1. Introduction
Hyperspectral Imaging (HSI) is an advanced imaging technique capable of capturing detailed spectral information across hundreds of continuous bands. HSI’s rich spectral data allow the precise identification of the chemical composition and physical properties of materials, making it widely applicable in fields such as environmental monitoring [
1,
2], military rescue [
3,
4], and material analysis [
5]. However, in practice, HSI is highly susceptible to external interferences, particularly Stray Light Interference (SLI), which degrades image quality and impacts the accuracy of analysis. SLI is notably severe in environments with strong sunlight or poor optical shielding, such as aerial remote sensing, where atmospheric scattering and solar reflections are prevalent, and in complex military scenarios where unpredictable conditions further exacerbate interference. Such interference reduces both the spatial and spectral accuracy of hyperspectral data, thereby limiting its effectiveness in critical applications. Hardware-based methods, such as optical shielding and system optimization, are frequently used to mitigate SLI. Nevertheless, these techniques face significant limitations, particularly in dynamic environments like aerial or urban monitoring, where scattering and reflections are difficult to fully control [
6,
7,
8,
9,
10]. Additionally, relying solely on hardware solutions often leads to increased system complexity and higher costs, making them impractical in many situations. Therefore, software-based restoration approaches act as an essential complement to hardware measures, improving data quality while effectively managing system complexity and ensuring cost efficiency.
SLI refers to the phenomenon in which light from non-target sources enters the imaging system and is superimposed on the target object’s spectral signals, resulting in data distortion [
11,
12,
13,
14]. This issue may arise from flaws in the internal optical system, such as lens reflection, scattering, and stray thermal radiation, or from external sources like sunlight or atmospheric scattering [
15]. SLI primarily affects HSIs in two dimensions. In the spatial dimension, it degrades pixel quality, reducing spatial resolution. In the spectral dimension, SLI leads to the overlapping of spectral signals from different wavelengths, distorting the true spectral characteristics of the target object. The simultaneous degradation of spatial and spectral dimensions reduces the accuracy of spectral data interpretation.
Currently, methods to solve the SLI problem can be broadly categorized into hardware-based and software-based approaches. Hardware methods include optimizing optical system design to reduce SLI or employing shielding components and optical filters to block unwanted light [
6,
7,
8,
9,
10,
16,
17,
18]. Although effective, these hardware approaches often increase system complexity and cost and may not fully eliminate SLI in complex environments. Traditional algorithmic approaches, such as sparse representation and low-rank matrix decomposition, have been widely applied to Hyperspectral Image restoration due to their ability to leverage structural priors [
19,
20]. However, these methods often struggle to capture the complex spatial–spectral interactions and nonlinear interference patterns commonly found in real-world SLI scenarios. In contrast, deep-learning-based restoration methods offer greater flexibility and superior performance in handling high-dimensional and complex data.
In recent years, deep learning has achieved significant progress in image processing and restoration, particularly in handling high-dimensional and complex data [
21,
22]. By training neural networks, systems can automatically extract spatial and spectral features, learn the characteristics of SLI, and effectively restore degraded images during inference. Compared to traditional rule-based or statistical restoration methods, deep learning is better suited to handle complex and dynamic scenarios [
23]. The main deep learning architectures currently used for HSI restoration include Convolutional Neural Networks (CNNs) and Transformer [
24]. CNNs excel at capturing local features, particularly in extracting spatial and spectral dependencies. However, CNNs struggle to capture long-range dependencies, making them less effective in handling images severely affected by SLI. In contrast, Transformer models, which utilize self-attention mechanisms, excel at capturing long-range dependencies, making them ideal for tasks requiring global context. Yet, since the computational complexity of Transformers grows quadratically with data dimensions, applying them to high-dimensional hyperspectral data incurs significant computational costs. To address the limitations of both CNNs and Transformers, State Space Models (SSMs) have recently emerged in HSI processing [
25,
26]. SSMs are mathematical models that describe system state evolution over time. They express system dynamics through relationships between state and observation variables and are widely used in control theory, signal processing, and time series analysis. In image processing, compared to other models, SSM-based methods offer lower computational complexity when processing high-dimensional data and can more efficiently capture long-range dependencies. Mamba is among the most advanced models developed using SSM. However, the original Mamba was designed for 2D image restoration and lacks the ability to learn spectral dependencies across channels in 3D HSIs. This limitation makes it less effective in handling the complex spatial–spectral relationships required for accurate HSI restoration, especially under challenging conditions such as SLI.
Building on this foundation, we propose MambaHR, a novel method specifically designed for HSI restoration under SLI. MambaHR employs a U-shaped architecture that integrates multi-scale feature extraction. The MambaHR architecture utilizes a 2D-SSM as the core of its spatial attention mechanism, responsible for extracting and processing two-dimensional spatial features. To enhance spectral information capture, MambaHR incorporates a channel attention mechanism, ensuring the accurate restoration of distorted spectral features.
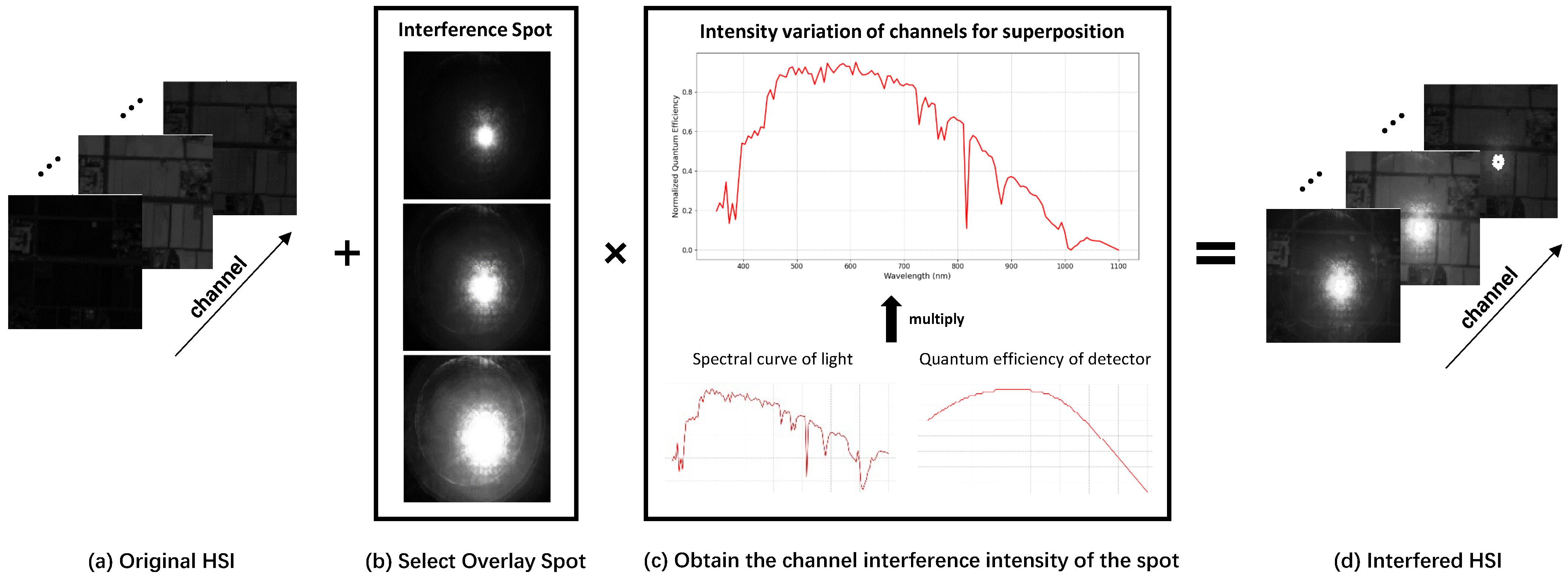
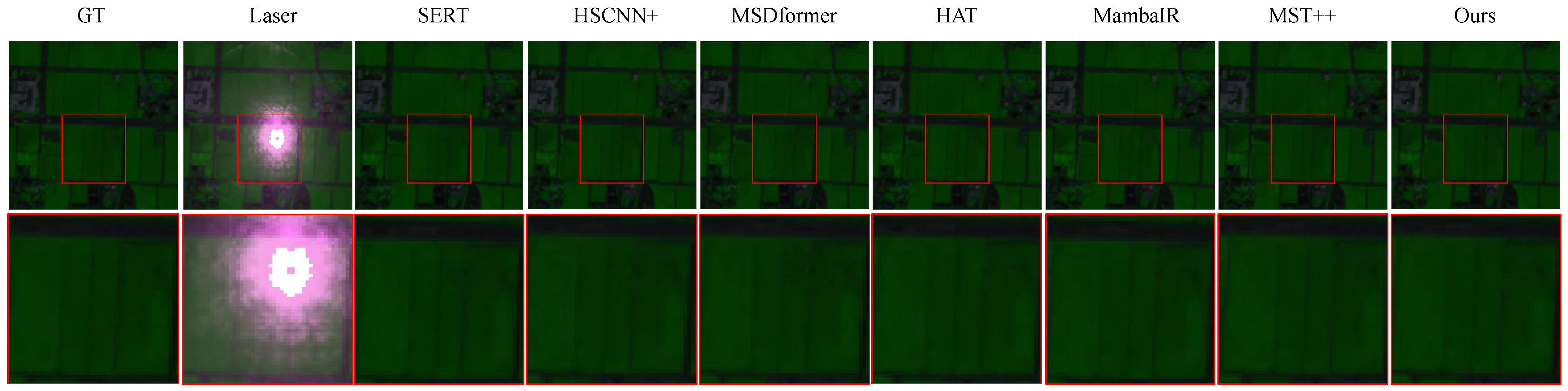
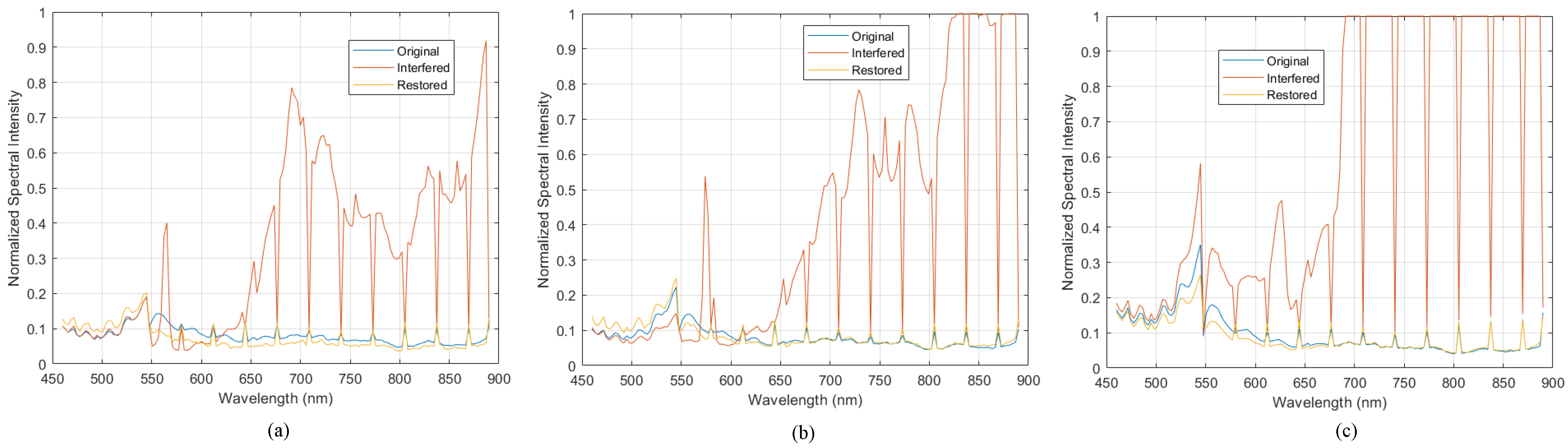
To effectively evaluate MambaHR’s performance in complex interference scenarios, we constructed a synthetic hyperspectral dataset with SLI. This dataset simulates HSIs with varying SLI intensities, reflecting real-world conditions and testing the model’s restoration capabilities under different levels of interference. Experimental results demonstrate that MambaHR achieves superior performance on multiple hyperspectral benchmark datasets, effectively recovering blurred spatial information and correcting spectral distortions.
In summary, the main contributions can be outlined as follows:
We advance the field of HSI restoration by applying deep learning techniques, incorporating transfer learning, to restore HSIs under SLI.
We propose MambaHR, an improved version of the original Mamba model, which integrates multi-scale feature extraction with a channel attention mechanism. This enables MambaHR to capture spectral dependencies across channels, overcoming Mamba’s limitations in 3D HSI restoration and significantly enhancing spectral fidelity and spatial detail under SLI.
We simulate real-world interference conditions and create a synthetic hyperspectral dataset with SLI, establishing a new benchmark for HSI restoration research.
3. Methodology
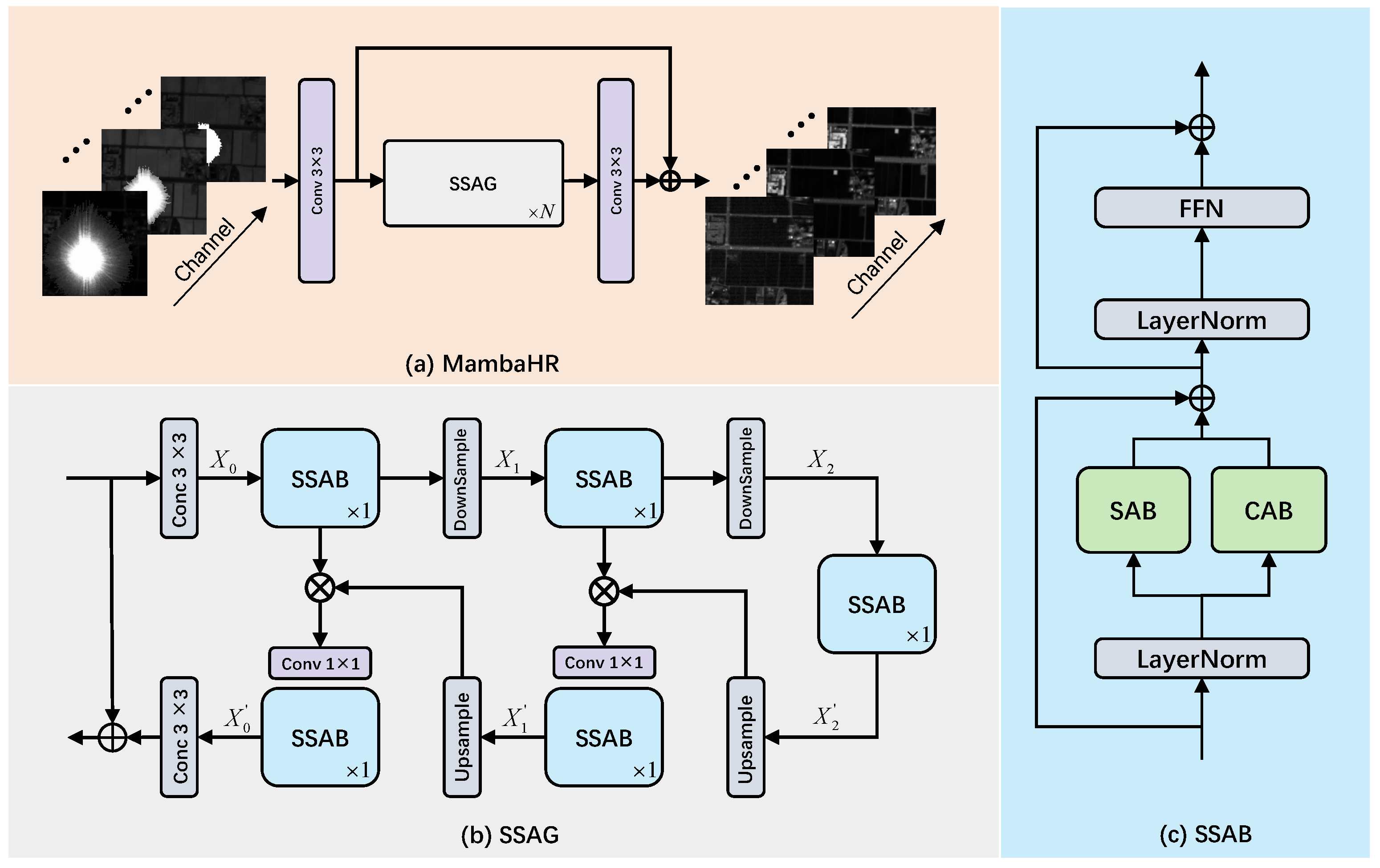
In this section, we introduce the proposed MambaHR architecture, a selective SSM designed for HSI restoration under strong light interference. The model efficiently captures and integrates both spatial and spectral information from HSIs through multi-scale feature extraction and attention-based modules.
3.1. Preliminaries: State Space Models
Recent advancements in structured state-space sequence models, especially the S4 model [
25], have significantly driven the development of continuous linear time-invariant systems. These systems map a one-dimensional input sequence
to an output sequence
through an implicit latent state
. Formally, the system can be described by the following ordinary differential equation (ODE):
where
represents the hidden state, and the matrices
,
,
, and
are the model parameters. The evolution of the hidden state
depends on the current input
and the previous hidden state
, while the output
is generated from both
and
.
To implement this in practical deep learning scenarios, the continuous ODE needs to be discretized. A commonly used method for discretization is the zero-order hold rule, which results in
where
is the sampling step. After discretization, these equations can be rewritten in a form similar to Recurrent Neural Networks (RNNs):
Additionally, the discretized equations can be further transformed into a convolutional form to enable more efficient computation:
where
is the convolutional kernel, ∗ denotes the convolution operation, and
k is the sequence length.
Gu et al. introduced the Mamba method [
26], which optimizes parameters using a selective scan mechanism, along with hardware-aware strategies to ensure efficient implementation in real-world applications. We applied the Mamba method and further explored its potential applications in spatial–spectral modeling of 3D images.
3.2. Overall Architecture
For a given hyperspectral input image
with interference, where the image has dimensions
,
H and
W represent the height and width of the image, and
N represents the number of spectral channels. A 3 × 3 convolution operation is initially applied to map the input to initial features
, as shown in
Figure 1:
where
represents the initial convolution operation.
Subsequently, the initial features are input into
N Spatial–Spectral Attention Groups (SSAGs). Each SSAG comprises multiple Spatial–Spectral Attention Blocks (SSABs), which are responsible for refining the input features. Within each SSAG, the features undergo a downsampling process to reduce the spatial dimensions, followed by an upsampling process to restore these dimensions, thereby achieving multi-scale feature fusion. The integration of downsampling, upsampling, and convolution layers enables the model to effectively capture both spatial and spectral information across various scales. Residual connections are utilized to enhance information flow, ensuring that crucial feature details are preserved throughout the deep network, as illustrated in
Figure 1. The overall process for each SSAG can be expressed as follows:
where
represents the operations within the
i-th SSAG module. Each SSAG contains a series of downsampling, upsampling, and convolution operations.
The SSAB serves as the fundamental component within each SSAG. The SSAB integrates both spectral attention and channel attention, which are responsible for capturing critical spatial and spectral information. It employs residual connections and layer normalization (LayerNorm) to facilitate stable feature propagation, thereby further enhancing feature representation. The specific mechanisms underlying spectral attention and channel attention will be elaborated upon in subsequent sections.
After passing through multiple SSAG modules, the final output features are processed by a convolution layer and added to the initial shallow features
. This residual connection ensures that the original shallow features are preserved in the final output, while deep features are effectively enhanced, as shown in
Figure 1. The final output is given by
where
is the final convolution operation, and
represents the deep features processed by the last SSAG.
This residual connection allows the model to retain the original shallow information while enhancing key feature details through deep convolution operations.
Overall, the MambaHR architecture utilizes a selective SSM for HSI restoration under SLI, integrating contemporary mainstream approaches to image restoration. It effectively extracts and aggregates spatial and spectral information through a combination of downsampling, upsampling, and convolutional layers across multiple SSAG modules. The attention mechanisms within the SSABs further refine the spatial and spectral details, ensuring a balance between the retention of the original information and the enhancement of critical features, as detailed in
Section 3.3 and
Section 3.4.
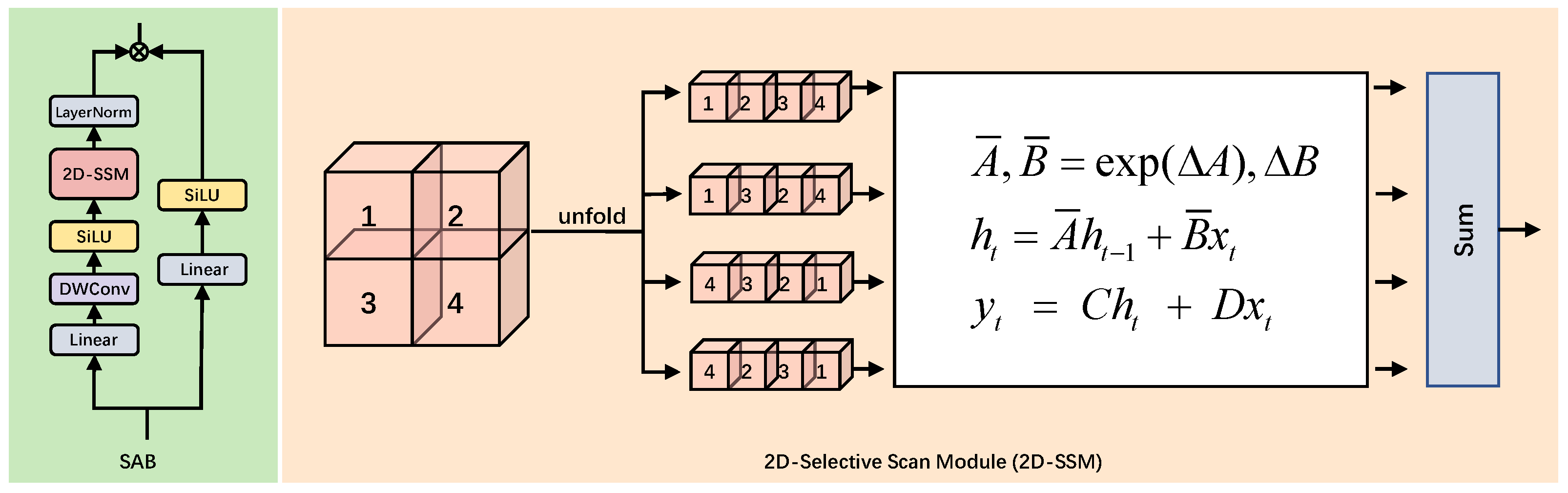
3.3. Spatial Attention Block
The Spatial Attention Block (SAB) is designed to enhance the modeling of long-range spatial dependencies in 2D image data. As shown in
Figure 2, the SAB consists of two main components: the processing path and the 2D Selective Scan Module (2D-SSM).
In the first branch, assuming the input feature has been processed to the feature
, it undergoes several transformations to extract spatial information. First, the input feature
is processed by a linear layer to reduce its dimensionality and enhance the representation of key features. Then, it passes through a depthwise convolution (DWConv) layer, which captures fine-grained spatial details by applying a filter to each input channel. The convolution result is followed by the SiLU activation function to introduce non-linearity, which helps capture complex relationships within the spatial domain. After SiLU activation, the feature is fed into the 2D-SSM module. The 2D-SSM unfolds the 2D feature map in multiple directions and effectively captures long-range dependencies. Finally, after passing through the 2D-SSM, LayerNorm is applied to stabilize training and maintain consistency across the feature map, producing output
:
In the second branch, the input feature
is processed in a simplified manner. First, the feature is mapped to a new feature space by a linear layer, followed by SiLU activation, producing the output
:
Then, the outputs from both branches,
and
, are combined using the Hadamard product (element-wise multiplication):
This fusion enables the model to integrate spatial information captured by the 2D-SSM in the first branch with the simpler linear feature representation from the second branch, producing the final output via element-wise multiplication.
The 2D-Selective Scan Module (2D-SSM) is the core part of the SAB, as illustrated on the right side of
Figure 2. This module unfolds the 2D feature map in four different directions, scanning the image along both the horizontal and vertical axes to capture dependencies between neighboring pixels. This unfolding process effectively captures the long-range spatial dependencies critical to image processing tasks.
After scanning in multiple directions, the results are aggregated and reshaped to reconstruct the original 2D structure of the feature map. This mechanism enables the model to account for both local and global interactions across the image, enhancing its effectiveness in processing complex spatial relationships.
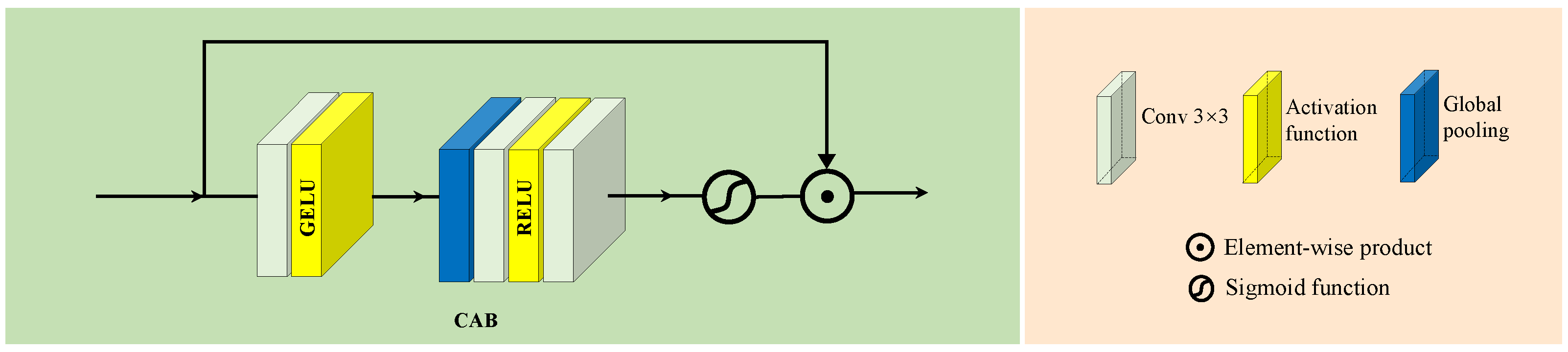
3.4. Channel Attention Block
The Channel Attention Block (CAB) is specifically designed to capture dependencies among different channels in HSIs. In
Section 3.3, the SAB focuses on extracting spatial features; however, the spectral dimension has not been sufficiently addressed. Therefore, we introduce the CAB to complement this and explicitly address channel information.
As illustrated in
Figure 3, the processing flow of the CAB module is as follows.
First, the input feature map is processed through a convolutional layer to capture initial channel dependencies. The output from this convolutional layer is then processed through the GELU activation function. GELU introduces non-linearity through a probabilistic approach, facilitating the more precise capture of complex channel-wise features.
Next, the features undergo global pooling, which aggregates information across all spatial locations, generating a comprehensive global descriptor for each channel. This step removes the influence of spatial positioning from the channel attention mechanism.
The globally pooled features are then processed through an additional series of convolutional layers to further refine channel dependencies. Afterward, the feature map is once again processed through the RELU activation function for non-linear transformation. Subsequently, the features pass through one final convolutional layer before being fed into a Sigmoid function for normalization. The Sigmoid function constrains the output to the range [0, 1], representing the relative importance of each channel.
Finally, the CAB module applies element-wise multiplication between the channel-wise weights and the input features, amplifying significant channel information while suppressing less relevant channels. This dynamic weighting enables the CAB to effectively enhance the spectral dimension representation within the feature map.
3.5. Loss Function
In our method, we utilize the Mean Relative Absolute Error (MRAE) as the objective function to measure the difference between the predicted and actual HSI cubes. The MRAE loss function is commonly used in HSI reconstruction tasks since it provides a relative measure of the reconstruction error.
Formally, the MRAE loss between the ground-truth HSI
and the predicted HSI
is defined as
where
represents the total number of pixels across all spectral channels in the HSI. Here,
H and
W denote the height and width of the image, while
represents the number of spectral bands. The MRAE loss function provides a normalized measurement of the absolute difference between the predicted pixel value
and the ground-truth pixel value
, relative to the true pixel value. This formulation ensures that the loss function is scale-invariant and effectively captures the reconstruction error in HSI tasks.
By minimizing the MRAE loss, the model is trained to produce high-quality reconstructed HSIs that are as close as possible to the ground-truth data.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}