
An Object-Aware Network Embedding Deep Superpixel for Semantic Segmentation of Remote Sensing Images


Abstract
1. Introduction
2. Related Work
2.1. VHR Semantic Segmentation
2.2. Learnable Superpixel
3. Methods
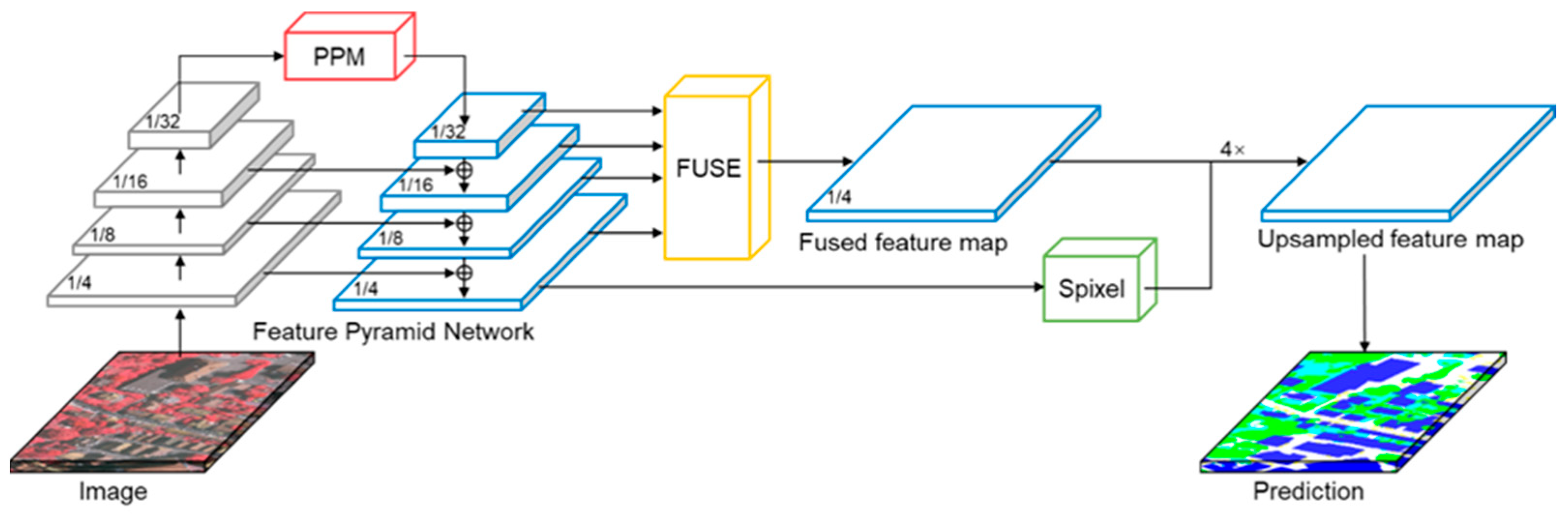
3.1. Network Structure
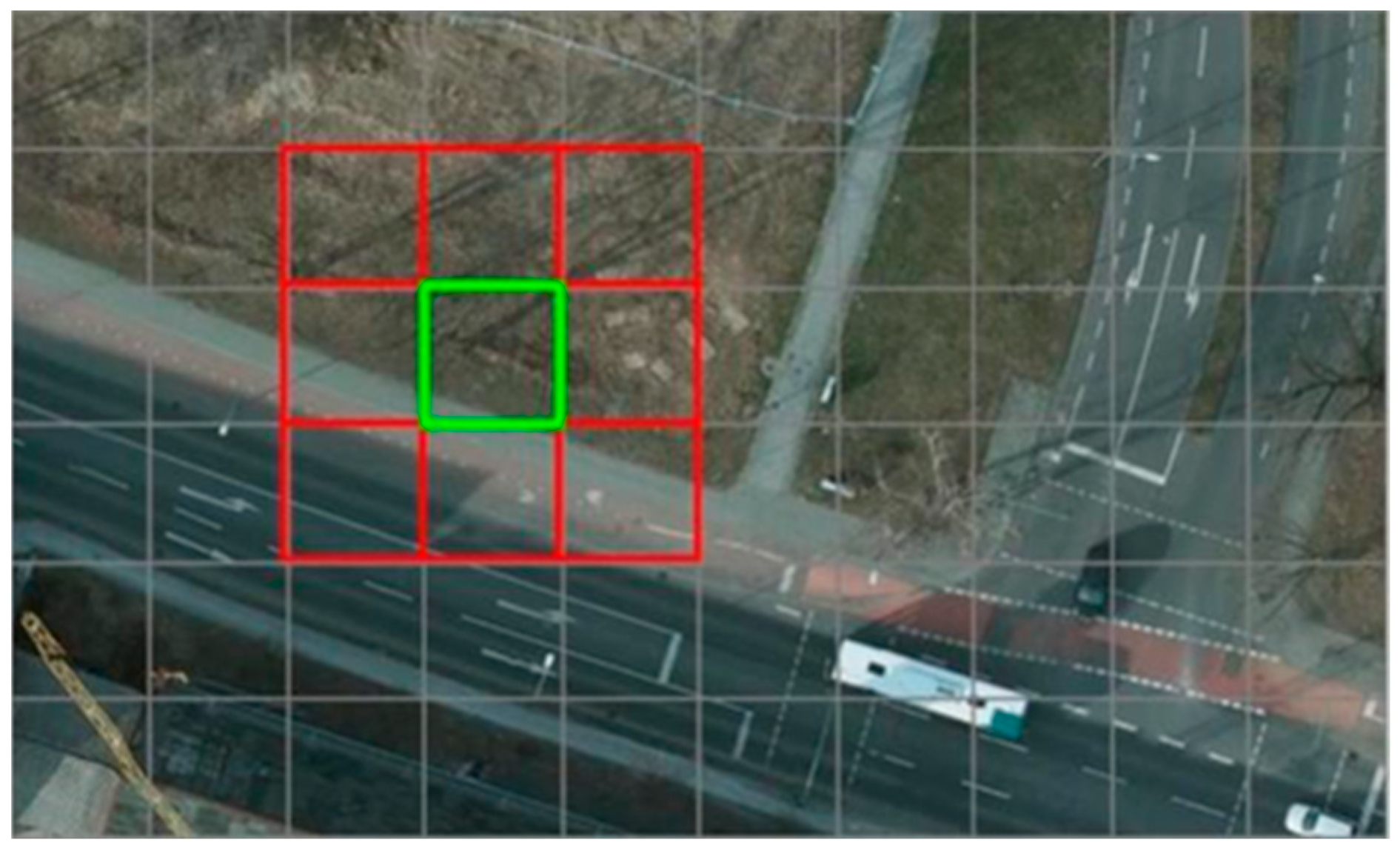
3.2. Superpixel Generation Module
3.3. Superpixel-Based Upsampling and Refinement
3.4. Loss Function
4. Experimental Settings
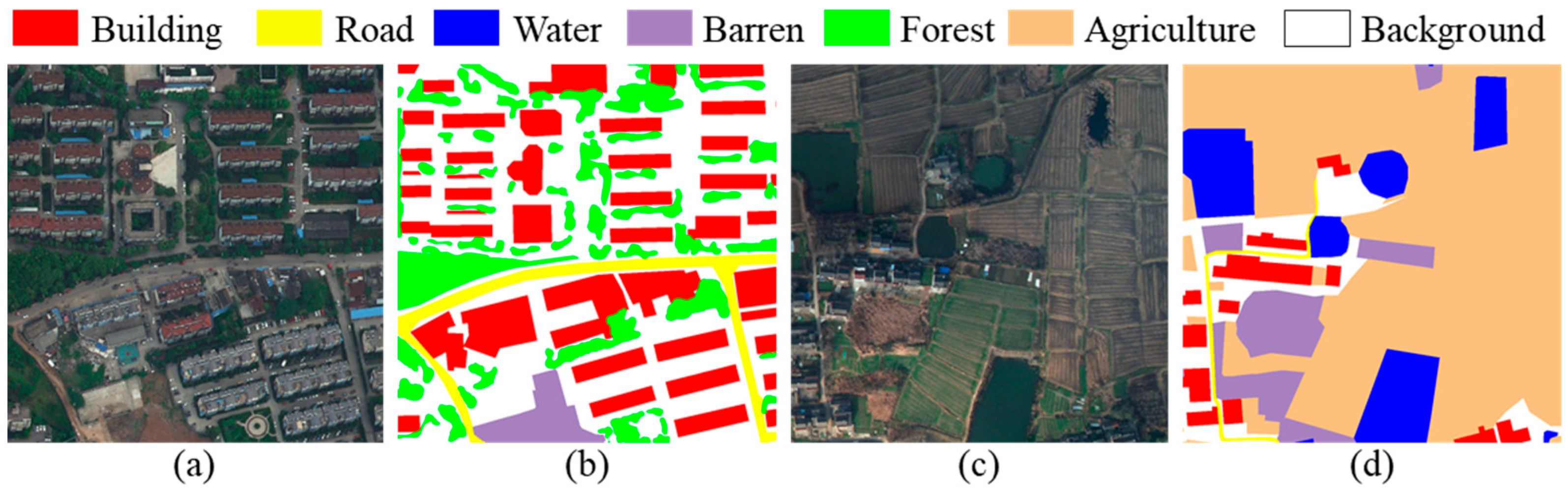
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Comparison Methods
5. Results and Analysis
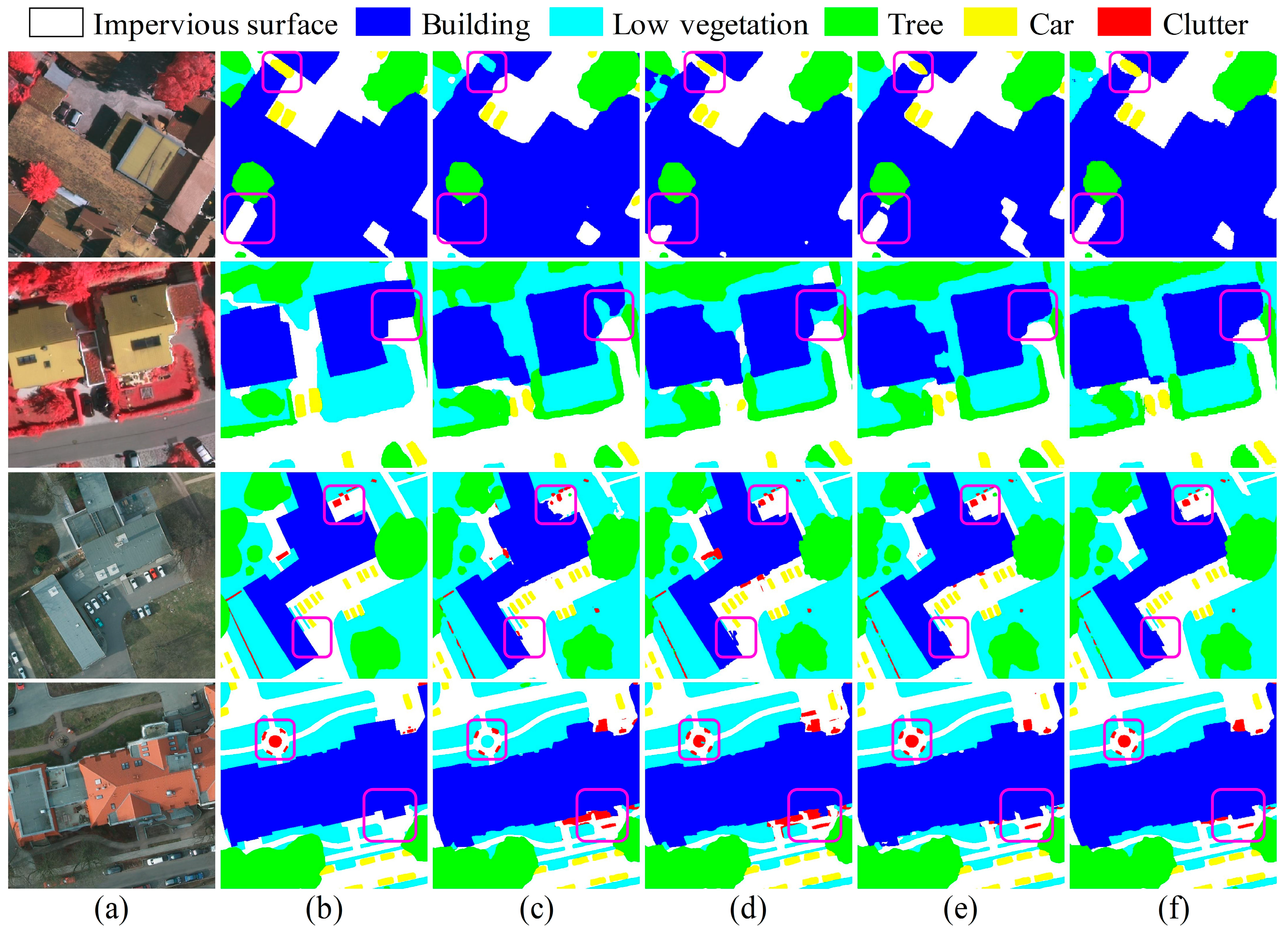
5.1. Results Obtained from the ISPRS Datasets
5.2. Results Obtained from the LoveDA Dataset
5.3. Ablation Experimental Results of Spixel Module
5.4. Visualization Analysis
5.5. Model Efficiency
5.6. Advantages of the Methodology
- The convnext backbone network. ConvNext draws inspiration from the hierarchical design of vision transformers but is entirely constructed from standard convnet modules. The “sliding window” strategy of convnets is an intrinsic feature of visual processing. The basic blocks of ConvNext utilize large 7 × 7 convolutional kernels, enabling it to excel in handling high-resolution images. Leveraging ConvNext’s strong capability in extracting discriminative features, we propose the use of multi-scale fused FPN features for the mainline semantic segmentation. Additionally, we employ high-resolution feature maps from the final FPN layer for the superpixel generation branch. Experimental results confirm the effectiveness of the improved network proposed in this study.
- The learnable superpixel module and the superpixel-enhanced upsampling strategy. As a re-representation of images, superpixels can complement object-level or sub-object-level shape prior information for pixel-wise segmentation. This is advantageous for improving object edge delineation in remote sensing semantic segmentation, although its effectiveness relies on the quality of superpixel generation. Similar to existing object-based CNN methods [26,37,38], the proposed method aims to exploit the object-level details. However, most methods are constrained by the non-differentiable algorithm of OBIA, separating deep segmentation from OBIA-based post-processing. In contrast, the learnable superpixel module introduced in this work can be embedded into the deep segmentation network, significantly accelerating the overall inference speed (Table A2). Furthermore, unlike the two-stage methods that extract features using CNNs for subsequent iterative superpixel generation [45], we explored directly generating learnable superpixels using a branch network to assist the main semantic segmentation task. As the parameters of the segmentation network are updated, the shape of the superpixels generated by the proposed module is iteratively optimized (Figure 9). By combining the two pathways through the superpixel-enhanced upsampling, the semantic segmentation and superpixel generation processes are incorporated into a complete one-stage FCN architecture. Additionally, the parameter size of the Spixel module is approximately 0.63 MB, and its computational complexity FLOPs is 10.28 G. This indicates that the module constitutes only a small fraction of the overall model’s size (as shown in Table 6), further underscoring its convenience. In this study, the introduction of the superpixel module enables the segmentation network to focus more on small objects during training. This leads to a significant improvement in accuracy for smaller objects, such as the “Car” category. Moreover, feature extraction, task-specific superpixel generation, and semantic segmentation stages are trained simultaneously under a unified end-to-end framework according to the task-specific loss functions. Thus, the output of semantic segmentation can be further refined.
5.7. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Mean F1 | mIoU |
|---|---|---|---|
| FPN | ConvNeXt-T | 89.24 | 82.18 |
| FPN + PPM | ConvNeXt-T | 89.61 | 82.27 |
| UperNet (FPN + PPM + Fusion) | ConvNeXt-T | 90.45 | 83.55 |
| ESPNet (FPN + PPM + Fusion + Spixel) | ConvNeXt-T | 91.06 | 84.32 |
| Method | Backbone | Mean F1 | mIoU | Prediction Time on Test Set |
|---|---|---|---|---|
| Object-based CNN [8] (FPN + PPM + Fusion + Graph-Seg) | ConvNeXt-T | 90.76 | 83.79 | 4099 min 30 s |
| ESPNet (FPN + PPM + Fusion + Spixel) | ConvNeXt-T | 91.06 | 84.32 | 1 min 35 s |

References
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Prabhat Deep Learning and Process Understanding for Data-Driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Wu, Y.; Zhao, B.; Chanussot, J.; Hong, D.; Yao, J.; Gao, L. Progress and Challenges in Intelligent Remote Sensing Satellite Systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1814–1822. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Li, Z.; Yan, X.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Oil Spill Contextual and Boundary-Supervised Detection Network Based on Marine SAR Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5213910. [Google Scholar] [CrossRef]
- Persello, C.; Grift, J.; Fan, X.; Paris, C.; Hänsch, R.; Koeva, M.; Nelson, A. AI4SmallFarms: A Dataset for Crop Field Delineation in Southeast Asian Smallholder Farms. IEEE Geosci. Remote Sens. Lett. 2023, 20, 2505705. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the MICCAI; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive Bilateral Contextual Network for Efficient Semantic Segmentation of Fine-Resolution Remotely Sensed Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Yang, M.Y.; Kumaar, S.; Lyu, Y.; Nex, F. Real-Time Semantic Segmentation with Context Aggregation Network. ISPRS J. Photogramm. Remote Sens. 2021, 178, 124–134. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Learning to Pay Attention on Spectral Domain: A Spectral Attention Module-Based Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 110–122. [Google Scholar] [CrossRef]
- Shakeel, A.; Sultani, W.; Ali, M. Deep Built-Structure Counting in Satellite Imagery Using Attention Based Re-Weighting. ISPRS J. Photogramm. Remote Sens. 2019, 151, 313–321. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Learning Multiscale and Deep Representations for Classifying Remotely Sensed Imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Li, L. Deep Residual Autoencoder with Multiscaling for Semantic Segmentation of Land-Use Images. Remote Sens. 2019, 11, 2142. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Y.; Wang, M.; Shen, Q.; Huang, J. Object-Scale Adaptive Convolutional Neural Networks for High-Spatial Resolution Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 283–299. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the ICCV, Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Meng, X.; Yang, Y.; Wang, L.; Wang, T.; Li, R.; Zhang, C. Class-Guided Swin Transformer for Semantic Segmentation of Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6517505. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Blaschke, T.; Lang, S.; Hay, G.J. (Eds.) Object-Based Image Analysis: Spatial Concepts for Knowledge-Driven Remote Sensing Applications; Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2008; ISBN 978-3-540-77057-2. [Google Scholar]
- Blaschke, T. Object Based Image Analysis for Remote Sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Huang, X.; Lu, Q.; Zhang, L. A Multi-Index Learning Approach for Classification of High-Resolution Remotely Sensed Images over Urban Areas. ISPRS J. Photogramm. Remote Sens. 2014, 90, 36–48. [Google Scholar] [CrossRef]
- Geiss, C.; Klotz, M.; Schmitt, A.; Taubenbock, H. Object-Based Morphological Profiles for Classification of Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5952–5963. [Google Scholar] [CrossRef]
- Liu, T.; Gu, Y.; Chanussot, J.; Dalla Mura, M. Multimorphological Superpixel Model for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6950–6963. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S.; Emery, W.J. Object-Based Convolutional Neural Network for High-Resolution Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3386–3396. [Google Scholar] [CrossRef]
- Liang, L.; Meyarian, A.; Yuan, X.; Runkle, B.R.K.; Mihaila, G.; Qin, Y.; Daniels, J.; Reba, M.L.; Rigby, J.R. The First Fine-Resolution Mapping of Contour-Levee Irrigation Using Deep Bi-Stream Convolutional Neural Networks. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102631. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-Resolution Aerial Image Labeling With Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building Extraction from Very High Resolution Aerial Imagery Using Joint Attention Deep Neural Network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing Transformers and Cnns for Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Proceedings, Part I 24. Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 14–24. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Fu, Y.; Liu, K.; Shen, Z.; Deng, J.; Gan, M.; Liu, X.; Lu, D.; Wang, K. Mapping Impervious Surfaces in Town–Rural Transition Belts Using China’s GF-2 Imagery and Object-Based Deep CNNs. Remote Sens. 2019, 11, 280. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Shangguan, B.; Wang, M.; Wu, Z. A Multi-Level Context-Guided Classification Method with Object-Based Convolutional Neural Network for Land Cover Classification Using Very High Resolution Remote Sensing Images. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102086. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban Land-Use Mapping Using a Deep Convolutional Neural Network with High Spatial Resolution Multispectral Remote Sensing Imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An Object-Based Convolutional Neural Network (OCNN) for Urban Land Use Classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef]
- Ma, Y.; Deng, X.; Wei, J. Land Use Classification of High-Resolution Multispectral Satellite Images with Fine-Grained Multiscale Networks and Superpixel Post Processing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3264–3278. [Google Scholar] [CrossRef]
- Dong, D.; Ming, D.; Weng, Q.; Yang, Y.; Fang, K.; Xu, L.; Du, T.; Zhang, Y.; Liu, R. Building Extraction from High Spatial Resolution Remote Sensing Images of Complex Scenes by Combining Region-Line Feature Fusion and OCNN. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4423–4438. [Google Scholar] [CrossRef]
- Nixon, M.S.; Aguado, A.S. 8—Region-Based Analysis. In Feature Extraction and Image Processing for Computer Vision, 4th ed.; Nixon, M.S., Aguado, A.S., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 399–432. ISBN 978-0-12-814976-8. [Google Scholar]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a New Paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Zanotta, D.C.; Zortea, M.; Ferreira, M.P. A Supervised Approach for Simultaneous Segmentation and Classification of Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2018, 142, 162–173. [Google Scholar] [CrossRef]
- Jampani, V.; Sun, D.; Liu, M.-Y.; Yang, M.-H.; Kautz, J. Superpixel Sampling Networks. arXiv 2018, arXiv:1807.10174. [Google Scholar]
- Yang, F.; Sun, Q.; Jin, H.; Zhou, Z. Superpixel Segmentation with Fully Convolutional Networks. In Proceedings of the CVPR, Seattle, WA, USA, 16–18 June 2020; pp. 13961–13970. [Google Scholar]
- Mi, L.; Chen, Z. Superpixel-Enhanced Deep Neural Forest for Remote Sensing Image Semantic Segmentation. ISPRS J. Photogramm. Remote Sens. 2020, 159, 140–152. [Google Scholar] [CrossRef]
- Zhang, H.; Zou, J.; Zhang, L. EMS-GCN: An End-to-End Mixhop Superpixel-Based Graph Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5526116. [Google Scholar] [CrossRef]
- Ma, F.; Zhang, F.; Xiang, D.; Yin, Q.; Zhou, Y. Fast Task-Specific Region Merging for SAR Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5222316. [Google Scholar] [CrossRef]
- Yu, H.; Hu, H.; Xu, B.; Shang, Q.; Wang, Z.; Zhu, Q. SuperpixelGraph: Semi-Automatic Generation of Building Footprint through Semantic-Sensitive Superpixel and Neural Graph Networks. Int. J. Appl. Earth Obs. Geoinf. 2023, 125, 103556. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the ECCV, Computer Vision, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Volume 11209, pp. 432–448. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, W.; Liu, J.; Luo, Z.; Zhang, H.; Gao, K.; Li, J. Weakly Supervised High Spatial Resolution Land Cover Mapping Based on Self-Training with Weighted Pseudo-Labels. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102931. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks; Vanschoren, J., Yeung, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 1. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very High Resolution Urban Remote Sensing with Multimodal Deep Networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, L.; Gong, S.; Zhong, S.; Yan, W.; Huang, Y. Swin Transformer Embedding Dual-Stream for Semantic Segmentation of Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 175–189. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]





| Method | Backbone | F1-Score | Mean F1 | mIoU | ||||
|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | ||||
| Deeplab v3plus [8] | ResNet101 | 90.89 | 93.25 | 82.12 | 88.67 | 80.63 | 87.11 | 78.73 |
| V-FuseNet [54] | VGG-16 | 91.00 | 94.40 | 84.50 | 89.90 | 86.30 | 89.20 | — |
| TransUNet [9] | VIT-Res50 | 91.66 | 96.48 | 76.14 | 92.77 | 69.56 | 87.34 | 78.26 |
| CG-Swin [19] | Swin-S | 93.55 | 96.24 | 85.70 | 90.59 | 87.98 | 90.81 | 83.39 |
| UNetFormer [20] | ResNet18 | 92.70 | 95.30 | 84.90 | 90.60 | 88.50 | 90.40 | 82.70 |
| STDSNet [55] | Swin-B | 86.09 | 92.18 | 72.82 | 81.17 | 76.57 | 89.81 | 81.77 |
| ESPNet (Ours) | ConvNeXt-T | 93.43 | 96.23 | 85.36 | 90.17 | 90.11 | 91.06 | 84.32 |
| Method | Backbone | F1-Score | Mean F1 | mIoU | ||||
|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Building | Low Veg. | Tree | Car | ||||
| Deeplab v3plus [8] | ResNet101 | 92.07 | 96.19 | 86.39 | 87.94 | 94.66 | 91.45 | 87.22 |
| V-FuseNet [54] | VGG-16 | 92.70 | 96.30 | 87.30 | 88.50 | 95.40 | 92.04 | — |
| TransUNet [9] | VIT-Res50 | 91.93 | 96.63 | 89.98 | 82.65 | 93.17 | 90.97 | 83.74 |
| CG-Swin [19] | Swin-S | 94.07 | 97.42 | 88.53 | 89.74 | 96.61 | 93.28 | 87.61 |
| UNetFormer [20] | ResNet18 | 93.60 | 97.20 | 87.70 | 88.90 | 96.50 | 92.80 | 86.80 |
| STDSNet [55] | Swin-B | 84.90 | 92.23 | 74.09 | 76.22 | 84.21 | 90.17 | 82.33 |
| ESPNet (Ours) | ConvNeXt-T | 94.38 | 97.63 | 88.77 | 90.11 | 96.80 | 93.54 | 90.13 |
| Method | Backbone | IoU | mIoU | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Background | Building | Road | Water | Barren | Forest | Agriculture | |||
| Deeplab v3plus [8] | ResNet101 | 43.75 | 54.61 | 51.60 | 78.75 | 20.82 | 42.62 | 65.78 | 51.13 |
| TransUNet [9] | VIT-Res50 | 43.00 | 56.10 | 53.70 | 78.0 | 9.30 | 44.90 | 56.90 | 48.90 |
| SwinUperNet [18] | Swin-T | 43.30 | 54.30 | 54.30 | 78.70 | 14.90 | 45.30 | 59.60 | 50.00 |
| DC-Swin [56] | Swin-T | 41.30 | 54.50 | 56.20 | 78.10 | 14.50 | 47.20 | 62.40 | 50.60 |
| UNetFormer [20] | ResNet18 | 44.70 | 58.80 | 54.90 | 79.60 | 20.10 | 46.00 | 62.50 | 52.40 |
| ESPNet (Ours) | ConvNeXt-T | 49.43 | 62.02 | 59.11 | 82.36 | 17.93 | 50.02 | 69.27 | 55.73 |
| Dataset | Method | Backbone | Mean F1 | mIoU |
|---|---|---|---|---|
| Vaihingen | UperNet | ConvNeXt-T | 90.45 | 83.55 |
| ESPNet | ConvNeXt-T | 91.06 | 84.32 | |
| Potsdam | UperNet | ConvNeXt-T | 93.06 | 89.59 |
| ESPNet | ConvNeXt-T | 93.54 | 90.13 | |
| LoveDA | UperNet | ConvNeXt-T | — | 54.75 |
| ESPNet | ConvNeXt-T | — | 55.73 |
| Dataset | Method | Backbone | Mean F1 | mIoU |
|---|---|---|---|---|
| Vaihingen | Deeplab v3plus | ResNet101 | 87.11 | 78.73 |
| Deeplab v3plus + spixel | ResNet101 | 89.69 | 82.76 | |
| UperNet | Swin-B | 89.61 | 82.27 | |
| UperNet + spixel | Swin-B | 90.10 | 82.98 | |
| Potsdam | Deeplab v3plus | ResNet101 | 91.45 | 87.22 |
| Deeplab v3plus + spixel | ResNet101 | 92.96 | 89.27 | |
| UperNet | Swin-B | 92.64 | 88.92 | |
| UperNet + spixel | Swin-B | 93.32 | 90.05 | |
| LoveDA | Deeplab v3plus | ResNet101 | — | 51.13 |
| Deeplab v3plus + spixel | ResNet101 | — | 52.23 | |
| UperNet | Swin-B | — | 52.84 | |
| UperNet + spixel | Swin-B | — | 53.64 |
| Method | Backbone | Parameters/MB | FLOPs/G | mIoU |
|---|---|---|---|---|
| Deeplab v3plus [8] | ResNet101 | 60.21 | 254.89 | 87.22 |
| TransUNet [9] | VIT-Res50 | 100.44 | 129.44 | 83.74 |
| SwinUperNet [18] | Swin-B | 64.01 | 247.38 | 88.92 |
| UNetFormer [20] | ResNet18 | 11.68 | 11.74 | 86.80 |
| CG-Swin [19] | Swin-S | 50.35 | / | 87.61 |
| STDSNet [55] | Swin-B | 130.13 | 327.66 | 82.33 |
| ESPNet (Ours) | ConvNeXt-T | 82.50 | 253.45 | 90.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Z.; Lin, Y.; Dong, B.; Tan, X.; Dai, M.; Kong, D. An Object-Aware Network Embedding Deep Superpixel for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2024, 16, 3805. https://doi.org/10.3390/rs16203805
Ye Z, Lin Y, Dong B, Tan X, Dai M, Kong D. An Object-Aware Network Embedding Deep Superpixel for Semantic Segmentation of Remote Sensing Images. Remote Sensing. 2024; 16(20):3805. https://doi.org/10.3390/rs16203805
Chicago/Turabian StyleYe, Ziran, Yue Lin, Baiyu Dong, Xiangfeng Tan, Mengdi Dai, and Dedong Kong. 2024. "An Object-Aware Network Embedding Deep Superpixel for Semantic Segmentation of Remote Sensing Images" Remote Sensing 16, no. 20: 3805. https://doi.org/10.3390/rs16203805
APA StyleYe, Z., Lin, Y., Dong, B., Tan, X., Dai, M., & Kong, D. (2024). An Object-Aware Network Embedding Deep Superpixel for Semantic Segmentation of Remote Sensing Images. Remote Sensing, 16(20), 3805. https://doi.org/10.3390/rs16203805