1. Introduction
Wildfires are among the most devastating natural disasters, causing extensive environmental, economic, and social harm [
1]. The early detection of wildfire smoke is critical for mitigating these impacts, as it provides the first opportunity for intervention before fires become uncontrollable. As climate change accelerates, the frequency, scale, and intensity of wildfires have been increasing globally, making it imperative to develop advanced and reliable early detection systems. One of the earliest indicators of a wildfire is the production of smoke, with video monitoring being the predominant method for detecting such early signs [
2]. However, in the initial stages of a wildfire, the smoke typically occupies only a small portion of the monitoring image, making the prompt detection of these small smoke targets vital for preventing the escalation of wildfire events [
3]. During this phase, incomplete combustion of fuel generates substantial smoke characterized by distinct texture and diffusion patterns [
4]. Efficient smoke detection can provide firefighters with critical time to swiftly extinguish fires, thereby making the development of effective early wildfire smoke detection methods an urgent and essential goal in wildfire monitoring.
Traditional wildfire detection methods, including satellite imagery, thermal sensors, and manual monitoring, often fail to meet the requirements for real-time detection and high accuracy. While satellite systems provide broad coverage, they are limited by temporal resolution and are less effective in detecting small-scale smoke in its early stages [
5]. Ground-based systems, relying on traditional computer vision techniques, often face issues such as poor generalization to diverse environmental conditions and difficulty in adapting to dynamic and complex backgrounds [
6]. Deep learning-based object detection models have shown great promise in addressing these limitations due to their ability to automatically extract features and perform real-time detections [
7]. Some researchers have employed deep learning methods for wildfire smoke detection and have achieved certain successes [
8,
9,
10,
11]. However, early wildfire smoke detection still faces significant challenges, including the detection of small and dispersed smoke targets [
12], high false alarm rates caused by interference from smoke-like objects such as clouds and fog [
13], and the limited availability of annotated datasets for training robust models [
14]. These challenges hinder the development of reliable and effective wildfire monitoring systems.
This study aims to address these challenges by proposing a novel detection framework, MEDA-YOLO, which enhances the YOLOv5 architecture through the integration of an Efficient Channel and Dilated Convolution Spatial Attention (EDA) mechanism [
15]. This hybrid attention module enables the model to focus on smoke-specific features while suppressing irrelevant information, such as clouds and fog. Additionally, to overcome the scarcity of training data, a diverse and realistic dataset, Smoke-Exp, was created by combining real-world images with synthetic data generated using Cycle-GAN.
The primary contributions of this study are as follows:
Creation of the Smoke-Exp Dataset: A novel dataset comprising real-world and synthetic wildfire smoke images generated using Cycle-GAN, which provides diverse and realistic training scenarios for small-scale smoke detection models.
Enhanced Detection Framework: An enhanced YOLOv5-based detection model incorporating a 4× downsampling detection head (Detect-Tiny) and optimized feature extraction techniques, significantly improving sensitivity to small smoke targets and reducing missed detections.
Hybrid Domain Attention Mechanism: A hybrid domain attention mechanism, Efficient Channel and Dilated Convolution Spatial Attention (EDA), is integrated into M-YOLO, enabling the model to filter out irrelevant information and focus on smoke-specific features, even in complex environmental conditions.
Comprehensive Evaluation: We conducted extensive experiments to demonstrate the effectiveness of our approach, achieving significant improvements over existing models in terms of accuracy and robustness, making it more applicable in real-world scenarios.
This paper is organized as follows:
Section 1 introduces the background and significance of this study, highlighting the key contributions.
Section 2 reviews related work, summarizing research progress in wildfire smoke detection and identifying the limitations of existing methods.
Section 3 details the construction of the Smoke-Exp dataset.
Section 4 presents the proposed MEDA-YOLO model, describing its architecture and innovations.
Section 5 provides the experimental results and an in-depth analysis of the model’s performance.
Section 6 discusses the advantages of the proposed method and explores potential applications of the EDA mechanism beyond wildfire detection.
Section 7 concludes the paper by summarizing the key findings and contributions of this work.
3. Construction of the Early Wildfire Smoke Dataset
Deep learning is a data-driven machine learning approach. The performance and generalization ability of deep learning models heavily depend on the quality of the dataset, as it enables the model to learn richer and more effective features, thereby improving detection accuracy and robustness [
36]. Consequently, constructing a high-quality wildfire smoke dataset is a critical step in the early detection of wildfire smoke. Currently, widely used public wildfire datasets include those provided by the Computer Vision and Pattern Recognition Laboratory at Keimyung University in South Korea [
37], the dataset from Bilkent University in Turkey [
38], the dataset compiled by Professor Yuan’s team [
39], and the dataset produced and publicly released by the State Key Laboratory of Fire Science at the University of Science and Technology of China [
40]. However, these public datasets generally suffer from limitations such as small sample sizes, limited background diversity, and insufficient complexity, rendering them less suitable for the specific research objectives of this study. Furthermore, there is a notable lack of datasets specifically designed for early wildfire smoke imagery. To address these gaps, this study introduces a new wildfire smoke dataset, named Smoke-Raw.
The Smoke-Raw dataset was curated by selecting content from 32 wildfire and smoke videos, along with over 1000 high-definition images collected from various sources. Through techniques such as video frame extraction and image filtering, a total of 3616 video frame images were obtained. Approximately 90% of these images are ideal for this study, featuring small-target wildfire smoke within large scenes viewed from long distances. The remaining images include other types of smoke and flames, such as close-range smoke.
To further enhance the background diversity of small-scale wildfire smoke in the Smoke-Raw dataset, we implemented a data augmentation method based on the Cycle-Generative Adversarial Network (Cycle-GAN) [
41]. Specifically, the original dataset was divided into two domains: spring-summer and autumn-winter. The well-trained Cycle-GAN model was then used to transform images from one domain to the other, generating a substantial number of synthetic smoke images that closely resemble realistic seasonal background variations. These augmented images were subsequently incorporated into the Smoke-Raw dataset, resulting in an expanded version named Smoke-Exp.
Figure 1 illustrates the structure of the Cycle-GAN. In this model,
and
represent two distinct image domains.
and
are the discriminators for each domain, respectively. These discriminators are composed of multiple residual blocks, convolutional layers, the Leaky ReLU activation function, and fully connected layers, and they are used to determine whether an image belongs to its corresponding domain.
is the generator that transforms images from domain
to domain
, while
is the generator that performs the reverse transformation, from domain
to domain
. Each generator consists of an encoder, a transformer, and a decoder, enabling the effective transformation between these domains.
When training Cycle-GAN, the process begins by randomly selecting an original image
from domain
and an image
y from domain
. These images are then passed through the generators
and
, respectively, resulting in the corresponding transformed image
and
. Subsequently,
and
are passed through the generators
and
again to obtain the reconstructed images
and
. Through this process, the generators
and
learn the mappings from domain
to domain
and vice versa. To ensure the effectiveness of these mappings, a cycle consistency loss is introduced. This loss function calculates the discrepancy between the original image in
domain (
) and its corresponding reconstructed image (
) after being mapped to
domain (
) and back to domain
. Similarly, it calculates the loss between the original image in
domain (
) and its corresponding reconstructed image (
) after being mapped to
domain (
) and back to domain
. This cycle consistency loss guides the network towards convergence and facilitates the accurate transfer of image styles between the two domains [
42].
The cycle consistency loss is expressed in Equation (1).
where
represents the L1 norm of the regenerated
with the original real data
from generator
, and
can be analogized.
The hyperparameter settings used for training Cycle-GAN in this paper were as follows: the number of input and output channels was 3, the discriminator network was set to “basic”, the generator network was set to “resnet_9blocks”, the batch size was 8, the number of epochs was 500, the initial learning rate was 0.0002, and the learning rate decreases according to the “linear” strategy every 50 epochs. The hardware used included an Intel Core i7-6700HQ processor (Intel Corporation, Santa Clara, California, United States, obtained from online retail channels) and NVIDIA GeForce GTX 2080Ti graphics card (NVIDIA Corporation, Santa Clara, California, United States, obtained from online retail channels, using ASUS XG STATION PRO Thunderbolt 3 GPU dock for connection), with PyTorch 1.7.1 as the framework and Python 3.7.
After training the Cycle-GAN model, two style transfer model files were saved: GA.pth, which transfers the style from spring-summer to autumn-winter, and GB.pth, which transfers the style from autumn-winter to spring-summer. These models were used to modify the seasonal background style of smoke images in the Smoke-Raw dataset, enabling data augmentation. Following the Cycle-GAN-based data augmentation, 2400 high-quality and relevant images were selected from the generated outputs and added to the Smoke-Raw dataset, resulting in the creation of the Smoke-Exp dataset. The Smoke-Exp dataset comprises a total of 6016 images. Examples of the generated images are shown in
Figure 2.
Subsequently, the LabelImg tool [
43] was utilized to annotate the wildfire smoke objects in the images with bounding boxes. Once the annotation process for all images was completed, the data were meticulously organized to ensure rigorous experimentation and ease of data handling. The images, annotation files, segmentation categories, and other related files were formatted and stored according to the PASCAL VOC standard dataset format [
44].
4. Early Wildfire Smoke Detection Method Based on EDA
Early or long-distance wildfire smoke often appears as small targets in images captured by electronic watchtowers. Timely detection and warning of such smoke are critical for preventing wildfire incidents. However, detecting this early smoke is challenging due to several factors: it typically occupies a small number of pixels, exhibits low resolution in the smoke area, and has blurry texture and contour features. Additionally, variations in the height and width of smoke, along with interference from clouds and fog in real forest environments, can lead to false alarms. To enhance the detection accuracy for these early small smoke targets, YOLOv5 [
45] was selected as the base model and adapted for small wildfire smoke detection. We propose an early wildfire smoke detection algorithm that integrates a hybrid domain attention mechanism, Efficient Channel and Dilated Convolution Spatial Attention (EDA). While more advanced YOLO algorithms exist, they incorporate a large number of general object detection methods that have not been validated for wildfire smoke detection. Therefore, we chose the more classic and mature YOLOv5 as the base model for its robustness and suitability for this specific application.
4.1. Multi-Scale Small Smoke Target Detection Algorithm M-YOLO
Detecting small smoke targets is a critical and challenging task in wildfire smoke detection [
46]. Small wildfire smoke targets occupy relatively few pixels, exhibit low resolution in the smoke area, and have indistinct texture and contour features. This makes it difficult for deep learning models to effectively extract relevant features, rendering them highly susceptible to background interference and noise. During image feature extraction in YOLO, as the network deepens, the resolution of the feature maps decreases, and the local receptive field (the original image area corresponding to each pixel) expands. Consequently, deeper feature maps capture more global information, while shallower feature maps retain positional and detailed information.
To address the limitations of single-scale feature detection for small objects, researchers have proposed multi-scale feature fusion [
47]. By integrating shallow and deep features, it becomes possible to leverage the positional, detailed, and semantic information contained in each feature map to predict object locations and categories across multiple scales. Studies have shown that multi-scale detection methods significantly improve algorithm performance. YOLOv5 achieves multi-scale object detection by employing three types of downsampling: 8×, 16×, and 32×, generating feature maps of different resolutions. For example, with an input image size of 640 × 640 × 3, the corresponding feature map sizes are 80 × 80, 40 × 40, and 20 × 20.
Figure 3a illustrates the YOLOv5 network structure. Each feature map output layer contains 255 channels, encoding information such as object category, confidence, and bounding box coordinates [
48]. The network uses anchor points at each scale to predict target positions and sizes, assigning larger targets to lower-level (32× downsampling) feature maps and smaller targets to higher-level (8× downsampling) feature maps.
To enhance the detection of small-scale wildfire smoke, a multi-scale improvement strategy was proposed. In addition to the existing three-scale detection heads in YOLOv5, a new detection head sensitive to small targets, with a minimum size of 4 × 4 pixels, was introduced. This improvement allows the network to detect early-stage wildfire smoke with a minimum resolution of 16 pixels. The enhanced model, named M-YOLO, incorporates an additional detection head, Detect-Tiny, which performs 4× downsampling. Furthermore, the feature fusion method at the Neck was adjusted. The improved multi-scale YOLO wildfire smoke detection model includes four additional modules in the upper Neck and introduces the Detect-Tiny head in the upper Prediction layer, as illustrated in
Figure 3b.
The wildfire smoke detection model based on M-YOLO achieves two key objectives, addressing critical challenges in early wildfire smoke detection:
Enhancing network depth and width: By increasing the depth and width of the network, the model is able to learn more comprehensive and multi-level feature information, which enables it to capture both low-level details and high-level semantic representations of smoke targets. This enhancement improves the model’s performance in detecting objects across multiple scales, especially in complex environments, allowing it to better differentiate smoke from surrounding background noise and achieve more accurate detections in diverse conditions.
Improving sensitivity to small smoke targets: The model increases its sensitivity to small smoke targets, allowing it to capture more detailed information on these smaller targets. This enhancement significantly improves the detection of small smoke targets, even under conditions of low visual quality.
4.2. Construction of Hybrid Domain Attention Mechanism EDA
To enhance the network’s ability to detect smoke and suppress interference from clouds, fog, and irrelevant background elements, a hybrid domain attention mechanism called EDA was developed. This mechanism integrates an efficient channel attention mechanism with a spatial attention mechanism incorporating dilated convolutions. By simultaneously focusing on both the spatial and channel dimensions, the EDA mechanism reduces the influence of irrelevant information and strengthens the representation of smoke-related features in the network. Consequently, it improves the detection performance for wildfire smoke targets.
4.2.1. Efficient Channel Attention (ECA)
The Efficient Channel Attention (ECA) mechanism [
49] is widely used in computer vision to dynamically adjust the weights of different feature channels based on the input image’s content. This adjustment enhances the feature representation and robustness by highlighting meaningful information and guiding the network’s focus toward target objects [
50]. ECA, a form of channel attention mechanism, employs a one-dimensional convolutional layer that adaptively adjusts the kernel size to fit varying feature map sizes and dimensions. The ECA module’s schematic is illustrated in
Figure 4.
4.2.2. Dilated Convolutional Spatial Attention (DCSA)
Dilated convolution [
51] is a convolutional variant that expands the receptive field by introducing gaps between kernel elements without increasing kernel size or parameters. The dilation factor
controls the gaps, where
corresponds to standard convolution, and
increases the receptive field. Dilated convolution is computed as shown in Equation (2):
where
is the original kernel size,
is the dilation factor, and
represents the effective kernel size after dilation.
The receptive field is the region in the input image that affects a point in the feature map of the convolutional neural network. Its size depends on the kernel size and stride. By increasing the dilation rate with fixed kernel size and stride, the receptive field grows exponentially, capturing richer feature map information. The receptive field size for a given layer is computed as shown in Equation (3):
where
is the receptive field size in the current layer,
is the receptive field size in the previous layer, and
is the stride of the convolution.
The spatial attention mechanism assigns weights to each spatial position based on feature map correlations, highlighting target features and suppressing background noise. In the DCSA module, the 7 × 7 convolution in the standard spatial attention mechanism is replaced with dilated convolution, reducing computational costs while maintaining the receptive field and controlling parameter growth after introducing the attention mechanism [
51]. A 3 × 3 dilated convolution with a dilation factor
is used, providing an effective 7 × 7 receptive field size.
Figure 5 illustrates the DCSA structure.
4.2.3. Hybrid Domain Attention Mechanism (EDA)
The hybrid domain attention (Efficient Channel and Dilated Convolution Spatial Attention, EDA) module combines the ECA and DCSA modules. Its structure is shown in
Figure 6.
4.3. Early Wildfire Smoke Detection Method MEDA-YOLO
The EDA module applies attention weighting across both the spatial and channel dimensions, emphasizing critical feature information within the feature map. The EDA module is integrated into the M-YOLO network, resulting in a new model, MEDA-YOLO. MEDA-YOLO incorporates the EDA module into the backbone of M-YOLO, which is a deep CNN designed to extract multi-scale image features and fuse them into a global feature vector. The backbone primarily consists of CBS, C3, and SPPF modules. CBS includes a convolution module (Conv), normalization module, and SiLU activation function. C3 consists of CBS modules and bottleneck layers, responsible for feature fusion within the network. The EDA module is embedded in the C3 structure to enhance feature extraction in both spatial and channel dimensions, as shown in
Figure 7.
4.4. Loss Function of MEDA-YOLO
The MEDA-YOLO model compares predicted results with ground truth labels to optimize its performance. The loss function measures the discrepancy between predictions and labels, guiding the model’s learning. The loss function consists of three components: bounding box loss , confidence loss , and classification loss .
Bounding box loss
: This loss uses the Generalized Intersection over Union (
) function for bounding box regression. The overlap between predicted and ground truth boxes is calculated for each anchor box, as shown in Equation (4).
where
stands for Generalized Intersection over Union, which is an improved metric of
. It takes into account the area of the convex hull between the two boxes. The formula for
is given by Equation (5):
stands for Intersection over Union, which is the ratio of the intersection area between two boxes to their union area. represents the minimum convex hull area that contains both boxes, while refers to the predicted bounding box of the target. Bgt is the target’s real box.
Confidence loss
: This refers to the error between the confidence scores of the predicted bounding boxes and the true labels during training. MEDA-YOLO uses the Binary Cross-Entropy (BCE) loss function to compute confidence loss, as shown in Equation (6):
where is the predicted value, and is the true label.
Classification loss
: This measures the difference between the predicted class probabilities and the true labels. Similar to confidence loss, MEDA-YOLO employs the BCE loss function to compute this loss for each anchor box, as shown in Equation (7).
5. Experiment and Result
To evaluate the performance of the proposed method, experiments were conducted on the self-constructed Smoke-Exp dataset. The dataset was divided into training, validation, and test sets in an 8:1:1 ratio.
5.1. Experiment Setup
The pseudo-labeled data obtained in the previous section were used for experiments. Comparative tests between the baseline model and the proposed algorithm were conducted under identical conditions, including the same training and test sets. The hyperparameters were consistent: input image size was 640 × 640, batch size was 4, initial learning rate was 0.0001, and the learning rate was reduced by 95% every five epochs. The hardware used included an Intel Core i7-6700HQ processor and NVIDIA GeForce GTX 2080Ti graphics card, with PyTorch 1.7.1 as the framework and Python 3.7.
5.2. Evaluation Metrics
The evaluation metrics for this experiment include precision (P), recall (R), mean average precision (mAP), and frames per second (FPS). Precision (P) and recall (R) are calculated using Equations (8) and (9).
Precision (P): Measures the ratio of correctly identified positive targets (TP) to the total identified positives (TP + FP).
Recall (R): Measures the ratio of correctly identified positive targets (TP) to the actual positives (TP + FN).
The average precision (AP) for each class can be calculated using precision (P) and recall (R). The mean average precision (mAP) is the average of the AP values for all classes, as shown in Equations (10) and (11). In this study, the
threshold used for mAP calculation is set to 0.5.
where
represents the total number of classes in the dataset, and
represents the average precision of the class
. In this study, the detection object has only one category of smoke, so the mAP is the AP under the same threshold.
5.3. Dataset Augmentation Experiment
To assess the effectiveness of the Cycle-GAN-based data augmentation method, YOLOv5s was trained four times on both the Smoke-Raw and Smoke-Exp datasets. All experiments were conducted with the same settings, utilizing early stopping mechanisms. For simplicity, the experiments on the Smoke-Raw and Smoke-Exp datasets are referred to as YOLO-Raw and YOLO-Exp, respectively. The results are presented in
Table 1.
The results demonstrate that dataset augmentation significantly improves model performance. The mAP on Smoke-Raw was 92.40%, which increased by 2.27% after applying Cycle-GAN augmentation. Similarly, both precision and recall improved, validating the efficacy of Cycle-GAN augmentation in enhancing model generalization.
5.4. EDA Embedding Position Experiment
To determine the optimal embedding position for the EDA module, we conducted experiments by integrating the EDA module into different parts of the M-YOLO network.
MEDA-YOLO-Backbone: The EDA module was embedded into the Backbone.
MEDA-YOLO-Neck: The EDA module was embedded into the Neck.
MEDA-YOLO-Output: The EDA module was embedded into the Output.
These experiments were designed to compare the effectiveness of different embedding positions and identify the most suitable configuration for enhancing the model’s performance. The results of these experiments are summarized in
Table 2, providing insights into the impact of the EDA module’s placement on detection accuracy and efficiency.
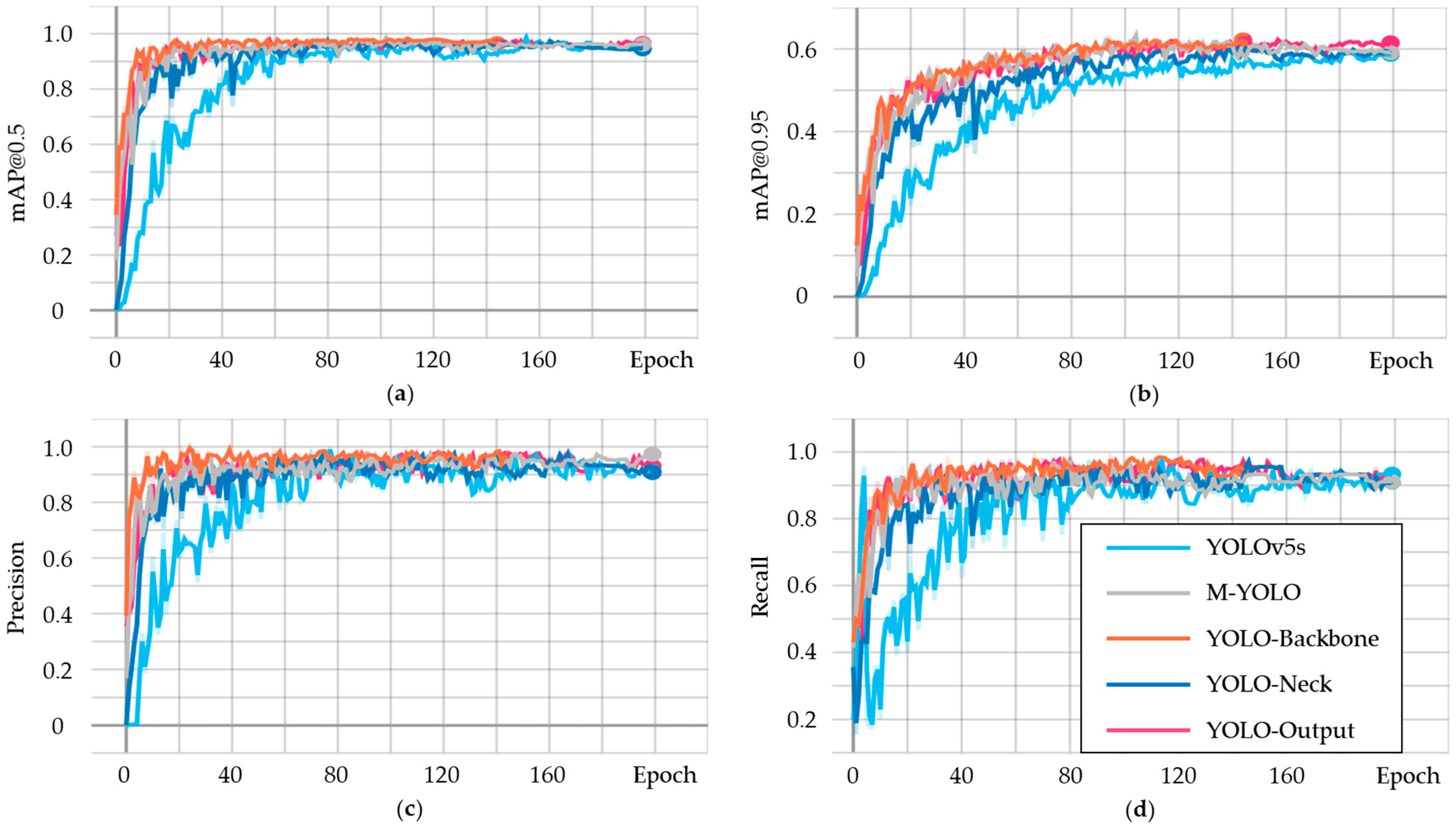
The results demonstrate that mAP improved across all embedding positions. Among the different configurations, MEDA-YOLO-Backbone, which integrates the EDA hybrid domain attention mechanism into the Backbone, achieved the highest mAP of 97.58%, while YOLOv5 had the lowest at 95.42%. MEDA-YOLO-Backbone also attained the highest precision and recall. Additionally, the precision of the entire MEDA-YOLO series was consistently higher than that of M-YOLO, indicating that the EDA module effectively guides the network to focus on smoke details and reduces the miss rate by adjusting channel and spatial attention on the feature map. Moreover, the addition of a small object detection layer significantly improved the model’s ability to detect small objects, leading to higher accuracy and recall compared to YOLOv5s.
In terms of FPS, adding the small object detection layer significantly decreases the FPS, while the EDA attention mechanism moderately mitigates this reduction. MEDA-YOLO-Neck achieves the highest FPS because the EDA attention mechanism is applied between the Concat and C3 layers of PAN. This allows the EDA module to adjust the channel and spatial attention of only the multi-scale fusion features obtained after Concat, without altering the feature maps at every scale. As a result, the computational load and number of parameters of the EDA module are reduced, enhancing the model’s running speed.
Figure 8 illustrates the four training metrics: mAP@0.5, mAP@0.95, precision, and recall for the five models. Overall, all models demonstrate strong performance in detection accuracy, precision, and recall, with MEDA-YOLO-Backbone exhibiting the best performance, while YOLOv5s shows the weakest results.
Additionally, we conducted experiments and analyzed the loss variation of the algorithm.
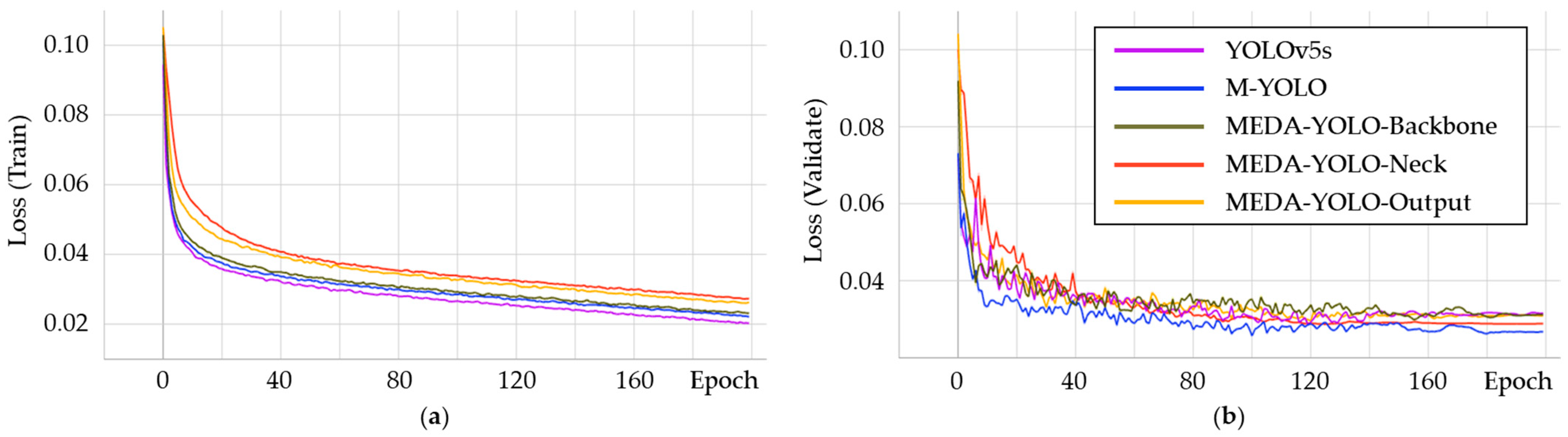
Figure 9 illustrates the bounding box loss curves across epochs for the five models during training. Bounding box loss measures the difference between the predicted and actual bounding box positions, with lower values indicating higher localization accuracy. In
Figure 9a, YOLOv5s exhibits the lowest curve, with a loss value of 0.02017, indicating the highest localization accuracy on the training set. In comparison, the curves for M-YOLO, MEDA-YOLO-Backbone, MEDA-YOLO-Neck, and MEDA-YOLO-Output are slightly higher, though the differences are minimal.
Figure 9b shows the bounding box loss on the validation set, where M-YOLO achieves the lowest loss value of 0.02665, followed by MEDA-YOLO-Neck at 0.02874, with the latter showing the smoothest curve. YOLOv5s has the highest loss value of 0.03110. Overall, all models demonstrate strong convergence during training, as their bounding box losses consistently decrease with increasing epochs, eventually stabilizing at relatively low levels. This suggests that all models successfully fit the data without signs of overfitting or underfitting.
Objectness loss is a key metric for evaluating the classification accuracy of YOLO models. Lower objectness loss indicates greater accuracy in predicting target classes. To compare the performance of YOLOv5s with other models based on M-YOLO and MEDA-YOLO, we plotted the objectness loss curves for both the training set (
Figure 10a) and the validation set (
Figure 10b) and analyzed the results, highlighting the strengths and weaknesses of each model.
Figure 10a illustrates that, on the training set, YOLOv5s has the highest curve, indicating the largest objectness loss. In contrast, the curves for M-YOLO, MEDA-YOLO-Backbone, MEDA-YOLO-Neck, and MEDA-YOLO-Output are slightly lower, demonstrating that these models can accurately identify small smoke targets and exhibit comparable detection performance. During training, the objectness loss of all models decreases steadily with the number of training epochs, eventually stabilizing at low values, indicating that the models fit the data well and converge efficiently. Notably, during the first six epochs, the objectness loss for all models except YOLOv5s rises briefly before declining. This may be attributed to the use of a small object detection layer, which takes some time to adapt to the data distribution and might introduce minor noise or redundant information.
Figure 10b presents the objectness loss curves for the validation set, where YOLOv5s again exhibits the highest curve with slight oscillations, signifying lower detection accuracy and weaker generalization. The other four models maintain low and smooth objectness loss curves. After 100 epochs, the difference between their loss values is minimal, demonstrating good classification performance and strong generalization ability. From
Figure 10, it is clear that YOLOv5s performs the worst, while the other improved models demonstrate superior performance, characterized by lower loss, higher accuracy, and stronger generalization.
These experimental results confirm that all models effectively minimize the loss function during training, achieving good convergence. The EDA module, when embedded in the Backbone, delivers the best performance. This configuration enables deep feature extraction and residual learning while adjusting feature importance across dimensions. It guides the network to focus on smoke details and reduces the influence of irrelevant information such as clouds and fog, thereby significantly lowering the false detection rate.
The MEDA-YOLO-Backbone will be adopted as the improved MEDA-YOLO algorithm.
5.5. Model Comparison Experiment
To validate the effectiveness of the proposed model, performance comparisons were conducted between our method and several others, including the single-stage YOLOv5s, M-YOLO, YOLOv7 [
52], and YOLOv8 [
53] models, as well as the two-stage Faster R-CNN [
54] model and the Transformer-based RT-DETR [
55] model. The results of these comparisons are presented in
Table 3. Compared to the YOLOv5s model, MEDA-YOLO demonstrates a slight reduction in FPS by 3 frames but achieves notable improvements in precision, recall, and mAP, with increases of 4.51%, 4.37%, and 2.16%, respectively.
In terms of the mAP metric, the proposed M-YOLO model achieves a score of 96.74%, representing a 1.32% improvement over the original YOLOv5s model and a 3.26% improvement over the Faster R-CNN model. This demonstrates that the multi-scale enhancement strategy employed in this study significantly improves the model’s detection accuracy. Moreover, MEDA-YOLO achieves the highest mAP value of 97.58%, marking a 0.84% improvement over M-YOLO. Regarding precision and recall, the M-YOLO model shows a 2.41% increase in precision and a 3.56% increase in recall compared to YOLOv5s. This suggests that the inclusion of the Detect-Tiny head for small object detection effectively enhances the model’s capability to detect small smoke targets, reducing missed detections and false alarms. Although the Transformer-based RT-DETR model achieves the highest precision and recall scores, the differences between MEDA-YOLO and RT-DETR in these metrics are minimal. In terms of FPS, the addition of the Detect-Tiny head slightly reduces the detection speed of the MEDA-YOLO model to 75 FPS, which is 3 FPS lower than YOLOv5s. However, this remains a high speed, meeting the demands of real-time detection. Both YOLOv8 and YOLOv5 achieve similar speeds of 78 FPS. On the other hand, RT-DETR’s FPS decreases significantly compared to MEDA-YOLO due to the large number of parameters, which is 19 FPS. The Faster R-CNN model, with its complex network structure and two-stage detection process, has the slowest speed of only 9 FPS, making it unsuitable for real-time detection.
To comprehensively and accurately evaluate the performance of the wildfire smoke detection model, test images featuring large smoke targets were included. The qualitative analysis images in this section are categorized into two types:
Forest Background Images: These include smoke-like targets such as haze, clouds or fog.
Small-Scale Wildfire Smoke Images: These are captured in the early stages of a wildfire or from a distance.
These images are obtained from real forest monitoring cameras, providing a more realistic simulation of actual detection environments, which encompass common difficulties and challenges in wildfire detection, and are of crucial significance in verifying the robustness and generalization ability of the detection model.
Figure 11 shows the results of different models for detecting small smoke objects.
It can be observed that all six models successfully detect small smoke objects in the images. Comparing the results in
Figure 11b,e,f, MEDA-YOLO demonstrates higher detection confidence than both M-YOLO and YOLOv5s, indicating that the improved network is more sensitive to detecting small smoke objects. For the small smoke objects in the first column of the images, MEDA-YOLO outperforms YOLOv7 and YOLOv8, while the detection confidence for large smoke objects remains comparable among the three models. Notably, Faster R-CNN, as shown in
Figure 11a, exhibits the highest prediction confidence, but it has the lowest mAP among the quantitative metrics. Despite this, it performs well in detecting small smoke objects during qualitative analysis. However, both Faster R-CNN in
Figure 11a and YOLOv5s in
Figure 11b exhibit false detections of a tent in the bottom left corner of the images. In contrast, MEDA-YOLO in
Figure 11f successfully avoids such false detections.
The detection results for smoke-like objects are presented in
Figure 12. It is evident that the first five networks—Faster R-CNN, YOLOv5s, YOLOv7, YOLOv8, and M-YOLO—exhibit a relatively high number of false detections for cloud-like and fog-like smoke objects.
In
Figure 12a, Faster R-CNN generates the highest number of incorrect prediction boxes in the left image, with one instance even mistakenly detecting the forest background as smoke. It also exhibits the highest false detection confidence in the right image, indicating that Faster R-CNN has the weakest performance in recognizing smoke and smoke-like targets, resulting in the highest false detection rate. In
Figure 12b, YOLOv5s, due to its smaller model size, fails to capture sufficient detailed features, leading to numerous incorrect prediction boxes for clouds and fog. This suggests a limitation in its ability to distinguish smoke from similar-looking objects.
Figure 12c demonstrates that YOLOv7 produces many incorrect prediction boxes for cloud and fog images in the first column, highlighting its poor performance in suppressing interference from these elements. Similarly,
Figure 12d shows YOLOv8 also generates false detections for clouds and fog.
In
Figure 12e, M-YOLO shows improved performance with only three incorrect prediction boxes in the left image of clouds and fog and no false detections in the right image. This improvement is attributed to M-YOLO’s enhanced multi-scale detection capabilities, which expand the feature fusion network scale by four times, reduce local receptive fields, and better capture smoke details in small targets. Despite this progress, further enhancement is still possible.
Figure 12f illustrates that MEDA-YOLO, incorporating the EDA attention mechanism, demonstrates superior discrimination capabilities for cloud and fog images. It virtually eliminates false alarms for these images, indicating a significant improvement in distinguishing smoke from interfering elements.
6. Discussion
Wildfire smoke detection is an essential task for early wildfire management, and deep learning models have become a cornerstone for addressing this challenge. While existing methods have made significant strides in improving detection accuracy, they often struggle with small smoke targets and interference from environmental factors and complex backgrounds. In this study, we proposed MEDA-YOLO, a novel model that incorporates the Efficient Channel and Dilated Convolution Spatial Attention (EDA) mechanism into an enhanced YOLO framework to address these challenges. MEDA-YOLO significantly improves the detection of small smoke targets, which is critical in the early stages of wildfire detection, where smoke often occupies only a few pixels in the image.
Beyond wildfire smoke detection, the proposed MEDA-YOLO model has broader potential applications in fields such as drone-based aerial imagery and satellite remote sensing. In both aerial and satellite imagery, small targets are often present against complex and dynamic backgrounds, similar to the conditions encountered in wildfire detection. The ability to detect small objects amidst interference makes MEDA-YOLO highly applicable in these domains. This cross-domain applicability highlights the versatility of the model and adds to its overall contribution to the field.
Despite these advancements, the computational demands of the EDA mechanism and the added detection head slightly reduce inference speed, posing challenges for deployment on resource-constrained edge devices. Moreover, while the Smoke-Exp dataset, enriched with synthetic data from Cycle-GAN, provides diverse training scenarios, there remains a need for further validation using larger real-world datasets to ensure robustness across diverse conditions. These limitations highlight the importance of developing lightweight and efficient detection frameworks to facilitate widespread deployment in real-time wildfire monitoring systems.
7. Conclusions
This study presents MEDA-YOLO, a novel wildfire smoke detection model designed to address key challenges such as detecting small smoke targets and minimizing false alarms in complex environmental conditions. By integrating the Efficient Channel and Dilated Convolution Spatial Attention (EDA) mechanism into an enhanced YOLO framework, MEDA-YOLO significantly improves detection accuracy and robustness. Experimental results demonstrate that MEDA-YOLO achieves a mean Average Precision (mAP) of 97.58% on the Smoke-Exp dataset, outperforming YOLOv5, YOLOv8, and M-YOLO by 2.16%, 1.24%, and 0.84%, respectively, while maintaining real-time detection speed.
Another contribution of this research is the creation of the Smoke-Exp dataset, which combines 3616 real-world wildfire smoke images with 2400 synthetic images generated using Cycle-GAN. This diverse dataset enables the model to generalize effectively across various wildfire detection scenarios, providing a strong foundation for training and evaluation. Additionally, the introduction of the Detect-Tiny head in M-YOLO enhances the network’s sensitivity to small smoke targets, addressing a key limitation in traditional object detection methods.
While MEDA-YOLO demonstrates superior performance and meets the requirements for real-time detection, it has only been tested on a PC and has not yet been deployed on resource-constrained edge devices. This limitation highlights an important direction for future work. Specifically, optimizing the model for deployment on edge devices, such as mobile or embedded systems, remains a key challenge. Future research will focus on enhancing the model’s computational efficiency and reducing its resource consumption, ensuring that it can be effectively deployed in real-time, low-latency environments. Additionally, expanding the dataset with more real-world images will further improve the model’s robustness and adaptability across diverse operational conditions.







 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}