
Attention Swin Transformer UNet for Landslide Segmentation in Remotely Sensed Images


Abstract
:
1. Introduction
- (1)
- The CASI module introduces spatial intersection attention to reduce noise within landslides and address the issue of “holes”. It also helps to compensate for the loss of global contextual information resulting from the hierarchical structure of SwinUNet, ultimately optimizing feature extraction in the encoder.
- (2)
- The channel attention in the CASI module enhances the differentiation of visually similar targets in images and fine-tunes the outputs of the spatial attention module. The fusion of the convolution branch and transformer backbone maximizes the strengths of both, thus improving the feature modeling performance for landslide segmentation in the encoder.
- (3)
- The SDE module establishes a connection between the shallow feature maps of the network and the decoding side to enhance detailed information in the skip connection. This optimization enhances the decoder’s ability to recover detailed features, consequently improving accuracy in identifying landslide boundaries.
2. Materials and Methods
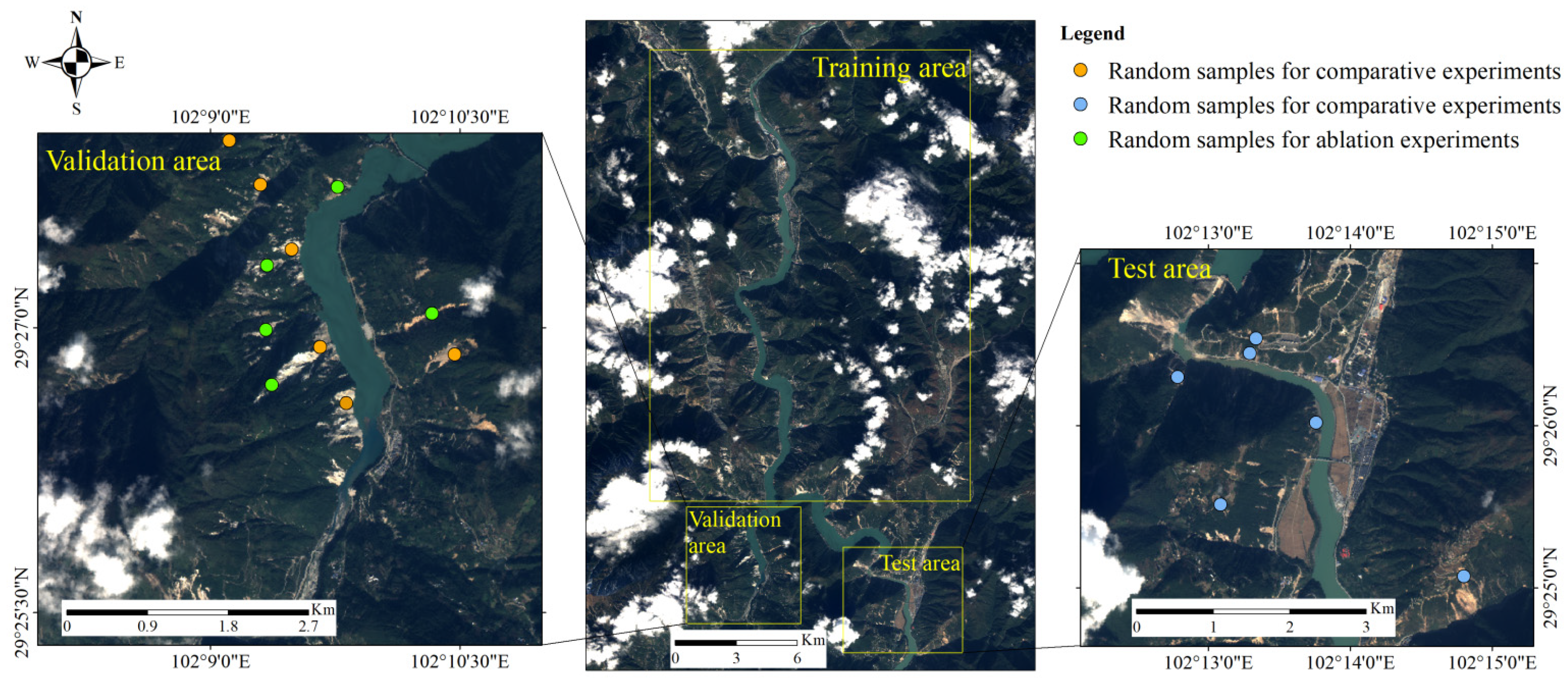
2.1. Data
2.2. Method
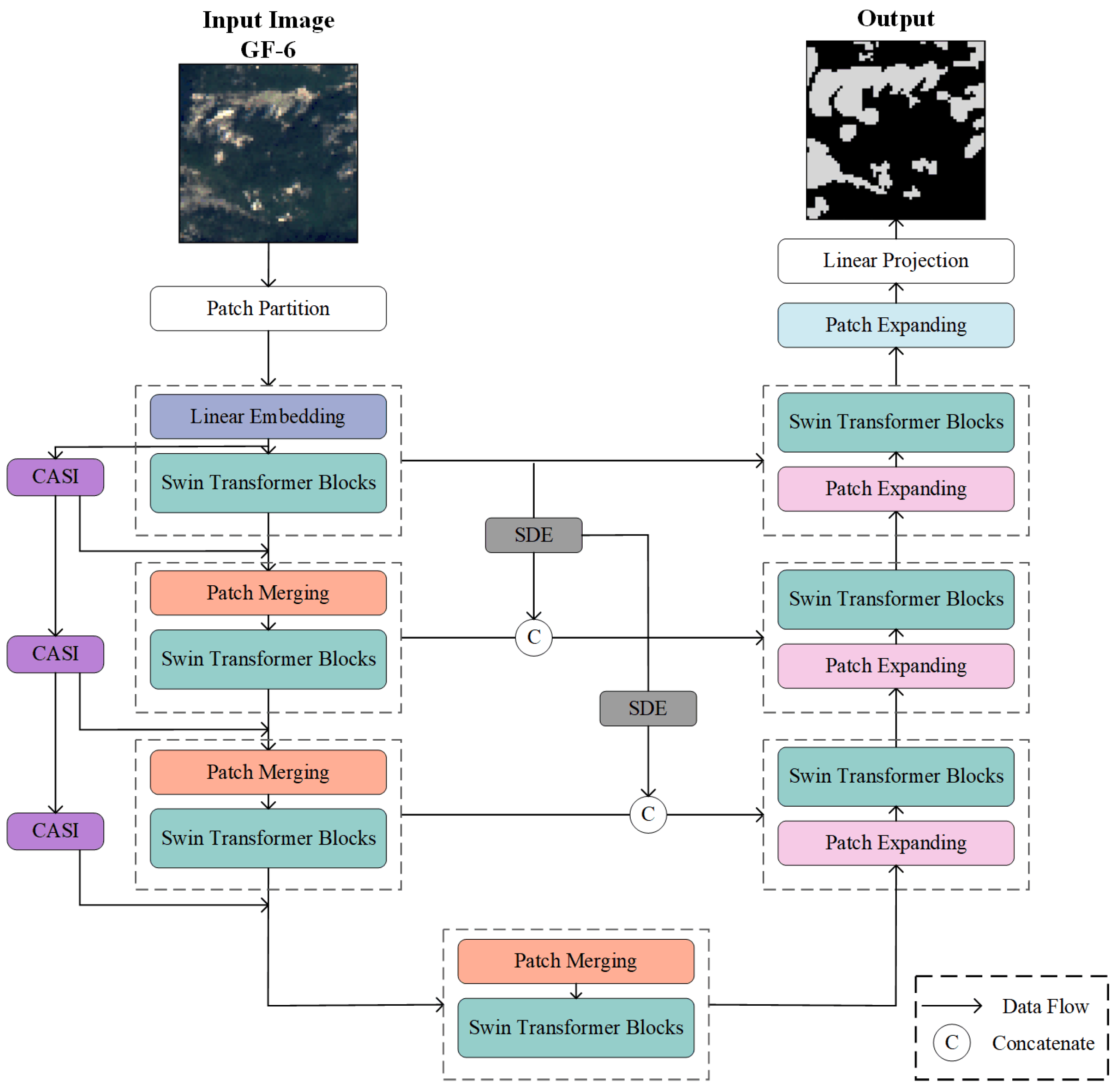
2.2.1. Overview of the Network
2.2.2. Swin Transformer Block
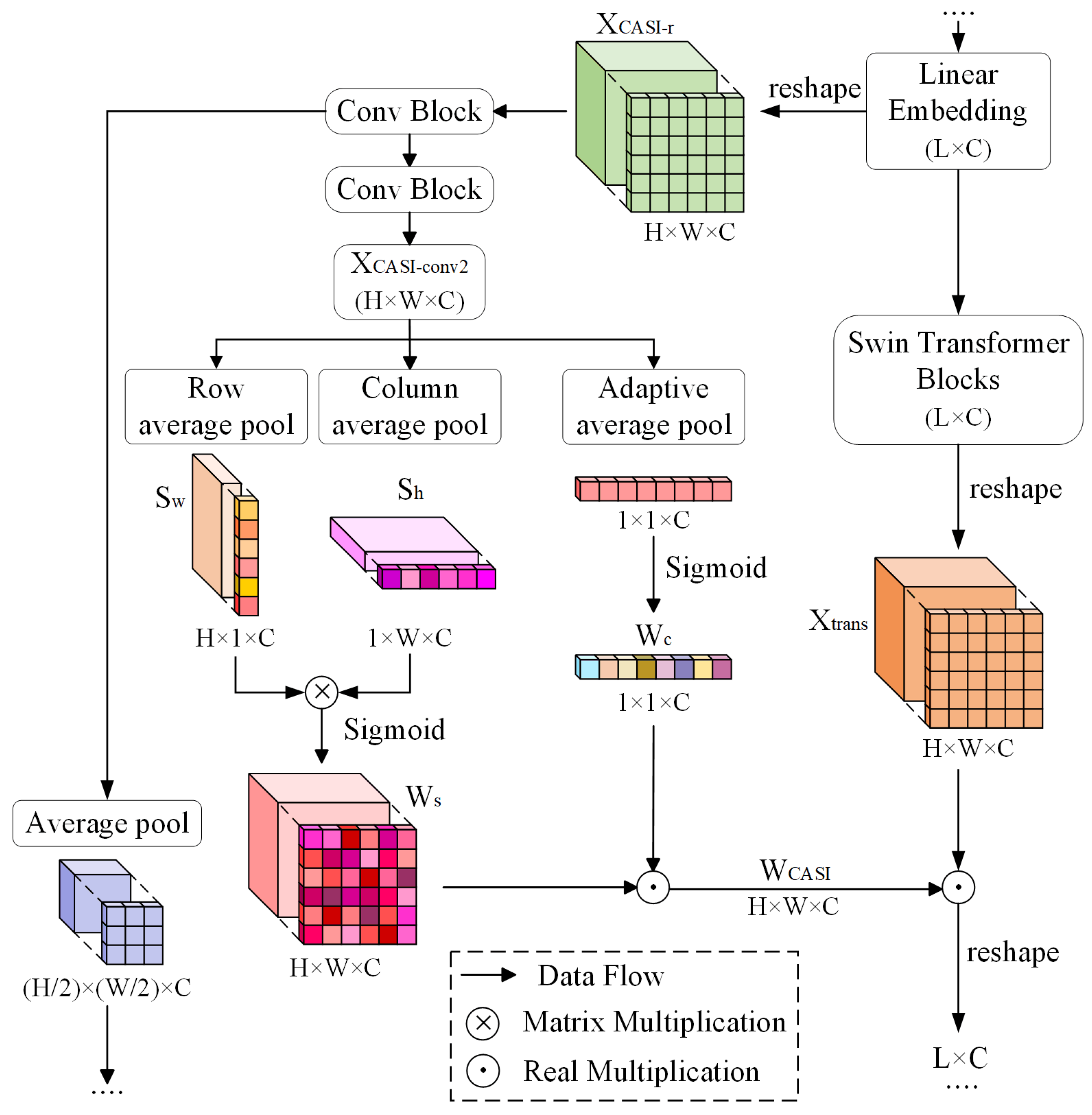
2.2.3. Channel Attention and Spatial Intersection (CASI) Module
2.2.4. Spatial Detail Enhancement (SDE) Module
2.2.5. Experimental Settings
3. Results
3.1. Quantitative Results
3.2. Qualitative Results on Validation Datasets
3.3. Qualitative Results on Test Datasets
4. Discussion
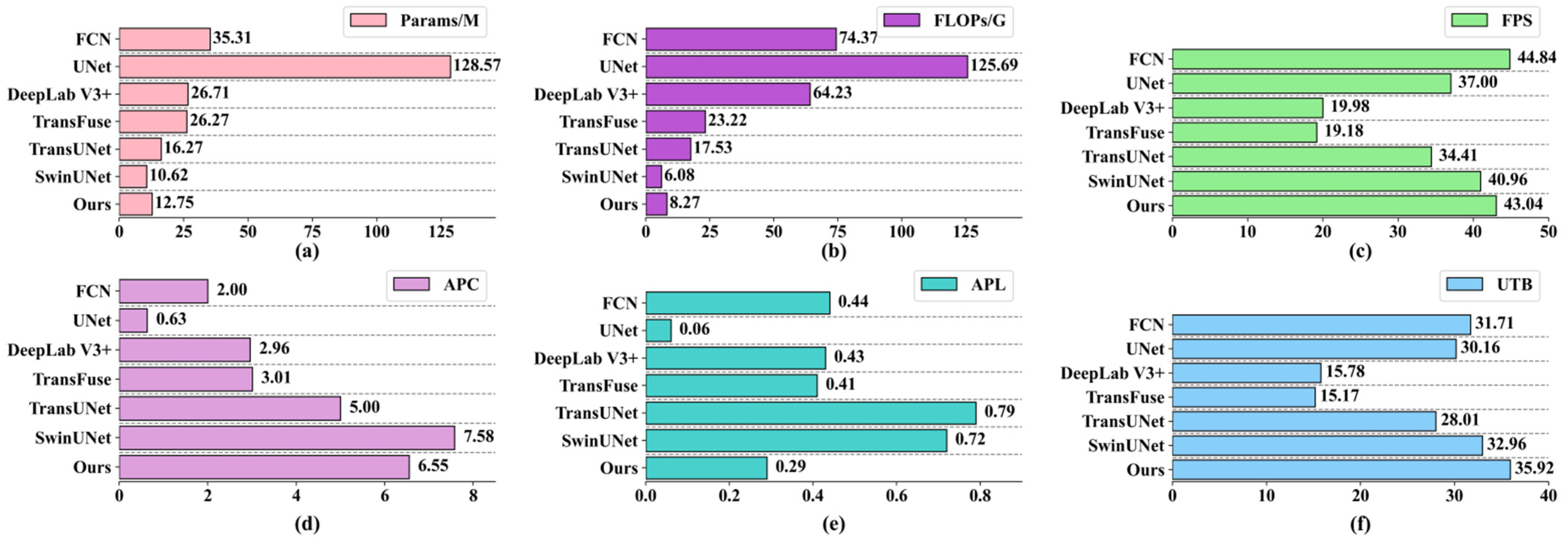
4.1. Computational Efficiency Analysis of Models
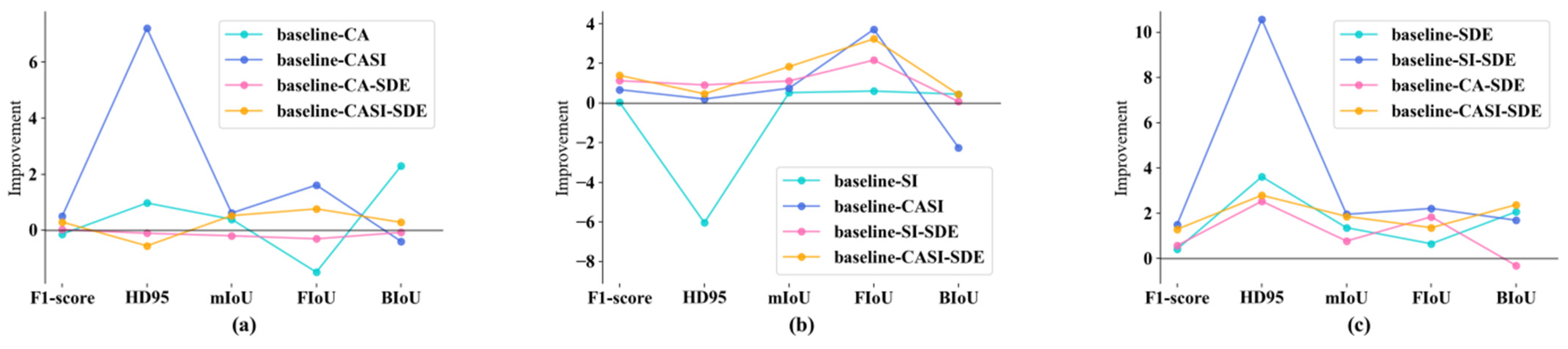
4.2. Ablation Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide Inventory Mapping From Bitemporal Images Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Wang, X.; Fan, X.; Xu, Q.; Du, P. Change detection-based co-seismic landslide mapping through extended morphological profiles and ensemble strategy. ISPRS J. Photogramm. Remote Sens. 2022, 187, 225–239. [Google Scholar] [CrossRef]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Tang, X.; Tu, Z.; Wang, Y.; Liu, M.; Li, D.; Fan, X. Automatic Detection of Coseismic Landslides Using a New Transformer Method. Remote Sens. 2022, 14, 2884. [Google Scholar] [CrossRef]
- Mondini, A.C.; Guzzetti, F.; Chang, K.-T.; Monserrat, O.; Martha, T.R.; Manconi, A. Landslide failures detection and mapping using Synthetic Aperture Radar: Past, present and future. Earth-Sci. Rev. 2021, 216, 103574. [Google Scholar] [CrossRef]
- Tehrani, F.S.; Santinelli, G.; Herrera, M.H. Multi-Regional landslide detection using combined unsupervised and supervised machine learning. Geomat. Nat. Haz. Risk 2021, 12, 1015–1038. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Xin, L.B.; Han, L.; Li, L.Z. Landslide Intelligent Recognition Based on Multi-source Data Fusion. J. Earth Sci. Environ. 2023, 45, 920–928. [Google Scholar] [CrossRef]
- Mao, J.Q.; He, J.; Liu, G.; Fu, R. Landslide recognition based on improved DeepLabV3+ algorithm. J. Nat. Disaster. 2023, 32, 227–234. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Ke, H.; Fang, X.; Zhan, Z.; Chen, S. Landslide recognition by deep convolutional neural network and change detection. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4654–4672. [Google Scholar] [CrossRef]
- Fu, B.; Li, Y.; Han, Z.; Fang, Z.; Chen, N.; Hu, G.; Wang, W. RIPF-Unet for regional landslides detection: A novel deep learning model boosted by reversed image pyramid features. Nat. Hazards 2023, 119, 701–719. [Google Scholar] [CrossRef]
- Meena, S.R.; Soares, L.P.; Grohmann, C.H.; van Westen, C.; Bhuyan, K.; Singh, R.P.; Floris, M.; Catani, F. Landslide detection in the Himalayas using machine learning algorithms and U-Net. Landslides 2022, 19, 1209–1229. [Google Scholar] [CrossRef]
- Ganerød, A.J.; Franch, G.; Lindsay, E.; Calovi, M. Automating global landslide detection with heterogeneous ensemble deep-learning classification. Remote Sens. Appl. Soc. Environ. 2024, 36, 101384. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B. Landslide detection using residual networks and the fusion of spectral and topographic information. IEEE Access 2019, 7, 114363–114373. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Peng, H.; Zheng, S.; Li, X.; Yang, Z. Residual Module and Multi-scale Feature Attention Module for Exudate Segmentation. In Proceedings of the 2018 International Conference on Sensor Networks and Signal Processing (SNSP), Xi’an, China, 28–31 October 2018. [Google Scholar] [CrossRef]
- Shi, W.; Jiang, F.; Zhao, D. Single image super-resolution with dilated convolution based multi-scale information learning inception module. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar] [CrossRef]
- Sun, Y.; Dai, D.; Zhang, Q.; Wang, Y.; Xu, S.; Lian, C. MSCA-Net: Multi-scale contextual attention network for skin lesion segmentation. Pattern Recognit. 2023, 139, 109524. [Google Scholar] [CrossRef]
- Zhang, J.; Pan, B.; Zhang, Y.; Liu, Z.; Zheng, X. Building Change Detection in Remote Sensing Images Based on Dual Multi-Scale Attention. Remote Sens. 2022, 14, 5405. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, Z.; Feng, J.; Liu, L.; Jiao, L. Remote Sensing Image Change Detection Based on Deep Multi-Scale Multi-Attention Siamese Transformer Network. Remote Sens. 2023, 15, 842. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, D.; Gao, D.; Shi, G. A novel spectral-spatial multi-scale network for hyperspectral image classification with the Res2Net block. Int. J. Remote Sens. 2022, 43, 751–777. [Google Scholar] [CrossRef]
- Lu, Z.; Peng, Y.; Li, W.; Yu, J.; Ge, D.; Han, L.; Xiang, W. An Iterative Classification and Semantic Segmentation Network for Old Landslide Detection Using High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4408813. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, L.; Hu, H.; Xu, B.; Zhang, Y.; Li, H. Deep fusion of local and non-local features for precision landslide recognition. arXiv 2020, arXiv:2002.08547. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Y.; Zhang, L. Multiplanar Data Augmentation and Lightweight Skip Connection Design for Deep-Learning-Based Abdominal CT Image Segmentation. IEEE Trans. Instrum. Meas. 2023, 72, 2532111. [Google Scholar] [CrossRef]
- Locke, W.; Lokhmachev, N.; Huang, Y.; Li, X. Radio Map Estimation with Deep Dual Path Autoencoders and Skip Connection Learning. In Proceedings of the 2023 IEEE 34th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Toronto, ON, Canada, 5–8 September 2023. [Google Scholar] [CrossRef]
- Shi, Y.; Guo, E.; Zhu, S.; Gu, J.; Bai, L.; Han, J. Research on optimal skip connection scale in learning-based scattering imaging. In Proceedings of the Seventh Symposium on Novel Photoelectronic Detection Technology and Applications 2020, Kunming, China, 5–7 November 2020. [Google Scholar] [CrossRef]
- Xiong, S.; Tan, Y.; Li, Y.; Wen, C.; Yan, P. Subtask Attention Based Object Detection in Remote Sensing Images. Remote Sens. 2021, 13, 1925. [Google Scholar] [CrossRef]
- Fan, R.; Wang, L.; Feng, R.; Zhu, Y. Attention based Residual Network for High-Resolution Remote Sensing Imagery Scene Classification. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Yokohama, Japan, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Zhao, C.; Shikang, L.; Zhangjian, Q. SENet-optimized Deeplabv3+ landslide detection. Sci. Technol. Eng. 2022, 22, 14635–14643. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Peng, N.; Sun, S.; Wang, R.; Zhong, P. Combining interior and exterior characteristics for remote sensing image denoising. J. Appl. Remote Sens. 2016, 10, 025016. [Google Scholar] [CrossRef]
- Zhou, X.; Shao, Z.; Liu, J. Geographic ontology driven hierarchical semantic of remote sensing image. In Proceedings of the 2012 International Conference on Computer Vision in Remote Sensing, Xiamen, China, 16–18 December 2012. [Google Scholar] [CrossRef]
- Vasvani, A. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Lv, P.; Ma, L.; Li, Q.; Du, F. ShapeFormer: A Shape-Enhanced Vision Transformer Model for Optical Remote Sensing Image Landslide Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2681–2689. [Google Scholar] [CrossRef]
- Li, D.; Tang, X.; Tu, Z.; Fang, C.; Ju, Y. Automatic Detection of Forested Landslides: A Case Study in Jiuzhaigou County, China. Remote Sens. 2023, 15, 3850. [Google Scholar] [CrossRef]
- Tang, X.; Tu, Z.; Ren, X.; Fang, C.; Wang, Y.; Liu, X.; Fan, X. A Multi-modal Deep Neural Network Model for Forested Landslide Detection. Geomat. Inf. Sci. Wuhan Univ. 2023, 49, 1566–1573. [Google Scholar] [CrossRef]
- Zhou, Y.; Peng, Y.; Li, W.; Yu, J.; Ge, D.; Xiang, W. A Hyper-pixel-wise Contrastive Learning Augmented Segmentation Network for Old Landslide Detection Using High-Resolution Remote Sensing Images and Digital Elevation Model Data. arXiv 2023, arXiv:2308.01251. [Google Scholar] [CrossRef]
- Li, P.; Wang, Y.; Si, T.; Ullah, K.; Han, W.; Wang, L. MFFSP: Multi-scale feature fusion scene parsing network for landslides detection based on high-resolution satellite images. Eng. Appl. Artif. Intell. 2024, 127, 107337. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, C.; Li, L. Landslide Detection Based on ResU-Net with Transformer and CBAM Embedded: Two Examples with Geologically Different Environments. Remote Sens. 2022, 14, 2885. [Google Scholar] [CrossRef]
- Du, Y.; Huang, L.; Zhao, Z.; Li, G. Landslide body identification and detection of high-resolution remote sensing image based on DETR. Bull. Surv. Mapp. 2023, 5, 16–20. [Google Scholar] [CrossRef]
- Fu, R.; He, J.; Liu, G.; Li, W.; Mao, J.; He, M.; Lin, Y. Fast Seismic Landslide Detection Based on Improved Mask R-CNN. Remote Sens. 2022, 14, 3928. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, J.; He, H.; Jia, Y.; Chen, R.; Ge, Y.; Ming, Z.; Zhang, L.; Li, H. MAST: An Earthquake-Triggered Landslides Extraction Method Combining Morphological Analysis Edge Recognition With Swin-Transformer Deep Learning Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2586–2595. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. In Proceedings of the Computer Vision—ECCV 2022 Workshops, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2023; Volume 13803, pp. 205–218. [Google Scholar]
- Ge, C.; Nie, Y.; Kong, F.; Xu, X. Improving Road Extraction for Autonomous Driving Using Swin Transformer Unet. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022. [Google Scholar] [CrossRef]
- Jing, Y.; Zhang, T.; Liu, Z.; Hou, Y.; Sun, C. Swin-ResUNet+: An edge enhancement module for road extraction from remote sensing images. Comput. Vis. Image Underst. 2023, 237, 103807. [Google Scholar] [CrossRef]
- Chen, X.; Liu, M.; Li, D.; Jia, J.; Yang, A.; Zheng, W.; Yin, L. Conv-trans dual network for landslide detection of multi-channel optical remote sensing images. Front. Earth Sci. 2023, 11, 1182145. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | F1-Score (%) | HD95 | mIoU (%) | FIoU (%) | BIoU (%) |
|---|---|---|---|---|---|
| FCN | 80.55 | 15.7 | 70.7 | 53 | 88.4 |
| UNet | 89.09 | 7.53 | 81.51 | 69.08 | 93.95 |
| DeepLab V3+ | 86.79 | 11.59 | 78.98 | 62.53 | 95.43 |
| TransFuse | 87.51 | 10.74 | 79.1 | 65.32 | 92.89 |
| TransUNet | 88.92 | 12.91 | 81.39 | 68.18 | 94.59 |
| SwinUNet | 88.32 | 7.69 | 80.46 | 67.24 | 93.68 |
| AST-UNet(ours) | 90.14 | 3.73 | 83.45 | 70.81 | 96.09 |
| Method | Modules | Evaluation Indexes | ||||||
|---|---|---|---|---|---|---|---|---|
| CA | SI | SDE | F1-Score (%) | HD95 | mIoU (%) | FIoU (%) | BIoU (%) | |
| Baseline | 88.32 | 7.69 | 80.46 | 67.24 | 93.68 | |||
| Baseline-CA | √ | 88.18 | 6.72 | 80.85 | 65.74 | 95.97 | ||
| Baseline-SI | √ | 88.35 | 13.73 | 80.98 | 67.84 | 94.12 | ||
| Baseline-SDE | √ | 88.73 | 4.08 | 81.82 | 67.89 | 95.74 | ||
| Baseline-CASI | √ | √ | 88.85 | 6.52 | 81.59 | 69.45 | 93.72 | |
| Baseline-CA-SDE | √ | √ | 88.75 | 4.19 | 81.62 | 67.58 | 95.66 | |
| Baseline-SI-SDE | √ | √ | 89.85 | 3.17 | 82.93 | 70.05 | 95.81 | |
| AST-UNet(ours) | √ | √ | √ | 90.14 | 3.73 | 83.45 | 70.81 | 96.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Wang, W.; Wu, Y.; Gao, X. Attention Swin Transformer UNet for Landslide Segmentation in Remotely Sensed Images. Remote Sens. 2024, 16, 4464. https://doi.org/10.3390/rs16234464
Liu B, Wang W, Wu Y, Gao X. Attention Swin Transformer UNet for Landslide Segmentation in Remotely Sensed Images. Remote Sensing. 2024; 16(23):4464. https://doi.org/10.3390/rs16234464
Chicago/Turabian StyleLiu, Bingxue, Wei Wang, Yuming Wu, and Xing Gao. 2024. "Attention Swin Transformer UNet for Landslide Segmentation in Remotely Sensed Images" Remote Sensing 16, no. 23: 4464. https://doi.org/10.3390/rs16234464
APA StyleLiu, B., Wang, W., Wu, Y., & Gao, X. (2024). Attention Swin Transformer UNet for Landslide Segmentation in Remotely Sensed Images. Remote Sensing, 16(23), 4464. https://doi.org/10.3390/rs16234464