

Global Semantic Classification of Fluvial Landscapes with Attention-Based Deep Learning
Abstract
:
1. Introduction
- Produce a state-of-the-art dataset of high quality manual labels that sample the non-polar globe and cover multiple seasons and multiple years.
- Leverage, adapt and fine-tune recent deep learning architectures based on the attention mechanism [15].
- Deliver an inference pipeline that can significantly cut processing times and bring global scale repeated monitoring within reach.
2. Materials and Methods
2.1. Hardware and Software
2.2. Data
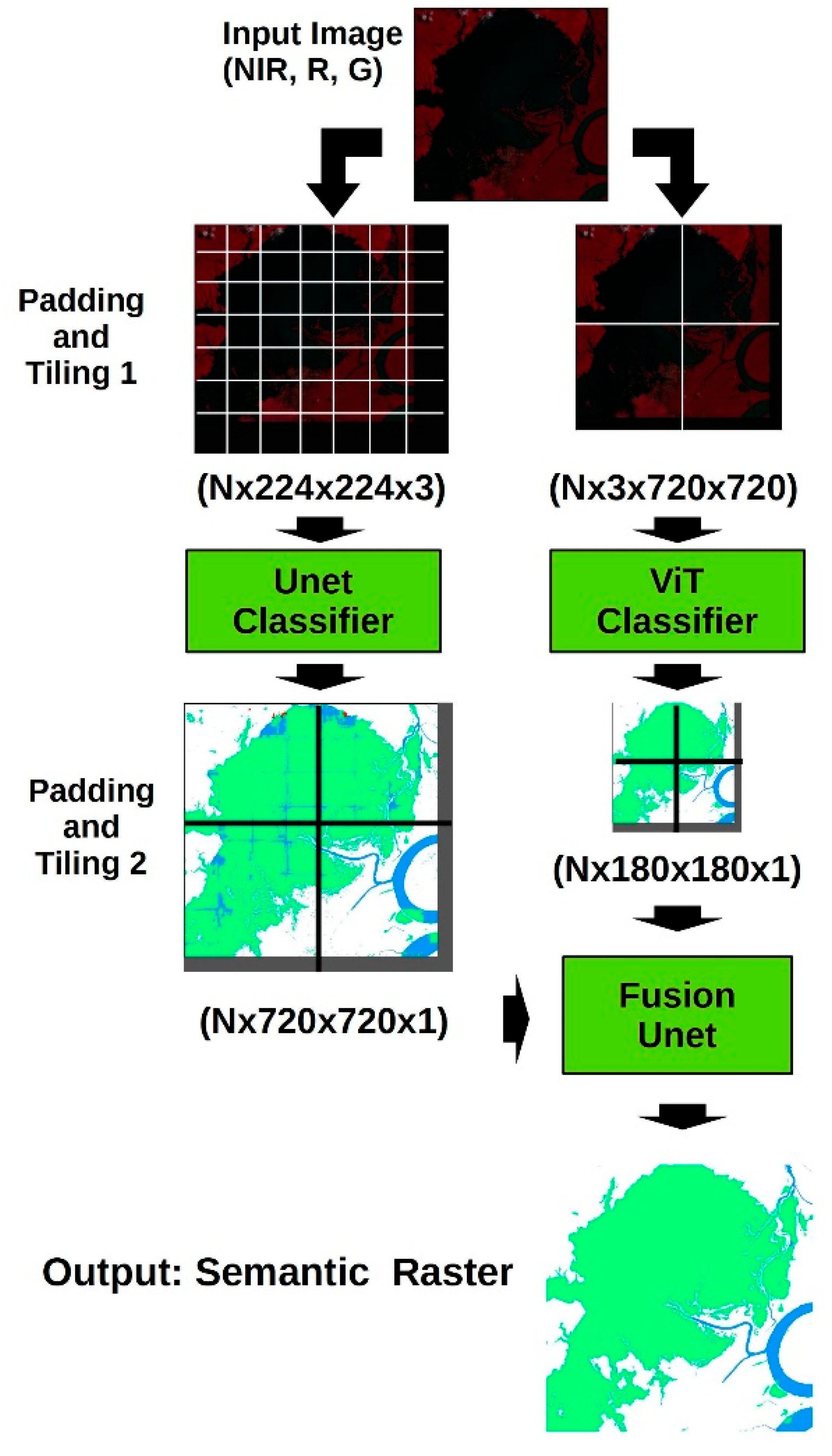
2.3. Model Architectures
2.4. Training
2.5. Inference and Accuracy Assessment
3. Results
4. Discussion
5. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Downing, J.; Cole, J.; Duarte, C.; Middelburg, J.; Melack, J.; Prairie, Y.; Kortelainen, P.; Striegl, R.; McDowell, W.; Tranvik, L. Global abundance and size distribution of streams and rivers. Inland Waters 2012, 2, 229–236. [Google Scholar] [CrossRef]
- Downing, J.A.; Prairie, Y.T.; Cole, J.J.; Duarte, C.M.; Tranvik, L.J.; Striegl, R.G.; McDowell, W.H.; Kortelainen, P.; Caraco, N.F.; Melack, J.M.; et al. The global abundance and size distribution of lakes, ponds, and impoundments. Limnol. Oceanogr. 2006, 51, 2388–2397. [Google Scholar] [CrossRef]
- Vörösmarty, C.J.; McIntyre, P.B.; Gessner, M.O.; Dudgeon, D.; Prusevich, A.; Green, P.; Glidden, S.; Bunn, S.E.; Sullivan, C.A.; Liermann, C.R.; et al. Global threats to human water security and river biodiversity. Nature 2010, 467, 555–561. [Google Scholar] [CrossRef]
- Dudgeon, D.; Arthington, A.H.; Gessner, M.O.; Kawabata, Z.-I.; Knowler, D.J.; Lévêque, C.; Naiman, R.J.; Prieur-Richard, A.-H.; Soto, D.; Stiassny, M.L.J.; et al. Freshwater biodiversity: Importance, threats, status and conservation challenges. Biol. Rev. 2006, 81, 163–182. [Google Scholar] [CrossRef]
- Tockner, K.; Stanford, J.A. Riverine flood plains: Present state and future trends. Environ. Conserv. 2002, 29, 308–330. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; Daems, D.; De Keersmaecker, W.; Brockmann, C.; Kirches, G.; Wevers, J.; Cartus, O.; Santoro, M.; Fritz, S.; et al. ESA WorldCover 10 m 2021 V200 2022. Available online: https://developers.google.com/earth-engine/datasets/catalog/ESA_WorldCover_v200 (accessed on 1 July 2024).
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Pekel, J.-F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Wieland, M.; Fichtner, F.; Martinis, S.; Groth, S.; Krullikowski, C.; Plank, S.; Motagh, M. S1S2-Water: A Global Dataset for Semantic Segmentation of Water Bodies from Sentinel-1 and Sentinel-2 Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1084–1099. [Google Scholar] [CrossRef]
- Carbonneau, P.E.; Bizzi, S. Global mapping of river sediment bars. Earth Surf. Process. Landf. 2023, 49, 15–23. [Google Scholar] [CrossRef]
- Allen, G.H.; Pavelsky, T.M. Global extent of rivers and streams. Science 2018, 361, 585–588. [Google Scholar] [CrossRef]
- Dallaire, C.O.; Lehner, B.; Sayre, R.; Thieme, M. A multidisciplinary framework to derive global river reach classifications at high spatial resolution. Environ. Res. Lett. 2019, 14, 024003. [Google Scholar] [CrossRef]
- Nyberg, B.; Henstra, G.; Gawthorpe, R.L.; Ravnås, R.; Ahokas, J. Global scale analysis on the extent of river channel belts. Nat. Commun. 2023, 14, 2163. [Google Scholar] [CrossRef] [PubMed]
- Lehner, B.; Verdin, K.; Jarvis, A. New Global Hydrography Derived from Spaceborne Elevation Data. Eos Trans. Am. Geophys. Union 2008, 89, 93–94. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467v2. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-Image: Image Processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- GDAL Dev. Team GDAL—Geospatial Data Abstraction Library; GD Arabia Ltd.: Riyadh, Saudi Arabia, 2018. [Google Scholar]
- Carbonneau, P.; Bizzi, S. Seasonal Monitoring of River and Lake Water Surface Areas at Global Scale with Deep Learning. 2022. Available online: https://assets-eu.researchsquare.com/files/rs-2254580/v2_covered.pdf?c=1670341515 (accessed on 1 July 2024).
- Zhou, N.; Xu, M.; Shen, B.; Hou, K.; Liu, S.; Sheng, H.; Liu, Y.; Wan, J. ViT-UNet: A Vision Transformer Based UNet Model for Coastal Wetland Classification Based on High Spatial Resolution Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19575–19587. [Google Scholar] [CrossRef]
- Tong, Q.; Wu, J.; Zhu, Z.; Zhang, M.; Xing, H. STIRUnet: SwinTransformer and Inverted Residual Convolution Embedding in Unet for Sea–Land Segmentation. J. Environ. Manag. 2024, 357, 120773. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, H.; Liu, L.; Zhang, Y.; Liu, J.; Qu, T.; Tian, H.; Lu, Y. A Method for Extracting Lake Water Using ViTenc-UNet: Taking Typical Lakes on the Qinghai-Tibet Plateau as Examples. Remote Sens. 2023, 15, 4047. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Wang, F.; Silvestre, G.; Curran, K. MiTU-Net: A Fine-Tuned U-Net with SegFormer Backbone for Segmenting Pubic Symphysis-Fetal Head. arXiv 2024, arXiv:2401.15513. [Google Scholar]
- Yeom, S.-K.; von Klitzing, J. U-MixFormer: UNet-like Transformer with Mix-Attention for Efficient Semantic Segmentation. arXiv 2023, arXiv:2312.06272. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Xie, Z.; Jin, J.; Wang, J.; Zhang, R.; Li, S. Application of Deep Learning Techniques in Water Level Measurement: Combining Improved SegFormer-UNet Model with Virtual Water Gauge. Appl. Sci. 2023, 13, 5614. [Google Scholar] [CrossRef]
- Tarboton, D.G.; Bras, R.L.; Rodriguez-Iturbe, I. The Fractal Nature of River Networks. Water Resour. Res. 1988, 24, 1317–1322. [Google Scholar] [CrossRef]
- Ghassemian, H. A Review of Remote Sensing Image Fusion Methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Choudhary, G.; Sethi, D. From Conventional Approach to Machine Learning and Deep Learning Approach: An Experimental and Comprehensive Review of Image Fusion Techniques. Arch. Comput. Methods Eng. 2023, 30, 1267–1304. [Google Scholar] [CrossRef]
- Smikrud, K.M.; Prakash, A.; Nichols, J.V. Decision-Based Fusion for Improved Fluvial Landscape Classification Using Digital Aerial Photographs and Forward Looking Infrared Images. Photogramm. Eng. Remote Sens. 2008, 74, 903–911. [Google Scholar] [CrossRef]
- Zhang, Y.; Chi, M. Mask-R-FCN: A Deep Fusion Network for Semantic Segmentation. IEEE Access 2020, 8, 155753–155765. [Google Scholar] [CrossRef]
- Tomar, N. Nikhilroxtomar/Semantic-Segmentation-Architecture 2024. Available online: https://github.com/nikhilroxtomar/Semantic-Segmentation-Architecture (accessed on 1 July 2024).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef]
- HuggingFace, H. Transformers: State-of-the-Art Machine Learning for JAX, PyTorch and TensorFlow 2024. Available online: https://github.com/huggingface/transformers (accessed on 1 July 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Isikdogan, L.F.; Bovik, A.; Passalacqua, P. Seeing Through the Clouds with DeepWaterMap. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1662–1666. [Google Scholar] [CrossRef]
- Hao, M.; Dong, X.; Jiang, D.; Yu, X.; Ding, F.; Zhuo, J. Land-Use Classification Based on High-Resolution Remote Sensing Imagery and Deep Learning Models. PLoS ONE 2024, 19, e0300473. [Google Scholar] [CrossRef]
- Carbonneau, P.E. Global Scale Attention-Based Deep Learning for River Landscape Classification [Dataset]; Durham University: Durham, UK, 2024. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attention Unet Output | Segformer ViT Output | Fused Outputs | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | ||
| Seen | River | 0.895 | 0.806 | 0.848 | 0.874 | 0.907 | 0.890 | 0.947 | 0.932 | 0.939 |
| Lake | 0.876 | 0.947 | 0.910 | 0.908 | 0.950 | 0.929 | 0.955 | 0.972 | 0.963 | |
| Bar | 0.778 | 0.669 | 0.719 | 0.802 | 0.750 | 0.775 | 0.844 | 0.757 | 0.798 | |
| Unseen | River | 0.819 | 0.712 | 0.762 | 0.822 | 0.894 | 0.857 | 0.927 | 0.913 | 0.920 |
| Lake | 0.856 | 0.937 | 0.895 | 0.927 | 0.957 | 0.942 | 0.965 | 0.963 | 0.964 | |
| Bar | 0.372 | 0.588 | 0.456 | 0.685 | 0.780 | 0.729 | 0.734 | 0.781 | 0.757 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carbonneau, P.E. Global Semantic Classification of Fluvial Landscapes with Attention-Based Deep Learning. Remote Sens. 2024, 16, 4747. https://doi.org/10.3390/rs16244747
Carbonneau PE. Global Semantic Classification of Fluvial Landscapes with Attention-Based Deep Learning. Remote Sensing. 2024; 16(24):4747. https://doi.org/10.3390/rs16244747
Chicago/Turabian StyleCarbonneau, Patrice E. 2024. "Global Semantic Classification of Fluvial Landscapes with Attention-Based Deep Learning" Remote Sensing 16, no. 24: 4747. https://doi.org/10.3390/rs16244747
APA StyleCarbonneau, P. E. (2024). Global Semantic Classification of Fluvial Landscapes with Attention-Based Deep Learning. Remote Sensing, 16(24), 4747. https://doi.org/10.3390/rs16244747