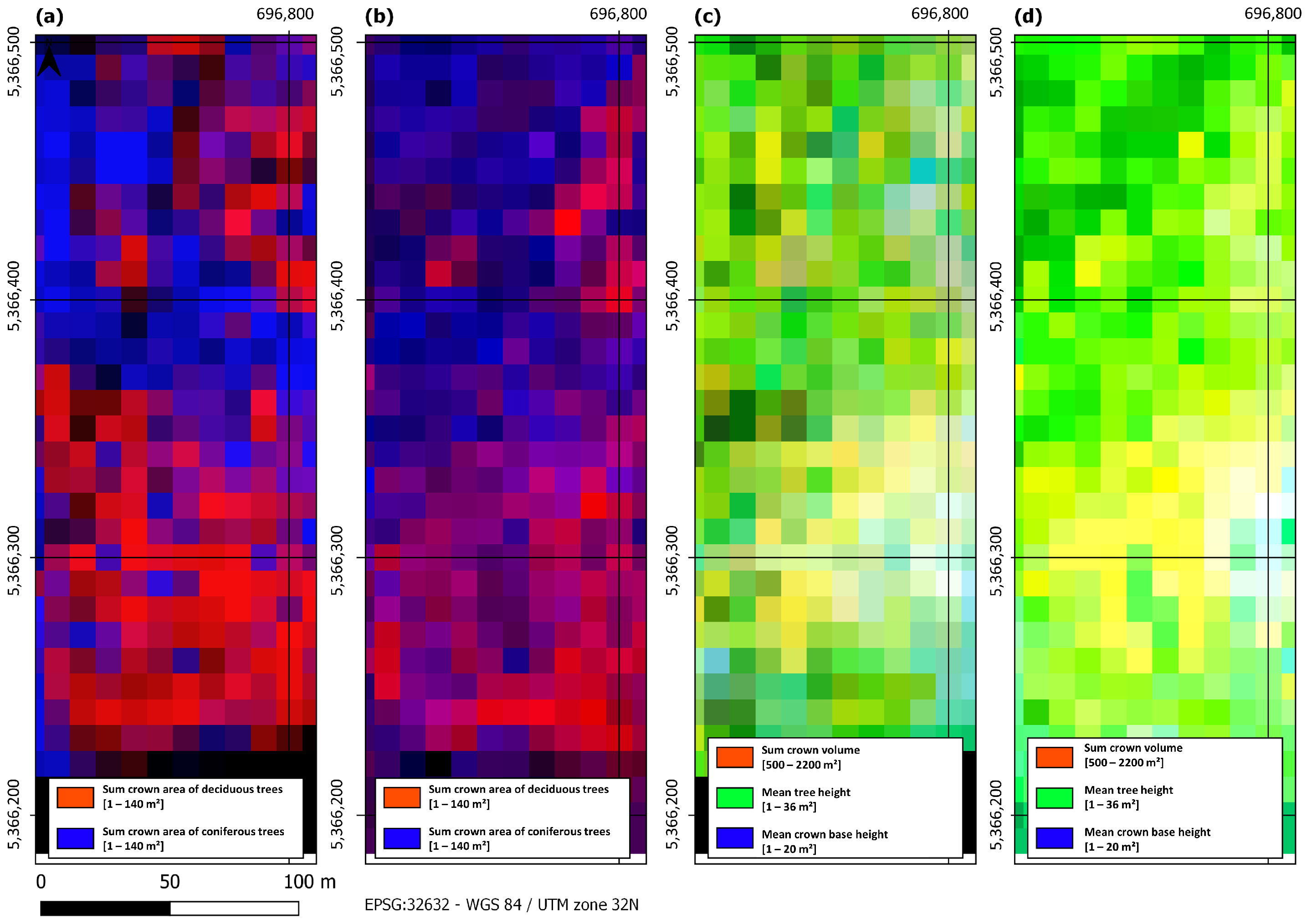
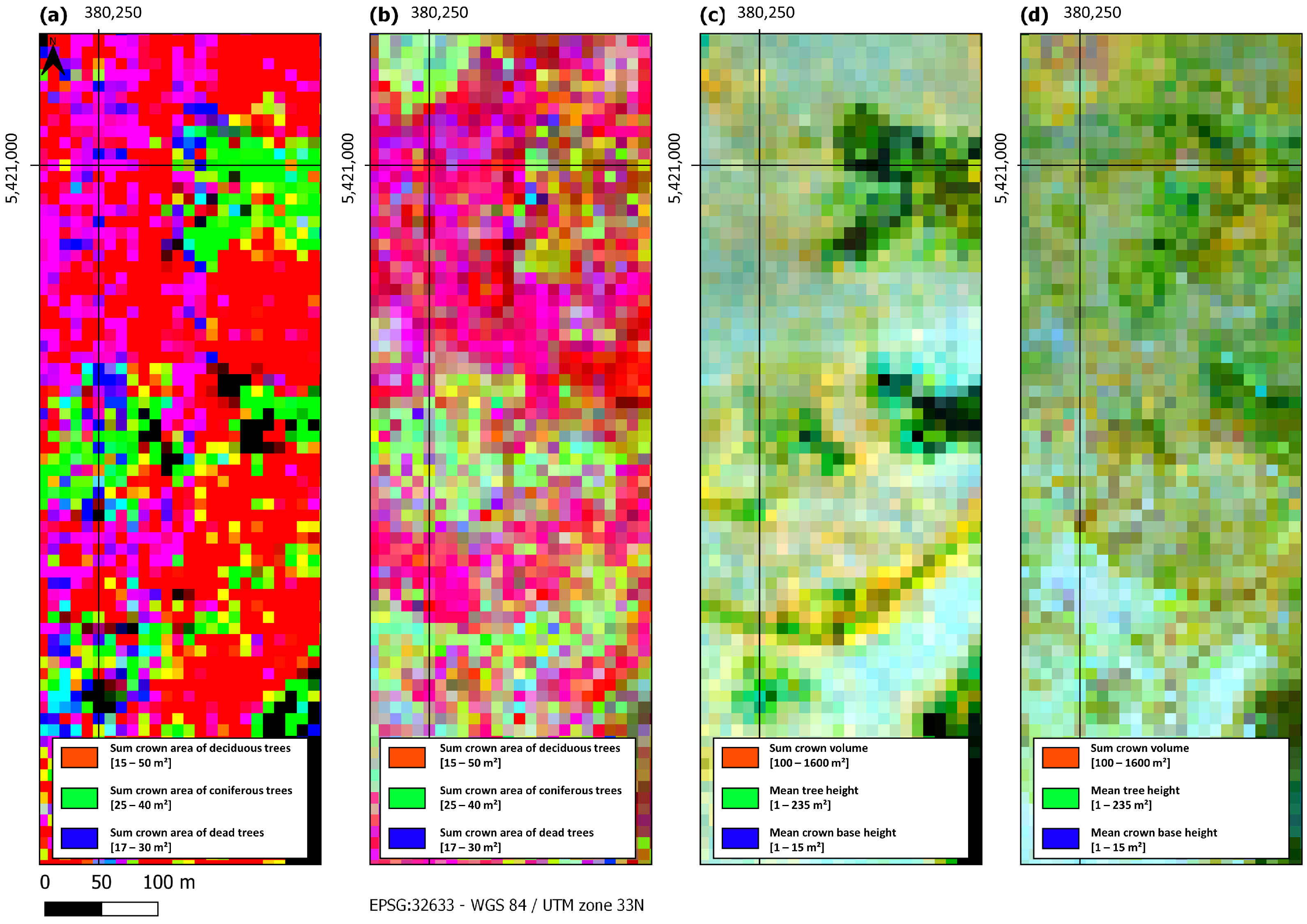
4.1. Labeled ARD Cube
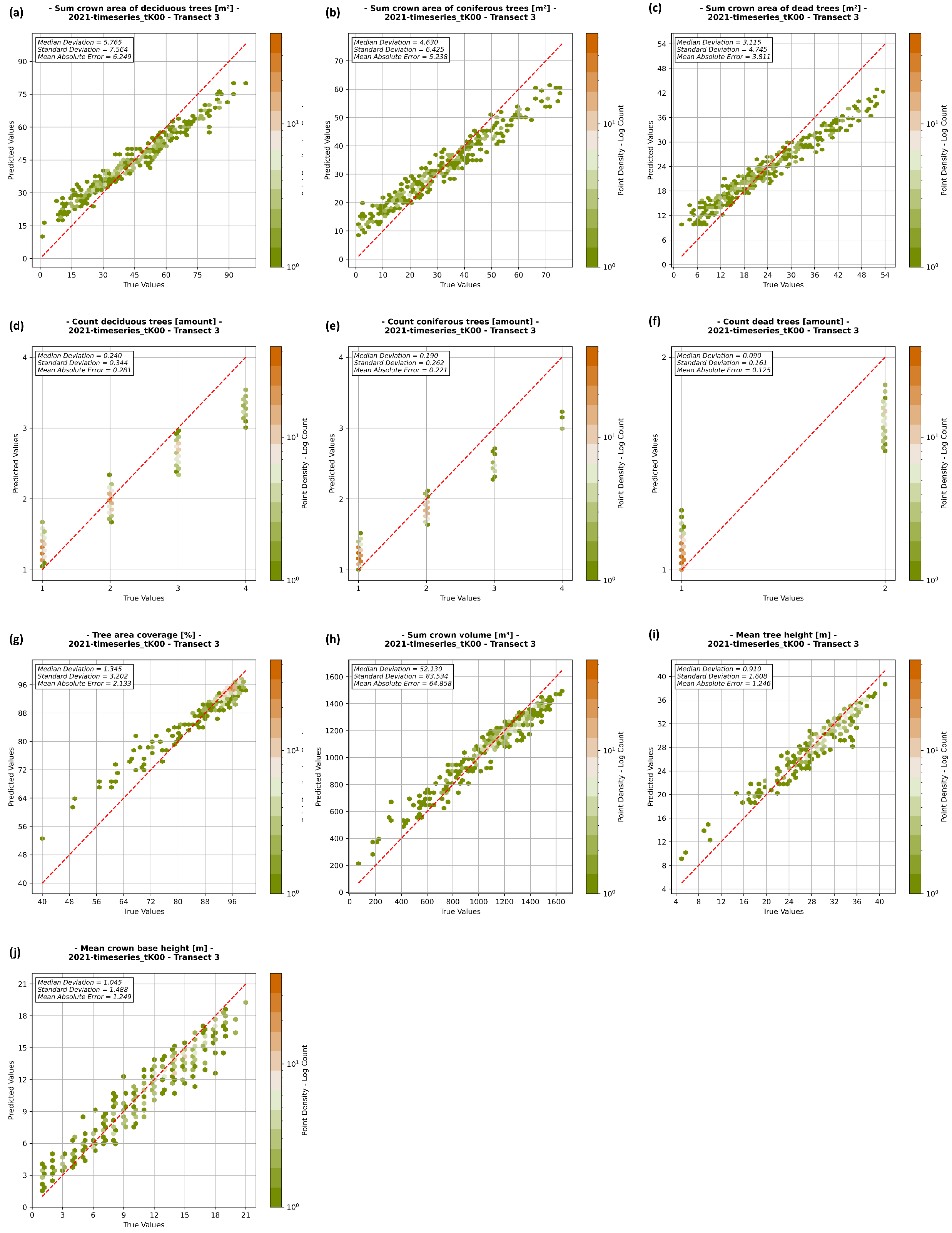
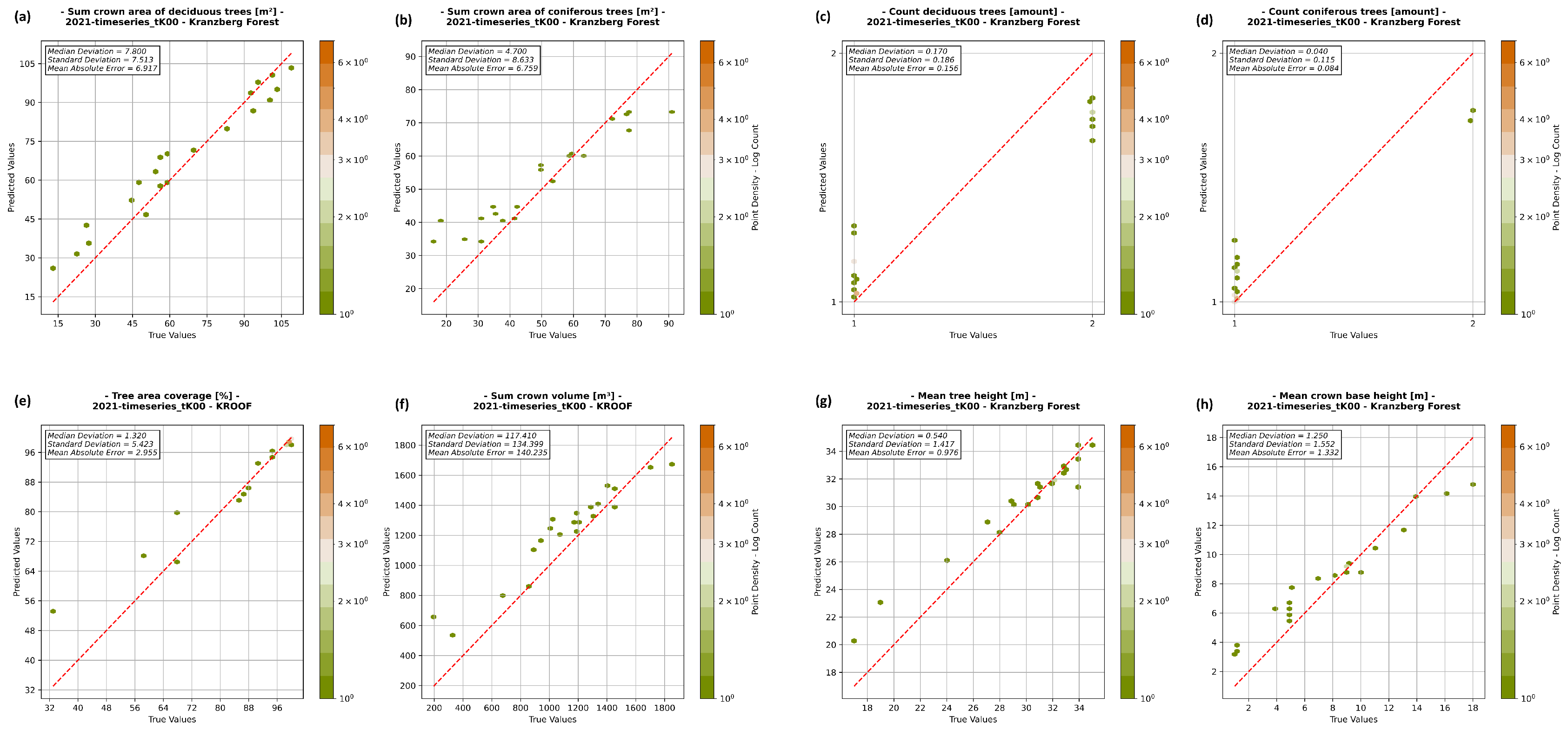
4.2. Regression Analysis and Quality Assurance
4.2.1. Steigerwald
4.2.2. Bavarian Forest National Park
4.2.3. Kranzberg Forest
5. Discussion
5.1. Selection of Test Sites
5.2. Temporal Discrepancy
5.3. Transferability
5.4. Implications and Applications
5.5. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| ARD | Analysis-ready data |
| ESA | European Space Agency |
| HCB | Hyper-complex bases |
| LiDAR | Light detection and ranging |
| MAD | Median absolute deviation |
| MAE | Mean absolute error |
| MSI | Multi-spectral imager |
| Q-Q | Quantile–quantile |
| RADAR | Radio detection and ranging |
| RF | Random forest |
| RS | Remote sensing |
| SAR | Synthetic aperture radar |
| STD | Standard deviation |
| UAV | Unmanned aerial vehicle |
References
- Reiersen, G.; Dao, D.; Lütjens, B.; Klemmer, K.; Amara, K.; Steinegger, A.; Zhang, C.; Zhu, X. ReforesTree: A Dataset for Estimating Tropical Forest Carbon Stock with Deep Learning and Aerial Imagery. Proc. Aaai Conf. Artif. Intell. 2022, 36, 12119–12125. [Google Scholar] [CrossRef]
- FAO. The State of the World’s Forests 2022: Forest Pathways for Green Recovery and Building Inclusive, Resilient and Sustainable Economies; FAO: Rome, Italy, 2022. [Google Scholar]
- Hirschmugl, M.; Ofner, M.; Raggam, J.; Schardt, M. Single tree detection in very high resolution remote sensing data. Remote Sens. Environ. 2007, 110, 533–544. [Google Scholar] [CrossRef]
- Brice Mora, M.A.W.; White, J.C. Identifying leading species using tree crown metrics derived from very high spatial resolution imagery in a boreal forest environment. Can. J. Remote Sens. 2010, 36, 332–344. [Google Scholar] [CrossRef]
- Fang, F.; McNeil, B.E.; Warner, T.A.; Maxwell, A.E.; Dahle, G.A.; Eutsler, E.; Li, J. Discriminating tree species at different taxonomic levels using multi-temporal WorldView-3 imagery in Washington D.C., USA. Remote Sens. Environ. 2020, 246, 111811. [Google Scholar] [CrossRef]
- Tong, F.; Tong, H.; Mishra, R.; Zhang, Y. Delineation of Individual Tree Crowns Using High Spatial Resolution Multispectral WorldView-3 Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7751–7761. [Google Scholar] [CrossRef]
- Wallace, L.; Sun, Q.C.; Hally, B.; Hillman, S.; Both, A.; Hurley, J.; San, D. Linking urban tree inventories to remote sensing data for individual tree mapping. Urban For. Urban Green. 2021, 61, 127106. [Google Scholar] [CrossRef]
- Freudenberg, M.; Magdon, P.; Nölke, N. Individual tree crown delineation in high-resolution remote sensing images based on U-Net. Neural Comput. Appl. 2022, 34, 22197–22207. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; White, J.C.; Wulder, M.A.; Næsset, E. Remote sensing in forestry: Current challenges, considerations and directions. For. Int. J. For. Res. 2023, 97, 11–37. Available online: https://academic.oup.com/forestry/article-pdf/97/1/11/55125114/cpad024.pdf (accessed on 18 January 2024). [CrossRef]
- Ball, J.G.C.; Hickman, S.H.M.; Jackson, T.D.; Koay, X.J.; Hirst, J.; Jay, W.; Archer, M.; Aubry-Kientz, M.; Vincent, G.; Coomes, D.A. Accurate delineation of individual tree crowns in tropical forests from aerial RGB imagery using Mask R-CNN. Remote Sens. Ecol. Conserv. 2023, 9, 641–655. Available online: https://zslpublications.onlinelibrary.wiley.com/doi/pdf/10.1002/rse2.332 (accessed on 18 January 2024). [CrossRef]
- Brandtberg, T.; Warner, T. High-spatial-resolution remote sensing. In Computer Applications in Sustainable Forest Management: Including Perspectives on Collaboration and Integration; Shao, G., Reynolds, K.M., Eds.; Springer: Dordrecht, The Netherlands, 2006; pp. 19–41. [Google Scholar] [CrossRef]
- Lines, E.R.; Fischer, F.J.; Owen, H.J.F.; Jucker, T. The shape of trees: Reimagining forest ecology in three dimensions with remote sensing. J. Ecol. 2022, 110, 1730–1745. Available online: https://besjournals.onlinelibrary.wiley.com/doi/pdf/10.1111/1365-2745.13944 (accessed on 18 January 2024). [CrossRef]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. Isprs J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Lines, E.R.; Allen, M.; Cabo, C.; Calders, K.; Debus, A.; Grieve, S.W.D.; Miltiadou, M.; Noach, A.; Owen, H.J.F.; Puliti, S. AI applications in forest monitoring need remote sensing benchmark datasets. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 4528–4533. [Google Scholar] [CrossRef]
- Lechner, A.M.; Foody, G.M.; Boyd, D.S. Applications in remote sensing to forest ecology and management. One Earth 2020, 2, 405–412. [Google Scholar] [CrossRef]
- Franklin, S.E. Remote Sensing for Sustainable Forest Management; CRC Press: Boca Raton, FL, USA, 2001. [Google Scholar]
- Camarretta, N.; Harrison, P.A.; Bailey, T.; Potts, B.; Lucieer, A.; Davidson, N.; Hunt, M. Monitoring forest structure to guide adaptive management of forest restoration: A review of remote sensing approaches. New For. 2020, 51, 573–596. [Google Scholar] [CrossRef]
- Jin, L.; Kuang, X.; Huang, H.; Qin, Z.; Wang, Y. Over-fitting Study of Artificial Neural Network Prediction Model. J. Meteorol 2004, 62, 62–70. [Google Scholar]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Introduction to KDD and Data Science. In Learning from Imbalanced Data Sets; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Schürholt, K.; Taskiran, D.; Knyazev, B.; i Nieto, X.G.; Borth, D. Model Zoos: A Dataset of Diverse Populations of Neural Network Models. arXiv 2022, arXiv:2209.14764. [Google Scholar]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Bénitez, S.; Breitkopf, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, I-3, 293–298. [Google Scholar] [CrossRef]
- Hu, J.; Liu, R.; Hong, D.; Camero, A.; Yao, J.; Schneider, M.; Kurz, F.; Segl, K.; Zhu, X.X. MDAS: A new multimodal benchmark dataset for remote sensing. Earth Syst. Sci. Data 2023, 15, 113. [Google Scholar] [CrossRef]
- Hu, Y. Automated Extraction of Digital Terrain Models, Roads and Buildings Using Airborne Lidar Data. Ph.D Thesis, University of Calgary, Calgary, AB, Canada, 2003. [Google Scholar]
- Dai, D.; Yang, W. Satellite Image Classification via Two-Layer Sparse Coding with Biased Image Representation. IEEE Geosci. Remote Sens. Lett. 2011, 8, 173–176. [Google Scholar] [CrossRef]
- Newsam, S.D. UC Merced Land Use Dataset. 2010. Available online: http://vision.ucmerced.edu/datasets/landuse.html (accessed on 18 January 2024).
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS), San Jose, CA, USA, 2–5 November 2010; p. 666. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Hurt, J.A.; Scott, G.J.; Anderson, D.T.; Davis, C.H. Benchmark Meta-Dataset of High-Resolution Remote Sensing Imagery for Training Robust Deep Learning Models in Machine-Assisted Visual Analytics. In Proceedings of the 2018 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 9–11 October 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Ahlswede, S.; Schulz, C.; Gava, C.; Helber, P.; Bischke, B.; Förster, M.; Arias, F.; Hees, J.; Demir, B.; Kleinschmit, B. TreeSatAI Benchmark Archive: A multi-sensor, multi-label dataset for tree species classification in remote sensing. Earth Syst. Sci. Data 2023, 15, 681–695. [Google Scholar] [CrossRef]
- Carpentier, M.; Giguère, P.; Gaudreault, J. Tree Species Identification from Bark Images Using Convolutional Neural Networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1075–1081. [Google Scholar] [CrossRef]
- Weinstein, B.G.; Graves, S.J.; Marconi, S.; Singh, A.; Zare, A.; Stewart, D.; Bohlman, S.A.; White, E.P. A benchmark dataset for canopy crown detection and delineation in co-registered airborne RGB, LiDAR and hyperspectral imagery from the National Ecological Observation Network. PLoS Comput. Biol. 2021, 17, e1009180. [Google Scholar] [CrossRef]
- Cao, Z.; Jiang, L.; Yue, P.; Gong, J.; Hu, X.; Liu, S.; Tan, H.; Liu, C.; Shangguan, B.; Yu, D. A large scale training sample database system for intelligent interpretation of remote sensing imagery. Geo-Spat. Inf. Sci. 2023, 1–20. [Google Scholar] [CrossRef]
- Xia, J.; Yokoya, N.; Adriano, B.; Broni-Bediako, C. OpenEarthMap: A Benchmark Dataset for Global High-Resolution Land Cover Mapping. arXiv 2022, arXiv:2210.10732. [Google Scholar]
- Zhang, L.; Zhang, L. Artificial Intelligence for Remote Sensing Data Analysis: A review of challenges and opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 270–294. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Aaron, E.; Maxwell, T.A.W.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.; Gong, J. Deep neural network for remote-sensing image interpretation: Status and perspectives. Natl. Sci. Rev. 2019, 6, 1082–1086. Available online: https://academic.oup.com/nsr/article-pdf/6/6/1082/38917206/nwz058.pdf (accessed on 18 January 2024). [CrossRef] [PubMed]
- Janga, B.; Asamani, G.P.; Sun, Z.; Cristea, N. A Review of Practical AI for Remote Sensing in Earth Sciences. Remote Sens. 2023, 15, 4112. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Tatnall, A.R.L. Introduction Neural networks in remote sensing. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Pintelas, P. Mixture of expert agents for handling imbalanced data sets. Ann. Math. Comput. Teleinform. 2003, 1, 46–55. [Google Scholar]
- Schmitt, A.; Wendleder, A.; Kleynmans, R.; Hell, M.; Roth, A.; Hinz, S. Multi-Source and Multi-Temporal Image Fusion on Hypercomplex Bases. Remote Sens. 2020, 12, 943. [Google Scholar] [CrossRef]
- Weigand, M.; Staab, J.; Wurm, M.; Taubenböck, H. Spatial and semantic effects of LUCAS samples on fully automated land use/land cover classification in high-resolution Sentinel-2 data. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102065. [Google Scholar] [CrossRef]
- Gschwantner, T.; Alberdi, I.; Bauwens, S.; Bender, S.; Borota, D.; Bosela, M.; Bouriaud, O.; Breidenbach, J.; Donis, J.; Fischer, C.; et al. Growing stock monitoring by European National Forest Inventories: Historical origins, current methods and harmonisation. For. Ecol. Manag. 2022, 505, 119868. [Google Scholar] [CrossRef]
- Zielewska-Büttner, K.; Heurich, M.; Müller, J.; Braunisch, V. Remotely Sensed Single Tree Data Enable the Determination of Habitat Thresholds for the Three-Toed Woodpecker (Picoides tridactylus). Remote Sens. 2018, 10, 1972. [Google Scholar] [CrossRef]
- Amiri, N.; Krzystek, P.; Heurich, M.; Skidmore, A. Classification of Tree Species as Well as Standing Dead Trees Using Triple Wavelength ALS in a Temperate Forest. Remote Sens. 2019, 11, 2614. [Google Scholar] [CrossRef]
- Heidrich, L.; Bae, S.E.; Levick, S.; Seibold, S.; Weisser, W.; Krzystek, P.; Magdon, P.; Nauss, T.; Schall, P.; Serebryanyk, A.; et al. Heterogeneity-diversity relationships differ between and within trophic levels in temperate forests. Nat. Ecol. Evol. 2020, 4, 1431. [Google Scholar] [CrossRef] [PubMed]
- Dersch, S.; Schöttl, A.; Krzystek, P.; Heurich, M. Towards complete tree crown delineation by instance segmentation with Mask R–CNN and DETR using UAV-based multispectral imagery and lidar data. ISPRS Open J. Photogramm. Remote Sens. 2023, 8, 100037. [Google Scholar] [CrossRef]
- Krzystek, P.; Serebryanyk, A.; Schnörr, C.; Červenka, J.; Heurich, M. Large-Scale Mapping of Tree Species and Dead Trees in Šumava National Park and Bavarian Forest National Park Using Lidar and Multispectral Imagery. Remote Sens. 2020, 12, 661. [Google Scholar] [CrossRef]
- Bertram, A.; Wendleder, A.; Schmitt, A.; Huber, M. Long-term monitoring of water dynamics in the Sahel region using the Multi-SAR-System. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-Isprs Arch. 2016, 41, 313–320. [Google Scholar] [CrossRef]
- Schmitt, A.; Wendleder, A.; Hinz, S. The Kennaugh element framework for multi-scale, multi-polarized, multi-temporal and multi-frequency SAR image preparation. Isprs J. Photogramm. Remote Sens. 2015, 102, 122–139. [Google Scholar] [CrossRef]
- Schmitt, A. Multiscale and Multidirectional Multilooking for SAR Image Enhancement. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5117–5134. [Google Scholar] [CrossRef]
- German Aerospace Center (DLR). Sentinel-2 MSI—Level 2A (MAJA Tiles)—Germany. 2019. Available online: https://geoservice.dlr.de/data-assets/ifczsszkcp63.html (accessed on 18 January 2024).
- Schmitt, A.; Wendleder, A. SAR-Sharpening in the Kennaugh Framework Applied to the Fusion of Multi-modal SAR and Opticle Images. Isprs Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, IV-1, 133–140. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Ramezan, C.A.; Warner, T.A.; Maxwell, A.E.; Price, B.S. Effects of Training Set Size on Supervised Machine-Learning Land-Cover Classification of Large-Area High-Resolution Remotely Sensed Data. Remote Sens. 2021, 13, 368. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D.; Kut, A. Multi-target regression for quality prediction in a mining process. In Proceedings of the 2019 4th International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; pp. 639–644. [Google Scholar]
- König, S.; Thonfeld, F.; Förster, M.; Dubovyk, O.; Heurich, M. Assessing Combinations of Landsat, Sentinel-2 and Sentinel-1 Time series for Detecting Bark Beetle Infestations. Gisci. Remote Sens. 2023, 60, 2226515. [Google Scholar] [CrossRef]
- van der Knaap, W.O.; van Leeuwen, J.F.N.; Fahse, L.; Szidat, S.; Studer, T.; Baumann, J.; Heurich, M.; Tinner, W. Vegetation and disturbance history of the Bavarian Forest National Park, Germany. Veg. Hist. Archaeobotany 2020, 29, 277–295. [Google Scholar] [CrossRef]
- Bae, S.; Levick, S.; Heidrich, L.; Magdon, P.; Leutner, B.; Wöllauer, S.; Serebryanyk, A.; Nauss, T.; Krzystek, P.; Gossner, M.; et al. Radar vision in the mapping of forest biodiversity from space. Nat. Commun. 2019, 10, 4757. [Google Scholar] [CrossRef] [PubMed]
- Müller, J.; Bußler, H.; Kneib, T. Saproxylic Beetle Assemblages Related to Silvicultural Management Intensity and Stand Structures in a Beech Forest in Southern Germany. J. Insect Conserv. 2008, 12, 107–124. [Google Scholar] [CrossRef]
- Caudullo, G.; De Rigo, D.; Mauri, A.; Houston Durrant, T.; San-Miguel-Ayanz, J. (Eds.) European Atlas of Forest Tree Species; Publications Office of the European Union: Luxembourg, 2016. [Google Scholar]
- Song, C.; Dickinson, M.B.; Su, L.; Zhang, S.; Yaussey, D. Estimating average tree crown size using spatial information from Ikonos and QuickBird images: Across-sensor and across-site comparisons. Remote Sens. Environ. 2010, 114, 1099–1107. [Google Scholar] [CrossRef]
- Skidmore, A.K.; Pettorelli, N.; Coops, N.C.; Geller, G.N.; Hansen, M.; Lucas, R.; Mücher, C.A.; O’Connor, B.; Paganini, M.; Pereira, H.M.; et al. Environmental science: Agree on biodiversity metrics to track from space. Nature 2015, 523, 403–405. [Google Scholar] [CrossRef] [PubMed]
- Blickensdörfer, L.; Oehmichen, K.; Pflugmacher, D.; Kleinschmit, B.; Hostert, P. Dominant Tree Species for Germany (2017/2018); Data Set; Thünen-Institut, Institut für Waldökosysteme: Eberswalde, Germany, 2022. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AOI No. | Name | Rough Coordinates | Airborne Platform | Year | Area | No. of Trees |
|---|---|---|---|---|---|---|
| 1 | Steigerwald | 48°25′N, 11°40′E | Helicopter | 2017 | 2600 ha | 1,106,073 |
| 2 | Bavarian Forest National Park | 49°15′N, 13°15′E | Helicopter | 2016 | 1443 ha | 512,489 |
| 3 | Kranzberg Forest | 49°53′N, 10°32′E | UAV | 2020 | 7 ha | 1467 |
| Band | Variable | Unit | Value Range |
|---|---|---|---|
| 1 | Sum crown area of deciduous trees | m2 | 0–170 |
| 2 | Sum crown area of coniferous trees | m2 | 0–170 |
| 3 | Sum crown area of dead trees | m2 | 0–120 |
| 4 | Count of deciduous trees | amount | 0–9 |
| 5 | Count of coniferous trees | amount | 0–9 |
| 6 | Count of dead trees | amount | 0–7 |
| 7 | Tree area coverage | % | 0–100 |
| 8 | Sum crown volume | m3 | 0–3000 |
| 9 | Mean tree height | m | 0–43 |
| 10 | Mean crown base height | m | 0–24 |
| Variable | MAD | MAE | STD | Unit |
|---|---|---|---|---|
| Sum crown area of deciduous trees | 4.120 | 5.195 | 6.768 | m2 |
| Sum crown area of coniferous trees | 3.510 | 4.326 | 5.433 | m2 |
| Count of deciduous trees | 0.200 | 0.248 | 0.317 | amount |
| Count of coniferous trees | 0.090 | 0.133 | 0.193 | amount |
| Tree area coverage | 0.710 | 1.075 | 1.602 | % |
| Sum crown volume | 24.330 | 31.140 | 40.601 | m3 |
| Mean tree height | 0.709 | 0.962 | 1.220 | m |
| Mean crown base height | 0.430 | 0.530 | 0.692 | m |
| Variable | MAD | MAE | STD | Unit |
|---|---|---|---|---|
| Sum crown area of deciduous trees | 5.765 | 6.249 | 7.564 | m2 |
| Sum crown area of coniferous trees | 4.630 | 5.238 | 6.525 | m2 |
| Sum crown area of dead trees | 3.115 | 3.811 | 4.745 | m2 |
| Count of deciduous trees | 0.240 | 0.281 | 0.344 | amount |
| Count of coniferous trees | 0.190 | 0.221 | 0.262 | amount |
| Count of dead trees | 0.090 | 0.125 | 0.161 | amount |
| Tree area coverage | 1.345 | 2.133 | 3.202 | % |
| Sum crown volume | 52.130 | 64.858 | 83.534 | m3 |
| Mean tree height | 0.910 | 1.246 | 1.608 | m |
| Mean crown base height | 1.045 | 1.249 | 1.488 | m |
| Variable | MAD | MAE | STD | Unit |
|---|---|---|---|---|
| Sum crown area of deciduous trees | 7.800 | 6.917 | 7.513 | m2 |
| Sum crown area of coniferous trees | 4.700 | 6.759 | 8.663 | m2 |
| Count of deciduous trees | 0.170 | 0.156 | 0.186 | amount |
| Count of coniferous trees | 0.040 | 0.084 | 0.115 | amount |
| Tree area coverage | 1.320 | 2.955 | 5.423 | % |
| Sum crown volume | 117.410 | 140.235 | 134.399 | m3 |
| Mean tree height | 0.540 | 0.976 | 1.417 | m |
| Mean crown base height | 1.250 | 1.332 | 1.552 | m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hauser, S.; Ruhhammer, M.; Schmitt, A.; Krzystek, P. An Open Benchmark Dataset for Forest Characterization from Sentinel-1 and -2 Time Series. Remote Sens. 2024, 16, 488. https://doi.org/10.3390/rs16030488
Hauser S, Ruhhammer M, Schmitt A, Krzystek P. An Open Benchmark Dataset for Forest Characterization from Sentinel-1 and -2 Time Series. Remote Sensing. 2024; 16(3):488. https://doi.org/10.3390/rs16030488
Chicago/Turabian StyleHauser, Sarah, Michael Ruhhammer, Andreas Schmitt, and Peter Krzystek. 2024. "An Open Benchmark Dataset for Forest Characterization from Sentinel-1 and -2 Time Series" Remote Sensing 16, no. 3: 488. https://doi.org/10.3390/rs16030488
APA StyleHauser, S., Ruhhammer, M., Schmitt, A., & Krzystek, P. (2024). An Open Benchmark Dataset for Forest Characterization from Sentinel-1 and -2 Time Series. Remote Sensing, 16(3), 488. https://doi.org/10.3390/rs16030488