

Stereo Matching Method for Remote Sensing Images Based on Attention and Scale Fusion


Abstract

1. Introduction
- We employ a parameter-free attention module based on pixel importance to optimize feature information and enhance feature representation;
- We discuss the performance of various scale fusion strategies and select the most effective scale fusion strategy within the network, which contributes to the enhancement of the network’s performance.
2. Materials and Methods
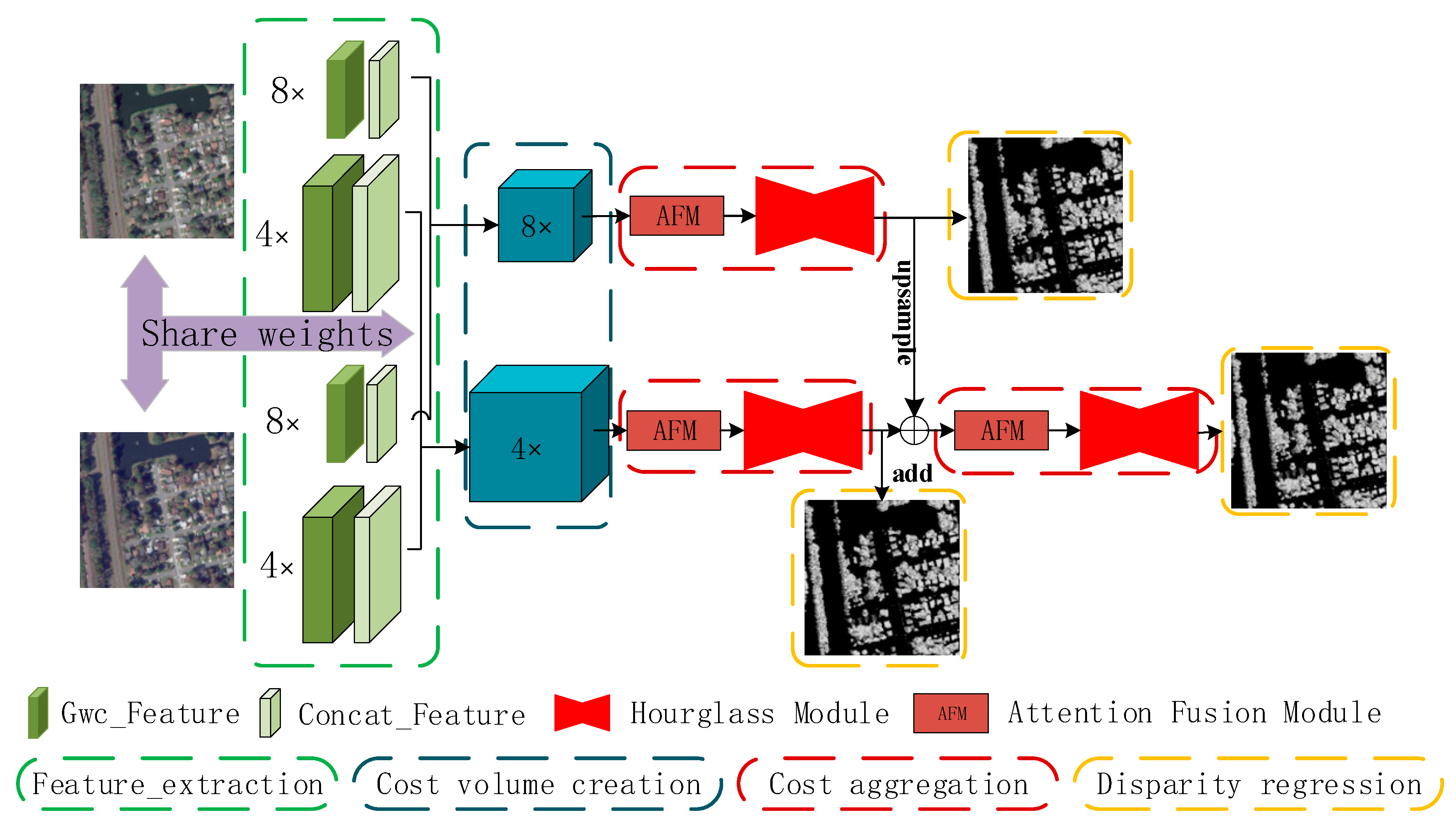
2.1. The Architecture of the Proposed Network
2.2. Component Modules
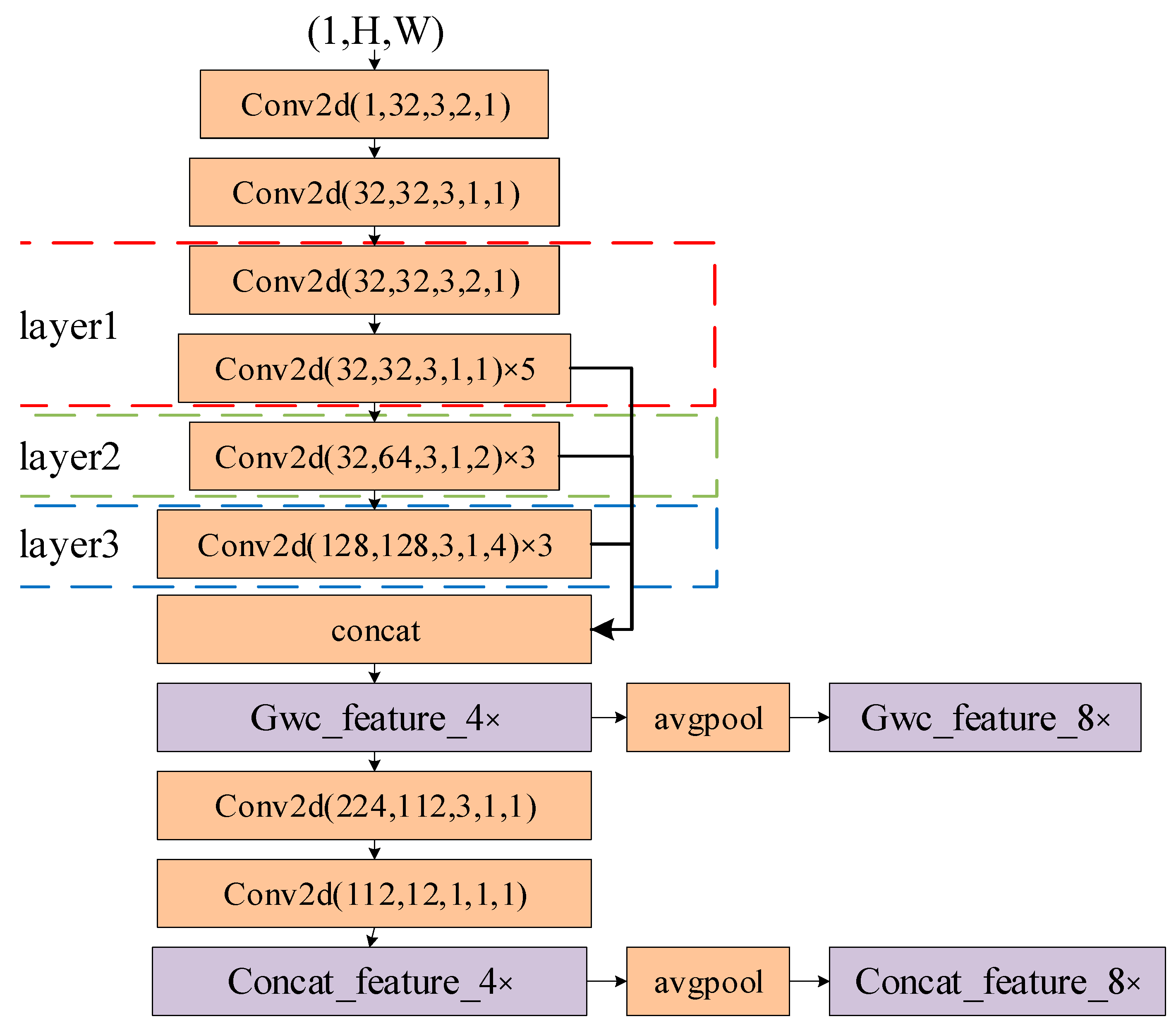
2.2.1. Feature Extraction
2.2.2. Cost Volume Fusion
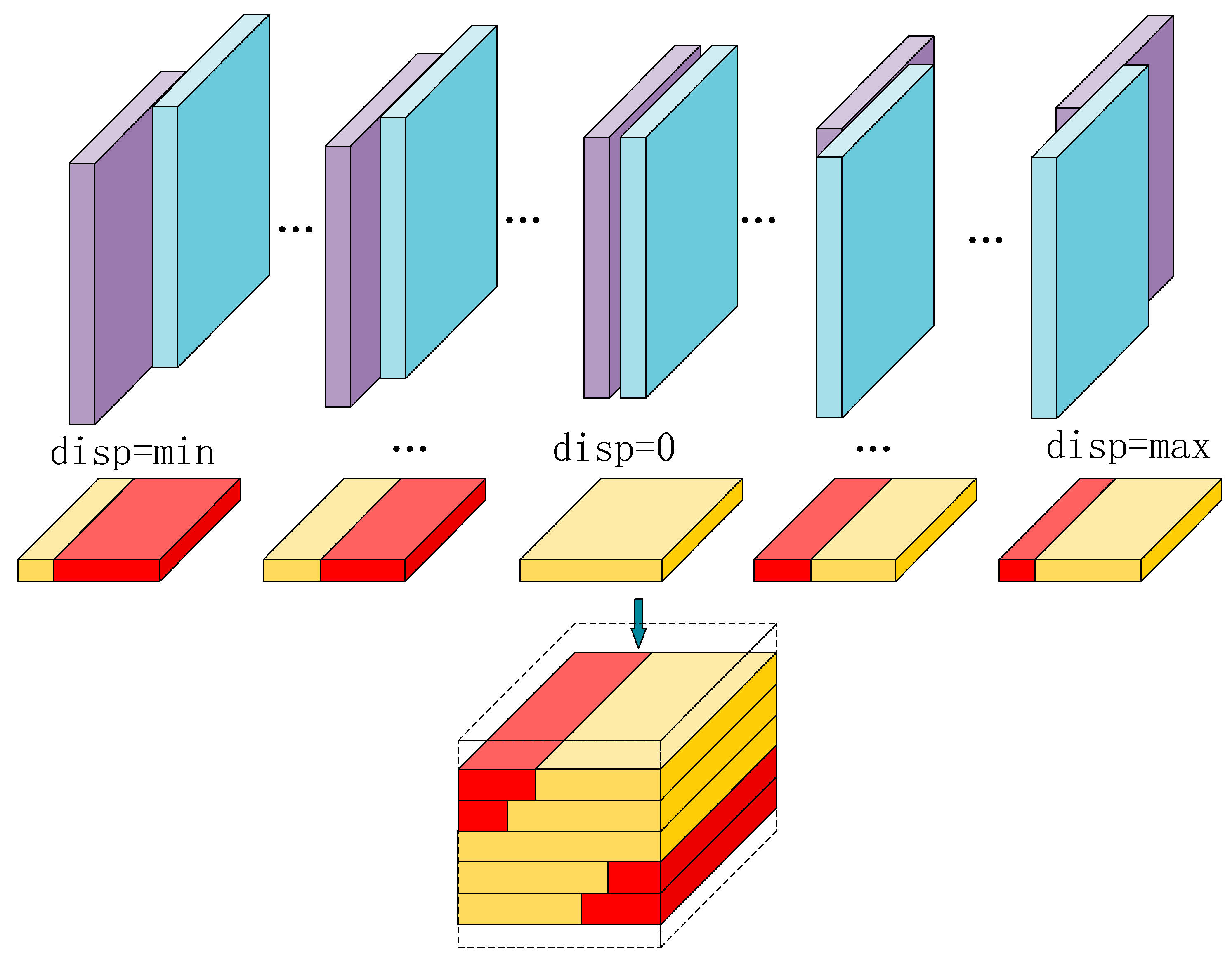
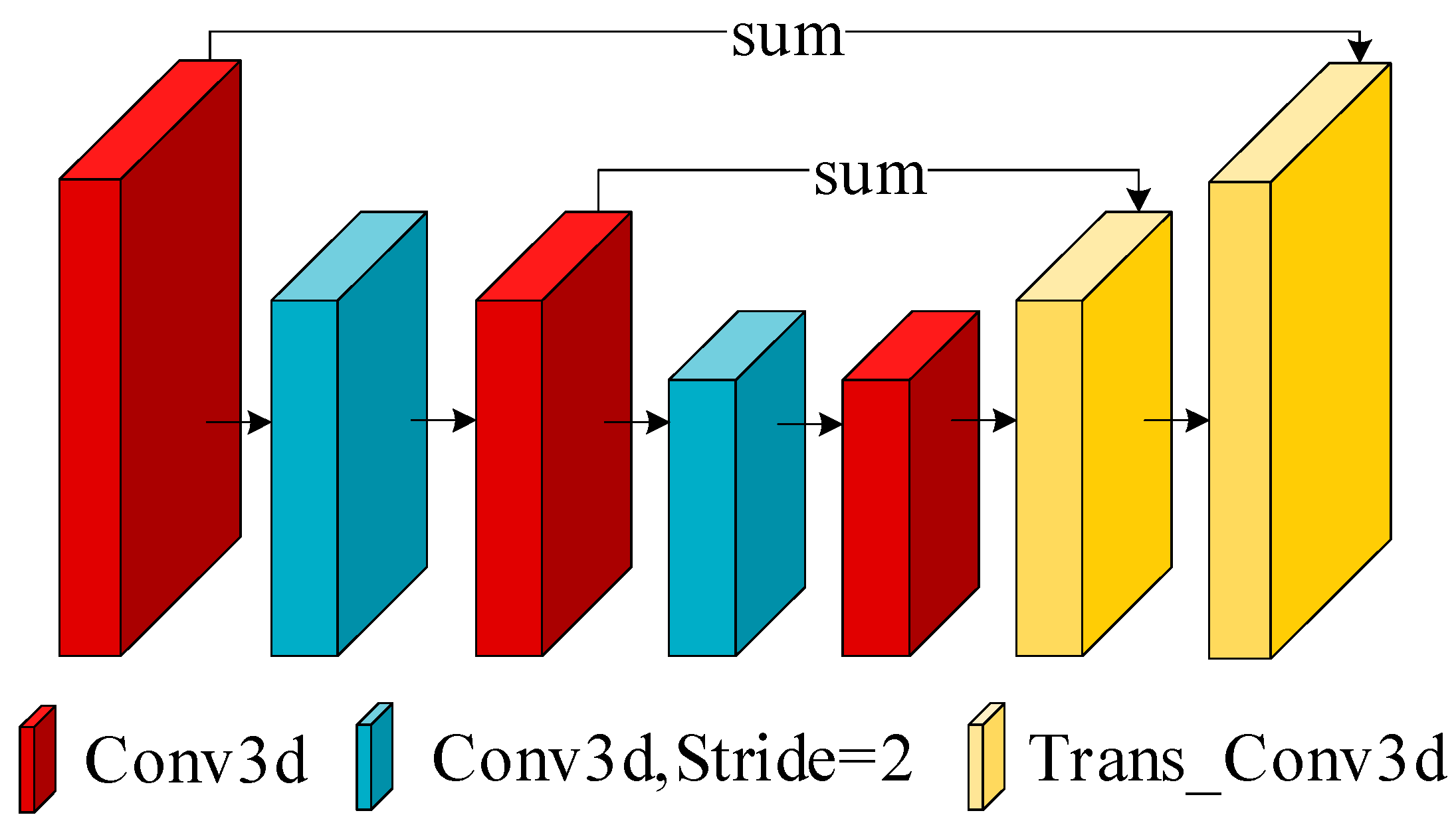
2.2.3. Cost Aggregation

2.2.4. Disparity Regression
3. Results
3.1. Dataset
3.2. Evaluation Metrics
3.3. Loss Function
3.4. Implementation Details
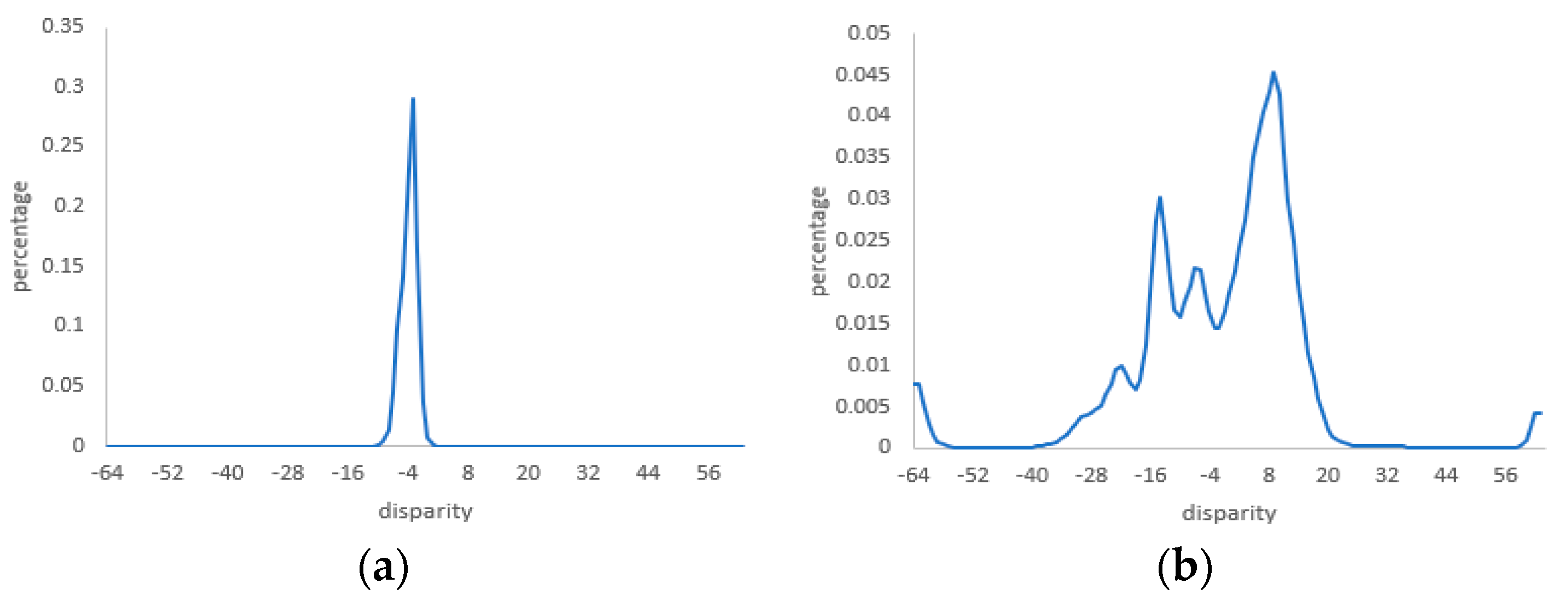
3.5. Comparisons with Other Stereo Methods
- Untextured regions
- 2.
- Repetitive-texture regions
- 3.
- Discontinuous disparities
3.6. Ablation Experiments
- Multiscale features and fused scale-based cost volumes;
- Attention fusion modules.
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Niu, J.; Song, R.; Li, Y. A Stereo Matching Method Based on Kernel Density Estimation. In Proceedings of the 2006 IEEE International Conference on Information Acquisition, Veihai, China, 20–23 August 2006; pp. 321–325. [Google Scholar]
- Sonka, M.; Hlavac, V.; Boyle, R. Image Processing, Analysis and Machine Vision; Springer: Cham, Switzerland, 2013. [Google Scholar]
- Suliman, A.; Zhang, Y.; Al-Tahir, R. Enhanced disparity maps from multi-view satellite images. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2356–2359. [Google Scholar]
- Scharstein, D. A taxonomy and evaluation of dense two-frame stereo correspondence. In Proceedings of the IEEE Workshop on Stereo and Multi-Baseline Vision, Kauai, HI, USA, 9–10 December 2001. [Google Scholar]
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the Computer Vision—ECCV’94: Third European Conference on Computer Vision, Stockholm, Sweden, 2–6 May 1994; Volume II 3, pp. 151–158. [Google Scholar]
- Min, D.; Sohn, K. Cost aggregation and occlusion handling with WLS in stereo matching. IEEE Trans. Image Process. 2008, 17, 1431–1442. [Google Scholar]
- Ohta, Y.; Kanade, T. Stereo by intra-and inter-scanline search using dynamic programming. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 7, 139–154. [Google Scholar] [CrossRef] [PubMed]
- Hong, L.; Chen, G. Segment-based stereo matching using graph cuts. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; p. I-I. [Google Scholar]
- Sun, J.; Zheng, N.-N.; Shum, H.-Y. Stereo matching using belief propagation. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 787–800. [Google Scholar]
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 807–814. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar]
- Zbontar, J.; LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–2 June 2015; pp. 1592–1599. [Google Scholar]
- Chen, Z.; Sun, X.; Wang, L.; Yu, Y.; Huang, C. A deep visual correspondence embedding model for stereo matching costs. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 972–980. [Google Scholar]
- Batsos, K.; Mordohai, P. Recresnet: A recurrent residual cnn architecture for disparity map enhancement. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 238–247. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Khamis, S.; Fanello, S.; Rhemann, C.; Kowdle, A.; Valentin, J.; Izadi, S. Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 573–590. [Google Scholar]
- Chang, J.-R.; Chen, Y.-S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3273–3282. [Google Scholar]
- Yang, G.; Manela, J.; Happold, M.; Ramanan, D. Hierarchical deep stereo matching on high-resolution images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5515–5524. [Google Scholar]
- Tao, R.; Xiang, Y.; You, H. An edge-sense bidirectional pyramid network for stereo matching of vhr remote sensing images. Remote Sens. 2020, 12, 4025. [Google Scholar]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Ying, X.; Wang, Y.; Wang, L.; Sheng, W.; An, W.; Guo, Y. A stereo attention module for stereo image super-resolution. IEEE Signal Process. Lett. 2020, 27, 496–500. [Google Scholar] [CrossRef]
- Chen, C.; Qing, C.; Xu, X.; Dickinson, P. Cross parallax attention network for stereo image super-resolution. IEEE Trans. Multimed. 2021, 24, 202–216. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Paoletti, M.E.; Moreno-Álvarez, S.; Xue, Y.; Haut, J.M.; Plaza, A. AAtt-CNN: Automatical Attention-based Convolutional Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5511118. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Tao, X.; Han, L.; Wu, Z.; Moreno-Álvarez, S.; Roy, S.K.; Plaza, A.; Haut, J.M. Parameter-free attention network for spectral-spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5516817. [Google Scholar] [CrossRef]
- Rao, Z.; He, M.; Zhu, Z.; Dai, Y.; He, R. Bidirectional guided attention network for 3-D semantic detection of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6138–6153. [Google Scholar] [CrossRef]
- Rao, Z.; Xiong, B.; He, M.; Dai, Y.; He, R.; Shen, Z.; Li, X. Masked representation learning for domain generalized stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5435–5444. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 783–792. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Almahairi, A.; Ballas, N.; Cooijmans, T.; Zheng, Y.; Larochelle, H.; Courville, A. Dynamic capacity networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2549–2558. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Le Saux, B.; Yokoya, N.; Hansch, R.; Brown, M.; Hager, G. 2019 data fusion contest [technical committees]. IEEE Geosci. Remote Sens. Mag. 2019, 7, 103–105. [Google Scholar] [CrossRef]
- Bosch, M.; Foster, K.; Christie, G.; Wang, S.; Hager, G.D.; Brown, M. Semantic stereo for incidental satellite images. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1524–1532. [Google Scholar]
- He, S.; Li, S.; Jiang, S.; Jiang, W. HMSM-Net: Hierarchical multi-scale matching network for disparity estimation of high-resolution satellite stereo images. ISPRS J. Photogramm. Remote Sens. 2022, 188, 314–330. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, S.; Wei, Z.; Xu, W.; Zhang, L.; Wang, Y.; Zhou, X.; Liu, J. DSC-MVSNet: Attention aware cost volume regularization based on depthwise separable convolution for multi-view stereo. Complex Intell. Syst. 2023, 9, 6953–6969. [Google Scholar]
- Tulyakov, S.; Ivanov, A.; Fleuret, F. Practical deep stereo (pds): Toward applications-friendly deep stereo matching. arXiv 2018, arXiv:1806.01677. [Google Scholar]
- Chen, C.; Chen, X.; Cheng, H. On the over-smoothing problem of cnn based disparity estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8997–9005. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | EPE/pixel | D1/% | RMSE/pixel | TIME/ms |
|---|---|---|---|---|
| StereoNet | 1.488 | 9.954 | 2.509 | 80 |
| PsmNet | 1.321 | 7.008 | 2.195 | 436 |
| GwcNet | 1.292 | 6.338 | 2.112 | 136 |
| HmsmNet | 1.193 | 6.343 | 2.118 | 82 |
| Proposed model | 1.115 | 5.320 | 1.994 | 92 |
| Tile | JAX236_001_003 | OMA059_041_003 | OMA258_025_026 | |
|---|---|---|---|---|
| EPE/pixel | StereoNet | 3.561 | 1.424 | 2.388 |
| PsmNet | 3.616 | 1.975 | 2.193 | |
| GwcNet | 3.437 | 2.332 | 1.930 | |
| HmsmNet | 3.294 | 1.085 | 1.819 | |
| Proposed model | 2.889 | 0.818 | 1.481 | |
| D1/% | StereoNet | 28.863 | 2.345 | 30.426 |
| PsmNet | 26.582 | 7.326 | 22.155 | |
| GwcNet | 24.505 | 18.604 | 13.944 | |
| HmsmNet | 25.086 | 0.384 | 11.077 | |
| Proposed model | 20.360 | 0.058 | 6.671 | |
| RMSE/pixel | StereoNet | 6.224 | 1.637 | 3.393 |
| PsmNet | 6.511 | 2.101 | 2.912 | |
| GwcNet | 6.053 | 2.441 | 2.678 | |
| HmsmNet | 5.828 | 1.252 | 2.531 | |
| Proposed model | 5.604 | 0.982 | 2.297 | |
| Tile | JAX280_005_004 | OMA212_003_037 | OMA389_039_005 | |
|---|---|---|---|---|
| EPE/pixel | StereoNet | 2.833 | 1.673 | 1.976 |
| PsmNet | 2.264 | 1.302 | 1.793 | |
| GwcNet | 2.383 | 1.568 | 1.598 | |
| HmsmNet | 2.573 | 1.349 | 1.493 | |
| Proposed model | 1.975 | 1.113 | 1.235 | |
| D1/% | StereoNet | 25.613 | 6.741 | 15.367 |
| PsmNet | 16.417 | 4.411 | 13.107 | |
| GwcNet | 17.971 | 6.596 | 12.485 | |
| HmsmNet | 21.367 | 10.058 | 12.218 | |
| Proposed model | 14.005 | 3.334 | 7.347 | |
| RMSE/pixel | StereoNet | 5.261 | 2.704 | 3.201 |
| PsmNet | 4.808 | 2.399 | 3.383 | |
| GwcNet | 4.743 | 2.513 | 2.631 | |
| HmsmNet | 4.895 | 2.241 | 2.523 | |
| Proposed model | 4.289 | 1.984 | 2.212 | |
| Tile | JAX165_008_006 | OMA251_006_001 | OMA287_033_030 | |
|---|---|---|---|---|
| EPE/pixel | StereoNet | 4.002 | 2.283 | 2.791 |
| PsmNet | 2.331 | 2.282 | 2.536 | |
| GwcNet | 2.722 | 2.413 | 2.463 | |
| HmsmNet | 3.674 | 2.175 | 2.432 | |
| Proposed model | 1.667 | 1.463 | 1.668 | |
| D1/% | StereoNet | 33.692 | 17.258 | 21.194 |
| PsmNet | 15.911 | 13.601 | 19.493 | |
| GwcNet | 20.424 | 15.020 | 15.331 | |
| HmsmNet | 29.261 | 17.018 | 15. 149 | |
| Proposed model | 12.117 | 7.656 | 11.651 | |
| RMSE/pixel | StereoNet | 7.031 | 4.362 | 5.682 |
| PsmNet | 4.904 | 3.999 | 4.852 | |
| GwcNet | 5.190 | 4.087 | 4.882 | |
| HmsmNet | 5.611 | 4.239 | 5.032 | |
| Proposed model | 3.850 | 3.609 | 4.112 | |
| Model | EPE/pixel | D1/% | RMSE/pixel | TIME/ms |
|---|---|---|---|---|
| Net-v1 | 1.309 | 6.913 | 2.164 | 82 |
| Net-v2 | 1.301 | 6.619 | 2.129 | 82 |
| Net-v3 | 1.296 | 6.781 | 2.162 | 86 |
| Net-v4 | 1.272 | 6.388 | 2.109 | 91 |
| Net-v5 | 1.206 | 5.923 | 2.081 | 166 |
| Net-v6 | 1.160 | 5.823 | 2.078 | 326 |
| Net | 1.115 | 5.320 | 1.994 | 93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, K.; Huang, X.; Li, H. Stereo Matching Method for Remote Sensing Images Based on Attention and Scale Fusion. Remote Sens. 2024, 16, 387. https://doi.org/10.3390/rs16020387
Wei K, Huang X, Li H. Stereo Matching Method for Remote Sensing Images Based on Attention and Scale Fusion. Remote Sensing. 2024; 16(2):387. https://doi.org/10.3390/rs16020387
Chicago/Turabian StyleWei, Kai, Xiaoxia Huang, and Hongga Li. 2024. "Stereo Matching Method for Remote Sensing Images Based on Attention and Scale Fusion" Remote Sensing 16, no. 2: 387. https://doi.org/10.3390/rs16020387
APA StyleWei, K., Huang, X., & Li, H. (2024). Stereo Matching Method for Remote Sensing Images Based on Attention and Scale Fusion. Remote Sensing, 16(2), 387. https://doi.org/10.3390/rs16020387